⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-01 更新
Evaluation of Polarimetric Fusion for Semantic Segmentation in Aquatic Environments
Authors:Luis F. W. Batista, Tom Bourbon, Cedric Pradalier
Accurate segmentation of floating debris on water is often compromised by surface glare and changing outdoor illumination. Polarimetric imaging offers a single-sensor route to mitigate water-surface glare that disrupts semantic segmentation of floating objects. We benchmark state-of-the-art fusion networks on PoTATO, a public dataset of polarimetric images of plastic bottles in inland waterways, and compare their performance with single-image baselines using traditional models. Our results indicate that polarimetric cues help recover low-contrast objects and suppress reflection-induced false positives, raising mean IoU and lowering contour error relative to RGB inputs. These sharper masks come at a cost: the additional channels enlarge the models increasing the computational load and introducing the risk of new false positives. By providing a reproducible, diagnostic benchmark and publicly available code, we hope to help researchers choose if polarized cameras are suitable for their applications and to accelerate related research.
水上漂浮垃圾的精确定位常常受到水面反光和室外照明变化的影响。极化成像提供了一种单传感器路径,可以缓解破坏漂浮物语义分割的水面反光问题。我们在PoTATO(内陆水道塑料瓶极化图像公共数据集)上评估了最先进的融合网络,并将其性能与采用传统模型的单图像基线进行了比较。我们的结果表明,极化线索有助于恢复低对比度物体并抑制由反射引起的误报。相较于RGB输入,极化成像提高了平均交并比(IoU),并降低了轮廓误差。但这些更精确的掩膜也有代价:额外的通道扩大了模型,增加了计算负载,并引入了新增误报的风险。我们希望通过提供可重复、可诊断的基准和公开可用的代码,帮助研究人员判断极化相机是否适合其应用,并加速相关研究。
论文及项目相关链接
PDF Accepted to VCIP 2025
Summary
极光学成像技术能有效缓解水面反光对漂浮物分割的干扰,提升语义分割精度。本文对比了极光学图像融合网络与单图像基线的性能,并指出极光学特征有助于识别低对比度物体并抑制反射造成的误检。但这也带来了计算负载增加的风险和新的误检可能。
Key Takeaways
- 极光学成像技术有助于解决水面漂浮物分割时受到的表面反光和室外光照变化问题。
- 极光学图像融合网络性能优于单图像基线。
- 极光学特征能提高低对比度物体的识别能力,并抑制反射导致的误检。
- 使用极光学相机需要权衡计算负载增加的风险和新的误检可能性。
- 公共数据集PoTATO为极光学图像研究提供了可复现的基准测试。
- 公开可用的代码有助于研究者判断极化相机是否适合其应用,并加速相关研究。
点此查看论文截图
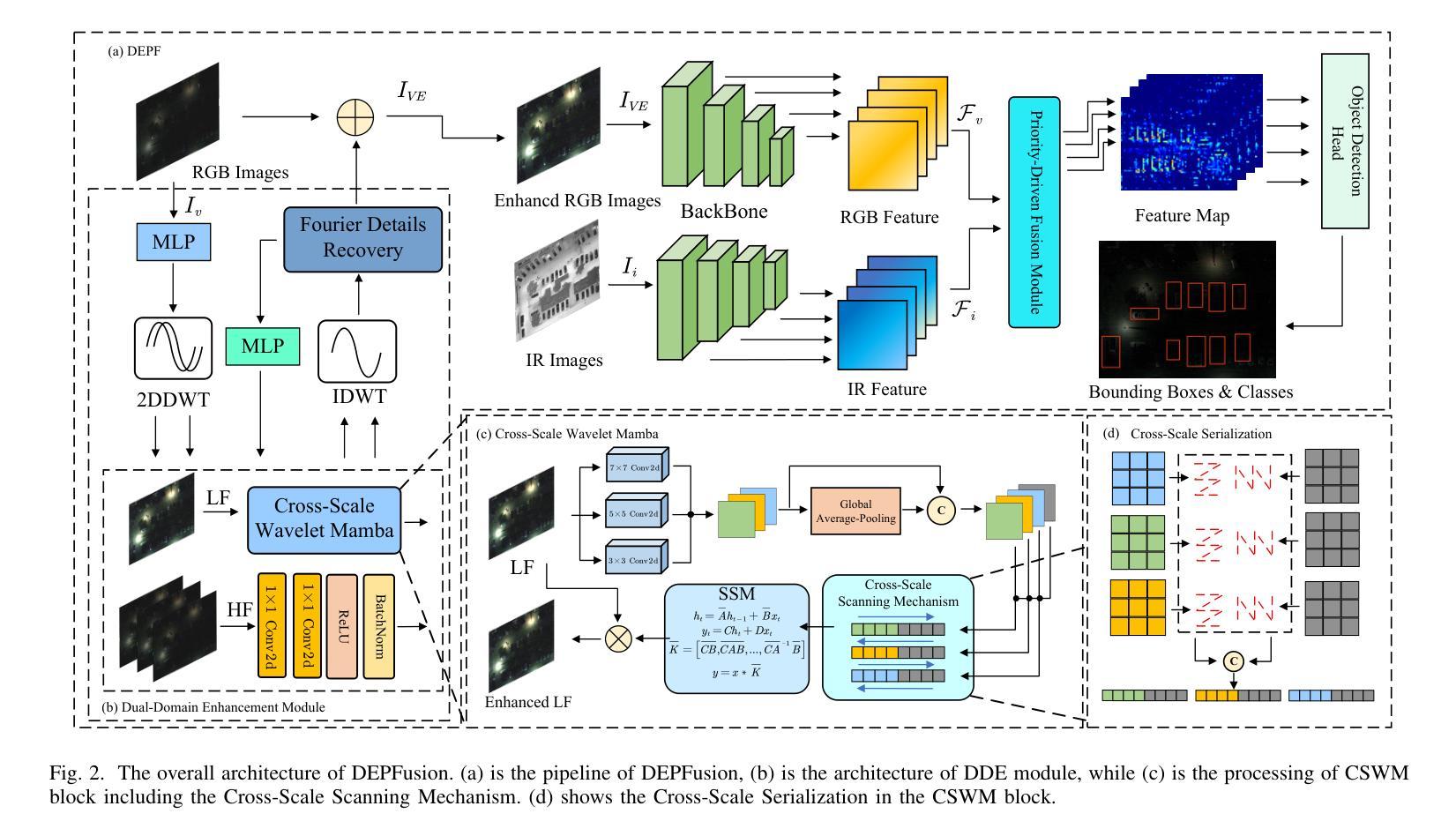
DEPFusion: Dual-Domain Enhancement and Priority-Guided Mamba Fusion for UAV Multispectral Object Detection
Authors:Shucong Li, Zhenyu Liu, Zijie Hong, Zhiheng Zhou, Xianghai Cao
Multispectral object detection is an important application for unmanned aerial vehicles (UAVs). However, it faces several challenges. First, low-light RGB images weaken the multispectral fusion due to details loss. Second, the interference information is introduced to local target modeling during multispectral fusion. Third, computational cost poses deployment challenge on UAV platforms, such as transformer-based methods with quadratic complexity. To address these issues, a framework named DEPFusion consisting of two designed modules, Dual-Domain Enhancement (DDE) and Priority-Guided Mamba Fusion (PGMF) , is proposed for UAV multispectral object detection. Firstly, considering the adoption of low-frequency component for global brightness enhancement and frequency spectra features for texture-details recovery, DDE module is designed with Cross-Scale Wavelet Mamba (CSWM) block and Fourier Details Recovery (FDR) block. Secondly, considering guiding the scanning of Mamba from high priority score tokens, which contain local target feature, a novel Priority-Guided Serialization is proposed with theoretical proof. Based on it, PGMF module is designed for multispectral feature fusion, which enhance local modeling and reduce interference information. Experiments on DroneVehicle and VEDAI datasets demonstrate that DEPFusion achieves good performance with state-of-the-art methods.
多光谱目标检测是无人机的重要应用领域,但面临诸多挑战。首先,低光RGB图像因细节丢失而削弱了多光谱融合的效果。其次,在多光谱融合过程中引入了干扰信息,影响局部目标建模。再次,计算成本对无人机平台构成了部署挑战,例如基于二次复杂度的transformer方法。为了解决这些问题,提出了一种名为DEPFusion的框架,包含两个设计模块:双域增强(DDE)和优先级引导融合(PGMF),用于无人机多光谱目标检测。首先,考虑到采用低频分量进行全局亮度增强和频谱特征进行纹理细节恢复,设计了DDE模块,包括跨尺度小波分解(CSWM)块和傅里叶细节恢复(FDR)块。其次,考虑到从高优先级分数标记引导Mamba扫描,其中包含局部目标特征,提出了一种新的优先级引导序列化方法并给出了理论证明。基于此,设计了PGMF模块进行多光谱特征融合,增强局部建模并减少干扰信息。在DroneVehicle和VEDAI数据集上的实验表明,DEPFusion与最先进的方法相比具有良好的性能。
论文及项目相关链接
Summary
无人机多光谱目标检测面临低光照RGB图像细节丢失、干扰信息引入局部目标建模以及计算成本高昂等挑战。提出一种名为DEPFusion的框架,包含Dual-Domain Enhancement(DDE)和Priority-Guided Mamba Fusion(PGMF)两个模块,以提高无人机多光谱目标检测性能。DDE模块通过低频成分增强全局亮度和频率谱特征恢复纹理细节,PGMF模块则通过优先引导Mamba扫描高优先级令牌来实现多光谱特征融合,提高局部建模并减少干扰信息。在DroneVehicle和VEDAI数据集上的实验表明,DEPFusion达到了业界先进水平。
Key Takeaways
- 多光谱目标检测在无人机领域具有重要意义,但面临若干挑战。
- 低光照RGB图像会导致细节丢失和多光谱融合问题。
- 干扰信息在局部目标建模中是一个挑战。
- 计算成本高昂是无人机平台上部署算法的一大难题。
- DEPFusion框架包含DDE和PGMF两个模块来解决这些问题。
- DDE模块通过增强全局亮度和恢复纹理细节来提高图像质量。
- PGMF模块通过优先引导Mamba扫描高优先级令牌实现多光谱特征融合,提高局部建模并减少干扰信息。
点此查看论文截图
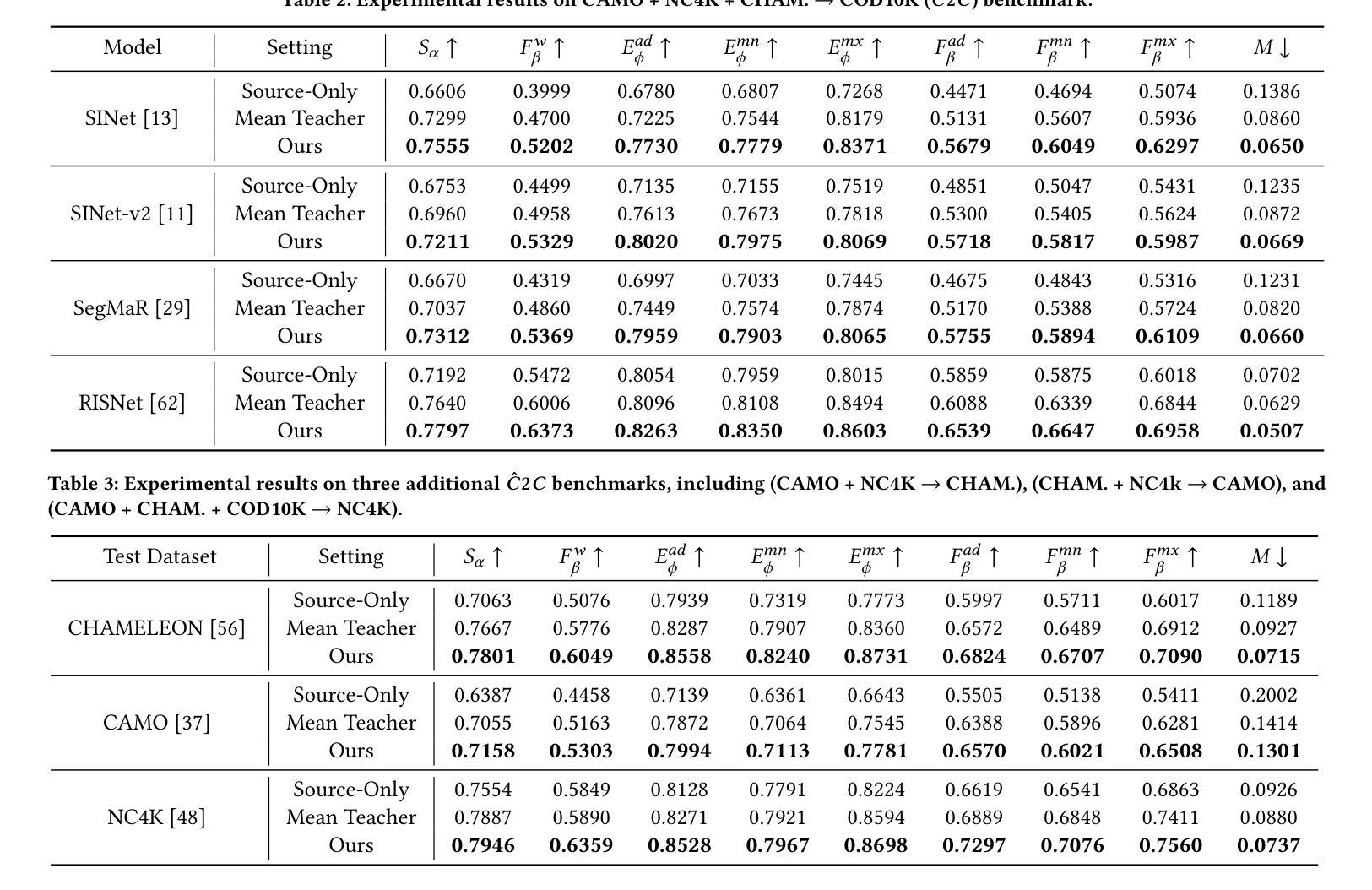
Synthetic-to-Real Camouflaged Object Detection
Authors:Zhihao Luo, Luojun Lin, Zheng Lin
Due to the high cost of collection and labeling, there are relatively few datasets for camouflaged object detection (COD). In particular, for certain specialized categories, the available image dataset is insufficiently populated. Synthetic datasets can be utilized to alleviate the problem of limited data to some extent. However, directly training with synthetic datasets compared to real datasets can lead to a degradation in model performance. To tackle this problem, in this work, we investigate a new task, namely Syn-to-Real Camouflaged Object Detection (S2R-COD). In order to improve the model performance in real world scenarios, a set of annotated synthetic camouflaged images and a limited number of unannotated real images must be utilized. We propose the Cycling Syn-to-Real Domain Adaptation Framework (CSRDA), a method based on the student-teacher model. Specially, CSRDA propagates class information from the labeled source domain to the unlabeled target domain through pseudo labeling combined with consistency regularization. Considering that narrowing the intra-domain gap can improve the quality of pseudo labeling, CSRDA utilizes a recurrent learning framework to build an evolving real domain for bridging the source and target domain. Extensive experiments demonstrate the effectiveness of our framework, mitigating the problem of limited data and handcraft annotations in COD. Our code is publicly available at: https://github.com/Muscape/S2R-COD.
由于收集和标注的高成本,用于伪装目标检测(COD)的数据集相对较少。特别是针对某些特定类别,可用的图像数据集并不充足。合成数据集可以在一定程度上缓解数据有限的问题。然而,与真实数据集相比,直接使用合成数据集进行训练可能会导致模型性能下降。为了解决这个问题,我们在本文中研究了一个新的任务,即合成到现实的伪装目标检测(S2R-COD)。为了提高模型在现实世界的性能,必须使用一组注释的合成伪装图像和数量有限的未注释的真实图像。我们提出了循环合成到现实领域适应框架(CSRDA),这是一种基于师生模型的方法。特别是,CSRDA通过伪标签和一致性正则化将源域的类别信息传递给无标签的目标域。考虑到缩小域内差距可以提高伪标签的质量,CSRDA利用递归学习框架构建不断发展的真实域,以缩小源域和目标域之间的差距。大量实验证明了我们框架的有效性,缓解了COD中数据有限和手工标注的问题。我们的代码公开在:https://github.com/Muscape/S2R-COD。
论文及项目相关链接
PDF Accepted by ACM MM 2025
Summary
该文本介绍了在伪装目标检测领域面临的数据集问题及其解决方案。针对训练和标签成本高导致的有限数据集问题,文章提出了一种名为CSRDA的新框架,利用合成图像和真实图像的结合,通过学生-教师模型进行跨域传播,提高模型在现实场景中的性能。该框架利用循环学习和一致性正则化等技术手段实现伪装对象在合成与真实数据间的检测与转换。相关实验验证了其有效性,缓解了有限数据和手工标注带来的问题。具体信息访问上述公开代码库链接查看更多内容。
Key Takeaways
- 在伪装目标检测领域,由于收集与标注成本高昂,数据集相对较少且特定类别图像数据集不足。
- 合成数据集在一定程度上缓解了数据有限的问题,但直接使用合成数据训练会导致模型性能下降。
- 提出新的任务——合成到现实的伪装目标检测(S2R-COD),旨在提高模型在现实场景中的性能。
- 采用CSRDA框架,结合学生-教师模型,利用标注的合成伪装图像和少量未标注的真实图像进行训练。
- CSRDA通过伪标签和一致性正则化技术实现跨域传播类信息。
- 使用循环学习框架缩小源域和目标域间的差距,提高伪标签质量。
点此查看论文截图


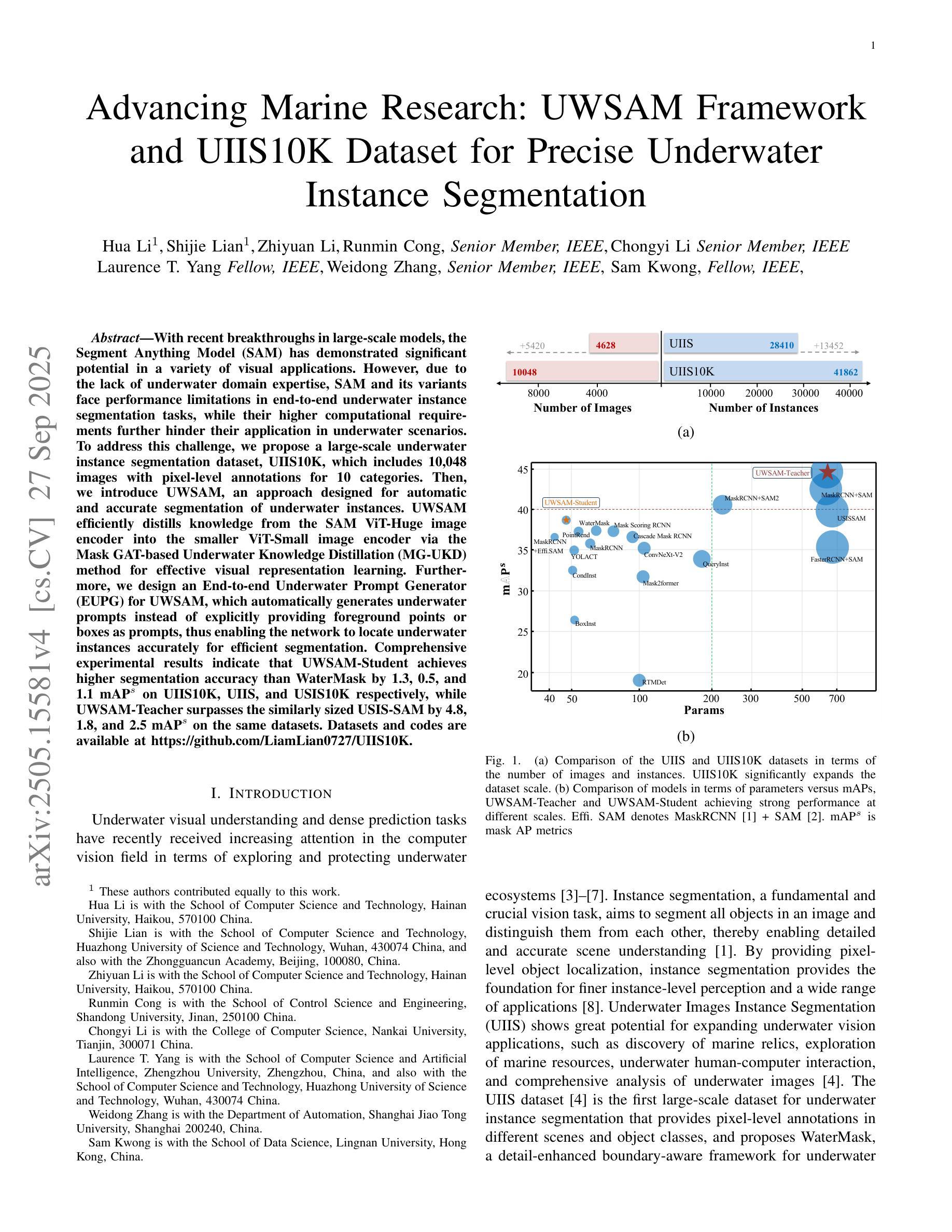
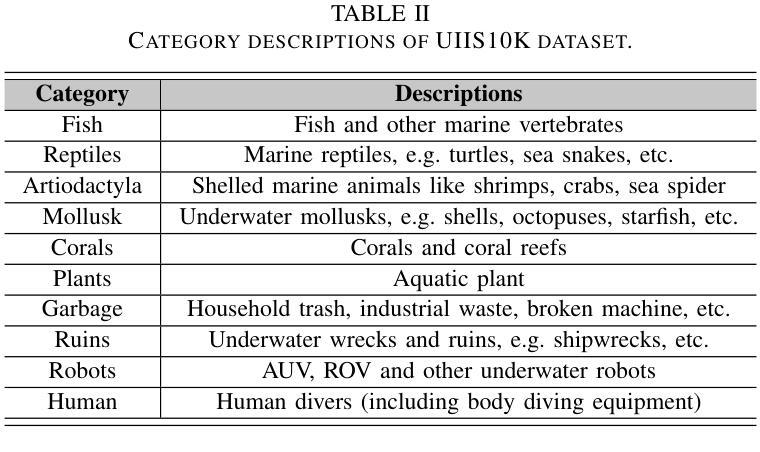
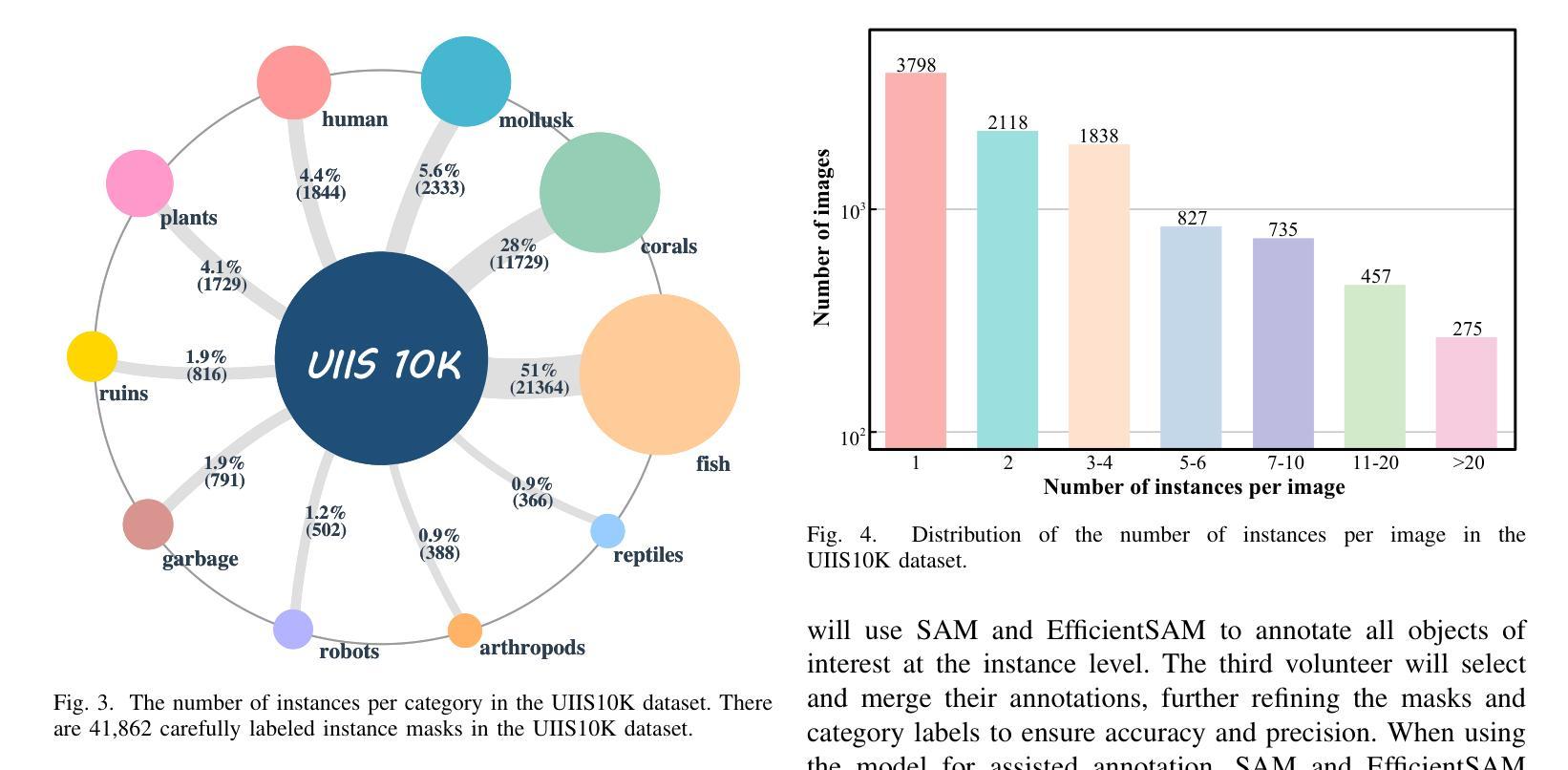
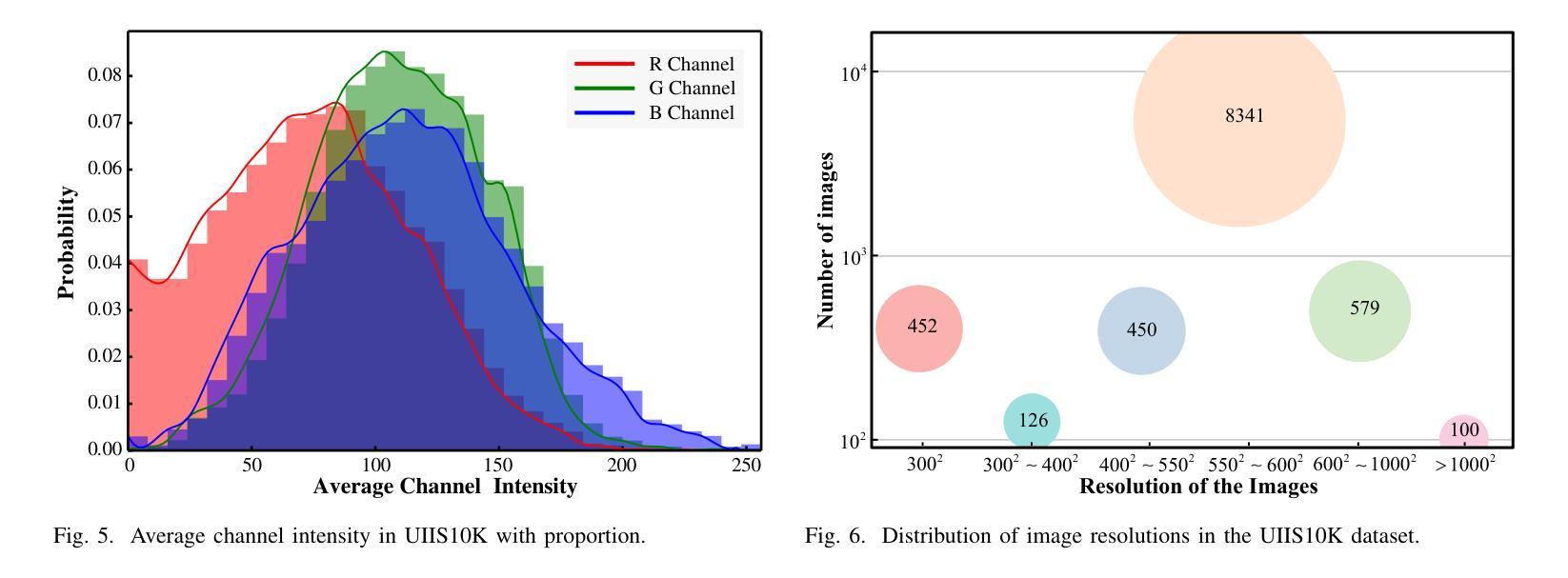
Advancing Marine Research: UWSAM Framework and UIIS10K Dataset for Precise Underwater Instance Segmentation
Authors:Hua Li, Shijie Lian, Zhiyuan Li, Runmin Cong, Chongyi Li, Laurence T. Yang, Weidong Zhang, Sam Kwong
With recent breakthroughs in large-scale modeling, the Segment Anything Model (SAM) has demonstrated significant potential in a variety of visual applications. However, due to the lack of underwater domain expertise, SAM and its variants face performance limitations in end-to-end underwater instance segmentation tasks, while their higher computational requirements further hinder their application in underwater scenarios. To address this challenge, we propose a large-scale underwater instance segmentation dataset, UIIS10K, which includes 10,048 images with pixel-level annotations for 10 categories. Then, we introduce UWSAM, an efficient model designed for automatic and accurate segmentation of underwater instances. UWSAM efficiently distills knowledge from the SAM ViT-Huge image encoder into the smaller ViT-Small image encoder via the Mask GAT-based Underwater Knowledge Distillation (MG-UKD) method for effective visual representation learning. Furthermore, we design an End-to-end Underwater Prompt Generator (EUPG) for UWSAM, which automatically generates underwater prompts instead of explicitly providing foreground points or boxes as prompts, thus enabling the network to locate underwater instances accurately for efficient segmentation. Comprehensive experimental results show that our model is effective, achieving significant performance improvements over state-of-the-art methods on multiple underwater instance datasets. Datasets and codes are available at https://github.com/LiamLian0727/UIIS10K.
随着大规模建模领域的最新突破,Segment Anything Model(SAM)在各种视觉应用中显示出巨大潜力。然而,由于缺乏水下领域的专业知识,SAM及其变体在端到端水下实例分割任务中的性能受到限制,而它们较高的计算要求进一步阻碍了在水下场景中的应用。为了应对这一挑战,我们提出了大规模水下实例分割数据集UIIS10K,其中包括10,048张具有10类像素级注释的图像。然后,我们介绍了UWSAM,这是一个专为水下实例自动准确分割而设计的高效模型。UWSAM通过基于Mask GAT的水下知识蒸馏(MG-UKD)方法,有效地从SAM的ViT-Huge图像编码器蒸馏知识到较小的ViT-Small图像编码器,从而实现有效的视觉表示学习。此外,我们为UWSAM设计了端到端水下提示生成器(EUPG),它会自动生成水下提示,而不是显式提供前景点或盒子作为提示,从而使网络能够准确定位水下实例,实现高效分割。综合实验结果表明,我们的模型是有效的,在多个水下实例数据集上实现了对最先进方法的显著性能改进。数据集和代码可在https://github.com/LiamLian0727/UIIS10K找到。
论文及项目相关链接
Summary:针对大型建模的突破,Segment Anything Model(SAM)在各种视觉应用中展现出巨大潜力。然而,由于缺乏水下领域的专业知识,SAM及其变体在端到端的水下实例分割任务中面临性能限制。为此,我们提出了大规模水下实例分割数据集UIIS10K,包含10,048张带有像素级注释的10类图像。同时,我们引入了专为水下实例自动准确分割而设计的UWSAM模型。UWSAM通过基于Mask GAT的水下知识蒸馏(MG-UKD)方法,有效地从SAM的ViT-Huge图像编码器中提炼知识,用于小型ViT-Small图像编码器的有效视觉表示学习。此外,我们还为UWSAM设计了端到端的水下提示生成器(EUPG),能够自动生成水下提示,而无需明确提供前景点或盒子作为提示,从而能够准确定位水下实例,实现高效分割。
Key Takeaways:
- Segment Anything Model(SAM)在视觉应用方面展现出显著潜力,但在水下实例分割任务中面临性能限制。
- 缺乏水下领域的专业知识是SAM及其变体在水下任务中性能受限的主要原因。
- UIIS10K数据集包含大量水下实例分割的图像和像素级注释,有助于模型训练。
- UWSAM模型专为水下实例自动准确分割设计,通过知识蒸馏技术提高性能。
- UWSAM使用Mask GAT-based Underwater Knowledge Distillation(MG-UKD)方法进行知识提炼。
- End-to-end Underwater Prompt Generator(EUPG)能够自动生成水下提示,提高网络定位水下实例的准确度。
点此查看论文截图