⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-10 更新
UNH at CheckThat! 2025: Fine-tuning Vs Prompting in Claim Extraction
Authors:Joe Wilder, Nikhil Kadapala, Benji Xu, Mohammed Alsaadi, Aiden Parsons, Mitchell Rogers, Palash Agarwal, Adam Hassick, Laura Dietz
We participate in CheckThat! Task 2 English and explore various methods of prompting and in-context learning, including few-shot prompting and fine-tuning with different LLM families, with the goal of extracting check-worthy claims from social media passages. Our best METEOR score is achieved by fine-tuning a FLAN-T5 model. However, we observe that higher-quality claims can sometimes be extracted using other methods, even when their METEOR scores are lower.
我们参与了CheckThat! Task 2的英语任务,探索了各种提示和上下文学习的方法,包括少量提示和不同LLM家族的微调,旨在从社交媒体段落中提取值得检查的声明。我们通过微调FLAN-T5模型获得了最佳METEOR分数。然而,我们观察到即使使用其他方法获得的METEOR分数较低,有时也能提取出更高质量的声明。
论文及项目相关链接
PDF 16 pages,3 tables, CLEF 2025 Working Notes, 9-12 September 2025, Madrid, Spain
Summary
本文介绍了在CheckThat! Task 2 English任务中,通过不同的LLM家族模型进行少样本提示和微调的方法,旨在从社交媒体段落中提取值得验证的声明。最佳METEOR得分是通过微调FLAN-T5模型实现的,但其他方法有时也能提取出更高质量的声明,即使其METEOR得分较低。
Key Takeaways
- 参与CheckThat! Task 2 English任务,专注于从社交媒体段落中提取值得验证的声明。
- 探索了多种方法,包括少样本提示和针对不同LLM家族的微调。
- 通过微调FLAN-T5模型获得了最佳METEOR得分。
- 高质量的声明有时可以通过其他方法提取。
- METEOR得分并非唯一衡量声明质量的指标。
- 在处理社交媒体文本时,需要考虑多种策略来提高提取声明质量的效果。
点此查看论文截图



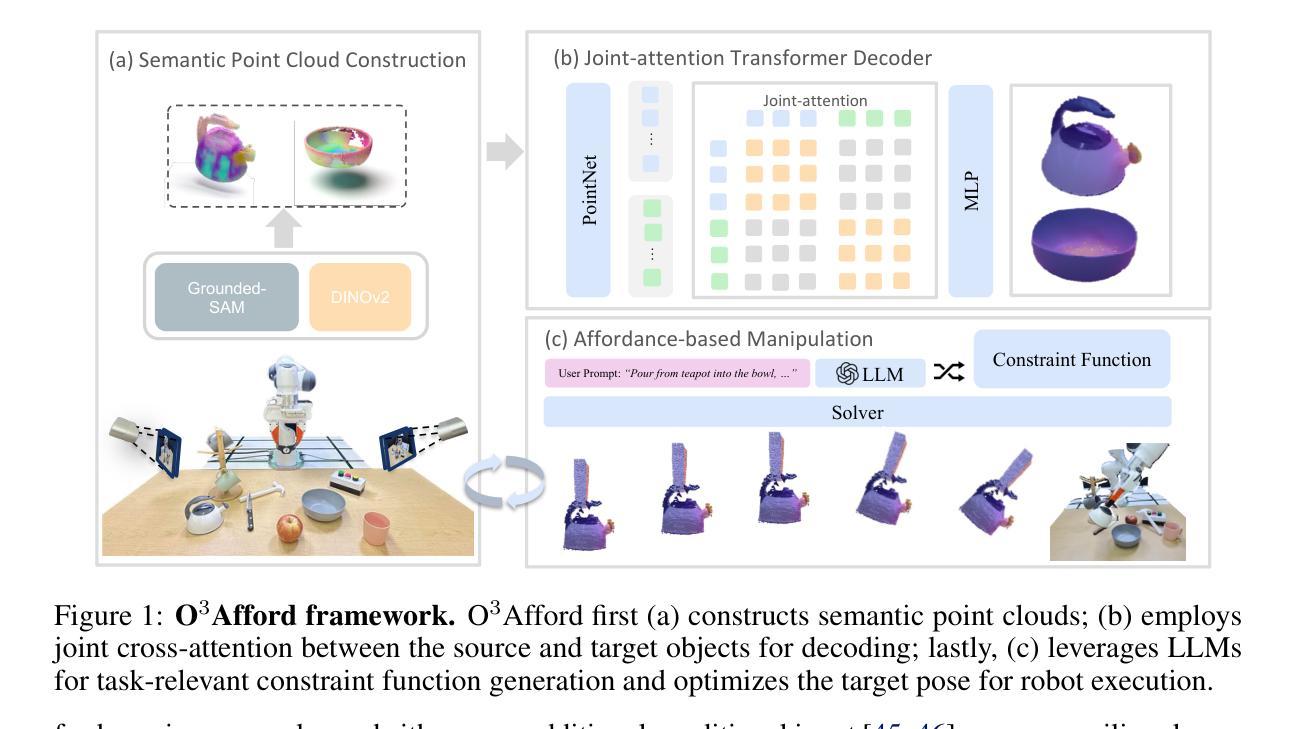
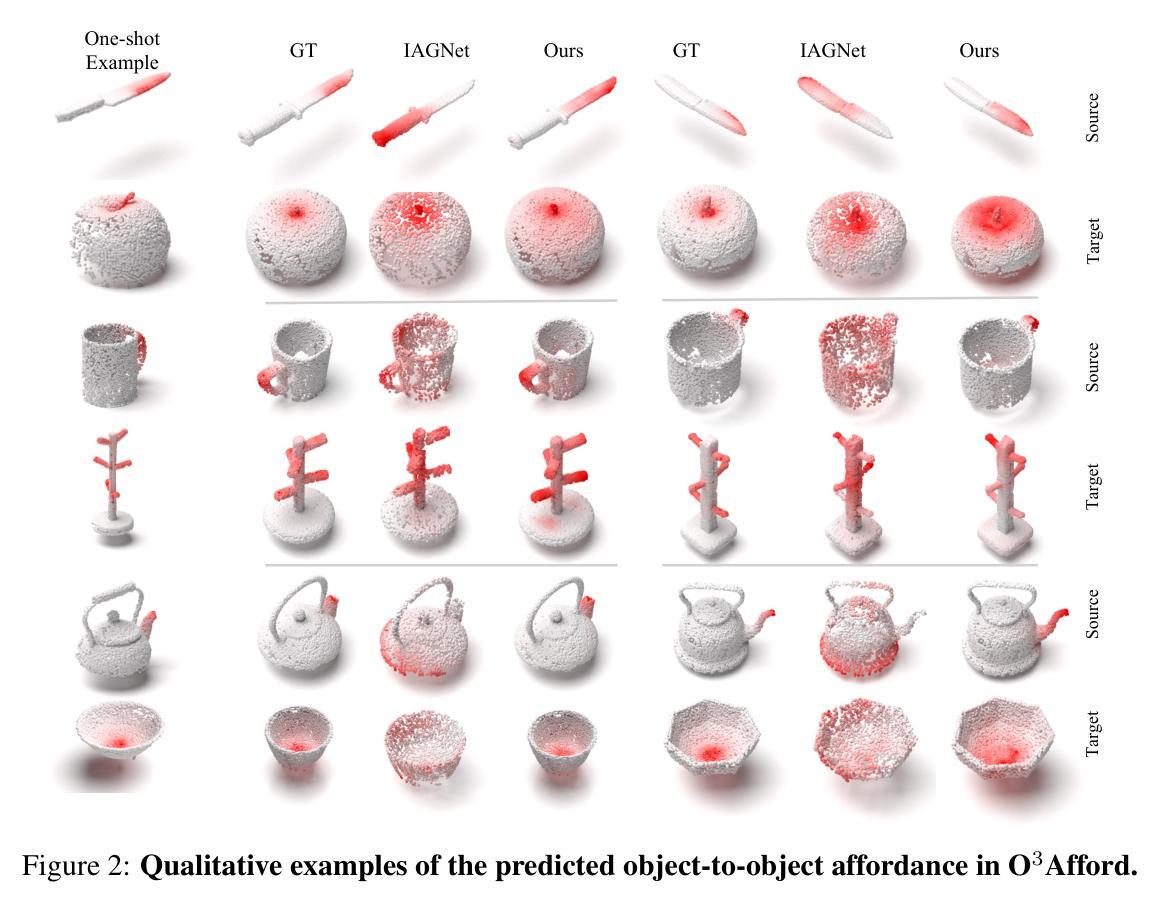
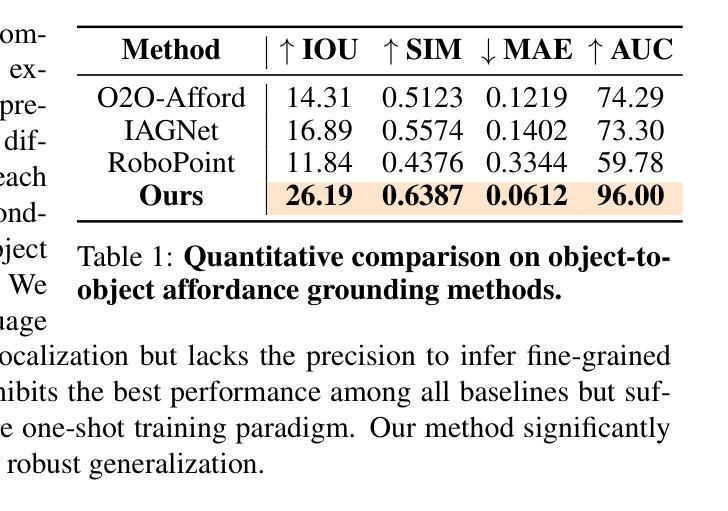
O$^3$Afford: One-Shot 3D Object-to-Object Affordance Grounding for Generalizable Robotic Manipulation
Authors:Tongxuan Tian, Xuhui Kang, Yen-Ling Kuo
Grounding object affordance is fundamental to robotic manipulation as it establishes the critical link between perception and action among interacting objects. However, prior works predominantly focus on predicting single-object affordance, overlooking the fact that most real-world interactions involve relationships between pairs of objects. In this work, we address the challenge of object-to-object affordance grounding under limited data contraints. Inspired by recent advances in few-shot learning with 2D vision foundation models, we propose a novel one-shot 3D object-to-object affordance learning approach for robotic manipulation. Semantic features from vision foundation models combined with point cloud representation for geometric understanding enable our one-shot learning pipeline to generalize effectively to novel objects and categories. We further integrate our 3D affordance representation with large language models (LLMs) for robotics manipulation, significantly enhancing LLMs’ capability to comprehend and reason about object interactions when generating task-specific constraint functions. Our experiments on 3D object-to-object affordance grounding and robotic manipulation demonstrate that our O$^3$Afford significantly outperforms existing baselines in terms of both accuracy and generalization capability.
对象功能认知在机器人操控中起到基础性作用,因为它建立了交互对象间感知与行动的关键联系。然而,早期的研究主要集中于预测单个对象的功能认知,忽略了现实中大多数互动都涉及两个对象间关系的事实。在本研究中,我们解决了在有限数据约束下的对象间功能认知定位挑战。受近期少量学习2D视觉基础模型的启发,我们提出了一种新颖的针对机器人操控的一次性3D对象间功能认知学习方法。视觉基础模型中的语义特征与点云表示相结合进行几何理解,使我们的单次学习管道能够有效地推广到新型对象和类别上。我们将我们的三维功能认知表现与用于机器人操控的大型语言模型(LLM)进一步整合,显著提高了LLM在生成特定任务的约束函数时理解和推理对象交互的能力。我们在三维对象间功能认知定位和机器人操控上的实验表明,我们的O$^3$Afford在精度和泛化能力上均显著超越了现有基准测试模型。
论文及项目相关链接
PDF Conference on Robot Learning (CoRL) 2025. Project website: https://o3afford.github.io/
Summary
该文关注机器人操作中的对象间可负担性(object-to-object affordance)问题,强调在现实世界中,对象间的交互是常态。针对数据有限的情况,研究团队受二维视觉基础模型的启发,提出一种针对机器人操作的一次性三维对象间可负担性学习(one-shot 3D object-to-object affordance learning)方法。结合视觉基础模型的语义特征与点云表示法,此方法能更有效地推广至新对象和类别。此外,该研究团队还整合了他们的三维可负担性表示法与大型语言模型(LLMs),显著提高了LLMs在生成特定任务约束函数时对对象交互的理解和推理能力。实验证明,他们的方法在三维对象间可负担性和机器人操作方面显著优于现有基线。
Key Takeaways
- 机器人操作中对象间可负担性的重要性被强调,反映了现实世界中对象交互的普遍性。
- 面对数据限制的挑战,提出了一种一次性三维对象间可负担性学习的新方法。
- 结合视觉基础模型的语义特征和点云表示法,提高对新对象和类别的适应能力。
- 利用大型语言模型(LLMs)进行机器人操作任务中的理解和推理能力增强。
- 该方法不仅关注单个对象的可负担性预测,更注重对象间的交互关系。
- 实验证明,该方法在三维对象间可负担性和机器人操作方面的性能优于现有基线。
点此查看论文截图

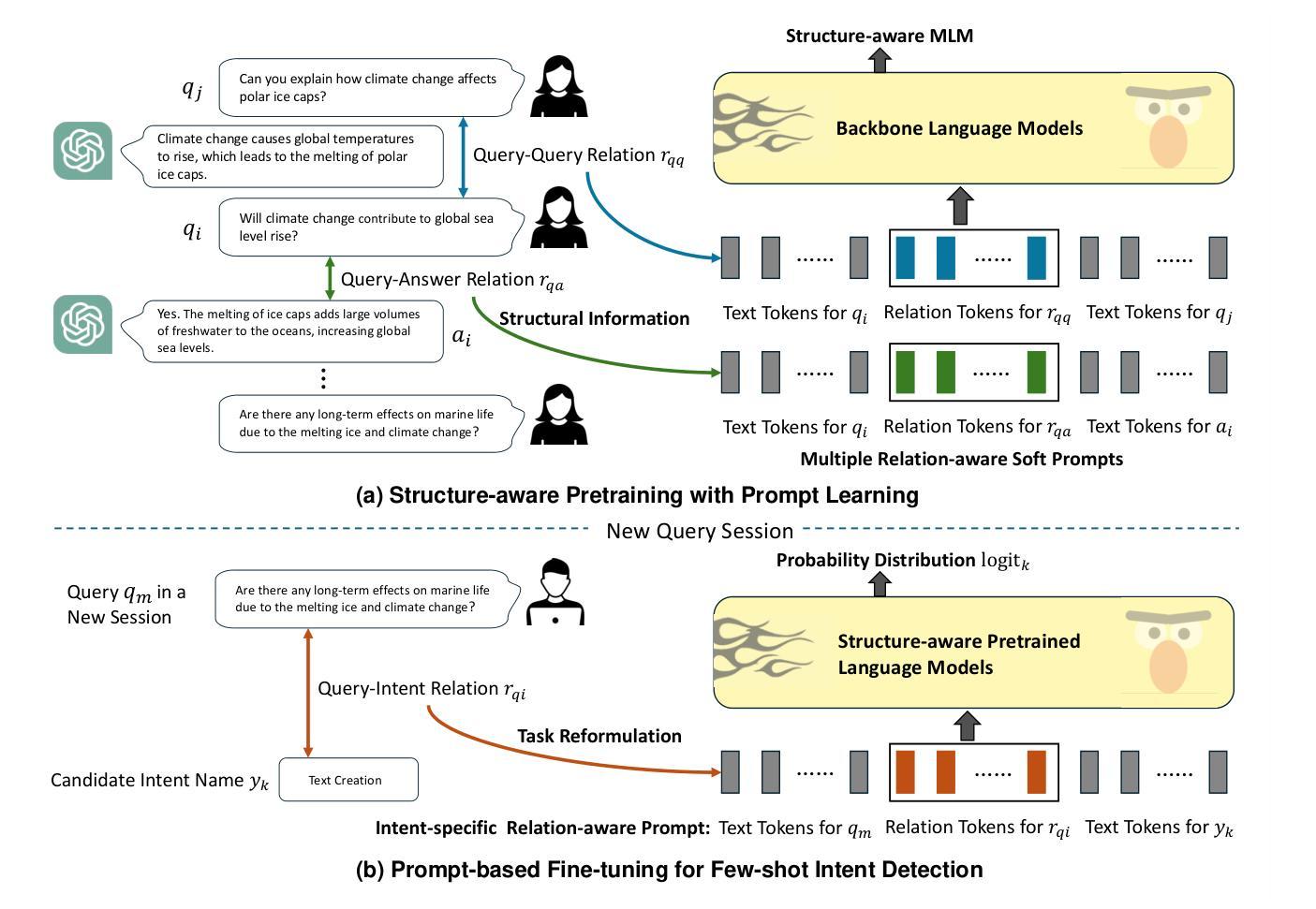
Few-Shot Query Intent Detection via Relation-Aware Prompt Learning
Authors:Liang Zhang, Yuan Li, Shijie Zhang, Zheng Zhang, Xitong Li
Intent detection is a crucial component of modern conversational systems, since accurately identifying user intent at the beginning of a conversation is essential for generating effective responses. Recent efforts have focused on studying this problem under a challenging few-shot scenario. These approaches primarily leverage large-scale unlabeled dialogue text corpora to pretrain language models through various pretext tasks, followed by fine-tuning for intent detection with very limited annotations. Despite the improvements achieved, existing methods have predominantly focused on textual data, neglecting to effectively capture the crucial structural information inherent in conversational systems, such as the query-query relation and query-answer relation. To address this gap, we propose SAID, a novel framework that integrates both textual and relational structure information in a unified manner for model pretraining for the first time. Building on this framework, we further propose a novel mechanism, the query-adaptive attention network (QueryAdapt), which operates at the relation token level by generating intent-specific relation tokens from well-learned query-query and query-answer relations explicitly, enabling more fine-grained knowledge transfer. Extensive experimental results on two real-world datasets demonstrate that SAID significantly outperforms state-of-the-art methods.
意图检测是现代对话系统的重要组成部分,因为在对话开始时准确识别用户意图对于生成有效的响应至关重要。近期的研究工作主要集中在具有挑战性的少样本场景下的这个问题上。这些方法主要利用大规模的未标注对话文本语料库,通过各种前序任务来预训练语言模型,然后使用非常有限的注释进行意图检测的微调。尽管取得了改进,但现有方法主要集中在文本数据上,忽视了有效捕获对话系统中固有的关键结构信息,如查询-查询关系和查询-答案关系。为了弥补这一空白,我们提出了SAID,这是一个新的框架,首次以统一的方式将文本和关系结构信息整合在一起进行模型预训练。在此基础上,我们进一步提出了一种新的机制,即查询自适应注意力网络(QueryAdapt),它在关系令牌级别操作,通过从学习良好的查询-查询和查询-答案关系中生成特定的意图关系令牌,实现更精细的知识转移。在两个真实数据集上的大量实验结果表明,SAID显著优于最先进的方法。
论文及项目相关链接
Summary
文本描述了意图检测在现代对话系统中的重要性和现有方法的不足。针对这一问题,提出了一种新的框架SAID,该框架首次将文本和关系结构信息统一起来进行模型预训练。此外,还提出了一种新的机制QueryAdapt,通过在关系令牌级别生成特定意图的关系令牌,实现了更精细的知识迁移。实验结果表明,SAID在真实世界数据集上显著优于现有方法。
Key Takeaways
- 意图检测是现代对话系统的核心组件,对生成有效响应至关重要。
- 当前方法主要依赖大规模未标注对话文本语料库进行预训练,然后通过对有限注释进行微调来进行意图检测。
- 现有方法主要关注文本数据,忽略了对话系统中固有的关键结构信息,如查询-查询关系和查询-答案关系。
- 提出了一个新的框架SAID,首次统一了文本和关系结构信息进行模型预训练。
5.SAI提出了一个查询自适应注意力网络(QueryAdapt)的新机制,通过在关系令牌级别生成特定意图的关系令牌来实现更精细的知识迁移。 - 实验结果表明,SAID在真实世界数据集上的表现显著优于现有方法。
点此查看论文截图

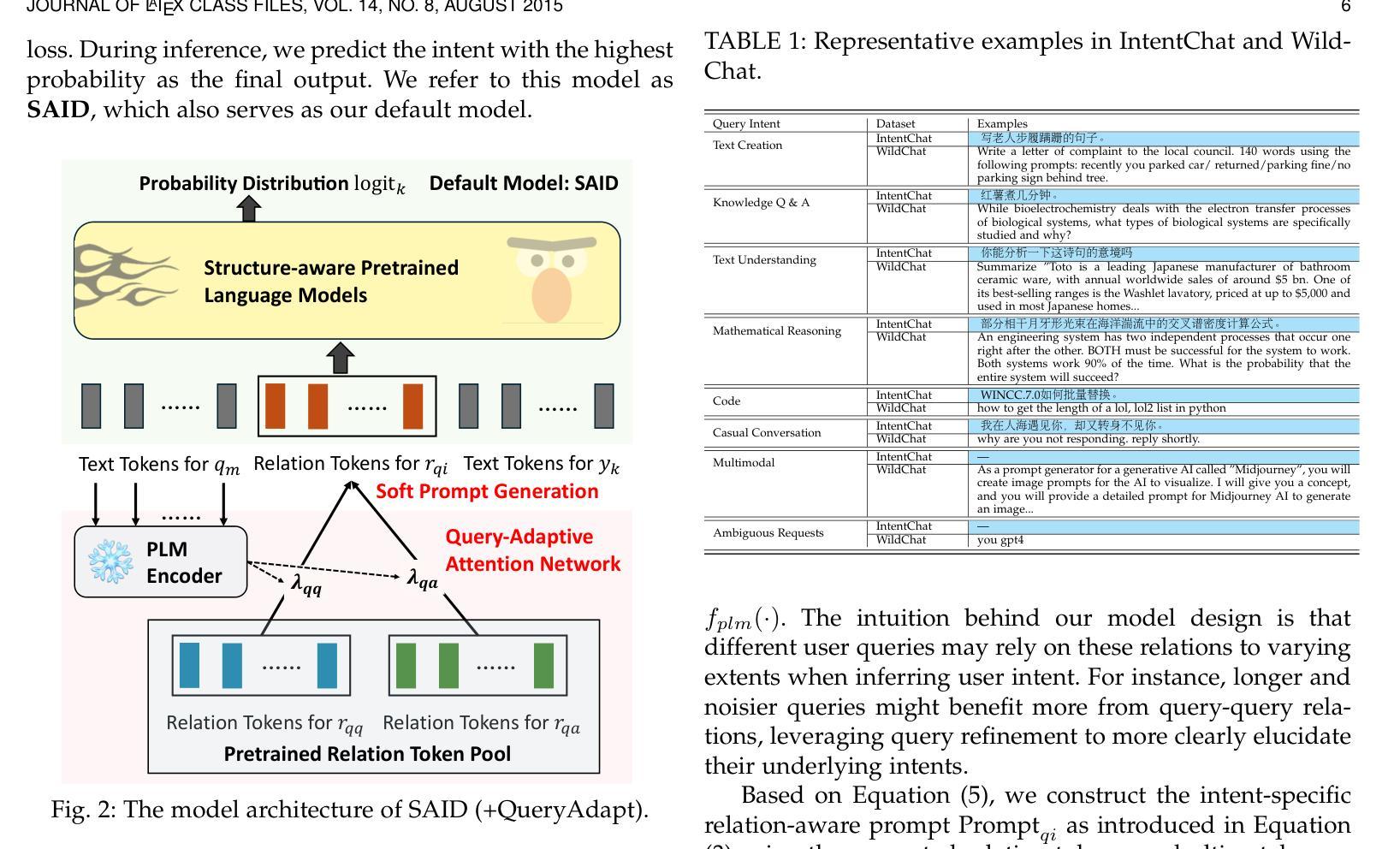

Amortized In-Context Mixed Effect Transformer Models: A Zero-Shot Approach for Pharmacokinetics
Authors:César Ali Ojeda Marin, Wilhelm Huisinga, Purity Kavwele, Niklas Hartung
Accurate dose-response forecasting under sparse sampling is central to precision pharmacotherapy. We present the Amortized In-Context Mixed-Effect Transformer (AICMET) model, a transformer-based latent-variable framework that unifies mechanistic compartmental priors with amortized in-context Bayesian inference. AICMET is pre-trained on hundreds of thousands of synthetic pharmacokinetic trajectories with Ornstein-Uhlenbeck priors over the parameters of compartment models, endowing the model with strong inductive biases and enabling zero-shot adaptation to new compounds. At inference time, the decoder conditions on the collective context of previously profiled trial participants, generating calibrated posterior predictions for newly enrolled patients after a few early drug concentration measurements. This capability collapses traditional model-development cycles from weeks to hours while preserving some degree of expert modelling. Experiments across public datasets show that AICMET attains state-of-the-art predictive accuracy and faithfully quantifies inter-patient variability – outperforming both nonlinear mixed-effects baselines and recent neural ODE variants. Our results highlight the feasibility of transformer-based, population-aware neural architectures as offering a new alternative for bespoke pharmacokinetic modeling pipelines, charting a path toward truly population-aware personalized dosing regimens.
在稀疏采样下进行准确的剂量反应预测是精准药物治疗的核心。我们提出了平均上下文混合效应变压器(AICMET)模型,这是一个基于变压器的潜在变量框架,它将机械室模型先验与平均上下文贝叶斯推理统一起来。AICMET在数以万计合成药物代谢动力学轨迹上进行预训练,其中Ornstein-Uhlenbeck为室模型的参数提供了先验知识,为模型提供了强烈的归纳偏见,并实现了对新化合物的零样本适应。在推理时,解码器根据先前受试者的集体上下文进行条件化,在新招募的患者进行了几次早期药物浓度测量后生成校准的后验预测。这种能力将传统的模型开发周期从几周缩短到几小时,同时保留了一定程度的专家建模能力。在公共数据集上的实验表明,AICMET达到了最先进的预测精度,并忠实量化了患者间的变异性,超越了非线性混合效应基准和最新的神经ODE变体。我们的结果突出了基于变压器的、具有人群意识的神经网络架构的可行性,为定制药物代谢动力学建模管道提供了新的选择,为真正具有人群意识个性化给药方案铺平了道路。
论文及项目相关链接
Summary
AICMET模型是一种基于转化器的潜变量框架,它将机械室模型先验与摊销上下文贝叶斯推理相结合,实现了稀疏采样下的精准剂量反应预测。该模型经过数十万条合成药物代谢轨迹的预训练,并具备强大的归纳偏置能力,可适应新化合物。在推断时,解码器根据先前受试者的集体上下文进行条件处理,在少数早期药物浓度测量后生成新患者的校准后预测。这大大缩短了传统模型开发周期,同时保持了专家建模的程度。实验表明,AICMET达到了最先进的预测精度,并忠实量化了患者间的变异性,超越了非线性混合效应基准和最新的神经ODE变体。
Key Takeaways
- AICMET模型是一个基于转化器的潜变量框架,结合了机械室模型先验和摊销上下文贝叶斯推理。
- 模型经过数十万条合成药物代谢轨迹的预训练,具备强大的归纳偏置能力,可适应新化合物。
- AICMET可以在少量早期药物浓度测量后生成新患者的校准预测。
- 模型实现了稀疏采样下的精准剂量反应预测,缩短了传统模型开发周期。
- AICMET达到了最先进的预测精度,并忠实量化了患者间的变异性。
- 该模型超越了现有的非线性混合效应基准和神经ODE变体。
点此查看论文截图

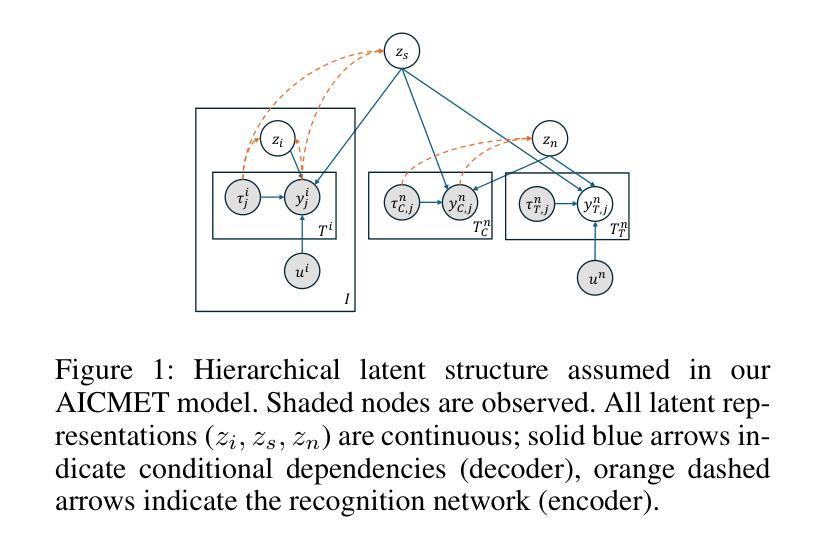
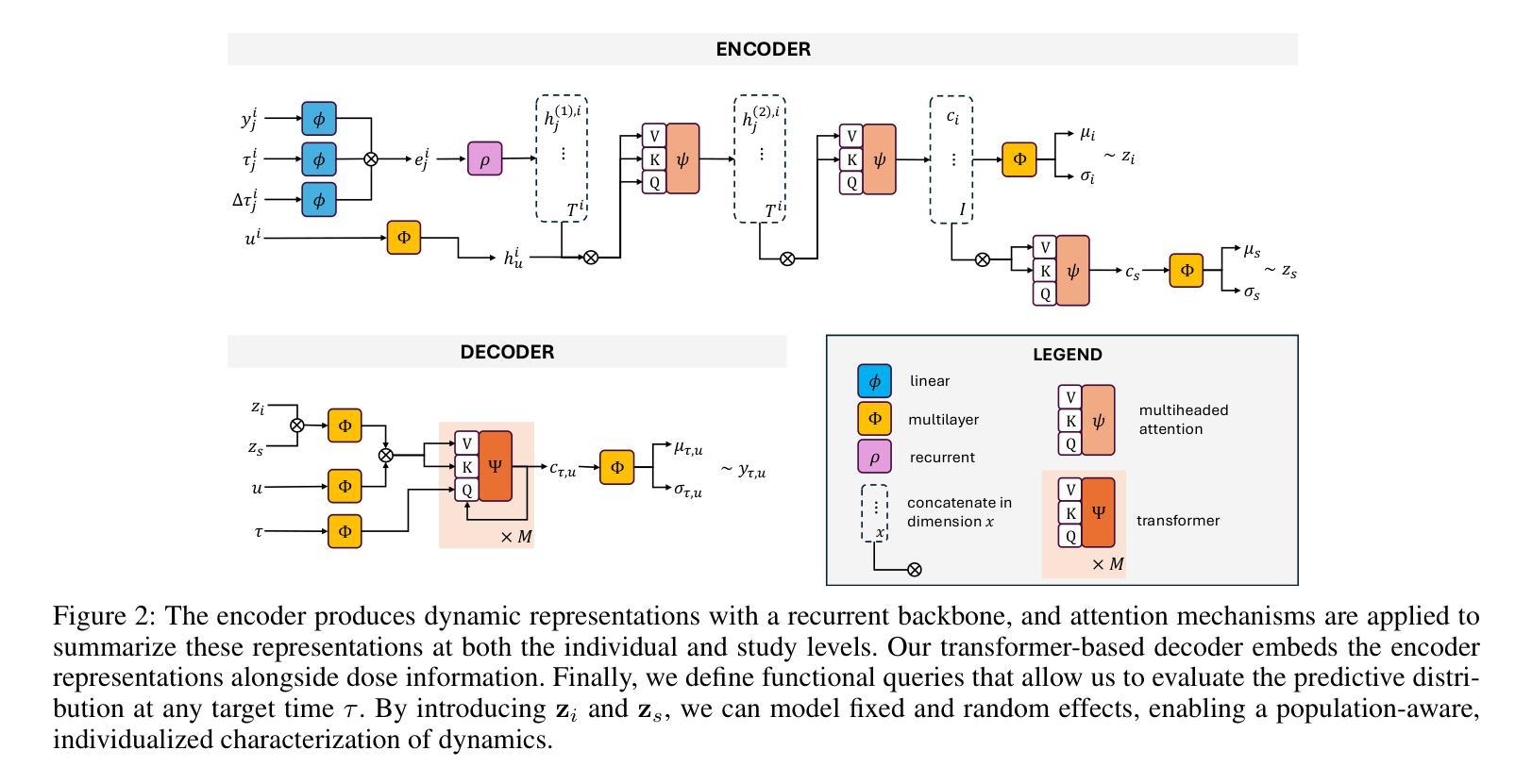
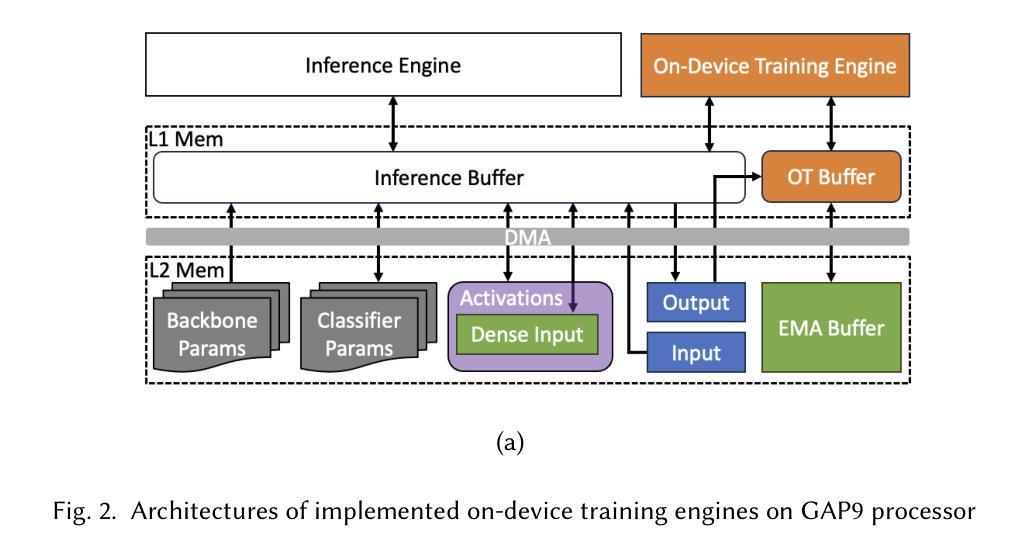
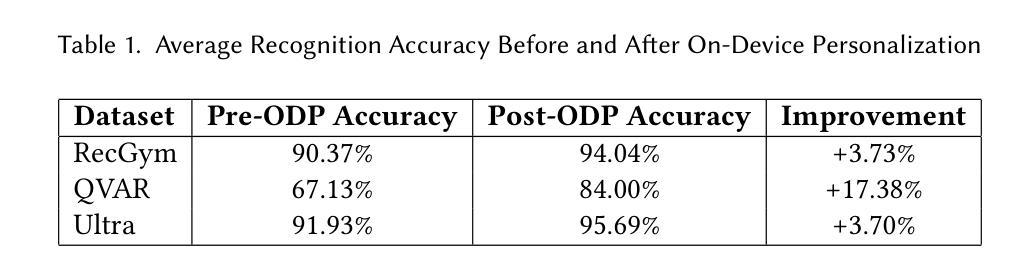
Bridging Generalization and Personalization in Human Activity Recognition via On-Device Few-Shot Learning
Authors:Pixi Kang, Julian Moosmann, Mengxi Liu, Bo Zhou, Michele Magno, Paul Lukowicz, Sizhen Bian
Human Activity Recognition (HAR) with different sensing modalities requires both strong generalization across diverse users and efficient personalization for individuals. However, conventional HAR models often fail to generalize when faced with user-specific variations, leading to degraded performance. To address this challenge, we propose a novel on-device few-shot learning framework that bridges generalization and personalization in HAR. Our method first trains a generalizable representation across users and then rapidly adapts to new users with only a few labeled samples, updating lightweight classifier layers directly on resource-constrained devices. This approach achieves robust on-device learning with minimal computation and memory cost, making it practical for real-world deployment. We implement our framework on the energy-efficient RISC-V GAP9 microcontroller and evaluate it on three benchmark datasets (RecGym, QVAR-Gesture, Ultrasound-Gesture). Across these scenarios, post-deployment adaptation improves accuracy by 3.73%, 17.38%, and 3.70%, respectively. These results demonstrate that few-shot on-device learning enables scalable, user-aware, and energy-efficient wearable human activity recognition by seamlessly uniting generalization and personalization. The related framework is open sourced for further research\footnote{https://github.com/kangpx/onlineTiny2023}.
人类活动识别(HAR)采用不同感知模式,需要强大的跨用户泛化能力和高效的个性化能力。然而,传统的HAR模型在面对用户特定变化时往往无法泛化,导致性能下降。为了应对这一挑战,我们提出了一种新型的设备端小样本学习框架,该框架能够在HAR中架起泛化与个性化之间的桥梁。我们的方法首先训练一个跨用户的通用表示,然后仅通过少量标记样本迅速适应新用户,直接在资源受限的设备上更新轻量级分类器层。这种方法实现了具有最小计算和内存成本稳健的设备端学习,使其成为现实世界部署的实际选择。我们在能效高的RISC-V GAP9微控制器上实现了我们的框架,并在三个基准数据集(RecGym、QVAR-Gesture、Ultrasound-Gesture)上对其进行了评估。在这些场景中,部署后的适应分别提高了3.73%、17.38%和3.70%的准确率。这些结果表明,小样本设备端学习能够通过无缝结合泛化和个性化,实现可扩展的、用户感知的和节能的可穿戴人类活动识别。相关框架已开源供进一步研究\footnote{https://github.com/kangpx/onlineTiny2023}。
论文及项目相关链接
Summary:针对人类活动识别(HAR)的不同感知模式,提出一种新型设备端少样本学习框架,融合跨用户的一般化和个体个性化需求。框架先训练跨用户的通用表示,再利用少量标注样本对新用户进行快速适应,直接在资源受限的设备上更新轻量级分类器层。该方法实现稳健的设备端学习,计算与内存成本低,适用于实际部署。在RISC-V GAP9微控制器上实现框架,并在三个基准数据集上评估,显示部署后适应性提高准确率。证明少样本学习可实现可扩展、用户友好和节能的可穿戴人类活动识别,融合一般化和个性化。
Key Takeaways:
- 提出一种新型少样本学习框架,适用于人类活动识别(HAR)。
- 框架融合了跨用户的一般化和个体用户的个性化需求。
- 通过训练通用表示和快速适应新用户的少量标注样本,实现稳健学习。
- 直接在资源受限的设备上更新轻量级分类器层。
- 框架适用于实际部署,计算与内存成本低。
- 在多个数据集上的评估显示,部署后的适应性提高了识别准确率。
点此查看论文截图

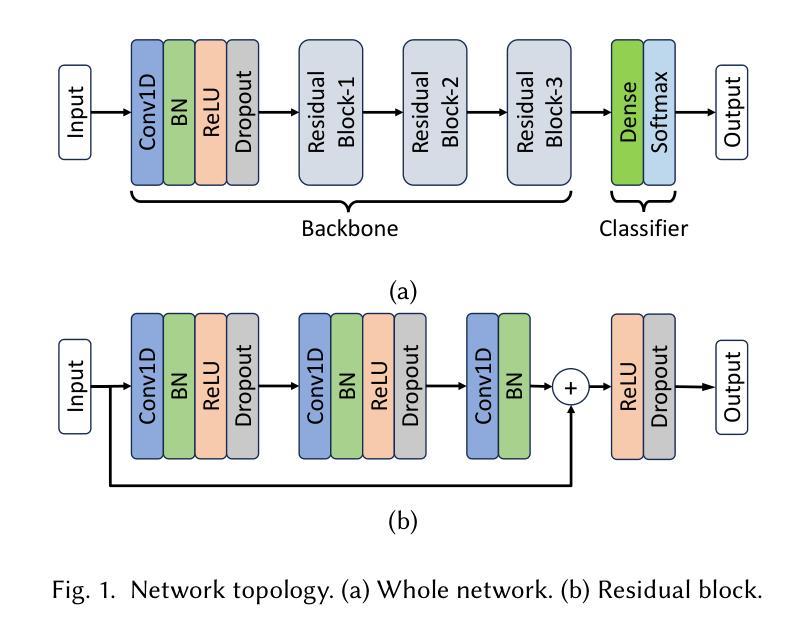
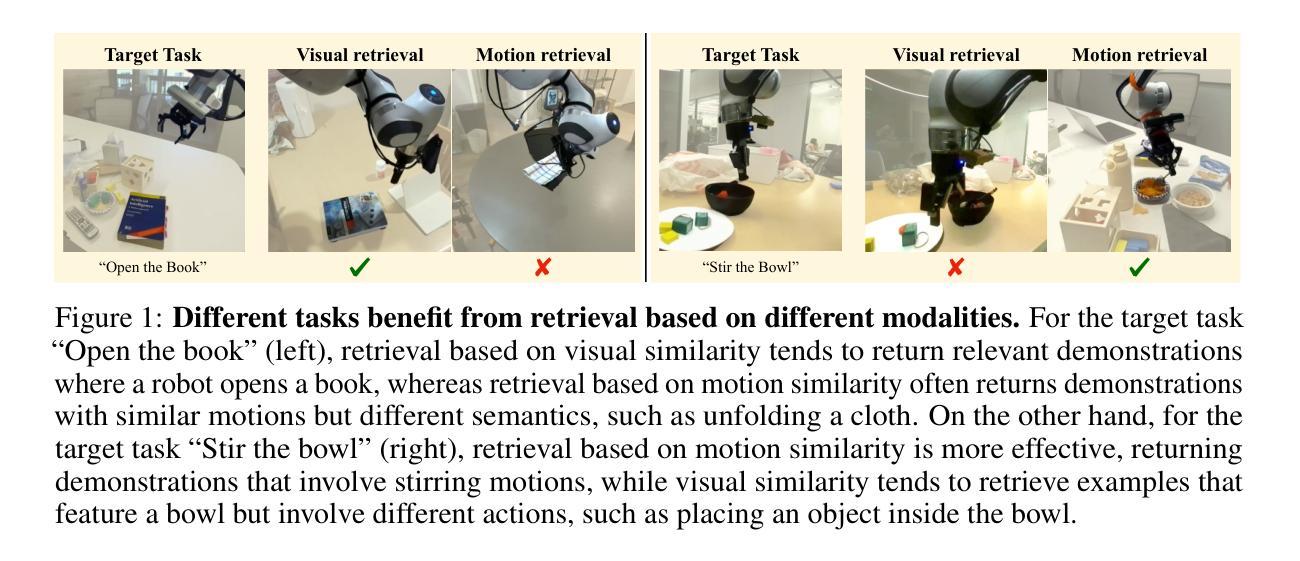
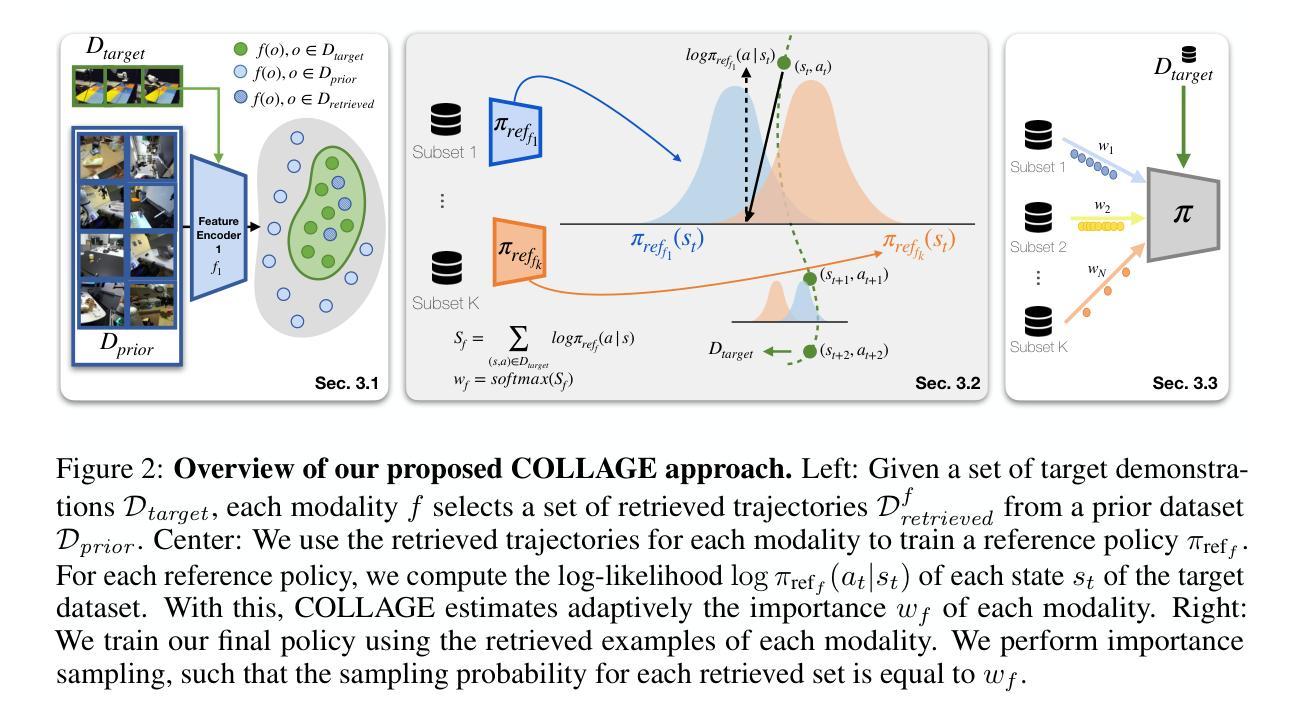
COLLAGE: Adaptive Fusion-based Retrieval for Augmented Policy Learning
Authors:Sateesh Kumar, Shivin Dass, Georgios Pavlakos, Roberto Martín-Martín
In this work, we study the problem of data retrieval for few-shot imitation learning: selecting data from a large dataset to train a performant policy for a specific task, given only a few target demonstrations. Prior methods retrieve data using a single-feature distance heuristic, assuming that the best demonstrations are those that most closely resemble the target examples in visual, semantic, or motion space. However, this approach captures only a subset of the relevant information and can introduce detrimental demonstrations, e.g., retrieving data from unrelated tasks due to similar scene layouts, or selecting similar motions from tasks with divergent goals. We present COLLAGE, a method for COLLective data AGgrEgation in few-shot imitation learning that uses an adaptive late fusion mechanism to guide the selection of relevant demonstrations based on a task-specific combination of multiple cues. COLLAGE follows a simple, flexible, and efficient recipe: it assigns weights to subsets of the dataset that are pre-selected using a single feature (e.g., appearance, shape, or language similarity), based on how well a policy trained on each subset predicts actions in the target demonstrations. These weights are then used to perform importance sampling during policy training, sampling data more densely or sparsely according to estimated relevance. COLLAGE is general and feature-agnostic, allowing it to combine any number of subsets selected by any retrieval heuristic, and to identify which subsets provide the greatest benefit for the target task. In extensive experiments, COLLAGE outperforms state-of-the-art retrieval and multi-task learning approaches by 5.1% in simulation across 10 tasks, and by 16.6% in the real world across 6 tasks, where we perform retrieval from the large-scale DROID dataset. More information at https://robin-lab.cs.utexas.edu/COLLAGE .
在这项工作中,我们研究了小样模仿学习的数据检索问题:从大型数据集中选择数据来训练针对特定任务的性能策略,仅使用少数目标演示。先前的方法使用单一特征距离启发式方法进行数据检索,假设最佳的演示是那些在视觉、语义或运动空间中最接近目标示例的演示。然而,这种方法只捕获了部分相关信息,并可能引入有害的演示,例如由于场景布局相似而从无关的任务中检索数据,或从具有不同目标的任务中选择相似的运动。我们提出了COLLAGE,这是一种用于小样模仿学习中的集体数据聚合方法。它使用自适应的后期融合机制,根据针对特定任务的多个线索组合来指导相关演示的选择。COLLAGE遵循简单、灵活和高效的方法:它为使用单一特征(例如外观、形状或语言相似性)预先选择的数据子集分配权重,基于在每个子集上训练的策略对目标演示的预测效果。这些权重然后被用于在策略训练期间执行重要性采样,根据估计的相关性更密集或更稀疏地采样数据。COLLAGE是通用的,与特征无关,能够结合任何数量的由任何检索启发式选择的数据子集,并确定哪些子集对目标任务提供最大的好处。在广泛的实验中,与最新检索和多任务学习方法相比,COLLAGE在模拟的10个任务上提高了5.1%的性能,在真实世界的6个任务上提高了16.6%的性能,其中我们从大规模DROID数据集中进行检索。更多信息请访问https://robin-lab.cs.utexas.edu/COLLAGE。
论文及项目相关链接
PDF Accepted at the Conference on Robot Learning (CoRL), 2025. Project page: https://robin-lab.cs.utexas.edu/COLLAGE
Summary
本文研究了小样学习中的数据采集问题。针对现有方法仅依赖单一特征距离启发式进行数据检索的局限性,提出了COLLAGE方法。该方法使用自适应后期融合机制,根据特定任务组合多种线索来指导相关演示的选择。实验表明,COLLAGE在模拟和真实世界中的多个任务上均优于现有检索和多任务学习方法。
Key Takeaways
- 研究背景:小样学习中的数据采集问题,即如何从大量数据集中选择用于训练高性能策略的数据。
- 问题现状:现有方法基于单一特征距离启发式进行数据检索,存在信息捕获不全和引入不相关演示的风险。
- 方法介绍:提出COLLAGE方法,采用自适应后期融合机制,根据任务特定组合多种线索来指导演示选择。
- COLLAGE特点:简单、灵活、高效,可结合任何数量的子集和任何检索启发式方法,并确定哪些子集对目标任务最有益。
- 实验结果:在模拟和真实世界的多个任务上,COLLAGE优于现有方法。
- 数据来源:从大型数据集DROID中进行数据检索。
点此查看论文截图


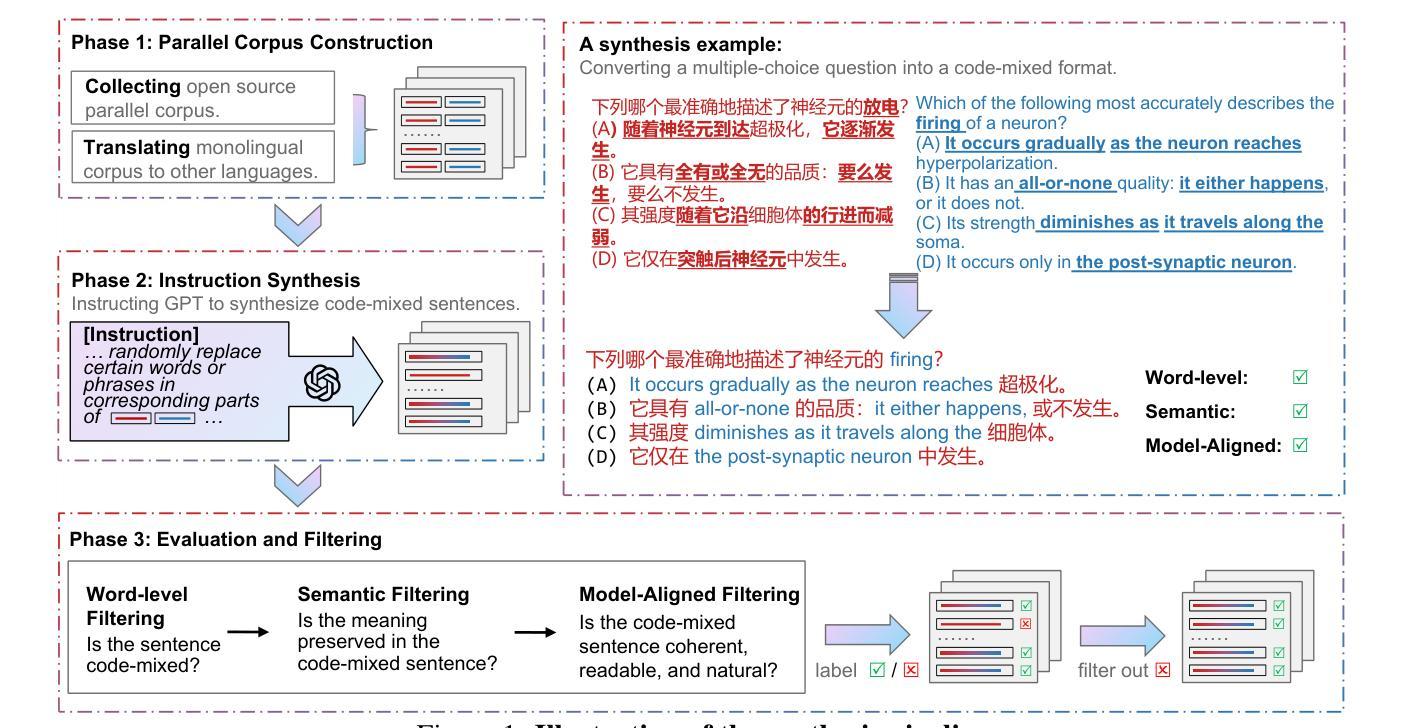
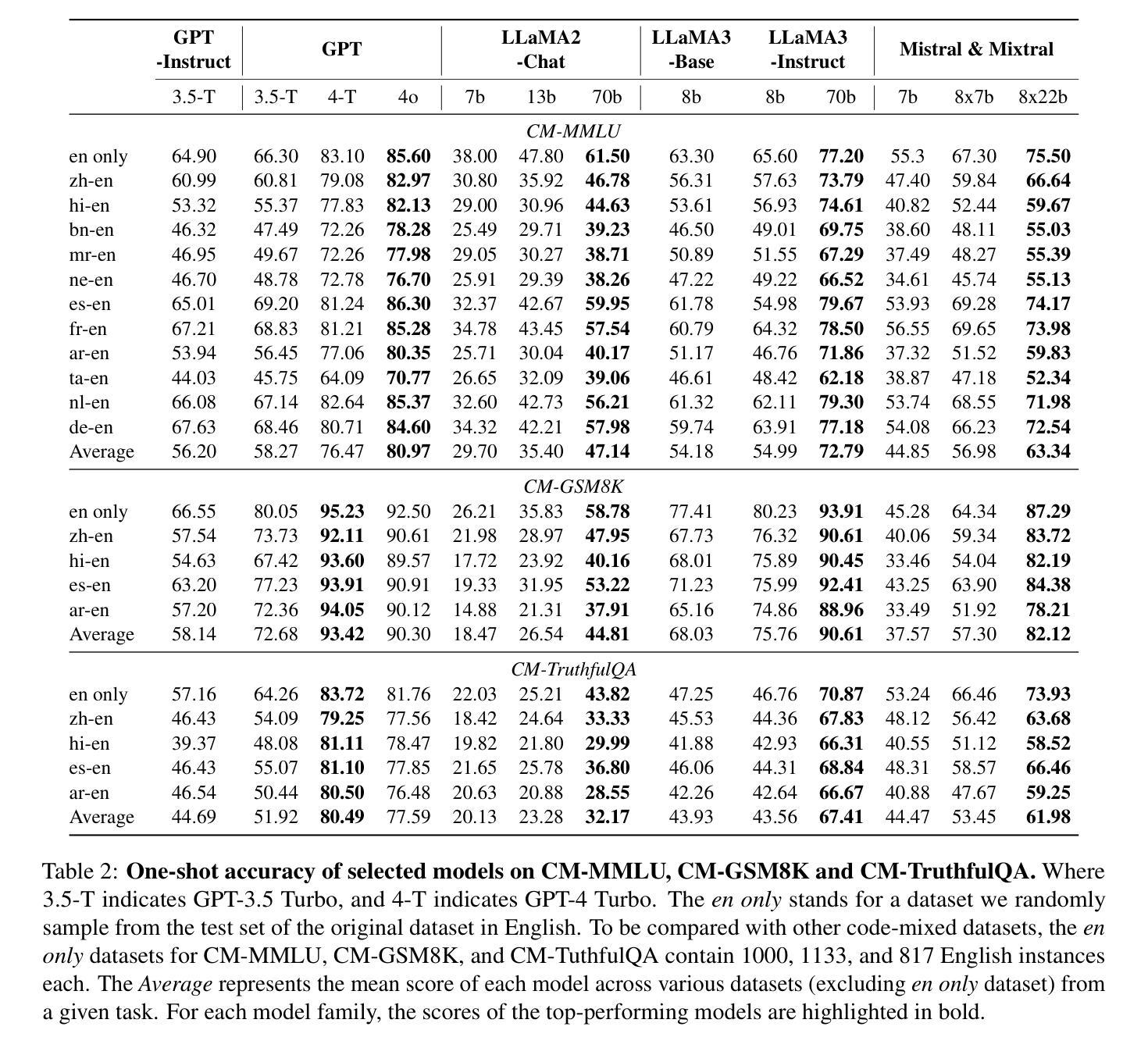
CodeMixBench: Evaluating Code-Mixing Capabilities of LLMs Across 18 Languages
Authors:Yilun Yang, Yekun Chai
Code-mixing, the practice of switching between languages within a conversation, poses unique challenges for traditional NLP. Existing benchmarks are limited by their narrow language pairs and tasks, failing to adequately assess large language models’ (LLMs) code-mixing abilities. Despite the recognized importance of code-mixing for multilingual users, research on LLMs in this context remains sparse. Additionally, current techniques for synthesizing code-mixed data are underdeveloped to generate code-mixing. In response, we introduce CodeMixBench, a comprehensive benchmark covering eight tasks, including three specific to LLMs and five traditional NLP tasks, and 18 languages across seven language families. We also propose a new method for generating large-scale synthetic code-mixed texts by combining word substitution with GPT-4 prompting. Our evaluation reveals consistent underperformance of LLMs on code-mixed datasets involving different language families. Enhancements in training data size, model scale, and few-shot learning could improve their performance. The code and dataset are available at https://github.com/Jeromeyluck/CodeMixBench.
代码混合(code-mixing)指的是在对话中切换不同语言的实践,这为传统自然语言处理(NLP)带来了独特的挑战。现有的基准测试受限于其狭窄的语言对和任务范围,无法充分评估大型语言模型(LLMs)的代码混合能力。尽管代码混合对于多语言用户的重要性已经得到认识,但在此背景下的LLM研究仍然稀少。此外,当前生成代码混合数据的合成技术尚不成熟。为了应对这些问题,我们推出了CodeMixBench,这是一个涵盖八个任务的全面基准测试,包括三个专门针对LLMs的任务和五个传统NLP任务,涉及七个语言家族的18种语言。我们还提出了一种新的方法,通过结合词替换和GPT-4提示来生成大规模的代码混合文本。我们的评估发现,在不同语言家族的代码混合数据集上,LLMs的表现持续不佳。通过增加训练数据大小、模型规模和少样本学习,可以改善其性能。相关代码和数据集可在https://github.com/Jeromeyluck/CodeMixBench获得。
论文及项目相关链接
PDF EMNLP 2025
Summary
本文介绍了传统NLP中代码混合(即在对话中切换语言)带来的挑战。现有的基准测试因语言对和任务范围有限,无法充分评估大型语言模型(LLMs)的代码混合能力。虽然代码混合对于多语言用户的重要性得到了认可,但关于LLMs在此背景下的研究仍然很少。此外,当前生成代码混合数据的合成技术尚不成熟。因此,本文引入了CodeMixBench基准测试,涵盖八项任务,包括三项针对LLMs的任务和五项传统NLP任务,涉及18种语言和七个语言家族。同时提出了一种新的方法,通过结合词替换和GPT-4提示来生成大规模的代码混合文本。评估结果显示大型语言模型在处理涉及不同语言家族的混合代码集时表现不佳。增加训练数据量、扩大模型规模以及采用小样本学习可望改善其表现。
Key Takeaways
- 代码混合(语言切换)在传统NLP中构成挑战。
- 当前基准测试对大型语言模型的代码混合能力评估不足。
- CodeMixBench基准测试涵盖八项任务和多个语言家族。
- 提出了一种结合词替换和GPT-4提示生成大规模代码混合文本的新方法。
- 大型语言模型在处理涉及不同语言家族的混合代码集时表现不佳。
- 增加训练数据量、扩大模型规模以及采用小样本学习可能有助于提高模型性能。
点此查看论文截图


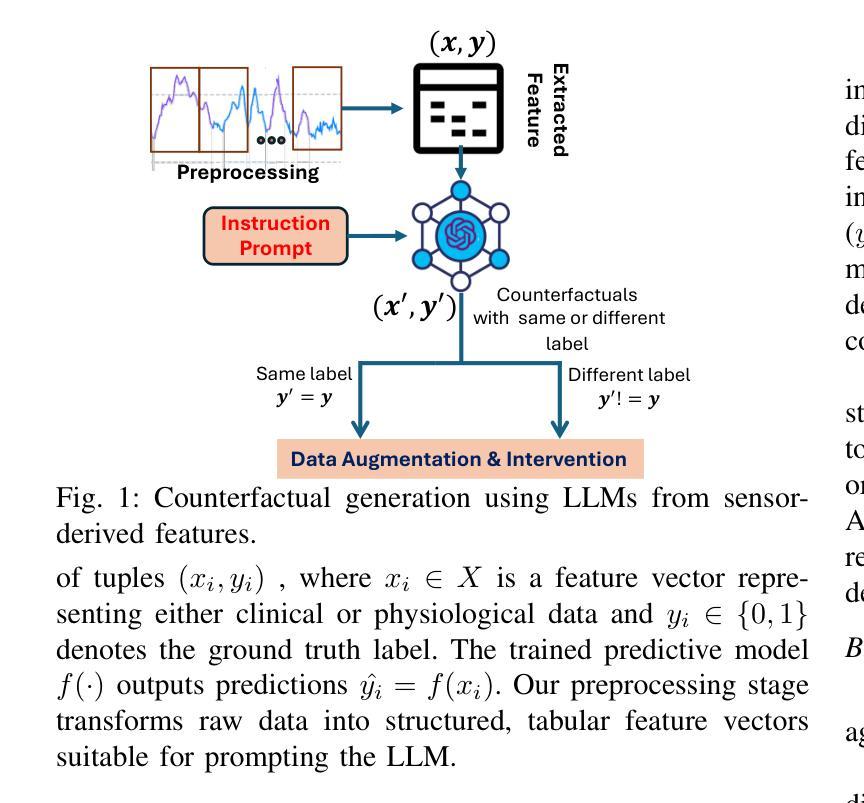
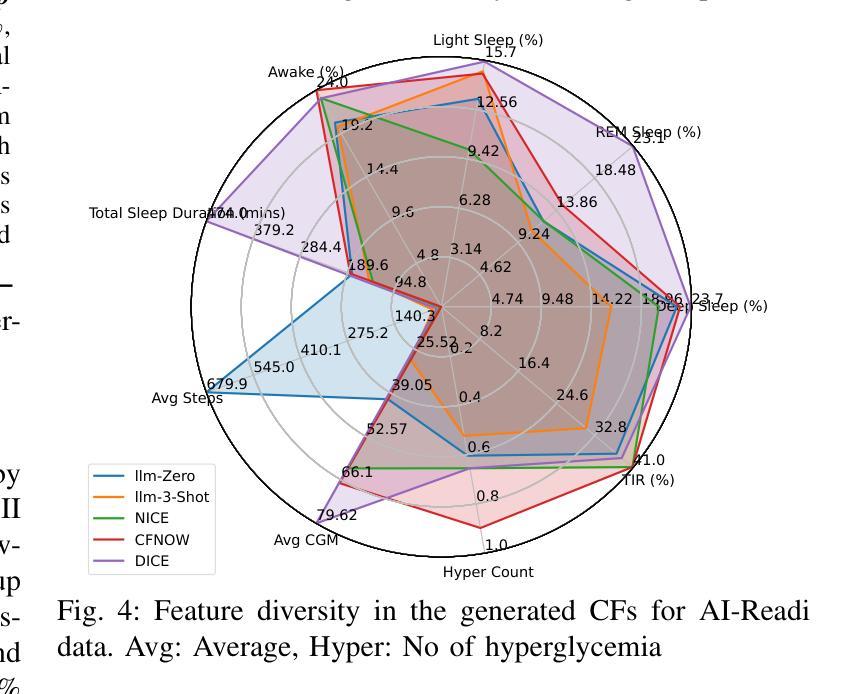
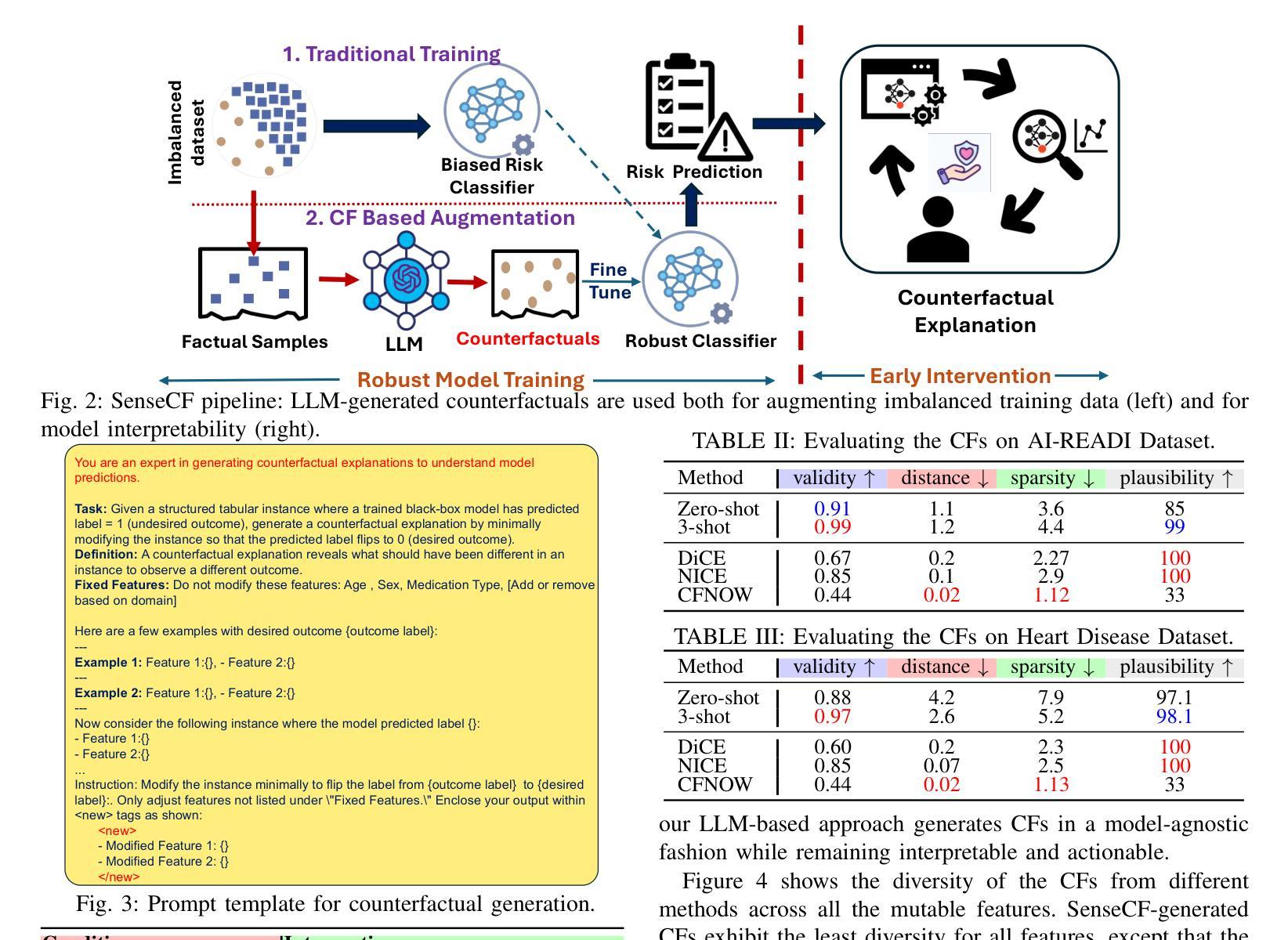
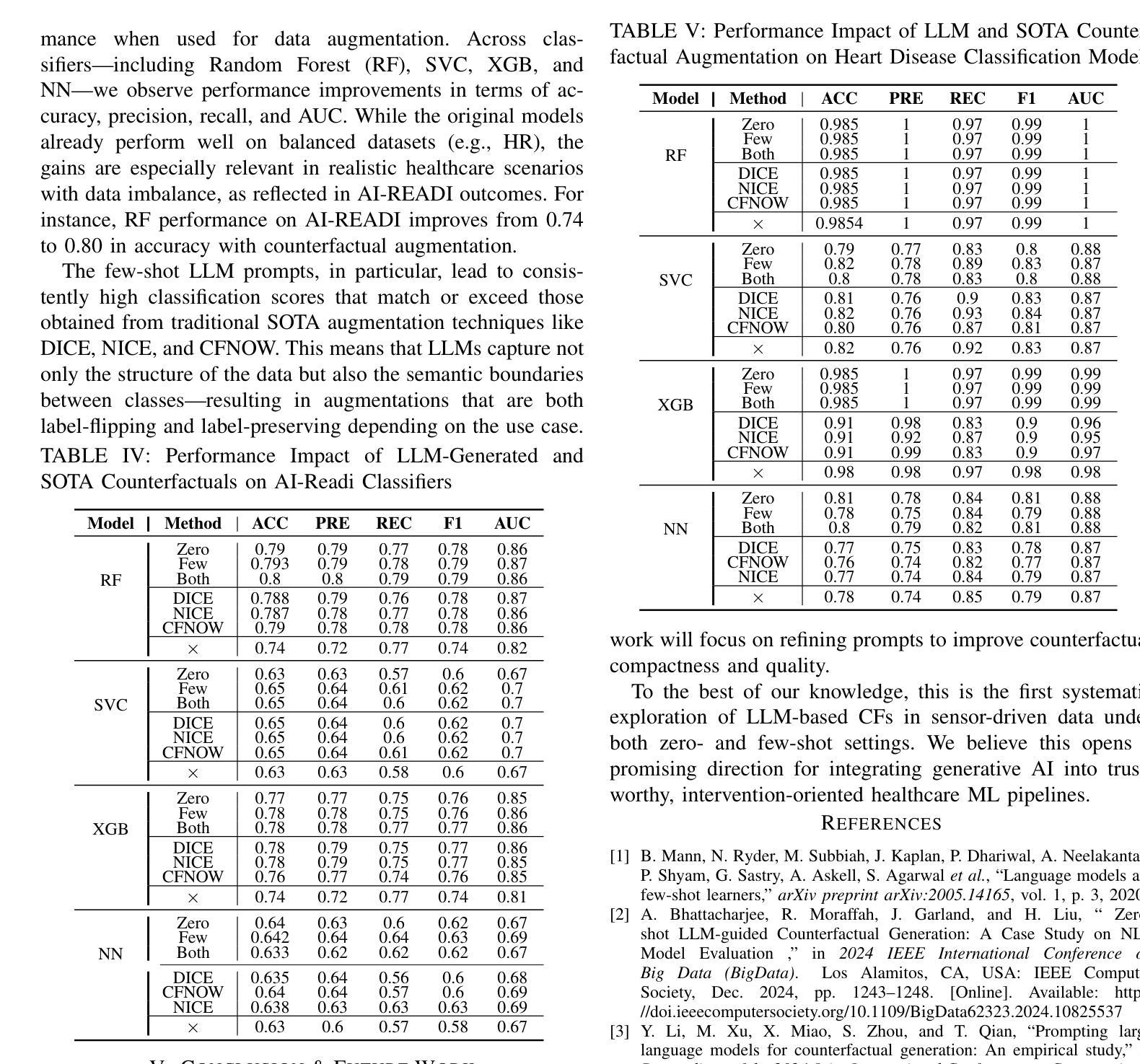
SenseCF: LLM-Prompted Counterfactuals for Intervention and Sensor Data Augmentation
Authors:Shovito Barua Soumma, Asiful Arefeen, Stephanie M. Carpenter, Melanie Hingle, Hassan Ghasemzadeh
Counterfactual explanations (CFs) offer human-centric insights into machine learning predictions by highlighting minimal changes required to alter an outcome. Therefore, CFs can be used as (i) interventions for abnormality prevention and (ii) augmented data for training robust models. In this work, we explore large language models (LLMs), specifically GPT-4o-mini, for generating CFs in a zero-shot and three-shot setting. We evaluate our approach on two datasets: the AI-Readi flagship dataset for stress prediction and a public dataset for heart disease detection. Compared to traditional methods such as DiCE, CFNOW, and NICE, our few-shot LLM-based approach achieves high plausibility (up to 99%), strong validity (up to 0.99), and competitive sparsity. Moreover, using LLM-generated CFs as augmented samples improves downstream classifier performance (an average accuracy gain of 5%), especially in low-data regimes. This demonstrates the potential of prompt-based generative techniques to enhance explainability and robustness in clinical and physiological prediction tasks. Code base: github.com/shovito66/SenseCF.
因果解释(CFs)通过强调改变结果所需的最小变化,为机器学习的预测提供了以人类为中心的洞察。因此,因果解释可以用作(i)异常预防的干预措施和(ii)增强数据以训练稳健模型。在这项工作中,我们探索了大型语言模型(LLM),特别是GPT-4o-mini,在零样本和三样本环境中生成因果解释。我们在两个数据集上评估了我们的方法:用于压力预测的AI-Readi旗舰数据集和用于心脏病检测的公开数据集。与传统的DiCE、CFNOW和NICE等方法相比,我们基于少量样本的LLM方法实现了高达99%的可信度和高达0.99的强有效性,并且稀疏性具有竞争力。此外,使用LLM生成的因果解释作为增强样本提高了下游分类器的性能(平均准确率提高5%),特别是在数据较少的情况下。这证明了基于提示的生成技术增强临床和生理预测任务的可解释性和稳健性的潜力。代码库:github.com/shovito66/SenseCF。
论文及项目相关链接
PDF Accepted at the IEEE-EMBS International Conference on Body Sensor Networks (IEEE-EMBS BSN) 2025, LA, CA, USA
Summary
这篇论文探讨了使用大型语言模型(LLMs)生成计数器事实解释(CFs)的方法,并将其应用于机器学习的预测解释中。研究集中在通过GPT-4o-mini生成CFs,并在零镜头和三镜头设置下进行评估。该研究在AI-Readi旗舰数据集和公共心脏病检测数据集上验证了方法的有效性,并实现了高可信度、有效性和竞争性稀疏性。此外,使用LLM生成的CFs作为增强样本可以提高下游分类器的性能,特别是在低数据条件下。这展示了基于提示的生成技术在临床和生理预测任务中提高解释性和稳健性的潜力。
Key Takeaways
- 计数器事实解释(CFs)可以突出显示改变结果所需的最小变化,为机器学习的预测提供以人类为中心的见解。
- LLMs,特别是GPT-4o-mini,被用于生成CFs,并在零镜头和三镜头设置下进行评估。
- 在AI-Readi旗舰数据集和公共心脏病检测数据集上,LLM方法实现了高可信度、有效性和竞争性稀疏性。
- 使用LLM生成的CFs作为增强样本,可以提高下游分类器的性能,尤其在低数据条件下。
- LLM方法显示出在解释性和稳健性方面提升临床和生理预测任务的潜力。
- 该研究的代码库位于github.com/shovito66/SenseCF。
- CFs可用于异常预防(作为干预措施)和训练稳健模型(作为增强数据)。
点此查看论文截图

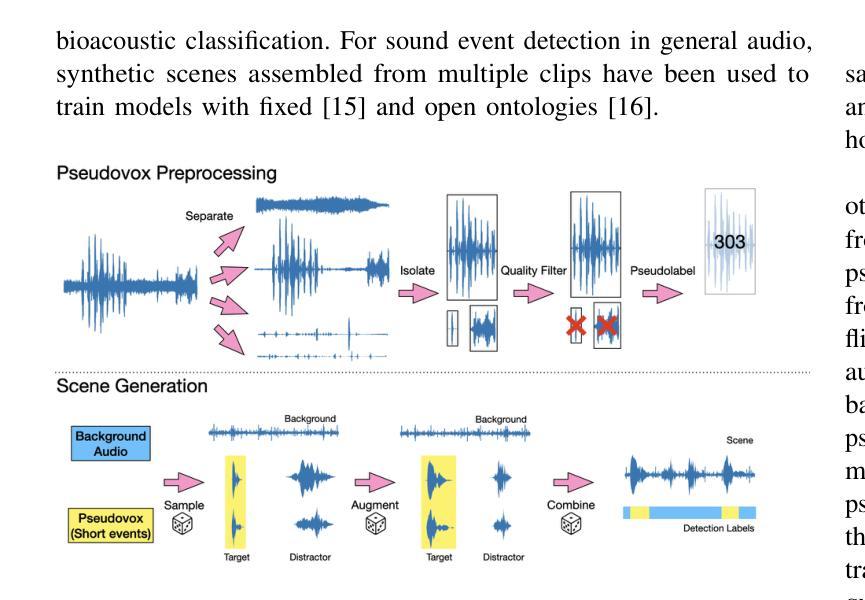
Synthetic data enables context-aware bioacoustic sound event detection
Authors:Benjamin Hoffman, David Robinson, Marius Miron, Vittorio Baglione, Daniela Canestrari, Damian Elias, Eva Trapote, Felix Effenberger, Maddie Cusimano, Masato Hagiwara, Olivier Pietquin
We propose a methodology for training foundation models that enhances their in-context learning capabilities within the domain of bioacoustic signal processing. We use synthetically generated training data, introducing a domain-randomization-based pipeline that constructs diverse acoustic scenes with temporally strong labels. We generate over 8.8 thousand hours of strongly-labeled audio and train a query-by-example, transformer-based model to perform few-shot bioacoustic sound event detection. Our second contribution is a public benchmark of 13 diverse few-shot bioacoustics tasks. Our model outperforms previously published methods, and improves relative to other training-free methods by $64%$. We demonstrate that this is due to increase in model size and data scale, as well as algorithmic improvements. We make our trained model available via an API, to provide ecologists and ethologists with a training-free tool for bioacoustic sound event detection.
我们提出了一种训练基础模型的方法,旨在提高其在生物声信号处理领域的上下文学习能力。我们使用合成生成的训练数据,引入基于域随机化的管道,构建具有时间上强标签的多样化声音场景。我们生成了超过8800小时的强标签音频,并训练了一个基于查询示例的变压器模型,以执行少数生物声音事件检测。我们的第二个贡献是包含13个多样少数生物声学任务的公开基准测试。我们的模型优于先前发布的方法,与其他无训练方法的相对改进幅度达到64%。我们证明这是由于模型大小和数据规模的增加以及算法的改进所致。我们通过API提供经过训练的模型,为生态学家和动物行为学家提供无需训练的生物声音事件检测工具。
论文及项目相关链接
Summary:
提出一种训练基础模型的方法,增强其在生物声信号处理领域的上下文学习能力。通过合成生成训练数据,引入基于域随机化的管道构建多样的声音场景,并带有时间强标签。训练基于查询示例的转换模型进行少量生物声音事件检测。同时提供公开基准测试和模型API,用于生态学和动物行为学研究人员使用。
Key Takeaways:
- 提出一种增强基础模型在生物声信号处理领域上下文学习能力的方法。
- 通过合成数据训练模型,使用基于域随机化的管道构建多样声音场景,并带有时间强标签。
- 训练了基于查询示例的转换模型进行少量生物声音事件检测。
- 公开了包含13种不同生物声学任务的基准测试。
- 模型表现优于先前发布的方法,相较于其他无训练方法提高了64%。
- 模型规模和数据规模的增加以及算法的改进是性能提升的主要原因。
点此查看论文截图

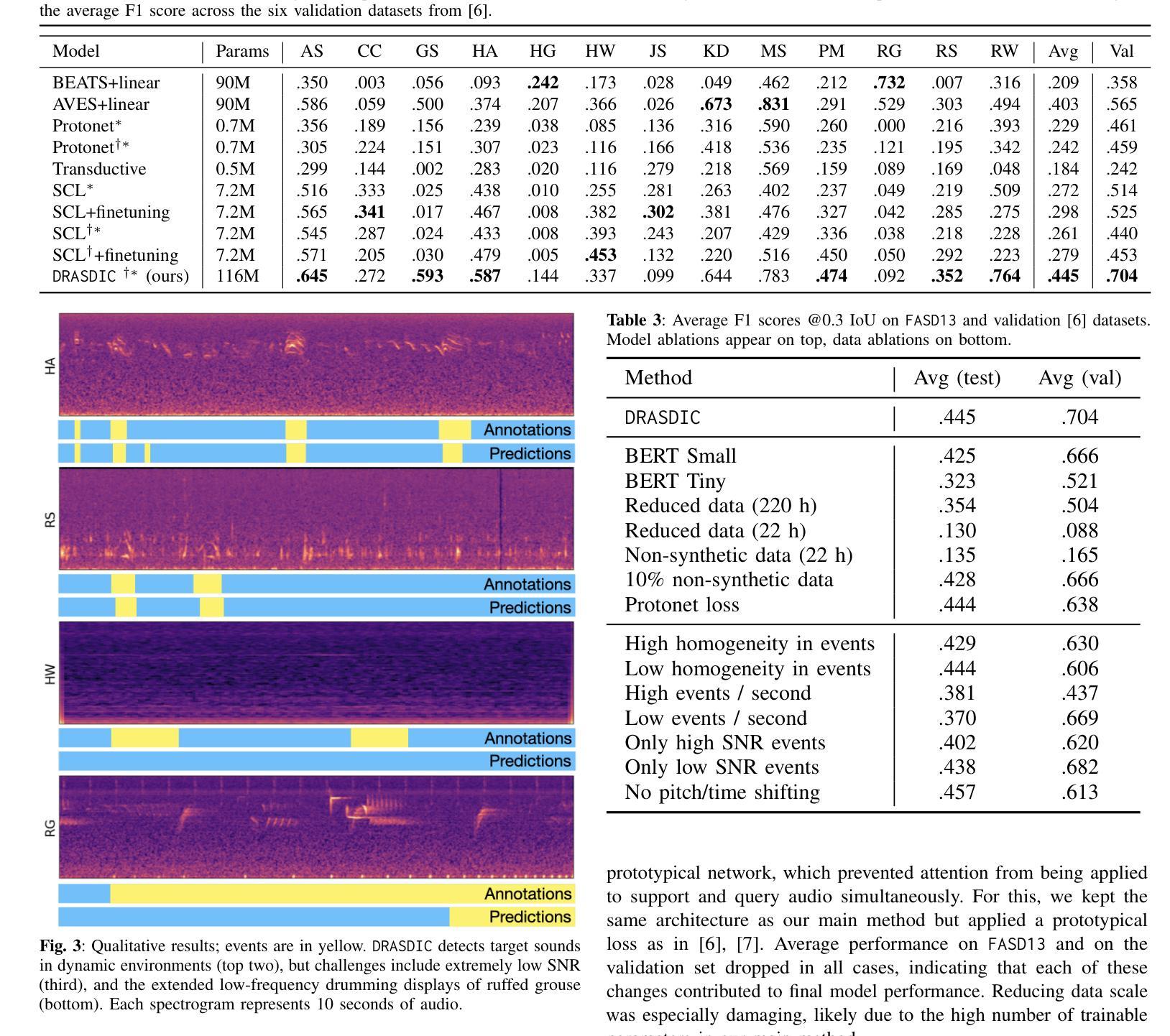
Knowledge Editing through Chain-of-Thought
Authors:Changyue Wang, Weihang Su, Qingyao Ai, Yichen Tang, Yiqun Liu
Knowledge Editing is a technique that updates large language models (LLMs) with new information to maintain their world knowledge. This approach avoids the need to rebuild the model from scratch, thereby addressing the high costs associated with frequent retraining. Among these, the in-context editing paradigm stands out for its effectiveness in integrating new knowledge while preserving the model’s original capabilities. Despite its potential, existing in-context knowledge editing methods are often task-specific, focusing primarily on multi-hop QA tasks using structured knowledge triples. Moreover, their reliance on few-shot prompting for task decomposition makes them unstable and less effective in generalizing across diverse tasks. In response to these limitations, we propose EditCoT, a novel knowledge editing framework that flexibly and efficiently updates LLMs across various tasks without retraining. EditCoT works by generating a chain-of-thought (CoT) for a given input and then iteratively refining this CoT process using a CoT editor based on updated knowledge. We evaluate EditCoT across a diverse range of benchmarks, covering multiple languages and tasks. The results demonstrate that our approach achieves state-of-the-art performance while offering superior generalization, effectiveness, and stability compared to existing methods, marking a significant advancement in the field of knowledge updating. The code and data of EditCoT are available at: https://github.com/bebr2/EditCoT .
知识编辑是一种更新大型语言模型(LLM)以维持其世界知识的新信息的技术。这种方法避免了从零开始重建模型的需要,从而解决了与频繁重新训练相关的高成本问题。在这些之中,上下文编辑范式因其能够在集成新知识的同时保留模型的原始功能而脱颖而出。尽管其具有潜力,但现有的上下文知识编辑方法往往是任务特定的,主要关注使用结构化知识三元组的多跳问答任务。此外,它们对少数提示的任务分解的依赖,使它们在跨不同任务泛化时变得不稳定且效果较差。为了应对这些局限性,我们提出了EditCoT,这是一种新型知识编辑框架,能够灵活有效地更新各种任务的LLM,而无需重新训练。EditCoT通过为给定输入生成思维链(CoT),然后使用基于更新知识的CoT编辑器迭代优化这一思维链过程。我们在涵盖多种语言和任务的多样化基准测试上对EditCoT进行了评估。结果表明,我们的方法达到了最先进的性能,与现有方法相比,在泛化能力、有效性和稳定性方面表现出优势,标志着知识更新领域的一个重大进展。EditCoT的代码和数据可在:https://github.com/bebr2/EditCoT上找到。
论文及项目相关链接
Summary
知识编辑技术是一种更新大型语言模型(LLM)的新信息以维持其世界知识的方法。该技术无需从零开始重建模型,从而降低了频繁重新训练的高成本。其中,上下文编辑范式在集成新知识的同时保持模型的原始功能方面表现出卓越的效果。针对现有上下文知识编辑方法的局限性和不足,提出了EditCoT这一新的知识编辑框架,它能够灵活、高效地更新各种任务下的LLM,而无需重新训练。EditCoT通过生成给定输入的思维链(CoT),然后使用基于更新知识的CoT编辑器进行迭代改进来实现这一点。我们在多个语言和任务的基准测试上对EditCoT进行了评估,结果表明,该方法在性能、通用性、有效性和稳定性方面均优于现有方法,标志着知识更新领域的一个重大进展。
Key Takeaways
- 知识编辑技术用于更新大型语言模型的世界知识,避免重建模型的昂贵成本。
- 上下文编辑范式能够集成新知识同时保持模型的原始功能。
- 现有上下文知识编辑方法具有任务特定性,对多跳问答任务使用结构化知识三元组,且在跨任务泛化方面表现不稳定。
- EditCoT是一个新的知识编辑框架,能够灵活、高效地在各种任务下更新LLM,无需重新训练。
- EditCoT通过生成思维链并使用基于更新知识的编辑器进行迭代改进来实现其效果。
- EditCoT在多个语言和任务的基准测试上表现出卓越的性能、泛化能力、有效性和稳定性。
点此查看论文截图

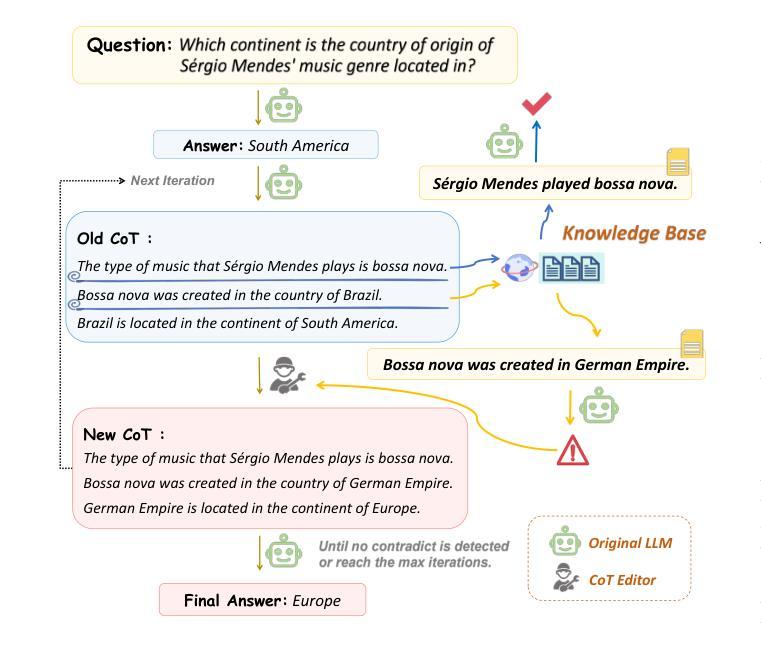
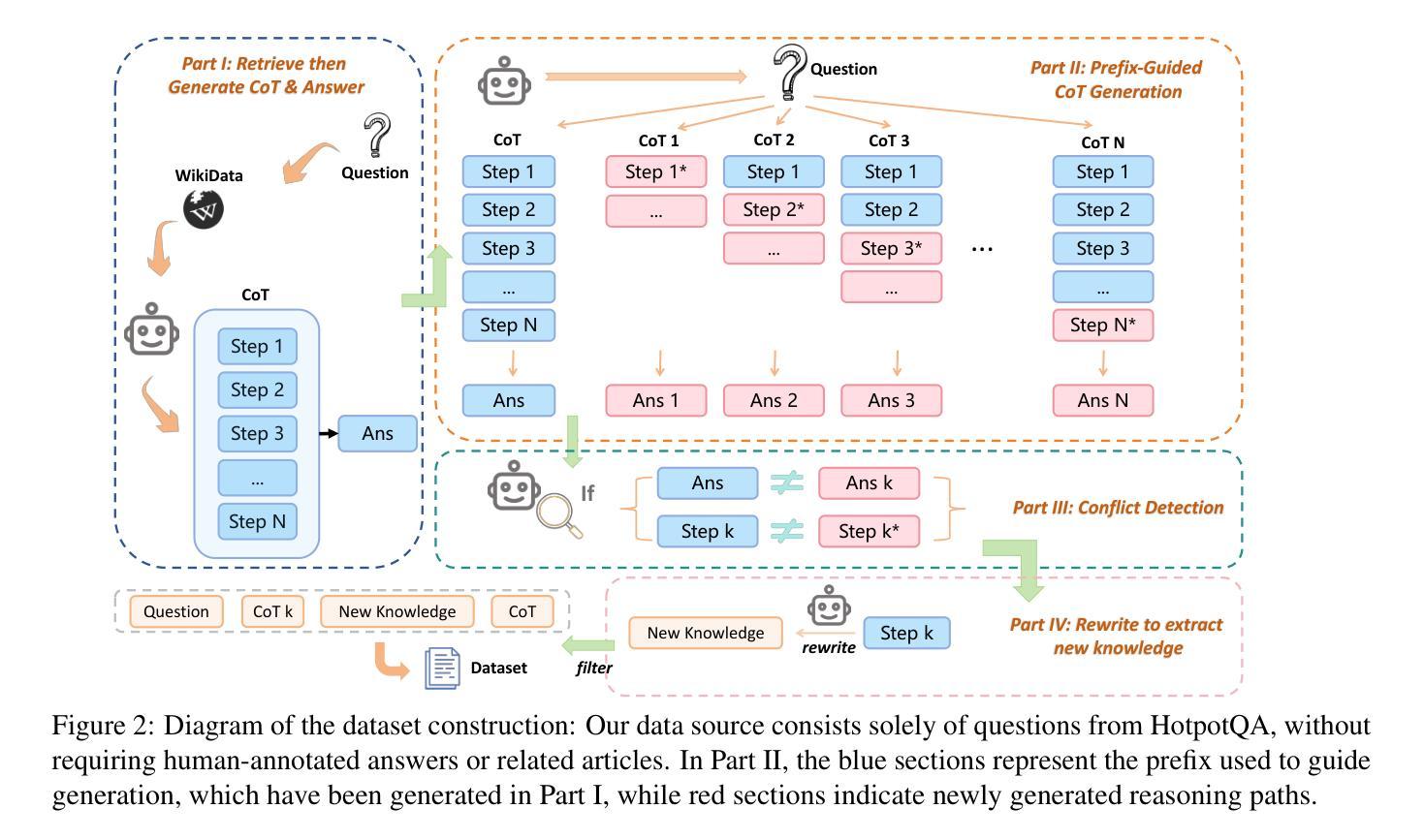

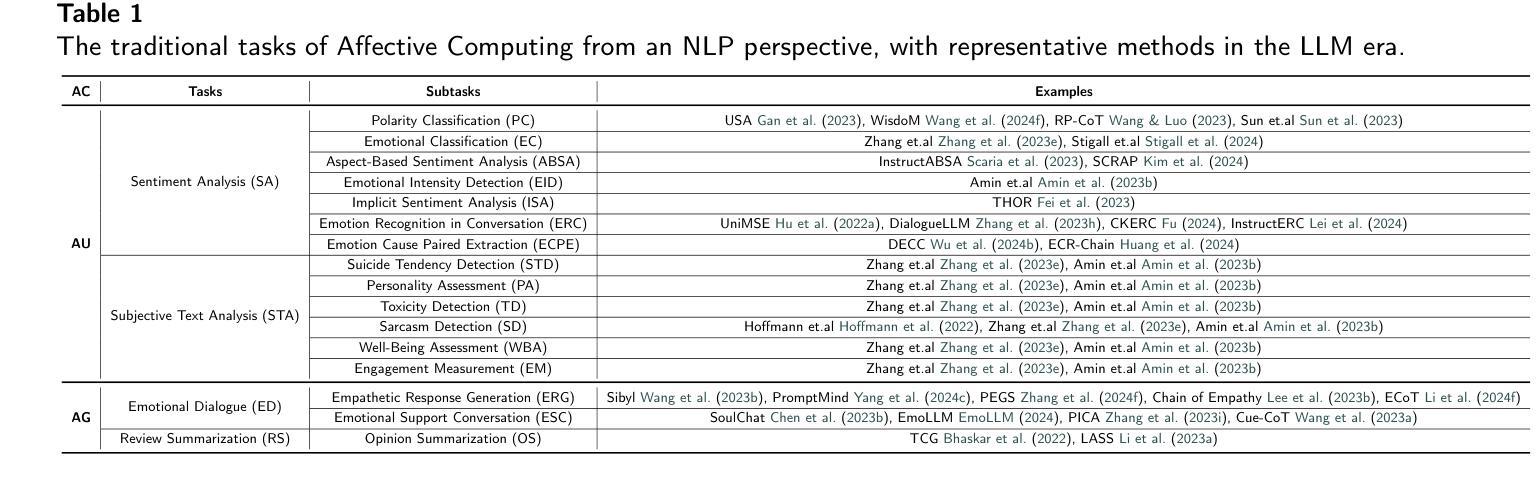
Affective Computing in the Era of Large Language Models: A Survey from the NLP Perspective
Authors:Yiqun Zhang, Xiaocui Yang, Xingle Xu, Zeran Gao, Yijie Huang, Shiyi Mu, Shi Feng, Daling Wang, Yifei Zhang, Kaisong Song, Ge Yu
Affective Computing (AC) integrates computer science, psychology, and cognitive science to enable machines to recognize, interpret, and simulate human emotions across domains such as social media, finance, healthcare, and education. AC commonly centers on two task families: Affective Understanding (AU) and Affective Generation (AG). While fine-tuned pre-trained language models (PLMs) have achieved solid AU performance, they often generalize poorly across tasks and remain limited for AG, especially in producing diverse, emotionally appropriate responses. The advent of Large Language Models (LLMs) (e.g., ChatGPT and LLaMA) has catalyzed a paradigm shift by offering in-context learning, broader world knowledge, and stronger sequence generation. This survey presents an NLP-oriented overview of AC in the LLM era. We (i) consolidate traditional AC tasks and preliminary LLM-based studies; (ii) review adaptation techniques that improve AU/AG, including Instruction Tuning (full and parameter-efficient methods such as LoRA, P-/Prompt-Tuning), Prompt Engineering (zero/few-shot, chain-of-thought, agent-based prompting), and Reinforcement Learning. For the latter, we summarize RL from human preferences (RLHF), verifiable/programmatic rewards (RLVR), and AI feedback (RLAIF), which provide preference- or rule-grounded optimization signals that can help steer AU/AG toward empathy, safety, and planning, achieving finer-grained or multi-objective control. To assess progress, we compile benchmarks and evaluation practices for both AU and AG. We also discuss open challenges-from ethics, data quality, and safety to robust evaluation and resource efficiency-and outline research directions. We hope this survey clarifies the landscape and offers practical guidance for building affect-aware, reliable, and responsible LLM systems.
情感计算(AC)融合了计算机科学、心理学和认知科学,使机器能够在社交媒体、金融、医疗保健和教育等领域识别、解释和模拟人类情绪。情感计算通常围绕两个任务家族:情感理解(AU)和情感生成(AG)。虽然经过微调预训练语言模型(PLM)在AU方面表现良好,但它们往往跨任务泛化能力较差,在AG方面仍存在局限性,尤其是在生成多样且情感恰当的反应方面。大型语言模型(LLM)(例如ChatGPT和LLaMA)的出现,通过提供上下文学习、更广泛的世界知识和更强的序列生成能力,催化了一种范式转变。这篇综述文章介绍了LLM时代的情感计算(AC)的NLP相关概述。我们(i)整合了传统的AC任务和基于LLM的初步研究;(ii)回顾了提高AU/AG的适应技术,包括指令微调(全面和参数高效的方法,如LoRA、P-/Prompt-Tuning)、提示工程(零/少样本、思维链、基于代理的提示)和强化学习。对于后者,我们总结了人类偏好强化学习(RLHF)、可验证/程序化奖励(RLVR)和人工智能反馈(RLAIF),这些提供偏好或规则基础的优化信号,有助于引导AU/AG朝向同理心、安全和规划,实现更精细或多目标控制。为了评估进展,我们汇总了AU和AG的基准测试和评估实践。我们还讨论了从伦理、数据质量和安全到稳健评估和资源效率的开放挑战,并概述了研究方向。我们希望这篇综述能澄清情感计算的景观,并为构建知情、可靠和负责任的LLM系统提供实用指导。
论文及项目相关链接
PDF Compared with the previous version, reinforcement learning has been added (as a new section), including RLHF, RLVR, and RLAIF
Summary
本文介绍了情感计算(AC)领域的研究进展,特别是大型语言模型(LLM)在该领域的应用。文章概述了情感理解(AU)和情感生成(AG)两大任务家族,指出预训练语言模型在AU方面的表现良好,但在AG方面的表现仍需提高。文章还介绍了适应技术,如指令调整、提示工程强化学习等,并讨论了挑战和研究方向。
Key Takeaways
- 情感计算(AC)结合了计算机科学、心理学和认知科学,使机器能够识别、解释和模拟人类情感。
- AC主要关注两大任务:情感理解(AU)和情感生成(AG)。
- 预训练语言模型在AU方面表现良好,但在AG方面的泛化能力有限。
- 大型语言模型(LLM)的出现提供了上下文学习、广泛的世界知识和强大的序列生成能力,推动了AC的发展。
- 适应技术如指令调整、提示工程和强化学习可改善AU/AG。
- 强化学习从人类偏好、可验证的程序奖励和AI反馈等方面为AU/AG提供了优化信号。
点此查看论文截图


MedualTime: A Dual-Adapter Language Model for Medical Time Series-Text Multimodal Learning
Authors:Jiexia Ye, Weiqi Zhang, Ziyue Li, Jia Li, Meng Zhao, Fugee Tsung
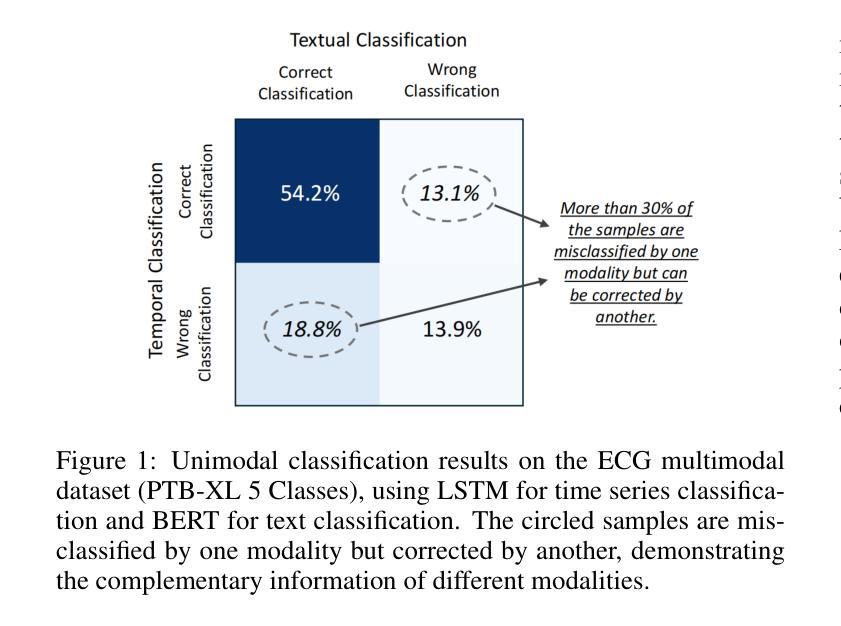
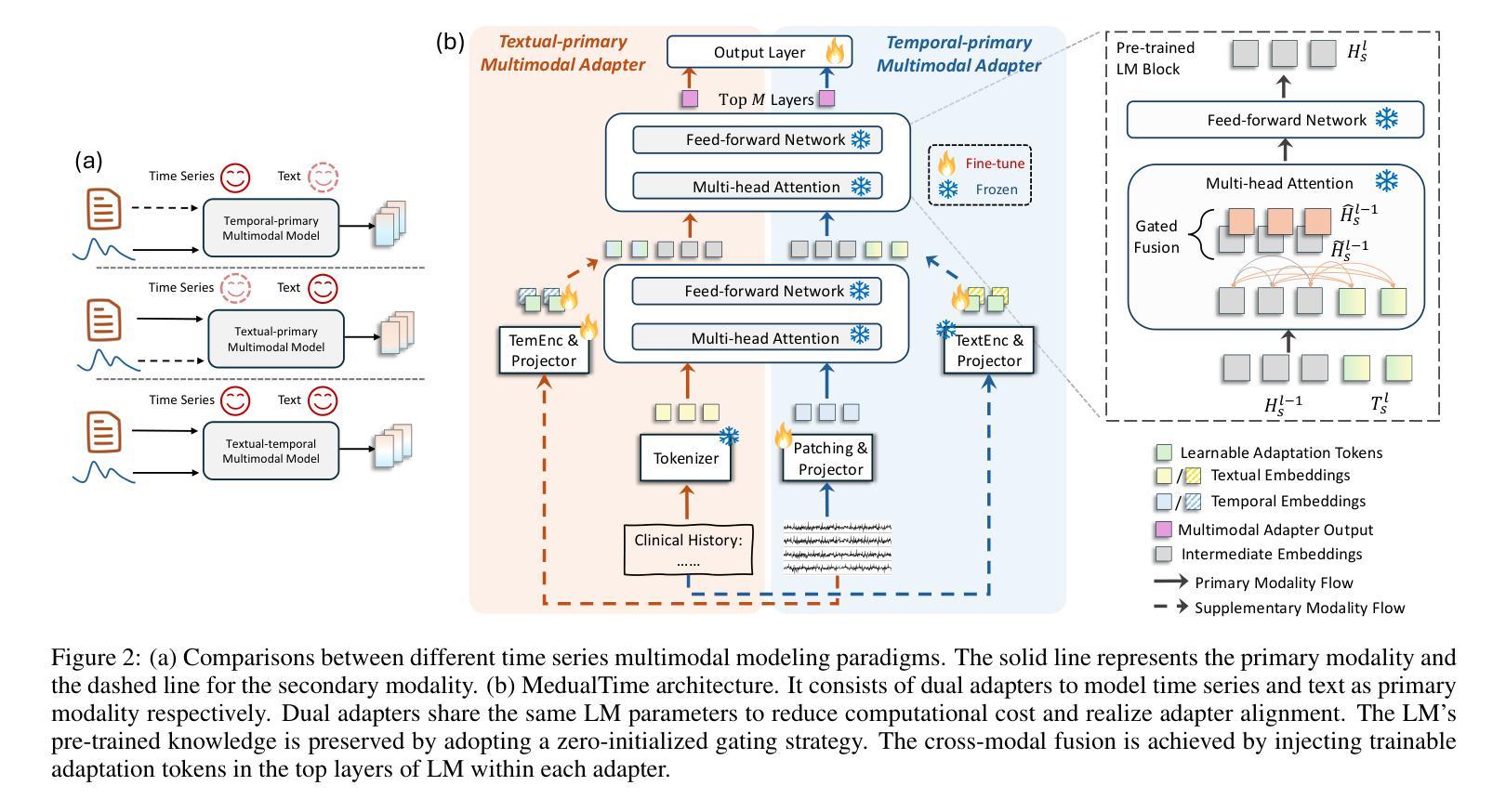
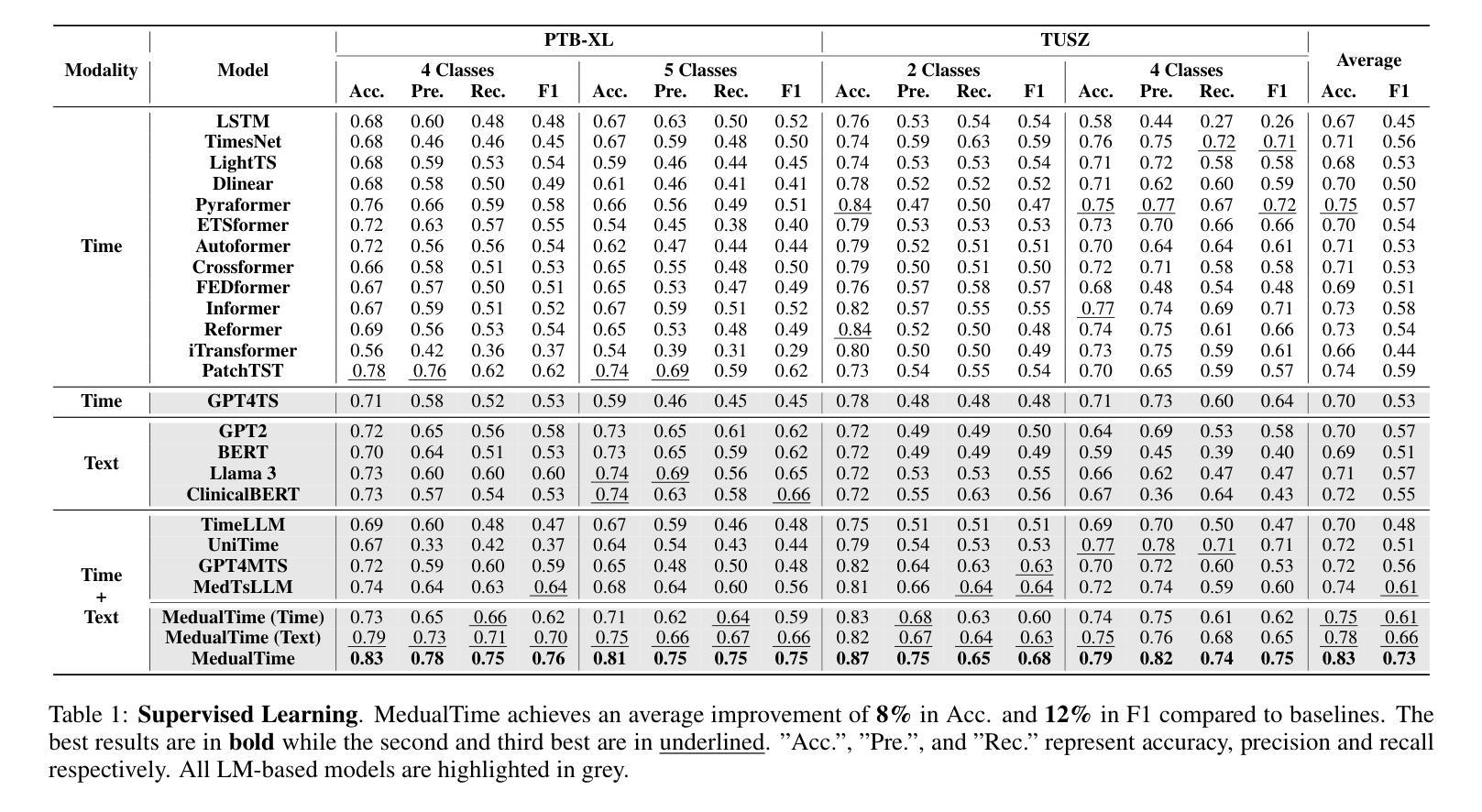
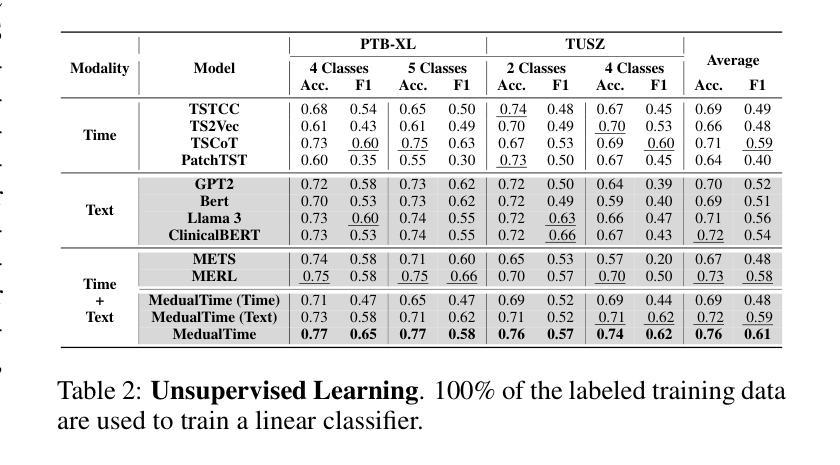
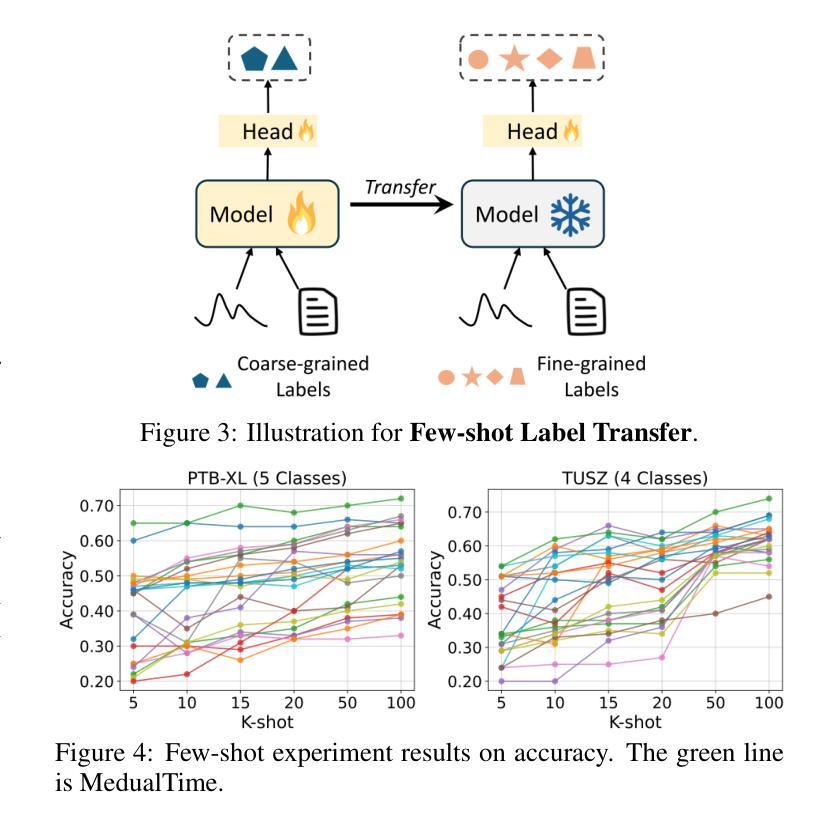
The recent rapid advancements in language models (LMs) have garnered attention in medical time series-text multimodal learning. However, existing contrastive learning-based and prompt-based LM approaches tend to be biased, often assigning a primary role to time series modality while treating text modality as secondary. We classify these approaches under a temporal-primary paradigm, which may overlook the unique and critical task-relevant information embedded in text modality like clinical reports, thus failing to fully leverage mutual benefits and complementarity of different modalities. To fill this gap, we propose a novel textual-temporal multimodal learning paradigm that enables either modality to serve as the primary while being enhanced by the other, thereby effectively capturing modality-specific information and fostering cross-modal interaction. In specific, we design MedualTime, a language model composed of dual adapters to implement temporal-primary and textual-primary modeling simultaneously. Within each adapter, lightweight adaptation tokens are injected into the top layers of LM to encourage high-level modality fusion. The shared LM pipeline by dual adapters not only achieves adapter alignment but also enables efficient fine-tuning, reducing computational resources. Empirically, MedualTime demonstrates superior performance on medical data, achieving notable improvements of 8% accuracy and 12% F1 in supervised settings. Furthermore, MedualTime’s transferability is validated by few-shot label transfer experiments from coarse-grained to fine-grained medical data. https://github.com/start2020/MedualTime
最近语言模型(LM)的快速发展引起了医学时间序列文本多模态学习的关注。然而,现有的基于对比学习和基于提示的LM方法往往存在偏见,经常将时间序列模态视为主要角色,而将文本模态视为次要。我们将这些方法归类为时间主导范式,这可能忽略了文本模态中嵌入的独特且关键的任务相关信息,如临床报告,因此无法充分利用不同模态的相互优势和互补性。为了填补这一空白,我们提出了一种新的文本-时间多模态学习范式,使任一模态都可以作为主要模态,同时受到另一模态的增强,从而有效地捕获特定于模态的信息并促进跨模态交互。具体来说,我们设计了MedualTime,一种由双适配器组成的语言模型,可以同时实现时间主导和文本主导建模。在每个适配器中,我们将轻量级适配令牌注入LM的顶层,以鼓励高级模态融合。双适配器共享的LM管道不仅实现了适配器对齐,还实现了高效的微调,减少了计算资源。实际上,MedualTime在医疗数据上表现出了卓越的性能,在监督设置下实现了8%的准确性和12%的F1值显著提高。此外,MedualTime的可转移性通过从粗粒度到细粒度医疗数据的少量标签转移实验得到了验证。https://github.com/start2020/MedualTime
论文及项目相关链接
PDF 9 pages, 6 figure, 3 tables
Summary
本文关注语言模型在医学时间序列文本多模态学习中的最新进展。针对现有对比学习和提示驱动的语言模型方法主要关注时间序列模态而忽视文本模态的问题,提出了一种新的文本时间多模态学习范式。该范式允许任一模态作为主要模态,同时被另一模态增强,从而有效捕获模态特定信息并促进跨模态交互。具体地,设计了一种名为MedualTime的语言模型,通过双适配器实现时间序列主导和文本主导建模的同时进行。该模型在医学数据上表现出卓越的性能,并在监督设置下实现了显著的改进,准确率提高8%,F1得分提高12%。此外,通过粗粒度到细粒度的医学数据少量标签迁移实验验证了MedualTime的迁移能力。
Key Takeaways
- 语言模型在医学时间序列文本多模态学习中取得迅速进展。
- 现有方法存在偏见,倾向于以时间序列为主,文本为辅。
- 提出一种新型文本时间多模态学习范式,促进不同模态之间的互补性。
- 介绍了名为MedualTime的语言模型,通过双适配器实现多种主导模式建模。
- MedualTime模型在医学数据上表现优越,准确率和F1得分均有显著提高。
- MedualTime模型具有良好的迁移能力,可通过少量标签迁移实验验证。
点此查看论文截图

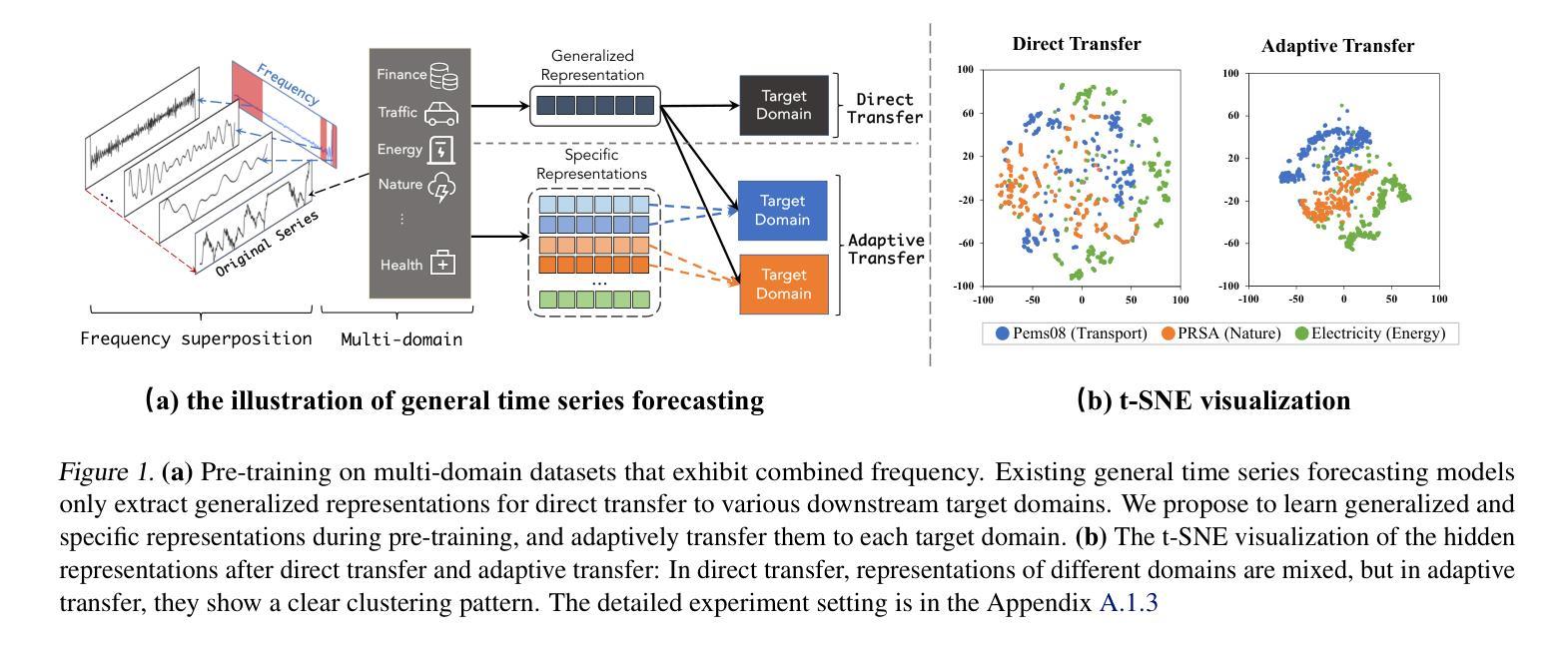
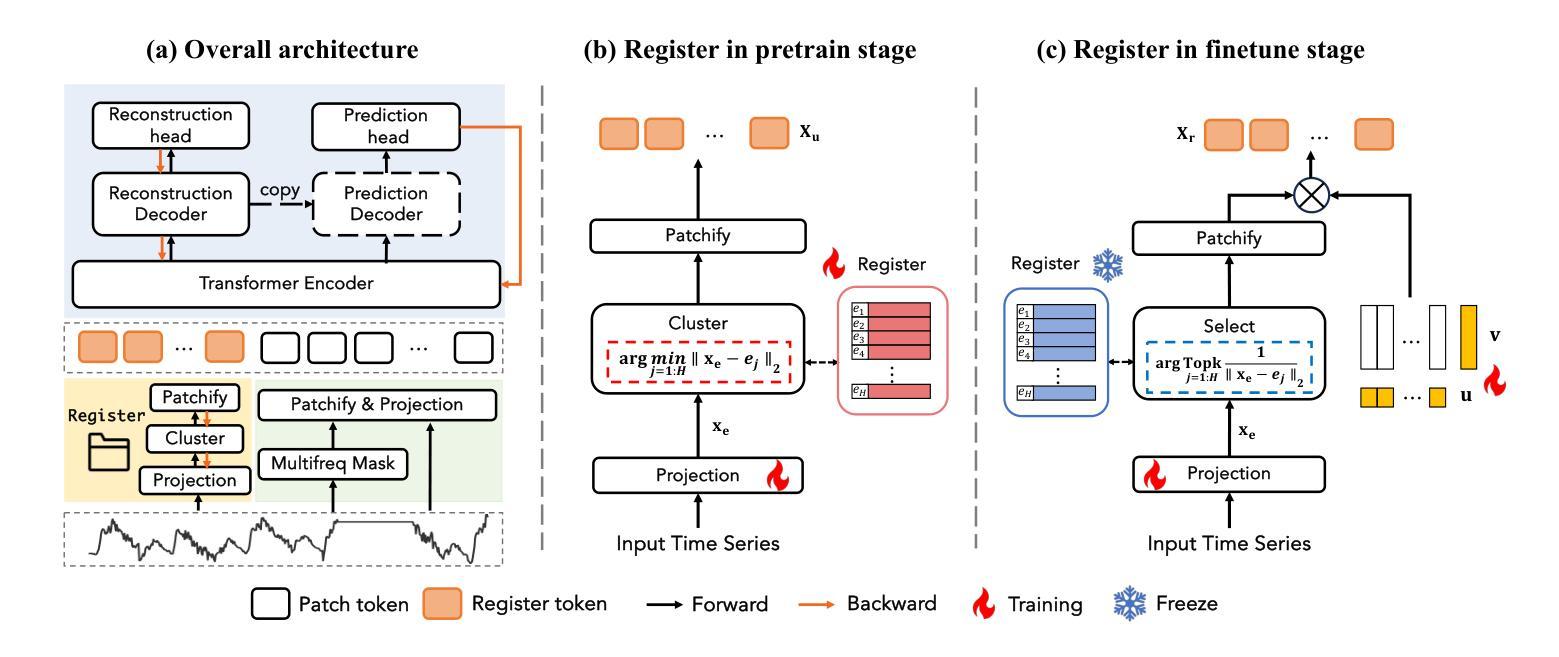
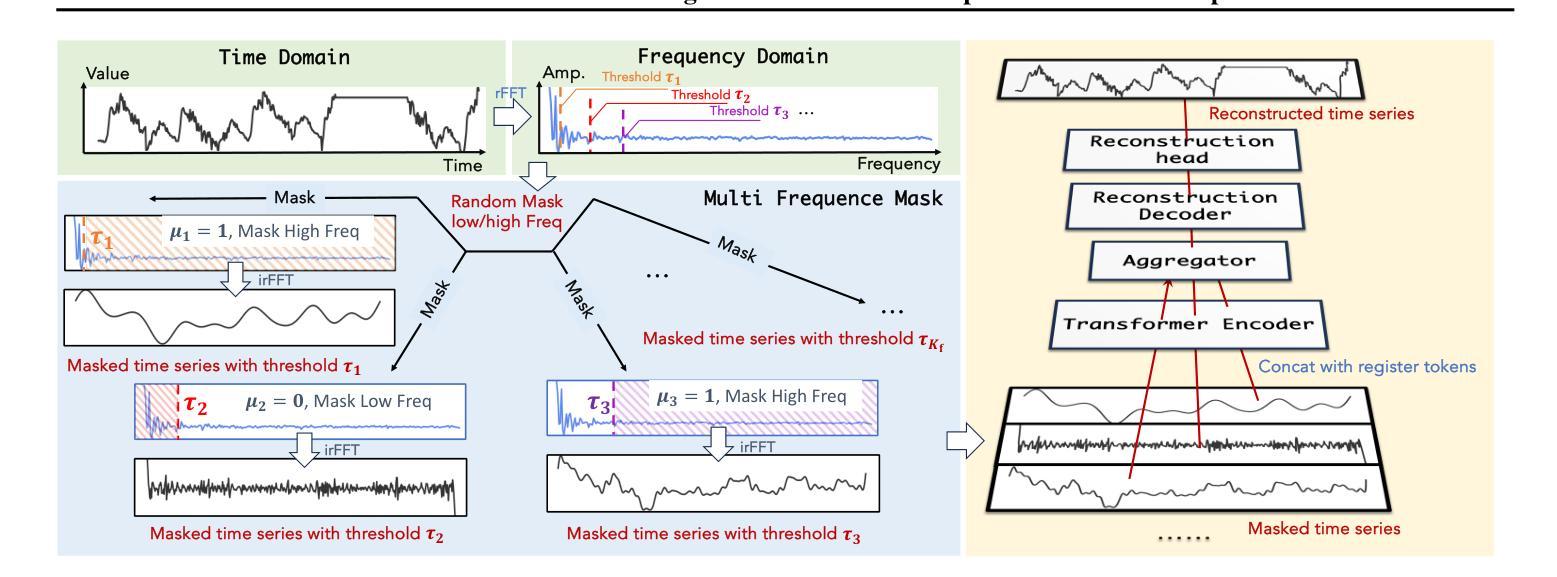
Towards a General Time Series Forecasting Model with Unified Representation and Adaptive Transfer
Authors:Yihang Wang, Yuying Qiu, Peng Chen, Kai Zhao, Yang Shu, Zhongwen Rao, Lujia Pan, Bin Yang, Chenjuan Guo
With the growing availability of multi-domain time series data, there is an increasing demand for general forecasting models pre-trained on multi-source datasets to support diverse downstream prediction scenarios. Existing time series foundation models primarily focus on scaling up pre-training datasets and model sizes to enhance generalization performance. In this paper, we take a different approach by addressing two critical aspects of general forecasting models: (1) how to derive unified representations from heterogeneous multi-domain time series data, and (2) how to effectively capture domain-specific features to enable adaptive transfer across various downstream scenarios. To address the first aspect, we propose Decomposed Frequency Learning as the pre-training task, which leverages frequency-based masking and reconstruction to decompose coupled semantic information in time series, resulting in unified representations across domains. For the second aspect, we introduce the Time Series Register, which captures domain-specific representations during pre-training and enhances adaptive transferability to downstream tasks. Our model achieves the state-of-the-art forecasting performance on seven real-world benchmarks, demonstrating remarkable few-shot and zero-shot capabilities.
随着多领域时间序列数据的日益普及,对预训练在多源数据集上的通用预测模型的需求也越来越高,以支持各种下游预测场景。现有的时间序列基础模型主要集中在扩大预训练数据集和模型规模上,以提高泛化性能。在本文中,我们采用了一种不同的方法,通过解决通用预测模型的两个关键问题:(1)如何从异质多领域时间序列数据中导出统一表示,以及(2)如何有效地捕获特定领域的特征,以实现跨各种下游场景的适应性迁移。为解决第一个问题,我们提出分解频率学习作为预训练任务,利用基于频率的掩蔽和重建来分解时间序列中耦合的语义信息,从而产生跨领域的统一表示。对于第二个问题,我们引入了时间序列寄存器,它在预训练过程中捕获特定领域的表示,并增强了对下游任务的适应性迁移能力。我们的模型在七个真实世界基准测试上实现了最先进的预测性能,展现了出色的小样本和零样本能力。
论文及项目相关链接
PDF Accepted by the Forty-second International Conference on Machine Learning (ICML2025)
Summary
本文提出一种基于多源数据预训练的时间序列预测模型,旨在解决多领域时间序列数据的统一表示和特定领域特征的有效捕捉问题。通过采用分解频率学习作为预训练任务和时间序列寄存器技术,模型实现了跨不同下游场景的适应性迁移,并在七个真实世界基准测试上取得了最先进的预测性能。
Key Takeaways
- 随着多领域时间序列数据的增长,对基于多源数据集预训练的通用预测模型的需求不断增加。
- 现有时间序列基础模型主要关注如何扩大预训练数据集和模型规模以提高泛化性能。
- 本文解决了一般预测模型中的两个关键问题:如何从异质多领域时间序列数据中提取统一表示以及如何有效地捕获领域特定特征以实现跨各种下游场景的适应性迁移。
- 为解决第一个问题,提出了基于频率掩蔽和重建的分解频率学习作为预训练任务,以分解时间序列中的耦合语义信息,得到跨领域的统一表示。
- 为解决第二个问题,引入了时间序列寄存器,在预训练过程中捕获特定领域的表示,提高了对下游任务的适应性迁移能力。
- 模型在七个真实世界基准测试上取得了最先进的预测性能。
点此查看论文截图