⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-09 更新
VCMamba: Bridging Convolutions with Multi-Directional Mamba for Efficient Visual Representation
Authors:Mustafa Munir, Alex Zhang, Radu Marculescu
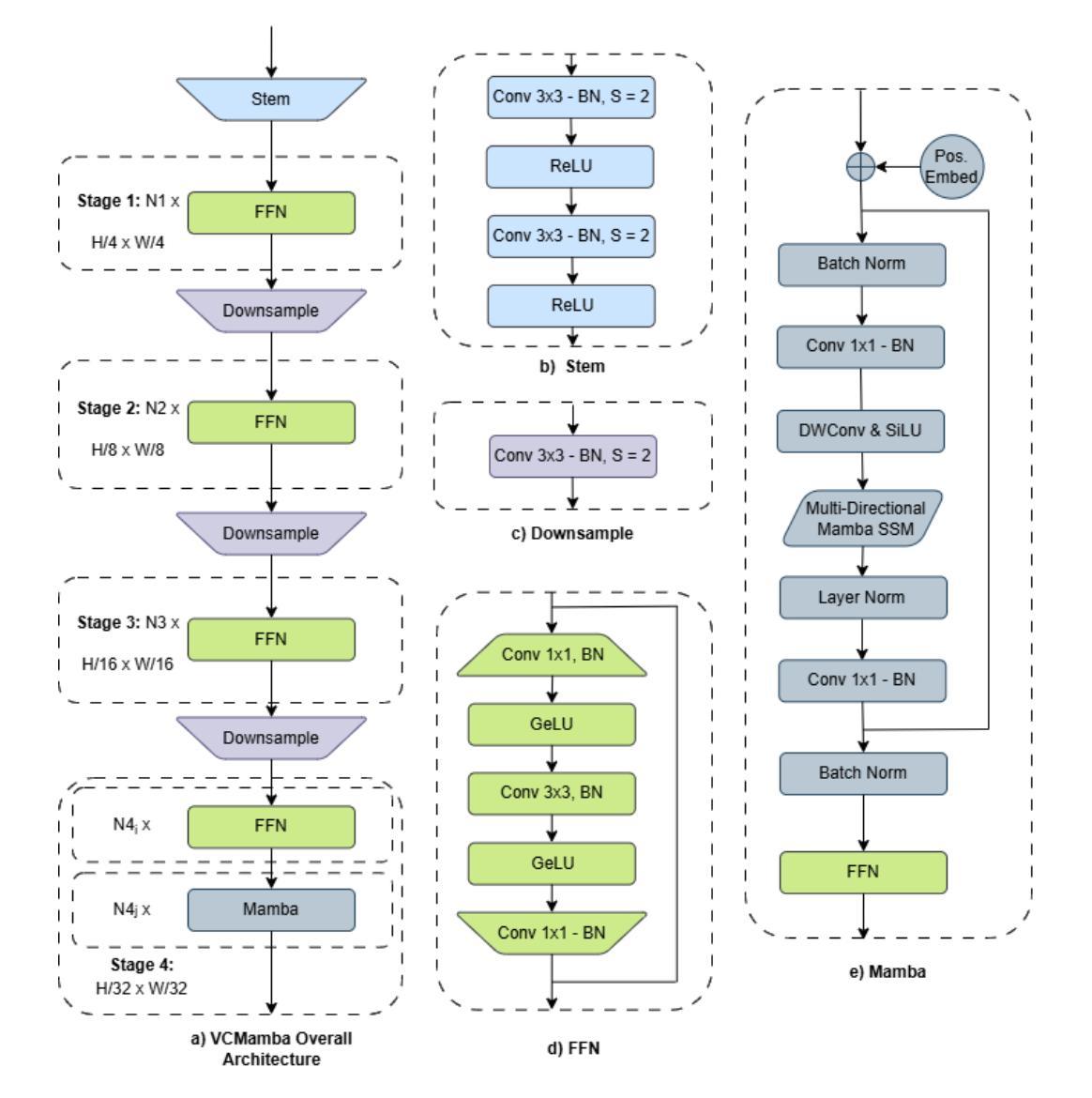
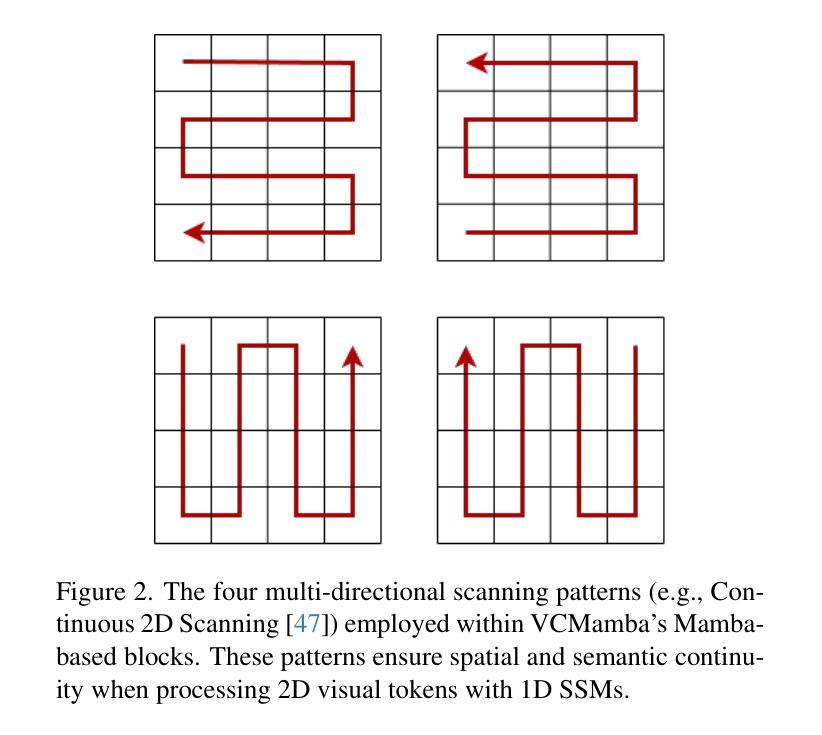
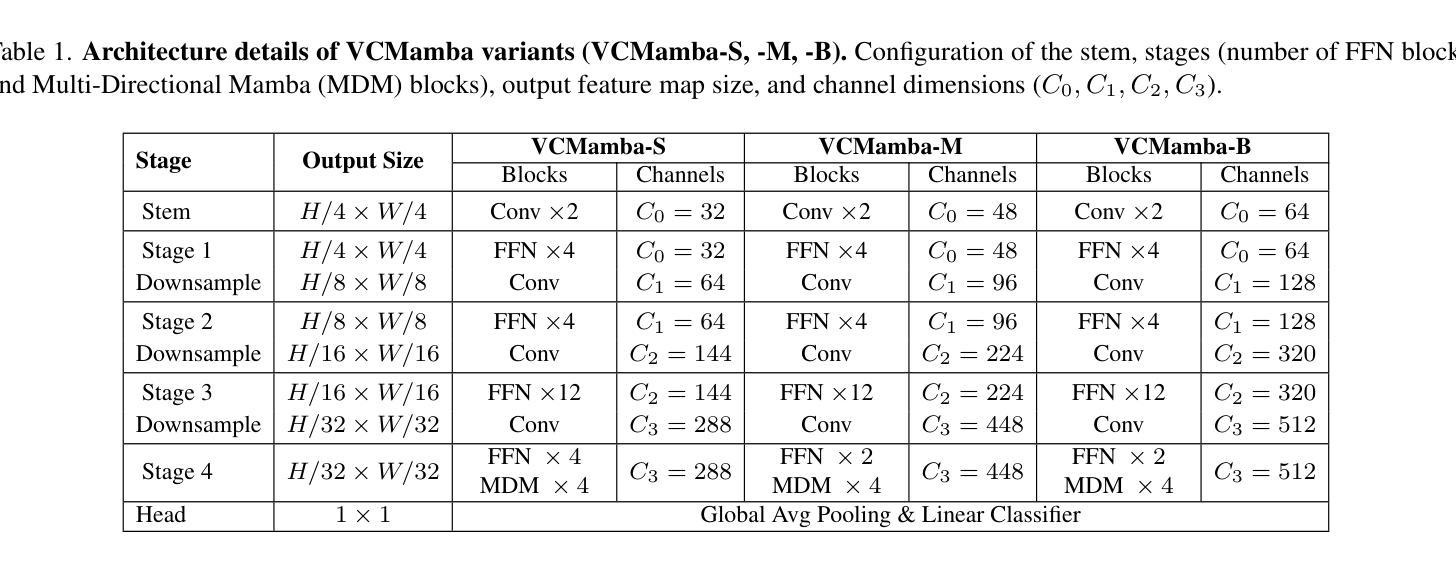
Recent advances in Vision Transformers (ViTs) and State Space Models (SSMs) have challenged the dominance of Convolutional Neural Networks (CNNs) in computer vision. ViTs excel at capturing global context, and SSMs like Mamba offer linear complexity for long sequences, yet they do not capture fine-grained local features as effectively as CNNs. Conversely, CNNs possess strong inductive biases for local features but lack the global reasoning capabilities of transformers and Mamba. To bridge this gap, we introduce \textit{VCMamba}, a novel vision backbone that integrates the strengths of CNNs and multi-directional Mamba SSMs. VCMamba employs a convolutional stem and a hierarchical structure with convolutional blocks in its early stages to extract rich local features. These convolutional blocks are then processed by later stages incorporating multi-directional Mamba blocks designed to efficiently model long-range dependencies and global context. This hybrid design allows for superior feature representation while maintaining linear complexity with respect to image resolution. We demonstrate VCMamba’s effectiveness through extensive experiments on ImageNet-1K classification and ADE20K semantic segmentation. Our VCMamba-B achieves 82.6% top-1 accuracy on ImageNet-1K, surpassing PlainMamba-L3 by 0.3% with 37% fewer parameters, and outperforming Vision GNN-B by 0.3% with 64% fewer parameters. Furthermore, VCMamba-B obtains 47.1 mIoU on ADE20K, exceeding EfficientFormer-L7 by 2.0 mIoU while utilizing 62% fewer parameters. Code is available at https://github.com/Wertyuui345/VCMamba.
最近,Vision Transformers(ViTs)和State Space Models(SSMs)的进展挑战了卷积神经网络(CNNs)在计算机视觉领域的统治地位。ViTs擅长捕捉全局上下文,而像Mamba这样的SSMs为长序列提供了线性复杂性,但它们不如CNN有效地捕捉精细的局部特征。相反,CNN具有对局部特征的强烈归纳偏见,但缺乏变压器和Mamba的全局推理能力。为了弥补这一差距,我们引入了VCMamba,这是一种结合了CNN和多方向Mamba SSMs优点的新型视觉主干。VCMamba采用卷积干和分层结构,其早期阶段采用卷积块来提取丰富的局部特征。这些卷积块然后通过后期阶段进行处理,融入多方向Mamba块,旨在有效地对长距离依赖关系和全局上下文进行建模。这种混合设计允许进行卓越的特征表示,同时保持关于图像分辨率的线性复杂性。我们通过在大规模ImageNet-1K分类和ADE20K语义分割实验上进行的广泛实验证明了VCMamba的有效性。我们的VCMamba-B在ImageNet-1K上达到了82.6%的top-1准确率,超越了PlainMamba-L3的0.3%,同时参数减少了37%,还超越了Vision GNN-B的0.3%,同时参数减少了64%。此外,VCMamba-B在ADE20K上获得了47.1 mIoU,超过了EfficientFormer-L7的2.0 mIoU,同时使用的参数减少了62%。代码可在https://github.com/Wertyuui345/VCMamba访问。
论文及项目相关链接
PDF Proceedings of the 2025 IEEE/CVF International Conference on Computer Vision (ICCV) Workshops
Summary
最新研究结合了Vision Transformers(ViTs)和State Space Models(SSMs)的优势,挑战了卷积神经网络(CNNs)在计算机视觉领域的统治地位。为弥补CNN和ViTs/SSMs在特征提取上的不足,提出一种新型视觉骨架网络VCMamba。它融合CNN和多方向Mamba SSMs的优点,既保持线性计算复杂度,又具备出色的特征表示能力。在ImageNet-1K分类和ADE20K语义分割的测试中,验证了VCMamba的有效性。
Key Takeaways
- Vision Transformers (ViTs) 和 State Space Models (SSMs) 在计算机视觉领域展现出新的潜力,挑战了卷积神经网络(CNNs)的主导地位。
- ViTs擅长捕捉全局上下文,而SSMs如Mamba提供线性复杂度的长序列处理,但两者在捕捉精细局部特征方面不如CNN。
- CNNs具有针对局部特征的强归纳偏见,但缺乏全局推理能力。
- 为结合CNN和ViTs/SSMs的优点,提出新型视觉骨架网络VCMamba。
- VCMamba采用卷积茎和层次结构,早期阶段使用卷积块提取丰富的局部特征,随后结合多方向Mamba块处理以有效建模长程依赖和全局上下文。
- VCMamba在ImageNet-1K分类和ADE20K语义分割测试中表现出卓越性能,相比其他模型具有更高的效率和准确性。
点此查看论文截图

Aesthetic Image Captioning with Saliency Enhanced MLLMs
Authors:Yilin Tao, Jiashui Huang, Huaze Xu, Ling Shao
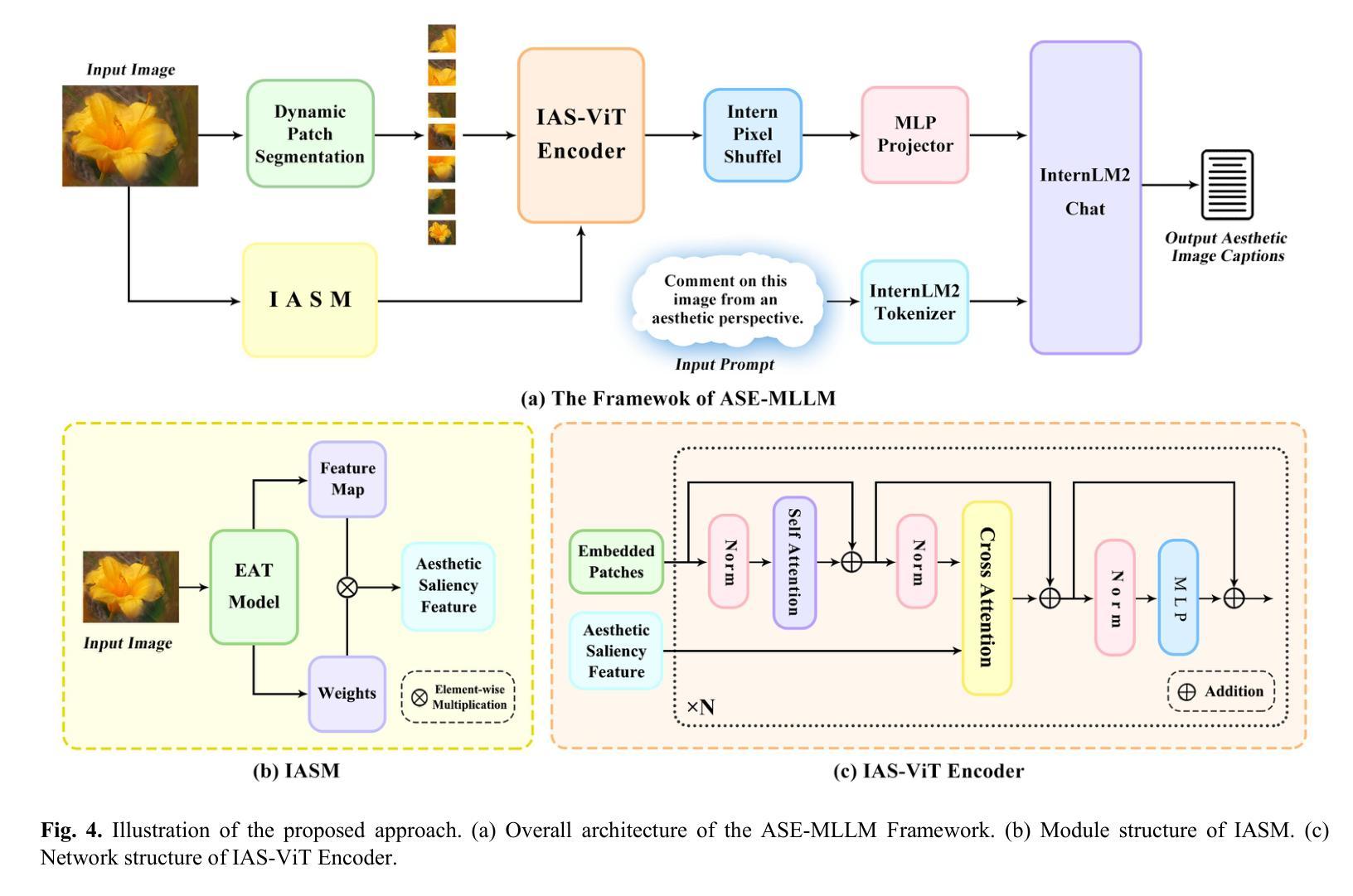
Aesthetic Image Captioning (AIC) aims to generate textual descriptions of image aesthetics, becoming a key research direction in the field of computational aesthetics. In recent years, pretrained Multimodal Large Language Models (MLLMs) have advanced rapidly, leading to a significant increase in image aesthetics research that integrates both visual and textual modalities. However, most existing studies on image aesthetics primarily focus on predicting aesthetic ratings and have shown limited application in AIC. Existing AIC works leveraging MLLMs predominantly rely on fine-tuning methods without specifically adapting MLLMs to focus on target aesthetic content. To address this limitation, we propose the Aesthetic Saliency Enhanced Multimodal Large Language Model (ASE-MLLM), an end-to-end framework that explicitly incorporates aesthetic saliency into MLLMs. Within this framework, we introduce the Image Aesthetic Saliency Module (IASM), which efficiently and effectively extracts aesthetic saliency features from images. Additionally, we design IAS-ViT as the image encoder for MLLMs, this module fuses aesthetic saliency features with original image features via a cross-attention mechanism. To the best of our knowledge, ASE-MLLM is the first framework to integrate image aesthetic saliency into MLLMs specifically for AIC tasks. Extensive experiments demonstrated that our approach significantly outperformed traditional methods and generic MLLMs on current mainstream AIC benchmarks, achieving state-of-the-art (SOTA) performance.
美学图像标题生成(AIC)旨在生成对图像美学的文本描述,已成为计算美学领域的关键研究方向。近年来,预训练的多模态大型语言模型(MLLM)迅速发展,推动了融合视觉和文本模态的图像美学研究的显著增加。然而,大多数现有的图像美学研究主要集中在预测美学评分上,在AIC中的应用有限。现有利用MLLM的AIC工作主要依赖于微调方法,而没有特定地适应MLLM以专注于目标美学内容。为了解决这一局限性,我们提出了美学显著性增强多模态大型语言模型(ASE-MLLM),这是一个端到端的框架,明确地将美学显著性纳入MLLM。在该框架中,我们引入了图像美学显著性模块(IASM),该模块能够高效地从图像中提取美学显著性特征。此外,我们设计了IAS-ViT作为MLLM的图像编码器,该模块通过交叉注意机制将美学显著性特征与原始图像特征相融合。据我们所知,ASE-MLLM是第一个将图像美学显著性融入MLLM的特定AIC任务框架。大量实验表明,我们的方法在当前主流的AIC基准测试中显著优于传统方法和通用MLLM,达到了最先进的性能。
论文及项目相关链接
摘要
基于预训练的多模态大型语言模型(MLLMs),提出了美学显著性增强多模态大型语言模型(ASE-MLLM)框架,该框架显式地结合了美学显著性,用于生成图像美学的文本描述。引入图像美学显著性模块(IASM)以有效地从图像中提取美学显著性特征,并与原图像特征通过交叉注意力机制融合。实验表明,该方法在主流美学图像标注(AIC)基准测试中显著优于传统方法和通用MLLMs,达到了当前最佳性能。
关键见解
- 美学图像标注(AIC)是计算美学领域的一个关键研究方向,旨在生成图像美学的文本描述。
- 预训练的多模态大型语言模型(MLLMs)近年来发展迅速,为集成视觉和文本模态的图像美学研究提供了显著增长。
- 现有图像美学研究主要关注预测美学评分,在AIC中的应用有限。
- 现有利用MLLMs的AIC工作主要依赖于微调方法,未专门针对目标美学内容进行适应。
- 提出的ASE-MLLM框架首次将图像美学显著性融入MLLMs,专门用于AIC任务。
- 在ASE-MLLM中,引入了图像美学显著性模块(IASM)以提取图像中的美学显著性特征。
点此查看论文截图



GCRPNet: Graph-Enhanced Contextual and Regional Perception Network For Salient Object Detection in Optical Remote Sensing Images
Authors:Mengyu Ren, Yutong Li, Hua Li, Runmin Cong, Sam Kwong
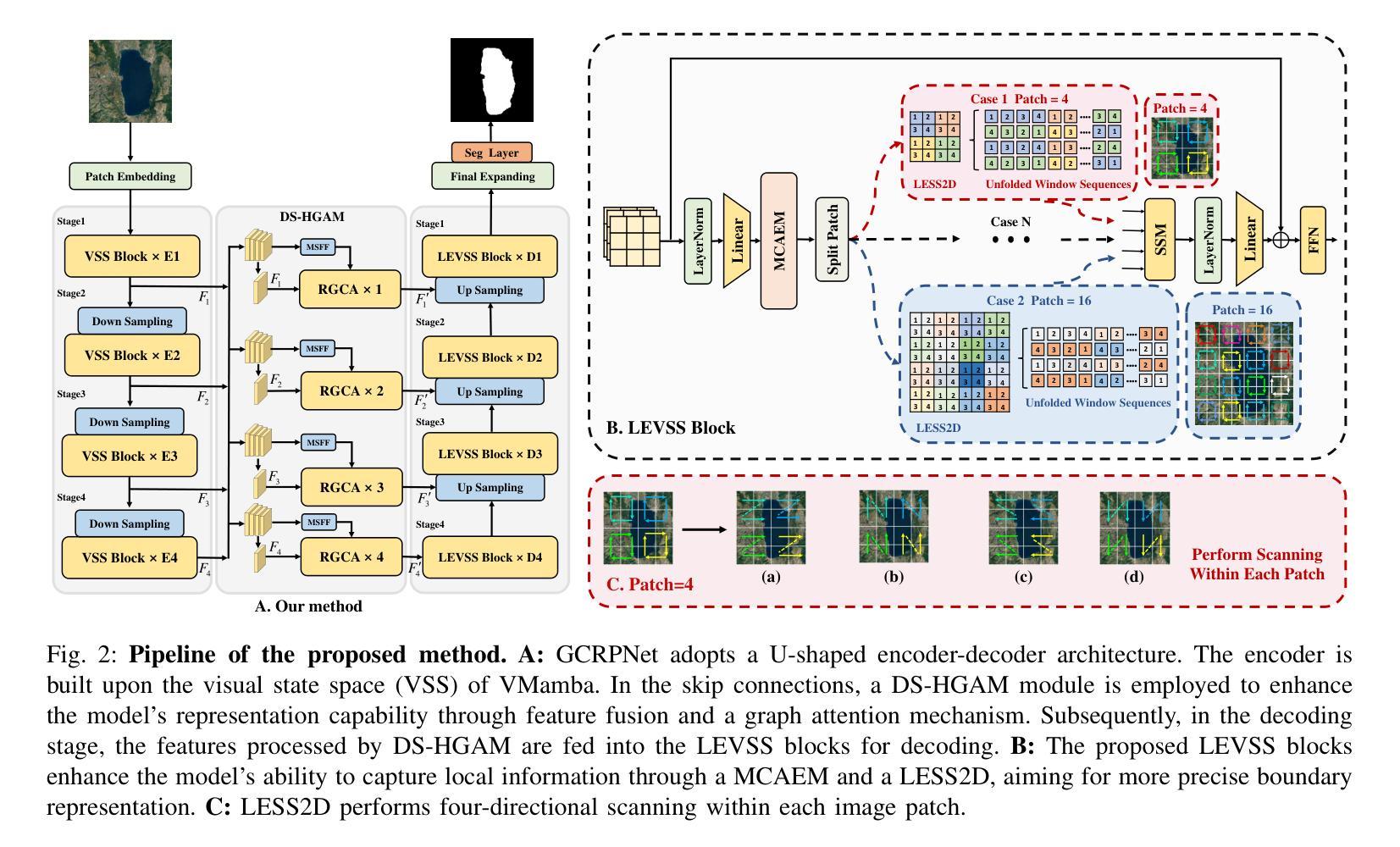
Salient object detection (SOD) in optical remote sensing images (ORSIs) faces numerous challenges, including significant variations in target scales and low contrast between targets and the background. Existing methods based on vision transformers (ViTs) and convolutional neural networks (CNNs) architectures aim to leverage both global and local features, but the difficulty in effectively integrating these heterogeneous features limits their overall performance. To overcome these limitations, we propose a graph-enhanced contextual and regional perception network (GCRPNet), which builds upon the Mamba architecture to simultaneously capture long-range dependencies and enhance regional feature representation. Specifically, we employ the visual state space (VSS) encoder to extract multi-scale features. To further achieve deep guidance and enhancement of these features, we first design a difference-similarity guided hierarchical graph attention module (DS-HGAM). This module strengthens cross-layer interaction capabilities between features of different scales while enhancing the model’s structural perception,allowing it to distinguish between foreground and background more effectively. Then, we design the LEVSS block as the decoder of GCRPNet. This module integrates our proposed adaptive scanning strategy and multi-granularity collaborative attention enhancement module (MCAEM). It performs adaptive patch scanning on feature maps processed via multi-scale convolutions, thereby capturing rich local region information and enhancing Mamba’s local modeling capability. Extensive experimental results demonstrate that the proposed model achieves state-of-the-art performance, validating its effectiveness and superiority.
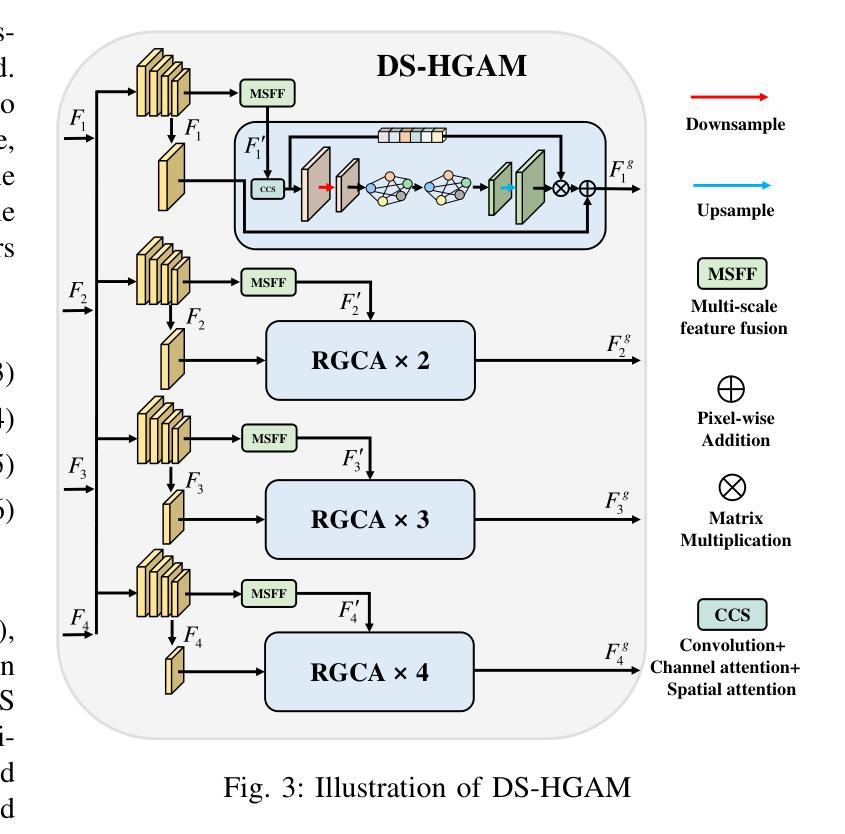
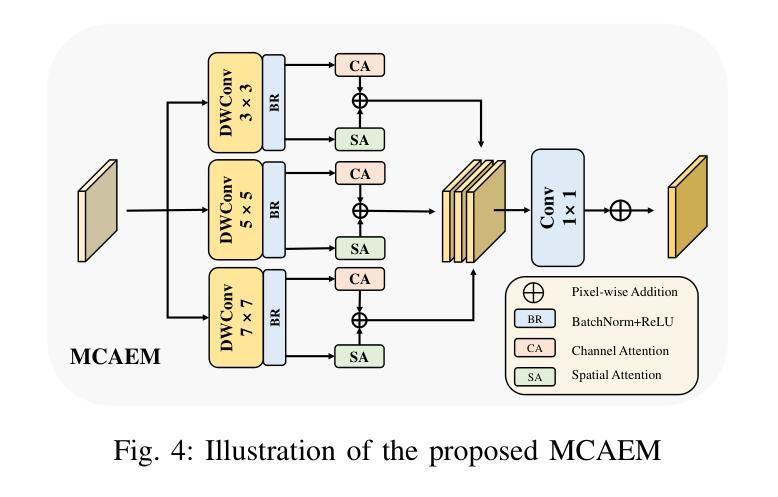
显著性目标检测(SOD)在光学遥感图像(ORSIs)中面临诸多挑战,包括目标尺度的显著变化和目标与背景之间的对比度低。现有的基于视觉转换器(ViTs)和卷积神经网络(CNNs)架构的方法旨在利用全局和局部特征,但有效整合这些异构特征的困难限制了其整体性能。为了克服这些局限性,我们提出了一种图增强上下文和区域感知网络(GCRPNet),它基于Mamba架构,同时捕捉长距离依赖关系并增强区域特征表示。具体来说,我们采用视觉状态空间(VSS)编码器提取多尺度特征。为了进一步实现这些特征的深度引导和增强,我们首先设计了一个差异相似性引导分层图注意力模块(DS-HGAM)。该模块加强了不同尺度特征之间的跨层交互能力,增强了模型的结构感知能力,使其更有效地区分前景和背景。然后,我们设计了LEVSS块作为GCRPNet的解码器。该模块结合了我们的自适应扫描策略和多粒度协同注意力增强模块(MCAEM)。它对经过多尺度卷积处理的特征图执行自适应补丁扫描,从而捕获丰富的局部区域信息并增强Mamba的局部建模能力。大量的实验结果证明了所提出模型达到了最先进的性能,验证了其有效性和优越性。
论文及项目相关链接
Summary
本文提出一种基于图增强的上下文与区域感知网络(GCRPNet),用于解决光学遥感图像中的显著目标检测问题。该网络利用Mamba架构同时捕获长程依赖关系并增强区域特征表示。通过视觉状态空间(VSS)编码器提取多尺度特征,并设计差异相似度引导层次图注意力模块(DS-HGAM)和LEVSS解码块来实现特征的深度引导和增强。这提高了模型的区分前景和背景的能力,并实现了先进的性能。
Key Takeaways
- GCRPNet旨在解决光学遥感图像中的显著目标检测的挑战,如目标尺度的变化和目标与背景之间的低对比度。
- 网络基于Mamba架构构建,可同时捕获长程依赖关系和增强区域特征表示。
- 采用视觉状态空间(VSS)编码器提取多尺度特征。
- DS-HGAM模块强化不同尺度特征之间的跨层交互能力,提高模型的结构感知能力。
- LEVSS解码块结合自适应扫描策略和MCAEM模块,对多尺度卷积处理的特征图进行自适应斑块扫描,捕获丰富的局部区域信息,增强Mamba的局部建模能力。
- 实验结果表明,所提出的模型实现了最先进的性能。
点此查看论文截图