⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-01 更新
Vision At Night: Exploring Biologically Inspired Preprocessing For Improved Robustness Via Color And Contrast Transformations
Authors:Lorena Stracke, Lia Nimmermann, Shashank Agnihotri, Margret Keuper, Volker Blanz
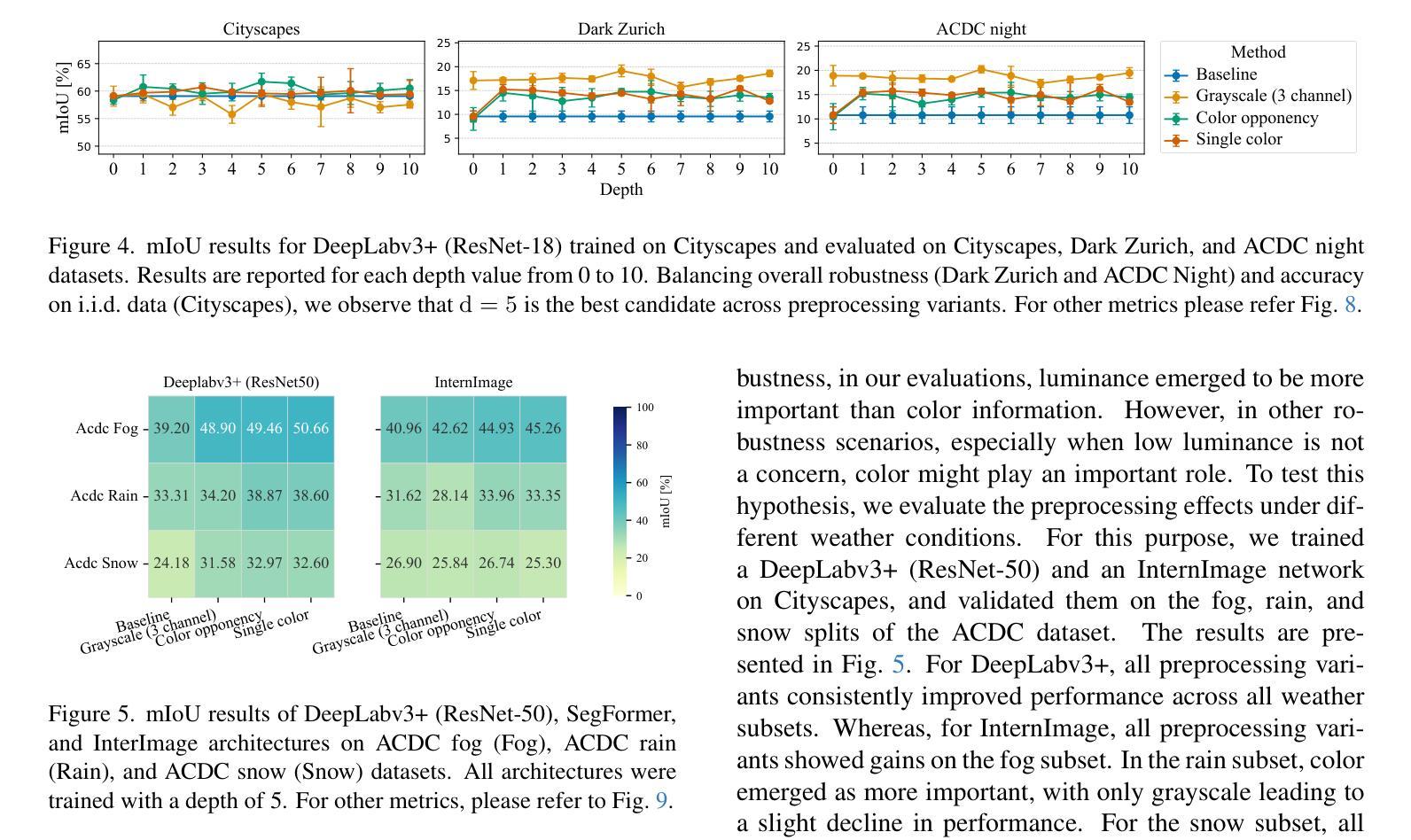
Inspired by the human visual system’s mechanisms for contrast enhancement and color-opponency, we explore biologically motivated input preprocessing for robust semantic segmentation. By applying Difference-of-Gaussians (DoG) filtering to RGB, grayscale, and opponent-color channels, we enhance local contrast without modifying model architecture or training. Evaluations on Cityscapes, ACDC, and Dark Zurich show that such preprocessing maintains in-distribution performance while improving robustness to adverse conditions like night, fog, and snow. As this processing is model-agnostic and lightweight, it holds potential for integration into imaging pipelines, enabling imaging systems to deliver task-ready, robust inputs for downstream vision models in safety-critical environments.
受人类视觉系统对比增强和颜色对立机制的启发,我们探索了用于稳健语义分割的生物激励输入预处理。通过对RGB、灰度图和颜色对立通道应用高斯差分(DoG)滤波,我们在不修改模型架构或训练的情况下增强了局部对比。在Cityscapes、ACDC和黑暗苏黎世上的评估表明,这种预处理在保持内部性能的同时,提高了对夜间、雾天和雪天等不利条件的稳健性。由于这种处理具有模型无关性和轻量化特点,因此有潜力集成到成像流水线中,使成像系统能够为安全关键环境中的下游视觉模型提供任务就绪的稳健输入。
论文及项目相关链接
PDF Accepted at the ICCV 2025 Workshop on Responsible Imaging
Summary
该研究受人类视觉系统对比增强和颜色对抗机制的启发,探索了用于稳健语义分割的生物动机输入预处理。通过应用Difference-of-Gaussians(DoG)滤波对RGB、灰度图和对手色通道进行处理,可在不修改模型架构或训练的情况下增强局部对比。在Cityscapes、ACDC和Dark Zurich上的评估表明,这种预处理在保持内部分布性能的同时,提高了对夜晚、雾和雪等不利条件的鲁棒性。该处理具有模型通用性和轻量级特点,具有潜力融入成像流水线,使成像系统为安全关键环境中的下游视觉模型提供任务就绪的稳健输入。
Key Takeaways
- 研究受人类视觉系统启发,探索了生物动机输入预处理以增强语义分割的稳健性。
- 应用Difference-of-Gaussians(DoG)滤波处理图像,增强局部对比。
- 处理过程不修改模型架构或训练,具有通用性和轻量级特点。
- 评估显示,该预处理在多种数据集上提高了模型对不利条件的鲁棒性。
- 预处理有助于在保持性能的同时,提高模型在不同环境条件下的适用性。
- 该方法具有潜力融入成像流水线,为下游视觉模型提供优化输入。
点此查看论文截图

An Efficient 3D Latent Diffusion Model for T1-contrast Enhanced MRI Generation
Authors:Zach Eidex, Mojtaba Safari, Jie Ding, Richard Qiu, Justin Roper, David Yu, Hui-Kuo Shu, Zhen Tian, Hui Mao, Xiaofeng Yang
Objective: Gadolinium-based contrast agents (GBCAs) are commonly employed with T1w MRI to enhance lesion visualization but are restricted in patients at risk of nephrogenic systemic fibrosis and variations in GBCA administration can introduce imaging inconsistencies. This study develops an efficient 3D deep-learning framework to generate T1-contrast enhanced images (T1C) from pre-contrast multiparametric MRI. Approach: We propose the 3D latent rectified flow (T1C-RFlow) model for generating high-quality T1C images. First, T1w and T2-FLAIR images are input into a pretrained autoencoder to acquire an efficient latent space representation. A rectified flow diffusion model is then trained in this latent space representation. The T1C-RFlow model was trained on a curated dataset comprised of the BraTS 2024 glioma (GLI; 1480 patients), meningioma (MEN; 1141 patients), and metastases (MET; 1475 patients) datasets. Selected patients were split into train (N=2860), validation (N=612), and test (N=614) sets. Results: Both qualitative and quantitative results demonstrate that the T1C-RFlow model outperforms benchmark 3D models (pix2pix, DDPM, Diffusion Transformers (DiT-3D)) trained in the same latent space. T1C-RFlow achieved the following metrics - GLI: NMSE 0.044 +/- 0.047, SSIM 0.935 +/- 0.025; MEN: NMSE 0.046 +/- 0.029, SSIM 0.937 +/- 0.021; MET: NMSE 0.098 +/- 0.088, SSIM 0.905 +/- 0.082. T1C-RFlow had the best tumor reconstruction performance and significantly faster denoising times (6.9 s/volume, 200 steps) than conventional DDPM models in both latent space (37.7s, 1000 steps) and patch-based in image space (4.3 hr/volume). Significance: Our proposed method generates synthetic T1C images that closely resemble ground truth T1C in much less time than previous diffusion models. Further development may permit a practical method for contrast-agent-free MRI for brain tumors.
目标:钆类造影剂(GBCAs)常与T1加权MRI一起使用,以增强病变的可见性,但其在有发生肾源性系统性纤维化风险的患者中受到限制,并且GBCA管理的变化可能会引入成像不一致性。本研究开发了一种高效的3D深度学习框架,用于从预造影多参数MRI生成T1加权造影增强图像(T1C)。方法:我们提出了用于生成高质量T1C图像的3D潜在校正流(T1C-RFlow)模型。首先,将T1加权和T2-FLAIR图像输入预训练的自编码器,以获得有效的潜在空间表示。然后在此潜在空间表示中训练校正流扩散模型。T1C-RFlow模型是在精选数据集上训练的,该数据集包含BraTS 2024胶质细胞瘤(GLI;1480例患者)、脑膜瘤(MEN;1141例患者)和转移瘤(MET;1475例患者)数据集。将选定患者分为训练组(N=2860)、验证组(N=612)和测试组(N=614)。结果:定性和定量结果均表明,T1C-RFlow模型在相同的潜在空间中超越了基准3D模型(pix2pix、DDPM、Diffusion Transformers(DiT-3D))的表现。在GLI中,T1C-RFlow实现了以下指标:NMSE 0.044±0.047,SSIM 0.935±0.025;在MEN中:NMSE 0.046±0.029,SSIM 0.937±0.021;在MET中:NMSE 0.098±0.088,SSIM 0.905±0.082。T1C-RFlow具有最佳的肿瘤重建性能,并且去噪时间显著更快(6.9秒/体积,200步),与传统的潜在空间DDPM模型(37.7秒,1000步)和基于图像的图像空间补丁(4.3小时/体积)相比。意义:我们提出的方法能够在比以前的扩散模型少得多的时间内生成模拟真实T1C的T1C图像。进一步的开发可能会提供一种无需造影剂的脑部肿瘤MRI检测方法。
论文及项目相关链接
摘要
本研究开发了一种高效的3D深度学习框架,用于从预对比的多参数MRI生成T1对比增强图像(T1C)。该研究使用T1加权和T2流液倒置恢复图像输入预训练的自编码器,获取有效的潜在空间表示。在此潜在空间表示中训练了校正流扩散模型。该模型在包括胶质细胞瘤、脑膜瘤和转移瘤的数据集上进行训练,并在这些疾病中表现出优异的性能。与在同一潜在空间中训练的基准3D模型相比,T1C-RFlow模型具有更高的性能,并且肿瘤重建性能最佳,去噪时间显著更快。本研究为生成合成T1C图像提供了一种新方法,这些图像在时间上更接近于真实T1C,为未来实现无造影剂MRI提供了可能。
关键见解
- 研究提出了一种名为T1C-RFlow的3D深度学习框架,用于从预对比的多参数MRI生成T1对比增强图像(T1C)。
- 该框架使用自编码器和校正流扩散模型,在潜在空间表示中生成高质量的T1C图像。
- T1C-RFlow在多种类型的脑部肿瘤数据集上进行了训练并表现出良好的性能。
- T1C-RFlow模型相较于其他在相同潜在空间中训练的模型有更好的性能表现。
- T1C-RFlow模型的肿瘤重建性能最佳,去噪时间显著更快。
- 该研究为无造影剂MRI的实现提供了可能,为未来的医学成像技术提供了新的视角。
点此查看论文截图

A Modality-Tailored Graph Modeling Framework for Urban Region Representation via Contrastive Learning
Authors:Yaya Zhao, Kaiqi Zhao, Zixuan Tang, Zhiyuan Liu, Xiaoling Lu, Yalei Du
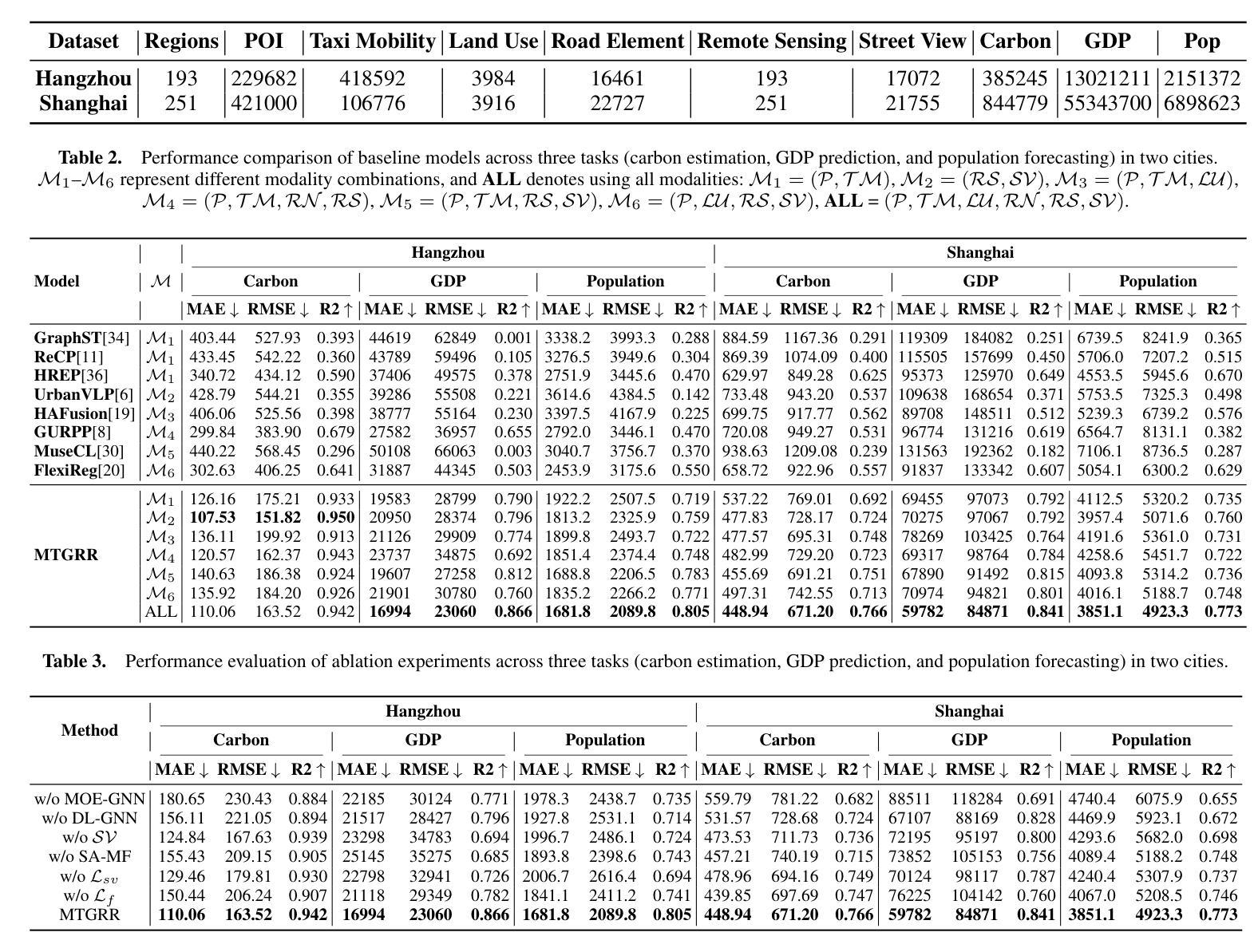
Graph-based models have emerged as a powerful paradigm for modeling multimodal urban data and learning region representations for various downstream tasks. However, existing approaches face two major limitations. (1) They typically employ identical graph neural network architectures across all modalities, failing to capture modality-specific structures and characteristics. (2) During the fusion stage, they often neglect spatial heterogeneity by assuming that the aggregation weights of different modalities remain invariant across regions, resulting in suboptimal representations. To address these issues, we propose MTGRR, a modality-tailored graph modeling framework for urban region representation, built upon a multimodal dataset comprising point of interest (POI), taxi mobility, land use, road element, remote sensing, and street view images. (1) MTGRR categorizes modalities into two groups based on spatial density and data characteristics: aggregated-level and point-level modalities. For aggregated-level modalities, MTGRR employs a mixture-of-experts (MoE) graph architecture, where each modality is processed by a dedicated expert GNN to capture distinct modality-specific characteristics. For the point-level modality, a dual-level GNN is constructed to extract fine-grained visual semantic features. (2) To obtain effective region representations under spatial heterogeneity, a spatially-aware multimodal fusion mechanism is designed to dynamically infer region-specific modality fusion weights. Building on this graph modeling framework, MTGRR further employs a joint contrastive learning strategy that integrates region aggregated-level, point-level, and fusion-level objectives to optimize region representations. Experiments on two real-world datasets across six modalities and three tasks demonstrate that MTGRR consistently outperforms state-of-the-art baselines, validating its effectiveness.
基于图模型的框架已成为处理多模态城市数据的有力工具,并能够用于学习区域表示为多种下游任务提供服务。然而,现有方法面临两大局限。(1)它们通常使用所有模态的相同图神经网络架构,无法捕捉模态特定的结构和特征。(2)在融合阶段,它们往往会忽略空间异质性,假设不同模态的聚合权重在各个区域保持不变,从而导致次优表示。为了解决这些问题,我们提出了MTGRR,这是一种针对城市区域表示的模态定制的图建模框架,建立在包含兴趣点(POI)、出租车流动性、土地利用、道路元素、遥感和街道视图图像的多模态数据集之上。(1)MTGRR根据空间密度和数据特性将模态分为两组:聚合级和点级模态。对于聚合级模态,MTGRR采用混合专家(MoE)图架构,其中每个模态由专门的专家GNN处理以捕获不同的模态特定特征。对于点级模态,构建双级GNN以提取精细粒度的视觉语义特征。(2)为了在空间异质性下获得有效的区域表示,设计了一种空间感知的多模态融合机制,以动态推断特定区域的模态融合权重。基于这个图建模框架,MTGRR进一步采用联合对比学习策略,该策略结合了区域聚合级、点级和融合级目标来优化区域表示。在两个真实世界数据集上的实验证明了MTGRR在六个模态和三个任务上始终优于最新基线,验证了其有效性。
论文及项目相关链接
Summary
本文提出了一种针对城市区域表示的模态定制图建模框架MTGRR,用于处理多模态城市数据。该框架解决了现有方法的两大局限性:一是未能捕捉模态特定结构和特性,二是在融合阶段忽略了空间异质性。MTGRR利用专门的图神经网络架构捕捉不同模态的特性,并设计了一种空间感知的多模态融合机制,以获取有效的区域表示。通过联合对比学习策略优化区域表示,实验证明MTGRR在真实世界数据集上的表现优于最新基线。
Key Takeaways
- 现有图模型在处理多模态城市数据时面临两大挑战:缺乏模态特定结构特性的捕捉和在融合阶段忽略空间异质性。
- MTGRR框架通过对模态进行分类,使用专门的图神经网络架构来捕捉不同模态的特性。
- 对于聚合级别的模态,MTGRR采用混合专家图架构,每个模态由专门的专家GNN处理,以捕捉不同的模态特性。
- 对于点级别模态,MTGRR构建了双级别GNN以提取精细的视觉语义特征。
- MTGRR设计了一种空间感知的多模态融合机制,以获取有效的区域表示,该机制可以动态推断特定区域的模态融合权重。
- MTGRR采用联合对比学习策略,结合区域聚合级别、点级别和融合级别的目标来优化区域表示。
点此查看论文截图
GenView++: Unifying Adaptive View Generation and Quality-Driven Supervision for Contrastive Representation Learning
Authors:Xiaojie Li, Bei Wang, Jianlong Wu, Yue Yu, Liqiang Nie, Min Zhang
The success of contrastive learning depends on the construction and utilization of high-quality positive pairs. However, current methods face critical limitations on two fronts: on the construction side, both handcrafted and generative augmentations often suffer from limited diversity and risk semantic corruption; on the learning side, the absence of a quality assessment mechanism leads to suboptimal supervision where all pairs are treated equally. To tackle these challenges, we propose GenView++, a unified framework that addresses both fronts by introducing two synergistic innovations. To improve pair construction, GenView++ introduces a multi-source adaptive view generation mechanism to synthesize diverse yet semantically coherent views by dynamically modulating generative parameters across image-conditioned, text-conditioned, and image-text-conditioned strategies. Second, a quality-driven contrastive learning mechanism assesses each pair’s semantic alignment and diversity to dynamically reweight their training contribution, prioritizing high-quality pairs while suppressing redundant or misaligned pairs. Extensive experiments demonstrate the effectiveness of GenView++ across both vision and vision-language tasks. For vision representation learning, it improves MoCov2 by +2.5% on ImageNet linear classification. For vision-language learning, it raises the average zero-shot classification accuracy by +12.31% over CLIP and +5.31% over SLIP across ten datasets, and further improves Flickr30k text retrieval R@5 by +3.2%. The code is available at https://github.com/xiaojieli0903/GenViewPlusPlus.
对比学习的成功取决于高质量正对的构建和利用。然而,当前的方法在两个方面都面临着关键的局限性:在构建方面,手工制作和生成式增强通常受限于有限的多样性,并存在语义损坏的风险;在学习方面,由于缺乏质量评估机制,所有对都被平等对待,导致监督效果不佳。为了解决这些挑战,我们提出了GenView++,这是一个通过引入两项协同创新来解决这些问题的统一框架。为提高配对构建,GenView++引入了一种多源自适应视图生成机制,通过动态调制图像条件、文本条件和图像文本混合条件下的生成参数,合成多样但语义连贯的视图。其次,质量驱动对比学习机制评估每对语义对齐和多样性,以动态调整其训练贡献的权重,优先高质量配对,同时抑制冗余或错位配对。大量实验表明,GenView++在视觉和视觉语言任务中均有效。在视觉表示学习中,它在ImageNet线性分类上提高了MoCov2的性能+2.5%。在视觉语言学习中,与CLIP相比提高了零样本分类平均准确度+12.31%,与SLIP相比提高了+5.31%,跨十个数据集;同时提高了Flickr30k文本检索的R@5指标+3.2%。代码可用在https://github.com/xiaojieli0903/GenViewPlusPlus。
论文及项目相关链接
PDF The code is available at \url{https://github.com/xiaojieli0903/GenViewPlusPlus}
Summary
该论文探讨了对比学习中高质量正样本对的重要性及其构建和利用的挑战。针对当前方法的局限性,提出了一种名为GenView++的统一框架,通过两项协同创新来解决这些问题。一是改进对样本对的构建,通过多源自适应视图生成机制,动态调整生成参数,合成多样且语义连贯的视图;二是引入质量驱动对比学习机制,根据每对样本的语义对齐程度和多样性来动态调整训练贡献的权重,优先高质量样本对,抑制冗余或误对齐样本对。实验表明,GenView++在视觉和视觉语言任务中都取得了显著效果。
Key Takeaways
- 对比学习的成功取决于高质量正样本对的构建和利用。
- 当前方法在样本对构建和学习方面存在局限性。
- GenView++通过两项协同创新解决这些问题:改进样本对构建和提高学习质量。
- GenView++采用多源自适应视图生成机制,合成多样且语义连贯的视图。
- GenView++通过质量驱动对比学习机制,优先高质量样本对,抑制冗余或误对齐样本对。
- GenView++在视觉和视觉语言任务中取得了显著效果,如MoCov2在ImageNet上的线性分类提高了+2.5%,CLIP和SLIP在多个数据集上的零射击分类准确率分别提高了+12.31%和+5.31%,Flickr30k文本检索R@5提高了+3.2%。
点此查看论文截图


CCD: Mitigating Hallucinations in Radiology MLLMs via Clinical Contrastive Decoding
Authors:Xi Zhang, Zaiqiao Meng, Jake Lever, Edmond S. L. Ho
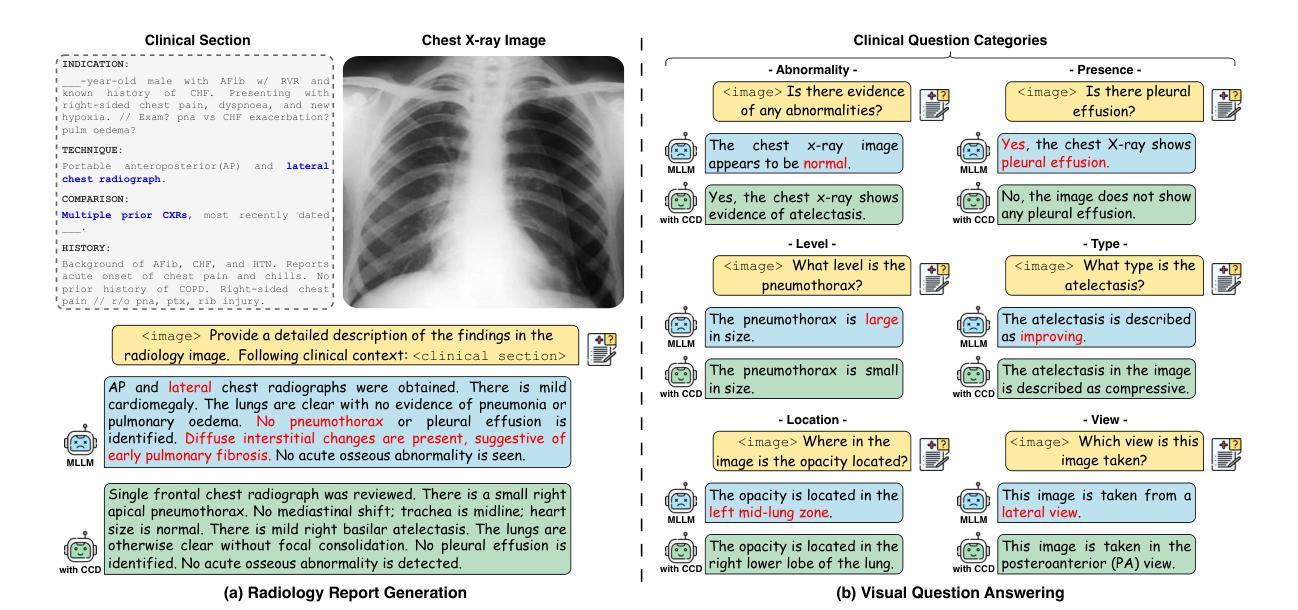
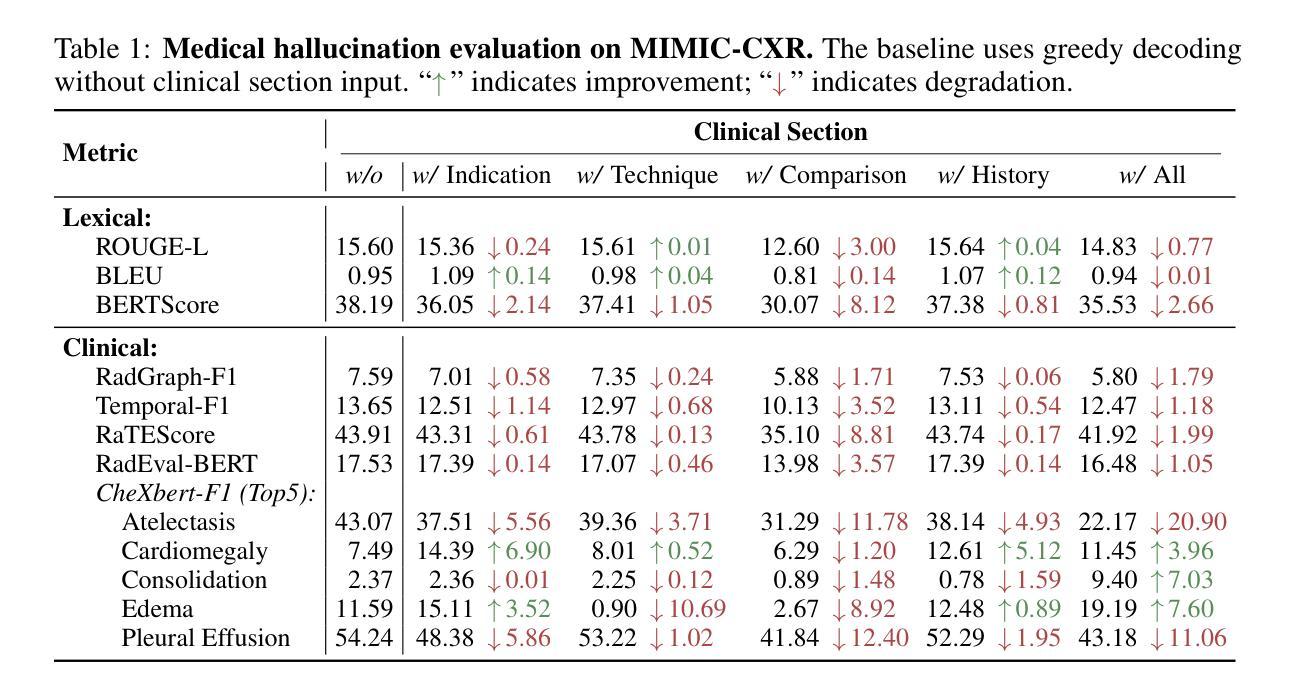
Multimodal large language models (MLLMs) have recently achieved remarkable progress in radiology by integrating visual perception with natural language understanding. However, they often generate clinically unsupported descriptions, known as medical hallucinations, which pose serious risks in medical applications that demand accuracy and image-grounded outputs. Through empirical analysis, we find that prompt-induced hallucinations remain prevalent in radiology MLLMs, largely due to over-sensitivity to clinical sections. To address this, we introduce Clinical Contrastive Cecoding (CCD), a training-free and retrieval-free inference framework that integrates structured clinical signals from task-specific radiology expert models. CCD introduces a dual-stage contrastive mechanism to refine token-level logits during generation, thereby enhancing clinical fidelity without modifying the base MLLM. Experiments on three datasets and multiple models demonstrate that CCD consistently improves overall performance on radiology report generation (RRG). On the MIMIC-CXR dataset, it yields up to a 17% improvement in RadGraph-F1 when applied to state-of-the-art RRG models. Our approach provides a lightweight and generalisable solution for mitigating medical hallucinations, effectively bridging expert models and MLLMs in radiology.
多模态大型语言模型(MLLMs)最近通过整合视觉感知与自然语言理解在放射学领域取得了显著进展。然而,它们经常产生临床上不支持的描述,被称为医学幻觉,这在需要准确性和图像基础输出的医学应用中带来了严重的风险。通过实证分析,我们发现提示诱导的幻觉在放射学MLLM中仍然普遍存在,主要是由于对临床部分的过度敏感。为了解决这一问题,我们引入了临床对比编码(CCD),这是一种无需训练和检索的推理框架,它整合了特定任务放射学专家模型的结构化临床信号。CCD引入了一种双阶段对比机制,在生成过程中细化令牌级别的逻辑,从而提高临床保真度,而不会修改基础MLLM。在三个数据集和多个模型上的实验表明,CCD在放射学报告生成(RRG)方面始终提高总体性能。在MIMIC-CXR数据集上,当应用于最先进的RRG模型时,它在RadGraph-F1上提高了高达17%。我们的方法提供了一种轻便且通用的解决方案来缓解医学幻觉问题,有效地桥接了专家模型和MLLM在放射学领域的应用。
论文及项目相关链接
PDF Preprint
Summary
本文介绍了多模态大型语言模型(MLLMs)在放射学领域的最新进展,它们通过融合视觉感知和自然语言理解取得了显著成效。然而,MLLMs常常产生未经临床支持的描述,即所谓的医学幻觉,这在需要精确性和图像基础输出的医学应用中带来了严重风险。研究发现,提示诱导的幻觉在放射学MLLMs中普遍存在,主要是由于对临床部分的过度敏感。为解决这一问题,本文提出了临床对比编码(CCD)技术,这是一种无需训练和检索的推断框架,它整合了来自特定任务放射学专家模型的结构化临床信号。CCD引入了一种双阶段对比机制,在生成过程中优化令牌级别的逻辑,从而提高临床保真度,同时不修改基础MLLM。实验表明,CCD在放射学报告生成方面表现优异,特别是在MIMIC-CXR数据集上应用最先进的RRG模型时,RadGraph-F1得分提高了17%。该方法为缓解医学幻觉问题提供了一种轻便且通用的解决方案,有效地架起了专家模型和MLLMs之间的桥梁。
Key Takeaways
- 多模态大型语言模型(MLLMs)在放射学领域通过融合视觉感知和自然语言理解取得了进展。
- MLLMs常产生未经临床支持的描述(医学幻觉),存在临床风险。
- 医学幻觉在放射学MLLMs中普遍存在的原因是过度敏感于临床部分。
- 为解决上述问题,提出了临床对比编码(CCD)技术。
- CCD是一种无需训练和检索的推断框架,整合了特定任务放射学专家模型的结构化临床信号。
- CCD通过双阶段对比机制优化生成过程中的令牌级别逻辑,提高临床保真度。
点此查看论文截图
Benchmarking DINOv3 for Multi-Task Stroke Analysis on Non-Contrast CT
Authors:Donghao Zhang, Yimin Chen, Kauê TN Duarte, Taha Aslan, Mohamed AlShamrani, Brij Karmur, Yan Wan, Shengcai Chen, Bo Hu, Bijoy K Menon, Wu Qiu
Non-contrast computed tomography (NCCT) is essential for rapid stroke diagnosis but is limited by low image contrast and signal to noise ratio. We address this challenge by leveraging DINOv3, a state-of-the-art self-supervised vision transformer, to generate powerful feature representations for a comprehensive set of stroke analysis tasks. Our evaluation encompasses infarct and hemorrhage segmentation, anomaly classification (normal vs. stroke and normal vs. infarct vs. hemorrhage), hemorrhage subtype classification (EDH, SDH, SAH, IPH, IVH), and dichotomized ASPECTS classification (<=6 vs. >6) on multiple public and private datasets. This study establishes strong benchmarks for these tasks and demonstrates the potential of advanced self-supervised models to improve automated stroke diagnosis from NCCT, providing a clear analysis of both the advantages and current constraints of the approach. The code is available at https://github.com/Zzz0251/DINOv3-stroke.
非对比计算机断层扫描(NCCT)对于快速中风诊断至关重要,但由于图像对比度和信噪比低而受到限制。我们通过利用最先进的自监督视觉转换器DINOv3来解决这一挑战,为一系列中风分析任务生成强大的特征表示。我们的评估涵盖了梗死和出血分割、异常分类(正常与中风、正常与梗死与出血)、出血亚型分类(EDH、SDH、SAH、IPH、IVH),以及在多个公共和私有数据集上进行二分化的ASPECTS分类(<=6与>6)。本研究为这些任务建立了强大的基准测试,证明了先进的自监督模型在提高非对比计算机断层扫描(NCCT)自动化中风诊断方面的潜力,同时提供了该方法的优势和当前局限性的清晰分析。代码可在https://github.com/Zzz0251/DINOv3-stroke获取。
论文及项目相关链接
Summary
基于非对比计算层析成像(NCCT)在快速卒中诊断中的重要性,但受限于图像对比度和信噪比的问题,研究团队利用先进的自监督视觉转换器DINOv3生成强大的特征表示,以解决这一问题。该研究在梗死、出血分割、异常分类(正常与卒中、正常与梗死与出血)、出血亚型分类(EDH、SDH、SAH、IPH、IVH)以及分级的ASPECTS分类(<=6与> 6)等多个公共和私有数据集上进行了评估。研究确立了强有力的基准线,证明了先进的自监督模型在提高NCCT自动化卒中诊断方面的潜力,并对该方法的优点和当前限制进行了清晰分析。
Key Takeaways
- 非对比计算层析成像(NCCT)在快速卒中诊断中扮演重要角色,但存在图像对比度和信噪比的问题。
- 研究使用DINOv3这一先进的自监督视觉转换器来解决上述问题,生成强大的特征表示。
- 研究涵盖了梗死和出血分割、异常分类、出血亚型分类等多个卒中分析任务。
- 在多个公共和私有数据集上进行了评估,确立了强有力的基准线。
- 先进自监督模型在改善NCCT自动化卒中诊断方面的潜力得到了验证。
- 研究提供了关于该方法的优点和限制的清晰分析。
点此查看论文截图
A Survey on Self-supervised Contrastive Learning for Multimodal Text-Image Analysis
Authors:Asifullah Khan, Laiba Asmatullah, Anza Malik, Shahzaib Khan, Hamna Asif
Self-supervised learning is a machine learning approach that generates implicit labels by learning underlined patterns and extracting discriminative features from unlabeled data without manual labelling. Contrastive learning introduces the concept of “positive” and “negative” samples, where positive pairs (e.g., variation of the same image/object) are brought together in the embedding space, and negative pairs (e.g., views from different images/objects) are pushed farther away. This methodology has shown significant improvements in image understanding and image text analysis without much reliance on labeled data. In this paper, we comprehensively discuss the terminologies, recent developments and applications of contrastive learning with respect to text-image models. Specifically, we provide an overview of the approaches of contrastive learning in text-image models in recent years. Secondly, we categorize the approaches based on different model structures. Thirdly, we further introduce and discuss the latest advances of the techniques used in the process such as pretext tasks for both images and text, architectural structures, and key trends. Lastly, we discuss the recent state-of-art applications of self-supervised contrastive learning Text-Image based models.
自监督学习是一种机器学习的方法,它通过学习和识别潜在的模式,并从无标签的数据中提取辨别特征,生成隐含的标签,无需人工标注。对比学习引入了“正样本”和“负样本”的概念,其中正样本对(例如,同一图像/对象的变体)被汇集到嵌入空间中,而负样本对(例如,来自不同图像/对象的视图)则被推开得更远。这种方法在图像理解和图像文本分析方面取得了显著的改进,无需大量依赖标记数据。在本文中,我们全面探讨了与文本图像模型相关的对比学习的术语、最新发展以及应用。具体来说,我们概述了近年来文本图像模型中对比学习的方法。其次,我们根据不同的模型结构对这些方法进行了分类。此外,我们还进一步介绍了对比学习过程中的最新技术进展,如图像和文本的预训练任务、架构结构和关键趋势。最后,我们讨论了基于文本图像的最新先进的自监督对比学习的应用。
论文及项目相关链接
PDF 38 pages, 8 figures, survey paper
Summary
自我监督学习是一种机器学习的方法,通过隐式标签生成学习底层模式并从无标签数据中提取判别特征,无需手动标注。对比学习引入了“正样本”和“负样本”的概念,通过将同一图像或对象的不同变化作为正样本在嵌入空间中聚合,而将不同图像或对象的视图作为负样本推开,取得了显著成效。本文全面探讨了对比学习的术语、最新进展及其在文本图像模型中的应用。文章概述了近年来的文本图像模型对比学习方法,按模型结构分类,并介绍了最新的技术进展,如图像和文本的预训练任务、架构结构和关键趋势等。最后讨论了基于文本图像的自我监督对比学习的最新应用。
Key Takeaways
- 自我监督学习通过隐式标签学习底层模式并从无标签数据中提取判别特征。
- 对比学习是自我监督学习的一种形式,引入正样本和负样本的概念,以提升学习效果。
- 正样本指的是同一图像或对象的不同变化,在嵌入空间中聚合;负样本则是不同图像或对象的视图,被推开。
- 对比学习方法在图像理解和文本分析方面表现出显著的改进,减少了对标注数据的依赖。
- 文章提供了关于文本图像模型对比学习的全面概述,包括近年来的方法和按模型结构的分类。
- 介绍了最新的技术进展,包括图像和文本的预训练任务、架构结构和关键趋势等。
点此查看论文截图

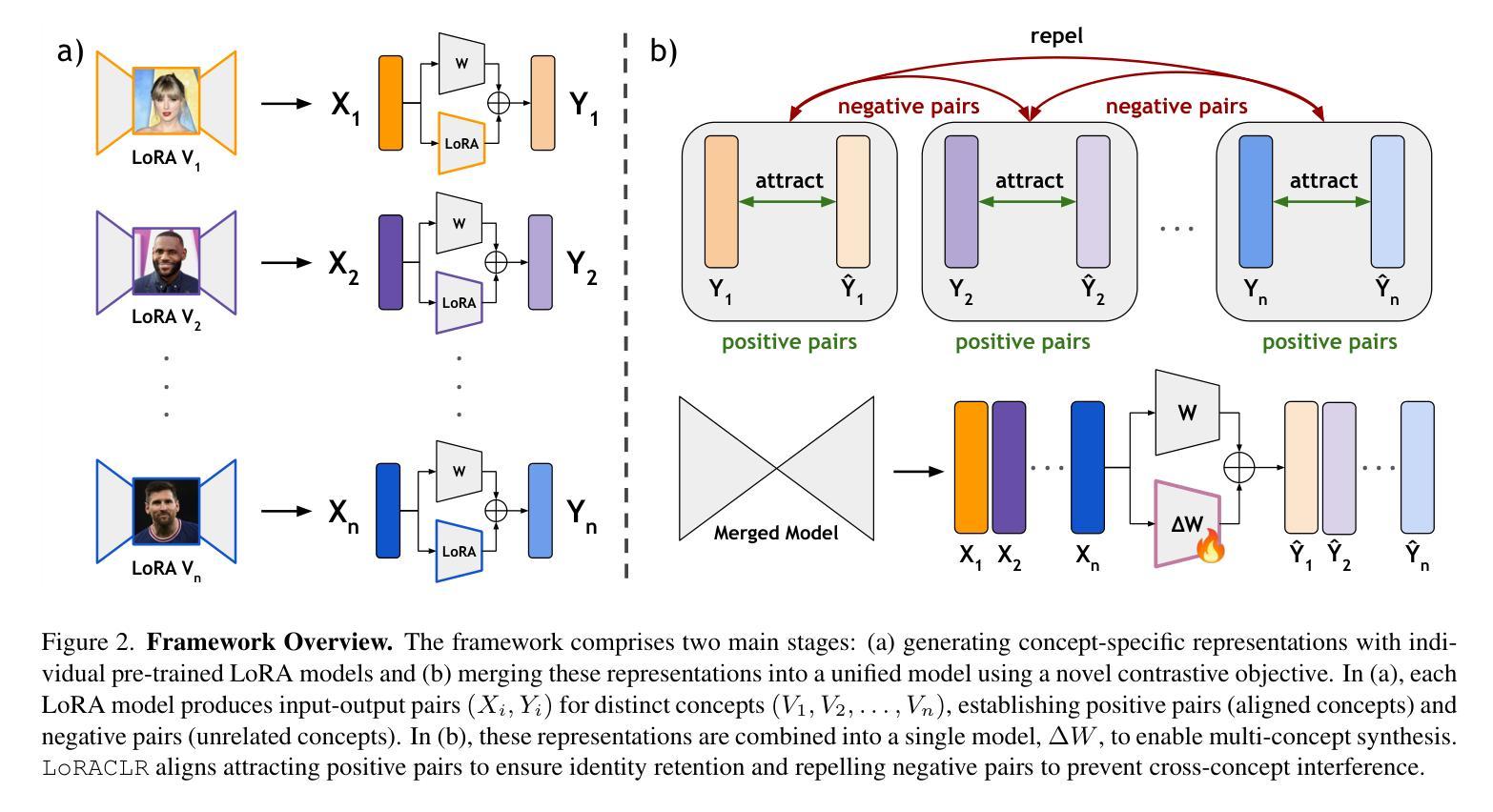
LoRACLR: Contrastive Adaptation for Customization of Diffusion Models
Authors:Enis Simsar, Thomas Hofmann, Federico Tombari, Pinar Yanardag
Recent advances in text-to-image customization have enabled high-fidelity, context-rich generation of personalized images, allowing specific concepts to appear in a variety of scenarios. However, current methods struggle with combining multiple personalized models, often leading to attribute entanglement or requiring separate training to preserve concept distinctiveness. We present LoRACLR, a novel approach for multi-concept image generation that merges multiple LoRA models, each fine-tuned for a distinct concept, into a single, unified model without additional individual fine-tuning. LoRACLR uses a contrastive objective to align and merge the weight spaces of these models, ensuring compatibility while minimizing interference. By enforcing distinct yet cohesive representations for each concept, LoRACLR enables efficient, scalable model composition for high-quality, multi-concept image synthesis. Our results highlight the effectiveness of LoRACLR in accurately merging multiple concepts, advancing the capabilities of personalized image generation.
文本到图像的定制技术的最新进展已经实现了高保真、富含语境的个性化图像生成,允许特定概念出现在多种场景中。然而,当前的方法在结合多个个性化模型时遇到了困难,经常导致属性纠缠,或者需要单独的培训来保持概念的独特性。我们提出了LoRACLR,这是一种新的多概念图像生成方法,它将多个针对特定概念进行微调LoRA模型合并为一个单一、统一的模型,而无需额外的个别微调。LoRACLR使用对比目标来对齐和合并这些模型的权重空间,确保兼容性同时最小化干扰。通过实施清晰而连贯的表示,每个概念都有自己的特点,LoRACLR能够实现高效、可扩展的模型组合,用于高质量的多概念图像合成。我们的结果突出了LoRACLR在准确合并多个概念方面的有效性,提高了个性化图像生成的能力。
论文及项目相关链接
PDF Accepted to CVPR’25. Project page: https://loraclr.github.io/
Summary
本文介绍了LoRACLR方法,这是一种将多个针对特定概念进行微调(fine-tuned)的LoRA模型合并为一个统一模型的技术。该方法使用对比目标(contrastive objective)来对齐和合并这些模型的权重空间,确保它们之间的兼容性并最小化干扰。通过为每个概念强制实施独特而连贯的表示,LoRACLR实现了高效、可扩展的模型组合,用于高质量的多概念图像合成。
Key Takeaways
- LoRACLR是一种用于多概念图像生成的新方法,可以合并多个LoRA模型,每个模型针对一个特定概念进行微调。
- LoRACLR使用对比目标来对齐和合并这些模型的权重空间,确保它们在合并过程中的兼容性和稳定性。
- 该方法通过强制实施独特且连贯的表示形式,为每个概念在图像合成中提供清晰的定义和表现。
- LoRACLR不需要对每个模型进行单独的微调,从而提高了效率,并简化了多概念图像合成的过程。
- 该方法实现了高效、可扩展的模型组合,可以应用于高质量、多概念的图像合成。
- LoRACLR在准确合并多个概念方面表现出良好的效果,进一步提高了个性化图像生成的能力。
点此查看论文截图

Similarity-Dissimilarity Loss for Multi-label Supervised Contrastive Learning
Authors:Guangming Huang, Yunfei Long, Cunjin Luo
Supervised contrastive learning has achieved remarkable success by leveraging label information; however, determining positive samples in multi-label scenarios remains a critical challenge. In multi-label supervised contrastive learning (MSCL), multi-label relations are not yet fully defined, leading to ambiguity in identifying positive samples and formulating contrastive loss functions to construct the representation space. To address these challenges, we: (i) systematically formulate multi-label relations in MSCL, (ii) propose a novel Similarity-Dissimilarity Loss, which dynamically re-weights samples based on similarity and dissimilarity factors, (iii) further provide theoretical grounded proofs for our method through rigorous mathematical analysis that supports the formulation and effectiveness, and (iv) offer a unified form and paradigm for both single-label and multi-label supervised contrastive loss. We conduct experiments on both image and text modalities and further extend the evaluation to the medical domain. The results show that our method consistently outperforms baselines in comprehensive evaluations, demonstrating its effectiveness and robustness. Moreover, the proposed approach achieves state-of-the-art performance on MIMIC-III-Full.
监督对比学习通过利用标签信息取得了显著的成功;然而,在多标签场景中确定正样本仍然是一个关键挑战。在多标签监督对比学习(MSCL)中,多标签关系尚未得到充分定义,导致在识别正样本和制定对比损失函数以构建表示空间时存在模糊性。为了应对这些挑战,我们:(i)系统地制定了MSCL中的多标签关系,(ii)提出了一种新的相似性-差异性损失,该损失根据相似性和差异性因素动态地重新加权样本,(iii)通过严格的数学分析进一步为我们的方法提供了理论证明,支持其制定和有效性,(iv)为单标签和多标签监督对比损失提供了统一的形式和范式。我们在图像和文本模式上进行了实验,并将评估扩展到了医疗领域。结果表明,我们的方法在综合评估中始终优于基线,证明了其有效性和稳健性。此外,所提出的方法在MIMIC-III-Full上达到了最先进的性能。
论文及项目相关链接
Summary
无监督对比学习取得了显著的成功,但在多标签场景中确定正样本是一个挑战。在多标签监督对比学习(MSCL)中,由于多标签关系尚未明确界定,导致难以确定正样本并构建对比损失函数以构建表示空间。为解决这些问题,我们系统地提出了多标签关系的界定、新的相似性-差异性损失函数设计,提供了理论支撑与数学分析证明其有效性,并给出了统一的多标签和单标签监督对比损失范式。实验结果表明,我们的方法在图像和文本模态上的表现均优于基线方法,且在医疗领域的表现尤其突出。我们的方法在MIMIC-III-Full数据集上取得了最优的性能表现。
Key Takeaways
- 多标签监督对比学习(MSCL)在确定正样本方面存在挑战,因为多标签关系尚未明确界定。
- 提出了一种新的相似性-差异性损失函数,根据相似性和差异性因素动态地重新加权样本。
- 通过严格的数学分析证明了我们方法的有效性和理论支撑。
- 提供了统一的多标签和单标签监督对比损失范式。
- 实验结果表明,该方法在图像和文本模态上的表现均优于基线方法。
- 在医疗领域的评估中,该方法表现出强大的性能表现,尤其在MIMIC-III-Full数据集上取得了最优表现。