⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-09 更新
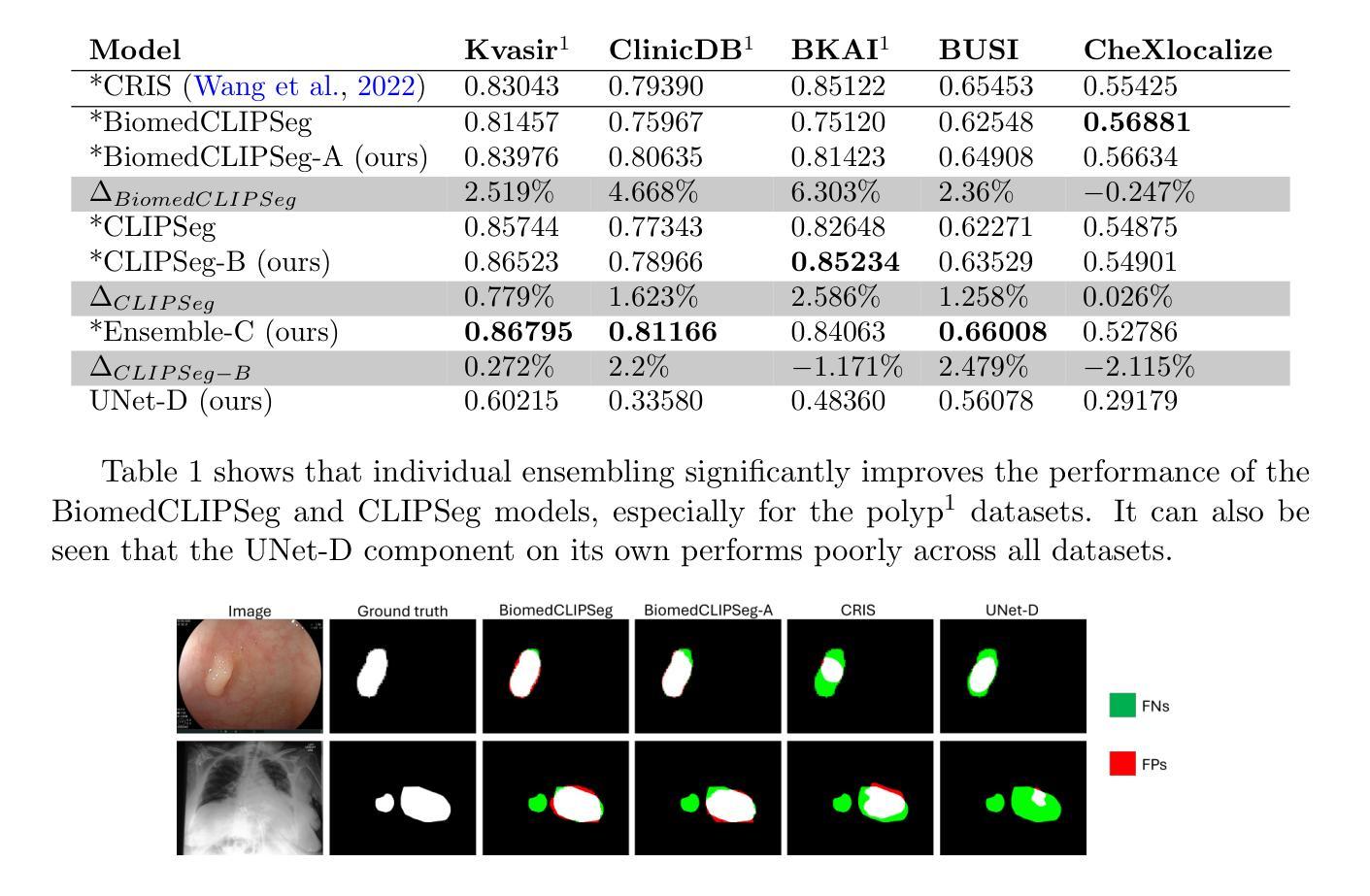
VLSM-Ensemble: Ensembling CLIP-based Vision-Language Models for Enhanced Medical Image Segmentation
Authors:Julia Dietlmeier, Oluwabukola Grace Adegboro, Vayangi Ganepola, Claudia Mazo, Noel E. O’Connor
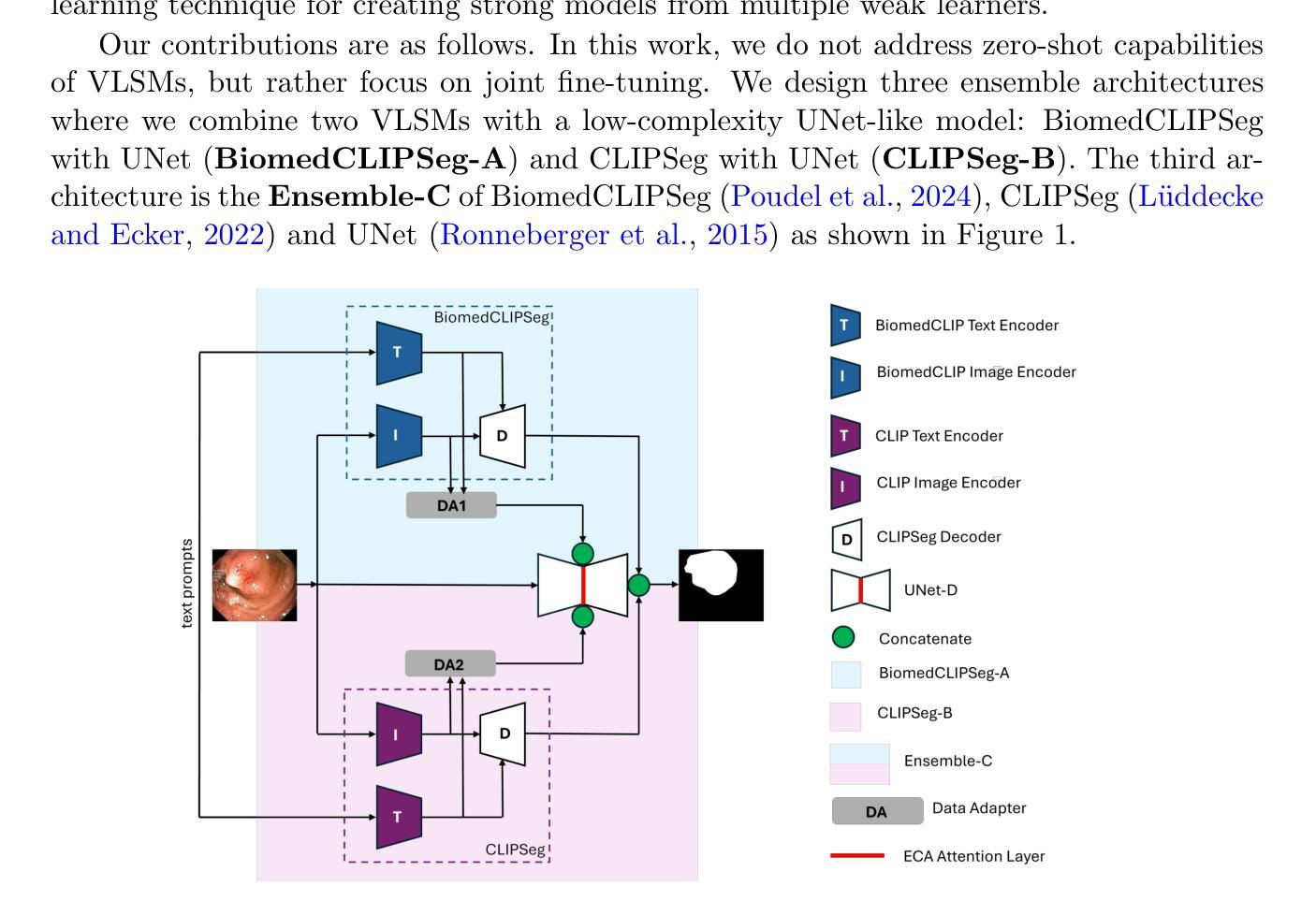
Vision-language models and their adaptations to image segmentation tasks present enormous potential for producing highly accurate and interpretable results. However, implementations based on CLIP and BiomedCLIP are still lagging behind more sophisticated architectures such as CRIS. In this work, instead of focusing on text prompt engineering as is the norm, we attempt to narrow this gap by showing how to ensemble vision-language segmentation models (VLSMs) with a low-complexity CNN. By doing so, we achieve a significant Dice score improvement of 6.3% on the BKAI polyp dataset using the ensembled BiomedCLIPSeg, while other datasets exhibit gains ranging from 1% to 6%. Furthermore, we provide initial results on additional four radiology and non-radiology datasets. We conclude that ensembling works differently across these datasets (from outperforming to underperforming the CRIS model), indicating a topic for future investigation by the community. The code is available at https://github.com/juliadietlmeier/VLSM-Ensemble.
视觉语言模型及其在图像分割任务中的适应性表现出巨大的潜力,能够产生高度准确和可解释的结果。然而,基于CLIP和BiomedCLIP的实施仍然落后于更先进的架构,如CRIS。在这项工作中,我们没有关注常见的文本提示工程,而是尝试通过展示如何将视觉语言分割模型(VLSM)与低复杂度CNN结合来缩小这一差距。通过这样做,我们在BKAI息肉数据集上使用集成的BiomedCLIPSeg实现了6.3%的Dice得分提升,而其他数据集则显示出从1%到6%不等的增益。此外,我们还提供了关于其他四个放射科和非放射科数据集的初步结果。我们得出结论,集成模型在这些数据集上的表现各不相同(从超越到低于CRIS模型),这为未来社区的研究提供了一个话题。代码可从https://github.com/juliadietlmeier/VLSM-Ensemble获取。
论文及项目相关链接
PDF Medical Imaging with Deep Learning (MIDL 2025) short paper
Summary
本文探讨了视觉语言模型在图像分割任务中的应用潜力,通过集成低复杂度的CNN与视觉语言分割模型(VLSMs),实现了在BKAI息肉数据集上Dice得分提高6.3%的显著成果。同时,该研究还涉及四个放射科和非放射科数据集的初步结果,并指出集成效果在不同数据集上存在差异,为未来的研究提供了方向。代码已公开在GitHub上。
Key Takeaways
- 视觉语言模型在图像分割任务中具有巨大潜力。
- 通过集成低复杂度的CNN与视觉语言分割模型(VLSMs),实现了在特定数据集上的显著性能提升。
- 在BKAI息肉数据集上,集成的BiomedCLIPSeg模型实现了Dice得分提高6.3%。
- 研究涉及四个放射科和非放射科数据集的初步实验结果。
- 集成效果在不同数据集上表现不同,既有超过CRIS模型的情况,也有未能超越的情况。
- 该研究为未来的研究提供了方向,即进一步探索集成方法在不同数据集上的表现。
点此查看论文截图

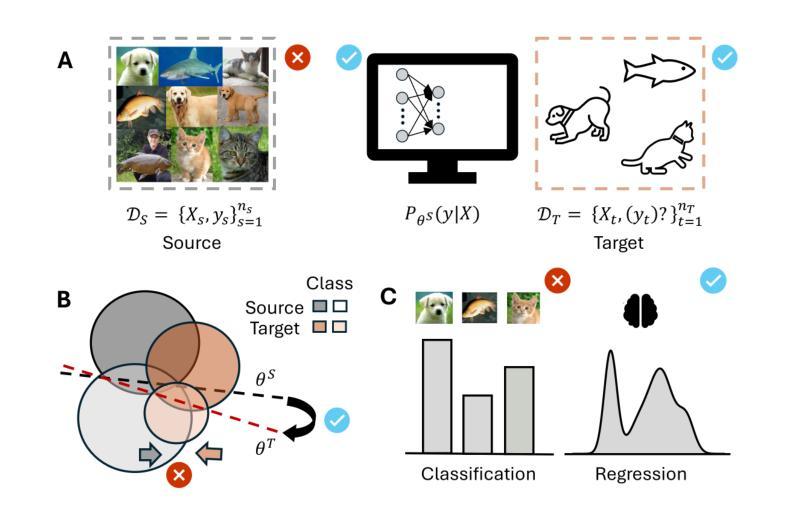
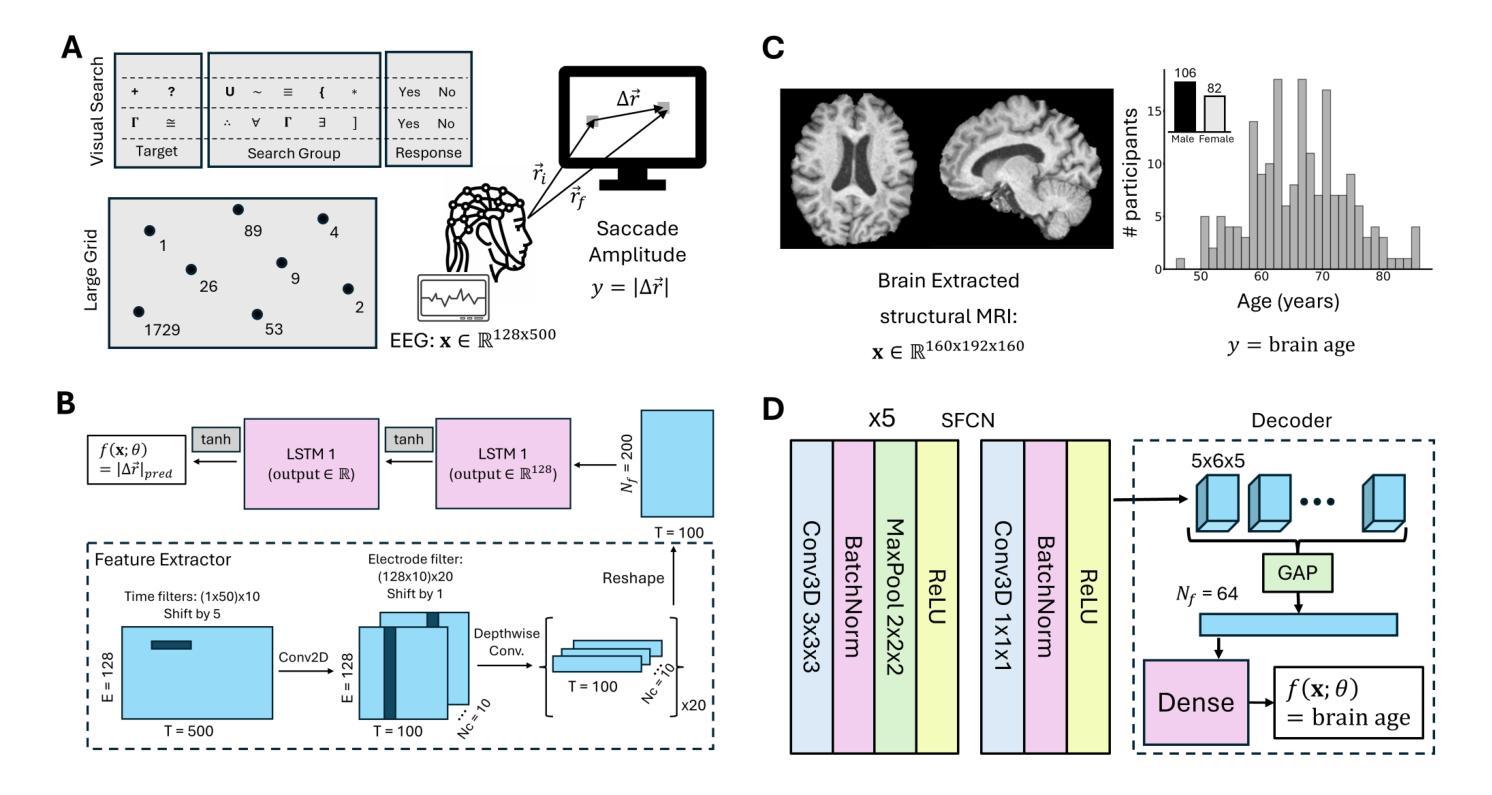
Semi-supervised Deep Transfer for Regression without Domain Alignment
Authors:Mainak Biswas, Ambedkar Dukkipati, Devarajan Sridharan
Deep learning models deployed in real-world applications (e.g., medicine) face challenges because source models do not generalize well to domain-shifted target data. Many successful domain adaptation (DA) approaches require full access to source data. Yet, such requirements are unrealistic in scenarios where source data cannot be shared either because of privacy concerns or because it is too large and incurs prohibitive storage or computational costs. Moreover, resource constraints may limit the availability of labeled targets. We illustrate this challenge in a neuroscience setting where source data are unavailable, labeled target data are meager, and predictions involve continuous-valued outputs. We build upon Contradistinguisher (CUDA), an efficient framework that learns a shared model across the labeled source and unlabeled target samples, without intermediate representation alignment. Yet, CUDA was designed for unsupervised DA, with full access to source data, and for classification tasks. We develop CRAFT – a Contradistinguisher-based Regularization Approach for Flexible Training – for source-free (SF), semi-supervised transfer of pretrained models in regression tasks. We showcase the efficacy of CRAFT in two neuroscience settings: gaze prediction with electroencephalography (EEG) data and ``brain age’’ prediction with structural MRI data. For both datasets, CRAFT yielded up to 9% improvement in root-mean-squared error (RMSE) over fine-tuned models when labeled training examples were scarce. Moreover, CRAFT leveraged unlabeled target data and outperformed four competing state-of-the-art source-free domain adaptation models by more than 3%. Lastly, we demonstrate the efficacy of CRAFT on two other real-world regression benchmarks. We propose CRAFT as an efficient approach for source-free, semi-supervised deep transfer for regression that is ubiquitous in biology and medicine.
在现实世界应用(如医学)中部署的深度学习模型面临挑战,因为源模型不能很好地推广到域偏移的目标数据。许多成功的域适应(DA)方法需要完全访问源数据。然而,在源数据因隐私担忧或数据过大导致存储和计算成本高昂而无法共享的情况下,这种要求是不现实的。此外,资源约束可能限制标记目标的可用性。我们以神经科学环境为例来说明这一挑战,在该环境中源数据不可用,标记的目标数据很少,预测涉及连续值输出。我们基于Contradistinguisher(CUDA)构建了一个模型,这是一个在标记源和无标签目标样本上学习共享模型的有效框架,无需中间表示对齐。然而,CUDA是为具有完整源数据访问权限的无监督DA和分类任务而设计的。我们开发了CRAFT–一种基于Contradistinguisher的正则化灵活训练方法,用于无源(SF)半监督预训练模型的迁移。我们在两个神经科学环境中展示了CRAFT的有效性:使用脑电图(EEG)数据的目光预测和使用结构MRI数据的“脑年龄”预测。对于这两个数据集,当标记的训练样本稀缺时,与微调模型相比,CRAFT在均方根误差(RMSE)上最多提高了9%。此外,CRAFT利用无标签的目标数据并超越了其他四个竞争性的前沿无源域适应模型超过3%。最后,我们在另外两个现实世界回归基准测试上证明了CRAFT的有效性。我们提出CRAFT作为一种在无源、半监督深度迁移中有效的方法,这在生物学和医学中是普遍存在的。
论文及项目相关链接
PDF 15 pages, 6 figures, International Conference on Computer Vision 2025
摘要
深度学习模型在实际应用(如医学)中面临的挑战是源模型不能很好地泛化到域转移的目标数据。许多成功的域适应(DA)方法需要完全访问源数据,但在隐私担忧或源数据过大导致存储和计算成本高昂的情况下,这种要求不切实际。此外,资源约束可能限制标记目标的可用性。我们在神经科学环境中说明了这一挑战,该环境中源数据不可用,标记的目标数据很少,预测涉及连续值输出。我们基于Contradistinguisher(CUDA)构建了一个模型,可以在标记的源样本和无标记的目标样本上学习共享模型,而无需中间表示对齐。然而,CUDA是为具有完整源数据和无监督的DA以及分类任务而设计的。我们开发了CRAFT——一种基于Contradistinguisher的正则化方法,用于源免费的半监督预训练模型回归任务。我们在两个神经科学环境中展示了CRAFT的有效性:使用脑电图(EEG)数据的目光预测和用结构MRI数据进行“脑年龄”预测。对于这两个数据集,当标记训练样本稀缺时,CRAFT在均方根误差(RMSE)上最多提高了9%,并且相较于仅依赖标签数据的模型展现出了更强大的性能。此外,CRAFT利用无标签的目标数据并超越了四种竞争性的前沿源自由域适应模型超过3%。最后,我们在另外两个真实世界的回归基准测试上展示了CRAFT的有效性。我们提出CRAFT是一种高效的源自由、半监督深度转移回归方法,在生物学和医学中普遍存在。
关键见解
- 深度学习模型在实际应用中面临域适应挑战,特别是在源数据无法泛化到目标数据时。
- 当前许多域适应方法要求完全访问源数据,这在隐私或成本约束下不切实际。
- CRAFT基于Contradistinguisher构建,可在源数据不可用或半监督设置中进行域适应。
- CRAFT在神经科学环境中(如EEG和MRI数据)进行回归任务时表现出色。
- CRAFT在标记训练样本稀缺时提高了模型性能,并在多个基准测试中超越了其他方法。
- CRAFT利用无标签目标数据增强模型性能。
点此查看论文截图

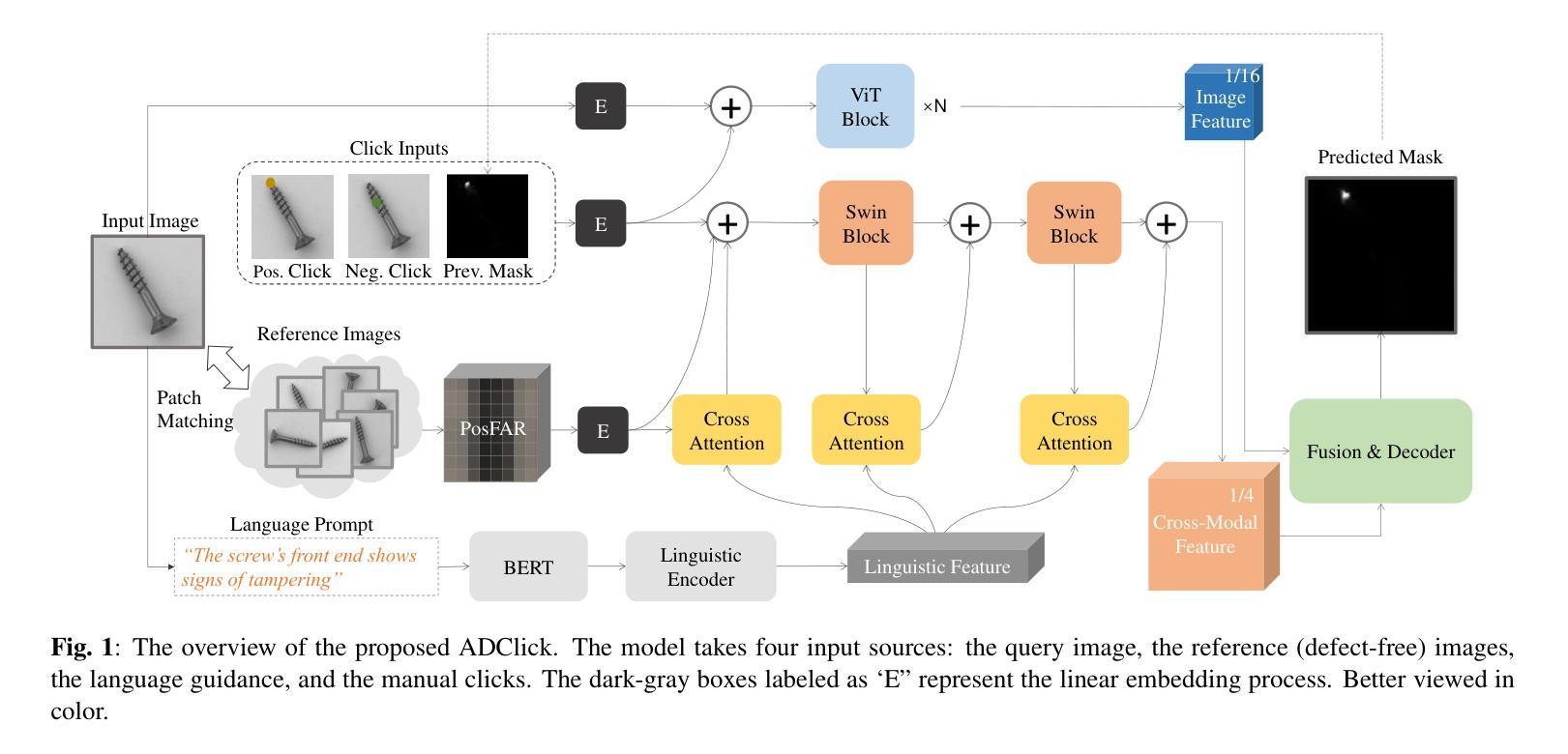
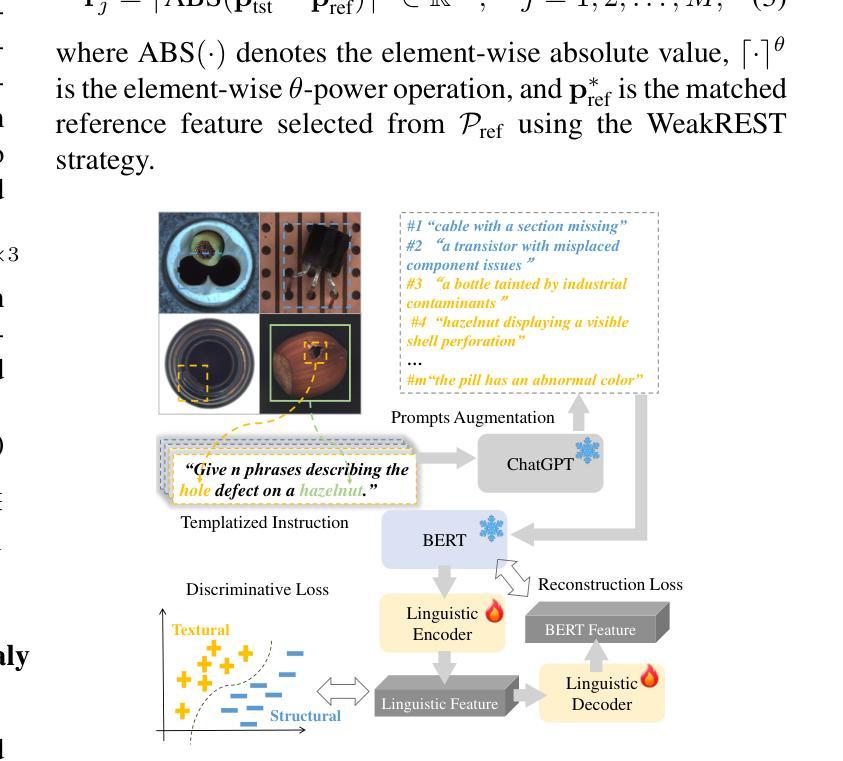
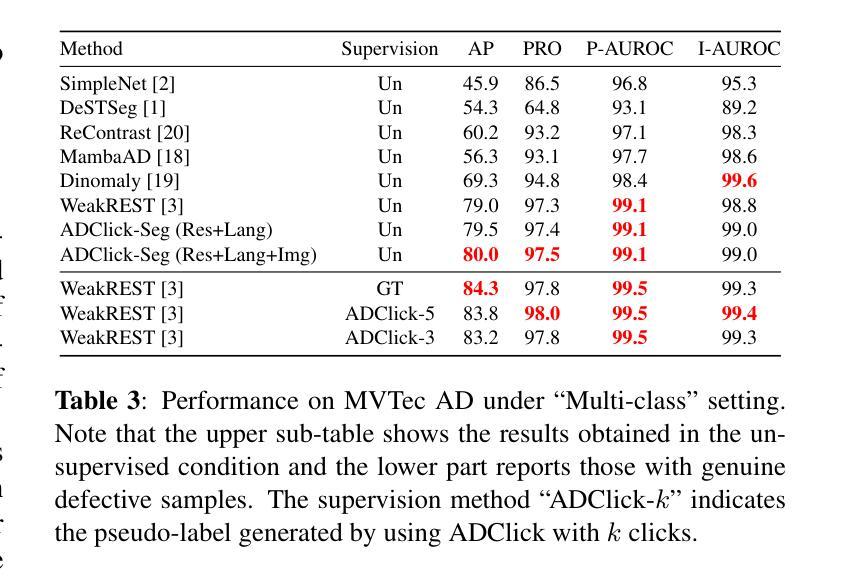
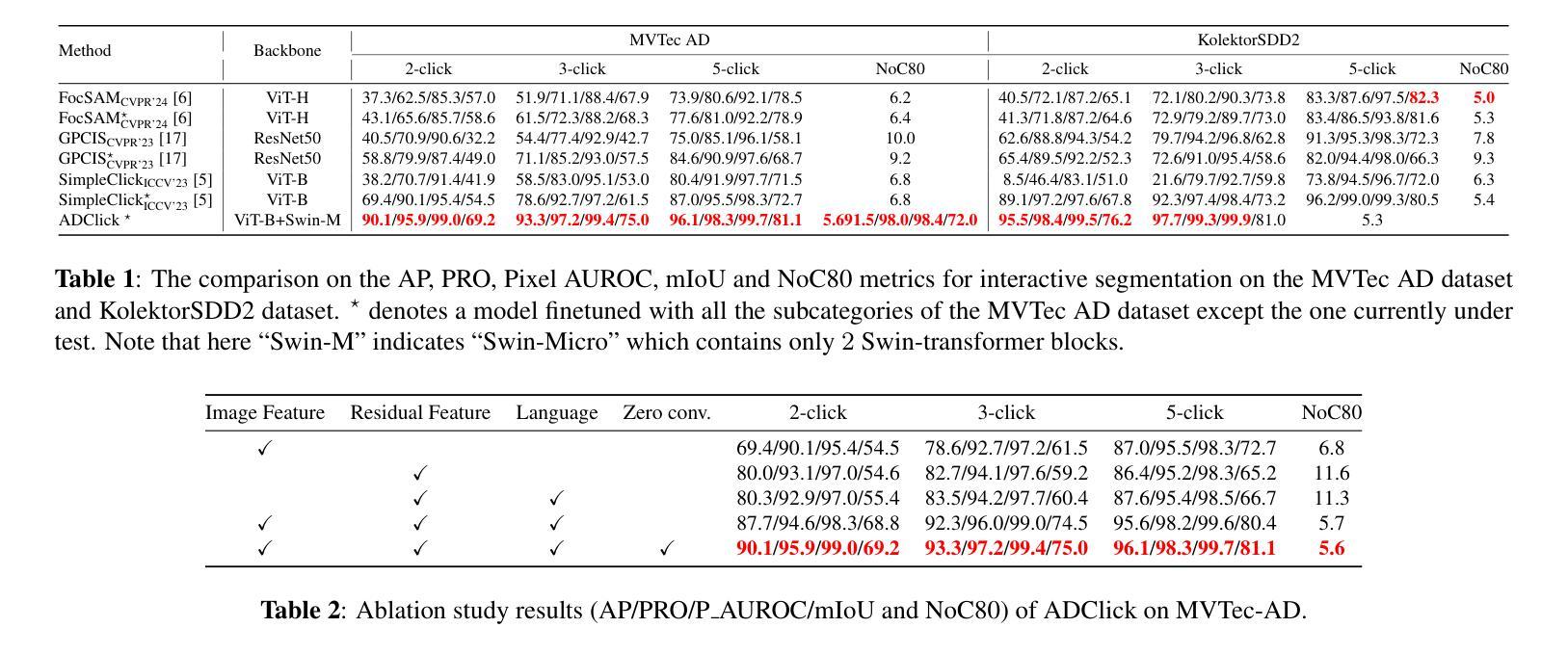
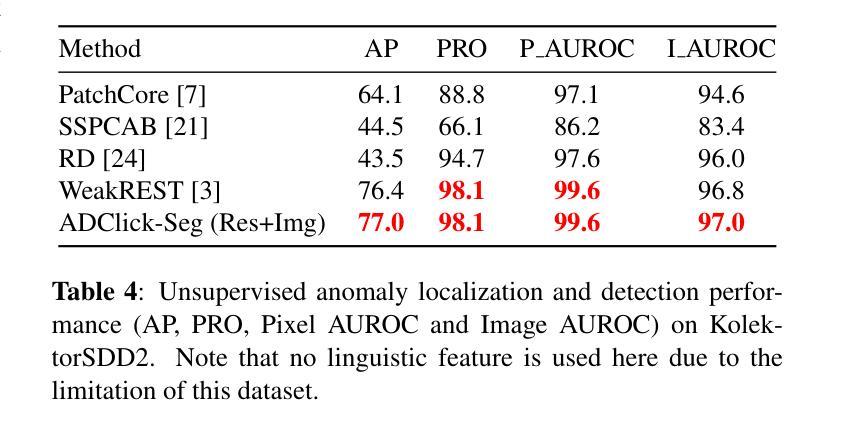
Towards Efficient Pixel Labeling for Industrial Anomaly Detection and Localization
Authors:Jingqi Wu, Hanxi Li, Lin Yuanbo Wu, Hao Chen, Deyin Liu, Peng Wang
Industrial product inspection is often performed using Anomaly Detection (AD) frameworks trained solely on non-defective samples. Although defective samples can be collected during production, leveraging them usually requires pixel-level annotations, limiting scalability. To address this, we propose ADClick, an Interactive Image Segmentation (IIS) algorithm for industrial anomaly detection. ADClick generates pixel-wise anomaly annotations from only a few user clicks and a brief textual description, enabling precise and efficient labeling that significantly improves AD model performance (e.g., AP = 96.1% on MVTec AD). We further introduce ADClick-Seg, a cross-modal framework that aligns visual features and textual prompts via a prototype-based approach for anomaly detection and localization. By combining pixel-level priors with language-guided cues, ADClick-Seg achieves state-of-the-art results on the challenging ``Multi-class’’ AD task (AP = 80.0%, PRO = 97.5%, Pixel-AUROC = 99.1% on MVTec AD).
工业产品检测通常使用仅对非缺陷样本进行训练的异常检测(AD)框架来完成。虽然生产过程中可以收集缺陷样本,但利用它们通常需要进行像素级标注,这限制了其可扩展性。为了解决这一问题,我们提出了ADClick,这是一种用于工业异常检测的交互式图像分割(IIS)算法。ADClick仅通过少量用户点击和简短文本描述即可生成像素级的异常标注,从而实现精确高效的标注,显著提高了异常检测模型性能(例如,在MVTec AD上的平均精度为96.1%)。我们还引入了ADClick-Seg,这是一个跨模态框架,通过基于原型的方法对齐视觉特征和文本提示,用于异常检测和定位。通过将像素级先验知识与语言引导线索相结合,ADClick-Seg在多类别的异常检测任务上取得了最新成果(在MVTec AD上的平均精度为80.0%,召回率为97.5%,像素级AUROC为99.1%)。
论文及项目相关链接
Summary
工业产品检测通常使用异常检测(AD)框架进行,该框架仅对非缺陷样本进行训练。虽然可以在生产期间收集缺陷样本,但利用它们通常需要像素级注释,限制了可扩展性。为解决这一问题,我们提出了ADClick,这是一种交互式图像分割(IIS)算法,用于工业异常检测。ADClick仅通过少量用户点击和简短文字描述即可生成像素级异常注释,实现精确高效的标注,显著提高AD模型性能(例如,在MVTec AD上的AP=96.1%)。我们还介绍了ADClick-Seg,这是一个跨模态框架,通过基于原型的方法对齐视觉特征和文本提示,用于异常检测和定位。通过结合像素级先验知识和语言引导线索,ADClick-Seg在多类AD任务上实现了最佳结果(在MVTec AD上的AP=80.0%,PRO=97.5%,Pixel-AUROC=99.1%)。
Key Takeaways
- 异常检测(AD)在工业产品检测中主要依赖非缺陷样本进行训练。
- 缺陷样本的利用受限于像素级注释的需求,限制了异常检测模型的扩展性。
- ADClick是一种交互式图像分割算法,通过少量用户点击和文本描述生成像素级异常注释,提高AD模型性能。
- ADClick在MVTec AD上的异常检测准确率达到了96.1%。
- ADClick-Seg是一个跨模态框架,结合了视觉特征和文本提示,用于更准确的异常检测和定位。
- ADClick-Seg在MVTec AD上的多类异常检测任务上取得了最佳性能,包括AP、PRO和Pixel-AUROC等指标。
点此查看论文截图

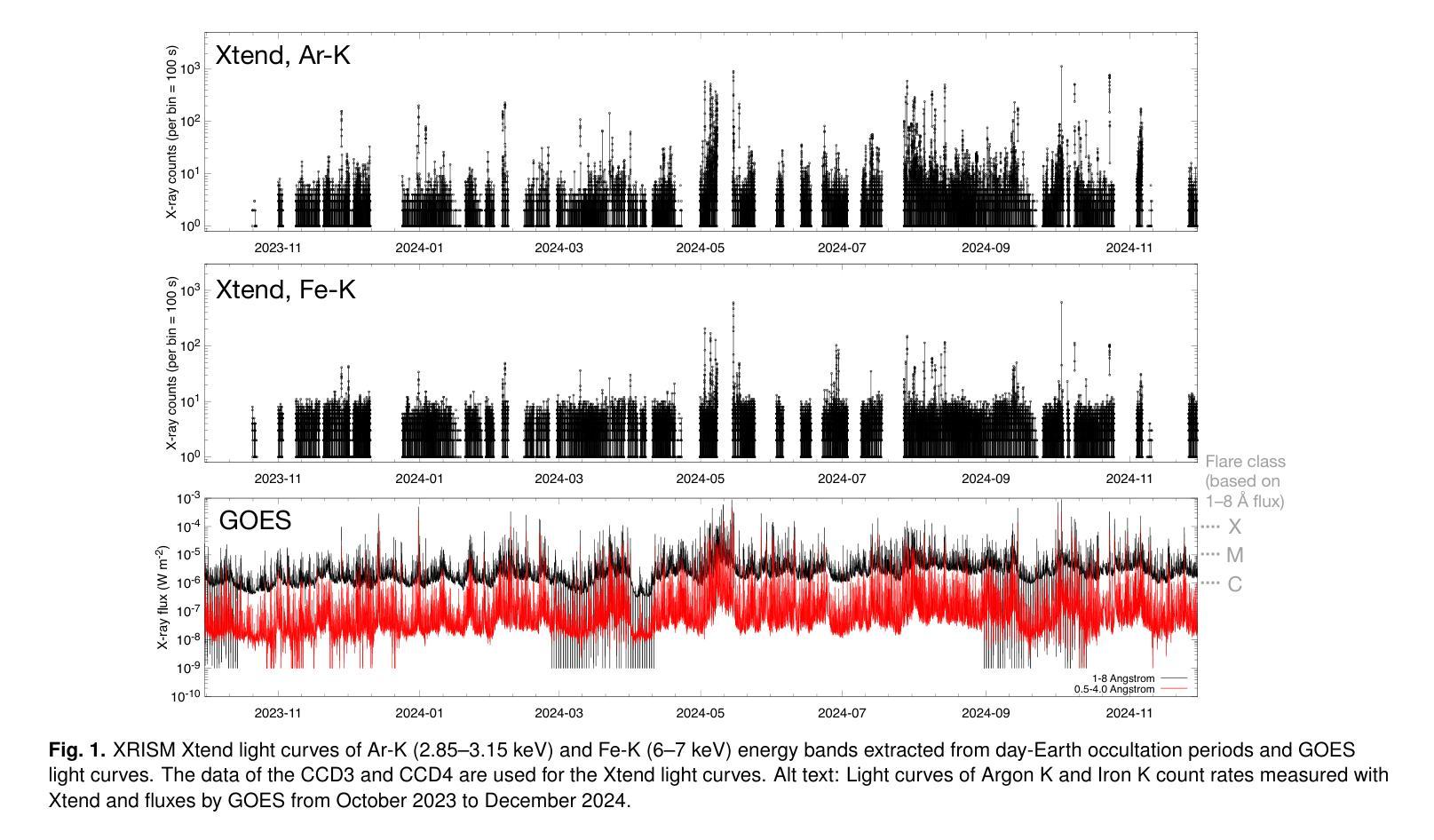
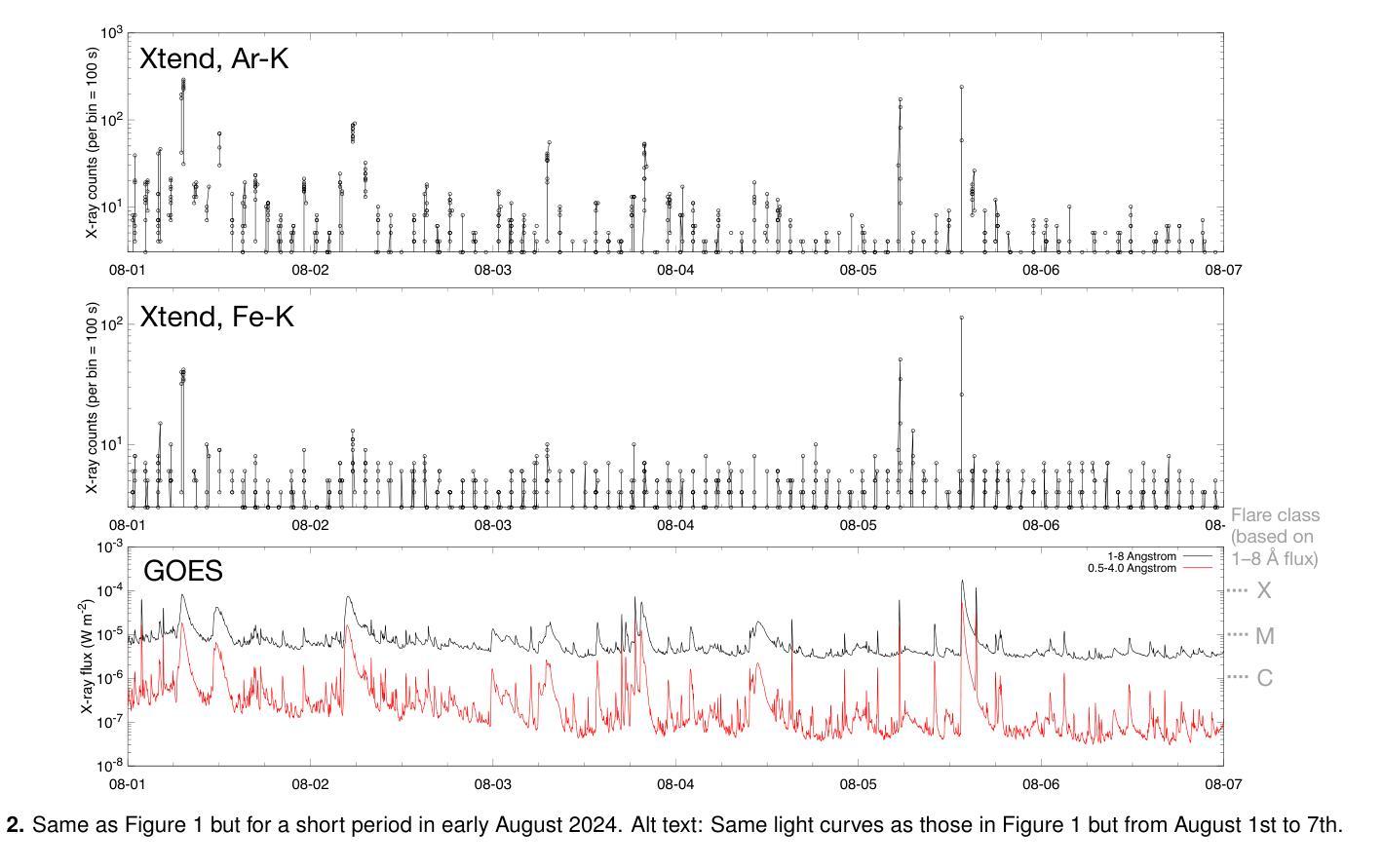
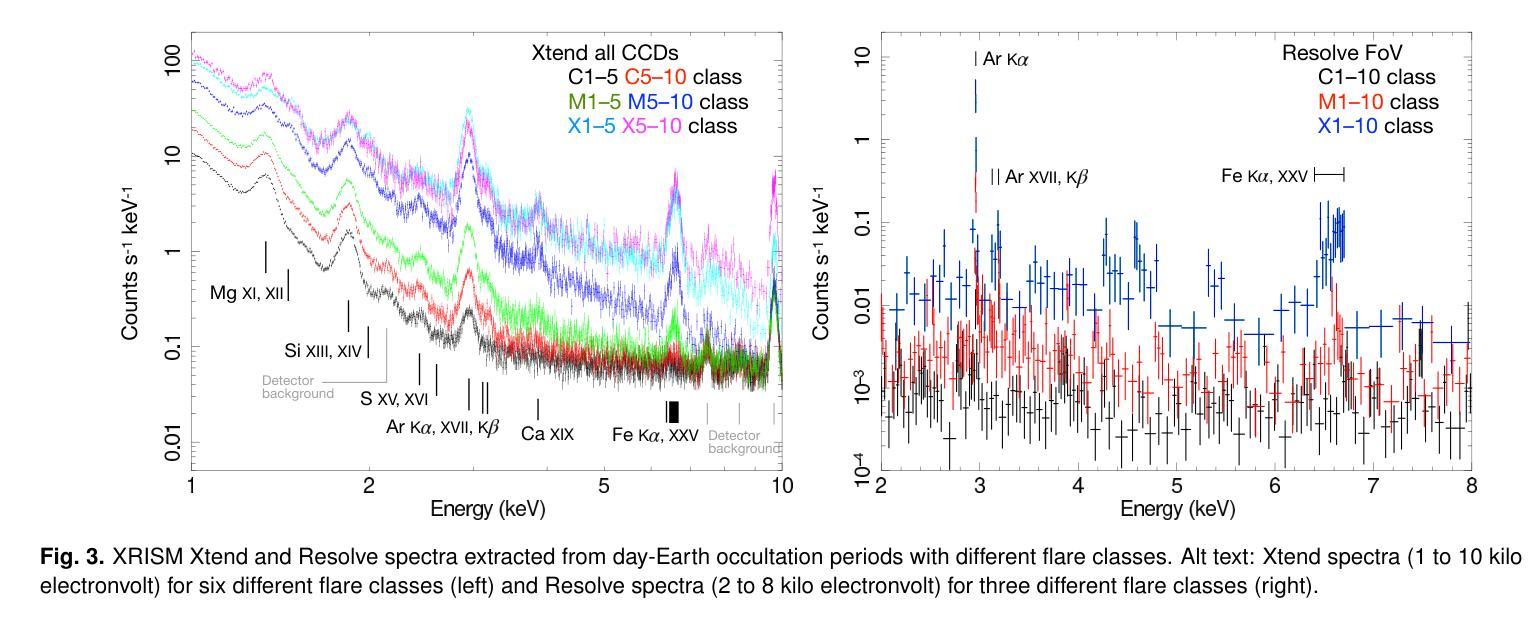
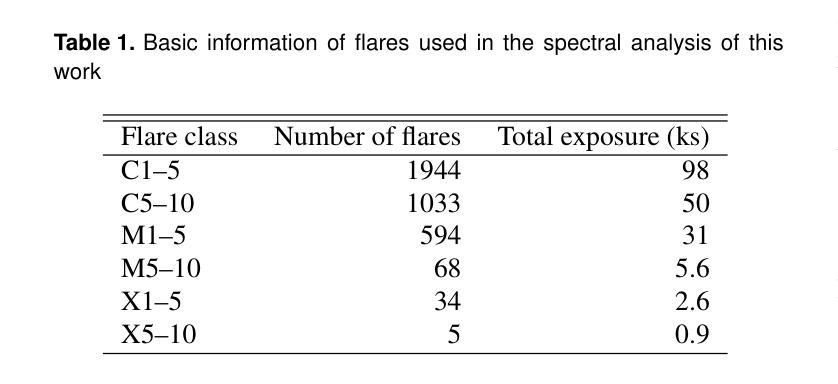
XRISM observations of solar flare X-ray emission reflected in the Earth’s atmosphere
Authors:Hiromasa Suzuki, Jun Kurashima, Koji Mori, Satoru Katsuda, Shun Inoue, Daiki Ishi, Eugene M. Churazov, Rashid A. Sunyaev, Ildar Khabibullin, Tsunefumi Mizuno, Caroline Kilbourne, Yuichiro Ezoe, Hiroshi Nakajima, Kosuke Sato, Eric Miller, Kyoko Matsushita
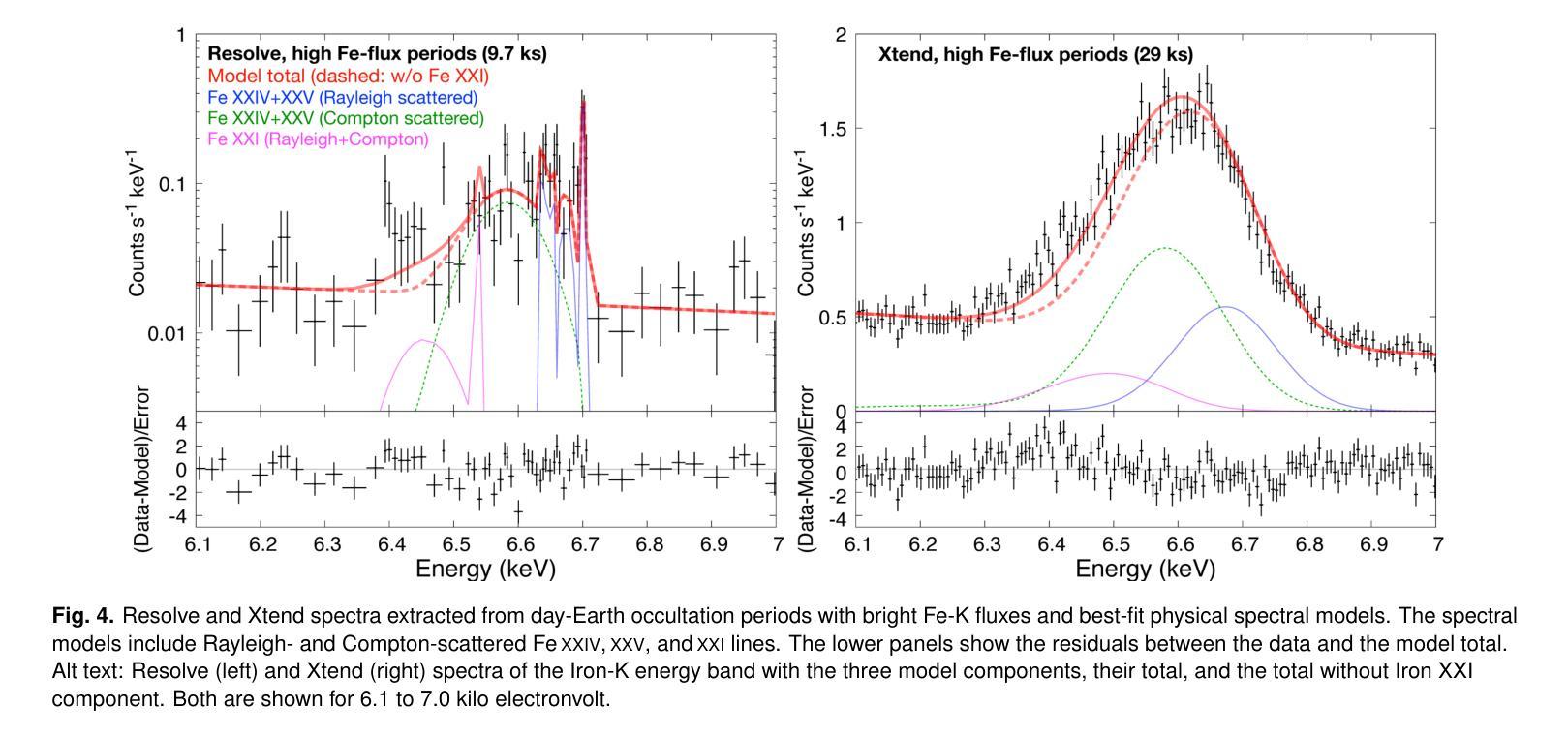
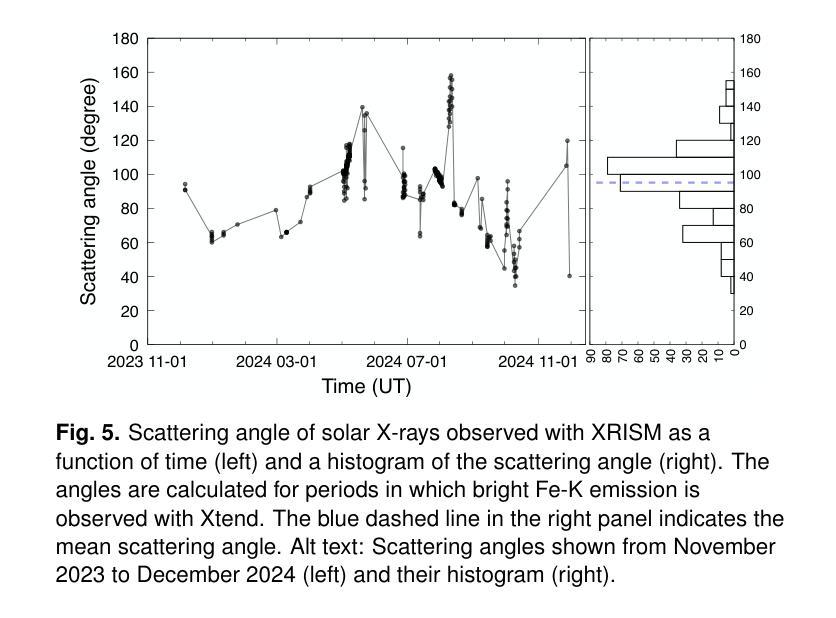
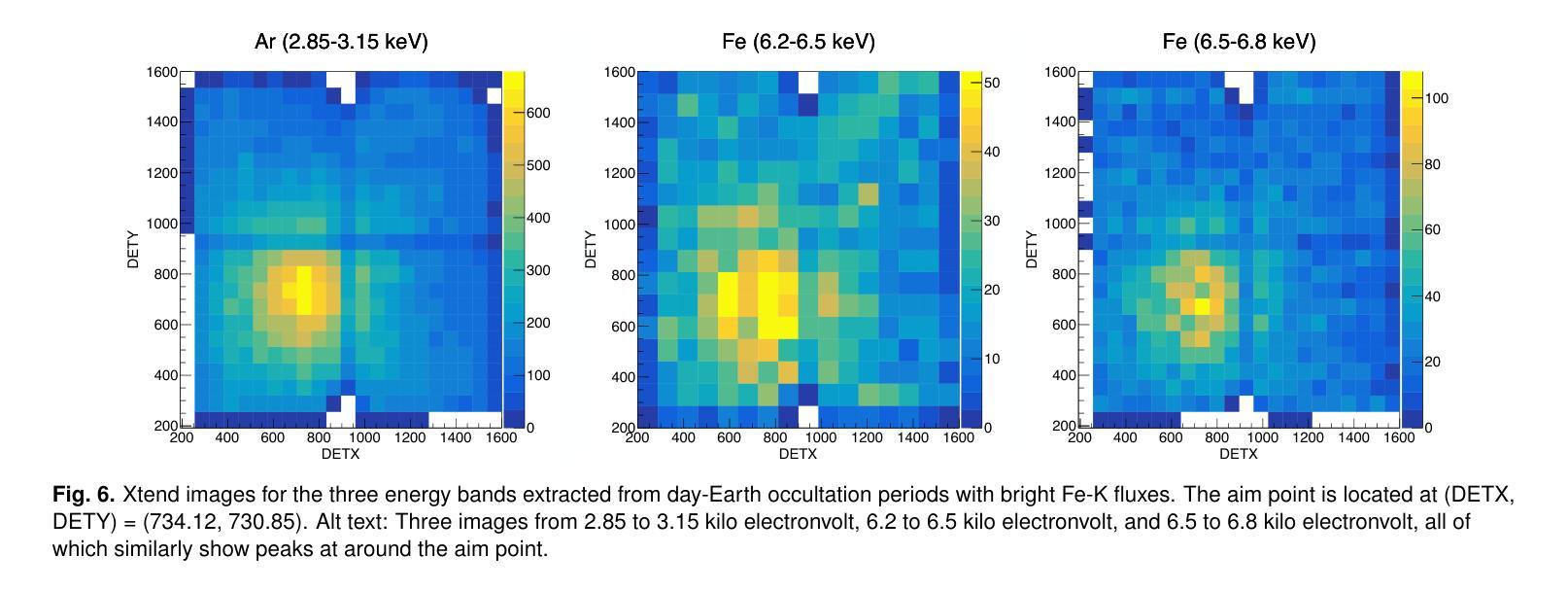
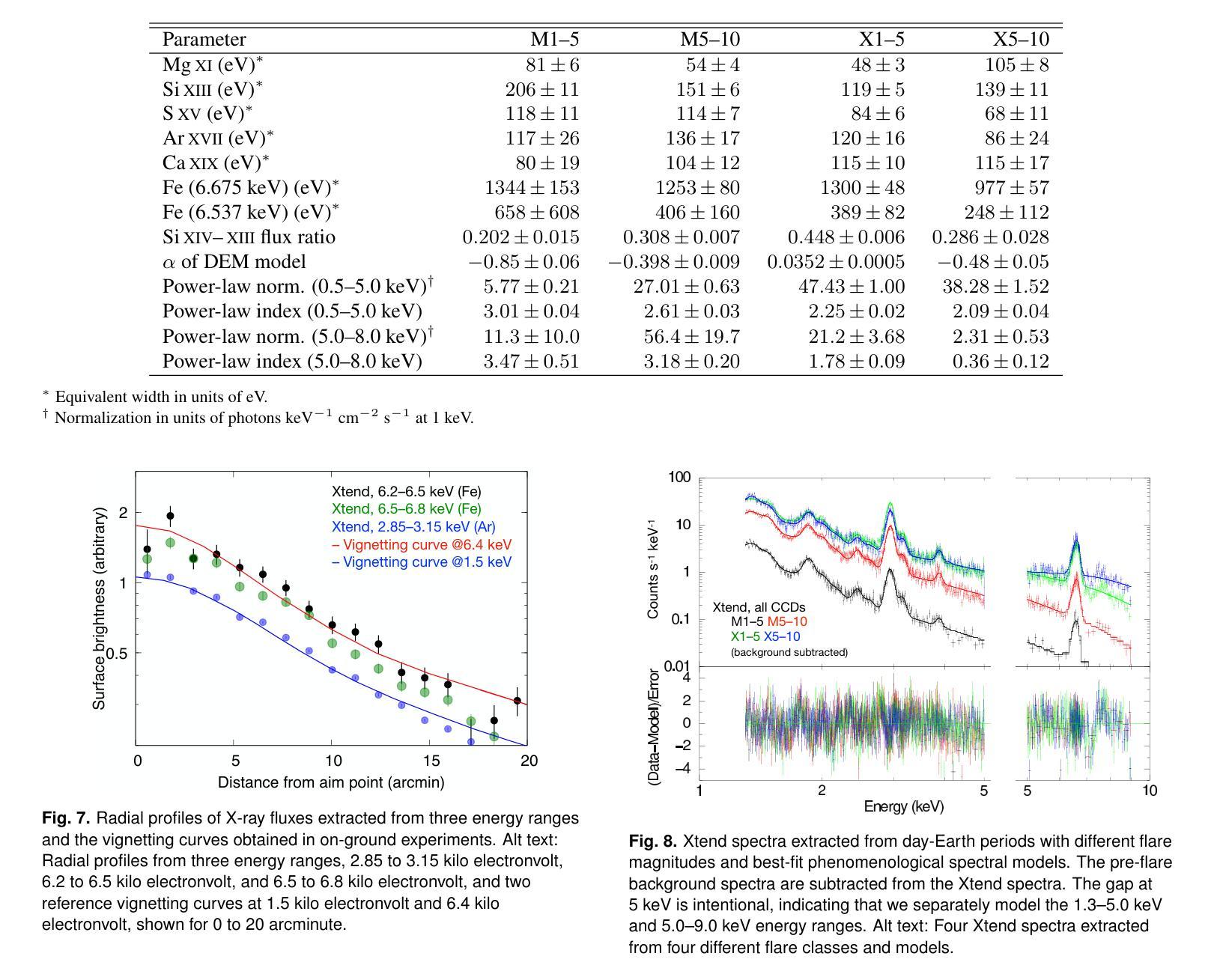
The X-ray Imaging and Spectroscopy Mission (XRISM), launched into low-Earth orbit in 2023, observes the reflection of solar flare X-rays in the Earth’s atmosphere as a by-product of celestial observations. Using a $\sim$one-year data set covering from October 2023 to November 2024, we report on our first results of the measurement of the metal abundance pattern and high-resolution Fe-K spectroscopy. The abundances of Mg, Si, S, Ar, Ca, and Fe measured with the CCD detector Xtend during M- and X-class flares show the inverse-first-ionization-potential (inverse-FIP) effect, which is consistent with the results of Katsuda et al., ApJ, 2020 using the Suzaku satellite. The abundances of Si, S, and Ar are found to decrease with increasing flare magnitude, which is consistent with the theoretical model by Laming (Laming, ApJ, 2021), whereas Ca exhibits an opposite trend. The large effective area and field of view of Xtend allow us to trace the evolution of the abundances in several X-class flare loops on a timescale of a few 100 s, finding an enrichment of low-FIP elements before flare peaks. The high-resolution Fe-K spectrum obtained with the microcalorimeter Resolve successfully separates the Rayleigh- and Compton-scattered Fe XXIV/XXV lines and neutral or low-ionized Fe-K$\alpha$ lines. The neutral/low-ionized Fe-K$\alpha$ equivalent width shows an anti-correlation with hard X-ray flux with the best-fit power-law slope of $-0.14 \pm 0.09$, suggesting that hard X-rays from flare loops are stimulating the Fe K$\alpha$ fluorescence. This work demonstrates that XRISM can be a powerful tool in the field of solar physics, offering valuable high-statistic CCD data and high-resolution microcalorimeter spectra in the energy range extending to the Fe-K band.
X射线成像与光谱任务(XRISM)于2023年发射至低地球轨道,作为天体观测的副产品,观测太阳耀斑X射线在地球大气中的反射。我们使用从2023年10月至2024年11月的约一年数据集,报告了我们首次测量的金属丰度模式和高分辨率Fe-K光谱的结果。使用CCD检测器Xtend在M级和X级耀斑期间测量的Mg、Si、S、Ar、Ca和Fe的丰度表现出逆首电离电位(inverse-FIP)效应,这与使用Suzaku卫星的Katsuda等人的结果一致(ApJ,2020年)。随着耀斑强度的增加,Si、S和Ar的丰度减少,这与Laming的理论模型一致(Laming,ApJ,2021年),而Ca则表现出相反的趋势。Xtend的大有效面积和视野使我们能够追踪几个X级耀斑环在数百秒时间尺度上的丰度演变,发现在耀斑峰值之前低FIP元素的富集。使用微热量计Resolve获得的高分辨率Fe-K光谱成功地分离了Rayleigh和Compton散射的Fe XXIV/XXV线以及中性或低电离的Fe-Kα线。中性/低电离Fe-Kα等价宽度与硬X射线流量呈反相关,最佳拟合幂律斜率为$-0.14 \pm 0.09$,这表明来自耀斑环的硬X射线激发了Fe Kα荧光。这项工作表明,XRISM在太阳物理学领域可以成为一个强大的工具,提供有价值的高统计CCD数据和高分辨率微热量计光谱,能量范围延伸到Fe-K波段。
论文及项目相关链接
PDF 12 pages, 15 figures, accepted for publication in PASJ
Summary
XRISM任务观测太阳耀斑X射线在地球大气中的反射,其首次结果揭示了金属丰度模式和高分辨率Fe-K光谱的测量。研究结果表明,金属元素丰度与耀斑等级有关,并呈现出逆FIP效应。XRISM的Xtend探测器能够追踪几个X级耀斑环中元素的丰度演变,而高分辨率的Resolve微热量计成功分离了Fe XXIV/XXV线和中性或低电离的Fe-Kα线。这项研究展示了XRISM在太阳物理学领域的强大潜力。
Key Takeaways
- XRISM任务在地球低轨道上观测到太阳耀斑X射线反射现象。
- 金属元素丰度与耀斑等级相关,表现出逆FIP效应。
- Xtend探测器能够追踪多个X级耀斑环中元素的丰度演变。
- 高分辨率的Resolve微热量计成功分离了Fe的不同形态线。
- 中性/低电离的Fe-Kα等效宽度与硬X射线流量呈负相关。
- 硬X射线可能刺激Fe Kα荧光。
- XRISM在太阳物理学领域具有强大的潜力。
点此查看论文截图

Interpretable Deep Transfer Learning for Breast Ultrasound Cancer Detection: A Multi-Dataset Study
Authors:Mohammad Abbadi, Yassine Himeur, Shadi Atalla, Wathiq Mansoor
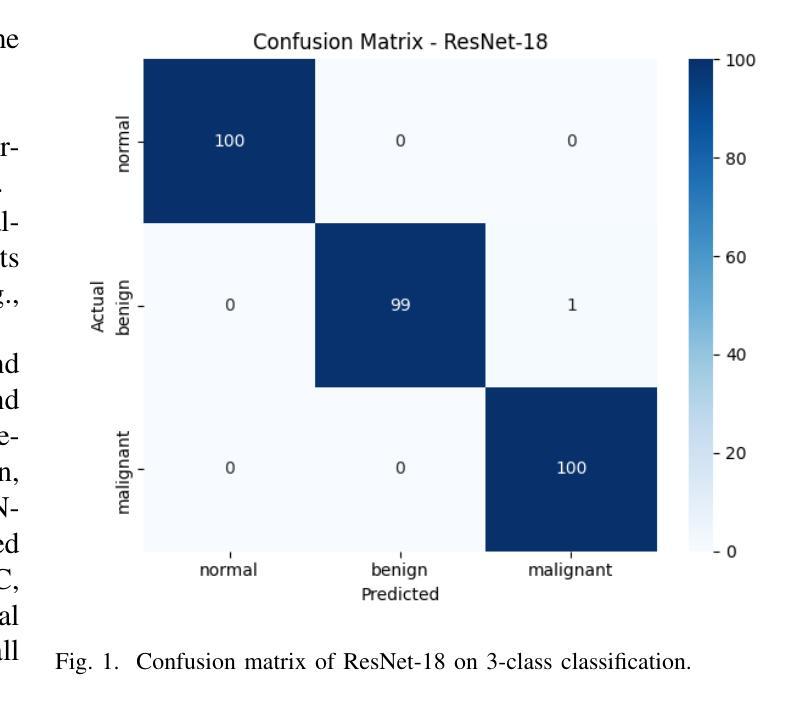
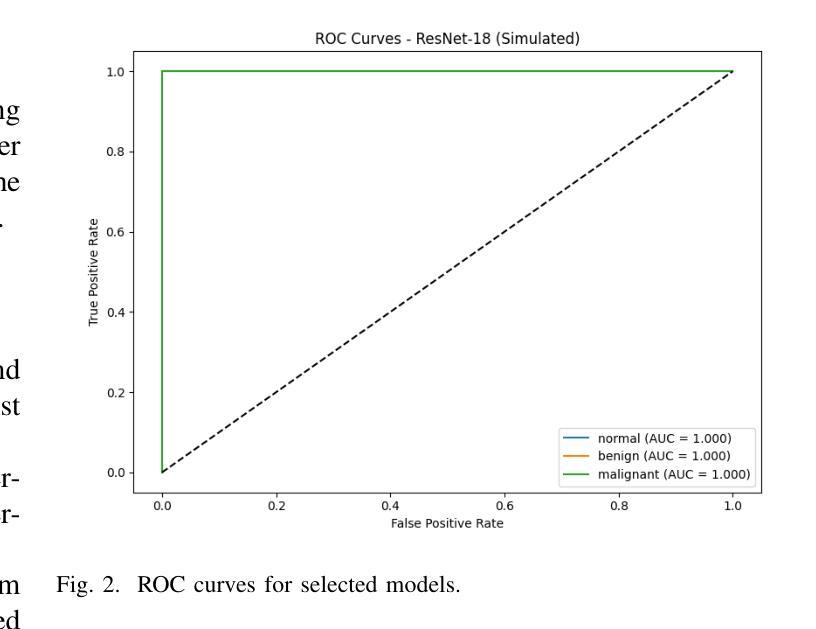
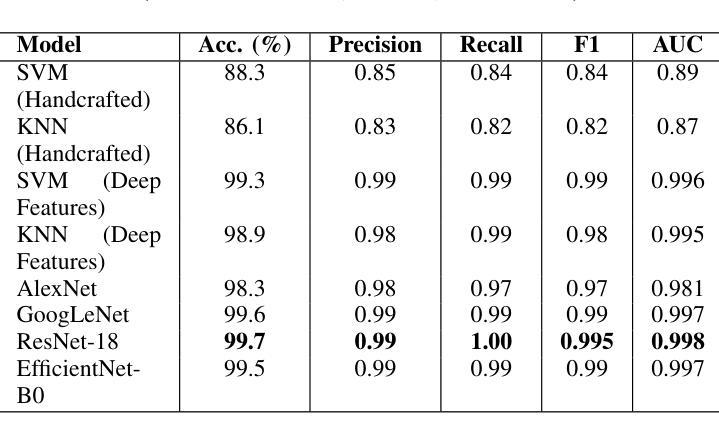
Breast cancer remains a leading cause of cancer-related mortality among women worldwide. Ultrasound imaging, widely used due to its safety and cost-effectiveness, plays a key role in early detection, especially in patients with dense breast tissue. This paper presents a comprehensive study on the application of machine learning and deep learning techniques for breast cancer classification using ultrasound images. Using datasets such as BUSI, BUS-BRA, and BrEaST-Lesions USG, we evaluate classical machine learning models (SVM, KNN) and deep convolutional neural networks (ResNet-18, EfficientNet-B0, GoogLeNet). Experimental results show that ResNet-18 achieves the highest accuracy (99.7%) and perfect sensitivity for malignant lesions. Classical ML models, though outperformed by CNNs, achieve competitive performance when enhanced with deep feature extraction. Grad-CAM visualizations further improve model transparency by highlighting diagnostically relevant image regions. These findings support the integration of AI-based diagnostic tools into clinical workflows and demonstrate the feasibility of deploying high-performing, interpretable systems for ultrasound-based breast cancer detection.
乳腺癌仍然是全球女性癌症死亡的主要原因之一。超声成像因其安全性和成本效益而得到广泛应用,在早期检测中发挥着关键作用,特别是在乳腺组织致密的患者中。本文全面研究了应用机器学习和深度学习技术对超声图像进行乳腺癌分类的方法。我们使用BUSI、BUS-BRA和BrEaST-Lesions USG等数据集,评估了经典机器学习模型(SVM、KNN)和深度卷积神经网络(ResNet-18、EfficientNet-B0、GoogLeNet)。实验结果表明,ResNet-18的准确率最高(99.7%),对恶性病变的敏感性完美。虽然被卷积神经网络超越,但经典机器学习模型在增强深度特征提取后表现良好。Grad-CAM可视化通过突出显示诊断相关的图像区域,进一步提高了模型的透明度。这些发现支持将基于人工智能的诊断工具整合到临床工作流程中,并展示了部署高性能、可解释的超声乳腺癌检测系统可行性。
论文及项目相关链接
PDF 6 pages, 2 figures and 1 table
Summary
本文研究了应用机器学习和深度学习技术在超声图像上进行乳腺癌分类的应用。实验结果表明,ResNet-18模型在恶性病变检测方面取得了最高准确性(99.7%)和完美的敏感性。梯度加权类激活映射(Grad-CAM)可视化提高了模型的透明度,突出了诊断相关的图像区域。这些发现支持将人工智能诊断工具集成到临床工作流程中,并展示了部署高性能、可解释的超声乳腺癌检测系统的可行性。
Key Takeaways
- 乳腺癌是世界范围内导致女性死亡的主要原因之一。
- 超声波成像在乳腺癌的早期检测中扮演着关键角色,特别是在乳腺组织密集的患者中。
- 机器学习和深度学习技术在超声图像乳腺癌分类方面表现出巨大潜力。
- ResNet-18模型在恶性病变检测方面取得了最高准确性(99.7%)和完美的敏感性。
- 经典机器学习模型虽然被卷积神经网络所超越,但在深度特征提取的增强下仍表现出竞争力。
- Grad-CAM可视化提高了模型的透明度,有助于解释诊断过程。
点此查看论文截图


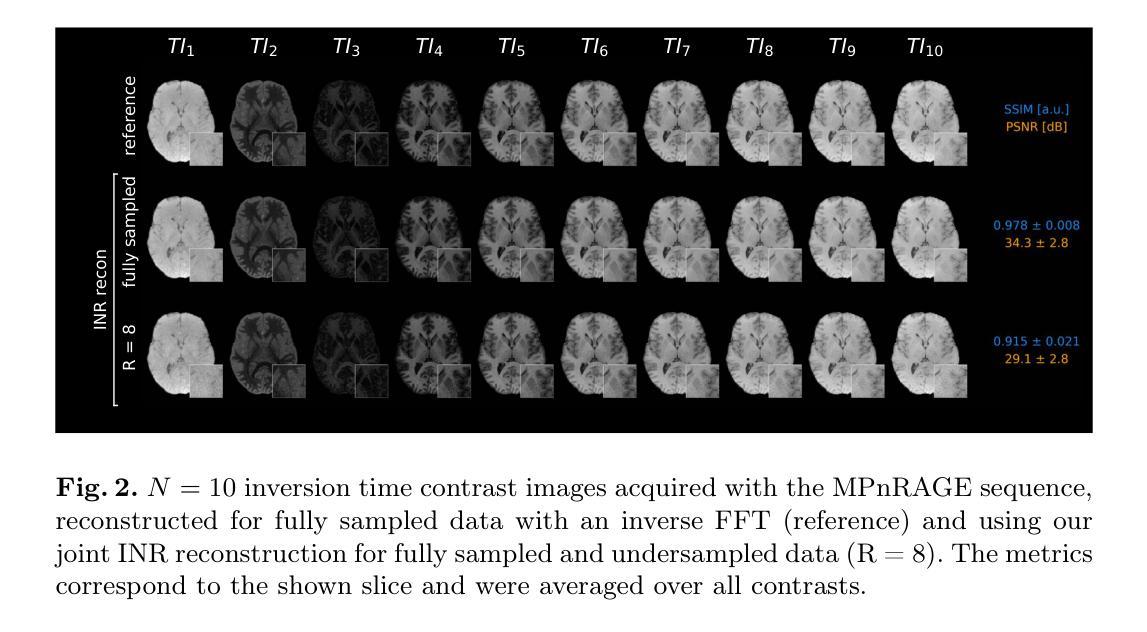
INR meets Multi-Contrast MRI Reconstruction
Authors:Natascha Niessen, Carolin M. Pirkl, Ana Beatriz Solana, Hannah Eichhorn, Veronika Spieker, Wenqi Huang, Tim Sprenger, Marion I. Menzel, Julia A. Schnabel
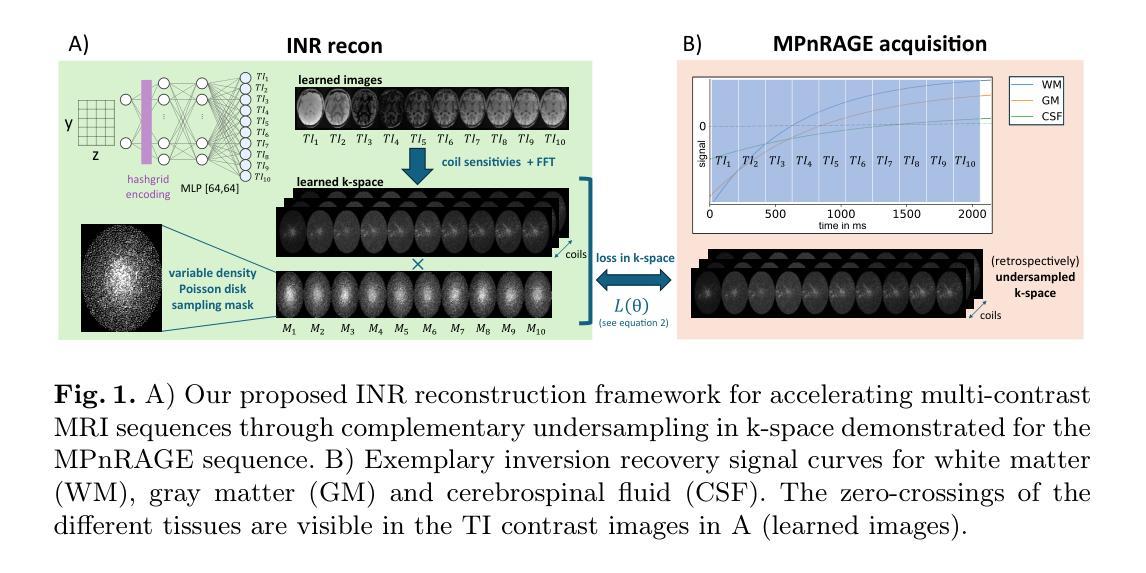
Multi-contrast MRI sequences allow for the acquisition of images with varying tissue contrast within a single scan. The resulting multi-contrast images can be used to extract quantitative information on tissue microstructure. To make such multi-contrast sequences feasible for clinical routine, the usually very long scan times need to be shortened e.g. through undersampling in k-space. However, this comes with challenges for the reconstruction. In general, advanced reconstruction techniques such as compressed sensing or deep learning-based approaches can enable the acquisition of high-quality images despite the acceleration. In this work, we leverage redundant anatomical information of multi-contrast sequences to achieve even higher acceleration rates. We use undersampling patterns that capture the contrast information located at the k-space center, while performing complementary undersampling across contrasts for high frequencies. To reconstruct this highly sparse k-space data, we propose an implicit neural representation (INR) network that is ideal for using the complementary information acquired across contrasts as it jointly reconstructs all contrast images. We demonstrate the benefits of our proposed INR method by applying it to multi-contrast MRI using the MPnRAGE sequence, where it outperforms the state-of-the-art parallel imaging compressed sensing (PICS) reconstruction method, even at higher acceleration factors.
多对比度MRI序列能够在单次扫描中获取具有不同组织对比度的图像。得到的多对比度图像可用于提取有关组织微观结构的定量信息。为了使这样的多对比度序列适用于临床常规应用,通常需要缩短非常长的扫描时间,例如通过k空间中的欠采样。然而,这给重建带来了挑战。通常,先进的重建技术,如压缩感知或基于深度学习的方法,尽管加速了扫描,但仍能获取高质量的图像。在这项工作中,我们利用多对比度序列的冗余解剖信息来实现更高的加速率。我们使用欠采样模式来捕获位于k空间中心的对比度信息,同时在不同对比度之间进行互补欠采样以获取高频信息。为了重建这种高度稀疏的k空间数据,我们提出了一种隐式神经表示(INR)网络,它非常适合使用不同对比度之间获取的互补信息进行联合重建所有对比度图像。我们通过将所提出的方法应用于使用MPnRAGE序列的多对比度MRI,展示了其优势,即使在较高的加速因子下,该方法也优于最新的并行成像压缩感知(PICS)重建方法。
论文及项目相关链接
Summary
本文介绍了一种利用多对比度MRI序列冗余解剖学信息实现更高加速率的方法。通过在k空间中心捕捉对比信息,并跨对比度进行互补欠采样,以及使用理想于利用跨对比度获取互补信息的隐式神经表示(INR)网络进行重建,实现了高质量图像的恢复。在MPnRAGE序列的多对比度MRI中应用此方法,即使在较高的加速因子下也优于现有的并行成像压缩感知(PICS)重建方法。
Key Takeaways
- 多对比度MRI序列能够在单次扫描中获取具有不同组织对比度的图像。
- 重建技术如压缩感知或深度学习方法可加速图像获取并保持高质量。
- 利用多对比度序列的冗余解剖学信息可实现更高的加速率。
- 通过对k空间中心的对比信息进行欠采样,并跨对比度进行互补欠采样,处理高度稀疏的k空间数据。
- 提出使用隐式神经表示(INR)网络进行重建,该网络可利用跨对比度的互补信息。
- 在MPnRAGE序列的多对比度MRI中应用了该方法,表现出优于现有PICS重建方法的性能。
点此查看论文截图

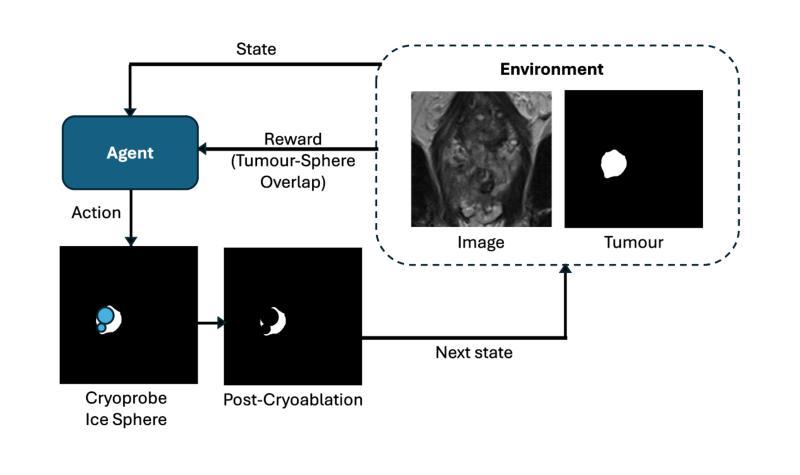
Cryo-RL: automating prostate cancer cryoablation planning with reinforcement learning
Authors:Trixia Simangan, Ahmed Nadeem Abbasi, Yipeng Hu, Shaheer U. Saeed
Cryoablation is a minimally invasive localised treatment for prostate cancer that destroys malignant tissue during de-freezing, while sparing surrounding healthy structures. Its success depends on accurate preoperative planning of cryoprobe placements to fully cover the tumour and avoid critical anatomy. This planning is currently manual, expertise-dependent, and time-consuming, leading to variability in treatment quality and limited scalability. In this work, we introduce Cryo-RL, a reinforcement learning framework that models cryoablation planning as a Markov decision process and learns an optimal policy for cryoprobe placement. Within a simulated environment that models clinical constraints and stochastic intraoperative variability, an agent sequentially selects cryoprobe positions and ice sphere diameters. Guided by a reward function based on tumour coverage, this agent learns a cryoablation strategy that leads to optimal cryoprobe placements without the need for any manually-designed plans. Evaluated on 583 retrospective prostate cancer cases, Cryo-RL achieved over 8 percentage-point Dice improvements compared with the best automated baselines, based on geometric optimisation, and matched human expert performance while requiring substantially less planning time. These results highlight the potential of reinforcement learning to deliver clinically viable, reproducible, and efficient cryoablation plans.
冷冻消融是一种针对前列腺癌的微创局部治疗方法,在解冻过程中破坏恶性组织,同时保留周围的健康结构。其成功取决于冷冻探针放置的术前规划准确,以全面覆盖肿瘤并避免关键解剖结构。当前的规划是手动进行的,依赖于专家经验,并且耗时,导致治疗质量存在差异性且扩展性有限。在这项工作中,我们引入了冷冻强化学习(Cryo-RL),这是一种强化学习框架,将冷冻消融规划建模为马尔可夫决策过程,并学习冷冻探针放置的最优策略。在一个模拟环境中,该环境模拟了临床约束和术中随机变化,智能体按顺序选择冷冻探针的位置和冰球直径。在肿瘤覆盖率的奖励函数指导下,智能体学习了一种冷冻消融策略,该策略能够实现最优的冷冻探针放置,无需任何手动设计计划。在583例回顾性前列腺癌病例中,与基于几何优化的最佳自动化基线相比,Cryo-RL实现了超过8个百分点的Dice改善,并达到了人类专家的表现水平,同时大大减少了规划时间。这些结果突出了强化学习在提供临床可行、可复制和高效的冷冻消融计划方面的潜力。
论文及项目相关链接
PDF Accepted at MICAD (Medical Imaging and Computer-Aided Diagnosis) 2025
Summary
本文介绍了冷冻消融(Cryoablation)治疗前列腺癌的方法,并指出其成功依赖于精确的术前规划冷冻探针放置位置。文中提出了一种新的强化学习框架Cryo-RL,模拟冷冻消融手术的计划过程并自动选择最佳的冷冻探针位置和冰球直径。相比传统的几何优化方法和专家手动规划,Cryo-RL在模拟环境中实现了更高的肿瘤覆盖率和更短的规划时间。
Key Takeaways
- 冷冻消融是一种治疗前列腺癌的微创局部疗法,通过冷冻破坏恶性组织,同时保留周围健康结构。
- 冷冻消融的成功取决于术前对冷冻探针放置位置的精确规划,以覆盖整个肿瘤并避免关键部位。
- 当前规划依赖于手动操作和专家经验,具有耗时且可变性大的缺点。
- 提出了一种强化学习框架Cryo-RL,模拟冷冻消融手术的计划过程。
- Cryo-RL将冷冻消融手术规划建模为马尔可夫决策过程,学习冷冻探针放置的最优策略。
- 在模拟环境中,Cryo-RL实现了高效的冷冻消融计划,与几何优化方法相比,Dice改善率超过8个百分点,并达到了与人类专家的匹配性能。
点此查看论文截图

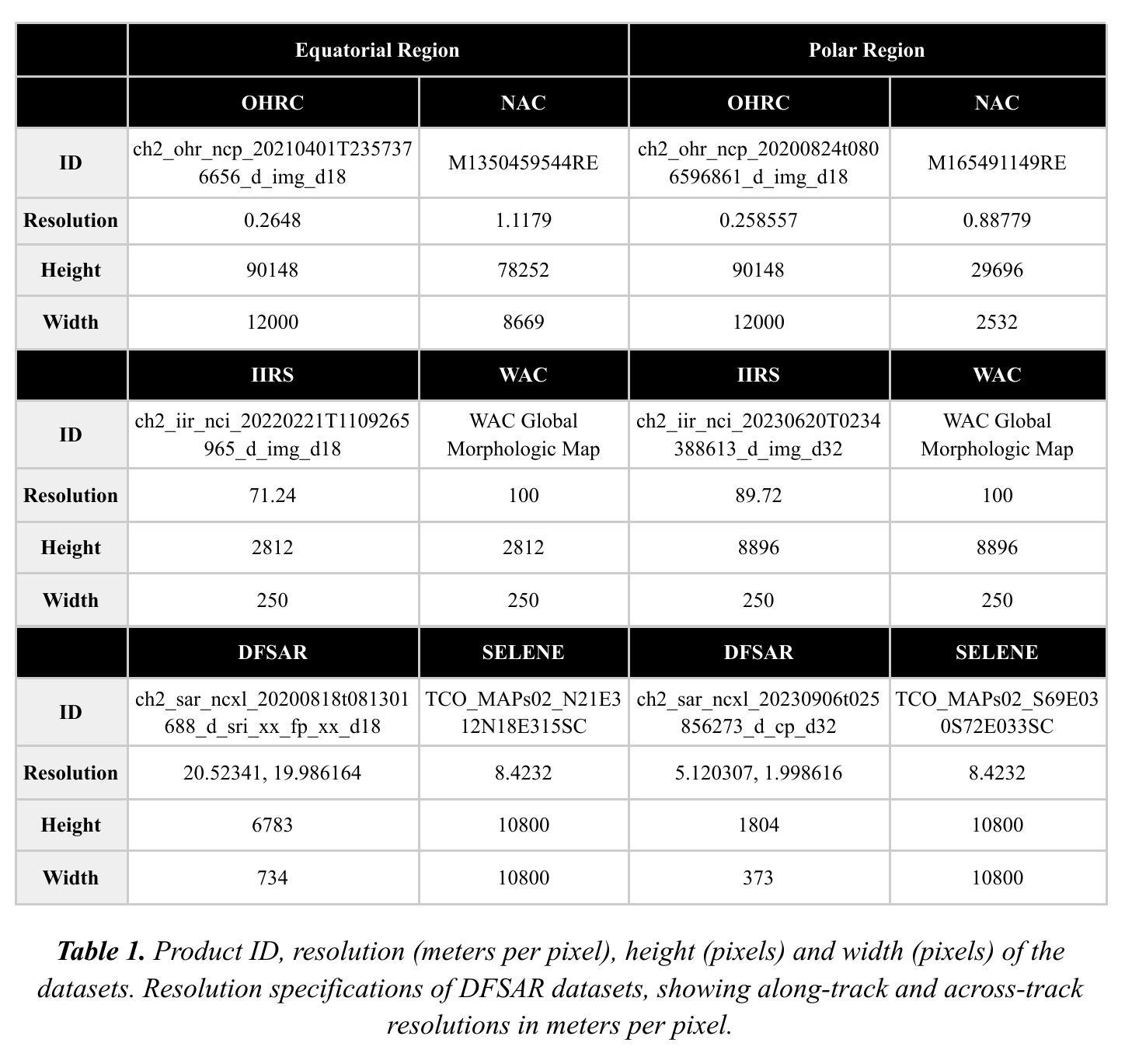
Comparative Evaluation of Traditional and Deep Learning Feature Matching Algorithms using Chandrayaan-2 Lunar Data
Authors:R. Makharia, J. G. Singla, Amitabh, N. Dube, H. Sharma
Accurate image registration is critical for lunar exploration, enabling surface mapping, resource localization, and mission planning. Aligning data from diverse lunar sensors – optical (e.g., Orbital High Resolution Camera, Narrow and Wide Angle Cameras), hyperspectral (Imaging Infrared Spectrometer), and radar (e.g., Dual-Frequency Synthetic Aperture Radar, Selene/Kaguya mission) – is challenging due to differences in resolution, illumination, and sensor distortion. We evaluate five feature matching algorithms: SIFT, ASIFT, AKAZE, RIFT2, and SuperGlue (a deep learning-based matcher), using cross-modality image pairs from equatorial and polar regions. A preprocessing pipeline is proposed, including georeferencing, resolution alignment, intensity normalization, and enhancements like adaptive histogram equalization, principal component analysis, and shadow correction. SuperGlue consistently yields the lowest root mean square error and fastest runtimes. Classical methods such as SIFT and AKAZE perform well near the equator but degrade under polar lighting. The results highlight the importance of preprocessing and learning-based approaches for robust lunar image registration across diverse conditions.
精确图像配准对于月球探索至关重要,可实现表面地图绘制、资源定位和任务规划。由于分辨率、照明和传感器失真等方面的差异,对齐来自各种月球传感器(光学传感器,例如轨道高分辨率相机、广角镜头和窄角相机、成像红外光谱仪以及雷达传感器,例如双频合成孔径雷达和Selene/Kaguya任务)的数据是一个挑战。我们评估了五种特征匹配算法:SIFT、ASIFT、AKAZE、RIFT2和基于深度学习的匹配器SuperGlue,使用的是赤道和极地地区的跨模态图像对。提出了预处理管道,包括地理参考、分辨率对齐、强度归一化以及自适应直方图均衡化、主成分分析和阴影校正等增强功能。SuperGlue始终产生最低的均方根误差和最快的运行时间。像SIFT和AKAZE这样的经典方法在赤道附近表现良好,但在极地光照条件下性能下降。结果强调了预处理和基于学习的方法对于在各种条件下实现稳健的月球图像配准的重要性。
论文及项目相关链接
PDF 27 pages, 11 figures, 3 tables
Summary
精准图像配准对于月球探索至关重要,可实现表面地图绘制、资源定位和任务规划。针对光学、高光谱和雷达等不同月球传感器的数据对齐具有挑战性,因为存在分辨率、照明和传感器失真等方面的差异。评估了五种特征匹配算法,包括SIFT、ASIFT、AKAZE、RIFT2和基于深度学习的SuperGlue匹配器。经过地理参考、分辨率对齐、强度归一化等预处理流程,SuperGlue表现最佳,产生最低的均方根误差并具备最快的运行时间。古典方法如SIFT和AKAZE在接近赤道时表现良好,但在极地照明条件下性能下降。结果强调了在各种条件下实现稳健的月球图像配准时预处理和基于学习的方法的重要性。
Key Takeaways
- 精准图像配准在月球探索中非常重要,有助于表面地图绘制、资源定位和任务规划。
- 对齐来自不同月球传感器的数据(如光学、高光谱和雷达)具有挑战性,因为存在分辨率、照明和传感器失真差异。
- 评估了五种特征匹配算法,包括SIFT、ASIFT、AKAZE、RIFT2和SuperGlue,其中SuperGlue表现最佳。
- 预处理流程,如地理参考、分辨率对齐和强度归一化,对于实现稳健的月球图像配准至关重要。
- SuperGlue产生最低的均方根误差,并具备最快的运行时间。
- 古典特征匹配方法(如SIFT和AKAZE)在特定条件下表现良好,但在极地照明条件下可能性能下降。
点此查看论文截图

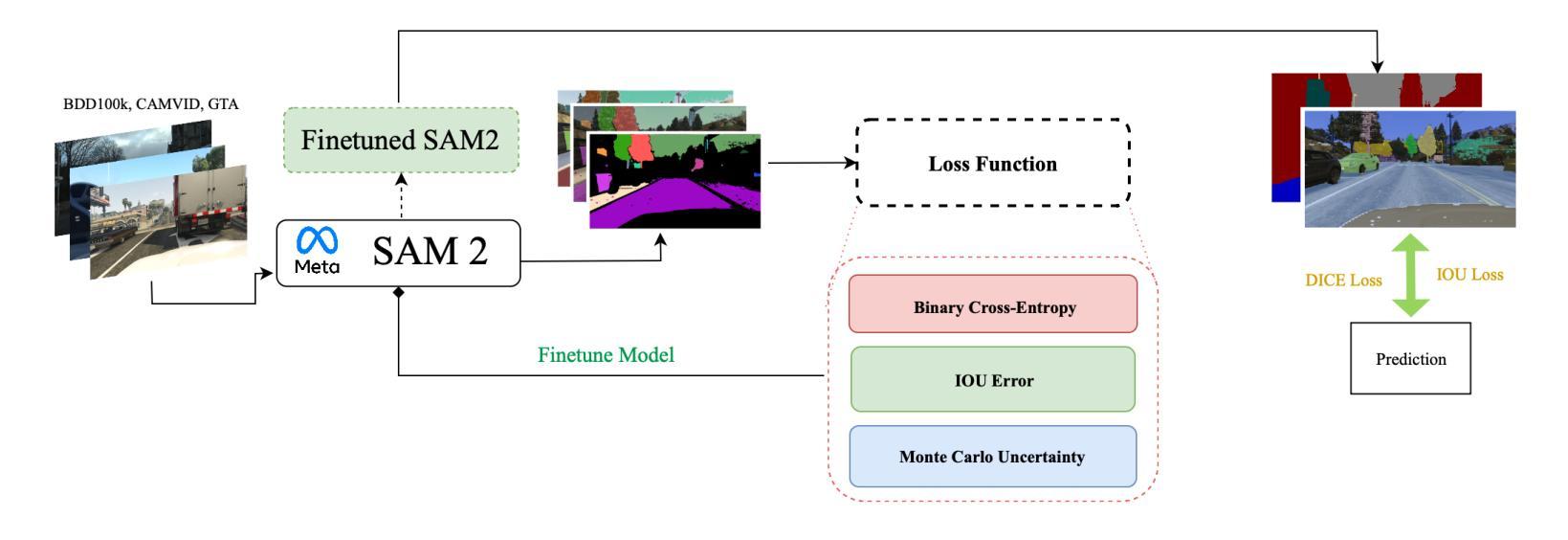
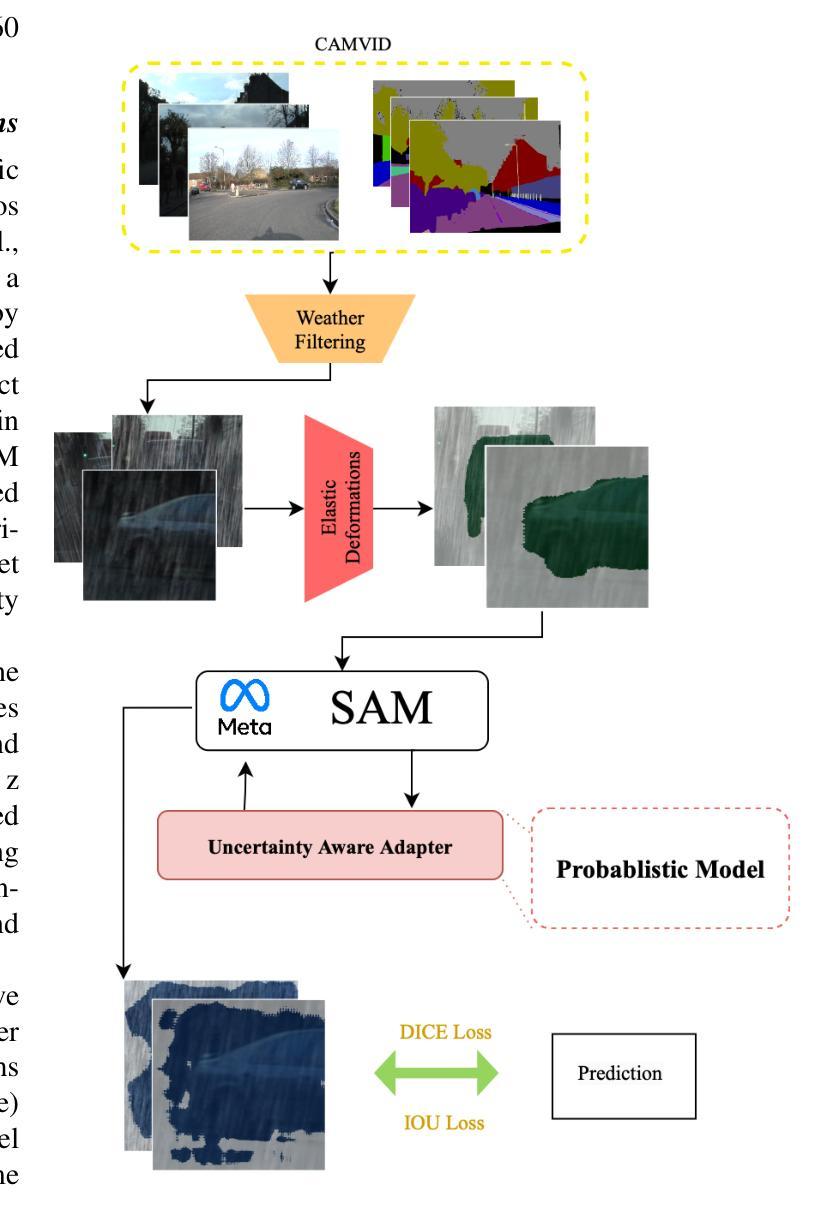
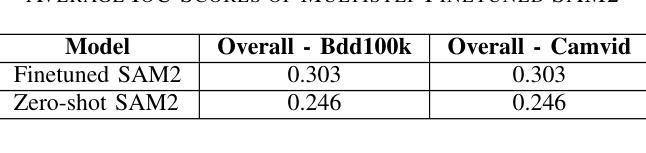
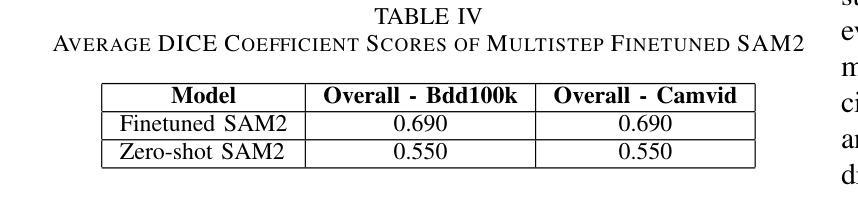
Enhancing Self-Driving Segmentation in Adverse Weather Conditions: A Dual Uncertainty-Aware Training Approach to SAM Optimization
Authors:Dharsan Ravindran, Kevin Wang, Zhuoyuan Cao, Saleh Abdelrahman, Jeffery Wu
Recent advances in vision foundation models, such as the Segment Anything Model (SAM) and its successor SAM2, have achieved state-of-the-art performance on general image segmentation benchmarks. However, these models struggle in adverse weather conditions where visual ambiguity is high, largely due to their lack of uncertainty quantification. Inspired by progress in medical imaging, where uncertainty-aware training has improved reliability in ambiguous cases, we investigate two approaches to enhance segmentation robustness for autonomous driving. First, we introduce a multi-step finetuning procedure for SAM2 that incorporates uncertainty metrics directly into the loss function, improving overall scene recognition. Second, we adapt the Uncertainty-Aware Adapter (UAT), originally designed for medical image segmentation, to driving contexts. We evaluate both methods on CamVid, BDD100K, and GTA driving datasets. Experiments show that UAT-SAM outperforms standard SAM in extreme weather, while SAM2 with uncertainty-aware loss achieves improved performance across diverse driving scenes. These findings underscore the value of explicit uncertainty modeling for safety-critical autonomous driving in challenging environments.
最近,视觉基础模型(如Segment Anything Model(SAM)及其后继者SAM2)在通用图像分割基准测试中实现了最先进的性能。然而,这些模型在恶劣天气条件下表现较差,尤其在视觉模糊的情况下,这主要是因为它们缺乏不确定性量化。受医学成像领域进步启发,不确定性感知训练已提高了模糊病例的可靠性。我们研究两种增强自动驾驶分割稳健性的方法。首先,我们为SAM2引入了一个多步骤微调程序,将不确定性指标直接纳入损失函数,从而提高整体场景识别能力。其次,我们调整原本为医学图像分割设计的Uncertainty-Aware Adapter(UAT),以适应驾驶环境。我们在CamVid、BDD100K和GTA驾驶数据集上评估了这两种方法。实验表明,UAT-SAM在极端天气条件下表现优于标准SAM,而具有不确定性感知损失的SAM2在不同驾驶场景中的性能有所提高。这些发现强调了在具有挑战性的环境中,对关键自动驾驶系统进行明确的不确定性建模的价值。
论文及项目相关链接
总结
随着在医学图像领域的最新进展,尤其是通过不确定性的感知训练策略的引入,现已提高SAM模型和SAM2模型等在恶劣天气条件下的稳健性。通过对原有模型进行多步骤微调以及适配不确定性感知适配器UAT的应用,这两者在自动驾驶的上下文中展示出其对驾驶环境识别和天气干扰抑制的提升作用。研究表明明确的模型不确定性对于确保在复杂环境中驾驶的安全性至关重要。研究证明不确定性的量化策略能有效改善通用图像分割模型的稳健性,有助于在恶劣天气条件下的场景识别与自主驾驶。
关键见解
- 最新进展的医学图像技术提供了不确定性的感知训练策略,有助于提高模型的稳健性。
- 在恶劣天气条件下,不确定性感知训练对模型性能的提升尤为重要。这是因为恶劣天气条件导致视觉模糊和不确定性增加。因此,缺乏不确定性量化的模型可能无法准确处理这些情况。通过对模型的改进和优化,可以有效地解决这一问题。引入不确定性感知训练策略的模型可以更好地适应各种环境并增强场景识别能力。
点此查看论文截图




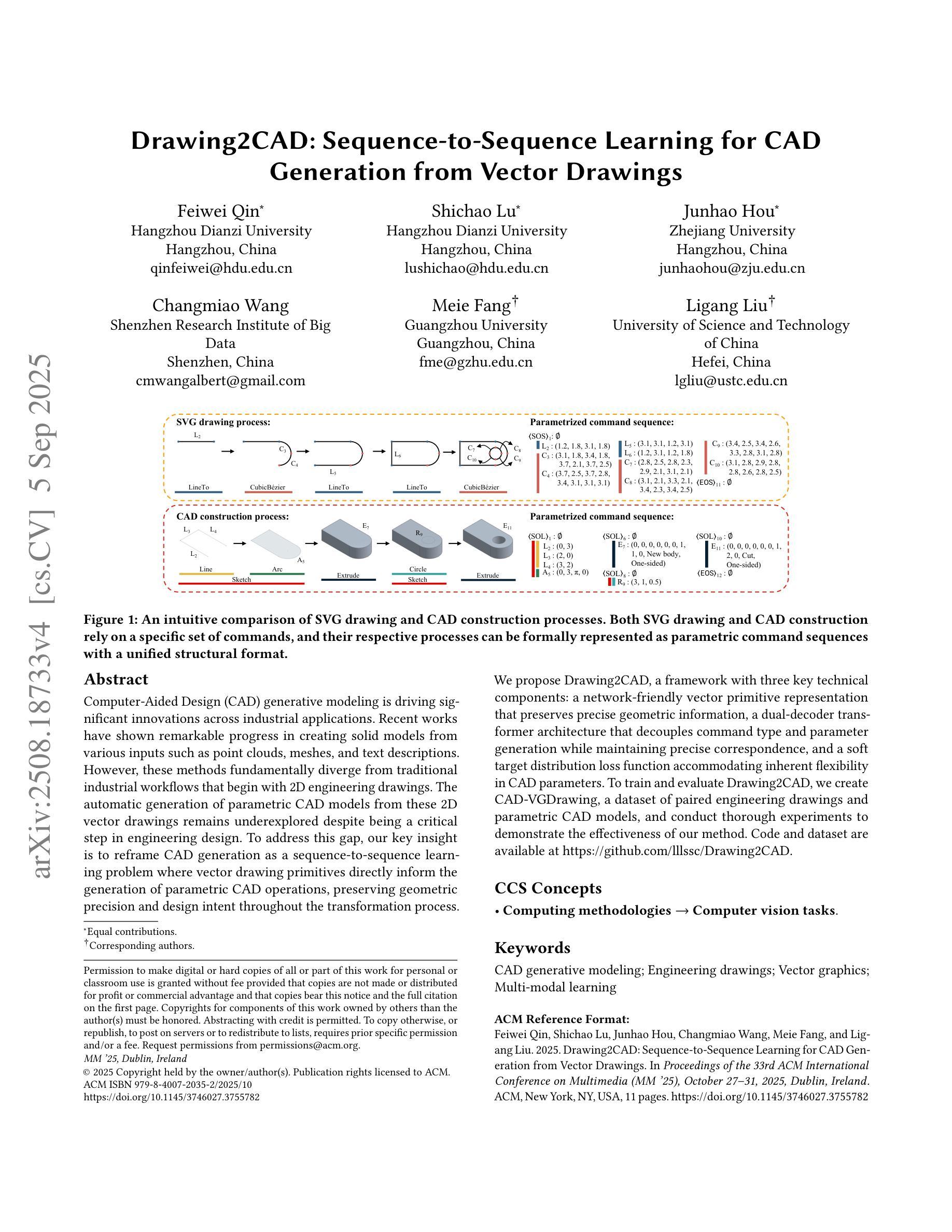
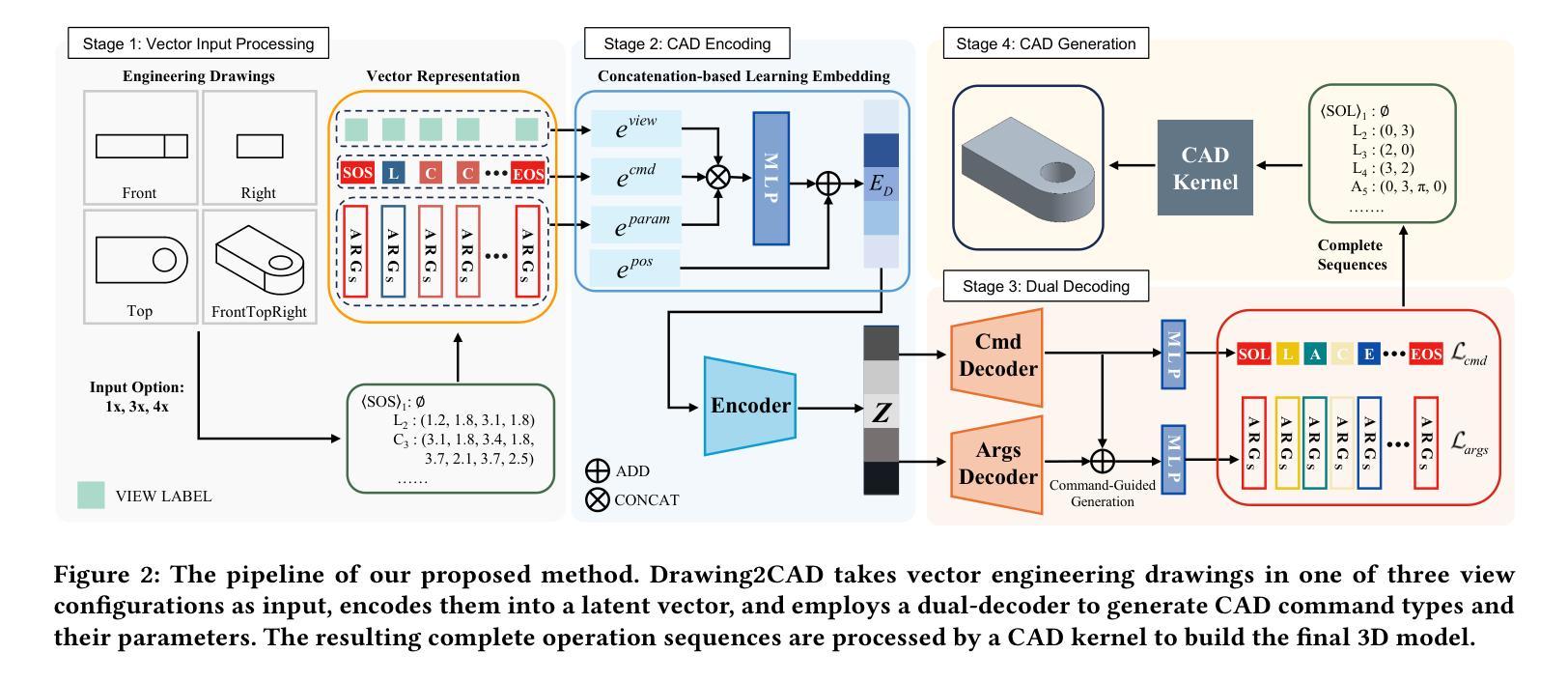
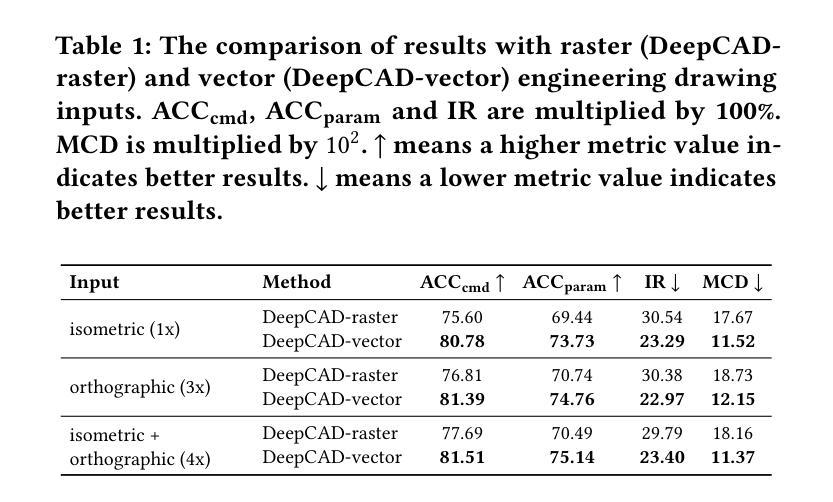
Drawing2CAD: Sequence-to-Sequence Learning for CAD Generation from Vector Drawings
Authors:Feiwei Qin, Shichao Lu, Junhao Hou, Changmiao Wang, Meie Fang, Ligang Liu
Computer-Aided Design (CAD) generative modeling is driving significant innovations across industrial applications. Recent works have shown remarkable progress in creating solid models from various inputs such as point clouds, meshes, and text descriptions. However, these methods fundamentally diverge from traditional industrial workflows that begin with 2D engineering drawings. The automatic generation of parametric CAD models from these 2D vector drawings remains underexplored despite being a critical step in engineering design. To address this gap, our key insight is to reframe CAD generation as a sequence-to-sequence learning problem where vector drawing primitives directly inform the generation of parametric CAD operations, preserving geometric precision and design intent throughout the transformation process. We propose Drawing2CAD, a framework with three key technical components: a network-friendly vector primitive representation that preserves precise geometric information, a dual-decoder transformer architecture that decouples command type and parameter generation while maintaining precise correspondence, and a soft target distribution loss function accommodating inherent flexibility in CAD parameters. To train and evaluate Drawing2CAD, we create CAD-VGDrawing, a dataset of paired engineering drawings and parametric CAD models, and conduct thorough experiments to demonstrate the effectiveness of our method. Code and dataset are available at https://github.com/lllssc/Drawing2CAD.
计算机辅助设计(CAD)生成建模正在推动工业应用的重大创新。近期的研究工作显示,从点云、网格和文本描述等各种输入创建实体模型取得了显著进展。然而,这些方法从根本上偏离了始于二维工程绘图的传统工业工作流程。尽管从二维矢量图中自动生成参数化CAD模型是工程设计中的关键步骤,但这一领域的探索仍然不足。为了弥补这一空白,我们的核心见解是将CAD生成重新构建为一个序列到序列的学习问题,其中矢量绘图元素直接为参数化CAD操作生成提供信息,并在整个转换过程中保持几何精度和设计意图。我们提出了Drawing2CAD框架,包含三个关键技术组件:一种友好的网络矢量元素表示,保留精确的几何信息;一种双解码器转换器架构,该架构在保持精确对应的同时解耦命令类型和参数生成;一种适应CAD参数固有灵活性的软目标分布损失函数。为了训练和评估Drawing2CAD,我们创建了CAD-VGDrawing数据集,其中包含配对的工程图纸和参数化CAD模型,并通过全面的实验证明了我们的方法的有效性。代码和数据集可在https://github.com/lllssc/Drawing2CAD获得。
论文及项目相关链接
PDF Accepted to ACM MM 2025
Summary
基于计算机辅助设计(CAD)的生成建模正在推动工业应用的重大创新。近期作品展示了从点云、网格和文本描述等创建实体模型的显著进展,但与传统从二维工程图纸开始的工业工作流程相比,这些方法仍存在明显差异。针对这一空白,本文的关键见解是将CAD生成重新构建为序列到序列的学习问题,其中矢量绘图原始元素直接告知参数化CAD操作生成过程,保持几何精度和设计意图在转换过程中的保留。本文提出Drawing2CAD框架,包括三个关键技术部分:网络友好的矢量原始元素表示法保留精确几何信息,双解码器转换架构将命令类型和参数生成解耦同时保持精确对应关系,以及适应CAD参数固有灵活性的软目标分布损失函数。为训练和评估Drawing2CAD,我们创建了CAD-VGDrawing数据集,包含配对工程图纸和参数化CAD模型,并通过实验证明方法的有效性。代码和数据集可在链接中找到。
Key Takeaways
- CAD生成建模在工业应用中具有显著创新意义。
- 现有方法主要关注从点云、网格和文本描述创建实体模型,但未能涵盖传统工业工作流程中的二维工程图纸。
- Drawing2CAD框架解决了从二维矢量图纸自动生成参数化CAD模型的问题,保留了几何精度和设计意图。
- Drawing2CAD框架包括三个关键技术部分:矢量原始元素表示法、双解码器转换架构和软目标分布损失函数。
点此查看论文截图
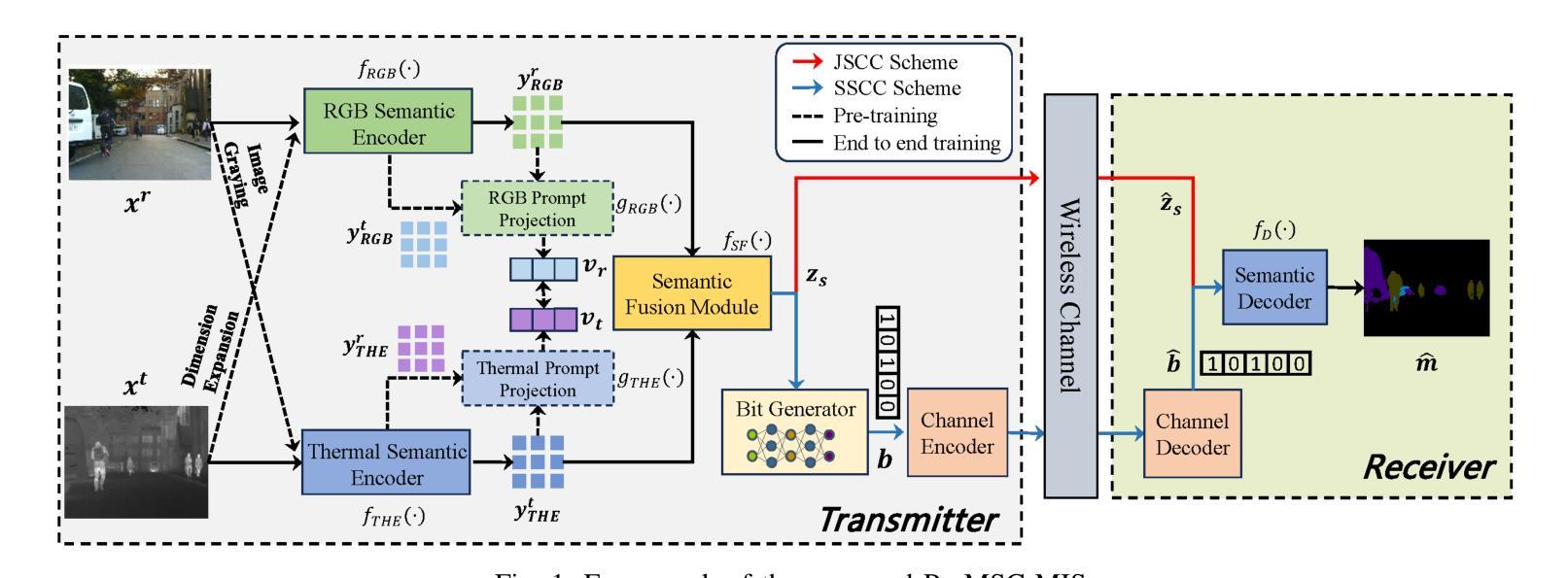
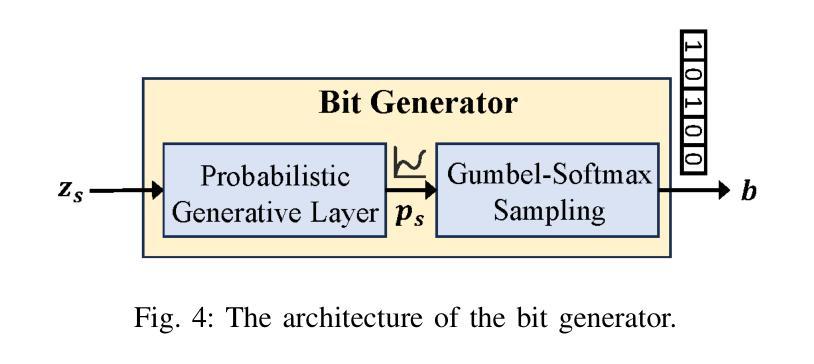
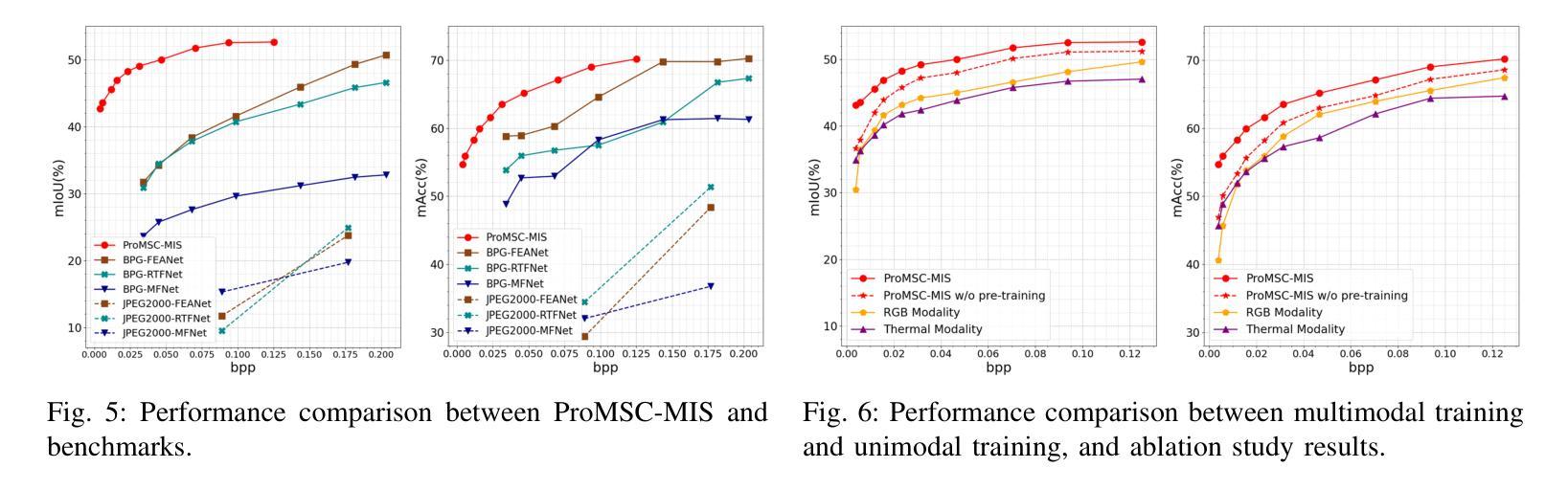
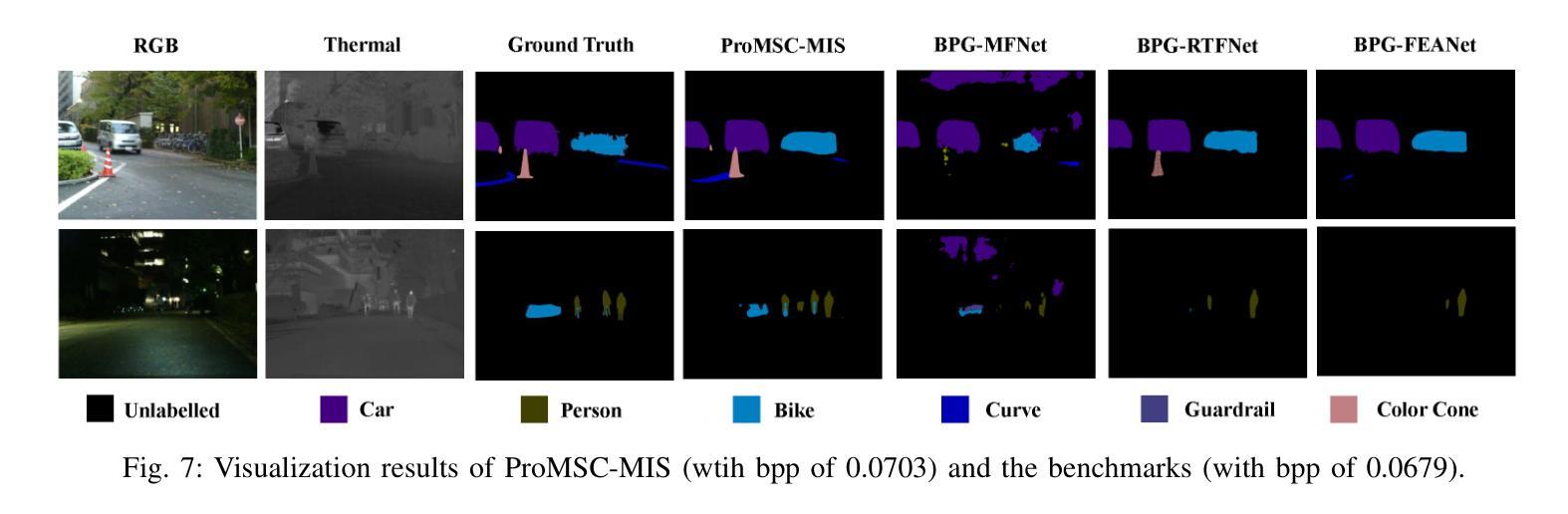
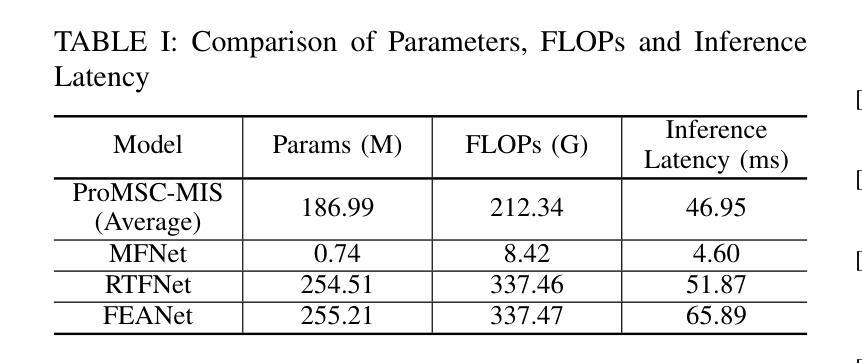
Prompt-based Multimodal Semantic Communication for Multi-spectral Image Segmentation
Authors:Haoshuo Zhang, Yufei Bo, Hongwei Zhang, Meixia Tao
Multimodal semantic communication has gained widespread attention due to its ability to enhance downstream task performance. A key challenge in such systems is the effective fusion of features from different modalities, which requires the extraction of rich and diverse semantic representations from each modality. To this end, we propose ProMSC-MIS, a Prompt-based Multimodal Semantic Communication system for Multi-spectral Image Segmentation. Specifically, we propose a pre-training algorithm where features from one modality serve as prompts for another, guiding unimodal semantic encoders to learn diverse and complementary semantic representations. We further introduce a semantic fusion module that combines cross-attention mechanisms and squeeze-and-excitation (SE) networks to effectively fuse cross-modal features. Simulation results show that ProMSC-MIS significantly outperforms benchmark methods across various channel-source compression levels, while maintaining low computational complexity and storage overhead. Our scheme has great potential for applications such as autonomous driving and nighttime surveillance.
多模态语义通信因其能增强下游任务性能而受到广泛关注。此类系统的关键挑战在于有效地融合不同模态的特征,这需要从每个模态中提取丰富和多样的语义表示。为此,我们提出了基于提示的多模态语义通信系统ProMSC-MIS(用于多光谱图像分割)。具体来说,我们提出了一种预训练算法,其中一个模态的特征为另一个模态提供提示,引导单模态语义编码器学习多样且互补的语义表示。我们还引入了一个语义融合模块,该模块结合了交叉注意机制和挤压激发(SE)网络,以有效地融合跨模态特征。仿真结果表明,在各种通道源压缩级别上,ProMSC-MIS明显优于基准方法,同时保持较低的计算复杂性和存储开销。我们的方案在自动驾驶和夜间监控等应用中具有巨大的潜力。
论文及项目相关链接
PDF The full-length version, arXiv:2508.20057, has been updated
摘要
基于提示的多模态语义通信系统用于多光谱图像分割,提出ProMSC-MIS系统。该系统通过跨模态特征融合提升下游任务性能,采用预训练算法实现不同模态特征的有效融合,并引入语义融合模块结合交叉注意力机制和挤压激励网络进行跨模态特征的有效融合。仿真结果表明,ProMSC-MIS在各种通道源压缩级别上显著优于基准方法,且计算复杂度和存储开销较低,具有自动驾驶和夜间监控等应用的潜力。
关键见解
- 多模态语义通信因其能提升下游任务性能而受到广泛关注。
- ProMSC-MIS系统是一种基于提示的多模态语义通信系统,用于多光谱图像分割。
- 提出预训练算法实现不同模态特征的有效融合。
- 引入语义融合模块结合交叉注意力机制和挤压激励网络。
- 仿真结果表明ProMSC-MIS在多种通道源压缩级别上性能优越。
- ProMSC-MIS系统具有低计算复杂度和存储开销的特点。
点此查看论文截图

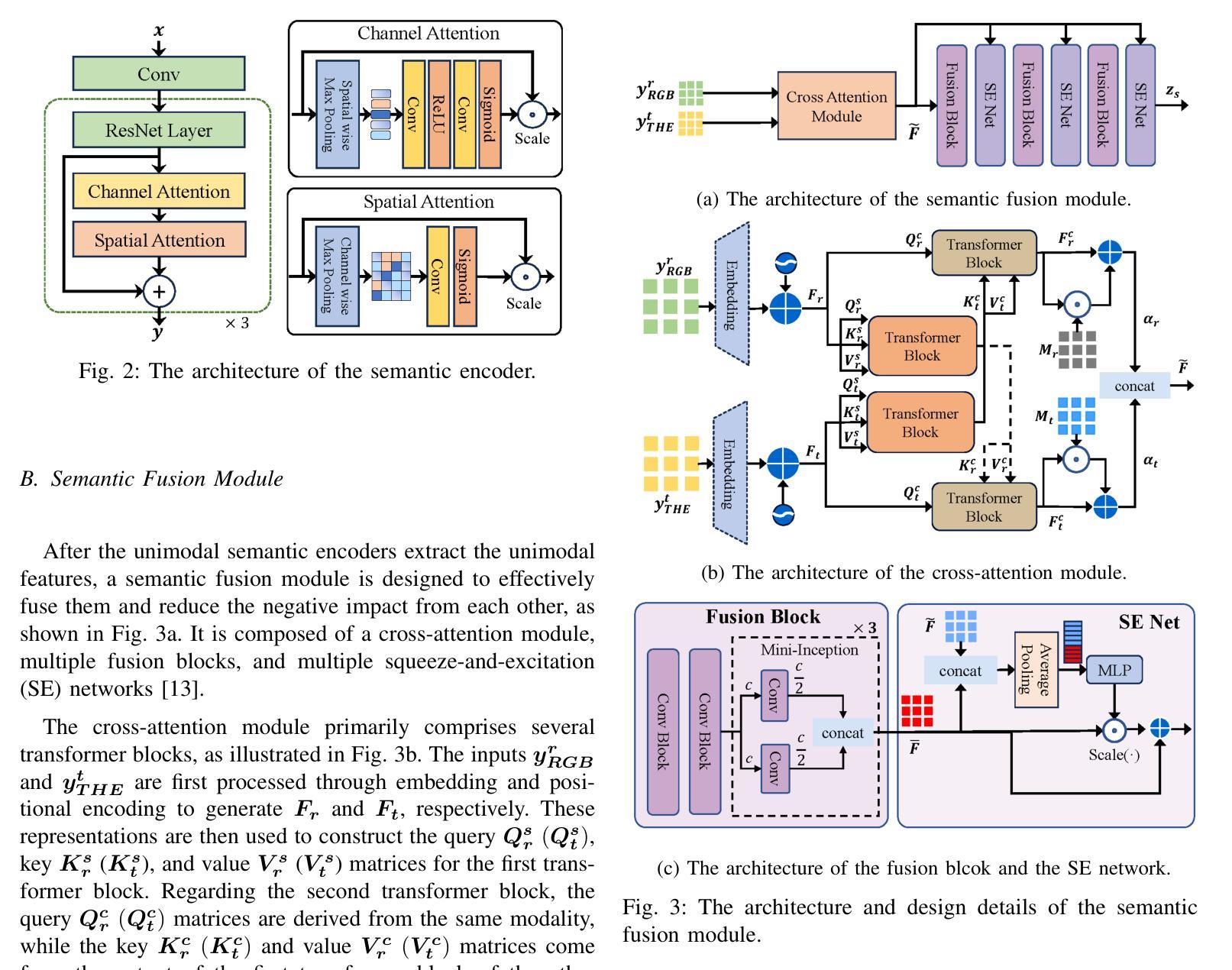
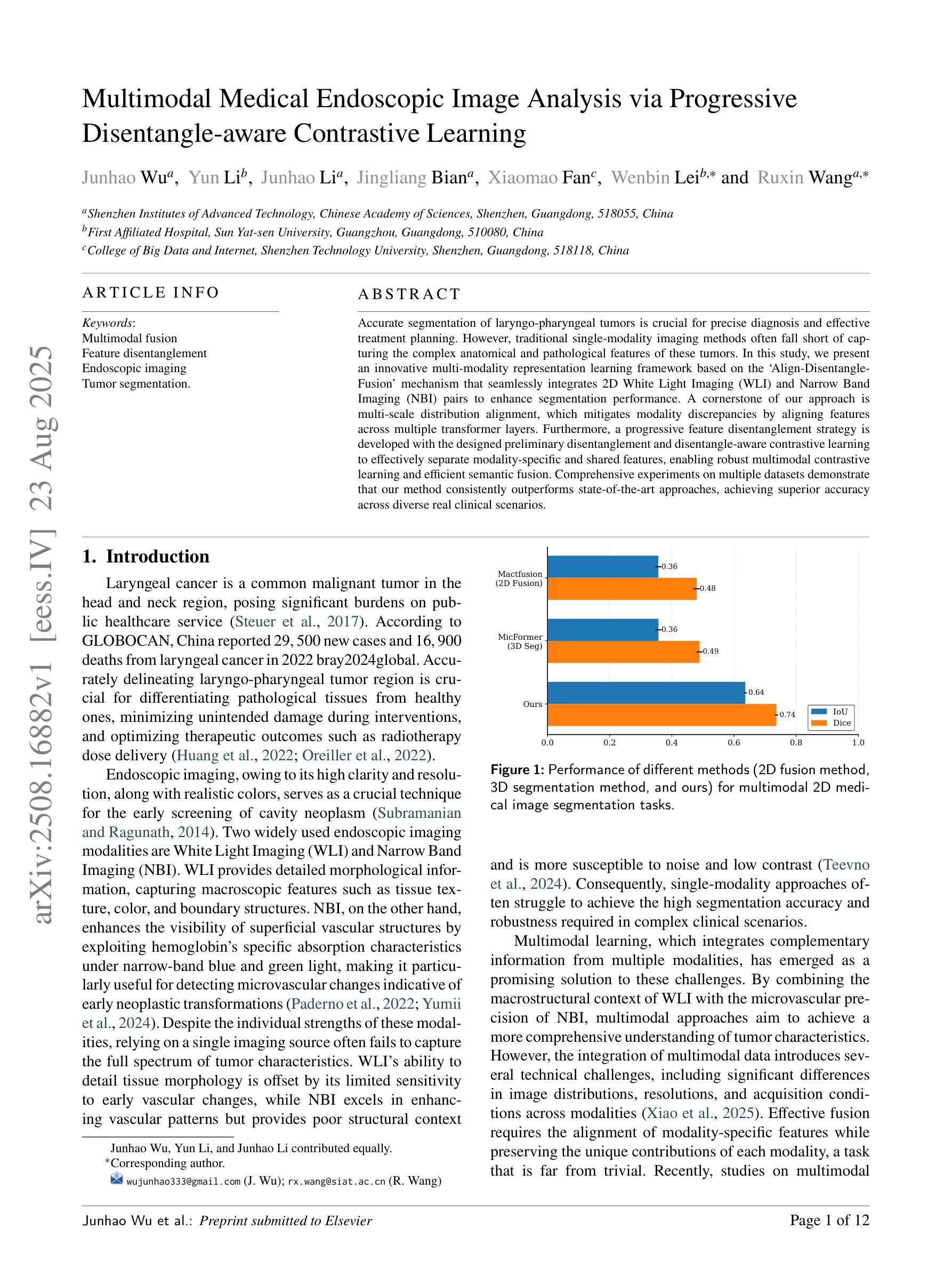
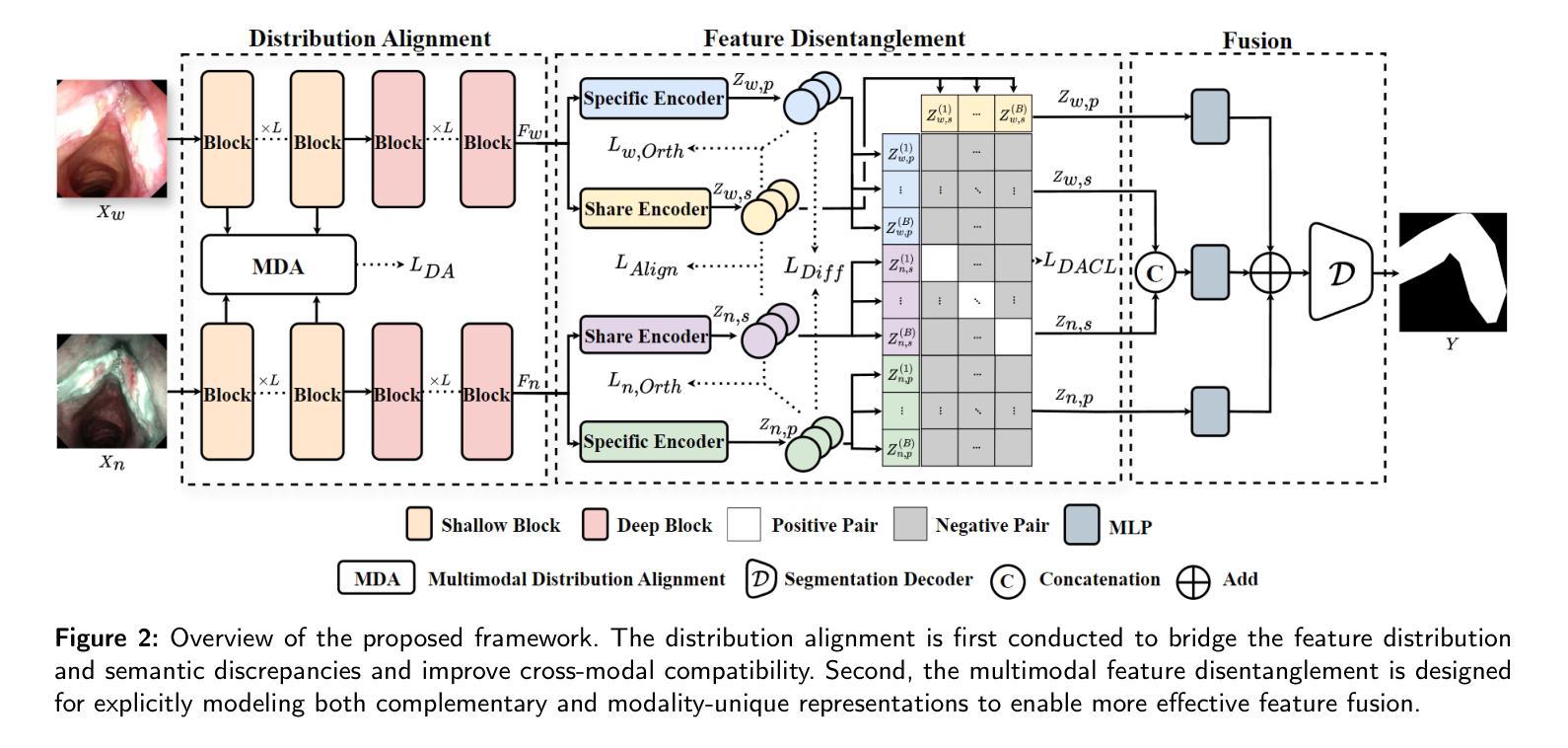
Multimodal Medical Endoscopic Image Analysis via Progressive Disentangle-aware Contrastive Learning
Authors:Junhao Wu, Yun Li, Junhao Li, Jingliang Bian, Xiaomao Fan, Wenbin Lei, Ruxin Wang
Accurate segmentation of laryngo-pharyngeal tumors is crucial for precise diagnosis and effective treatment planning. However, traditional single-modality imaging methods often fall short of capturing the complex anatomical and pathological features of these tumors. In this study, we present an innovative multi-modality representation learning framework based on the `Align-Disentangle-Fusion’ mechanism that seamlessly integrates 2D White Light Imaging (WLI) and Narrow Band Imaging (NBI) pairs to enhance segmentation performance. A cornerstone of our approach is multi-scale distribution alignment, which mitigates modality discrepancies by aligning features across multiple transformer layers. Furthermore, a progressive feature disentanglement strategy is developed with the designed preliminary disentanglement and disentangle-aware contrastive learning to effectively separate modality-specific and shared features, enabling robust multimodal contrastive learning and efficient semantic fusion. Comprehensive experiments on multiple datasets demonstrate that our method consistently outperforms state-of-the-art approaches, achieving superior accuracy across diverse real clinical scenarios.
喉咽肿瘤准确分割对于精确诊断和治疗计划至关重要。然而,传统的单一成像模式方法往往难以捕捉这些肿瘤的复杂解剖和病理特征。本研究提出了一种基于“对齐-分离-融合”机制的创新多模式表示学习框架,无缝集成了2D白光成像(WLI)和窄带成像(NBI)对,以提高分割性能。我们的方法的一个关键组成部分是多尺度分布对齐,它通过对齐多个转换器层中的特征来缓解模式差异。此外,开发了一种渐进的特征分离策略,通过设计初步分离和解纠缠感知对比学习,有效地分离了模式特定特征和共享特征,实现了稳健的多模式对比学习和有效的语义融合。在多个数据集上的综合实验表明,我们的方法始终优于最先进的方法,在多种真实临床场景中实现了较高的准确性。
论文及项目相关链接
PDF 12 pages,6 figures, 6 tables
摘要
本研究提出一种基于”对齐-分离-融合”机制的多模态表示学习框架,旨在准确分割喉咽肿瘤,为精确诊断和治疗计划提供支持。该框架无缝集成了2D白光成像(WLI)和窄带成像(NBI)对,以提高分割性能。多尺度分布对齐是该方法的核心,通过多个transformer层特征对齐,缓解了模态差异。同时,研究团队还开发了一种渐进的特征分离策略,通过初步的特征分离和感知分离的对比学习,有效地分离了模态特定特征和共享特征,实现了稳健的多模态对比学习和高效的语义融合。在多个数据集上的综合实验表明,该方法较其他前沿技术表现更优,在各种真实临床场景中均实现了较高的准确性。
关键见解
- 喉咽肿瘤准确分割对精确诊断和治疗计划至关重要。
- 传统单一成像模式在捕捉肿瘤复杂解剖和病理特征时存在局限性。
- 研究提出了一种多模态表示学习框架,集成了2D白光成像和窄带成像,以提高分割性能。
- 多尺度分布对齐是该框架的核心,有助于缓解不同模态之间的差异。
- 渐进的特征分离策略能有效分离模态特定特征和共享特征。
- 该方法通过对比学习和语义融合实现了稳健的多模态学习。
- 在多个数据集上的实验表明,该方法较其他技术表现优越,具有较高的准确性。
点此查看论文截图

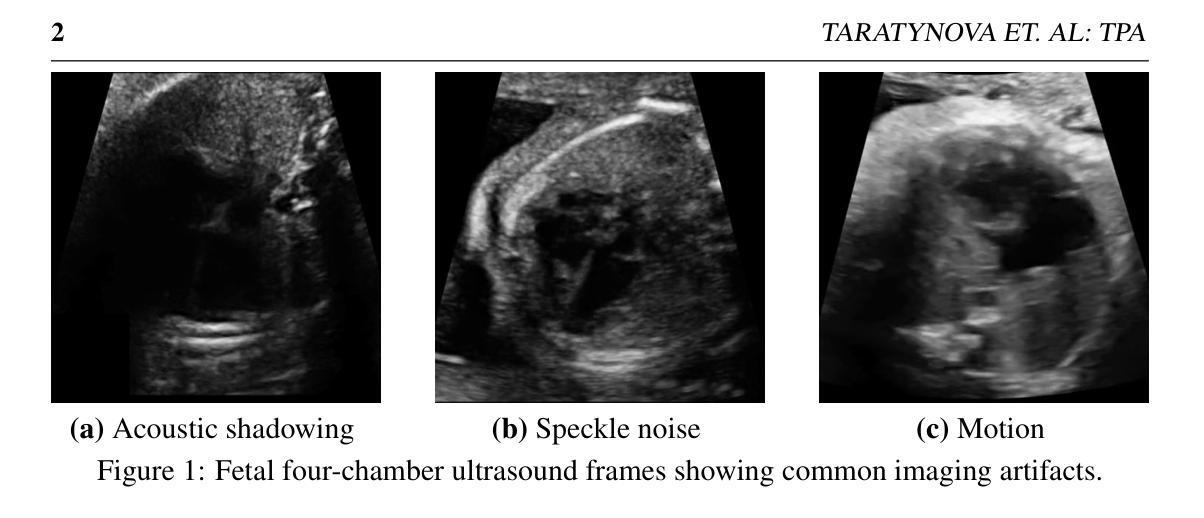
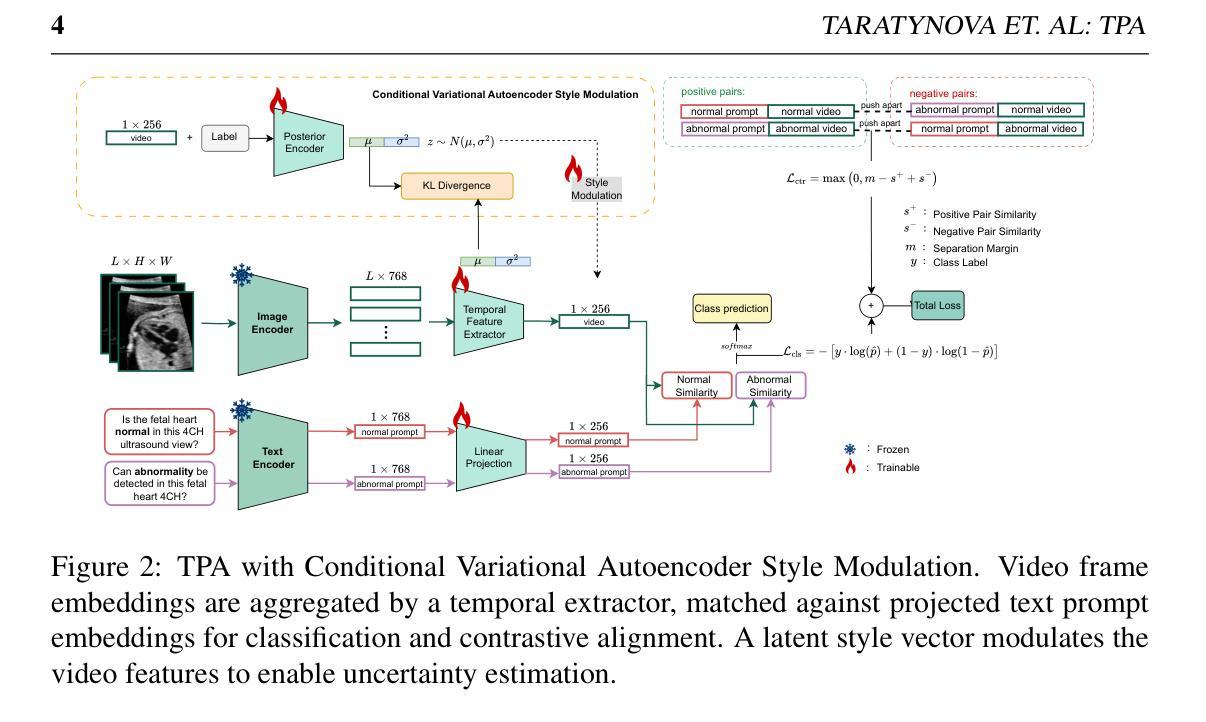
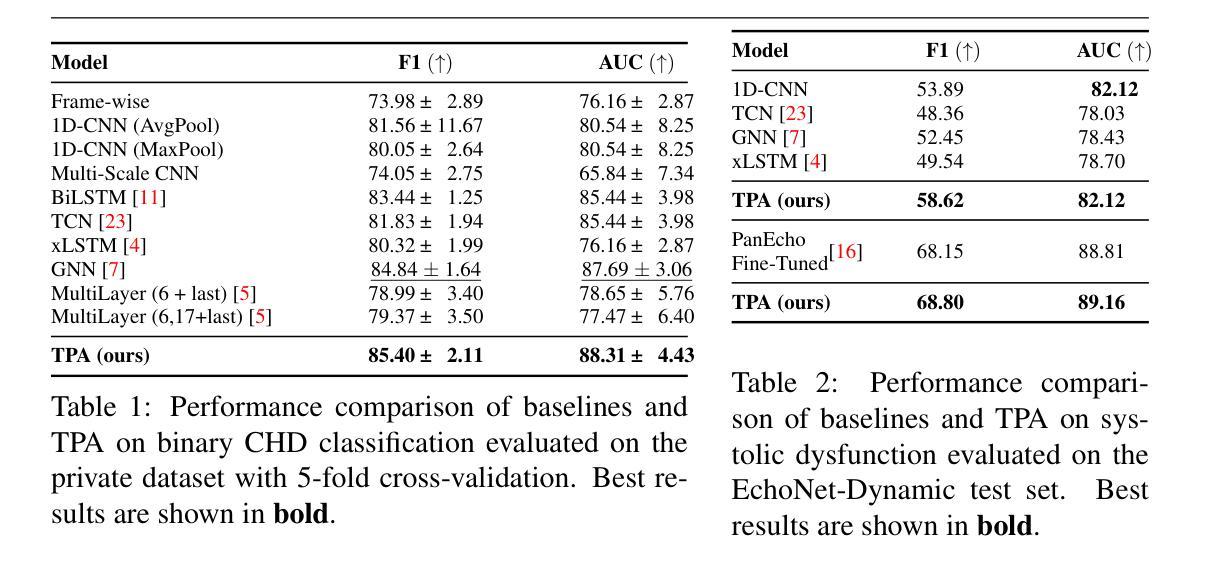
TPA: Temporal Prompt Alignment for Fetal Congenital Heart Defect Classification
Authors:Darya Taratynova, Alya Almsouti, Beknur Kalmakhanbet, Numan Saeed, Mohammad Yaqub
Congenital heart defect (CHD) detection in ultrasound videos is hindered by image noise and probe positioning variability. While automated methods can reduce operator dependence, current machine learning approaches often neglect temporal information, limit themselves to binary classification, and do not account for prediction calibration. We propose Temporal Prompt Alignment (TPA), a method leveraging foundation image-text model and prompt-aware contrastive learning to classify fetal CHD on cardiac ultrasound videos. TPA extracts features from each frame of video subclips using an image encoder, aggregates them with a trainable temporal extractor to capture heart motion, and aligns the video representation with class-specific text prompts via a margin-hinge contrastive loss. To enhance calibration for clinical reliability, we introduce a Conditional Variational Autoencoder Style Modulation (CVAESM) module, which learns a latent style vector to modulate embeddings and quantifies classification uncertainty. Evaluated on a private dataset for CHD detection and on a large public dataset, EchoNet-Dynamic, for systolic dysfunction, TPA achieves state-of-the-art macro F1 scores of 85.40% for CHD diagnosis, while also reducing expected calibration error by 5.38% and adaptive ECE by 6.8%. On EchoNet-Dynamic’s three-class task, it boosts macro F1 by 4.73% (from 53.89% to 58.62%). Temporal Prompt Alignment (TPA) is a framework for fetal congenital heart defect (CHD) classification in ultrasound videos that integrates temporal modeling, prompt-aware contrastive learning, and uncertainty quantification.
先天性心脏缺陷(CHD)在超声视频中的检测受到图像噪声和探头定位变化的影响。虽然自动化方法可以减少对操作员的依赖,但当前的机器学习方法常常忽略了时间信息,仅限于二元分类,并且没有考虑到预测校准。我们提出了“时间提示对齐”(TPA)方法,该方法利用基础图像文本模型和提示感知对比学习来对胎儿CHD进行心脏超声视频分类。TPA通过图像编码器从视频的每个片段中提取特征,并使用可训练的时间提取器来捕捉心脏运动,然后通过边距铰链对比损失将视频表示与特定类别的文本提示对齐。为了提高临床可靠性的校准,我们引入了条件变分自动编码器风格调制(CVAESM)模块,它学习潜在的风格向量来调制嵌入并量化分类的不确定性。在针对CHD检测的私有数据集和用于收缩功能障碍的大型公共数据集EchoNet-Dynamic上进行了评估,TPA达到了最先进的宏观F1分数,CHD诊断的F1分数为85.40%,同时降低了期望校准误差5.38%和自适应ECE 6.8%。在EchoNet-Dynamic的三类任务中,它提高了宏观F1分数4.73%(从53.89%提高到58.62%)。时间提示对齐(TPA)是一个框架,用于超声视频中胎儿先天性心脏缺陷(CHD)的分类,它集成了时间建模、提示感知对比学习和不确定性量化。
论文及项目相关链接
Summary
本文提出一种基于图像-文本模型和提示感知对比学习的先天性心脏缺陷(CHD)视频分类方法,称为Temporal Prompt Alignment(TPA)。该方法利用视频子剪辑的每一帧特征,结合心脏运动的时间信息,通过与类别特定的文本提示对齐的视频表示,实现CHD的自动分类。为提高临床可靠性,引入条件变分自编码器风格调制模块,学习潜在的风格向量以调制嵌入并量化分类不确定性。在私人数据集和公共数据集EchoNet-Dynamic上的评估表明,TPA在CHD检测方面达到了最先进的宏观F1分数,同时降低了预期校准误差和自适应ECE。总体而言,TPA是一个集成了时间建模、提示感知对比学习和不确定性量化的框架,用于胎儿先天性心脏缺陷(CHD)的超声视频分类。
Key Takeaways
1.TPA利用图像-文本模型和提示感知对比学习进行分类。
2.TPA提取视频每一帧的特征并结合心脏运动的时间信息。
3.视频表示与类别特定的文本提示通过边缘铰链对比损失进行对齐。
4.引入条件变分自编码器风格调制模块以提高分类的可靠性并量化不确定性。
5.在私人数据集和公共数据集上的评估显示TPA表现优越。
6.TPA达到了最先进的宏观F1分数,降低预期校准误差和自适应ECE。
点此查看论文截图

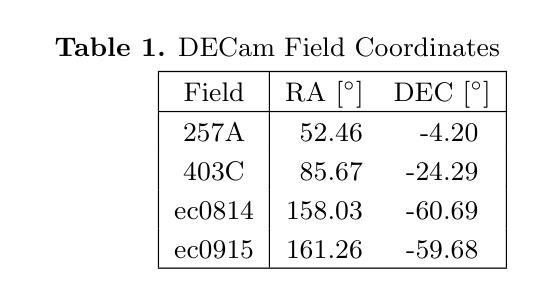
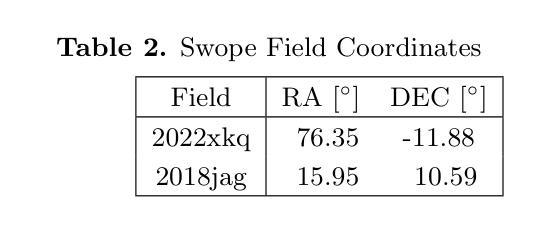
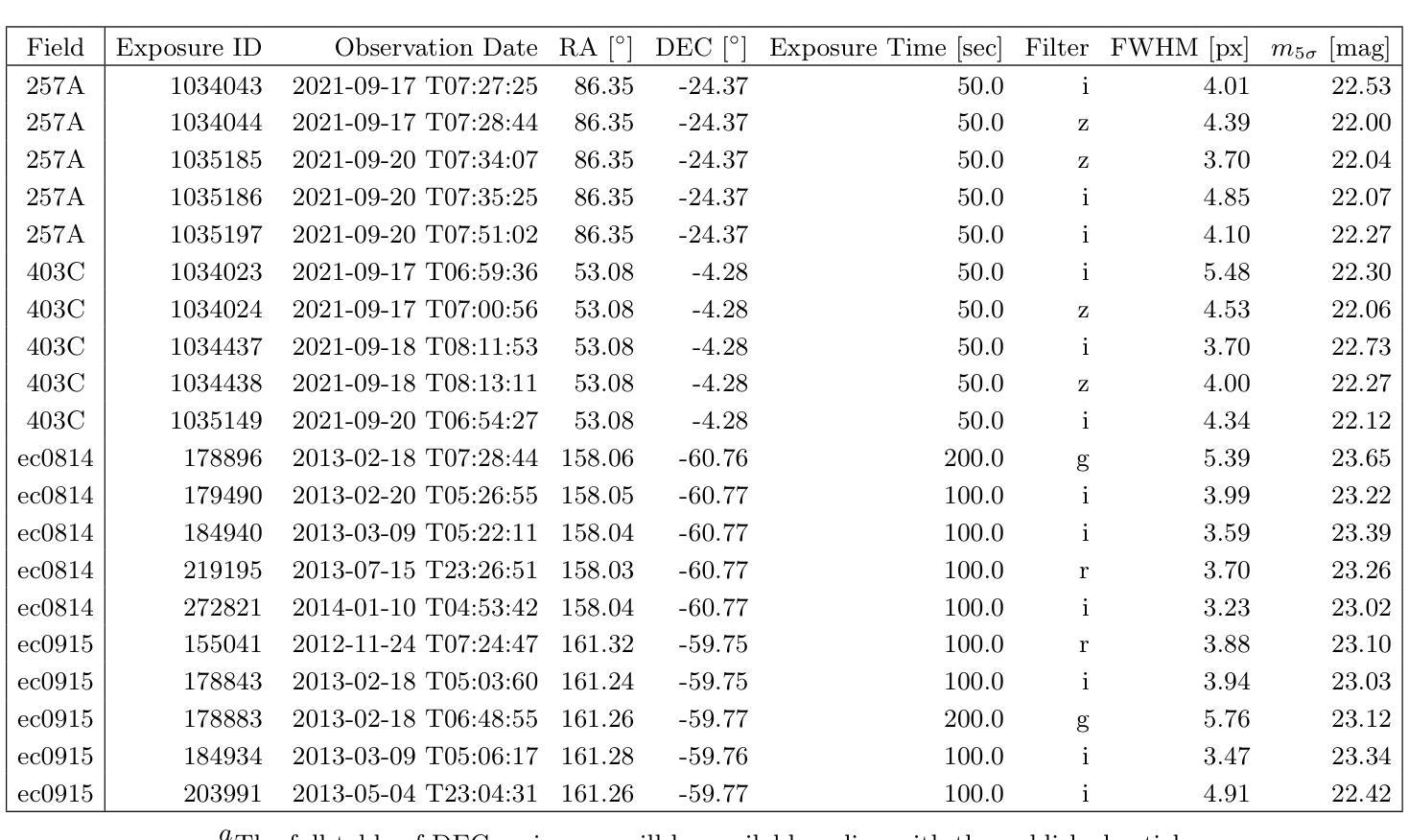
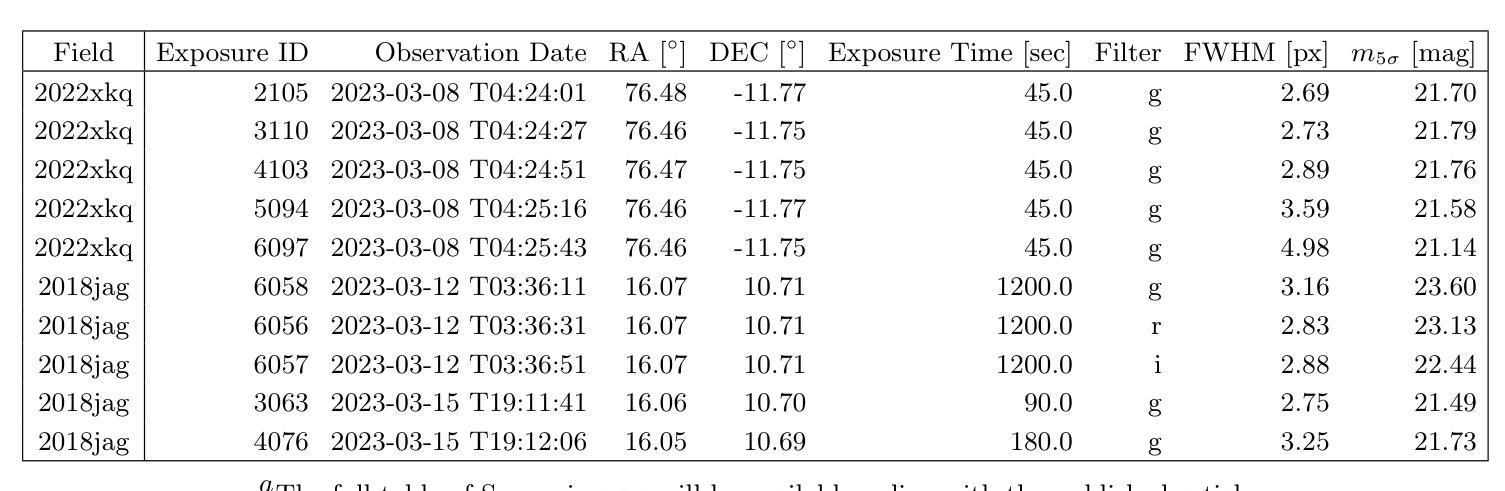
Optimizing Convolution Direction and Template Selection for Difference Image Analysis
Authors:Rodrigo Angulo, Armin Rest, William P. Blair, Jacob Jencson, David A. Coulter, Qinan Wang, Ryan J. Foley, Charles D. Kilpatrick, Xiaolong Li, César Rojas-Bravo, Anthony L. Piro
Difference image analysis (DIA) is a powerful tool for studying time-variable phenomena, and has been used by many time-domain surveys. Most DIA algorithms involve matching the spatially-varying PSF shape between science and template images, and then convolving that shape in one image to match the other. The wrong choice of which image to convolve can introduce one of the largest sources of artifacts in the final difference image. We introduce a quantitative metric to determine the optimal convolution direction that depends not only on the sharpness of the images measured by their FWHM, but also on their exposure depths. With this metric, the optimal convolution direction can be determined a priori, depending only on the FWHM and depth of the images. This not only simplifies the process, but also makes it more robust and less prone to creating sub-optimal difference images due to the wrong choice of the convolution direction. As an additional benefit, for a large set of images, we define a Figure-of-Merit based on this metric, which allows us to rank a list of images and determine the ones best suited to be used as templates, thus streamlining and automating the data reduction process.
差异图像分析(DIA)是研究时变现象的有力工具,已被许多时域调查所使用。大多数DIA算法都涉及匹配科学和模板图像之间空间变化的PSF形状,然后将该形状卷积以匹配另一个图像。选择错误的图像进行卷积可能会引入最终差异图像中最大的伪影来源之一。我们引入了一个定量指标,以确定最佳的卷积方向,该方向不仅取决于通过其FWHM测量的图像清晰度,还取决于它们的曝光深度。使用这个指标,可以根据图像的FWHM和深度预先确定最佳的卷积方向。这不仅简化了流程,而且使其更加稳健,并且由于选择了错误的卷积方向而不太容易产生次优差异图像。作为附加好处,对于大量图像,我们基于该指标定义了一个品质因数,这使我们能够对图像列表进行排名,并确定最适合用作模板的图像,从而简化和自动化数据缩减过程。
论文及项目相关链接
PDF 17 pages, 11 figures
摘要
差异图像分析(DIA)是研究时变现象的有力工具,已被许多时域调查所使用。大多数DIA算法涉及匹配科学和模板图像之间空间变化的点扩散函数(PSF)形状,然后将该形状卷积以匹配另一图像。选择哪个图像进行卷积的错误选择可能是最终差异图像中最大的伪影来源之一。我们引入了一种定量指标来确定最佳卷积方向,该方向不仅取决于通过其FWHM测量的图像清晰度,还取决于它们的曝光深度。通过这种指标,可以事先确定最佳卷积方向,这取决于图像的FWHM和深度。这不仅简化了流程,而且使其更加稳健,不太容易产生由于卷积方向选择错误而导致的不理想的差异图像。此外,对于大量图像,我们基于该指标定义了一个品质因数,可以让我们对图像列表进行排名并确定最适合用作模板的图像,从而简化和自动化数据缩减过程。
要点
- 差异图像分析(DIA)是研究时变现象的重要工具,广泛应用于时域调查。
- DIA算法的关键步骤之一是匹配科学和模板图像之间的点扩散函数(PSF)形状。
- 卷积方向的正确选择对于避免差异图像中的伪影至关重要。
- 引入了一种定量指标来确定最佳卷积方向,该指标考虑了图像的清晰度和曝光深度。
- 通过该指标,可以预先确定最佳卷积方向,从而提高流程的稳定性和效率。
- 定义了一个品质因数,可以根据该指标对大量图像进行排名,确定最适合作为模板的图像。
点此查看论文截图

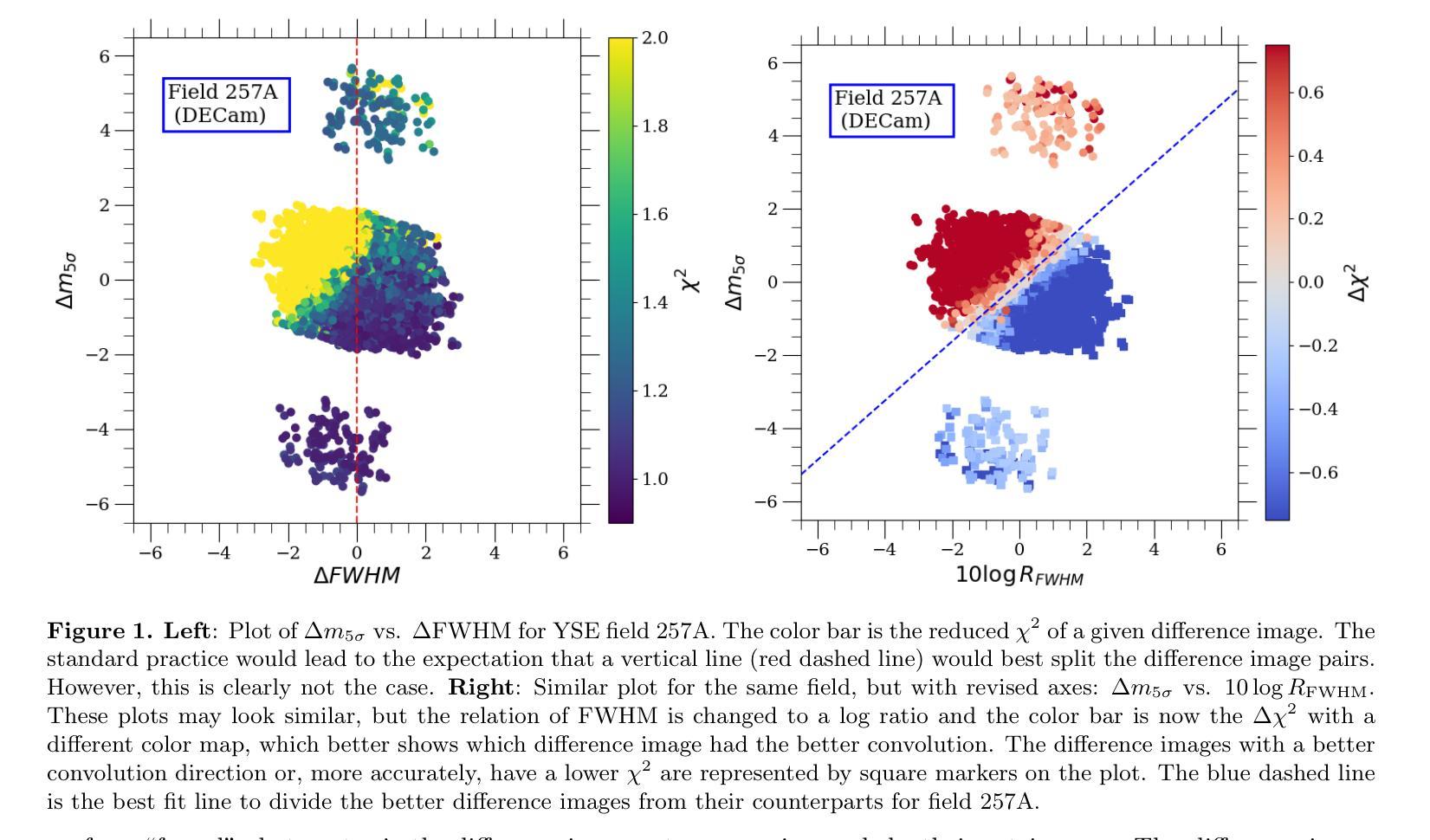
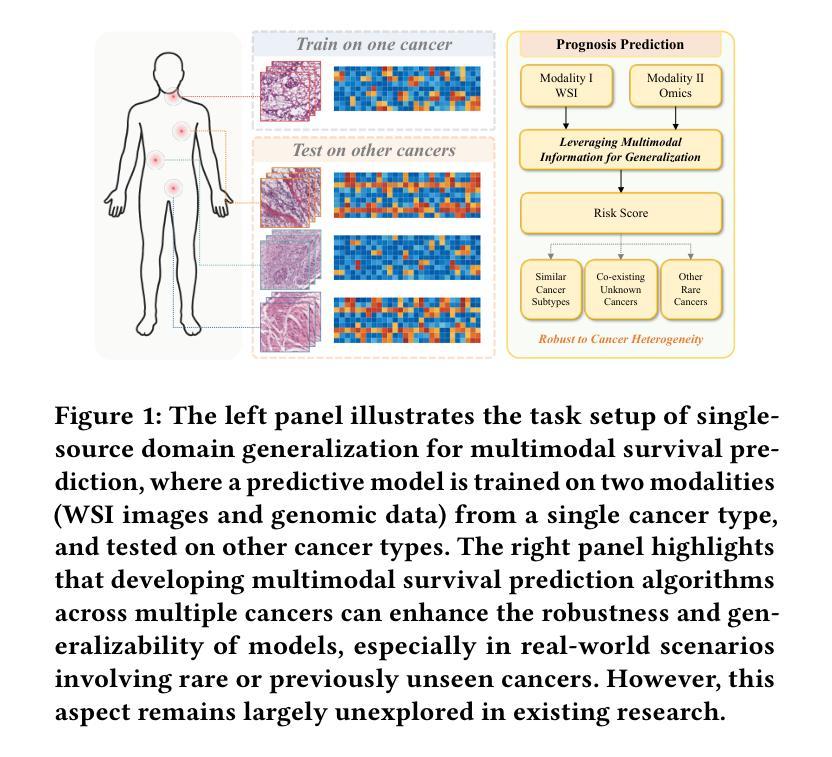
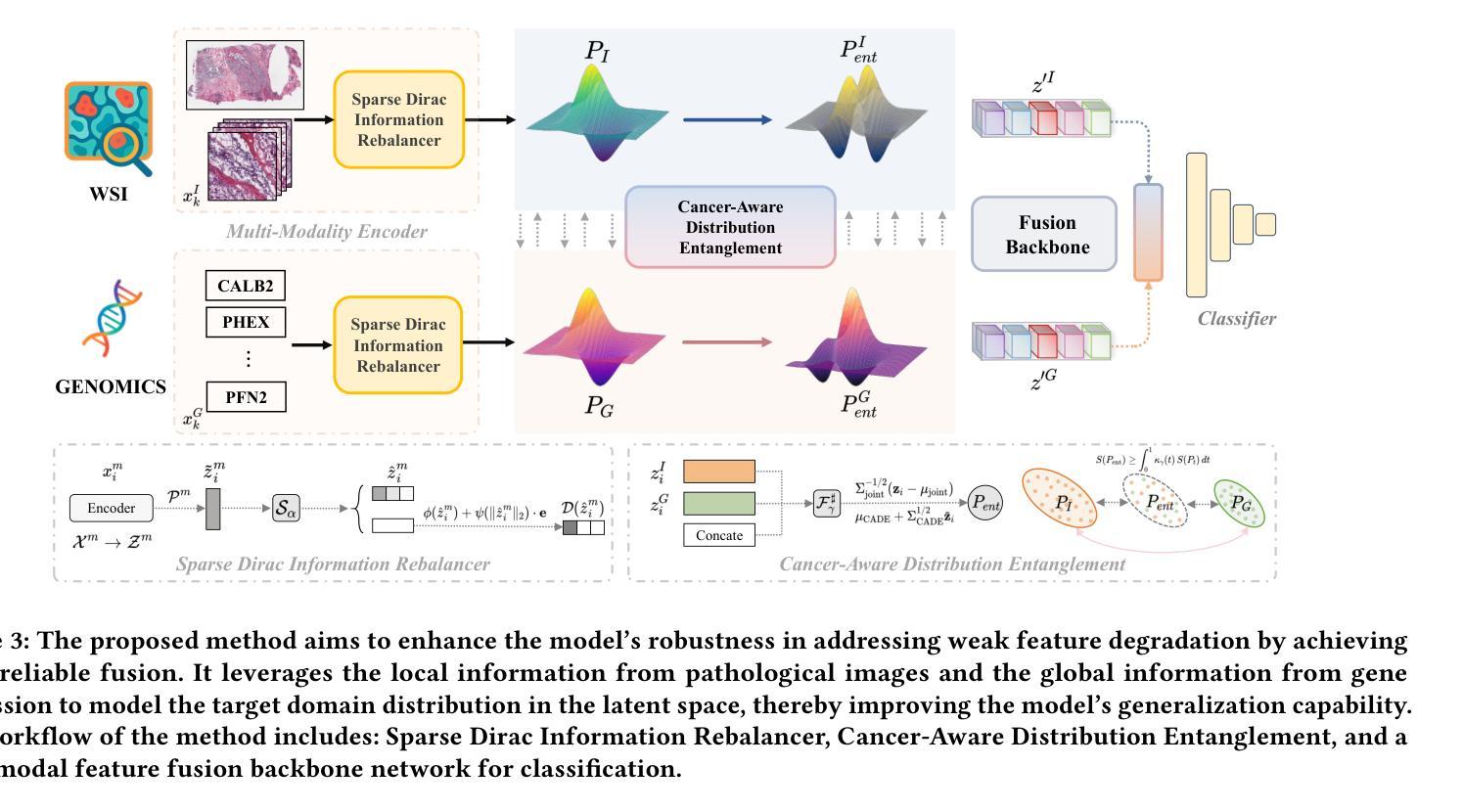
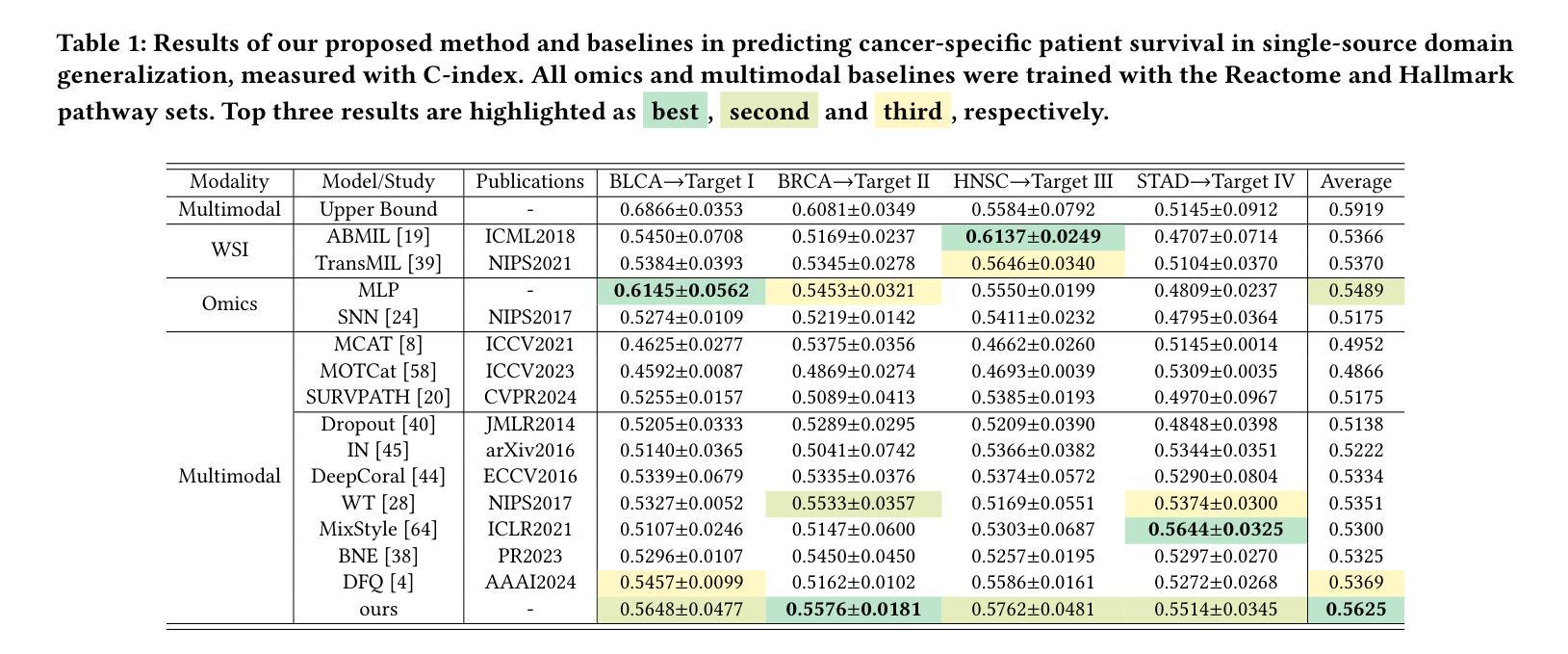
Single Domain Generalization for Multimodal Cross-Cancer Prognosis via Dirac Rebalancer and Distribution Entanglement
Authors:Jia-Xuan Jiang, Jiashuai Liu, Hongtao Wu, Yifeng Wu, Zhong Wang, Qi Bi, Yefeng Zheng
Deep learning has shown remarkable performance in integrating multimodal data for survival prediction. However, existing multimodal methods mainly focus on single cancer types and overlook the challenge of generalization across cancers. In this work, we are the first to reveal that multimodal prognosis models often generalize worse than unimodal ones in cross-cancer scenarios, despite the critical need for such robustness in clinical practice. To address this, we propose a new task: Cross-Cancer Single Domain Generalization for Multimodal Prognosis, which evaluates whether models trained on a single cancer type can generalize to unseen cancers. We identify two key challenges: degraded features from weaker modalities and ineffective multimodal integration. To tackle these, we introduce two plug-and-play modules: Sparse Dirac Information Rebalancer (SDIR) and Cancer-aware Distribution Entanglement (CADE). SDIR mitigates the dominance of strong features by applying Bernoulli-based sparsification and Dirac-inspired stabilization to enhance weaker modality signals. CADE, designed to synthesize the target domain distribution, fuses local morphological cues and global gene expression in latent space. Experiments on a four-cancer-type benchmark demonstrate superior generalization, laying the foundation for practical, robust cross-cancer multimodal prognosis. Code is available at https://github.com/HopkinsKwong/MCCSDG
深度学习在融合多模态数据进行生存预测方面表现出卓越的性能。然而,现有的多模态方法主要集中在单一癌症类型上,忽视了跨癌症的泛化挑战。在这项工作中,我们首次揭示,尽管在临床实践中对这种稳健性有着迫切需求,但在跨癌症的情况下,多模态预后模型的泛化性能往往比单模态模型更差。为了解决这个问题,我们提出了一个新的任务:跨癌症单域泛化的多模态预后模型评估,该任务旨在评估在单一癌症类型上训练的模型是否能够推广到未见过的癌症类型。我们确定了两个关键挑战:来自较弱模态的特征退化以及无效的多模态融合。为了解决这些问题,我们引入了两种即插即用的模块:稀疏狄拉克信息平衡器(SDIR)和癌症感知分布纠缠(CADE)。SDIR通过应用基于伯努利的稀疏化和狄拉克启发式的稳定化来减轻强特征的主导作用,从而增强弱模态信号。而CADE旨在合成目标域分布,融合了局部形态线索和全局基因表达隐性空间的信息。在四种癌症类型的基准测试上的实验显示了优越的泛化性能,这为实际应用中的稳健跨癌症多模态预后模型奠定了基础。相关代码可通过链接 https://github.com/HopkinsKwong/MCCSDG 获取。
论文及项目相关链接
PDF Accepted by ACMMM 25
Summary
本文揭示了跨癌症的多模态预后模型的泛化性能较差的问题,并提出了解决该问题的新任务和挑战。为应对这些挑战,文章引入了Sparse Dirac信息平衡器和癌症感知分布纠缠两个即插即用模块,以提高模型的泛化能力。实验证明,该方法在四癌种基准测试上表现优越。
Key Takeaways
- 多模态数据融合在生存预测中表现卓越,但现有方法主要关注单一癌种,忽视泛化能力。
- 跨癌种的多模态预后模型泛化性能较差,需要提高。
- 跨癌种单域泛化的新任务被提出,以评估在未见过的癌症上训练的模型的性能。
- 主要挑战包括:来自较弱模态的特征退化以及无效的多模态融合。
- 引入Sparse Dirac信息平衡器(SDIR)和癌症感知分布纠缠(CADE)两个模块来解决这些挑战。
- SDIR通过应用基于伯努利的方法稳定Dirac来增强较弱模态信号。
点此查看论文截图

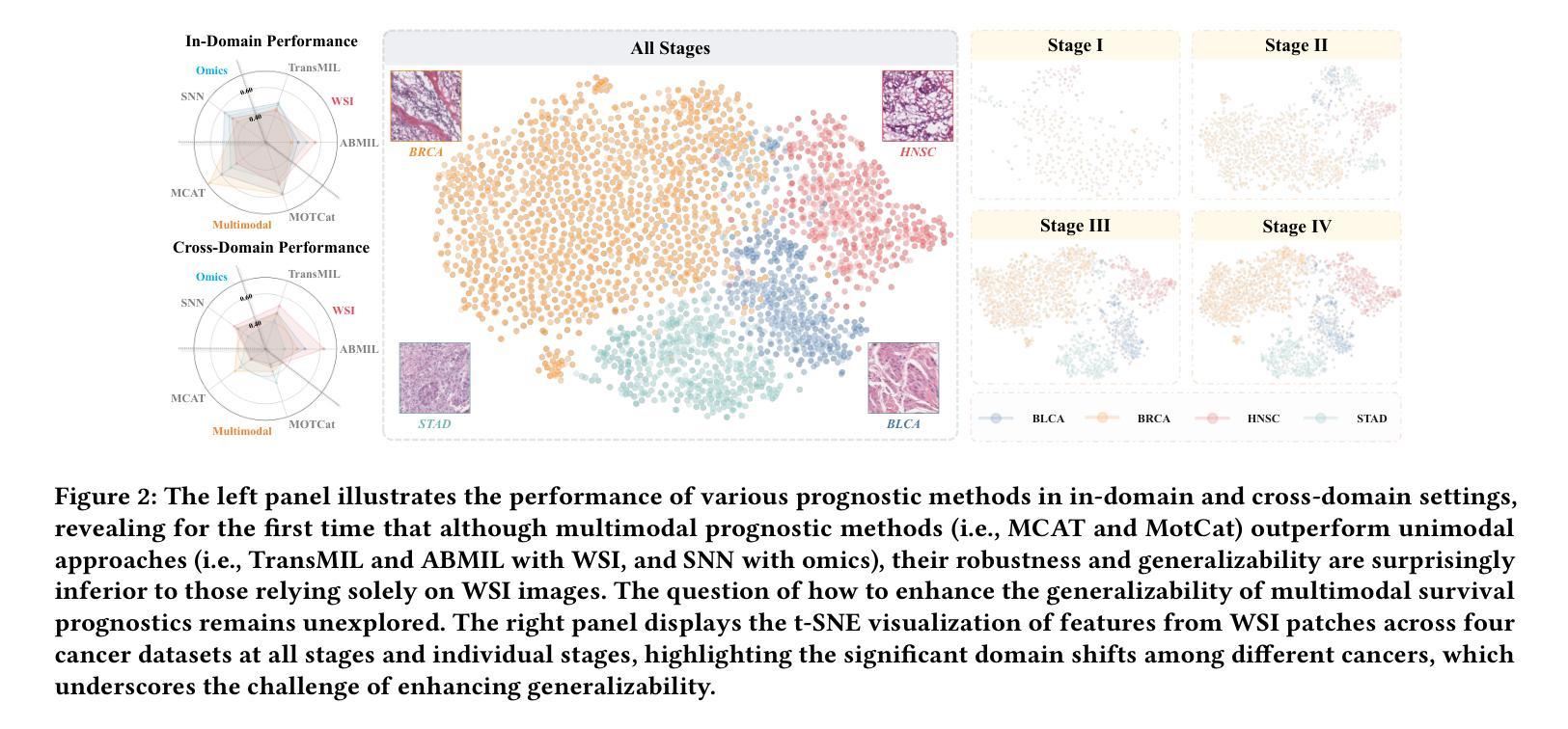
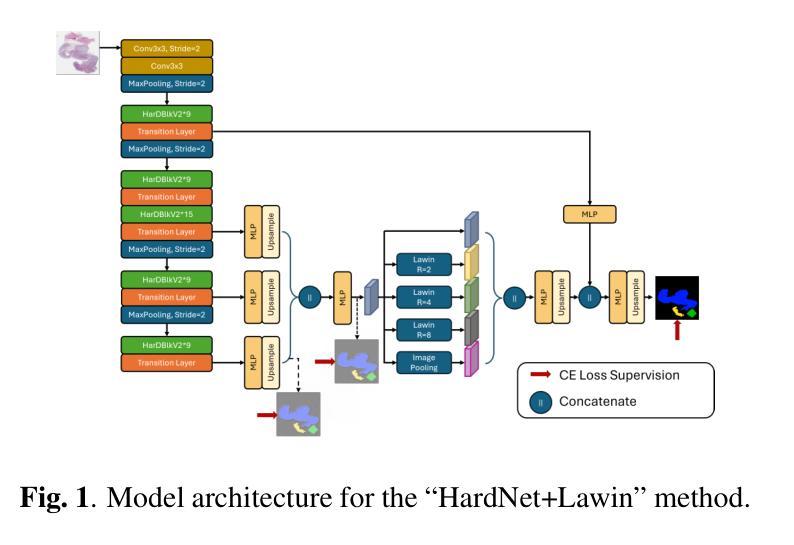
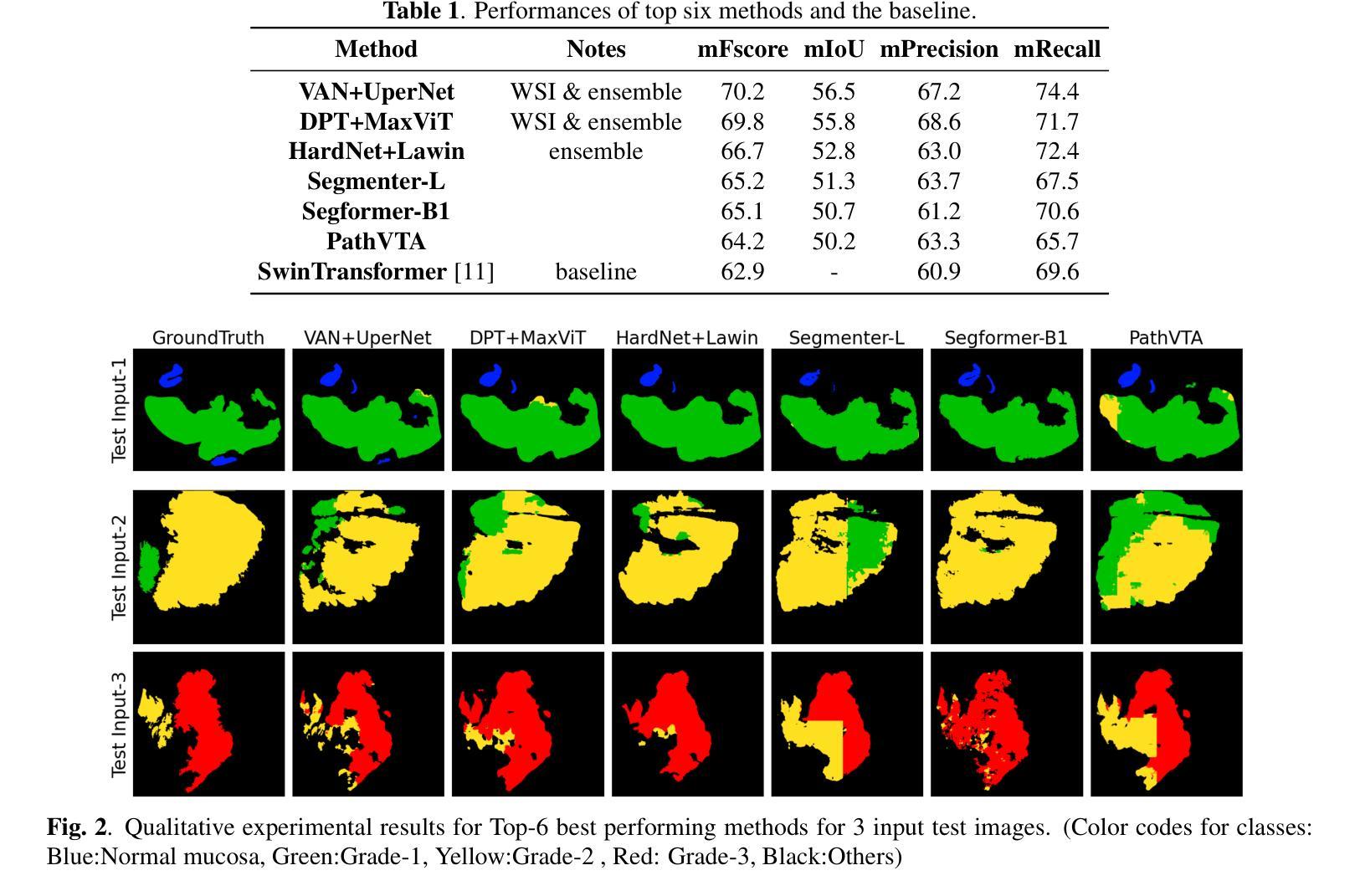
Colorectal Cancer Tumor Grade Segmentation in Digital Histopathology Images: From Giga to Mini Challenge
Authors:Alper Bahcekapili, Duygu Arslan, Umut Ozdemir, Berkay Ozkirli, Emre Akbas, Ahmet Acar, Gozde B. Akar, Bingdou He, Shuoyu Xu, Umit Mert Caglar, Alptekin Temizel, Guillaume Picaud, Marc Chaumont, Gérard Subsol, Luc Téot, Fahad Alsharekh, Shahad Alghannam, Hexiang Mao, Wenhua Zhang
Colorectal cancer (CRC) is the third most diagnosed cancer and the second leading cause of cancer-related death worldwide. Accurate histopathological grading of CRC is essential for prognosis and treatment planning but remains a subjective process prone to observer variability and limited by global shortages of trained pathologists. To promote automated and standardized solutions, we organized the ICIP Grand Challenge on Colorectal Cancer Tumor Grading and Segmentation using the publicly available METU CCTGS dataset. The dataset comprises 103 whole-slide images with expert pixel-level annotations for five tissue classes. Participants submitted segmentation masks via Codalab, evaluated using metrics such as macro F-score and mIoU. Among 39 participating teams, six outperformed the Swin Transformer baseline (62.92 F-score). This paper presents an overview of the challenge, dataset, and the top-performing methods
结直肠癌(CRC)是全球诊断率第三高的癌症,也是导致癌症相关死亡的第二大主要原因。CRC的准确组织病理学分级对预后和治疗计划至关重要,但仍是一个主观过程,容易受观察者变异性的影响,并受到全球训练有素病理学家短缺的限制。为了促进自动化和标准化解决方案,我们利用公开可用的METU CCTGS数据集,组织了国际图像挑战赛(ICIP)结直肠癌肿瘤分级和分割挑战赛。该数据集包含103张全片图像,包含五个组织类别的专家像素级注释。参赛者通过Codalab提交分割掩膜,使用宏观F分数和mIoU等度量指标进行评估。在3 9支参赛队伍中,有六支队伍的表现超过了Swin Transformer基线(F分数为62.92)。本文介绍了挑战、数据集和表现最佳的方法概况。
论文及项目相关链接
PDF Accepted Grand Challenge Paper ICIP 2025
Summary
本文介绍了结直肠癌(CRC)的全球性诊断与治疗现状,强调了准确病理分级的重要性及其面临的挑战。为推进自动化与标准化解决方案,作者组织了一场大规模挑战——使用METU CCTGS数据集进行结直肠癌肿瘤分级与分割的ICIP挑战赛。数据集包含带有专家像素级注释的五类组织的103张全幻灯片图像。通过Codalab提交分割掩膜,并使用宏观F得分和mIoU等指标进行评估。共有39支队伍参与挑战,其中六支队伍的表现超过了基线模型的性能(Swin Transformer,F得分为62.92)。本文回顾了挑战赛概况、数据集以及表现最好的方法。
Key Takeaways
- 结直肠癌是全球第三常见的癌症诊断类型和第二大癌症致死原因。
- 准确的病理分级对结直肠癌的预后和治疗计划至关重要,但仍然是主观过程,存在观察者差异和病理医生全球短缺的限制。
- 为解决这些问题,举办了ICIP挑战赛,旨在通过METU CCTGS数据集实现结直肠癌肿瘤的自动和标准化分级与分割。
- 数据集包含带有专家像素级注释的五类组织的全幻灯片图像。
- 挑战赛吸引了39支队伍参与,其中六支队伍的表现超过了基线模型(Swin Transformer)的性能。
点此查看论文截图

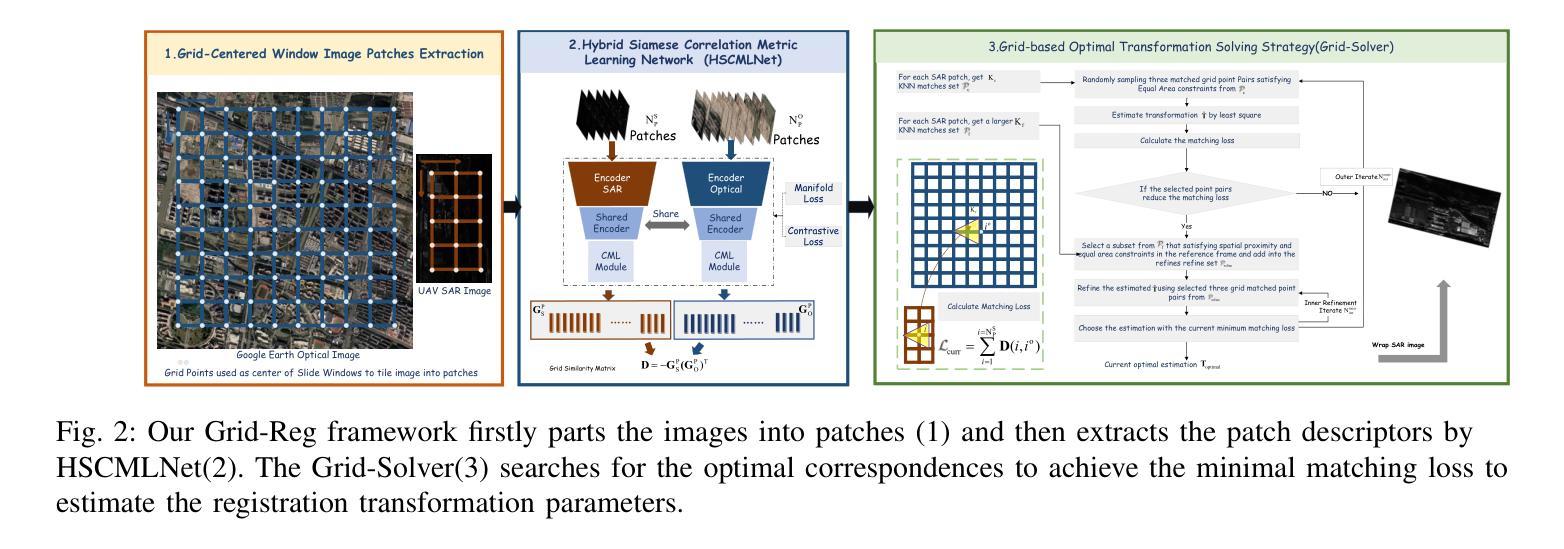
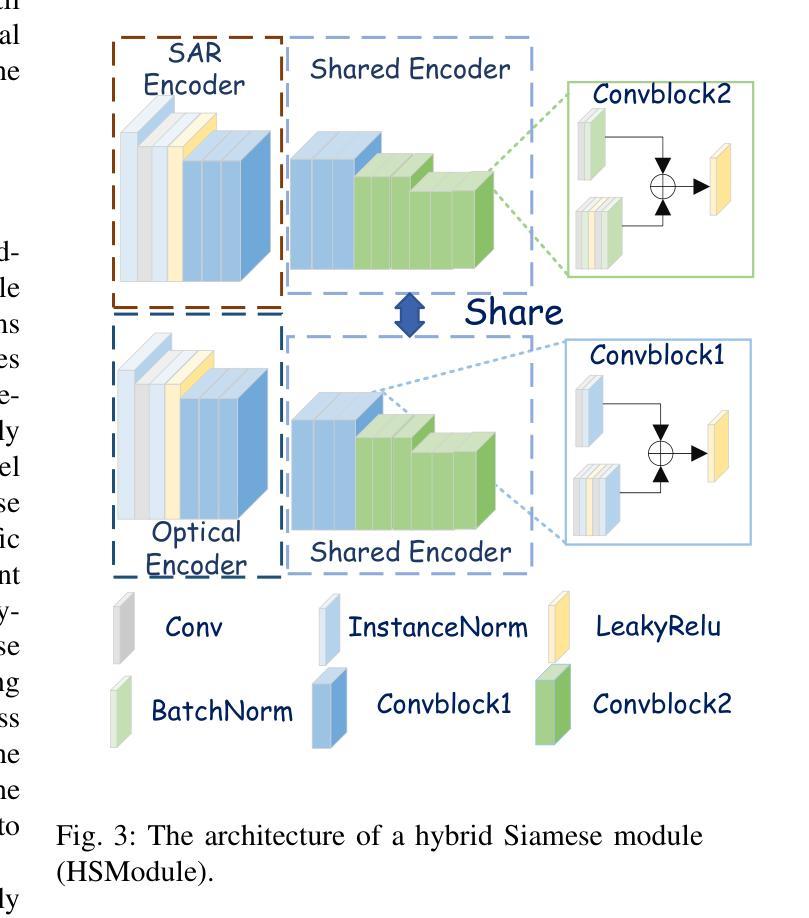
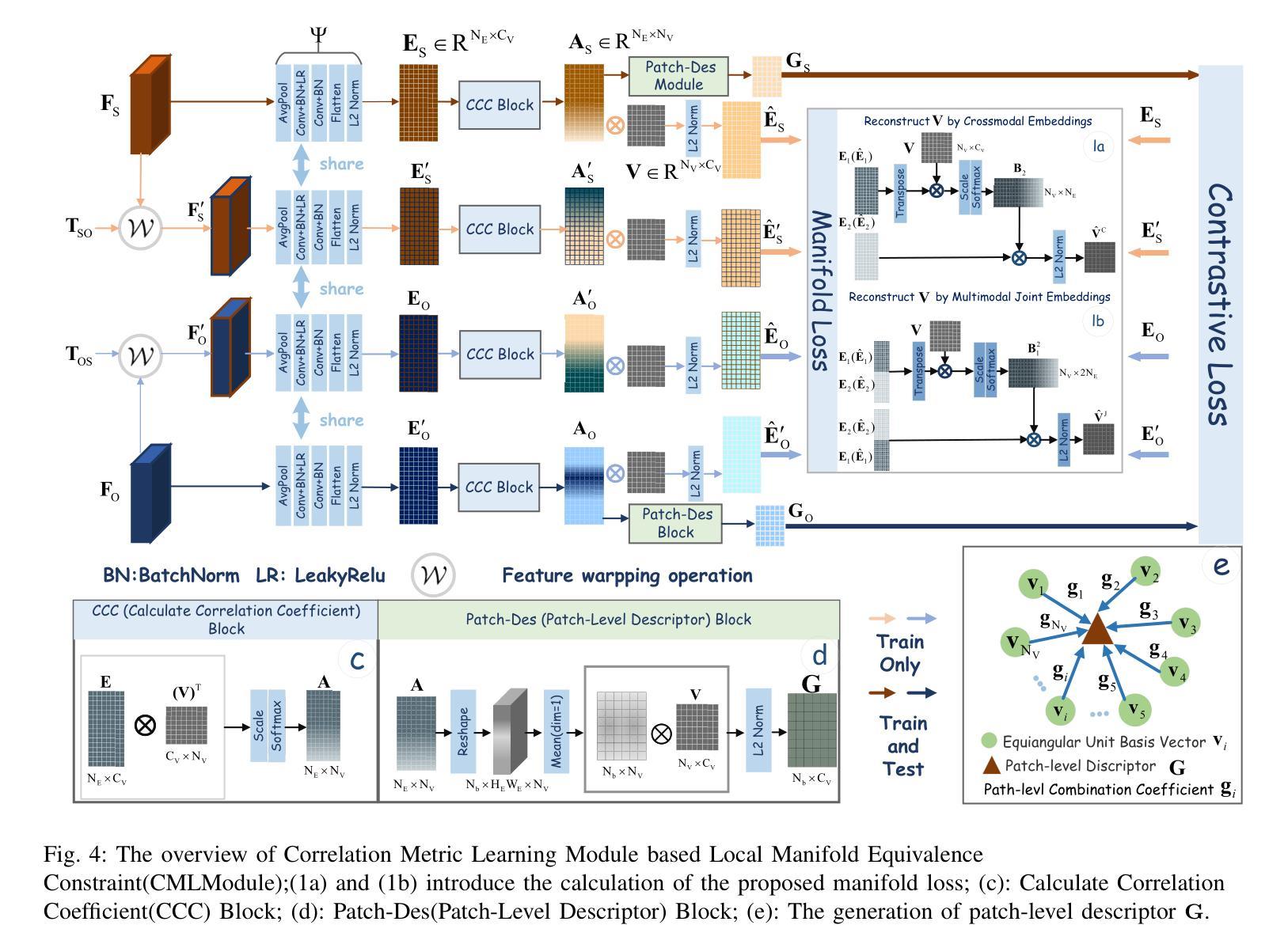
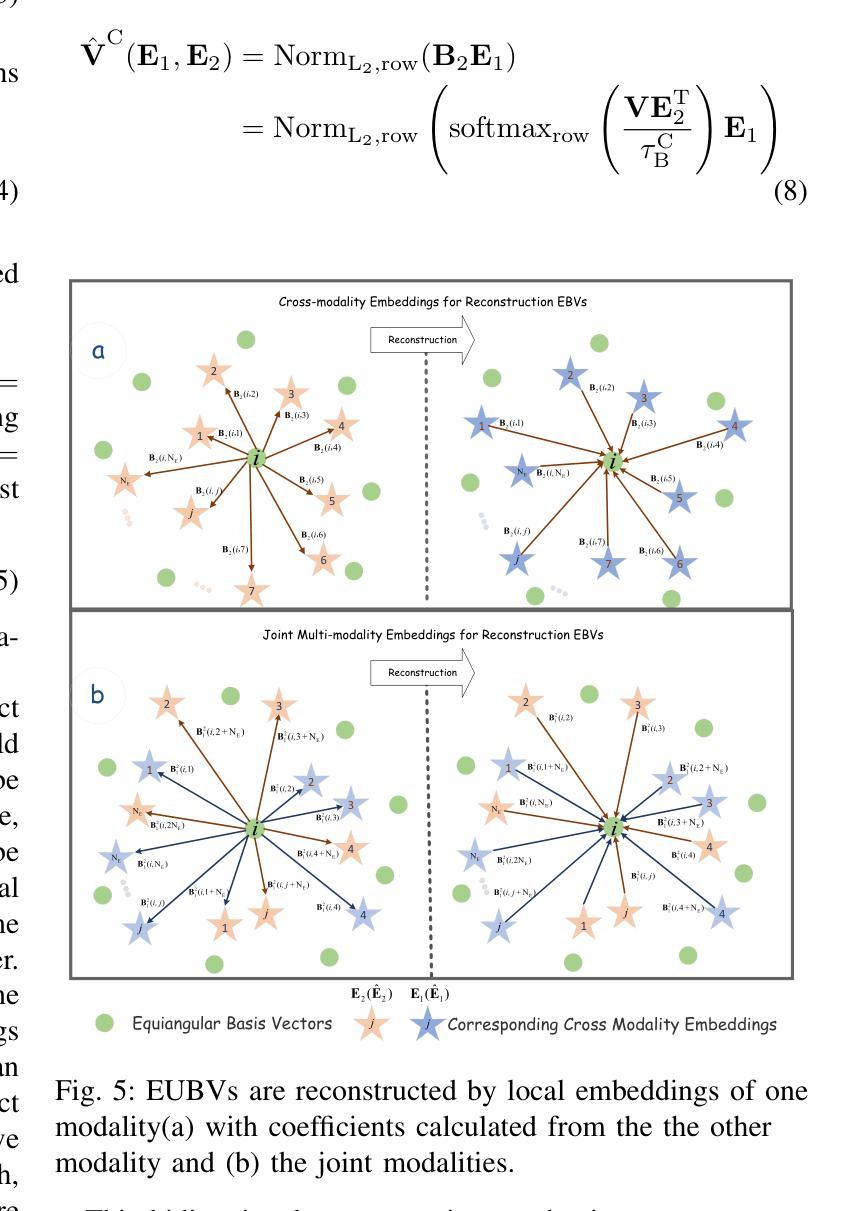
Grid-Reg: Detector-Free Gridized Feature Learning and Matching for Large-Scale SAR-Optical Image Registration
Authors:Xiaochen Wei, Weiwei Guo, Zenghui Zhang, Wenxian Yu
It is highly challenging to register large-scale, heterogeneous SAR and optical images, particularly across platforms, due to significant geometric, radiometric, and temporal differences, which most existing methods struggle to address. To overcome these challenges, we propose Grid-Reg, a grid-based multimodal registration framework comprising a domain-robust descriptor extraction network, Hybrid Siamese Correlation Metric Learning Network (HSCMLNet), and a grid-based solver (Grid-Solver) for transformation parameter estimation. In heterogeneous imagery with large modality gaps and geometric differences, obtaining accurate correspondences is inherently difficult. To robustly measure similarity between gridded patches, HSCMLNet integrates a hybrid Siamese module with a correlation metric learning module (CMLModule) based on equiangular unit basis vectors (EUBVs), together with a manifold consistency loss to promote modality-invariant, discriminative feature learning. The Grid-Solver estimates transformation parameters by minimizing a global grid matching loss through a progressive dual-loop search strategy to reliably find patch correspondences across entire images. Furthermore, we curate a challenging benchmark dataset for SAR-to-optical registration using real-world UAV MiniSAR data and Google Earth optical imagery. Extensive experiments demonstrate that our proposed approach achieves superior performance over state-of-the-art methods.
在大规模、异质SAR和光学图像配准中,特别是在跨平台的情况下,由于几何、辐射和时间的显著差异,面临巨大的挑战。大多数现有方法都难以解决这些问题。为了克服这些挑战,我们提出了Grid-Reg,这是一种基于网格的多模式配准框架,包括域稳健描述符提取网络、混合Siamese关联度量学习网络(HSCMLNet)和基于网格的求解器(Grid-Solver)用于变换参数估计。在具有大模态差距和几何差异的非均匀图像中,获得准确的对应关系是固有的困难。为了稳健地测量网格化补丁之间的相似性,HSCMLNet将混合Siamese模块与基于等角单位基向量(EUBVs)的关联度量学习模块(CMLModule)相结合,以及流形一致性损失,以促进模态不变、有判别力的特征学习。Grid-Solver通过渐进的双循环搜索策略来最小化全局网格匹配损失,从而可靠地找到整个图像中的补丁对应关系。此外,我们使用真实的无人机MiniSAR数据和Google地球光学图像,创建了一个用于SAR到光学配准的具有挑战性的基准数据集。大量实验表明,我们提出的方法在最新技术方法上实现了优越的性能。
论文及项目相关链接
PDF This work has been submitted to the IEEE for possible publication
Summary
针对大规模、异构SAR和光学图像,特别是跨平台图像注册的挑战,提出Grid-Reg网格基多模态注册框架。该框架包括域稳健描述符提取网络、混合Siamese关联度量学习网络(HSCMLNet)和用于变换参数估计的网格基求解器(Grid-Solver)。通过结合网格化补丁的相似性度量,HSCMLNet使用混合Siamese模块与基于等角单位基向量(EUBVs)的关联度量学习模块(CMLModule),借助流形一致性损失促进模态不变、鉴别性特征学习。Grid-Solver通过渐进的双循环搜索策略最小化全局网格匹配损失,以可靠地找到整个图像中的补丁对应关系。
Key Takeaways
- 现有方法在大规模、异构SAR和光学图像注册方面存在挑战,特别是在跨平台情况下。
- 提出Grid-Reg框架来解决这一挑战,包括域稳健描述符提取网络、HSCMLNet和Grid-Solver。
- HSCMLNet结合了混合Siamese模块和基于EUBVs的CMLModule,用于在网格化补丁之间实现稳健的相似性度量。
- Grid-Solver通过最小化全局网格匹配损失来估计变换参数。
- 使用无人机SAR数据和Google Earth光学图像创建了一个具有挑战性的基准数据集。
- 实验表明,所提出的方法在性能上优于现有技术。
- 该方法对于处理大规模、异构图像注册问题具有实用价值。
点此查看论文截图

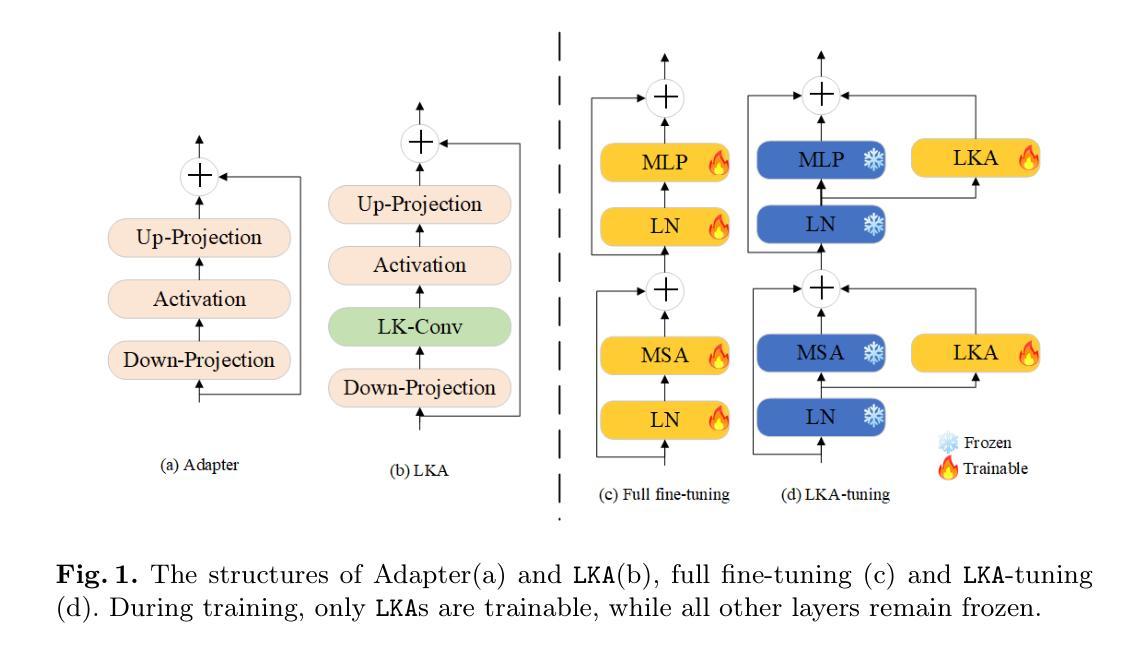
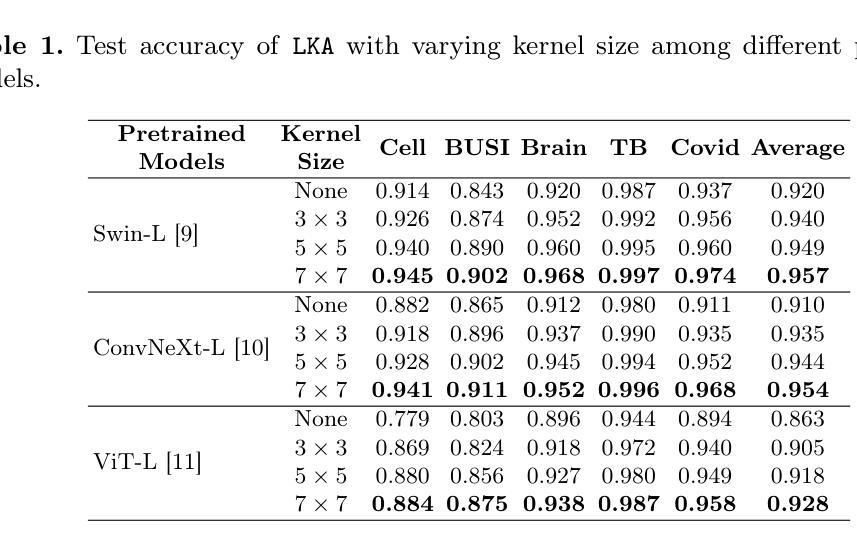
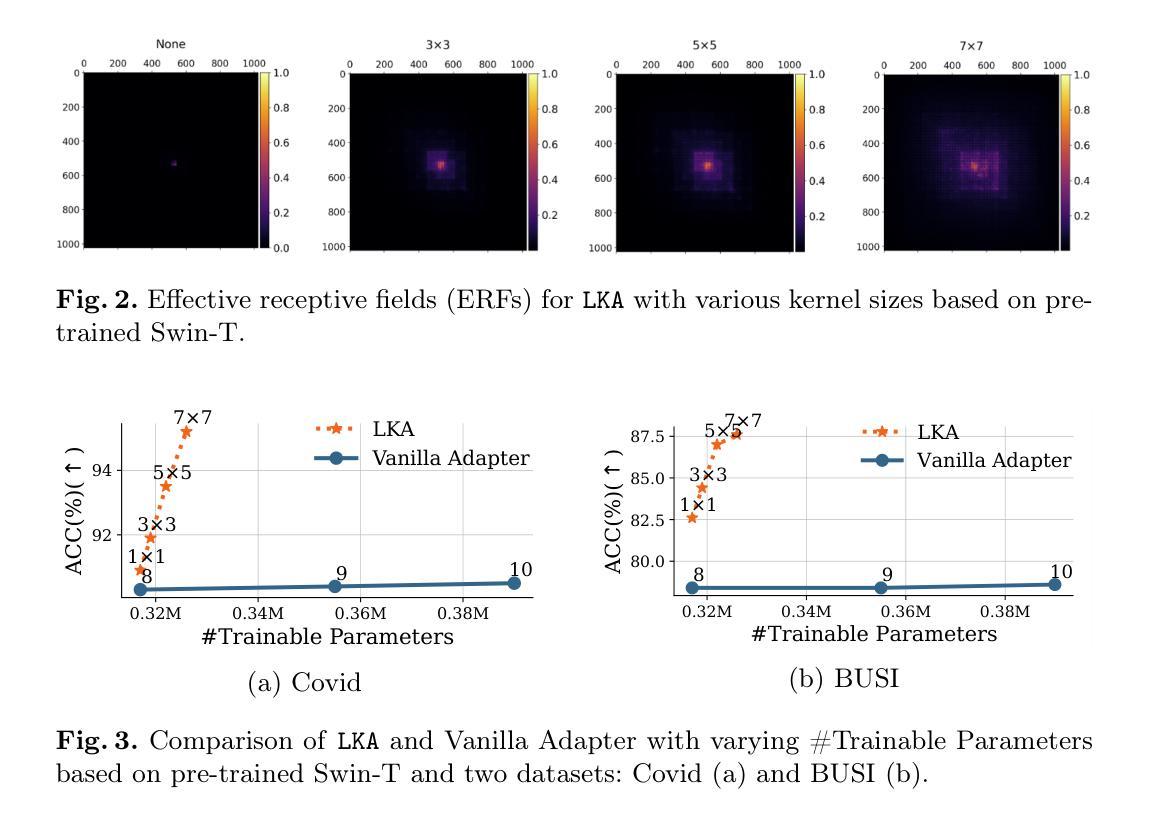
LKA: Large Kernel Adapter for Enhanced Medical Image Classification
Authors:Ziquan Zhu, Si-Yuan Lu, Tianjin Huang, Lu Liu, Zhe Liu
Despite the notable success of current Parameter-Efficient Fine-Tuning (PEFT) methods across various domains, their effectiveness on medical datasets falls short of expectations. This limitation arises from two key factors: (1) medical images exhibit extensive anatomical variation and low contrast, necessitating a large receptive field to capture critical features, and (2) existing PEFT methods do not explicitly address the enhancement of receptive fields. To overcome these challenges, we propose the Large Kernel Adapter (LKA), designed to expand the receptive field while maintaining parameter efficiency. The proposed LKA consists of three key components: down-projection, channel-wise large kernel convolution, and up-projection. Through extensive experiments on various datasets and pre-trained models, we demonstrate that the incorporation of a larger kernel size is pivotal in enhancing the adaptation of pre-trained models for medical image analysis. Our proposed LKA outperforms 11 commonly used PEFT methods, surpassing the state-of-the-art by 3.5% in top-1 accuracy across five medical datasets.
尽管当前参数高效微调(PEFT)方法在不同领域取得了显著的成功,它们在医学数据集上的效果却未能达到预期。这一局限性源于两个关键因素:(1)医学图像表现出广泛的解剖变异和低对比度,需要较大的感受野来捕捉关键特征;(2)现有的PEFT方法没有明确解决感受野增强的问题。为了克服这些挑战,我们提出了大型内核适配器(LKA),旨在在保持参数效率的同时扩大感受野。所提出的LKA由三个关键组件组成:下投影、通道大型内核卷积和上投影。通过对各种数据集和预训练模型的广泛实验,我们证明了使用更大的内核尺寸对于增强预训练模型在医学图像分析中的适应性至关重要。我们提出的大型内核适配器(LKA)在五个医学数据集上超过了11种常用的PEFT方法,在top-1准确率上超越了最新技术3.5%。
论文及项目相关链接
PDF The manuscript has been withdrawn in order to revise key technical components and improve experimental validation. We plan to substantially update the model design and resubmit after further evaluation
Summary
当前参数高效微调(PEFT)方法在多领域表现显著,但在医学数据集上的效果不尽如人意。医学图像具有广泛的解剖变异和低对比度,需要较大的感受野捕捉关键特征,而现有PEFT方法未明确解决感受野增强问题。为克服这些挑战,提出Large Kernel Adapter(LKA),旨在扩大感受野的同时保持参数效率。LKA包含三个关键组件:下投影、通道大内核卷积和上投影。在多个数据集和预训练模型上的实验表明,采用更大的内核尺寸对于提高预训练模型在医学图像分析中的适应性至关重要。所提出的LKA在五个医学数据集上超越11种常用的PEFT方法,在top-1准确率上高出最新技术3.5%。
Key Takeaways
- 当前PEFT方法在医学数据集上的效果有限,主要因为医学图像特性(如解剖变异和低对比度)需要更大的感受野。
- 现有PEFT方法未充分解决感受野增强的问题。
- 为改善在医学图像上的表现,提出了Large Kernel Adapter(LKA)。
- LKA包含下投影、通道大内核卷积和上投影三个关键组件。
- 实验证明,更大的内核尺寸对提高预训练模型在医学图像分析中的适应性至关重要。
- LKA在多个医学数据集上超越多种PEFT方法。
点此查看论文截图

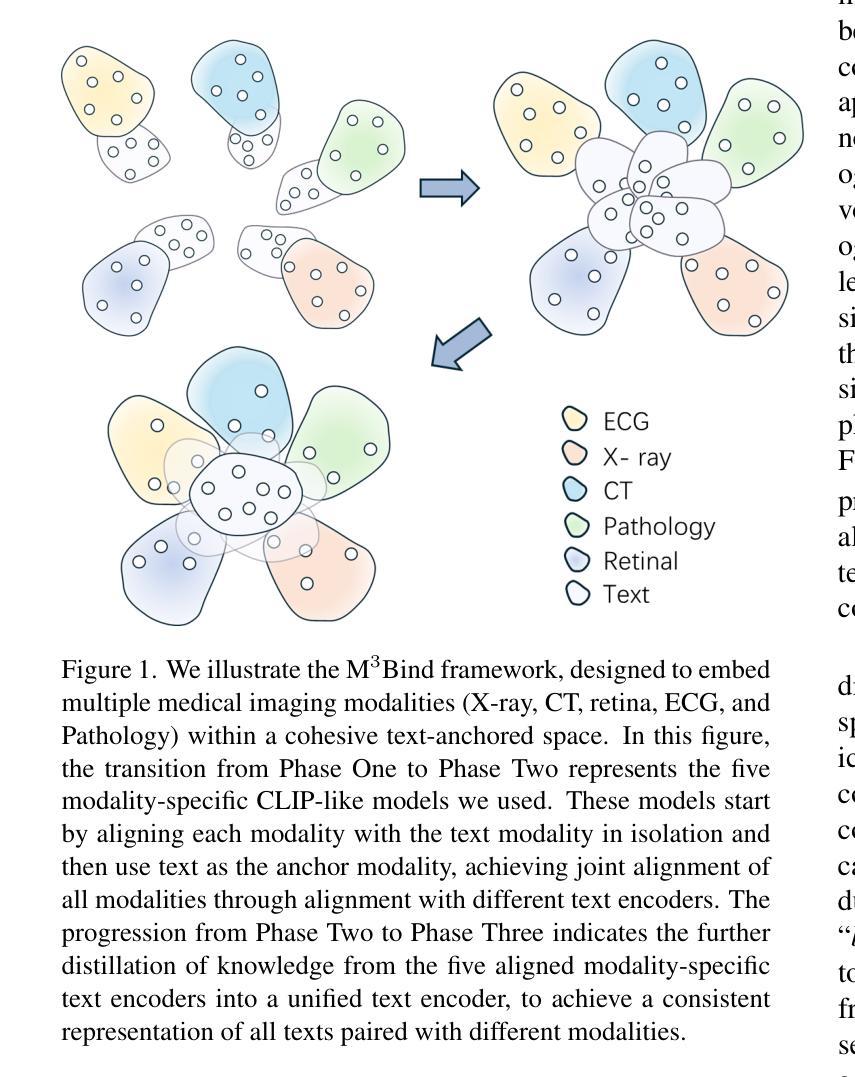
Multimodal Medical Image Binding via Shared Text Embeddings
Authors:Yunhao Liu, Suyang Xi, Shiqi Liu, Hong Ding, Chicheng Jin, Chong Zhong, Junjun He, Catherine C. Liu, Yiqing Shen
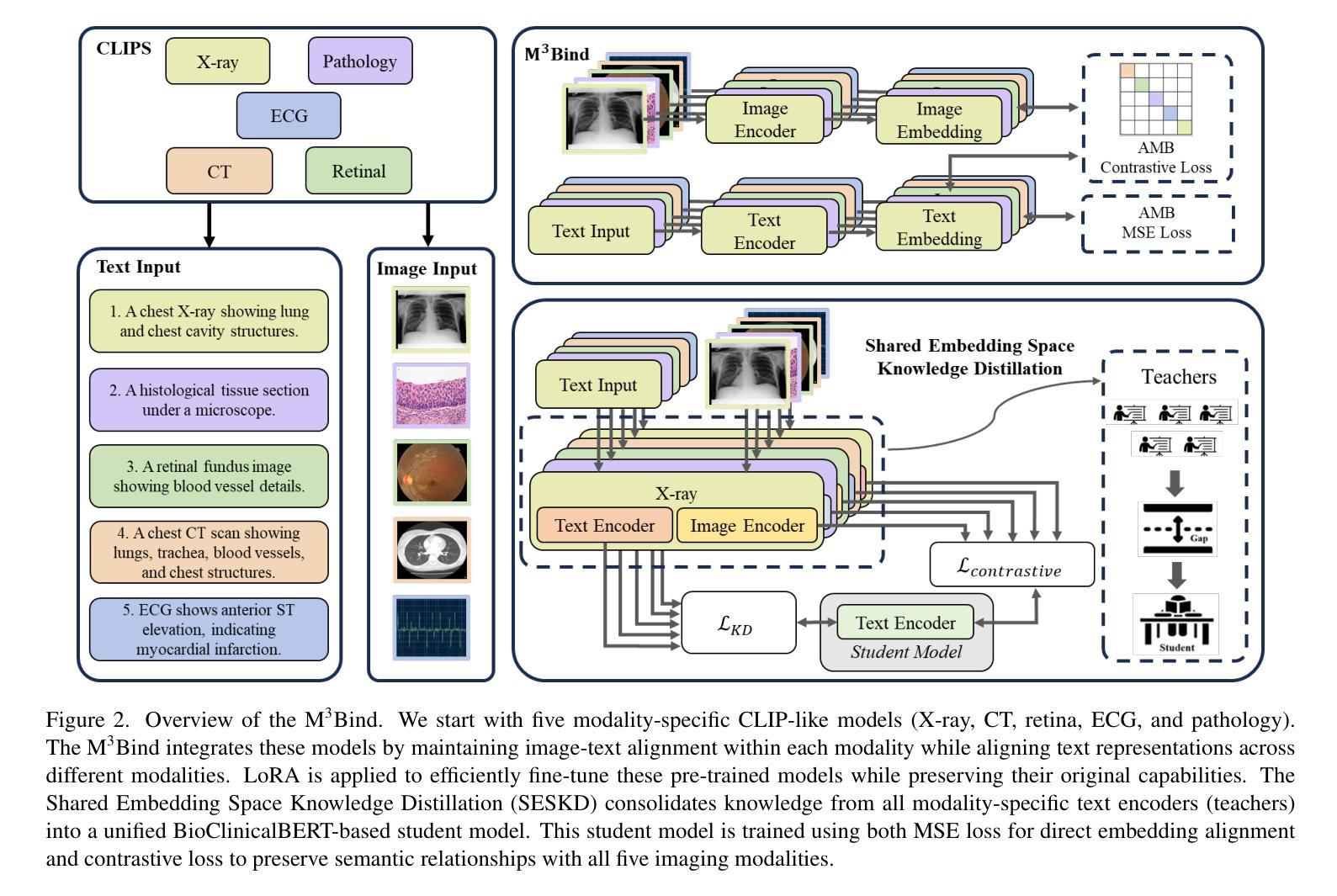
Medical image analysis increasingly relies on the integration of multiple imaging modalities to capture complementary anatomical and functional information, enabling more accurate diagnosis and treatment planning. Achieving aligned feature representations across these diverse modalities is therefore important for effective multimodal analysis. While contrastive language-image pre-training (CLIP) and its variant have enabled image-text alignments, they require explicitly paired data between arbitrary two modalities, which is difficult to acquire in medical contexts. To address the gap, we present Multimodal Medical Image Binding with Text (M\textsuperscript{3}Bind), a novel pre-training framework that enables seamless alignment of multiple medical imaging modalities through a shared text representation space without requiring explicit paired data between any two medical image modalities. Specifically, based on the insight that different images can naturally bind with text, M\textsuperscript{3}Bind first fine-tunes pre-trained CLIP-like image-text models to align their modality-specific text embedding space while preserving their original image-text alignments. Subsequently, we distill these modality-specific text encoders into a unified model, creating a shared text embedding space. Experiments on X-ray, CT, retina, ECG, and pathological images on multiple downstream tasks demonstrate that M\textsuperscript{3}Bind achieves state-of-the-art performance in zero-shot, few-shot classification and cross-modal retrieval tasks compared to its CLIP-like counterparts. These results validate M\textsuperscript{3}Bind’s effectiveness in achieving cross-image-modal alignment for medical analysis.
医学图像分析越来越依赖于多种成像模式的集成,以捕获互补的解剖和功能性信息,从而实现更准确的诊断和治疗计划。因此,实现这些不同模式之间的对齐特征表示对于有效的多模态分析至关重要。虽然对比语言图像预训练(CLIP)及其变体实现了图像文本对齐,但它们需要在任意两种模式之间明确配对的数据,这在医学背景下很难获取。为了解决这一差距,我们提出了多模态医学图像与文本绑定(M\textsuperscript{3}Bind),这是一种新的预训练框架,它能够通过共享文本表示空间无缝对齐多种医学成像模式,而无需在任意两种医学图像模式之间明确配对数据。具体来说,基于不同图像可以自然绑定文本的见解,M\textsuperscript{3}Bind首先微调预训练的CLIP类似图像文本模型,以对齐其特定的文本嵌入空间,同时保留其原始的图像文本对齐。然后,我们将这些特定于模态的文本编码器蒸馏到统一模型中,创建一个共享的文本嵌入空间。在X光、CT、视网膜、心电图和病理图像等多种下游任务上的实验表明,与CLIP类似的对标模型相比,M\textsuperscript{3}Bind在零样本、少样本分类和跨模态检索任务上实现了最先进的性能。这些结果验证了M\textsuperscript{3}Bind在实现医学分析中的跨图像模态对齐的有效性。
论文及项目相关链接
PDF 10 pages, 3 figures
Summary
医学图像分析越来越依赖于多种成像模式的整合,以捕捉互补的解剖和功能性信息,使诊断和治疗计划更加准确。实现这些不同模式之间的对齐特征表示对于有效的多模式分析至关重要。为解决医疗环境中难以获取任意两种模式之间的明确配对数据的问题,我们提出了多模式医学图像与文本绑定(M\textsuperscript{3}Bind)的预训练框架,它能够在无需明确配对数据的情况下,通过共享文本表示空间实现多种医学成像模式无缝对齐。M\textsuperscript{3}Bind基于不同图像自然绑定文本的理解,首先微调预训练的CLIP类图像-文本模型,以对齐其模态特定的文本嵌入空间,同时保留其原始的图像-文本对齐。然后,我们将这些模态特定的文本编码器蒸馏到统一模型中,创建共享文本嵌入空间。在X光、CT、视网膜、心电图和病理图像等多种下游任务上的实验表明,与CLIP类模型相比,M\textsuperscript{3}Bind在零样本、少样本分类和跨模态检索任务上实现了最佳性能。这验证了M\textsuperscript{3}Bind在医学分析中的跨图像模态对齐的有效性。
Key Takeaways
- 医学图像分析通过整合多种成像模式来提高诊断准确性。
- 实现不同医学成像模式之间的特征对齐对于多模式分析至关重要。
- M\textsuperscript{3}Bind是一种新型预训练框架,能在无需配对数据的情况下实现多种医学成像模式的无缝对齐。
- M\textsuperscript{3}Bind基于不同图像自然绑定文本的理解进行工作。
- M\textsuperscript{3}Bind首先微调预训练的CLIP类图像-文本模型以进行模态对齐,并保留原始图像-文本对齐功能。
- M\textsuperscript{3}Bind通过在共享文本嵌入空间中蒸馏模态特定的文本编码器来创建统一的模型。
点此查看论文截图

FlatCAD: Fast Curvature Regularization of Neural SDFs for CAD Models
Authors:Haotian Yin, Aleksander Plocharski, Michal Jan Wlodarczyk, Mikolaj Kida, Przemyslaw Musialski
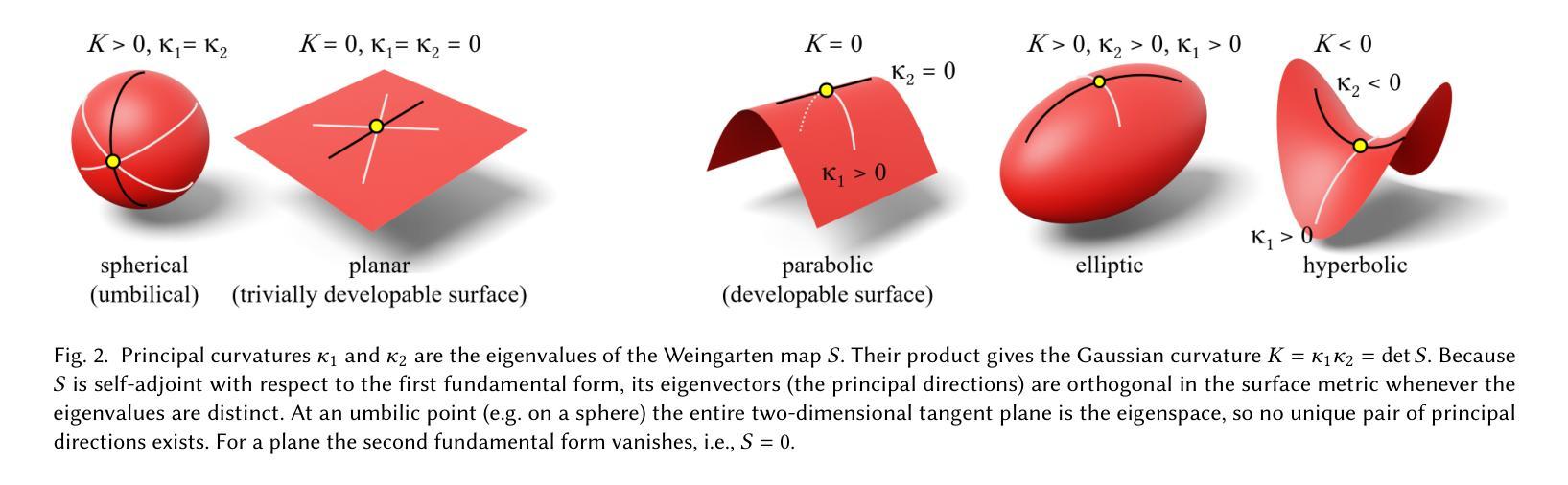
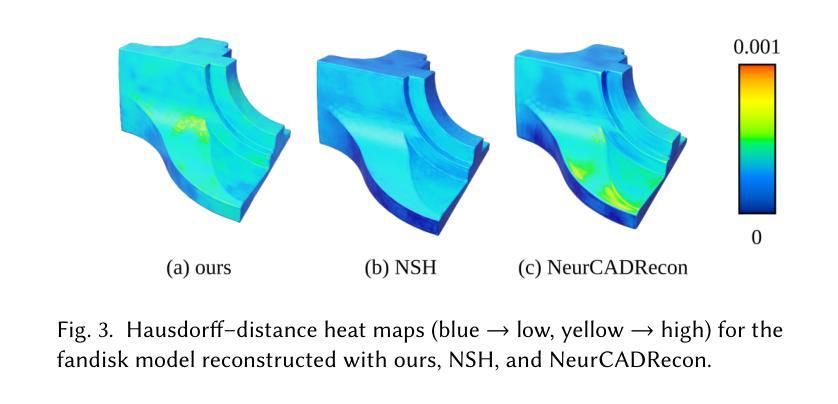
Neural signed-distance fields (SDFs) are a versatile backbone for neural geometry representation, but enforcing CAD-style developability usually requires Gaussian-curvature penalties with full Hessian evaluation and second-order differentiation, which are costly in memory and time. We introduce an off-diagonal Weingarten loss that regularizes only the mixed shape operator term that represents the gap between principal curvatures and flattens the surface. We present two variants: a finite-difference version using six SDF evaluations plus one gradient, and an auto-diff version using a single Hessian-vector product. Both converge to the exact mixed term and preserve the intended geometric properties without assembling the full Hessian. On the ABC benchmarks the losses match or exceed Hessian-based baselines while cutting GPU memory and training time by roughly a factor of two. The method is drop-in and framework-agnostic, enabling scalable curvature-aware SDF learning for engineering-grade shape reconstruction. Our code is available at https://flatcad.github.io/.
神经距离场(SDFs)是神经几何表示的一个多功能基础,但强制实施CAD风格的开发性通常需要带有全Hessian评估和二阶导数的高斯曲率惩罚,这在内存和时间上成本很高。我们引入了一种非对角Weingarten损失,该损失仅对混合形状运算符项进行正则化,该项代表主曲率之间的差距并平整表面。我们提出了两个版本:一个使用六个SDF评估和一个梯度的有限差分版本,以及一个使用单个Hessian-vector产品的自动差分版本。两者都收敛到精确的混合项并保留了预期的几何属性,而无需组装完整的Hessian矩阵。在ABC基准测试中,这些损失与基于Hessian的基线相匹配或表现更好,同时将GPU内存和训练时间减少了大约一半。该方法即插即用,框架中立,可实现工程级形状重建的规模化曲率感知SDF学习。我们的代码可在https://flatcad.github.io/上找到。
论文及项目相关链接
PDF Computer Graphics Forum, Proceedings of Pacific Graphics 2025, 12 pages, 10 figures, preprint
Summary
神经网络符号距离场(SDFs)在神经几何表示中具有通用性,但强制实施CAD风格的开发性通常需要高斯曲率惩罚并进行全面Hessian评估和二次微分,这在内存和时间上成本较高。本文引入了一种离对角线Weingarten损失,仅对混合形状操作符术语进行正则化,该术语代表了主曲率之间的差距并压平了表面。本文提出了两个版本:一个使用六个SDF评估和一次梯度的有限差分版本,以及一个使用单个Hessian-vector产品的自动微分版本。两者都收敛到精确的混合术语并保持预期的几何属性,而无需组装完整的Hessian。在ABC基准测试中,这些损失与基于Hessian的基线相匹配或超越,同时将GPU内存和训练时间大致减少了一半。该方法具有可替代性和框架独立性,可实现用于工程级形状重建的可扩展曲率感知SDF学习。
Key Takeaways
- 神经网络符号距离场(SDFs)是神经几何表示中的通用工具。
- 现有方法通过高斯曲率惩罚和全面的Hessian评估来执行CAD风格的开发性要求,这增加了内存和时间成本。
- 引入了一种新型的离对角线Weingarten损失方法,仅对混合形状操作符进行正则化,代表主曲率之间的差距并平滑表面。
- 提出了两种新方法来求解这种损失:有限差分版本和自动微分版本。
- 这两个方法都能在无需完整Hessian的情况下收敛到精确的混合术语并保持预期的几何属性。
- 在ABC基准测试中,该方法在匹配或超越基于Hessian的基线的同时,可将GPU内存和训练时间大致减少一半。
点此查看论文截图