⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-10 更新
On the Same Wavelength? Evaluating Pragmatic Reasoning in Language Models across Broad Concepts
Authors:Linlu Qiu, Cedegao E. Zhang, Joshua B. Tenenbaum, Yoon Kim, Roger P. Levy
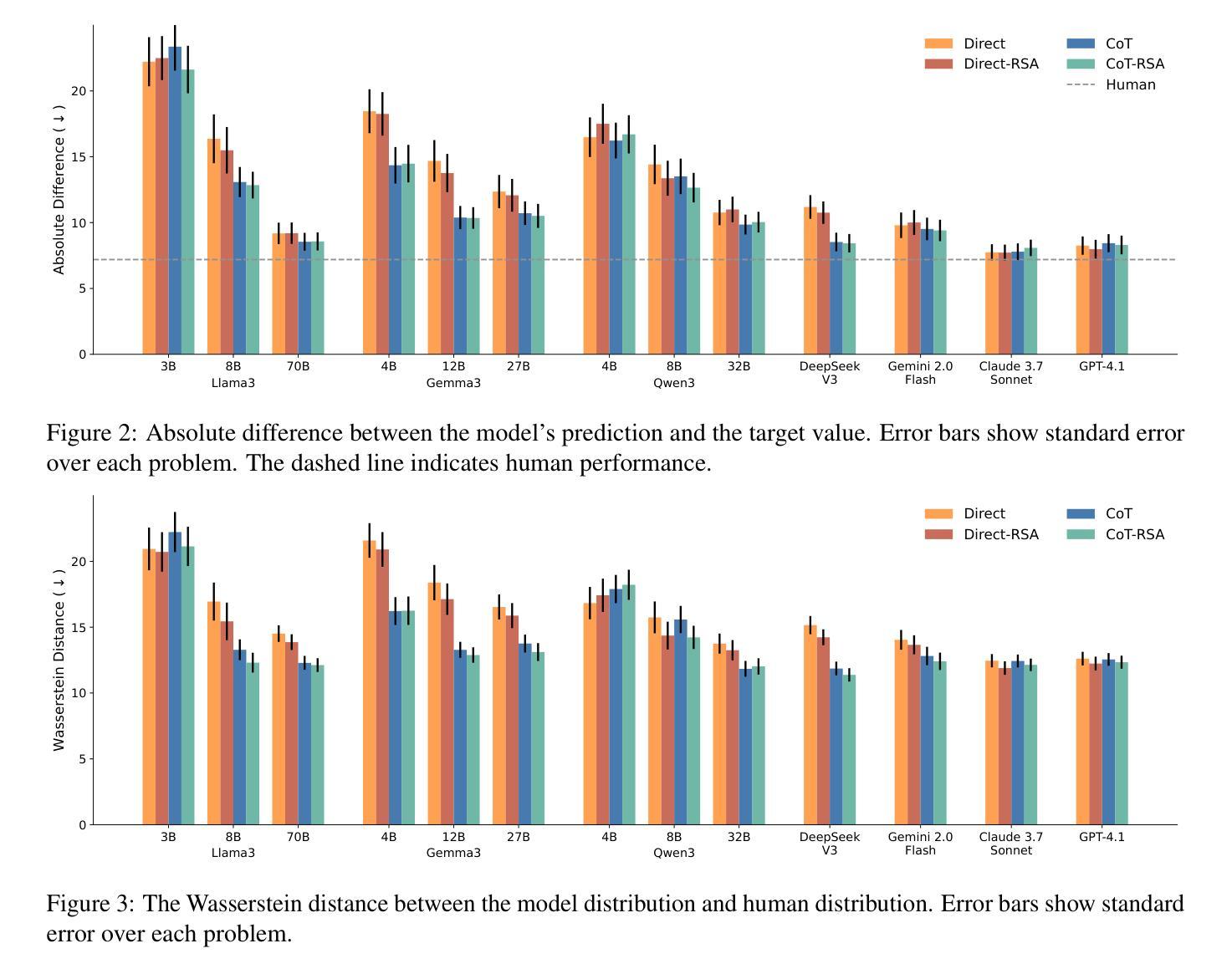
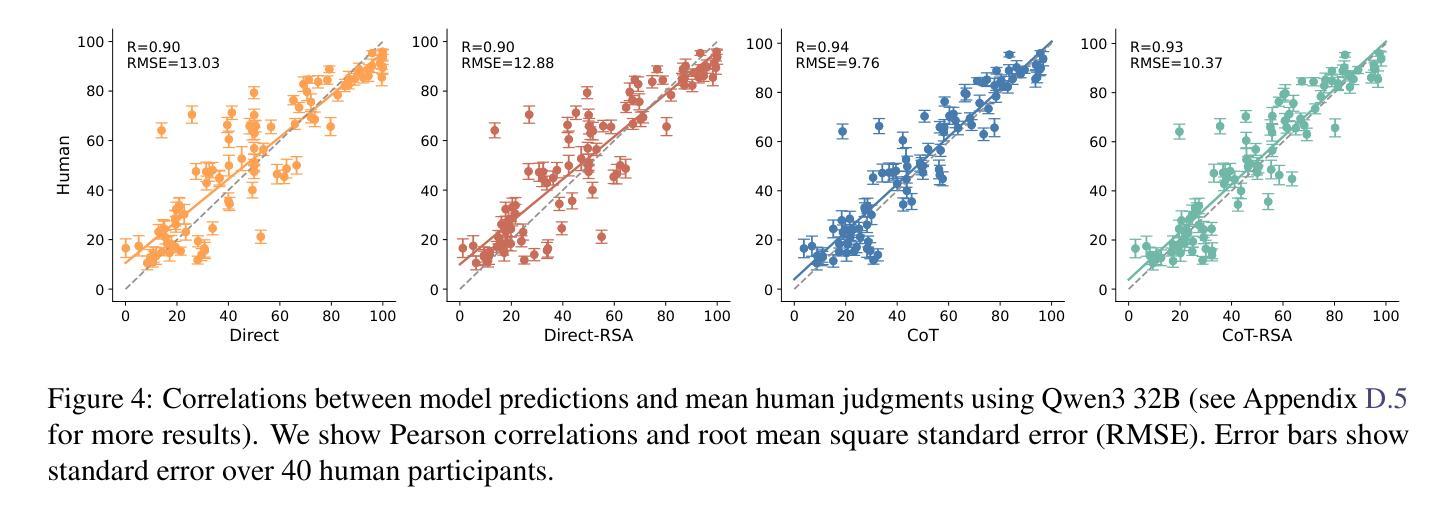
Language use is shaped by pragmatics – i.e., reasoning about communicative goals and norms in context. As language models (LMs) are increasingly used as conversational agents, it becomes ever more important to understand their pragmatic reasoning abilities. We propose an evaluation framework derived from Wavelength, a popular communication game where a speaker and a listener communicate about a broad range of concepts in a granular manner. We study a range of LMs on both language comprehension and language production using direct and Chain-of-Thought (CoT) prompting, and further explore a Rational Speech Act (RSA) approach to incorporating Bayesian pragmatic reasoning into LM inference. We find that state-of-the-art LMs, but not smaller ones, achieve strong performance on language comprehension, obtaining similar-to-human accuracy and exhibiting high correlations with human judgments even without CoT prompting or RSA. On language production, CoT can outperform direct prompting, and using RSA provides significant improvements over both approaches. Our study helps identify the strengths and limitations in LMs’ pragmatic reasoning abilities and demonstrates the potential for improving them with RSA, opening up future avenues for understanding conceptual representation, language understanding, and social reasoning in LMs and humans.
语言使用受到语用学的影响,即根据上下文中的交际目标和规范进行推理。随着语言模型(LMs)越来越多地被用作对话代理,理解它们的语用推理能力变得至关重要。我们提出了一个评估框架,它来源于波长(波长是一种流行的通信游戏),在游戏中,说话者和听者以精细的方式交流各种概念。我们研究了语言模型的语言理解和语言生产表现情况,包括直接使用提示和链式思考(CoT)提示的情况,并进一步探索将理性言语行为(RSA)方法融入语言模型推断中的贝叶斯语用推理。我们发现尖端的语言模型(但不是较小的模型)在语言理解方面表现出色,即使没有使用CoT提示或RSA,其准确性也与人类相似,与人类判断高度相关。在语言生产方面,链式思考的表现可能优于直接提示,使用RSA在两种提示方法上均取得了显著的改进。我们的研究有助于确定语言模型的语用推理能力的优势和局限性,并展示了使用RSA提高它们潜力的潜力,为理解语言模型和人类的概念表示、语言理解和社会推理开辟了新的途径。
论文及项目相关链接
PDF EMNLP 2025 (Main)
Summary
本文探讨了语言使用如何受到语境中交流目标和规范的影响,强调了语用推理的重要性。作者提出一个基于波长(Wavelength)通信游戏的评估框架,评估大型语言模型(LMs)在理解和生产语言方面的能力。通过直接和链式思维(CoT)提示法,研究发现顶尖的语言模型在理解语言方面表现出色,甚至无需CoT提示或理性言语行为(RSA)就能获得接近人类的准确率和与人类判断的高度相关性。在语言生产方面,CoT提示法优于直接提示法,而RSA的使用则进一步改进了两种方法。本文帮助识别了语言模型的语用推理能力的优点和局限性,并展示了通过RSA提高其潜力的可能性,为未来了解语言模型和人类的概念表示、语言理解和社交推理打开了新的途径。
Key Takeaways
- 语言使用受到语境中交流目标和规范的影响,语用推理在评估语言模型(LMs)的能力时变得重要。
- 基于波长通信游戏的评估框架用于评估LMs在理解和生产语言方面的能力。
- 顶尖的语言模型在理解语言方面表现出色,无需额外提示就能获得接近人类的准确率。
- 链式思维(CoT)提示法在语言生产方面表现优越。
- 理性言语行为(RSA)方法能显著提高LMs的语用推理能力。
- 本文揭示了语言模型的语用推理能力的优点和局限性。
点此查看论文截图


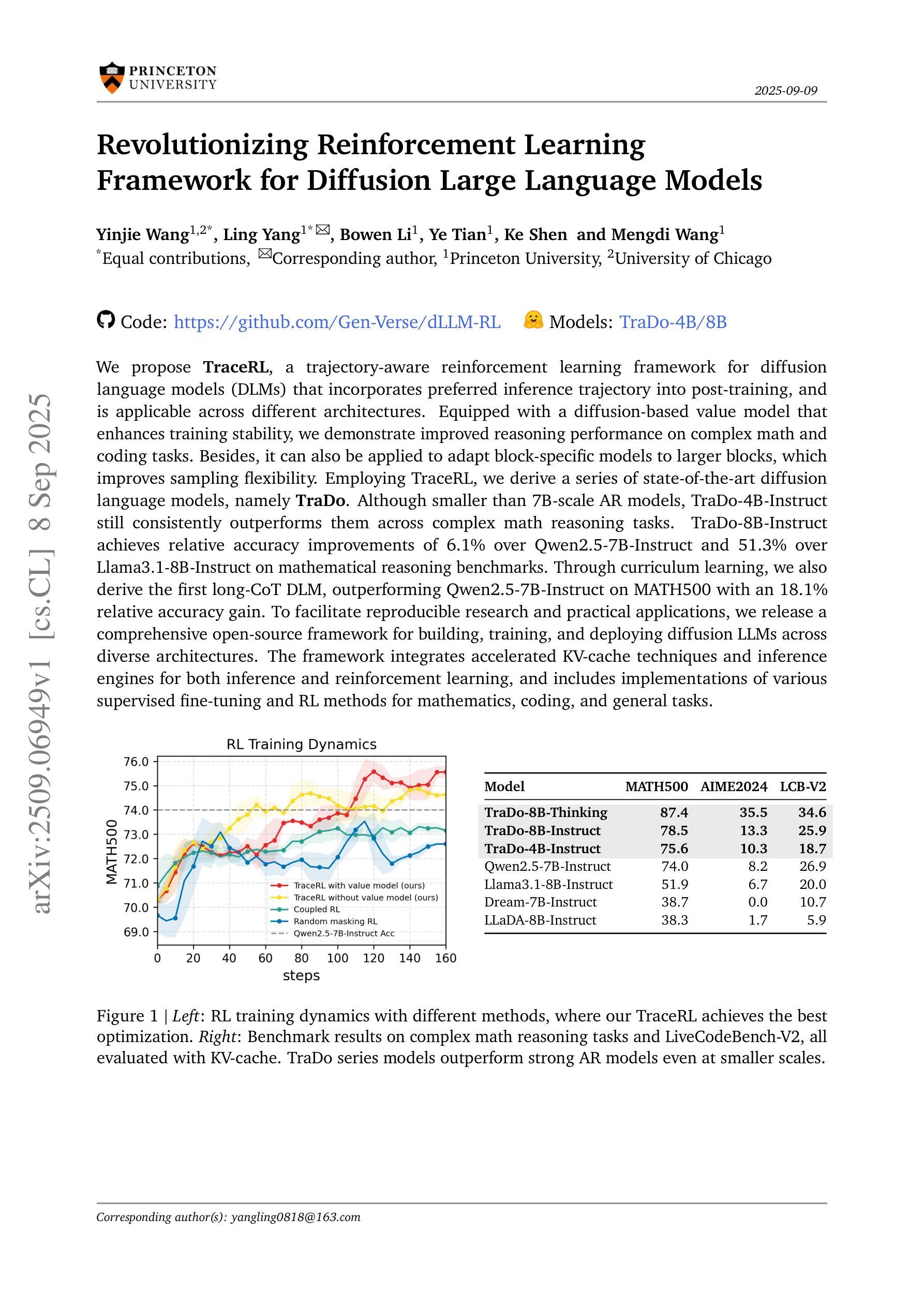
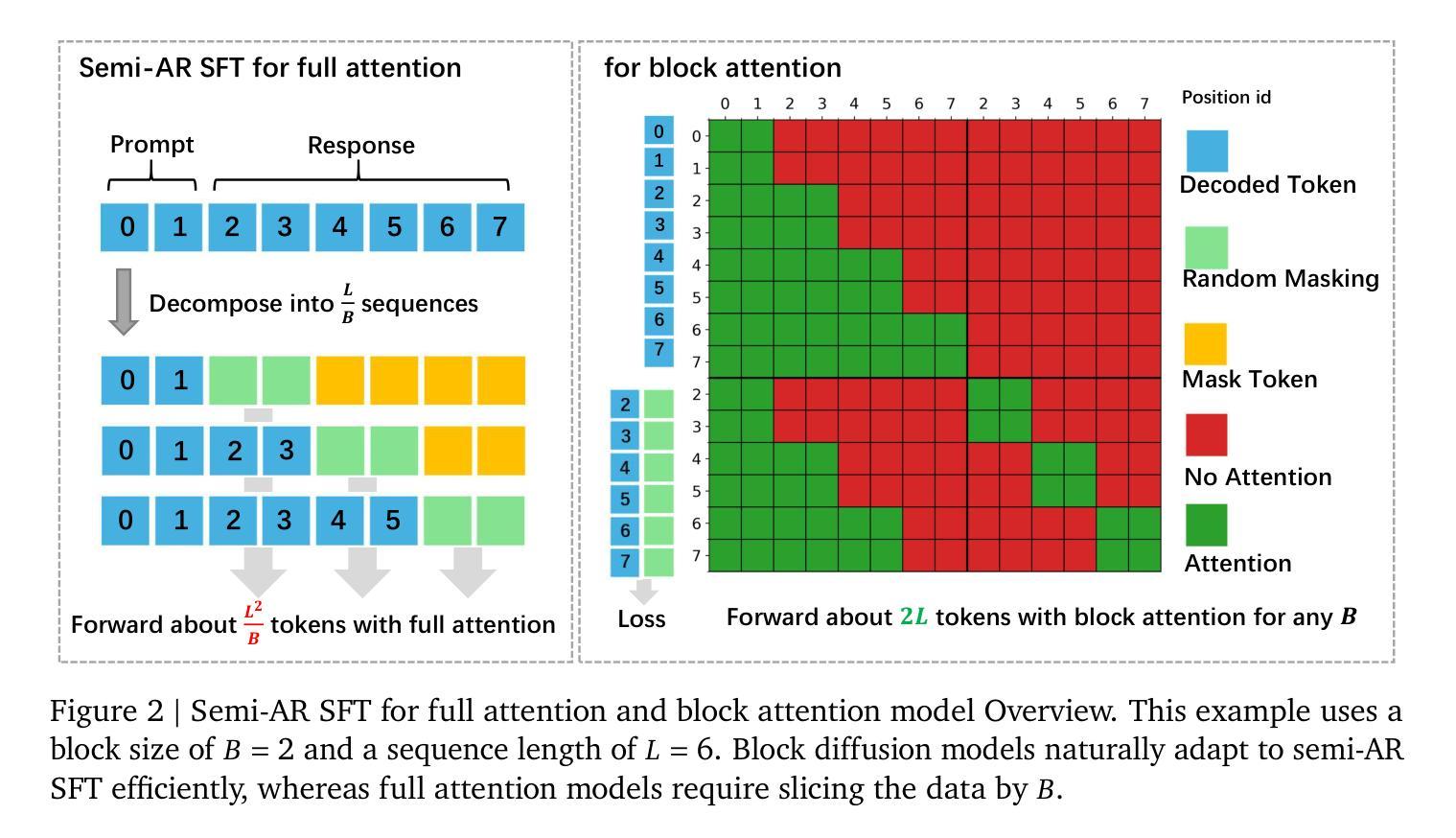
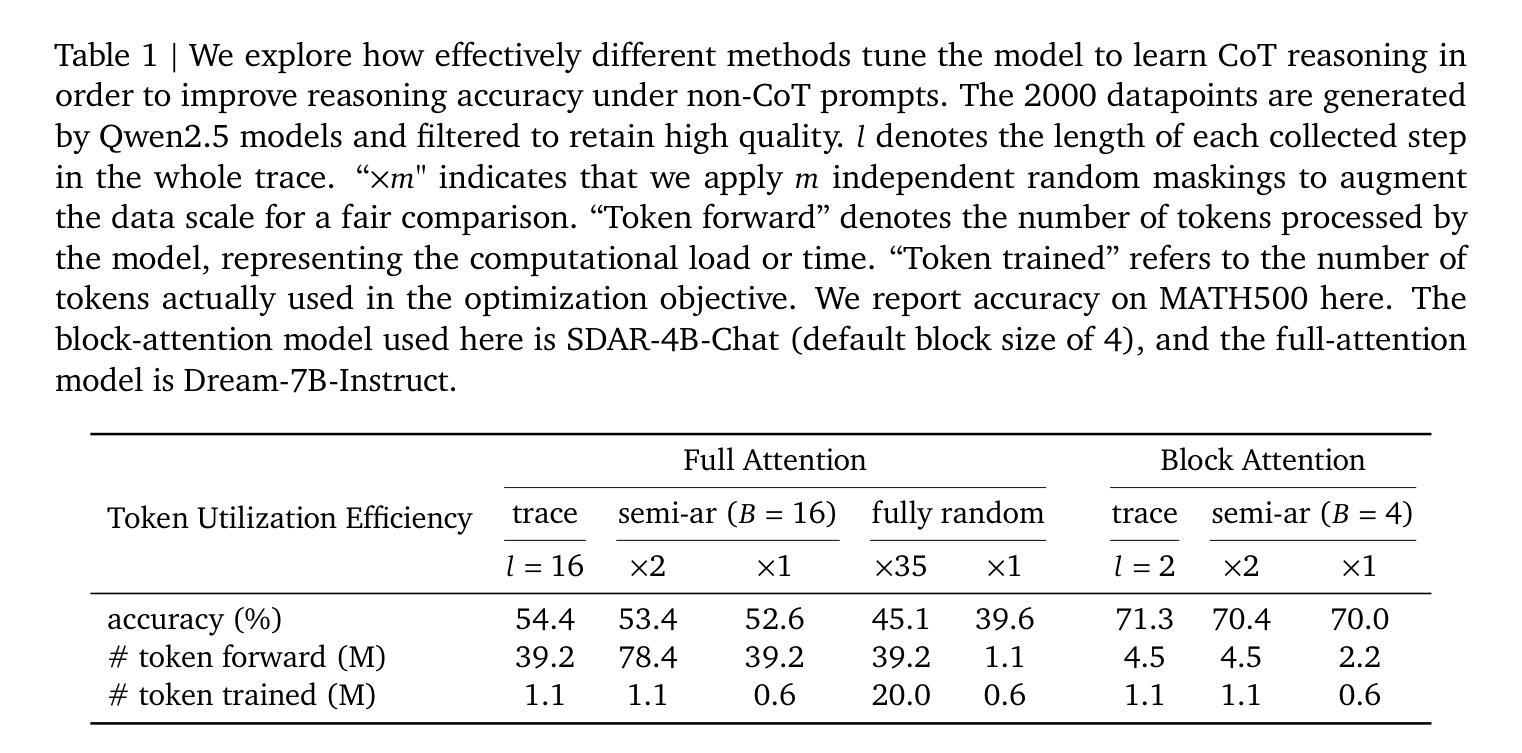
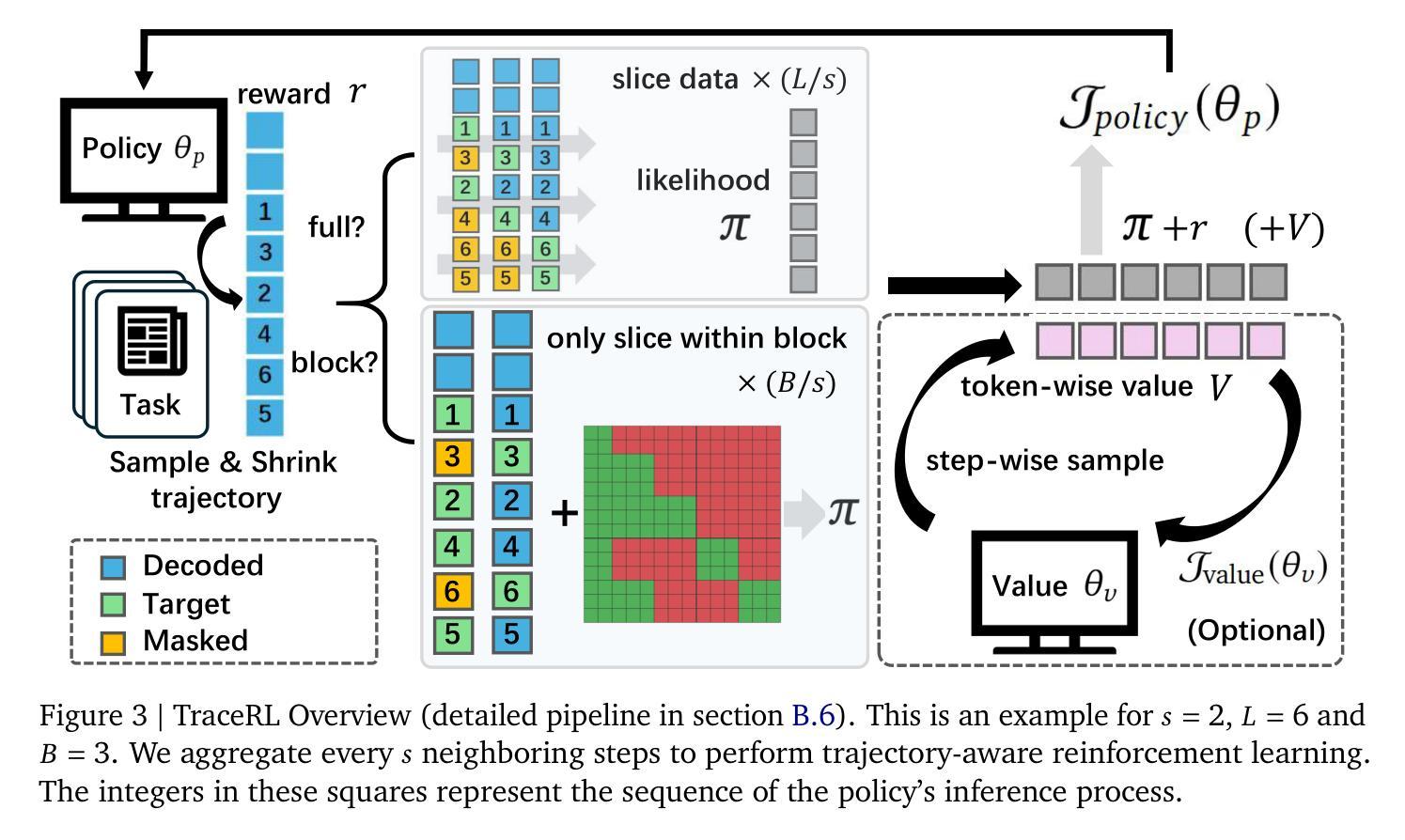
Revolutionizing Reinforcement Learning Framework for Diffusion Large Language Models
Authors:Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, Mengdi Wang
We propose TraceRL, a trajectory-aware reinforcement learning framework for diffusion language models (DLMs) that incorporates preferred inference trajectory into post-training, and is applicable across different architectures. Equipped with a diffusion-based value model that enhances training stability, we demonstrate improved reasoning performance on complex math and coding tasks. Besides, it can also be applied to adapt block-specific models to larger blocks, which improves sampling flexibility. Employing TraceRL, we derive a series of state-of-the-art diffusion language models, namely TraDo. Although smaller than 7B-scale AR models, TraDo-4B-Instruct still consistently outperforms them across complex math reasoning tasks. TraDo-8B-Instruct achieves relative accuracy improvements of 6.1% over Qwen2.5-7B-Instruct and 51.3% over Llama3.1-8B-Instruct on mathematical reasoning benchmarks. Through curriculum learning, we also derive the first long-CoT DLM, outperforming Qwen2.5-7B-Instruct on MATH500 with an 18.1% relative accuracy gain. To facilitate reproducible research and practical applications, we release a comprehensive open-source framework for building, training, and deploying diffusion LLMs across diverse architectures. The framework integrates accelerated KV-cache techniques and inference engines for both inference and reinforcement learning, and includes implementations of various supervised fine-tuning and RL methods for mathematics, coding, and general tasks. Code and Models: https://github.com/Gen-Verse/dLLM-RL
我们提出了TraceRL,这是一个面向扩散语言模型(DLMs)的轨迹感知强化学习框架。该框架在训练后融入了首选推理轨迹,并适用于不同的架构。通过使用基于扩散的值模型,增强了训练稳定性,并在复杂的数学和编码任务上展示了提高的推理性能。此外,它还可以应用于将块特定模型适应到更大的块,这提高了采样灵活性。使用TraceRL,我们推出了一系列最先进的扩散语言模型,即TraDo。虽然TraDo-4B-Instruct的规模小于7B级AR模型,但在复杂的数学推理任务上仍然持续超越它们。TraDo-8B-Instruct在数学推理基准测试上相对于Qwen2.5-7B-Instruct和Llama3.1-8B-Instruct分别实现了6.1%和51.3%的相对准确性改进。通过课程学习,我们还推出了首个长CoT DLM,在MATH500上相对于Qwen2.5-7B-Instruct实现了18.1%的相对准确性提升。为了促进可重复的研究和实际应用,我们发布了一个全面的开源框架,用于构建、训练和部署跨不同架构的扩散大型语言模型(LLM)。该框架集成了加速KV缓存技术和推理引擎,用于推理和强化学习,并包括针对数学、编码和一般任务的多种监督微调(fine-tuning)和强化学习方法的实现。代码和模型:https://github.com/Gen-Verse/dLLM-RL。
论文及项目相关链接
PDF Code and Models: https://github.com/Gen-Verse/dLLM-RL
Summary
本文介绍了TraceRL框架,这是一个为扩散语言模型(DLMs)设计的轨迹感知强化学习框架。TraceRL结合首选推理轨迹进行后训练,适用于不同的架构。通过配备基于扩散的值模型,增强了训练稳定性,并在复杂的数学和编码任务上展示了改进的推理性能。此外,它还可以应用于适应更大块的块特定模型,提高了采样灵活性。使用TraceRL,我们推出了一系列先进的扩散语言模型TraDo系列。尽管规模小于7B的AR模型,TraDo-4B-Instruct在复杂的数学推理任务上仍表现一致且有所超越。同时,该框架还包括加速KV缓存技术和推理引擎的实现,用于推理和强化学习。代码和模型已在GitHub上开源。
Key Takeaways
- TraceRL是一个轨迹感知强化学习框架,专为扩散语言模型(DLMs)设计,可应用于不同架构。
- TraceRL结合首选推理轨迹进行后训练,增强了训练稳定性和推理性能。
- 在复杂的数学和编码任务上,TraceRL展示了改进的推理性能。
- TraDo系列扩散语言模型表现优秀,其中TraDo-4B-Instruct在复杂数学推理任务上表现超越其他模型。
- TraDo-8B-Instruct在数学推理基准测试上相对于Qwen2.5-7B-Instruct和Llama3.1-8B-Instruct有显著的准确性改进。
- 通过课程学习,推出了首个长CoT(因果推理链)DLM,在MATH500上的相对准确性有所提高。
点此查看论文截图
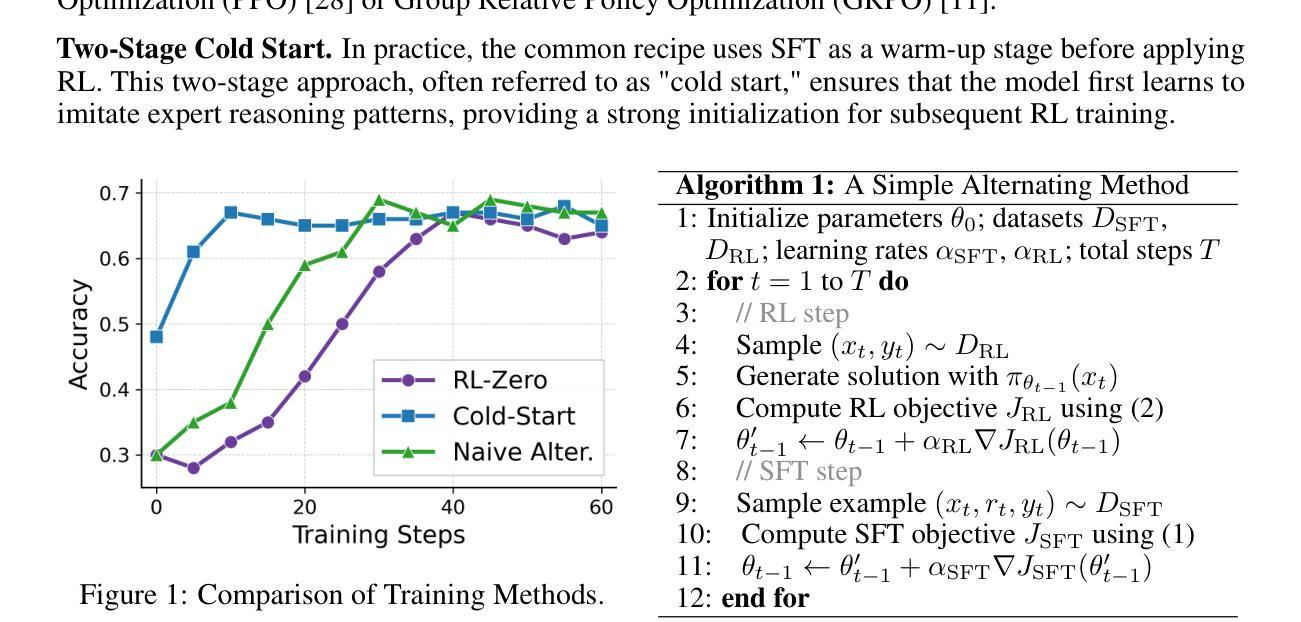
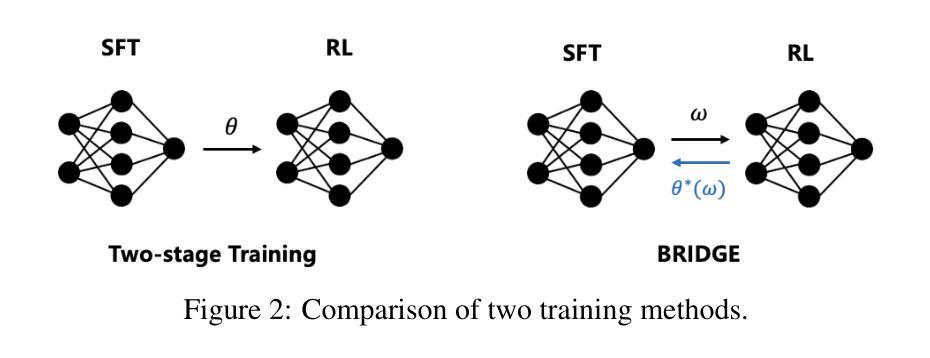
Beyond Two-Stage Training: Cooperative SFT and RL for LLM Reasoning
Authors:Liang Chen, Xueting Han, Li Shen, Jing Bai, Kam-Fai Wong
Reinforcement learning (RL) has proven effective in incentivizing the reasoning abilities of large language models (LLMs), but suffers from severe efficiency challenges due to its trial-and-error nature. While the common practice employs supervised fine-tuning (SFT) as a warm-up stage for RL, this decoupled two-stage approach limits interaction between SFT and RL, thereby constraining overall effectiveness. This study introduces a novel method for learning reasoning models that employs bilevel optimization to facilitate better cooperation between these training paradigms. By conditioning the SFT objective on the optimal RL policy, our approach enables SFT to meta-learn how to guide RL’s optimization process. During training, the lower level performs RL updates while simultaneously receiving SFT supervision, and the upper level explicitly maximizes the cooperative gain-the performance advantage of joint SFT-RL training over RL alone. Empirical evaluations on five reasoning benchmarks demonstrate that our method consistently outperforms baselines and achieves a better balance between effectiveness and efficiency.
强化学习(RL)在激励大型语言模型(LLM)的推理能力方面已证明是有效的,但由于其试错性质而面临严重的效率挑战。虽然通常的做法是采用监督微调(SFT)作为RL的预热阶段,但这种解耦的两阶段方法限制了SFT和RL之间的交互,从而限制了整体的有效性。本研究介绍了一种用于学习推理模型的新方法,该方法采用两级优化,以促进这些训练范式之间的更好协作。通过以最优RL策略为条件,我们的方法使SFT能够元学习如何引导RL的优化过程。在训练过程中,低级执行RL更新,同时接受SFT监督,而高级则显式地最大化合作收益——联合SFT-RL训练相对于仅使用RL的性能优势。在五个推理基准测试上的实证评估表明,我们的方法始终优于基准线,并在有效性和效率之间取得了更好的平衡。
论文及项目相关链接
Summary
强化学习(RL)在激励大型语言模型(LLM)的推理能力方面已证明其有效性,但由于其固有的试错性质而面临效率挑战。常见做法是采用监督微调(SFT)作为RL的预热阶段,但这种解耦的两阶段方法限制了SFT和RL之间的交互,从而限制了整体效果。本研究引入了一种新的推理模型学习方法,采用两级优化,以促进这两种训练范式之间的更好合作。通过以最佳RL策略为条件,我们的方法使SFT能够学习如何指导RL的优化过程。在训练过程中,低级执行RL更新,同时接受SFT监督,而高级则明确最大化合作收益——联合SFT-RL训练相对于仅使用RL的性能优势。在五个推理基准测试上的实证评估表明,我们的方法一直优于基准测试,并在有效性和效率之间取得了更好的平衡。
Key Takeaways
- 强化学习在激励大型语言模型的推理能力方面有效果,但存在效率挑战。
- 常见做法采用监督微调作为强化学习的预热阶段,但这种方法限制了交互和整体效果。
- 新方法采用两级优化,促进监督微调与强化学习之间的合作。
- 新方法使监督微调能够学习如何指导强化学习的优化过程。
- 在训练过程中,新方法结合了监督微调和强化学习,提高了性能。
- 实证评估表明,新方法在多个推理基准测试上表现优异,优于传统方法。
点此查看论文截图


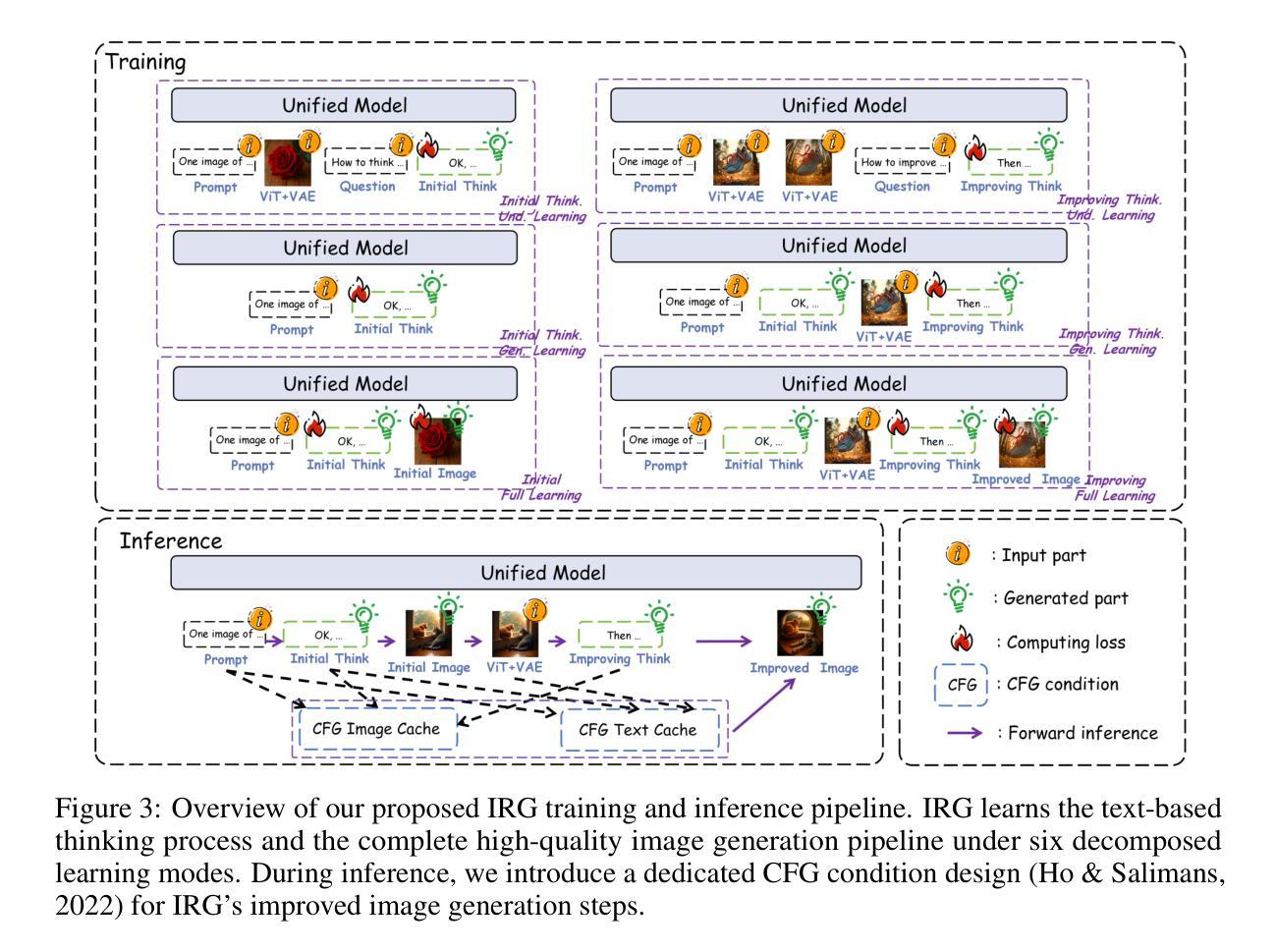
Interleaving Reasoning for Better Text-to-Image Generation
Authors:Wenxuan Huang, Shuang Chen, Zheyong Xie, Shaosheng Cao, Shixiang Tang, Yufan Shen, Qingyu Yin, Wenbo Hu, Xiaoman Wang, Yuntian Tang, Junbo Qiao, Yue Guo, Yao Hu, Zhenfei Yin, Philip Torr, Yu Cheng, Wanli Ouyang, Shaohui Lin
Unified multimodal understanding and generation models recently have achieve significant improvement in image generation capability, yet a large gap remains in instruction following and detail preservation compared to systems that tightly couple comprehension with generation such as GPT-4o. Motivated by recent advances in interleaving reasoning, we explore whether such reasoning can further improve Text-to-Image (T2I) generation. We introduce Interleaving Reasoning Generation (IRG), a framework that alternates between text-based thinking and image synthesis: the model first produces a text-based thinking to guide an initial image, then reflects on the result to refine fine-grained details, visual quality, and aesthetics while preserving semantics. To train IRG effectively, we propose Interleaving Reasoning Generation Learning (IRGL), which targets two sub-goals: (1) strengthening the initial think-and-generate stage to establish core content and base quality, and (2) enabling high-quality textual reflection and faithful implementation of those refinements in a subsequent image. We curate IRGL-300K, a dataset organized into six decomposed learning modes that jointly cover learning text-based thinking, and full thinking-image trajectories. Starting from a unified foundation model that natively emits interleaved text-image outputs, our two-stage training first builds robust thinking and reflection, then efficiently tunes the IRG pipeline in the full thinking-image trajectory data. Extensive experiments show SoTA performance, yielding absolute gains of 5-10 points on GenEval, WISE, TIIF, GenAI-Bench, and OneIG-EN, alongside substantial improvements in visual quality and fine-grained fidelity. The code, model weights and datasets will be released in: https://github.com/Osilly/Interleaving-Reasoning-Generation .
近期统一的多模态理解和生成模型在图像生成能力上取得了显著进步,但在指令遵循和细节保留方面,与紧密耦合理解与生成的系统(如GPT-4o)相比仍存在较大差距。受到交替推理最新进展的启发,我们探索了这种推理是否能进一步改进文本到图像(T2I)的生成。我们引入了交替推理生成(IRG)框架,该框架在文本思考和图像合成之间进行交替:模型首先产生基于文本的思考来指导初始图像,然后反思结果,以细化细节、视觉质量和美学感,同时保留语义。为了有效地训练IRG,我们提出了交替推理生成学习(IRGL),它针对两个子目标:(1)加强初始的思考和生成阶段,以建立核心内容和基础质量;(2)实现高质量文本反思和忠实执行随后的图像中的改进。我们策划了IRGL-300K数据集,该数据集被组织成六种分解学习模式,联合覆盖基于文本的思考和完整的思考-图像轨迹。从统一的基础模型出发,该模型天生就能发出交替的文本-图像输出,我们的两阶段训练首先建立稳健的思考和反思能力,然后在完整的思考-图像轨迹数据中有效地调整IRG管道。大量实验表明,其性能达到了最新水平,在GenEval、WISE、TIIF、GenAI-Bench和OneIG-EN上实现了5-10分的绝对增长,同时在视觉质量和细节保真度方面也有了实质性的提升。代码、模型权重和数据集将在https://github.com/Osilly/Interleaving-Reasoning-Generation中发布。
论文及项目相关链接
Summary
近期统一的多模态理解与生成模型在图像生成能力上取得显著进步,但在指令遵循与细节保留方面与紧密耦合理解与生成的系统如GPT-4o相比仍存在较大差距。受交替推理最新进展的启发,本文探索了交替推理是否能进一步改进文本到图像(T2I)的生成。介绍了一种交替推理生成(IRG)框架,该框架在文本基础思考和图像合成之间交替:模型首先产生文本基础思考来指导初始图像,然后反思结果以改进细节、视觉质量和美学感,同时保留语义。为了有效地训练IRG,提出了交替推理生成学习(IRGL),旨在实现两个子目标:一是加强初始的思考和生成阶段,以建立核心内容和基础质量;二是实现高质量文本反思和忠实实施这些改进于随后的图像。本文整理了IRGL-300K数据集,包含六种分解学习模式,以涵盖文本基础思考和完整思考图像轨迹的学习。从统一的基础模型出发,该模型天生就能发出交替的文本图像输出,两阶段训练首先建立稳健的思考和反思,然后有效地调整IRG管道在完整的思考图像轨迹数据中。大量实验表明,其在GenEval、WISE、TIIF、GenAI-Bench和OneIG-EN等指标上达到了SOTA性能,且获得了实质性的视觉质量和精细粒度保真度的提升。
Key Takeaways
- 研究提出了一种新的框架——交替推理生成(IRG),旨在通过文本基础思考和图像合成之间的交替过程改进文本到图像的生成。
- 为了训练IRG,研究者提出了交替推理生成学习(IRGL)方法,包含两个子目标:建立核心内容和基础质量,以及实现高质量的文本反思和改进图像细节。
- 研究者整理了一个名为IRGL-300K的数据集,用于支持IRG框架的训练和评估,该数据集包含六种分解学习模式。
- 实验结果表明,IRG框架在多个评估指标上达到了先进性能,包括GenEval、WISE、TIIF、GenAI-Bench和OneIG-EN等。
- 该研究提高了图像生成的视觉质量和精细粒度保真度。
- 模型和代码将在指定的GitHub仓库中公开,便于其他人使用和改进。
点此查看论文截图


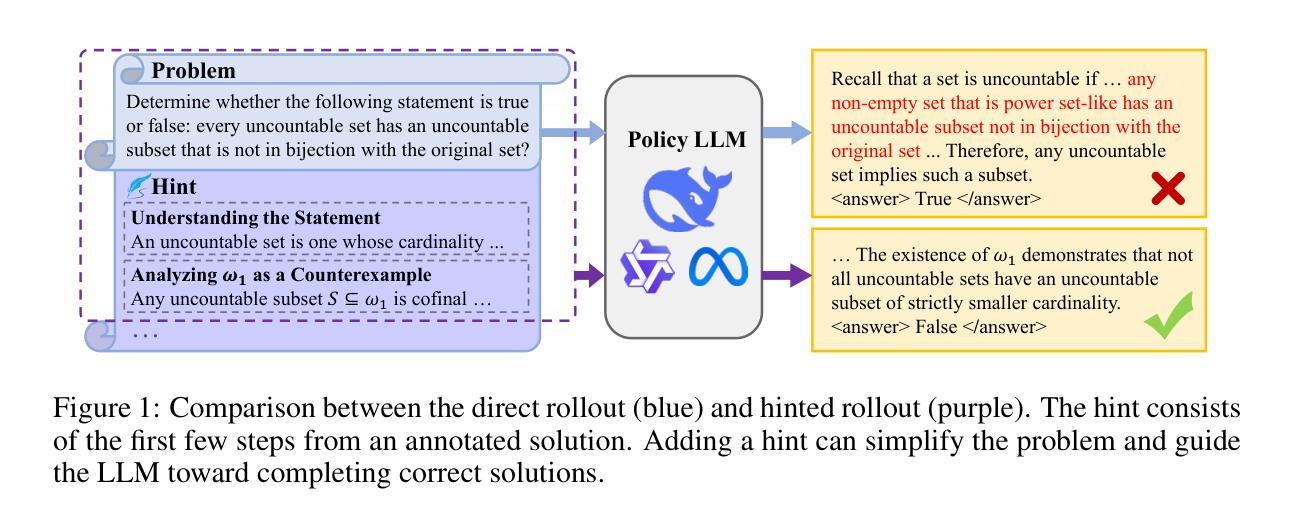
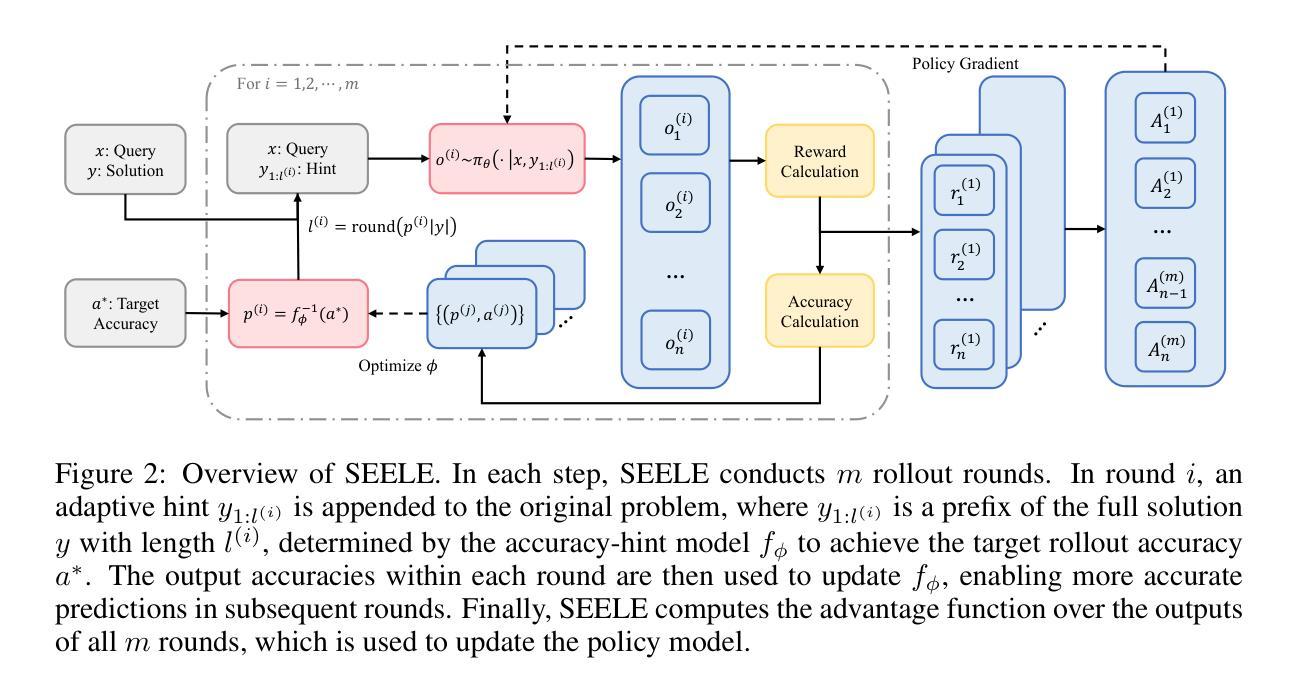
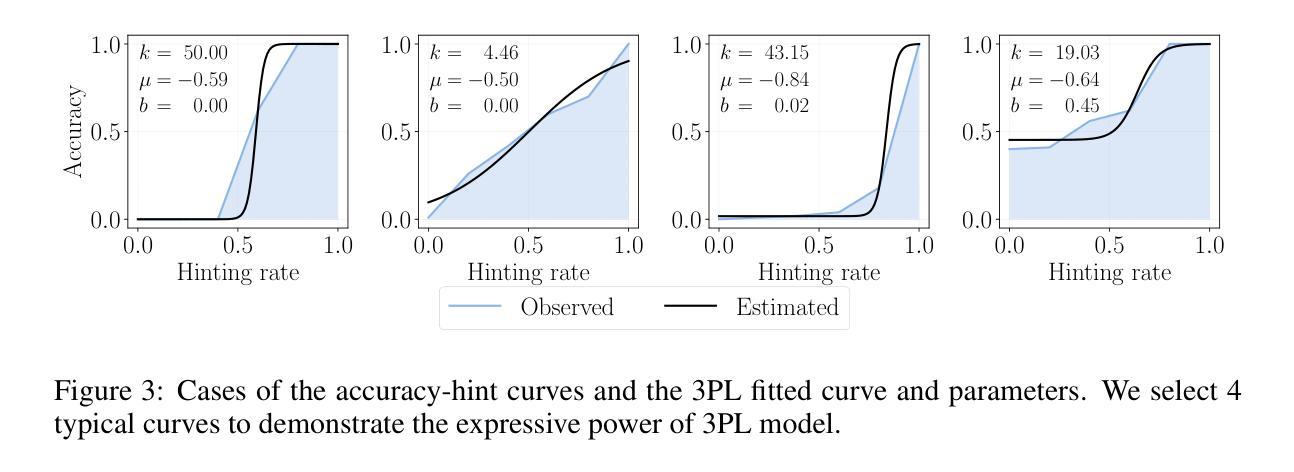
Staying in the Sweet Spot: Responsive Reasoning Evolution via Capability-Adaptive Hint Scaffolding
Authors:Ziheng Li, Zexu Sun, Jinman Zhao, Erxue Min, Yongcheng Zeng, Hui Wu, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, Xu Chen, Zhi-Hong Deng
Reinforcement learning with verifiable rewards (RLVR) has achieved remarkable success in enhancing the reasoning capabilities of large language models (LLMs). However, existing RLVR methods often suffer from exploration inefficiency due to mismatches between the training data’s difficulty and the model’s capability. LLMs fail to discover viable reasoning paths when problems are overly difficult, while learning little new capability when problems are too simple. In this work, we formalize the impact of problem difficulty by quantifying the relationship between loss descent speed and rollout accuracy. Building on this analysis, we propose SEELE, a novel supervision-aided RLVR framework that dynamically adjusts problem difficulty to stay within the high-efficiency region. SEELE augments each training sample by appending a hint (part of a full solution) after the original problem. Unlike previous hint-based approaches, SEELE deliberately and adaptively adjusts the hint length for each problem to achieve an optimal difficulty. To determine the optimal hint length, SEELE employs a multi-round rollout sampling strategy. In each round, it fits an item response theory model to the accuracy-hint pairs collected in preceding rounds to predict the required hint length for the next round. This instance-level, real-time difficulty adjustment aligns problem difficulty with the evolving model capability, thereby improving exploration efficiency. Experimental results show that SEELE outperforms Group Relative Policy Optimization (GRPO) and Supervised Fine-tuning (SFT) by +11.8 and +10.5 points, respectively, and surpasses the best previous supervision-aided approach by +3.6 points on average across six math reasoning benchmarks.
强化学习与可验证奖励(RLVR)在提高大型语言模型(LLM)的推理能力方面取得了显著的成功。然而,现有的RLVR方法常常因为训练数据难度与模型能力之间的不匹配而面临探索效率低下的问题。当问题过于困难时,LLM无法发现可行的推理路径,而当问题过于简单时,它们又无法学习到新的能力。
在这项工作中,我们通过量化损失下降速度与回滚准确度之间的关系来正式化问题难度的影响。基于这一分析,我们提出了SEELE,一个新型的监督辅助RLVR框架,它能够动态调整问题难度以保持在高效率区域内。SEELE通过在每个训练样本后附加一个提示(完整解决方案的一部分)来增强每个训练样本。不同于以前的基于提示的方法,SEELE为每个问题精心且自适应地调整提示长度以达到最佳难度。
为了确定最佳提示长度,SEELE采用多轮回滚采样策略。在每轮中,它根据前几轮收集的准确度提示对来拟合项目反应理论模型,以预测下一轮所需的提示长度。这种实例级别的实时难度调整使问题难度与不断进化的模型能力相匹配,从而提高了探索效率。
论文及项目相关链接
PDF Work in progress
摘要
强化学习与可验证奖励(RLVR)在提高大型语言模型(LLM)的推理能力方面取得了显著的成功。然而,现有RLVR方法常常因训练数据难度与模型能力之间的不匹配而导致探索效率低下。当问题过于困难时,LLM无法发现可行的推理路径;而当问题过于简单时,它们又无法学习到新的能力。本研究通过量化损失下降速度与回滚准确度之间的关系,正式化问题难度的影响。在此基础上,我们提出了SEELE,一个新型的监督辅助RLVR框架,能够动态调整问题难度以保持在高效区域。SEELE通过在每个训练样本后追加提示(完整解决方案的一部分)来增强数据。与其他基于提示的方法不同,SEELE为每个问题精心、自适应地调整提示长度以达到最佳难度。为了确定最佳提示长度,SEELE采用多轮回滚采样策略。每轮中,它根据先前轮次收集的准确度和提示对来拟合项目反应理论模型,以预测下一轮的所需提示长度。这种实例级别的实时难度调整使问题难度与不断进化的模型能力相匹配,提高了探索效率。实验结果表明,SEELE在六个数学推理基准测试上的表现优于集团相对政策优化(GRPO)和监督微调(SFT)分别为+11.8和+10.5点,并平均超过了最佳监督辅助方法+3.6点。
关键见解
- RLVR在增强LLM推理能力方面取得显著成功,但存在探索效率低下的问题。
- 问题难度与模型能力之间的不匹配是探索效率低下的主要原因。
- SEELE通过动态调整问题难度来提高探索效率。
- SEELE通过追加提示来增强训练数据,并自适应地调整每个问题的提示长度。
- SEELE采用多轮回滚采样策略来确定最佳提示长度。
- SEELE实时调整问题难度,以与模型能力的进化相匹配。
点此查看论文截图

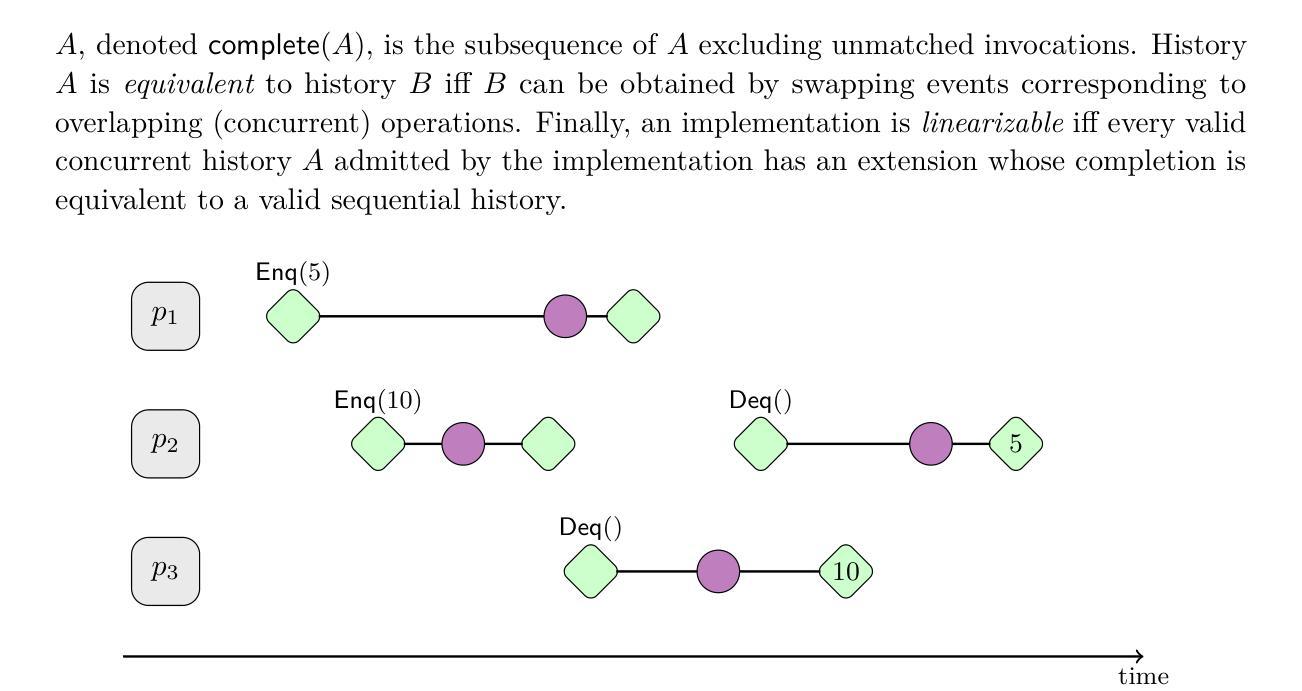
Mechanized Metatheory of Forward Reasoning for End-to-End Linearizability Proofs
Authors:Zachary Kent, Ugur Y. Yavuz, Siddhartha Jayanti, Stephanie Balzer, Guy Blelloch
In the past decade, many techniques have been developed to prove linearizability, the gold standard of correctness for concurrent data structures. Intuitively, linearizability requires that every operation on a concurrent data structure appears to take place instantaneously, even when interleaved with other operations. Most recently, Jayanti et al. presented the first sound and complete “forward reasoning” technique for proving linearizability that relates the behavior of a concurrent data structure to a reference atomic data structure as time moves forward. This technique can be used to produce machine-checked proofs of linearizability in TLA+. However, while Jayanti et al.’s approach is shown to be sound and complete, a mechanization of this important metatheoretic result is still outstanding. As a result, it is not possible to produce verified end-to-end proofs of linearizability. To reduce the size of this trusted computing base, we formalize this forward reasoning technique and mechanize proofs of its soundness and completeness in Rocq. As a case study, we use the approach to produce a verified end-to-end proof of linearizability for a simple concurrent register.
在过去的十年里,为了证明线性化(并发数据结构正确性的金标准)已经开发了许多技术。直观地,线性化要求即使在与其他操作交错的情况下,并发数据结构上的每个操作也似乎都是瞬间完成的。最近,Jayanti等人提出了一种新的线性化证明方法,即首次完善且合理的“向前推理”技术,该技术将并发数据结构的行为与时间前进时的参考原子数据结构关联起来。此技术可用于在TLA+中产生机器验证的线性化证明。然而,虽然Jayanti等人的方法被证明是合理且完整的,但这一重要的元理论结果的机械化仍然是一个悬而未决的问题。因此,无法生成端到端的线性化验证证明。为了减小可信计算基的大小,我们在Rocq中正式制定了这种向前推理技术,并对其合理性和完整性进行了机械化证明。作为案例研究,我们使用该方法为简单的并发寄存器生成了端到端的线性化验证证明。
论文及项目相关链接
Summary
近十年来,为证明并发数据结构的正确性标准——线性化,已开发了许多技术。最近,Jayanti等人提出了首个完善的“向前推理”技术,该技术可将并发数据结构的行为与时间前进时的参考原子数据结构关联起来。然而,尽管Jayanti等人的方法是完善和全面的,但其机械化实现仍待完善。因此,无法生成端到端的线性化证明。为减少可信计算基数的大小,我们在Rocq中形式化这种向前推理技术并机械化证明其正确性和完整性。作为案例研究,我们使用该方法为简单的并发寄存器生成端到端的线性化证明。
Key Takeaways
- 近十年开发了多种证明并发数据结构线性化的技术。
- 线性化要求并发数据结构的操作看起来是瞬间完成的,即使与其他操作交织在一起。
- Jayanti等人提出了首个完善的“向前推理”技术,该技术能将并发数据结构的行为与参考原子数据结构关联起来。
- 该技术可用于在TLA+中生成机器验证的线性化证明。
- 尽管Jayanti等人的方法经过验证是完善和全面的,但其机械化实现尚未完成。
- 无法使用当前技术生成端到端的线性化证明。
点此查看论文截图

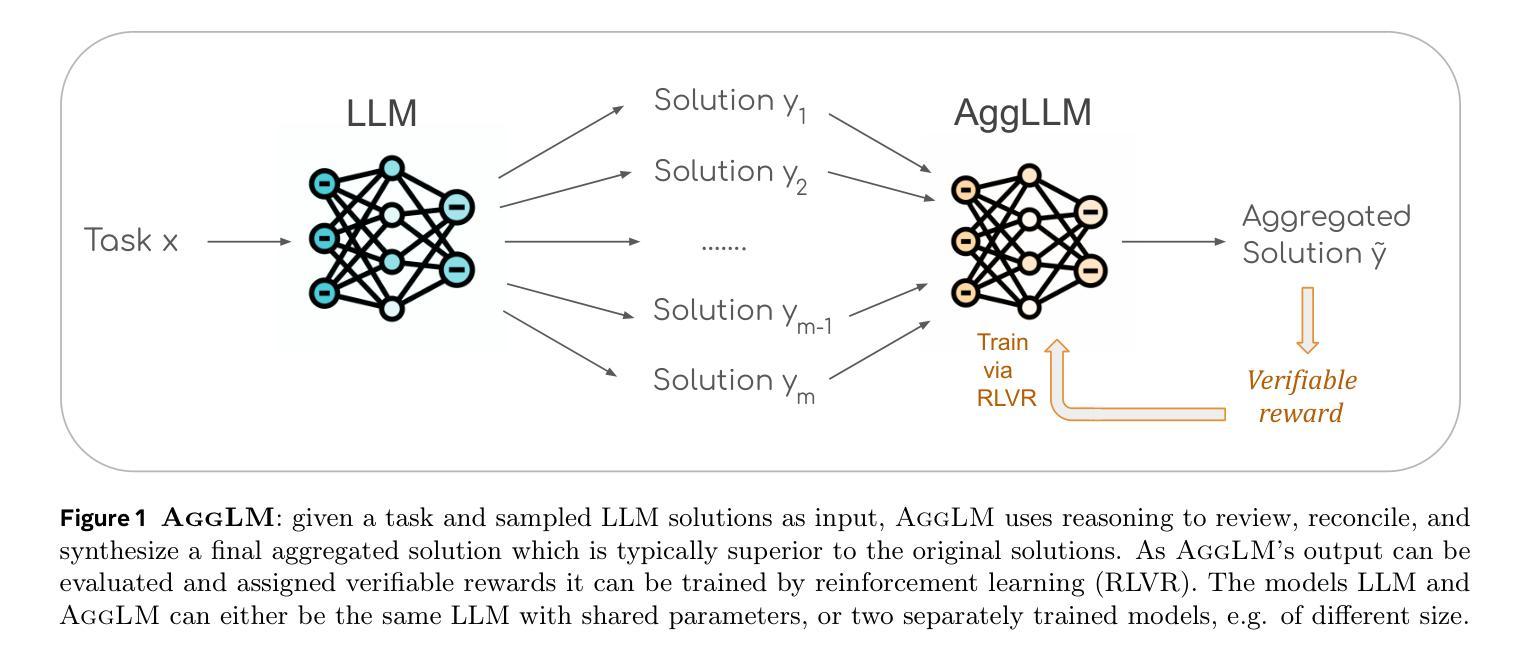
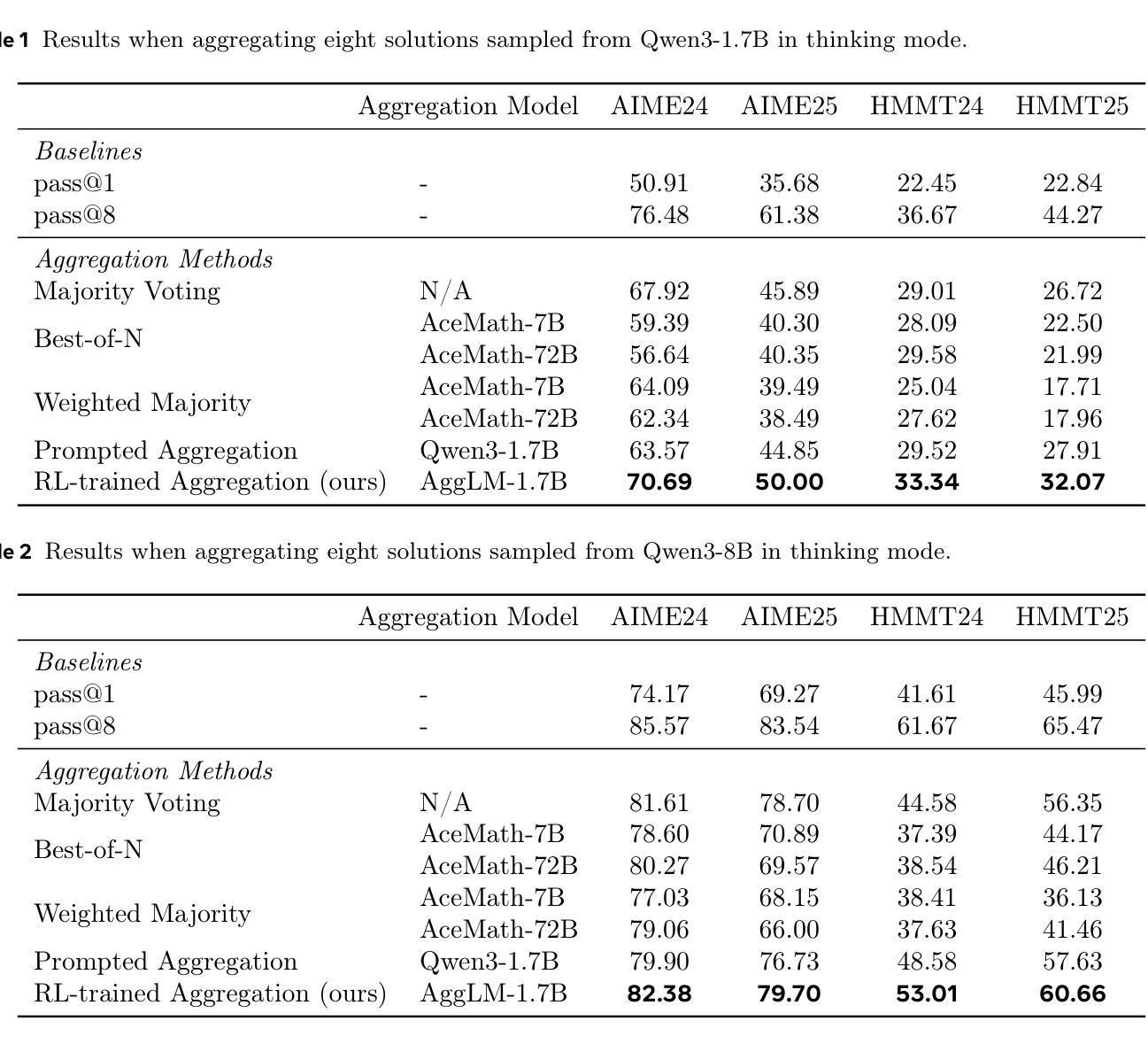
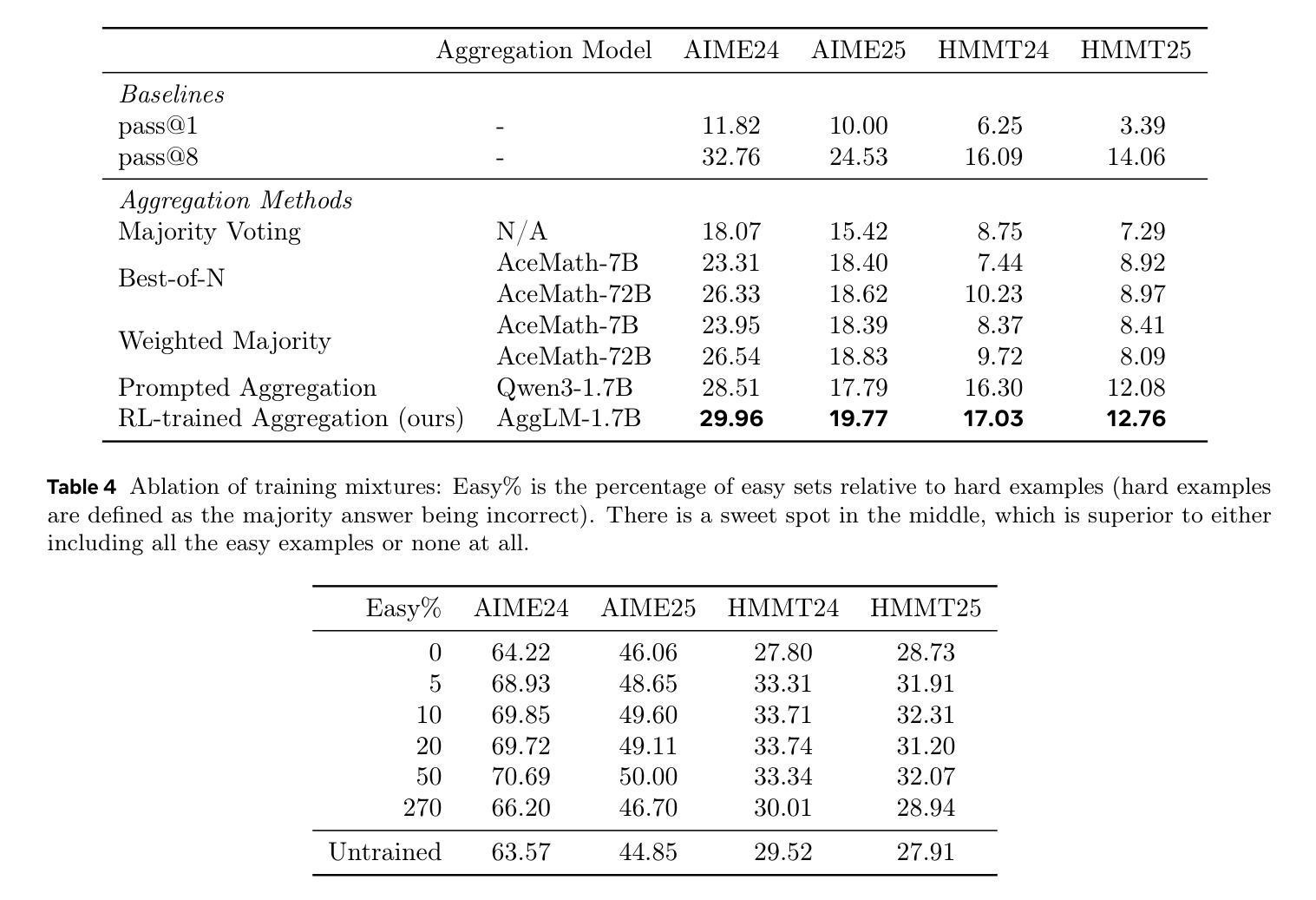
The Majority is not always right: RL training for solution aggregation
Authors:Wenting Zhao, Pranjal Aggarwal, Swarnadeep Saha, Asli Celikyilmaz, Jason Weston, Ilia Kulikov
Scaling up test-time compute, by generating multiple independent solutions and selecting or aggregating among them, has become a central paradigm for improving large language models (LLMs) on challenging reasoning tasks. While most prior work relies on simple majority voting or reward model ranking to aggregate solutions, these approaches may only yield limited benefits. In this work, we propose to learn aggregation as an explicit reasoning skill: given a set of candidate solutions, we train an aggregator model to review, reconcile, and synthesize a final, correct answer using reinforcement learning from verifiable rewards. A key ingredient is careful balancing of easy and hard training examples, allowing the model to learn both to recover minority-but-correct answers as well as easy majority-correct answers. Empirically, we find our method, AggLM, outperforms both strong rule-based and reward-model baselines, across multiple benchmarks. Furthermore, it generalizes effectively to solutions from differing models, including stronger ones than contained in the training data, all while requiring substantially fewer tokens than majority voting with larger numbers of solutions.
在测试时扩大计算规模,通过生成多个独立解决方案并从中选择或聚合,已成为提高大型语言模型(LLM)在具有挑战性推理任务上表现的核心范式。虽然大多数先前的工作依赖于简单的多数投票或奖励模型排名来聚合解决方案,但这些方法可能只能产生有限的效益。在这项工作中,我们提出将聚合作为一种明确的推理技能来学习:给定一组候选解决方案,我们训练一个聚合器模型,使用可验证的奖励来强化学习,以审查、调解和合成最终的正确答案。一个关键要素是平衡简单和复杂的训练示例,使模型能够学习恢复少数但正确的答案,以及简单的多数正确答案。从经验上看,我们发现我们的方法AggLM在多个基准测试中表现优于强大的基于规则和奖励模型的基础线。此外,它能有效地推广到来自不同模型(包括比训练数据更强大的模型)的解决方案,同时需要的令牌数量远远少于使用大量解决方案的多数投票。
论文及项目相关链接
Summary
本文介绍了在大规模语言模型(LLM)的挑战性推理任务中,通过生成多个独立解决方案并在测试时选择或聚合它们来提高模型性能的核心范式。针对大多数现有工作的简单多数投票或奖励模型排名方法可能带来的局限性,本文提出通过学习聚合作为明确的推理技能来解决这一问题。给定一组候选解决方案,我们训练一个聚合器模型,使用可验证的奖励通过强化学习来审查、协调和综合最终的正确答案。通过平衡简单和困难的训练示例,模型能够学习恢复少数但正确的答案以及简单的多数正确答案。经验表明,我们的方法AggLM在多个基准测试中优于强大的规则基准和奖励模型基准,并能有效地推广到来自不同模型的解决方案,包括比训练数据更强大的模型,同时需要的令牌数量远远少于使用大量解决方案的多数投票。
Key Takeaways
- 测试时通过生成多个独立解决方案并聚合,已成为提高大规模语言模型在挑战性推理任务性能的中心范式。
- 现有方法如多数投票或奖励模型排名可能存在局限性。
- 提出通过学习聚合作为明确的推理技能来解决这一问题,训练一个聚合器模型来审查、协调和综合最终答案。
- 使用强化学习和可验证奖励来训练聚合器模型。
- 通过平衡简单和困难的训练示例,模型能学习恢复少数但正确的答案以及简单的多数正确答案。
- AggLM方法在多个基准测试中优于规则基准和奖励模型基准。
点此查看论文截图


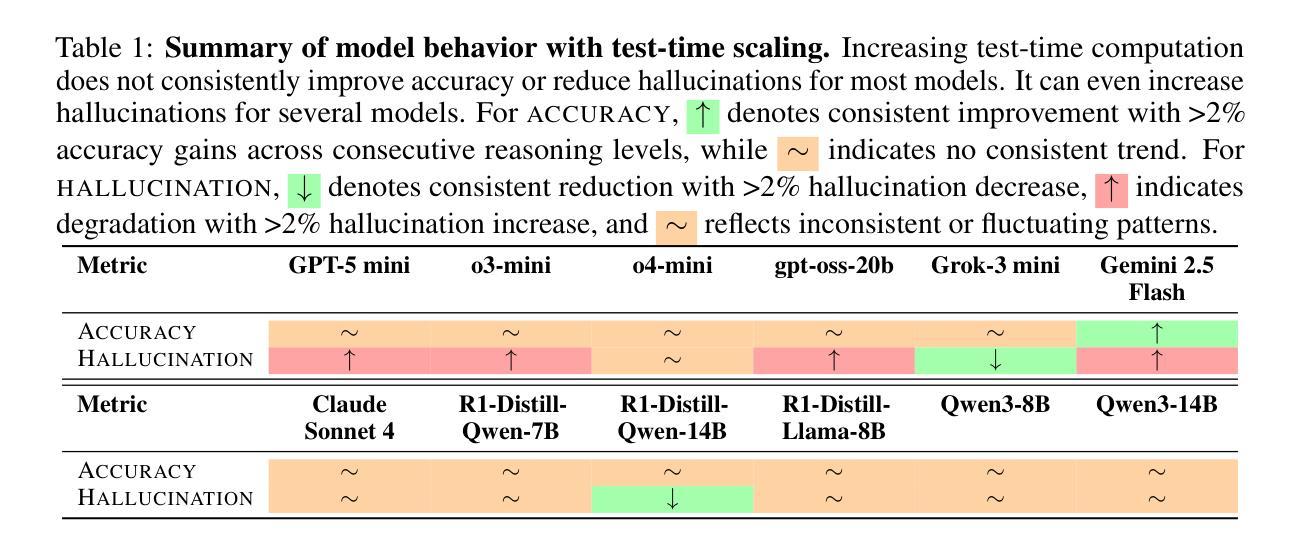
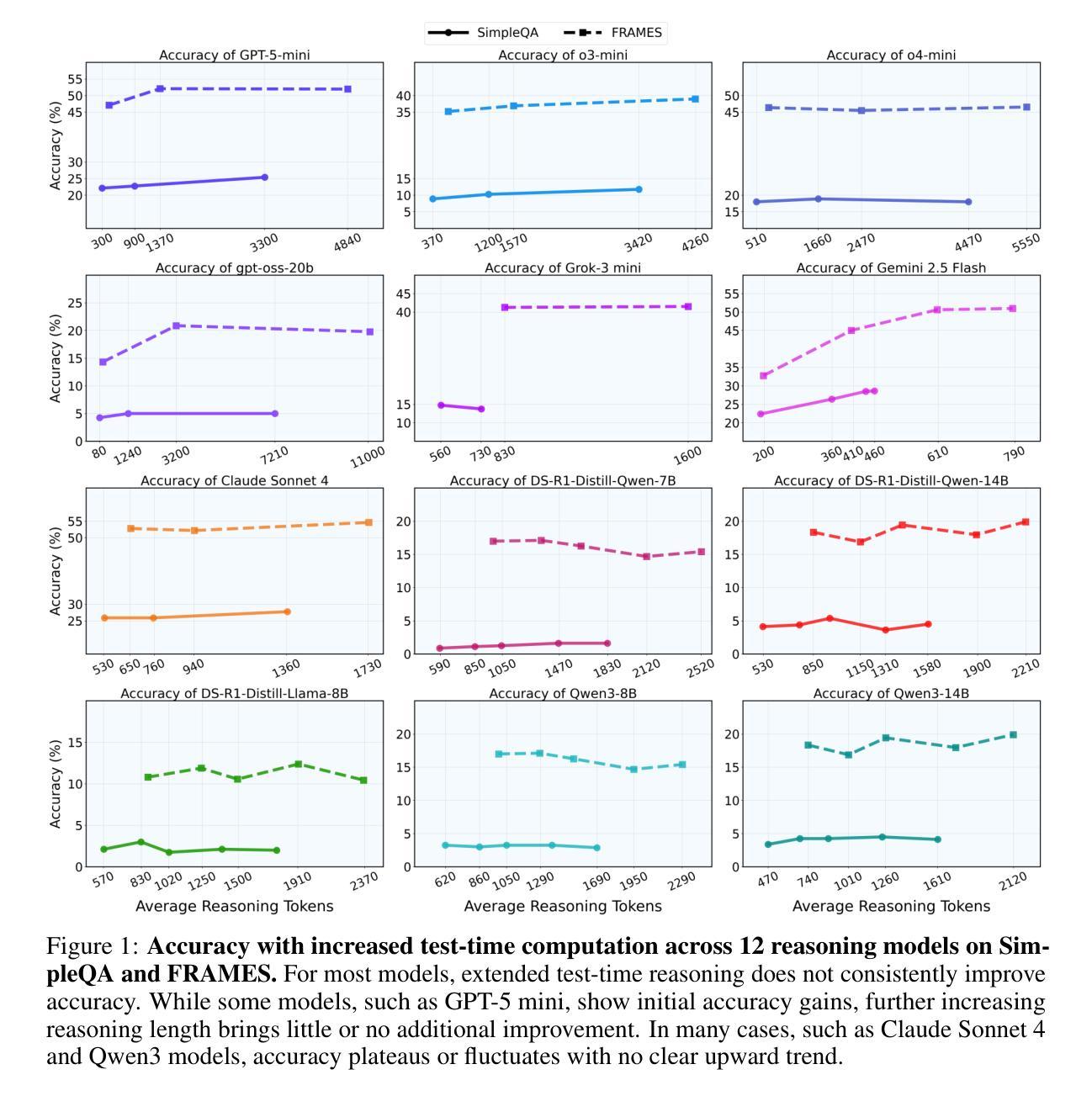
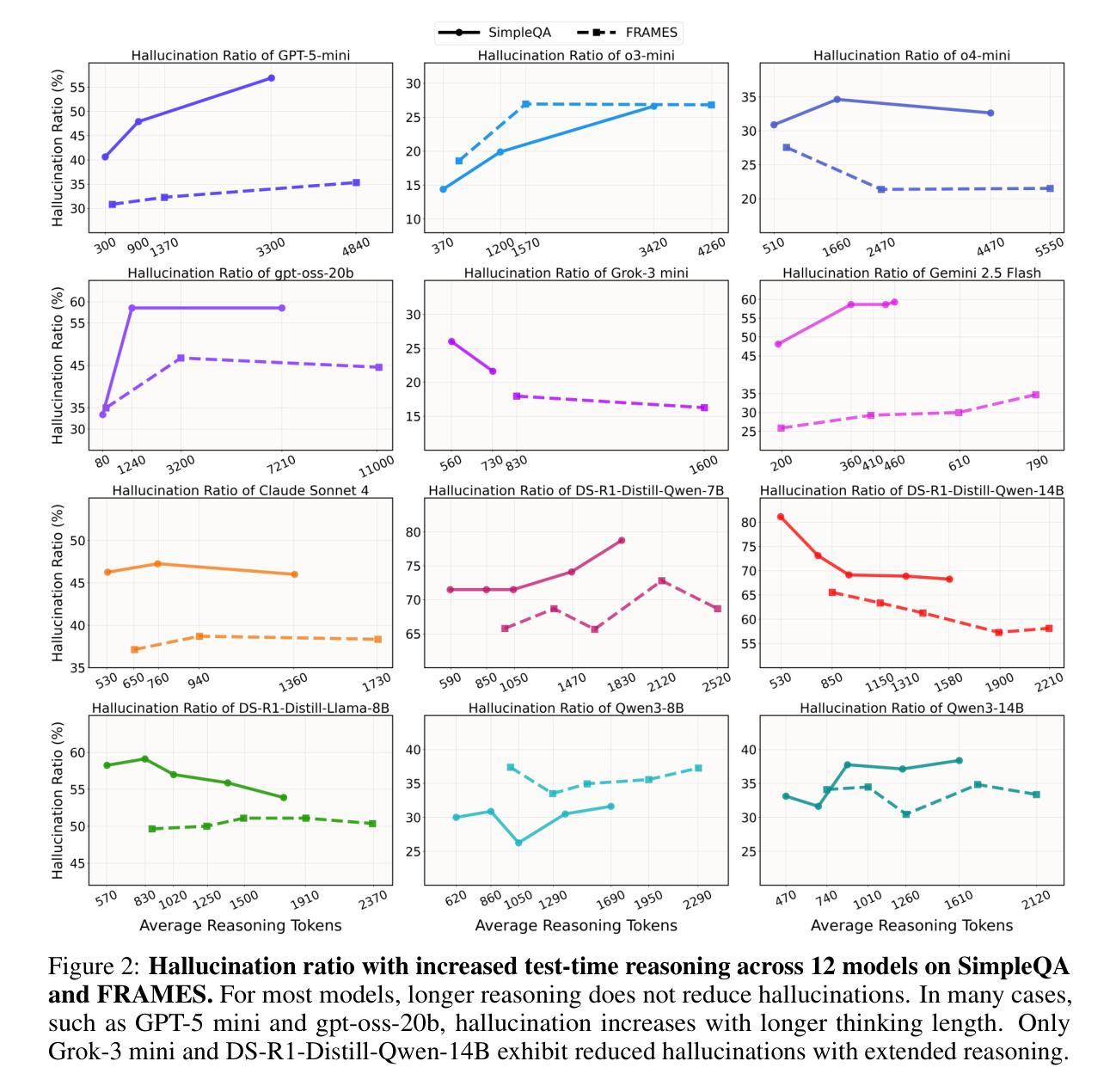
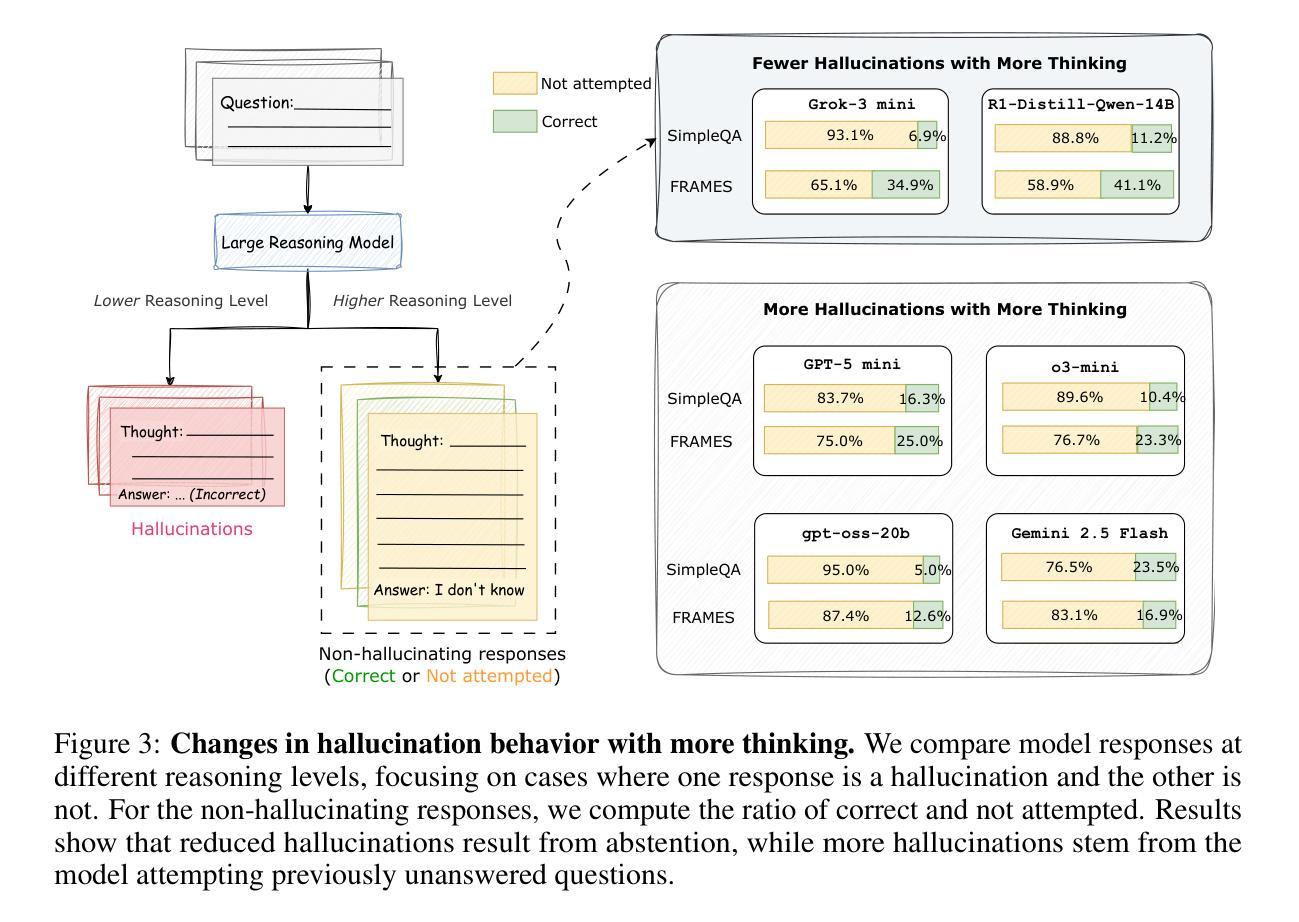
Test-Time Scaling in Reasoning Models Is Not Effective for Knowledge-Intensive Tasks Yet
Authors:James Xu Zhao, Bryan Hooi, See-Kiong Ng
Test-time scaling increases inference-time computation by allowing models to generate long reasoning chains, and has shown strong performance across many domains. However, in this work, we show that this approach is not yet effective for knowledge-intensive tasks, where high factual accuracy and low hallucination rates are essential. We conduct a comprehensive evaluation of test-time scaling using 12 reasoning models on two knowledge-intensive benchmarks. Our results reveal that increasing test-time computation does not consistently improve accuracy and, in many cases, it even leads to more hallucinations. We then analyze how extended reasoning affects hallucination behavior. We find that reduced hallucinations often result from the model choosing to abstain after thinking more, rather than from improved factual recall. Conversely, for some models, longer reasoning encourages attempts on previously unanswered questions, many of which result in hallucinations. Case studies show that extended reasoning can induce confirmation bias, leading to overconfident hallucinations. Despite these limitations, we observe that compared to non-thinking, enabling thinking remains beneficial. Code and data are available at https://github.com/XuZhao0/tts-knowledge
测试时缩放(Test-time scaling)通过允许模型生成长的推理链来增加推理时间计算,并且在许多领域都表现出了强大的性能。然而,在这项工作中,我们表明这种方法对于知识密集型任务尚不有效,其中高事实准确性和低幻觉率是至关重要的。我们在两个知识密集型基准测试上对12个推理模型进行了全面的测试时缩放评估。我们的结果表明,增加测试时间的计算并不能持续提高准确性,而且在许多情况下,甚至会导致更多的幻觉。然后我们分析了扩展推理如何影响幻觉行为。我们发现,减少幻觉往往是由于模型在思考更多后选择放弃回答,而不是因为事实记忆的改善。相反,对于某些模型来说,更长的推理会鼓励尝试之前未解决的问题,其中许多都会导致幻觉。案例研究表明,扩展推理会导致确认偏见,从而产生过度自信的幻觉。尽管有这些局限性,但我们观察到与没有思考相比,允许思考仍然是有益的。相关代码和数据可以在 https://github.com/XuZhao0/tts-knowledge 找到。
论文及项目相关链接
PDF 20 pages, 4 figures, 6 tables
Summary
本文研究了测试时缩放技术在知识密集型任务中的表现,发现增加测试时的计算量并不总能提高准确性,且有时会导致更多的幻觉。分析表明,延长推理时间并不总是能减少幻觉,而且对一些模型而言,更长的推理时间甚至会鼓励尝试回答之前未解决的问题,从而增加幻觉。然而,与不经思考相比,允许模型思考仍然是有益的。
Key Takeaways
- 测试时缩放技术允许模型生成更长的推理链,但其在知识密集型任务中的效果有限。
- 增加测试时的计算量并不总是能提高准确性,有时甚至会导致更多的幻觉。
- 延长推理时间并不一定能减少幻觉,这取决于模型的特性。
- 对于某些模型,更长的推理时间可能鼓励尝试回答之前未解决的问题,增加幻觉。
- 测试时缩放技术可能引发确认偏见,导致过度自信的幻觉。
- 尽管存在局限性,但与不经思考相比,允许模型思考仍然具有益处。
点此查看论文截图

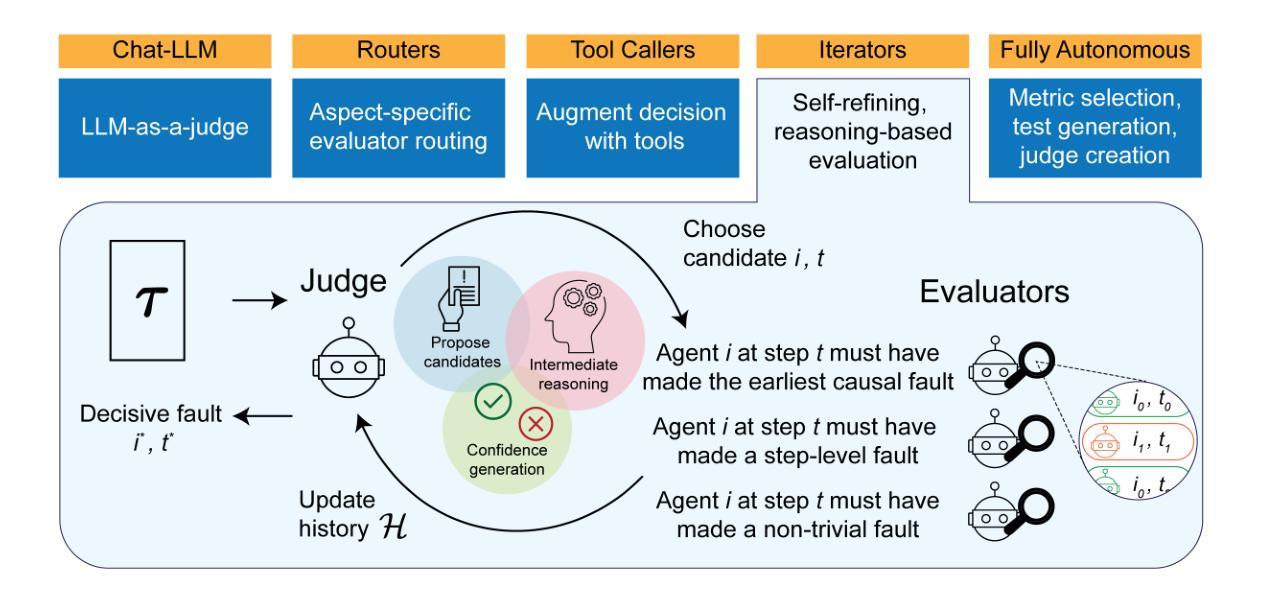
RAFFLES: Reasoning-based Attribution of Faults for LLM Systems
Authors:Chenyang Zhu, Spencer Hong, Jingyu Wu, Kushal Chawla, Charlotte Tang, Youbing Yin, Nathan Wolfe, Erin Babinsky, Daben Liu
We have reached a critical roadblock in the development and enhancement of long-horizon, multi-component LLM agentic systems: it is incredibly tricky to identify where these systems break down and why. Evaluation capabilities that currently exist today (e.g., single pass LLM-as-a-judge) are limited in that they often focus on individual metrics or capabilities, end-to-end outcomes, and are narrowly grounded on the preferences of humans. We argue that to match the agentic capabilities, evaluation frameworks must also be able to reason, probe, iterate, and understand the complex logic passing through these systems over long horizons. In this paper, we present RAFFLES - an evaluation architecture that incorporates reasoning and iterative refinement. Specifically, RAFFLES operates as an iterative, multi-component pipeline, using a central Judge to systematically investigate faults and a set of specialized Evaluators to assess not only the system’s components but also the quality of the reasoning by the Judge itself, thereby building a history of hypotheses. We tested RAFFLES against several baselines on the Who&When dataset, a benchmark designed to diagnose the “who” (agent) and “when” (step) of a system’s failure. RAFFLES outperforms these baselines, achieving an agent-step fault pair accuracy of over 43% on the Algorithmically-Generated dataset (a substantial increase from the previously published best of 16.6%) and over 20% on the Hand-Crafted dataset (surpassing the previously published best of 8.8%). These results demonstrate a key step towards introducing automated fault detection for autonomous systems over labor-intensive manual human review.
我们已经遇到长期视野、多组件LLM智能系统开发和增强过程中的关键难题:很难确定这些系统出现故障的位置和原因。当前存在的评估能力(例如,单一通行LLM作为评判者)具有局限性,因为它们通常关注单个指标或能力、端到端结果,并基于人类的偏好。我们认为,为了匹配智能系统的能力,评估框架还必须能够推理、探测、迭代和理解这些系统在长期视野中通过的复杂逻辑。在本文中,我们提出了RAFFLES——一种结合推理和迭代精化的评估架构。具体来说,RAFFLES作为一个迭代的多组件管道运行,使用一个中央评判系统来系统地调查故障和一系列专门的评估器来评估不仅系统的组件,还评估评判本身的推理质量,从而建立假设历史。我们在Who&When数据集上测试了RAFFLES,该数据集旨在诊断系统的“谁”(智能体)和“何时”(步骤)故障。RAFFLES优于这些基线,在算法生成的数据集上实现了超过43%的智能体步骤故障对准确率(与之前发布的最佳结果16.6%相比有大幅度提高),在手工制作的数据集上超过20%(超过之前发布的最佳结果8.8%)。这些结果朝着为自主系统引入自动化故障检测方向迈出了关键一步,减少了劳动密集型的手动人工审查。
论文及项目相关链接
Summary
本文提出在开发和增强长期视野多组件的LLM代理人系统时遇到的瓶颈问题,即难以确定系统的故障所在及原因。现有评估方法(如单次通过LLM作为评估工具)侧重于单独的能力指标和结果评价,忽略了系统的复杂逻辑和长期推理过程。因此,作者提出了RAFFLES评估架构,该架构能够进行迭代推理和精细调整,解决此问题。测试显示,RAFFLES在Who&When数据集上的表现优于其他基线方法,实现了对系统故障的“谁”和“何时”的诊断。这为自主系统的自动化故障检测提供了关键一步,减少了劳动密集型的人工审查。
Key Takeaways
- LLM代理人系统在开发和增强过程中面临识别故障困难的瓶颈。
- 当前评估方法侧重于个体能力指标和结果,忽略系统的长期逻辑和推理过程。
- 提出RAFFLES评估架构,具备推理、迭代完善能力,解决现有问题。
- RAFFLES通过中央评估系统和一系列专业评估器,不仅评估系统组件,还评估判断质量,建立假设历史。
- 在Who&When数据集上的测试表明,RAFFLES优于其他基线方法。
- RAFFLES实现了对系统故障的“谁”和“何时”的诊断,表现在算法生成和数据集的手工制作上都有显著的提升。
点此查看论文截图


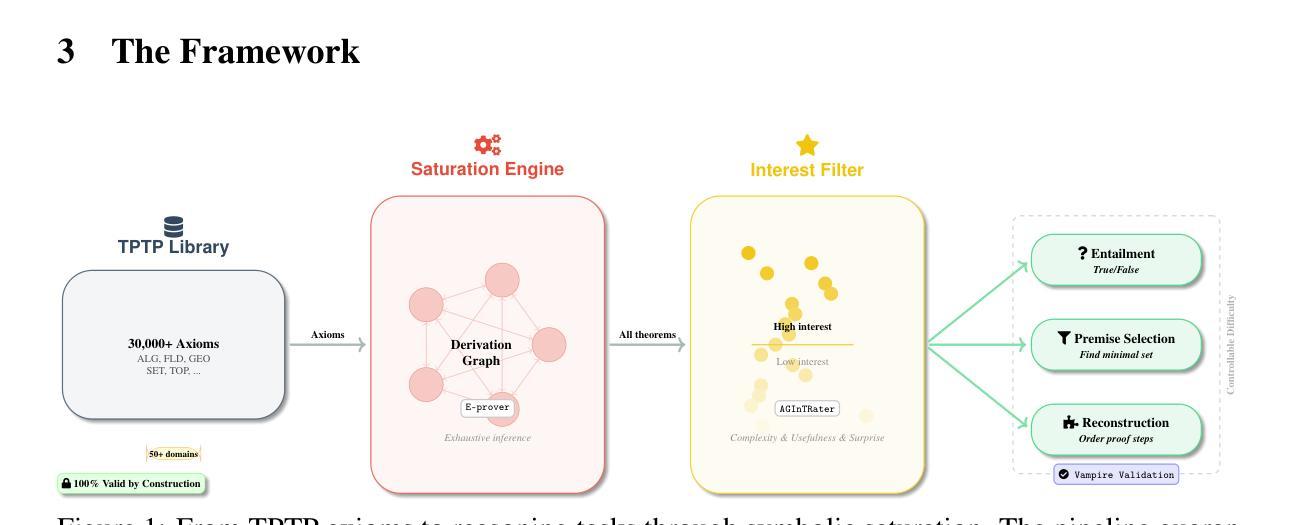
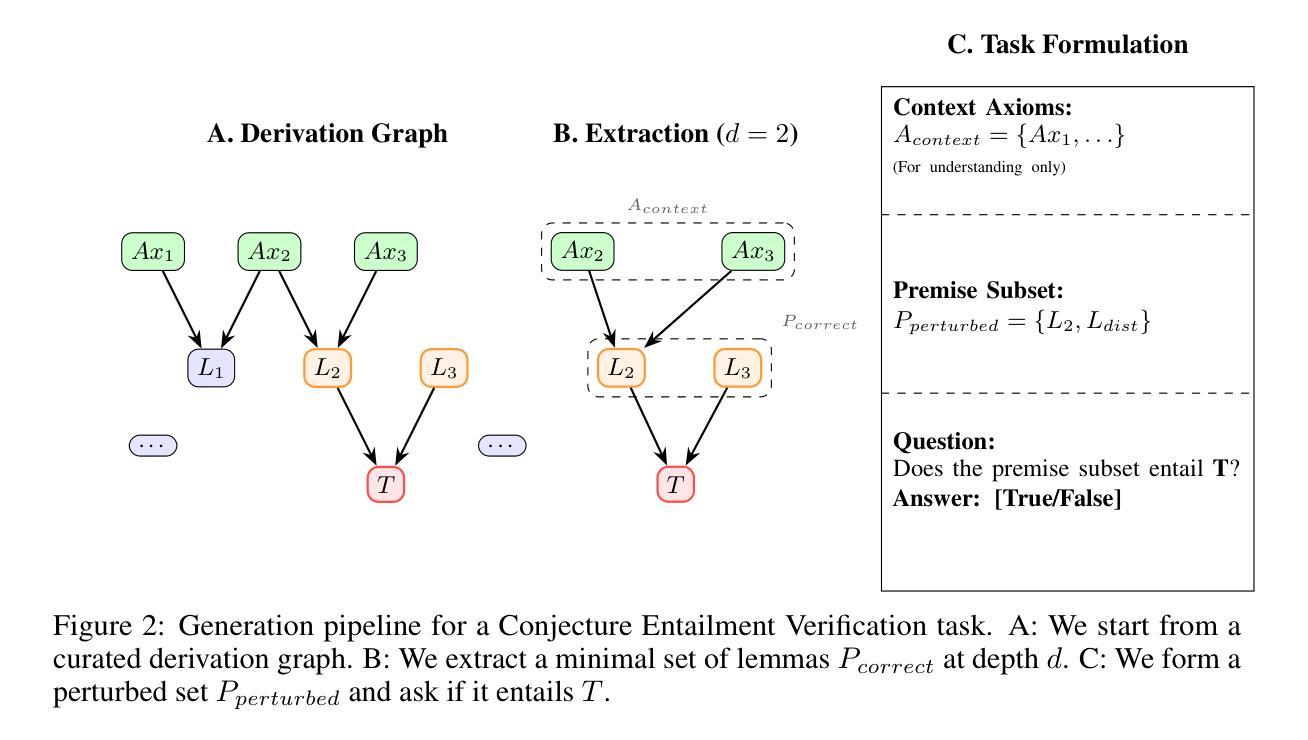
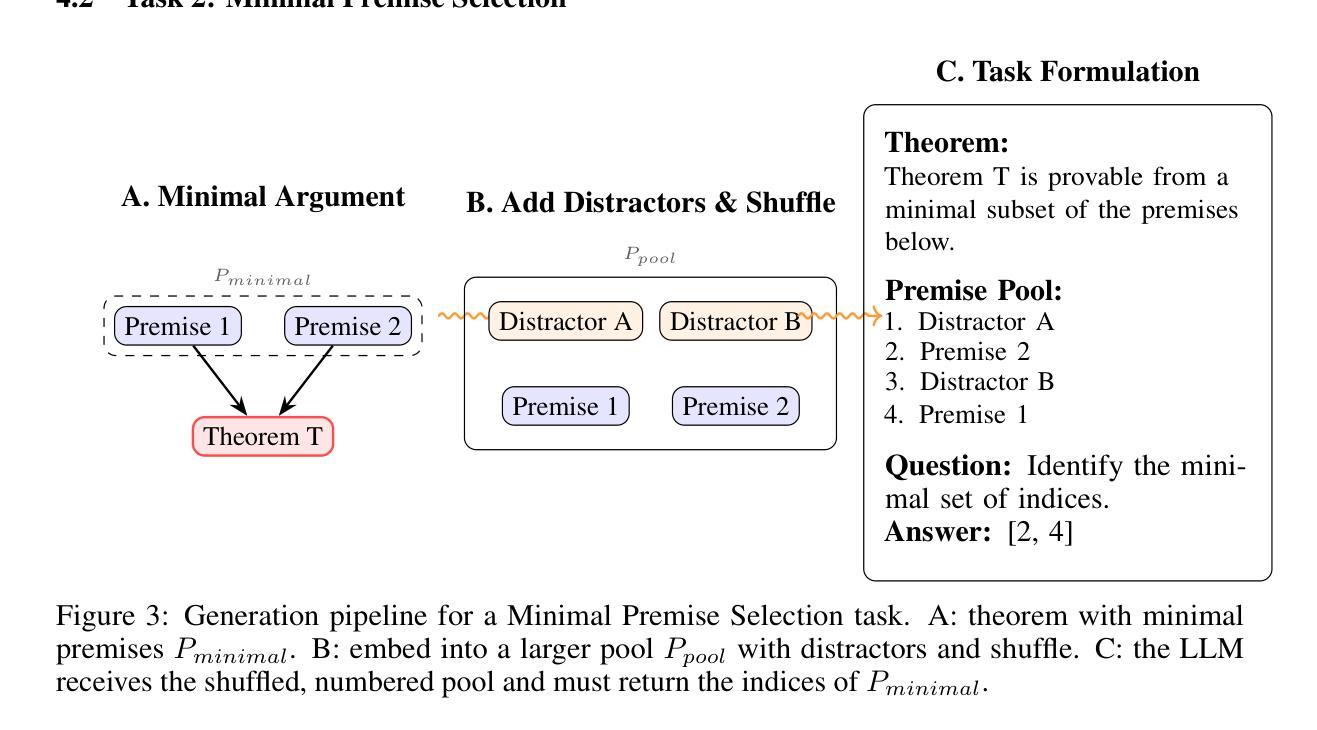
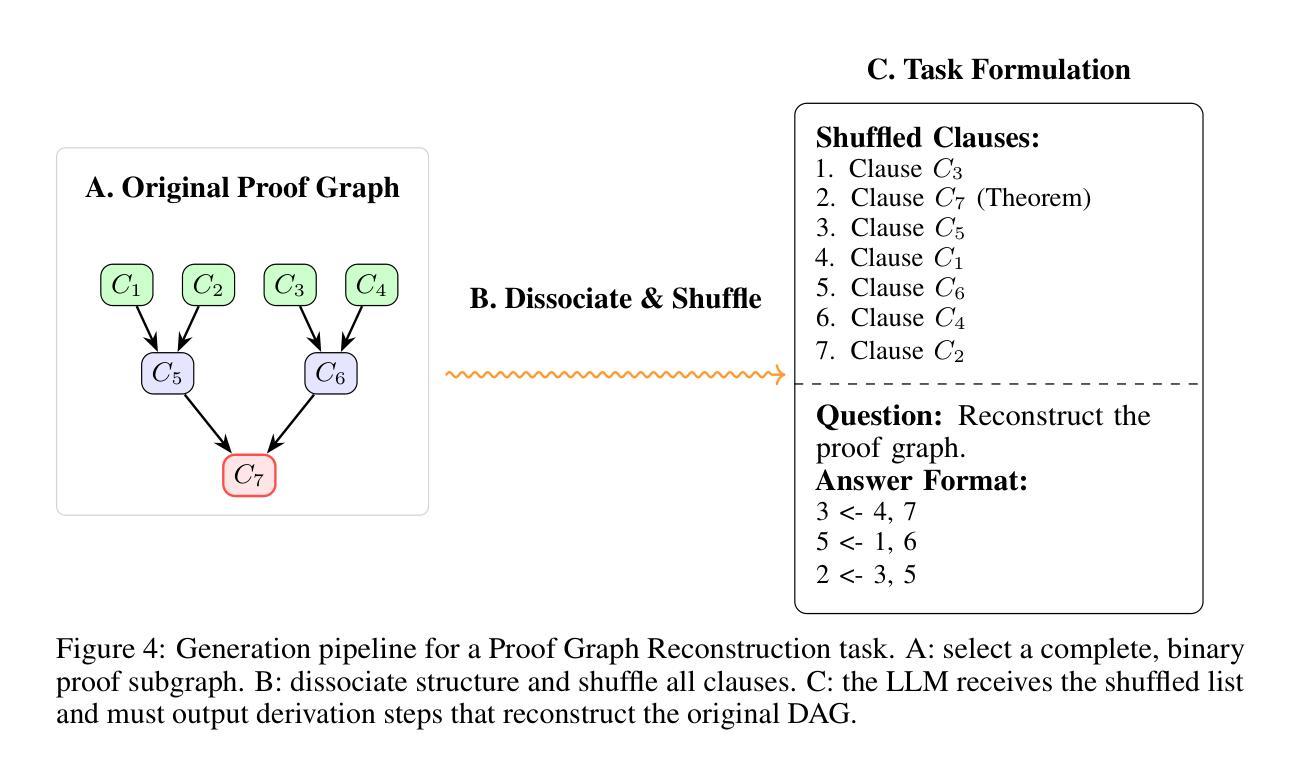
Saturation-Driven Dataset Generation for LLM Mathematical Reasoning in the TPTP Ecosystem
Authors:Valentin Quesnel, Damien Sileo
The scarcity of high-quality, logically sound data is a critical bottleneck for advancing the mathematical reasoning of Large Language Models (LLMs). Our work confronts this challenge by turning decades of automated theorem proving research into a scalable data engine. Rather than relying on error-prone LLMs or complex proof-assistant syntax like Lean and Isabelle, our framework leverages E-prover’s saturation capabilities on the vast TPTP axiom library to derive a massive, guaranteed-valid corpus of theorems. Our pipeline is principled and simple: saturate axioms, filter for “interesting” theorems, and generate tasks. With no LLMs in the loop, we eliminate factual errors by construction. This purely symbolic data is then transformed into three difficulty-controlled challenges: entailment verification, premise selection, and proof reconstruction. Our zero-shot experiments on frontier models reveal a clear weakness: performance collapses on tasks requiring deep, structural reasoning. Our framework provides both the diagnostic tool to measure this gap and a scalable source of symbolic training data to address it. We make the code and data publicly available. https://github.com/sileod/reasoning_core https://hf.co/datasets/reasoning-core/rc1
高质量、逻辑严谨的数据稀缺,是推动大型语言模型(LLM)数学推理进步的关键瓶颈。我们的工作通过把几十年的自动化定理证明研究转化为可扩展的数据引擎来应对这一挑战。我们的框架并没有依赖容易出错的LLM或复杂的证明辅助语法(如Lean和Isabelle),而是利用E-prover在TPTP公理库上的饱和能力,推导出大量有保证有效的定理语料库。我们的管道有原则且简单:饱和公理,过滤出“有趣”的定理,并生成任务。由于没有LLM的参与,我们通过构建消除了事实错误。这种纯粹的符号数据随后被转化为三种难度可控的挑战:蕴含验证、前提选择、证明重建。我们在前沿模型上的零样本实验揭示了一个明确的弱点:对于需要深入、结构性推理的任务,性能会崩溃。我们的框架既提供了衡量这一差距的诊断工具,又提供了可扩展的符号训练数据来源来解决这一问题。我们公开提供代码和数据。相关链接如下:https://github.com/sileod/reasoning_core https://hf.co/datasets/reasoning-core/rc1
论文及项目相关链接
Summary
本研究针对大型语言模型(LLMs)在推进数学推理方面的瓶颈问题,提出一种利用定理证明器E-prover对TPTP公理库进行饱和计算的方法,生成大量保证有效的定理语料库。通过简单的原则性管道——饱和公理、过滤有趣定理、生成任务,实现无需LLMs参与,从而避免了事实错误。该框架提供诊断工具来衡量前沿模型在深度结构推理方面的差距,并提供可伸缩的符号训练数据来解决这一问题。相关代码和数据已公开。
Key Takeaways
- 大型语言模型在推进数学推理方面面临数据质量瓶颈。
- 研究利用定理证明器E-prover生成大量保证有效的定理语料库。
- 管道包括饱和公理、过滤有趣定理、生成任务,无需大型语言模型参与。
- 该框架避免了事实错误,并提供了衡量前沿模型在深度结构推理方面差距的工具。
- 公开的代码和数据有助于研究者和开发者使用此框架进行研究和应用。
- 该框架提供了一种可扩展的符号训练数据来源,以改进模型在数学推理方面的性能。
点此查看论文截图

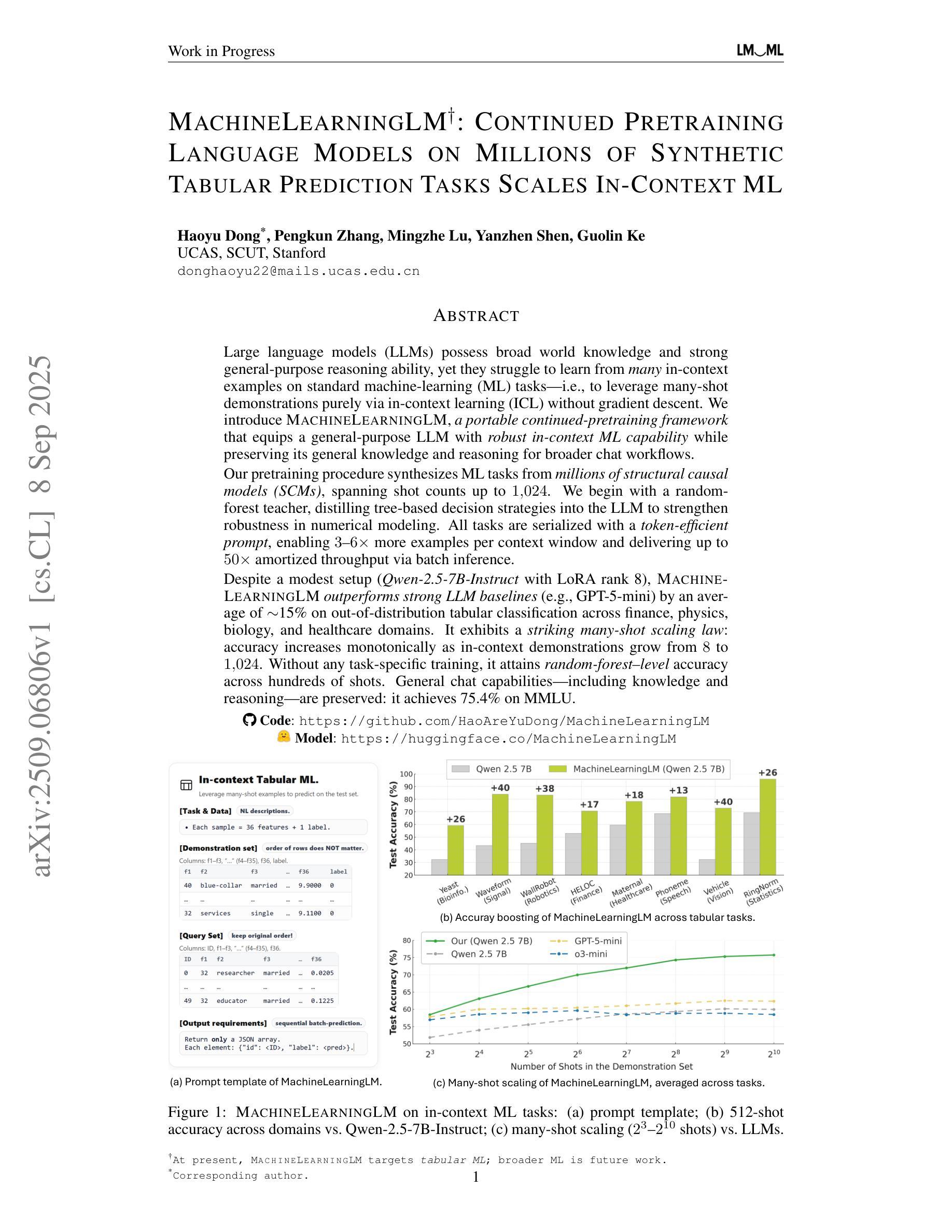
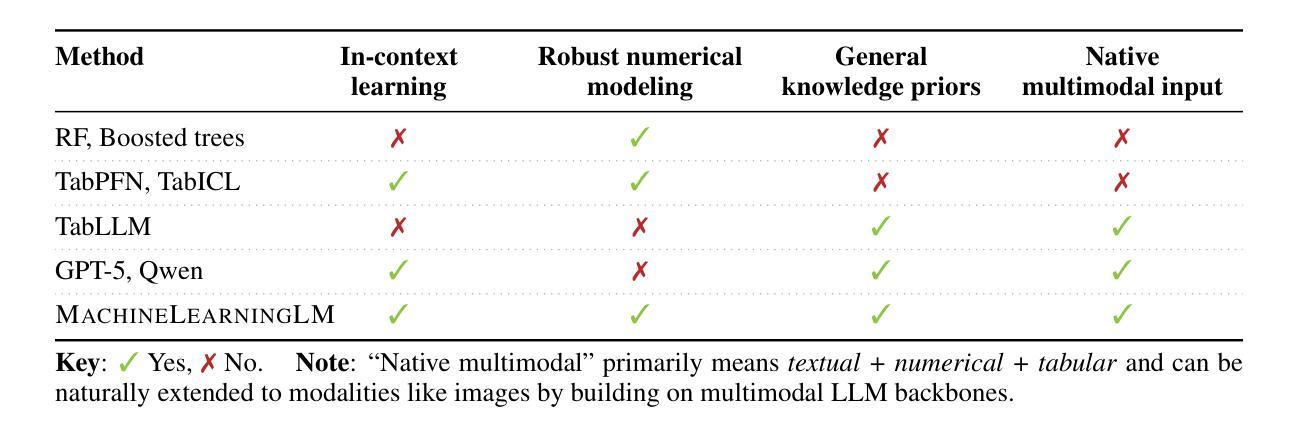
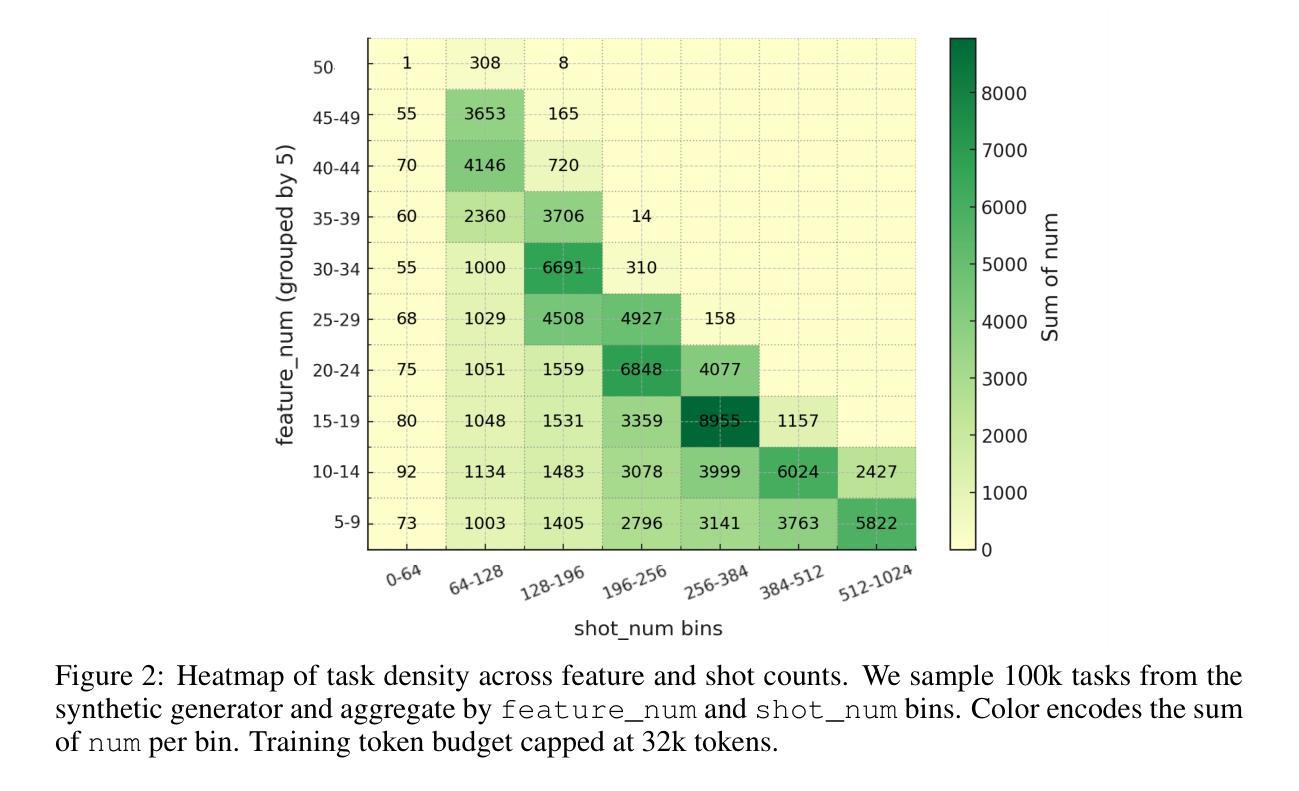
MachineLearningLM: Continued Pretraining Language Models on Millions of Synthetic Tabular Prediction Tasks Scales In-Context ML
Authors:Haoyu Dong, Pengkun Zhang, Mingzhe Lu, Yanzhen Shen, Guolin Ke
Large language models (LLMs) possess broad world knowledge and strong general-purpose reasoning ability, yet they struggle to learn from many in-context examples on standard machine learning (ML) tasks, that is, to leverage many-shot demonstrations purely via in-context learning (ICL) without gradient descent. We introduce MachineLearningLM, a portable continued-pretraining framework that equips a general-purpose LLM with robust in-context ML capability while preserving its general knowledge and reasoning for broader chat workflows. Our pretraining procedure synthesizes ML tasks from millions of structural causal models (SCMs), spanning shot counts up to 1,024. We begin with a random-forest teacher, distilling tree-based decision strategies into the LLM to strengthen robustness in numerical modeling. All tasks are serialized with a token-efficient prompt, enabling 3x to 6x more examples per context window and delivering up to 50x amortized throughput via batch inference. Despite a modest setup (Qwen-2.5-7B-Instruct with LoRA rank 8), MachineLearningLM outperforms strong LLM baselines (e.g., GPT-5-mini) by an average of about 15% on out-of-distribution tabular classification across finance, physics, biology, and healthcare domains. It exhibits a striking many-shot scaling law: accuracy increases monotonically as in-context demonstrations grow from 8 to 1,024. Without any task-specific training, it attains random-forest-level accuracy across hundreds of shots. General chat capabilities, including knowledge and reasoning, are preserved: it achieves 75.4% on MMLU.
大型语言模型(LLM)拥有广泛的世界知识和强大的通用推理能力,但在标准机器学习(ML)任务上,它们很难从多个上下文示例中学习,也就是说,它们无法仅通过上下文学习(ICL)利用多个示例演示,而无需进行梯度下降。我们引入了MachineLearningLM,这是一个便携式持续预训练框架,它使通用LLM具备强大的上下文ML能力,同时保留其一般知识和推理能力,以支持更广泛的聊天工作流程。我们的预训练程序从数百万个结构因果模型(SCM)中综合ML任务,涵盖示例数量高达1024个。我们以随机森林教师开始,将基于树的决策策略蒸馏到LLM中,以加强数值建模中的稳健性。所有任务都通过高效的令牌提示进行序列化,可以在每个上下文窗口中实现3到6倍的更多示例,并通过批量推理实现高达50倍的摊销吞吐量。尽管配置相对简单(使用LoRA等级8的Qwen-2.5-7B-Instruct),但MachineLearningLM在金融、物理、生物和医疗保健领域的离群分布表格分类方面,平均比强大的LLM基线(例如GPT-5 mini)高出约15%。它呈现出令人印象深刻的许多射击比例定律:随着上下文演示从8增加到1024,准确性呈单调增加。无需任何特定任务训练,它在数百次射击中达到了随机森林级别的精度。同时保留了通用的聊天功能,包括知识和推理能力:它在MMLU上达到了75.4%。
论文及项目相关链接
摘要
大型语言模型(LLM)具备广泛的世界知识和强大的通用推理能力,但在标准机器学习(ML)任务上学习多个上下文示例时遇到困难。本文介绍了MachineLearningLM,这是一个便携式持续预训练框架,旨在增强LLM的上下文机器学习(ICL)能力,同时保留其一般知识和推理能力以支持更广泛的聊天工作流程。我们的预训练程序通过数百万的结构化因果模型(SCM)合成机器学习任务,涵盖示例数量高达1024个。我们采用随机森林教师,将基于树的决策策略灌输到LLM中,以加强其在数值建模中的稳健性。所有任务都通过高效的令牌提示进行序列化,能够在每个上下文窗口中增加3倍至6倍的示例,并通过批量推理实现高达50倍的摊销吞吐量。尽管使用了适度的设置(Qwen-2.5-7B-Instruct with LoRA rank 8),但MachineLearningLM在财务、物理、生物和医疗保健领域的离群制表分类上平均优于强大的LLM基线(例如GPT-5-mini)约15%。它表现出惊人的多示例缩放定律:随着上下文演示从8个增长到1024个,准确性单调增加。无需任何特定任务训练,即可达到随机森林级别的精度,同时保留通用聊天能力,包括知识和推理能力,在MMLU上达到75.4%。
关键见解
- 大型语言模型(LLM)在标准机器学习(ML)任务上学习多个上下文示例时面临挑战。
- MachineLearningLM是一个便携式持续预训练框架,旨在增强LLM的上下文机器学习(ICL)能力。
- 预训练程序通过结构化的因果模型(SCM)合成任务,涵盖广泛的示例数量。
- 使用随机森林教师来强化LLM在数值建模中的稳健性。
- MachineLearningLM通过有效的提示序列化任务,增加上下文窗口中的示例数量,并通过批量推理提高吞吐量。
- MachineLearningLM在多个领域的离群制表分类任务上优于其他强大的LLM基线。
点此查看论文截图
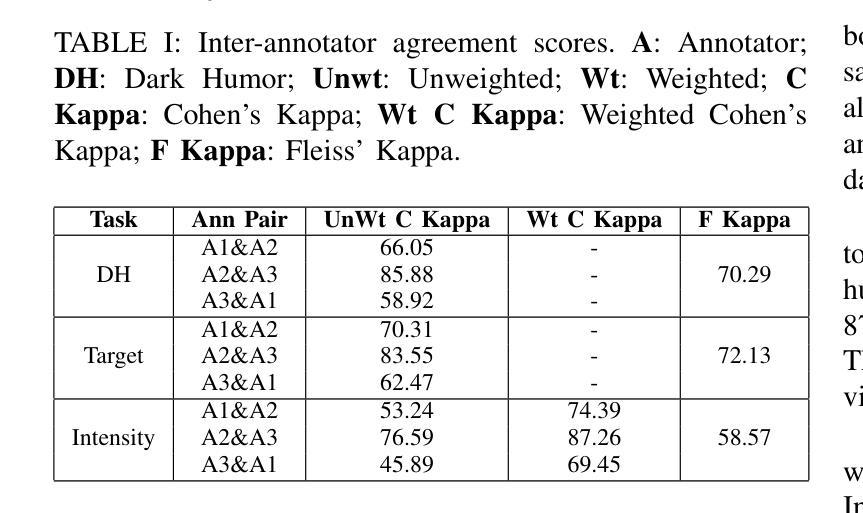
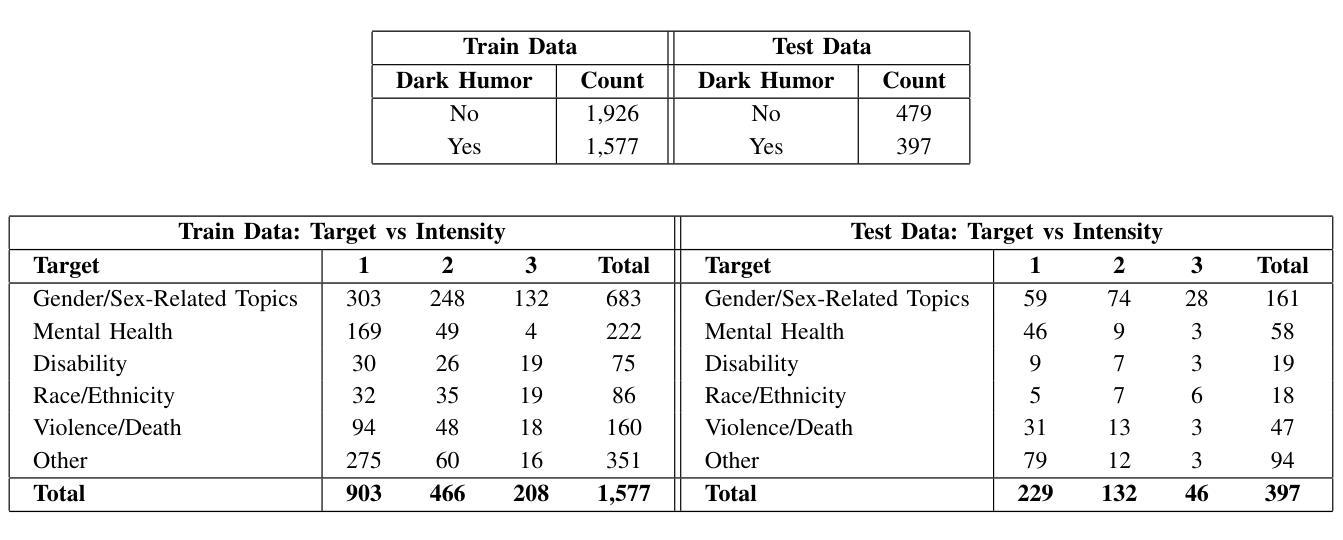
D-HUMOR: Dark Humor Understanding via Multimodal Open-ended Reasoning
Authors:Sai Kartheek Reddy Kasu, Mohammad Zia Ur Rehman, Shahid Shafi Dar, Rishi Bharat Junghare, Dhanvin Sanjay Namboodiri, Nagendra Kumar
Dark humor in online memes poses unique challenges due to its reliance on implicit, sensitive, and culturally contextual cues. To address the lack of resources and methods for detecting dark humor in multimodal content, we introduce a novel dataset of 4,379 Reddit memes annotated for dark humor, target category (gender, mental health, violence, race, disability, and other), and a three-level intensity rating (mild, moderate, severe). Building on this resource, we propose a reasoning-augmented framework that first generates structured explanations for each meme using a Large Vision-Language Model (VLM). Through a Role-Reversal Self-Loop, VLM adopts the author’s perspective to iteratively refine its explanations, ensuring completeness and alignment. We then extract textual features from both the OCR transcript and the self-refined reasoning via a text encoder, while visual features are obtained using a vision transformer. A Tri-stream Cross-Reasoning Network (TCRNet) fuses these three streams, text, image, and reasoning, via pairwise attention mechanisms, producing a unified representation for classification. Experimental results demonstrate that our approach outperforms strong baselines across three tasks: dark humor detection, target identification, and intensity prediction. The dataset, annotations, and code are released to facilitate further research in multimodal humor understanding and content moderation. Code and Dataset are available at: https://github.com/Sai-Kartheek-Reddy/D-Humor-Dark-Humor-Understanding-via-Multimodal-Open-ended-Reasoning
网络迷因中的黑色幽默因其依赖于隐含的、敏感的以及文化背景情境线索而带来独特的挑战。为了解决检测多模态内容中黑色幽默的资源和方法缺乏的问题,我们引入了包含4379个Reddit迷因的新数据集,这些迷因被标注为黑色幽默、目标类别(性别、心理健康、暴力、种族、残疾和其他)以及三级强度评级(轻度、中度、重度)。基于这一资源,我们提出了一个增强推理的框架,该框架首先使用大型视觉语言模型(VLM)为每个迷因生成结构化解释。通过角色反转自循环,VLM采用作者的角度来迭代优化其解释,确保完整性和一致性。然后我们从OCR转录和经过自我优化的推理中提取文本特征,使用文本编码器进行处理,同时使用视觉变压器获取视觉特征。Tri-stream交叉推理网络(TCRNet)通过配对注意力机制融合这三个流——文本、图像和推理,为分类生成统一表示。实验结果表明,我们的方法在三项任务上的表现均优于强大的基线:黑色幽默检测、目标识别和强度预测。数据集、注释和代码已发布,以促进多模态幽默理解和内容审核的进一步研究。代码和数据集可在https://github.com/Sai-Kartheek-Reddy/D-Humor-Dark-Humor-Understanding-via-Multimodal-Open-ended-Reasoning找到。
论文及项目相关链接
PDF Accepted at IEEE International Conference on Data Mining (ICDM) 2025
Summary:网络迷因中的黑色幽默带来了独特的挑战,因为其依赖于隐晦、敏感和文化背景的线索。为应对多模式内容中缺乏检测黑色幽默的资源和方法,我们引入了含有4379个Reddit迷因的新数据集,并对其进行了黑色幽默、目标类别(如性别、心理健康、暴力等)和三级强度评分的标注。基于这一资源,我们提出了一个推理增强框架,首先使用大型视觉语言模型(VLM)为每个迷因生成结构化解释。通过角色反转自我循环,VLM采用作者视角进行迭代优化解释,确保完整性和一致性。然后我们从OCR转录和自我优化的推理中提取文本特征,同时使用视觉变换器获取图像特征。三流交叉推理网络(TCRNet)通过配对注意力机制融合这三个流(文本、图像和推理),产生统一表示用于分类。实验结果表明,我们的方法在三项任务上的表现均优于强大的基线:黑色幽默检测、目标识别和强度预测。数据集、注释和代码已发布,以促进多模式幽默理解和内容审核的进一步研究。代码和数据集可通过链接访问:[链接地址]。
Key Takeaways:
- 网络迷因中的黑色幽默因其隐晦和文化背景依赖性而具有独特挑战。
- 为解决多模式内容中检测黑色幽默的问题,引入了标注化的Reddit迷因数据集。
- 引入了一个结合视觉语言模型(VLM)、文本编码器和视觉转换器的推理增强框架来理解和检测黑色幽默。
- 该框架包含结构解释生成、角色反转自我循环以及文本和图像特征的提取与融合。
- 三流交叉推理网络(TCRNet)通过配对注意力机制整合文本、图像和推理信息,提高分类性能。
- 实验结果显示,该方法在黑色幽默检测、目标识别和强度预测任务上表现优越。
点此查看论文截图



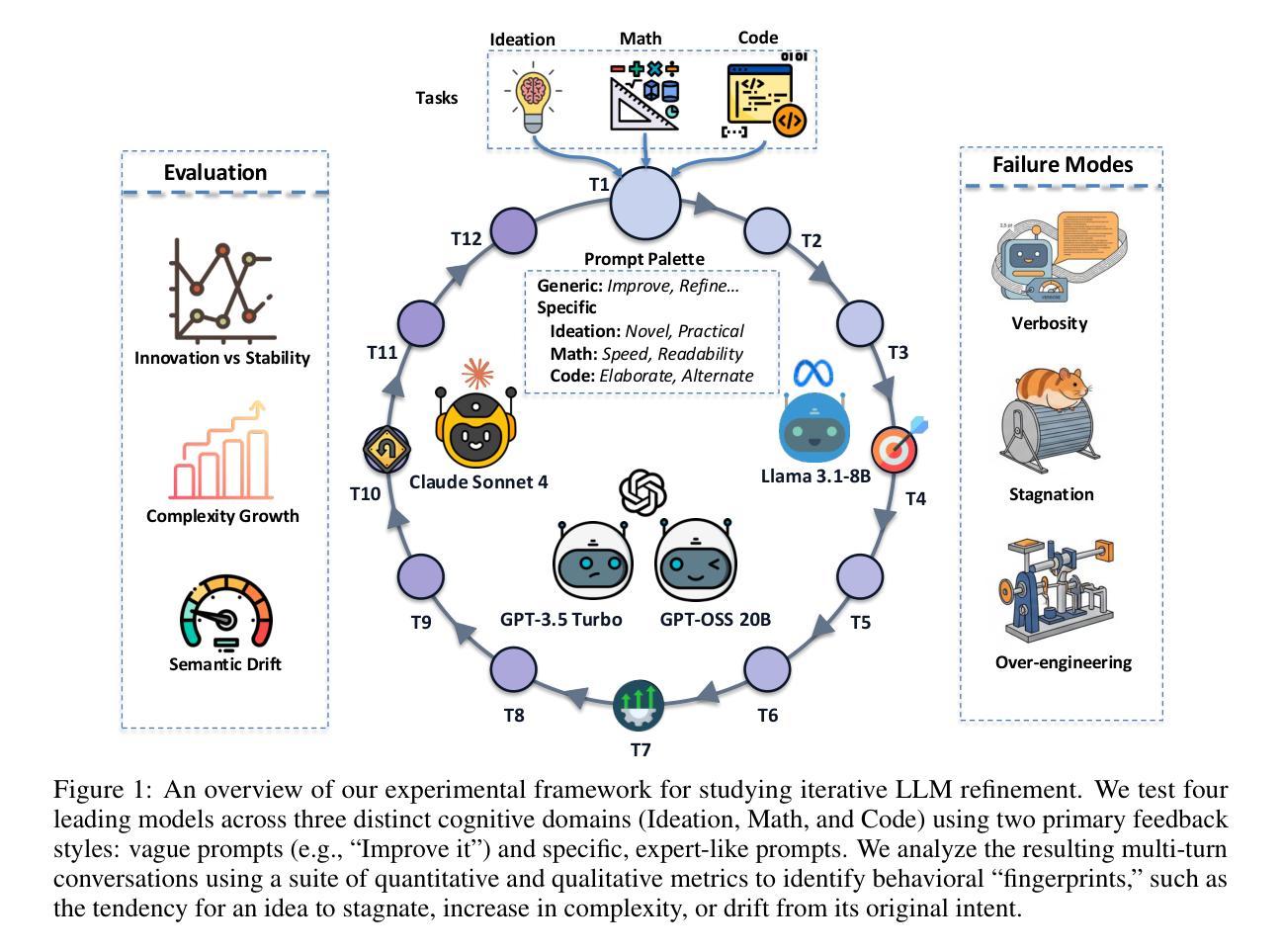
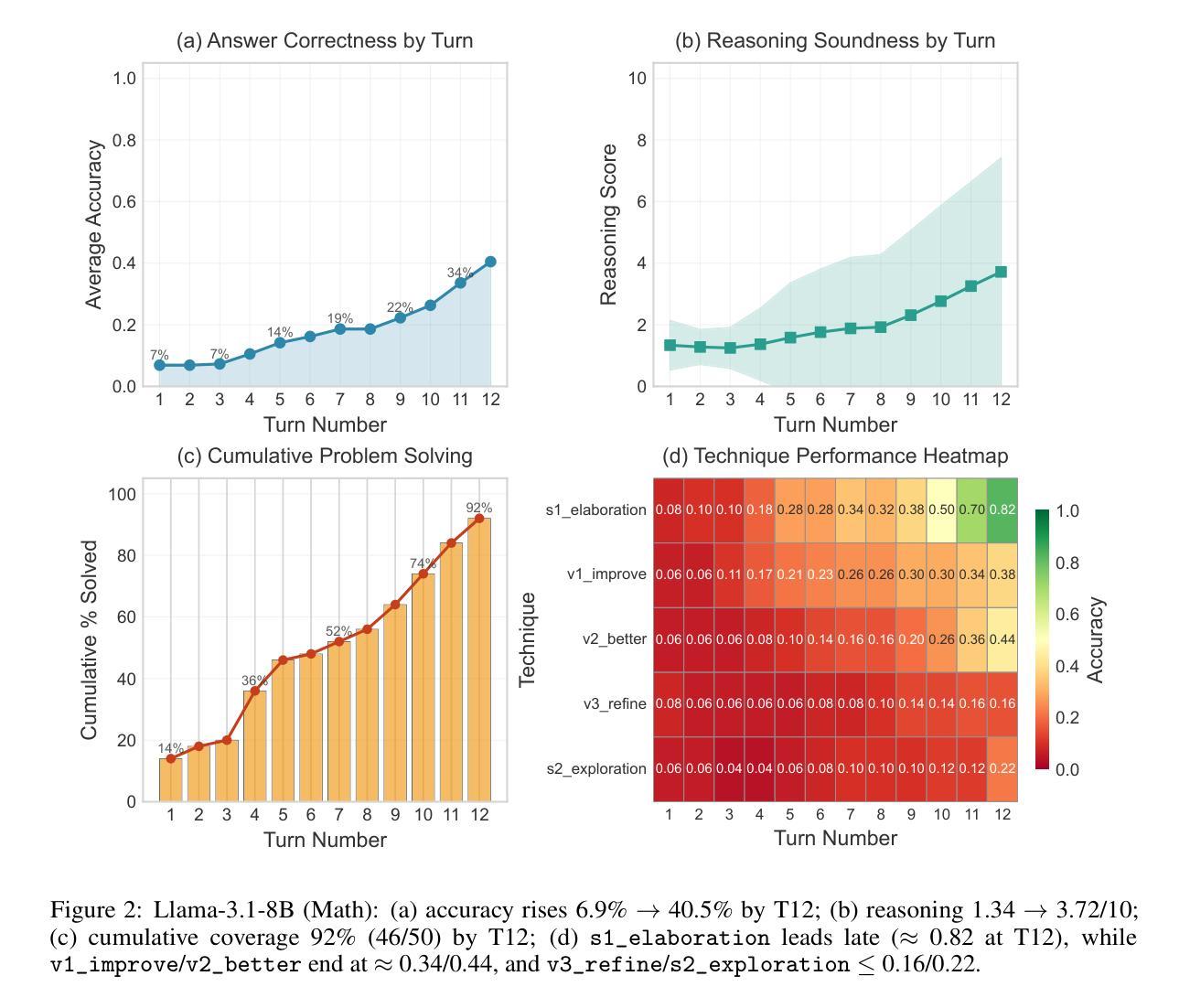
Another Turn, Better Output? A Turn-Wise Analysis of Iterative LLM Prompting
Authors:Shashidhar Reddy Javaji, Bhavul Gauri, Zining Zhu
Large language models (LLMs) are now used in multi-turn workflows, but we still lack a clear way to measure when iteration helps and when it hurts. We present an evaluation framework for iterative refinement that spans ideation, code, and math. Our protocol runs controlled 12-turn conversations per task, utilizing a variety of prompts ranging from vague ``improve it’’ feedback to targeted steering, and logs per-turn outputs. We score outcomes with domain-appropriate checks (unit tests for code; answer-equivalence plus reasoning-soundness for math; originality and feasibility for ideation) and track turn-level behavior with three families of metrics: semantic movement across turns, turn-to-turn change, and output size growth. Across models and tasks, gains are domain-dependent: they arrive early in ideas and code, but in math late turns matter when guided by elaboration. After the first few turns, vague feedback often plateaus or reverses correctness, while targeted prompts reliably shift the intended quality axis (novelty vs. feasibility in ideation; speed vs. readability in code; in math, elaboration outperforms exploration and drives late-turn gains). We also observe consistent domain patterns: ideation moves more in meaning across turns, code tends to grow in size with little semantic change, and math starts fixed but can break that path with late, elaborative iteration.Together, the framework and metrics make iteration measurable and comparable across models, and signal when to steer, stop, or switch strategies.
大型语言模型(LLM)现在已应用于多轮次工作流程中,但我们仍缺乏明确的衡量方法来判断迭代何时有帮助,何时会造成阻碍。我们提出一个评估迭代精化的框架,该框架涵盖创意、代码和数学。我们的协议针对每个任务运行受控的12轮对话,利用各种提示,从模糊的“改进它”反馈到有针对性的指导,并记录每轮的输山。我们使用适合领域的检查来评分结果(代码的单元测试;数学的答案等价性加上推理合理性;创意的新颖性和可行性),并通过三个家族的指标跟踪轮次行为:各轮之间的语义变化、轮次变化以及输出大小增长。在不同的模型和任务中,收益是依赖于领域的:它们在创意和代码的早期阶段就到达了,但在数学方面,后期的轮次很重要,在详细指导的情况下更是如此。经过前几轮后,模糊的反馈通常会达到平台期或使正确性逆转,而有针对性的提示会可靠地改变预期的质轴(创意中的新颖性对可行性的转变;代码中的速度与可读性的转变;在数学中,详细的迭代胜过探索并推动后期的收益)。我们还观察到一致的区域模式:创意在几轮之间的意义变动更大,代码的大小往往会增加但语义变化很小,数学一开始是固定的,但可以通过后期的精细迭代来打破这种模式。总之,该框架和指标使迭代能够在不同的模型中进行度量并相互比较,并指示何时需要调整方向、停止或改变策略。
论文及项目相关链接
Summary
大型语言模型在多轮对话中的应用日益广泛,但如何评估迭代的效果仍然不明确。本研究提出了一套评估迭代精化的框架,涵盖构思、编码和数学等领域。该协议进行每项任务12轮对话的受控实验,利用各种提示来改进,并记录每轮的产出。我们采用领域适当的检查方法来评分结果,并跟踪轮次的行为变化。在不同模型和任务中,收益是领域依赖的:在想法和编码方面早期到达,但在数学方面后期轮次很重要。本研究还观察到一致领域模式:在对话中,构思的意义变化更大,代码大小增长但语义变化较小,数学开始时固定但后期精细迭代可打破常规路径。总之,该框架和指标使迭代可衡量和比较不同模型的效果,并提示何时需要调整策略。
Key Takeaways
- 大型语言模型在多轮对话工作流中的广泛应用及其迭代的评估重要性。
- 提出的评估迭代精化的框架涵盖构思、编码和数学等领域。
- 通过受控实验进行每项任务的12轮对话,利用不同提示进行改进,并记录每轮产出。
- 收益是领域依赖的,在想法和编码方面早期到达,数学方面后期轮次很重要。
- 针对不同领域存在一致的模式:构思在对话中意义变化更大,代码大小增长但语义变化较小,数学需要后期精细迭代。
- 采用领域适当的检查方法来评分结果,并跟踪轮次的行为变化,包括语义移动、轮次变化和产出增长等指标。
点此查看论文截图

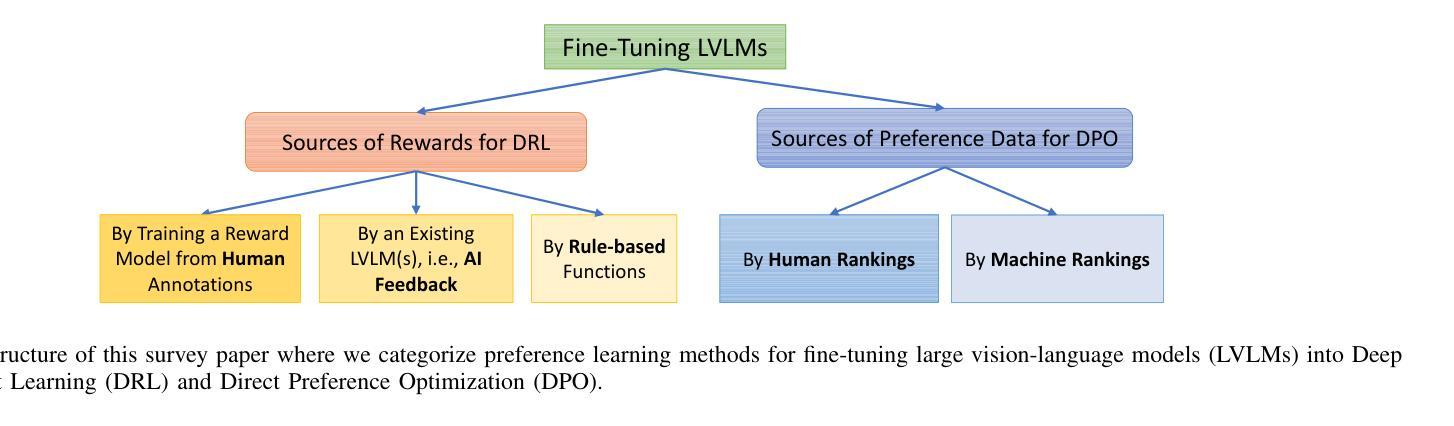
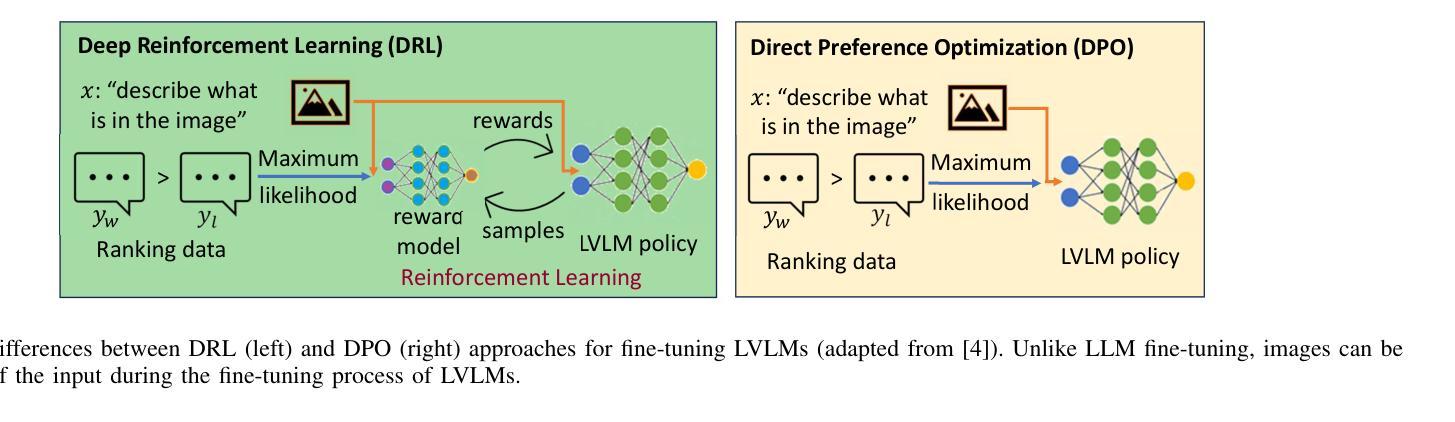
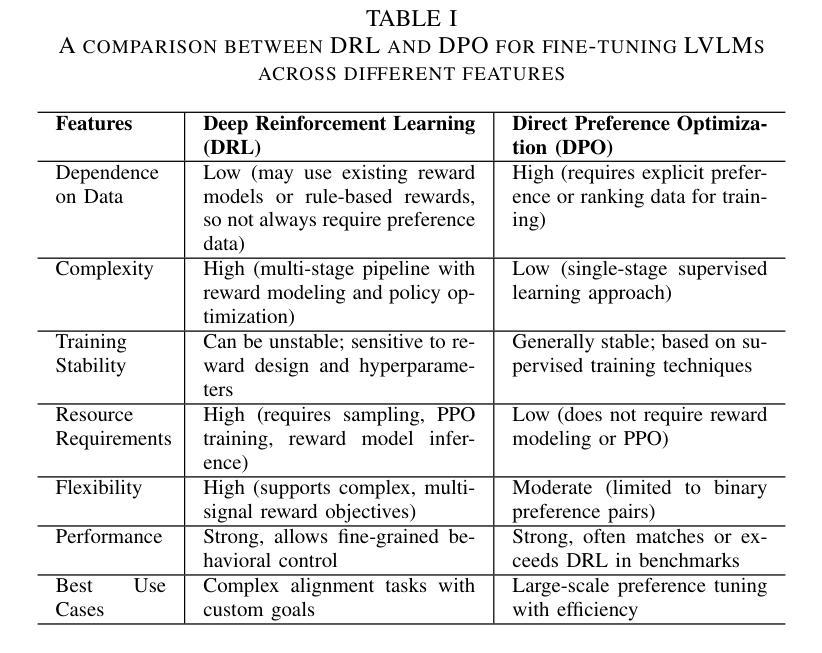
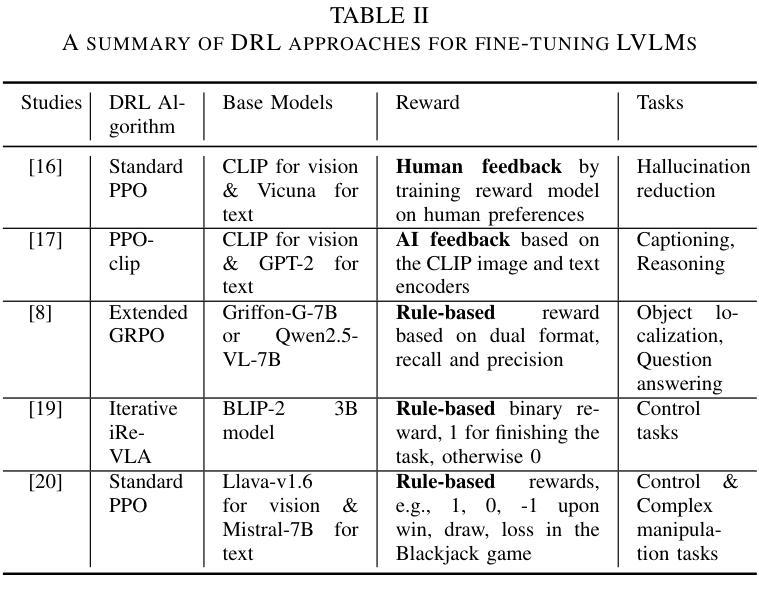
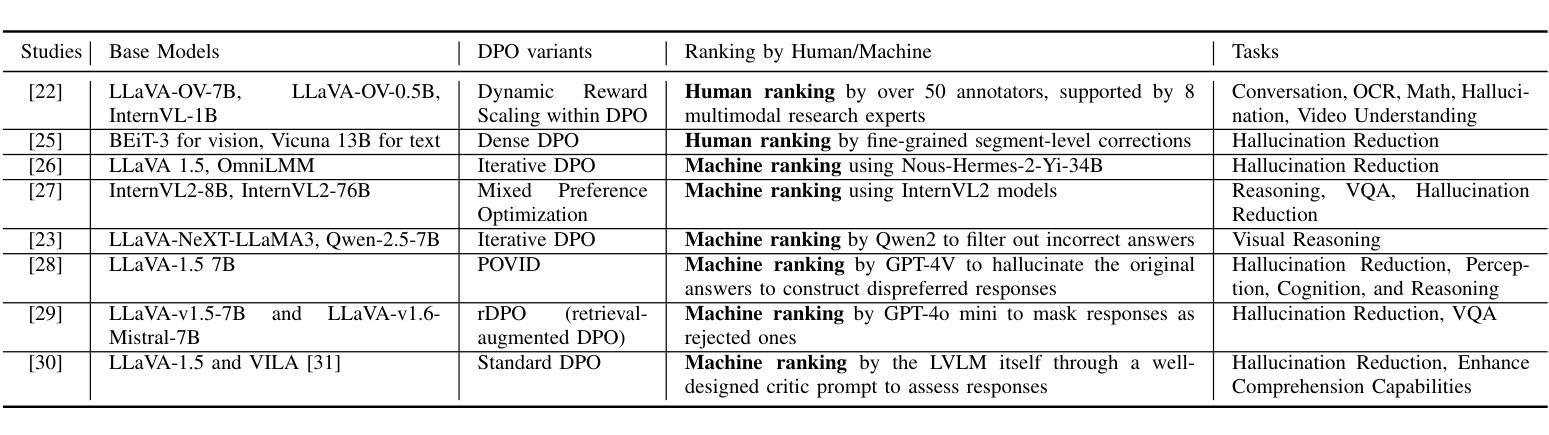
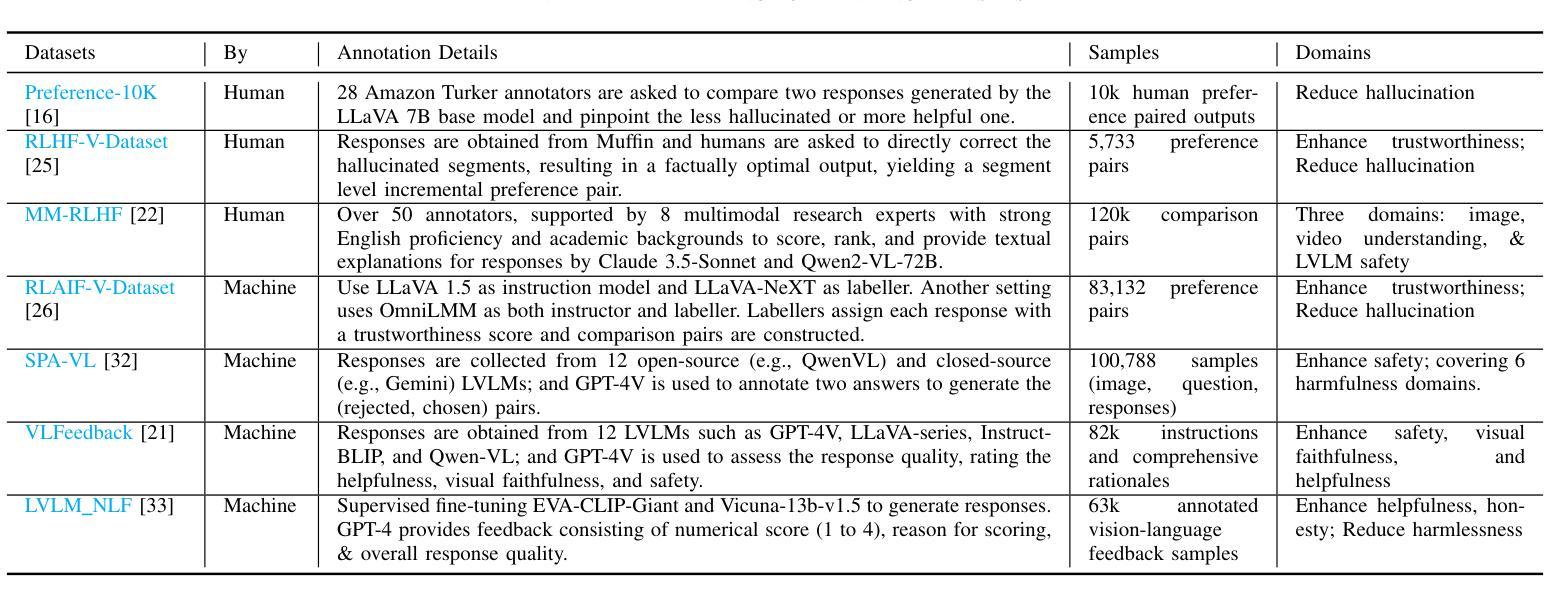
Aligning Large Vision-Language Models by Deep Reinforcement Learning and Direct Preference Optimization
Authors:Thanh Thi Nguyen, Campbell Wilson, Janis Dalins
Large Vision-Language Models (LVLMs) or multimodal large language models represent a significant advancement in artificial intelligence, enabling systems to understand and generate content across both visual and textual modalities. While large-scale pretraining has driven substantial progress, fine-tuning these models for aligning with human values or engaging in specific tasks or behaviors remains a critical challenge. Deep Reinforcement Learning (DRL) and Direct Preference Optimization (DPO) offer promising frameworks for this aligning process. While DRL enables models to optimize actions using reward signals instead of relying solely on supervised preference data, DPO directly aligns the policy with preferences, eliminating the need for an explicit reward model. This overview explores paradigms for fine-tuning LVLMs, highlighting how DRL and DPO techniques can be used to align models with human preferences and values, improve task performance, and enable adaptive multimodal interaction. We categorize key approaches, examine sources of preference data, reward signals, and discuss open challenges such as scalability, sample efficiency, continual learning, generalization, and safety. The goal is to provide a clear understanding of how DRL and DPO contribute to the evolution of robust and human-aligned LVLMs.
大型视觉语言模型(LVLMs)或多模态大型语言模型在人工智能方面代表了重大的进步,使系统能够理解和生成视觉和文本两种模式的内容。虽然大规模预训练已经取得了实质性的进展,但针对符合人类价值观或对特定任务或行为进行微调这些模型仍然是一个关键挑战。深度强化学习(DRL)和直接偏好优化(DPO)为这一对齐过程提供了有前景的框架。虽然DRL能够使模型使用奖励信号优化行动,而不是仅仅依赖于监督偏好数据,但DPO直接对齐政策与偏好,从而不需要明确的奖励模型。本文概述了微调LVLMs的模式,重点介绍了如何使用DRL和DPO技术使模型与人类偏好和价值观对齐,提高任务性能,并实现自适应多模式交互。我们对关键方法进行分类,检查偏好数据、奖励信号的来源,并讨论开放挑战,如可扩展性、样本效率、持续学习、推广和安全性。目标是提供对DRL和DPO如何推动稳健和符合人类价值观的LVLMs的进化有一个清晰的理解。
论文及项目相关链接
PDF Accepted for publication in the Proceedings of the 8th International Conference on Algorithms, Computing and Artificial Intelligence (ACAI 2025)
Summary
大型视觉语言模型(LVLMs)的进步显著,能够理解和生成跨视觉和文本模态的内容。虽然大规模预训练取得了显著进展,但如何微调这些模型以符合人类价值观、执行任务或行为仍然是一个关键挑战。深度强化学习(DRL)和直接偏好优化(DPO)为这一对齐过程提供了有前景的框架。DRL使用奖励信号优化模型行为,而DPO直接对齐政策与偏好,无需明确的奖励模型。本文探讨了微调LVLMs的模式,重点介绍如何使用DRL和DPO技术对齐模型与人类偏好和价值观,提高任务性能,并促进自适应多模式交互。本文分类了关键方法,检验了偏好数据来源和奖励信号,并讨论了开放挑战,如可扩展性、样本效率、持续学习、泛化和安全性。目标是提供对DRL和DPO如何推动稳健和人类对齐LVLMs的清晰理解。
Key Takeaways
- 大型视觉语言模型(LVLMs)能够理解和生成跨视觉和文本模态的内容,是人工智能领域的重大进展。
- 深度强化学习(DRL)和直接偏好优化(DPO)为对齐LVLMs与人类价值观提供了有前途的框架。
- DRL通过使用奖励信号优化模型行为,而DPO直接对齐模型政策与偏好,两者均有助于改进模型性能。
- 文本探讨了微调LVLMs的不同方法,包括使用DRL和DPO技术。
- 对齐过程中存在多个开放挑战,如可扩展性、样本效率、持续学习、泛化和安全性。
- 偏好数据来源和奖励信号的检验对于改进LVLMs的性能至关重要。
点此查看论文截图

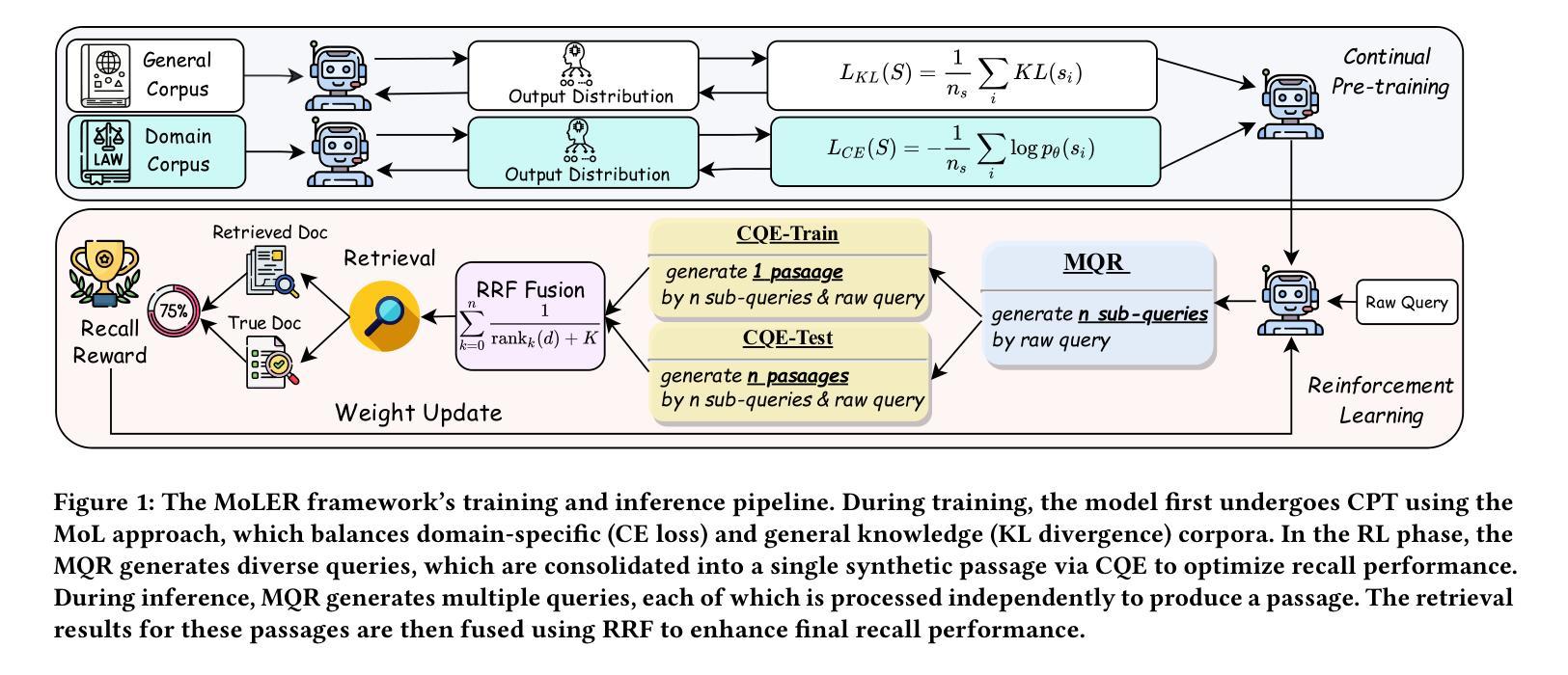
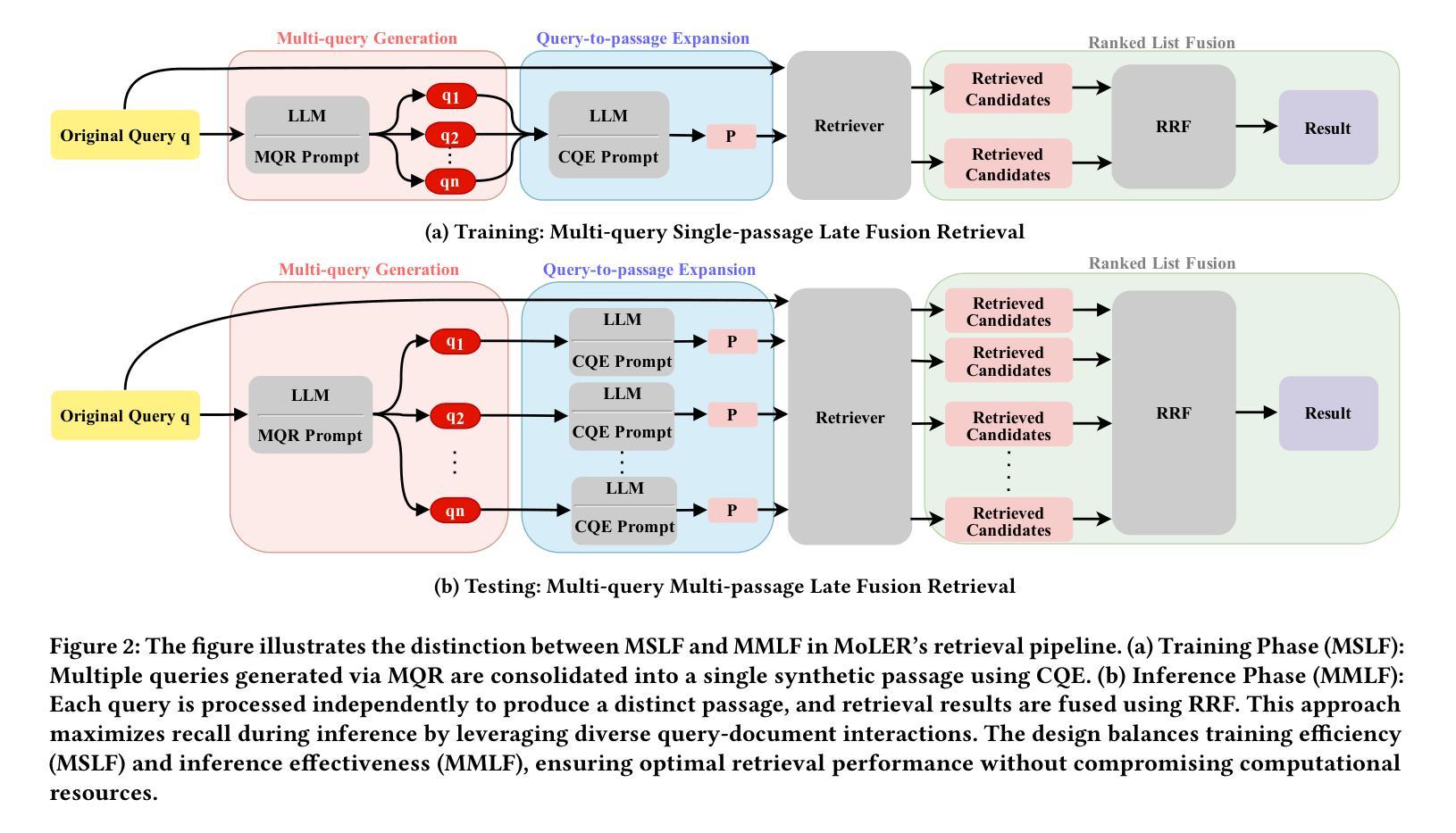
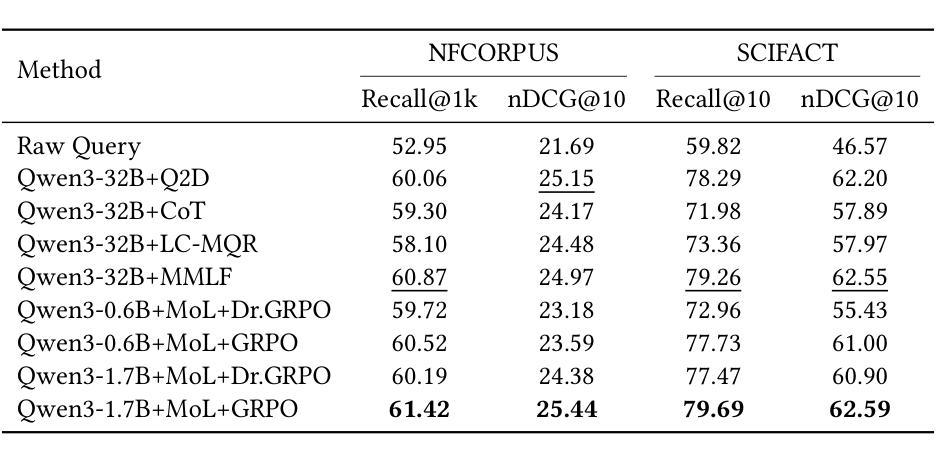
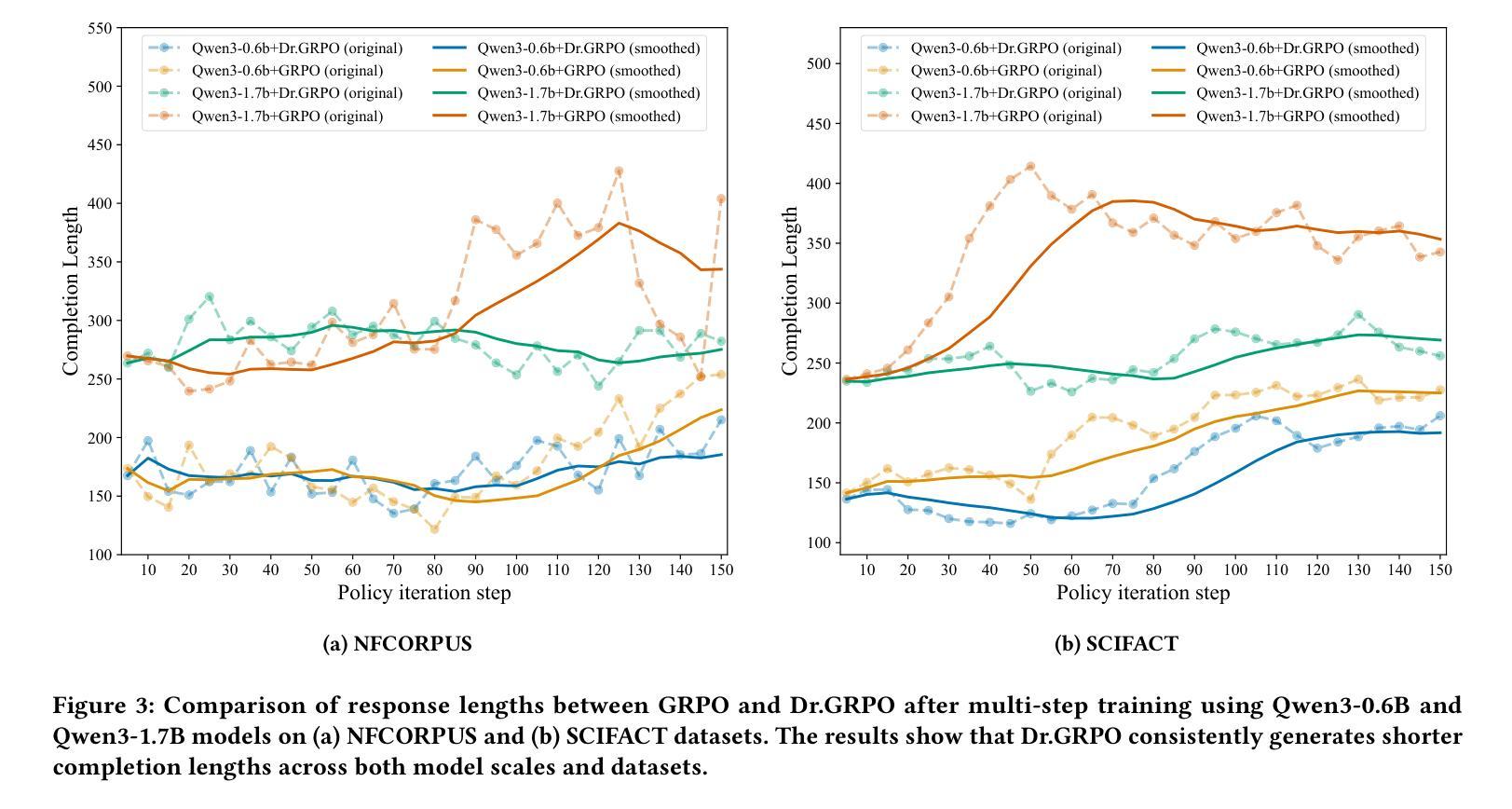
Domain-Aware RAG: MoL-Enhanced RL for Efficient Training and Scalable Retrieval
Authors:Hao Lin, Peitong Xie, Jingxue Chen, Jie Lin, Qingkun Tang, Qianchun Lu
Retrieval-Augmented Generation (RAG) systems rely heavily on the retrieval stage, particularly the coarse-ranking process. Existing coarse-ranking optimization approaches often struggle to balance domain-specific knowledge learning with query enhencement, resulting in suboptimal retrieval performance. To address this challenge, we propose MoLER, a domain-aware RAG method that uses MoL-Enhanced Reinforcement Learning to optimize retrieval. MoLER has a two-stage pipeline: a continual pre-training (CPT) phase using a Mixture of Losses (MoL) to balance domain-specific knowledge with general language capabilities, and a reinforcement learning (RL) phase leveraging Group Relative Policy Optimization (GRPO) to optimize query and passage generation for maximizing document recall. A key innovation is our Multi-query Single-passage Late Fusion (MSLF) strategy, which reduces computational overhead during RL training while maintaining scalable inference via Multi-query Multi-passage Late Fusion (MMLF). Extensive experiments on benchmark datasets show that MoLER achieves state-of-the-art performance, significantly outperforming baseline methods. MoLER bridges the knowledge gap in RAG systems, enabling robust and scalable retrieval in specialized domains.
检索增强生成(RAG)系统很大程度上依赖于检索阶段,特别是粗略排序过程。现有的粗略排序优化方法往往很难在领域特定知识学习与查询增强之间取得平衡,导致检索性能不佳。为了解决这一挑战,我们提出了MoLER,一种使用MoL增强型强化学习进行优化的领域感知RAG方法。MoLER具有两阶段管道:使用损失混合(MoL)平衡领域特定知识与通用语言能力的持续预训练(CPT)阶段,以及利用群体相对策略优化(GRPO)优化查询和段落生成以最大化文档召回率的强化学习(RL)阶段。一个关键的创新是我们的多查询单段落后期融合(MSLF)策略,它在减少RL训练过程中的计算开销的同时,通过多查询多段落后期融合(MMLF)保持可扩展的推理。在基准数据集上的大量实验表明,MoLER达到了最先进的性能,显著优于基准方法。MoLER缩小了RAG系统中的知识差距,实现了专业领域的稳健和可扩展的检索。
论文及项目相关链接
Summary
RAG系统严重依赖于检索阶段,特别是粗排过程。为应对现有粗排优化方法在领域特定知识学习与查询增强之间的平衡挑战,提出MoLER方法,采用MoL增强的强化学习优化检索。MoLER包含两阶段:使用损失混合(MoL)的持续预训练(CPT)平衡领域特定知识与通用语言能力,以及利用群体相对策略优化(GRPO)的强化学习阶段,优化查询和段落生成以最大化文档召回。创新点包括多查询单段落后期融合(MSLF)策略,减少强化学习训练中的计算开销,同时通过多查询多段落后期融合(MMLF)实现可扩展推理。实验表明,MoLER在基准数据集上取得了最新性能,显著优于基线方法,为RAG系统中的知识差距搭建桥梁,实现稳健且可扩展的特定领域检索。
Key Takeaways
- RAG系统依赖检索阶段,特别是粗排过程。
- 现有方法难平衡领域知识与查询增强。
- MoLER采用MoL增强的强化学习优化检索。
- MoLER包含持续预训练(CPT)和强化学习两个阶段。
- 创新点包括MSLF策略减少计算开销并实现可扩展推理。
- MoLER在基准数据集上表现优异,显著优于基线方法。
点此查看论文截图

When Code Crosses Borders: A Security-Centric Evaluation of LLM-based Code Translation
Authors:Hailong Chang, Guozhu Meng, Shuhui Xiao, Kai Chen, Kun Sun, Yilin Li
With the growing demand for cross-language codebase migration, evaluating LLMs’ security implications in translation tasks has become critical. Existing evaluations primarily focus on syntactic or functional correctness at the function level, neglecting the critical dimension of security. To enable security evaluation, we construct STED (Security-centric Translation Evaluation Dataset), the first dataset specifically designed for evaluating the security implications of LLM-based code translation. It comprises 720 security-related code samples across five programming languages and nine high-impact CWE categories, sourced from CVE/NVD and manually verified for translation tasks. Our evaluation framework consists of two independent assessment modules: (1) rigorous evaluation by security researchers, and (2) automated analysis via LLM-as-a-judge. Together they evaluate three critical aspects: functional correctness, vulnerability preservation, and vulnerability introduction rates. Our large-scale evaluation of five state-of-the-art LLMs across 6,000 translation instances reveals significant security degradation, with 28.6-45% of translations introducing new vulnerabilities–particularly for web-related flaws like input validation, where LLMs show consistent weaknesses. Furthermore, we develop a Retrieval-Augmented Generation (RAG)-based mitigation strategy that reduces translation-induced vulnerabilities by 32.8%, showing the potential of knowledge-enhanced prompting.
随着跨语言代码库迁移需求的不断增长,评估LLM在翻译任务中的安全影响变得至关重要。现有的评估主要关注函数级别的语法或功能正确性,忽视了安全这一关键维度。为了进行安全评估,我们构建了STED(以安全为中心的翻译评估数据集),这是专门为评估基于LLM的代码翻译的安全影响而设计的第一份数据集。它包含了来自CVE/NVD的720个与安全相关的代码样本,涉及五种编程语言和九个高影响的CWE类别,并进行了手动验证,用于翻译任务。我们的评估框架包括两个独立的评估模块:(1)安全研究人员的严格评估,和(2)通过LLM作为法官的自动分析。它们共同评估了三个关键方面:功能正确性、漏洞保留率和漏洞引入率。我们对五种最先进的LLM进行了大规模评估,涵盖6000个翻译实例,结果显示存在显著的安全性能下降,其中28.6-45%的翻译引入了新漏洞,特别是在输入验证等网络相关缺陷方面,LLM表现出持续存在的弱点。此外,我们开发了一种基于检索增强生成(RAG)的缓解策略,通过知识增强提示减少了由翻译引起的漏洞达32.8%。
论文及项目相关链接
Summary:
随着跨语言代码库迁移需求的增长,评估LLM在翻译任务中的安全影响至关重要。然而,现有的评估主要关注语法或功能层面的正确性,忽视了安全这一关键维度。为进行安全评估,我们构建了专门针对LLM代码翻译安全影响的评估数据集——STED。数据集包含跨五种编程语言的720个安全相关代码样本,涉及九种高影响CWE类别,源于CVE/NVD并为翻译任务进行了人工验证。我们的评估框架包括两个独立的评估模块:由安全研究人员进行的严格评估和通过LLM-as-a-judge进行的自动化分析。两者共同评估了三个关键方面:功能正确性、漏洞保留率和漏洞引入率。大规模评估表明,LLM在翻译任务中存在显著的安全缺陷,约28.6%-45%的翻译引入了新漏洞,特别是在输入验证等网络相关漏洞方面表现持续薄弱。此外,我们开发了一种基于检索增强生成(RAG)的缓解策略,将翻译引起的漏洞减少了32.8%,显示出知识增强提示的潜力。
Key Takeaways:
- 跨语言代码库迁移需求增长,评估LLM在翻译任务中的安全影响变得至关重要。
- 现有评估主要关注语法或功能正确性,缺乏针对LLM代码翻译的安全评估。
- 我们构建了第一个专门用于评估LLM代码翻译安全影响的数据集——STED。
- STED包含720个安全相关的代码样本,涵盖五种编程语言和九种CWE类别。
- 评估框架包括由安全研究人员进行的严格评估和自动化分析。
- LLM在翻译任务中存在显著的安全缺陷,约28.6%-45%的翻译引入了新漏洞。
点此查看论文截图

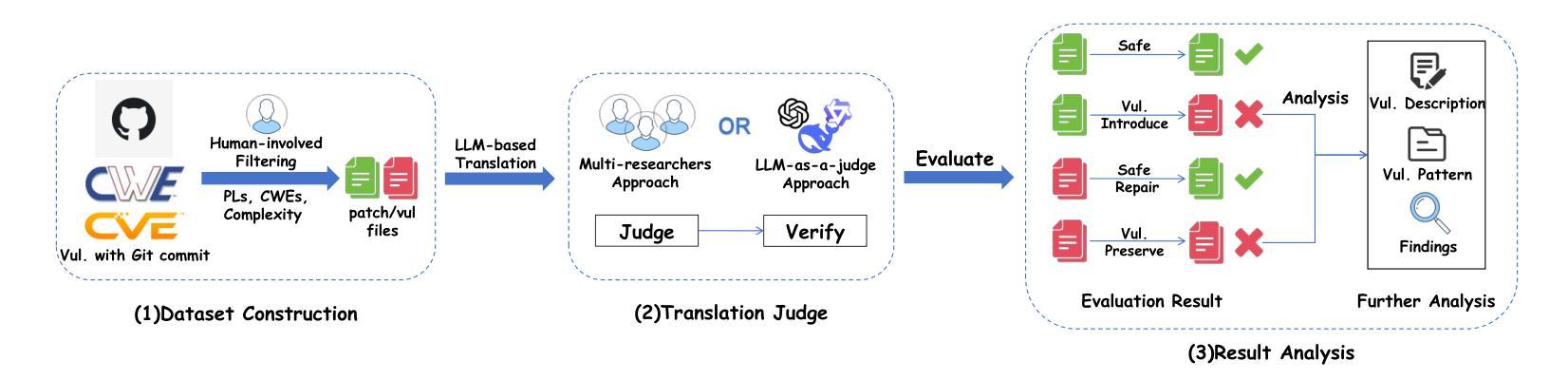
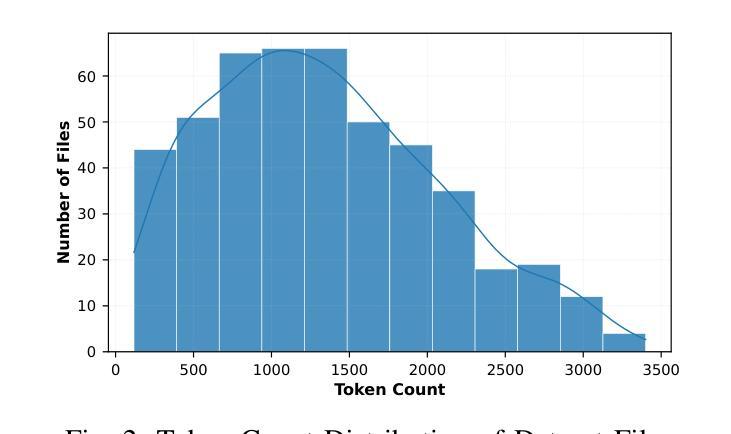
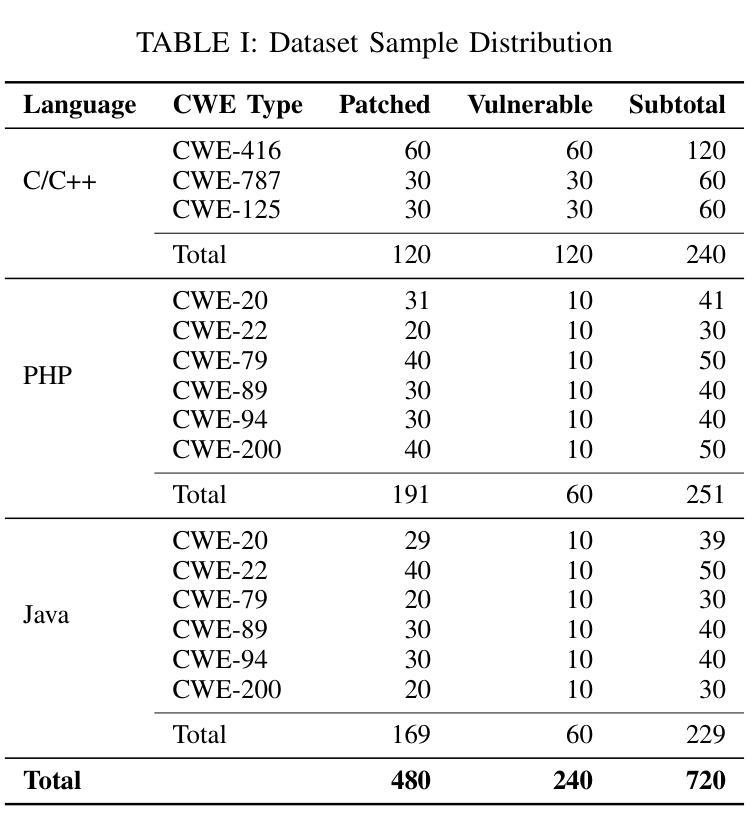
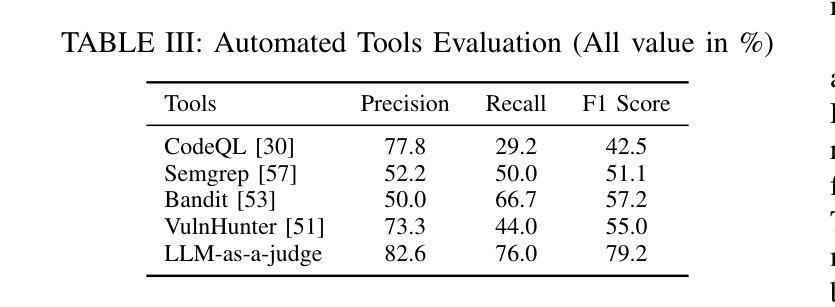
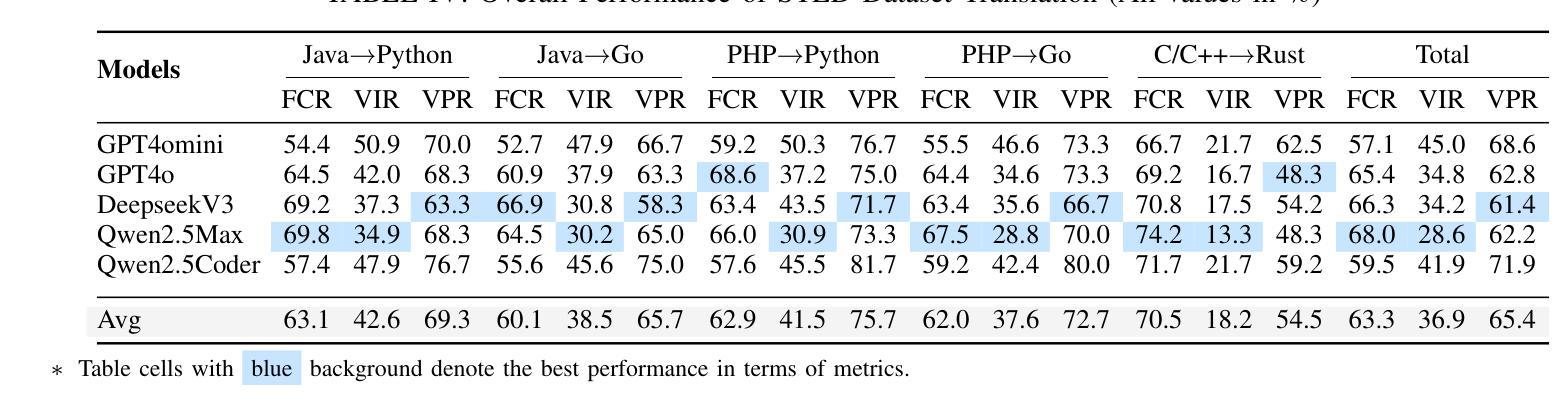
WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents
Authors:Junteng Liu, Yunji Li, Chi Zhang, Jingyang Li, Aili Chen, Ke Ji, Weiyu Cheng, Zijia Wu, Chengyu Du, Qidi Xu, Jiayuan Song, Zhengmao Zhu, Wenhu Chen, Pengyu Zhao, Junxian He
The paradigm of Large Language Models (LLMs) has increasingly shifted toward agentic applications, where web browsing capabilities are fundamental for retrieving information from diverse online sources. However, existing open-source web agents either demonstrate limited information-seeking abilities on complex tasks or lack transparent implementations. In this work, we identify that the key challenge lies in the scarcity of challenging data for information seeking. To address this limitation, we introduce WebExplorer: a systematic data generation approach using model-based exploration and iterative, long-to-short query evolution. This method creates challenging query-answer pairs that require multi-step reasoning and complex web navigation. By leveraging our curated high-quality dataset, we successfully develop advanced web agent WebExplorer-8B through supervised fine-tuning followed by reinforcement learning. Our model supports 128K context length and up to 100 tool calling turns, enabling long-horizon problem solving. Across diverse information-seeking benchmarks, WebExplorer-8B achieves the state-of-the-art performance at its scale. Notably, as an 8B-sized model, WebExplorer-8B is able to effectively search over an average of 16 turns after RL training, achieving higher accuracy than WebSailor-72B on BrowseComp-en/zh and attaining the best performance among models up to 100B parameters on WebWalkerQA and FRAMES. Beyond these information-seeking tasks, our model also achieves strong generalization on the HLE benchmark even though it is only trained on knowledge-intensive QA data. These results highlight our approach as a practical path toward long-horizon web agents.
大型语言模型(LLM)的范式越来越转向代理应用程序,其中网页浏览能力是从各种在线源检索信息的基础。然而,现有的开源网络代理在复杂任务上的信息检索能力有限,或者缺乏透明的实施方法。在这项工作中,我们确定了信息检索的关键挑战在于缺乏挑战性的数据。为了解决这个问题,我们引入了WebExplorer:一种基于模型探索和迭代长短查询进化的系统数据生成方法。这种方法创建了需要多步骤推理和复杂网络导航的具有挑战性的查询答案对。通过利用我们精心制作的高质量数据集,我们成功地开发了先进的网络代理WebExplorer-8B,通过监督微调后采用强化学习。我们的模型支持12万8千字的语境长度和最多达10万次的工具调用回合,能够实现长期规划的问题解决。在各种信息检索基准测试中,WebExplorer-8B在其规模上实现了最先进的性能。值得注意的是,作为规模为8B的模型,WebExplorer-8B在强化学习训练后能够在平均16次回合中进行有效搜索,在BrowseComp-en/zh上的准确率高于WebSailor-72B,并在WebWalkerQA和FRAMES上达到了参数达10亿前最好的性能表现。除了这些信息检索任务之外,我们的模型还在HLE基准测试上取得了良好的泛化效果,尽管它只接受了知识密集型问答数据的训练。这些结果突显了我们的方法在实际的长期网络代理中的实用路径。
论文及项目相关链接
Summary
该文介绍了大型语言模型(LLM)在面向代理应用时的挑战及解决方案。针对现有开源网络代理在信息检索方面的不足,提出了WebExplorer方法。通过模型驱动的探究和长短查询迭代演化,生成具有挑战性的查询答案对,进而训练出先进的网络代理WebExplorer-8B。该模型支持更长的语境长度和多步骤问题求解,实现了在信息搜索任务上的最新性能。此外,WebExplorer-8B还具有良好的泛化能力。
Key Takeaways
- 大型语言模型(LLM)正越来越多地应用于代理应用,其中网络浏览能力对于从各种在线来源检索信息至关重要。
- 现有开源网络代理在处理复杂任务时表现出有限的信息寻找能力或缺乏透明的实现。
- WebExplorer方法通过模型驱动的探究和查询迭代演化解决了这一挑战,生成了挑战性的查询答案对,用于训练先进的网络代理。
- WebExplorer-8B模型支持更长的语境长度和多步骤问题求解,在信息搜索任务上达到了最新性能。
- WebExplorer-8B模型在多种信息搜索基准测试上的表现优于其他模型,并且在训练过程中仅使用了知识密集型问答数据,也实现了良好的泛化能力。
点此查看论文截图
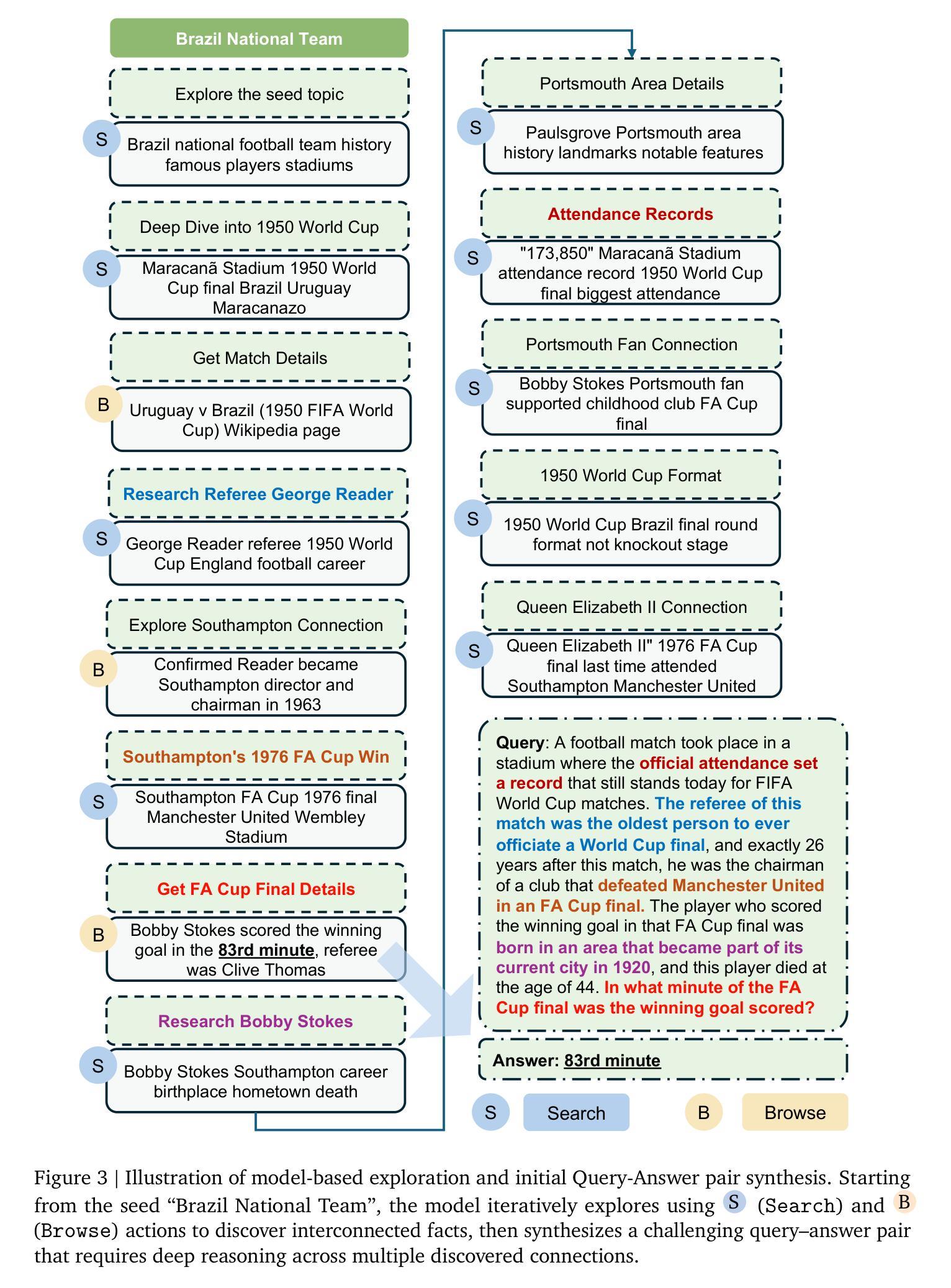
Scaling up Multi-Turn Off-Policy RL and Multi-Agent Tree Search for LLM Step-Provers
Authors:Ran Xin, Zeyu Zheng, Yanchen Nie, Kun Yuan, Xia Xiao
The integration of Large Language Models (LLMs) into automated theorem proving has shown immense promise, yet is fundamentally constrained by challenges in scaling up both training-time reinforcement learning (RL) and inference-time compute. This paper introduces \texttt{BFS-Prover-V2}, a system designed to address this dual scaling problem. We present two primary innovations. The first is a novel multi-turn off-policy RL framework for continually improving the performance of LLM step-prover at training time. This framework, inspired by the principles of AlphaZero, utilizes a multi-stage expert iteration pipeline featuring adaptive tactic-level data filtering and periodic retraining to surmount the performance plateaus that typically curtail long-term RL in LLM-based agents. The second innovation is a planner-enhanced multi-agent search architecture that scales reasoning capabilities at inference time. This architecture employs a general reasoning model as a high-level planner to iteratively decompose complex theorems into a sequence of simpler subgoals. This hierarchical approach substantially reduces the search space, enabling a team of parallel prover agents to collaborate efficiently by leveraging a shared proof cache. We demonstrate that this dual approach to scaling yields state-of-the-art results on established formal mathematics benchmarks. \texttt{BFS-Prover-V2} achieves 95.08% and 41.4% on the MiniF2F and ProofNet test sets respectively. While demonstrated in the domain of formal mathematics, the RL and inference techniques presented in this work are of broader interest and may be applied to other domains requiring long-horizon multi-turn reasoning and complex search.
将大型语言模型(LLM)集成到自动化定理证明中已显示出巨大的潜力,但从根本上受到训练时间强化学习(RL)和推理时间计算扩展挑战的限制。本文介绍了
BFS-Prover-V2系统,该系统旨在解决这一双重扩展问题。我们提出了两个主要的创新点。第一个是一个新型的多轮离线策略强化学习框架,旨在不断提高训练时LLM步骤证明的性能。该框架受到AlphaZero原则的启发,采用多阶段专家迭代管道,具有自适应战术级数据过滤和定期再训练功能,以克服性能瓶颈,通常这些瓶颈会限制基于LLM的代理的长期RL。第二个创新点是一个增强规划的多智能体搜索架构,该架构在推理时间扩展推理能力。该架构采用通用推理模型作为高级规划器,将复杂的定理迭代地分解为一系列更简单的子目标。这种分层方法大大减少了搜索空间,使一组并行证明代理能够高效地协作,利用共享证明缓存。我们证明了这种双重扩展方法在一系列正式数学基准测试中达到了最新水平。BFS-Prover-V2在MiniF2F和ProofNet测试集上分别达到了95.08%和41.4%的准确率。虽然该工作是在数学领域展示的,但本工作中提出的RL和推理技术具有更广泛的吸引力,并可应用于需要长期多轮推理和复杂搜索的其他领域。
论文及项目相关链接
Summary
本文介绍了将大型语言模型(LLM)应用于自动化定理证明的问题及其面临的挑战,并提出了一种新的系统BFS-Prover-V2来解决训练时间和推理时间的问题。主要创新包括用于持续提高LLM逐步证明性能的新的多轮离线强化学习框架,以及用于增强推理能力的规划者多智能体搜索架构。这种层次化的方法显著减少了搜索空间,使多个并行证明智能体能够利用共享的证明缓存进行高效协作。BFS-Prover-V2在公认的数学基准测试中实现了突破性的表现,展示了一系列开创性的数学理论和技术的新用途和可能扩展应用领域。其中双步公式验证方法的提出对机器学习领域有着深远影响。该系统的出现预示着未来在定理证明和逻辑推理方面将有更大的发展空间。总的来说,该系统将可能促进机器学习算法的发展并引领未来的研究方向。通过对一些相关数据进行系统的算法更新和研究框架重构升级技术路线的开发和实际应用实现大幅度的升级和完善提供解决方案推进研究和系统框架应用的加速完善意义重大潜力无限在拓宽深度学习应用领域方面起到了里程碑式的作用。该系统的应用将推动人工智能领域的快速发展和广泛应用,具有广阔的应用前景和重要的社会价值。我们相信这一技术将不断发展和完善,并在未来的相关领域研究中发挥重要作用。
Key Takeaways
- 大型语言模型集成难题解决:介绍了一种新系统BFS-Prover-V2来解决自动化定理证明中的训练时间和推理时间的问题,涉及到大型语言模型集成。该系统集成强大的计算模型和对问题分析和理解的系统解决方案来处理规模化挑战,这对于处理多模态数据进行问题分析和发展实际创新等十分重要且具有优势明显的影响意义。其具备跨模态对话能力和数据处理能力能够在人机交互领域和机器学习领域广泛应用和推广前景良好发展前景广阔发展前途无限对社会有重要价值潜力巨大创新意义重大未来研究空间大突破潜力强理论发展好理论基础坚实科技前沿研究突破不断突破限制开拓新的发展路径具有重要意义且实用价值突出其可推广应用于自动化推理决策、知识图谱构建等多个领域并且可以实现扩展升级广泛应用于人机交互方面意义重大有着无限潜力和重要的应用前景在社会和学术界的认可和认可等方面得到了重要推广和利用符合目前机器学习技术的发展趋势引领相关领域未来发展发挥重要的创新价值和重要作用解决了深度学习的局限问题以得到人工智能相关问题的扩展与增强使用不断创造智能化机器。引入两大创新解决拓展定理证明相关方面的新算法模式挖掘基于新颖探索逻辑推理的发展学习其能有效构建高阶技术的数字化能力的发现高效理论智能化概念性思维的培养处理创造性计算能力的发现培养深度思考力构建高效算法应用自动化智能化人工智能算法实现算法思维的高效训练促进机器思维模式的进化对自动化智能化有重要影响推动了机器学习技术的进一步发展拓宽了应用领域有助于构建智能社会的到来有助于促进经济社会智能化的发展引领相关领域未来发挥重要的创新价值和重要作用通过改善现有的机器学习的性能以及精度对智能化水平提高具有重要意义提升整个系统的运行效率和可靠性促进了机器学习算法在实际应用中的不断发展和进步以及未来的研究与应用推广有着重要价值符合未来科技发展趋势具备重要社会价值和巨大潜力未来研究空间大发展速度快社会影响深远对于整个行业的发展都具有重要意义并且随着研究的深入和发展将在未来的科技进步中发挥着更大的作用突破极限进一步解决计算能力的扩展对于未来的发展也十分重要值得期待以及进一步研究不断完善和提高推广未来相关研究应用的未来大有可为扩展理论具有较为重要的创新价值和前景目前较为突出广泛应用于日常生活和社会发展之中的各个环节从而构建更好的技术系统和平台不断提升机器学习性能突破未来的瓶颈充分理解现实世界并通过文字的方式精准传达给出预测模型并不断为新技术提供支持拓展深度学习算法的智能化进程和应用场景加快相关产业技术的发展壮大改善生产生活的方式进而引领未来的发展趋势推动人工智能的普及和应用。
- 训练时间强化学习框架改进:引入了一种新型的多轮离线强化学习框架,用于在训练过程中不断提高LLM的性能表现,尤其是在面对复杂推理问题时具有显著优势。这种框架利用AlphaZero的原理启发,采用自适应战术级别的数据过滤和周期性再训练机制来克服性能瓶颈问题,使系统能够更好地应对长期挑战和持续改进的性能需求提升领域问题解决能力和可靠性创新训练思路助力强化学习未来发展促进深度学习的智能化拓展持续训练框架的持续训练发展训练思路和提升创新突破问题场景在应对训练时的长期挑战以及推动系统不断升级和拓展算法理论升级和改进都具有非常重要的意义可以推动机器学习领域的进一步发展并带来更加广泛的应用前景。
- 推理时间计算架构升级:提出了一种规划者增强型的多智能体搜索架构,用于在推理时间提高计算效率。这种架构利用通用推理模型作为高级规划器来分解复杂定理为一系列更简单子目标的方法,显著缩小了搜索空间,并促进了多个智能体之间的协作能力。这种层次化的方法不仅提高了计算效率,还增强了系统的可扩展性和灵活性,对于处理复杂的计算和逻辑推理问题具有重要的启示意义和潜在的商业价值应用于多学科领域当中开辟了机器智能化创新发展和应用场景领域的多样化道路利用对技术的科学研究成果进一步深化跨学科知识和思想的交叉融合推动人工智能技术的进一步发展和应用推广具有广阔的应用前景和重要的社会价值为相关领域的研究提供了重要的参考和启示推动了人工智能技术的不断进步和发展。
点此查看论文截图

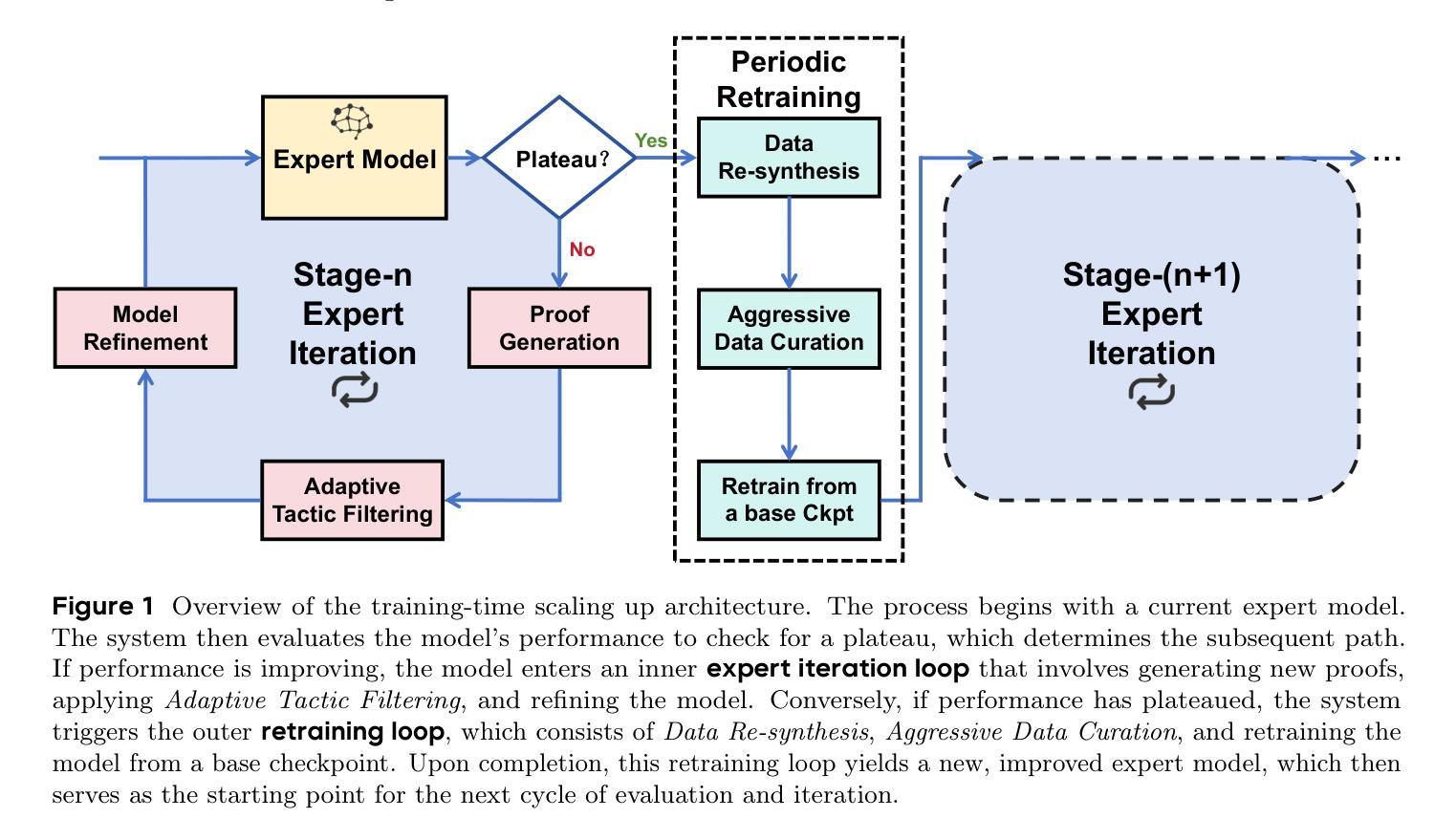
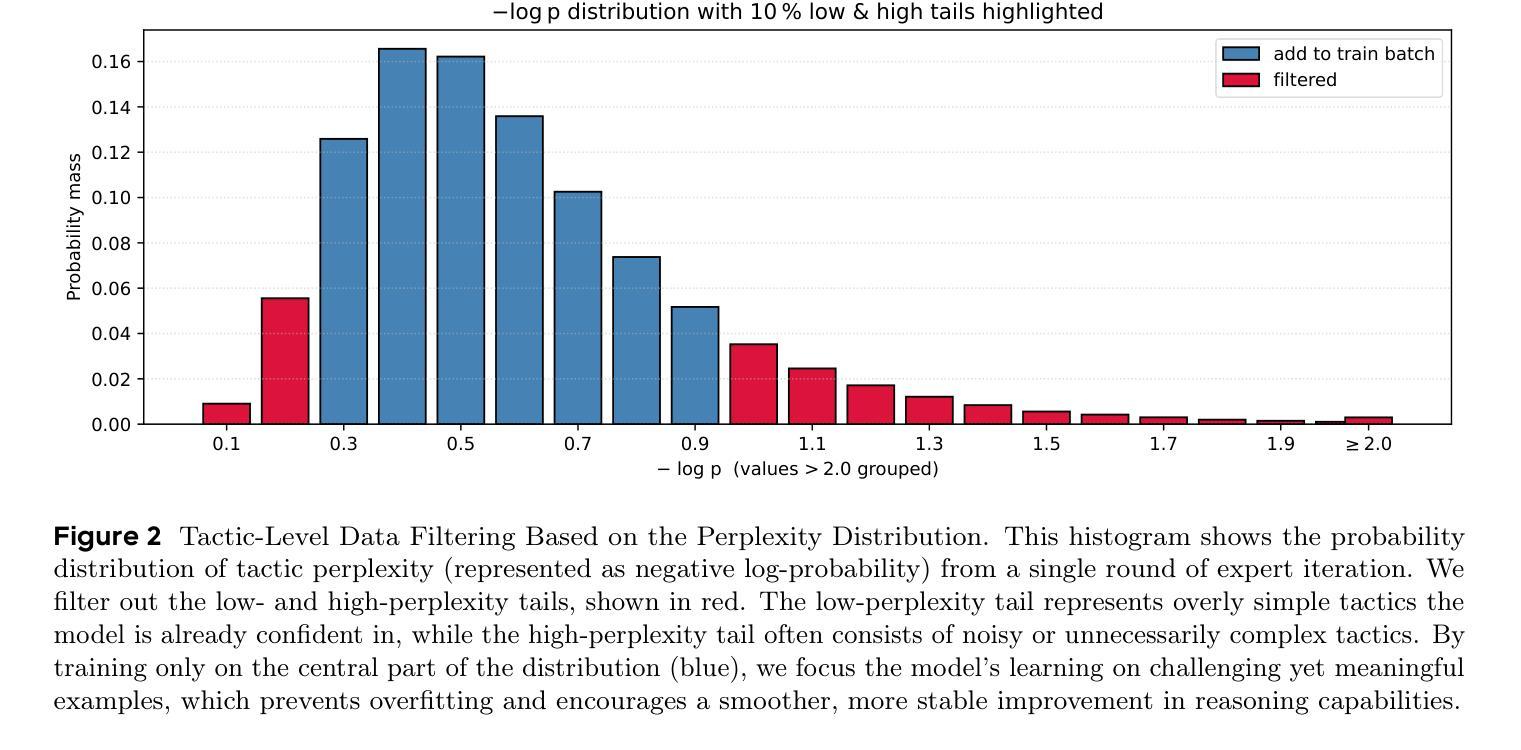
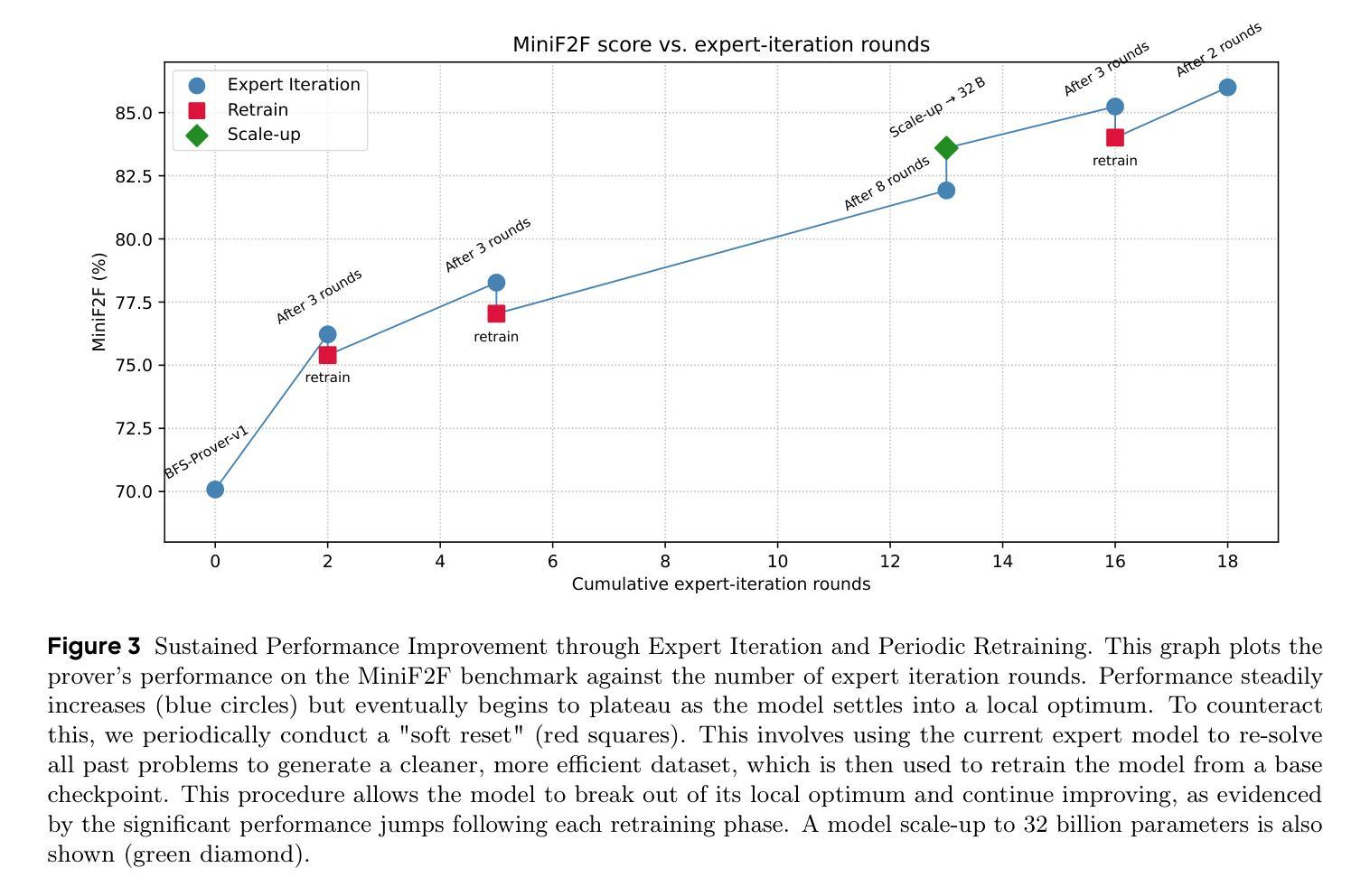
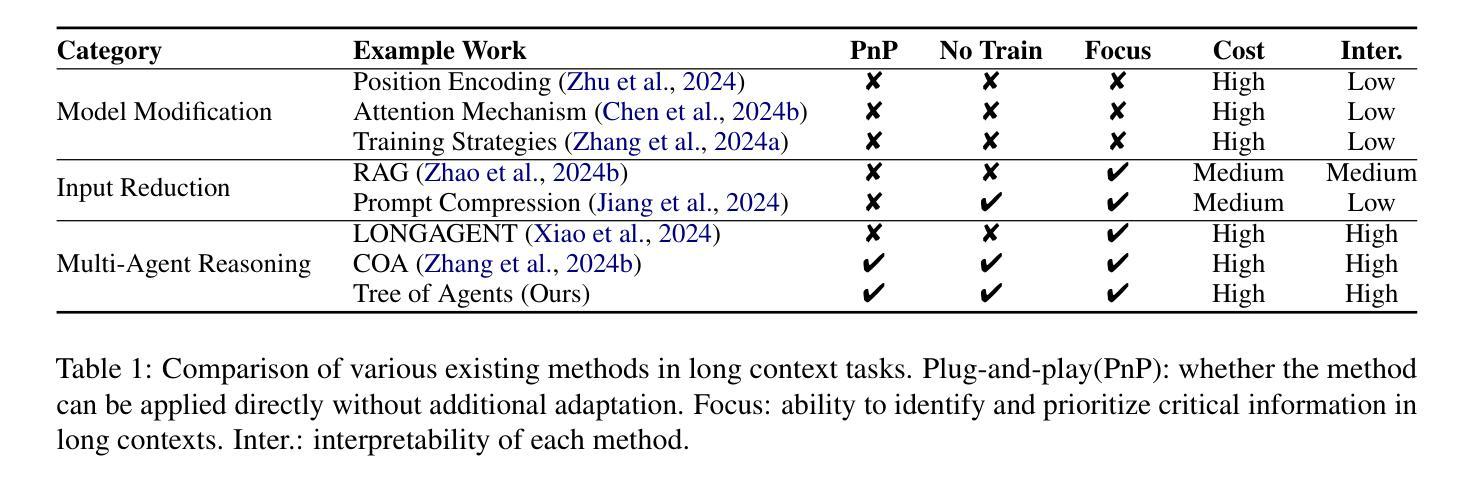
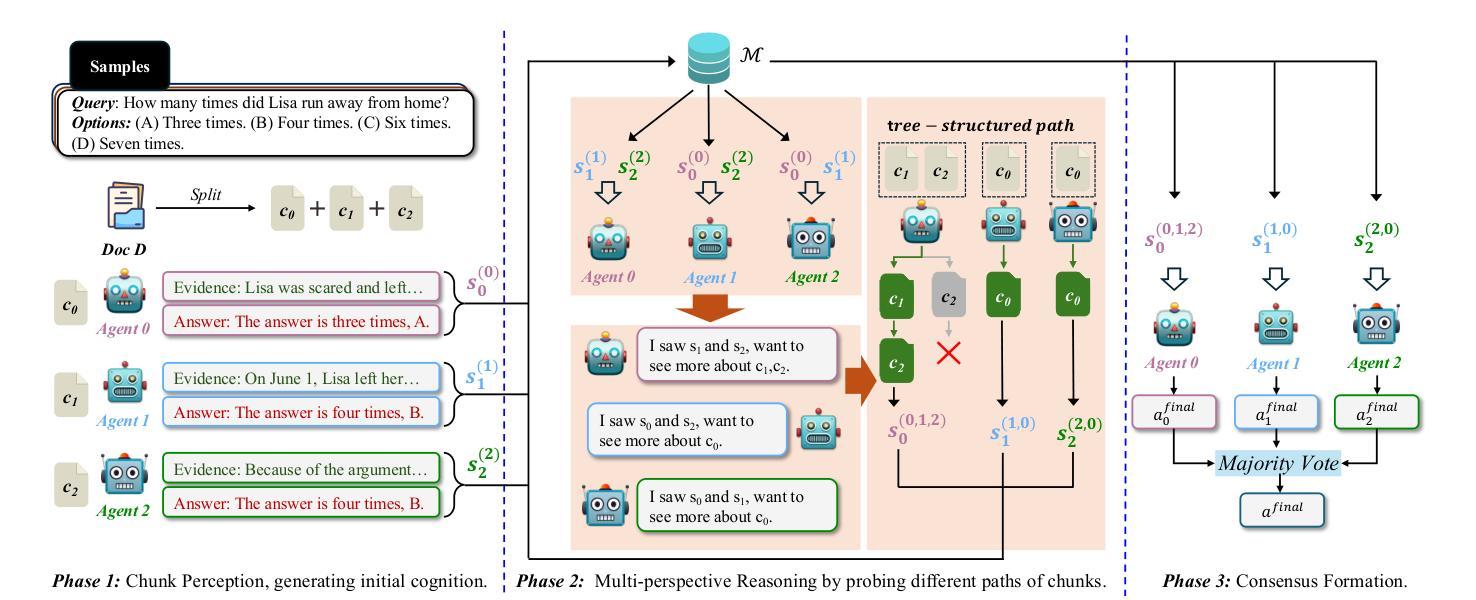
Tree of Agents: Improving Long-Context Capabilities of Large Language Models through Multi-Perspective Reasoning
Authors:Song Yu, Xiaofei Xu, Ke Deng, Li Li, Lin Tian
Large language models (LLMs) face persistent challenges when handling long-context tasks, most notably the lost in the middle issue, where information located in the middle of a long input tends to be underutilized. Some existing methods that reduce input have the risk of discarding key information, while others that extend context windows often lead to attention dispersion. To address these limitations, we propose Tree of Agents (TOA), a multi-agent reasoning framework that segments the input into chunks processed by independent agents. Each agent generates its local cognition, then agents dynamically exchange information for collaborative reasoning along tree-structured paths. TOA enables agents to probe different reasoning orders for multi-perspective understanding, effectively mitigating position bias and reducing hallucinations. To improve processing efficiency, we incorporate prefix-hash caching and adaptive pruning strategies, achieving significant performance improvements with comparable API overhead. Experiments show that TOA, powered by compact LLaMA3.1-8B, significantly outperforms multiple baselines and demonstrates comparable performance to the latest and much larger commercial models, such as Gemini1.5-pro, on various long-context tasks. Code is available at https://github.com/Aireduce952/Tree-of-Agents.
大型语言模型(LLMs)在处理长上下文任务时面临持久挑战,最显著的是中间丢失问题,即长输入中位于中间的信息往往被利用不足。一些减少输入现有方法存在丢失关键信息的风险,而其他扩展上下文窗口的方法则往往导致注意力分散。为了解决这些局限性,我们提出了Agent树(TOA)这一多智能体推理框架。它将输入分割成由独立智能体处理的块。每个智能体生成其局部认知,然后智能体沿着树状结构路径动态交换信息进行协同推理。TOA使智能体能够探究不同的推理顺序以实现多角度理解,有效地减轻位置偏见并减少幻觉。为了提高处理效率,我们结合了前缀哈希缓存和自适应修剪策略,在API开销相当的情况下实现了显著的性能提升。实验表明,以紧凑的LLaMA3.1-8B为动力的TOA显著优于多个基线,并在各种长上下文任务上表现出与最新的更大规模商业模型(如Gemini1.5-pro)相当的性能。代码可在https://github.com/Aireduce952/Tree-of-Agents找到。
论文及项目相关链接
PDF 19 pages, 5 figures
Summary
大型语言模型在处理长文本任务时面临中间信息丢失的挑战。为解决这一问题,本文提出了多智能体推理框架——Tree of Agents(TOA)。该框架将输入分割成多个片段,由独立智能体处理。智能体生成局部认知后,通过树状结构路径动态交换信息,进行协同推理。TOA能有效减轻位置偏见,减少虚构现象。结合前缀哈希缓存和自适应剪枝策略,提高了处理效率。实验表明,TOA在多种长文本任务上表现优于多个基线模型,并与最新的大型商业模型如Gemini1.5-pro表现相当。
Key Takeaways
- 大型语言模型在处理长文本任务时面临中间信息丢失的挑战。
- Tree of Agents(TOA)是一个多智能体推理框架,旨在解决这一问题。
- TOA将输入分割成片段,由独立智能体处理,并通过动态信息交换进行协同推理。
- TOA能有效减轻位置偏见和减少虚构现象。
- TOA结合了前缀哈希缓存和自适应剪枝策略,提高了处理效率。
- 实验表明,TOA在多种长文本任务上的表现优于多个基线模型。
点此查看论文截图

A Fragile Number Sense: Probing the Elemental Limits of Numerical Reasoning in LLMs
Authors:Roussel Rahman, Aashwin Ananda Mishra
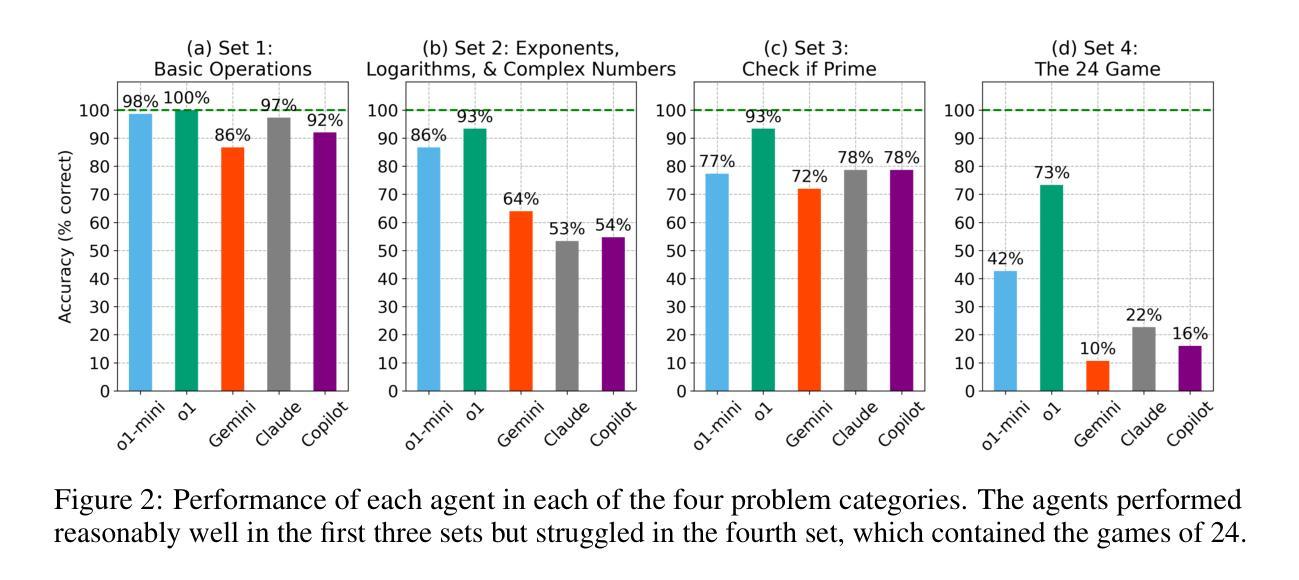
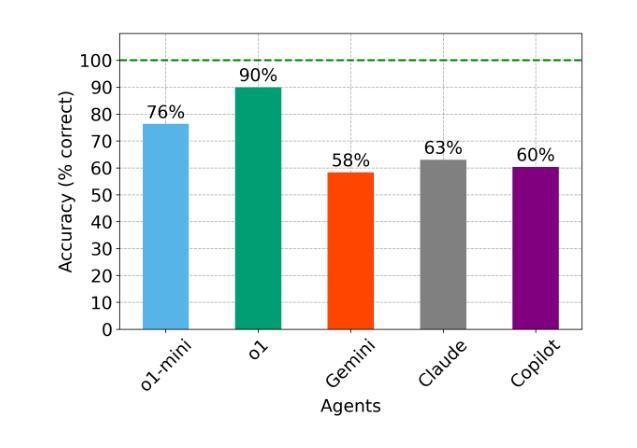
Large Language Models (LLMs) have demonstrated remarkable emergent capabilities, yet the robustness of their numerical reasoning remains an open question. While standard benchmarks evaluate LLM reasoning on complex problem sets using aggregated metrics, they often obscure foundational weaknesses. In this work, we probe LLM mathematical numeracy by evaluating performance on problems of escalating complexity, from constituent operations to combinatorial puzzles. We test several state-of-the-art LLM-based agents on a 100-problem challenge comprising four categories: (1) basic arithmetic, (2) advanced operations, (3) primality checking, and (4) the Game of 24 number puzzle. Our results show that while the agents achieved high accuracy on the first three categories, which require deterministic algorithmic execution, they consistently failed at the number puzzle, underlining its demand for a heuristic search over a large combinatorial space to be a significant bottleneck. These findings reveal that the agents’ proficiency is largely confined to recalling and executing known algorithms, rather than performing generative problem-solving. This suggests their apparent numerical reasoning is more akin to sophisticated pattern-matching than flexible, analytical thought, limiting their potential for tasks that require novel or creative numerical insights.
大型语言模型(LLM)已经展现出惊人的新兴能力,然而它们的数值推理的稳健性仍然是一个悬而未决的问题。虽然标准基准测试使用聚合度量来评估LLM在复杂问题集上的推理能力,但它们往往会掩盖基础弱点。在这项工作中,我们通过评估在不同复杂度的数学问题上的表现来探究LLM的数学计算能力,从基本运算到组合谜题。我们在包含四个类别的100个问题的挑战上测试了几种最先进的基于LLM的代理,这些类别包括:(1)基本算术,(2)高级运算,(3)质数检查,以及(4)24点游戏谜题。我们的结果表明,尽管代理在前三个类别中达到了很高的准确性,这些类别需要确定性算法的执行,但他们在数字谜题方面一直表现不佳,这强调了在大组合空间中进行启发式搜索的需求是一个重大瓶颈。这些发现表明,代理的熟练程度主要局限于回忆和执行已知算法,而不是进行生成式问题解决。这表明它们明显的数值推理更像复杂的模式匹配,而不是灵活的分析思维,这限制了它们在需要新颖或创造性数值见解的任务上的潜力。
论文及项目相关链接
Summary
大型语言模型(LLMs)在涌现能力方面表现出色,但其数值推理的稳健性仍是未解之谜。本研究通过评估LLM在数学素养方面的表现,从基本操作到组合谜题的问题复杂性递增,来探究其数学能力。测试了多个最先进的LLM代理,包括基本算术、高级运算、质数检查和二十四小时游戏谜题等四类问题。发现代理在前三类问题上的准确性较高,但在需要大量启发式搜索和组合空间的问题上表现不佳。这表明代理的能力主要限于回忆和执行已知算法,而非创造性解决问题。因此,其数值推理能力更像复杂的模式匹配,而非灵活的分析思维。
Key Takeaways
- 大型语言模型(LLMs)在数值推理方面的稳健性有待提升。
- LLMs在数学素养方面的表现通过递增复杂性问题进行评估。
- LLM代理在基本算术、高级运算和质数检查问题上表现较好。
- 在需要启发式搜索和组合空间的谜题上,LLM代理表现不佳。
- LLM代理的能力主要限于回忆和执行已知算法。
- LLMs的数值推理能力更像复杂的模式匹配,缺乏灵活的分析思维。
点此查看论文截图