⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-30 更新
From Coarse to Fine: Recursive Audio-Visual Semantic Enhancement for Speech Separation
Authors:Ke Xue, Rongfei Fan, Lixin, Dawei Zhao, Chao Zhu, Han Hu
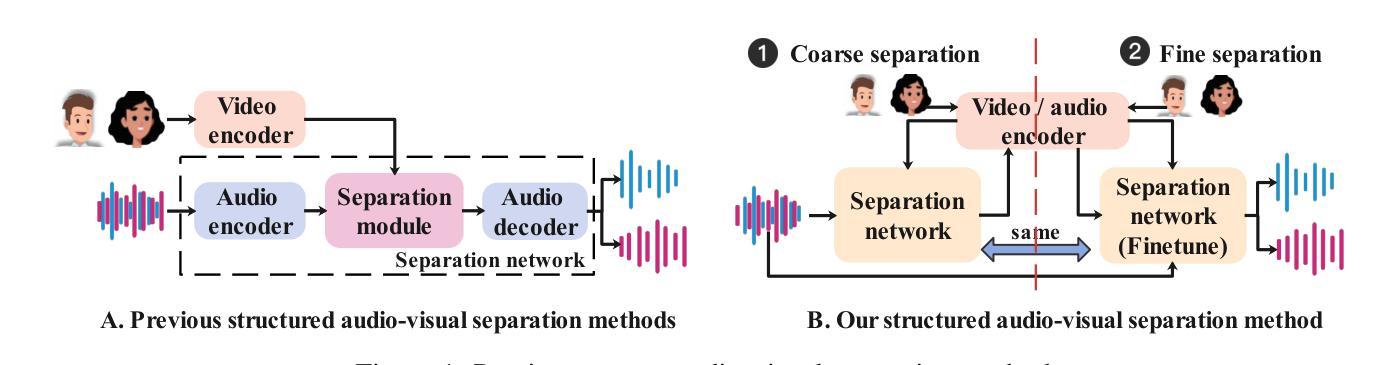
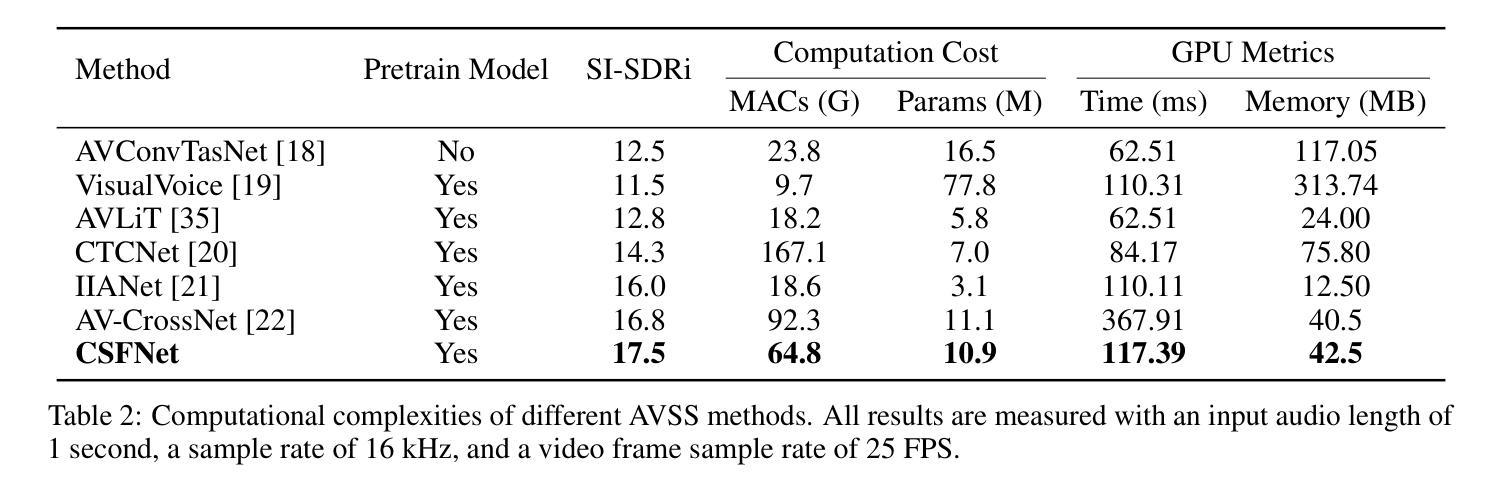
Audio-visual speech separation aims to isolate each speaker’s clean voice from mixtures by leveraging visual cues such as lip movements and facial features. While visual information provides complementary semantic guidance, existing methods often underexploit its potential by relying on static visual representations. In this paper, we propose CSFNet, a Coarse-to-Separate-Fine Network that introduces a recursive semantic enhancement paradigm for more effective separation. CSFNet operates in two stages: (1) Coarse Separation, where a first-pass estimation reconstructs a coarse audio waveform from the mixture and visual input; and (2) Fine Separation, where the coarse audio is fed back into an audio-visual speech recognition (AVSR) model together with the visual stream. This recursive process produces more discriminative semantic representations, which are then used to extract refined audio. To further exploit these semantics, we design a speaker-aware perceptual fusion block to encode speaker identity across modalities, and a multi-range spectro-temporal separation network to capture both local and global time-frequency patterns. Extensive experiments on three benchmark datasets and two noisy datasets show that CSFNet achieves state-of-the-art (SOTA) performance, with substantial coarse-to-fine improvements, validating the necessity and effectiveness of our recursive semantic enhancement framework.
视听语音分离旨在利用视觉线索(如嘴唇动作和面部特征)来从混合声音中隔离每个说话人的清晰声音。虽然视觉信息提供了补充语义指导,但现有方法常常通过依赖静态视觉表示而未能充分发掘其潜力。在本文中,我们提出了CSFNet,这是一个从粗略到分离的精细网络,它引入了一种递归语义增强范式,以实现更有效的分离。CSFNet分为两个阶段:1)粗略分离,第一阶段估计从混合声音和视觉输入重建粗略的音频波形;2)精细分离,将粗略的音频反馈输入到视听语音识别(AVSR)模型以及视觉流中。这种递归过程产生了更具区分性的语义表示,然后用于提取精炼的音频。为了进一步利用这些语义信息,我们设计了一个感知融合块,用于编码跨模态的说话人身份,以及一个多范围的时频分离网络,用于捕捉局部和全局的时间-频率模式。在三个基准数据集和两个噪声数据集的广泛实验表明,CSFNet达到了最先进的性能,在粗略到精细的改进上有显著的提升,验证了我们递归语义增强框架的必要性和有效性。
论文及项目相关链接
Summary
音频视觉语音分离技术利用视觉线索(如嘴唇动作和面部特征)来分离混合语音中的每个发言人的清晰声音。现有方法未能充分利用视觉信息的潜力,本文提出了CSFNet——一个从粗到细分离网络,采用递归语义增强范式来实现更有效的分离。CSFNet分为两个阶段:粗分离阶段,通过初步估算从混合语音和视觉输入重建粗略的音频波形;精细分离阶段,将粗略的音频反馈到音频视觉语音识别(AVSR)模型,与视觉流一起生成更具鉴别力的语义表示,用于提取精细的音频。为了充分利用这些语义信息,设计了一个感知融合模块和多范围谱时间分离网络来捕捉跨模态的局部和全局时间频率模式。实验表明,CSFNet在多个数据集上取得了最佳性能,验证了递归语义增强框架的必要性和有效性。
Key Takeaways
- 音频视觉语音分离技术利用视觉线索(如嘴唇动作和面部特征)进行语音分离。
- 现有方法未充分发掘视觉信息的潜力。
- CSFNet采用递归语义增强范式,分为粗分离和精细分离两个阶段。
- 粗分离阶段通过初步估算从混合语音和视觉输入重建粗略音频波形。
- 精细分离阶段利用递归过程生成更具鉴别力的语义表示。
- 设计了感知融合模块以利用跨模态的语义信息。
点此查看论文截图
Comprehend and Talk: Text to Speech Synthesis via Dual Language Modeling
Authors:Junjie Cao, Yichen Han, Ruonan Zhang, Xiaoyang Hao, Hongxiang Li, Shuaijiang Zhao, Yue Liu, Xiao-Ping Zhng
Existing Large Language Model (LLM) based autoregressive (AR) text-to-speech (TTS) systems, while achieving state-of-the-art quality, still face critical challenges. The foundation of this LLM-based paradigm is the discretization of the continuous speech waveform into a sequence of discrete tokens by neural audio codec. However, single codebook modeling is well suited to text LLMs, but suffers from significant information loss; hierarchical acoustic tokens, typically generated via Residual Vector Quantization (RVQ), often lack explicit semantic structure, placing a heavy learning burden on the model. Furthermore, the autoregressive process is inherently susceptible to error accumulation, which can degrade generation stability. To address these limitations, we propose CaT-TTS, a novel framework for robust and semantically-grounded zero-shot synthesis. First, we introduce S3Codec, a split RVQ codec that injects explicit linguistic features into its primary codebook via semantic distillation from a state-of-the-art ASR model, providing a structured representation that simplifies the learning task. Second, we propose an Understand-then-Generate'' dual-Transformer architecture that decouples comprehension from rendering. An initial Understanding’’ Transformer models the cross-modal relationship between text and the audio’s semantic tokens to form a high-level utterance plan. A subsequent ``Generation’’ Transformer then executes this plan, autoregressively synthesizing hierarchical acoustic tokens. Finally, to enhance generation stability, we introduce Masked Audio Parallel Inference (MAPI), a nearly parameter-free inference strategy that dynamically guides the decoding process to mitigate local errors.
现有基于大型语言模型(LLM)的自动回归(AR)文本到语音(TTS)系统虽然达到了最先进的品质,但仍面临重大挑战。基于LLM的范式的基础是将连续的语音波形离散化为一系列离散令牌,通过神经音频编解码器实现。然而,单一编码本建模适合文本LLM,但存在信息损失较大的问题;通过残差向量量化(RVQ)生成的分层声学令牌通常缺乏明确的语义结构,给模型带来了沉重的学习负担。此外,自动回归过程本质上容易受到误差累积的影响,可能会降低生成稳定性。为了克服这些局限性,我们提出了CaT-TTS,这是一个用于稳健和语义化零拍合成的全新框架。首先,我们引入了S3Codec,这是一种分裂RVQ编解码器,它通过来自最新语音识别模型的语义蒸馏将其主要编解码器中注入明确的语言特征,提供结构化表示,从而简化学习任务。其次,我们提出了一种“理解然后生成”的双Transformer架构,将理解与渲染解耦。最初的“理解”Transformer对文本和音频语义令牌之间的跨模态关系进行建模,以形成高级话语计划。随后的“生成”Transformer则执行此计划,自动回归地合成分层声学令牌。最后,为了提高生成的稳定性,我们引入了掩码音频并行推理(MAPI),这是一种几乎无需参数的推理策略,可以动态指导解码过程,减少局部错误。
论文及项目相关链接
PDF conference paper about TTS
摘要
基于现有大型语言模型(LLM)的自动回归(AR)文本到语音(TTS)系统虽然达到了最先进的水平,但仍面临关键挑战。本文提出了一种新型的TTS框架CaT-TTS,以实现稳健且语义化的零样本合成。通过引入S3Codec编码器和“理解后生成”双Transformer架构等技术手段,解决了传统LLM模型在信息损失和错误累积等方面的问题。同时,还引入了Masked Audio Parallel Inference(MAPI)策略以提高生成稳定性。
关键见解
- 基于大型语言模型的TTS系统在文本到语音转换中仍面临挑战,特别是在信息损失和错误累积方面。
- S3Codec编码器通过语义蒸馏技术注入显式语言特征,提供了结构化的表示以简化学习任务。
- “理解后生成”双Transformer架构将理解和渲染过程解耦,形成高级话语计划并执行。
- CaT-TTS框架通过引入S3Codec编码器和双Transformer架构,实现了稳健且语义化的零样本合成。
- Masked Audio Parallel Inference(MAPI)策略能动态引导解码过程,减少局部错误,提高生成稳定性。
- 分裂RVQ编码器的使用有效解决了单一编码书在信息表达和灵活性方面的问题。
- 通过结合以上技术,CaT-TTS框架有望提高TTS系统的性能并克服现有挑战。
点此查看论文截图
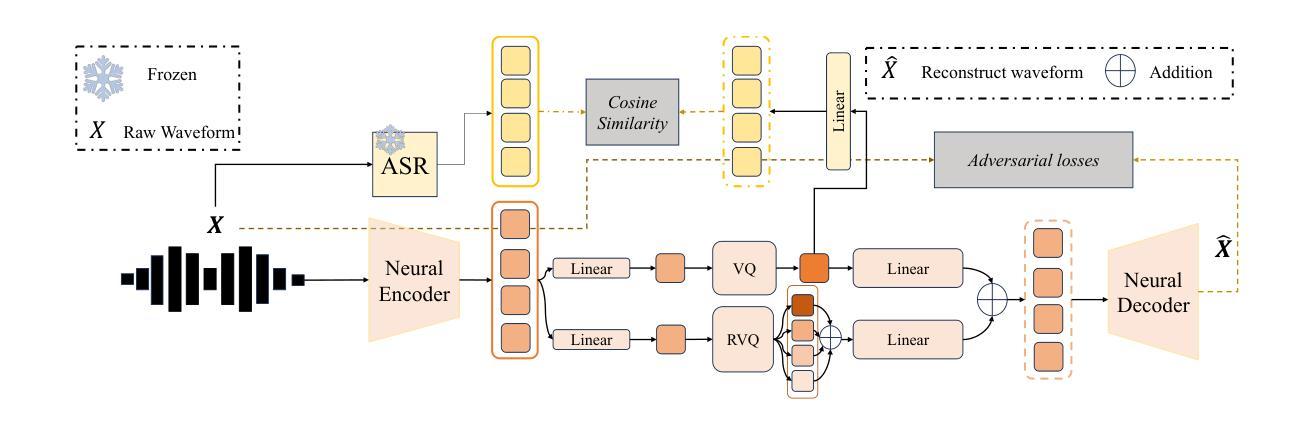
Decoding Deception: Understanding Automatic Speech Recognition Vulnerabilities in Evasion and Poisoning Attacks
Authors:Aravindhan G, Yuvaraj Govindarajulu, Parin Shah
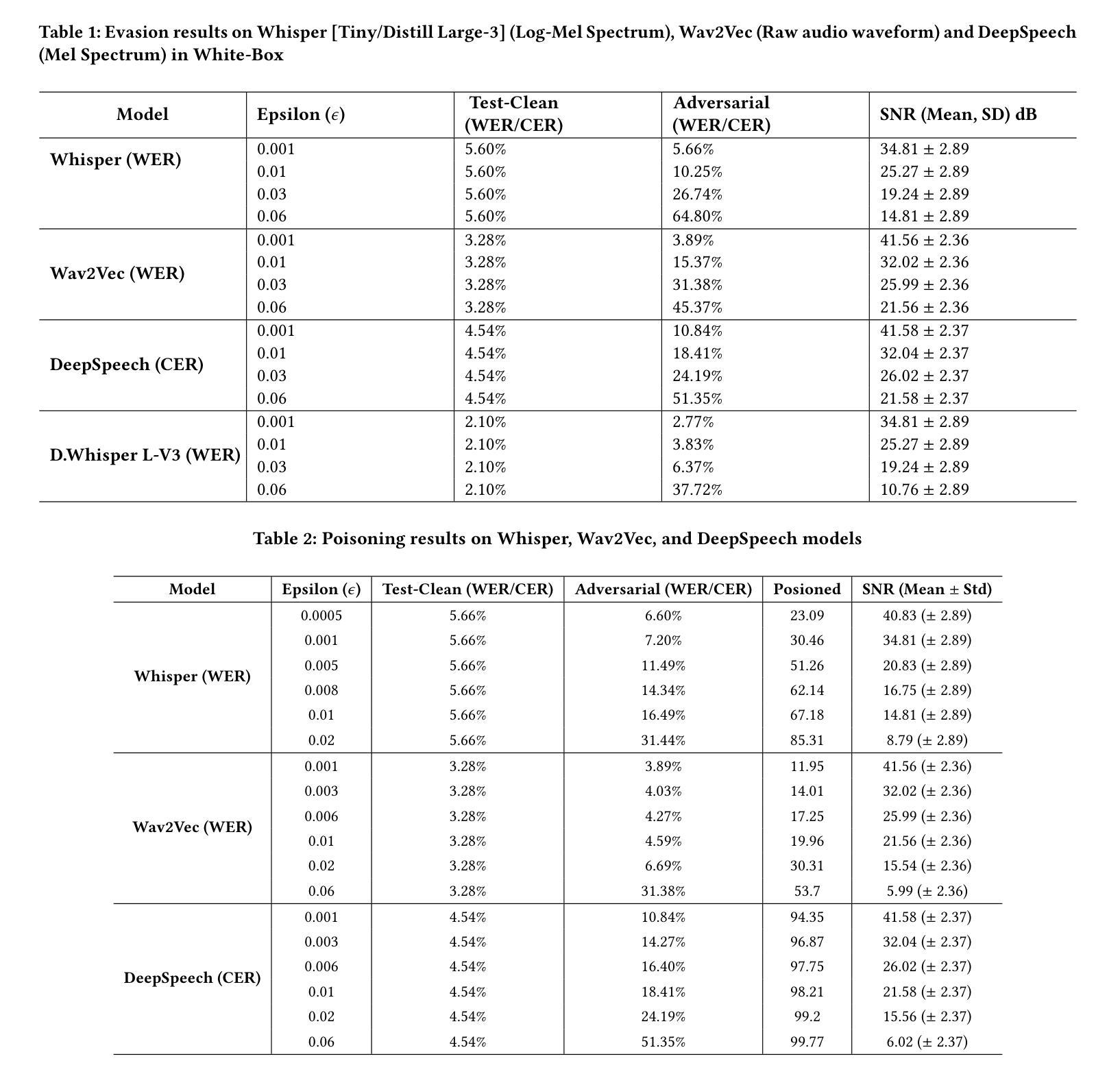
Recent studies have demonstrated the vulnerability of Automatic Speech Recognition systems to adversarial examples, which can deceive these systems into misinterpreting input speech commands. While previous research has primarily focused on white-box attacks with constrained optimizations, and transferability based black-box attacks against commercial Automatic Speech Recognition devices, this paper explores cost efficient white-box attack and non transferability black-box adversarial attacks on Automatic Speech Recognition systems, drawing insights from approaches such as Fast Gradient Sign Method and Zeroth-Order Optimization. Further, the novelty of the paper includes how poisoning attack can degrade the performances of state-of-the-art models leading to misinterpretation of audio signals. Through experimentation and analysis, we illustrate how hybrid models can generate subtle yet impactful adversarial examples with very little perturbation having Signal Noise Ratio of 35dB that can be generated within a minute. These vulnerabilities of state-of-the-art open source model have practical security implications, and emphasize the need for adversarial security.
最近的研究表明,自动语音识别系统容易受到对抗样本的威胁,这些对抗样本可以欺骗系统误解输入的语音命令。虽然之前的研究主要集中在具有约束优化的白盒攻击和基于迁移性的黑盒攻击商业自动语音识别设备,但本文探讨了成本效益高的白盒攻击和非迁移性的黑盒对抗攻击自动语音识别系统,从快速梯度符号法和零阶优化等方法中汲取灵感。此外,本文的新颖之处在于,如何使毒物攻击能降低最先进的模型的性能,导致对音频信号的误解。通过试验和分析,我们说明了混合模型如何生成细微但影响重大的对抗样本,这些样本的扰动非常小,信号噪声比为35分贝,且可在一分钟内生成。这些最新开源模型的漏洞对实际安全有重大影响,并强调了对抗性安全的需求。
论文及项目相关链接
Summary:近期研究表明,自动语音识别系统易受对抗样本攻击,这些对抗样本能误导系统误解语音指令。本文探讨了成本效益高的白盒攻击和非迁移性黑盒对抗攻击,并从快速梯度符号法和零阶优化等方法中汲取灵感。此外,本文还介绍了中毒攻击如何导致先进模型性能下降,误解音频信号。实验和分析表明,混合模型可以生成具有很小扰动但对自动语音识别系统影响显著的对抗样本,信噪比高达35分贝,生成时间仅需一分钟。这些先进开源模型的漏洞具有实际的安全影响,并强调对抗性安全的重要性。
Key Takeaways:
- 自动语音识别系统易受对抗样本攻击,可能误导系统误解语音指令。
- 本文探讨了成本效益高的白盒攻击和非迁移性黑盒对抗攻击。
- 中毒攻击可导致先进模型性能下降,甚至误解音频信号。
- 混合模型能生成具有微小扰动的对抗样本,但对系统影响显著。
- 信噪比高达35分贝的对抗样本可在一分钟内生成。
- 先进开源模型的漏洞具有实际的安全影响。
点此查看论文截图

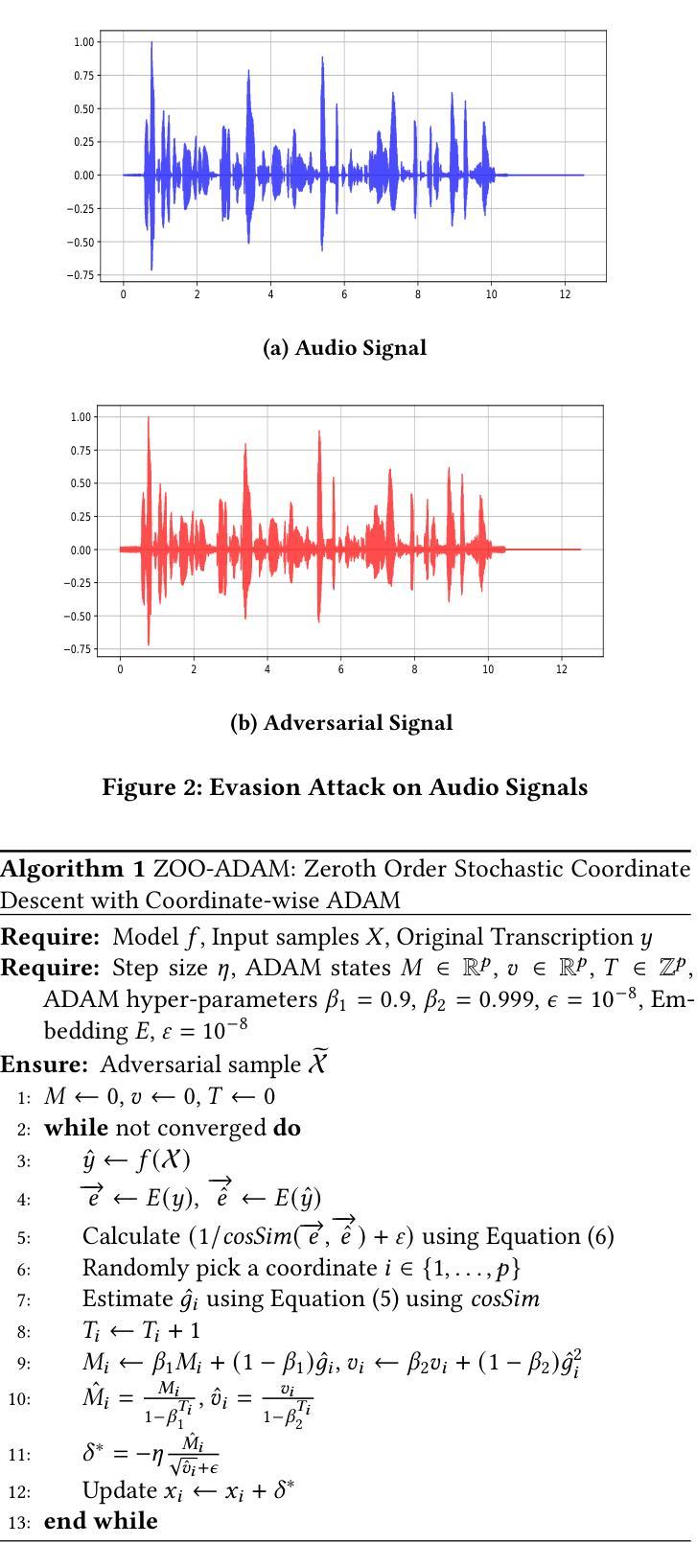

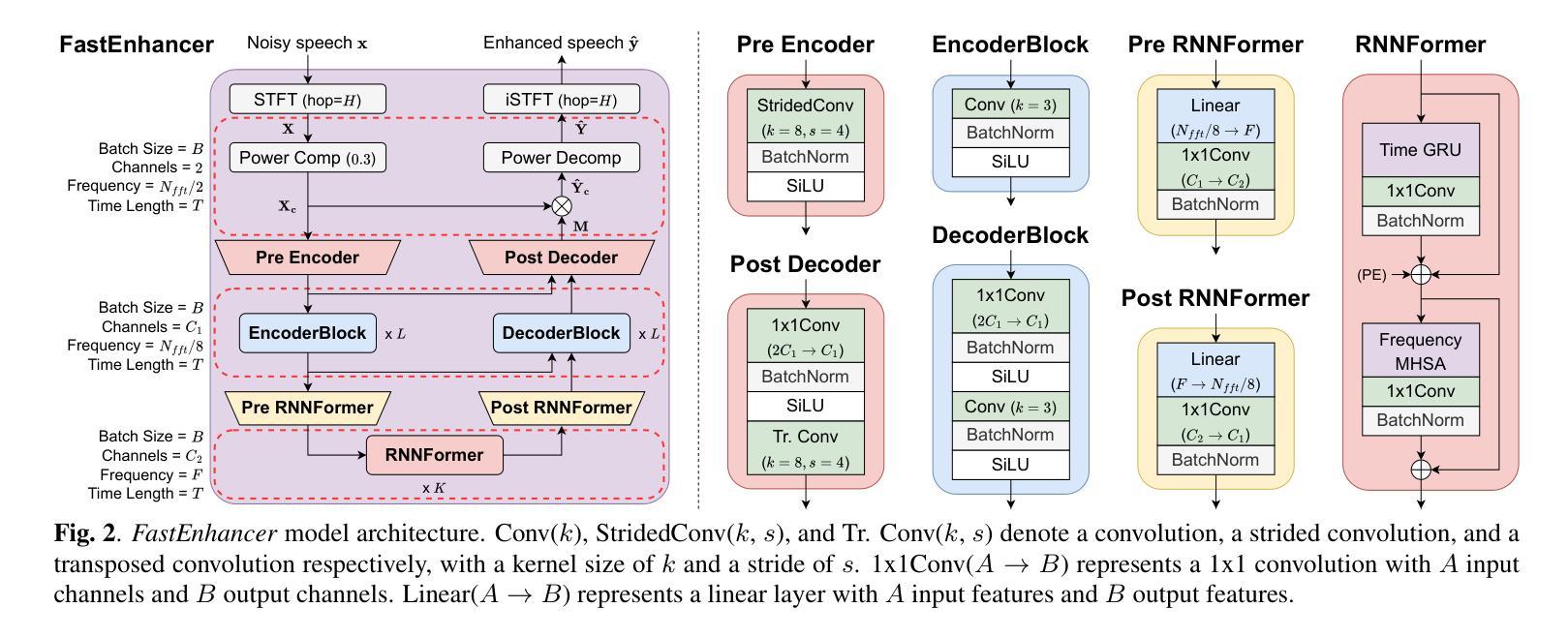
FastEnhancer: Speed-Optimized Streaming Neural Speech Enhancement
Authors:Sunghwan Ahn, Jinmo Han, Beom Jun Woo, Nam Soo Kim
Streaming speech enhancement is a crucial task for real-time applications such as online meetings, smart home appliances, and hearing aids. Deep neural network-based approaches achieve exceptional performance while demanding substantial computational resources. Although recent neural speech enhancement models have succeeded in reducing the number of parameters and multiply-accumulate operations, their sophisticated architectures often introduce significant processing latency on common hardware. In this work, we propose FastEnhancer, a streaming neural speech enhancement model designed explicitly to minimize real-world latency. It features a simple encoder-decoder structure with efficient RNNFormer blocks. Evaluations on various objective metrics show that FastEnhancer achieves state-of-the-art speech quality and intelligibility while simultaneously demonstrating the fastest processing speed on a single CPU thread. Code and pre-trained weights are publicly available (https://github.com/aask1357/fastenhancer).
流式语音增强是实时应用(如在线会议、智能家电和助听器)中的一项关键任务。基于深度神经网络的方法在性能上取得了卓越的表现,但需要大量的计算资源。尽管最近的神经网络语音增强模型成功减少了参数和乘积累操作的数量,但它们复杂的架构通常在常见硬件上引入显著的处理延迟。在这项工作中,我们提出了FastEnhancer,这是一个专门设计用于最小化现实世界延迟的流式神经网络语音增强模型。它采用简单的编码器-解码器结构,并配备了高效的RNNFormer块。在多种客观指标上的评估表明,FastEnhancer在语音质量和清晰度方面达到了最新水平,同时在单个CPU线程上展示了最快的处理速度。代码和预训练权重可公开获取(https://github.com/aask1357/fastenhancer)。
论文及项目相关链接
Summary
实时语音增强对于在线会议、智能家电和助听器等实时应用至关重要。基于深度神经网络的方法取得了卓越的性能,但需要大量的计算资源。FastEnhancer是一个专为减少实际延迟而设计的流式神经语音增强模型,具有简单的编码器-解码器结构,采用高效的RNNFormer块。它在单线程CPU上实现了最快的处理速度,同时达到了最先进的语音质量和清晰度。代码和预训练权重已公开可用。
Key Takeaways
- 实时语音增强对于在线会议、智能家电和助听器等应用至关重要。
- 基于深度神经网络的方法在语音增强方面表现出卓越性能。
- FastEnhancer模型专为减少实际延迟而设计,适用于流式处理。
- FastEnhancer具有简单的编码器-解码器结构,采用高效的RNNFormer块。
- FastEnhancer在单线程CPU上实现了最快的处理速度。
- FastEnhancer达到了最先进的语音质量和清晰度。
点此查看论文截图
Thinking with Sound: Audio Chain-of-Thought Enables Multimodal Reasoning in Large Audio-Language Models
Authors:Zhen Xiong, Yujun Cai, Zhecheng Li, Junsong Yuan, Yiwei Wang
Recent Large Audio-Language Models (LALMs) have shown strong performance on various audio understanding tasks such as speech translation and Audio Q&A. However, they exhibit significant limitations on challenging audio reasoning tasks in complex acoustic scenarios. These situations would greatly benefit from the use of acoustic tools like noise suppression, source separation, and precise temporal alignment, but current LALMs lack access to such tools. To address this limitation, we introduce Thinking-with-Sound (TwS), a framework that equips LALMs with Audio CoT by combining linguistic reasoning with on-the-fly audio-domain analysis. Unlike existing approaches that treat audio as static input, TwS enables models to actively think with audio signals, performing numerical analysis and digital manipulation through multimodal reasoning. To evaluate this approach, we construct MELD-Hard1k, a new robustness benchmark created by introducing various acoustic perturbations. Experiments reveal that state-of-the-art LALMs suffer dramatic performance degradation on MELD-Hard1k, with accuracy dropping by more than $50%$ compared to clean audio. TwS achieves substantial improvements in robustness, demonstrating both effectiveness and scalability: small models gain $24.73%$ absolute accuracy, with improvements scaling consistently up to $36.61%$ for larger models. Our findings demonstrate that Audio CoT can significantly enhance robustness without retraining, opening new directions for developing more robust audio understanding systems.
最新的大型音频语言模型(LALMs)在各种音频理解任务(如语音识别和音频问答)上表现出了强大的性能。然而,它们在复杂的声学场景中的挑战性音频推理任务上存在显著局限性。这些情况将大大受益于使用噪声抑制、音源分离和精确时间对齐等声学工具,但当前的LALMs无法访问这些工具。为了解决这一局限性,我们引入了Thinking-with-Sound(TwS)框架,它通过结合语言推理和即时音频域分析,为LALMs配备音频认知。不同于将音频视为静态输入的方法,TwS使模型能够主动与音频信号进行交互思考,通过多模态推理进行数值分析和数字操作。为了评估这种方法,我们构建了MELD-Hard1k,这是一个新的鲁棒性基准测试,通过引入各种声学扰动来创建。实验表明,最先进的LALMs在MELD-Hard1k上遭受了显著的性能下降,与干净音频相比,准确率下降了超过50%。TwS在鲁棒性方面取得了实质性改进,证明了其有效性和可扩展性:小型模型的准确率提高了24.73%,大型模型的准确率则稳定提高至36.61%。我们的研究结果表明,音频认知可以在无需重新训练的情况下显著提高鲁棒性,为开发更稳健的音频理解系统打开了新的方向。
论文及项目相关链接
摘要
最近的大型音频语言模型(LALM)在多种音频理解任务中表现出强大的性能,如语音识别和音频问答。然而,它们在面对复杂声学场景中的挑战音频推理任务时存在明显局限。这些情况将极大受益于使用噪声抑制、声源分离和精确时间对齐等声学工具,但当前的LALM无法访问这些工具。为解决此局限,我们提出Thinking-with-Sound(TwS)框架,通过结合语言推理和即时音频域分析,为LALM配备音频认知推理能力。不同于将音频视为静态输入现有方法,TwS使模型能够主动与音频信号思考,执行数值分析和数字操作通过多模态推理。为评估此方法,我们构建了MELD-Hard1k新鲁棒性基准测试,通过引入各种声学扰动。实验表明,最先进的LALM在MELD-Hard1k上表现剧烈下降,与干净音频相比,准确性下降超过50%。TwS在鲁棒性方面取得实质性改进,证明了其有效性和可扩展性:小型模型获得24.73%的绝对准确性提升,且改进在大型模型中一直扩大到36.61%。我们的研究结果表明,音频认知推理可显著提高鲁棒性而无需重新训练,为开发更稳健的音频理解系统打开了新的方向。
关键见解
- 大型音频语言模型(LALM)在音频理解任务上表现出强大的性能,但在复杂声学场景中的音频推理任务上存在局限。
- 现有模型无法充分利用噪声抑制、声源分离和精确时间对齐等声学工具。
- Thinking-with-Sound(TwS)框架结合了语言推理和即时音频域分析,使模型能够主动与音频信号互动。
- TwS通过多模态推理执行数值分析和数字操作。
- MELD-Hard1k基准测试揭示了现有模型在面临声学扰动时的性能局限。
- TwS显著提高了模型的鲁棒性,无需重新训练。
点此查看论文截图

Align2Speak: Improving TTS for Low Resource Languages via ASR-Guided Online Preference Optimization
Authors:Shehzeen Hussain, Paarth Neekhara, Xuesong Yang, Edresson Casanova, Subhankar Ghosh, Roy Fejgin, Ryan Langman, Mikyas Desta, Leili Tavabi, Jason Li
Developing high-quality text-to-speech (TTS) systems for low-resource languages is challenging due to the scarcity of paired text and speech data. In contrast, automatic speech recognition (ASR) models for such languages are often more accessible, owing to large-scale multilingual pre-training efforts. We propose a framework based on Group Relative Policy Optimization (GRPO) to adapt an autoregressive, multilingual TTS model to new languages. Our method first establishes a language-agnostic foundation for TTS synthesis by training a multilingual baseline with International Phonetic Alphabet (IPA) tokens. Next, we fine-tune this model on limited paired data of the new languages to capture the target language’s prosodic features. Finally, we apply GRPO to optimize the model using only unpaired text and speaker prompts, guided by a multi-objective reward from pretrained ASR, speaker verification, and audio quality estimation models. Experiments demonstrate that this pipeline produces intelligible and speaker-consistent speech in low-resource languages, substantially outperforming fine-tuning alone. Furthermore, our GRPO-based framework also improves TTS performance in high-resource languages, surpassing offline alignment methods such as Direct Preference Optimization (DPO) yielding superior intelligibility, speaker similarity, and audio quality.
针对低资源语言的优质文本到语音(TTS)系统的发展面临挑战,因为配对文本和语音数据的稀缺。相比之下,由于大规模的多语言预训练努力,此类语言的自动语音识别(ASR)模型通常更容易获得。我们提出了一种基于组相对策略优化(GRPO)的框架,以适应新的多语言自回归TTS模型。我们的方法首先通过与国际音标(IPA)符号一起训练多语言基线,为TTS合成建立一种语言无关的基础。接下来,我们在新语言的有限配对数据上微调此模型,以捕获目标语言的韵律特征。最后,我们应用GRPO仅使用未配对的文本和演讲提示来优化模型,通过预训练的ASR、说话人验证和音频质量估计模型的多目标奖励进行引导。实验表明,该管道在资源贫乏的语言中产生可理解的、与说话人一致的语音,明显优于单纯的微调。此外,我们基于GRPO的框架还提高了高资源语言的TTS性能,超越了直接偏好优化(DPO)等离线对齐方法,产生了更好的可理解性、说话人相似性和音频质量。
论文及项目相关链接
PDF Submitted to ICASSP 2026
Summary
本文提出一种基于Group Relative Policy Optimization (GRPO)的新框架,用于适应低资源语言的文本转语音(TTS)系统。该框架首先建立一个多语言基线模型,以国际音标(IPA)令牌进行训练,形成语言无关的基础。然后,在新语言的有限配对数据上微调模型,捕捉目标语言的韵律特征。最后,利用预训练的语音识别、说话人验证和音频质量估计模型的多元目标奖励来优化模型。实验证明,该管道在低资源语言中生成了可理解的、具有说话人特色的语音,明显优于仅进行微调的方法。此外,基于GRPO的框架在高资源语言中也能提高TTS性能,超越直接偏好优化(DPO)等离线对齐方法,带来更高的可理解性、说话人相似性和音频质量。
Key Takeaways
- 提出了一种基于Group Relative Policy Optimization (GRPO)的框架,用于低资源语言的文本转语音(TTS)系统。
- 通过建立多语言基线模型,并利用国际音标(IPA)令牌进行训练,形成语言无关的基础。
- 利用有限的配对数据对模型进行微调,捕捉目标语言的韵律特征。
- 利用预训练的语音识别(ASR)模型、说话人验证和音频质量估计模型作为多元目标奖励来优化模型。
- 实验证明该框架在低资源语言中表现优越,能生成可理解的、具有说话人特色的语音。
- 该框架在高资源语言中也能提高TTS性能,超越了离线对齐方法如Direct Preference Optimization (DPO)。
点此查看论文截图
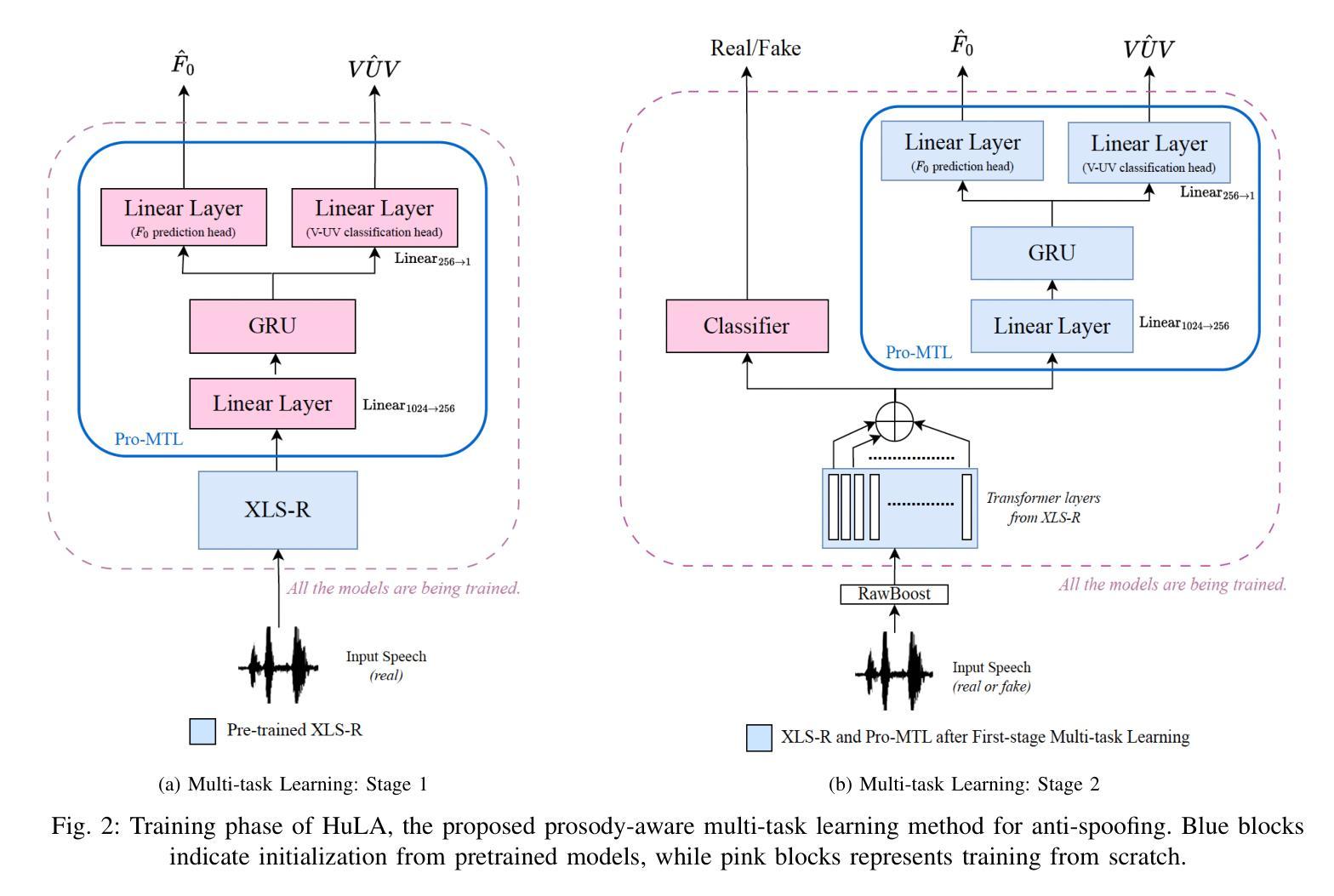
HuLA: Prosody-Aware Anti-Spoofing with Multi-Task Learning for Expressive and Emotional Synthetic Speech
Authors:Aurosweta Mahapatra, Ismail Rasim Ulgen, Berrak Sisman
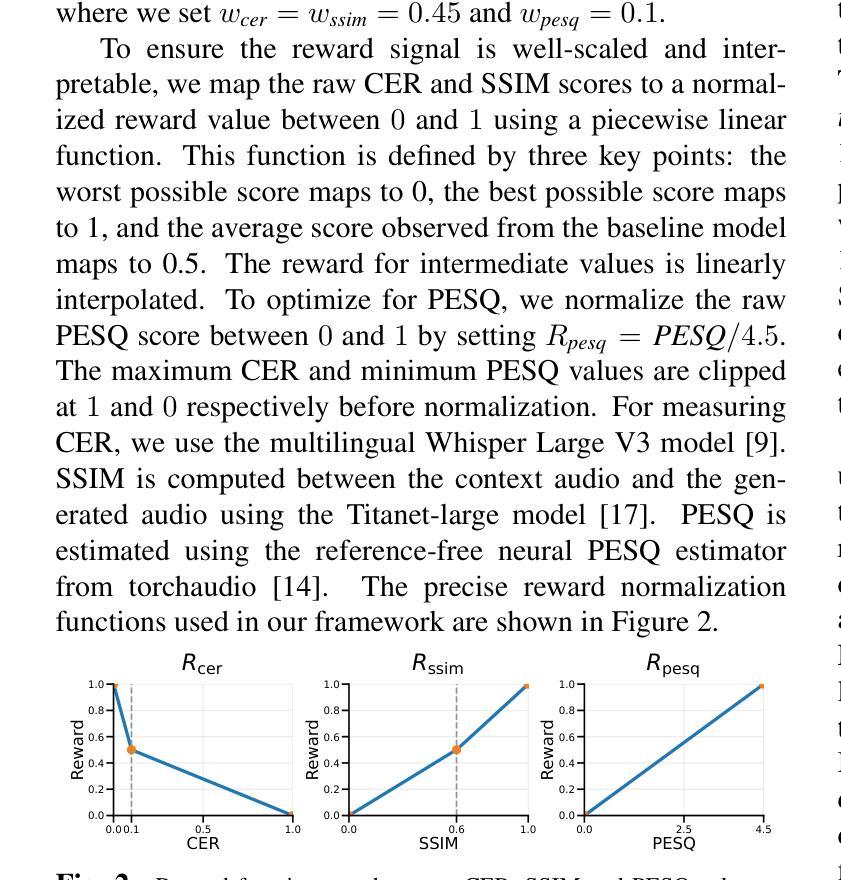
Current anti-spoofing systems remain vulnerable to expressive and emotional synthetic speech, since they rarely leverage prosody as a discriminative cue. Prosody is central to human expressiveness and emotion, and humans instinctively use prosodic cues such as F0 patterns and voiced/unvoiced structure to distinguish natural from synthetic speech. In this paper, we propose HuLA, a two-stage prosody-aware multi-task learning framework for spoof detection. In Stage 1, a self-supervised learning (SSL) backbone is trained on real speech with auxiliary tasks of F0 prediction and voiced/unvoiced classification, enhancing its ability to capture natural prosodic variation similar to human perceptual learning. In Stage 2, the model is jointly optimized for spoof detection and prosody tasks on both real and synthetic data, leveraging prosodic awareness to detect mismatches between natural and expressive synthetic speech. Experiments show that HuLA consistently outperforms strong baselines on challenging out-of-domain dataset, including expressive, emotional, and cross-lingual attacks. These results demonstrate that explicit prosodic supervision, combined with SSL embeddings, substantially improves robustness against advanced synthetic speech attacks.
当前的反欺骗系统在面对表达性和情感性合成语音时仍然容易受到影响,因为它们很少利用韵律作为判别线索。韵律在人类表达和情感中起着核心作用,人类本能地使用诸如F0模式和有声无声结构等韵律线索来区分自然语音和合成语音。在本文中,我们提出了HuLA,这是一个两阶段的韵律感知多任务学习框架,用于欺骗检测。在第一阶段,通过真实语音数据训练自监督学习(SSL)主干网络,并辅以F0预测和有声无声分类的辅助任务,增强了其捕捉自然韵律变化的能力,类似于人类感知学习。在第二阶段,模型对真实和合成数据上的欺骗检测和韵律任务进行联合优化,利用韵律感知来检测自然语音和表达性合成语音之间的不匹配。实验表明,在包括表达性、情感性和跨语言攻击在内的具有挑战性的数据集上,HuLA始终优于强大的基线系统。这些结果证明,明确的韵律监督与SSL嵌入相结合,大大提高了对高级合成语音攻击的鲁棒性。
论文及项目相关链接
PDF Submitted to IEEE Transactions on Affective Computing
Summary
该文本提出了一种名为HuLA的两阶段韵律感知多任务学习框架,用于抗欺骗检测。该框架通过自我监督学习(SSL)训练真实语音的模型,并辅以F0预测和声音分类任务,增强了捕捉自然韵律变化的能力。随后,该模型在真实和合成数据上联合优化欺骗检测和韵律任务,利用韵律感知来检测自然和合成语音之间的差异。实验表明,HuLA在具有挑战性的跨域数据集上持续优于基线模型,证明韵律感知对于识别情感表达和跨语言攻击的有效性。此结果表明,通过结合韵律感知监督和SSL嵌入,可显著提高模型的稳健性。
Key Takeaways
- 当前反欺骗系统容易受到表达和情感合成语音的攻击,因为它们很少利用韵律作为辨别线索。
- 韵律在人类表达和情感中起关键作用,人类本能地使用韵律线索来区分自然和合成语音。
- HuLA是一个两阶段的韵律感知多任务学习框架,旨在提高欺骗检测能力。
- 第一阶段通过自我监督学习(SSL)训练模型,辅以F0预测和声音分类任务,增强捕捉自然韵律变化的能力。
- 第二阶段在真实和合成数据上联合优化欺骗检测和韵律任务,利用韵律感知来检测自然和合成语音之间的差异。
- 实验证明HuLA在挑战性数据集上表现优异,特别是在处理情感表达和跨语言攻击时。
点此查看论文截图
Shortcut Flow Matching for Speech Enhancement: Step-Invariant flows via single stage training
Authors:Naisong Zhou, Saisamarth Rajesh Phaye, Milos Cernak, Tijana Stojkovic, Andy Pearce, Andrea Cavallaro, Andy Harper
Diffusion-based generative models have achieved state-of-the-art performance for perceptual quality in speech enhancement (SE). However, their iterative nature requires numerous Neural Function Evaluations (NFEs), posing a challenge for real-time applications. On the contrary, flow matching offers a more efficient alternative by learning a direct vector field, enabling high-quality synthesis in just a few steps using deterministic ordinary differential equation~(ODE) solvers. We thus introduce Shortcut Flow Matching for Speech Enhancement (SFMSE), a novel approach that trains a single, step-invariant model. By conditioning the velocity field on the target time step during a one-stage training process, SFMSE can perform single, few, or multi-step denoising without any architectural changes or fine-tuning. Our results demonstrate that a single-step SFMSE inference achieves a real-time factor (RTF) of 0.013 on a consumer GPU while delivering perceptual quality comparable to a strong diffusion baseline requiring 60 NFEs. This work also provides an empirical analysis of the role of stochasticity in training and inference, bridging the gap between high-quality generative SE and low-latency constraints.
基于扩散的生成模型在语音增强(SE)的感知质量方面已经达到了最先进的性能。然而,它们的迭代性质需要大量的神经功能评估(NFE),这为其在实时应用方面带来了挑战。相比之下,流匹配提供了一种更高效的替代方案,它通过学习一个直接的向量场,使用确定性常微分方程(ODE)求解器,能够在几步内实现高质量合成。因此,我们引入了语音增强的快捷方式流匹配(SFMSE),这是一种新的方法,训练一个单一、步骤不变型的模型。通过在单阶段训练过程中以目标时间步长作为条件,SFMSE可以执行单步、少步或多步去噪,无需进行任何结构更改或微调。我们的结果表明,单步SFMSE推理在消费者GPU上实现了实时因子(RTF)为0.013,同时提供了与需要60个NFE的强大扩散基准相当的可感知质量。这项工作还对训练和推理过程中随机性的作用进行了实证分析,缩小了高质量生成SE和低延迟约束之间的差距。
论文及项目相关链接
PDF 5 pages, 2 figures, submitted to ICASSP2026
Summary
本文介绍了针对语音增强任务的新型方法——Shortcut Flow Matching for Speech Enhancement(SFMSE)。该法利用直接矢量场学习,能在少量步骤内实现高质量语音合成,且通过普通微分方程求解器实现。SFMSE训练单一、步骤不变的模型,能在单步、少步或多步去噪中表现优异,无需架构调整或微调。在消费者GPU上,单步SFMSE推理实现实时因子(RTF)为0.013,感知质量与需要60次NFE的扩散基线相当。同时,本文也进行了关于训练中随机性作用的实证分析,缩小了高质量生成式SE和低延迟约束之间的差距。
Key Takeaways
- Diffusion-based generative models在语音增强任务中表现卓越,但迭代性质需要大量Neural Function Evaluations (NFEs),不利于实时应用。
- Flow matching作为一种更高效的替代方法,通过直接学习矢量场实现高质量合成,使用确定性常微分方程求解器,仅需要少量步骤。
- Shortcut Flow Matching for Speech Enhancement (SFMSE)是新型方法,训练单一、步骤不变的模型,可在不同去噪步骤中表现优异,无需额外调整。
- 单步SFMSE推理实现实时因子(RTF)为0.013,感知质量与需要多次迭代的扩散模型相当。
- SFMSE桥接了高质量生成式语音增强和低延迟约束之间的差距。
- 实证分析表明训练中随机性作用对模型性能有影响。
点此查看论文截图

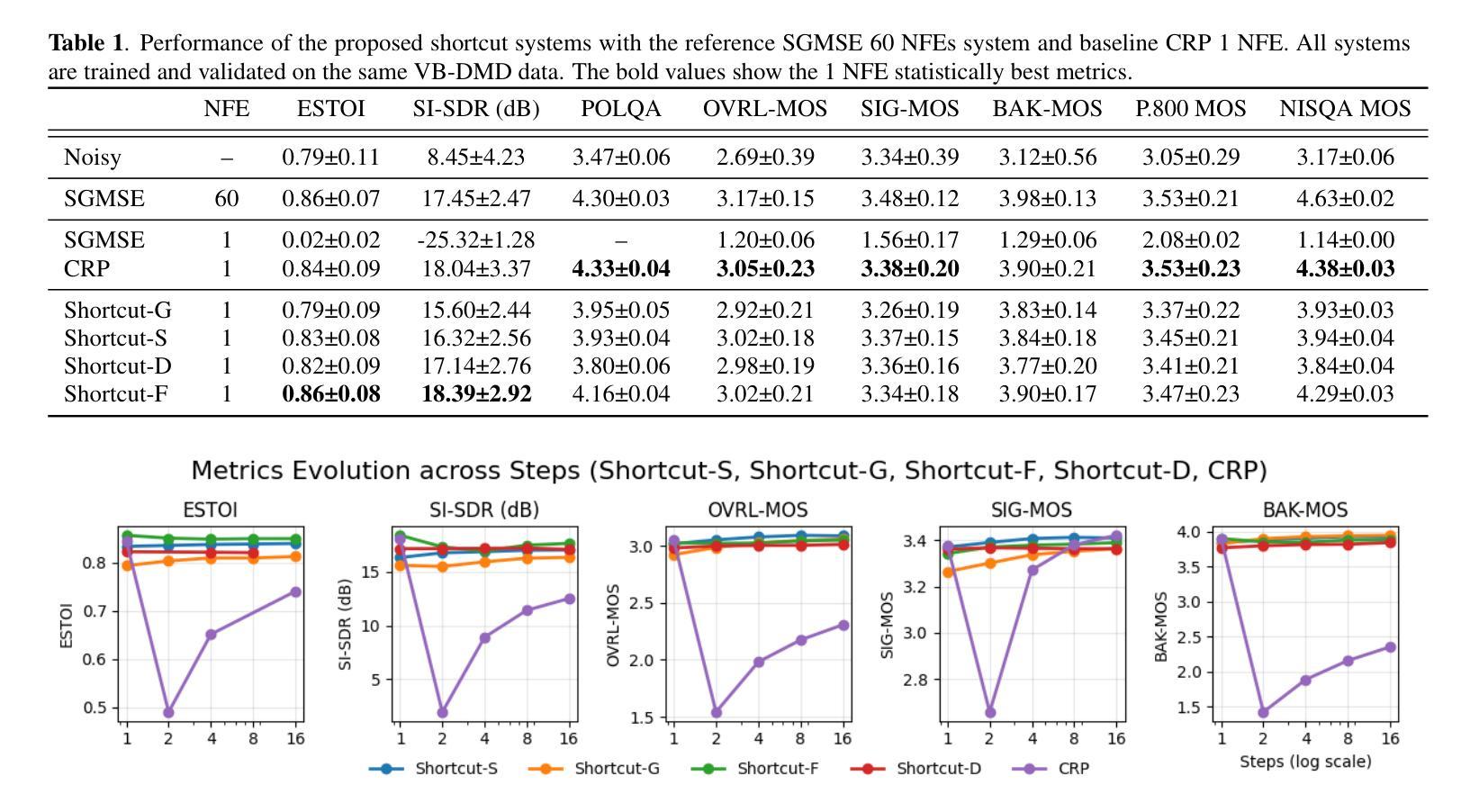
MMedFD: A Real-world Healthcare Benchmark for Multi-turn Full-Duplex Automatic Speech Recognition
Authors:Hongzhao Chen, XiaoYang Wang, Jing Lan, Hexiao Ding, Yufeng Jiang, MingHui Yang, DanHui Xu, Jun Luo, Nga-Chun Ng, Gerald W. Y. Cheng, Yunlin Mao, Jung Sun Yoo
Automatic speech recognition (ASR) in clinical dialogue demands robustness to full-duplex interaction, speaker overlap, and low-latency constraints, yet open benchmarks remain scarce. We present MMedFD, the first real-world Chinese healthcare ASR corpus designed for multi-turn, full-duplex settings. Captured from a deployed AI assistant, the dataset comprises 5,805 annotated sessions with synchronized user and mixed-channel views, RTTM/CTM timing, and role labels. We introduce a model-agnostic pipeline for streaming segmentation, speaker attribution, and dialogue memory, and fine-tune Whisper-small on role-concatenated audio for long-context recognition. ASR evaluation includes WER, CER, and HC-WER, which measures concept-level accuracy across healthcare settings. LLM-generated responses are assessed using rubric-based and pairwise protocols. MMedFD establishes a reproducible framework for benchmarking streaming ASR and end-to-end duplex agents in healthcare deployment. The dataset and related resources are publicly available at https://github.com/Kinetics-JOJO/MMedFD
自动语音识别(ASR)在临床对话中需要应对全双工交互、说话人重叠和低延迟约束的稳健性挑战,然而可用的开放基准测试仍然稀缺。我们推出了MMedFD,这是首个为多轮、全双工环境设计的现实世界中文医疗ASR语料库。该数据集来自部署的AI助手,包含5805个已标注会话,具备同步的用户和混合通道视图、RTTM/CTM时间以及角色标签。我们引入了一个模型无关的管道,用于流式分割、说话人归属和对话记忆,并对用于长上下文识别的角色串联音频进行微调Whisper-small。ASR评估包括词错误率(WER)、字符错误率(CER)和医疗保健环境中的概念级准确率的HC-WER。通过基于规则和成对协议评估大型语言模型生成的响应。MMedFD为医疗保健部署中的流式ASR和端到端双工代理的基准测试建立了可重复使用的框架。数据集和相关资源可在https://github.com/Kinetics-JOJO/MMedFD公开访问。
论文及项目相关链接
Summary
本文介绍了针对临床对话中的自动语音识别(ASR)系统所面临的挑战,如全双工交互、说话人重叠和低延迟约束。为此,作者提出了MMedFD,首个为多轮、全双工设置设计的现实世界中汉语医疗ASR语料库。该数据集包含从部署的AI助理捕获的5805个注释会话,具有同步的用户和混合通道视图、RTTM/CTM定时和角色标签。作者还介绍了一种模型无关的管道,用于流式分割、说话人归属和对话记忆,并使用角色连接的音频对Whisper小型模型进行微调,以实现长上下文识别。ASR评估包括字错误率(WER)、字符错误率(CER)和概念级别错误率(HC-WER),后者用于衡量医疗保健环境中的准确性。对于大型语言模型生成的响应,采用基于规则和成对协议进行评估。MMedFD为医疗保健部署中的流式ASR和端到端双工代理提供了可重复使用的基准测试框架。数据集和相关资源可在公开访问的链接中找到。
Key Takeaways
- MMedFD是首个为临床对话设计的汉语医疗ASR语料库,适用于多轮、全双工设置。
- 数据集包含5805个注释会话,具备多种重要特性,如同步的用户和混合通道视图、RTTM/CTM定时以及角色标签。
- 作者提出了一个模型无关的管道,用于流式分割、说话人归属和对话记忆处理。
- 采用概念级别错误率(HC-WER)来衡量医疗保健环境中的ASR准确性。
- MMedFD为流式ASR和端到端双工代理提供了可重复使用的基准测试框架。
- 数据集和相关资源可公开访问,链接已提供。
点此查看论文截图
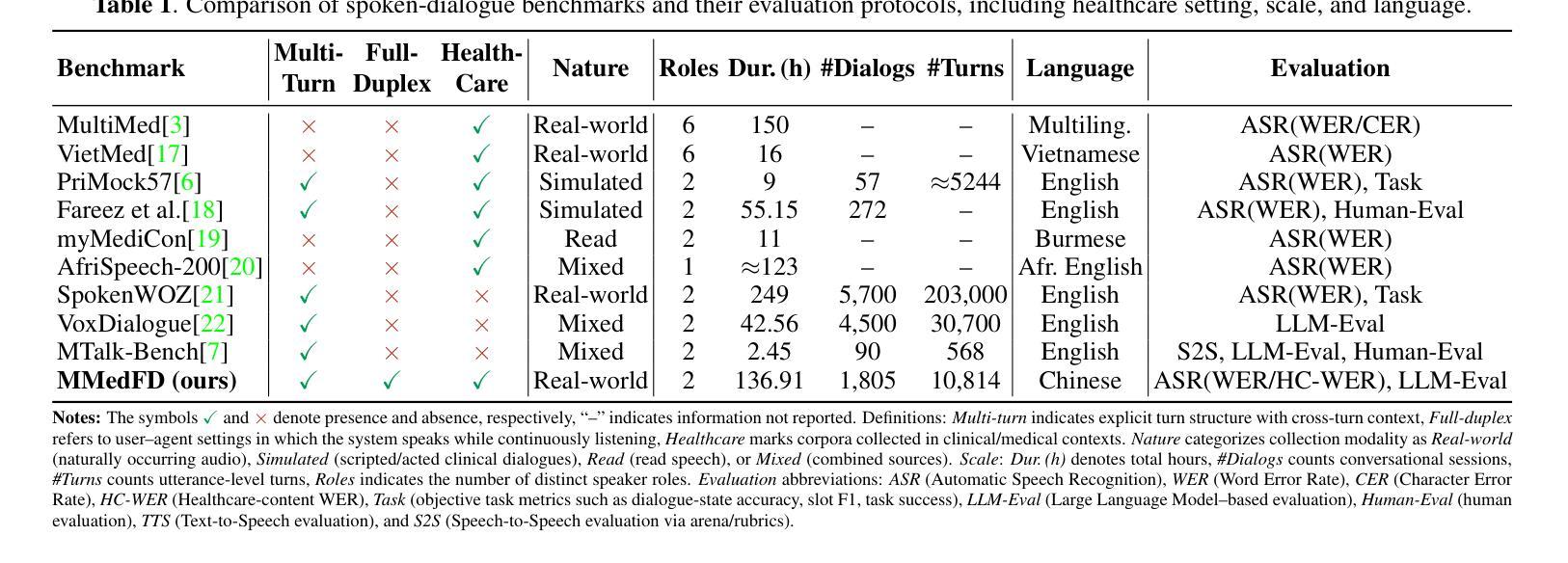
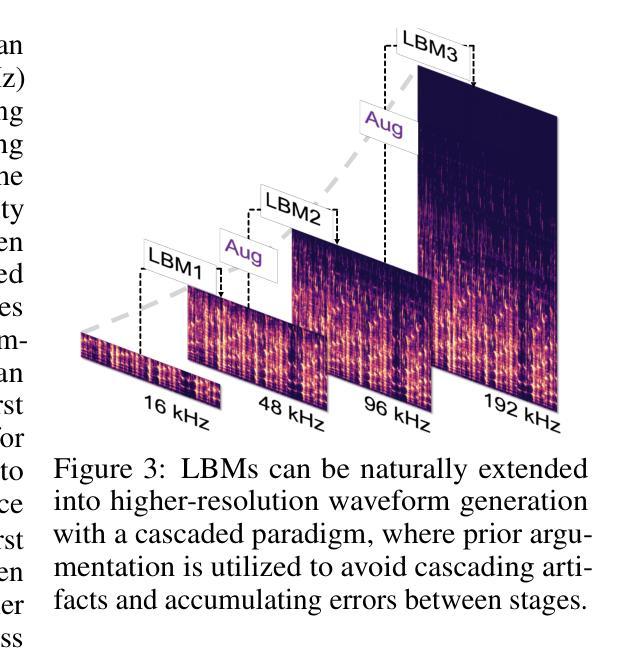
Audio Super-Resolution with Latent Bridge Models
Authors:Chang Li, Zehua Chen, Liyuan Wang, Jun Zhu
Audio super-resolution (SR), i.e., upsampling the low-resolution (LR) waveform to the high-resolution (HR) version, has recently been explored with diffusion and bridge models, while previous methods often suffer from sub-optimal upsampling quality due to their uninformative generation prior. Towards high-quality audio super-resolution, we present a new system with latent bridge models (LBMs), where we compress the audio waveform into a continuous latent space and design an LBM to enable a latent-to-latent generation process that naturally matches the LR-toHR upsampling process, thereby fully exploiting the instructive prior information contained in the LR waveform. To further enhance the training results despite the limited availability of HR samples, we introduce frequency-aware LBMs, where the prior and target frequency are taken as model input, enabling LBMs to explicitly learn an any-to-any upsampling process at the training stage. Furthermore, we design cascaded LBMs and present two prior augmentation strategies, where we make the first attempt to unlock the audio upsampling beyond 48 kHz and empower a seamless cascaded SR process, providing higher flexibility for audio post-production. Comprehensive experimental results evaluated on the VCTK, ESC-50, Song-Describer benchmark datasets and two internal testsets demonstrate that we achieve state-of-the-art objective and perceptual quality for any-to-48kHz SR across speech, audio, and music signals, as well as setting the first record for any-to-192kHz audio SR. Demo at https://AudioLBM.github.io/.
音频超分辨率(SR)即将低分辨率(LR)波形上采样到高分辨率(HR)版本,最近已经通过扩散和桥梁模型进行了探索。而之前的方法由于其缺乏信息生成先验,往往遭受次优上采样质量的困扰。为了获得高质量音频超分辨率,我们提出了一种新的潜藏桥梁模型(LBMs)系统,我们将音频波形压缩到连续潜藏空间,并设计了一个LBM,以启用自然匹配LR到HR上采样过程的潜藏到潜藏生成过程,从而充分利用LR波形中包含的指示性先验信息。为了进一步提高训练结果,即使高质量样本有限,我们引入了频率感知LBMs,将先验和目标频率作为模型输入,使LBMs能够在训练阶段显式地学习任何到任何的上采样过程。此外,我们设计了级联LBMs,并提出了两种先验增强策略。我们首次尝试解锁超过48kHz的音频上采样,赋能无缝级联SR过程,为音频后期制作提供更高的灵活性。在VCTK、ESC-50、Song-Describer基准数据集和两个内部测试集上的综合实验结果表明,我们在语音、音频和音乐信号的任何到48kHz SR方面实现了最先进的客观和感知质量,并首次创造了任何到1:到高音质的记录SR为每秒采样率为192kHz的记录。演示地址为:https://AudioLBM.github.io/。
论文及项目相关链接
PDF Accepted at NeurIPS 2025
摘要
基于潜在桥模型(LBMs)的新系统实现音频超分辨率,通过压缩音频波形到连续潜在空间,设计LBM进行潜在到潜在生成过程,自然匹配LR到HR的上采样过程。引入频率感知LBMs,利用频率信息增强训练结果。设计级联LBMs和两种先验增强策略,实现超过48kHz的音频上采样,提供音频后期制作更高灵活性。在多个数据集上的实验结果表明,该方法在语音、音频和音乐信号的任何到48kHz的SR中实现了最先进的客观和感知质量,并在任何到192kHz的音频SR中创下了首个记录。
关键见解
- 提出了一种新的基于潜在桥模型(LBMs)的音频超分辨率系统,该系统通过压缩音频波形到连续潜在空间进行优化。
- LBMs的设计能够自然匹配低分辨率到高分辨率的上采样过程,充分利用低分辨率波形中的先验信息。
- 引入频率感知LBMs,使模型在训练阶段能够显式学习任何到任何的上采样过程。
- 设计了级联LBMs和两种先验增强策略,实现了超过48kHz的音频上采样,为音频后期制作提供了更高的灵活性。
- 在多个基准数据集上的实验结果表明,该系统在语音、音频和音乐信号的任何到48kHz的超分辨率中达到了最先进的性能。
- 该系统在任何到192kHz的音频超分辨率上创下了首个记录。
- 提供了演示网站链接,可以直观地体验该系统的效果。
点此查看论文截图

Towards Inclusive ASR: Investigating Voice Conversion for Dysarthric Speech Recognition in Low-Resource Languages
Authors:Chin-Jou Li, Eunjung Yeo, Kwanghee Choi, Paula Andrea Pérez-Toro, Masao Someki, Rohan Kumar Das, Zhengjun Yue, Juan Rafael Orozco-Arroyave, Elmar Nöth, David R. Mortensen
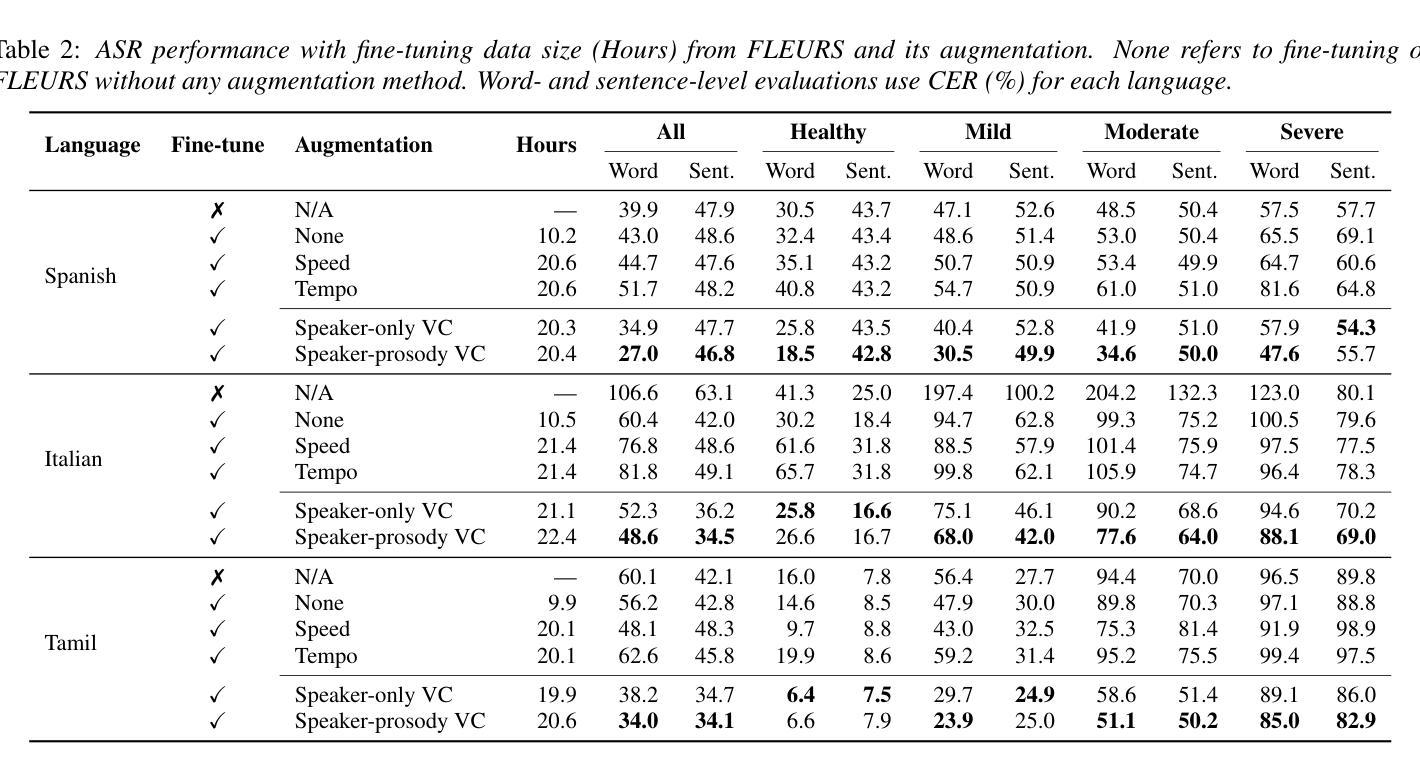
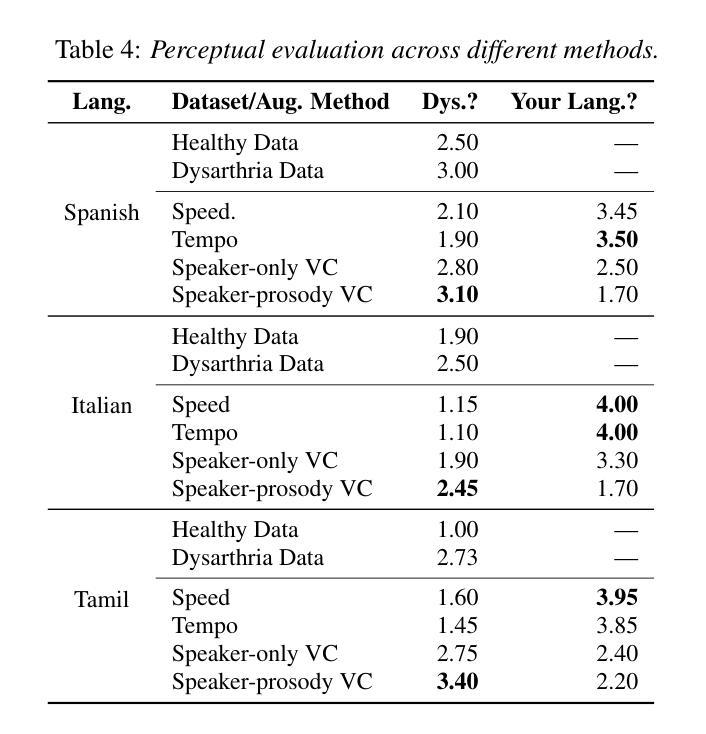
Automatic speech recognition (ASR) for dysarthric speech remains challenging due to data scarcity, particularly in non-English languages. To address this, we fine-tune a voice conversion model on English dysarthric speech (UASpeech) to encode both speaker characteristics and prosodic distortions, then apply it to convert healthy non-English speech (FLEURS) into non-English dysarthric-like speech. The generated data is then used to fine-tune a multilingual ASR model, Massively Multilingual Speech (MMS), for improved dysarthric speech recognition. Evaluation on PC-GITA (Spanish), EasyCall (Italian), and SSNCE (Tamil) demonstrates that VC with both speaker and prosody conversion significantly outperforms the off-the-shelf MMS performance and conventional augmentation techniques such as speed and tempo perturbation. Objective and subjective analyses of the generated data further confirm that the generated speech simulates dysarthric characteristics.
针对发音障碍者的语音识别(ASR)仍然是一个挑战,这主要是由于数据的稀缺性,特别是在非英语环境中。为了解决这个问题,我们对英语发音障碍语音(UASpeech)进行微调,以编码说话人的特征和韵律扭曲,然后将其应用于将健康的非英语语音(FLEURS)转换为非英语发音障碍语音。生成的数据随后用于微调多语言语音识别模型Massively Multilingual Speech(MMS),以提高对发音障碍语音的识别能力。在PC-GITA(西班牙语)、EasyCall(意大利语)和SSNCE(泰米尔语)上的评估表明,同时实现说话人和韵律转换的语音转换技术显著优于现成的MMS性能和传统的增强技术,如速度和节奏扰动。对生成数据的客观和主观分析进一步证实,生成的语音模拟了发音障碍的特征。
论文及项目相关链接
PDF 5 pages, 1 figure, Proceedings of Interspeech
Summary
在自动语音识别(ASR)中,对发音障碍的语音识别仍是一大挑战,原因在于数据的稀缺性,特别是在非英语环境中。本研究通过微调英语发音障碍语音(UASpeech)的语音转换模型来解决这一问题,该模型能够编码说话人的特性和韵律失真。接着将此模型应用于将健康的非英语语音(FLEURS)转换成非英语的发音障碍类语音。生成的语音数据被用来微调多语种自动语音识别模型Massively Multilingual Speech(MMS),以提高对发音障碍语音的识别能力。在PC-GITA(西班牙语)、EasyCall(意大利语)和SSNCE(泰米尔语)上的评估显示,同时转换说话人和韵律的语音转换方法显著优于现成的MMS性能和传统的增强技术,如速度和节奏扰动。对生成数据的客观和主观分析进一步证实,生成的语音模拟了发音障碍的特性。
Key Takeaways
- 自动语音识别(ASR)在识别发音障碍的语音时面临挑战,主要是由于数据的稀缺性,特别是在非英语环境中。
- 研究者通过微调一个英语发音障碍语音的语音转换模型来解决这一问题。
- 该模型不仅能编码说话人的特性,还能编码韵律失真。
- 研究者使用该模型将健康的非英语语音转换成非英语的发音障碍类语音。
- 生成的语音数据用于微调多语种ASR模型,提高识别发音障碍语音的性能。
- 实验结果表明,该方法的性能优于传统的ASR模型和增强技术。
点此查看论文截图