⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-09 更新
Refining Transcripts With TV Subtitles by Prompt-Based Weakly Supervised Training of ASR
Authors:Xinnian Zhao, Hugo Van Hamme
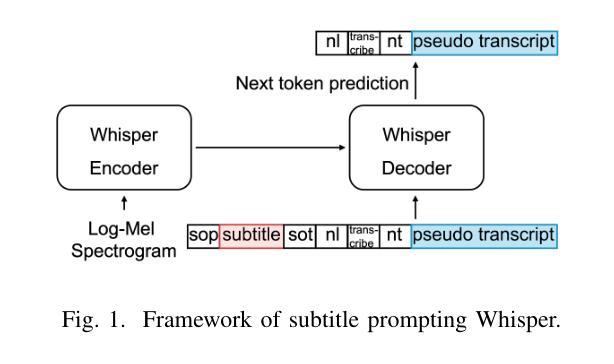
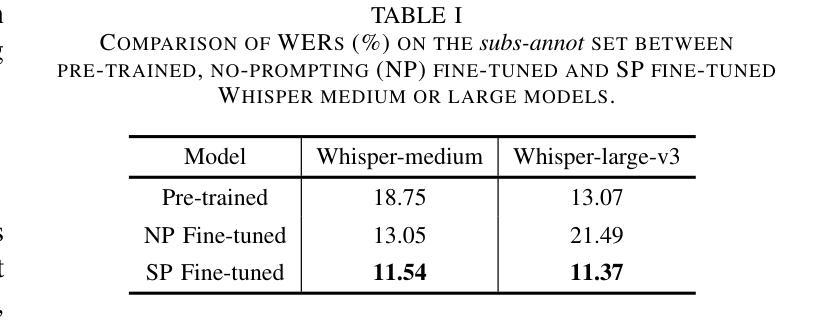
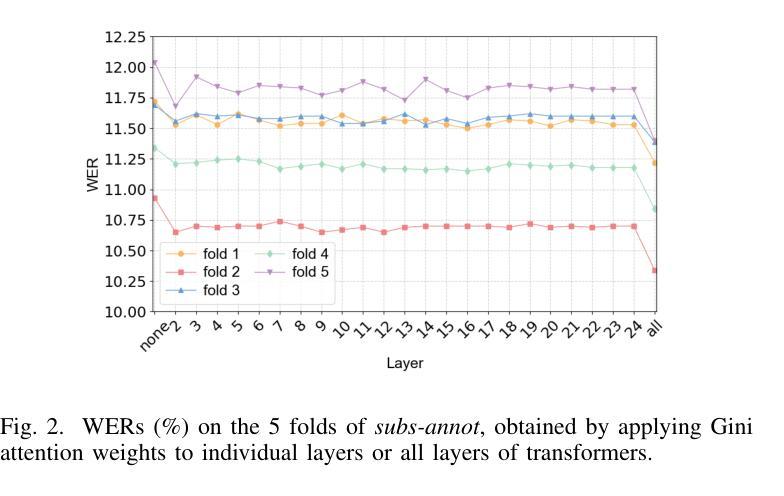
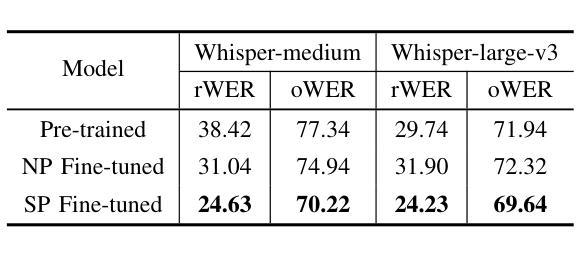
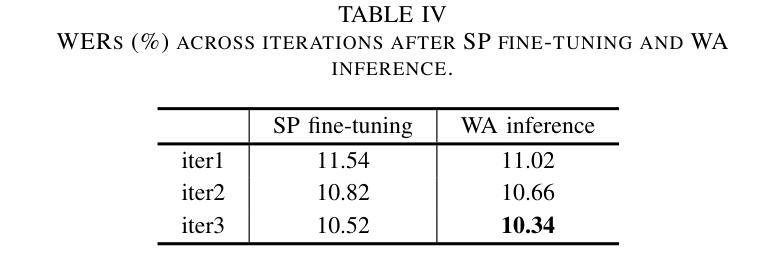
This study proposes a novel approach to using TV subtitles within a weakly supervised (WS) Automatic Speech Recognition (ASR) framework. Although TV subtitles are readily available, their imprecise alignment with corresponding audio limits their applicability as supervised targets for verbatim transcription. Rather than using subtitles as direct supervision signals, our method reimagines them as context-rich prompts. This design enables the model to handle discrepancies between spoken audio and subtitle text. Instead, generated pseudo transcripts become the primary targets, with subtitles acting as guiding cues for iterative refinement. To further enhance the process, we introduce a weighted attention mechanism that emphasizes relevant subtitle tokens during inference. Our experiments demonstrate significant improvements in transcription accuracy, highlighting the effectiveness of the proposed method in refining transcripts. These enhanced pseudo-labeled datasets provide high-quality foundational resources for training robust ASR systems.
本研究提出了一种在弱监督(WS)语音识别(ASR)框架中使用电视字幕的新方法。虽然电视字幕容易获取,但它们与对应音频的不精确对齐限制了它们作为准确文字转录的监督目标的应用。我们的方法并没有将字幕作为直接的监督信号,而是将其重新构想为丰富的上下文提示。这种设计使模型能够处理口语音频和字幕文本之间的差异。相反,生成的伪转录成为主要目标,字幕作为迭代细化的引导线索。为了进一步增强过程,我们引入了一种加权注意力机制,在推理过程中强调相关的字幕标记。我们的实验证明了在转录准确性方面的显著提高,突出了所提出方法在细化转录方面的有效性。这些增强的伪标记数据集为训练稳健的ASR系统提供了高质量的基础资源。
论文及项目相关链接
PDF eusipco2025
摘要
本研究提出了一种利用电视字幕进行弱监督(WS)自动语音识别(ASR)框架的新方法。尽管电视字幕容易获取,但它们与相应音频的不精确对齐限制了它们在直接监督文字转录中的应用。本研究不将字幕作为直接监督信号,而是将其重新构想为丰富的上下文提示。这种设计使模型能够处理口语音频和字幕文本之间的差异。相反,生成的伪转录成为主要目标,字幕作为迭代细化的引导线索。为了进一步增强这一过程,我们引入了一种加权注意力机制,在推理过程中强调相关的字幕标记。实验表明,转录准确性显著提高,突显了该方法在改进转录方面的有效性。这些增强的伪标签数据集为训练稳健的ASR系统提供了高质量的基础资源。
要点摘要
- 提出了一种新方法,利用电视字幕在弱监督自动语音识别框架中进行应用。
- 认识到电视字幕与音频之间的不精确对齐问题,并为此提出了解决方案。
- 创新的将字幕视为上下文丰富的提示,而非直接监督信号,以处理音频和字幕之间的差异。
- 利用生成的伪转录作为主要目标,使用字幕作为迭代细化的引导。
- 引入了加权注意力机制,在推理过程中强调关键的字幕标记。
- 实验结果证明了该方法在改善转录准确性方面的显著效果。
点此查看论文截图


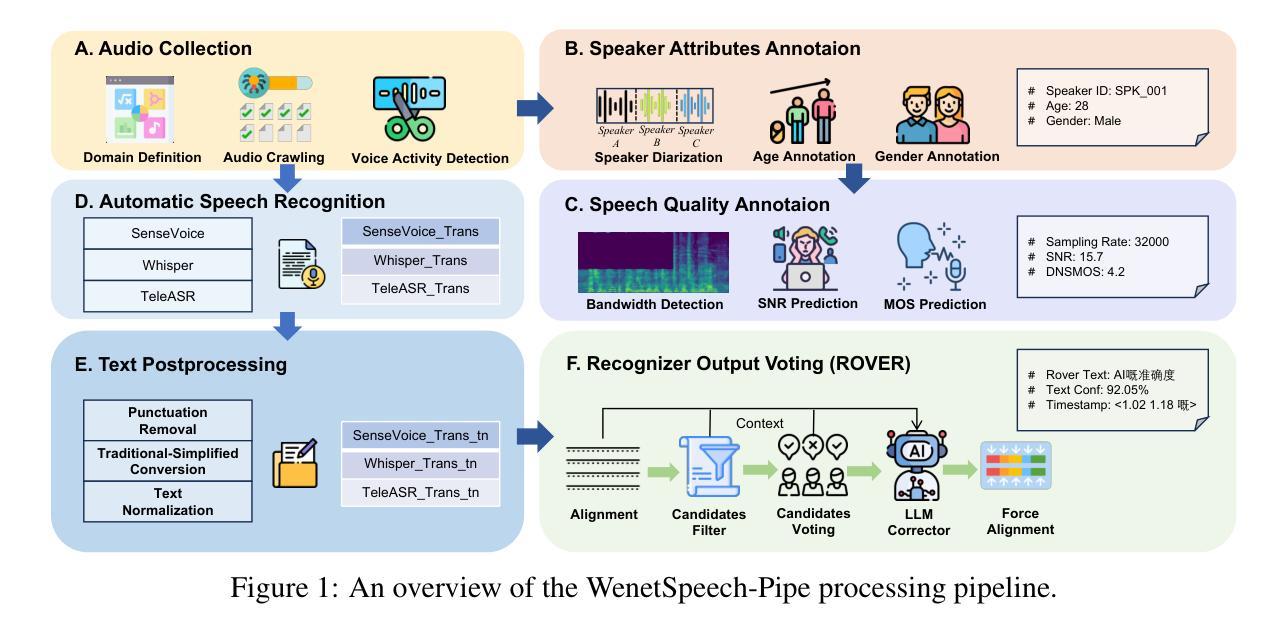
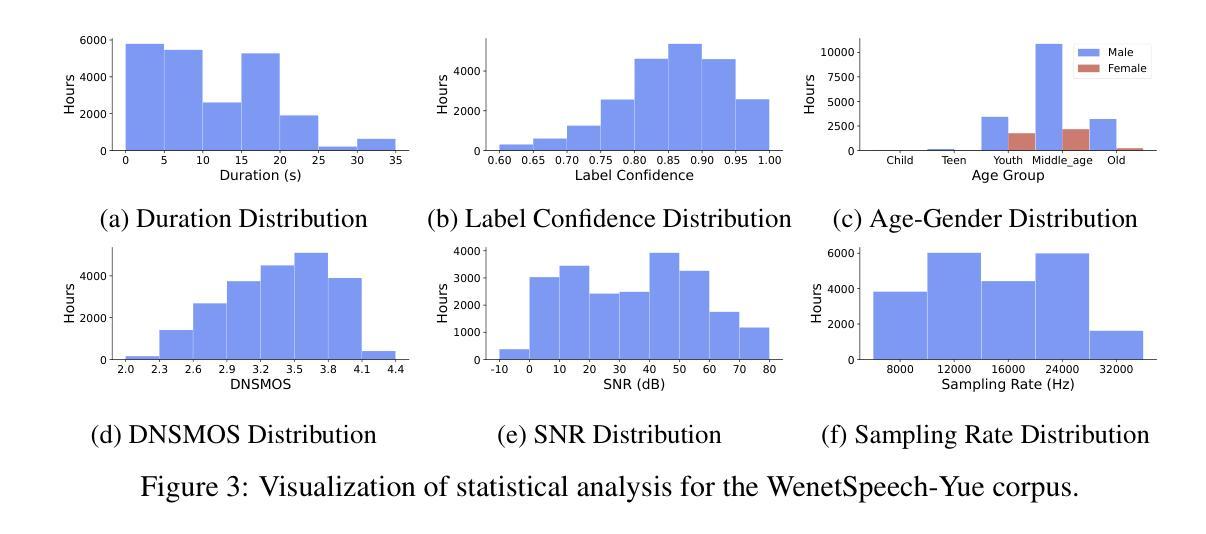
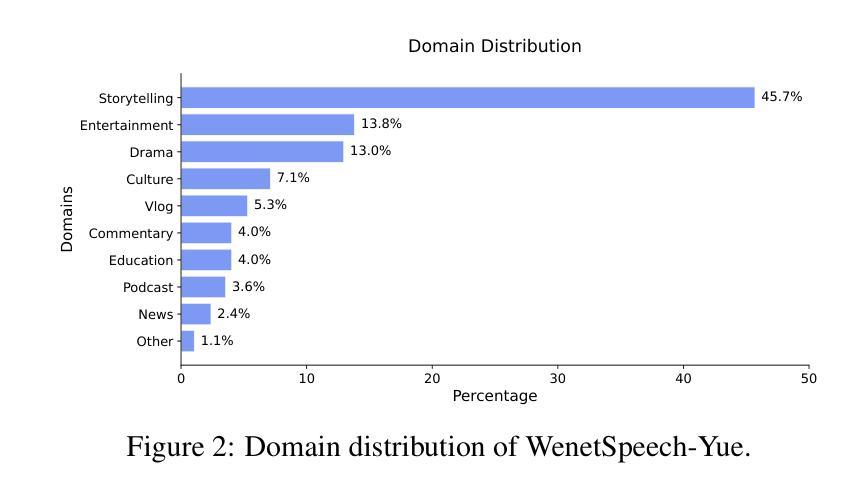
WenetSpeech-Yue: A Large-scale Cantonese Speech Corpus with Multi-dimensional Annotation
Authors:Longhao Li, Zhao Guo, Hongjie Chen, Yuhang Dai, Ziyu Zhang, Hongfei Xue, Tianlun Zuo, Chengyou Wang, Shuiyuan Wang, Jie Li, Jian Kang, Xin Xu, Hui Bu, Binbin Zhang, Ruibin Yuan, Ziya Zhou, Wei Xue, Lei Xie
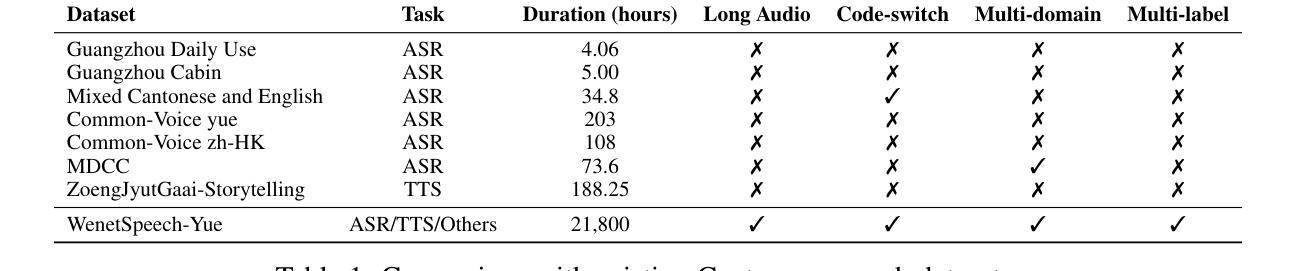
The development of speech understanding and generation has been significantly accelerated by the availability of large-scale, high-quality speech datasets. Among these, ASR and TTS are regarded as the most established and fundamental tasks. However, for Cantonese (Yue Chinese), spoken by approximately 84.9 million native speakers worldwide, limited annotated resources have hindered progress and resulted in suboptimal ASR and TTS performance. To address this challenge, we propose WenetSpeech-Pipe, an integrated pipeline for building large-scale speech corpus with multi-dimensional annotation tailored for speech understanding and generation. It comprises six modules: Audio Collection, Speaker Attributes Annotation, Speech Quality Annotation, Automatic Speech Recognition, Text Postprocessing and Recognizer Output Voting, enabling rich and high-quality annotations. Based on this pipeline, we release WenetSpeech-Yue, the first large-scale Cantonese speech corpus with multi-dimensional annotation for ASR and TTS, covering 21,800 hours across 10 domains with annotations including ASR transcription, text confidence, speaker identity, age, gender, speech quality scores, among other annotations. We also release WSYue-eval, a comprehensive Cantonese benchmark with two components: WSYue-ASR-eval, a manually annotated set for evaluating ASR on short and long utterances, code-switching, and diverse acoustic conditions, and WSYue-TTS-eval, with base and coverage subsets for standard and generalization testing. Experimental results show that models trained on WenetSpeech-Yue achieve competitive results against state-of-the-art (SOTA) Cantonese ASR and TTS systems, including commercial and LLM-based models, highlighting the value of our dataset and pipeline.
语音理解和生成的发展得益于大规模高质量语音数据集的可用性,得到了显著加速。其中,语音识别和文本转语音被视为最成熟和基本任务。然而,对于世界上约有8490万母语使用者的粤语(粤中文),标注资源有限阻碍了其进展,导致语音识别和文本转语音性能不尽人意。为了应对这一挑战,我们提出了WenetSpeech-Pipe,这是一个专为语音理解和生成量身定制的大规模语音语料库集成管道,具有多维度注释。它包含六个模块:音频收集、说话人属性注释、语音质量注释、自动语音识别、文本后处理和识别器输出投票,可实现丰富且高质量注释。基于此管道,我们发布了WenetSpeech-Yue,这是首个具有多维度注释的粤语语音识别和文本转语音大规模语音语料库,涵盖10个领域的21800小时,注释包括语音识别转录、文本置信度、说话人身份、年龄、性别、语音质量评分等。我们还发布了WSYue-eval,这是一个全面的粤语基准测试,包含两个组成部分:WSYue-ASR-eval,一个手动标注集,用于评估短句和长句的语音识别、代码切换和各种声学条件;以及WSYue-TTS-eval,包含基本和覆盖子集,用于标准和泛化测试。实验结果表明,在WenetSpeech-Yue上训练的模型与最新粤语语音识别和文本转语音系统相比具有竞争力,包括商业和基于大型语言模型的系统,这凸显了我们数据集和管道的价值。
论文及项目相关链接
Summary:
针对粤语(Yue Chinese)自动语音识别(ASR)和文本转语音合成(TTS)任务中资源受限的问题,提出了一种集成的大型语音语料库构建方案——WenetSpeech-Pipe。该方案包含六个模块,可实现丰富的多维度高质量注释。基于该方案,发布了首个大规模带多维度注释的粤语语音语料库WenetSpeech-Yue和相应的评估基准测试WSYue-eval。实验结果显示,在WenetSpeech-Yue上训练的模型在粤语ASR和TTS任务上取得了与顶尖系统相近的结果。
Key Takeaways:
- 粤语(Yue Chinese)在自动语音识别(ASR)和文本转语音合成(TTS)方面面临资源受限的挑战。
- WenetSpeech-Pipe是一个用于构建大型语音语料库的集成方案,包含六个模块,支持丰富的多维度高质量注释。
- WenetSpeech-Yue是基于WenetSpeech-Pipe方案发布的首个大规模粤语语音语料库,包含21,800小时的数据,适用于ASR和TTS任务。
- WSYue-eval是粤语ASR和TTS的基准测试,包括WSYue-ASR-eval和WSYue-TTS-eval两部分。
- 在WenetSpeech-Yue上训练的模型在粤语ASR和TTS任务上取得了与顶尖系统相近的结果,证明了数据集的价值。
- 该研究为粤语语音理解和生成的发展提供了重要支持,有助于推动相关技术的进步。
点此查看论文截图

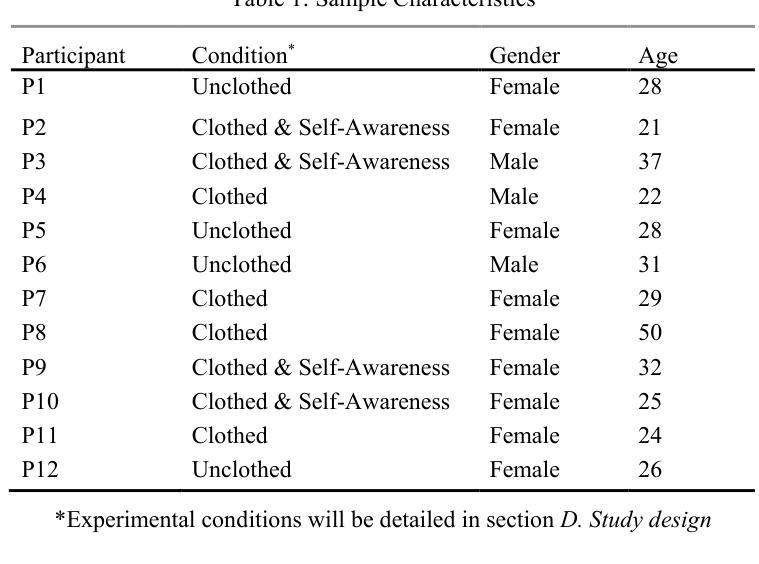
Exploring persuasive interactions with generative social robots: An experimental framework
Authors:Stephan Vonschallen, Larissa Julia Corina Finsler, Theresa Schmiedel, Friederike Eyssel
Integrating generative AI such as Large Language Models into social robots has improved their ability to engage in natural, human-like communication. This study presents a method to examine their persuasive capabilities. We designed an experimental framework focused on decision making and tested it in a pilot that varied robot appearance and self-knowledge. Using qualitative analysis, we evaluated interaction quality, persuasion effectiveness, and the robot’s communicative strategies. Participants generally experienced the interaction positively, describing the robot as competent, friendly, and supportive, while noting practical limits such as delayed responses and occasional speech-recognition errors. Persuasiveness was highly context dependent and shaped by robot behavior: Participants responded well to polite, reasoned suggestions and expressive gestures, but emphasized the need for more personalized, context-aware arguments and clearer social roles. These findings suggest that generative social robots can influence user decisions, but their effectiveness depends on communicative nuance and contextual relevance. We propose refinements to the framework to further study persuasive dynamics between robots and human users.
将大型语言模型等生成式人工智能融入社交机器人,增强了它们进行自然、拟人通信的能力。本研究提出了一种方法来检验它们的劝服能力。我们设计了一个以决策制定为重点的实验框架,并在机器人外观和自我知识各异的试点中对其进行了测试。通过定性分析,我们评估了交互质量、劝说有效性和机器人的交际策略。参与者普遍对交互体验持积极态度,认为机器人有能力、友好、支持,同时也指出了实际限制,如响应延迟和偶尔的语音识别错误。劝服力在很大程度上取决于上下文和机器人行为:参与者对礼貌、理性的建议和表情丰富的手势反应良好,但强调需要更多个性化、意识到的论证和更清晰的社会角色。这些结果表明,生成式社交机器人可以影响用户的决策,但其有效性取决于交际细微差别和上下文相关性。我们提议对框架进行改进,以进一步研究机器人和人类用户之间的劝服力动态。
论文及项目相关链接
PDF A shortened version of this paper was accepted as poster for the Thirteenth International Conference on Human-Agent Interaction (HAI2025)
摘要
集成大型语言模型等生成式人工智能的社会机器人,在参与自然、类似人类的交流方面能力有所提升。本研究提出了一种方法来研究其说服力。我们设计了一个以决策制定为重点的实验框架,并在机器人外观和自我知识不同的试点中进行了测试。通过定性分析,我们评估了交互质量、说服有效性和机器人的交流策略。参与者总体上对互动持积极态度,描述机器人具有能力、友好、支持,但也提到了实际应用中的局限性,如反应延迟和偶尔的语音识别错误。说服能力是高度依赖情境的,并受机器人行为的影响:参与者对礼貌、理性的建议和表达性手势反应良好,但强调需要更多个性化、情境感知的论据和更清晰的社会角色。这些发现表明,生成式社会机器人可以影响用户的决策,但其有效性取决于交流的细微差别和情境的关联性。我们提出了对框架的改进,以进一步研究机器人和人类用户之间的说服动态。
要点
- 生成式AI增强了社会机器人的自然交流能力。
- 实验框架旨在研究机器人在决策过程中的说服力。
- 参与者对机器人互动持积极态度,认为机器人具有能力和友好性。
- 实际应用中存在局限性,如反应延迟和语音识别错误。
- 说服能力是高度情境化的,受机器人行为影响。
- 礼貌、理性的建议和表达性手势对参与者有良好影响。
点此查看论文截图