⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-30 更新
SpecXNet: A Dual-Domain Convolutional Network for Robust Deepfake Detection
Authors:Inzamamul Alam, Md Tanvir Islam, Simon S. Woo
The increasing realism of content generated by GANs and diffusion models has made deepfake detection significantly more challenging. Existing approaches often focus solely on spatial or frequency-domain features, limiting their generalization to unseen manipulations. We propose the Spectral Cross-Attentional Network (SpecXNet), a dual-domain architecture for robust deepfake detection. The core \textbf{Dual-Domain Feature Coupler (DDFC)} decomposes features into a local spatial branch for capturing texture-level anomalies and a global spectral branch that employs Fast Fourier Transform to model periodic inconsistencies. This dual-domain formulation allows SpecXNet to jointly exploit localized detail and global structural coherence, which are critical for distinguishing authentic from manipulated images. We also introduce the \textbf{Dual Fourier Attention (DFA)} module, which dynamically fuses spatial and spectral features in a content-aware manner. Built atop a modified XceptionNet backbone, we embed the DDFC and DFA modules within a separable convolution block. Extensive experiments on multiple deepfake benchmarks show that SpecXNet achieves state-of-the-art accuracy, particularly under cross-dataset and unseen manipulation scenarios, while maintaining real-time feasibility. Our results highlight the effectiveness of unified spatial-spectral learning for robust and generalizable deepfake detection. To ensure reproducibility, we released the full code on \href{https://github.com/inzamamulDU/SpecXNet}{\textcolor{blue}{\textbf{GitHub}}}.
由生成对抗网络(GANs)和扩散模型生成的内容的日益逼真的特性使得深度伪造检测面临更大的挑战。现有方法通常仅专注于空间域或频率域特征,限制了其在未见操纵情况下的泛化能力。我们提出了谱交叉注意力网络(SpecXNet),这是一种用于稳健深度伪造检测的双向领域架构。核心部分是双域特征耦合器(DDFC),它将特征分解为局部空间分支以捕获纹理级异常和全局光谱分支,该分支利用快速傅里叶变换来模拟周期性不一致。这种双域公式允许SpecXNet共同利用局部细节和全局结构一致性,这对于区分真实图像和操作过的图像至关重要。我们还引入了双傅里叶注意力(DFA)模块,它以内容感知的方式动态融合空间和光谱特征。基于修改后的XceptionNet骨干网,我们将DDFC和DFA模块嵌入到可分离卷积块中。在多个深度伪造基准测试上的广泛实验表明,SpecXNet达到了最先进的准确性,特别是在跨数据集和未见操纵情况下,同时保持了实时可行性。我们的结果突出了统一的空间光谱学习在稳健和可泛化的深度伪造检测中的有效性。为确保可重复性,我们已在GitHub上发布了完整代码。
论文及项目相关链接
PDF ACM MM Accepted
Summary
本文指出GAN和扩散模型生成内容的逼真性使得检测假数据变得更加困难。现有方法常常只关注空间域或频域特征,限制了其对未见操纵的泛化能力。为此,本文提出了Spectral Cross-Attentional Network(SpecXNet),一种用于稳健检测假数据的双域架构。其核心Dual-Domain Feature Coupler(DDFC)将特征分解为局部空间分支以捕捉纹理级异常和全局频谱分支,利用快速傅里叶变换建模周期性不一致。SpecXNet通过结合局部细节和全局结构一致性,实现了对真实和操纵图像的区分。此外,还引入了Dual Fourier Attention(DFA)模块,以内容感知的方式动态融合空间和频谱特征。实验证明,SpecXNet在多个假数据基准测试上实现了最先进的准确性,特别是在跨数据集和未见操纵场景下,同时保持了实时可行性。
Key Takeaways
- GAN和扩散模型生成内容的逼真性使得检测假数据更具挑战性。
- 现有方法主要关注空间域或频域特征,限制了其对未见操纵的泛化能力。
- SpecXNet是一种双域架构,通过结合局部空间分支和全局频谱分支来实现稳健的假数据检测。
- Dual-Domain Feature Coupler(DDFC)用于捕捉纹理级异常和建模周期性不一致。
- Dual Fourier Attention(DFA)模块能够动态融合空间和频谱特征,增强模型的判别能力。
- SpecXNet在多个基准测试上实现了最先进的检测准确性。
点此查看论文截图
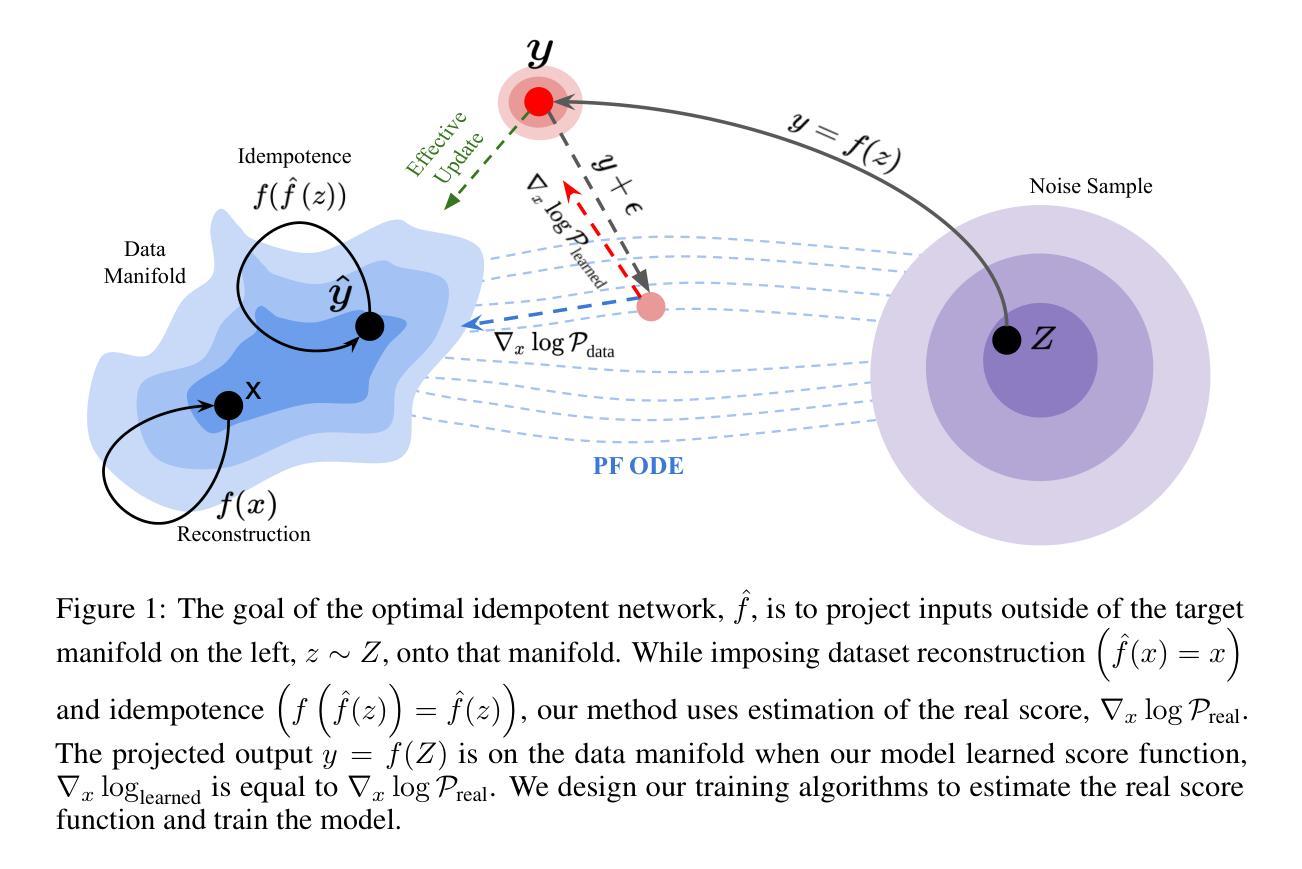
Score-based Idempotent Distillation of Diffusion Models
Authors:Shehtab Zaman, Chengyan Liu, Kenneth Chiu
Idempotent generative networks (IGNs) are a new line of generative models based on idempotent mapping to a target manifold. IGNs support both single-and multi-step generation, allowing for a flexible trade-off between computational cost and sample quality. But similar to Generative Adversarial Networks (GANs), conventional IGNs require adversarial training and are prone to training instabilities and mode collapse. Diffusion and score-based models are popular approaches to generative modeling that iteratively transport samples from one distribution, usually a Gaussian, to a target data distribution. These models have gained popularity due to their stable training dynamics and high-fidelity generation quality. However, this stability and quality come at the cost of high computational cost, as the data must be transported incrementally along the entire trajectory. New sampling methods, model distillation, and consistency models have been developed to reduce the sampling cost and even perform one-shot sampling from diffusion models. In this work, we unite diffusion and IGNs by distilling idempotent models from diffusion model scores, called SIGN. Our proposed method is highly stable and does not require adversarial losses. We provide a theoretical analysis of our proposed score-based training methods and empirically show that IGNs can be effectively distilled from a pre-trained diffusion model, enabling faster inference than iterative score-based models. SIGNs can perform multi-step sampling, allowing users to trade off quality for efficiency. These models operate directly on the source domain; they can project corrupted or alternate distributions back onto the target manifold, enabling zero-shot editing of inputs. We validate our models on multiple image datasets, achieving state-of-the-art results for idempotent models on the CIFAR and CelebA datasets.
自同构生成网络(IGNs)是一种基于自同构映射到目标流形的新生成模型。IGNs支持单步和多步生成,能够在计算成本和样本质量之间实现灵活的权衡。但是与生成对抗网络(GANs)类似,传统的IGNs需要进行对抗训练,容易出现训练不稳定和模式崩溃的问题。扩散和基于分数的模型是生成建模的流行方法,它们通过迭代将样本从一种分布(通常为高斯分布)传输到目标数据分布。这些模型由于其稳定的训练动态和高保真生成质量而备受关注。然而,这种稳定性和质量是以高昂的计算成本为代价的,因为数据必须沿着整个轨迹逐步传输。为了降低采样成本,甚至从扩散模型进行一次采样,已经开发了新的采样方法、模型蒸馏和一致性模型。在这项工作中,我们通过从扩散模型的分数中蒸馏自同构模型,将扩散和IGNs结合起来,称为SIGN。我们提出的方法高度稳定,不需要对抗性损失。我们对所提出的基于分数的训练方法进行了理论分析,并实证表明可以从预训练的扩散模型中有效蒸馏IGNs,实现比迭代基于分数的模型更快的推理速度。SIGNs可以进行多步采样,允许用户根据需要进行质量和效率之间的权衡。这些模型直接在源域上运行;它们可以将损坏或替代的分布投影回目标流形,实现输入的零样本编辑。我们在多个图像数据集上验证了我们的模型,在CIFAR和CelebA数据集上实现了最先进的自同构模型结果。
论文及项目相关链接
Summary
本文介绍了基于幂等映射的生成网络(IGNs)与扩散模型的结合产物——SIGN。SIGN通过蒸馏扩散模型的分数来构建幂等模型,实现了稳定的训练和高质量的生成,同时降低了计算成本。它支持多步采样,可根据用户需求在质量和效率之间进行权衡。此外,SIGN可直接在源域上操作,实现零样本编辑输入。在多个图像数据集上的实验结果表明,SIGN在CIFAR和CelebA数据集上达到了最先进的水平。
Key Takeaways
- IGNs结合扩散模型形成新的生成模型——SIGN。
- SIGN通过蒸馏扩散模型的分数构建幂等模型,实现稳定训练和高质量生成。
- SIGN降低了计算成本,并支持多步采样,实现了质量与效率之间的灵活权衡。
- SIGN可直接在源域上操作,实现零样本编辑输入。
- SIGN实现了稳定的训练动力学,解决了传统GANs的训练不稳定和模式崩溃问题。
- 在CIFAR和CelebA数据集上的实验验证了SIGN的优越性。
点此查看论文截图