⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-10 更新
BIR-Adapter: A Low-Complexity Diffusion Model Adapter for Blind Image Restoration
Authors:Cem Eteke, Alexander Griessel, Wolfgang Kellerer, Eckehard Steinbach
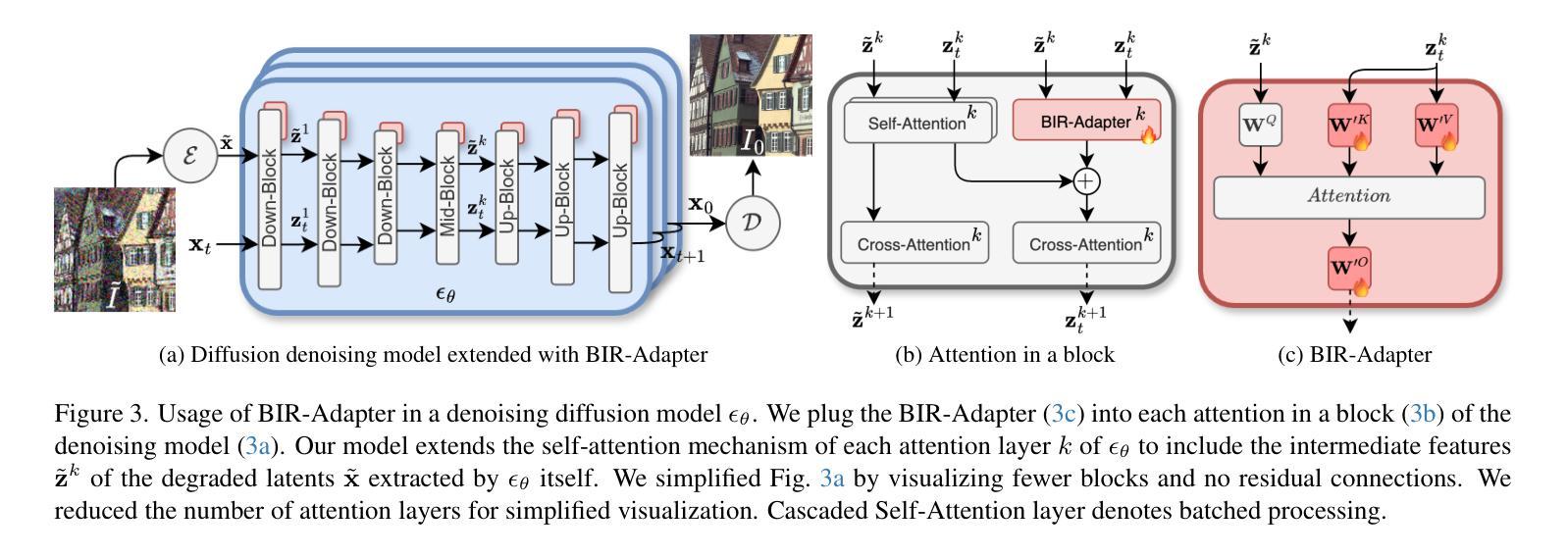
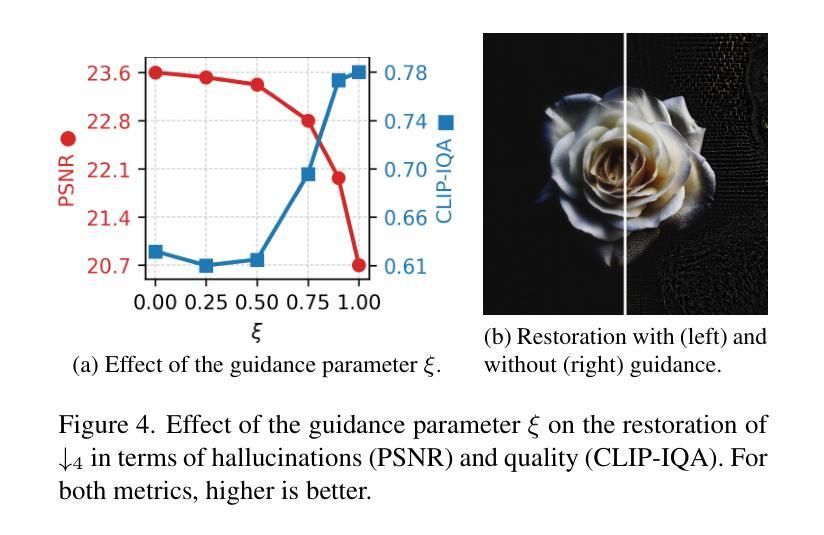
This paper introduces BIR-Adapter, a low-complexity blind image restoration adapter for diffusion models. The BIR-Adapter enables the utilization of the prior of pre-trained large-scale diffusion models on blind image restoration without training any auxiliary feature extractor. We take advantage of the robustness of pretrained models. We extract features from degraded images via the model itself and extend the self-attention mechanism with these degraded features. We introduce a sampling guidance mechanism to reduce hallucinations. We perform experiments on synthetic and real-world degradations and demonstrate that BIR-Adapter achieves competitive or better performance compared to state-of-the-art methods while having significantly lower complexity. Additionally, its adapter-based design enables integration into other diffusion models, enabling broader applications in image restoration tasks. We showcase this by extending a super-resolution-only model to perform better under additional unknown degradations.
本文介绍了 BIR-Adapter,一种用于扩散模型的低复杂度盲图像恢复适配器。BIR-Adapter 实现了利用预训练的大型扩散模型对盲图像恢复的先验信息,无需训练任何辅助特征提取器。我们充分利用了预训练模型的稳健性。我们通过模型本身从退化图像中提取特征,并利用这些退化特征扩展自注意力机制。我们引入了一种采样引导机制来减少幻觉。我们在合成和真实世界的退化上进行了实验,结果表明 BIR-Adapter 在具有显著降低复杂性的同时,与最先进的方法相比具有竞争力或更好的性能。此外,其基于适配器的设计可以集成到其他扩散模型中,从而在图像恢复任务中具有更广泛的应用。我们通过将一个仅用于超分辨率的模型扩展到在额外的未知退化下表现更好来展示这一点。
论文及项目相关链接
PDF 20 pages, 14 figures
Summary
本文介绍了BIR-Adapter,这是一种用于扩散模型的低复杂度盲图像恢复适配器。BIR-Adapter利用预训练的大型扩散模型的先验信息,无需训练任何辅助特征提取器即可进行盲图像恢复。通过利用预训练模型的稳健性,直接从退化图像中提取特征,并扩展自注意力机制以利用这些退化特征。通过引入采样指导机制减少幻象。实验表明,BIR-Adapter在合成和真实世界退化数据上表现出具有竞争力的性能或更优秀的性能,且复杂度显著降低。此外,其基于适配器的设计可与其他扩散模型集成,扩大了在图像恢复任务中的应用范围。例如,将一个仅用于超分辨率的模型扩展到在未知退化条件下表现更佳。
Key Takeaways
- BIR-Adapter是一种用于扩散模型的盲图像恢复适配器,具有低复杂度。
- 它利用预训练的大型扩散模型的先验信息,无需训练额外的特征提取器。
- 通过利用预训练模型的稳健性,直接从退化图像中提取特征。
- 扩展了自注意力机制以利用退化特征,并引入采样指导机制减少幻象。
- 实验表明,BIR-Adapter在合成和真实退化数据上表现出竞争力,复杂度更低。
- BIR-Adapter基于适配器的设计可与其他扩散模型集成,提高图像恢复任务的适用范围。
点此查看论文截图


UMO: Scaling Multi-Identity Consistency for Image Customization via Matching Reward
Authors:Yufeng Cheng, Wenxu Wu, Shaojin Wu, Mengqi Huang, Fei Ding, Qian He
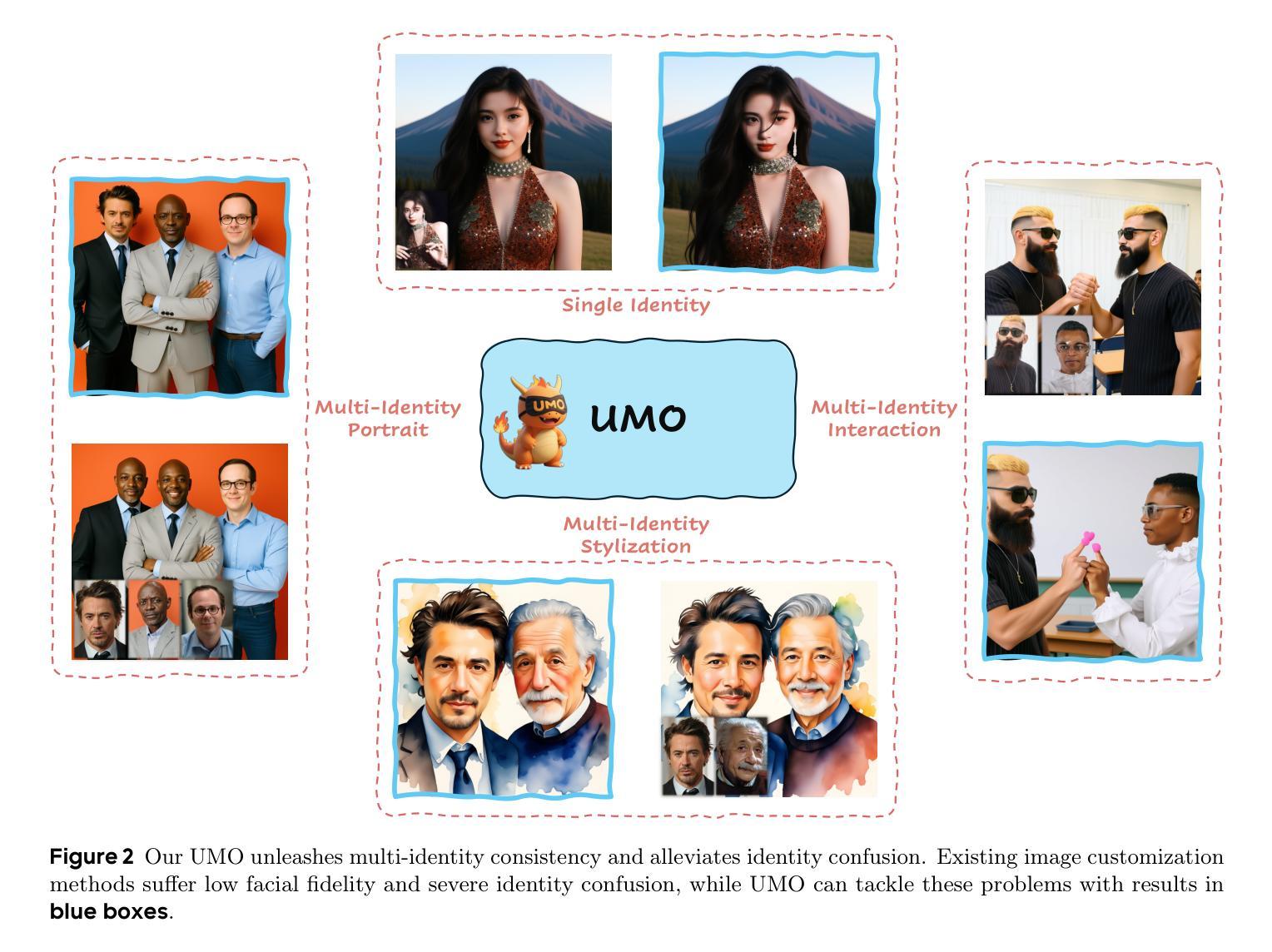
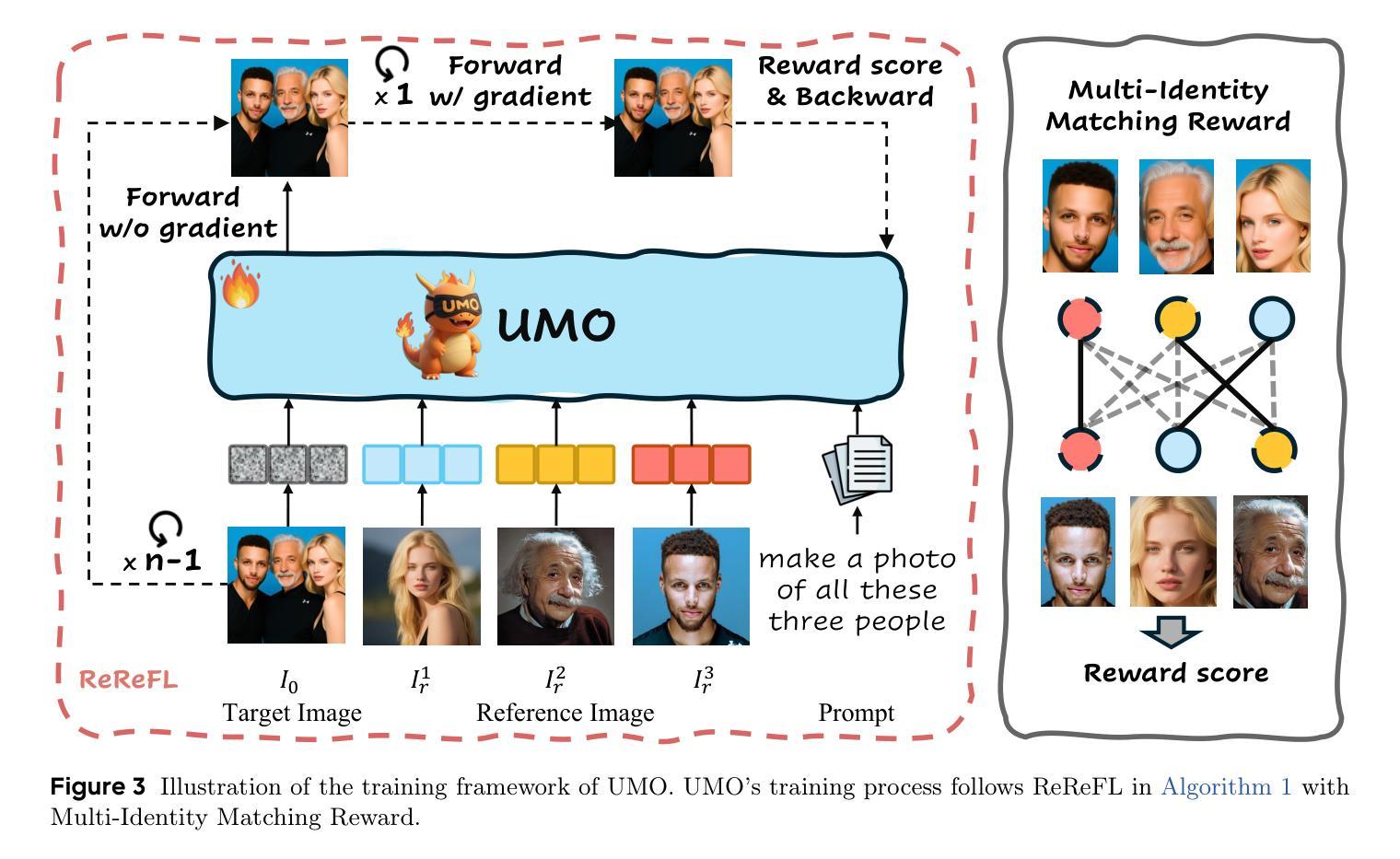
Recent advancements in image customization exhibit a wide range of application prospects due to stronger customization capabilities. However, since we humans are more sensitive to faces, a significant challenge remains in preserving consistent identity while avoiding identity confusion with multi-reference images, limiting the identity scalability of customization models. To address this, we present UMO, a Unified Multi-identity Optimization framework, designed to maintain high-fidelity identity preservation and alleviate identity confusion with scalability. With “multi-to-multi matching” paradigm, UMO reformulates multi-identity generation as a global assignment optimization problem and unleashes multi-identity consistency for existing image customization methods generally through reinforcement learning on diffusion models. To facilitate the training of UMO, we develop a scalable customization dataset with multi-reference images, consisting of both synthesised and real parts. Additionally, we propose a new metric to measure identity confusion. Extensive experiments demonstrate that UMO not only improves identity consistency significantly, but also reduces identity confusion on several image customization methods, setting a new state-of-the-art among open-source methods along the dimension of identity preserving. Code and model: https://github.com/bytedance/UMO
近期图像定制技术的进展展现出广阔的应用前景,因其更强大的定制能力。然而,由于人类对人脸更为敏感,因此在多参考图像中保持身份一致并避免身份混淆仍是一项重大挑战,这限制了定制模型的身份可扩展性。为解决此问题,我们提出了UMO(Unified Multi-identity Optimization)框架,旨在保持高保真身份保留,并通过可扩展性缓解身份混淆。采用“多对多匹配”范式,UMO将多身份生成重新构建为全球分配优化问题,并为现有的图像定制方法一般通过扩散模型的强化学习释放多身份一致性。为帮助训练UMO,我们开发了一个可伸缩的定制数据集,包含多参考图像,既有合成部分也有真实部分。此外,我们还提出了一种新指标来衡量身份混淆。大量实验表明,UMO不仅显著提高身份一致性,而且在多种图像定制方法中减少了身份混淆,在身份保留的维度上成为开源方法中的最新先进技术。代码和模型:https://github.com/bytedance/UMO
论文及项目相关链接
PDF Project page: https://bytedance.github.io/UMO/ Code and model: https://github.com/bytedance/UMO
Summary
近期图像定制技术取得了进展,具有广泛的应用前景,但仍面临身份一致性保护和避免身份混淆的挑战。针对此问题,本文提出了一种统一的多身份优化框架UMO,旨在通过强化学习在扩散模型上维护高保真身份并缓解身份混淆问题。UMO将多身份生成重新定义为全局分配优化问题,并引入“多对多匹配”范式来提高现有图像定制方法的身份一致性。此外,本研究还建立了一个用于UMO训练的可扩展定制化数据集,并提出了一个全新的身份混淆度量标准。实验证明,UMO不仅在提高身份一致性方面表现卓越,而且在多种图像定制方法中减少了身份混淆,成为开源方法中身份保留维度的最新最佳。
Key Takeaways
- 图像定制技术的发展带来了广泛的应用前景,尤其在更强的定制化能力方面。
- 身份一致性的保护和避免身份混淆是当前面临的主要挑战。
- UMO框架旨在通过强化学习在扩散模型上维护高保真身份并缓解身份混淆问题。
- UMO采用“多对多匹配”范式,将多身份生成重新定义为全局分配优化问题。
- UMO的开发依赖于一个用于训练的可扩展定制化数据集,该数据集包含合成和真实图像。
- 研究人员提出了一种新的度量标准来衡量身份混淆。
点此查看论文截图



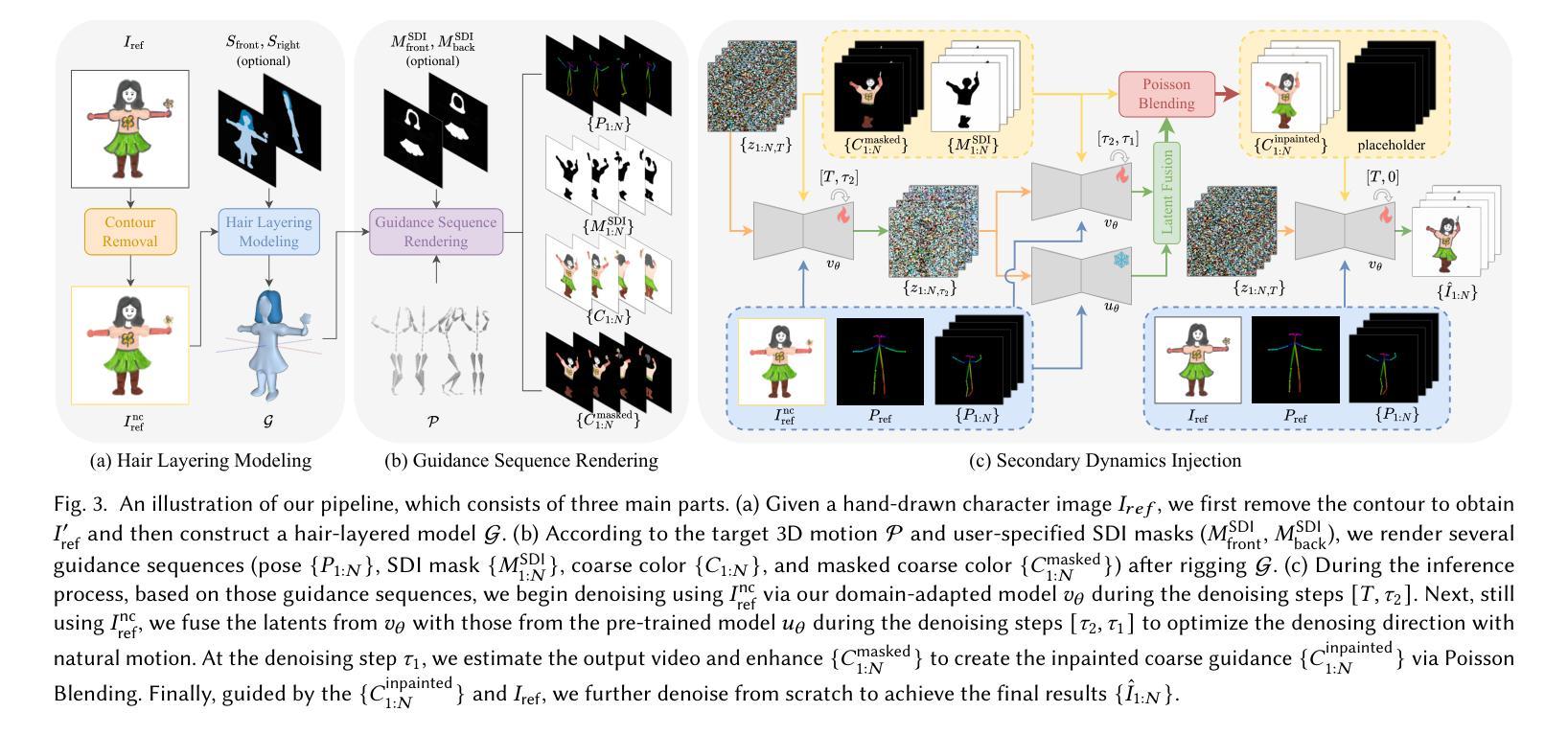
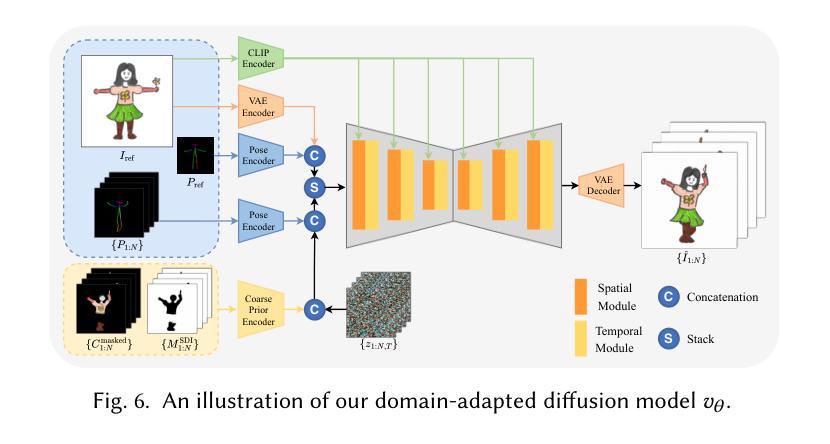
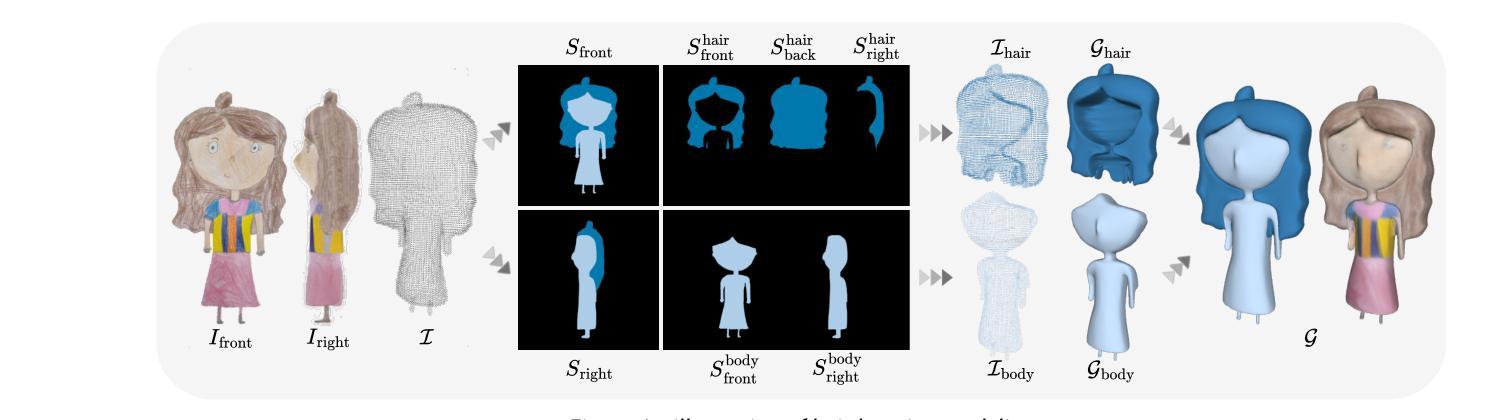
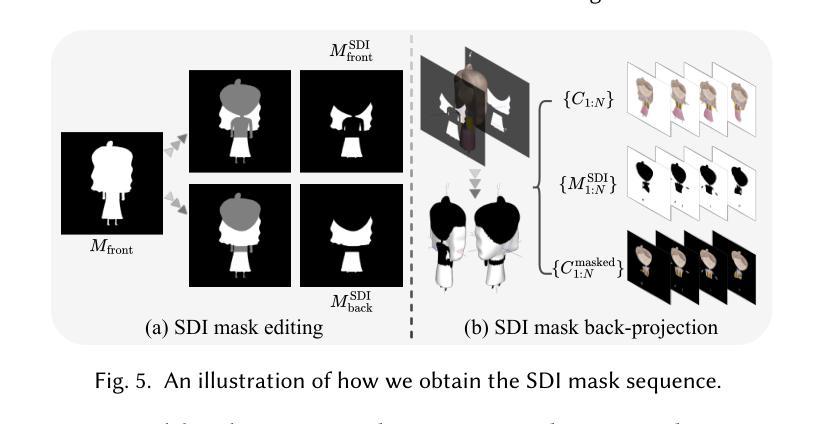
From Rigging to Waving: 3D-Guided Diffusion for Natural Animation of Hand-Drawn Characters
Authors:Jie Zhou, Linzi Qu, Miu-Ling Lam, Hongbo Fu
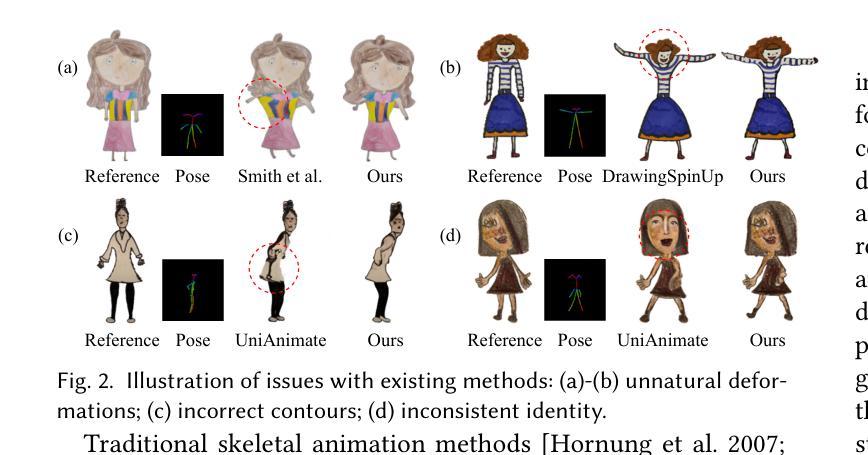
Hand-drawn character animation is a vibrant field in computer graphics, presenting challenges in achieving geometric consistency while conveying expressive motion. Traditional skeletal animation methods maintain geometric consistency but struggle with complex non-rigid elements like flowing hair and skirts, leading to unnatural deformation. Conversely, video diffusion models synthesize realistic dynamics but often create geometric distortions in stylized drawings due to domain gaps. This work proposes a hybrid animation system that combines skeletal animation and video diffusion. Initially, coarse images are generated from characters retargeted with skeletal animations for geometric guidance. These images are then enhanced in texture and secondary dynamics using video diffusion priors, framing this enhancement as an inpainting task. A domain-adapted diffusion model refines user-masked regions needing improvement, especially for secondary dynamics. To enhance motion realism further, we introduce a Secondary Dynamics Injection (SDI) strategy in the denoising process, incorporating features from a pre-trained diffusion model enriched with human motion priors. Additionally, to tackle unnatural deformations from low-poly single-mesh character modeling, we present a Hair Layering Modeling (HLM) technique that uses segmentation maps to separate hair from the body, allowing for more natural animation of long-haired characters. Extensive experiments show that our system outperforms state-of-the-art methods in both quantitative and qualitative evaluations.
手绘字符动画是计算机图形学中的一个充满生机的领域,它在实现几何一致性的同时,还面临着表达运动的挑战。传统骨骼动画方法能够保持几何一致性,但在处理流动头发和裙子等复杂的非刚性元素时却感到困难,导致变形不自然。相反,视频扩散模型能够合成逼真的动态图像,但由于领域差异,往往在风格化的绘画中产生几何失真。本文提出了一种结合骨骼动画和视频扩散的混合动画系统。首先,利用骨骼动画对角色进行重定向,生成粗略图像,以提供几何指导。然后,利用视频扩散先验增强这些图像的纹理和次要动力学,将这一增强过程视为一种填充任务。域适应扩散模型会精细化用户掩罩的区域,尤其是需要改进的次要动力学区域。为了进一步提高运动逼真度,我们在去噪过程中引入了一种次要动力学注入(SDI)策略,该策略结合了预训练扩散模型的人类运动先验特征。此外,为了解决低多边形单网格角色建模带来的不自然变形问题,我们提出了一种头发分层建模(HLM)技术,利用分割图将头发与身体分开,从而实现长发角色的更自然动画。大量实验表明,我们的系统在定量和定性评估上均优于最新技术。
论文及项目相关链接
摘要
该文介绍了一种结合骨骼动画和视频扩散模型的混合动画系统。该系统首先通过骨骼动画对角色进行几何指导生成粗图像,然后利用视频扩散先验增强纹理和次要动力学,将其视为修复任务。通过域适应扩散模型对用户需要改进的区域进行细化处理,尤其是次要动力学。为了进一步提高运动真实感,我们在去噪过程中引入了次要动力学注入(SDI)策略,利用预训练扩散模型融入人类运动先验的特征。此外,为了解决低多边形单网格角色建模带来的不自然变形问题,提出了一种头发分层建模(HLM)技术,利用分割图将头发与身体分离,使长发角色的动画更加自然。实验表明,该系统在定量和定性评估方面均优于现有先进技术。
关键见解
- 混合动画系统结合了骨骼动画和视频扩散模型,以实现几何一致性和表达性运动。
- 系统通过骨骼动画生成角色的粗图像,为动画提供几何指导。
- 利用视频扩散先验增强图像的纹理和次要动力学,将其表述为修复任务。
- 域适应扩散模型用于细化用户需要改进的区域,尤其是次要动力学方面的改进。
- 引入次要动力学注入(SDI)策略,提高运动真实感,结合预训练扩散模型和人类运动先验。
- 提出头发分层建模(HLM)技术,利用分割图改善长发角色的动画自然度。
- 实验结果显示,该系统在动画质量和现实性方面显著优于现有技术。
点此查看论文截图


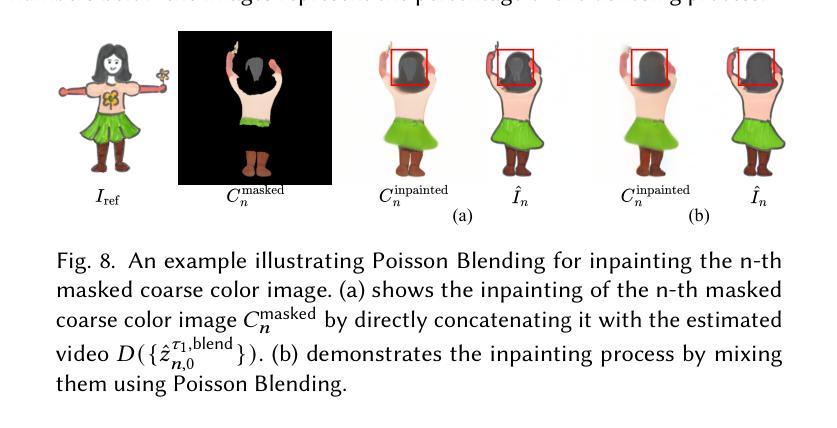
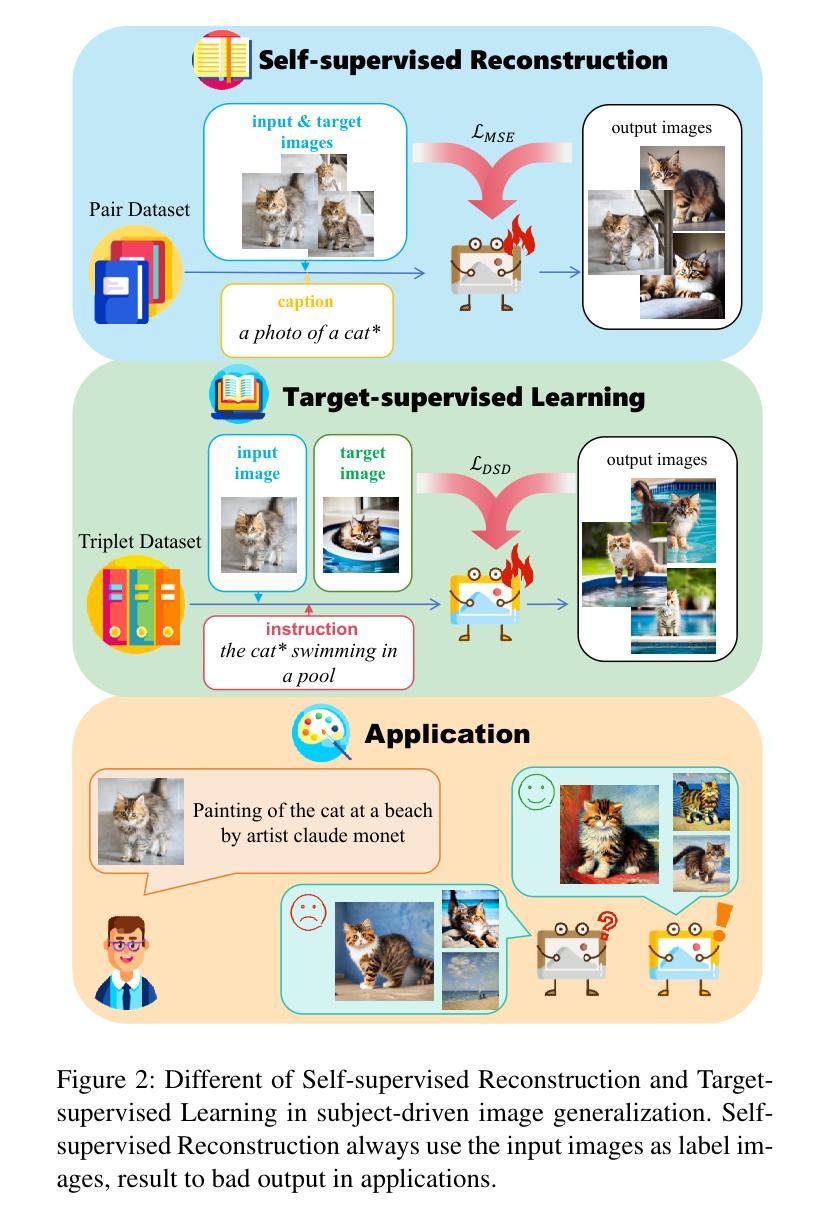
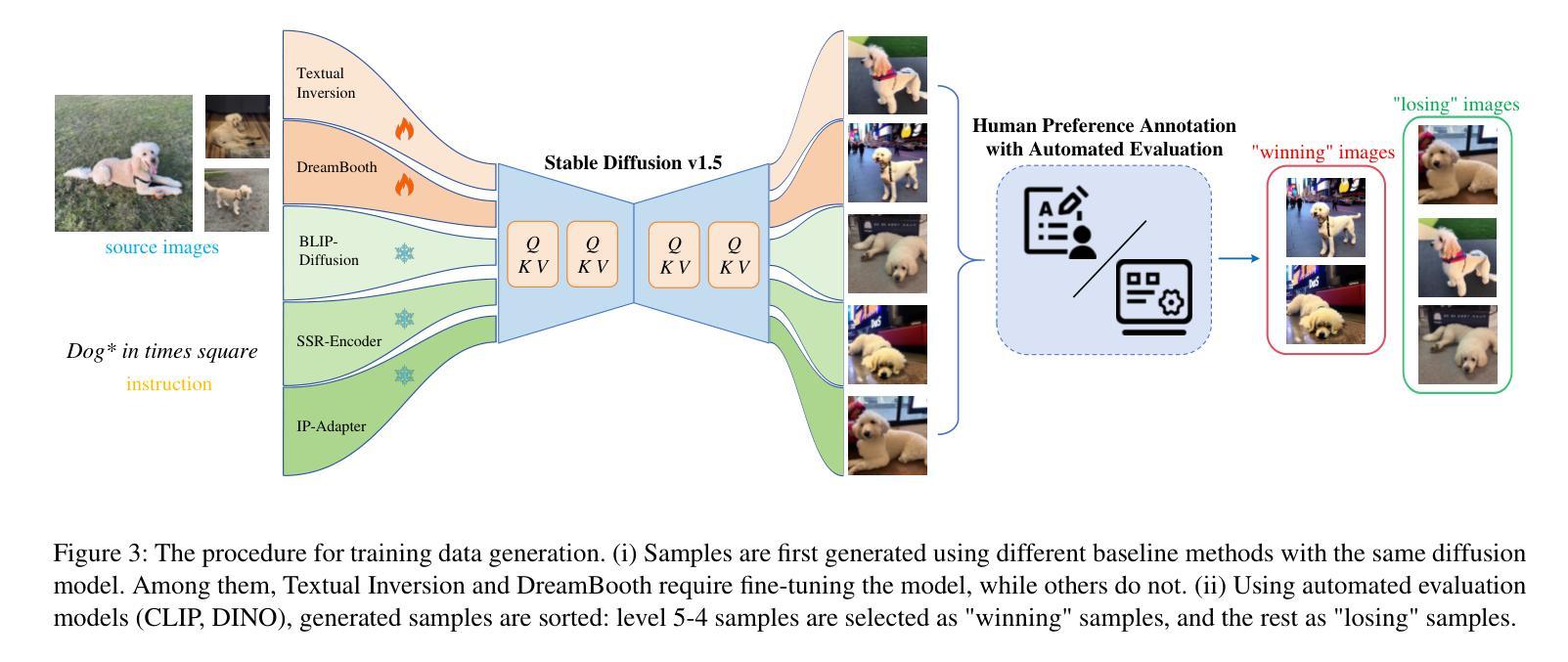
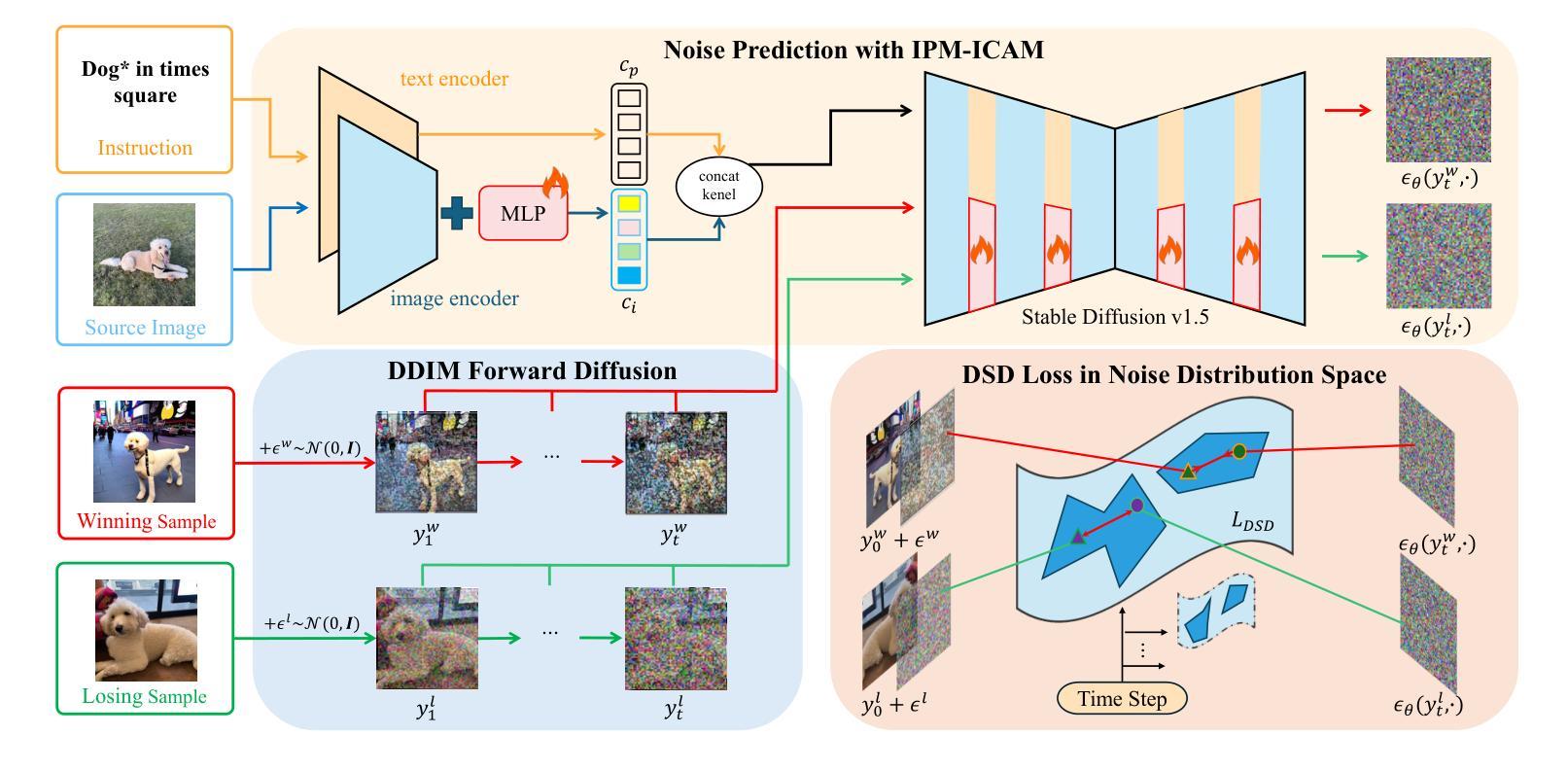
TIDE: Achieving Balanced Subject-Driven Image Generation via Target-Instructed Diffusion Enhancement
Authors:Jibai Lin, Bo Ma, Yating Yang, Rong Ma, Turghun Osman, Ahtamjan Ahmat, Rui Dong, Lei Wang, Xi Zhou
Subject-driven image generation (SDIG) aims to manipulate specific subjects within images while adhering to textual instructions, a task crucial for advancing text-to-image diffusion models. SDIG requires reconciling the tension between maintaining subject identity and complying with dynamic edit instructions, a challenge inadequately addressed by existing methods. In this paper, we introduce the Target-Instructed Diffusion Enhancing (TIDE) framework, which resolves this tension through target supervision and preference learning without test-time fine-tuning. TIDE pioneers target-supervised triplet alignment, modelling subject adaptation dynamics using a (reference image, instruction, target images) triplet. This approach leverages the Direct Subject Diffusion (DSD) objective, training the model with paired “winning” (balanced preservation-compliance) and “losing” (distorted) targets, systematically generated and evaluated via quantitative metrics. This enables implicit reward modelling for optimal preservation-compliance balance. Experimental results on standard benchmarks demonstrate TIDE’s superior performance in generating subject-faithful outputs while maintaining instruction compliance, outperforming baseline methods across multiple quantitative metrics. TIDE’s versatility is further evidenced by its successful application to diverse tasks, including structural-conditioned generation, image-to-image generation, and text-image interpolation. Our code is available at https://github.com/KomJay520/TIDE.
主题驱动图像生成(SDIG)旨在根据文本指令操作图像中的特定主题,这对于推进文本到图像的扩散模型至关重要。SDIG需要在保持主题身份和遵守动态编辑指令之间找到平衡,现有方法对此挑战解决不足。在本文中,我们引入了目标指令扩散增强(TIDE)框架,通过目标监督和偏好学习解决这一平衡问题,而无需进行测试时微调。TIDE首创目标监督三元组对齐,使用(参考图像、指令、目标图像)三元组对主题适应动态进行建模。该方法利用直接主题扩散(DSD)目标,用配对的“获胜”(平衡保留和合规性)和“失败”(失真)目标训练模型,这些目标通过定量指标系统生成并进行评估。这为实现最优保留合规平衡提供了隐式奖励建模。在标准基准测试上的实验结果表明,TIDE在生成忠实于主题的输出并保持指令合规方面表现出卓越性能,在多个定量指标上优于基线方法。TIDE的通用性进一步体现在其在结构条件生成、图像到图像生成和文本图像插值等多样化任务的成功应用上。我们的代码位于https://github.com/KomJay520/TIDE。
论文及项目相关链接
Summary
本文介绍了针对文本指令驱动图像生成的任务,提出了一种名为TIDE(目标指导扩散增强)的框架。该框架解决了在维持主题身份与遵循动态编辑指令之间的平衡问题,通过目标监督与偏好学习,无需测试时微调即可实现。TIDE采用目标监督的三重对准技术,使用(参考图像、指令、目标图像)三重结构来模拟主题适应动态。通过采用直接主题扩散(DSD)目标,训练模型以平衡保存和合规性的“获胜”和“失败”目标,并通过定量指标进行系统的生成与评估。实验结果证明TIDE在生成忠实于主题且符合指令的输出方面表现出卓越性能,且在多种定量指标上优于基准方法。TIDE的通用性还体现在其在结构条件生成、图像到图像生成、文本图像插值等任务的成功应用。
Key Takeaways
- TIDE框架解决了在文本指令驱动图像生成中维持主题身份与遵循动态编辑指令之间的平衡问题。
- TIDE采用目标监督的三重对准技术,实现主题适应动态的建模。
- 通过采用直接主题扩散(DSD)目标,训练模型以平衡保存和合规性。
- TIDE通过系统的生成与评估,采用定量指标来衡量模型性能。
- 实验结果证明TIDE在生成忠实于主题且符合指令的图像方面表现出卓越性能。
- TIDE在多种定量指标上优于其他基准方法,显示出其优越性。
点此查看论文截图


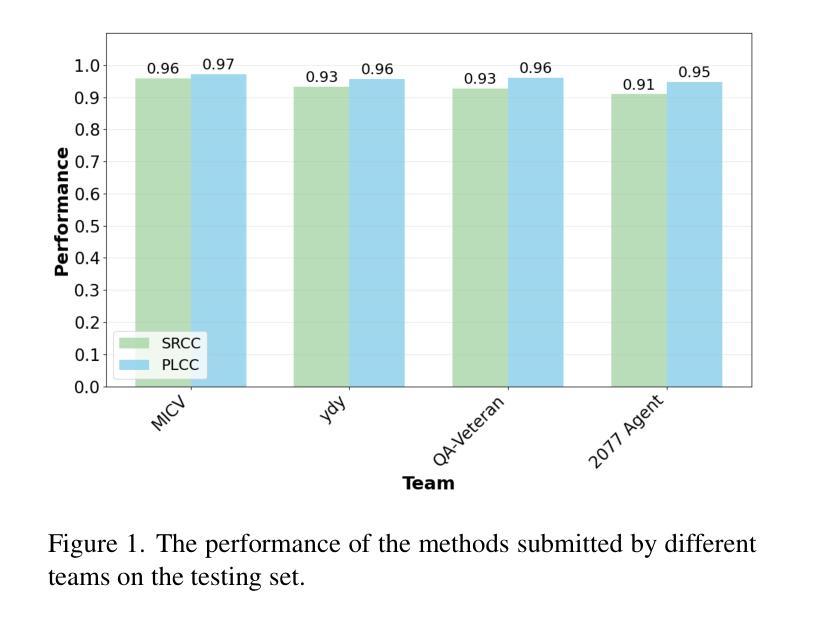
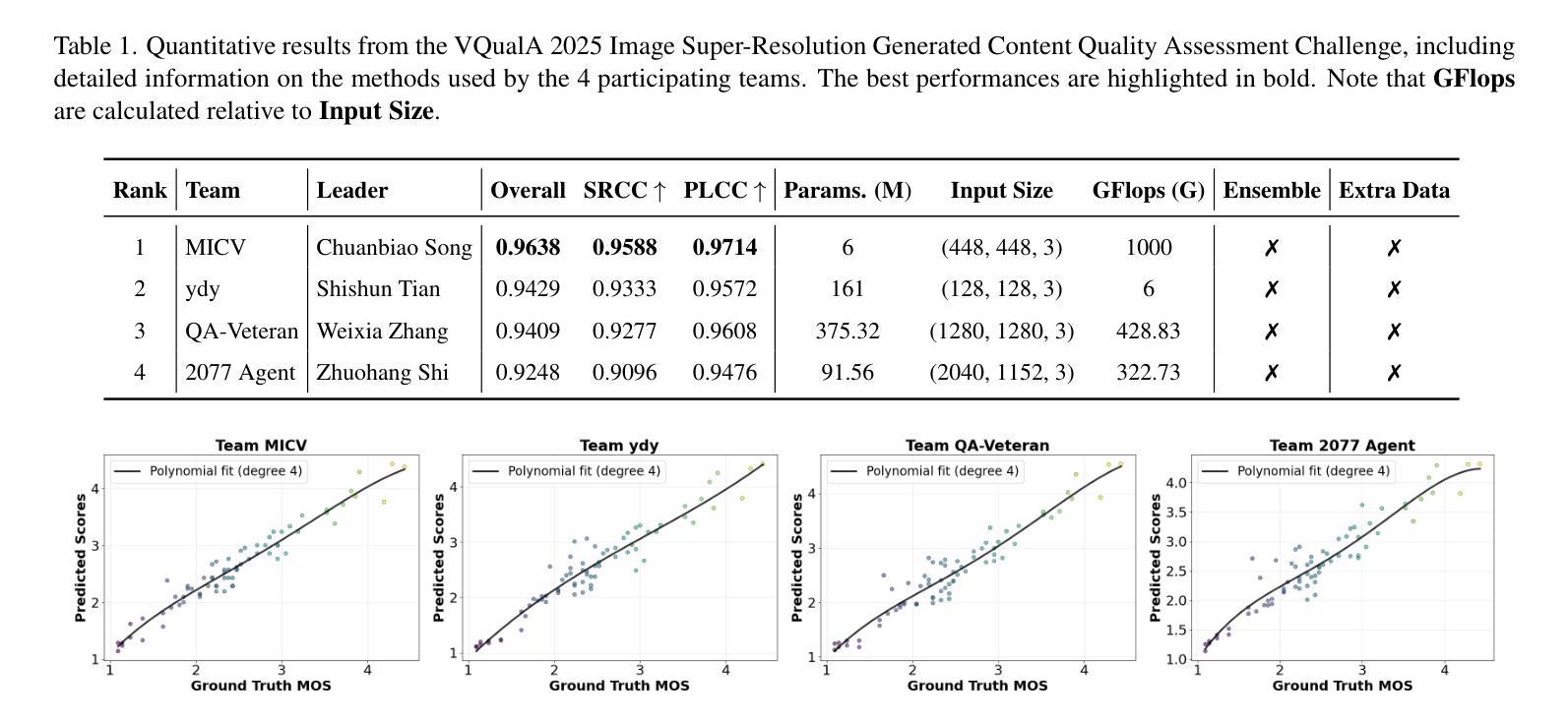
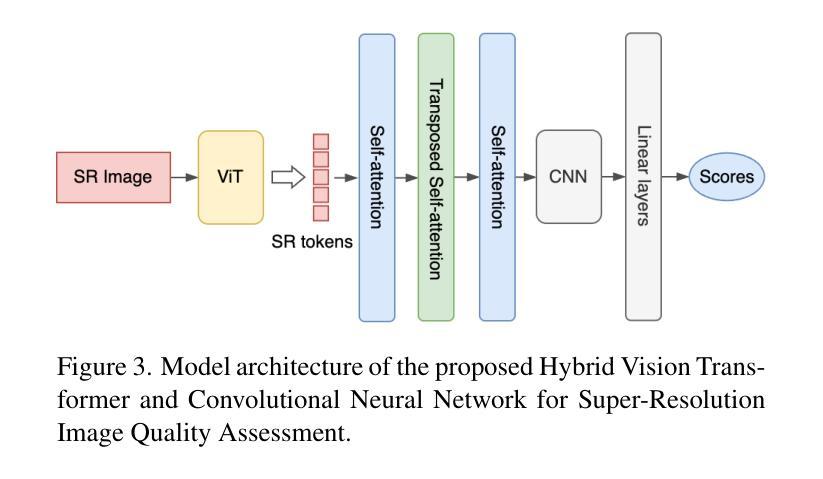
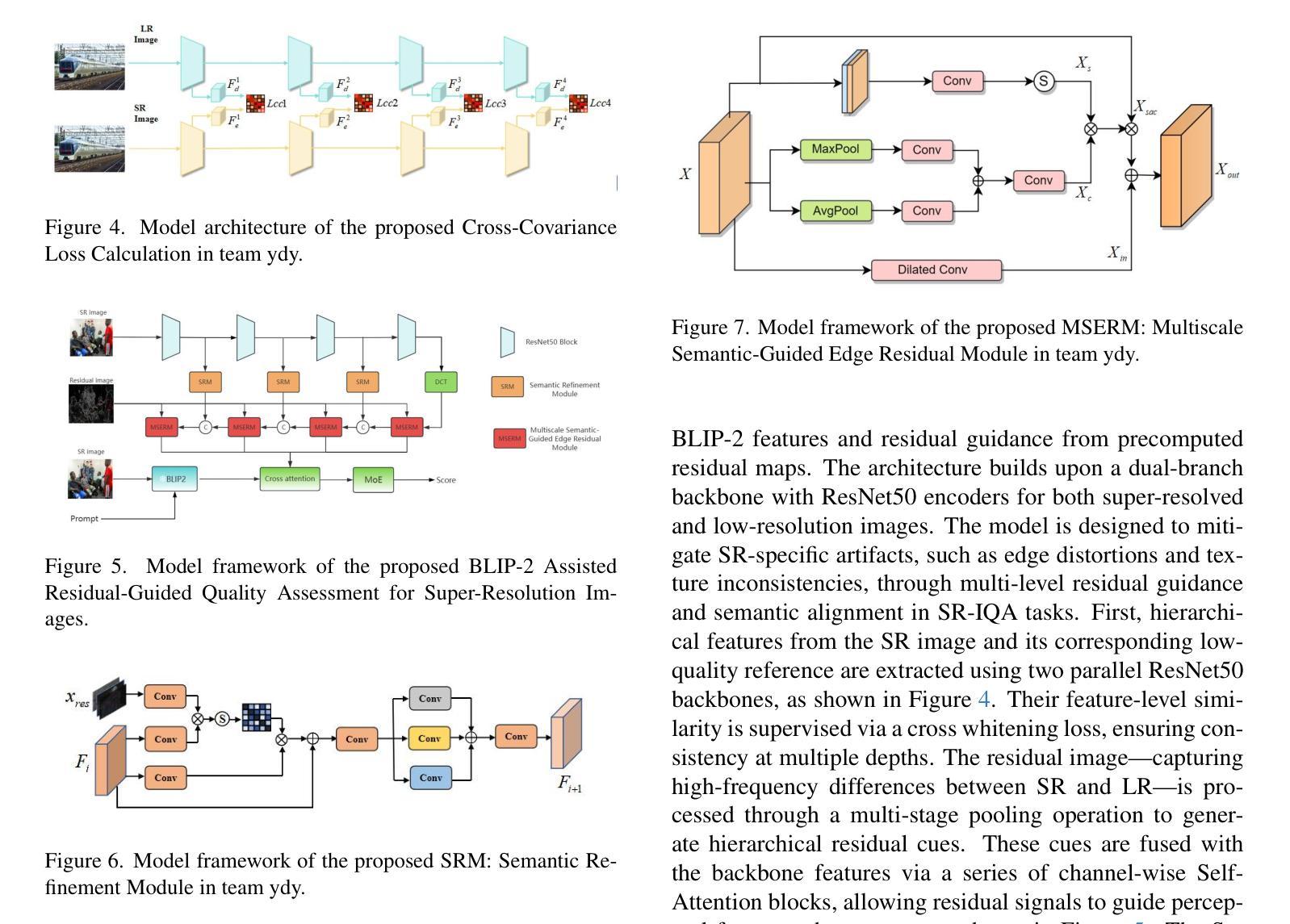
VQualA 2025 Challenge on Image Super-Resolution Generated Content Quality Assessment: Methods and Results
Authors:Yixiao Li, Xin Li, Chris Wei Zhou, Shuo Xing, Hadi Amirpour, Xiaoshuai Hao, Guanghui Yue, Baoquan Zhao, Weide Liu, Xiaoyuan Yang, Zhengzhong Tu, Xinyu Li, Chuanbiao Song, Chenqi Zhang, Jun Lan, Huijia Zhu, Weiqiang Wang, Xiaoyan Sun, Shishun Tian, Dongyang Yan, Weixia Zhang, Junlin Chen, Wei Sun, Zhihua Wang, Zhuohang Shi, Zhizun Luo, Hang Ouyang, Tianxin Xiao, Fan Yang, Zhaowang Wu, Kaixin Deng
This paper presents the ISRGC-Q Challenge, built upon the Image Super-Resolution Generated Content Quality Assessment (ISRGen-QA) dataset, and organized as part of the Visual Quality Assessment (VQualA) Competition at the ICCV 2025 Workshops. Unlike existing Super-Resolution Image Quality Assessment (SR-IQA) datasets, ISRGen-QA places a greater emphasis on SR images generated by the latest generative approaches, including Generative Adversarial Networks (GANs) and diffusion models. The primary goal of this challenge is to analyze the unique artifacts introduced by modern super-resolution techniques and to evaluate their perceptual quality effectively. A total of 108 participants registered for the challenge, with 4 teams submitting valid solutions and fact sheets for the final testing phase. These submissions demonstrated state-of-the-art (SOTA) performance on the ISRGen-QA dataset. The project is publicly available at: https://github.com/Lighting-YXLI/ISRGen-QA.
本文介绍了基于图像超分辨率生成内容质量评估(ISRGen-QA)数据集构建的ISRGC-Q挑战,该挑战作为ICCV 2025研讨会视觉质量评估(VQualA)竞赛的一部分而组织。与现有的超分辨率图像质量评估(SR-IQA)数据集不同,ISRGen-QA更侧重于由最新生成方法(包括生成对抗网络(GANs)和扩散模型)生成的SR图像。此挑战的主要目标是分析现代超分辨率技术引入的独特特征,并有效地评估其感知质量。共有108名参与者注册参加此次挑战,其中4支队伍为最终测试阶段提交了有效解决方案和情况介绍表。这些提交在ISRGen-QA数据集上展现了最新前沿的性能。该项目可在https://github.com/Lighting-YXLI/ISRGen-QA公开访问。
论文及项目相关链接
PDF 11 pages, 12 figures, VQualA ICCV Workshop
Summary
本文介绍了ISRGC-Q挑战,该挑战基于图像超分辨率生成内容质量评估(ISRGen-QA)数据集,作为ICCV 2025研讨会视觉质量评估(VQualA)竞赛的一部分。挑战的重点在于分析现代超分辨率技术引入的独特特征,并有效评估其感知质量。共有108支队伍报名参加,最终有4支队伍在测试阶段提交了有效解决方案和事实资料,展现了在ISRGen-QA数据集上的最新技术水平。项目公开可访问于:https://github.com/Lighting-YXLI/ISRGen-QA。
Key Takeaways
- ISRGC-Q挑战基于ISRGen-QA数据集构建,专注于现代生成技术(如GANs和扩散模型)生成的SR图像质量评估。
- 此挑战的主要目标是分析现代超分辨率技术的独特特征,并有效评估其感知质量。
- 一共有108支队伍注册参加了此挑战。
- 最终有4支队伍在测试阶段提交了有效解决方案和事实资料。
- 这些提交的方案在ISRGen-QA数据集上展现了最新技术水平。
- 该项目公开可访问,方便公众了解和使用。
点此查看论文截图

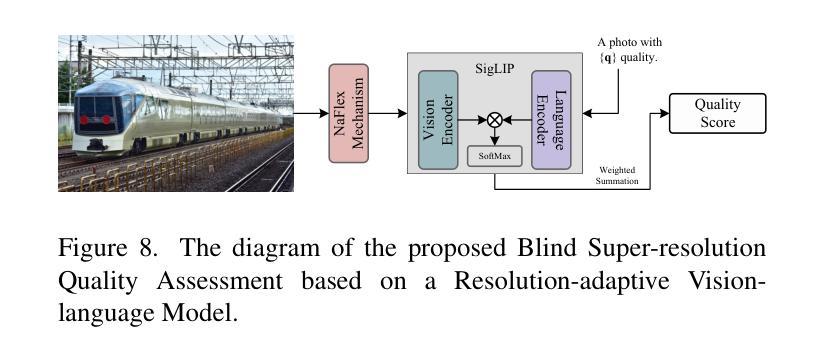
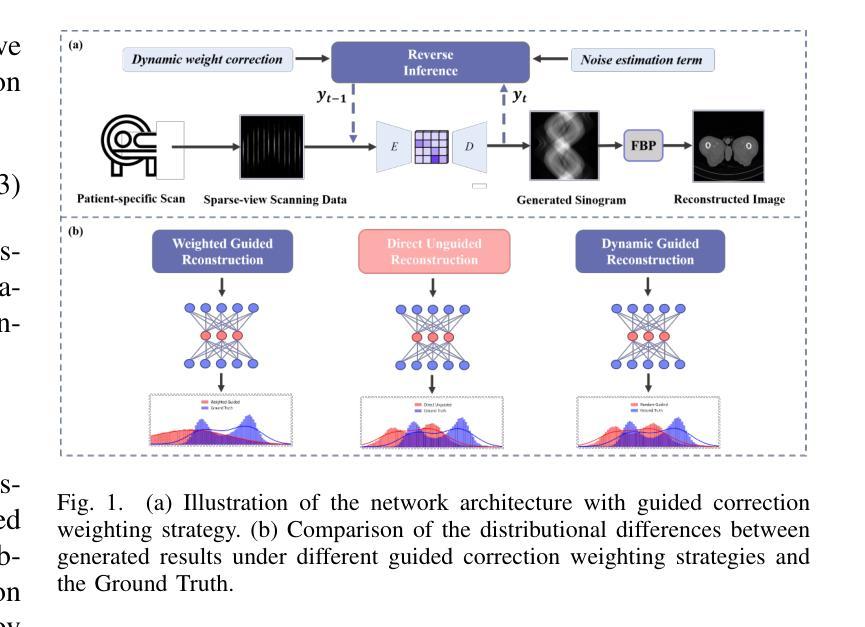
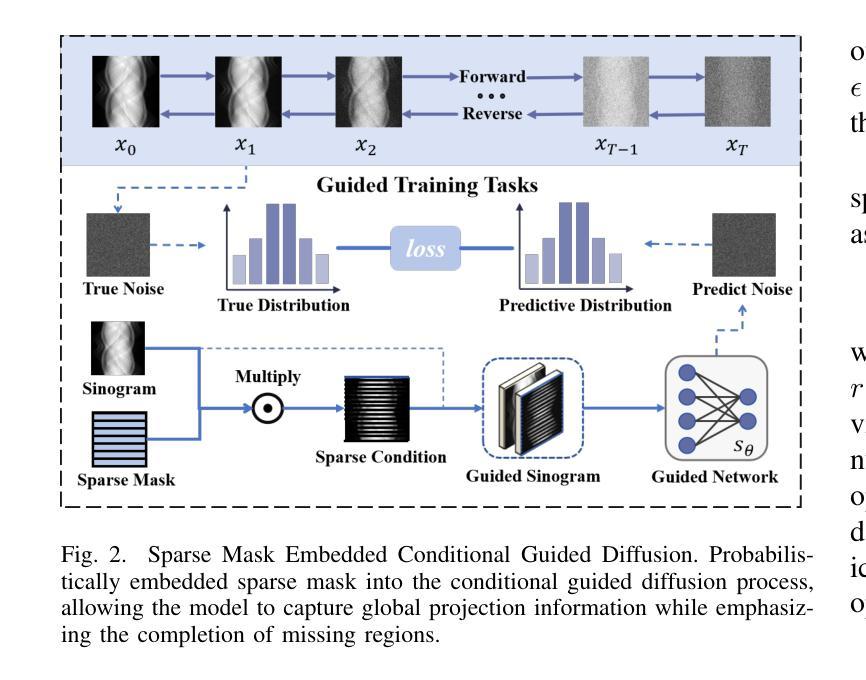
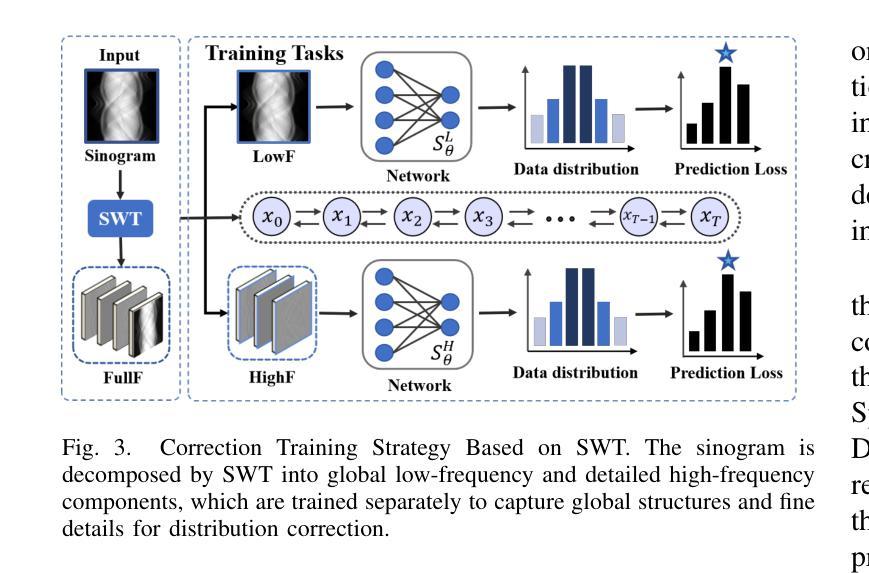
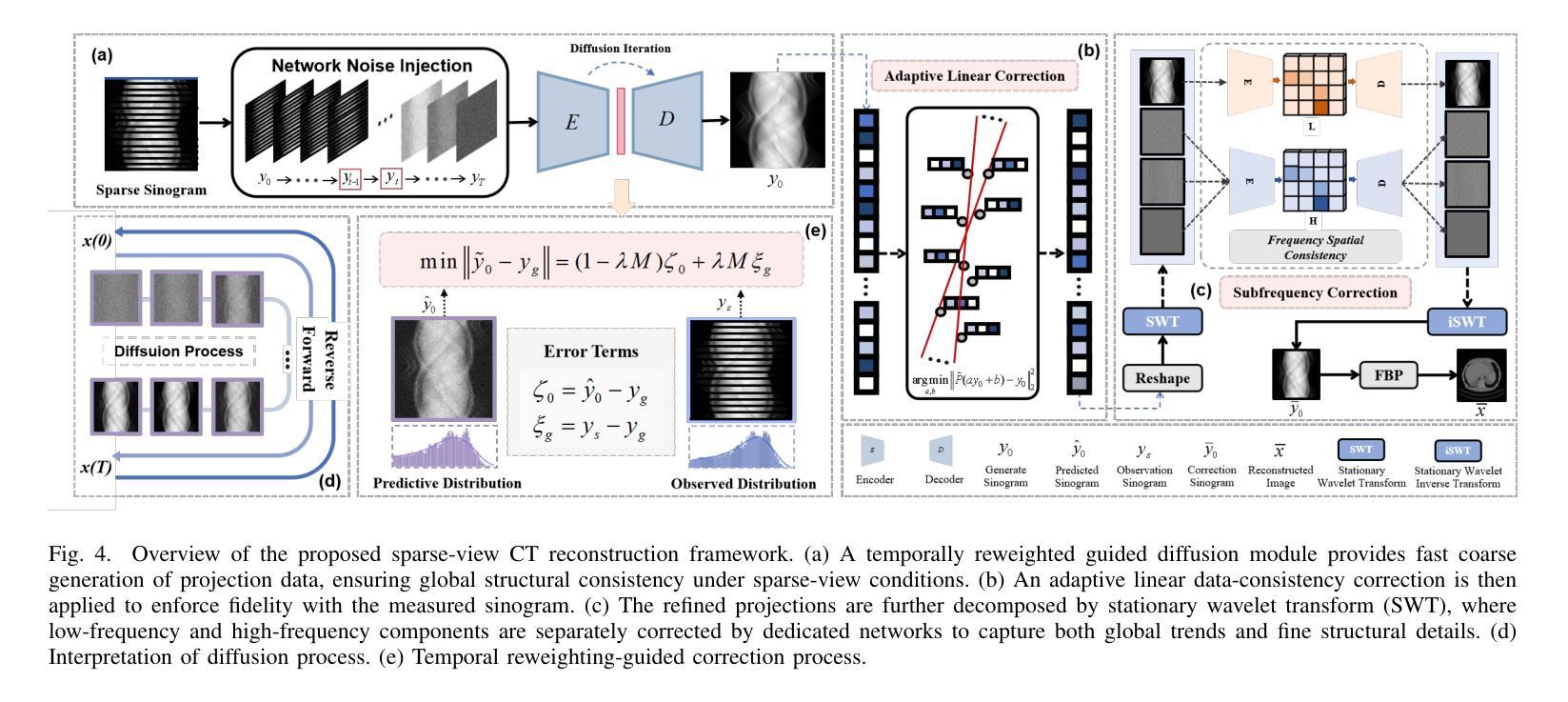
Multi-Strategy Guided Diffusion via Sparse Masking Temporal Reweighting Distribution Correction
Authors:Zekun Zhou, Yanru Gong, Liu Shi, Qiegen Liu
Diffusion models have demonstrated remarkable generative capabilities in image processing tasks. We propose a Sparse condition Temporal Rewighted Integrated Distribution Estimation guided diffusion model (STRIDE) for sparse-view CT reconstruction. Specifically, we design a joint training mechanism guided by sparse conditional probabilities to facilitate the model effective learning of missing projection view completion and global information modeling. Based on systematic theoretical analysis, we propose a temporally varying sparse condition reweighting guidance strategy to dynamically adjusts weights during the progressive denoising process from pure noise to the real image, enabling the model to progressively perceive sparse-view information. The linear regression is employed to correct distributional shifts between known and generated data, mitigating inconsistencies arising during the guidance process. Furthermore, we construct a dual-network parallel architecture to perform global correction and optimization across multiple sub-frequency components, thereby effectively improving the model capability in both detail restoration and structural preservation, ultimately achieving high-quality image reconstruction. Experimental results on both public and real datasets demonstrate that the proposed method achieves the best improvement of 2.58 dB in PSNR, increase of 2.37% in SSIM, and reduction of 0.236 in MSE compared to the best-performing baseline methods. The reconstructed images exhibit excellent generalization and robustness in terms of structural consistency, detail restoration, and artifact suppression.
扩散模型在图像处理任务中表现出了显著的生成能力。我们提出了一种用于稀疏视图CT重建的稀疏条件时间加权积分分布估计引导扩散模型(STRIDE)。具体来说,我们设计了一种由稀疏条件概率引导的联合训练机制,以促进模型有效地学习缺失投影视图补全和全局信息建模。基于系统的理论分析,我们提出了一种随时间变化 的稀疏条件重加权指导策略,在由纯噪声逐渐变为真实图像的渐进去噪过程中动态调整权重,使模型能够逐渐感知稀疏视图信息。采用线性回归校正已知数据和生成数据之间的分布偏移,减轻指导过程中产生的不一致性。此外,我们构建了一个双网络并行架构,以在多个子频率分量上执行全局校正和优化,从而有效地提高了模型在细节恢复和结构保持方面的能力,最终实现了高质量图像重建。在公共和真实数据集上的实验结果表表明,与表现最佳的基线方法相比,所提出的方法在PSNR上提高了2.58 dB,在SSIM上提高了2.37%,在MSE上降低了0.236。重建的图像在结构一致性、细节恢复和伪影抑制方面表现出良好的泛化能力和鲁棒性。
论文及项目相关链接
Summary
扩散模型在图像处理任务中展现出惊人的生成能力。本文提出一种用于稀疏视图CT重建的稀疏条件时间加权积分分布估计引导扩散模型(STRIDE)。通过设计联合训练机制和稀疏条件概率引导,模型能更有效地学习缺失投影视图补全和全局信息建模。提出动态调整权重的时间变化稀疏条件重加权引导策略,在从纯噪声到真实图像的渐进去噪过程中逐步感知稀疏视图信息。采用线性回归校正已知和生成数据之间的分布偏移,减轻指导过程中的不一致性。构建双网络并行架构,进行跨多个子频率组件的全局校正和优化,有效提高模型在细节恢复和结构保持方面的能力,实现高质量图像重建。实验结果表明,该方法在公开和真实数据集上均取得最佳效果,与最佳基线方法相比,PSNR提高2.58 dB,SSIM提高2.37%,MSE降低0.236。重建的图像在结构一致性、细节恢复和伪影抑制方面表现出优异的泛化和鲁棒性。
Key Takeaways
- 扩散模型在图像处理中表现出强大的生成能力。
- 提出了一种名为STRIDE的稀疏条件时间加权集成分布估计引导扩散模型,用于稀疏视图CT重建。
- 通过联合训练机制和稀疏条件概率引导设计,模型能学习缺失投影视图补全和全局信息建模。
- 提出时间变化的稀疏条件重加权策略,以在去噪过程中逐步感知稀疏视图信息。
- 采用线性回归校正数据分布偏移,减少指导过程中的不一致性。
- 构建双网络并行架构,提高模型在细节恢复和结构保持方面的能力。
- 实验结果表明,该方法在图像重建任务上取得了显著成果,包括PSNR、SSIM和MSE等指标的改善。
点此查看论文截图

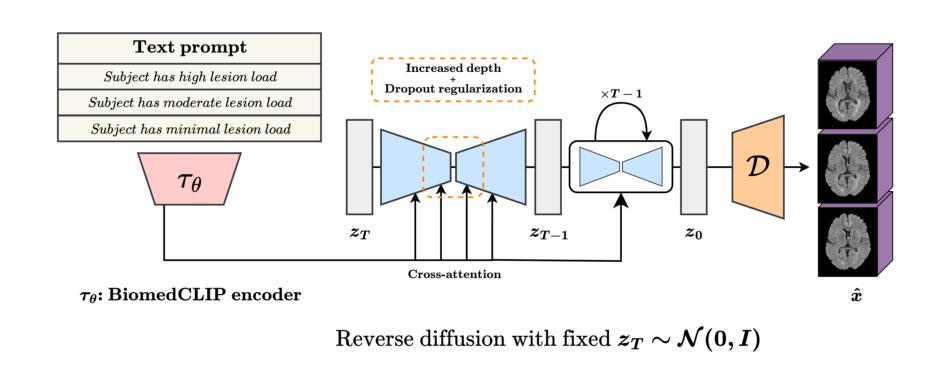
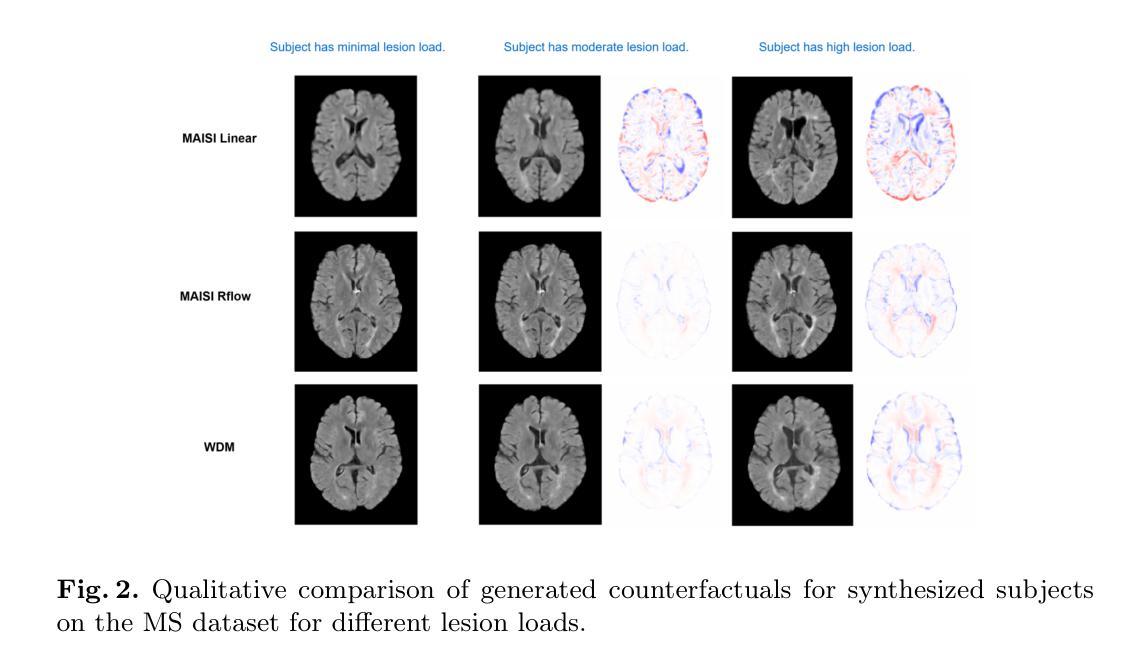
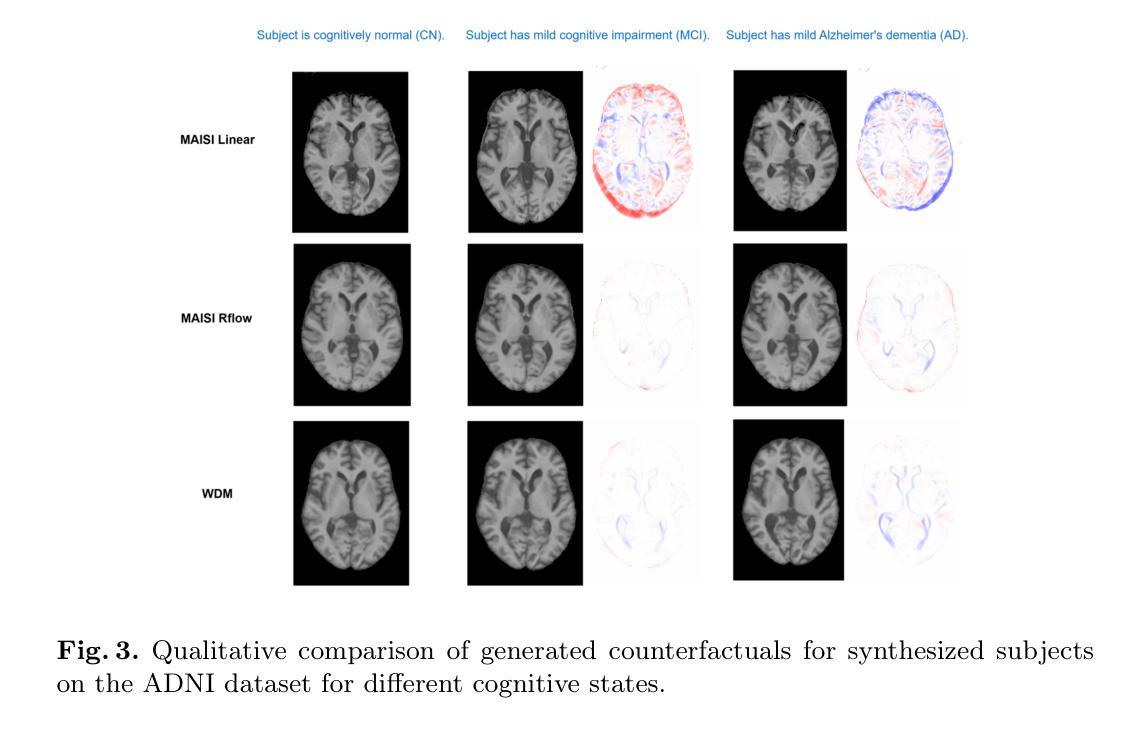
Imagining Alternatives: Towards High-Resolution 3D Counterfactual Medical Image Generation via Language Guidance
Authors:Mohamed Mohamed, Brennan Nichyporuk, Douglas L. Arnold, Tal Arbel
Vision-language models have demonstrated impressive capabilities in generating 2D images under various conditions; however the impressive performance of these models in 2D is largely enabled by extensive, readily available pretrained foundation models. Critically, comparable pretrained foundation models do not exist for 3D, significantly limiting progress in this domain. As a result, the potential of vision-language models to produce high-resolution 3D counterfactual medical images conditioned solely on natural language descriptions remains completely unexplored. Addressing this gap would enable powerful clinical and research applications, such as personalized counterfactual explanations, simulation of disease progression scenarios, and enhanced medical training by visualizing hypothetical medical conditions in realistic detail. Our work takes a meaningful step toward addressing this challenge by introducing a framework capable of generating high-resolution 3D counterfactual medical images of synthesized patients guided by free-form language prompts. We adapt state-of-the-art 3D diffusion models with enhancements from Simple Diffusion and incorporate augmented conditioning to improve text alignment and image quality. To our knowledge, this represents the first demonstration of a language-guided native-3D diffusion model applied specifically to neurological imaging data, where faithful three-dimensional modeling is essential to represent the brain’s three-dimensional structure. Through results on two distinct neurological MRI datasets, our framework successfully simulates varying counterfactual lesion loads in Multiple Sclerosis (MS), and cognitive states in Alzheimer’s disease, generating high-quality images while preserving subject fidelity in synthetically generated medical images. Our results lay the groundwork for prompt-driven disease progression analysis within 3D medical imaging.
视觉语言模型在各种条件下生成2D图像的能力令人印象深刻。然而,这些模型在2D方面的出色表现很大程度上是由于丰富且易于获取的预训练基础模型的支撑。关键的是,3D领域的预训练基础模型还不存在,这极大地限制了该领域的进展。因此,视觉语言模型在仅根据自然语言描述生成高分辨率的3D反事实医学图像方面的潜力尚未得到探索。填补这一空白将能够推动强大的临床和研究应用,如个性化反事实解释、疾病进展情景模拟以及通过详细可视化假设医学状况增强医学培训。我们的工作通过引入一个框架,该框架能够根据自由形式的语言提示生成由合成患者的高分辨率3D反事实医学图像指导的医学图像,朝着解决这一挑战迈出了有意义的一步。我们采用最先进的3D扩散模型,借助Simple Diffusion的增强功能并进行扩展,并增加附加条件来改善文本对齐和图像质量。据我们所知,这是首次将语言指导的本地3D扩散模型专门应用于神经成像数据,其中忠实的三维建模对于表示大脑的三维结构至关重要。通过两个不同的神经MRI数据集的结果,我们的框架成功模拟了多发性硬化症(MS)中的不同反事实病变负荷以及阿尔茨海默病中的认知状态,在生成高质量图像的同时保持合成医学图像的主体保真度。我们的研究结果奠定了基于提示的疾病进展分析在3D医学成像中的基础。
论文及项目相关链接
Summary
本文介绍了针对3D扩散模型的研究进展。由于缺少适用于3D的预训练基础模型,当前视觉语言模型在生成高质量3D图像方面存在局限。研究团队引入了一种框架,利用先进的3D扩散模型并结合增强条件技术,生成由自然语言提示引导的高质量3D医学图像。该研究成功应用于神经系统成像数据,可模拟多发性硬化症和阿尔茨海默病的虚构病变,生成高质量且保留患者特性的医学图像。这标志着为语言驱动的疾病进展分析在3D医学成像领域奠定了坚实基础。
Key Takeaways
- 当前视觉语言模型在生成高质量3D图像方面的局限性源于缺乏相应的预训练基础模型。
- 研究引入了首个专门针对神经系统成像数据的语言引导原生3D扩散模型框架。
- 该框架结合了增强条件技术,提高了文本对齐和图像质量。
- 成功应用于多发性硬化症和阿尔茨海默病的虚构病变模拟,生成高质量医学图像。
- 该研究为语言驱动的疾病进展分析在3D医学成像领域提供了坚实基础。
点此查看论文截图

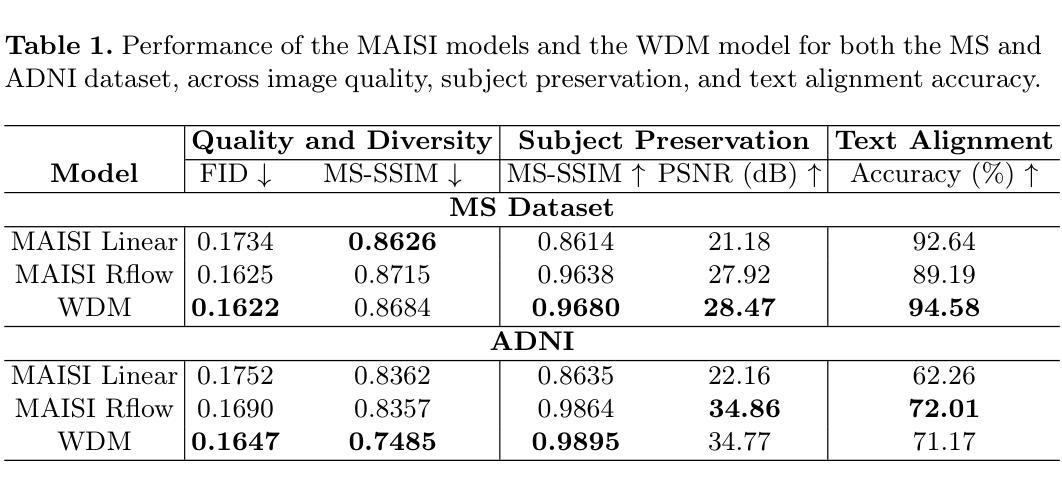
SuMa: A Subspace Mapping Approach for Robust and Effective Concept Erasure in Text-to-Image Diffusion Models
Authors:Kien Nguyen, Anh Tran, Cuong Pham
The rapid growth of text-to-image diffusion models has raised concerns about their potential misuse in generating harmful or unauthorized contents. To address these issues, several Concept Erasure methods have been proposed. However, most of them fail to achieve both robustness, i.e., the ability to robustly remove the target concept., and effectiveness, i.e., maintaining image quality. While few recent techniques successfully achieve these goals for NSFW concepts, none could handle narrow concepts such as copyrighted characters or celebrities. Erasing these narrow concepts is critical in addressing copyright and legal concerns. However, erasing them is challenging due to their close distances to non-target neighboring concepts, requiring finer-grained manipulation. In this paper, we introduce Subspace Mapping (SuMa), a novel method specifically designed to achieve both robustness and effectiveness in easing these narrow concepts. SuMa first derives a target subspace representing the concept to be erased and then neutralizes it by mapping it to a reference subspace that minimizes the distance between the two. This mapping ensures the target concept is robustly erased while preserving image quality. We conduct extensive experiments with SuMa across four tasks: subclass erasure, celebrity erasure, artistic style erasure, and instance erasure and compare the results with current state-of-the-art methods. Our method achieves image quality comparable to approaches focused on effectiveness, while also yielding results that are on par with methods targeting completeness.
文本到图像扩散模型的快速发展引发了人们对它们可能滥用生成有害或未经授权内容的关注。为了解决这些问题,已经提出了几种概念消除方法。然而,其中大多数方法无法达到稳健性和有效性的平衡,即同时消除目标概念并保持图像质量。虽然最近的一些技术成功地实现了对非安全内容概念的这些目标,但没有一种能够处理狭窄的概念,如版权角色或名人。消除这些狭窄的概念是解决版权和法律问题的关键。然而,由于它们与目标相邻概念的近距离,消除它们具有挑战性,需要更精细的操纵。在本文中,我们引入了子空间映射(SuMa),这是一种专门设计的方法,旨在实现稳健性和有效性,以解决这些狭窄概念的问题。SuMa首先推导出代表要消除概念的目标子空间,然后将其映射到参考子空间进行中和,以最小化两者之间的距离。这种映射确保目标概念被稳健地消除,同时保持图像质量。我们在四个任务上进行了广泛的SuMa实验,包括子类消除、名人消除、艺术风格消除和实例消除,并与当前最先进的方法比较了结果。我们的方法产生的图像质量与注重有效性的方法相当,同时与注重完整性的方法的结果持平。
论文及项目相关链接
Summary
本文关注文本转图像扩散模型的潜在滥用问题,特别是生成有害或未经授权内容的风险。针对此,提出了若干概念消除方法,但大多数方法无法在鲁棒性和有效性之间取得平衡。最新技术虽成功处理不适当内容的概念,但无法处理如版权角色或名人等细分概念。本文介绍了一种新的方法——子空间映射(SuMa),旨在同时实现鲁棒性和有效性,以消除这些细分概念。SuMa通过映射目标子空间和参考子空间来中和目标概念,确保稳健地消除目标概念,同时保持图像质量。
Key Takeaways
- 文本转图像扩散模型的快速增长引发了关于其潜在滥用的关注。
- 大多数概念消除方法无法在鲁棒性和有效性之间取得平衡。
- 最新技术成功处理不适当内容的概念,但无法处理版权角色或名人等细分概念。
- 子空间映射(SuMa)是一种新的方法,旨在同时实现鲁棒性和有效性。
- SuMa通过映射目标子空间和参考子空间来中和目标概念。
- SuMa能稳健地消除目标概念,同时保持图像质量。
点此查看论文截图


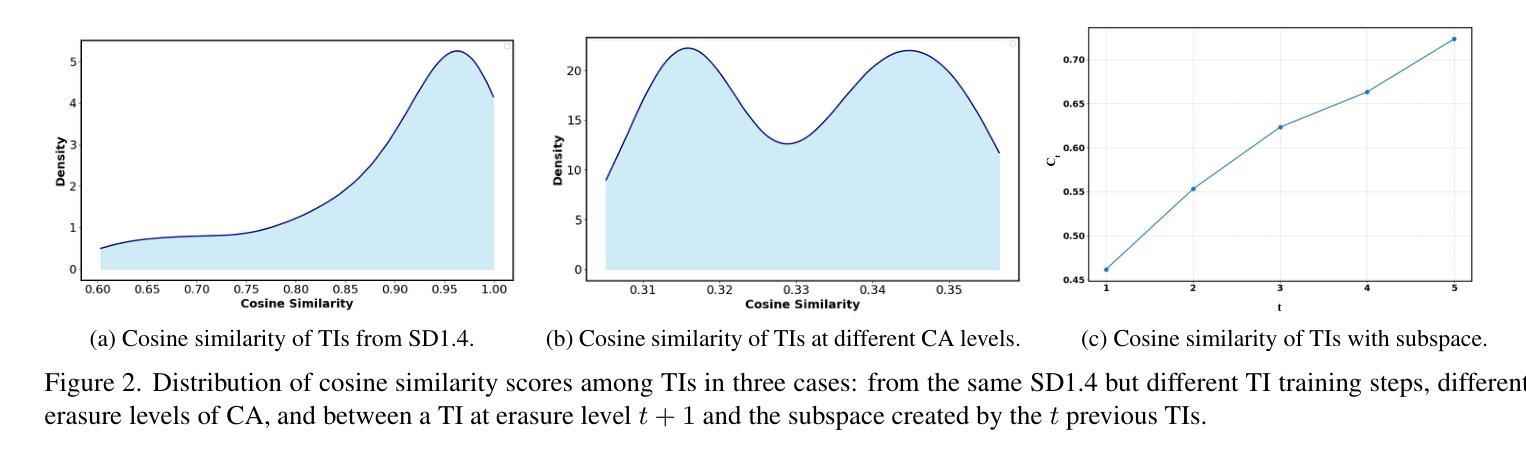
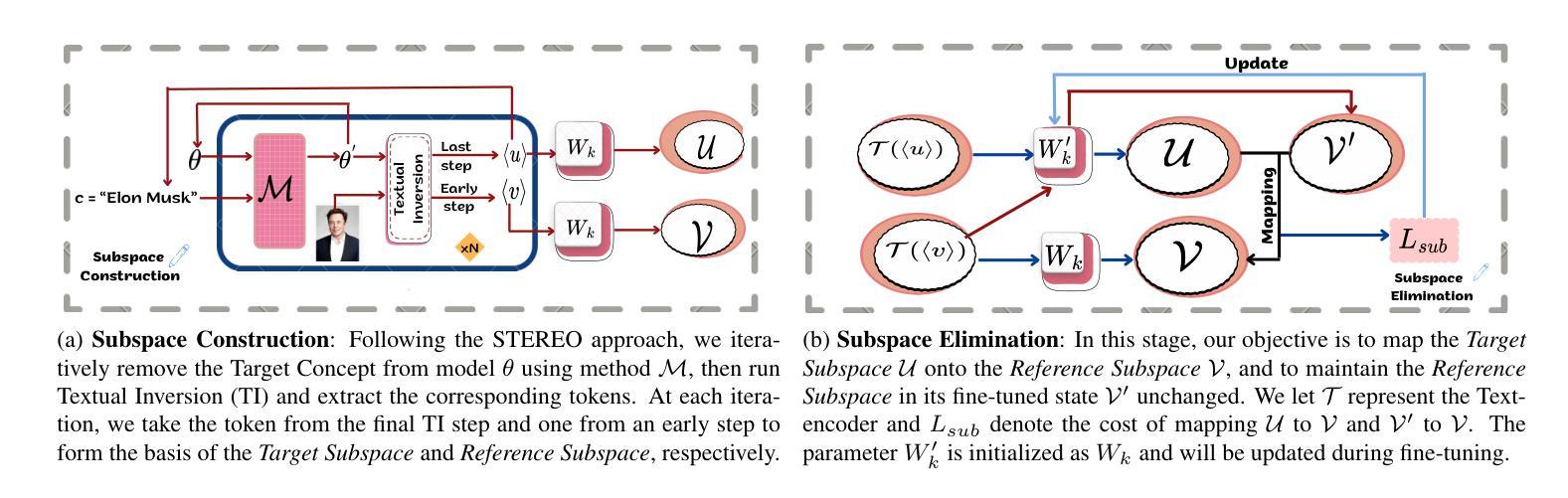
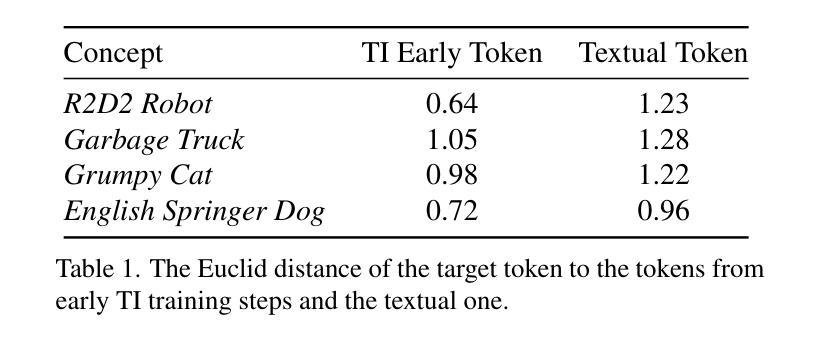

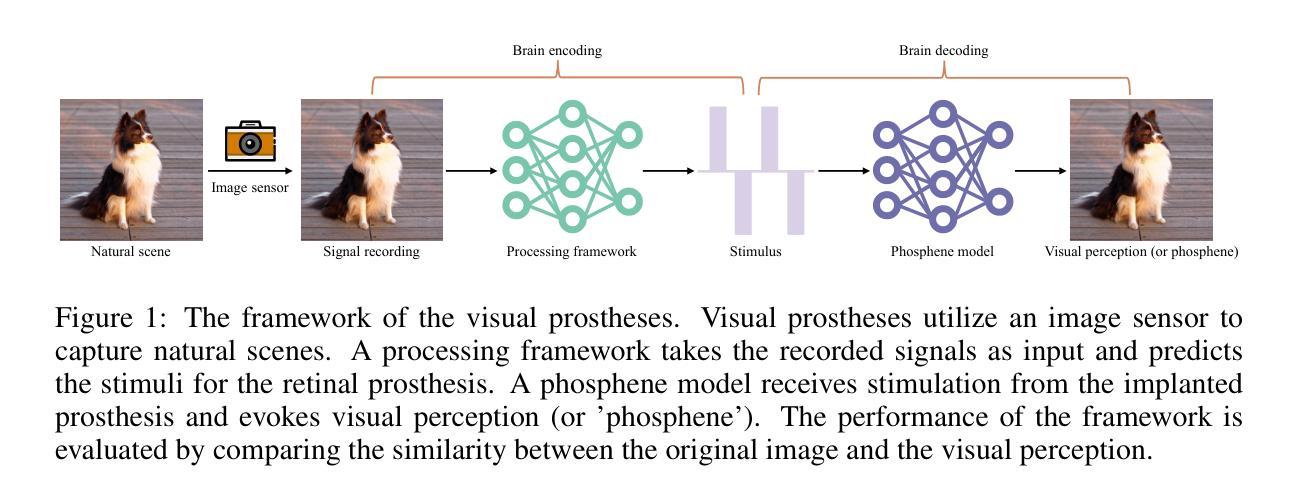
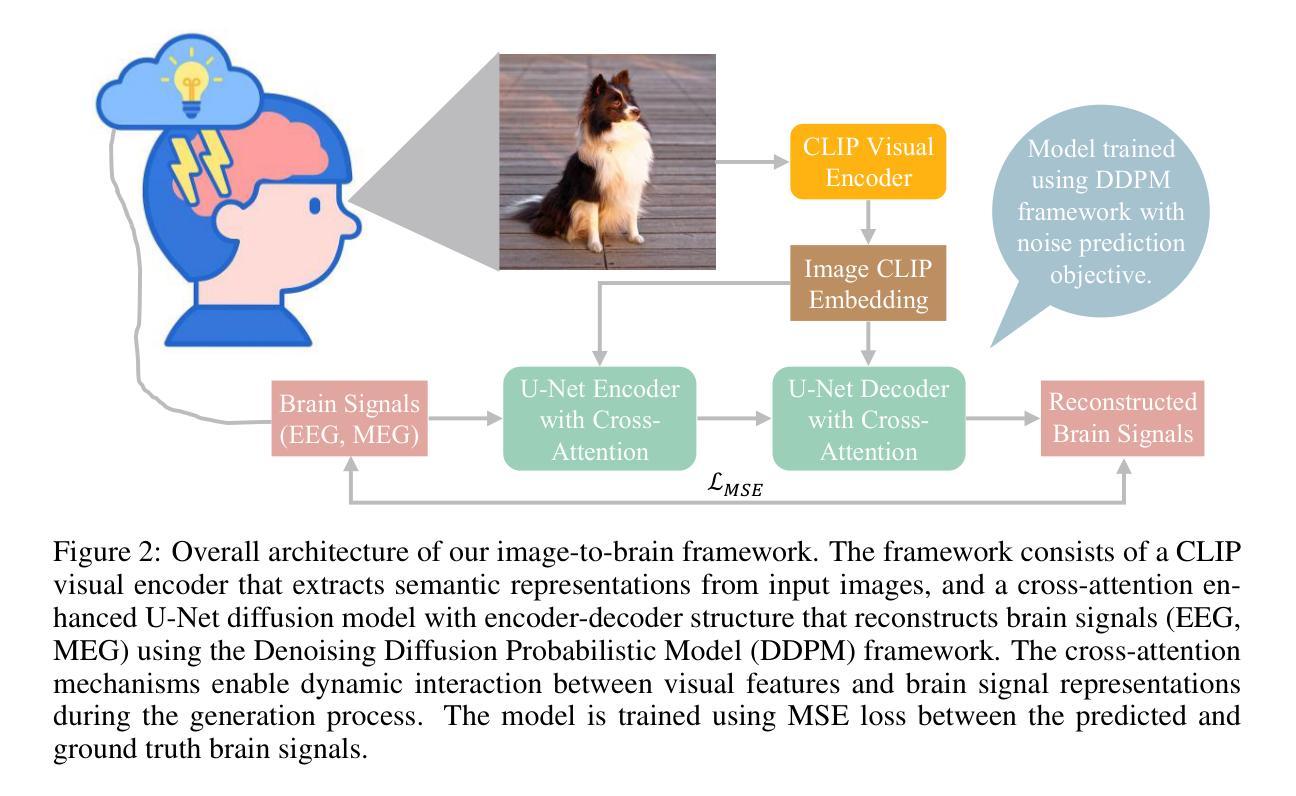
Diffusion-Based Image-to-Brain Signal Generation with Cross-Attention Mechanisms for Visual Prostheses
Authors:Ganxi Xu, Jinyi Long, Jia Zhang
Visual prostheses have shown great potential in restoring vision for blind individuals. However, while researchers have successfully utilized M/EEG signals to evoke visual perceptions during the brain decoding stage of visual prostheses, the complementary process-converting images to M/EEG signals in the brain encoding stage-remains largely unexplored. Thus, we present the first image-to-brain signal (M/EEG) framework based on denoising diffusion probabilistic models enhanced with cross-attention mechanisms. Our framework consists of two key architectural components: a pre-trained CLIP visual encoder that extracts rich semantic representations from input images, and a cross-attention enhanced U-Net diffusion model that learns to reconstruct biologically plausible brain signals through iterative denoising. Unlike conventional generative models that rely on simple concatenation for conditioning, our cross-attention modules enable dynamic interaction between visual features and brain signal representations, facilitating fine-grained alignment during the generation process. Furthermore, we evaluate our framework on two multimodal datasets (THINGS-EEG2 and THINGS-MEG) to demonstrate its effectiveness in generating biologically plausible brain signals. Additionally, we pioneer the visualization of M/EEG topographies across all subjects in both datasets, providing intuitive demonstrations of intra-subject and inter-subject variations in brain signals.
视觉假体在恢复盲人的视觉方面已显示出巨大潜力。虽然研究者已成功利用脑电图(M/EEG)信号在视觉假体的脑解码阶段诱发视觉感知,但互补过程——将图像转换为大脑编码阶段的M/EEG信号——仍大多未被探索。因此,我们首次提出了基于去噪扩散概率模型的图像到脑信号(M/EEG)框架,并借助跨注意力机制进行了增强。我们的框架包含两个主要组成部分:预训练的CLIP视觉编码器,用于从输入图像中提取丰富的语义表示;以及采用跨注意力增强的U-Net扩散模型,学习通过迭代去噪重建生物学上合理的脑信号。不同于依赖简单拼接进行条件设定的传统生成模型,我们的跨注意力模块实现了视觉特征和脑信号表示之间的动态交互,有助于生成过程中的精细对齐。此外,我们在两个多模式数据集(THINGS-EEG2和THINGS-MEG)上评估了我们的框架,以证明其在生成生物学上合理的脑信号方面的有效性。我们还率先在这两个数据集的所有受试者中展示脑电图(M/EEG)地形图,为脑信号的受试者内部和受试者之间的差异提供了直观演示。
论文及项目相关链接
Summary
本文介绍了视觉假体的潜力及其在恢复盲人视觉方面的应用。针对视觉假体在大脑解码阶段的成功应用,提出在大脑编码阶段将图像转换为M/EEG信号的过程尚未得到充分探索。因此,本文提出了基于去噪扩散概率模型与交叉注意力机制的首个图像到脑信号(M/EEG)框架。该框架包含两个关键组件:预训练的CLIP视觉编码器和增强交叉注意力的U-Net扩散模型。前者从输入图像中提取丰富的语义表示,后者学习通过迭代去噪重建生物合理的脑信号。通过交叉注意力模块实现视觉特征和脑信号表示之间的动态交互,促进生成过程中的精细对齐。在两个多模式数据集(THINGS-EEG2和THINGS-MEG)上评估了该框架生成生物合理脑信号的有效性,并率先可视化M/EEG地形图,提供直观展示不同受试者间的脑信号差异。
Key Takeaways
- 视觉假体的研究具有巨大的潜力,特别是在恢复盲人的视觉方面。
- 虽然研究者已经成功利用M/EEG信号在视觉假体的解码阶段激发视觉感知,但编码阶段的图像到M/EEG信号的转换过程尚未得到充分研究。
- 提出首个基于去噪扩散概率模型和交叉注意力机制的图像到脑信号(M/EEG)框架。
- 框架包含预训练的CLIP视觉编码器和增强交叉注意力的U-Net扩散模型两个关键组件。
- CLIP视觉编码器可以从输入图像中提取丰富的语义表示。
- 增强交叉注意力的U-Net扩散模型学习通过迭代去噪重建生物合理的脑信号。
点此查看论文截图

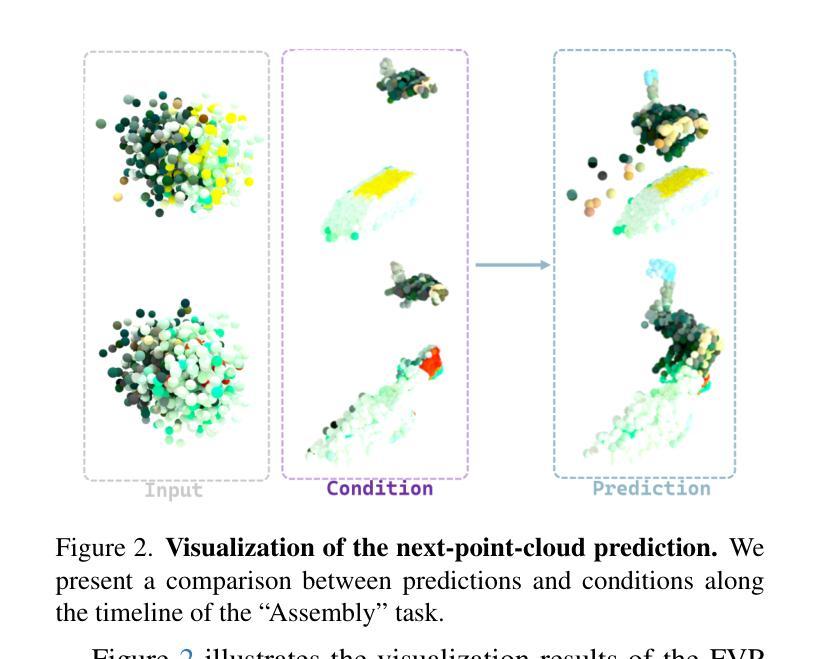
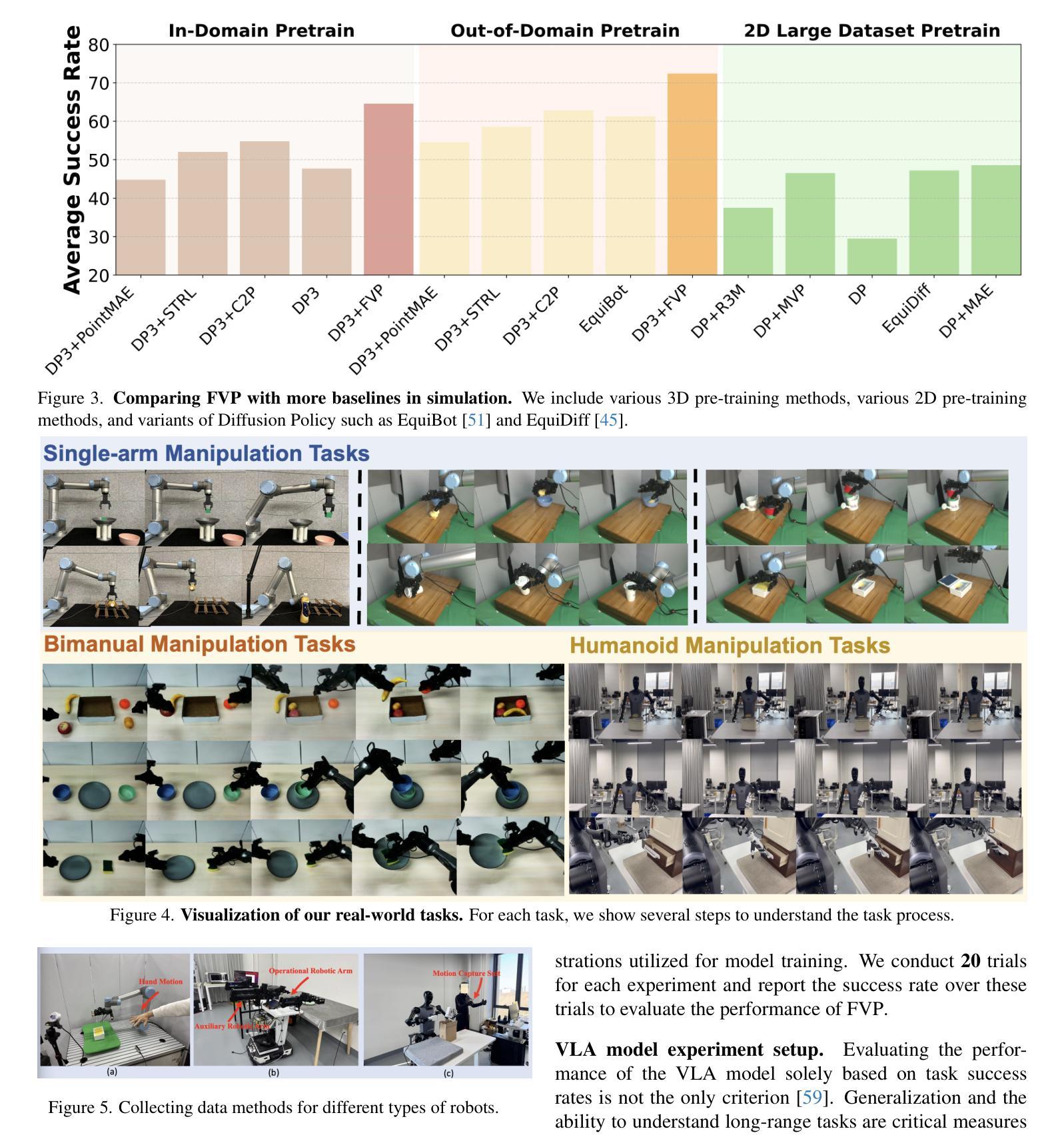
4D Visual Pre-training for Robot Learning
Authors:Chengkai Hou, Yanjie Ze, Yankai Fu, Zeyu Gao, Songbo Hu, Yue Yu, Shanghang Zhang, Huazhe Xu
General visual representations learned from web-scale datasets for robotics have achieved great success in recent years, enabling data-efficient robot learning on manipulation tasks; yet these pre-trained representations are mostly on 2D images, neglecting the inherent 3D nature of the world. However, due to the scarcity of large-scale 3D data, it is still hard to extract a universal 3D representation from web datasets. Instead, we are seeking a general visual pre-training framework that could improve all 3D representations as an alternative. Our framework, called FVP, is a novel 4D Visual Pre-training framework for real-world robot learning. FVP frames the visual pre-training objective as a next-point-cloud-prediction problem, models the prediction model as a diffusion model, and pre-trains the model on the larger public datasets directly. Across twelve real-world manipulation tasks, FVP boosts the average success rate of 3D Diffusion Policy (DP3) for these tasks by 28%. The FVP pre-trained DP3 achieves state-of-the-art performance across imitation learning methods. Moreover, the efficacy of FVP adapts across various point cloud encoders and datasets. Finally, we apply FVP to the RDT-1B, a larger Vision-Language-Action robotic model, enhancing its performance on various robot tasks. Our project page is available at: https://4d-visual-pretraining.github.io/
从网络规模数据集学习到的通用视觉表示在机器人领域的操作任务上近年来取得了巨大的成功,使得数据高效的机器人学习成为可能;然而,这些预训练的表示主要基于二维图像,忽略了世界本身的三维特性。然而,由于大规模三维数据的稀缺,从网络数据集中提取通用三维表示仍然很困难。因此,我们正在寻找一种能够改进所有三维表示的通用视觉预训练框架作为替代方案。我们的框架称为FVP,这是一个用于现实世界机器人学习的新型四维视觉预训练框架。FVP将视觉预训练目标设定为下一个点云预测问题,将预测模型建模为扩散模型,并在更大的公共数据集上直接进行模型预训练。在十二个现实世界的操作任务中,FVP将3D扩散策略(DP3)的平均成功率提高了28%。FVP预训练的DP3在模仿学习方法中达到了最先进的性能。此外,FVP的有效性适用于各种点云编码器和数据集。最后,我们将FVP应用于更大的视觉语言行动机器人模型RDT-1B,提高了其在各种机器人任务上的性能。我们的项目页面可访问于:https://4d-visual-pretraining.github.io/
论文及项目相关链接
Summary
近年来,从网页规模数据集学习到的通用视觉表示在机器人执行任务上取得了巨大成功,但大多数预训练表示侧重于2D图像,忽略了世界的固有3D性质。针对从网页数据集提取通用3D表示的挑战,我们提出了FVP(四维视觉预训练框架),作为一种改进所有3D表示的通用视觉预训练框架。FVP将视觉预训练目标设定为下一个点云预测问题,将预测模型建模为扩散模型,并在更大的公共数据集上直接进行预训练。在十二个真实世界操作任务中,FVP提高了3D扩散策略(DP3)的平均成功率28%,且在模仿学习方法中达到最佳性能。此外,FVP在多种点云编码器和数据集上的效果良好。最后,我们将FVP应用于更大的Vision-Language-Action机器人模型RDT-1B,提高了其在各种机器人任务上的性能。
Key Takeaways
- 通用视觉表示在机器人执行任务上取得巨大成功,但大多数预训练表示局限于2D图像,忽略了世界的3D性质。
- 提出FVP框架,一个用于改进所有3D表示的通用视觉预训练框架。
- FVP将视觉预训练目标设定为下一个点云预测问题,并采用扩散模型进行预测。
- FVP在十二个真实世界操作任务中提高了3D扩散策略(DP3)的平均成功率28%。
- FVP在模仿学习方法中达到最佳性能。
- FVP适用于多种点云编码器和数据集。
点此查看论文截图

SGDFuse: SAM-Guided Diffusion for High-Fidelity Infrared and Visible Image Fusion
Authors:Xiaoyang Zhang, Zhen Hua, Yakun Ju, Wei Zhou, Jun Liu, Alex C. Kot
Infrared and visible image fusion (IVIF) aims to combine the thermal radiation information from infrared images with the rich texture details from visible images to enhance perceptual capabilities for downstream visual tasks. However, existing methods often fail to preserve key targets due to a lack of deep semantic understanding of the scene, while the fusion process itself can also introduce artifacts and detail loss, severely compromising both image quality and task performance. To address these issues, this paper proposes SGDFuse, a conditional diffusion model guided by the Segment Anything Model (SAM), to achieve high-fidelity and semantically-aware image fusion. The core of our method is to utilize high-quality semantic masks generated by SAM as explicit priors to guide the optimization of the fusion process via a conditional diffusion model. Specifically, the framework operates in a two-stage process: it first performs a preliminary fusion of multi-modal features, and then utilizes the semantic masks from SAM jointly with the preliminary fused image as a condition to drive the diffusion model’s coarse-to-fine denoising generation. This ensures the fusion process not only has explicit semantic directionality but also guarantees the high fidelity of the final result. Extensive experiments demonstrate that SGDFuse achieves state-of-the-art performance in both subjective and objective evaluations, as well as in its adaptability to downstream tasks, providing a powerful solution to the core challenges in image fusion. The code of SGDFuse is available at https://github.com/boshizhang123/SGDFuse.
红外与可见光图像融合(IVIF)旨在将红外图像中的热辐射信息与可见光图像中的丰富纹理细节相结合,以提高下游视觉任务的感知能力。然而,现有方法往往由于缺乏场景的深度语义理解而无法保留关键目标,同时融合过程本身也可能引入伪影和细节损失,严重损害图像质量和任务性能。为了解决这些问题,本文提出了SGDFuse,一个由Segment Anything Model(SAM)引导的条件扩散模型,实现高保真和语义感知的图像融合。我们的方法的核心是利用SAM生成的高质量语义掩膜作为显式先验,通过条件扩散模型引导融合过程的优化。具体来说,该框架分为两个阶段:首先进行多模态特征的初步融合,然后利用SAM的语义掩膜与初步融合图像一起作为条件,驱动扩散模型的从粗到细的降噪生成。这确保了融合过程不仅具有明确的语义方向性,而且还保证了最终结果的高保真度。大量实验表明,SGDFuse在主观和客观评估以及适应下游任务方面均达到最佳性能,为解决图像融合的核心挑战提供了强大的解决方案。SGDFuse的代码可在[https://github.com/boshizhang123/SGDFuse获取。]
论文及项目相关链接
PDF Submitted to Information Fusion
Summary
本论文提出SGDFuse方法,利用Segment Anything Model(SAM)生成的语义掩膜作为先验知识,指导融合过程的优化,实现高质量和语义感知的图像融合。该方法通过两阶段操作,初步融合多模态特征,然后使用语义掩膜与初步融合图像作为条件,驱动扩散模型的从粗到细的降噪生成。确保融合过程具有明确的语义方向性并保证了最终结果的保真度。
Key Takeaways
- 红外和可见光图像融合(IVIF)结合了红外图像的热辐射信息与可见图像的丰富纹理细节,提高下游视觉任务感知能力。
- 现有方法缺乏深度语义理解,难以保留关键目标,融合过程可能引入伪影和细节损失。
- SGDFuse方法利用SAM生成的语义掩膜作为先验知识,指导融合过程的优化。
- SGDFuse采用两阶段操作,初步融合多模态特征,然后使用语义掩膜与初步融合图像作为条件,驱动扩散模型的降噪生成。
- SGDFuse确保了融合过程的语义方向性和结果的高保真度。
- 实验表明SGDFuse在主观和客观评估以及下游任务适应性方面达到最佳性能。
点此查看论文截图



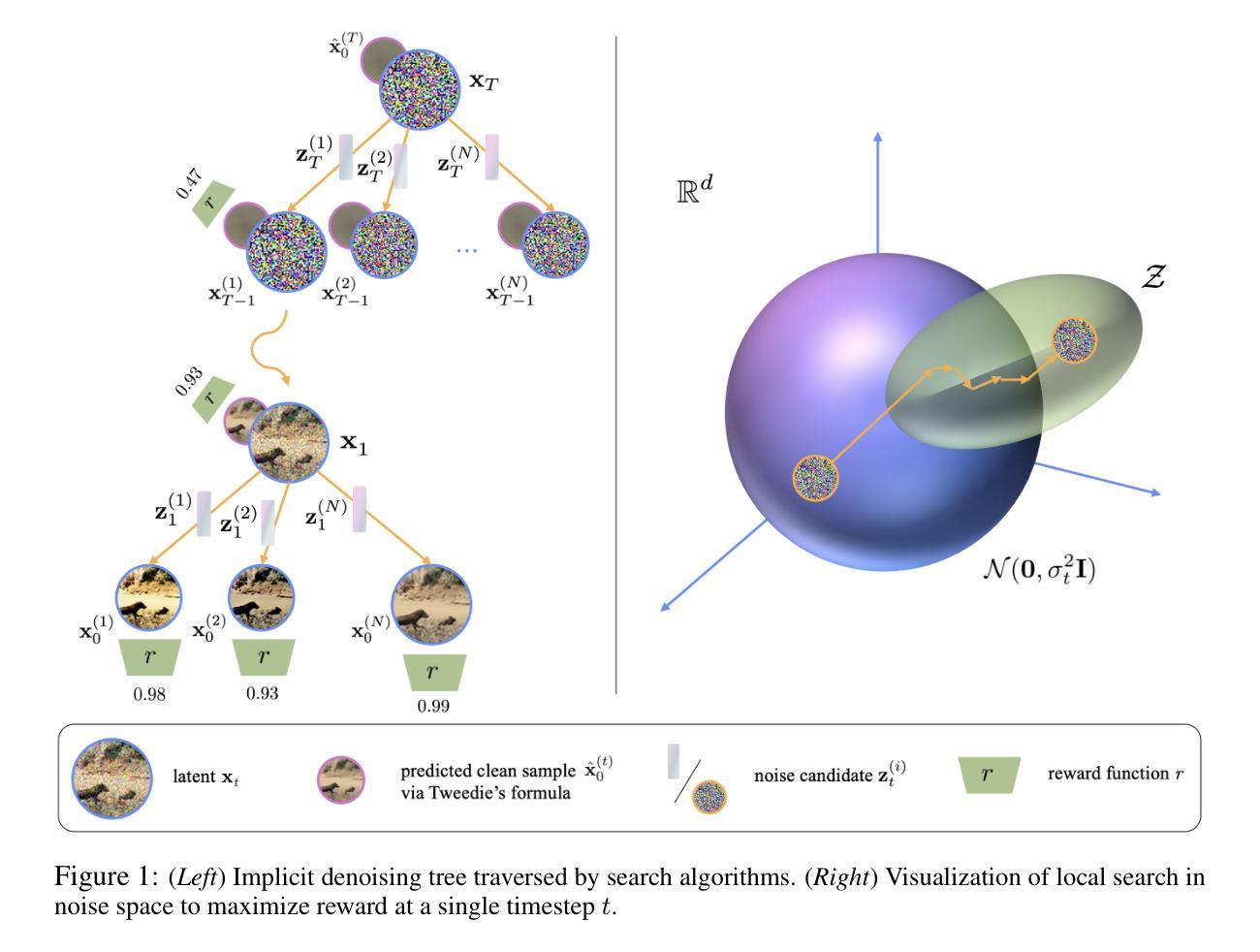
Test-Time Scaling of Diffusion Models via Noise Trajectory Search
Authors:Vignav Ramesh, Morteza Mardani
The iterative and stochastic nature of diffusion models enables test-time scaling, whereby spending additional compute during denoising generates higher-fidelity samples. Increasing the number of denoising steps is the primary scaling axis, but this yields quickly diminishing returns. Instead optimizing the noise trajectory–the sequence of injected noise vectors–is promising, as the specific noise realizations critically affect sample quality; but this is challenging due to a high-dimensional search space, complex noise-outcome interactions, and costly trajectory evaluations. We address this by first casting diffusion as a Markov Decision Process (MDP) with a terminal reward, showing tree-search methods such as Monte Carlo tree search (MCTS) to be meaningful but impractical. To balance performance and efficiency, we then resort to a relaxation of MDP, where we view denoising as a sequence of independent contextual bandits. This allows us to introduce an $\epsilon$-greedy search algorithm that globally explores at extreme timesteps and locally exploits during the intermediate steps where de-mixing occurs. Experiments on EDM and Stable Diffusion reveal state-of-the-art scores for class-conditioned/text-to-image generation, exceeding baselines by up to $164%$ and matching/exceeding MCTS performance. To our knowledge, this is the first practical method for test-time noise trajectory optimization of arbitrary (non-differentiable) rewards.
扩散模型的迭代性和随机性使其能够实现测试时缩放,即在去噪过程中花费额外的计算资源会产生更高保真度的样本。增加去噪步骤的数量是主要缩放轴,但这样做产生的回报迅速减少。优化噪声轨迹——注入的噪声向量的序列——是有前途的,因为特定的噪声实现严重影响样本质量;然而,由于高维搜索空间、复杂的噪声结果交互和昂贵的轨迹评估,这使得面临挑战。我们通过首先将扩散转化为具有终端奖励的马尔可夫决策过程(MDP)来解决这个问题,并展示树搜索方法(如蒙特卡洛树搜索(MCTS))虽然有意义但不实用。为了平衡性能和效率,我们转而采取对MDP的放松方法,将去噪视为一系列独立的上下文bandit。这允许我们引入一种ε贪婪搜索算法,在极端时间步长时进行全局探索,在发生解混的中间步骤中进行局部利用。在EDM和Stable Diffusion上的实验显示,在类别条件/文本到图像生成方面达到了最新水平,超过基线最多达164%,并匹配或超过MCTS的性能。据我们所知,这是测试时针对任意(不可微分)奖励进行噪声轨迹优化的第一种实用方法。
论文及项目相关链接
Summary
扩散模型的迭代性和随机性使得测试时缩放成为可能,通过增加去噪过程中的计算量可以生成更高保真度的样本。本文主要探讨了通过优化噪声轨迹来提高样本质量的方法,但由于搜索空间高维、噪声与结果互动复杂、轨迹评估成本高昂,这一任务极具挑战性。本研究将扩散过程转化为马尔可夫决策过程,并引入ε贪婪搜索算法,在全局和局部之间取得平衡,实现性能与效率的优化。实验结果显示,该方法在类条件/文本到图像生成任务上达到领先水平,超越基线最多达164%,并匹配或超越蒙特卡洛树搜索的性能。这是首次实现测试时针对任意(不可微)奖励的噪声轨迹优化的实用方法。
Key Takeaways
- 扩散模型的测试时缩放通过增加去噪步骤提高样本保真度,但收益递减。
- 噪声轨迹优化是提高样本质量的关键,但面临高维搜索空间、复杂互动和评估成本高的挑战。
- 将扩散过程转化为马尔可夫决策过程(MDP)有意义但不太实用。
- 通过将去噪视为一系列独立上下文相关的问题,引入ε贪婪搜索算法在全局和局部之间取得平衡。
- 实验结果表明,该方法在类条件/文本到图像生成任务上表现优异,超越现有基线。
- 该方法是首次实现测试时针对任意(不可微)奖励的噪声轨迹优化的实用方法。
点此查看论文截图

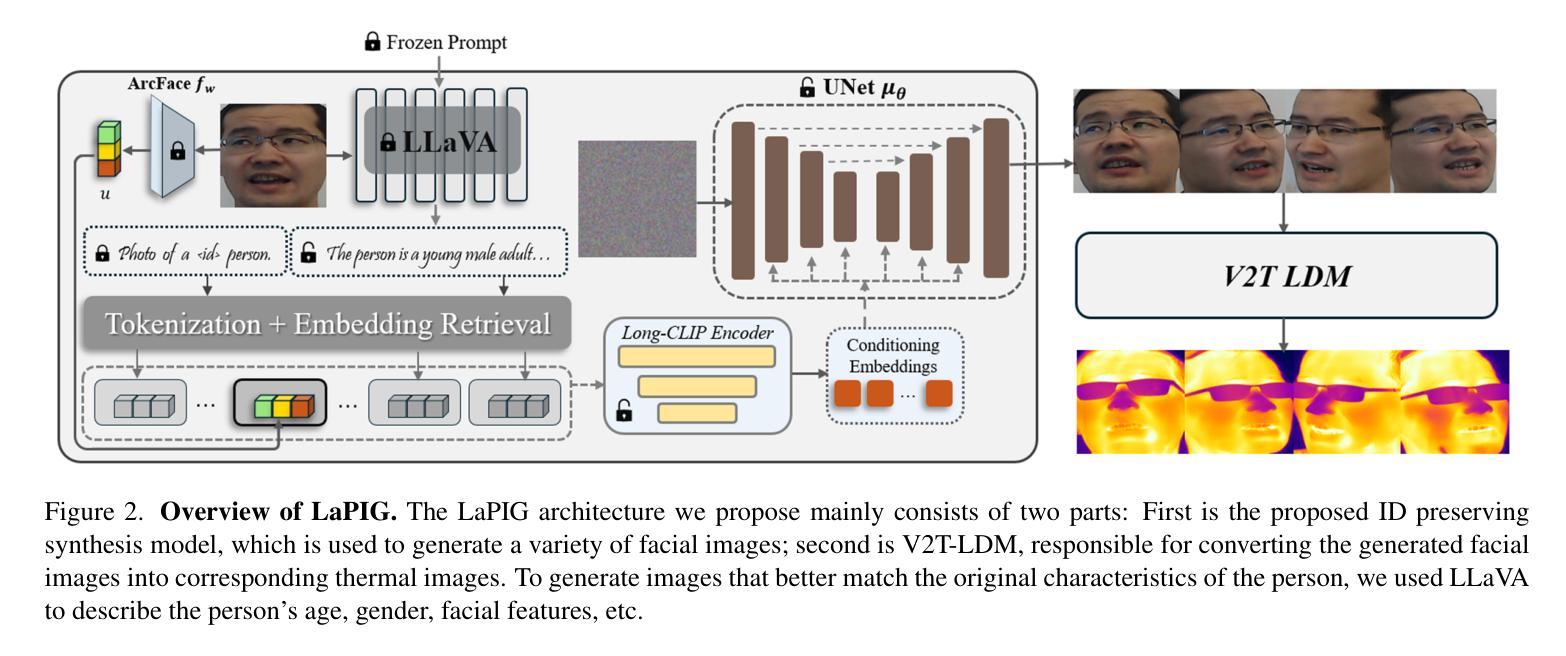
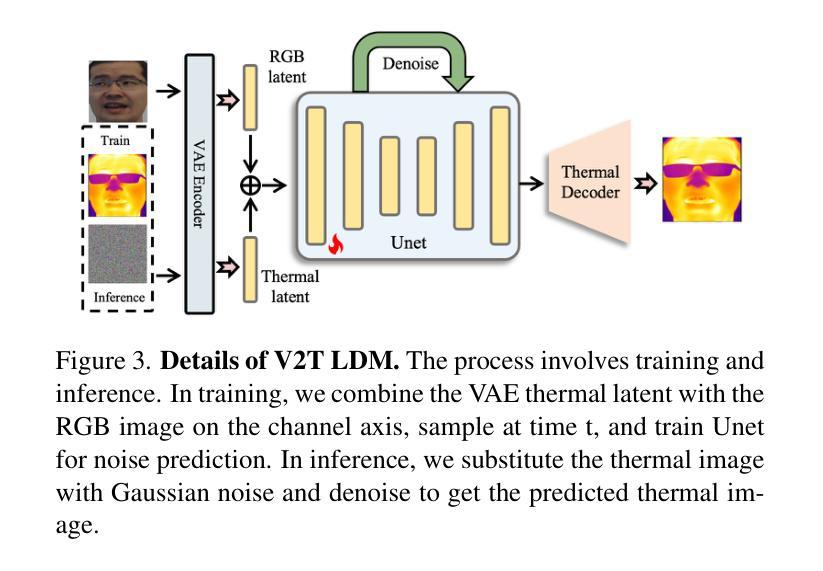
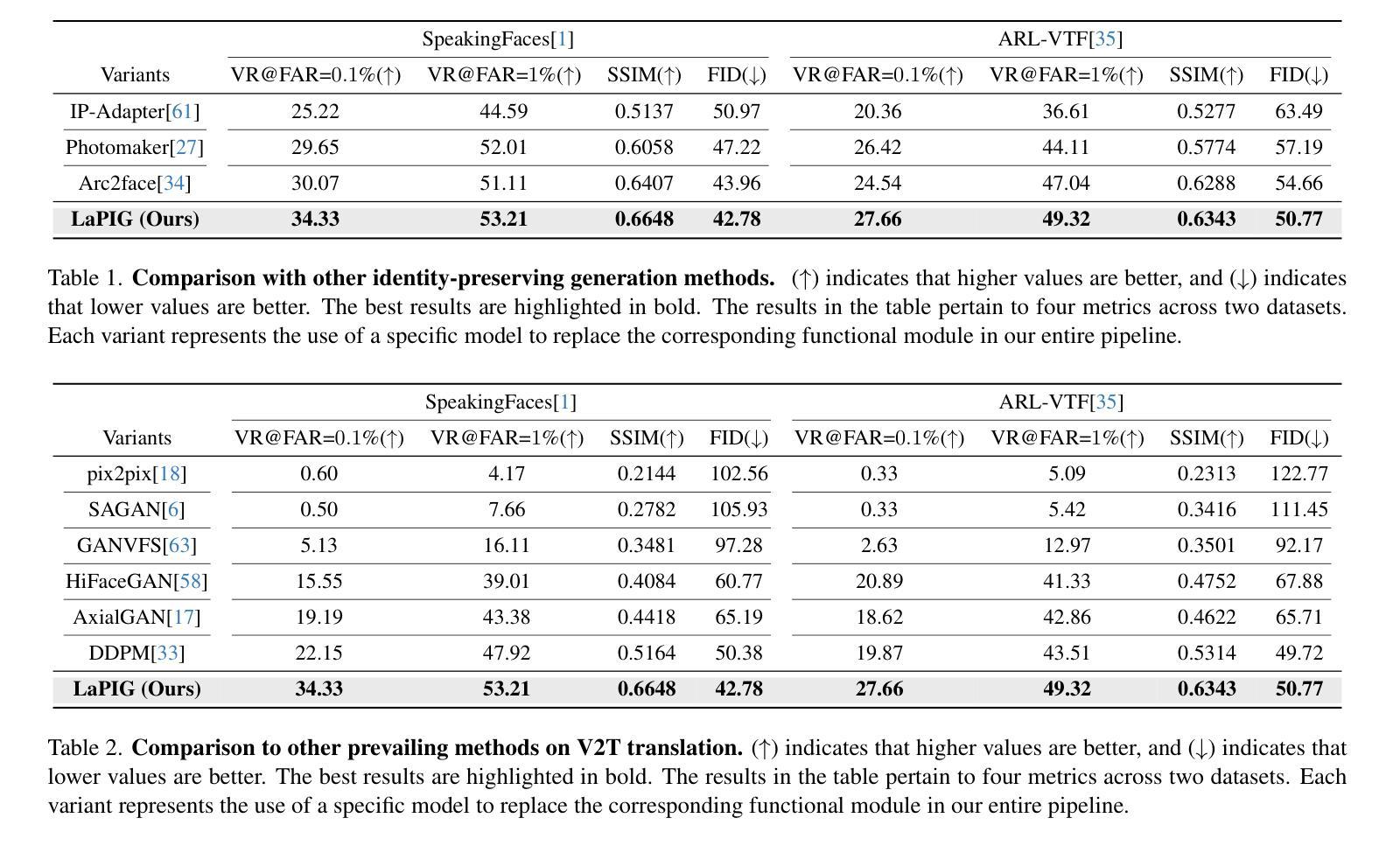
LaPIG: Cross-Modal Generation of Paired Thermal and Visible Facial Images
Authors:Leyang Wang, Joice Lin
The success of modern machine learning, particularly in facial translation networks, is highly dependent on the availability of high-quality, paired, large-scale datasets. However, acquiring sufficient data is often challenging and costly. Inspired by the recent success of diffusion models in high-quality image synthesis and advancements in Large Language Models (LLMs), we propose a novel framework called LLM-assisted Paired Image Generation (LaPIG). This framework enables the construction of comprehensive, high-quality paired visible and thermal images using captions generated by LLMs. Our method encompasses three parts: visible image synthesis with ArcFace embedding, thermal image translation using Latent Diffusion Models (LDMs), and caption generation with LLMs. Our approach not only generates multi-view paired visible and thermal images to increase data diversity but also produces high-quality paired data while maintaining their identity information. We evaluate our method on public datasets by comparing it with existing methods, demonstrating the superiority of LaPIG.
现代机器学习,特别是在面部翻译网络方面的成功,在很大程度上依赖于高质量、配对、大规模数据集的可获得性。然而,获取足够的数据通常具有挑战性和成本高昂。受扩散模型在高质量图像合成和大型语言模型(LLM)方面的最新成功启发,我们提出了一种名为LLM辅助配对图像生成(LaPIG)的新型框架。该框架能够利用LLM生成的描述来构建全面、高质量的配对可见光和热红外图像。我们的方法包括三部分:使用ArcFace嵌入的可见图像合成、使用潜在扩散模型(LDM)的热红外图像翻译,以及使用LLM的描述生成。我们的方法不仅生成多视角配对可见光和热红外图像,以增加数据多样性,而且还生成高质量配对数据,同时保持其身份信息的完整性。我们在公共数据集上评估了我们的方法,通过与现有方法进行对比,证明了LaPIG的优越性。
论文及项目相关链接
Summary
本文介绍了现代机器学习在面部翻译网络方面的成功高度依赖于高质量、配对的大规模数据集的可获得性。然而,获取足够的数据常常具有挑战性和成本高昂。受扩散模型在高质量图像合成和自然语言模型(LLMs)进展的启发,本文提出了一种新型框架——LLM辅助配对图像生成(LaPIG)。该框架能够利用LLMs生成的标题,构建全面、高质量配对的可见光和热红外图像。该方法包括三部分:使用ArcFace嵌入的可见图像合成、使用潜在扩散模型(LDMs)的热红外图像翻译,以及使用LLMs的标题生成。该方法不仅生成多视角配对可见光和热红外图像以增加数据多样性,而且生成高质量配对数据的同时保持身份信息。在公共数据集上的评估表明,LaPIG相比现有方法具有优越性。
Key Takeaways
- 现代机器学习的成功在很大程度上依赖于高质量、配对的大规模数据集。
- 获取足够的数据具有挑战性和成本高昂。
- LaPIG框架结合了扩散模型、LLMs和图像合成技术。
- LaPIG能够构建全面、高质量的配对可见和红外图像。
- 该方法包括可见图像合成、热图像翻译和标题生成三个主要部分。
- LaPIG不仅提高了数据多样性,还能生成高质量且保持身份信息的配对数据。
点此查看论文截图

TASR: Timestep-Aware Diffusion Model for Image Super-Resolution
Authors:Qinwei Lin, Xiaopeng Sun, Yu Gao, Yujie Zhong, Dengjie Li, Zheng Zhao, Haoqian Wang
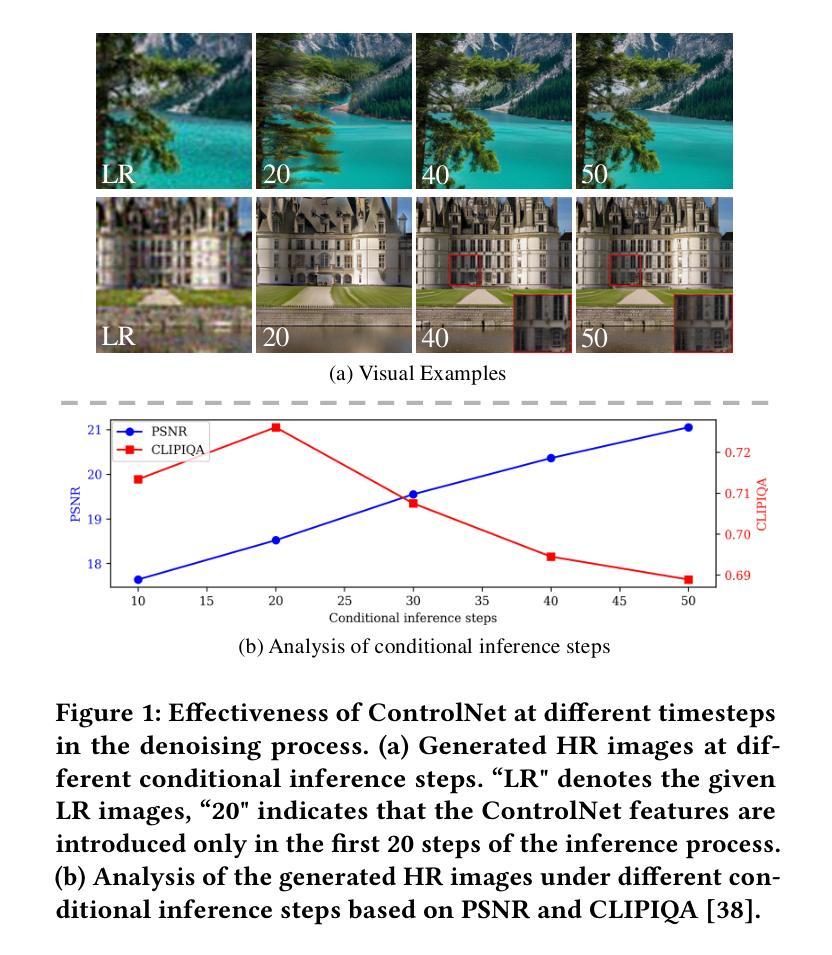
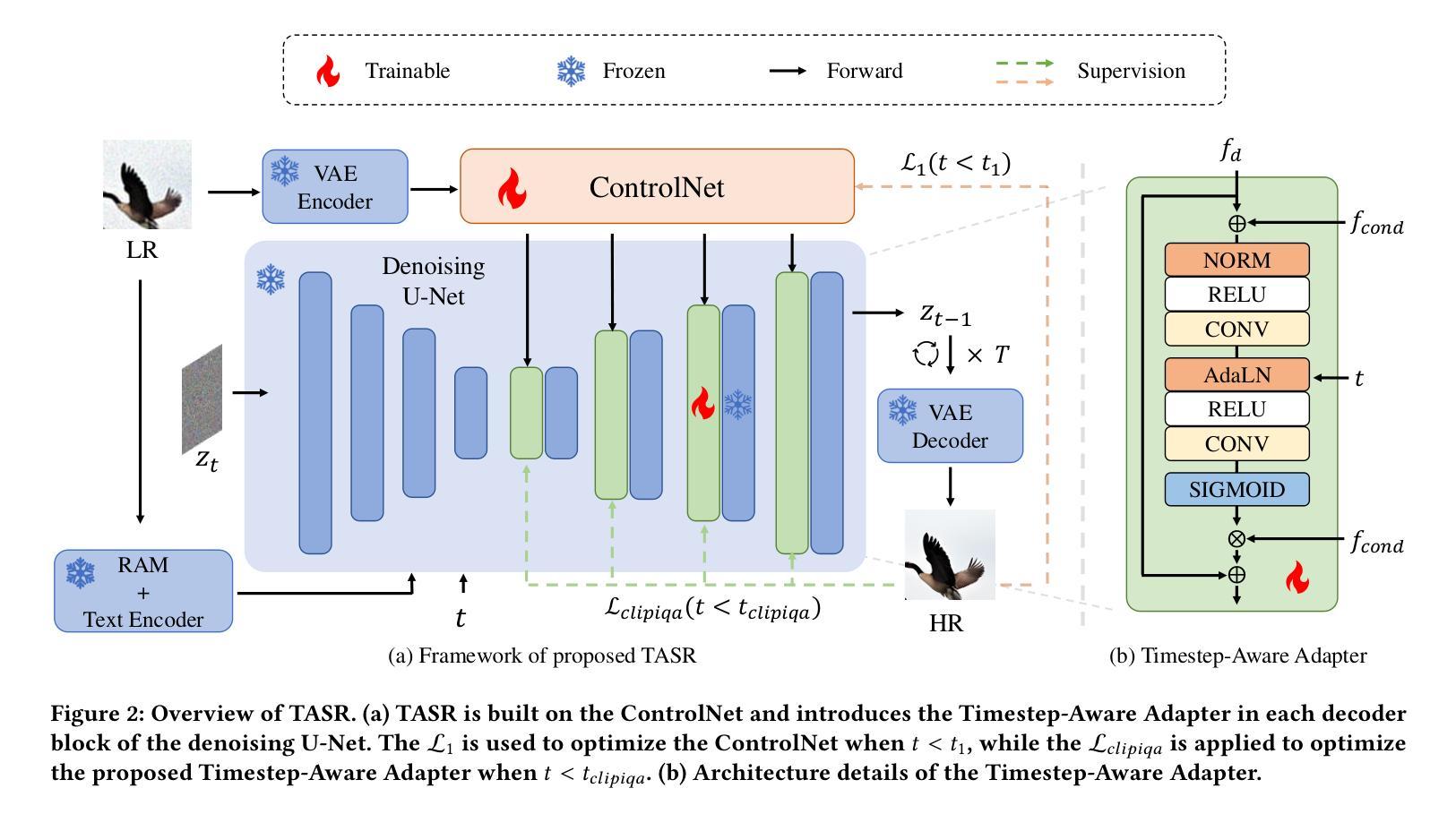
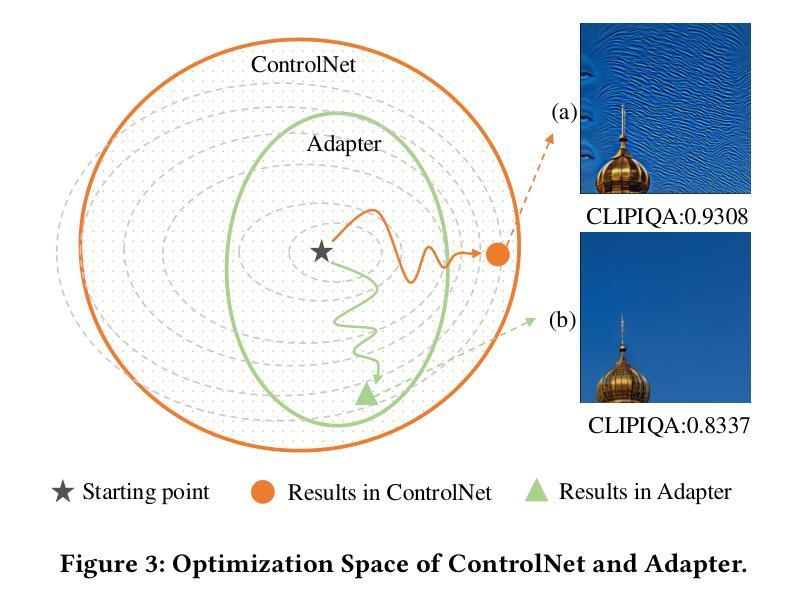
Diffusion models have recently achieved outstanding results in the field of image super-resolution. These methods typically inject low-resolution (LR) images via ControlNet.In this paper, we first explore the temporal dynamics of information infusion through ControlNet, revealing that the input from LR images predominantly influences the initial stages of the denoising process. Leveraging this insight, we introduce a novel timestep-aware diffusion model that adaptively integrates features from both ControlNet and the pre-trained Stable Diffusion (SD). Our method enhances the transmission of LR information in the early stages of diffusion to guarantee image fidelity and stimulates the generation ability of the SD model itself more in the later stages to enhance the detail of generated images. To train this method, we propose a timestep-aware training strategy that adopts distinct losses at varying timesteps and acts on disparate modules. Experiments on benchmark datasets demonstrate the effectiveness of our method. Code: https://github.com/SleepyLin/TASR
扩散模型在图像超分辨率领域取得了显著成果。这些方法通常通过ControlNet注入低分辨率(LR)图像。在本文中,我们首先探索了ControlNet中信息注入的时间动态,发现低分辨率图像的输入主要影响去噪过程的初始阶段。利用这一见解,我们引入了一种新型的时间步感知扩散模型,该模型自适应地融合了ControlNet和预训练的稳定扩散(SD)的特征。我们的方法提高了扩散早期阶段低分辨率信息的传输,以保证图像的真实性,并在后期更多地刺激了SD模型本身的生成能力,提高了生成图像的细节。为了训练这种方法,我们提出了一种时间步感知的训练策略,该策略在不同的时间步长采用不同的损失,并对不同的模块起作用。在基准数据集上的实验证明了我们的方法的有效性。代码地址:https://github.com/SleepyLin/TASR
论文及项目相关链接
PDF Accepted to ACM MM2025
Summary
扩散模型在图像超分辨率领域取得了显著成果。本文通过研究ControlNet的信息注入时间动态,发现低分辨率图像输入主要影响去噪过程的初始阶段。基于此,提出了一种新型的时间步长感知扩散模型,该模型自适应地结合了ControlNet和预训练稳定扩散(SD)的特征。该方法在扩散的早期阶段加强低分辨率信息的传输,保证图像保真度,并在后期更多地激发SD模型本身的生成能力,以提高生成图像的细节。Key Takeaways
- 扩散模型在图像超分辨率领域表现出卓越性能,常用ControlNet注入低分辨率图像。
- 本文探索了ControlNet的信息注入时间动态,发现LR图像输入对去噪过程初始阶段有主要影响。
- 引入了一种新的时间步长感知扩散模型,该模型自适应结合ControlNet和预训练稳定扩散(SD)的特征。
- 该方法在扩散的早期阶段加强低分辨率信息传输,保证图像保真度。
- 在后期,该方法更多地激发SD模型本身的生成能力,提高生成图像的细节。
- 为训练此方法,提出了时间步长感知训练策略,采用不同时间步长的损失和不同模块进行操作。
点此查看论文截图


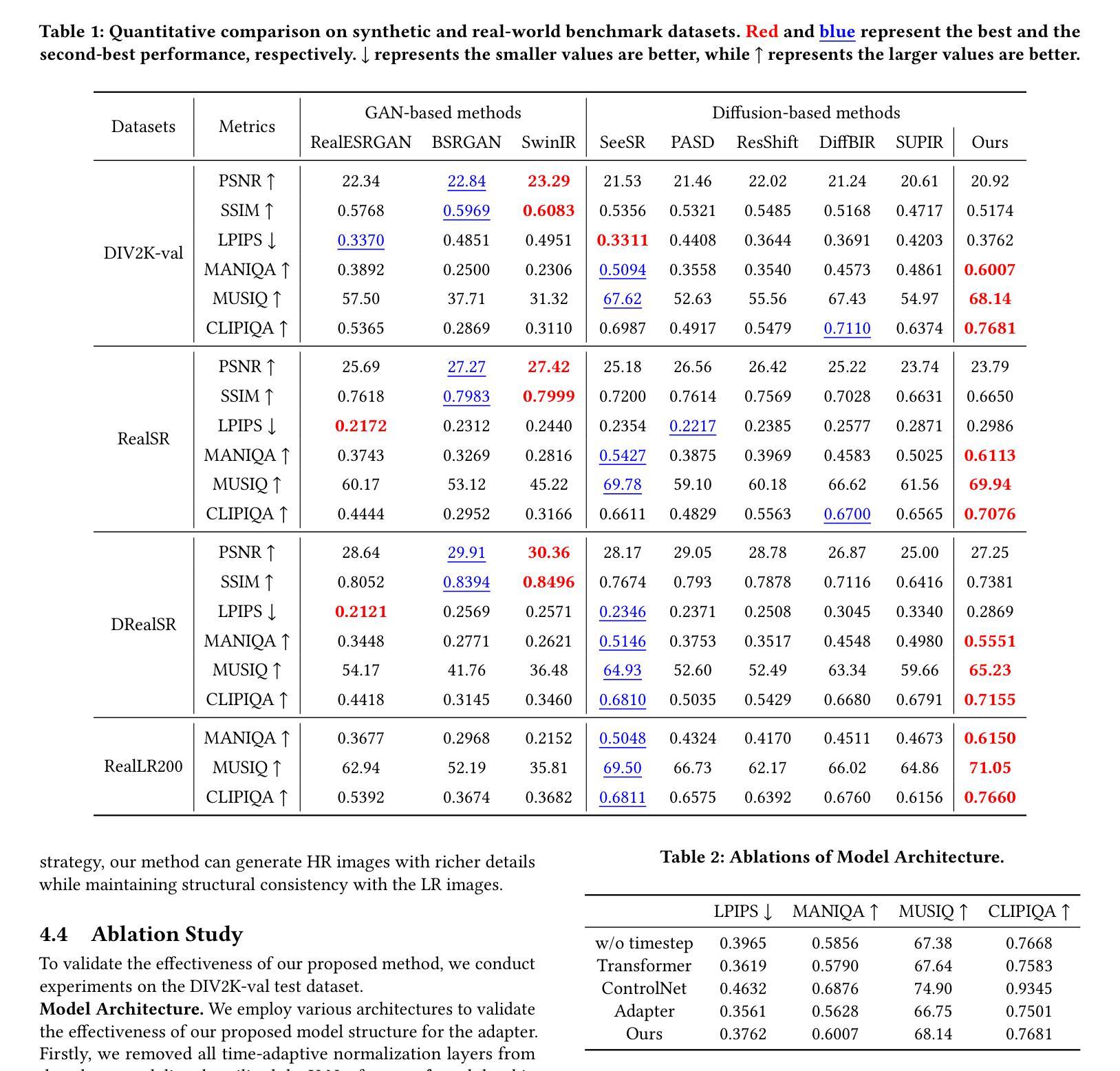
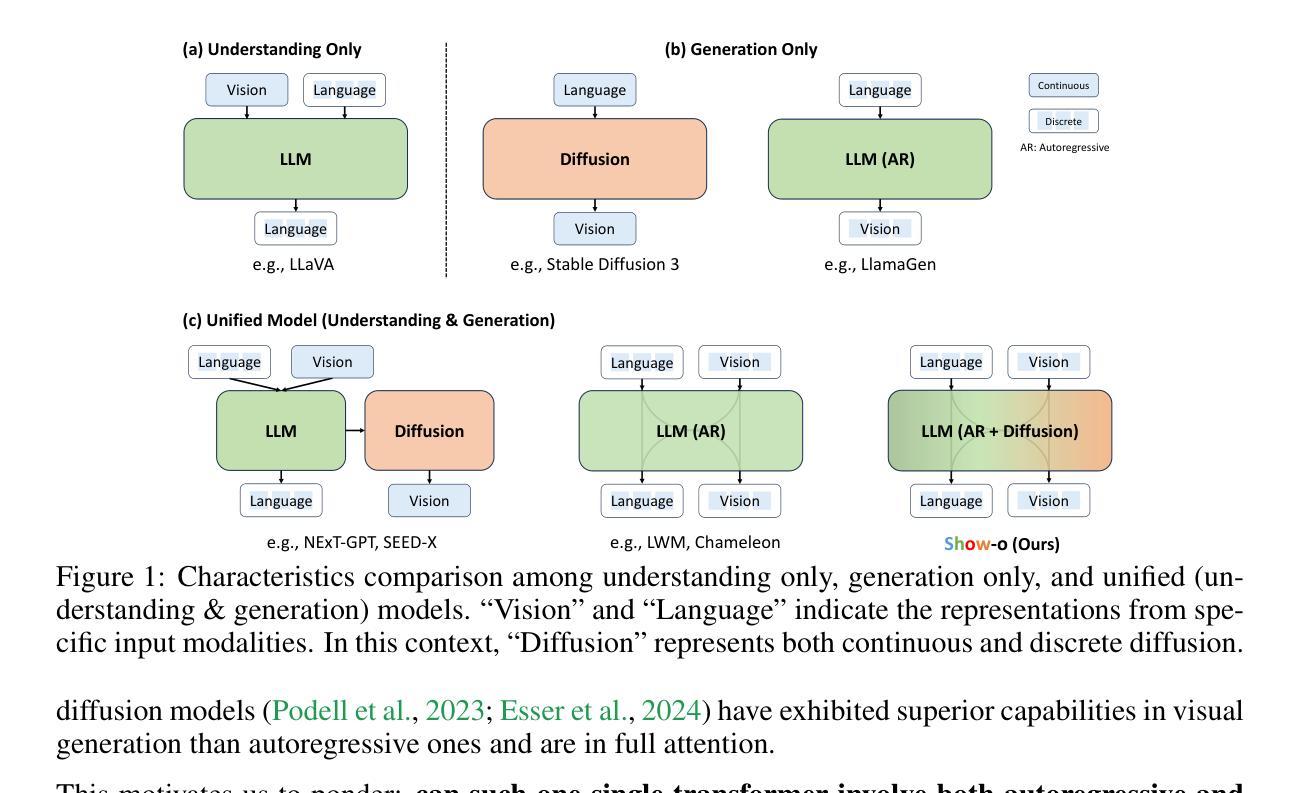
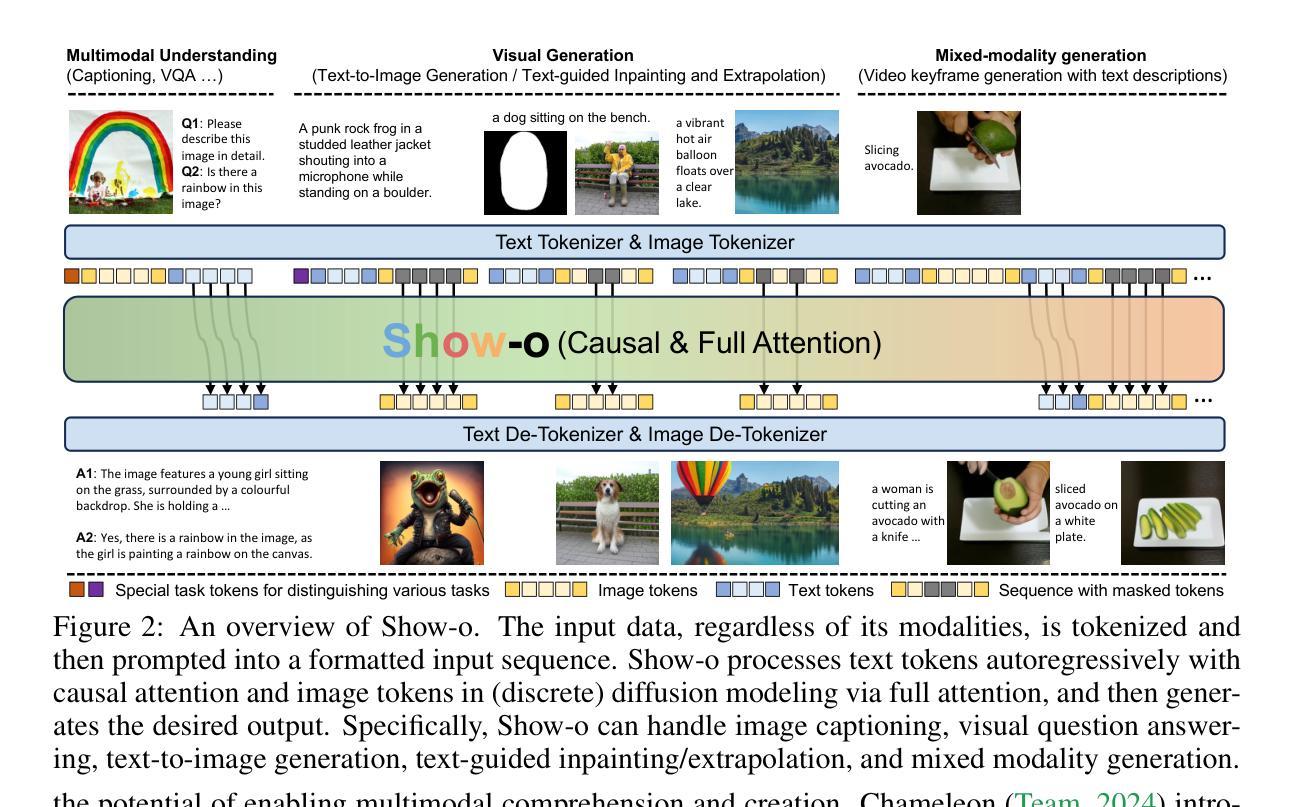
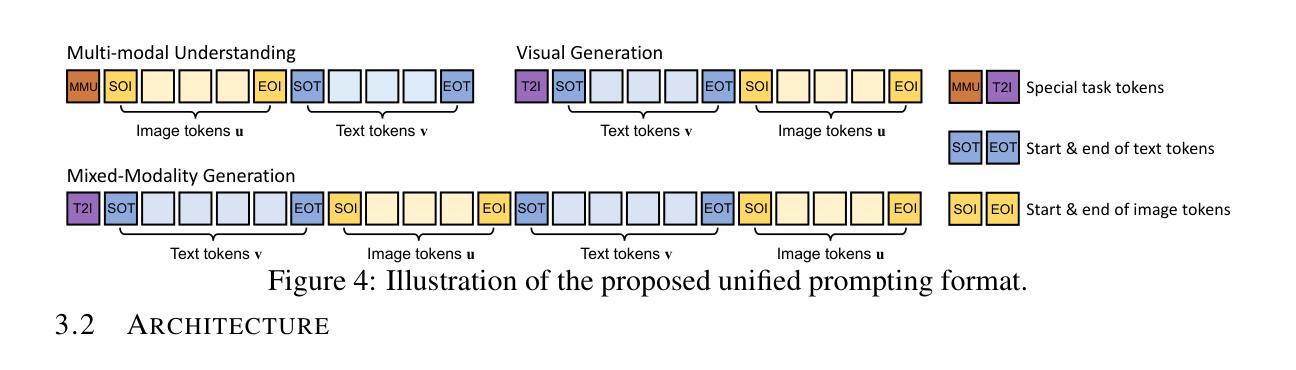
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Authors:Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, Mike Zheng Shou
We present a unified transformer, i.e., Show-o, that unifies multimodal understanding and generation. Unlike fully autoregressive models, Show-o unifies autoregressive and (discrete) diffusion modeling to adaptively handle inputs and outputs of various and mixed modalities. The unified model flexibly supports a wide range of vision-language tasks including visual question-answering, text-to-image generation, text-guided inpainting/extrapolation, and mixed-modality generation. Across various benchmarks, it demonstrates comparable or superior performance to existing individual models with an equivalent or larger number of parameters tailored for understanding or generation. This significantly highlights its potential as a next-generation foundation model. Code and models are released at https://github.com/showlab/Show-o.
我们提出了一种统一的一体式转换器,即Show-o,它融合了多模态理解和生成。不同于完全的自回归模型,Show-o融合了自回归和(离散)扩散建模,以自适应地处理各种和混合模态的输入和输出。该统一模型灵活支持广泛的视觉语言任务,包括视觉问答、文本到图像生成、文本引导的图像修复/外推以及混合模态生成。在各种基准测试中,其性能与现有针对理解或生成任务设计的具有相同或更多参数的模型相比表现相当或更好。这充分展示了其作为下一代基础模型的潜力。相关代码和模型已发布在https://github.com/showlab/Show-o。
论文及项目相关链接
PDF ICLR 2025
Summary
本文介绍了一种统一的多模态理解和生成转换器——Show-o。它结合了自回归和离散扩散建模技术,可灵活处理各种混合模态的输入和输出,支持广泛的视觉语言任务,包括视觉问答、文本到图像生成、文本引导的图像修复/外推和混合模态生成等。Show-o的性能与现有模型相比具有竞争力,甚至在某些方面表现更优秀,显示其作为下一代基础模型的潜力。
Key Takeaways
- Show-o是一个统一的多模态理解和生成转换器。
- 它结合了自回归和离散扩散建模技术。
- Show-o可灵活处理各种混合模态的输入和输出。
- 支持广泛的视觉语言任务,包括视觉问答、文本到图像生成等。
- Show-o的性能与现有模型相当,甚至在某些方面表现更优秀。
- Show-o有潜力成为下一代基础模型。
点此查看论文截图


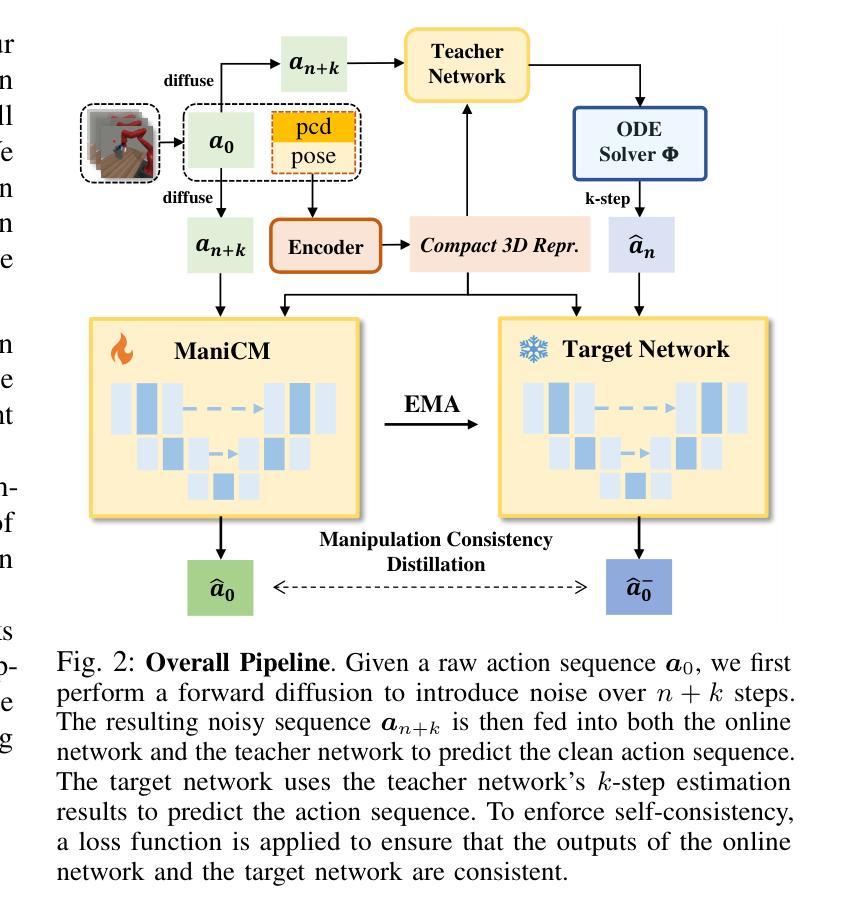
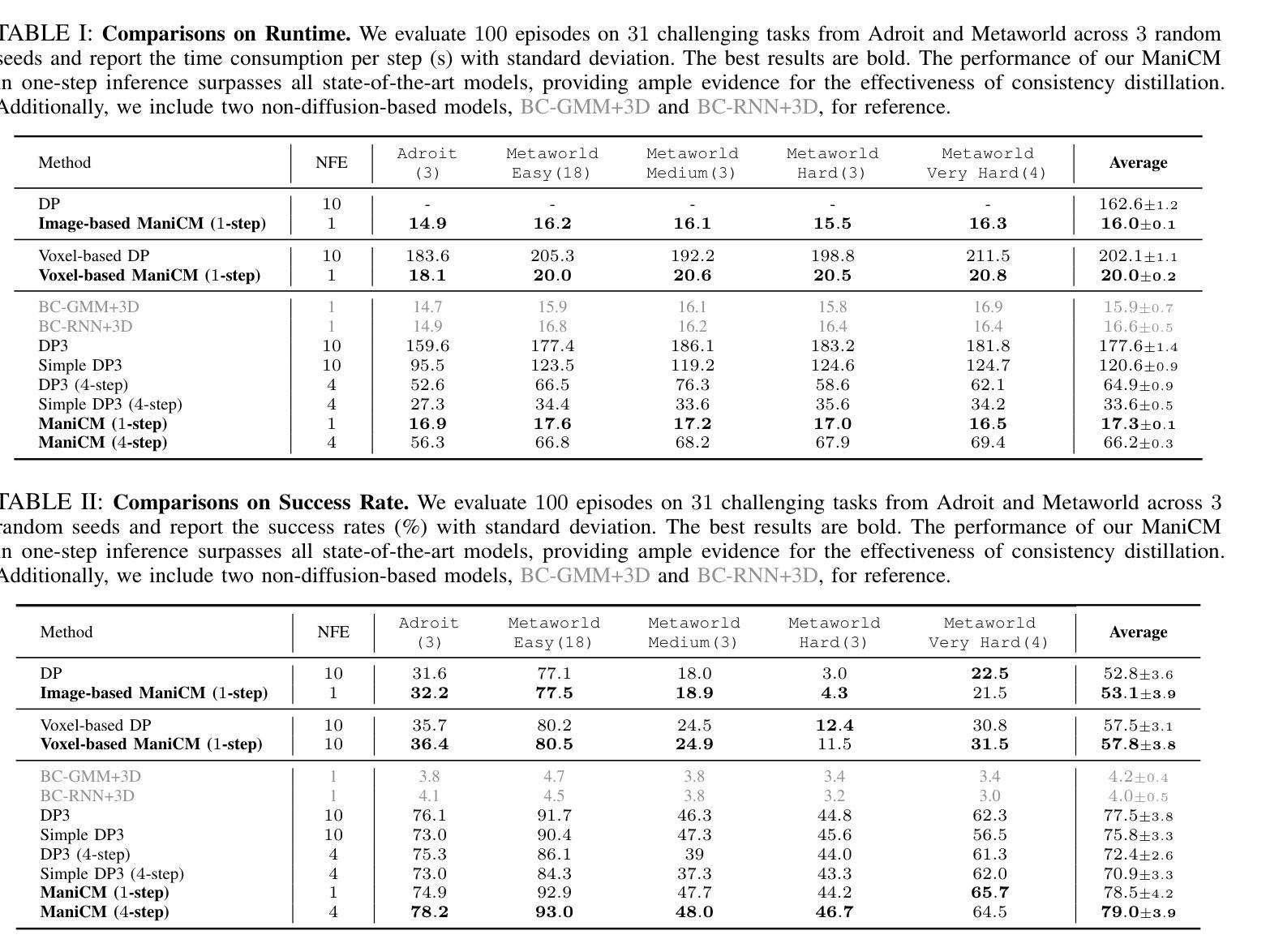
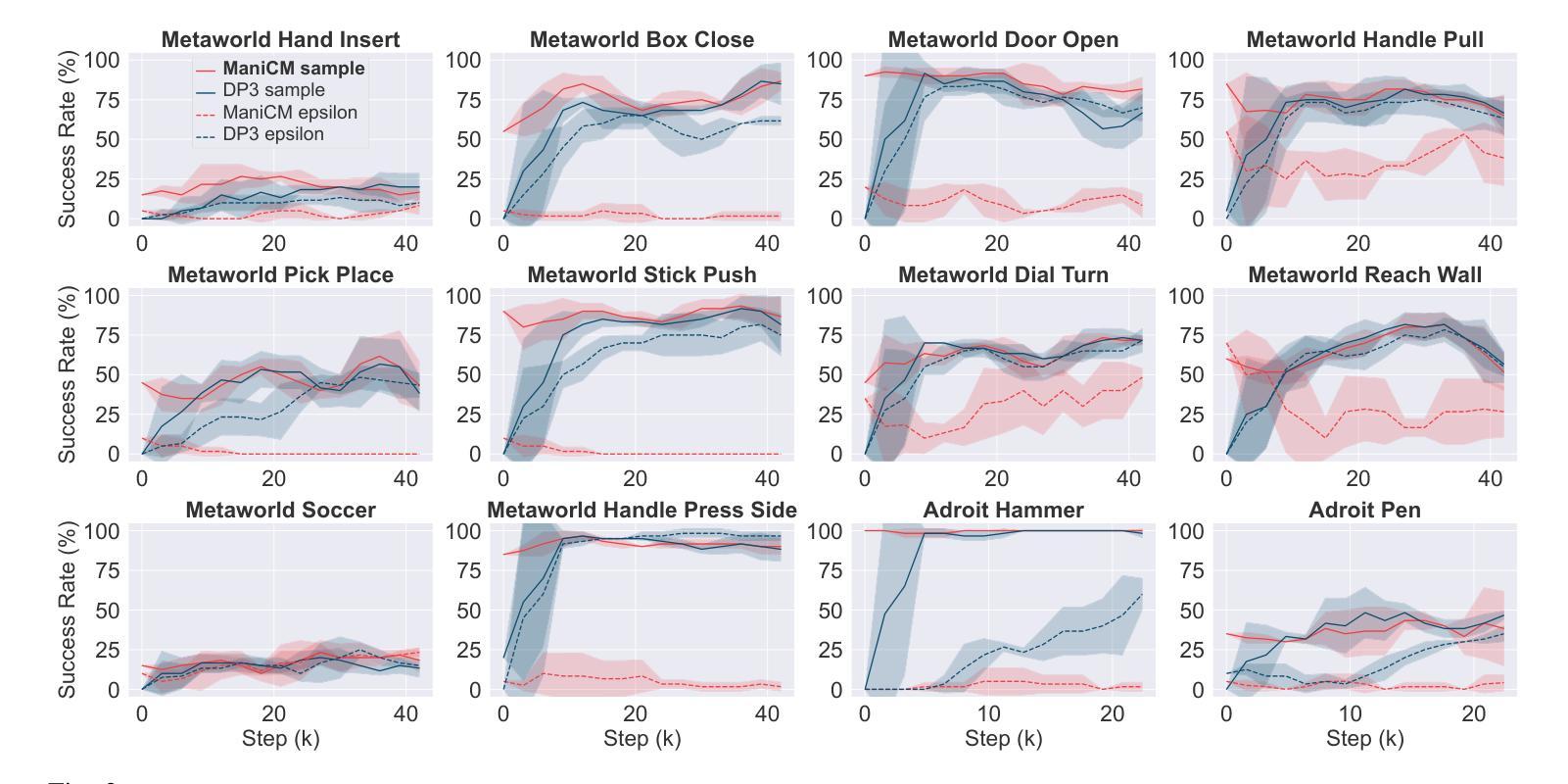
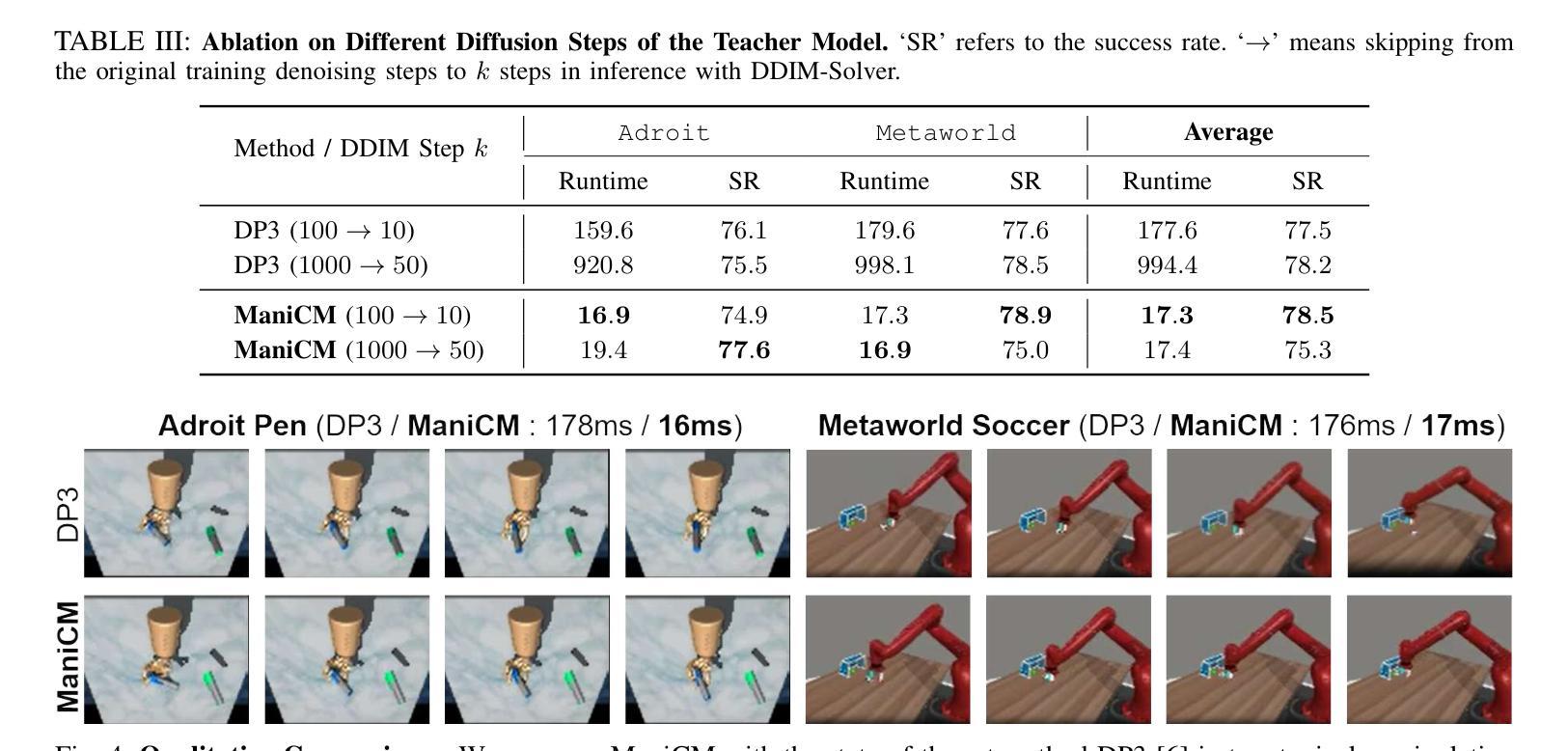
ManiCM: Real-time 3D Diffusion Policy via Consistency Model for Robotic Manipulation
Authors:Guanxing Lu, Zifeng Gao, Tianxing Chen, Wenxun Dai, Ziwei Wang, Wenbo Ding, Yansong Tang
Diffusion models have been verified to be effective in generating complex distributions from natural images to motion trajectories. Recent diffusion-based methods show impressive performance in 3D robotic manipulation tasks, whereas they suffer from severe runtime inefficiency due to multiple denoising steps, especially with high-dimensional observations. To this end, we propose a real-time robotic manipulation model named ManiCM that imposes the consistency constraint to the diffusion process, so that the model can generate robot actions in only one-step inference. Specifically, we formulate a consistent diffusion process in the robot action space conditioned on the point cloud input, where the original action is required to be directly denoised from any point along the ODE trajectory. To model this process, we design a consistency distillation technique to predict the action sample directly instead of predicting the noise within the vision community for fast convergence in the low-dimensional action manifold. We evaluate ManiCM on 31 robotic manipulation tasks from Adroit and Metaworld, and the results demonstrate that our approach accelerates the state-of-the-art method by 10 times in average inference speed while maintaining competitive average success rate.
扩散模型已经被验证可以从自然图像到运动轨迹生成复杂的分布。最近的基于扩散的方法在3D机器人操作任务中表现出令人印象深刻的性能,但由于多次去噪步骤,特别是在高维观察下,它们遭受严重的运行时间效率低下的问题。为此,我们提出了一种实时机器人操作模型ManiCM,对扩散过程施加一致性约束,使模型能够在一次推理中生成机器人动作。具体来说,我们在机器人动作空间中制定了基于点云输入的连续扩散过程,要求从ODE轨迹的任何一点直接对原始动作进行去噪。为了模拟这一过程,我们设计了一种一致性蒸馏技术,直接预测动作样本,而不是在视觉社区内预测噪声,以在低维动作流形中实现快速收敛。我们在Adroit和Metaworld的31个机器人操作任务上评估了ManiCM,结果表明我们的方法平均推理速度提高了10倍,同时保持了具有竞争力的平均成功率。
论文及项目相关链接
PDF https://manicm-fast.github.io/
Summary
扩散模型在自然图像生成和运动轨迹生成方面表现出良好的效果。针对当前扩散模型在机器人操控任务中存在的高维观察和多次去噪导致的运行时效率低下的问题,我们提出了一种名为ManiCM的实时机器人操控模型。该模型对扩散过程施加一致性约束,实现了一步推断机器人动作。通过在机器人动作空间内构建一致性扩散过程并设计一致性蒸馏技术,该模型可直接从ODE轨迹的任何点去噪原始动作样本,从而提高了收敛速度并保持了动作流形的低维度。在Adroit和Metaworld的31个机器人操控任务上的评估结果表明,我们的方法在平均推理速度上加快了10倍,同时保持了具有竞争力的平均成功率。
Key Takeaways
- 扩散模型已在多个领域证明其生成复杂分布的有效性。
- 当前扩散模型在机器人操控任务中存在运行时效率低下的问题。
- 提出了一种名为ManiCM的实时机器人操控模型,通过施加一致性约束实现了一步推断机器人动作。
- ManiCM模型在机器人动作空间内构建一致性扩散过程。
- 设计了一致性蒸馏技术,直接预测动作样本以提高收敛速度并保持动作流形的低维度。
- 在多个机器人操控任务上的评估显示,ManiCM显著提高了推理速度并保持了高成功率。
点此查看论文截图