⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-01 更新
VT-FSL: Bridging Vision and Text with LLMs for Few-Shot Learning
Authors:Wenhao Li, Qiangchang Wang, Xianjing Meng, Zhibin Wu, Yilong Yin
Few-shot learning (FSL) aims to recognize novel concepts from only a few labeled support samples. Recent studies enhance support features by incorporating additional semantic information or designing complex semantic fusion modules. However, they still suffer from hallucinating semantics that contradict the visual evidence due to the lack of grounding in actual instances, resulting in noisy guidance and costly corrections. To address these issues, we propose a novel framework, bridging Vision and Text with LLMs for Few-Shot Learning (VT-FSL), which constructs precise cross-modal prompts conditioned on Large Language Models (LLMs) and support images, seamlessly integrating them through a geometry-aware alignment. It mainly consists of Cross-modal Iterative Prompting (CIP) and Cross-modal Geometric Alignment (CGA). Specifically, the CIP conditions an LLM on both class names and support images to generate precise class descriptions iteratively in a single structured reasoning pass. These descriptions not only enrich the semantic understanding of novel classes but also enable the zero-shot synthesis of semantically consistent images. The descriptions and synthetic images act respectively as complementary textual and visual prompts, providing high-level class semantics and low-level intra-class diversity to compensate for limited support data. Furthermore, the CGA jointly aligns the fused textual, support, and synthetic visual representations by minimizing the kernelized volume of the 3-dimensional parallelotope they span. It captures global and nonlinear relationships among all representations, enabling structured and consistent multimodal integration. The proposed VT-FSL method establishes new state-of-the-art performance across ten diverse benchmarks, including standard, cross-domain, and fine-grained few-shot learning scenarios. Code is available at https://github.com/peacelwh/VT-FSL.
少样本学习(FSL)旨在从仅有的少量标记支持样本中识别新概念。最近的研究通过融入额外的语义信息或设计复杂的语义融合模块来增强支持特征。然而,由于缺乏在实际实例中的定位,它们仍然会遭受与视觉证据相矛盾的幻觉语义的困扰,导致产生嘈杂的指导和昂贵的修正。为了解决这些问题,我们提出了一种新的框架——基于大型语言模型(LLM)进行视觉和文本桥接的少样本学习(VT-FSL),该框架构建了精确跨模态提示,该提示基于大型语言模型和支持图像,通过几何感知对齐无缝集成它们。它主要由跨模态迭代提示(CIP)和跨模态几何对齐(CGA)组成。具体而言,CIP根据类别名称和支持图像对大型语言模型进行条件处理,以在单个结构化推理过程中迭代生成精确类别描述。这些描述不仅丰富了对新颖类别的语义理解,还实现了语义一致图像的零样本合成。这些描述和合成图像分别作为补充的文本和视觉提示,提供高级类别语义和低级类别内多样性,以弥补有限的支持数据。此外,CGA通过最小化它们所跨越的3D平行四边形的核化体积来联合对齐融合的文本、支持和合成视觉表示。它捕捉了所有表示之间的全局和非线性关系,实现了结构化且一致的多模态集成。所提出的VT-FSL方法在包括标准、跨域和细粒度少样本学习场景在内的十个不同基准测试上达到了新的最新性能水平。代码可在https://github.com/peacelwh/VT-FSL找到。
论文及项目相关链接
PDF Accepted by NeurIPS 2025
Summary
该文本介绍了一种新的面向少样本学习的跨模态框架VT-FSL,它结合了视觉和文本信息,利用大型语言模型(LLMs)和支持图像生成精确跨模态提示。该框架包括跨模态迭代提示(CIP)和跨模态几何对齐(CGA)。CIP通过结合类名和图像生成精确类描述,而CGA则联合对齐文本、支持图像和合成视觉表示,实现结构化一致的多模态融合。VT-FSL在多个基准测试中实现了最佳性能。
Key Takeaways
- VT-FSL是一个面向少样本学习的跨模态学习框架,结合了视觉和文本信息。
- 它利用大型语言模型和支持图像生成精确跨模态提示。
- CIP通过结合类名和图像生成精确的类描述,提高语义理解并合成语义一致图像。
- CGA联合对齐文本、支持图像和合成视觉表示,实现结构化一致的多模态融合。
- VT-FSL框架通过最小化他们跨越的核化体积的平行四边形的体积来捕捉所有表示之间的全局和非线性关系。
- 该方法在多个基准测试中实现了最佳性能,包括标准、跨域和细粒度少样本学习场景。
点此查看论文截图



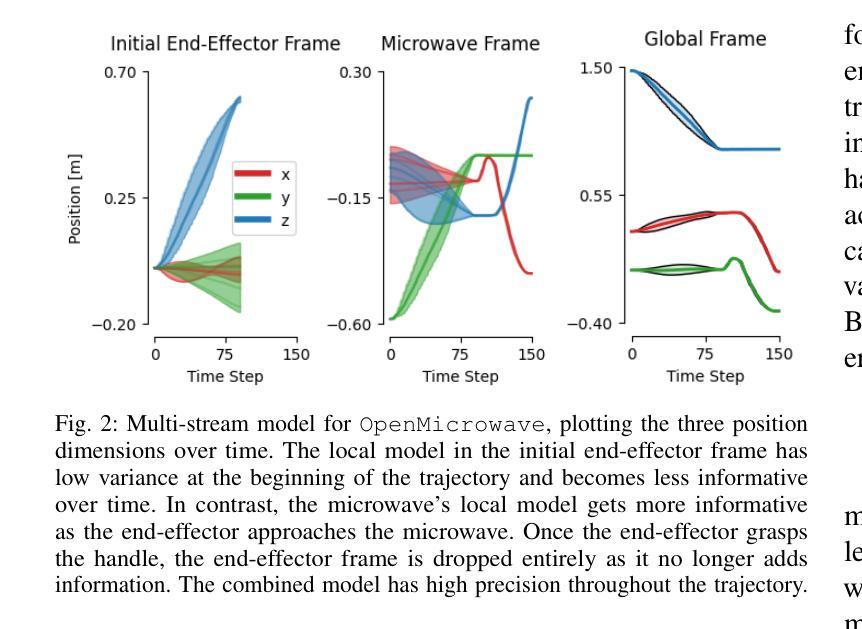
MSG: Multi-Stream Generative Policies for Sample-Efficient Robotic Manipulation
Authors:Jan Ole von Hartz, Lukas Schweizer, Joschka Boedecker, Abhinav Valada
Generative robot policies such as Flow Matching offer flexible, multi-modal policy learning but are sample-inefficient. Although object-centric policies improve sample efficiency, it does not resolve this limitation. In this work, we propose Multi-Stream Generative Policy (MSG), an inference-time composition framework that trains multiple object-centric policies and combines them at inference to improve generalization and sample efficiency. MSG is model-agnostic and inference-only, hence widely applicable to various generative policies and training paradigms. We perform extensive experiments both in simulation and on a real robot, demonstrating that our approach learns high-quality generative policies from as few as five demonstrations, resulting in a 95% reduction in demonstrations, and improves policy performance by 89 percent compared to single-stream approaches. Furthermore, we present comprehensive ablation studies on various composition strategies and provide practical recommendations for deployment. Finally, MSG enables zero-shot object instance transfer. We make our code publicly available at https://msg.cs.uni-freiburg.de.
生成式机器人策略,如流匹配(Flow Matching),提供了灵活多变模态的策略学习,但样本效率不高。尽管以对象为中心的策略提高了样本效率,但并没有解决这一局限性。在这项工作中,我们提出了多流生成策略(MSG),这是一种推理时间组合框架,训练多个以对象为中心的策略,并在推理时将它们结合起来,以提高泛化和样本效率。MSG具有模型无关性和仅推理性,因此可广泛应用于各种生成策略和训练范式。我们在模拟和真实机器人上进行了大量实验,结果表明我们的方法能从仅五个演示中学习高质量生成策略,演示减少了95%,并且相较于单流方法,策略性能提高了89%。此外,我们对各种组合策略进行了全面的消融研究,并为部署提供了实用建议。最后,MSG实现了零镜头对象实例迁移。我们在https://msg.cs.uni-freiburg.de公开了我们的代码。
论文及项目相关链接
Summary
提出一种名为Multi-Stream Generative Policy(MSG)的新方法,它在推理时组合多个对象中心策略以提高泛化和样本效率。 MSG是模型无关的,仅在推理时使用,因此可广泛应用于各种生成策略和训练范式。实验表明,该方法在模拟和真实机器人上的表现均优于单流方法,从五个演示中学习高质量生成策略,演示减少95%,性能提高89%。此外,还提供各种组合策略的全面消融研究及实际部署建议。 MSG还支持零射击对象实例转移。
Key Takeaways
- 提出了一种新的Multi-Stream Generative Policy(MSG)方法,结合了多个对象中心策略以提高泛化和样本效率。
- MSG方法通过训练多个对象中心策略并在推理时进行组合,解决了生成策略样本效率低的问题。
- MSG具有广泛的应用性,可以适用于各种生成策略和训练范式。
- 实验表明,MSG方法在模拟和真实机器人上的表现均优于单流方法。
- MSG方法能够从少量的演示中学习高质量的生成策略,演示数量减少95%,并且性能提升89%。
- MSG提供了全面的消融研究,探讨了不同的组合策略。
点此查看论文截图
Metaphor identification using large language models: A comparison of RAG, prompt engineering, and fine-tuning
Authors:Matteo Fuoli, Weihang Huang, Jeannette Littlemore, Sarah Turner, Ellen Wilding
Metaphor is a pervasive feature of discourse and a powerful lens for examining cognition, emotion, and ideology. Large-scale analysis, however, has been constrained by the need for manual annotation due to the context-sensitive nature of metaphor. This study investigates the potential of large language models (LLMs) to automate metaphor identification in full texts. We compare three methods: (i) retrieval-augmented generation (RAG), where the model is provided with a codebook and instructed to annotate texts based on its rules and examples; (ii) prompt engineering, where we design task-specific verbal instructions; and (iii) fine-tuning, where the model is trained on hand-coded texts to optimize performance. Within prompt engineering, we test zero-shot, few-shot, and chain-of-thought strategies. Our results show that state-of-the-art closed-source LLMs can achieve high accuracy, with fine-tuning yielding a median F1 score of 0.79. A comparison of human and LLM outputs reveals that most discrepancies are systematic, reflecting well-known grey areas and conceptual challenges in metaphor theory. We propose that LLMs can be used to at least partly automate metaphor identification and can serve as a testbed for developing and refining metaphor identification protocols and the theory that underpins them.
隐喻是话语的普遍特征和强大的认知、情感和意识形态研究工具。然而,由于隐喻的语境敏感性,大规模分析一直受到需要手动注释的限制。本研究探讨了大型语言模型(LLM)在全文自动隐喻识别中的潜力。我们比较了三种方法:(i)检索增强生成(RAG),该方法为模型提供一个代码本,并根据其规则和示例进行文本注释;(ii)指令工程,我们设计针对任务的特定口头指令;(iii)微调,该方法将模型训练在手工编码的文本上,以优化性能。在指令工程中,我们测试了零样本、小样本和链式思维策略。结果表明,最新的封闭源代码LLM可以达到高准确率,微调后的中位数F1分数为0.79。对比人类和LLM的输出结果,发现大部分差异具有系统性,反映了隐喻理论中的灰色地带和概念挑战。我们提出,可以利用LLM至少部分自动进行隐喻识别,并可以作为开发和优化隐喻识别协议及其理论基础的测试平台。
论文及项目相关链接
Summary
本文探讨了大型语言模型在自动识别文本中的隐喻方面的潜力。研究比较了三种方法:基于规则库的检索增强生成方法、基于特定任务提示的设计方法和通过微调模型以提高性能的方法。结果显示,经过微调的语言模型可以达到较高的准确性,其中位F1分数为0.79。对比人类与语言模型的输出,大部分差异在于隐喻理论中的灰色地带和概念挑战。本文认为,语言模型至少可以部分地自动进行隐喻识别,并可作为开发和优化隐喻识别协议及其理论基础的测试平台。
Key Takeaways
- 大型语言模型在自动隐喻识别方面具有潜力。
- 研究比较了三种隐喻识别方法:基于规则库的检索增强生成、基于任务提示的工程设计和微调模型。
- 微调模型的方法取得了最高的准确性,中位F1分数为0.79。
- 人与语言模型的输出差异主要源于隐喻理论中的灰色地带和概念挑战。
- 语言模型可部分自动进行隐喻识别。
- 语言模型可作为开发和优化隐喻识别协议及其理论基础的测试平台。
点此查看论文截图


LEAF: A Robust Expert-Based Framework for Few-Shot Continual Event Detection
Authors:Bao-Ngoc Dao, Quang Nguyen, Luyen Ngo Dinh, Minh Le, Linh Ngo Van
Few-shot Continual Event Detection (FCED) poses the dual challenges of learning from limited data and mitigating catastrophic forgetting across sequential tasks. Existing approaches often suffer from severe forgetting due to the full fine-tuning of a shared base model, which leads to knowledge interference between tasks. Moreover, they frequently rely on data augmentation strategies that can introduce unnatural or semantically distorted inputs. To address these limitations, we propose LEAF, a novel and robust expert-based framework for FCED. LEAF integrates a specialized mixture of experts architecture into the base model, where each expert is parameterized with low-rank adaptation (LoRA) matrices. A semantic-aware expert selection mechanism dynamically routes instances to the most relevant experts, enabling expert specialization and reducing knowledge interference. To improve generalization in limited-data settings, LEAF incorporates a contrastive learning objective guided by label descriptions, which capture high-level semantic information about event types. Furthermore, to prevent overfitting on the memory buffer, our framework employs a knowledge distillation strategy that transfers knowledge from previous models to the current one. Extensive experiments on multiple FCED benchmarks demonstrate that LEAF consistently achieves state-of-the-art performance.
少量样本持续事件检测(FCED)面临着从有限数据中学习和缓解顺序任务中的灾难性遗忘的双重挑战。现有方法常常因为共享基础模型的全面微调而遭受严重的遗忘问题,这导致任务之间的知识干扰。此外,它们经常依赖数据增强策略,这可能引入不自然或语义扭曲的输入。为了解决这些局限性,我们提出了LEAF,这是一个针对FCED的新型稳健的专家基础框架。LEAF将专业化的混合专家架构集成到基础模型中,其中每个专家都用低秩适应(LoRA)矩阵进行参数化。语义感知的专家选择机制动态地将实例路由到最相关的专家,实现专家专业化并减少知识干扰。为了提高有限数据环境中的泛化能力,LEAF采用了由标签描述引导的对比学习目标,捕获有关事件类型的高级语义信息。此外,为了防止对内存缓冲区的过度拟合,我们的框架采用知识蒸馏策略,将先前模型的知识转移到当前模型中。在多个FCED基准测试上的广泛实验表明,LEAF始终实现了最先进的性能。
论文及项目相关链接
Summary
本文介绍了针对Few-Shot Continual Event Detection(FCED)任务的新型稳健专家框架LEAF。该框架通过集成特定专家模型和语义感知的专家选择机制,解决了有限数据学习和顺序任务中的灾难性遗忘问题。此外,它结合了低秩适应矩阵参数化的专家模型和对比学习损失来提高泛化能力,并采用知识蒸馏策略防止对内存缓冲区的过度拟合。实验证明,LEAF在多个FCED基准测试中实现了卓越的性能。
Key Takeaways
- LEAF是一个针对Few-Shot Continual Event Detection(FCED)的新型专家框架,旨在解决有限数据学习和任务连续性中的灾难性遗忘问题。
- LEAF通过集成特定专家模型和语义感知的专家选择机制来增强模型性能。
- 每个专家模型通过低秩适应(LoRA)矩阵进行参数化,有助于减少知识干扰和提高模型适应性。
- LEAF利用对比学习损失来提高在有限数据环境下的泛化能力,通过标签描述捕捉事件类型的高级语义信息。
- LEAF采用知识蒸馏策略,防止对内存缓冲区的过度拟合,并提升模型的持续学习能力。
- 实验证明,LEAF在多个FCED基准测试中表现出卓越的性能,证明了其有效性和优越性。
点此查看论文截图


EVLF-FM: Explainable Vision Language Foundation Model for Medicine
Authors:Yang Bai, Haoran Cheng, Yang Zhou, Jun Zhou, Arun Thirunavukarasu, Yuhe Ke, Jie Yao, Kanae Fukutsu, Chrystie Wan Ning Quek, Ashley Hong, Laura Gutierrez, Zhen Ling Teo, Darren Shu Jeng Ting, Brian T. Soetikno, Christopher S. Nielsen, Tobias Elze, Zengxiang Li, Linh Le Dinh, Hiok Hong Chan, Victor Koh, Marcus Tan, Kelvin Z. Li, Leonard Yip, Ching Yu Cheng, Yih Chung Tham, Gavin Siew Wei Tan, Leopold Schmetterer, Marcus Ang, Rahat Hussain, Jod Mehta, Tin Aung, Lionel Tim-Ee Cheng, Tran Nguyen Tuan Anh, Chee Leong Cheng, Tien Yin Wong, Nan Liu, Iain Beehuat Tan, Soon Thye Lim, Eyal Klang, Tony Kiat Hon Lim, Rick Siow Mong Goh, Yong Liu, Daniel Shu Wei Ting
Despite the promise of foundation models in medical AI, current systems remain limited - they are modality-specific and lack transparent reasoning processes, hindering clinical adoption. To address this gap, we present EVLF-FM, a multimodal vision-language foundation model (VLM) designed to unify broad diagnostic capability with fine-grain explainability. The development and testing of EVLF-FM encompassed over 1.3 million total samples from 23 global datasets across eleven imaging modalities related to six clinical specialties: dermatology, hepatology, ophthalmology, pathology, pulmonology, and radiology. External validation employed 8,884 independent test samples from 10 additional datasets across five imaging modalities. Technically, EVLF-FM is developed to assist with multiple disease diagnosis and visual question answering with pixel-level visual grounding and reasoning capabilities. In internal validation for disease diagnostics, EVLF-FM achieved the highest average accuracy (0.858) and F1-score (0.797), outperforming leading generalist and specialist models. In medical visual grounding, EVLF-FM also achieved stellar performance across nine modalities with average mIOU of 0.743 and Acc@0.5 of 0.837. External validations further confirmed strong zero-shot and few-shot performance, with competitive F1-scores despite a smaller model size. Through a hybrid training strategy combining supervised and visual reinforcement fine-tuning, EVLF-FM not only achieves state-of-the-art accuracy but also exhibits step-by-step reasoning, aligning outputs with visual evidence. EVLF-FM is an early multi-disease VLM model with explainability and reasoning capabilities that could advance adoption of and trust in foundation models for real-world clinical deployment.
尽管医疗人工智能中的基础模型前景广阔,但当前系统仍存在局限性,它们具有特定的模态,缺乏透明的推理过程,阻碍了其在临床上的采用。为了解决这一差距,我们推出了EVLF-FM,这是一款多模态视觉语言基础模型(VLM),旨在将广泛的诊断能力与精细的颗粒解释性结合起来。EVLF-FM的开发和测试涵盖了来自全球23个数据集的超过130万样本,涉及与六个临床专业相关的十一种成像模态,包括皮肤科、肝病科、眼科、病理学、肺病学和放射学。外部验证采用了来自五个成像模态的另外十个数据集的8884个独立测试样本。在技术上,EVLF-FM的开发旨在协助具有像素级视觉定位和推理能力的多种疾病诊断和视觉问答。在内部验证疾病诊断中,EVLF-FM获得了最高的平均准确度(0.858)和F1分数(0.797),优于领先的综合模型和专家模型。在医疗视觉定位中,EVLF-FM在九个模态上的平均mIOU为0.743,Acc@0.5为0.837,表现卓越。外部验证进一步证实了其零样本和少样本的强大性能,尽管模型规模较小,但F1分数具有竞争力。通过结合有监督学习和视觉强化精细调整的混合训练策略,EVLF-FM不仅实现了最先进的准确性,而且展现出逐步推理的能力,使输出与视觉证据保持一致。EVLF-FM是一款早期具有解释性和推理能力的多疾病VLM模型,可以促进基础模型在实际临床部署中的应用和信任。
论文及项目相关链接
Summary
本文介绍了针对医疗AI领域的基础模型存在的局限性,提出了一种多模态视觉语言基础模型(EVLF-FM)。该模型融合了广泛的诊断能力与精细的解释性,适用于多种疾病诊断与视觉问答任务。经过全球23个数据集的训练与测试,并在独立测试样本中验证其性能。EVLF-FM在疾病诊断与医疗视觉定位任务中表现出卓越性能,通过混合训练策略实现高级准确性和逐步推理,有助于推动基础模型在临床实际应用中的普及与信任。
Key Takeaways
- 当前医疗AI基础模型存在局限性,缺乏跨模态的通用性和透明推理过程。
- EVLF-FM是一种多模态视觉语言基础模型(VLM),旨在统一广泛的诊断能力和精细的解释性。
- EVLF-FM经过全球23个数据集的训练和测试,涵盖六种临床专业和十一种成像模态。
- 在疾病诊断和医疗视觉定位任务中,EVLF-FM性能卓越,平均准确率和F1分数领先。
- EVLF-FM通过混合训练策略实现高级准确性和逐步推理,增强模型性能。
- EVLF-FM在零样本和少样本情况下表现出强大的性能,具有竞争力。
点此查看论文截图

ASTROCO: Self-Supervised Conformer-Style Transformers for Light-Curve Embeddings
Authors:Antony Tan, Pavlos Protopapas, Martina Cádiz-Leyton, Guillermo Cabrera-Vives, Cristobal Donoso-Oliva, Ignacio Becker
We present AstroCo, a Conformer-style encoder for irregular stellar light curves. By combining attention with depthwise convolutions and gating, AstroCo captures both global dependencies and local features. On MACHO R-band, AstroCo outperforms Astromer v1 and v2, yielding 70 percent and 61 percent lower error respectively and a relative macro-F1 gain of about 7 percent, while producing embeddings that transfer effectively to few-shot classification. These results highlight AstroCo’s potential as a strong and label-efficient foundation for time-domain astronomy.
我们介绍了AstroCo,这是一种用于不规则恒星光曲线的Conformer风格编码器。通过结合注意力、深度卷积和门控机制,AstroCo能够捕捉全局依赖关系和局部特征。在MACHO R波段上,AstroCo的表现优于Astromer v1和v2,分别降低了70%和61%的错误率,相对宏观F1得分提高了约7%,同时产生了有效迁移至小样本分类的嵌入。这些结果突出了AstroCo作为时间域天文学强大且标签效率高的基础的潜力。
论文及项目相关链接
PDF Accepted at the NeurIPS 2025 Workshop on Machine Learning and the Physical Sciences (ML4PS), camera-ready version in progress
Summary
AstroCo是一种基于Conformer编码器的恒星不规则光曲线模型。通过结合注意力机制、深度卷积和门控机制,AstroCo能够捕捉全局依赖关系和局部特征。在MACHO R波段上,AstroCo的表现优于Astromer v1和v2,分别降低了70%和61%的错误率,相对宏观F1得分提高了约7%,同时产生的嵌入能够有效地应用于小样分类。这些结果突显了AstroCo作为时间域天文学强大且标签效率高的基础的潜力。
Key Takeaways
- AstroCo是一个用于不规则恒星光曲线的Conformer风格编码器。
- AstroCo结合注意力机制、深度卷积和门控机制,捕捉全局依赖和局部特征。
- 在MACHO R波段上,AstroCo表现优于Astromer v1和v2。
- AstroCo降低了错误率,相对宏观F1得分有所提高。
- AstroCo产生的嵌入适用于小样分类。
- AstroCo具有潜力成为时间域天文学强大且标签效率高的基础。
点此查看论文截图
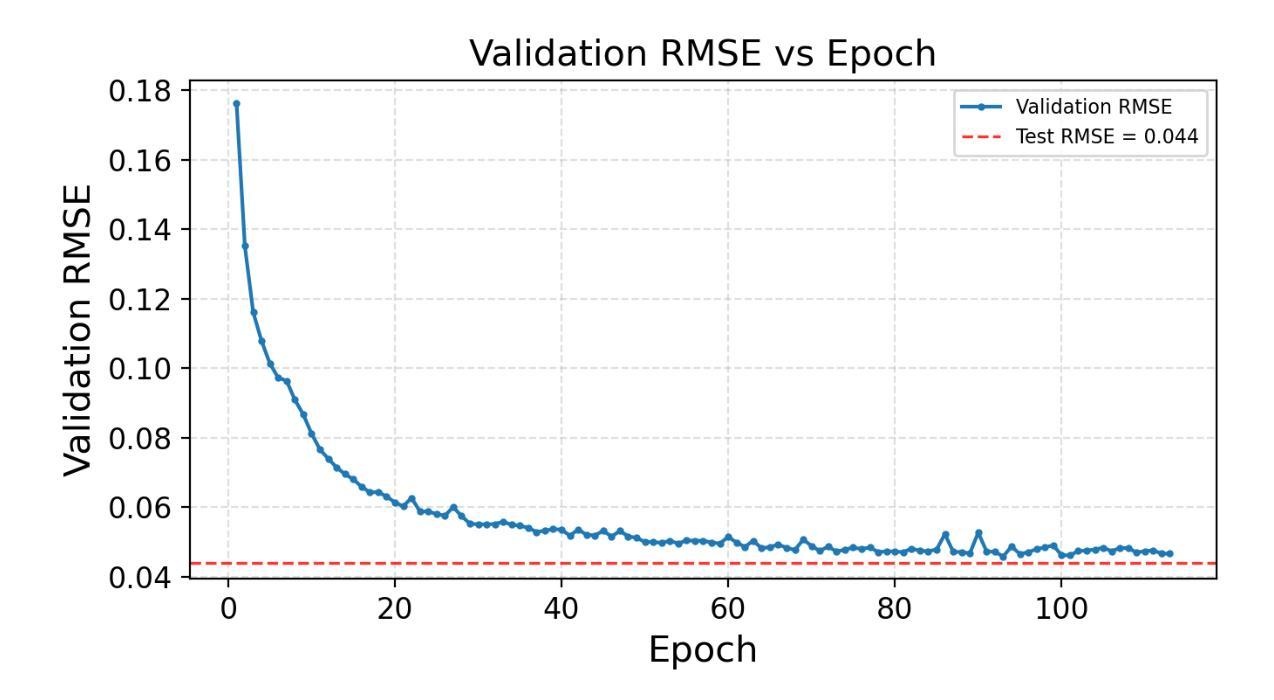
CE-FAM: Concept-Based Explanation via Fusion of Activation Maps
Authors:Michihiro Kuroki, Toshihiko Yamasaki
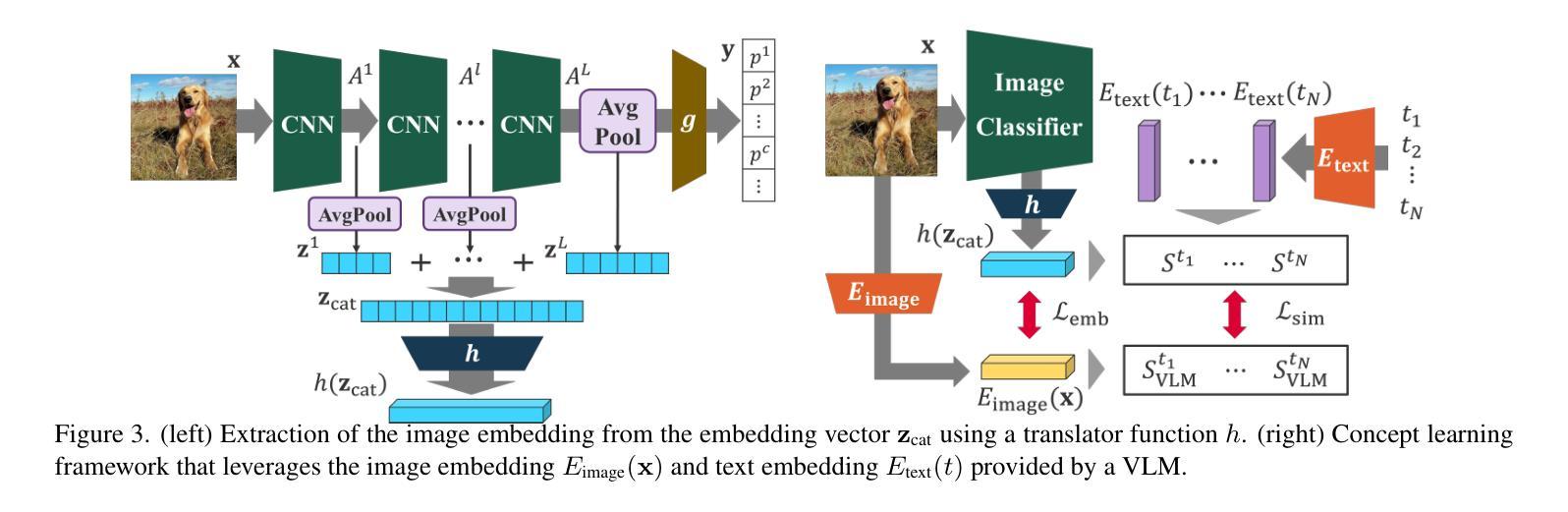
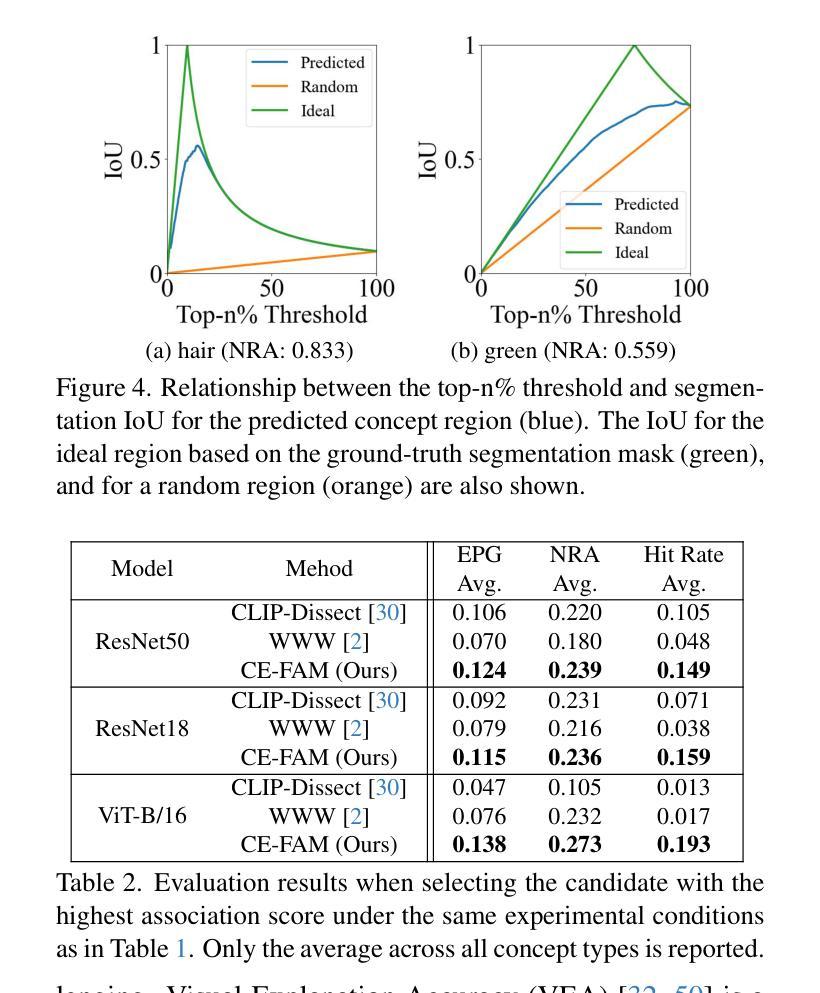
Although saliency maps can highlight important regions to explain the reasoning behind image classification in artificial intelligence (AI), the meaning of these regions is left to the user’s interpretation. In contrast, conceptbased explanations decompose AI predictions into humanunderstandable concepts, clarifying their contributions. However, few methods can simultaneously reveal what concepts an image classifier learns, which regions are associated with them, and how they contribute to predictions. We propose a novel concept-based explanation method, Concept-based Explanation via Fusion of Activation Maps (CE-FAM). It employs a branched network that shares activation maps with an image classifier and learns to mimic the embeddings of a Vision and Language Model (VLM). The branch network predicts concepts in an image, and their corresponding regions are represented by a weighted sum of activation maps, with weights given by the gradients of the concept prediction scores. Their contributions are quantified based on their impact on the image classification score. Our method provides a general framework for identifying the concept regions and their contributions while leveraging VLM knowledge to handle arbitrary concepts without requiring an annotated dataset. Furthermore, we introduce a novel evaluation metric to assess the accuracy of the concept regions. Our qualitative and quantitative evaluations demonstrate our method outperforms existing approaches and excels in zero-shot inference for unseen concepts.
虽然显著性图可以突出强调人工智能(AI)图像分类背后的重要区域以解释其推理过程,但这些区域的含义仍留给用户自行解读。相比之下,基于概念的解释将AI预测分解成人类可理解的概念,澄清了它们的贡献。然而,很少有方法能同时揭示图像分类器学习了哪些概念,哪些区域与之相关,以及它们如何对预测做出贡献。我们提出了一种新颖的概念解释方法——基于激活图的融合概念解释法(CE-FAM)。它采用分支网络,该网络与图像分类器共享激活图,并学习模仿视觉语言模型(VLM)的嵌入。分支网络预测图像中的概念,其相应区域由激活图的加权和表示,权重由概念预测分数的梯度给出。它们的贡献是基于对图像分类分数的影响进行量化的。我们的方法提供了一个通用的框架,用于识别概念区域及其贡献,同时利用VLM的知识来处理任意概念,而无需标注数据集。此外,我们引入了一种新的评估指标,以评估概念区域的准确性。我们的定性和定量评估表明,我们的方法在未见过的概念的零样本推理方面优于现有方法。
论文及项目相关链接
PDF This paper has been accepted to ICCV 2025
Summary
本文提出了一种基于概念的解释方法CE-FAM,用于揭示图像分类器学习的概念、图像中的相关区域以及这些概念对预测的贡献。该方法利用分支网络共享激活图,并模仿视觉语言模型(VLM)的嵌入,预测图像中的概念及其对应区域。分支网络通过加权和激活图表示这些区域,权重由概念预测分数的梯度给出。此外,本文还引入了一种新的评估指标来评估概念区域的准确性。该方法在未见过的概念上实现了零样本推理的优异表现。
Key Takeaways
- CE-FAM方法结合了激活图和概念预测来解释图像分类器的决策过程。
- 该方法通过分支网络预测图像中的概念及其对应区域,并利用激活图的加权和表示这些区域。
- CE-FAM利用视觉语言模型(VLM)的知识来处理任意概念,无需标注数据集。
- 方法提供了一种通用框架来识别概念区域及其贡献。
- 引入了一种新的评估指标来评估概念区域的准确性。
- CE-FAM在零样本推理任务上表现优异,尤其是在未见过的概念上。
点此查看论文截图


Online Specific Emitter Identification via Collision-Alleviated Signal Hash
Authors:Hongyu Wang, Wenjia Xu, Guangzuo Li, Siyuan Wan, Yaohua Sun, Jiuniu Wang, Mugen Peng
Specific Emitter Identification (SEI) has been widely studied, aiming to distinguish signals from different emitters given training samples from those emitters. However, real-world scenarios often require identifying signals from novel emitters previously unseen. Since these novel emitters only have a few or no prior samples, existing models struggle to identify signals from novel emitters online and tend to bias toward the distribution of seen emitters. To address these challenges, we propose the Online Specific Emitter Identification (OSEI) task, comprising both online \revise{few-shot and generalized zero-shot} learning tasks. It requires constructing models using signal samples from seen emitters and then identifying new samples from seen and novel emitters online during inference. We propose a novel hash-based model, Collision-Alleviated Signal Hash (CASH), providing a unified approach for addressing the OSEI task. The CASH operates in two steps: in the seen emitters identifying step, a signal encoder and a seen emitters identifier determine whether the signal sample is from seen emitters, mitigating the model from biasing toward seen emitters distribution. In the signal hash coding step, an online signal hasher assigns a hash code to each signal sample, identifying its specific emitter. Experimental results on real-world signal datasets (i.e., ADSB and ORACLE) demonstrate that our method accurately identifies signals from both seen and novel emitters online. This model outperforms existing methods by a minimum of 6.08% and 8.55% in accuracy for the few-shot and \revise{generalized zero-shot learning }tasks, respectively. The code will be open-sourced at \href{https://github.com/IntelliSensing/OSEI-CASH}{https://github.com/IntelliSensing/OSEI-CASH}.
特定发射器识别(SEI)已经得到了广泛的研究,其目标是根据来自这些发射器的训练样本区分来自不同发射器的信号。然而,现实世界的情况通常需要识别来自以前未见过的新型发射器的信号。由于这些新型发射器只有少量或没有先验样本,现有模型在在线识别新型发射器的信号时遇到困难,并往往偏向于已见发射器的分布。为了解决这些挑战,我们提出了在线特定发射器识别(OSEI)任务,该任务涵盖了在线的\revise{小样本学习和广义零样本学习}。它需要使用来自已见发射器的信号样本构建模型,然后在推断期间在线识别来自已知和新型发射器的新样本。我们提出了一种基于哈希的新型模型,即碰撞缓解信号哈希(CASH),为OSEI任务提供了一种统一的方法。CASH分两步操作:在已见发射器识别步骤中,信号编码器和已见发射器识别器确定信号样本是否来自已见发射器,减轻模型偏向于已见发射器分布的问题。在信号哈希编码步骤中,在线信号哈希器为每个信号样本分配一个哈希代码,以识别其特定发射器。在真实世界信号数据集(例如ADSB和ORACLE)上的实验结果表明,我们的方法准确地在线识别了来自已知和新型发射器的信号。与现有方法相比,该模型在小样本学习和\revise{广义零样本学习任务上的准确率分别提高了至少6.08%和8.55%}。代码将在\href{https://github.com/IntelliSensing/OSEI-CASH}{https://github.com/IntelliSensing/OSEI-CASH}上开源。
论文及项目相关链接
PDF This paper has been accepted by IEEE Transactions on Vehicular Technology
摘要
本文研究了在线特定发射器识别(OSEI)任务,旨在解决从已知和未知发射器识别信号的问题。针对现有模型在识别来自新型发射器的信号时存在的偏见问题,提出了基于哈希的碰撞缓解信号哈希(CASH)模型。该模型通过两个步骤进行工作:首先确定信号是否来自已知发射器,然后为每个信号样本分配哈希码以识别其特定发射器。实验结果表明,该方法在真实信号数据集上能够准确识别来自已知和未知发射器的信号,并在少样本和广义零样本学习任务上分别优于现有方法至少6.08%和8.55%。
关键见解
- 介绍了在线特定发射器识别(OSEI)任务,该任务旨在识别来自已知和未知发射器的信号。
- 提出了碰撞缓解信号哈希(CASH)模型,该模型通过两个步骤进行工作:确定信号是否来自已知发射器和为每个信号样本分配哈希码以识别其特定发射器。
- 实验结果表明,CASH模型在真实信号数据集上表现优异,能够准确识别来自已知和未知发射器的信号。
- CASH模型在少样本和广义零样本学习任务上的准确率高于现有方法。
- CASH模型的编码将开源,便于其他研究者使用。
- 该模型有助于解决现有模型对已知发射器分布的偏见问题。
- CASH模型通过统一的方法处理OSEI任务,具有广泛的应用前景。
点此查看论文截图
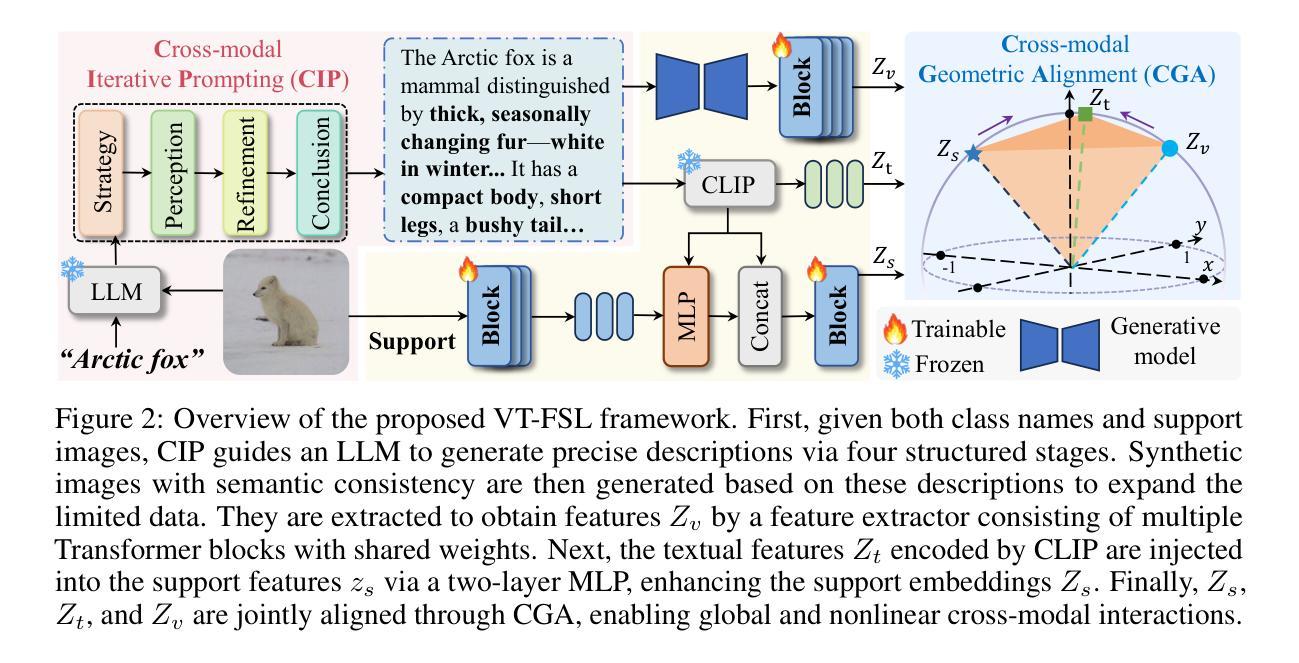
How to Make Large Language Models Generate 100% Valid Molecules?
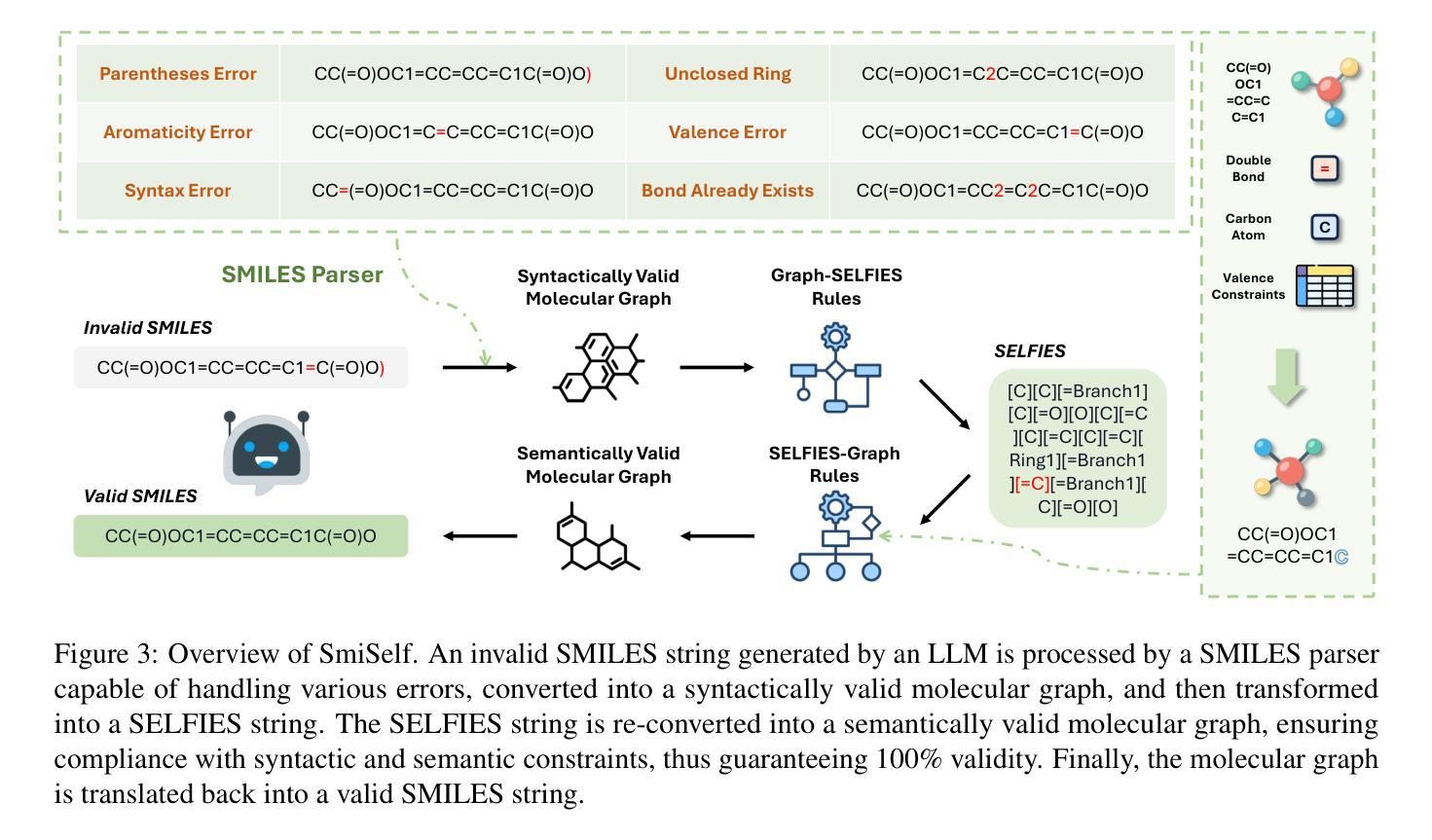
Authors:Wen Tao, Jing Tang, Alvin Chan, Bryan Hooi, Baolong Bi, Nanyun Peng, Yuansheng Liu, Yiwei Wang
Molecule generation is key to drug discovery and materials science, enabling the design of novel compounds with specific properties. Large language models (LLMs) can learn to perform a wide range of tasks from just a few examples. However, generating valid molecules using representations like SMILES is challenging for LLMs in few-shot settings. In this work, we explore how LLMs can generate 100% valid molecules. We evaluate whether LLMs can use SELFIES, a representation where every string corresponds to a valid molecule, for valid molecule generation but find that LLMs perform worse with SELFIES than with SMILES. We then examine LLMs’ ability to correct invalid SMILES and find their capacity limited. Finally, we introduce SmiSelf, a cross-chemical language framework for invalid SMILES correction. SmiSelf converts invalid SMILES to SELFIES using grammatical rules, leveraging SELFIES’ mechanisms to correct the invalid SMILES. Experiments show that SmiSelf ensures 100% validity while preserving molecular characteristics and maintaining or even enhancing performance on other metrics. SmiSelf helps expand LLMs’ practical applications in biomedicine and is compatible with all SMILES-based generative models. Code is available at https://github.com/wentao228/SmiSelf.
分子生成对于药物发现和材料科学至关重要,它能够使人们设计出具有特定属性的新型化合物。大型语言模型(LLMs)只需要从少量样本中学习便可以执行各种任务。然而,在少量样本的情况下,使用SMILES等表示法生成有效的分子对LLMs来说具有挑战性。在这项工作中,我们探讨了LLMs如何生成100%有效的分子。我们评估了LLMs是否可以使用SELFIES(一种每个字符串都对应一个有效分子的表示法)来进行有效分子生成,但发现LLMs在SELFIES上的表现不如SMILES。然后我们研究了LLMs纠正无效SMILES的能力,并发现其能力有限。最后,我们推出了SmiSelf,这是一个跨化学语言框架,用于纠正无效的SMILES。SmiSelf使用语法规则将无效的SMILES转换为SELFIES,利用SELFIES的机制纠正无效的SMILES。实验表明,SmiSelf在确保100%有效性的同时,能够保持分子特性,并在其他指标上甚至提高性能。SmiSelf有助于扩大LLMs在生物医学中的实际应用,并且与所有基于SMILES的生成模型兼容。代码可在https://github.com/wentao228/SmiSelf找到。
论文及项目相关链接
PDF EMNLP 2025 Main
Summary
大型语言模型(LLM)在分子生成中具有潜力,特别是在药物发现和材料科学领域。然而,LLM在少样本环境下生成SMILES表示的有效分子具有挑战性。本研究探讨了LLM如何生成百分之百有效分子的问题。尽管尝试使用SELFIES表示方法,但发现LLM的表现不如SMILES。因此,本研究引入了SmiSelf框架,用于校正无效的SMILES并将其转换为SELFIES表示形式。实验表明,SmiSelf确保了百分之百的有效性,同时保持了分子特性,并在其他指标上维持或提高了性能。这为LLM在生物医学中的实际应用提供了帮助,并与所有基于SMILES的生成模型兼容。
Key Takeaways
- 大型语言模型(LLM)在药物发现和材料科学中的分子生成方面展现出潜力。
- 在少样本环境下,LLM生成SMILES表示的有效分子具有挑战性。
- 尝试使用SELFIES表示方法生成分子,但LLM表现不佳。
- 引入SmiSelf框架用于校正无效的SMILES表示并将其转换为SELFIES表示形式。
- SmiSelf确保了百分之百的有效性并保证分子特性得到保持。
- SmiSelf维持或提高了在其他指标上的性能表现。
点此查看论文截图
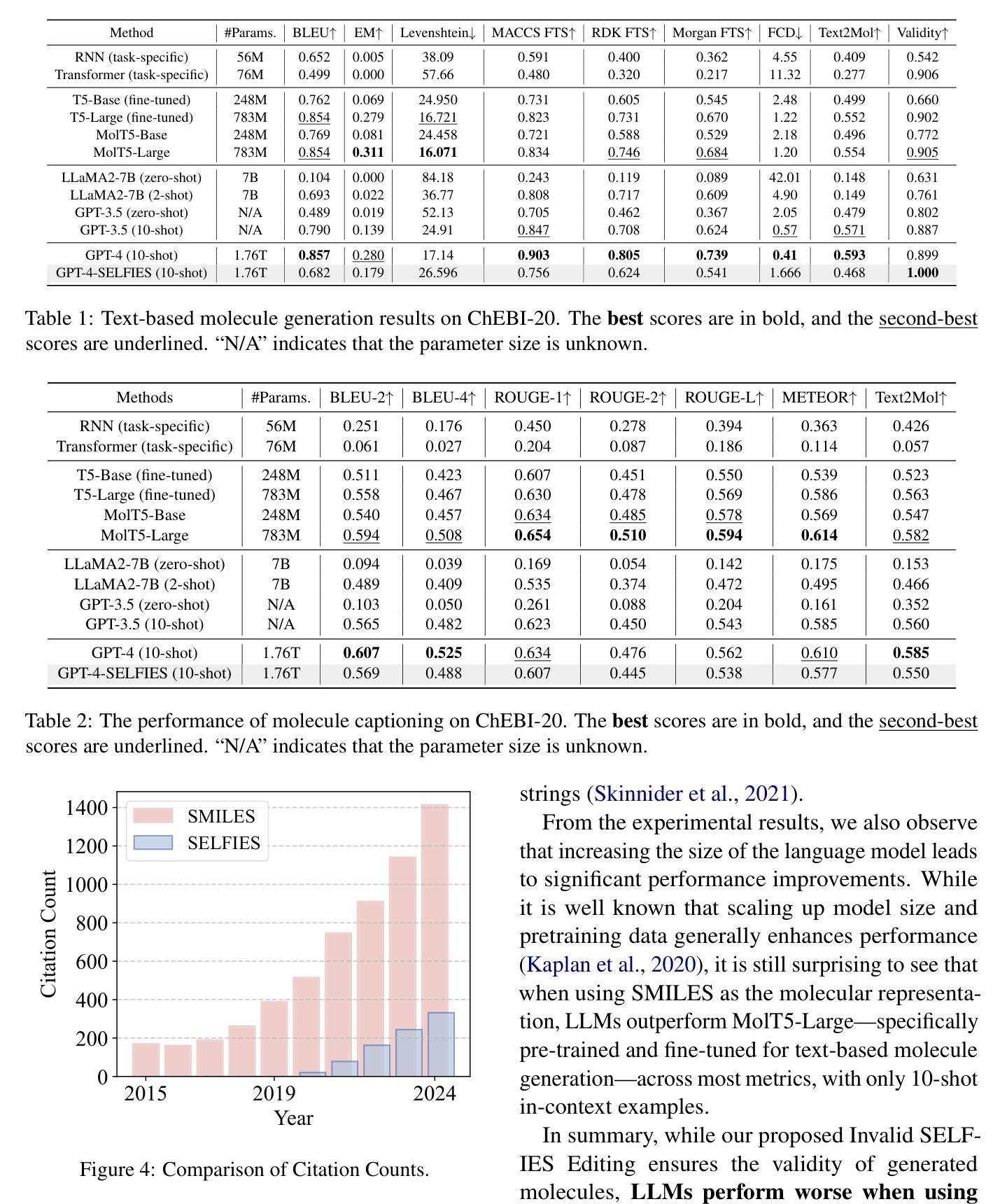
What Matters More For In-Context Learning under Matched Compute Budgets: Pretraining on Natural Text or Incorporating Targeted Synthetic Examples?
Authors:Mohammed Sabry, Anya Belz
Does explicitly exercising the induction circuit during pretraining improve in-context learning (ICL), or is natural text sufficient when compute is held constant (iso-FLOPs)? To test whether targeted synthetic data can accelerate induction-head emergence and enhance ICL, we introduce Bi-Induct, a lightweight curriculum that injects forward-copy (Induction), backward-copy (Anti), or a balanced mix into the pretraining stream. We train models from 0.13B to 1B parameters under iso-FLOPs, evaluating (i) few-shot ICL benchmarks, (ii) head-level telemetry, and (iii) held-out language modeling perplexity. Our findings challenge the assumption that early induction circuit activation directly improves ICL. While Bi-Induct accelerates induction-head emergence at small scales, this does not consistently yield stronger generalization. On standard LM benchmarks, Bi-Induct matches natural-only training; on function-style ICL probes, the 1B natural-only performs best. Stress tests (e.g., label permutation, HITS@1 vs. HITS@3, 1 vs. 10 shots) preserve these trends. Telemetry shows larger natural-only models develop broader, earlier induction heads without explicit induction patterns. Anti-induction data fails to elicit meaningful activation. Perplexity penalties from synthetic data shrink with scale, suggesting larger models can absorb non-natural patterns with minimal cost. Crucially, ablating the top 2% of induction heads degrades ICL more than random ablations, especially for natural-only models, indicating more centralized, load-bearing circuits. Bi-Induct variants exhibit more redundant induction activity, implying different circuit utilization. Overall, inducing activation is not sufficient: ICL gains depend on these circuits becoming functionally necessary. These results underscore mechanism-aware pretraining diagnostics and data mixtures that foster load-bearing, not merely present, structure.
在预训练过程中明确锻炼归纳电路是否会改善上下文学习(ICL),或者在保持计算量不变(iso-FLOPs)时自然文本是否足够?为了测试有针对性的合成数据是否可以加速归纳头(induction-head)的出现并增强ICL,我们引入了Bi-Induct,这是一种轻量级的课程学习法,将正向复制(归纳)、反向复制(Anti)或平衡混合注入预训练流中。我们在iso-FLOPs条件下,对从0.13B到1B参数的模型进行训练,评估(i)少量ICL基准测试,(ii)头部级别遥测,以及(iii)保持的语言建模困惑度。我们的研究结果表明,早期归纳电路激活直接改善ICL的假设不成立。虽然Bi-Induct在小型规模上加速了归纳头的出现,但这并不一定会产生更强的泛化能力。在自然语言模型基准测试中,Bi-Induct的表现与仅自然训练相匹配;在功能型ICL探测中,规模为1B的仅自然训练表现最佳。在压力测试(如标签置换、HITS@1与HITS@3、1与10次射击)中,这些趋势依旧保持不变。遥测显示,规模较大的自然模型能够开发出更广泛、更早的归纳头而没有明显的归纳模式。反向归纳数据未能引发有意义的激活。来自合成数据的困惑度惩罚随着规模的扩大而缩小,这表明大型模型可以吸收非自然模式而代价极小。关键的是,消除前2%的归纳头对ICL的破坏程度超过随机消除,特别是对于仅自然的模型,这表明更为集中、负载承载的电路。Bi-Induct变体表现出更多的冗余归纳活动,暗示不同的电路利用方式。总的来说,诱发激活并不足以依赖:ICL的增益取决于这些电路是否成为功能上的必需品。这些结果强调了机制感知的预训练诊断和数据混合物,它们促进了负载承载,而不仅仅是现有的结构。
论文及项目相关链接
Summary
本文研究了在预训练过程中是否需要通过明确训练归纳电路来改善上下文学习(ICL)。通过引入Bi-Induct课程,将归纳(Induction)和反向归纳(Anti)的平衡混合注入预训练流中,对模型进行测试。研究发现,虽然Bi-Induct可以加速小规模归纳头的出现,但并不总是导致更强的泛化能力。对于标准LM基准测试,Bi-Induct与仅自然训练相匹配;而在功能样式的ICL测试中,规模为1B的自然模型表现最佳。这表明仅仅激活归纳电路并不足以提高ICL的效果,而是需要这些电路成为功能上的必要组成部分。
Key Takeaways
- Bi-Induct课程旨在通过注入归纳和反向归纳数据来加速归纳电路的激活。
- 在预训练过程中,明确训练归纳电路并不总是提高模型的泛化能力。
- 对于标准语言建模基准测试,Bi-Induct的表现与仅使用自然训练数据相当。
- 在特定功能样式的ICL测试中,规模为1B的自然模型表现最佳。
- 归纳电路的作用不仅仅是呈现结构,而是需要成为功能上的必要组成部分。
- 较大规模的自然模型可以吸收非自然模式,且代价较小。
- 废除归纳头对ICL的影响更大,特别是对于自然模型,表明电路利用更加集中和承载负载。
点此查看论文截图

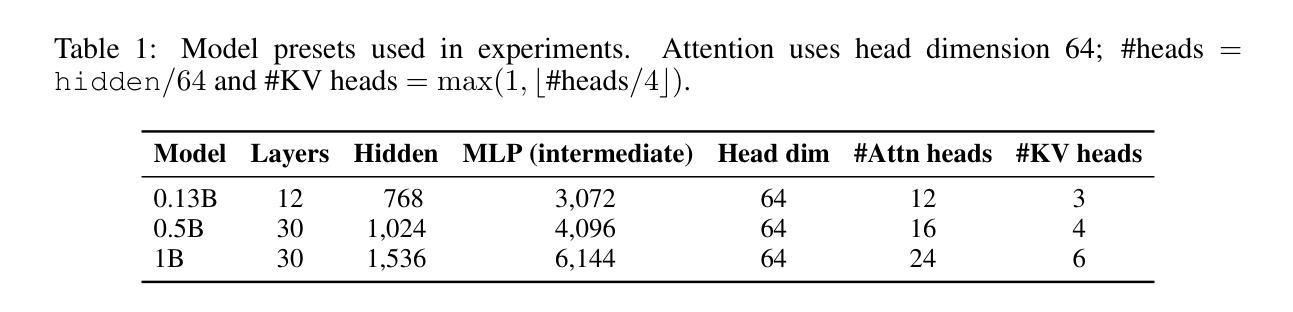
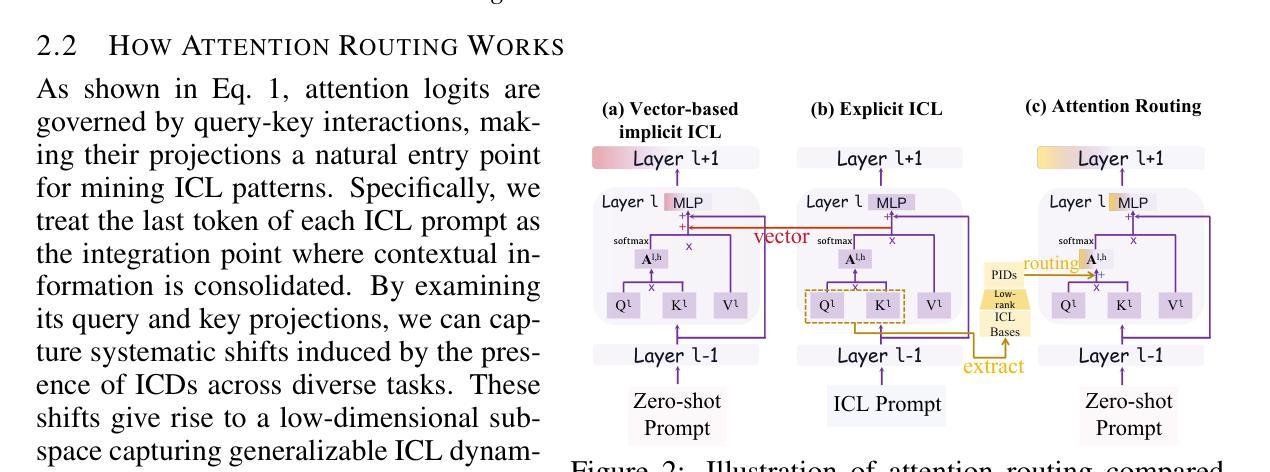
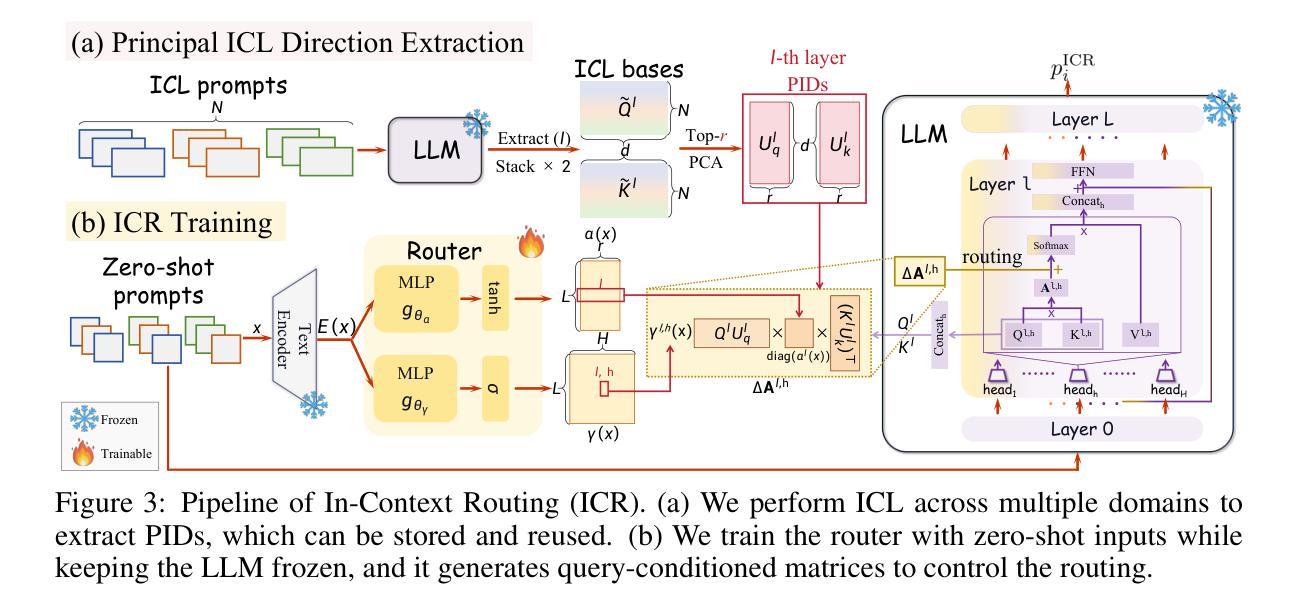
Towards Generalizable Implicit In-Context Learning with Attention Routing
Authors:Jiaqian Li, Yanshu Li, Ligong Han, Ruixiang Tang, Wenya Wang
Implicit in-context learning (ICL) has newly emerged as a promising paradigm that simulates ICL behaviors in the representation space of Large Language Models (LLMs), aiming to attain few-shot performance at zero-shot cost. However, existing approaches largely rely on injecting shift vectors into residual flows, which are typically constructed from labeled demonstrations or task-specific alignment. Such designs fall short of utilizing the structural mechanisms underlying ICL and suffer from limited generalizability. To address this, we propose In-Context Routing (ICR), a novel implicit ICL method that internalizes generalizable ICL patterns at the attention logits level. It extracts reusable structural directions that emerge during ICL and employs a learnable input-conditioned router to modulate attention logits accordingly, enabling a train-once-and-reuse framework. We evaluate ICR on 12 real-world datasets spanning diverse domains and multiple LLMs. The results show that ICR consistently outperforms prior implicit ICL methods that require task-specific retrieval or training, while demonstrating robust generalization to out-of-domain tasks where existing methods struggle. These findings position ICR to push the boundary of ICL’s practical value.
隐式上下文学习(ICL)作为一种新兴的有前途的范式,模拟了大型语言模型(LLM)的表示空间中的ICL行为,旨在以零成本达到小样本性能。然而,现有方法大多依赖于向残差流注入迁移向量,这通常是由带标签的演示或任务特定的对齐构建的。这种设计未能充分利用ICL的内在结构机制,且其通用性有限。为了解决这个问题,我们提出了上下文路由(ICR),这是一种新型的隐式ICL方法,在注意力得分层面内部化可泛化的ICL模式。它提取了在ICL过程中出现的可重复使用的结构方向,并采用可学习的输入条件路由器来相应地调整注意力得分,从而实现了一次训练、多次复用的框架。我们在涵盖多个领域和多种大型语言模型的12个真实世界数据集上评估了ICR。结果表明,ICR持续优于先前需要任务特定检索或训练的隐式ICL方法,同时在现有方法表现挣扎的跨域任务中表现出稳健的泛化能力。这些发现确立了ICR在推动ICL实用价值方面的地位。
论文及项目相关链接
Summary
隐式上下文学习(ICL)模拟大型语言模型(LLM)的表示空间中的ICL行为,旨在以零成本达到少量样本的表现。但现有方法大多依赖于将偏移向量注入残差流中,这些通常是由标签演示或任务特定对齐构建的。这样的设计未能充分利用ICL的内在结构机制,且通用性有限。为解决此问题,我们提出In-Context Routing(ICR),这是一种新的隐式ICL方法,在注意力日志级别内化可泛化的ICL模式。它提取了ICL期间出现的可重复使用的结构方向,并使用可学习的输入条件路由器相应地调整注意力日志,从而实现了一次训练多次使用的框架。我们在跨越不同领域的12个真实世界数据集和多个LLM上评估了ICR。结果表明,ICR在不需要特定任务检索或训练的隐式ICL方法上表现一致,同时在现有方法难以应对的域外任务上展现出稳健的泛化能力。这些发现使ICR在推动ICL的实际价值方面取得突破性进展。
Key Takeaways
- 隐式上下文学习(ICL)旨在模拟大型语言模型(LLM)的上下文行为,实现零成本下的少量样本性能。
- 现有方法主要通过注入偏移向量到残差流来实现,但这种设计限制了其通用性且未能充分利用结构机制。
- In-Context Routing(ICR)是一种新的隐式ICL方法,它通过内化注意力日志级别的可泛化的ICL模式来改进现有方法。
- ICR能够从ICL过程中提取可重复使用的结构方向。
- ICR使用一个可学习的输入条件路由器来调整注意力日志,实现一次训练多次使用的框架。
- ICR在多个真实世界数据集上的表现优于之前的隐式ICL方法,特别是在需要任务特定检索或训练的情境中。
点此查看论文截图
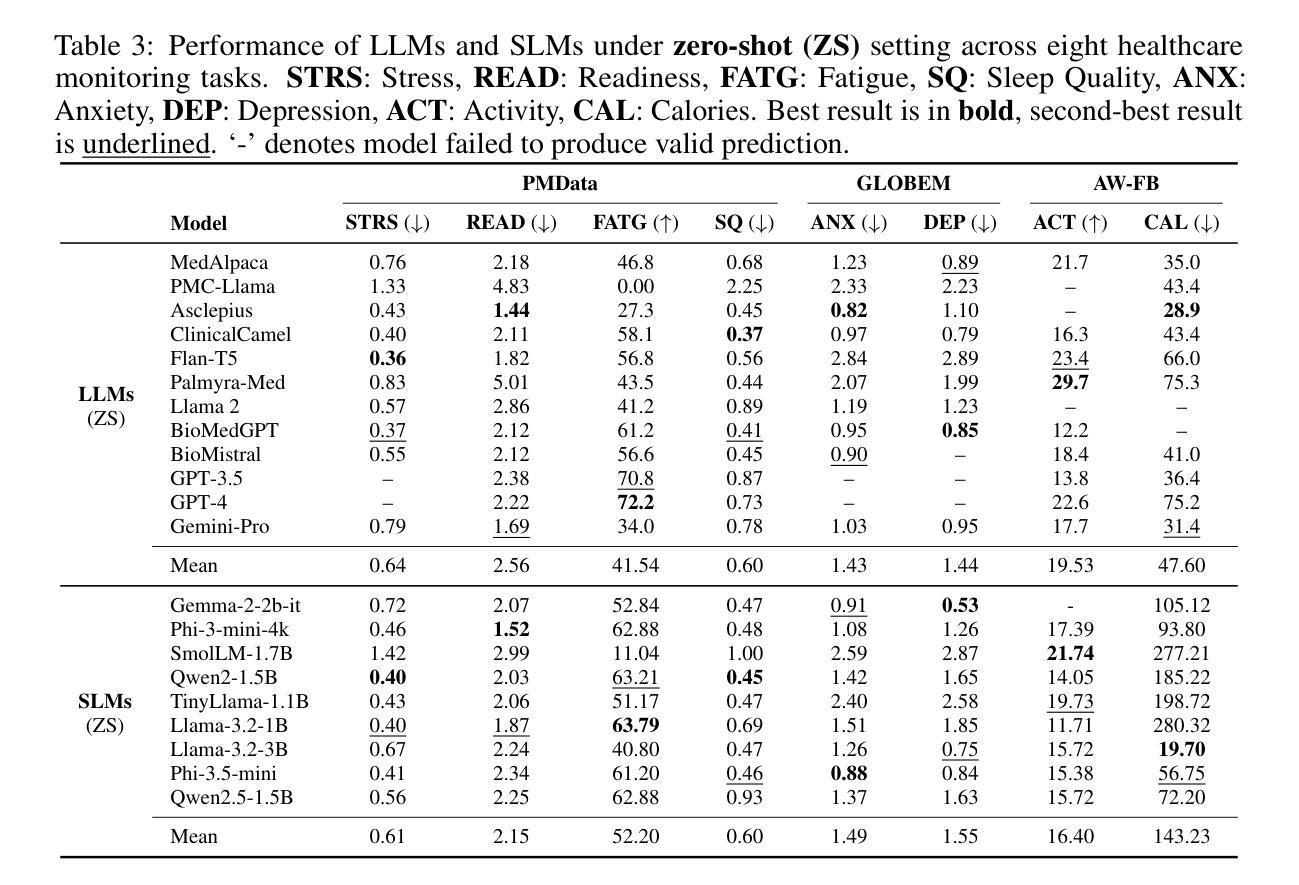
HealthSLM-Bench: Benchmarking Small Language Models for Mobile and Wearable Healthcare Monitoring
Authors:Xin Wang, Ting Dang, Xinyu Zhang, Vassilis Kostakos, Michael J. Witbrock, Hong Jia
Mobile and wearable healthcare monitoring play a vital role in facilitating timely interventions, managing chronic health conditions, and ultimately improving individuals’ quality of life. Previous studies on large language models (LLMs) have highlighted their impressive generalization abilities and effectiveness in healthcare prediction tasks. However, most LLM-based healthcare solutions are cloud-based, which raises significant privacy concerns and results in increased memory usage and latency. To address these challenges, there is growing interest in compact models, Small Language Models (SLMs), which are lightweight and designed to run locally and efficiently on mobile and wearable devices. Nevertheless, how well these models perform in healthcare prediction remains largely unexplored. We systematically evaluated SLMs on health prediction tasks using zero-shot, few-shot, and instruction fine-tuning approaches, and deployed the best performing fine-tuned SLMs on mobile devices to evaluate their real-world efficiency and predictive performance in practical healthcare scenarios. Our results show that SLMs can achieve performance comparable to LLMs while offering substantial gains in efficiency and privacy. However, challenges remain, particularly in handling class imbalance and few-shot scenarios. These findings highlight SLMs, though imperfect in their current form, as a promising solution for next-generation, privacy-preserving healthcare monitoring.
移动和可穿戴式健康监测在促进及时干预、管理慢性健康状况以及最终提高个人生活质量方面发挥着至关重要的作用。以往关于大型语言模型(LLM)的研究已经突出了其在医疗保健预测任务中的强大泛化能力和效果。然而,大多数基于LLM的医疗保健解决方案都是基于云的,这引发了关于隐私的重要担忧,并导致内存使用和延迟增加。为了解决这些挑战,人们对小型语言模型(SLM)的兴趣日益浓厚,这些模型轻便、设计用于在移动和可穿戴设备上本地运行且效率高。然而,这些模型在医疗保健预测方面的表现如何仍然知之甚少。我们系统地评估了SLM在健康预测任务中的零样本、少样本和指令微调方法,并在移动设备上部署了表现最佳的微调SLM,以评估其在现实世界的效率和预测性能在真实医疗保健场景中的表现。结果表明,SLM可以在实现与LLM相当的性能的同时,在效率和隐私方面提供了实质性的提升。然而,仍然存在挑战,特别是在处理类别不平衡和少样本场景方面。这些研究结果表明,虽然当前的SLM并不完美,但它们作为下一代隐私保护健康监测的潜在解决方案具有广阔的发展前景。
论文及项目相关链接
PDF 9 pages, 6 tables, 6 figures. Accepted at NeurIPS 2025 Workshop on GenAI4Health
Summary
小型语言模型(SLMs)在移动和可穿戴设备上的健康监测中展现出潜力。相较于大型语言模型(LLMs),SLMs具有更高的效率和隐私保护性能。本文通过系统评估,验证了SLMs在健康预测任务中的性能,并发现其在处理不平衡数据和少量样本时的挑战。尽管存在不足,但SLMs有望成为下一代隐私保护健康监测的可行解决方案。
Key Takeaways
- 移动和可穿戴设备在医疗保健监测中扮演重要角色,有助于及时干预、管理慢性疾病并改善个人生活质量。
- 大型语言模型(LLMs)在医疗保健预测任务中表现出良好的泛化能力和效果。
- LLMs主要作为云解决方案,存在隐私问题和资源消耗大的挑战。
- 小型语言模型(SLMs)是一种轻量级的解决方案,可本地运行,效率高,适用于移动和可穿戴设备。
- 通过系统评估,发现SLMs在健康预测任务中的性能与LLMs相当。
- SLMs在处理不平衡数据和少量样本时面临挑战。
点此查看论文截图

CC-Time: Cross-Model and Cross-Modality Time Series Forecasting
Authors:Peng Chen, Yihang Wang, Yang Shu, Yunyao Cheng, Kai Zhao, Zhongwen Rao, Lujia Pan, Bin Yang, Chenjuan Guo
With the success of pre-trained language models (PLMs) in various application fields beyond natural language processing, language models have raised emerging attention in the field of time series forecasting (TSF) and have shown great prospects. However, current PLM-based TSF methods still fail to achieve satisfactory prediction accuracy matching the strong sequential modeling power of language models. To address this issue, we propose Cross-Model and Cross-Modality Learning with PLMs for time series forecasting (CC-Time). We explore the potential of PLMs for time series forecasting from two aspects: 1) what time series features could be modeled by PLMs, and 2) whether relying solely on PLMs is sufficient for building time series models. In the first aspect, CC-Time incorporates cross-modality learning to model temporal dependency and channel correlations in the language model from both time series sequences and their corresponding text descriptions. In the second aspect, CC-Time further proposes the cross-model fusion block to adaptively integrate knowledge from the PLMs and time series model to form a more comprehensive modeling of time series patterns. Extensive experiments on nine real-world datasets demonstrate that CC-Time achieves state-of-the-art prediction accuracy in both full-data training and few-shot learning situations.
随着预训练语言模型(PLMs)在自然语言处理以外的各种应用领域的成功,语言模型在时间序列预测(TSF)领域引起了广泛的关注,并显示出巨大的潜力。然而,当前的基于PLM的时间序列预测方法仍未能实现令人满意的预测精度,无法匹配语言模型的强大序列建模能力。为了解决这一问题,我们提出了基于PLM的跨模型跨模态学习时间序列预测方法(CC-Time)。我们从两个方面探讨了PLM在时间序列预测中的潜力:1)PLM能够建模哪些时间序列特征;2)仅依靠PLM是否足以构建时间序列模型。在第一方面,CC-Time通过跨模态学习来建模语言模型中的时间依赖性和通道相关性,这些关联来自时间序列序列及其相应的文本描述。在第二方面,CC-Time进一步提出了跨模型融合模块,以自适应地整合来自PLM和时序模型的知识,以实现对时间序列模式的更全面的建模。在九个真实世界数据集上的广泛实验表明,无论是在全数据训练还是小样学习情况下,CC-Time都实现了最先进的预测精度。
论文及项目相关链接
Summary
基于预训练语言模型(PLMs)在多个领域应用上的成功,时间序列预测(TSF)领域开始关注语言模型的应用,并展现出巨大的潜力。针对当前PLM-based TSF方法预测准确度不足的问题,提出一种名为CC-Time的跨模型跨模态学习方法。从两个方面探讨了PLMs在时间序列预测中的潜力,并设计实验验证了该方法在多种真实数据集上的表现。
Key Takeaways
- 预训练语言模型(PLMs)在非自然语言处理领域的应用受到关注,特别是在时间序列预测(TSF)领域。
- 当前PLM-based TSF方法在预测准确度上仍有提升空间。
- CC-Time方法从两个方面探讨PLMs在时间序列预测中的潜力:时间序列表征建模和是否仅依赖PLMs构建时间序列模型。
- CC-Time引入跨模态学习来建模语言模型中时间序列序列和时间序列描述之间的时间依赖性和通道相关性。
- CC-Time提出跨模型融合块,自适应地整合PLMs和时序模型的知识,形成更全面的时间序列模式建模。
- 在九个真实数据集上的实验表明,CC-Time在完整数据训练和少样本学习情况下均实现了最先进的预测准确度。
点此查看论文截图

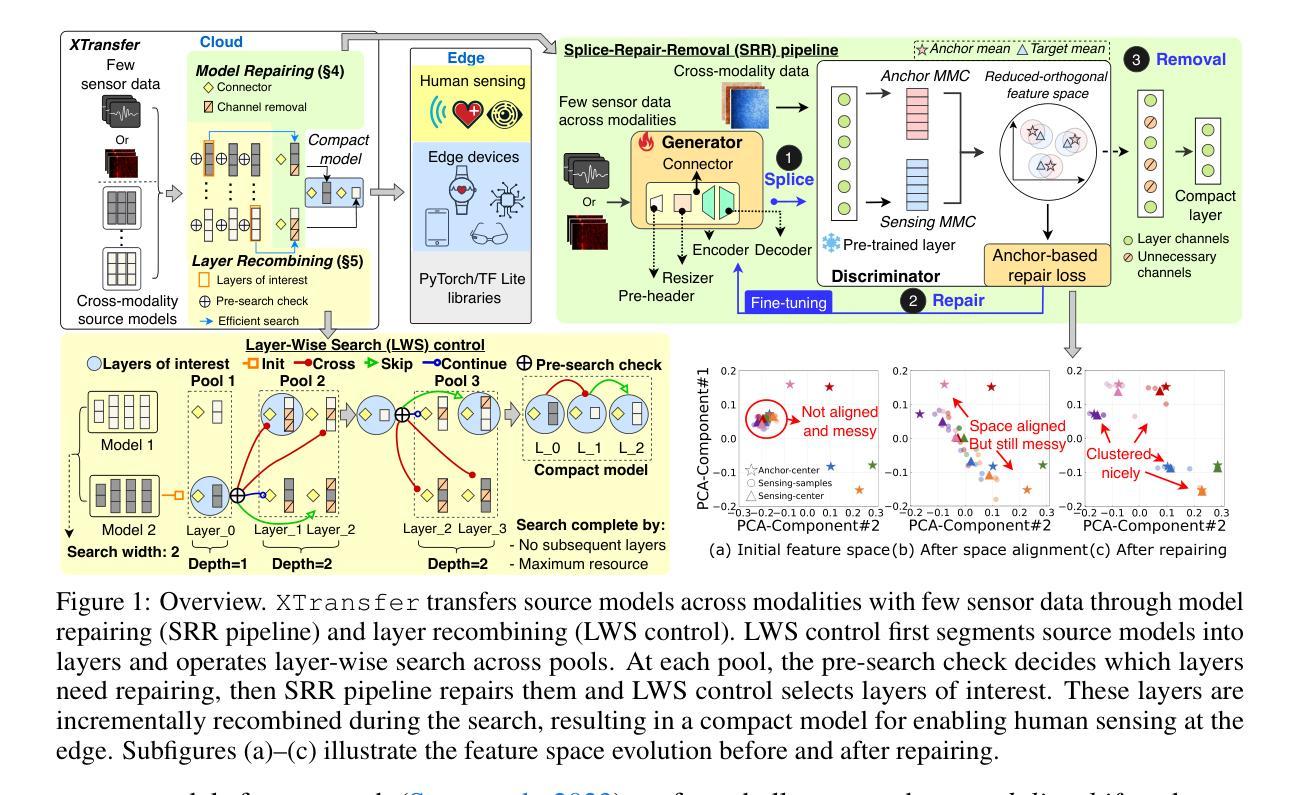
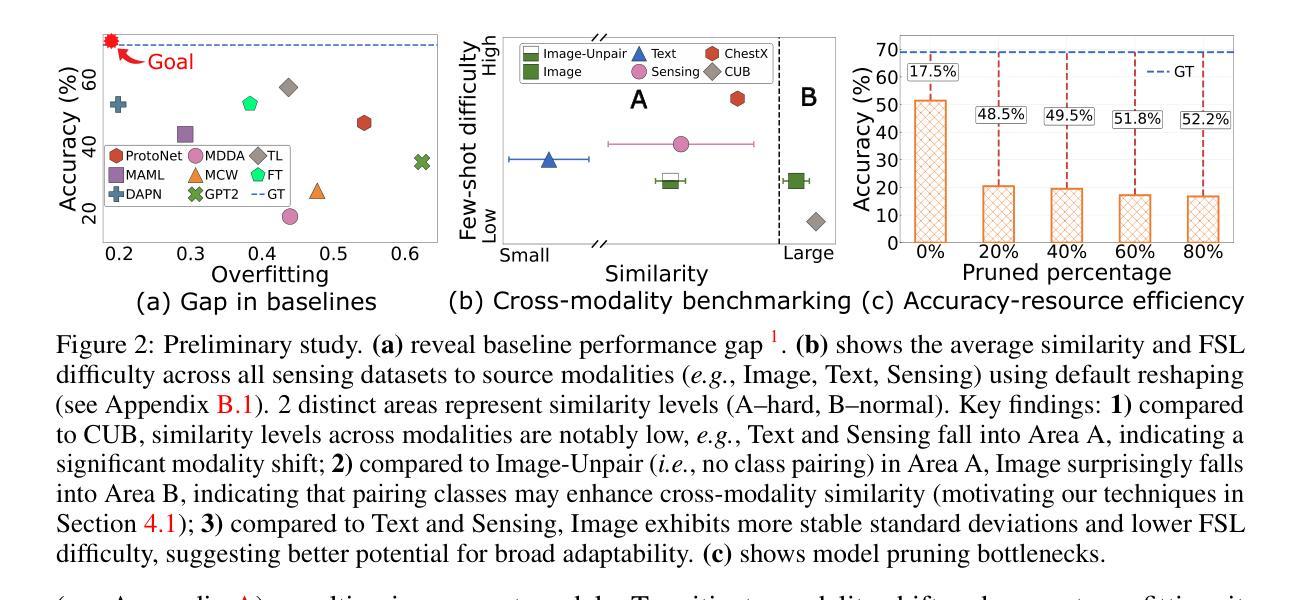
XTransfer: Modality-Agnostic Few-Shot Model Transfer for Human Sensing at the Edge
Authors:Yu Zhang, Xi Zhang, Hualin zhou, Xinyuan Chen, Shang Gao, Hong Jia, Jianfei Yang, Yuankai Qi, Tao Gu
Deep learning for human sensing on edge systems presents significant potential for smart applications. However, its training and development are hindered by the limited availability of sensor data and resource constraints of edge systems. While transferring pre-trained models to different sensing applications is promising, existing methods often require extensive sensor data and computational resources, resulting in high costs and poor adaptability in practice. In this paper, we propose XTransfer, a first-of-its-kind method enabling modality-agnostic, few-shot model transfer with resource-efficient design. XTransfer flexibly uses single or multiple pre-trained models and transfers knowledge across different modalities by (i) model repairing that safely mitigates modality shift by adapting pre-trained layers with only few sensor data, and (ii) layer recombining that efficiently searches and recombines layers of interest from source models in a layer-wise manner to create compact models. We benchmark various baselines across diverse human sensing datasets spanning different modalities. Comprehensive results demonstrate that XTransfer achieves state-of-the-art performance while significantly reducing the costs of sensor data collection, model training, and edge deployment.
深度学习在边缘系统上进行人体感知具有巨大的智能应用潜力。然而,其训练和开发受到传感器数据有限和边缘系统资源限制的阻碍。虽然将预训练模型转移到不同的感知应用中前景广阔,但现有方法通常需要大量的传感器数据和计算资源,导致实践中的成本高昂和适应性差。在本文中,我们提出了XTransfer,这是一种新型的方法,能够实现模态无关的、少样本模型转移并具有资源高效的设计。XTransfer可以灵活地使用单个或多个预训练模型,并通过(i)模型修复来安全地减轻模态偏移,仅使用少量传感器数据适应预训练层;(ii)层重组有效地逐层搜索和重组源模型的感兴趣层以创建紧凑模型。我们在跨越不同模态的多样化人体感知数据集上对各种基线进行了基准测试。综合结果表明,XTransfer在达到最新性能的同时,大大降低了传感器数据采集、模型训练和边缘部署的成本。
论文及项目相关链接
Summary
深度学习在边缘系统上进行人类感知展现出巨大的智能应用潜力。然而,其训练和开发的局限性在于传感器数据的有限性和边缘系统的资源限制。虽然将预训练模型转移到不同的感知应用上很有前景,但现有方法往往需要大量的传感器数据和计算资源,导致高成本和实践中适应性差。本文提出了XTransfer方法,这是一种全新的模态无关、小样本模型转移和资源高效设计的方法。XTransfer灵活地使用单个或多个预训练模型,并通过(i)模型修复,仅使用少量传感器数据适应预训练层,安全缓解模态转换;(ii)逐层搜索和重组源模型的感兴趣层,创建紧凑模型。我们在不同模态的人类感知数据集上评估了各种基线。综合结果表明,XTransfer实现了卓越的性能,在收集传感器数据、模型训练和环境部署方面的成本大大降低。
Key Takeaways
- 深度学习在边缘系统的智能应用潜力巨大,但受限于传感器数据的有限性和边缘系统的资源限制。
- 预训练模型转移到不同感知应用上是一个有前途的方向,但现有方法成本高且适应性差。
- XTransfer是一种新的模态无关、小样本模型转移方法,通过模型修复和层重组来适应不同的传感器数据和模态。
- XTransfer灵活使用单个或多个预训练模型,并能安全地缓解模态转换的问题。
- XTransfer在创建紧凑模型方面表现出卓越的性能,显著降低传感器数据收集、模型训练和环境部署的成本。
- 在多种人类感知数据集上的实验结果表明XTransfer具有显著的优势和先进性能。
点此查看论文截图

Prior Reinforce: Mastering Agile Tasks with Limited Trials
Authors:Yihang Hu, Pingyue Sheng, Yuyang Liu, Shengjie Wang, Yang Gao
Embodied robots nowadays can already handle many real-world manipulation tasks. However, certain other real-world tasks involving dynamic processes (e.g., shooting a basketball into a hoop) are highly agile and impose high precision requirements on the outcomes, presenting additional challenges for methods primarily designed for quasi-static manipulations. This leads to increased efforts in costly data collection, laborious reward design, or complex motion planning. Such tasks, however, are far less challenging for humans. Say a novice basketball player typically needs only about 10 attempts to make their first successful shot, by roughly imitating some motion priors and then iteratively adjusting their motion based on the past outcomes. Inspired by this human learning paradigm, we propose Prior Reinforce(P.R.), a simple and scalable approach which first learns a motion pattern from very few demonstrations, then iteratively refines its generated motions based on feedback of a few real-world trials, until reaching a specific goal. Experiments demonstrated that Prior Reinforce can learn and accomplish a wide range of goal-conditioned agile dynamic tasks with human-level precision and efficiency directly in real-world, such as throwing a basketball into the hoop in fewer than 10 trials. Project website:https://adap-robotics.github.io/.
如今,嵌入式机器人已经能够处理许多现实世界的操作任务。然而,涉及动态过程的其他某些现实任务(例如,将篮球投进篮筐)需要高度的敏捷性和对结果的高精度要求,这为主要设计用于准静态操作的方法带来了额外的挑战。这导致了成本高昂的数据收集、繁琐的奖励设计或复杂的运动规划的努力增加。然而,对于人类来说,此类任务要容易得多。比如说,一个新手篮球运动员通常只需要大约10次尝试就能投进第一个成功的球,通过粗略模仿一些动作优先事项,然后根据过去的结果迭代调整他们的动作。受这种人类学习模式的启发,我们提出了Prior Reinforce(PR),这是一种简单且可扩展的方法,它首先通过很少的演示来学习一种运动模式,然后根据几次现实世界的试验反馈迭代地改进其生成的动作,直到达到特定的目标。实验表明,Prior Reinforce能够在现实世界中直接学习和完成多种目标条件下的敏捷动态任务,达到人类水平的精确度和效率,如在少于10次试验中将篮球投入篮筐。项目网站:https://adap-robotics.github.io/。
论文及项目相关链接
Summary
少样本的动态任务操作:借助人类学习模式的灵感,提出了一种名为Prior Reinforce(P.R.)的方法,能够从极少演示中学习动作模式,并根据真实世界试验的反馈进行迭代优化,达到特定目标。该方法可实现人类水平的精度和效率,直接完成一系列目标导向的动态任务。
Key Takeaways
- 现实世界的动态操作任务需要高度的敏捷性和精确性。
- 目前的方法在应对这类任务时面临数据收集成本高、奖励设计繁琐或运动规划复杂等挑战。
- 人类学习此类任务的能力远超现有方法,仅需少量尝试即可达到高精度。
- Prior Reinforce方法从少量演示中学习动作模式,并根据真实世界的反馈进行迭代优化。
- 该方法能够在少于10次试验内完成如投篮等动态任务,达到人类水平的精度和效率。
- Prior Reinforce方法可直接在真实世界中进行学习并完成任务。
点此查看论文截图
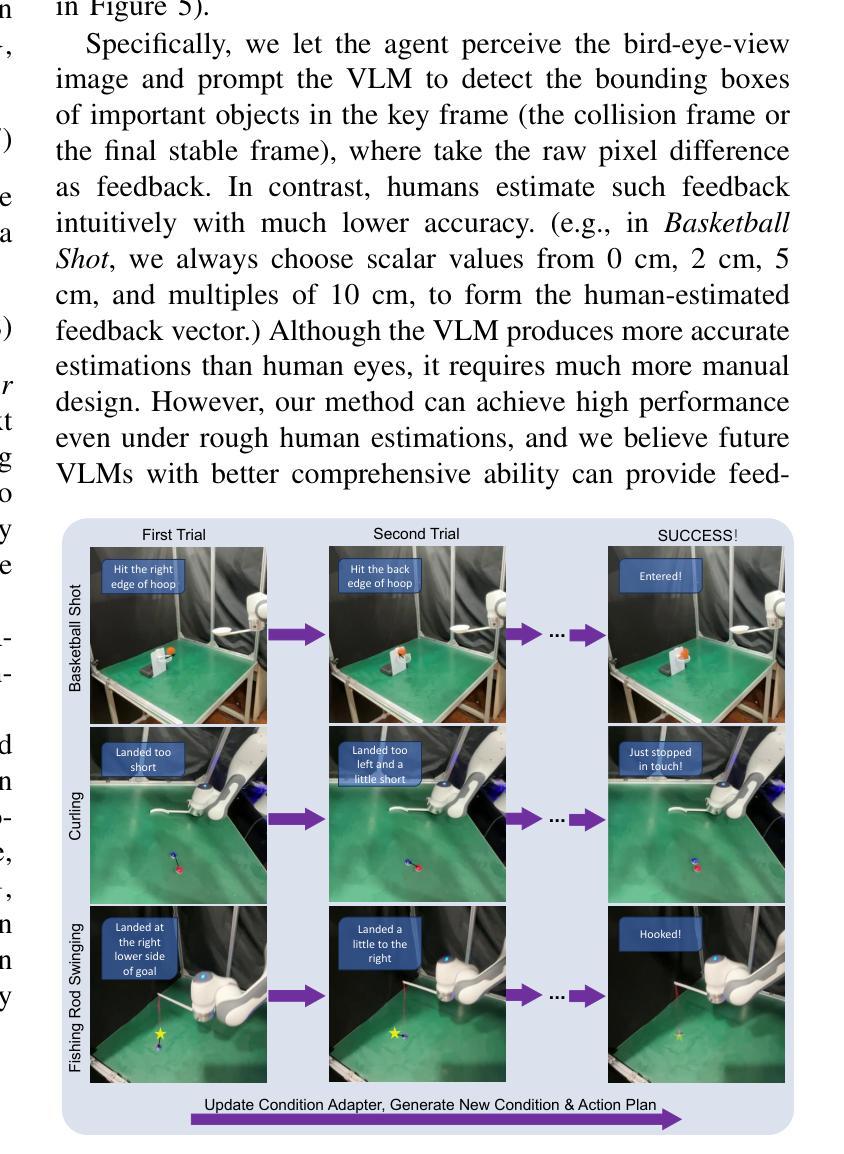

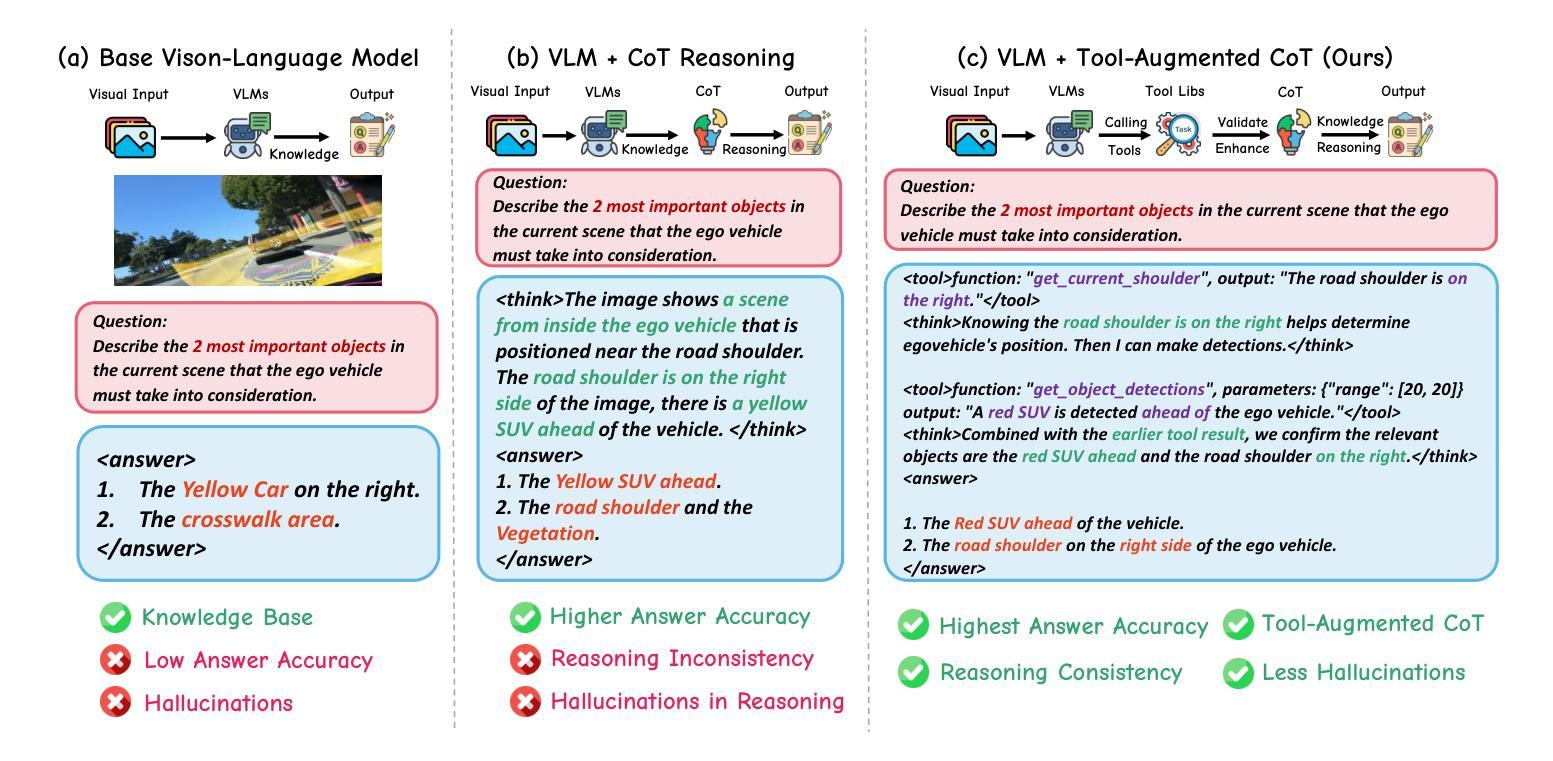
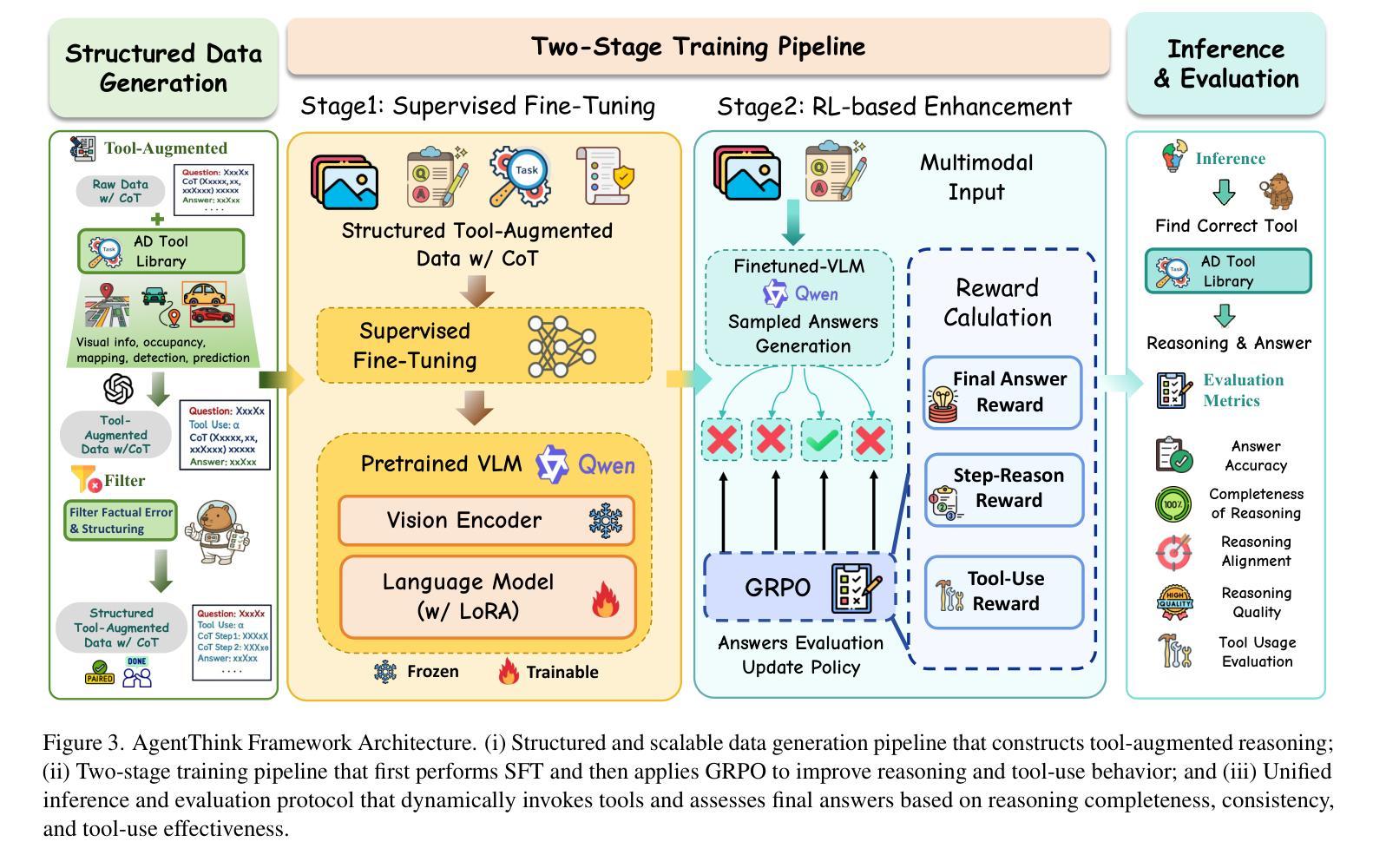
AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
Authors:Kangan Qian, Sicong Jiang, Yang Zhong, Ziang Luo, Zilin Huang, Tianze Zhu, Kun Jiang, Mengmeng Yang, Zheng Fu, Jinyu Miao, Yining Shi, He Zhe Lim, Li Liu, Tianbao Zhou, Huang Yu, Yifei Hu, Guang Li, Guang Chen, Hao Ye, Lijun Sun, Diange Yang
Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink’s core innovations include: \textbf{(i) Structured Data Generation}, which establishes an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model’s tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate that AgentThink significantly boosts overall reasoning scores by \textbf{53.91%} and enhances answer accuracy by \textbf{33.54%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models. Code is available at https://github.com/curryqka/AgentThink.
视觉语言模型(VLMs)在自动驾驶领域具有广阔前景,然而它们面临的幻觉、推理效率低下和现实世界验证有限等问题阻碍了准确的感知和稳健的逐步推理。为了克服这一问题,我们推出了AgentThink,这是一个开创性的统一框架,它将思维链(CoT)推理与动态、代理式工具调用相结合,用于自动驾驶任务。AgentThink的核心创新包括:**(i)结构化数据生成,建立自动驾驶工具库,自动构建结构化、自我验证的推理数据,明确融入各种驾驶场景的工具使用;(ii)两阶段训练管道,采用监督微调(SFT)和群组相对策略优化(GRPO),使VLMs具备自主工具调用的能力;(iii)代理式工具使用评估,引入一种新的多工具评估协议,严格评估模型的工具调用和使用情况。在DriveLMM-o1基准测试上的实验表明,AgentThink整体推理得分提高了53.91%,答案准确性提高了33.54%**,同时显著提高了推理质量和一致性。此外,消融研究和各种基准测试上的稳健零样本/少样本泛化实验突出了其强大的能力。这些发现展示了开发可信且工具感知的自动驾驶模型的广阔前景。代码可访问https://github.com/curryqka/AgentThink。
论文及项目相关链接
PDF 19 pages, 8 figures
Summary
本文介绍了面向自动驾驶的先进框架AgentThink,该框架结合了链式思维推理和动态工具调用技术。AgentThink的创新点包括结构化数据生成、两阶段训练管道和工具使用评估协议。实验证明,AgentThink能够显著提高自动驾驶模型的推理能力和答案准确性。
Key Takeaways
- AgentThink是一个统一的框架,集成了链式思维(CoT)推理和动态工具调用,用于解决自动驾驶中的认知任务。
- 结构化数据生成:建立了一个自动驾驶工具库,用于自动生成包含工具使用的结构化、自验证推理数据。
- 两阶段训练管道:采用监督微调(SFT)和群组相对策略优化(GRPO),使VLM具备自主工具调用的能力。
- 引入了新型的多工具评估协议,用于严格评估模型的工具调用和使用情况。
- 在DriveLMM-o1基准测试上,AgentThink显著提高了总体推理得分和答案准确性。
- 消融研究和在各种基准测试上的零样本/少样本泛化实验证明了AgentThink的强大能力。
点此查看论文截图


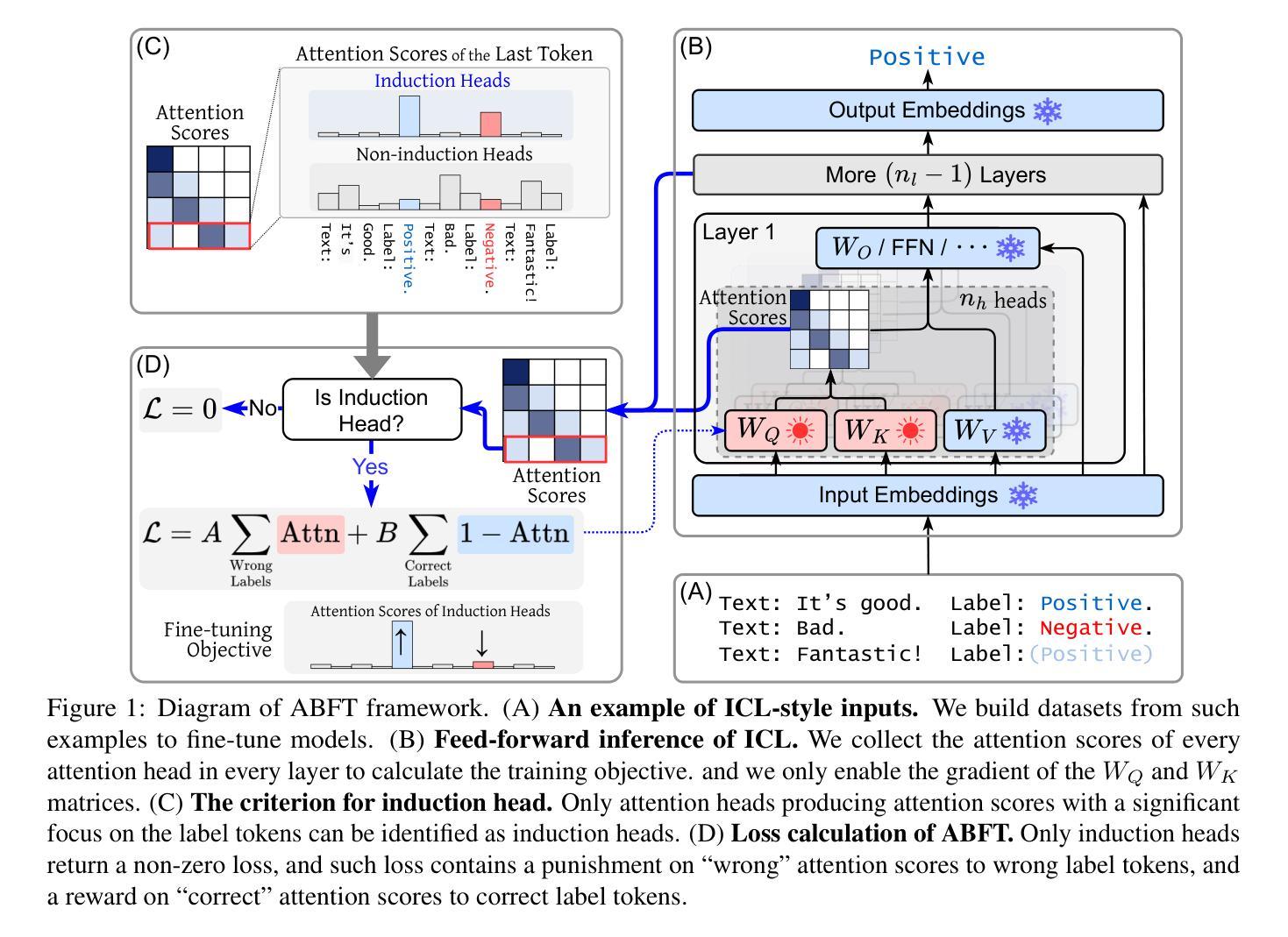
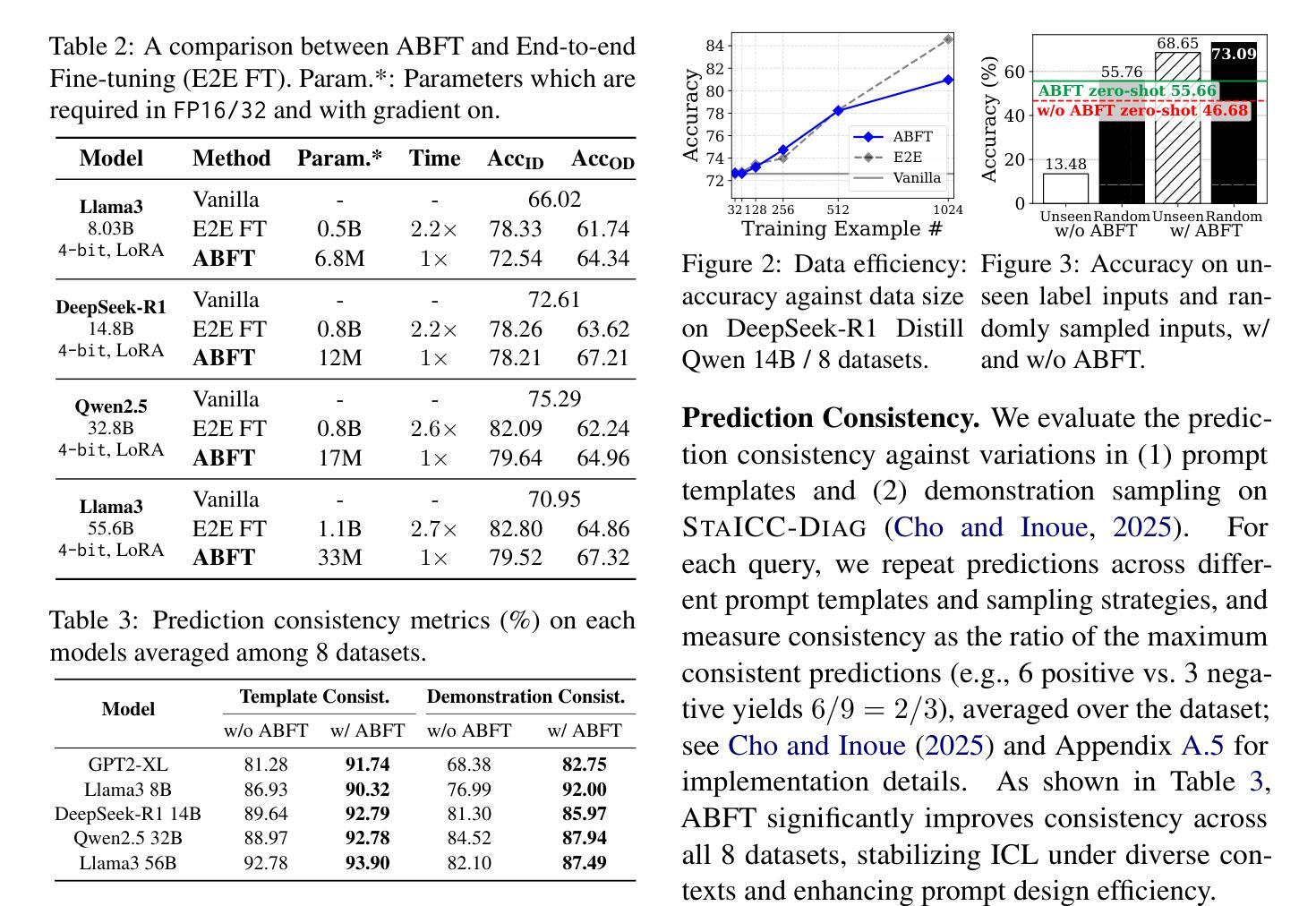
Mechanistic Fine-tuning for In-context Learning
Authors:Hakaze Cho, Peng Luo, Mariko Kato, Rin Kaenbyou, Naoya Inoue
In-context Learning (ICL) utilizes structured demonstration-query inputs to induce few-shot learning on Language Models (LMs), which are not originally pre-trained on ICL-style data. To bridge the gap between ICL and pre-training, some approaches fine-tune LMs on large ICL-style datasets by an end-to-end paradigm with massive computational costs. To reduce such costs, in this paper, we propose Attention Behavior Fine-Tuning (ABFT), utilizing the previous findings on the inner mechanism of ICL, building training objectives on the attention scores instead of the final outputs, to force the attention scores to focus on the correct label tokens presented in the context and mitigate attention scores from the wrong label tokens. Our experiments on 9 modern LMs and 8 datasets empirically find that ABFT outperforms in performance, robustness, unbiasedness, and efficiency, with only around 0.01% data cost compared to the previous methods. Moreover, our subsequent analysis finds that the end-to-end training objective contains the ABFT objective, suggesting the implicit bias of ICL-style data to the emergence of induction heads. Our work demonstrates the possibility of controlling specific module sequences within LMs to improve their behavior, opening up the future application of mechanistic interpretability.
上下文学习(ICL)利用结构化演示查询输入,以在语言模型(LMs)上实现少量学习,这些语言模型最初并未在ICL风格的数据上进行预训练。为了弥合ICL和预训练之间的差距,一些方法采用端到端范式对大型ICL风格数据集对LM进行微调,这需要大量的计算成本。为了降低这些成本,本文提出了注意力行为微调(ABFT),它利用对ICL内在机制的先前发现,在注意力分数上构建训练目标,而不是最终的输出。这样可以迫使注意力分数关注上下文中出现的正确标签令牌,并减少来自错误标签令牌的注意力分数。我们在9个现代语言模型和8个数据集上的实验经验发现,ABFT在性能、稳健性、公正性和效率方面都优于以前的方法,而且只有约0.01%的数据成本。此外,我们的后续分析发现,端到端的训练目标包含ABFT目标,这表明ICL风格数据对归纳头出现的隐含偏见。我们的工作展示了控制LM内特定模块序列以改善其行为的可能性,为未来的机械解释性应用开辟了道路。
论文及项目相关链接
PDF 28 pages, 31 figures, 6 tables
Summary
本论文针对 In-context Learning(ICL)在预训练语言模型(LMs)上的应用进行了优化研究。针对ICL与预训练之间的鸿沟问题,提出了Attention Behavior Fine-Tuning(ABFT)方法,利用对ICL内在机制的研究结果构建训练目标,通过关注注意力分数而非最终输出,使注意力聚焦于正确标签,并减少错误标签的影响。实验证明,ABFT在性能、稳健性、公平性和效率方面均优于传统方法,且数据成本极低。同时,分析发现端到端的训练目标包含ABFT目标,揭示了ICL数据对归纳头出现的隐性偏见。本研究展示了控制LM内部特定模块序列以提高其性能的可能性,为未来的机械解释性应用开辟了道路。
Key Takeaways
- ICL利用结构化的演示查询输入来诱导语言模型的少样本学习。
- ABFT方法旨在减少大规模计算成本,通过利用对ICL内在机制的研究结果构建训练目标。
- ABFT方法关注注意力分数,使模型在上下文中聚焦于正确的标签标记。
- ABFT在性能、稳健性、公平性和效率方面优于传统方法,数据成本极低。
- 端到端的训练目标包含ABFT目标,显示ICL数据的隐性偏见。
- 本研究展示了控制LM内部特定模块序列以提高性能的可能性。
点此查看论文截图
Beyond Synthetic Replays: Turning Diffusion Features into Few-Shot Class-Incremental Learning Knowledge
Authors:Junsu Kim, Yunhoe Ku, Dongyoon Han, Seungryul Baek
Few-shot class-incremental learning (FSCIL) is challenging due to extremely limited training data while requiring models to acquire new knowledge without catastrophic forgetting. Recent works have explored generative models, particularly Stable Diffusion (SD), to address these challenges. However, existing approaches use SD mainly as a replay generator, whereas we demonstrate that SD’s rich multi-scale representations can serve as a unified backbone. Motivated by this observation, we introduce Diffusion-FSCIL, which extracts four synergistic feature types from SD by capturing real image characteristics through inversion, providing semantic diversity via class-conditioned synthesis, enhancing generalization through controlled noise injection, and enabling replay without image storage through generative features. Unlike conventional approaches requiring synthetic buffers and separate classification backbones, our unified framework operates entirely in the latent space with only lightweight networks ($\approx$6M parameters). Extensive experiments on CUB-200, miniImageNet, and CIFAR-100 demonstrate state-of-the-art performance, with comprehensive ablations confirming the necessity of each feature type. Furthermore, we confirm that our streamlined variant maintains competitive accuracy while substantially improving efficiency, establishing the viability of generative models as practical and effective backbones for FSCIL.
少量样本类增量学习(FSCIL)由于训练数据极为有限而具有挑战性,同时要求模型在获取新知识时避免灾难性遗忘。近期的研究开始探索生成模型,特别是Stable Diffusion(SD),来解决这些挑战。然而,现有方法主要将SD用作回放生成器,而我们证明了SD的丰富多尺度表征可以作为统一的后端架构。受这一观察的启发,我们引入了Diffusion-FSCIL,它通过反转捕获真实图像特征、通过类别条件合成提供语义多样性、通过受控噪声注入增强泛化能力、以及通过生成特征实现无需图像存储的回放,从SD中提取了四种协同特征类型。不同于需要合成缓冲器和独立分类后端的传统方法,我们的统一框架仅在潜在空间中进行操作,使用轻量级网络(约6M参数)。在CUB-200、miniImageNet和CIFAR-100上的大量实验证明了其卓越性能,综合消融研究证实了每种特征类型的必要性。此外,我们确认,我们的简化版本在保持竞争力的准确性的同时,大大提高了效率,证明了生成模型作为FSCIL实用有效后端的可行性。
论文及项目相关链接
PDF pre-print ver 2
Summary
本文探讨了基于Diffusion模型的Few-Shot类增量学习(FSCIL)方法。该方法利用Diffusion模型丰富的多尺度表示作为统一框架,通过提取四种协同特征类型,实现无需存储图像的回放功能,且操作完全在潜在空间中进行,具有高效性和实用性。实验结果表明,该方法在多个数据集上表现出优异性能。
Key Takeaways
- 介绍了几种挑战及其在解决这些挑战时面临的挑战。这些挑战包括有限的训练数据和模型需要获取新知识而不遗忘旧知识的问题。
- 强调了Diffusion模型在解决这些问题方面的潜力,并探讨了Diffusion模型的多尺度表示的优势。介绍了如何利用这种表示作为统一框架来处理FSCIL问题。
- 介绍了Diffusion-FSCIL方法中的四种协同特征类型,包括通过反转捕获真实图像特征、通过类别条件合成提供语义多样性、通过受控噪声注入增强泛化能力以及在潜在空间中进行回放的功能。
点此查看论文截图

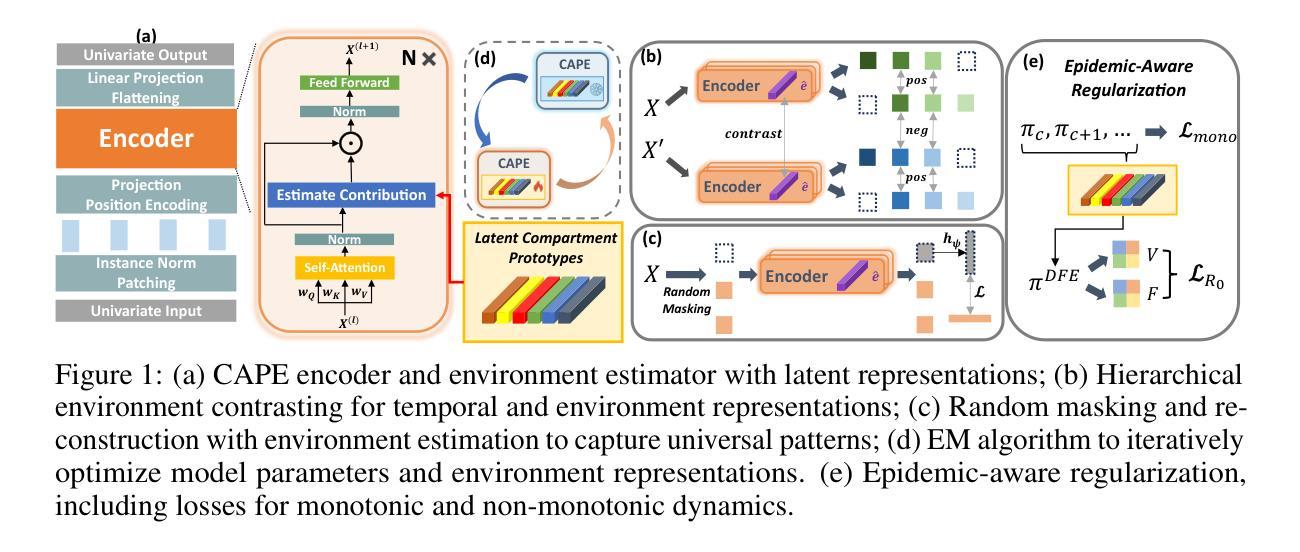
Pre-training Epidemic Time Series Forecasters with Compartmental Prototypes
Authors:Zewen Liu, Juntong Ni, Max S. Y. Lau, Wei Jin
Accurate epidemic forecasting is crucial for outbreak preparedness, but existing data-driven models are often brittle. Typically trained on a single pathogen, they struggle with data scarcity during new outbreaks and fail under distribution shifts caused by viral evolution or interventions. However, decades of surveillance data from diverse diseases offer an untapped source of transferable knowledge. To leverage the collective lessons from history, we propose CAPE, the first open-source pre-trained model for epidemic forecasting. Unlike existing time series foundation models that overlook epidemiological challenges, CAPE models epidemic dynamics as mixtures of latent population states, termed compartmental prototypes. It discovers a flexible dictionary of compartment prototypes directly from surveillance data, enabling each outbreak to be expressed as a time-varying mixture that links observed infections to latent population states. To promote robust generalization, CAPE combines self-supervised pre-training objectives with lightweight epidemic-aware regularizers that align the learned prototypes with epidemiological semantics. On a comprehensive benchmark spanning 17 diseases and 50+ regions, CAPE significantly outperforms strong baselines in zero-shot, few-shot, and full-shot forecasting. This work represents a principled step toward pre-trained epidemic models that are both transferable and epidemiologically grounded.
准确的疫情预测对于疫情准备至关重要,但现有的数据驱动模型往往很脆弱。这些模型通常针对单一病原体进行训练,在新疫情期间面临数据稀缺的问题,并且在病毒进化或干预措施引起的分布变化下会失效。然而,来自多种疾病的数十年监控数据提供了尚未开发的知识转移来源。为了利用历史的集体教训,我们提出了CAPE,这是用于疫情预测的第一个开源预训练模型。与忽视流行病学挑战的现有时间序列基础模型不同,CAPE将疫情动态建模为潜在人口状态混合体,称为“隔室原型”。它直接从监控数据中发现了灵活的隔室原型词典,使每个疫情都能表达为随时间变化混合体,将观察到的感染与潜在人口状态联系起来。为了促进稳健的泛化,CAPE结合了自我监督的预训练目标与轻量级的疫情意识调节器,使学到的原型与流行病学语义相符。在涵盖17种疾病和50多个地区的综合基准测试中,CAPE在零样本、少样本和全样本预测方面显著优于强大的基线。这项工作朝着既可转移又基于流行病学的预训练疫情模型迈出了有原则的一步。
论文及项目相关链接
PDF version 2.0
Summary
该研究强调了传染病精准预测对于应对疫情爆发的重要性,但现有数据驱动模型在面对新疫情爆发时常常存在局限性。为解决这一问题,研究团队利用数十年来的多种疾病监测数据提出了CAPE模型,这是一个开源的预先训练好的传染病预测模型。该模型采用分区原型法来模拟传染病的动态过程,使得模型能够更好地处理新的传染病和以往不同的疫情。同时,为了增强模型的通用性和泛化能力,研究团队还结合了自监督预训练目标和轻量级传染病相关正则化器来实现模型的学习与疾病的流行病学特征保持一致。经过大规模验证,CAPE模型在多种疾病和地区的预测中表现优异,显示出其跨病种和区域的预测能力。该研究的成功标志着预训练传染病模型的重大进步,这些模型既具有可迁移性又基于流行病学特征。
Key Takeaways
- 现有数据驱动模型在传染病预测方面存在局限性,特别是在面对新疫情爆发时。
- CAPE模型利用多种疾病的监测数据作为训练资源,提高了模型的泛化能力。
- CAPE模型采用分区原型法模拟传染病的动态过程,可以更好地处理新的传染病和以往不同的疫情。
- 自监督预训练目标和轻量级传染病相关正则化器的结合有助于提高模型的预测准确性并增强模型的泛化能力。
- CAPE模型在不同疾病和地区的预测中表现优异,显示出其跨病种和区域的预测能力。
- CAPE模型的提出标志着预训练传染病模型的重大进步,既具有可迁移性又基于流行病学特征。
点此查看论文截图