⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-10 更新
UniVerse-1: Unified Audio-Video Generation via Stitching of Experts
Authors:Duomin Wang, Wei Zuo, Aojie Li, Ling-Hao Chen, Xinyao Liao, Deyu Zhou, Zixin Yin, Xili Dai, Daxin Jiang, Gang Yu
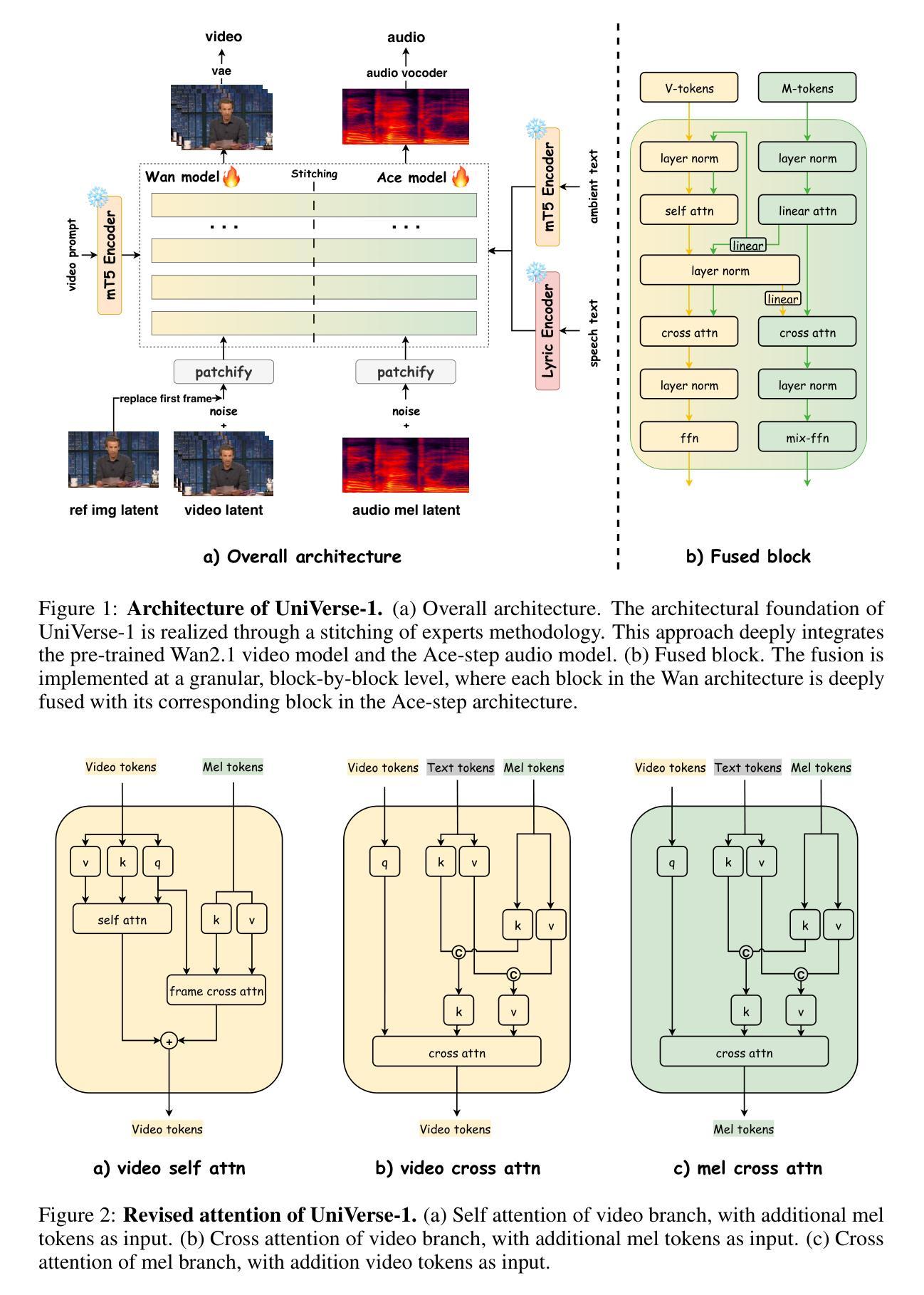
We introduce UniVerse-1, a unified, Veo-3-like model capable of simultaneously generating coordinated audio and video. To enhance training efficiency, we bypass training from scratch and instead employ a stitching of experts (SoE) technique. This approach deeply fuses the corresponding blocks of pre-trained video and music generation experts models, thereby fully leveraging their foundational capabilities. To ensure accurate annotations and temporal alignment for both ambient sounds and speech with video content, we developed an online annotation pipeline that processes the required training data and generates labels during training process. This strategy circumvents the performance degradation often caused by misalignment text-based annotations. Through the synergy of these techniques, our model, after being finetuned on approximately 7,600 hours of audio-video data, produces results with well-coordinated audio-visuals for ambient sounds generation and strong alignment for speech generation. To systematically evaluate our proposed method, we introduce Verse-Bench, a new benchmark dataset. In an effort to advance research in audio-video generation and to close the performance gap with state-of-the-art models such as Veo3, we make our model and code publicly available. We hope this contribution will benefit the broader research community. Project page: https://dorniwang.github.io/UniVerse-1/.
我们介绍了UniVerse-1,这是一个统一、类似于Veo-3的模型,能够同时生成协调的音频和视频。为了提高训练效率,我们没有从头开始训练,而是采用了一种“专家拼接”(SoE)技术。这种方法将预训练的视频和音乐生成专家模型的相应块进行深度融合,从而充分利用它们的基础能力。为了确保环境声音和语音与视频内容的精确标注和时间对齐,我们开发了一个在线标注管道,该管道在处理所需训练数据的同时在训练过程中生成标签。这一策略避免了由于文本标注不对齐而导致的性能下降。通过这些技术的协同作用,我们的模型在大约7600小时的音视频数据上进行微调后,能够生成协调良好的音视频结果,用于环境声音生成和语音生成的强对齐。为了系统地评估我们提出的方法,我们引入了Verse-Bench,这是一个新的基准数据集。我们致力于推进音视频生成研究,并缩小与国家先进模型(如Veo3)的性能差距。为了让广大研究人员受益,我们公开提供模型和代码。项目页面:https://dorniwang.github.io/UniVerse-1/。
论文及项目相关链接
PDF Project page: https://dorniwang.github.io/UniVerse-1/
Summary
UniVerse-1模型是一种能同时生成协调的音频和视频的统一模型。为提高训练效率,该模型采用专家拼接技术融合预训练的视频和音乐生成专家模型的对应块,从而充分利用其基础能力。为确保与视频内容相符的音频(包括环境声和语音)的标注准确性和时间对齐性,开发了一种在线标注管道,在训练过程中处理所需数据并生成标签。该模型在约7,600小时的音视频数据上进行微调后,音视频协调性和语音对齐性表现优异。为评估此新方法,研究团队推出了Verse-Bench数据集。相关模型和代码已公开,供进一步研究以缩小与前沿模型如Veo3的性能差距,并希望为更广泛的科研社区带来益处。更多信息可访问:链接。
Key Takeaways
- UniVerse-1是一个能够同时生成协调音频和视频的统一模型。
- 采用专家拼接技术以提高训练效率,融合预训练的视频和音乐生成专家模型。
- 开发在线标注管道,确保音频与视频内容的时间对齐和准确标注。
- 模型经过约7,600小时的音视频数据微调,表现出良好的音视频协调性和语音对齐性。
- 推出Verse-Bench数据集以评估新方法。
- 模型和代码已公开,以推动研究并缩小与顶尖模型的性能差距。
点此查看论文截图

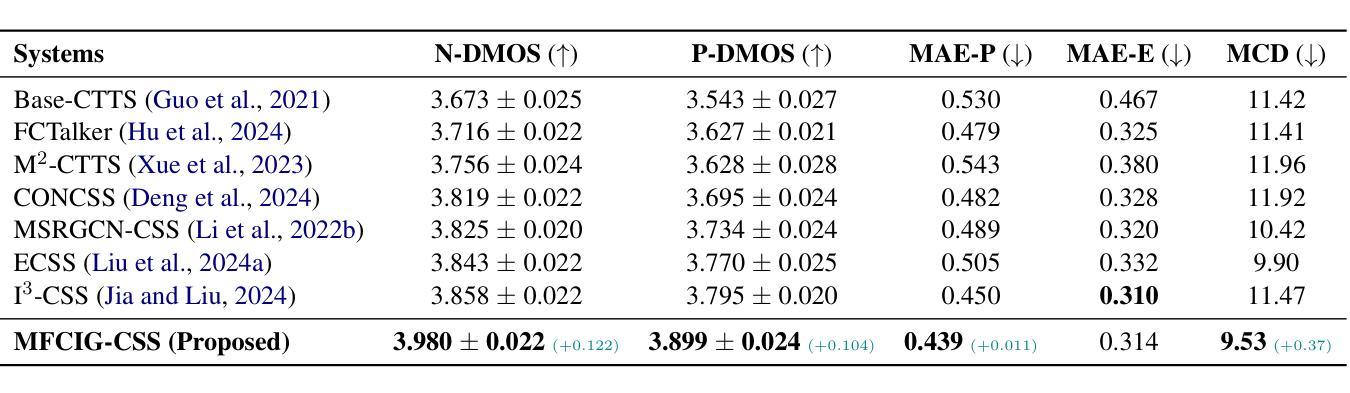
Multimodal Fine-grained Context Interaction Graph Modeling for Conversational Speech Synthesis
Authors:Zhenqi Jia, Rui Liu, Berrak Sisman, Haizhou Li
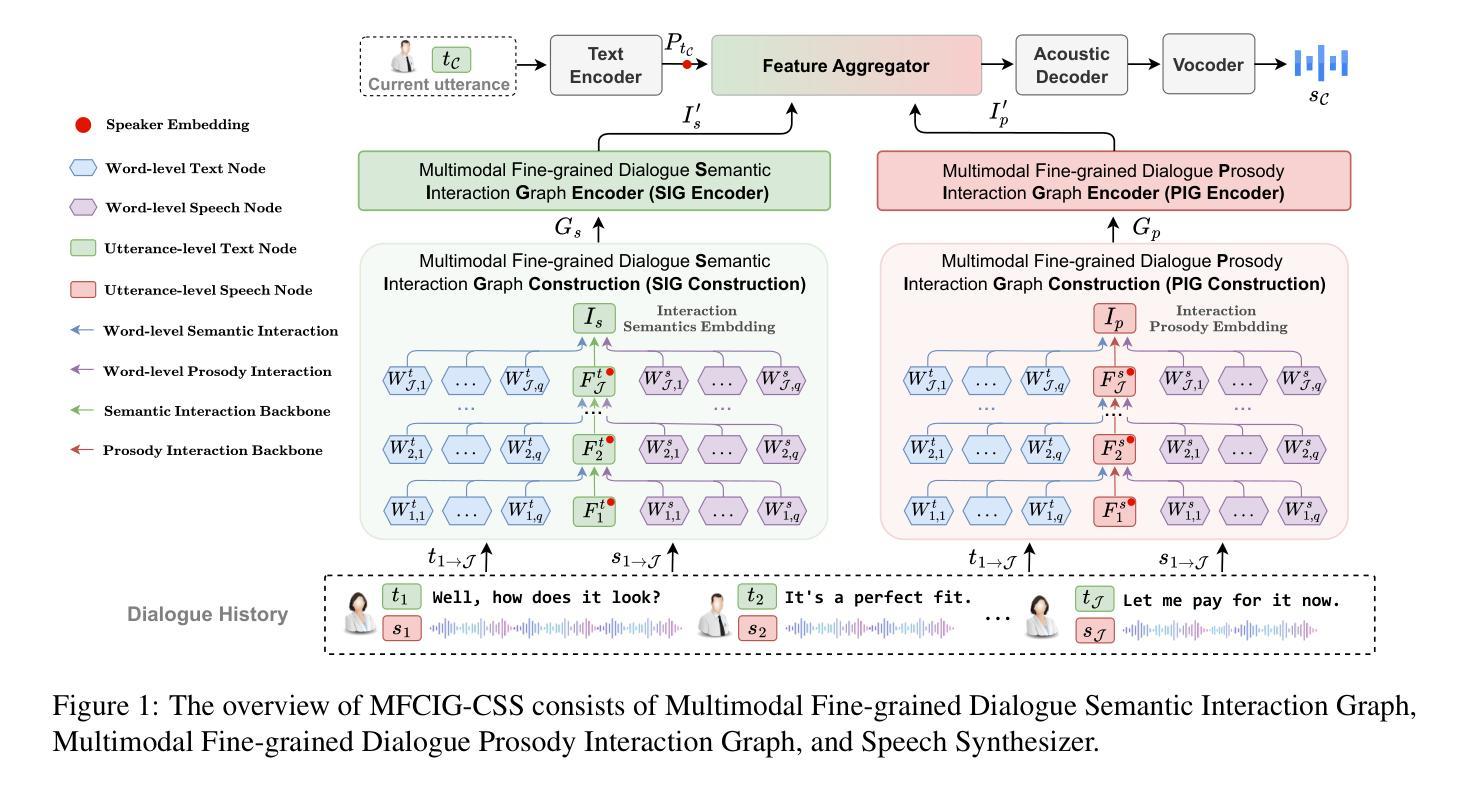
Conversational Speech Synthesis (CSS) aims to generate speech with natural prosody by understanding the multimodal dialogue history (MDH). The latest work predicts the accurate prosody expression of the target utterance by modeling the utterance-level interaction characteristics of MDH and the target utterance. However, MDH contains fine-grained semantic and prosody knowledge at the word level. Existing methods overlook the fine-grained semantic and prosodic interaction modeling. To address this gap, we propose MFCIG-CSS, a novel Multimodal Fine-grained Context Interaction Graph-based CSS system. Our approach constructs two specialized multimodal fine-grained dialogue interaction graphs: a semantic interaction graph and a prosody interaction graph. These two interaction graphs effectively encode interactions between word-level semantics, prosody, and their influence on subsequent utterances in MDH. The encoded interaction features are then leveraged to enhance synthesized speech with natural conversational prosody. Experiments on the DailyTalk dataset demonstrate that MFCIG-CSS outperforms all baseline models in terms of prosodic expressiveness. Code and speech samples are available at https://github.com/AI-S2-Lab/MFCIG-CSS.
对话式语音合成(CSS)旨在通过理解多模式对话历史(MDH)来生成具有自然韵律的语音。最新的工作通过建模MDH和目标话语的语句级交互特征来预测目标话语的准确韵律表达。然而,MDH在词语层面包含了精细的语义和韵律知识。现有方法忽视了精细的语义和韵律交互建模。为了弥补这一空白,我们提出了MFCIG-CSS,一种基于多模式精细上下文交互图的CSS系统。我们的方法构建了两个专门的多模式精细对话交互图:语义交互图和韵律交互图。这两个交互图有效地对词语层面的语义、韵律及其在多模式对话历史中对后续话语的影响之间的交互进行编码。然后利用编码的交互特征来提高合成语音的自然对话韵律。在DailyTalk数据集上的实验表明,MFCIG-CSS在韵律表现力方面优于所有基线模型。代码和语音样本可在https://github.com/AI-S2-Lab/MFCIG-CSS找到。
论文及项目相关链接
PDF Accepted by EMNLP 2025
Summary
本文介绍了基于多模态精细上下文交互图的对话语音合成系统MFCIG-CSS。该系统通过构建语义交互图和语调交互图,有效编码单词级别的语义和语调之间的交互,并影响多模态对话历史中的后续话语。实验证明,MFCIG-CSS在每日对话数据集上的语音合成表现优于所有基线模型。
Key Takeaways
- CSS旨在通过理解多模态对话历史生成具有自然语调的语音。
- 最新工作通过建模MDH和目标语句的语句级交互特征来预测目标语句的准确语调表达。
- MDH包含单词级别的精细语义和语调知识,但现有方法忽略了精细语义和语调交互建模。
- MFCIG-CSS是一个基于多模态精细上下文交互图的CSS系统,构建了两个专门的多模态精细对话交互图:语义交互图和语调交互图。
- 两个交互图有效地编码单词级别的语义、语调之间的交互,以及它们对后续话语的影响。
- MFCIG-CSS通过利用编码的交互特征,提高了合成语音的自然对话语调。
点此查看论文截图


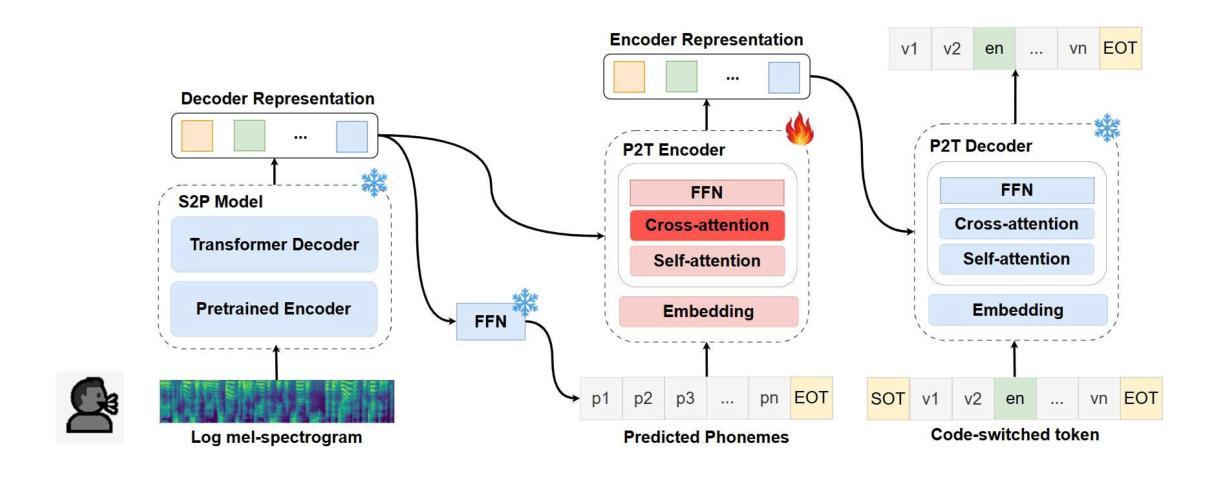
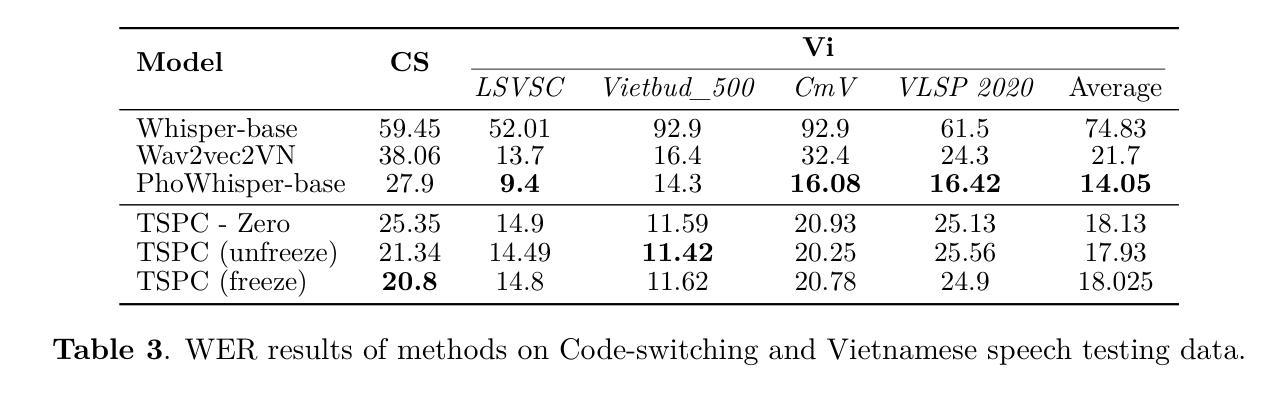
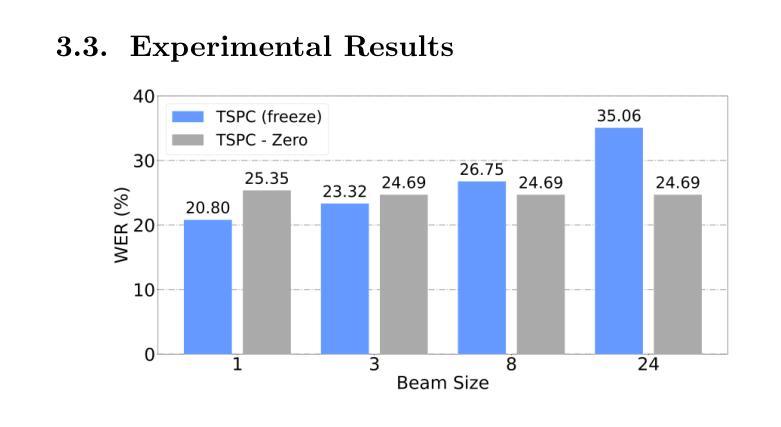
TSPC: A Two-Stage Phoneme-Centric Architecture for code-switching Vietnamese-English Speech Recognition
Authors:Minh N. H. Nguyen, Anh Nguyen Tran, Dung Truong Dinh, Nam Van Vo
Code-switching (CS) presents a significant challenge for general Auto-Speech Recognition (ASR) systems. Existing methods often fail to capture the subtle phonological shifts inherent in CS scenarios. The challenge is particularly difficult for language pairs like Vietnamese and English, where both distinct phonological features and the ambiguity arising from similar sound recognition are present. In this paper, we propose a novel architecture for Vietnamese-English CS ASR, a Two-Stage Phoneme-Centric model (TSPC). The TSPC employs a phoneme-centric approach, built upon an extended Vietnamese phoneme set as an intermediate representation to facilitate mixed-lingual modeling. Experimental results demonstrate that TSPC consistently outperforms existing baselines, including PhoWhisper-base, in Vietnamese-English CS ASR, achieving a significantly lower word error rate of 20.8% with reduced training resources. Furthermore, the phonetic-based two-stage architecture enables phoneme adaptation and language conversion to enhance ASR performance in complex CS Vietnamese-English ASR scenarios.
语言转换(CS)为通用自动语音识别(ASR)系统带来了重大挑战。现有方法往往无法捕捉到CS场景中固有的细微语音变化。对于像越南语和英语这样的语言对来说,挑战尤其艰巨,这两种语言具有不同的语音特征以及由相似声音识别引起的歧义。在本文中,我们针对越南语-英语CS ASR提出了一种新型架构,即两阶段音素中心模型(TSPC)。TSPC采用了一种音素中心方法,以扩展的越南语音素集作为中间表示,促进混合语言建模。实验结果表明,TSPC在越南语-英语CS ASR中始终优于现有基线,包括PhoWhisper-base,实现了显著降低的词错误率20.8%,同时减少了训练资源。此外,基于音素的两阶段架构能够实现音素适应和语言转换,以提高复杂CS越南语-英语ASR场景中的ASR性能。
论文及项目相关链接
总结
代码切换(CS)给通用自动语音识别(ASR)系统带来了重大挑战。现有方法往往无法捕捉CS场景中固有的细微语音变化。越南语和英语等语言对的挑战尤其艰巨,因为它们既有截然不同的语音特征,又有因相似声音识别而产生的歧义。本文提出了一种针对越南语-英语CS ASR的新型架构,即两阶段音素中心模型(TSPC)。TSPC采用音素中心方法,以扩展的越南语音素集作为中间表示,促进跨语言建模。实验结果表明,TSPC在越南语-英语CS ASR中始终优于现有基线,包括PhoWhisper-base,实现了显著降低的20.8%的词错误率,并减少了训练资源。此外,基于音素的两阶段架构能够实现音素适应和语言转换,从而提高复杂CS越南语-英语ASR场景中的ASR性能。
要点
- 代码切换(CS)对自动语音识别(ASR)系统构成挑战。
- 现有ASR方法难以捕捉CS场景中的细微语音变化。
- 越南语和英语的语音识别具有特殊挑战,因为两者的语音特征和识别歧义性。
- 提出的两阶段音素中心模型(TSPC)以越南语音素集为中间表示进行跨语言建模。
- 实验显示TSPC在越南语-英语CS ASR中表现优于现有方法,词错误率显著降低至20.8%。
- TSPC架构能够减少训练资源需求。
点此查看论文截图


Out of the Box, into the Clinic? Evaluating State-of-the-Art ASR for Clinical Applications for Older Adults
Authors:Bram van Dijk, Tiberon Kuiper, Sirin Aoulad si Ahmed, Armel Levebvre, Jake Johnson, Jan Duin, Simon Mooijaart, Marco Spruit
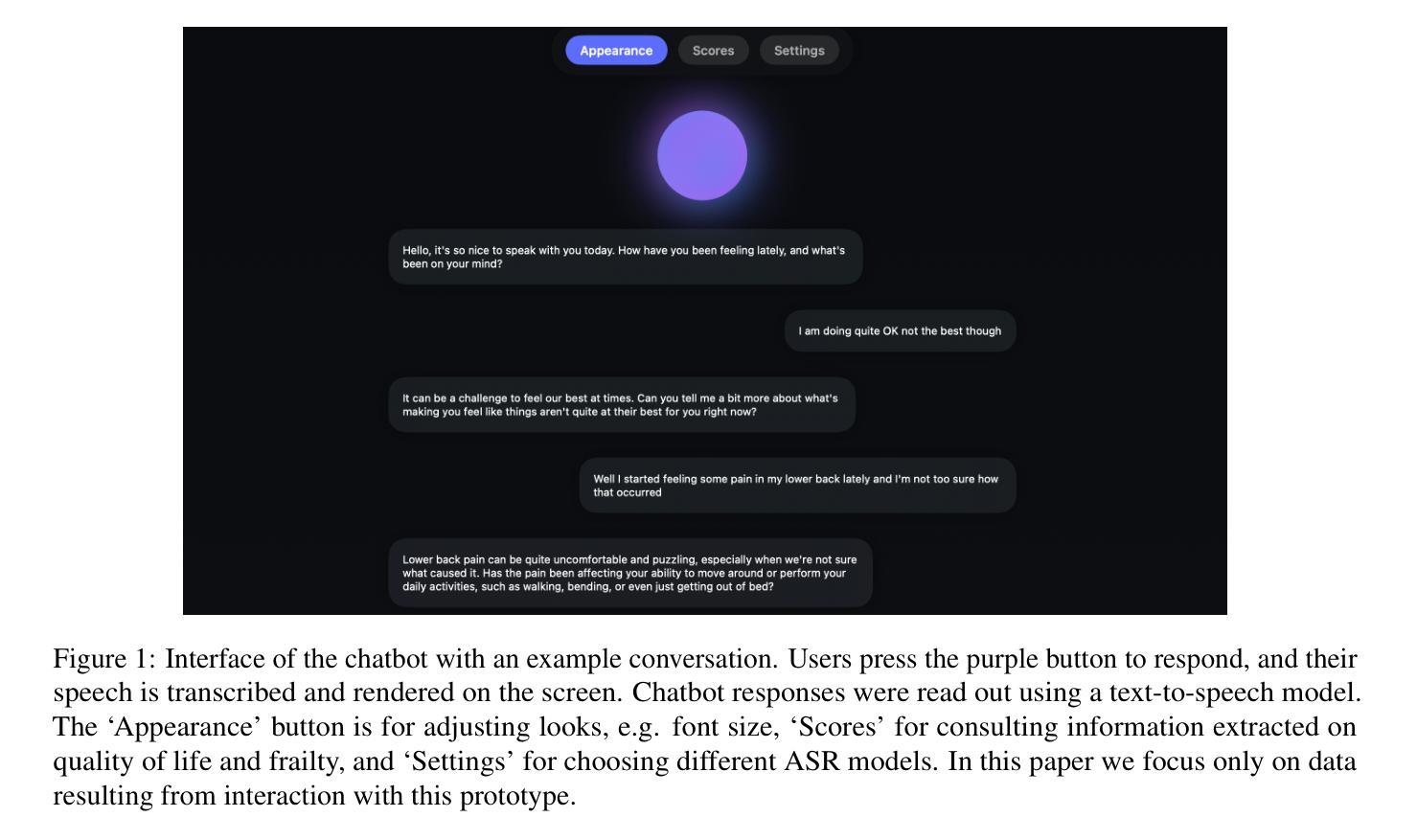
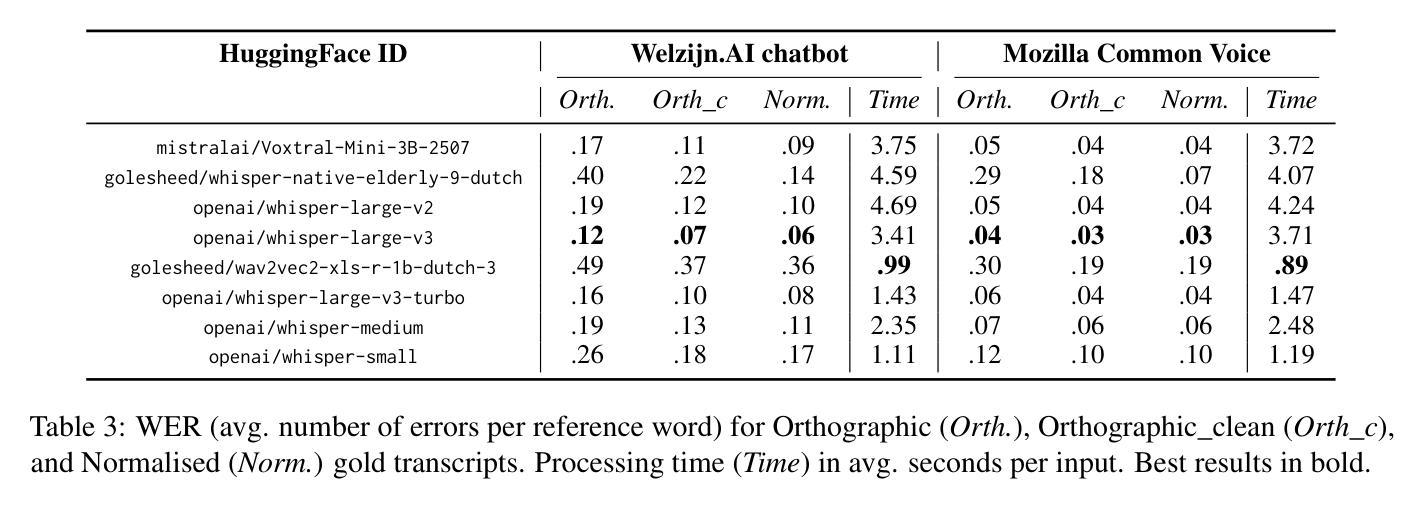
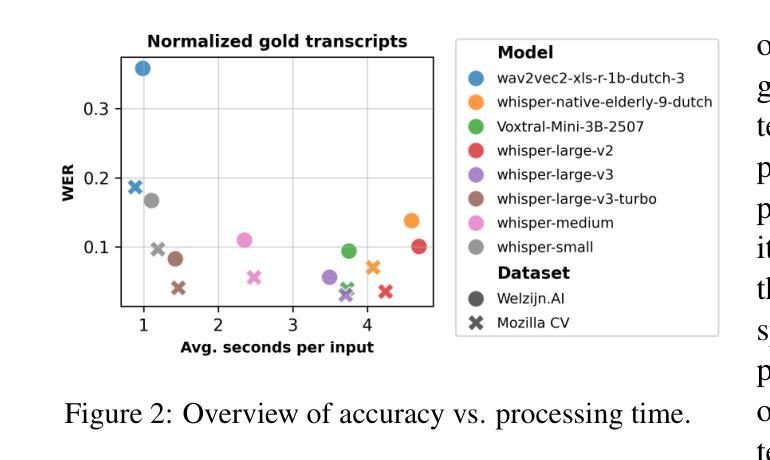
Voice-controlled interfaces can support older adults in clinical contexts, with chatbots being a prime example, but reliable Automatic Speech Recognition (ASR) for underrepresented groups remains a bottleneck. This study evaluates state-of-the-art ASR models on language use of older Dutch adults, who interacted with the \texttt{Welzijn.AI} chatbot designed for geriatric contexts. We benchmark generic multilingual ASR models, and models fine-tuned for Dutch spoken by older adults, while also considering processing speed. Our results show that generic multilingual models outperform fine-tuned models, which suggests recent ASR models can generalise well out of the box to realistic datasets. Furthermore, our results suggest that truncating existing architectures is helpful in balancing the accuracy-speed trade-off, though we also identify some cases with high WER due to hallucinations.
语音控制界面在临床环境中可以支持老年人,聊天机器人就是一个很好的例子,但是对未被充分研究的群体的可靠自动语音识别(ASR)仍然是一个瓶颈。本研究评估了最前沿的ASR模型在老年荷兰人与专为老年情境设计的“Welzijn.AI”聊天机器人的语言使用方面的表现。我们对比了通用多语种ASR模型和针对老年荷兰人微调过的模型,同时考虑了处理速度。我们的结果表明,通用多语种模型的表现优于微调模型,这表明最近的ASR模型可以很好地适应现实数据集,而无需专门定制。此外,我们的结果还表明,通过截断现有架构有助于平衡准确性与速度之间的权衡,尽管我们也发现了一些因幻想而产生的高词错率(WER)的情况。
论文及项目相关链接
Summary
语音控制界面在临床环境中可以支持老年人群,聊天机器人就是一个很好的例子。然而,对于代表性不足的群体的自动语音识别(ASR)仍然是一个瓶颈。本研究评估了针对老年荷兰成年人使用的语言,与专为老年情境设计的Welzijn.AI聊天机器人互动的当前最先进的ASR模型。我们对通用多语种ASR模型和针对荷兰老年人进行微调后的模型进行了基准测试,同时考虑了处理速度。结果表明,通用多语种模型优于微调模型,这表明最近的ASR模型在现实数据集上可以很好地通用。此外,我们的结果还表明,截断现有架构有助于平衡准确性与速度之间的权衡,但我们确实在某些情况下也发现一些因幻听导致的高词错率情况。
Key Takeaways
- 语音控制界面支持老年人在临床环境中的使用,聊天机器人是其中的一种实现方式。
- 自动语音识别(ASR)对于代表性不足的群体仍然是一个挑战。
- 本研究评估了针对老年荷兰成年人的语言与专为老年情境设计的聊天机器人的互动效果。
- 通用多语种ASR模型在针对老年荷兰成年人的数据集上表现出良好的性能。
- 对ASR模型的截断策略有助于平衡准确性和处理速度之间的权衡。
- 研究中存在因幻听导致的高词错率情况。
点此查看论文截图




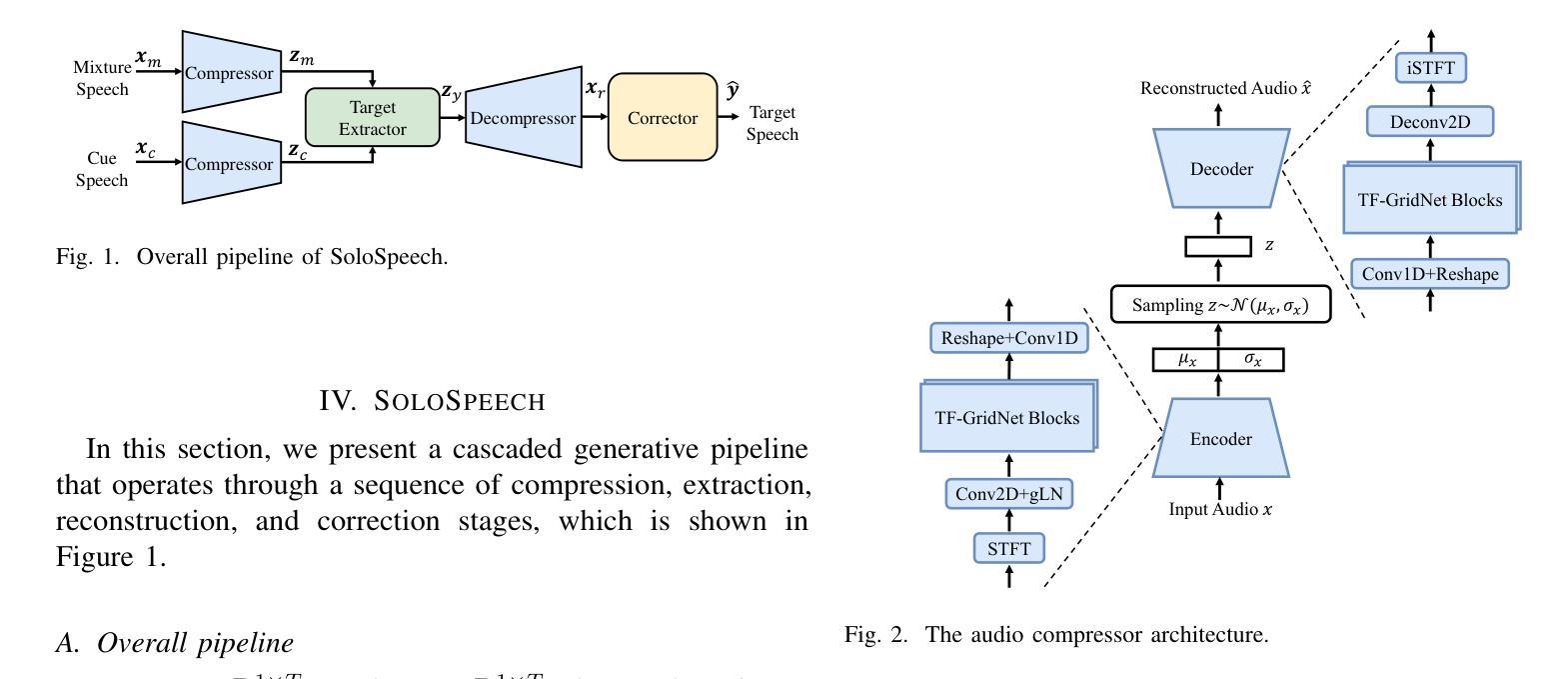
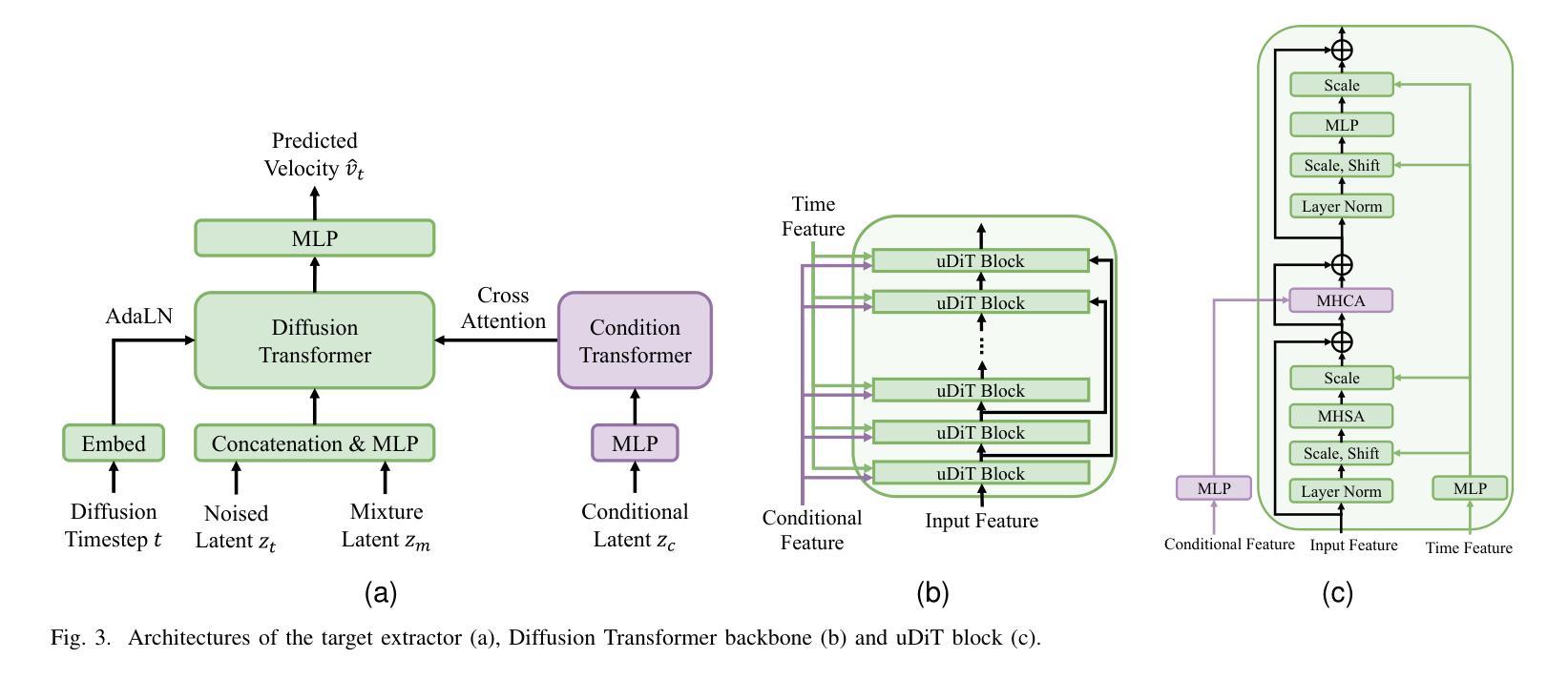
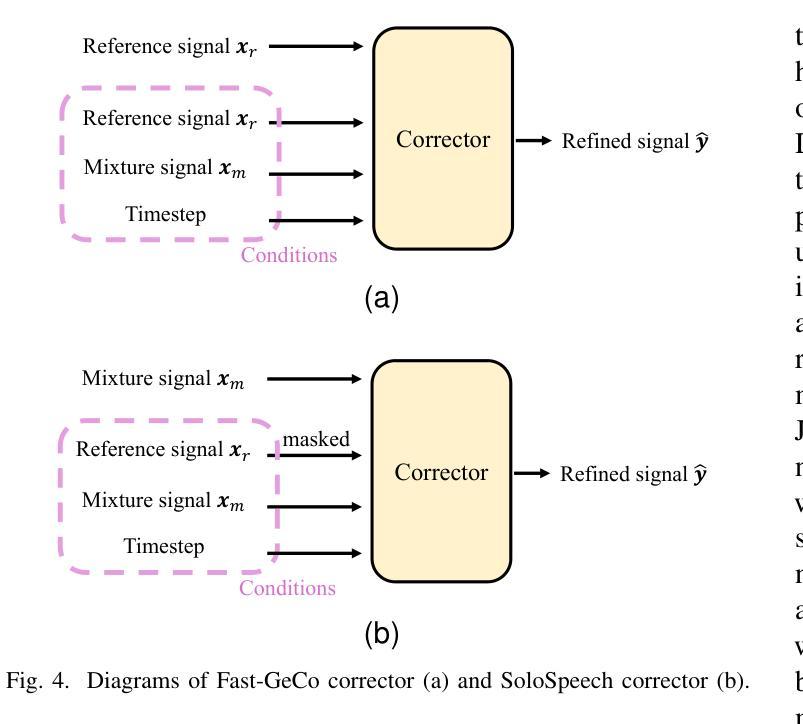
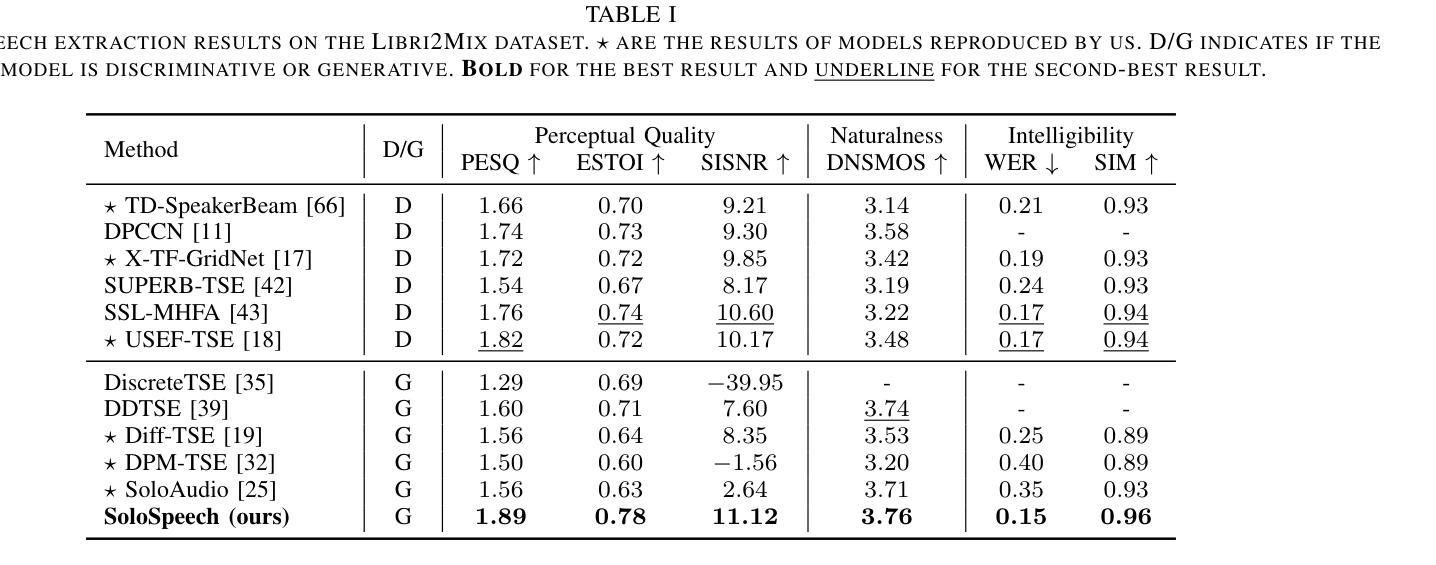
SoloSpeech: Enhancing Intelligibility and Quality in Target Speech Extraction through a Cascaded Generative Pipeline
Authors:Helin Wang, Jiarui Hai, Dongchao Yang, Chen Chen, Kai Li, Junyi Peng, Thomas Thebaud, Laureano Moro Velazquez, Jesus Villalba, Najim Dehak
Target Speech Extraction (TSE) aims to isolate a target speaker’s voice from a mixture of multiple speakers by leveraging speaker-specific cues, typically provided as auxiliary audio (a.k.a. cue audio). Although recent advancements in TSE have primarily employed discriminative models that offer high perceptual quality, these models often introduce unwanted artifacts, reduce naturalness, and are sensitive to discrepancies between training and testing environments. On the other hand, generative models for TSE lag in perceptual quality and intelligibility. To address these challenges, we present SoloSpeech, a novel cascaded generative pipeline that integrates compression, extraction, reconstruction, and correction processes. SoloSpeech features a speaker-embedding-free target extractor that utilizes conditional information from the cue audio’s latent space, aligning it with the mixture audio’s latent space to prevent mismatches. Evaluated on the widely-used Libri2Mix dataset, SoloSpeech achieves the new state-of-the-art intelligibility and quality in target speech extraction while demonstrating exceptional generalization on out-of-domain data and real-world scenarios.
目标语音提取(TSE)旨在利用特定于说话者的线索(通常作为辅助音频(又称线索音频)提供)从多个说话者的混合声音中分离出目标说话者的声音。尽管最近的TSE进展主要采用了提供高感知质量的判别模型,但这些模型往往会引入不需要的伪影,降低自然度,并对训练和测试环境之间的差异敏感。另一方面,TSE的生成模型在感知质量和清晰度方面有所不足。为了解决这些挑战,我们提出了SoloSpeech,这是一种新型级联生成管道,融合了压缩、提取、重建和校正过程。SoloSpeech的特点是无需使用说话人嵌入的目标提取器,它利用来自线索音频潜在空间的条件信息,将其与混合音频的潜在空间对齐,以防止不匹配。在广泛使用的Libri2Mix数据集上,SoloSpeech在目标语音提取方面达到了新的先进清晰度和质量水平,并在跨领域数据和真实场景上表现出卓越的泛化能力。
论文及项目相关链接
Summary
本文介绍了针对目标语音提取(TSE)的新方法——SoloSpeech。该方法采用级联生成管道,集成了压缩、提取、重建和校正过程,旨在从混合语音中隔离目标说话人的声音。它利用来自辅助音频的潜在空间的条件信息,与混合音频的潜在空间对齐,避免了不匹配的问题。在Libri2Mix数据集上,SoloSpeech达到了目标语音提取的最新最好水平,具有出色的泛化能力和质量。
Key Takeaways
- SoloSpeech是一个针对目标语音提取(TSE)的新方法,旨在从混合语音中隔离目标说话人的声音。
- 它采用级联生成管道,集成了压缩、提取、重建和校正过程。
- SoloSpeech利用来自辅助音频(又称提示音频)的潜在空间的条件信息,与混合音频的潜在空间对齐。
- 该方法避免了不匹配的问题,提高了目标语音提取的准确性和质量。
- 在Libri2Mix数据集上,SoloSpeech达到了新的最高水平的可理解性和质量。
- SoloSpeech具有出色的泛化能力,适用于跨领域数据和真实场景。
点此查看论文截图