⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-10 更新
Hyper Diffusion Avatars: Dynamic Human Avatar Generation using Network Weight Space Diffusion
Authors:Dongliang Cao, Guoxing Sun, Marc Habermann, Florian Bernard
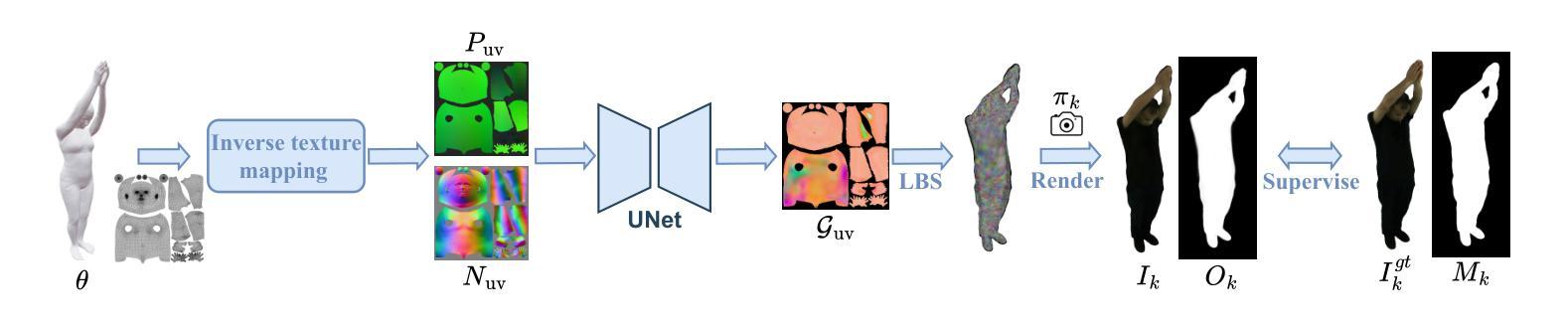
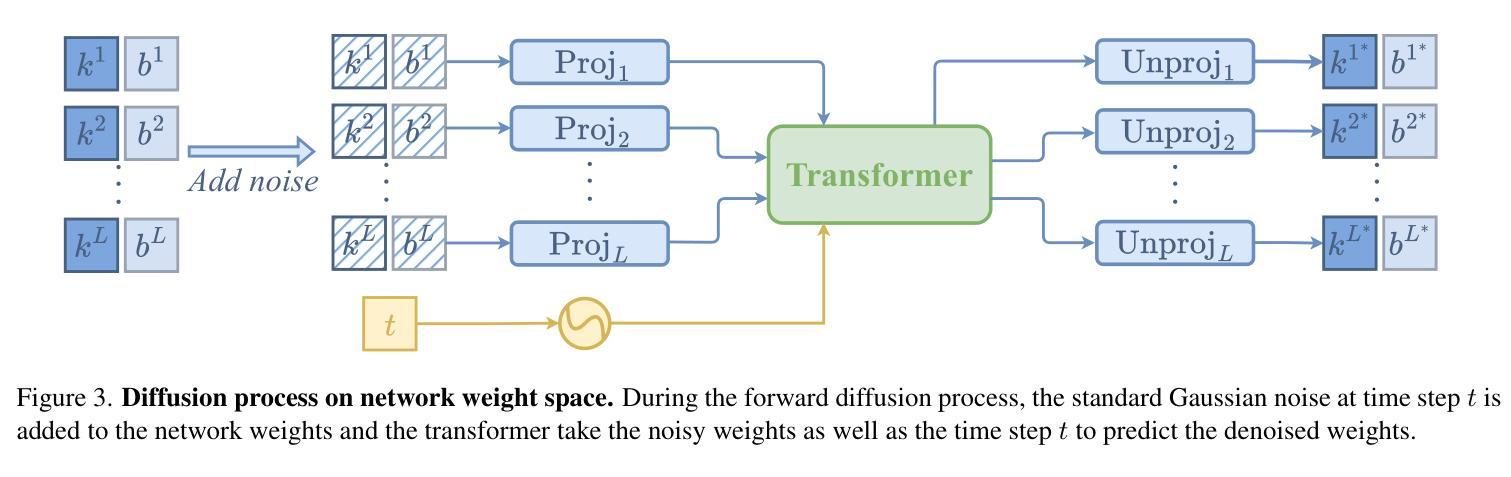
Creating human avatars is a highly desirable yet challenging task. Recent advancements in radiance field rendering have achieved unprecedented photorealism and real-time performance for personalized dynamic human avatars. However, these approaches are typically limited to person-specific rendering models trained on multi-view video data for a single individual, limiting their ability to generalize across different identities. On the other hand, generative approaches leveraging prior knowledge from pre-trained 2D diffusion models can produce cartoonish, static human avatars, which are animated through simple skeleton-based articulation. Therefore, the avatars generated by these methods suffer from lower rendering quality compared to person-specific rendering methods and fail to capture pose-dependent deformations such as cloth wrinkles. In this paper, we propose a novel approach that unites the strengths of person-specific rendering and diffusion-based generative modeling to enable dynamic human avatar generation with both high photorealism and realistic pose-dependent deformations. Our method follows a two-stage pipeline: first, we optimize a set of person-specific UNets, with each network representing a dynamic human avatar that captures intricate pose-dependent deformations. In the second stage, we train a hyper diffusion model over the optimized network weights. During inference, our method generates network weights for real-time, controllable rendering of dynamic human avatars. Using a large-scale, cross-identity, multi-view video dataset, we demonstrate that our approach outperforms state-of-the-art human avatar generation methods.
创建人类化身是一项极具吸引力但又具有挑战性的任务。最近,辐射场渲染技术的进展为实现个性化的动态人类化身提供了前所未有的真实感和实时性能。然而,这些方法通常仅限于针对单个个体的多视角视频数据训练的特定人员渲染模型,限制了它们在跨不同身份方面的泛化能力。另一方面,利用预训练的2D扩散模型的先验知识的生成方法,可以产生卡通式的静态人类化身,通过简单的基于骨骼的关节运动进行动画。因此,这些方法生成的化身与特定人员渲染方法相比,渲染质量较低,并且无法捕捉姿势相关的变形,如衣物褶皱。在本文中,我们提出了一种结合特定人员渲染和基于扩散的生成建模优点的新方法,以实现具有高度真实感和现实姿势相关变形的动态人类化身生成。我们的方法遵循两阶段管道:首先,我们优化了一组特定人员的UNet网络,每个网络代表一个动态人类化身,可以捕捉复杂的姿势相关变形。在第二阶段,我们在优化的网络权重上训练了一个超扩散模型。在推理过程中,我们的方法生成网络权重,用于实时、可控地呈现动态人类化身。使用大规模、跨身份、多视角的视频数据集,我们证明了我们的方法优于最先进的人类化身生成方法。
论文及项目相关链接
PDF Project webpage: https://vcai.mpi-inf.mpg.de/projects/HDA/
Summary
本文提出一种结合特定人物渲染和扩散生成模型的方法,生成高度逼真的动态人类虚拟角色。该方法采用两阶段流程,优化特定人物的U-Net网络,并训练超扩散模型。最终可实现实时、可控制的动态人类虚拟角色渲染,超越现有技术。
Key Takeaways
- 创建人类虚拟角色是一项既受欢迎又具挑战性的任务。
- 最新辐射场渲染技术已实现个性化动态人类虚拟角色的前所未有的逼真度和实时性能。
- 当前方法通常局限于针对单个个体的多视角视频数据进行训练的特定人物渲染模型,缺乏跨不同身份的泛化能力。
- 生成的虚拟角色在质量和姿态相关的变形方面存在局限,如衣物褶皱。
- 本文结合特定人物渲染和扩散生成建模,旨在实现高度逼真的动态人类虚拟角色生成,并捕捉姿态相关的变形。
- 方法采用两阶段流程:优化特定人物的U-Net网络,训练超扩散模型。
- 使用大规模跨身份多视角视频数据集,展示该方法在生成动态人类虚拟角色方面的优越性。
点此查看论文截图