⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-10 更新
Harnessing Object Grounding for Time-Sensitive Video Understanding
Authors:Tz-Ying Wu, Sharath Nittur Sridhar, Subarna Tripathi
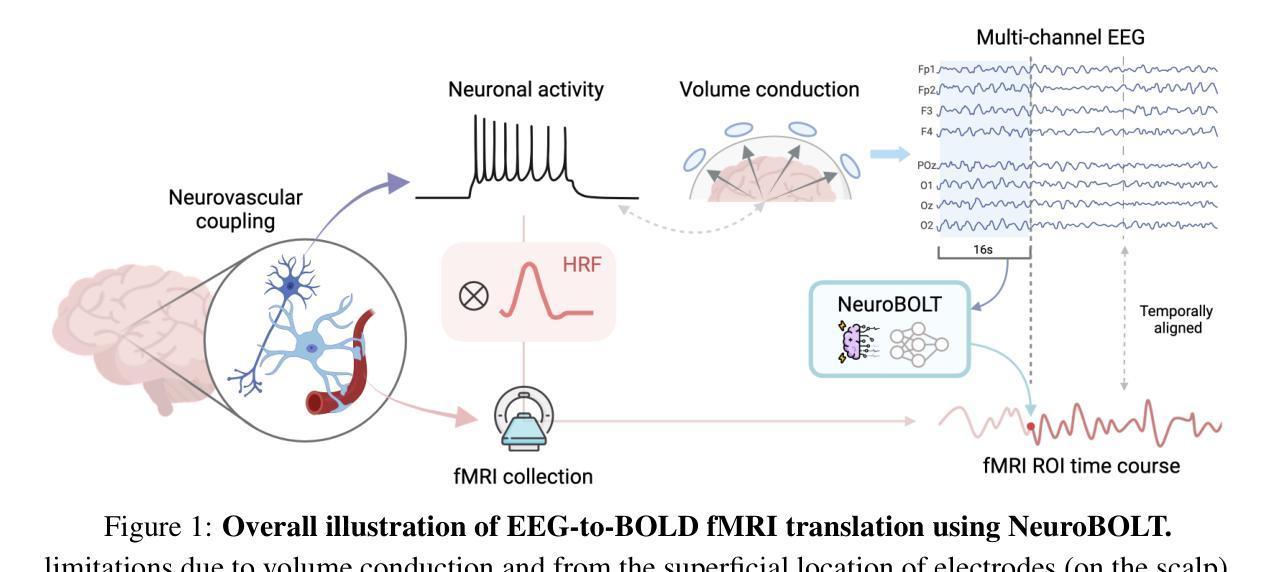
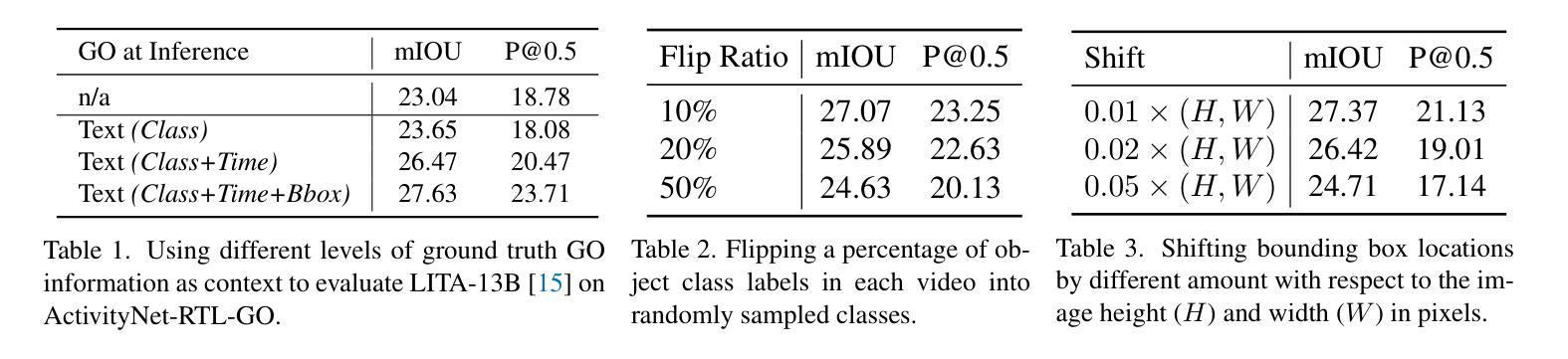
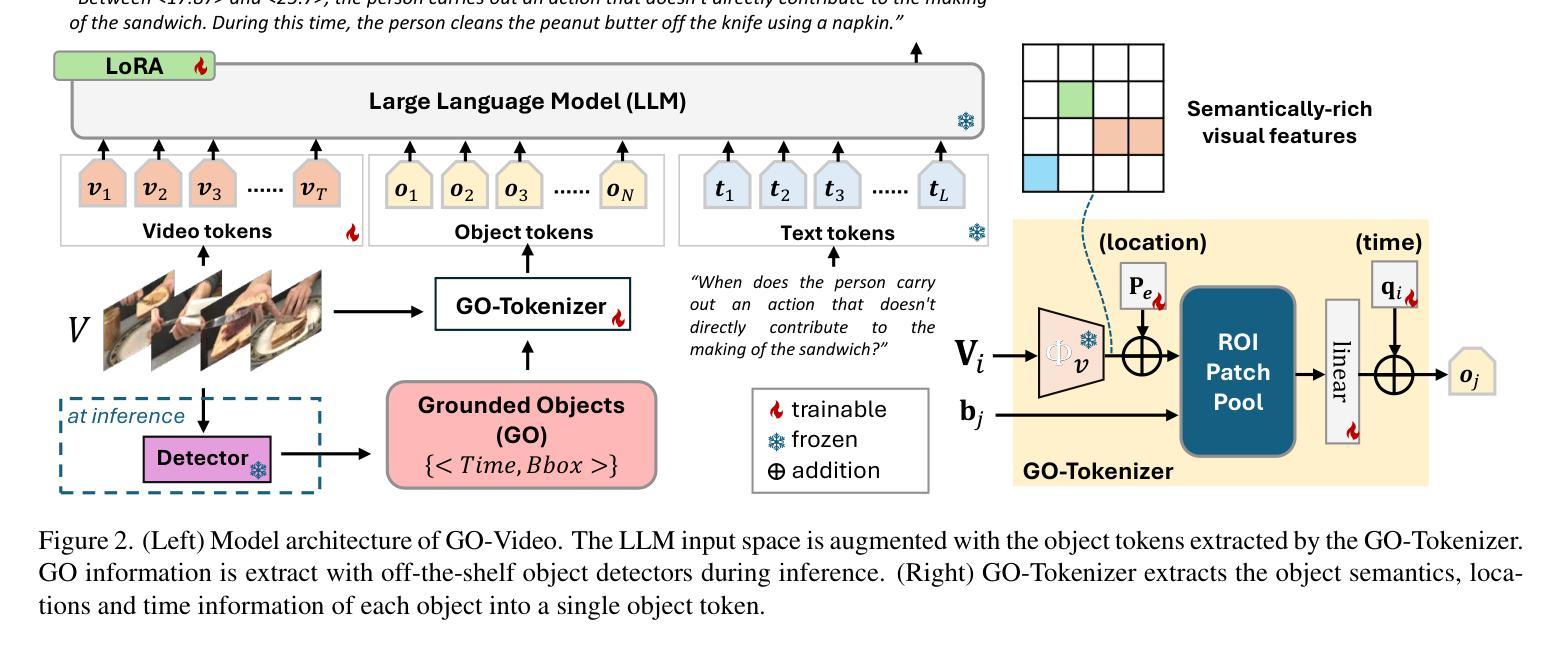
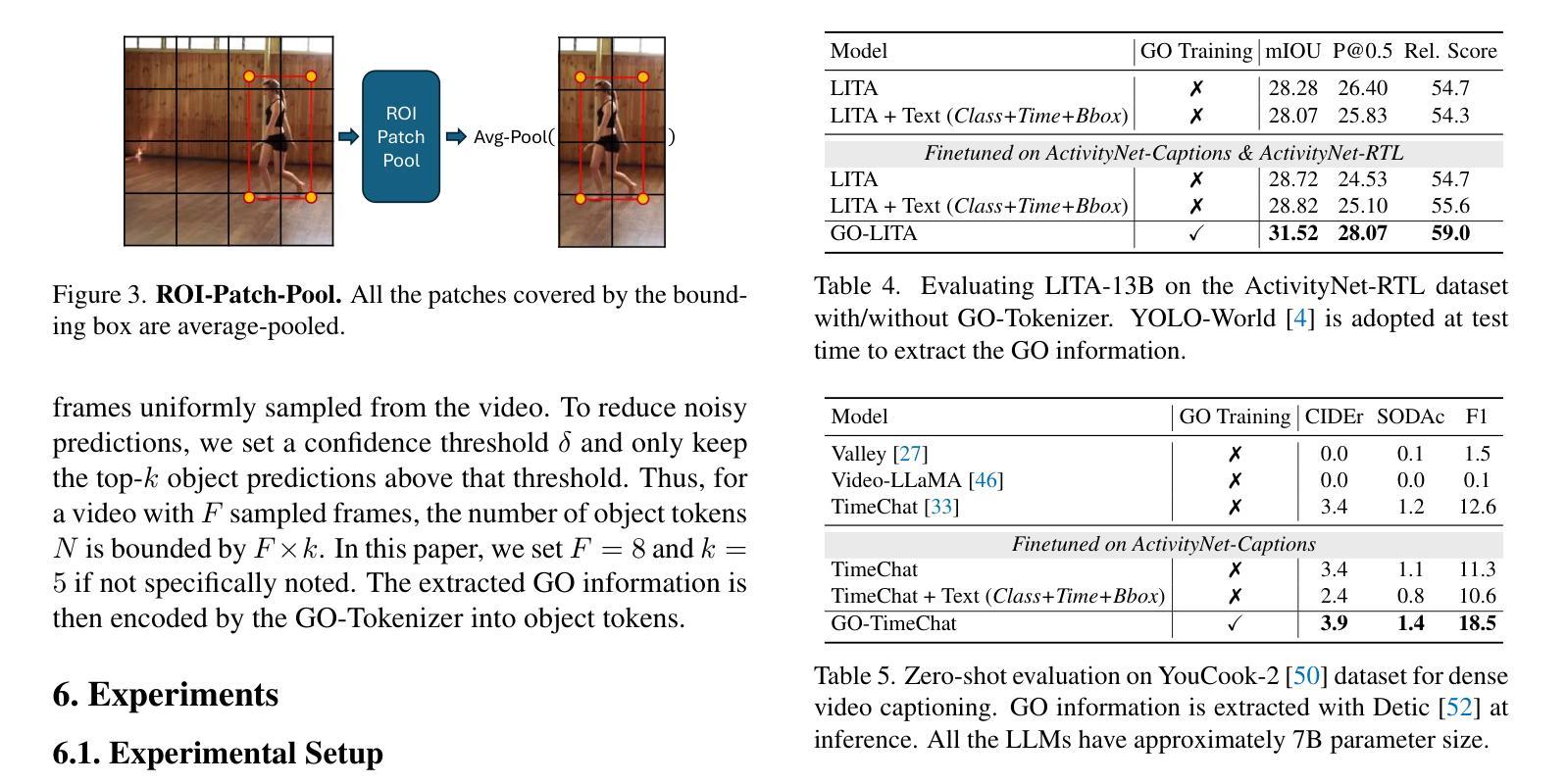
We propose to improve the time-sensitive video understanding (TSV) capability of video large language models (Video-LLMs) with grounded objects (GO). We hypothesize that TSV tasks can benefit from GO within frames, which is supported by our preliminary experiments on LITA, a state-of-the-art Video-LLM for reasoning temporal localization. While augmenting prompts with textual description of these object annotations improves the performance of LITA, it also introduces extra token length and susceptibility to the noise in object level information. To address this, we propose GO-Tokenizer, a lightweight add-on module for Video-LLMs leveraging off-the-shelf object detectors to encode compact object information on the fly. Experimental results demonstrate that pretraining with GO-Tokenizer outperforms the vanilla Video-LLM and its counterpart utilizing textual description of objects in the prompt. The gain generalizes across different models, datasets and video understanding tasks such as reasoning temporal localization and dense captioning.
我们提议利用基于对象(GO)的方法来提高视频大型语言模型(Video-LLM)的时间敏感视频理解(TSV)能力。我们假设TSV任务可以从帧内的基于对象受益,这一假设在LITA这一先进视频LLM的时间定位推理任务上的初步实验中得到支持。虽然通过增加带有这些对象注释文本描述提示可以提高LITA的性能,但它也增加了额外的令牌长度和对对象级别信息的噪声敏感性。为解决这一问题,我们提出了GO分词器(GO-Tokenizer),这是一个轻量级的为视频大型语言模型设计的附加模块,它利用现成的对象检测器来实时编码紧凑的对象信息。实验结果表明,使用GO-Tokenizer进行预训练优于原始的视频LLM以及使用提示中对象的文本描述的方法。这种收益在不同模型、数据集和视频理解任务(如时间定位推理和密集字幕)中都能体现出来。
论文及项目相关链接
摘要
我们提议通过引入实体对象(GO)来提升视频大型语言模型(Video-LLM)的时间敏感视频理解能力(TSV)。假设视频帧内的实体对象对TSV任务有益,并通过我们在先进Video-LLM——LITA上的初步实验证实了这一点。虽然通过在提示中添加这些对象注解的文本描述可以提高LITA的性能,但它也增加了额外的令牌长度并容易受到对象级别的噪声影响。为解决这一问题,我们提出了GO分词器(GO-Tokenizer),这是一款为Video-LLM设计的轻便插件模块,它利用现成的目标检测器即时编码紧凑的对象信息。实验结果表明,使用GO-Tokenizer进行预训练优于纯Video-LLM以及使用提示中对象描述的同类方法。这种优势在不同模型、数据集和视频理解任务(如推理时间定位和视频密集字幕)中都存在。
关键见解
- 引入实体对象(GO)能提升视频大型语言模型(Video-LLM)的时间敏感视频理解能力(TSV)。
- 假设视频帧内的实体对象对TSV任务有益,并在先进Video-LLM——LITA的初步实验中验证了这一点。
- 在提示中添加对象注解的文本描述可以提高性能,但同时也增加了额外的令牌长度和噪声敏感性。
- 提出GO分词器(GO-Tokenizer)——一个为Video-LLM设计的插件模块,利用现成的目标检测器即时编码紧凑的对象信息。
- 使用GO-Tokenizer进行预训练的效果优于纯Video-LLM以及使用带有对象描述的提示的方法。
- GO-Tokenizer的优势在不同模型、数据集以及视频理解任务中普遍存在。
- 该方法对于改善视频理解任务性能具有潜力,特别是在处理包含复杂对象和场景的视频时。
点此查看论文截图

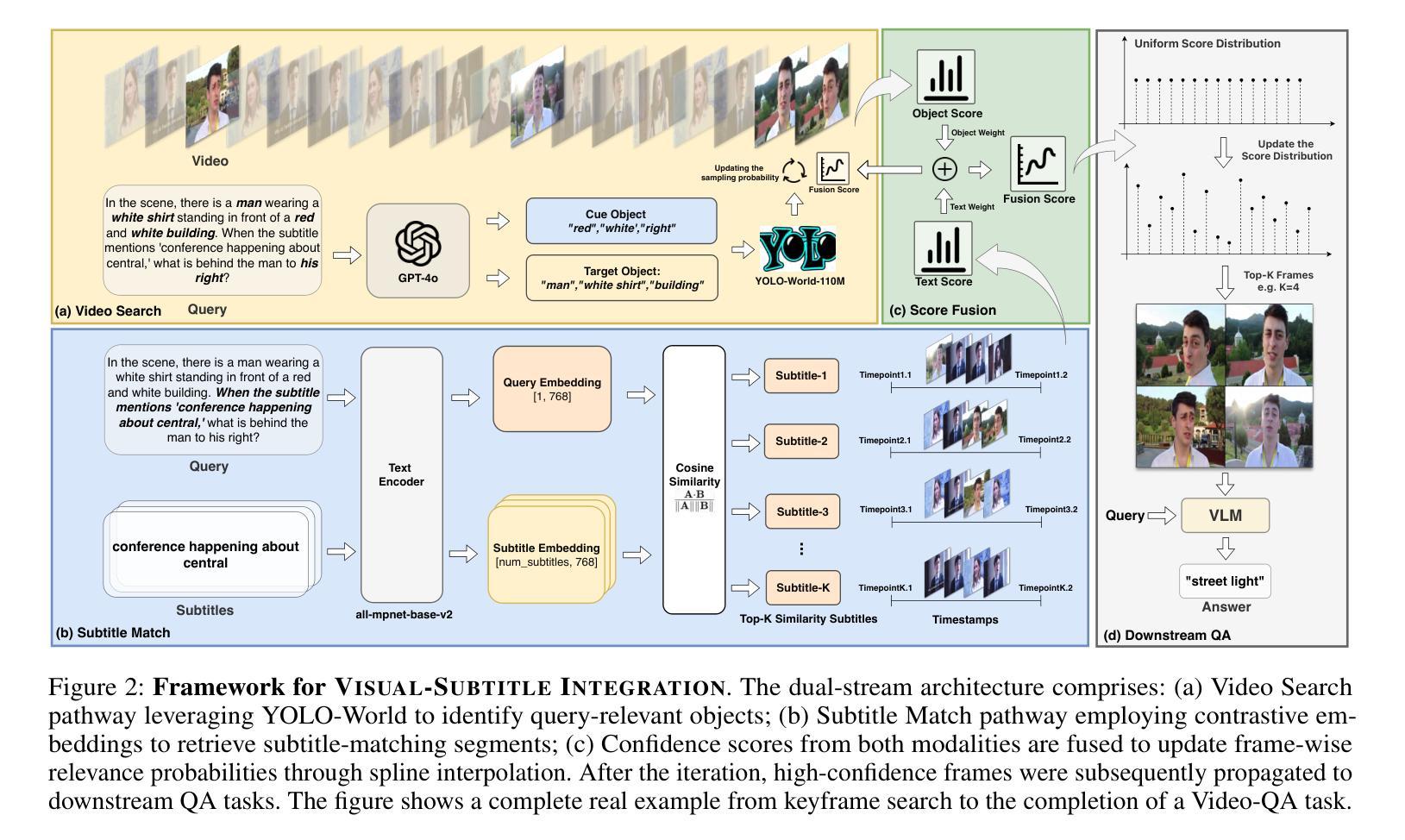
VSI: Visual Subtitle Integration for Keyframe Selection to enhance Long Video Understanding
Authors:Jianxiang He, Meisheng Hong, Jungang Li, Yijie Xu, Ziyang Chen, Weiyu Guo, Hui Xiong
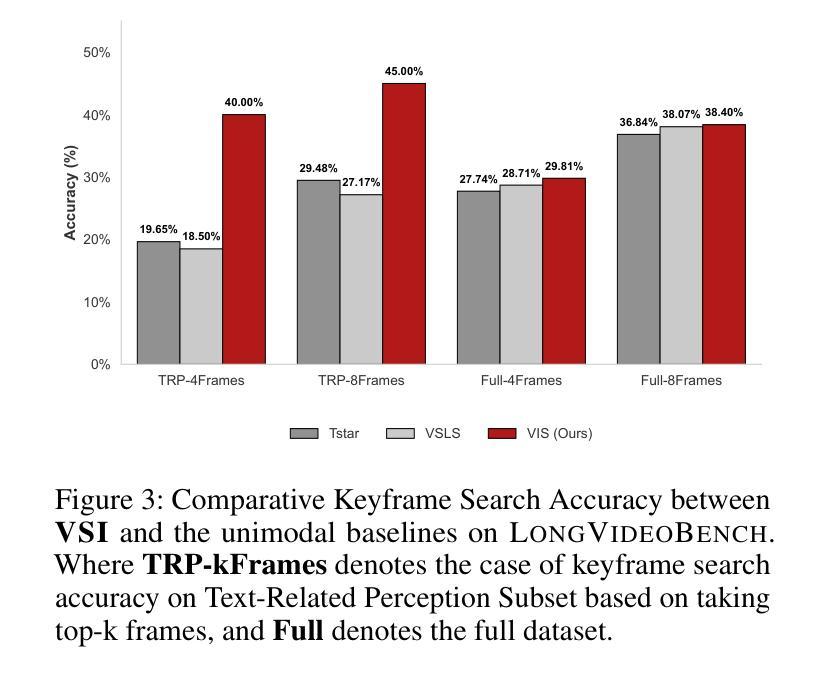
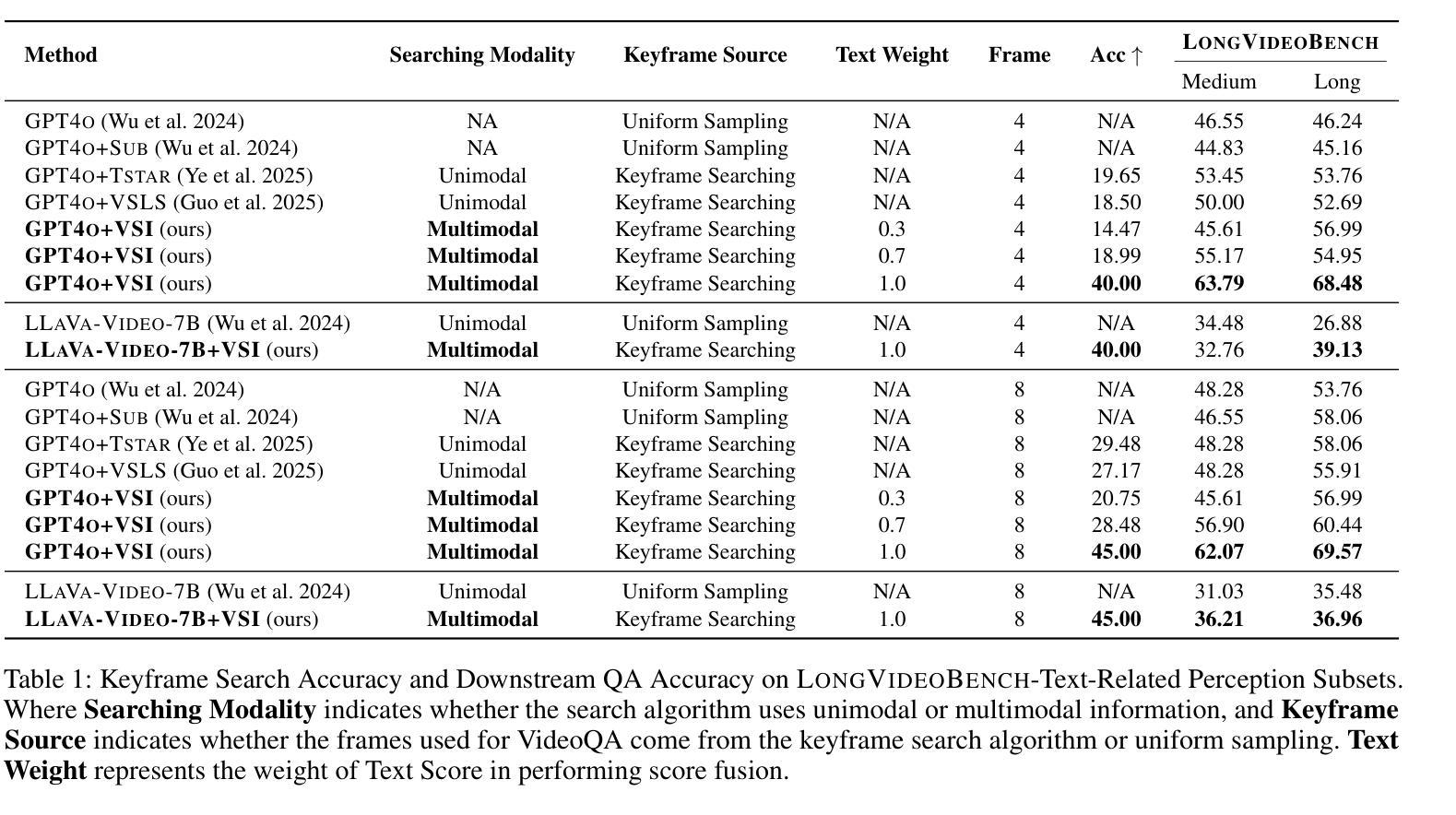
Long video understanding presents a significant challenge to multimodal large language models (MLLMs) primarily due to the immense data scale. A critical and widely adopted strategy for making this task computationally tractable is keyframe retrieval, which seeks to identify a sparse set of video frames that are most salient to a given textual query. However, the efficacy of this approach is hindered by weak multimodal alignment between textual queries and visual content and fails to capture the complex temporal semantic information required for precise reasoning. To address this, we propose Visual-Subtitle Integeration(VSI), a multimodal keyframe search method that integrates subtitles, timestamps, and scene boundaries into a unified multimodal search process. The proposed method captures the visual information of video frames as well as the complementary textual information through a dual-stream search mechanism by Video Search Stream as well as Subtitle Match Stream, respectively, and improves the keyframe search accuracy through the interaction of the two search streams. Experimental results show that VSI achieve 40.00% key frame localization accuracy on the text-relevant subset of LongVideoBench and 68.48% accuracy on downstream long Video-QA tasks, surpassing competitive baselines by 20.35% and 15.79%, respectively. Furthermore, on the LongVideoBench, VSI achieved state-of-the-art(SOTA) in medium-to-long video-QA tasks, demonstrating the robustness and generalizability of the proposed multimodal search strategy.
长视频理解对多模态大型语言模型(MLLMs)提出了重大挑战,这主要是因为其数据量巨大。为使这项任务在计算上变得可行,一个关键且被广泛采用的策略是关键帧检索,它旨在识别给定文本查询中最显著的一组稀疏视频帧。然而,这一方法的效力受到了文本查询和视觉内容之间弱多模态对齐的限制,并且无法捕获精确推理所需的确切时序语义信息。
针对这一问题,我们提出视觉字幕整合(VSI),这是一种多模态关键帧搜索方法,它将字幕、时间戳和场景边界整合到统一的多模态搜索过程中。该方法通过视频搜索流和字幕匹配流分别捕获视频帧的视觉信息和通过双流搜索机制补充的文本信息,并通过两个搜索流的交互提高关键帧搜索的准确性。
论文及项目相关链接
PDF 9 pages,3 figures
摘要
视频理解对多模态大型语言模型提出了巨大挑战,尤其是因为数据规模巨大。为了应对这一挑战,通常采用的关键帧检索策略试图识别一组稀疏的视频帧,这些帧对于给定的文本查询最为突出。然而,由于文本查询和视觉内容之间的多模态对齐较弱,这种方法的有效性受到限制,并且无法捕获精确推理所需的复杂时间语义信息。为了解决这一问题,我们提出了Visual-Subtitle Integration(VSI)的多模态关键帧搜索方法,通过将字幕、时间戳和场景边界整合到统一的多模态搜索过程中。该方法通过双流搜索机制捕捉视频帧的视觉信息以及字幕的文本信息,并通过视频搜索流和字幕匹配流的交互提高关键帧搜索的准确性。实验结果表明,VSI在LongVideoBench文本相关子集上实现40.00%的关键帧定位精度,在中长视频问答任务上取得最新成果,展现了该多模态搜索策略的稳健性和泛化能力。
关键见解
- 长视频理解对多模态大型语言模型构成挑战,主要原因是数据规模庞大。
- 关键帧检索是应对这一挑战的关键策略,但存在多模态对齐弱和缺乏复杂时间语义信息的问题。
- 提出的VSI方法通过整合字幕、时间戳和场景边界,在统一的多模态搜索过程中改善关键帧检索。
- VSI使用双流搜索机制,分别捕捉视频帧的视觉信息和字幕的文本信息。
- VSI通过两个搜索流的交互提高关键帧搜索的准确性。
- 实验结果表明,VSI在关键帧定位和视频问答任务上具有较高的准确性和性能。
点此查看论文截图