⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-10 更新
Multimodal Fine-grained Context Interaction Graph Modeling for Conversational Speech Synthesis
Authors:Zhenqi Jia, Rui Liu, Berrak Sisman, Haizhou Li
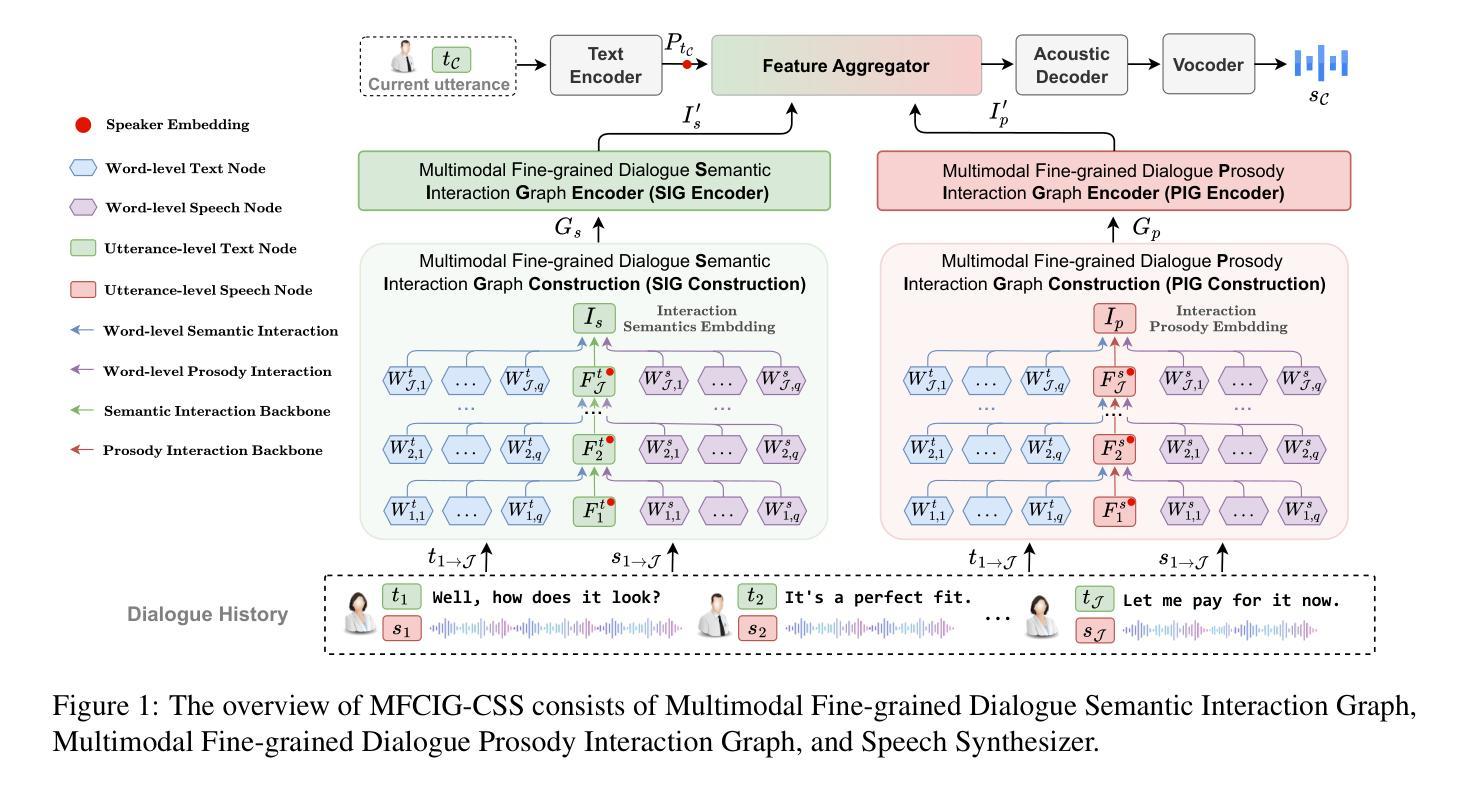
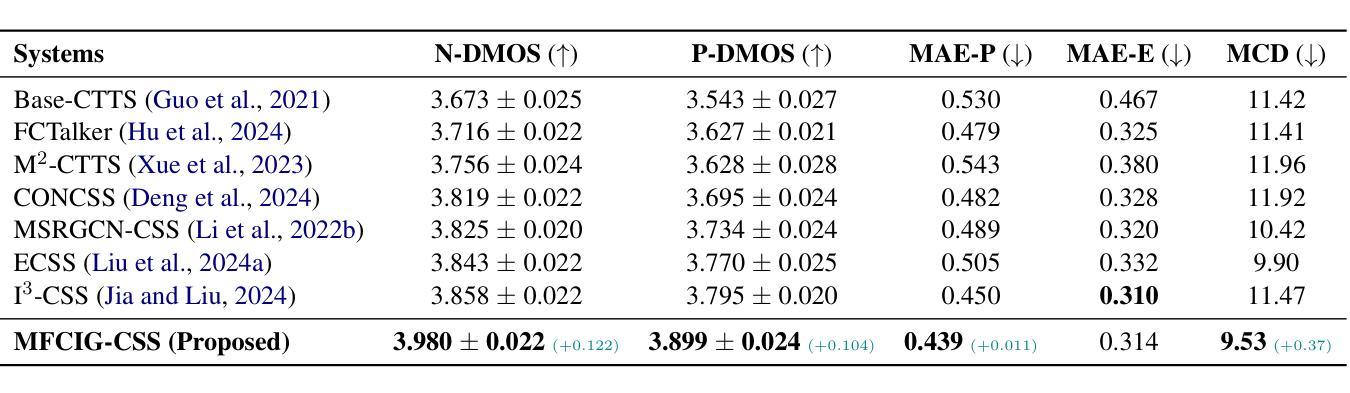
Conversational Speech Synthesis (CSS) aims to generate speech with natural prosody by understanding the multimodal dialogue history (MDH). The latest work predicts the accurate prosody expression of the target utterance by modeling the utterance-level interaction characteristics of MDH and the target utterance. However, MDH contains fine-grained semantic and prosody knowledge at the word level. Existing methods overlook the fine-grained semantic and prosodic interaction modeling. To address this gap, we propose MFCIG-CSS, a novel Multimodal Fine-grained Context Interaction Graph-based CSS system. Our approach constructs two specialized multimodal fine-grained dialogue interaction graphs: a semantic interaction graph and a prosody interaction graph. These two interaction graphs effectively encode interactions between word-level semantics, prosody, and their influence on subsequent utterances in MDH. The encoded interaction features are then leveraged to enhance synthesized speech with natural conversational prosody. Experiments on the DailyTalk dataset demonstrate that MFCIG-CSS outperforms all baseline models in terms of prosodic expressiveness. Code and speech samples are available at https://github.com/AI-S2-Lab/MFCIG-CSS.
对话式语音合成(CSS)旨在通过理解多模态对话历史(MDH)来生成具有自然韵律的语音。最新工作通过建模MDH和目标话语的语句级交互特征来预测目标话语的准确韵律表达。然而,MDH在词级包含了精细的语义和韵律知识。现有方法忽视了精细的语义和韵律交互建模。为了解决这一差距,我们提出了MFCIG-CSS,一种基于多模态细粒度上下文交互图的CSS系统。我们的方法构建了两个专门的多模态细粒度对话交互图:语义交互图和韵律交互图。这两个交互图有效地编码了词级语义、韵律之间的交互,以及它们对MDH中后续话语的影响。然后利用编码的交互特征来增强合成语音的自然对话韵律。在DailyTalk数据集上的实验表明,MFCIG-CSS在韵律表现力方面优于所有基准模型。代码和语音样本可在https://github.com/AI-S2-Lab/MFCIG-CSS上找到。
论文及项目相关链接
PDF Accepted by EMNLP 2025
Summary
基于多模态对话历史(MDH)的会话语音合成(CSS)旨在生成具有自然语调的语音。最新工作通过建模MDH和目标话语的语句级交互特征来预测目标话语的准确语调表达。然而,MDH在词级含有精细的语义和语调知识,现有方法忽略了精细的语义和语调交互建模。为解决这一差距,我们提出基于多模态精细上下文交互图的CSS系统MFCIG-CSS。该方法构建两个专门的多模态精细对话交互图:语义交互图和语调交互图。这两个交互图有效地对词级语义、语调之间的交互进行编码,以及它们对MDH中后续话语的影响。然后利用编码的交互特征来增强合成语音的自然对话语调。在DailyTalk数据集上的实验表明,MFCIG-CSS在语调表达方面优于所有基线模型。
Key Takeaways
- CSS旨在结合多模态对话历史(MDH)生成自然语调的语音。
- 最新方法通过建模MDH和目标话语的语句级交互特征来预测目标话语的准确语调。
- MDH含有词级的精细语义和语调知识,但现有方法忽略了这一点。
- 提出基于多模态精细上下文交互图的CSS系统MFCIG-CSS。
- MFCIG-CSS构建两个交互图:语义交互图和语调交互图。
- 这两个交互图有效编码词级语义和语调之间的交互,及其对后续话语的影响。
点此查看论文截图


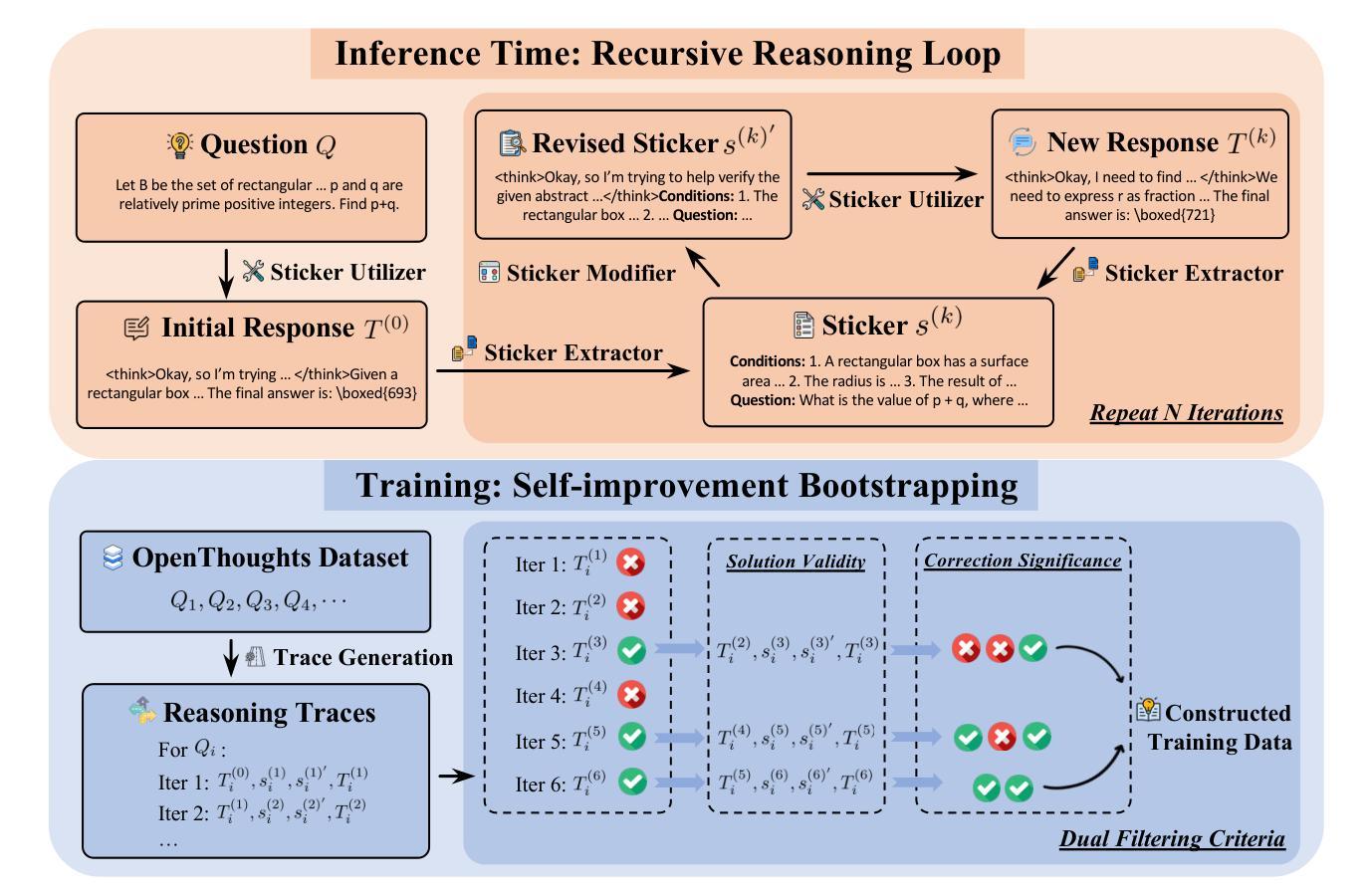
Sticker-TTS: Learn to Utilize Historical Experience with a Sticker-driven Test-Time Scaling Framework
Authors:Jie Chen, Jinhao Jiang, Yingqian Min, Zican Dong, Shijie Wang, Wayne Xin Zhao, Ji-Rong Wen
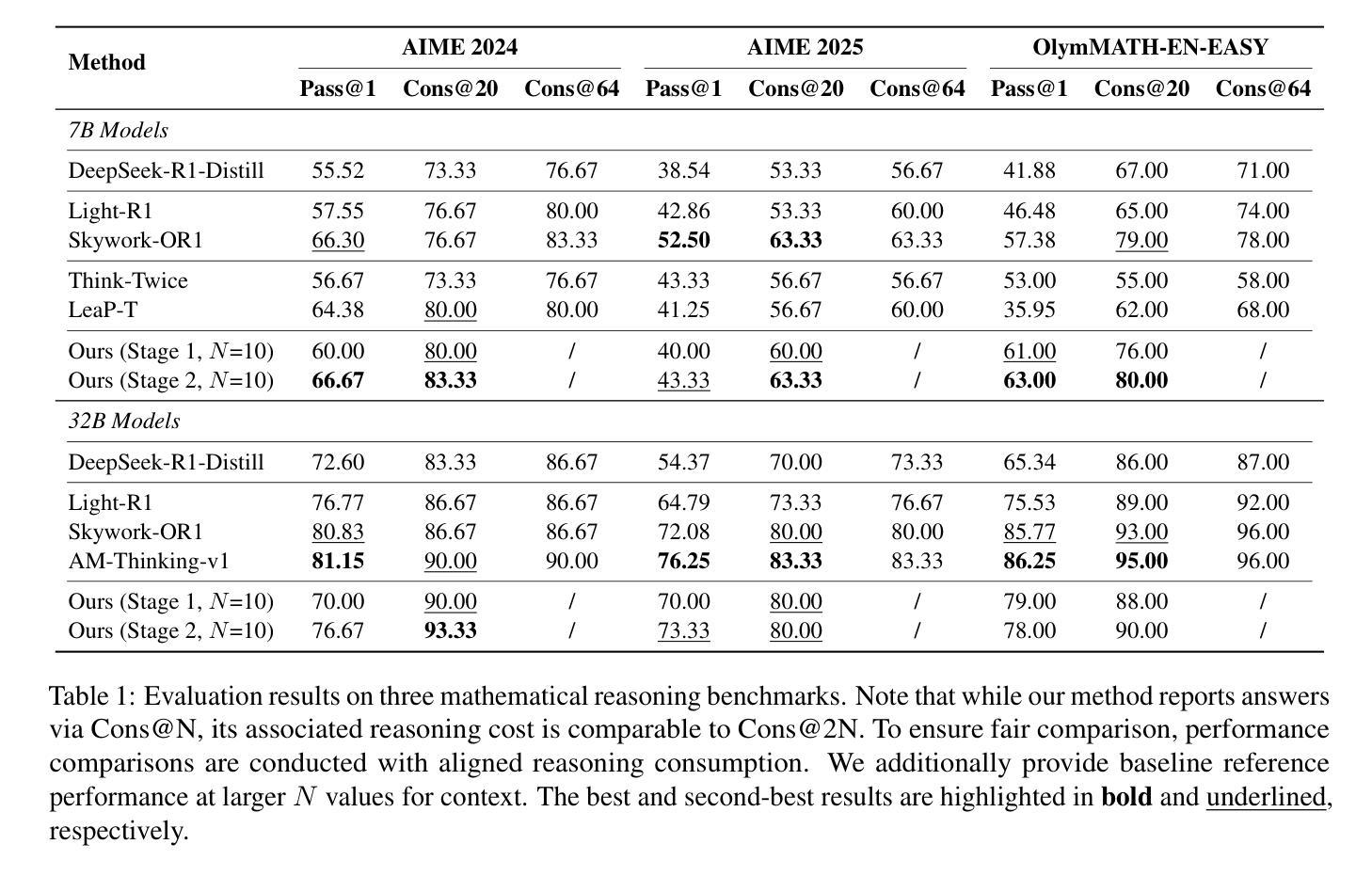
Large reasoning models (LRMs) have exhibited strong performance on complex reasoning tasks, with further gains achievable through increased computational budgets at inference. However, current test-time scaling methods predominantly rely on redundant sampling, ignoring the historical experience utilization, thereby limiting computational efficiency. To overcome this limitation, we propose Sticker-TTS, a novel test-time scaling framework that coordinates three collaborative LRMs to iteratively explore and refine solutions guided by historical attempts. At the core of our framework are distilled key conditions-termed stickers-which drive the extraction, refinement, and reuse of critical information across multiple rounds of reasoning. To further enhance the efficiency and performance of our framework, we introduce a two-stage optimization strategy that combines imitation learning with self-improvement, enabling progressive refinement. Extensive evaluations on three challenging mathematical reasoning benchmarks, including AIME-24, AIME-25, and OlymMATH, demonstrate that Sticker-TTS consistently surpasses strong baselines, including self-consistency and advanced reinforcement learning approaches, under comparable inference budgets. These results highlight the effectiveness of sticker-guided historical experience utilization. Our code and data are available at https://github.com/RUCAIBox/Sticker-TTS.
大型推理模型(LRMs)在复杂的推理任务中表现出了强大的性能,通过增加推理时的计算预算,可以进一步获得收益。然而,当前的测试时间缩放方法主要依赖于冗余采样,忽略了历史经验的利用,从而限制了计算效率。为了克服这一局限性,我们提出了Sticker-TTS,这是一种新型的测试时间缩放框架,它协调了三个协作式LRMs,以历史尝试为引导,迭代地探索和精炼解决方案。我们框架的核心是提炼出的关键条件——称为“贴纸”,它驱动了跨多个推理轮次的关键信息的提取、精炼和再利用。为了进一步提高我们框架的效率和性能,我们引入了一种两阶段优化策略,结合模仿学习与自我改进,实现渐进式精炼。在AIME-24、AIME-25和奥林巴斯数学三个具有挑战性的数学推理基准测试上的广泛评估表明,Sticker-TTS在可比较推理预算下,始终超过了包括自我一致性增强和先进强化学习在内的基线方法。这些结果突出了贴纸引导的历史经验利用的有效性。我们的代码和数据可在https://github.com/RUCAIBox/Sticker-TTS找到。
论文及项目相关链接
PDF 11 pages, 1 figures, 5 tables
Summary
贴纸辅助的推理时间缩放框架(Sticker-TTS)结合了历史经验,通过迭代探索和优化解决方案,实现了大规模推理模型(LRMs)在复杂推理任务上的性能提升。该框架以提取、精炼和重用关键信息为核心,引入了两阶段优化策略,结合了模仿学习和自我改进机制。实验结果表明,Sticker-TTS在多个数学推理基准测试上表现优异,超越了多种基线方法。
Key Takeaways
- LRMs在复杂推理任务上表现出强大的性能,可通过增加计算预算进一步提高。
- 当前推理时间缩放方法主要依赖冗余采样,未充分利用历史经验,限制了计算效率。
- Sticker-TTS框架通过历史经验的迭代利用,协调三个协作式LRMs进行推理。
- “贴纸”是框架中的关键条件,用于驱动信息的提取、精炼和重用。
- Sticker-TTS引入了两阶段优化策略,结合了模仿学习和自我改进机制,提高了效率和性能。
- 实验结果表明,Sticker-TTS在多个数学推理基准测试上表现优异,包括AIME-24、AIME-25和OlymMATH等。
点此查看论文截图