⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-01 更新
ThermalGen: Style-Disentangled Flow-Based Generative Models for RGB-to-Thermal Image Translation
Authors:Jiuhong Xiao, Roshan Nayak, Ning Zhang, Daniel Tortei, Giuseppe Loianno
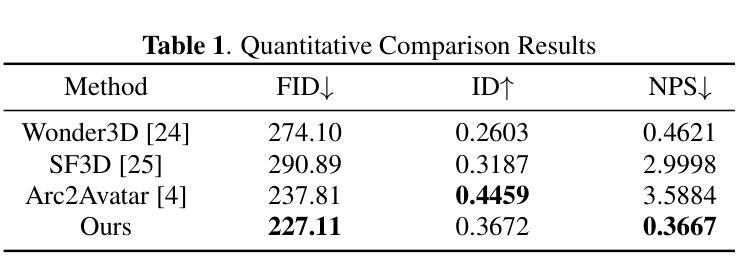
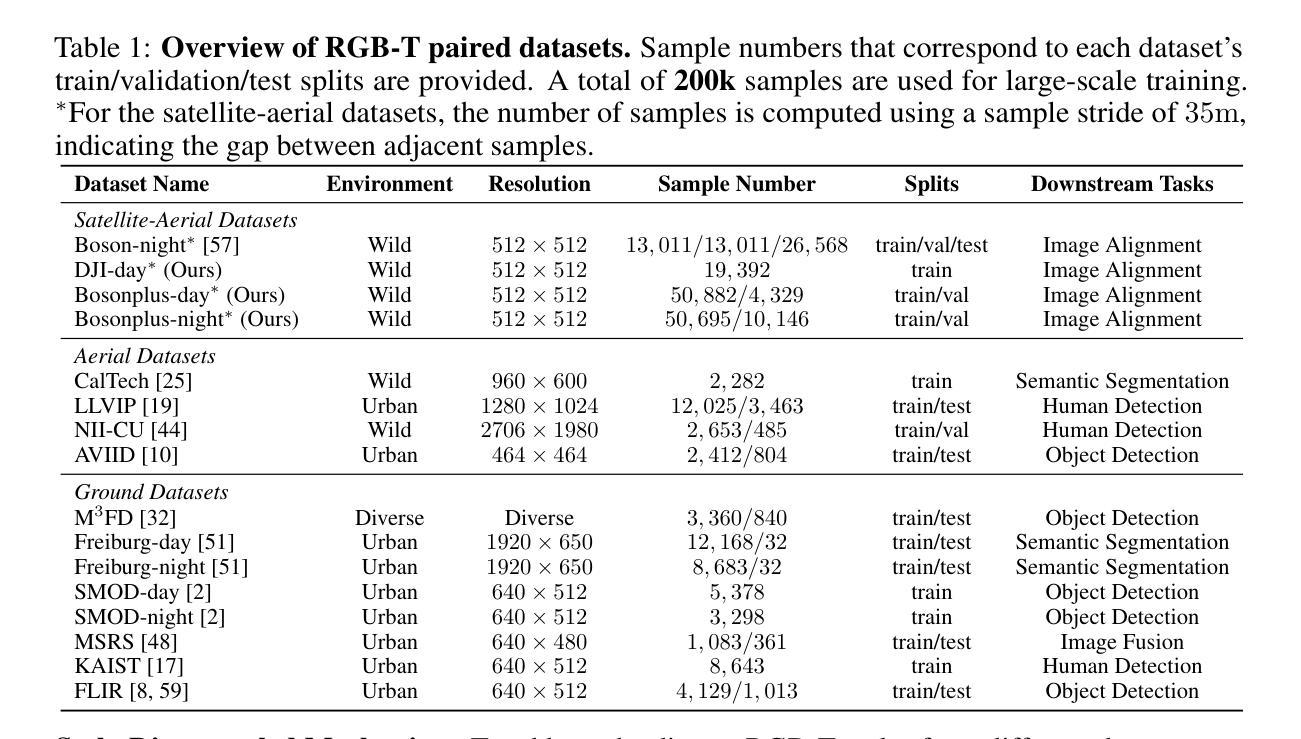
Paired RGB-thermal data is crucial for visual-thermal sensor fusion and cross-modality tasks, including important applications such as multi-modal image alignment and retrieval. However, the scarcity of synchronized and calibrated RGB-thermal image pairs presents a major obstacle to progress in these areas. To overcome this challenge, RGB-to-Thermal (RGB-T) image translation has emerged as a promising solution, enabling the synthesis of thermal images from abundant RGB datasets for training purposes. In this study, we propose ThermalGen, an adaptive flow-based generative model for RGB-T image translation, incorporating an RGB image conditioning architecture and a style-disentangled mechanism. To support large-scale training, we curated eight public satellite-aerial, aerial, and ground RGB-T paired datasets, and introduced three new large-scale satellite-aerial RGB-T datasets–DJI-day, Bosonplus-day, and Bosonplus-night–captured across diverse times, sensor types, and geographic regions. Extensive evaluations across multiple RGB-T benchmarks demonstrate that ThermalGen achieves comparable or superior translation performance compared to existing GAN-based and diffusion-based methods. To our knowledge, ThermalGen is the first RGB-T image translation model capable of synthesizing thermal images that reflect significant variations in viewpoints, sensor characteristics, and environmental conditions. Project page: http://xjh19971.github.io/ThermalGen
配对RGB-热数据对于视觉-热传感器融合和跨模态任务至关重要,包括多模态图像对齐和检索等重要应用。然而,同步且校准过的RGB-热图像对的稀缺性成为这些领域发展的主要障碍。为了克服这一挑战,RGB-到热(RGB-T)图像翻译作为一种有前景的解决方案应运而生,它能够从丰富的RGB数据集中合成热图像,用于训练目的。在这项研究中,我们提出了ThermalGen,这是一种基于自适应流的RGB-T图像翻译生成模型,它结合了RGB图像条件架构和风格分离机制。为了支持大规模训练,我们整理了八个公共卫星航空、航空和地面RGB-T配对数据集,并引入了三个新的大规模卫星航空RGB-T数据集——DJI日间、博森加日间和博森加夜间,这些数据集是在不同的时间、传感器类型和地理区域捕获的。在多个RGB-T基准测试上的广泛评估表明,与现有的基于GAN和基于扩散的方法相比,ThermalGen实现了相当的或更优越的翻译性能。据我们所知,ThermalGen是首个能够合成反映视点、传感器特性和环境条件等重大变化的热图像的RGB-T图像翻译模型。项目页面:http://xjh19971.github.io/ThermalGen
论文及项目相关链接
PDF 23 pages including the checklist and appendix. Accepted at NeurIPS 2025
Summary
本文提出一种基于自适应流生成模型的RGB-T图像翻译方法——ThermalGen,用于合成训练所需的热图像。该方法结合了RGB图像条件架构和风格分离机制,实现了多样化的RGB-热图像配对数据的合成。通过引入三个新的大规模卫星航空RGB-T数据集,ThermalGen展现出卓越的性能,能够合成反映视角、传感器特性和环境条件差异的热图像。
Key Takeaways
- RGB-热数据配对对于视觉-热传感器融合和跨模态任务至关重要。
- 缺乏同步和校准的RGB-热图像配对是主要的研究挑战。
- RGB-T图像翻译作为一种解决方案,能够从丰富的RGB数据集中合成热图像用于训练目的。
- 提出的ThermalGen模型是一种自适应流生成模型,用于RGB-T图像翻译。
- ThermalGen结合了RGB图像条件架构和风格分离机制,实现更好的性能。
- 引入了三个新的大规模卫星航空RGB-T数据集,支持大规模训练。
点此查看论文截图



From Satellite to Street: A Hybrid Framework Integrating Stable Diffusion and PanoGAN for Consistent Cross-View Synthesis
Authors:Khawlah Bajbaa, Abbas Anwar, Muhammad Saqib, Hafeez Anwar, Nabin Sharma, Muhammad Usman
Street view imagery has become an essential source for geospatial data collection and urban analytics, enabling the extraction of valuable insights that support informed decision-making. However, synthesizing street-view images from corresponding satellite imagery presents significant challenges due to substantial differences in appearance and viewing perspective between these two domains. This paper presents a hybrid framework that integrates diffusion-based models and conditional generative adversarial networks to generate geographically consistent street-view images from satellite imagery. Our approach uses a multi-stage training strategy that incorporates Stable Diffusion as the core component within a dual-branch architecture. To enhance the framework’s capabilities, we integrate a conditional Generative Adversarial Network (GAN) that enables the generation of geographically consistent panoramic street views. Furthermore, we implement a fusion strategy that leverages the strengths of both models to create robust representations, thereby improving the geometric consistency and visual quality of the generated street-view images. The proposed framework is evaluated on the challenging Cross-View USA (CVUSA) dataset, a standard benchmark for cross-view image synthesis. Experimental results demonstrate that our hybrid approach outperforms diffusion-only methods across multiple evaluation metrics and achieves competitive performance compared to state-of-the-art GAN-based methods. The framework successfully generates realistic and geometrically consistent street-view images while preserving fine-grained local details, including street markings, secondary roads, and atmospheric elements such as clouds.
街道景观图像已成为地理空间数据采集和城市分析的重要来源,能够提取有价值的见解,支持基于信息的决策制定。然而,从相应的卫星图像合成街道景观图像存在重大挑战,因为这两个领域在外观和观看角度上存在显著差异。本文提出了一个混合框架,该框架结合了基于扩散的模型和条件生成对抗网络,从卫星图像生成地理一致的街道景观图像。我们的方法采用多阶段训练策略,将Stable Diffusion作为双分支架构的核心组件。为了提高框架的能力,我们集成了一个条件生成对抗网络(GAN),能够生成地理上一致的全景街道景观。此外,我们实施了一种融合策略,利用两种模型的优势来创建稳健的表示,从而提高了生成街道景观图像的几何一致性和视觉质量。所提出的框架在具有挑战性的Cross-View USA(CVUSA)数据集上进行了评估,该数据集是跨视图图像合成的标准基准。实验结果表明,我们的混合方法在多个评估指标上优于仅使用扩散的方法,并与最先进的基于GAN的方法实现竞争性能。该框架能够成功生成逼真且几何一致的街道景观图像,同时保留精细的局部细节,包括街道标记、次要道路和大气要素,如云层。
论文及项目相关链接
Summary
本文提出一种混合框架,该框架结合了扩散模型和条件生成对抗网络,用于从卫星图像生成地理上一致的街道视图图像。该框架采用多阶段训练策略,以稳定扩散为核心组件,在双分支架构中实现。此外,还整合了条件生成对抗网络(GAN),以提高框架生成地理上一致的全景街道视图的能力。实验结果表明,该混合方法在多个评价指标上优于仅使用扩散的方法,与最新的GAN方法相比也具有竞争力。它能成功生成逼真的、几何上一致的街道视图图像,同时保留细致的局部细节,如街道标记、次要道路和大气元素如云。
Key Takeaways
- 街道视图图像已成为地理空间数据收集和城市分析的重要来源,支持决策制定。
- 从卫星图像合成街道视图图像面临外观和观看角度上的重大挑战。
- 本文提出一种混合框架,结合扩散模型和条件生成对抗网络(GAN)来解决这一问题。
- 框架的核心是稳定扩散,在一个双分支架构中采用多阶段训练策略。
- 整合条件GAN以生成地理上一致的全景街道视图。
- 实验结果表明,该框架在多个评价指标上表现出色,与最新技术相比具有竞争力。
点此查看论文截图

Tumor Synthesis conditioned on Radiomics
Authors:Jonghun Kim, Inye Na, Eun Sook Ko, Hyunjin Park
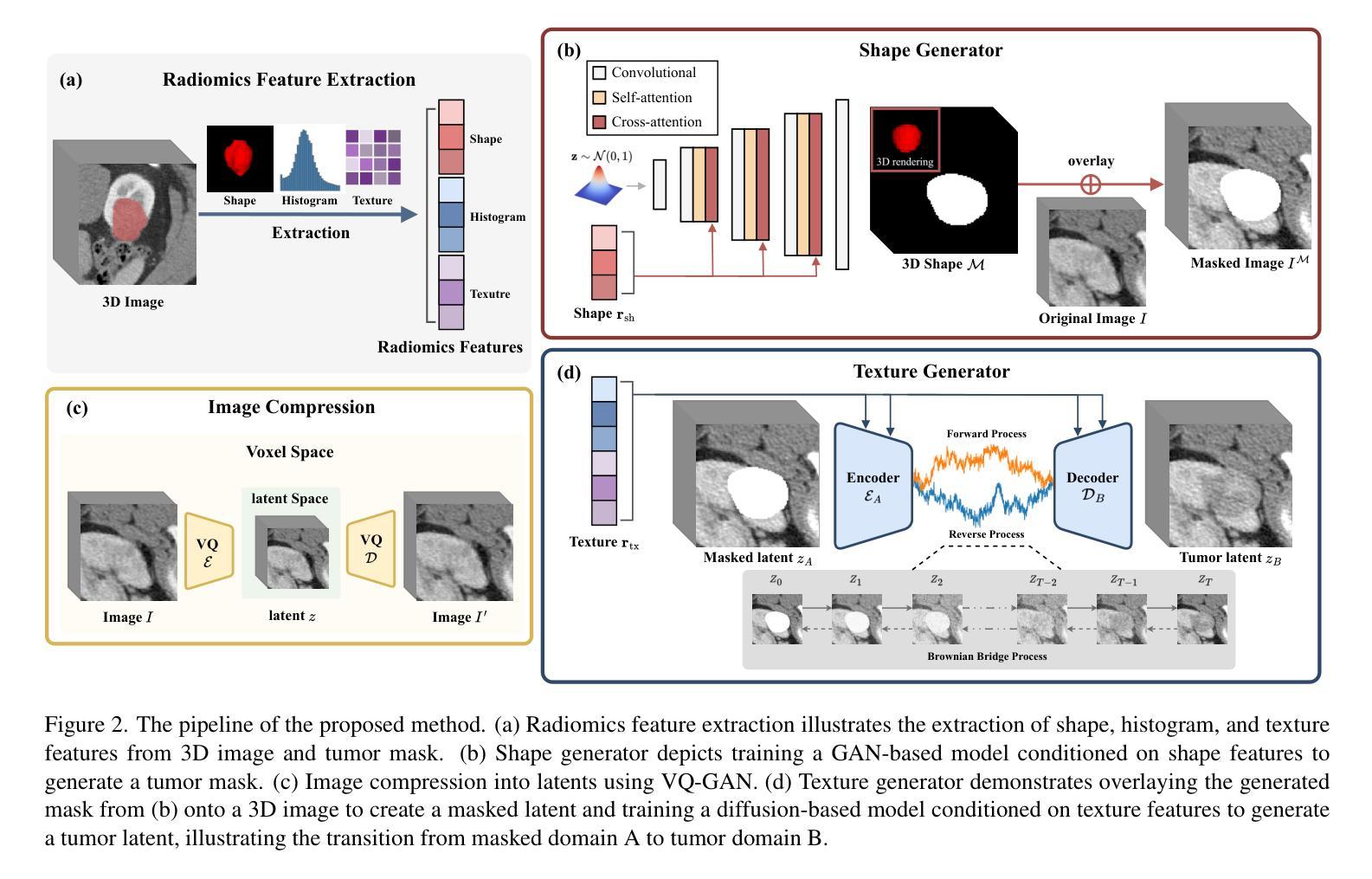
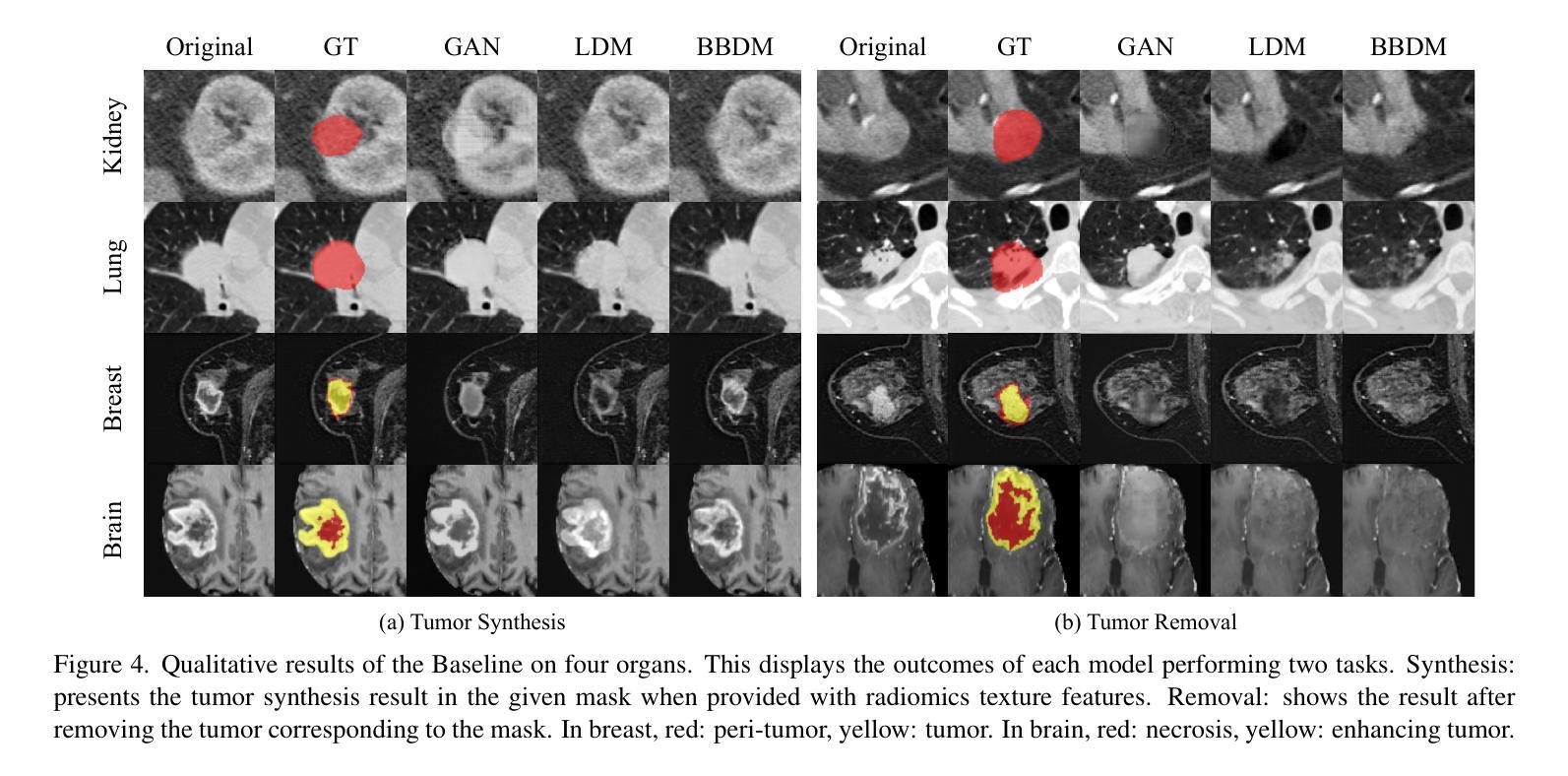
Due to privacy concerns, obtaining large datasets is challenging in medical image analysis, especially with 3D modalities like Computed Tomography (CT) and Magnetic Resonance Imaging (MRI). Existing generative models, developed to address this issue, often face limitations in output diversity and thus cannot accurately represent 3D medical images. We propose a tumor-generation model that utilizes radiomics features as generative conditions. Radiomics features are high-dimensional handcrafted semantic features that are biologically well-grounded and thus are good candidates for conditioning. Our model employs a GAN-based model to generate tumor masks and a diffusion-based approach to generate tumor texture conditioned on radiomics features. Our method allows the user to generate tumor images according to user-specified radiomics features such as size, shape, and texture at an arbitrary location. This enables the physicians to easily visualize tumor images to better understand tumors according to changing radiomics features. Our approach allows for the removal, manipulation, and repositioning of tumors, generating various tumor types in different scenarios. The model has been tested on tumors in four different organs (kidney, lung, breast, and brain) across CT and MRI. The synthesized images are shown to effectively aid in training for downstream tasks and their authenticity was also evaluated through expert evaluations. Our method has potential usage in treatment planning with diverse synthesized tumors.
在医学图像分析中,由于隐私问题,获取大型数据集具有挑战性,特别是在使用计算机断层扫描(CT)和磁共振成像(MRI)等3D模态时更是如此。为解决此问题而开发的现有生成模型通常面临输出多样性方面的局限,因此无法准确表示3D医学图像。我们提出了一种肿瘤生成模型,该模型利用放射学特征作为生成条件。放射学特征是生物上具有良好依据的高维手工语义特征,因此是条件选择的不错候选。我们的模型采用基于GAN的模型来生成肿瘤掩膜,并使用基于扩散的方法根据放射学特征生成肿瘤纹理。我们的方法允许用户根据用户指定的放射学特征(如大小、形状和纹理)在任意位置生成肿瘤图像。这使得医生能够轻松根据变化的放射学特征可视化肿瘤图像,从而更好地理解肿瘤。我们的方法允许删除、操作和重新定位肿瘤,在不同场景下生成各种肿瘤类型。该模型已在CT和MRI中的四个不同器官(肾脏、肺部、乳房和大脑)的肿瘤上进行了测试。合成的图像已证明可有效辅助下游任务训练,其真实性也通过专家评估得到了评价。我们的方法在治疗规划中具有使用多种合成肿瘤的潜力。
论文及项目相关链接
PDF WACV’25
Summary
本文提出一种基于放射学特征的肿瘤生成模型,利用GAN生成肿瘤掩膜,并采用扩散方法根据放射学特征生成肿瘤纹理。该模型可根据用户指定的放射学特征生成肿瘤图像,如大小、形状和纹理等,有助于医生更好地了解肿瘤情况。该模型已在四种不同器官的肿瘤(肾脏、肺部、乳房和大脑)中进行了测试,合成的图像可有效辅助下游任务训练,并经过专家评估验证其真实性。此模型在治疗规划中具有潜在应用价值。
Key Takeaways
- 医学图像分析中,获取大型数据集具有挑战性,特别是3D模态如CT和MRI。
- 现有生成模型在输出多样性方面存在局限,无法准确代表3D医学图像。
- 提出的肿瘤生成模型利用放射学特征作为生成条件,这些特征是生物上合理的高维手工语义特征。
- 模型采用GAN生成肿瘤掩膜,并采用扩散方法根据放射学特征生成肿瘤纹理。
- 该模型可根据用户指定的放射学特征生成肿瘤图像,如大小、形状和纹理,有助于医生更好地理解肿瘤情况。
- 模型在多种器官(肾脏、肺部、乳房和大脑)的肿瘤中进行了测试,合成的图像有助于下游任务训练。
点此查看论文截图
LatXGen: Towards Radiation-Free and Accurate Quantitative Analysis of Sagittal Spinal Alignment Via Cross-Modal Radiographic View Synthesis
Authors:Moxin Zhao, Nan Meng, Jason Pui Yin Cheung, Chris Yuk Kwan Tang, Chenxi Yu, Wenting Zhong, Pengyu Lu, Chang Shi, Yipeng Zhuang, Teng Zhang
Adolescent Idiopathic Scoliosis (AIS) is a complex three-dimensional spinal deformity, and accurate morphological assessment requires evaluating both coronal and sagittal alignment. While previous research has made significant progress in developing radiation-free methods for coronal plane assessment, reliable and accurate evaluation of sagittal alignment without ionizing radiation remains largely underexplored. To address this gap, we propose LatXGen, a novel generative framework that synthesizes realistic lateral spinal radiographs from posterior Red-Green-Blue and Depth (RGBD) images of unclothed backs. This enables accurate, radiation-free estimation of sagittal spinal alignment. LatXGen tackles two core challenges: (1) inferring sagittal spinal morphology changes from a lateral perspective based on posteroanterior surface geometry, and (2) performing cross-modality translation from RGBD input to the radiographic domain. The framework adopts a dual-stage architecture that progressively estimates lateral spinal structure and synthesizes corresponding radiographs. To enhance anatomical consistency, we introduce an attention-based Fast Fourier Convolution (FFC) module for integrating anatomical features from RGBD images and 3D landmarks, and a Spatial Deformation Network (SDN) to model morphological variations in the lateral view. Additionally, we construct the first large-scale paired dataset for this task, comprising 3,264 RGBD and lateral radiograph pairs. Experimental results demonstrate that LatXGen produces anatomically accurate radiographs and outperforms existing GAN-based methods in both visual fidelity and quantitative metrics. This study offers a promising, radiation-free solution for sagittal spine assessment and advances comprehensive AIS evaluation.
青少年特发性脊柱侧弯(AIS)是一种复杂的三维脊柱畸形,准确的形态评估需要评估冠状面和矢状面的对齐情况。虽然之前的研究在开发无辐射的冠状面评估方法方面取得了重大进展,但无电离辐射的矢状面对齐的可靠和准确评估仍然很大程度上被忽视。为了弥补这一空白,我们提出了LatXGen,这是一种新的生成框架,它可以从裸露背部的后侧红绿蓝深度(RGBD)图像中合成逼真的侧位脊柱放射线照片。这为实现准确的无辐射矢状脊柱对齐估计提供了可能。LatXGen解决了两个核心挑战:(1)基于前后表面几何的从侧位角度推断矢状脊柱形态变化;(2)执行从RGBD输入到放射线照相领域的跨模态翻译。该框架采用双阶段架构,逐步估计侧位脊柱结构并合成相应的放射线照片。为了提高解剖一致性,我们引入了一个基于注意力的快速傅里叶卷积(FFC)模块,用于集成RGBD图像和3D地标的解剖特征,以及一个空间变形网络(SDN)来模拟侧视图中的形态变化。此外,我们构建了针对此任务的第一大规模配对数据集,包含3264个RGBD和侧位放射线照片对。实验结果表明,LatXGen产生的放射线照片解剖准确,在视觉保真度和定量指标上均优于现有的基于GAN的方法。这项研究为矢状脊柱评估和全面的AIS评估提供了有前景的无辐射解决方案。
论文及项目相关链接
PDF 8 pages, 6 figures
Summary
提出了一种新型生成框架LatXGen,可从后背的红绿蓝深度(RGBD)图像合成逼真的侧面脊柱放射图像,从而实现无需辐射的脊柱侧弯矢状面排列准确评估。该框架解决了从侧面角度推断矢状面脊柱形态变化和跨模态从RGBD图像到放射影像领域的转换两个核心挑战。通过引入基于注意力的快速傅立叶卷积(FFC)模块和空间变形网络(SDN),提高了解构脊柱结构和放射影像合成的准确性。本研究为矢状面脊柱评估和青少年特发性脊柱侧弯的全面评估提供了无需辐射的潜在解决方案。
Key Takeaways
- LatXGen是一种新型的生成框架,能够从RGBD图像合成侧面脊柱放射图像。
- 该框架解决了从侧面角度推断矢状面脊柱形态变化和跨模态转换的核心挑战。
- LatXGen通过引入FFC模块和空间变形网络,提高了合成放射影像的准确性和解剖一致性。
- 构建了包含3,264个RGBD和侧面放射影像对的大型配对数据集。
- 实验结果表明,LatXGen在视觉逼真度和定量指标上均优于现有的GAN方法。
- LatXGen为实现无需辐射的脊柱侧弯矢状面评估提供了可能。
点此查看论文截图


GANji: A Framework for Introductory AI Image Generation
Authors:Chandon Hamel, Mike Busch
The comparative study of generative models often requires significant computational resources, creating a barrier for researchers and practitioners. This paper introduces GANji, a lightweight framework for benchmarking foundational AI image generation techniques using a dataset of 10,314 Japanese Kanji characters. It systematically compares the performance of a Variational Autoencoder (VAE), a Generative Adversarial Network (GAN), and a Denoising Diffusion Probabilistic Model (DDPM). The results demonstrate that while the DDPM achieves the highest image fidelity, with a Fr'echet Inception Distance (FID) score of 26.2, its sampling time is over 2,000 times slower than the other models. The GANji framework is an effective and accessible tool for revealing the fundamental trade-offs between model architecture, computational cost, and visual quality, making it ideal for both educational and research purposes.
生成模型的比较研究通常需要大量的计算资源,这成为了研究者和实践者的障碍。本文介绍了GANji,这是一个使用10,314个日语汉字字符数据集对基础AI图像生成技术进行基准测试的轻量级框架。它系统地比较了变分自编码器(VAE)、生成对抗网络(GAN)和去噪扩散概率模型(DDPM)的性能。结果表明,虽然DDPM的图像保真度最高,其Fréchet Inception Distance(FID)得分为26.2,但其采样时间是其他模型的2000倍以上。GANji框架是一个有效且易于使用的工具,能够揭示模型结构、计算成本和视觉质量之间的基本权衡,因此非常适合教育和研究目的。
论文及项目相关链接
Summary
该论文提出了一种名为GANji的轻量级框架,用于评估基于人工智能的图像生成技术。该框架使用包含10,314个日本汉字字符的数据集,对变分自编码器(VAE)、生成对抗网络(GAN)和去噪扩散概率模型(DDPM)的性能进行了系统比较。研究结果表明,虽然DDPM在图像保真度方面表现最佳,但其采样时间是其他模型超过2,000倍。GANji框架是揭示模型架构、计算成本和视觉质量之间基本权衡的有效且易于使用的工具,适合教育和研究目的。
Key Takeaways
- GANji框架用于评估人工智能图像生成技术的性能。
- 该研究比较了VAE、GAN和DDPM三种模型的性能。
- DDPM在图像保真度上表现最佳,但采样时间极长。
- GANji框架可有效地揭示模型架构、计算成本和视觉质量之间的权衡。
- GANji框架对于教育和研究目的均具理想性。
- 该研究使用了包含10,314个日本汉字字符的数据集。
点此查看论文截图
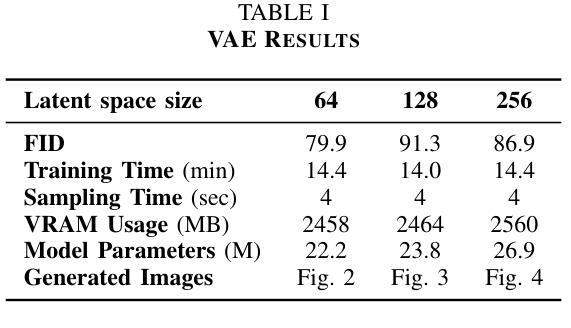

MAN: Latent Diffusion Enhanced Multistage Anti-Noise Network for Efficient and High-Quality Low-Dose CT Image Denoising
Authors:Tangtangfang Fang, Jingxi Hu, Xiangjian He, Jiaqi Yang
While diffusion models have set a new benchmark for quality in Low-Dose Computed Tomography (LDCT) denoising, their clinical adoption is critically hindered by extreme computational costs, with inference times often exceeding thousands of seconds per scan. To overcome this barrier, we introduce MAN, a Latent Diffusion Enhanced Multistage Anti-Noise Network for Efficient and High-Quality Low-Dose CT Image Denoising task. Our method operates in a compressed latent space via a perceptually-optimized autoencoder, enabling an attention-based conditional U-Net to perform the fast, deterministic conditional denoising diffusion process with drastically reduced overhead. On the LDCT and Projection dataset, our model achieves superior perceptual quality, surpassing CNN/GAN-based methods while rivaling the reconstruction fidelity of computationally heavy diffusion models like DDPM and Dn-Dp. Most critically, in the inference stage, our model is over 60x faster than representative pixel space diffusion denoisers, while remaining competitive on PSNR/SSIM scores. By bridging the gap between high fidelity and clinical viability, our work demonstrates a practical path forward for advanced generative models in medical imaging.
虽然扩散模型已经为低剂量计算机断层扫描(LDCT)去噪的质量设定了新的基准,但其临床采用受到极端计算成本的严重阻碍,推理时间通常每次扫描超过数千秒。为了克服这一障碍,我们引入了MAN,这是一个用于高效和高品质低剂量CT图像去噪任务的潜在扩散增强多阶段抗噪声网络。我们的方法在感知优化自编码器提供的压缩潜在空间内运行,使基于注意力的条件U-Net能够执行快速确定性条件去噪扩散过程,大幅降低开销。在LDCT和投影数据集上,我们的模型达到了优越的主观质量,超越了基于CNN/GAN的方法,同时在重建保真度方面与计算密集型的扩散模型(如DDPM和Dn-Dp)相匹敌。最关键的是,在推理阶段,我们的模型是代表性像素空间扩散去噪器的60倍以上,同时在峰值信噪比(PSNR)/结构相似性(SSIM)得分上保持竞争力。通过弥合高保真与临床可行性之间的差距,我们的工作展示了先进生成模型在未来医学影像中的实用发展路径。
论文及项目相关链接
PDF Submitted to ICASSP 2026
Summary
本文介绍了一种名为MAN的潜扩散增强多阶段抗噪声网络,用于高效高质量的低剂量CT图像去噪任务。MAN在压缩的潜在空间内工作,通过感知优化的自编码器,使基于注意力的U-Net能够进行快速、确定的条件去噪扩散过程,大大降低了开销。在LDCT和投影数据集上,MAN模型实现了超越CNN/GAN方法的高感知质量,同时与计算繁重的扩散模型如DDPM和Dn-Dp在重建保真度上竞争。最关键的在于推理阶段,与其他像素空间扩散去噪器相比,MAN模型速度超过60倍,同时在PSNR/SSIM得分上保持竞争力。该研究缩小了高保真与临床可行性之间的差距,为医学影像中的高级生成模型展示了一条实际可行的道路。
Key Takeaways
- MAN网络用于低剂量CT图像去噪任务,旨在解决扩散模型的高计算成本问题。
- MAN在压缩的潜在空间内操作,通过感知优化的自编码器实现快速、确定的条件去噪扩散过程。
- MAN模型实现了超越CNN/GAN方法的高感知质量,同时在重建保真度上与计算繁重的扩散模型竞争。
- 与其他像素空间扩散去噪器相比,MAN模型的推理速度显著提高。
- MAN模型在保证去噪质量的同时降低了计算成本,有助于其临床应用的实现。
- 该研究为医学影像中的高级生成模型提供了一种实际可行的道路。
点此查看论文截图
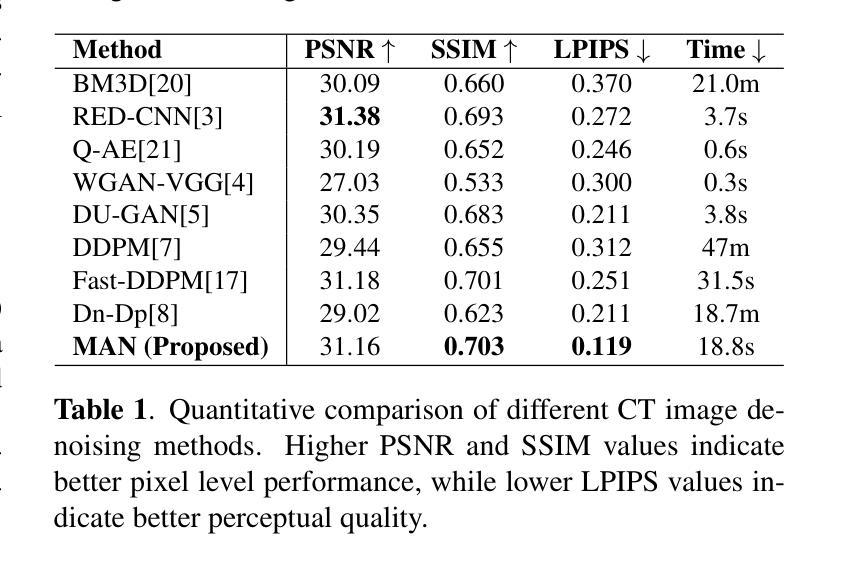
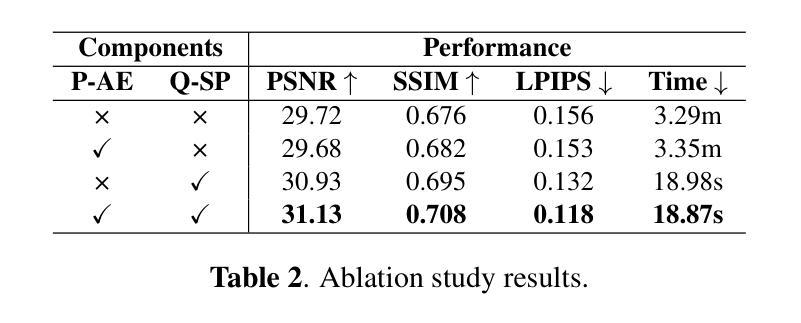
Soft-Di[M]O: Improving One-Step Discrete Image Generation with Soft Embeddings
Authors:Yuanzhi Zhu, Xi Wang, Stéphane Lathuilière, Vicky Kalogeiton
One-step generators distilled from Masked Diffusion Models (MDMs) compress multiple sampling steps into a single forward pass, enabling efficient text and image synthesis. However, they suffer two key limitations: they inherit modeling bias from the teacher, and their discrete token outputs block gradient flow, preventing post-distillation refinements such as adversarial training, reward-based fine-tuning, and Test-Time Embedding Optimization (TTEO). In this work, we introduce soft embeddings, a simple relaxation that replaces discrete tokens with the expected embeddings under the generator’s output distribution. Soft embeddings preserve representation fidelity for one-step discrete generator while providing a fully differentiable continuous surrogate that is compatible with teacher backbones and tokenizer decoders. Integrating soft embeddings into the Di[M]O distillation framework (denoted Soft-Di[M]O) makes one-step generators end-to-end trainable and enables straightforward application of GAN-based refinement, differentiable reward fine-tuning, and TTEO. Empirically, across multiple MDM teachers (e.g., MaskBit, MaskGen), Soft-Di[M]O achieves state-of-the-art one-step results: improved class-to-image performance, a one-step FID of 1.56 on ImageNet-256 with GAN-based refinement, along with higher GenEval and HPS scores on text-to-image with reward fine-tuning, and further gains from TTEO.
从Masked Diffusion Models(MDMs)提炼出的一步生成器将多个采样步骤压缩成一次前向传递,实现了高效的文本和图像合成。然而,它们存在两个主要局限性:它们继承了教师的建模偏见,并且它们的离散令牌输出阻止了梯度流,阻止了如对抗性训练、基于奖励的微调以及测试时间嵌入优化(TTEO)等提炼后的改进。在这项工作中,我们引入了软嵌入,这是一种简单的松弛方法,它用生成器输出分布下的预期嵌入来替换离散令牌。软嵌入保留了一步离散生成器的表示保真度,同时提供了一个与教师主干和分词器解码器兼容的全可微分的连续替代方案。将软嵌入集成到Di[M]O提炼框架(表示为Soft-Di[M]O)中,使得一步生成器端对端可训练,并便于应用基于GAN的改进、可微分的奖励微调以及TTEO。经验上,跨多个MDM教师(例如MaskBit、MaskGen),Soft-Di[M]O达到了最先进的单步结果:提高了类到图像的性能,在ImageNet-256上的单步FID为1.56,使用基于GAN的改进,以及在文本到图像上使用奖励微调时的GenEval和HPS分数更高,并且从TTEO中获得了进一步的收益。
论文及项目相关链接
Summary
文本介绍了基于Masked Diffusion Models(MDM)的一步生成器(one-step generator),它能在一次前向传递中实现高效的文本和图像合成。然而,它存在两个主要局限性:继承自教师的建模偏见和离散标记输出阻碍了梯度流,使得无法进行对抗训练、基于奖励的微调以及测试时间嵌入优化(TTEO)。为解决这些问题,本文引入了软嵌入(soft embeddings),它是一种简单的松弛方法,用生成器输出分布下的预期嵌入替换离散标记。软嵌入保留了一步离散生成器的表示保真度,并提供了一个与教师和分词器解码器兼容的全微分连续替代方案。将软嵌入集成到Di[M]O蒸馏框架中(称为Soft-Di[M]O),使得一步生成器可以进行端到端的训练,并能直接应用基于GAN的细化、可微分的奖励微调以及TTEO。实验结果表明,在多个MDM教师模型上,Soft-Di[M]O取得了最先进的单步结果。
Key Takeaways
- 一步生成器从Masked Diffusion Models(MDM)中蒸馏出多个采样步骤到一个前向传递中,实现文本和图像的高效合成。
- 一步生成器存在两个主要局限性:继承自教师的建模偏见和离散标记输出导致的梯度流阻碍。
- 软嵌入作为一种简单的松弛方法被引入,以预期嵌入替换离散标记,改善一步生成器的局限性。
- 软嵌入保留了一阶离散生成器的表示保真度,并提供了一个全微分连续替代方案,与教师和分词器解码器兼容。
- Soft-Di[M]O框架集成了软嵌入技术,使得一步生成器可以进行端到端的训练,并能应用基于GAN的细化、奖励微调以及测试时间嵌入优化(TTEO)。
- Soft-Di[M]O在多个MDM教师模型上取得了最先进的单步结果,包括改进类到图像的性能、更低的FID分数以及更高的GenEval和HPS分数等。
点此查看论文截图