⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-08 更新
GPT-FT: An Efficient Automated Feature Transformation Using GPT for Sequence Reconstruction and Performance Enhancement
Authors:Yang Gao, Dongjie Wang, Scott Piersall, Ye Zhang, Liqiang Wang
Feature transformation plays a critical role in enhancing machine learning model performance by optimizing data representations. Recent state-of-the-art approaches address this task as a continuous embedding optimization problem, converting discrete search into a learnable process. Although effective, these methods often rely on sequential encoder-decoder structures that cause high computational costs and parameter requirements, limiting scalability and efficiency. To address these limitations, we propose a novel framework that accomplishes automated feature transformation through four steps: transformation records collection, embedding space construction with a revised Generative Pre-trained Transformer (GPT) model, gradient-ascent search, and autoregressive reconstruction. In our approach, the revised GPT model serves two primary functions: (a) feature transformation sequence reconstruction and (b) model performance estimation and enhancement for downstream tasks by constructing the embedding space. Such a multi-objective optimization framework reduces parameter size and accelerates transformation processes. Experimental results on benchmark datasets show that the proposed framework matches or exceeds baseline performance, with significant gains in computational efficiency. This work highlights the potential of transformer-based architectures for scalable, high-performance automated feature transformation.
特征转换通过优化数据表示在提升机器学习模型性能中起到关键作用。最近的最先进方法将此任务解决为连续的嵌入优化问题,将离散搜索转换为可学习的过程。尽管这些方法有效,但它们通常依赖于高计算成本和参数要求的顺序编码器-解码器结构,从而限制了可扩展性和效率。为了解决这些局限性,我们提出了一种新的框架,通过四个步骤完成自动化特征转换:转换记录收集、使用修订的生成预训练转换器(GPT)模型构建嵌入空间、梯度上升搜索和自回归重建。在我们的方法中,修订后的GPT模型主要扮演两个角色:(a)特征转换序列重建和(b)通过构建嵌入空间进行下游任务模型性能评估和增强。这种多目标优化框架减小了参数规模并加速了转换过程。在基准数据集上的实验结果表明,该框架的性能与基线相当或超过基线,计算效率显著提高。这项工作突出了基于转换器架构在可扩展、高性能自动化特征转换方面的潜力。
论文及项目相关链接
PDF 17 pages, 9 figures. accepted by APWeb-WAIM 2025
摘要
在机器学习中,特征转换通过优化数据表示起着至关重要的作用。当前先进的方法将此任务视为一个持续的嵌入优化问题,将离散搜索转换为可学习的过程。然而,这些方法通常依赖于高计算成本和参数要求的顺序编码器-解码器结构,这限制了其可扩展性和效率。针对这些局限性,本文提出了一种通过四个步骤实现自动化特征转换的新框架:转换记录收集、使用修订的生成预训练转换器(GPT)模型构建嵌入空间、梯度上升搜索和自回归重建。修订的GPT模型在本方法中主要服务于两个功能:特征转换序列重建和下游任务的模型性能估计与增强。这种多目标优化框架减小了参数规模并加速了转换过程。在基准数据集上的实验结果表明,该框架达到了或超过了基线性能,并且在计算效率上有显著提高。本文突显了基于转换器架构在高性能自动化特征转换中的潜力。
关键见解
- 特征转换对于增强机器学习模型性能至关重要,它通过优化数据表示来实现。
- 当前先进的方法将特征转换视为一个持续的嵌入优化问题。
- 现有方法依赖于高计算成本和参数要求的顺序编码器-解码器结构。
- 本文提出了一种新的自动化特征转换框架,包括转换记录收集、嵌入空间构建、梯度上升搜索和自回归重建。
- 修订的GPT模型在框架中扮演了两个主要角色:特征转换序列重建和下游任务的模型性能估计与增强。
- 多目标优化框架减小了参数规模并加速了转换过程。
点此查看论文截图


Improving Alignment in LVLMs with Debiased Self-Judgment
Authors:Sihan Yang, Chenhang Cui, Zihao Zhao, Yiyang Zhou, Weilong Yan, Ying Wei, Huaxiu Yao
The rapid advancements in Large Language Models (LLMs) and Large Visual-Language Models (LVLMs) have opened up new opportunities for integrating visual and linguistic modalities. However, effectively aligning these modalities remains challenging, often leading to hallucinations–where generated outputs are not grounded in the visual input–and raising safety concerns across various domains. Existing alignment methods, such as instruction tuning and preference tuning, often rely on external datasets, human annotations, or complex post-processing, which limit scalability and increase costs. To address these challenges, we propose a novel approach that generates the debiased self-judgment score, a self-evaluation metric created internally by the model without relying on external resources. This enables the model to autonomously improve alignment. Our method enhances both decoding strategies and preference tuning processes, resulting in reduced hallucinations, enhanced safety, and improved overall capability. Empirical results show that our approach significantly outperforms traditional methods, offering a more effective solution for aligning LVLMs.
大型语言模型(LLMs)和大型视觉语言模型(LVLMs)的快速发展为整合视觉和语言模式提供了新的机会。然而,有效地对齐这些模式仍然具有挑战性,这常常导致生成的输出没有基于视觉输入,并且在各个领域引发安全担忧。现有的对齐方法,如指令调整和偏好调整,通常依赖于外部数据集、人工注释或复杂的后处理,这限制了可扩展性并增加了成本。为了解决这些挑战,我们提出了一种新颖的方法,生成无偏的自我判断分数,这是一个由模型内部创建的自评估指标,无需依赖外部资源。这使模型能够自主地改进对齐。我们的方法改进了解码策略和偏好调整过程,从而减少了幻觉、增强了安全性并提高了整体能力。经验结果表明,我们的方法显著优于传统方法,为LVLMs的对齐提供了更有效的解决方案。
论文及项目相关链接
PDF EMNLP 2025 Findings
Summary
大语言模型(LLM)和大型视觉语言模型(LVLM)的快速发展为整合视觉和语言模式提供了新的机会。然而,有效地对齐这些模式仍然具有挑战性,可能导致生成的输出不基于视觉输入,并在不同领域引发安全问题。现有对齐方法依赖外部数据集、人类注释或复杂的后期处理,这限制了可扩展性并增加了成本。为解决这些挑战,我们提出了一种生成偏差自我判断分数的新方法,这是一种由模型内部创建的自我评价指标,无需依赖外部资源。这使模型能够自主改进对齐。我们的方法改进了解码策略和偏好调整过程,减少了幻觉、增强了安全性并提高了整体能力。经验结果表明,我们的方法显著优于传统方法,为LVLM的对齐提供了更有效的解决方案。
Key Takeaways
- 大语言模型(LLM)和大型视觉语言模型(LVLM)的集成面临视觉与语言模式对齐的挑战。
- 现有对齐方法存在依赖外部资源、成本高和扩展性有限的问题。
- 提出了一种新的自我判断分数方法,用于生成偏差校正的对齐评估指标。
- 该方法无需依赖外部资源,提高了模型的自主对齐能力。
- 通过改进解码策略和偏好调整过程,减少了幻觉和增强了安全性。
- 实证结果表明,新方法在LVLM对齐方面显著优于传统方法。
点此查看论文截图



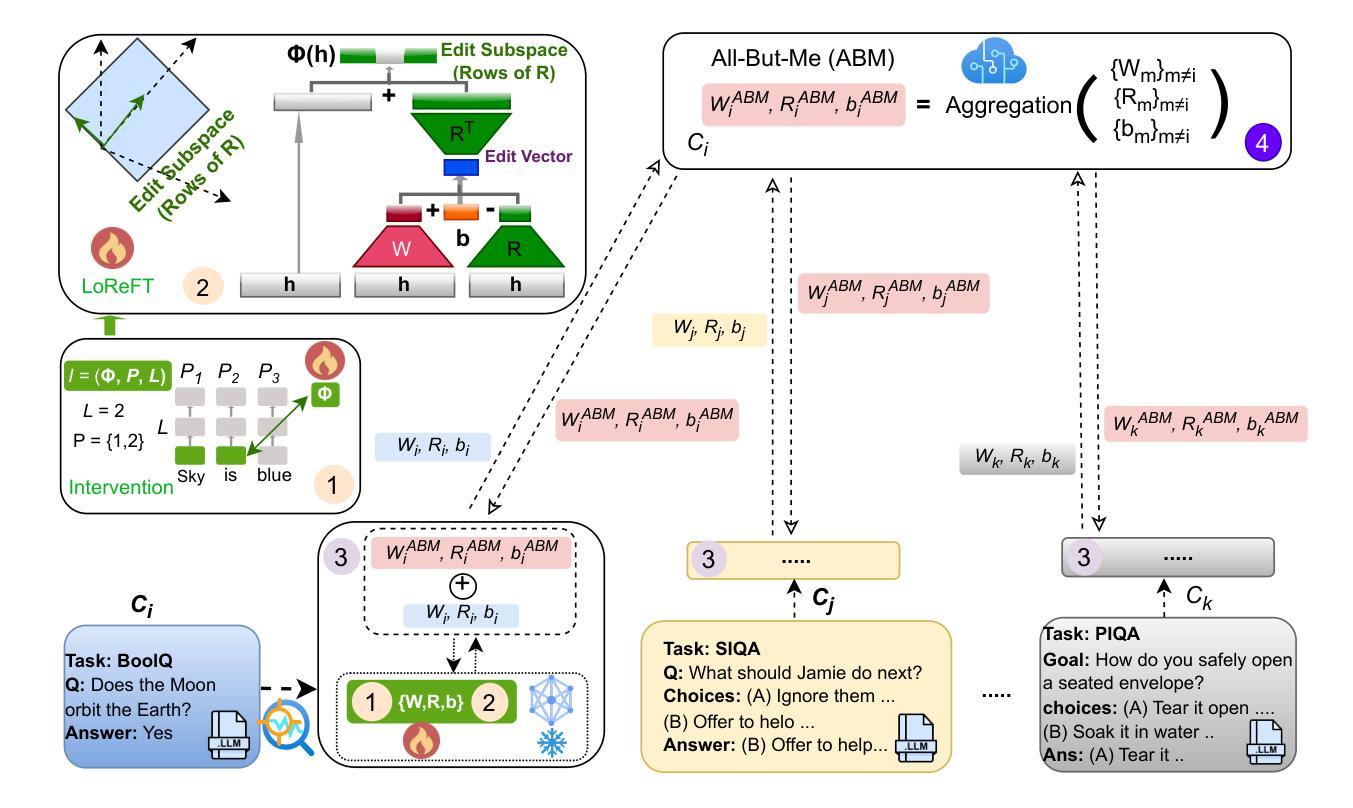
FedReFT: Federated Representation Fine-Tuning with All-But-Me Aggregation
Authors:Fatema Siddika, Md Anwar Hossen, J. Pablo Muñoz, Tanya Roosta, Anuj Sharma, Ali Jannesari
Parameter-efficient fine-tuning (PEFT) has attracted significant attention for adapting large pre-trained models by modifying a small subset of parameters. Recently, Representation Fine-tuning (ReFT) has emerged as an effective alternative. ReFT shifts the fine-tuning paradigm from updating model weights to directly manipulating hidden representations that capture rich semantic information, and performs better than state-of-the-art PEFTs in standalone settings. However, its application in Federated Learning (FL) remains challenging due to heterogeneity in clients’ data distributions, model capacities, and computational resources. To address these challenges, we introduce Federated Representation Fine-Tuning (FedReFT), a novel approach to fine-tune the client’s hidden representation. FedReFT applies sparse intervention layers to steer hidden representations directly, offering a lightweight and semantically rich fine-tuning alternative ideal for edge devices. However, representation-level updates are especially vulnerable to aggregation mismatch under different task heterogeneity, where naive averaging can corrupt semantic alignment. To mitigate this issue, we propose All-But-Me (ABM) aggregation, where each client receives the aggregated updates of others and partially incorporates them, enabling stable and personalized learning by balancing local focus with global knowledge. We evaluate FedReFT on commonsense reasoning, arithmetic reasoning, instruction-tuning, and GLUE, where it consistently outperforms state-of-the-art PEFT methods in FL, achieving 7x-15x higher parameter efficiency compared to leading LoRA-based approaches.
参数高效微调(PEFT)通过修改一小部分参数来适应大型预训练模型,已经引起了人们的广泛关注。最近,表示微调(ReFT)作为一种有效的替代方法而出现。ReFT改变了微调的模式,从更新模型权重转向直接操作隐藏表示,这些隐藏表示捕捉了丰富的语义信息,并在独立环境中表现得比最先进的PEFT更好。然而,它在联邦学习(FL)中的应用仍然具有挑战性,因为客户端的数据分布、模型容量和计算资源存在异质性。为了解决这些挑战,我们引入了联邦表示微调(FedReFT),这是一种对客户隐藏表示进行微调的新方法。FedReFT应用稀疏干预层来直接引导隐藏表示,提供了一种轻量级且语义丰富的微调替代方案,非常适合边缘设备。然而,表示级别的更新特别容易受到不同任务异质性下的聚合不匹配的影响,简单的平均可能会破坏语义对齐。为了缓解这个问题,我们提出了“除了我所有人”(ABM)聚合方法,每个客户端接收其他所有人的聚合更新,并部分地采用这些更新,通过平衡局部焦点和全局知识来实现稳定和个人化的学习。我们在常识推理、算术推理、指令调整和GLUE上评估了FedReFT,它在联邦学习中持续超越最先进的PEFT方法,与领先的LoRA方法相比,实现了7倍至15倍更高的参数效率。
论文及项目相关链接
Summary
在联邦学习环境下,针对大型预训练模型的微调,提出了Federated Representation Fine-Tuning(FedReFT)方法。通过直接操控捕获丰富语义信息的隐藏表征,引入稀疏干预层对客户端隐藏表征进行微调。并提出All-But-Me(ABM)聚合策略,解决不同任务异质性下的聚合不匹配问题。在常识推理、算术推理、指令调整和GLUE等任务上评估,FedReFT相较于主流PEFT方法在联邦学习中表现更优,参数效率提高7至15倍。
Key Takeaways
- Federated Representation Fine-Tuning (FedReFT) 是一种针对联邦学习环境中大型预训练模型的新的微调方法。
- FedReFT 通过直接操控隐藏表征,改变传统的模型权重更新方式。
- 隐藏表征的操控提供了丰富语义信息的利用,并在实践中表现优异。
- 联邦环境下的数据分布、模型容量和计算资源的异质性为应用带来了挑战。
- 提出All-But-Me(ABM)聚合策略,解决不同任务异质性下的聚合不匹配问题。
- FedReFT 在多个任务上的表现均优于主流的参数效率微调方法。
点此查看论文截图





Generative Models for Synthetic Data: Transforming Data Mining in the GenAI Era
Authors:Dawei Li, Yue Huang, Ming Li, Tianyi Zhou, Xiangliang Zhang, Huan Liu
Generative models such as Large Language Models, Diffusion Models, and generative adversarial networks have recently revolutionized the creation of synthetic data, offering scalable solutions to data scarcity, privacy, and annotation challenges in data mining. This tutorial introduces the foundations and latest advances in synthetic data generation, covers key methodologies and practical frameworks, and discusses evaluation strategies and applications. Attendees will gain actionable insights into leveraging generative synthetic data to enhance data mining research and practice. More information can be found on our website: https://syndata4dm.github.io/.
大型语言模型、扩散模型和生成对抗网络等生成模型最近彻底改变了合成数据的创建方式,为解决数据挖掘中的数据稀缺、隐私和注释挑战提供了可扩展的解决方案。本教程介绍了合成数据生成的基础知识和最新进展,涵盖了关键方法和实用框架,并讨论了评估策略和应用。与会者将获得关于如何利用生成合成数据来提升数据挖掘研究和实践的可行见解。更多信息请访问我们的网站:https://syndata4dm.github.io/。
论文及项目相关链接
PDF Accepted by CIKM 2025 Tutorial
Summary:
新一代生成模型,如大型语言模型、扩散模型和生成对抗网络,已彻底改变了合成数据的创建方式,为解决数据稀缺、隐私和标注挑战提供了可扩展的解决方案。本教程介绍合成数据生成的基础知识和最新进展,涵盖关键方法和实用框架,并讨论评估策略和应用。参加者可获得利用生成合成数据提升数据挖掘研究和实践的实用见解。更多信息请访问我们的网站。
Key Takeaways:
- 生成模型已改变合成数据的创建方式。
- 生成模型为解决数据稀缺、隐私和标注挑战提供了解决方案。
- 本教程介绍合成数据生成的基础知识和最新进展。
- 教程涵盖关键方法和实用框架。
- 评估策略和应用程序的讨论。
- 参加者可获得利用生成合成数据提升数据挖掘的实用见解。
点此查看论文截图

Stack Trace-Based Crash Deduplication with Transformer Adaptation
Authors:Md Afif Al Mamun, Gias Uddin, Lan Xia, Longyu Zhang
Automated crash reporting systems generate large volumes of duplicate reports, overwhelming issue-tracking systems and increasing developer workload. Traditional stack trace-based deduplication methods, relying on string similarity, rule-based heuristics, or deep learning (DL) models, often fail to capture the contextual and structural relationships within stack traces. We propose dedupT, a transformer-based approach that models stack traces holistically rather than as isolated frames. dedupT first adapts a pretrained language model (PLM) to stack traces, then uses its embeddings to train a fully-connected network (FCN) to rank duplicate crashes effectively. Extensive experiments on real-world datasets show that dedupT outperforms existing DL and traditional methods (e.g., sequence alignment and information retrieval techniques) in both duplicate ranking and unique crash detection, significantly reducing manual triage effort. On four public datasets, dedupT improves Mean Reciprocal Rank (MRR) often by over 15% compared to the best DL baseline and up to 9% over traditional methods while achieving higher Receiver Operating Characteristic Area Under the Curve (ROC-AUC) in detecting unique crash reports. Our work advances the integration of modern natural language processing (NLP) techniques into software engineering, providing an effective solution for stack trace-based crash deduplication.
自动崩溃报告系统生成大量重复报告,导致问题跟踪系统超载,增加了开发者的工作量。传统的基于堆栈跟踪的重复数据删除方法,依赖于字符串相似性、基于规则的策略或深度学习(DL)模型,往往无法捕捉堆栈跟踪中的上下文和结构关系。我们提出了一个基于变压器的dedupT方法,它可以全面地对堆栈跟踪进行建模,而不是孤立的帧。dedupT首先适应堆栈跟踪的预训练语言模型(PLM),然后使用其嵌入来训练全连接网络(FCN),以有效地对重复崩溃进行排名。在现实数据集上的大量实验表明,dedupT在重复排名和唯一崩溃检测方面优于现有的DL和传统方法(例如序列比对和信息检索技术),大大减少了手动诊断的工作量。在四个公共数据集上,与最佳的DL基准相比,dedupT的Mean Reciprocal Rank(MRR)经常提高了超过15%,与传统方法相比提高了高达9%,同时在检测唯一崩溃报告时实现了更高的ROC-AUC值。我们的工作推动了现代自然语言处理(NLP)技术在软件工程中的融合,为基于堆栈跟踪的崩溃重复数据删除提供了有效的解决方案。
论文及项目相关链接
PDF This work is currently under review at IEEE Transactions on Software Engineering. The replication package will be made publicly available upon acceptance
Summary
自动化崩溃报告系统产生大量重复报告,给问题跟踪系统带来负担并增加开发者工作量。传统基于堆栈跟踪的重复报告消除方法常常无法捕捉上下文和结构关系。本文提出一种基于转换器的解决方案dedupT,它能全面建模堆栈跟踪而非孤立框架。dedupT首先适应预训练的语言模型到堆栈跟踪,然后使用其嵌入值训练全连接网络以有效排名重复崩溃。在真实数据集上的广泛实验表明,dedupT在重复排名和唯一崩溃检测方面优于现有的深度学习和传统方法,显著减少手动审查工作量。在四个公共数据集上,与最佳深度学习基准相比,dedupT的Mean Reciprocal Rank(MRR)经常提高超过15%,与传统方法相比提高高达9%,同时在检测唯一崩溃报告时实现更高的ROC-AUC值。
Key Takeaways
- 自动化崩溃报告系统面临大量重复报告问题,需要有效方法来解决。
- 传统基于堆栈跟踪的重复报告消除方法存在缺陷,无法充分捕捉上下文和结构关系。
- dedupT基于转换器的方法全面建模堆栈跟踪,适应预训练语言模型并进行训练。
- dedupT通过有效排名重复崩溃,在真实数据集上表现优异。
- 与现有方法相比,dedupT在MRR和ROC-AUC方面有明显提升。
- dedupT减少了手动审查工作量,提高了效率。
点此查看论文截图





What do language models model? Transformers, automata, and the format of thought
Authors:Colin Klein
What do large language models actually model? Do they tell us something about human capacities, or are they models of the corpus we’ve trained them on? I give a non-deflationary defence of the latter position. Cognitive science tells us that linguistic capabilities in humans rely supralinear formats for computation. The transformer architecture, by contrast, supports at best a linear formats for processing. This argument will rely primarily on certain invariants of the computational architecture of transformers. I then suggest a positive story about what transformers are doing, focusing on Liu et al. (2022)’s intriguing speculations about shortcut automata. I conclude with why I don’t think this is a terribly deflationary story. Language is not (just) a means for expressing inner state but also a kind of ‘discourse machine’ that lets us make new language given appropriate context. We have learned to use this technology in one way; LLMs have also learned to use it too, but via very different means.
大型语言模型实际上在模拟什么?它们是否向我们展示了人类的某些能力,或者只是反映了我们训练它们的语料库的模型?我为后者进行了非贬低的辩护。认知科学告诉我们,人类的语言能力依赖于超线性计算格式。相比之下,transformer架构最多只支持线性处理格式。这个论证主要依赖于transformer计算架构的某些不变特性。然后,我讲述了一个关于transformer正在做什么的积极故事,重点关注了Liu等人(2022)关于快捷自动机的有趣推测。最后,为什么我并不认为这是一个很贬低的故事。语言不仅仅是表达内心状态的手段,也是一种让我们能在适当的语境下创造新语言的“话语机器”。我们已经学会以一种方式使用这项技术;大型语言模型也学会了使用它,但手段截然不同。
论文及项目相关链接
Summary
大型语言模型(LLM)究竟模拟了什么?它们揭示的是人类能力,还是我们训练它们所使用的语料库的模型?文章支持后者观点,并指出认知科学表明人类的语言能力依赖于超线性计算格式,而transformer架构最多只支持线性处理格式。文章通过讨论transformer的计算架构不变性,探讨了其处理语言的方式,并参考了Liu等人(2022)关于快捷方式自动机的有趣推测。文章最后指出,语言不仅是表达内心状态的工具,也是一种“话语机器”,能让我们在适当的语境下创造新的语言。我们学会以一种方式使用这项技术;LLM也学会了使用它,但手段截然不同。
Key Takeaways
- 大型语言模型(LLM)不仅仅是模拟人类能力的工具,更是对训练语料库的模拟。
- 认知科学表明人类的语言能力依赖于超线性计算格式。
- Transformer架构最多只支持线性处理格式,这与人类的超线性语言能力形成对比。
- Transformer的计算架构不变性是理解其处理语言方式的关键。
- Liu等人(2022)的快捷方式自动机推测为理解LLM提供了新视角。
- 语言不仅是表达内心状态的工具,也是一种“话语机器”,能在特定语境下创造新语言。
点此查看论文截图

Vectorized Attention with Learnable Encoding for Quantum Transformer
Authors:Ziqing Guo, Ziwen Pan, Alex Khan, Jan Balewski
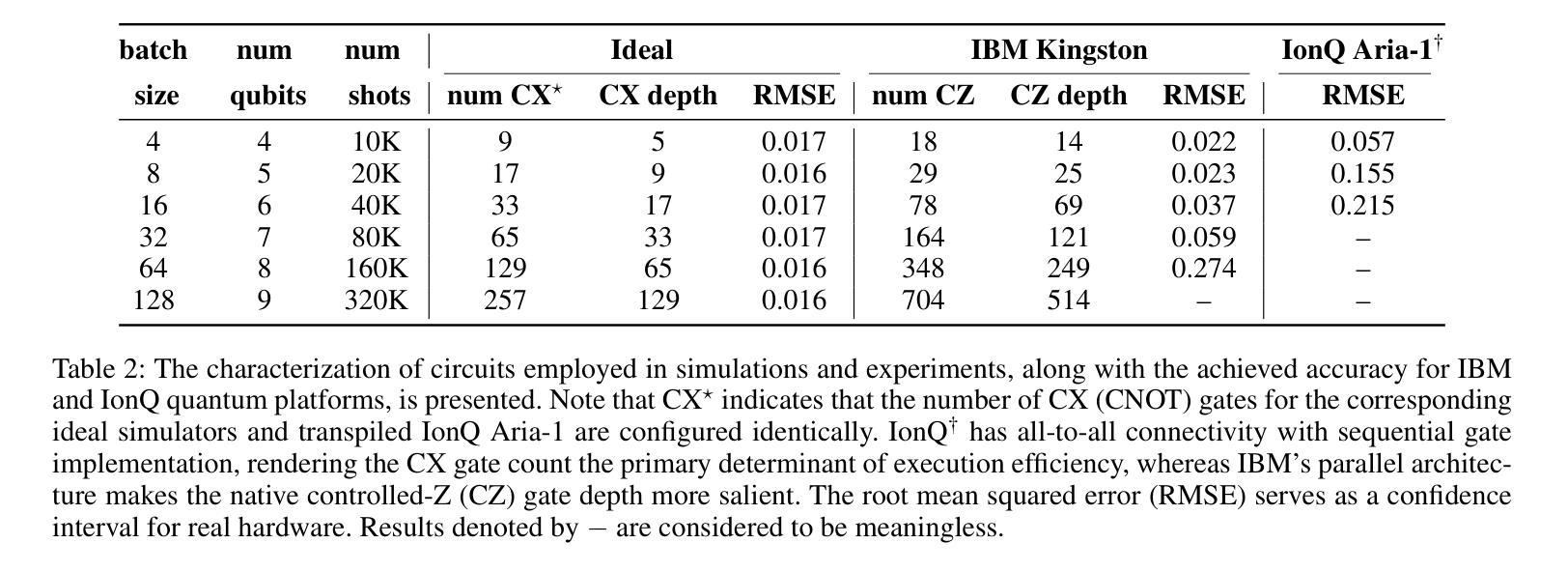
Vectorized quantum block encoding provides a way to embed classical data into Hilbert space, offering a pathway for quantum models, such as Quantum Transformers (QT), that replace classical self-attention with quantum circuit simulations to operate more efficiently. Current QTs rely on deep parameterized quantum circuits (PQCs), rendering them vulnerable to QPU noise, and thus hindering their practical performance. In this paper, we propose the Vectorized Quantum Transformer (VQT), a model that supports ideal masked attention matrix computation through quantum approximation simulation and efficient training via vectorized nonlinear quantum encoder, yielding shot-efficient and gradient-free quantum circuit simulation (QCS) and reduced classical sampling overhead. In addition, we demonstrate an accuracy comparison for IBM and IonQ in quantum circuit simulation and competitive results in benchmarking natural language processing tasks on IBM state-of-the-art and high-fidelity Kingston QPU. Our noise intermediate-scale quantum friendly VQT approach unlocks a novel architecture for end-to-end machine learning in quantum computing.
向量化量子编码块为将经典数据嵌入希尔伯特空间提供了一种方法,这为量子模型(如量子转换器(QT))提供了路径,这些模型通过用量子电路模拟替换经典的自注意力来更有效地运行。当前的QT依赖于深度参数化量子电路(PQC),使其容易受到量子处理器噪声的影响,从而阻碍了其实践性能。在本文中,我们提出了向量化量子转换器(VQT)模型,该模型通过量子近似模拟支持理想的掩模注意力矩阵计算,并通过向量化非线性量子编码器实现高效训练,从而产生高效且无梯度的量子电路模拟(QCS),并降低了经典采样开销。此外,我们展示了IBM和IonQ在量子电路模拟中的精度比较,以及在IBM先进和高保真金士顿量子处理器上执行自然语言处理任务的基准测试结果。我们的噪声中等规模友好的VQT方法解锁了量子计算端到端机器学习的新架构。
论文及项目相关链接
Summary
量子向量化转换器(VQT)是一种将经典数据嵌入希尔伯特空间的方法,它为量子模型(如量子转换器)提供了更高效的运行方式,通过量子近似模拟实现理想的掩码注意力矩阵计算,并通过向量化的非线性量子编码器实现高效训练。此外,本文提出了一种新型的VQT方法,该方法对IBM和IonQ的量子电路模拟进行了准确性比较,并在IBM尖端高保真度Kingston量子处理器上进行自然语言处理任务的基准测试表现出良好的性能。该噪音中间尺度量子友好的VQT方法为端到端的机器学习量子计算开启了一种新的架构。
Key Takeaways
- 量子向量化编码是一种将经典数据嵌入Hilbert空间的技术。
- 量子转换器(QT)通过利用量子电路模拟替代经典自注意力,以实现更高效运行。
- 现有QT依赖深度参数化量子电路(PQC),易受量子处理器噪声影响。
- 提出向量化量子转换器(VQT)模型,通过量子近似模拟实现掩码注意力矩阵计算。
- VQT利用向量化的非线性量子编码器实现高效训练、无梯度量子电路模拟和减少经典采样开销。
- VQT方法在IBM和IonQ的量子电路模拟中显示出准确性,并在自然语言处理任务的基准测试中表现良好。
点此查看论文截图





NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Authors: NVIDIA, :, Aarti Basant, Abhijit Khairnar, Abhijit Paithankar, Abhinav Khattar, Adithya Renduchintala, Aditya Malte, Akhiad Bercovich, Akshay Hazare, Alejandra Rico, Aleksander Ficek, Alex Kondratenko, Alex Shaposhnikov, Alexander Bukharin, Ali Taghibakhshi, Amelia Barton, Ameya Sunil Mahabaleshwarkar, Amy Shen, Andrew Tao, Ann Guan, Anna Shors, Anubhav Mandarwal, Arham Mehta, Arun Venkatesan, Ashton Sharabiani, Ashwath Aithal, Ashwin Poojary, Ayush Dattagupta, Balaram Buddharaju, Banghua Zhu, Barnaby Simkin, Bilal Kartal, Bita Darvish Rouhani, Bobby Chen, Boris Ginsburg, Brandon Norick, Brian Yu, Bryan Catanzaro, Charles Wang, Charlie Truong, Chetan Mungekar, Chintan Patel, Chris Alexiuk, Christian Munley, Christopher Parisien, Dan Su, Daniel Afrimi, Daniel Korzekwa, Daniel Rohrer, Daria Gitman, David Mosallanezhad, Deepak Narayanan, Dima Rekesh, Dina Yared, Dmytro Pykhtar, Dong Ahn, Duncan Riach, Eileen Long, Elliott Ning, Eric Chung, Erick Galinkin, Evelina Bakhturina, Gargi Prasad, Gerald Shen, Haifeng Qian, Haim Elisha, Harsh Sharma, Hayley Ross, Helen Ngo, Herman Sahota, Hexin Wang, Hoo Chang Shin, Hua Huang, Iain Cunningham, Igor Gitman, Ivan Moshkov, Jaehun Jung, Jan Kautz, Jane Polak Scowcroft, Jared Casper, Jian Zhang, Jiaqi Zeng, Jimmy Zhang, Jinze Xue, Jocelyn Huang, Joey Conway, John Kamalu, Jonathan Cohen, Joseph Jennings, Julien Veron Vialard, Junkeun Yi, Jupinder Parmar, Kari Briski, Katherine Cheung, Katherine Luna, Keith Wyss, Keshav Santhanam, Kezhi Kong, Krzysztof Pawelec, Kumar Anik, Kunlun Li, Kushan Ahmadian, Lawrence McAfee, Laya Sleiman, Leon Derczynski, Luis Vega, Maer Rodrigues de Melo, Makesh Narsimhan Sreedhar, Marcin Chochowski, Mark Cai, Markus Kliegl, Marta Stepniewska-Dziubinska, Matvei Novikov, Mehrzad Samadi, Meredith Price, Meriem Boubdir, Michael Boone, Michael Evans, Michal Bien, Michal Zawalski, Miguel Martinez, Mike Chrzanowski, Mohammad Shoeybi, Mostofa Patwary, Namit Dhameja, Nave Assaf, Negar Habibi, Nidhi Bhatia, Nikki Pope, Nima Tajbakhsh, Nirmal Kumar Juluru, Oleg Rybakov, Oleksii Hrinchuk, Oleksii Kuchaiev, Oluwatobi Olabiyi, Pablo Ribalta, Padmavathy Subramanian, Parth Chadha, Pavlo Molchanov, Peter Dykas, Peter Jin, Piotr Bialecki, Piotr Januszewski, Pradeep Thalasta, Prashant Gaikwad, Prasoon Varshney, Pritam Gundecha, Przemek Tredak, Rabeeh Karimi Mahabadi, Rajen Patel, Ran El-Yaniv, Ranjit Rajan, Ria Cheruvu, Rima Shahbazyan, Ritika Borkar, Ritu Gala, Roger Waleffe, Ruoxi Zhang, Russell J. Hewett, Ryan Prenger, Sahil Jain, Samuel Kriman, Sanjeev Satheesh, Saori Kaji, Sarah Yurick, Saurav Muralidharan, Sean Narenthiran, Seonmyeong Bak, Sepehr Sameni, Seungju Han, Shanmugam Ramasamy, Shaona Ghosh, Sharath Turuvekere Sreenivas, Shelby Thomas, Shizhe Diao, Shreya Gopal, Shrimai Prabhumoye, Shubham Toshniwal, Shuoyang Ding, Siddharth Singh, Siddhartha Jain, Somshubra Majumdar, Soumye Singhal, Stefania Alborghetti, Syeda Nahida Akter, Terry Kong, Tim Moon, Tomasz Hliwiak, Tomer Asida, Tony Wang, Tugrul Konuk, Twinkle Vashishth, Tyler Poon, Udi Karpas, Vahid Noroozi, Venkat Srinivasan, Vijay Korthikanti, Vikram Fugro, Vineeth Kalluru, Vitaly Kurin, Vitaly Lavrukhin, Wasi Uddin Ahmad, Wei Du, Wonmin Byeon, Ximing Lu, Xin Dong, Yashaswi Karnati, Yejin Choi, Yian Zhang, Ying Lin, Yonggan Fu, Yoshi Suhara, Zhen Dong, Zhiyu Li, Zhongbo Zhu, Zijia Chen
We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
我们介绍了Nemotron-Nano-9B-v2,这是一种混合Mamba-Transformer语言模型,旨在提高推理工作负载的吞吐量,同时与类似规模的模型相比实现最先进的准确性。Nemotron-Nano-9B-v2建立在Nemotron-H架构的基础上,将Transformer架构中大部分的自注意力层替换为Mamba-2层,以实现在生成推理所需的长思考轨迹时的更快推理速度。我们通过首先在20万亿个令牌上使用FP8训练配方预训练一个12亿参数模型(Nemotron-Nano-12B-v2-Base)来创建Nemotron-Nano-9B-v2。在对Nemotron-Nano-12B-v2-Base进行对齐后,我们采用Minitron策略来压缩和蒸馏模型,旨在能够在单个NVIDIA A10G GPU(具有22GiB内存,bfloat16精度)上进行最多达128k令牌的推理。与现有的类似规模模型(例如Qwen3-8B)相比,我们在推理基准测试中显示,Nemotron-Nano-9B-v2实现了相当或更好的准确性,同时在如8k输入和16k输出令牌的推理设置中实现了高达6倍的推理吞吐量。我们将Nemotron-Nano-9B-v2、Nemotron-Nano12B-v2-Base以及Nemotron-Nano-9B-v2的基点和多数预训练和后续训练数据集一起在Hugging Face上发布。
论文及项目相关链接
Summary
Nemotron-Nano-9B-v2是混合Mamba-Transformer语言模型,旨在提高推理工作负载的吞吐量,同时在类似规模的模型中实现最先进的准确性。它通过基于Nemotron-H架构,用Mamba-2层替换Transformer架构中的大部分自注意力层,以实现生成长思考轨迹时的推理速度提升。模型通过预训练12亿参数的模型(Nemotron-Nano-12B-v2-Base)在Hugging Face上发布,之后在单个NVIDIA A10G GPU上进行压缩和蒸馏,实现在推理设置中的高吞吐量和准确性。
Key Takeaways
- Nemotron-Nano-9B-v2是一个混合Mamba-Transformer语言模型,旨在提高推理的吞吐量并达到最先进的准确性。
- 该模型基于Nemotron-H架构,用Mamba-2层替换自注意力层以提高推理速度。
- 模型通过预训练一个12亿参数的模型(Nemotron-Nano-12B-v2-Base)进行训练。
- 模型可以在单个NVIDIA A10G GPU上进行推理,具有高达6倍的高吞吐量。
- 与现有的类似规模模型相比(例如Qwen3-8B),Nemotron-Nano-9B-v2在推理基准测试上实现了相当或更好的准确性。
- 模型及其相关数据集已在Hugging Face上发布。
点此查看论文截图



Let’s Use ChatGPT To Write Our Paper! Benchmarking LLMs To Write the Introduction of a Research Paper
Authors:Krishna Garg, Firoz Shaik, Sambaran Bandyopadhyay, Cornelia Caragea
As researchers increasingly adopt LLMs as writing assistants, generating high-quality research paper introductions remains both challenging and essential. We introduce Scientific Introduction Generation (SciIG), a task that evaluates LLMs’ ability to produce coherent introductions from titles, abstracts, and related works. Curating new datasets from NAACL 2025 and ICLR 2025 papers, we assess five state-of-the-art models, including both open-source (DeepSeek-v3, Gemma-3-12B, LLaMA 4-Maverick, MistralAI Small 3.1) and closed-source GPT-4o systems, across multiple dimensions: lexical overlap, semantic similarity, content coverage, faithfulness, consistency, citation correctness, and narrative quality. Our comprehensive framework combines automated metrics with LLM-as-a-judge evaluations. Results demonstrate LLaMA-4 Maverick’s superior performance on most metrics, particularly in semantic similarity and faithfulness. Moreover, three-shot prompting consistently outperforms fewer-shot approaches. These findings provide practical insights into developing effective research writing assistants and set realistic expectations for LLM-assisted academic writing. To foster reproducibility and future research, we will publicly release all code and datasets.
随着越来越多的研究者采用大型语言模型作为写作助手,生成高质量的研究论文引言仍然是一个既具挑战性又至关重要的任务。我们引入了科学引言生成(SciIG)这一任务,旨在评估大型语言模型从标题、摘要和相关文献中产生连贯引言的能力。我们使用了来自NAACL 2025和ICLR 2025论文的新数据集,评估了五种最新模型,包括开源模型(DeepSeek-v3、Gemma-3-12B、LLaMA 4-Maverick、MistralAI Small 3.1)和闭源GPT-4o系统,涉及多个维度:词汇重叠、语义相似性、内容覆盖、准确性、一致性、引用正确性和叙述质量。我们的综合框架结合了自动度量指标与大型语言模型作为法官的评价。结果表明,LLaMA-4 Maverick在大多数指标上表现优越,特别是在语义相似性和忠实性方面。此外,三提示法始终优于少提示法。这些发现为开发有效的研究写作助手提供了实际见解,并为大型语言模型辅助的学术写作设定了现实的期望。为了促进重现性和未来的研究,我们将公开发布所有代码和数据集。
论文及项目相关链接
PDF 20 pages, 15 figures
Summary
LLMs作为写作助手在学术界日益普及,生成高质量研究论文引言既具挑战性又至关重要。本研究提出了Scientific Introduction Generation(SciIG)任务,评估LLMs从标题、摘要和相关工作生成连贯引言的能力。研究使用NAACL 2025和ICLR 2025论文数据集,评估了五个最新模型,包括开源模型(DeepSeek-v3、Gemma-3-12B、LLaMA 4-Maverick、MistralAI Small 3.1)和闭源GPT-4o系统,涵盖多个维度。结果显示LLaMA-4 Maverick在多数指标上表现优异,特别是语义相似性和忠实性方面。此外,三提示提示法一贯优于少提示法。研究提供实用见解,有助于开发有效的研究写作助手,并为LLM辅助学术写作设定现实期望。
Key Takeaways
- LLMs被越来越多地用作写作助手,生成高质量研究论文引言具有挑战性。
- 提出Scientific Introduction Generation (SciIG)任务,评估LLMs在生成引言方面的能力。
- 使用NAACL 2025和ICLR 2025论文数据集进行实证研究。
- 评估了多个LLMs模型的表现,包括开源和闭源模型。
- 评估维度包括词汇重叠、语义相似性、内容覆盖、忠实性、一致性、引用正确性和叙事质量。
- LLaMA-4 Maverick在多数评估指标上表现最佳。
点此查看论文截图




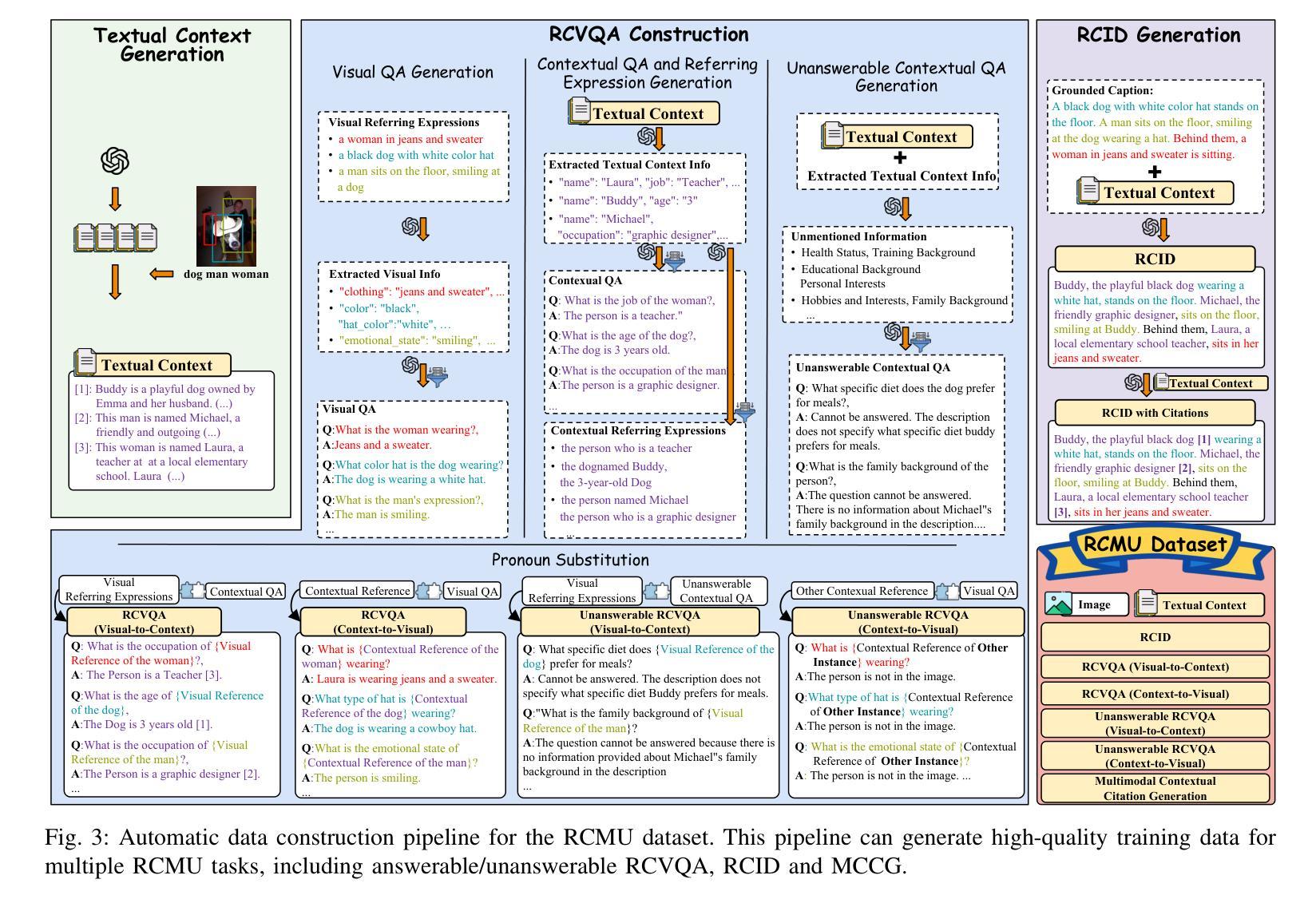
Region-Level Context-Aware Multimodal Understanding
Authors:Hongliang Wei, Xianqi Zhang, Xingtao Wang, Xiaopeng Fan, Debin Zhao
Despite significant progress, existing research on Multimodal Large Language Models (MLLMs) mainly focuses on general visual understanding, overlooking the ability to integrate textual context associated with objects for a more context-aware multimodal understanding – an ability we refer to as Region-level Context-aware Multimodal Understanding (RCMU). To address this limitation, we first formulate the RCMU task, which requires models to respond to user instructions by integrating both image content and textual information of regions or objects. To equip MLLMs with RCMU capabilities, we propose Region-level Context-aware Visual Instruction Tuning (RCVIT), which incorporates object information into the model input and enables the model to utilize bounding box coordinates to effectively associate objects’ visual content with their textual information. To address the lack of datasets, we introduce the RCMU dataset, a large-scale visual instruction tuning dataset that covers multiple RCMU tasks. We also propose RC&P-Bench, a comprehensive benchmark that can evaluate the performance of MLLMs in RCMU and multimodal personalized understanding tasks. Additionally, we propose a reference-free evaluation metric to perform a comprehensive and fine-grained evaluation of the region-level context-aware image descriptions. By performing RCVIT on Qwen2-VL models with the RCMU dataset, we developed RC-Qwen2-VL models. Experimental results indicate that RC-Qwen2-VL models not only achieve outstanding performance on multiple RCMU tasks but also demonstrate successful applications in multimodal RAG and personalized conversation. Our data, model and benchmark are available at https://github.com/hongliang-wei/RC-MLLM
尽管取得了显著进展,但关于多模态大型语言模型(MLLMs)的现有研究主要集中在一般的视觉理解上,忽略了整合与对象相关的文本上下文的能力,以实现更具上下文感知的多模态理解——我们称之为区域级上下文感知多模态理解(RCMU)。为了解决这个问题,我们首先制定了RCMU任务,要求模型通过整合图像内容和区域或对象的文本信息来响应用户指令。为了赋予MLLMs以RCMU能力,我们提出了区域级上下文感知视觉指令微调(RCVIT),它将对象信息融入模型输入,使模型能够利用边界框坐标有效地将对象的视觉内容与文本信息关联起来。为了解决数据集缺乏的问题,我们介绍了RCMU数据集,这是一个大规模视觉指令微调数据集,涵盖了多个RCMU任务。我们还提出了RC&P-Bench基准测试,它可以评估MLLMs在RCMU和多模态个性化理解任务中的性能。此外,我们还提出了一种无参考评估指标,对区域级上下文感知图像描述进行更全面和精细的评估。通过在Qwen2-VL模型上应用RCVIT和RCMU数据集,我们开发了RC-Qwen2-VL模型。实验结果表明,RC-Qwen2-VL模型不仅在多个RCMU任务上表现出卓越的性能,而且在多模态RAG和个性化对话中也表现出成功的应用。我们的数据、模型和基准测试可在https://github.com/hongliang-wei/RC-MLLM上获得。
论文及项目相关链接
PDF 12 pages, 6 figures
Summary
本文主要介绍了多模态大型语言模型(MLLMs)的研究现状及其局限性,特别是在区域级上下文感知多模态理解(RCMU)方面的不足。为弥补这一缺陷,文章提出了区域级上下文感知视觉指令调整(RCVIT)的方法,并引入了RCMU数据集和RC&P-Bench基准测试。通过RCVIT方法对Qwen2-VL模型进行训练,成功开发出RC-Qwen2-VL模型,该模型在多项RCMU任务中表现出卓越性能,并成功应用于多模态RAG和个性化对话。
Key Takeaways
- MLLMs虽然取得显著进展,但主要关注一般视觉理解,忽略了与对象相关的文本上下文的整合能力,即区域级上下文感知多模态理解(RCMU)。
- 为解决此问题,提出了区域级上下文感知视觉指令调整(RCVIT)方法,将对象信息纳入模型输入,并使用边界框坐标关联对象的视觉内容与文本信息。
- 引入RCMU数据集,这是一个大规模视觉指令调整数据集,涵盖多个RCMU任务。
- 提出RC&P-Bench基准测试,可评估MLLMs在RCMU和多模态个性化理解任务中的性能。
- 引入无参考评估指标,对区域级上下文感知图像描述进行更全面、精细的评估。
- 通过RCVIT方法对Qwen2-VL模型进行训练,成功开发出RC-Qwen2-VL模型,该模型在多项RCMU任务中表现出卓越性能。
- RC-Qwen2-VL模型成功应用于多模态RAG和个性化对话,展示了其实用性和潜力。
点此查看论文截图





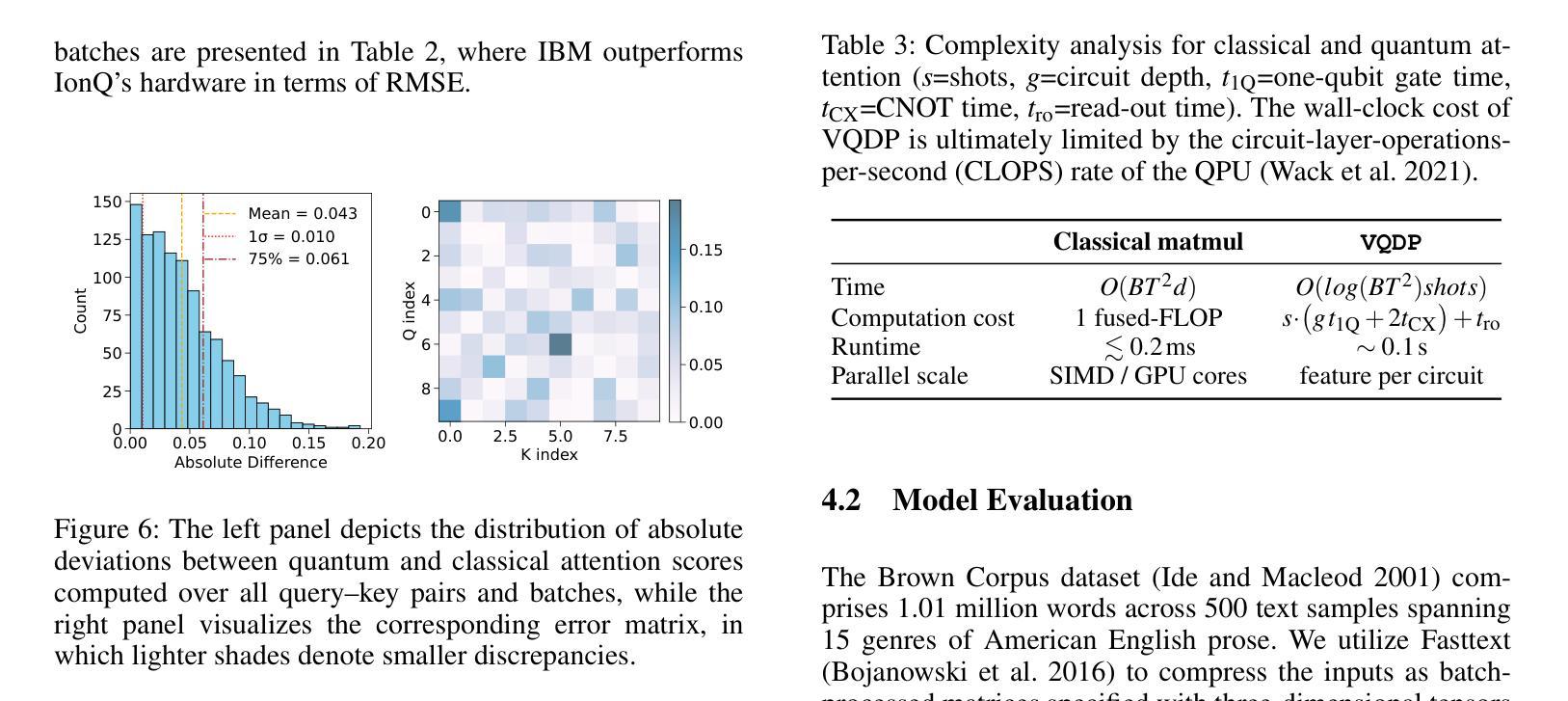
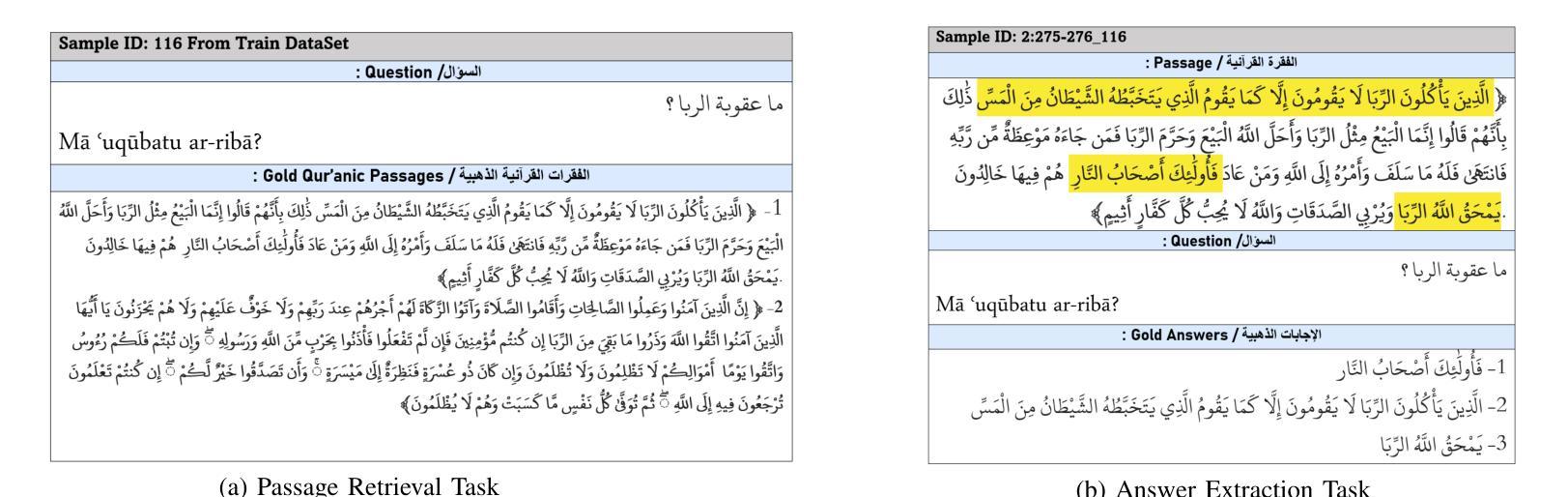
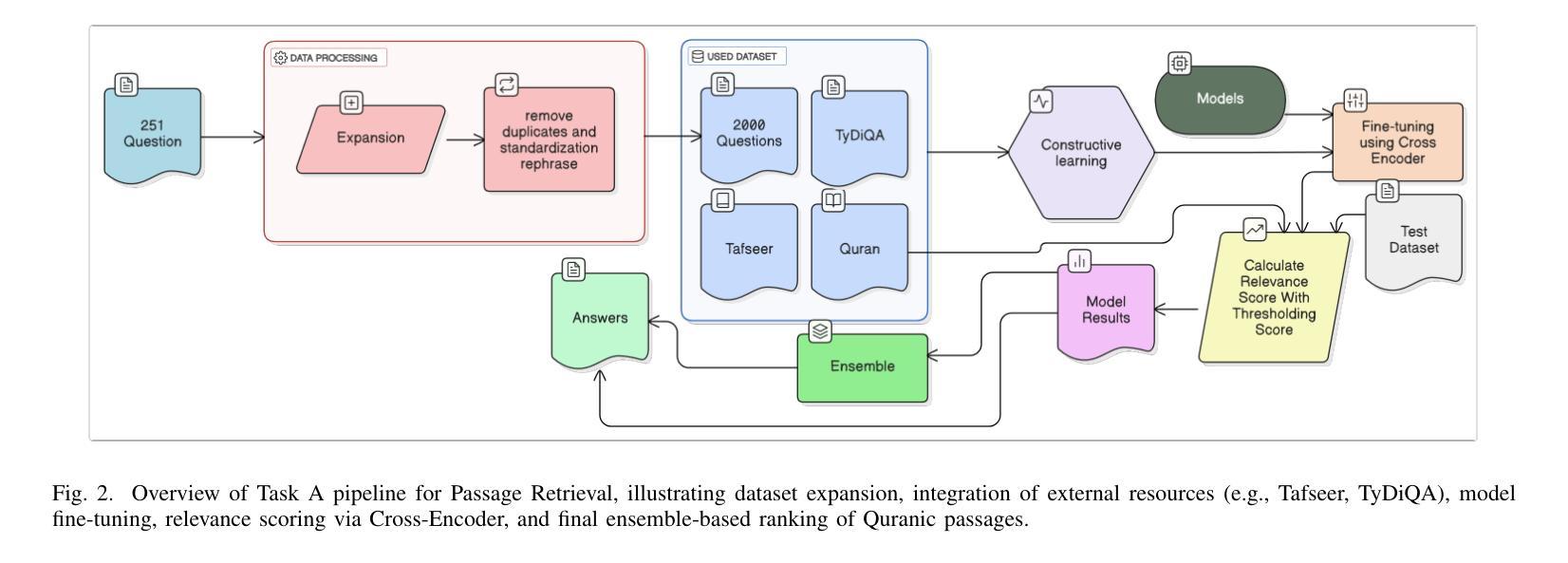
Two-Stage Quranic QA via Ensemble Retrieval and Instruction-Tuned Answer Extraction
Authors:Mohamed Basem, Islam Oshallah, Ali Hamdi, Khaled Shaban, Hozaifa Kassab
Quranic Question Answering presents unique challenges due to the linguistic complexity of Classical Arabic and the semantic richness of religious texts. In this paper, we propose a novel two-stage framework that addresses both passage retrieval and answer extraction. For passage retrieval, we ensemble fine-tuned Arabic language models to achieve superior ranking performance. For answer extraction, we employ instruction-tuned large language models with few-shot prompting to overcome the limitations of fine-tuning on small datasets. Our approach achieves state-of-the-art results on the Quran QA 2023 Shared Task, with a MAP@10 of 0.3128 and MRR@10 of 0.5763 for retrieval, and a pAP@10 of 0.669 for extraction, substantially outperforming previous methods. These results demonstrate that combining model ensembling and instruction-tuned language models effectively addresses the challenges of low-resource question answering in specialized domains.
由于古典阿拉伯语的语言复杂性和宗教文本丰富的语义内涵,伊斯兰问答提出了独特的挑战。在本文中,我们提出了一种新颖的两阶段框架,该框架同时解决了段落检索和答案提取。对于段落检索,我们通过微调阿拉伯语言模型来实现卓越的排名性能。对于答案提取,我们采用经过指令训练的大型语言模型,并通过几次提示来克服在小数据集上进行微调时的局限性。我们的方法在伊斯兰问答2023共享任务上取得了最新结果,检索的MAP@10为0.3128,MRR@10为0.5763,提取的pAP@10为0.669,显著优于以前的方法。这些结果表明,结合模型集成和指令训练的语言模型可以有效地解决特定领域低资源问答中的挑战。
论文及项目相关链接
PDF 8 pages , 4 figures , Accepted in Aiccsa 2025 , https://conferences.sigappfr.org/aiccsa2025/
Summary:
本文提出一种新颖的两阶段框架,用于解决因古典阿拉伯语的复杂性和宗教文本丰富的语义内涵所带来的古兰经问答挑战。通过微调阿拉伯语语言模型进行段落检索,并采用指令微调的大型语言模型进行答案提取,该方法在古兰经问答共享任务中取得了最新成果。通过模型组合,取得了优于以往方法的优异效果。此结果表明,模型组合和指令微调语言模型有效地解决了低资源专业领域的问答挑战。
Key Takeaways:
- 古兰经问答面临古典阿拉伯语的复杂性和宗教文本丰富语义的挑战。
- 提出一种新颖的两阶段框架,包括段落检索和答案提取。
- 使用微调阿拉伯语语言模型进行段落检索,达到优质排名性能。
- 采用指令微调的大型语言模型和少样本提示来克服在小型数据集上精细调整的局限性。
- 在古兰经问答共享任务中取得了最新成果,包括MAP@10和MRR@10的检索指标以及pAP@10的提取指标。
- 此方法显著优于以前的方法。
点此查看论文截图



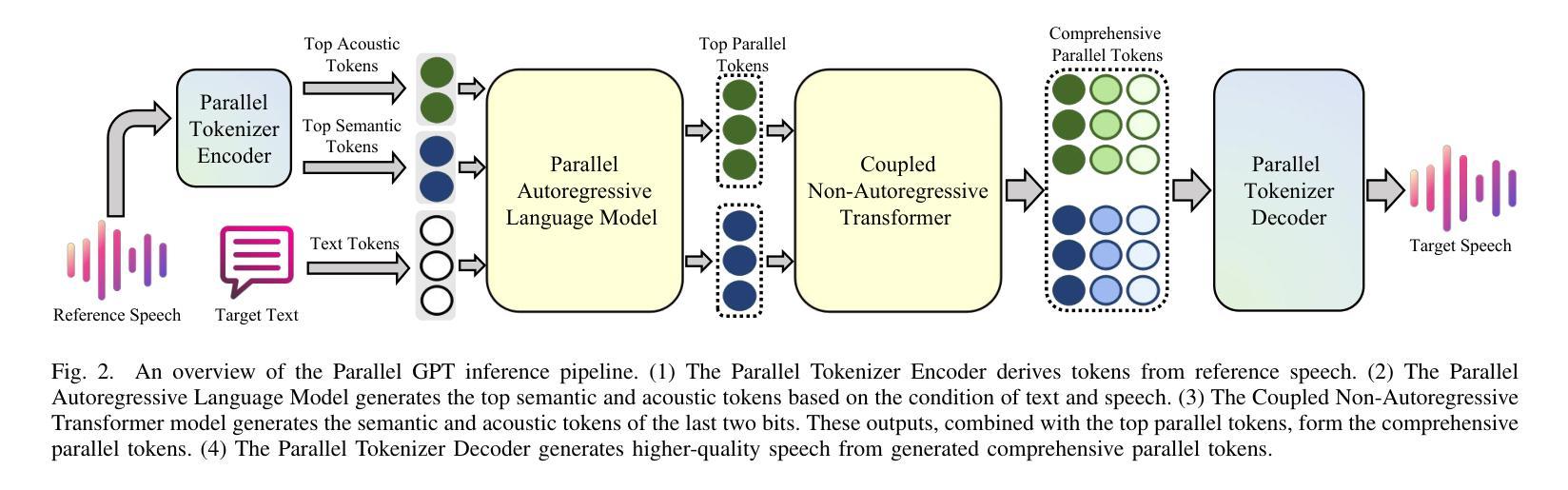
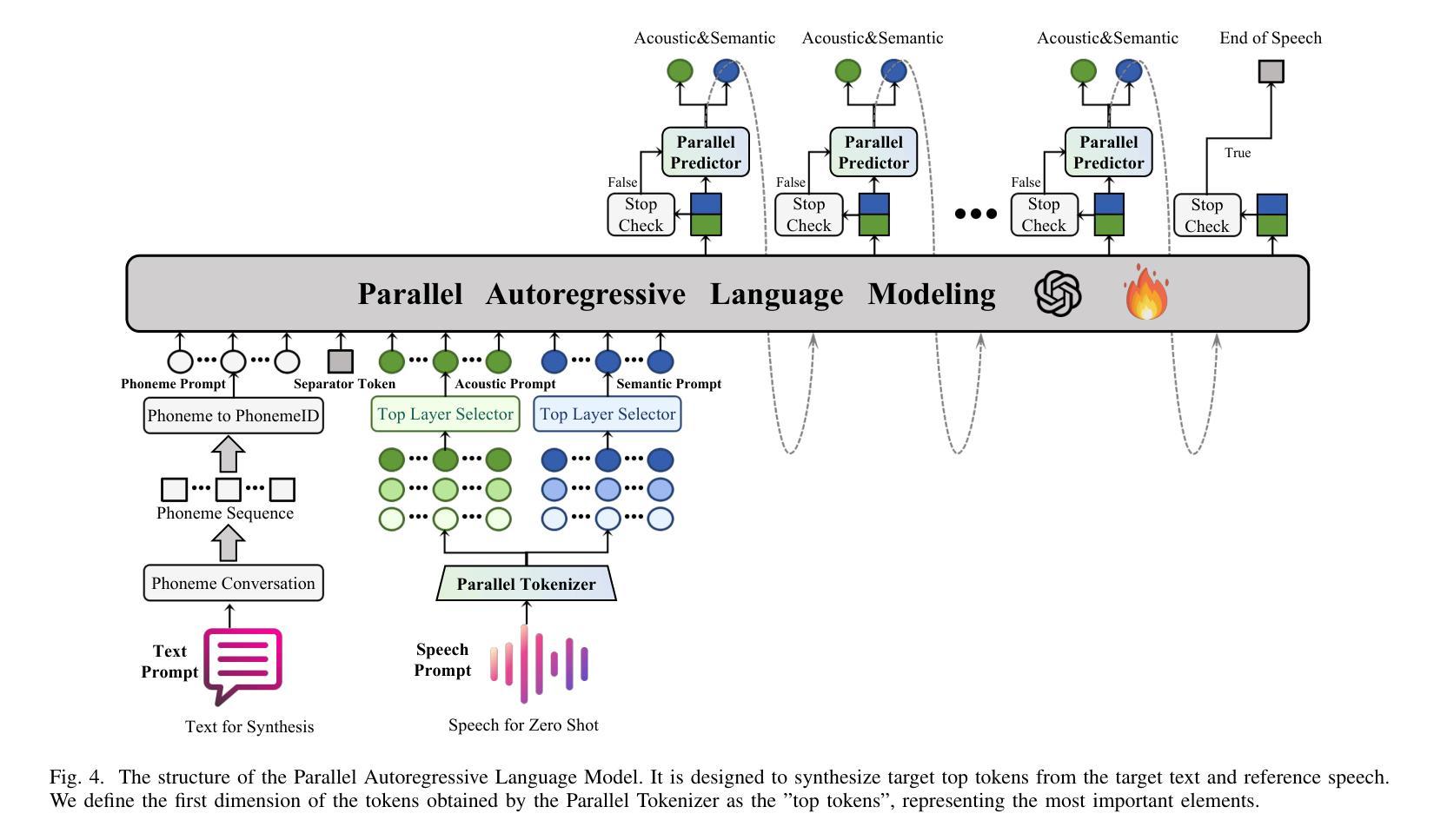
Parallel GPT: Harmonizing the Independence and Interdependence of Acoustic and Semantic Information for Zero-Shot Text-to-Speech
Authors:Jingyuan Xing, Zhipeng Li, Jialong Mai, Xiaofen Xing, Xiangmin Xu
Advances in speech representation and large language models have enhanced zero-shot text-to-speech (TTS) performance. However, existing zero-shot TTS models face challenges in capturing the complex correlations between acoustic and semantic features, resulting in a lack of expressiveness and similarity. The primary reason lies in the complex relationship between semantic and acoustic features, which manifests independent and interdependent aspects.This paper introduces a TTS framework that combines both autoregressive (AR) and non-autoregressive (NAR) modules to harmonize the independence and interdependence of acoustic and semantic information. The AR model leverages the proposed Parallel Tokenizer to synthesize the top semantic and acoustic tokens simultaneously. In contrast, considering the interdependence, the Coupled NAR model predicts detailed tokens based on the general AR model’s output. Parallel GPT, built on this architecture, is designed to improve zero-shot text-to-speech synthesis through its parallel structure. Experiments on English and Chinese datasets demonstrate that the proposed model significantly outperforms the quality and efficiency of the synthesis of existing zero-shot TTS models. Speech demos are available at https://t1235-ch.github.io/pgpt/.
语音表示和大语言模型的进步提高了零样本文本到语音(TTS)的性能。然而,现有的零样本TTS模型在捕捉声学特征和语义特征之间的复杂关联方面面临挑战,导致缺乏表达性和相似性。主要原因在于语义特征和声学特征之间的复杂关系,表现为独立和相互依赖的方面。本文介绍了一个结合了自回归(AR)和非自回归(NAR)模块的TTS框架,以协调声学信息和语义信息的独立性和相互依赖性。AR模型利用提出的并行分词器同时合成顶级语义和声音标记。相反,考虑到相互依赖性,耦合的NAR模型基于通用AR模型的输出预测详细的标记。基于此架构构建的并行GPT旨在通过其并行结构改进零样本文本到语音的合成。在英语和中文数据集上的实验表明,所提出的模型在合成质量和效率上显著优于现有的零样本TTS模型。语音演示可在https://t1-ch.github.io/pgpt/上查看。
论文及项目相关链接
PDF Submitted to IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP)
Summary
本文介绍了结合自回归(AR)和非自回归(NAR)模块的新型文本转语音(TTS)框架。这一框架旨在协调语音和语义信息的独立性和相互依赖性,通过合成顶级语义和声音标记以及基于AR模型的输出预测详细标记来提高零样本文本转语音的合成质量和效率。实验证明,该模型在英文和中文数据集上的表现均显著优于现有零样本TTS模型。
Key Takeaways
- 文本介绍了新的TTS框架如何通过使用AR和NAR模块来解决零样本文本转语音中语义和声音特征之间复杂关系的挑战。
- AR模型利用并行标记器同时合成顶级语义和声音标记,强调两者的同步处理。
- NAR模型基于AR模型的输出预测详细标记,体现了语音和语义的相互依赖性。
- 提出的Parallel GPT架构旨在提高零样本文本转语音的合成质量和效率。
- 实验结果显示,该模型在英文和中文数据集上的表现均优于现有模型。
- 模型的演示和更多细节可通过链接https://t1235-ch.github.io/pgpt/查看。
点此查看论文截图


TPTT: Transforming Pretrained Transformers into Titans
Authors:Fabien Furfaro
Transformer-based large language models (LLMs) have achieved strong performance across many natural language processing tasks. Nonetheless, their quadratic computational and memory requirements, particularly in self-attention layers, pose challenges for efficient inference on long contexts and for deployment in resource-limited environments. We present TPTT (Transforming Pretrained Transformers into Titans), a framework designed to augment pretrained Transformers with linearized attention (LiZA) and internal memory gating via Memory as Gate (MaG), applied without full retraining. TPTT supports parameter-efficient fine-tuning (LoRA) and integrates with standard toolkits such as Hugging Face Transformers. We evaluated TPTT on several pretrained models, including Llama-1B, OlMoE-1B-7B, Qwen2.5-1.5B, Gemma3-270m, OpenELM-1.3B, and Mistral-7B, in order to assess applicability across architectures of different scales. Experiments on models with approximately 1 billion parameters, evaluated primarily on the MMLU benchmark, suggest potential improvements in both efficiency and accuracy compared to baseline models. For example, Titans-Llama-1B exhibited up to a 20% relative increase in Exact Match scores in one-shot evaluation. An additional finding is that it is possible to convert a quadratic-attention model into a purely linear-attention model using the DeltaProduct mechanism. All training runs were carried out with modest computational resources. These preliminary findings indicate that TPTT may help adapt pretrained LLMs for long-context tasks with limited overhead. Further studies on larger models and a broader set of benchmarks will be necessary to evaluate the generality and robustness of the framework. Code is available at https://github.com/fabienfrfr/tptt . Python package at https://pypi.org/project/tptt/ .
基于Transformer的大型语言模型(LLM)在许多自然语言处理任务中取得了强大的性能。然而,它们的二次计算和内存要求,特别是在自注意力层中,对长文本的高效推理和资源受限环境中的部署提出了挑战。我们提出了TPTT(将预训练的Transformer转化为巨人)框架,旨在通过线性注意力(LiZA)和通过内存作为门控机制(MaG)的内部记忆门控来增强预训练的Transformer,而无需进行全面再训练。TPTT支持参数高效的微调(LoRA),并且可以与Hugging Face Transformers等标准工具包集成。我们在多个预训练模型上评估了TPTT,包括Llama-1B、OlMoE-1B-7B、Qwen2.5-1.5B、Gemma3-270m、OpenELM-1.3B和Mistral-7B等模型,以评估其在不同规模架构中的适用性。在MMLU基准测试上评估的约含1亿参数的模型实验表明,与基准模型相比,TPTT在效率和准确性方面都有潜在的提升。例如,Titans-Llama-1B在一次评估中的精确匹配得分提高了高达20%。另一个发现是使用DeltaProduct机制将二次注意力模型转换为纯线性注意力模型的可能性。所有的训练运行都是使用适中的计算资源完成的。这些初步结果表明,TPTT可能有助于适应长文本任务的预训练LLM,并且具有有限的额外开销。为了评估该框架的通用性和稳健性,还需要在更大的模型和更广泛的基准测试集上进行进一步研究。代码地址为https://github.com/fabienfrfr/tptt。Python包地址为https://pypi.org/project/tptt/。
论文及项目相关链接
PDF 14 pages, 2 figure
Summary
预训练的大型语言模型(LLM)在多自然语言处理任务中表现优秀,但计算与内存资源需求限制了其在长文本场景及资源受限环境下的效率部署能力。我们提出了基于Transforming Pretrained Transformers into Titans(TPTT)框架,通过线性注意力(LiZA)与内存门控技术(MaG)增强预训练模型的性能,无需全量重训即可应用。TPTT支持参数高效微调(LoRA),并能与Hugging Face Transformers等标准工具集集成。实验评估表明,该框架在不同规模的模型中具有潜在提升效率和准确性的潜力。例如,Llama-1B模型在一次评估中精确匹配得分提高了高达相对百分之二十。初步发现表明,使用DeltaProduct机制可将二次注意力模型转换为纯线性注意力模型。所有训练运行都在使用适度计算资源的情况下完成。代码已公开在GitHub上。Python包已发布在PyPI上。
Key Takeaways
- TPTT框架旨在增强预训练Transformer模型在长文本场景和资源受限环境中的性能。
- TPTT结合了线性注意力(LiZA)和内存门控技术(MaG)以增强模型性能,无需全量重训。
- TPTT支持参数高效微调(LoRA),并能与标准工具集集成,如Hugging Face Transformers。
- 实验评估表明,TPTT在不同规模的模型中有望提高效率和准确性。
- 使用DeltaProduct机制可将二次注意力模型转换为纯线性注意力模型。
点此查看论文截图

Bringing Attention to CAD: Boundary Representation Learning via Transformer
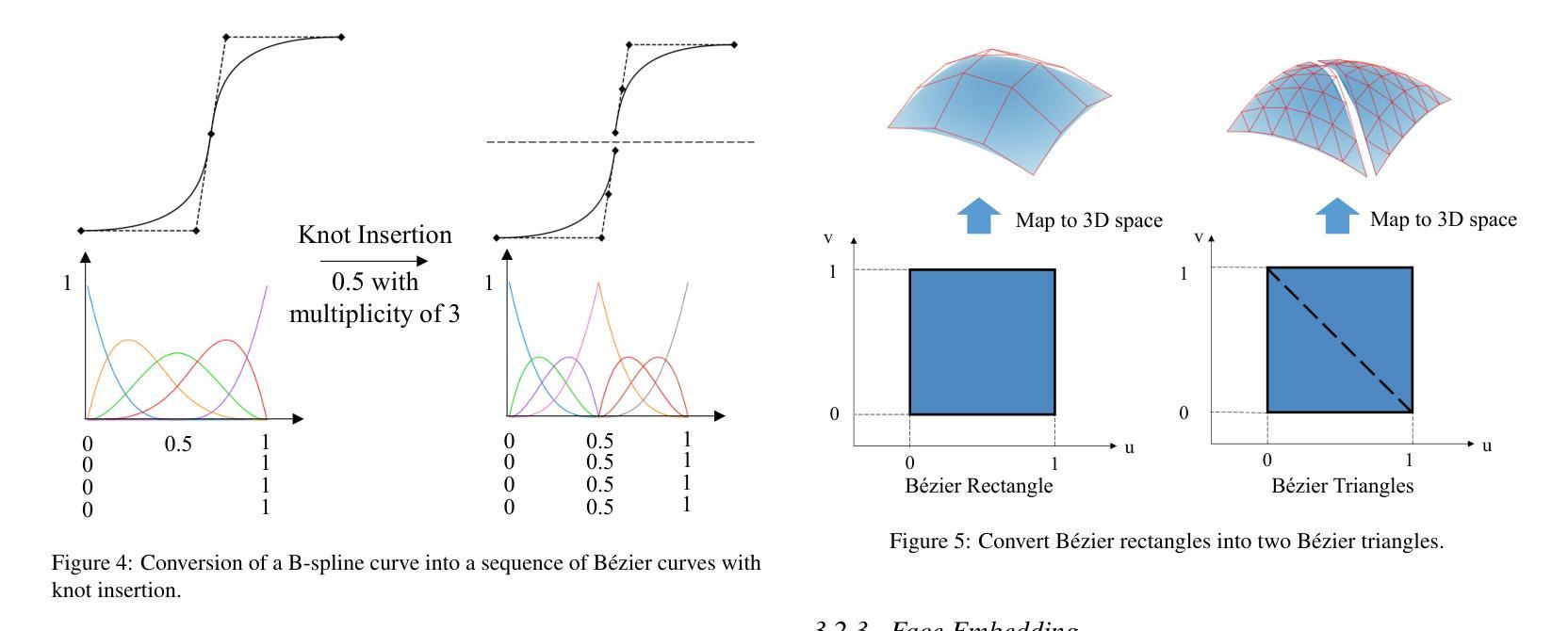
Authors:Qiang Zou, Lizhen Zhu
The recent rise of generative artificial intelligence (AI), powered by Transformer networks, has achieved remarkable success in natural language processing, computer vision, and graphics. However, the application of Transformers in computer-aided design (CAD), particularly for processing boundary representation (B-rep) models, remains largely unexplored. To bridge this gap, we propose a novel approach for adapting Transformers to B-rep learning, called the Boundary Representation Transformer (BRT). B-rep models pose unique challenges due to their irregular topology and continuous geometric definitions, which are fundamentally different from the structured and discrete data Transformers are designed for. To address this, BRT proposes a continuous geometric embedding method that encodes B-rep surfaces (trimmed and untrimmed) into Bezier triangles, preserving their shape and continuity without discretization. Additionally, BRT employs a topology-aware embedding method that organizes these geometric embeddings into a sequence of discrete tokens suitable for Transformers, capturing both geometric and topological characteristics within B-rep models. This enables the Transformer’s attention mechanism to effectively learn shape patterns and contextual semantics of boundary elements in a B-rep model. Extensive experiments demonstrate that BRT achieves state-of-the-art performance in part classification and feature recognition tasks.
最近,以Transformer网络为动力的生成式人工智能(AI)在自然语言处理、计算机视觉和图形领域取得了显著的成就。然而,Transformer在计算机辅助设计(CAD)中的应用,尤其是在处理边界表示(B-rep)模型方面,仍然未被充分探索。为了弥补这一空白,我们提出了一种新型的Transformer适应B-rep学习方法,称为边界表示转换器(BRT)。B-rep模型由于其不规则拓扑和连续几何定义而具有独特挑战,这些与Transformer所设计的结构化离散数据存在根本差异。为解决这一问题,BRT提出了一种连续几何嵌入方法,将B-rep表面(带修饰和不带修饰)编码为Bezier三角形,保留其形状和连续性,无需离散化。此外,BRT采用了一种拓扑感知嵌入方法,将这些几何嵌入组织成适合Transformer的离散令牌序列,捕捉B-rep模型中的几何和拓扑特征。这使得Transformer的注意力机制能够有效地学习B-rep模型中边界元素的形状模式和上下文语义。大量实验表明,BRT在零件分类和特征识别任务上达到了最先进的性能。
论文及项目相关链接
Summary
基于Transformer网络的生成式人工智能在自然语言处理、计算机视觉和图形领域取得了显著成功,但在计算机辅助设计(CAD)的边界表示(B-rep)模型应用方面仍鲜有探索。为弥补这一空白,提出了适应B-rep学习的全新方法——边界表示转换器(BRT)。BRT通过连续几何嵌入方法将B-rep曲面编码为Bezier三角形,并保留其形状和连续性。同时,利用拓扑感知嵌入法将几何嵌入转换为适合Transformer的离散令牌序列,捕捉B-rep模型的几何和拓扑特征。这使得Transformer的关注机制能有效学习B-rep模型中边界元素的形状模式和上下文语义。实验证明,BRT在零件分类和特征识别任务上达到了最先进的性能。
Key Takeaways
- Transformer网络在多个领域取得了显著成功,但在计算机辅助设计(CAD)的边界表示(B-rep)模型应用方面仍有待探索。
- BRT是一种适应B-rep学习的全新方法。
- BRT通过连续几何嵌入方法将B-rep曲面编码为Bezier三角形,保留其形状和连续性。
- BRT利用拓扑感知嵌入法将几何嵌入转换为适合Transformer的离散令牌序列。
- BRT能捕捉B-rep模型的几何和拓扑特征。
- Transformer的关注机制通过BRT能有效学习B-rep模型中边界元素的形状模式和上下文语义。
- 实验证明,BRT在零件分类和特征识别任务上达到了最先进的性能。
点此查看论文截图




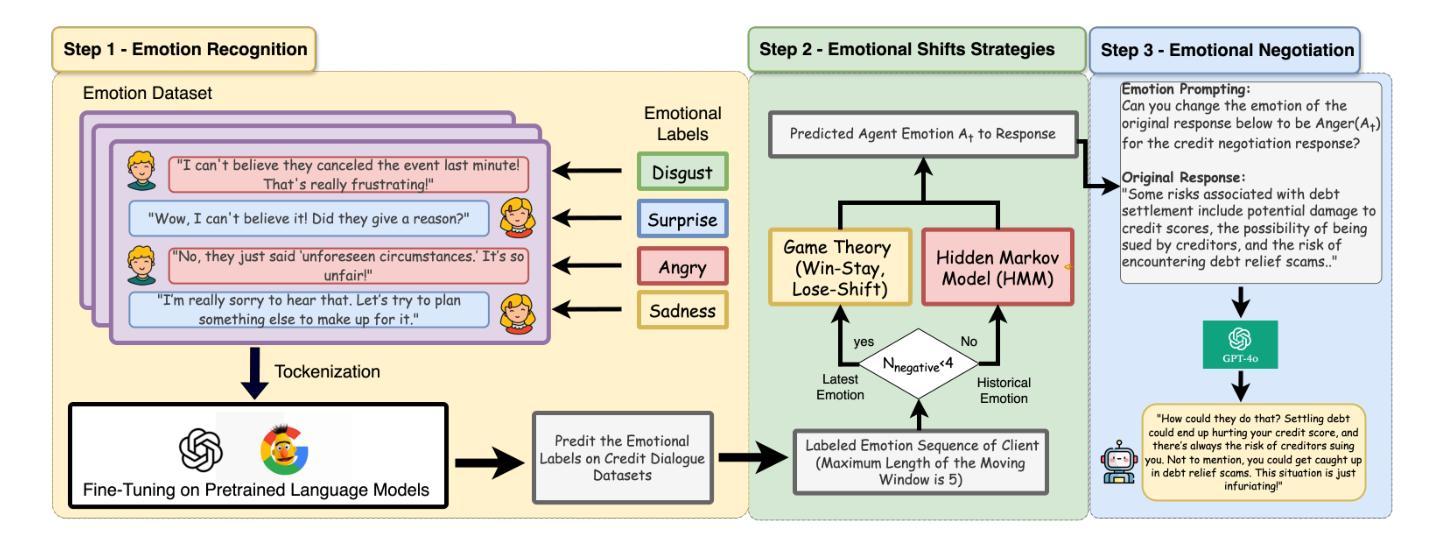
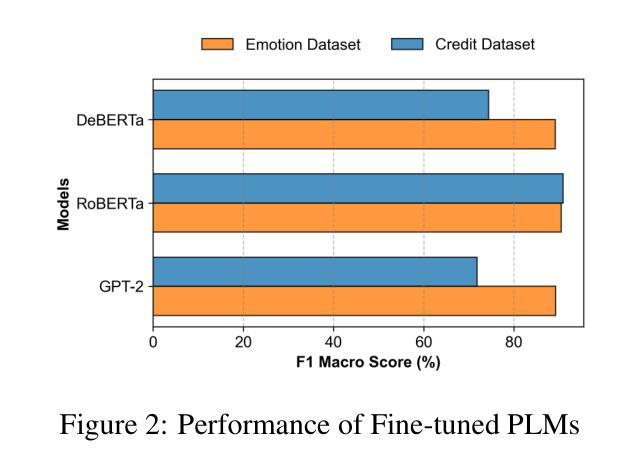
EQ-Knight: A Memory-Augmented LLM Agent for Strategic Affective Gaming in Debt Recovery
Authors:Yunbo Long, Yuhan Liu, Liming Xu, Alexandra Brintrup
Large language model-based chatbots have enhanced engagement in financial negotiations, but their overreliance on passive empathy introduces critical risks in credit collection. While empathy-driven approaches preserve client satisfaction in benign cases, they fail catastrophically against dishonest debtors–individuals who exploit conciliatory tactics to manipulate terms or evade repayment. Blindly prioritizing “customer experience” in such scenarios leads to creditor vulnerabilities: revenue leakage, moral hazard, and systemic exploitation. To address this, we propose EQ-Knight, an LLM agent that dynamically optimizes emotional strategy to defend creditor interests. Unlike naive empathy-centric bots, EQ-Knight integrates emotion memory and game-theoretic reasoning, powered by a Hidden Markov Model (HMM) to track and predict debtor emotional states. By analyzing both real-time and historical emotional cues, EQ-Knight strategically counters negative emotions (e.g., aggression, feigned distress) while preserving productive debtor relationships. Experiments demonstrate EQ-Knight’s superiority over conventional LLM negotiators: it achieves a 32% reduction in concession losses without compromising recovery rates, particularly in adversarial cases where debtors weaponize negative emotions (e.g., intimidation, guilt-tripping) to coerce concessions. For credit agencies, EQ-Knight transforms LLMs from high-risk “people-pleasers” into strategic emotion-defenders–balancing emotional intelligence with tactical rigor to enforce accountability and deter exploitation.
基于大型语言模型的聊天机器人在财务谈判中的参与度有所提高,但它们过于依赖被动共情,在收款方面存在重大风险。在良性情况下,以共情驱动的方法可以保持客户满意度,但它们对失信债务人(即利用和解策略来操纵条件或逃避还款的个人)却产生灾难性的失败。在这种情况下盲目优先重视“客户体验”,会导致债权人面临漏洞,如收入损失、道德风险和系统性剥削。为了解决这个问题,我们提出了EQ-Knight这一LLM代理,它能够动态优化情绪策略来维护债权人的利益。不同于简单的以共情为中心的机器人,EQ-Knight结合了情绪记忆和游戏理论推理,借助隐马尔可夫模型(HMM)跟踪和预测债务人的情绪状态。通过实时和历史情绪线索的分析,EQ-Knight能够战略性地应对消极情绪(如攻击性、假装的痛苦),同时保持与债务人的良好关系。实验证明,EQ-Knight优于传统的LLM谈判者:它在让步损失方面减少了32%,同时不妥协于回收率,特别是在债务人利用消极情绪(如恐吓、施加内疚感)来迫使让步的对立情况下表现尤为出色。对于信贷机构而言,EQ-Knight能够将LLM从高风险的人际取悦者转变为战略性的情绪捍卫者——平衡情商与战术严谨性,以执行问责制并遏制剥削。
论文及项目相关链接
Summary:基于大型语言模型的聊天机器人在财务谈判中的参与度有所提升,但过度依赖被动共情在信贷回收方面带来巨大风险。尽管在良性情况下,共情驱动的方法能保持客户满意度,但对不诚实债务人来说,他们利用和解策略来操纵条款或逃避还款。盲目优先考虑客户体验导致债权人面临收入损失、道德风险和系统性剥削等脆弱性。为解决这一问题,我们提出EQ-Knight这一LLM智能体,它能动态优化情感策略以维护债权人利益。不同于简单的共情中心机器人,EQ-Knight整合情感记忆和游戏理论推理,借助隐马尔可夫模型跟踪和预测债务人情感状态。通过分析实时和历史情感线索,EQ-Knight能战略性地应对负面情绪,同时维持与债务人的良好关系。实验证明,EQ-Knight相较于传统LLM谈判者更具优势,在债务人使用负面情绪(如威胁和内疚)胁迫让步的情况下,实现了让步损失减少32%,且回收率未受影响。对信贷机构而言,EQ-Knight将LLM从高风险的人情机器转变为战略情绪防御者,平衡情感智能与战术严谨性,以执行问责制并遏制剥削。
Key Takeaways:
- 大型语言模型聊天机器人在财务谈判中增强参与度的同时,过度依赖被动共情在信贷回收方面存在风险。
- 共情驱动的方法在良性情况下能维持客户满意度,但对不诚实债务人容易遭受操纵和剥削。
- 债权人面临因盲目优先考虑客户体验而导致的收入损失、道德风险和系统性剥削等问题。
- EQ-Knight通过整合情感记忆和游戏理论推理,动态优化情感策略以维护债权人利益。
- EQ-Knight借助隐马尔可夫模型跟踪和预测债务人情感状态,实现战略应对负面情绪同时维持与债务人的良好关系。
- 实验表明,EQ-Knight相较于传统LLM谈判者更具优势,能够在不影响回收率的情况下减少让步损失。
点此查看论文截图



InsBank: Evolving Instruction Subset for Ongoing Alignment
Authors:Jiayi Shi, Yiwei Li, Shaoxiong Feng, Peiwen Yuan, Xinglin Wang, Yueqi Zhang, Chuyi Tan, Boyuan Pan, Huan Ren, Yao Hu, Kan Li
Large language models (LLMs) typically undergo instruction tuning to enhance alignment. Recent studies emphasize that quality and diversity of instruction data are more crucial than quantity, highlighting the need to select diverse, high-quality subsets to reduce training costs. However, how to evolve these selected subsets alongside the development of new instruction data remains insufficiently explored. To achieve LLMs’ ongoing alignment, we introduce Instruction Bank (\textbf{InsBank}), a continuously updated repository that integrates the latest valuable instruction data. We further propose Progressive Instruction Bank Evolution (\textbf{PIBE}), a novel framework designed to evolve InsBank effectively and efficiently over time. PIBE employs a gradual data selection strategy to maintain long-term efficiency, leveraging a representation-based diversity score to capture relationships between data points and retain historical information for comprehensive diversity evaluation. This also allows for flexible combination of diversity and quality scores during data selection and ranking. Extensive experiments demonstrate that PIBE significantly outperforms baselines in InsBank evolution and is able to extract budget-specific subsets, demonstrating its effectiveness and adaptability.
大型语言模型(LLM)通常通过指令调整来增强对齐效果。最近的研究强调,指令数据的质量和多样性比数量更重要,这凸显了选择多样、高质量子集的需要,以降低训练成本。然而,如何随着新指令数据的发展而发展这些选择的子集尚未得到充分探索。为了实现LLM的持续对齐,我们引入了指令库(InsBank),这是一个不断更新的存储库,集成了最新的宝贵指令数据。我们进一步提出了渐进式指令库进化(PIBE)这一新型框架,旨在随时间有效地实现InsBank的进化。PIBE采用逐步数据选择策略来维持长期效率,利用基于表示的多样性分数来捕捉数据点之间的关系并保留历史信息进行全面的多样性评估。这也允许在数据选择和排名过程中灵活组合多样性和质量分数。大量实验表明,PIBE在InsBank进化方面显著优于基线,并且能够提取特定预算的子集,证明了其有效性和适应性。
论文及项目相关链接
Summary
LLM的指令调整是关注质量和多样性的新时代的研究重点。为此,研究者们提出一种新颖框架Progressive Instruction Bank Evolution(PIBE),用于有效地集成和更新高质量指令数据。PIBE使用逐步的数据选择策略维持长期效率,结合基于表现的多样性和质量分数进行数据筛选和排名,从而在资源预算方面展示出了其灵活性和有效性。这项研究的目的是为了在长期发展过程中维持LLM的持续对齐状态。
Key Takeaways
- LLM的研究重点已从数量转向指令数据的质量和多样性。
- 为实现LLM的持续对齐,引入了Instruction Bank(InsBank)这一持续更新的指令数据存储库。
- 提出了一种新颖的框架Progressive Instruction Bank Evolution(PIBE),旨在有效和高效地推进InsBank的进化。
- PIBE采用逐步数据选择策略,以维持长期效率。
- PIBE利用表现多样性分数进行数据筛选和排名,同时考虑多样性和质量因素。
- PIBE能够在预算限制下提取特定子集,表现出灵活性和适应性。
点此查看论文截图


ROSE: A Reward-Oriented Data Selection Framework for LLM Task-Specific Instruction Tuning
Authors:Yang Wu, Huayi Zhang, Yizheng Jiao, Lin Ma, Xiaozhong Liu, Jinhong Yu, Dongyu Zhang, Dezhi Yu, Wei Xu
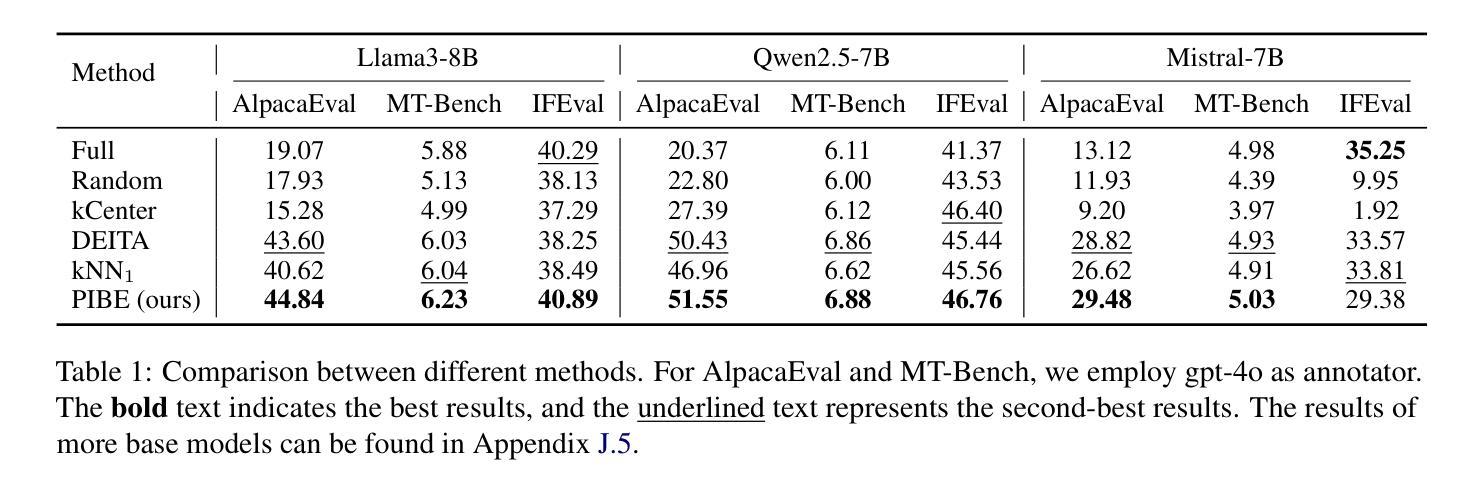
Instruction tuning has underscored the significant potential of large language models (LLMs) in producing more human controllable and effective outputs in various domains. In this work, we focus on the data selection problem for task-specific instruction tuning of LLMs. Prevailing methods primarily rely on the crafted similarity metrics to select training data that aligns with the test data distribution. The goal is to minimize instruction tuning loss on the test data, ultimately improving performance on the target task. However, it has been widely observed that instruction tuning loss (i.e., cross-entropy loss for next token prediction) in LLMs often fails to exhibit a monotonic relationship with actual task performance. This misalignment undermines the effectiveness of current data selection methods for task-specific instruction tuning. To address this issue, we introduce ROSE, a novel Reward-Oriented inStruction data sElection method which leverages pairwise preference loss as a reward signal to optimize data selection for task-specific instruction tuning. Specifically, ROSE adapts an influence formulation to approximate the influence of training data points relative to a few-shot preference validation set to select the most task-related training data points. Experimental results show that by selecting just 5% of the training data using ROSE, our approach can achieve competitive results compared to fine-tuning with the full training dataset, and it surpasses other state-of-the-art data selection methods for task-specific instruction tuning. Our qualitative analysis further confirms the robust generalizability of our method across multiple benchmark datasets and diverse model architectures.
指令微调已经凸显了大型语言模型(LLM)在各领域产生更多人类可控和有效输出的显著潜力。在这项工作中,我们专注于LLM任务特定指令调制的数选择问题。流行的方法主要依赖于手工制作的相似性度量标准来选择与测试数据分布一致的训练数据。目标是减小测试数据上的指令微调损失,最终提高目标任务的性能。然而,人们普遍观察到,LLM中的指令微调损失(即下一个标记预测的交叉熵损失)与实际任务性能之间往往没有单调关系。这种错位降低了当前数据选择方法在特定任务指令调整中的有效性。为了解决这个问题,我们引入了ROSE,这是一种新的奖励导向指令数据选择方法,它利用成对偏好损失作为奖励信号,优化针对特定任务指令的数据选择。具体来说,ROSE采用一种影响公式来近似训练数据点与少量偏好验证集的影响关系,以选择最相关的训练数据点。实验结果表明,使用ROSE仅选择5%的训练数据,我们的方法就可以取得与全训练数据集微调相竞争的结果,并且超越了其他针对特定任务指令的先进数据选择方法。我们的定性分析进一步证实了我们的方法在多个基准数据集和各种模型架构中的稳健泛化能力。
论文及项目相关链接
PDF EMNLP 2025 Findings
Summary
本文探讨了大型语言模型(LLM)在任务特定指令调整中的数据选择问题。针对现有方法主要依赖手工构建的相似性度量来选择与测试数据分布对齐的训练数据的问题,提出了ROSE方法。该方法利用成对偏好损失作为奖励信号来优化数据选择,通过影响公式来近似选择与少数偏好验证集相关的训练数据点。实验结果表明,ROSE只需选择5%的训练数据即可获得与全数据集微调相当的结果,并超越了其他先进的数据选择方法。
Key Takeaways
- 大型语言模型(LLM)在任务特定指令调整中展现巨大潜力。
- 当前数据选择方法主要依赖与测试数据分布的相似性度量来选择训练数据。
- 指令调整损失与实际任务性能之间经常存在不匹配,导致现有数据选择方法效果不佳。
- ROSE方法利用成对偏好损失作为奖励信号来优化数据选择。
- ROSE通过影响公式选择最相关的训练数据点,相对少数偏好验证集。
- 实验显示,ROSE仅选择5%的训练数据即可获得与全数据集微调相当的结果。
点此查看论文截图



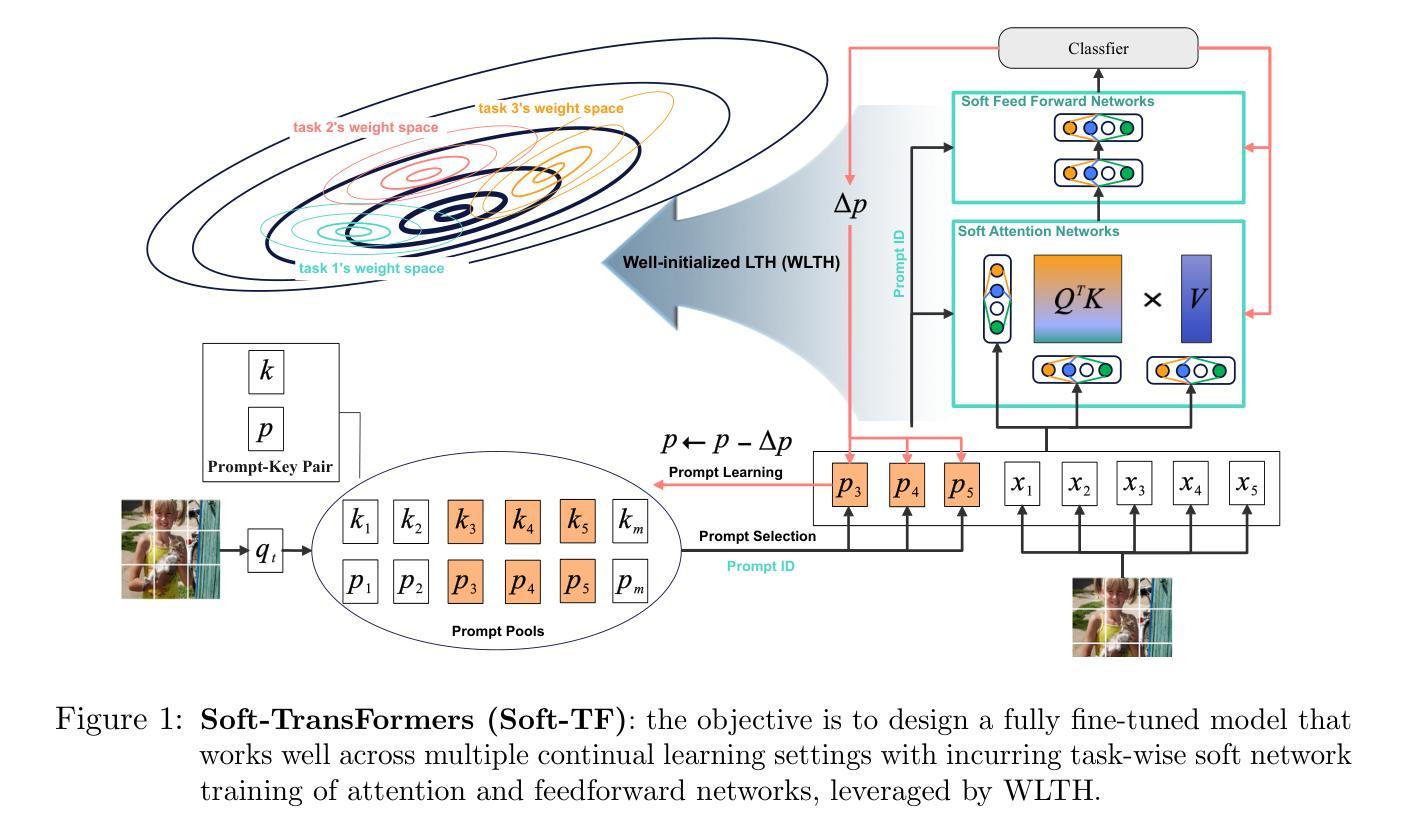
Soft-TransFormers for Continual Learning
Authors:Haeyong Kang, Chang D. Yoo
Inspired by the Well-initialized Lottery Ticket Hypothesis (WLTH), which provides suboptimal fine-tuning solutions, we propose a novel fully fine-tuned continual learning (CL) method referred to as Soft-TransFormers (Soft-TF). Soft-TF sequentially learns and selects an optimal soft-network for each task. During sequential training in CL, a well-initialized Soft-TF mask optimizes the weights of sparse layers to obtain task-adaptive soft (real-valued) networks, while keeping the well-pre-trained layer parameters frozen. In inference, the identified task-adaptive network of Soft-TF masks the parameters of the pre-trained network, mapping to an optimal solution for each task and minimizing Catastrophic Forgetting (CF) - the soft-masking preserves the knowledge of the pre-trained network. Extensive experiments on the Vision Transformer (ViT) and the Language Transformer (Bert) demonstrate the effectiveness of Soft-TF, achieving state-of-the-art performance across Vision and Language Class Incremental Learning (CIL) scenarios.
受初始状态良好的彩票票根假设(WLTH)的启发,该假设提供了次优的微调解决方案,我们提出了一种新型的完全微调连续学习(CL)方法,称为Soft-TransFormers(Soft-TF)。Soft-TF按顺序学习并为每个任务选择最佳软网络。在连续学习(CL)的序列训练中,良好初始化的Soft-TF掩码会优化稀疏层的权重,以获得任务适应性的软(实值)网络,同时保持预先训练好的层参数不变。在推理过程中,Soft-TF所确定的与任务相适应的网络会掩盖预训练网络的参数,为每一个任务映射出最佳解决方案,并尽量减少灾难性遗忘(CF)——软掩码会保留预训练网络的知识。在视觉转换器(ViT)和语言转换器(Bert)上的大量实验证明了Soft-TF的有效性,在视觉和语言类别增量学习(CIL)场景中实现了最先进的性能。
论文及项目相关链接
Summary
本文基于Well-initialized Lottery Ticket Hypothesis(WLTH)提出了全新的完全精细调整的持续学习方法——Soft-TransFormers(Soft-TF)。该方法能够按顺序学习和选择每个任务的最优软网络。在持续学习中进行顺序训练时,Soft-TF通过优化稀疏层的权重来获得任务适应性的软(实值)网络,同时保持预训练层参数冻结。在推理过程中,Soft-TF所确定的任务适应性网络会遮蔽预训练网络的参数,为每项任务找到最优解,并最小化灾难性遗忘。实验证明,Soft-TF在视觉变压器(ViT)和语言变压器(Bert)上实现了卓越的性能,在视觉和语言类别增量学习场景中达到领先水平。
Key Takeaways
- 基于Well-initialized Lottery Ticket Hypothesis(WLTH),提出全新的持续学习方法——Soft-TransFormers(Soft-TF)。
- Soft-TF能够按顺序学习和选择每个任务的最优软网络。
- 在持续学习中进行顺序训练时,Soft-TF通过优化稀疏层的权重来获得任务适应性的软网络,同时保持预训练层参数冻结。
- Soft-TF通过遮蔽预训练网络的参数来适应不同任务,找到每个任务的最优解。
- Soft-TF方法能够最小化灾难性遗忘。
- Soft-TF在视觉变压器(ViT)和语言变压器(Bert)上进行了实验验证。
点此查看论文截图


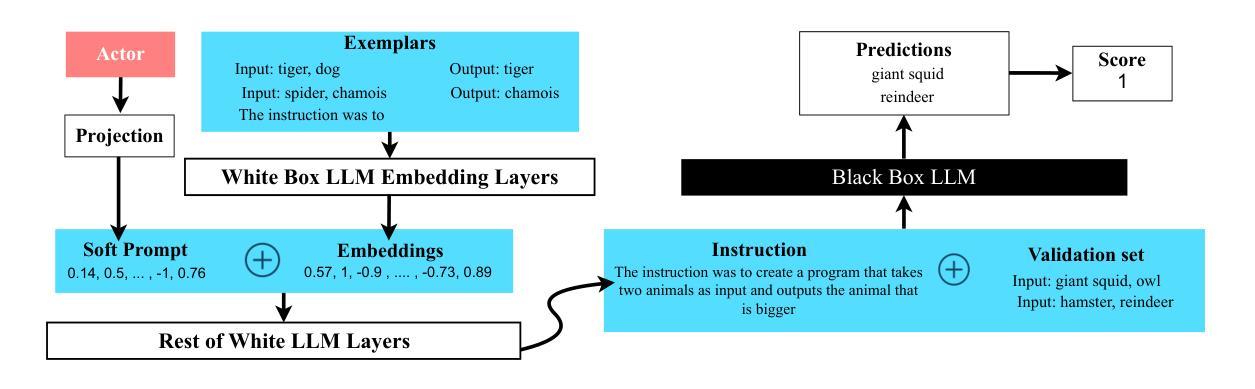
ACING: Actor-Critic for Instruction Learning in Black-Box LLMs
Authors:Salma Kharrat, Fares Fourati, Marco Canini
The effectiveness of Large Language Models (LLMs) in solving tasks depends significantly on the quality of their instructions, which often require substantial human effort to craft. This underscores the need for automated instruction optimization. However, optimizing instructions is particularly challenging when working with black-box LLMs, where model parameters and gradients are inaccessible. We introduce ACING, an actor-critic reinforcement learning framework that formulates instruction optimization as a stateless, continuous-action problem, enabling exploration of infinite instruction spaces using only black-box feedback. ACING automatically discovers prompts that outperform human-written prompts in 76% of instruction-induction tasks, with gains of up to 33 points and a 10-point median improvement over the best automatic baseline in 33 tasks spanning instruction-induction, summarization, and chain-of-thought reasoning. Extensive ablations highlight its robustness and efficiency. An implementation of ACING is available at https://github.com/salmakh1/ACING.
大型语言模型(LLM)在完成任务时的有效性很大程度上取决于指令的质量,而这通常需要大量的人工精力来制定。这强调了自动指令优化的必要性。然而,在与黑盒LLM(模型参数和梯度不可访问)一起工作时,优化指令具有特别大的挑战性。我们引入了ACING,这是一种基于强化学习的演员评论家框架,它将指令优化公式化为一个无状态、连续动作的问题,仅使用黑盒反馈就能探索无限的指令空间。在指令归纳任务的76%中,ACING自动发现的提示优于人类编写的提示,在涵盖指令归纳、摘要和链式思维推理的33项任务中,相较于最佳自动基线有高达33分的提升,中位数改善为10分。大量的消融实验突显了其稳健性和效率。有关ACING的实现可访问:https://github.com/salmakh1/ACING。
论文及项目相关链接
PDF Accepted at EMNLP 2025
Summary
大型语言模型(LLM)的有效性在很大程度上取决于指令的质量,这通常需要大量的人力来制定指令,这强调了自动指令优化的必要性。然而,在与黑盒LLM合作时,由于模型参数和梯度无法访问,指令优化具有挑战性。我们引入了名为“ACING”的演员评论家强化学习框架,它将指令优化表述为一个无状态、连续动作的问题,仅使用黑盒反馈即可探索无限的指令空间。在76%的指令感应任务中,自动发现的提示词表现优于人为编写的提示词,在包括指令感应在内的多个任务上获得最大至超过最高自动化基准点超过三点的积分增长值及十点中位数改善,表明其在多任务的鲁棒性和效率方面具有优越性。通过在“https://github.com/salmakh1/ACING”上实现。
Key Takeaways
- 大型语言模型(LLM)的有效性取决于指令的质量,这需要大量的手工定制工作,强调了自动指令优化的重要性。
- 在黑盒LLM环境中优化指令具有挑战性,因为模型参数和梯度无法访问。
- ACING框架通过强化学习自动优化指令,将指令优化表述为无状态、连续动作的问题。
- ACING能够在广泛的指令感应任务中自动发现超越人工制定的指令提示。
- ACING在各种任务中表现优异,如指令感应、摘要和链式思维推理等,并且在多数任务上的表现超过最高自动化基准点。
点此查看论文截图




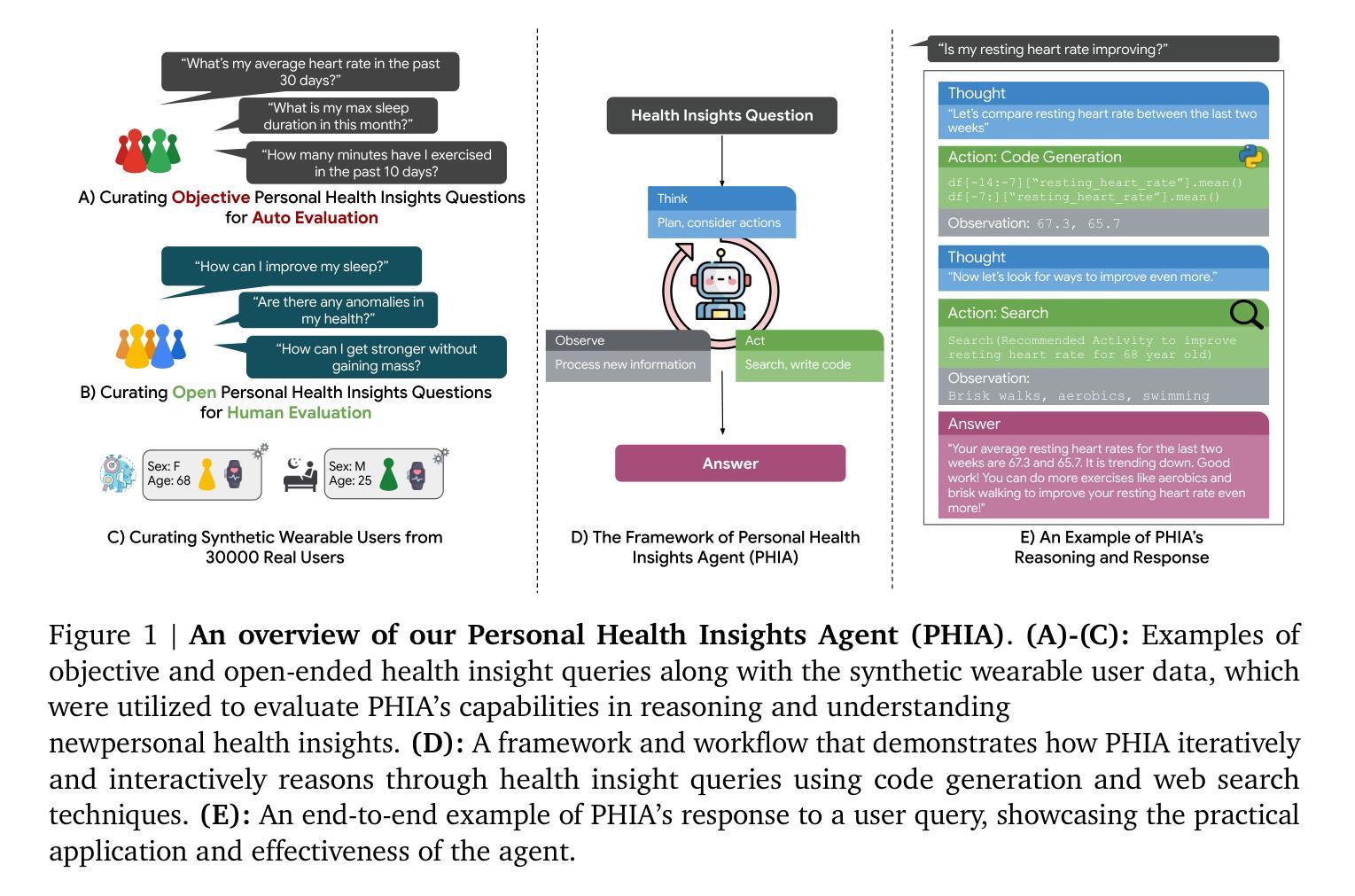
Transforming Wearable Data into Personal Health Insights using Large Language Model Agents
Authors:Mike A. Merrill, Akshay Paruchuri, Naghmeh Rezaei, Geza Kovacs, Javier Perez, Yun Liu, Erik Schenck, Nova Hammerquist, Jake Sunshine, Shyam Tailor, Kumar Ayush, Hao-Wei Su, Qian He, Cory Y. McLean, Mark Malhotra, Shwetak Patel, Jiening Zhan, Tim Althoff, Daniel McDuff, Xin Liu
Deriving personalized insights from popular wearable trackers requires complex numerical reasoning that challenges standard LLMs, necessitating tool-based approaches like code generation. Large language model (LLM) agents present a promising yet largely untapped solution for this analysis at scale. We introduce the Personal Health Insights Agent (PHIA), a system leveraging multistep reasoning with code generation and information retrieval to analyze and interpret behavioral health data. To test its capabilities, we create and share two benchmark datasets with over 4000 health insights questions. A 650-hour human expert evaluation shows that PHIA significantly outperforms a strong code generation baseline, achieving 84% accuracy on objective, numerical questions and, for open-ended ones, earning 83% favorable ratings while being twice as likely to achieve the highest quality rating. This work can advance behavioral health by empowering individuals to understand their data, enabling a new era of accessible, personalized, and data-driven wellness for the wider population.
从流行的可穿戴跟踪器中获取个性化洞察需要复杂的数值推理,这挑战了标准的大型语言模型(LLM),需要基于工具的方法,如代码生成。大型语言模型(LLM)代理人为这种大规模分析提供了有前景且尚未充分利用的解决方案。我们介绍了个人健康洞察代理(PHIA),这是一个系统,利用多步骤推理和代码生成以及信息检索来分析并解释行为健康数据。为了测试其能力,我们创建并分享了包含超过4000个健康洞察问题的两个基准数据集。一项为期650小时的人类专家评估表明,PHIA显著优于强大的代码生成基线,在客观数值问题上达到84%的准确率,在开放性问题上获得83%的好评,并且最有可能获得最高质量评分。这项工作可以通过帮助个人理解他们的数据,为更广泛的人群开启一个可访问、个性化、数据驱动的健康新时代,从而促进行为健康的发展。
论文及项目相关链接
PDF 53 pages, 7 main figures, 2 main tables, accepted to Nature Communications
Summary
穿戴式追踪器产生的个性化洞察需要复杂的数值推理,这挑战了标准的大型语言模型,需要基于工具的方法如代码生成来解决。我们引入了个人健康洞察代理(PHIA),这是一个系统,利用多步骤推理和代码生成来分析和解释行为健康数据。测试显示,PHIA在客观数值问题和开放性问题上的准确率分别达到了84%和83%,并且更有可能获得最高质量评分,显著优于强大的代码生成基线。这为行为健康领域带来了个性化的数据驱动福利的新时代。
Key Takeaways
- 穿戴式追踪器产生的数据需要复杂的数值推理来转化为个性化洞察。
- 标准的大型语言模型在处理这些数据时面临挑战。
- 个人健康洞察代理(PHIA)是一个多步骤推理系统,利用代码生成和信息检索来分析健康数据。
- PHIA在客观数值问题和开放性问题的准确率很高。
- PHIA显著优于基线代码生成方法。
- PHIA可以为个体提供理解其数据的工具,推动行为健康领域的发展。
点此查看论文截图