⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-01 更新
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
Authors:Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T. Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Yu Lee, Tomas Pfister
With the growing adoption of large language model agents in persistent real-world roles, they naturally encounter continuous streams of tasks. A key limitation, however, is their failure to learn from the accumulated interaction history, forcing them to discard valuable insights and repeat past errors. We propose ReasoningBank, a novel memory framework that distills generalizable reasoning strategies from an agent’s self-judged successful and failed experiences. At test time, an agent retrieves relevant memories from ReasoningBank to inform its interaction and then integrates new learnings back, enabling it to become more capable over time. Building on this powerful experience learner, we further introduce memory-aware test-time scaling (MaTTS), which accelerates and diversifies this learning process by scaling up the agent’s interaction experience. By allocating more compute to each task, the agent generates abundant, diverse experiences that provide rich contrastive signals for synthesizing higher-quality memory. The better memory in turn guides more effective scaling, establishing a powerful synergy between memory and test-time scaling. Across web browsing and software engineering benchmarks, ReasoningBank consistently outperforms existing memory mechanisms that store raw trajectories or only successful task routines, improving both effectiveness and efficiency; MaTTS further amplifies these gains. These findings establish memory-driven experience scaling as a new scaling dimension, enabling agents to self-evolve with emergent behaviors naturally arise.
随着大型语言模型代理在持久现实角色中的日益普及,它们自然会遇到连续的任务流。然而,一个关键的局限性在于它们无法从累积的交互历史中学习,迫使它们丢弃有价值的见解并重复过去的错误。我们提出了ReasoningBank,这是一个新的记忆框架,可以从代理的自我判断的成功和失败经验中提炼出可推广的推理策略。在测试时,代理从ReasoningBank中检索相关记忆以指导其交互,然后将新学习整合回来,随着时间的推移使其能力变得更强。在此基础上,我们进一步引入了记忆感知测试时缩放(MaTTS),通过扩大代理的交互经验来加速和多样化学习过程。通过为每个任务分配更多的计算资源,代理生成丰富、多样的经验,为合成高质量记忆提供丰富的对比信号。更好的记忆反过来又指导更有效的缩放,在记忆和测试时缩放之间建立强大的协同作用。在网页浏览和软件工程基准测试中,ReasoningBank始终优于现有的存储原始轨迹或仅存储成功任务例程的记忆机制,提高了有效性和效率;MaTTS进一步扩大了这些收益。这些发现确立了以记忆驱动的经验缩放作为新的缩放维度,使代理能够自然地自我进化并出现新兴行为。
论文及项目相关链接
PDF 11 pages, 7 figures, 4 tables
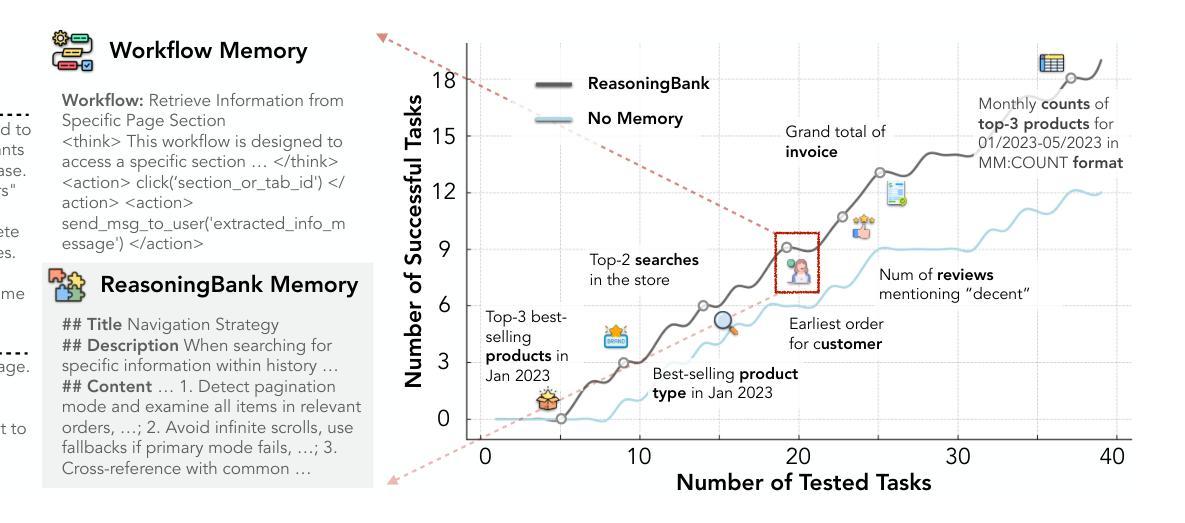
Summary
大型语言模型在处理持续现实世界任务时,面临无法从累积的互动历史中学习的问题,导致有价值的信息丢失和重复错误。为此,我们提出了ReasoningBank,一种能够蒸馏可概括推理策略的记忆框架,该框架基于智能体的自我判断成功和失败经验。测试时,智能体从ReasoningBank检索相关记忆以指导交互,并将新学习整合回框架中,使其随时间变得更加智能。在此基础上,我们进一步引入了记忆感知测试时间缩放(MaTTS),加速并优化这一学习过程。通过为每项任务分配更多计算资源,智能体产生丰富多样的经验,为合成高质量记忆提供丰富的对比信号。高质量记忆进一步引导更有效的缩放,在记忆和测试时间缩放之间建立强大协同作用。ReasoningBank在各种基准测试中表现优异,优于仅存储原始轨迹或成功任务例程的现有记忆机制;MaTTS进一步扩大了这些优势。这些发现确立了以记忆驱动的经验缩放作为一种新型缩放维度,使智能体能够自然地进行自我进化并产生新兴行为。
Key Takeaways
- 大型语言模型在自然处理持续现实世界任务时面临无法从互动历史中学习的限制。
- ReasoningBank作为一种新型记忆框架,能够基于智能体的自我判断成功和失败经验来提炼可概括的推理策略。
- 在测试阶段,智能体能够从ReasoningBank检索相关记忆以指导交互,并整合新学习。
- 记忆感知测试时间缩放(MaTTS)能够加速和优化智能体的学习过程。
- 通过为任务分配更多计算资源,智能体能产生丰富多样的经验,提升记忆质量。
- 高质量记忆能有效引导更高效的缩放过程,实现记忆与测试时间缩放之间的协同作用。
点此查看论文截图
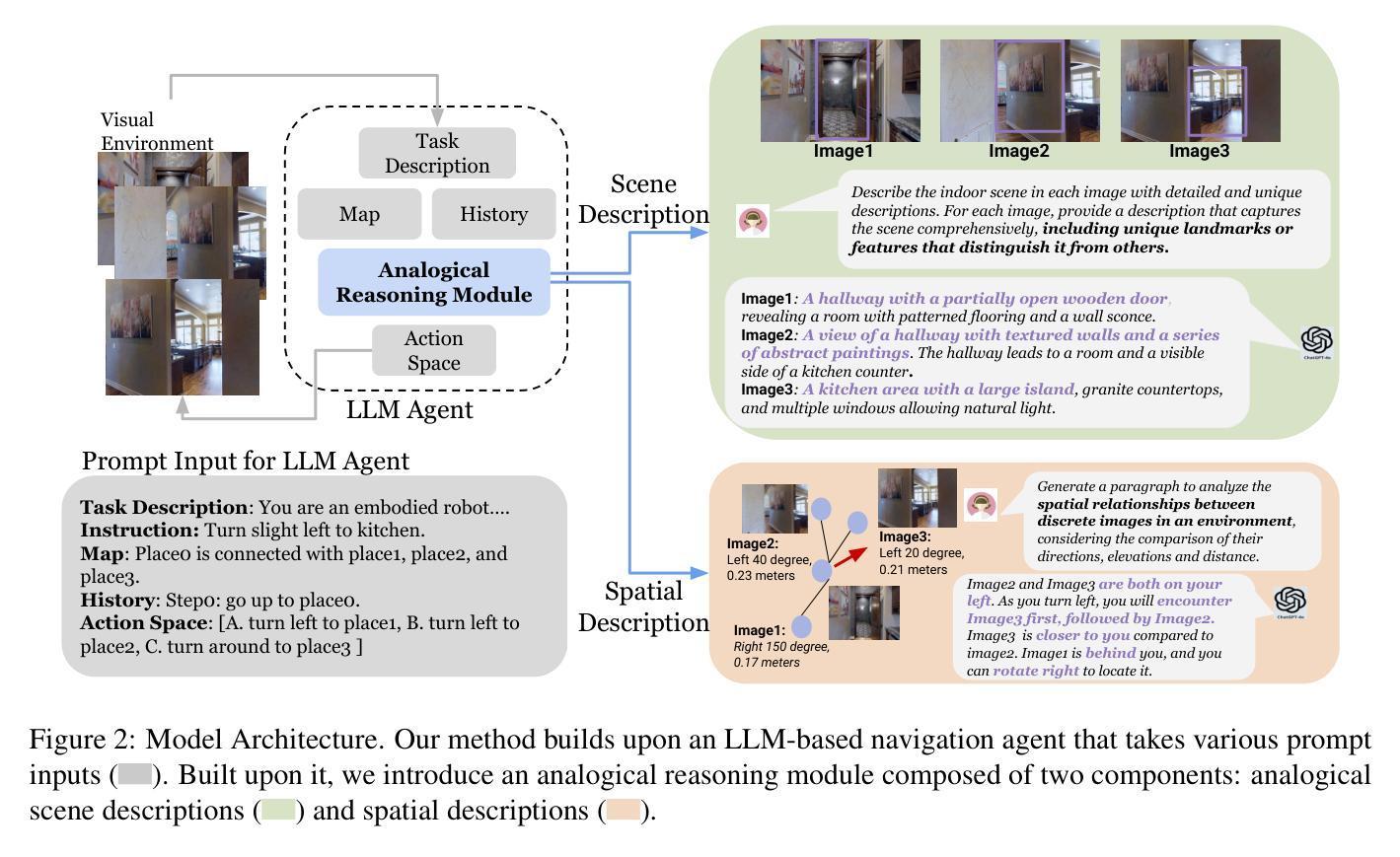
Vision-and-Language Navigation with Analogical Textual Descriptions in LLMs
Authors:Yue Zhang, Tianyi Ma, Zun Wang, Yanyuan Qiao, Parisa Kordjamshidi
Integrating large language models (LLMs) into embodied AI models is becoming increasingly prevalent. However, existing zero-shot LLM-based Vision-and-Language Navigation (VLN) agents either encode images as textual scene descriptions, potentially oversimplifying visual details, or process raw image inputs, which can fail to capture abstract semantics required for high-level reasoning. In this paper, we improve the navigation agent’s contextual understanding by incorporating textual descriptions from multiple perspectives that facilitate analogical reasoning across images. By leveraging text-based analogical reasoning, the agent enhances its global scene understanding and spatial reasoning, leading to more accurate action decisions. We evaluate our approach on the R2R dataset, where our experiments demonstrate significant improvements in navigation performance.
将大型语言模型(LLM)集成到嵌入式人工智能模型中的趋势日益普遍。然而,现有的基于零样本的LLM视觉与语言导航(VLN)代理要么将图像编码为文本场景描述,这可能简化了视觉细节,要么处理原始图像输入,这可能会忽略用于高级推理所需的抽象语义。在本文中,我们通过结合来自多个角度的文本描述来提高导航代理的上下文理解能力,这些描述有助于图像之间的类比推理。通过利用基于文本的类比推理,代理提高了其对全局场景的理解和空间推理能力,从而做出更准确的行动决策。我们在R2R数据集上评估了我们的方法,实验表明我们的方法在导航性能上有了显著提高。
论文及项目相关链接
Summary
本文探讨了将大型语言模型(LLM)融入实体AI模型中的趋势。现有的零样本LLM基础视觉语言导航(VLN)代理在处理图像时存在缺陷,要么将图像编码为文本场景描述从而可能简化视觉细节,要么处理原始图像输入以致难以捕获抽象语义用于高级推理。本文通过结合多视角的文本描述增强代理的上下文理解能力,并促进图像间的类比推理。利用基于文本的类比推理,代理提升了全局场景理解和空间推理能力,进而作出更准确的行动决策。在R2R数据集上的实验证明,该方法极大提升了导航性能。
Key Takeaways
- 大型语言模型(LLM)正在越来越多地被集成到实体AI模型中。
- 当前VLN代理在处理图像时存在局限性,要么简化视觉细节,要么难以捕获抽象语义。
- 本文通过结合多视角的文本描述来改善代理的上下文理解能力。
- 利用基于文本的类比推理增强了代理的全局场景理解和空间推理能力。
- 代理能够基于改进的理解做出更准确的行动决策。
- 在R2R数据集上的实验证明了该方法显著提升了导航性能。
点此查看论文截图
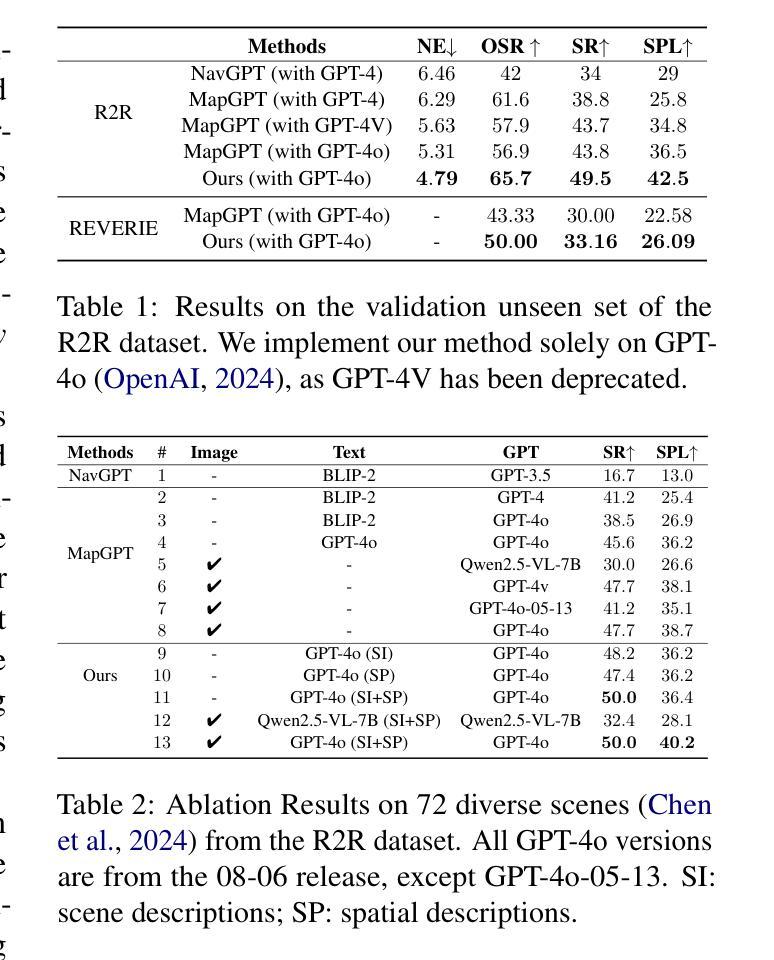
MGM-Omni: Scaling Omni LLMs to Personalized Long-Horizon Speech
Authors:Chengyao Wang, Zhisheng Zhong, Bohao Peng, Senqiao Yang, Yuqi Liu, Haokun Gui, Bin Xia, Jingyao Li, Bei Yu, Jiaya Jia
We present MGM-Omni, a unified Omni LLM for omni-modal understanding and expressive, long-horizon speech generation. Unlike cascaded pipelines that isolate speech synthesis, MGM-Omni adopts a “brain-mouth” design with a dual-track, token-based architecture that cleanly decouples multimodal reasoning from real-time speech generation. This design enables efficient cross-modal interaction and low-latency, streaming speech generation. For understanding, a unified training strategy coupled with a dual audio encoder design enables long-form audio perception across diverse acoustic conditions. For generation, a chunk-based parallel decoding scheme narrows the text speech token-rate gap, accelerating inference and supporting streaming zero-shot voice cloning with stable timbre over extended durations. Compared to concurrent work, MGM-Omni achieves these capabilities with markedly data-efficient training. Extensive experiments demonstrate that MGM-Omni outperforms existing open source models in preserving timbre identity across extended sequences, producing natural and context-aware speech, and achieving superior long-form audio and omnimodal understanding. MGM-Omni establishes an efficient, end-to-end paradigm for omnimodal understanding and controllable, personalised long-horizon speech generation.
我们推出了MGM-Omni,这是一款统一的Omni LLM,用于全模态理解和表达,以及长期视野的语音生成。不同于将语音合成孤立的级联管道,MGM-Omni采用了“大脑-嘴巴”设计,具有双轨、基于令牌的结构,能够干净地将多模态推理与实时语音生成分开。这种设计实现了高效的跨模态交互和低延迟的流式语音生成。在理解方面,采用统一的训练策略和双音频编码器设计,可实现不同声学环境下的长音频感知。在生成方面,基于块的并行解码方案缩小了文本语音令牌速率差距,加速了推理,并支持在扩展时间段上实现稳定的音色零射击克隆和流式传输。与同期工作相比,MGM-Omni在数据高效训练方面实现了这些功能。大量实验表明,MGM-Omni在保留扩展序列的音色身份、产生自然和上下文感知的语音以及实现长期音频和全模态理解方面优于现有的开源模型。MGM-Omni为全模态理解和可控、个性化的长期视野语音生成建立了高效、端到端的范式。
论文及项目相关链接
PDF Code is available at https://github.com/dvlab-research/MGM-Omni
Summary
MGM-Omni是一个统一的全模态大型语言模型,用于全模态理解和表达,以及长周期语音生成。它采用“脑-口”设计,具有双轨、基于令牌的结构,能够干净地解耦多模态推理和实时语音生成。这种设计实现了高效的跨模态交互和低延迟的流式语音生成。通过统一的训练策略和双音频编码器设计,提高了长音频感知能力,跨越不同的声学环境。在生成方面,基于分块的并行解码方案缩小了文本语音令牌率差距,加快了推理速度,支持扩展时长内的稳定音色零样本语音克隆和流式传输。与同期工作相比,MGM-Omni的数据训练效率显著。实验表明,MGM-Omni在保持扩展序列的音色身份、产生自然和语境感知的语音、实现长期音频和全能理解方面优于现有开源模型。MGM-Omni为全能理解和可控、个性化的长周期语音生成建立了高效、端到端的范式。
Key Takeaways
- MGM-Omni是一个全模态的大型语言模型,用于全模态理解和表达以及长周期语音生成。
- 采用“脑-口”设计和双轨、基于令牌的结构,实现多模态推理和实时语音生成的解耦。
- 通过统一的训练策略和双音频编码器设计,提高了长音频感知能力。
- 基于分块的并行解码方案支持零样本语音克隆和流式传输。
- 与其他模型相比,MGM-Omni的数据训练效率显著。
- MGM-Omni在保持音色身份、产生自然和语境感知的语音方面优于现有开源模型。
点此查看论文截图

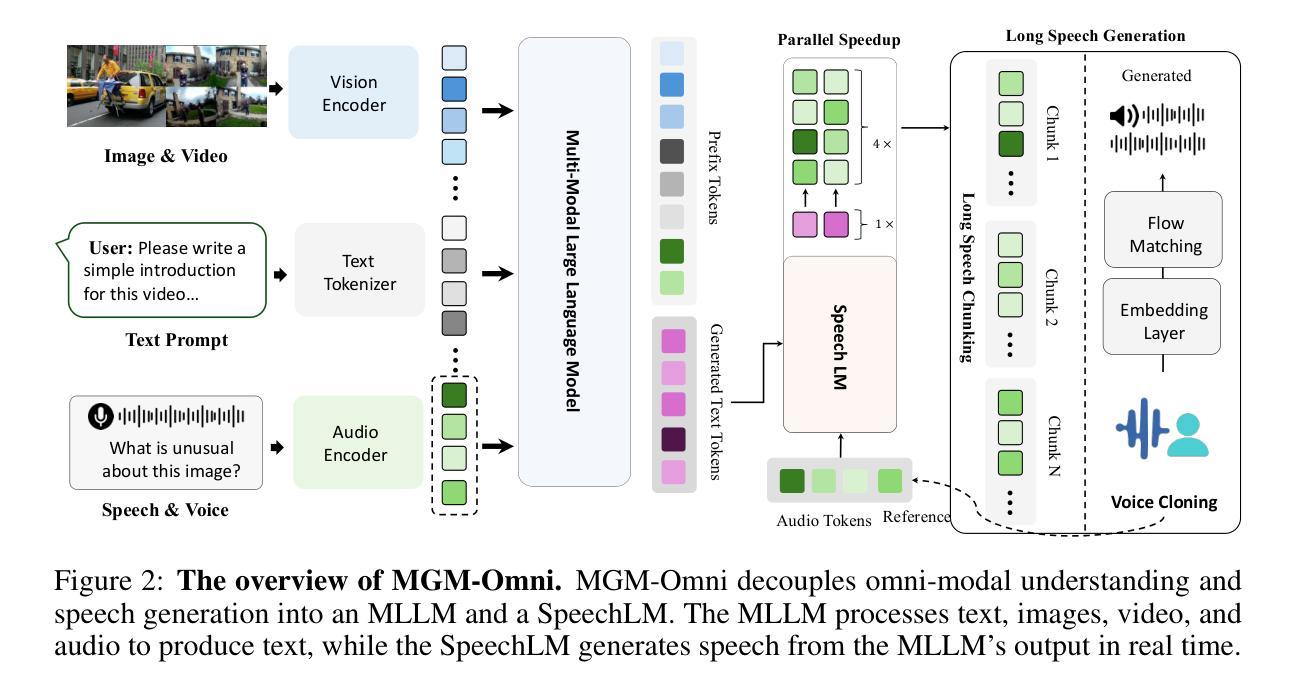
ORPO-Distill: Mixed-Policy Preference Optimization for Cross-Architecture LLM Distillation
Authors:Aasheesh Singh, Vishal Vaddina, Dagnachew Birru
We introduce ORPO-Distill, a general-purpose method for cross-architecture LLM distillation that formulates the problem as a preference optimization task. Unlike standard CoT distillation, the approach transfers knowledge through diverse reasoning traces. It employs an Odds-Ratio Preference Optimization objective that contrasts teacher and student traces for more effective learning, and adopts a mixed-policy strategy for utilizing student-generated outputs, outperforming both off- and on-policy alternatives. Experiments on five datasets and multiple student models show consistent improvements over conventional black-box KD baselines.
我们介绍了ORPO-Distill,这是一种跨架构大型语言模型蒸馏的通用方法,它将问题表述为偏好优化任务。不同于标准的认知轨迹蒸馏,该方法通过多样的推理轨迹进行知识迁移。它采用Odds-Ratio Preference Optimization目标,对比教师模型和学生模型的轨迹以实现更有效的学习,并采纳混合策略利用学生模型生成的输出,超越了离线策略和在线策略的选择。在五个数据集和多个学生模型上的实验表明,相较于传统的黑盒知识蒸馏基线,其表现持续提高。
论文及项目相关链接
PDF Accepted at NeurIPS 2025, Efficient Reasoning Workshop
Summary
ORPO-Distill方法是一种通用的跨架构大型语言模型蒸馏方法,将问题表述为偏好优化任务。不同于传统的认知链蒸馏,该方法通过多样的推理轨迹进行知识迁移。它采用Odds-Ratio Preference Optimization目标,对比教师模型和学生模型的推理轨迹以更有效地学习,同时采用混合策略利用学生模型生成的输出,超越了离线与在线策略的选择。在五个数据集和多个学生模型上的实验表明,相较于传统的黑箱知识蒸馏基线方法,该方法具有持续的提升效果。
Key Takeaways
- ORPO-Distill是一种跨架构的大型语言模型蒸馏方法。
- 该方法将问题表述为偏好优化任务,不同于传统的认知链蒸馏。
- ORPO-Distill通过多样的推理轨迹进行知识迁移。
- 采用Odds-Ratio Preference Optimization目标,对比教师模型和学生模型的推理轨迹以更有效地学习。
- 该方法采用混合策略利用学生模型生成的输出,超越了离线与在线策略的选择。
- 在多个数据集和学生模型上的实验表明,ORPO-Distill方法较传统方法具有持续的提升效果。
- 该方法对于提升大型语言模型的性能具有潜在的重要性。
点此查看论文截图


Cogito, Ergo Ludo: An Agent that Learns to Play by Reasoning and Planning
Authors:Sai Wang, Yu Wu, Zhongwen Xu
The pursuit of artificial agents that can learn to master complex environments has led to remarkable successes, yet prevailing deep reinforcement learning methods often rely on immense experience, encoding their knowledge opaquely within neural network weights. We propose a different paradigm, one in which an agent learns to play by reasoning and planning. We introduce Cogito, ergo ludo (CEL), a novel agent architecture that leverages a Large Language Model (LLM) to build an explicit, language-based understanding of its environment’s mechanics and its own strategy. Starting from a tabula rasa state with no prior knowledge (except action set), CEL operates on a cycle of interaction and reflection. After each episode, the agent analyzes its complete trajectory to perform two concurrent learning processes: Rule Induction, where it refines its explicit model of the environment’s dynamics, and Strategy and Playbook Summarization, where it distills experiences into an actionable strategic playbook. We evaluate CEL on diverse grid-world tasks (i.e., Minesweeper, Frozen Lake, and Sokoban), and show that the CEL agent successfully learns to master these games by autonomously discovering their rules and developing effective policies from sparse rewards. Ablation studies confirm that the iterative process is critical for sustained learning. Our work demonstrates a path toward more general and interpretable agents that not only act effectively but also build a transparent and improving model of their world through explicit reasoning on raw experience.
追求能够学习掌握复杂环境的智能代理已经取得了显著的成果,然而流行的深度强化学习方法往往依赖于大量的经验,将他们的知识编码在神经网络权重中。我们提出了一种不同的范式,即代理通过推理和规划来学习玩耍。我们引入了Cogito,ergo ludo(CEL),这是一种新的代理架构,它利用大型语言模型(LLM)来建立基于语言的对环境机制和自身策略的明确理解。从无知的状态开始(仅知道动作集),CEL进行交互和反思的循环。在每一集之后,代理分析其完整的轨迹,同时进行两个并行学习过程:规则归纳,它精炼了对环境动态的明确模型;策略和剧本摘要,它将经验提炼成可操作的战略剧本。我们在多样的网格世界任务(如扫雷、冰冻湖和索科班)中对CEL进行了评估,并显示CEL代理通过自主发现规则并从稀疏奖励中发展出有效策略,成功掌握了这些游戏。消融研究证实,迭代过程对于持续学习至关重要。我们的工作展示了一条通往更通用和可解释的代理的道路,这些代理不仅有效地行动,而且通过原始经验的明确推理来建立透明且不断改善的世界模型。
论文及项目相关链接
Summary
该文本介绍了一种名为Cogito,ergo ludo(CEL)的新型智能体架构。该架构利用大型语言模型(LLM)建立对环境机制和自身策略的语言化理解。通过互动和反思循环,CEL智能体在经历每一集后,同时进行规则归纳和策略及行动指南总结,从而自主发现游戏规则并发展出有效的策略。在多种网格世界任务中,CEL智能体成功掌握了游戏。研究证实迭代过程对持续学习至关重要。此研究展示了一种通用且可解释的智能体路径,这些智能体不仅能够有效行动,而且能够通过原始经验进行明确推理来构建其世界的透明性和改进模型。
Key Takeaways
- Cogito,ergo ludo(CEL)是一个基于大型语言模型(LLM)的智能体架构,它能够通过语言理解环境和制定策略。
- CEL智能体通过互动和反思循环进行学习,自主发现游戏规则并发展出有效的策略。
- CEL智能体在多种网格世界任务中成功掌握游戏,显示出强大的学习能力。
- 迭代过程对于智能体的持续学习至关重要。
- 与传统深度强化学习方法不同,CEL智能体通过明确推理和总结经验来构建其环境模型,使其知识更加透明和可解释。
- CEL智能体的学习方法具有通用性,能够在不同任务中适应并学习新规则。
点此查看论文截图

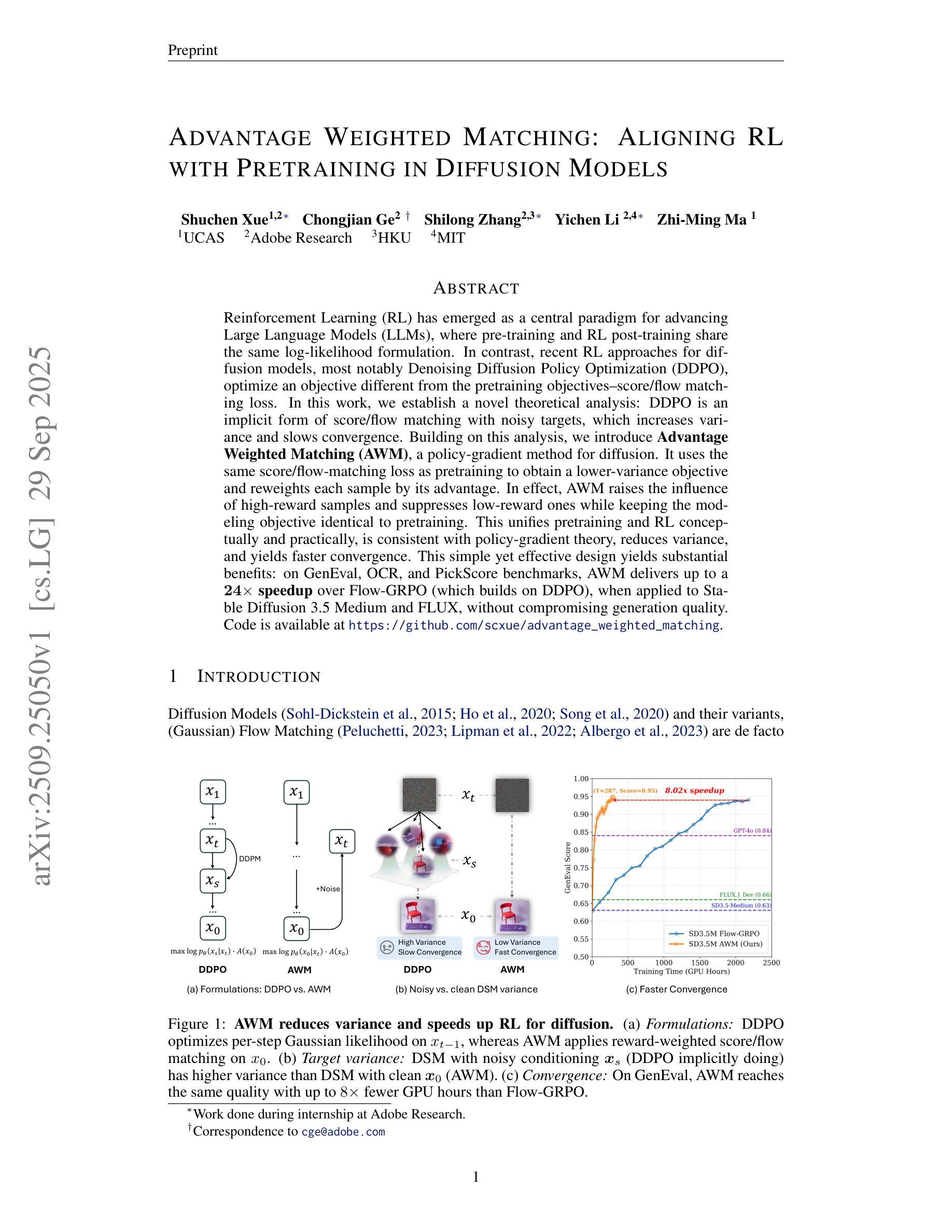
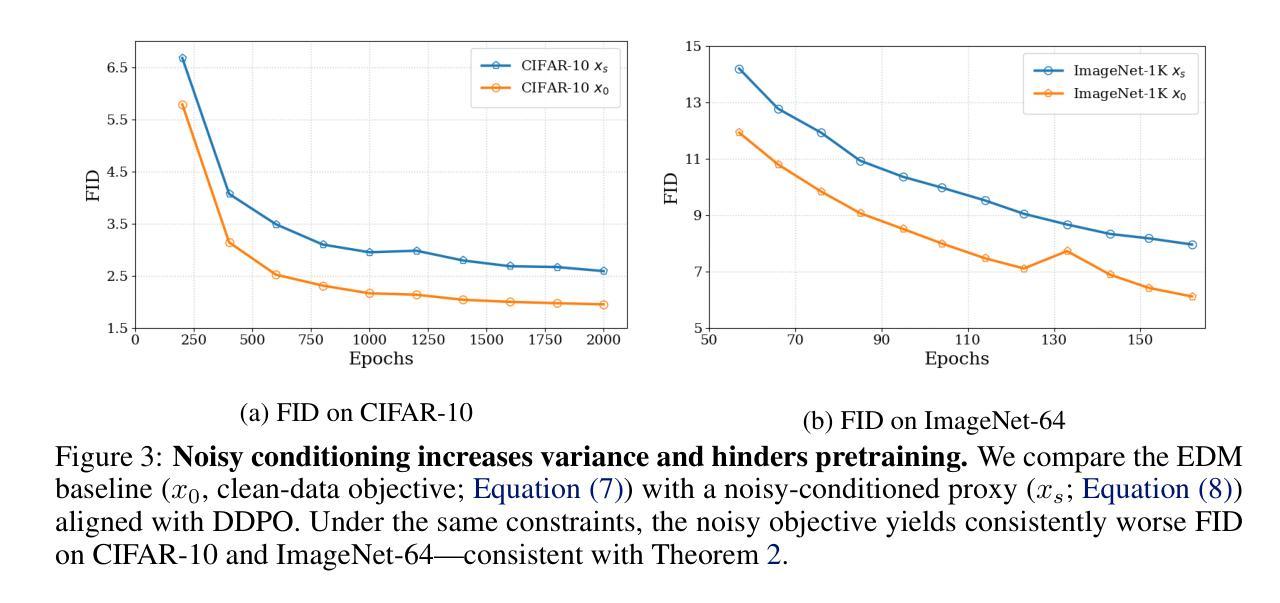
Advantage Weighted Matching: Aligning RL with Pretraining in Diffusion Models
Authors:Shuchen Xue, Chongjian Ge, Shilong Zhang, Yichen Li, Zhi-Ming Ma
Reinforcement Learning (RL) has emerged as a central paradigm for advancing Large Language Models (LLMs), where pre-training and RL post-training share the same log-likelihood formulation. In contrast, recent RL approaches for diffusion models, most notably Denoising Diffusion Policy Optimization (DDPO), optimize an objective different from the pretraining objectives–score/flow matching loss. In this work, we establish a novel theoretical analysis: DDPO is an implicit form of score/flow matching with noisy targets, which increases variance and slows convergence. Building on this analysis, we introduce \textbf{Advantage Weighted Matching (AWM)}, a policy-gradient method for diffusion. It uses the same score/flow-matching loss as pretraining to obtain a lower-variance objective and reweights each sample by its advantage. In effect, AWM raises the influence of high-reward samples and suppresses low-reward ones while keeping the modeling objective identical to pretraining. This unifies pretraining and RL conceptually and practically, is consistent with policy-gradient theory, reduces variance, and yields faster convergence. This simple yet effective design yields substantial benefits: on GenEval, OCR, and PickScore benchmarks, AWM delivers up to a $24\times$ speedup over Flow-GRPO (which builds on DDPO), when applied to Stable Diffusion 3.5 Medium and FLUX, without compromising generation quality. Code is available at https://github.com/scxue/advantage_weighted_matching.
强化学习(RL)已经成为推进大型语言模型(LLM)的核心范式,其中预训练和RL后训练采用相同的对数似然公式。相比之下,最近的扩散模型中的RL方法,尤其是降噪扩散策略优化(DDPO),优化的目标与预训练目标不同——分数/流匹配损失。在这项工作中,我们建立了新的理论分析:DDPO是带有噪声目标的分数/流匹配的隐式形式,这增加了方差并减缓了收敛速度。基于这一分析,我们引入了优势加权匹配(AWM),这是一种用于扩散的策略梯度方法。它使用与预训练相同的分数/流匹配损失来获得低方差目标,并按优势对每个样本进行加权。实际上,AWM提高了高奖励样本的影响,并抑制了低奖励样本,同时保持建模目标与预训练相同。这在概念和实践上统一了预训练和RL,符合策略梯度理论,降低了方差,并实现了更快的收敛速度。这种简单而有效的设计带来了实质性的好处:在GenEval、OCR和PickScore基准测试中,与基于DDPO的Flow-GRPO相比,AWM在应用于Stable Diffusion 3.5 Medium和FLUX时实现了高达24倍的加速,同时不损害生成质量。代码可在https://github.com/scxue/advantage_weighted_matching找到。
论文及项目相关链接
Summary
本文探讨了强化学习(RL)在大语言模型(LLM)中的应用,特别是针对扩散模型的RL方法,如Denoising Diffusion Policy Optimization(DDPO)。文章提出了一种新型理论分析方法,指出DDPO是带有噪声目标隐式的score/flow匹配形式,会增加方差并减慢收敛速度。基于此分析,文章引入了Advantage Weighted Matching(AWM)方法,这是一种用于扩散模型的策略梯度方法。AWM使用与预训练相同的score/flow匹配损失来获得低方差目标,并通过优势对每个样本进行加权。该方法在概念和实践上将预训练和RL统一起来,符合策略梯度理论,减少方差并实现更快的收敛。在GenEval、OCR和PickScore基准测试中,AWM在Stable Diffusion 3.5 Medium和FLUX上应用时,生成质量不降低的情况下,速度比基于DDPO的Flow-GRPO提高了24倍。
Key Takeaways
- 强化学习(RL)在大语言模型(LLM)中扮演重要角色,特别是在扩散模型中的应用。
- Denoising Diffusion Policy Optimization(DDPO)作为当前主流的RL方法,存在增加方差和减慢收敛速度的问题。
- 文章提出了Advantage Weighted Matching(AWM)方法,这是一种新的策略梯度方法用于扩散模型。
- AWM使用与预训练相同的score/flow匹配损失,获得低方差目标并提升高回报样本的影响。
- AWM在保证生成质量的同时,可以显著提高训练速度,例如在某些基准测试中实现了高达24倍的速度提升。
- AWM将预训练和RL在理论和实践层面统一起来,与策略梯度理论一致。
点此查看论文截图
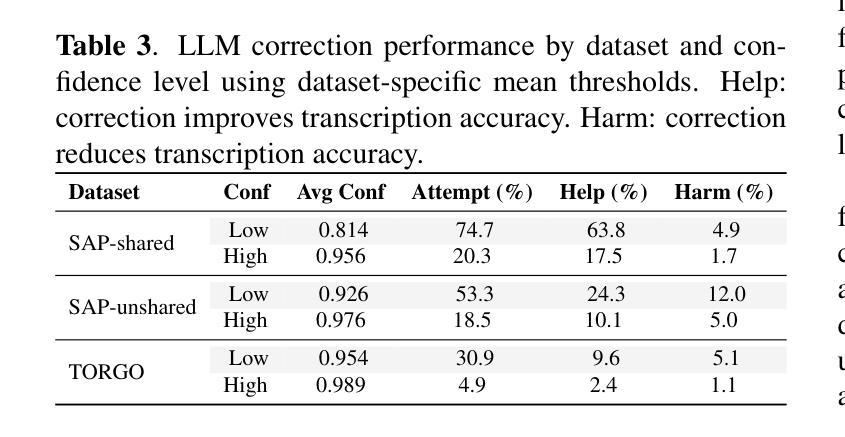
Confidence-Guided Error Correction for Disordered Speech Recognition
Authors:Abner Hernandez, Tomás Arias Vergara, Andreas Maier, Paula Andrea Pérez-Toro
We investigate the use of large language models (LLMs) as post-processing modules for automatic speech recognition (ASR), focusing on their ability to perform error correction for disordered speech. In particular, we propose confidence-informed prompting, where word-level uncertainty estimates are embedded directly into LLM training to improve robustness and generalization across speakers and datasets. This approach directs the model to uncertain ASR regions and reduces overcorrection. We fine-tune a LLaMA 3.1 model and compare our approach to both transcript-only fine-tuning and post hoc confidence-based filtering. Evaluations show that our method achieves a 10% relative WER reduction compared to naive LLM correction on the Speech Accessibility Project spontaneous speech and a 47% reduction on TORGO, demonstrating the effectiveness of confidence-aware fine-tuning for impaired speech.
我们研究了大型语言模型(LLM)在自动语音识别(ASR)后处理模块中的应用,重点研究其在纠正乱序语音方面的能力。特别是,我们提出了基于信心的提示方法,将词级不确定性估计直接嵌入到LLM训练中,以提高跨说话者和数据集的稳健性和泛化能力。这种方法引导模型进入不确定的ASR区域,减少过度纠正。我们对LLaMA 3.1模型进行了微调,并将我们的方法与仅基于文本的微调以及基于事后信心的过滤方法进行了比较。评估表明,我们的方法在语音无障碍项目自然语音上的相对词错误率(WER)降低了10%,在TORGO上降低了47%,证明了信心感知微调对于受损语音的有效性。
论文及项目相关链接
PDF Preprint submitted to ICASSP
Summary
本文研究了大型语言模型(LLMs)在自动语音识别(ASR)后处理模块中的应用,重点探讨了其在纠正混乱语音方面的错误纠正能力。研究提出了一种基于置信度的提示方法,将词级不确定性估计直接嵌入到LLM训练中,以提高模型对不同发言者和数据集的稳健性和泛化能力。该方法引导模型定位到不确定的ASR区域,并减少过度纠正。通过对LLaMA 3.1模型的微调,与仅基于文本的微调以及基于置信度的后期过滤方法进行比较,评估结果显示,该方法在语音可访问性项目的即兴演讲上相对于简单的LLM校正实现了10%的相对字词错误率(WER)降低,在TORGO上的降低幅度更是高达47%,证明了基于置信度调教的精细调整对于受损语音的有效性。
Key Takeaways
- 大型语言模型(LLMs)被用作自动语音识别(ASR)的后处理模块,用于改善混乱语音的错误纠正能力。
- 提出了置信度感知提示方法,将词级不确定性估计融入LLM训练中,提高模型稳健性和泛化能力。
- 方法定位ASR中的不确定区域,减少过度纠正。
- 通过微调LLaMA 3.1模型,与仅基于文本的微调及基于置信度的后期过滤比较,评估证实所提方法有效性。
- 在语音可访问性项目的即兴演讲上,该方法相对简单的LLM校正实现了10%的WER降低。
- 在TORGO数据集上,该方法实现了高达47%的WER降低。
点此查看论文截图


Large Language Models for Software Testing: A Research Roadmap
Authors:Cristian Augusto, Antonia Bertolino, Guglielmo De Angelis, Francesca Lonetti, Jesús Morán
Large Language Models (LLMs) are starting to be profiled as one of the most significant disruptions in the Software Testing field. Specifically, they have been successfully applied in software testing tasks such as generating test code, or summarizing documentation. This potential has attracted hundreds of researchers, resulting in dozens of new contributions every month, hardening researchers to stay at the forefront of the wave. Still, to the best of our knowledge, no prior work has provided a structured vision of the progress and most relevant research trends in LLM-based testing. In this article, we aim to provide a roadmap that illustrates its current state, grouping the contributions into different categories, and also sketching the most promising and active research directions for the field. To achieve this objective, we have conducted a semi-systematic literature review, collecting articles and mapping them into the most prominent categories, reviewing the current and ongoing status, and analyzing the open challenges of LLM-based software testing. Lastly, we have outlined several expected long-term impacts of LLMs over the whole software testing field.
大型语言模型(LLMs)开始被视为软件测试领域最重要的技术突破之一。特别是,它们已成功应用于软件测试任务,如生成测试代码或总结文档。这种潜力吸引了数百名研究人员,每月都有数十项新贡献,推动研究人员站在浪潮的前沿。然而,据我们所知,没有先前的工作提供过基于LLM的测试的进步和相关研究趋势的结构性视角。在本文中,我们旨在提供一条路线图,以说明其当前状态,将贡献分组成不同的类别,并描绘该领域最有前途和活跃的研究方向。为了实现这一目标,我们进行了半系统的文献综述,收集文章并将其映射到最突出的类别中,回顾当前和正在进行的状态,并分析基于LLM的软件测试所面临的开放挑战。最后,我们概述了LLMs对整个软件测试领域的几个预期长期影响。
论文及项目相关链接
PDF 40 pages & 10 figures Submitted on 29th September 2025
Summary
大型语言模型(LLM)在软件测试领域展现出重大突破,被应用于生成测试代码、总结文档等任务。本文旨在提供该领域当前状态的道路图,将贡献分为不同类别,并概述最活跃和最有希望的研究方向。通过半系统性文献综述,本文收集了文章并将其映射到最突出的类别中,回顾当前和正在进行的状态,并分析LLM在软件测试中的开放挑战。同时,本文还概述了LLM对软件测试领域的长期影响。
Key Takeaways
- 大型语言模型(LLM)在软件测试领域具有显著的应用潜力。
- LLM已被成功应用于生成测试代码和总结文档等任务。
- 目前尚未有研究工作全面概述LLM在软件测试中的进展和相关研究趋势。
- 本文通过半系统性文献综述,对LLM在软件测试中的研究进行了分类和回顾。
- 当前和正在进行的研究主要集中在解决LLM在软件测试中的开放挑战。
- LLM对软件测试领域具有长期的预期影响。
点此查看论文截图
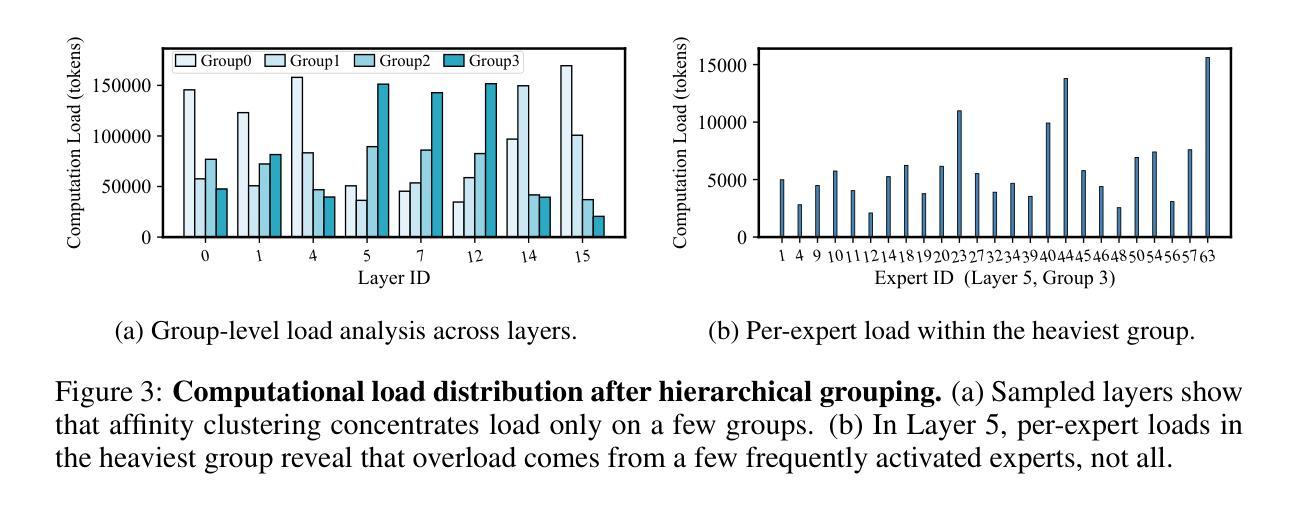
GRACE-MoE: Grouping and Replication with Locality-Aware Routing for Efficient Distributed MoE Inference
Authors:Yu Han, Lehan Pan, Jie Peng, Ziyang Tao, Wuyang Zhang, Yanyong Zhang
Sparse Mixture of Experts (SMoE) performs conditional computation by selectively activating a subset of experts, thereby enabling scalable parameter growth in large language models (LLMs). However, the expanded parameter scale exceeds the memory capacity of a single device, necessitating distributed deployment for inference. This setup introduces two critical challenges: (1) Communication Issue: Transferring features to devices with activated experts leads to significant communication overhead. (2) Computational Load Issue: Skewed expert activation overloads certain GPUs, resulting in load imbalance across devices. Among these, communication overhead is identified as the main bottleneck in SMoE inference. Nevertheless, reducing communication between devices may exacerbate computational load imbalance, leading to device idleness and resource waste. Therefore, we present GRACE-MoE, short for Grouping and Replication with Locality-Aware Routing for SMoE inference. GRACE-MoE is a co-optimization framework that jointly reduces communication overhead and alleviates computational load imbalance. Specifically, the framework comprises two key phases: (1) Grouping & Replication: This phase groups experts based on their affinity to reduce cross-device communication. Additionally, dynamic replication is applied to address load skew, improving computational load balance across GPUs. (2) Routing: This phase employs a locality-aware routing strategy with load prediction. It prioritizes local replicas to minimize communication overhead and balances requests across remote replicas when necessary. Experiments on diverse models and multi-node, multi-GPU environments demonstrate that GRACE-MoE efficiently reduces end-to-end inference latency, achieving up to 3.79x speedup over state-of-the-art systems. Code for GRACE-MoE will be released upon acceptance.
Sparse Mixture of Experts(SMoE)通过有选择地激活专家子集来实现条件计算,从而在大规模语言模型(LLM)中实现了可扩展的参数增长。然而,扩展的参数规模超出了单个设备的内存容量,需要进行分布式部署以进行推理。这种设置带来了两个关键挑战:(1)通信问题:将特征传输到有激活专家的设备会导致通信开销显著增加。(2)计算负载问题:不均衡的专家激活会过载某些GPU,导致设备间负载不均衡。其中,通信开销被识别为SMoE推理中的主要瓶颈。然而,减少设备之间的通信可能会加剧计算负载不平衡,导致设备闲置和资源浪费。因此,我们提出了GRACE-MoE,全称基于局部感知路由的SMoE推理分组与复制策略。GRACE-MoE是一个协同优化框架,可以同时减少通信开销并缓解计算负载不平衡。具体来说,该框架包括两个阶段:(1)分组与复制:此阶段根据专家的亲和力对专家进行分组,以减少跨设备通信。此外,应用动态复制来解决负载偏斜问题,以提高GPU之间的计算负载平衡。(2)路由:此阶段采用具有负载预测功能的局部感知路由策略。它优先本地副本以最小化通信开销,并在必要时平衡远程副本的请求。在多种模型和多节点、多GPU环境上的实验表明,GRACE-MoE有效地减少了端到端推理延迟,比最新系统实现了高达3.79倍的速度提升。GRACE-MoE的代码将在接受后发布。
论文及项目相关链接
摘要
Sparse Mixture of Experts (SMoE)通过选择性激活专家来实现条件计算,这在大规模语言模型(LLM)中实现了可扩展的参数增长。然而,随着参数规模的扩大,超出了单个设备的内存容量,需要进行分布式部署以进行推理。这带来了两个关键挑战:一是通信问题,将特征转移到激活的专家设备上导致了巨大的通信开销;二是计算负载问题,专家激活不均衡导致某些GPU过载。在这其中,通信开销被认为是SMoE推理的主要瓶颈。GRACE-MoE是一个协同优化框架,旨在同时减少通信开销并缓解计算负载不平衡问题。它通过分组和复制以及路由策略实现这一目标。实验表明,GRACE-MoE能显著提高效率,降低端到端推理延迟,较现有系统最高可实现3.79倍加速。
关键见解
- SMoE通过选择性激活专家实现条件计算,推动LLM中的参数增长。
- 分布式部署带来通信和计算负载两大挑战。
- 通信开销被认为是SMoE推理的主要瓶颈。
- GRACE-MoE是一个协同优化框架,旨在减少通信开销并缓解计算负载不平衡。
- GRACE-MoE通过分组和复制以及路由策略实现目标。
- 分组与复制阶段基于专家亲和度进行分组,应用动态复制以解决负载倾斜问题。
- 路由阶段采用局部感知路由策略,优先本地副本以最小化通信开销,并在必要时平衡远程请求。
点此查看论文截图
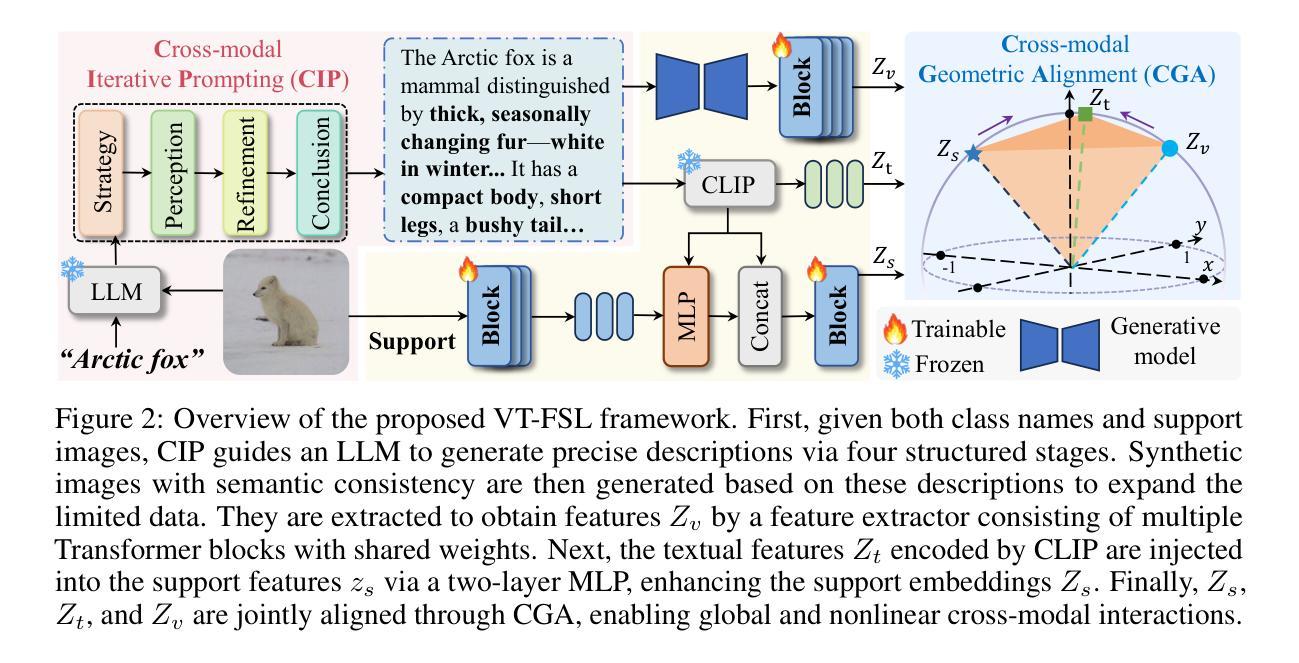
VT-FSL: Bridging Vision and Text with LLMs for Few-Shot Learning
Authors:Wenhao Li, Qiangchang Wang, Xianjing Meng, Zhibin Wu, Yilong Yin
Few-shot learning (FSL) aims to recognize novel concepts from only a few labeled support samples. Recent studies enhance support features by incorporating additional semantic information or designing complex semantic fusion modules. However, they still suffer from hallucinating semantics that contradict the visual evidence due to the lack of grounding in actual instances, resulting in noisy guidance and costly corrections. To address these issues, we propose a novel framework, bridging Vision and Text with LLMs for Few-Shot Learning (VT-FSL), which constructs precise cross-modal prompts conditioned on Large Language Models (LLMs) and support images, seamlessly integrating them through a geometry-aware alignment. It mainly consists of Cross-modal Iterative Prompting (CIP) and Cross-modal Geometric Alignment (CGA). Specifically, the CIP conditions an LLM on both class names and support images to generate precise class descriptions iteratively in a single structured reasoning pass. These descriptions not only enrich the semantic understanding of novel classes but also enable the zero-shot synthesis of semantically consistent images. The descriptions and synthetic images act respectively as complementary textual and visual prompts, providing high-level class semantics and low-level intra-class diversity to compensate for limited support data. Furthermore, the CGA jointly aligns the fused textual, support, and synthetic visual representations by minimizing the kernelized volume of the 3-dimensional parallelotope they span. It captures global and nonlinear relationships among all representations, enabling structured and consistent multimodal integration. The proposed VT-FSL method establishes new state-of-the-art performance across ten diverse benchmarks, including standard, cross-domain, and fine-grained few-shot learning scenarios. Code is available at https://github.com/peacelwh/VT-FSL.
少量学习(FSL)旨在从仅有的几个标记支持样本中识别出新概念。最近的研究通过融入额外的语义信息或设计复杂的语义融合模块来增强支持特征。然而,由于缺乏在实际实例中的基础,它们仍然会出现与视觉证据相矛盾的幻觉语义,导致产生嘈杂的指导和昂贵的修正。为了解决这些问题,我们提出了一种新的框架——跨视界与文本结合大型语言模型进行少量学习(VT-FSL),该框架构建精确的跨模态提示,基于大型语言模型(LLM)和支持图像,通过几何感知对齐无缝集成它们。它主要由跨模态迭代提示(CIP)和跨模态几何对齐(CGA)组成。具体来说,CIP根据类名和图像提示大型语言模型,生成精确类描述,并在单个结构化推理过程中进行迭代。这些描述不仅丰富了对新颖类的语义理解,还实现了语义一致图像的零样本合成。这些描述和合成图像分别作为互补的文本和视觉提示,提供高级类语义和低级类内多样性,以弥补有限的支持数据。此外,CGA通过最小化其跨越的三维平行四边形的内核体积来联合对齐融合的文本、支持和合成视觉表示。它捕捉所有表示之间的全局和非线性关系,实现结构化且一致的多模式集成。提出的VT-FSL方法在包括标准、跨域和精细粒度少量学习场景在内的十个不同基准测试上取得了最新的卓越性能。代码可在https://github.com/peacelwh/VT-FSL找到。
论文及项目相关链接
PDF Accepted by NeurIPS 2025
Summary
本文提出了一种基于大型语言模型(LLM)和图像支持的跨模态精确提示框架,旨在解决少样本学习(FSL)中由于缺乏实际实例而导致的语义混淆问题。该框架通过跨模态迭代提示和跨模态几何对齐,将LLM与视觉和文本相结合,生成精确的分类描述和合成图像,以丰富对新型类别的语义理解并补偿有限的支持数据。该框架在多种基准测试中实现了最佳性能。
Key Takeaways
- 少样本学习旨在从少量标记样本中识别新概念。
- 现有研究通过引入额外语义信息或设计复杂语义融合模块来增强支持特征。
- 缺乏基于实际实例的接地会导致语义混淆和噪声指导。
- 提出了一种新的跨模态框架VT-FSL,利用大型语言模型(LLM)和支持图像进行少样本学习。
- VT-FSL主要包括跨模态迭代提示和跨模态几何对齐。
- 跨模态迭代提示通过结合类名和图像生成精确的分类描述,并通过合成图像增强语义一致性。
点此查看论文截图
MARCOS: Deep Thinking by Markov Chain of Continuous Thoughts
Authors:Jiayu Liu, Zhenya Huang, Anya Sims, Enhong Chen, Yee Whye Teh, Ning Miao
The current paradigm for reasoning in large language models (LLMs) involves models “thinking out loud” via a sequence of tokens, known as chain-of-thought (CoT). This approach, while effective, has several significant drawbacks. Firstly, inference requires autoregressive generation of often thousands of CoT tokens, which is slow and computationally expensive. Secondly, it constrains reasoning to the discrete space of tokens, creating an information bottleneck across reasoning steps. Thirdly, it fundamentally entangles reasoning with token generation, forcing LLMs to “think while speaking,” which causes potentially short-sighted reasoning. In light of these limitations, we re-imagine reasoning in LLMs and present a new paradigm: MARCOS. In our approach, rather than autoregressively generating tokens, we model reasoning as a hidden Markov chain of continuous, high-dimensional “thoughts”. Each reasoning step involves a transition of the internal thoughts, where explicit reasoning steps (which may consist of hundreds of tokens) serve as observable variables, which are windows to peek into the implicit thoughts. Since this latent process is incompatible with the standard supervised learning, we further propose a two-phase variational training scheme. Our experiments on three benchmarks demonstrate that MARCOS outperforms existing continuous reasoning methods and, for the first time, achieves performance comparable to token-based CoT, even surpassing it by 4.7% on GSM8K with up to 15.7x speedup in inference. Beyond this, MARCOS offers additional advantages, such as step-level instead of token-level control over randomness, opening significant opportunities for reinforcement learning and reasoning in LLMs.
当前大型语言模型(LLM)的推理范式是通过一系列标记(token)进行模型“大声思考”,这被称为思维链(CoT)。虽然这种方法很有效,但它有几个重大缺点。首先,推理需要自回归生成往往数千个思维链标记,这既缓慢又计算成本高。其次,它将推理限制在离散标记空间中,在推理步骤之间造成信息瓶颈。第三,它从根本上将推理与标记生成纠缠在一起,迫使LLM“思考时说话”,导致潜在的短视推理。鉴于这些局限性,我们重新想象LLM中的推理并呈现一种新的范式:MARCOS。我们的方法中,我们不是自回归地生成标记,而是将推理建模为连续的、高维度的“思维”的隐马尔可夫链。每个推理步骤涉及内部思维的过渡,其中明确的推理步骤(可能包含数百个标记)作为可观察变量,是窥探隐性思维的窗口。由于这种潜在过程与标准监督学习不兼容,我们进一步提出了一个两阶段的变分训练方案。我们在三个基准测试上的实验表明,MARCOS优于现有的连续推理方法,并且首次实现了与基于标记的CoT相当的性能,甚至在GSM8K上超越了它4.7%,同时推理速度提高了高达15.7倍。除此之外,MARCOS还提供了额外的优势,如步骤级别的控制,而不是标记级别的控制随机性,这为强化学习和LLM中的推理打开了重要的机会。
论文及项目相关链接
Summary
本文介绍了大型语言模型(LLM)中的推理新范式MARCOS。该范式将推理过程视为一个隐藏的马尔可夫链中的连续高维“思维”,而非通过生成一系列标记(token)来进行。MARCOS通过隐性思维过程的转换实现推理,并通过观察到的标记(可能是数百个标记)来观察内部思维。实验表明,MARCOS在基准测试上的性能与基于标记的推理相当甚至更优,并大大加快了推理速度。此外,MARCOS还提供了额外的优势,如步骤级别的控制,为强化学习和LLM中的推理提供了重大机会。
Key Takeaways
- 大型语言模型(LLM)的当前推理范式是通过“思维外化”的方式,即生成一系列标记(token)进行推理,称为链式思维(CoT)。
- CoT范式存在多个显著缺点,包括计算成本高、约束在离散标记空间、以及将推理与标记生成紧密结合。
- MARCOS是一种新型的LLM推理范式,将推理过程视为一个隐藏的马尔可夫链中的连续高维思维。
- 在MARCOS中,推理步骤是内部思维的转换,而观察到的标记是了解这些思维的窗口。
- MARCOS通过两阶段变分训练方案实现,这一方案解决了隐性过程与标准监督学习的不兼容问题。
- 实验表明,MARCOS在基准测试上的性能与CoT相当甚至更优,同时大大提高了推理速度。
点此查看论文截图
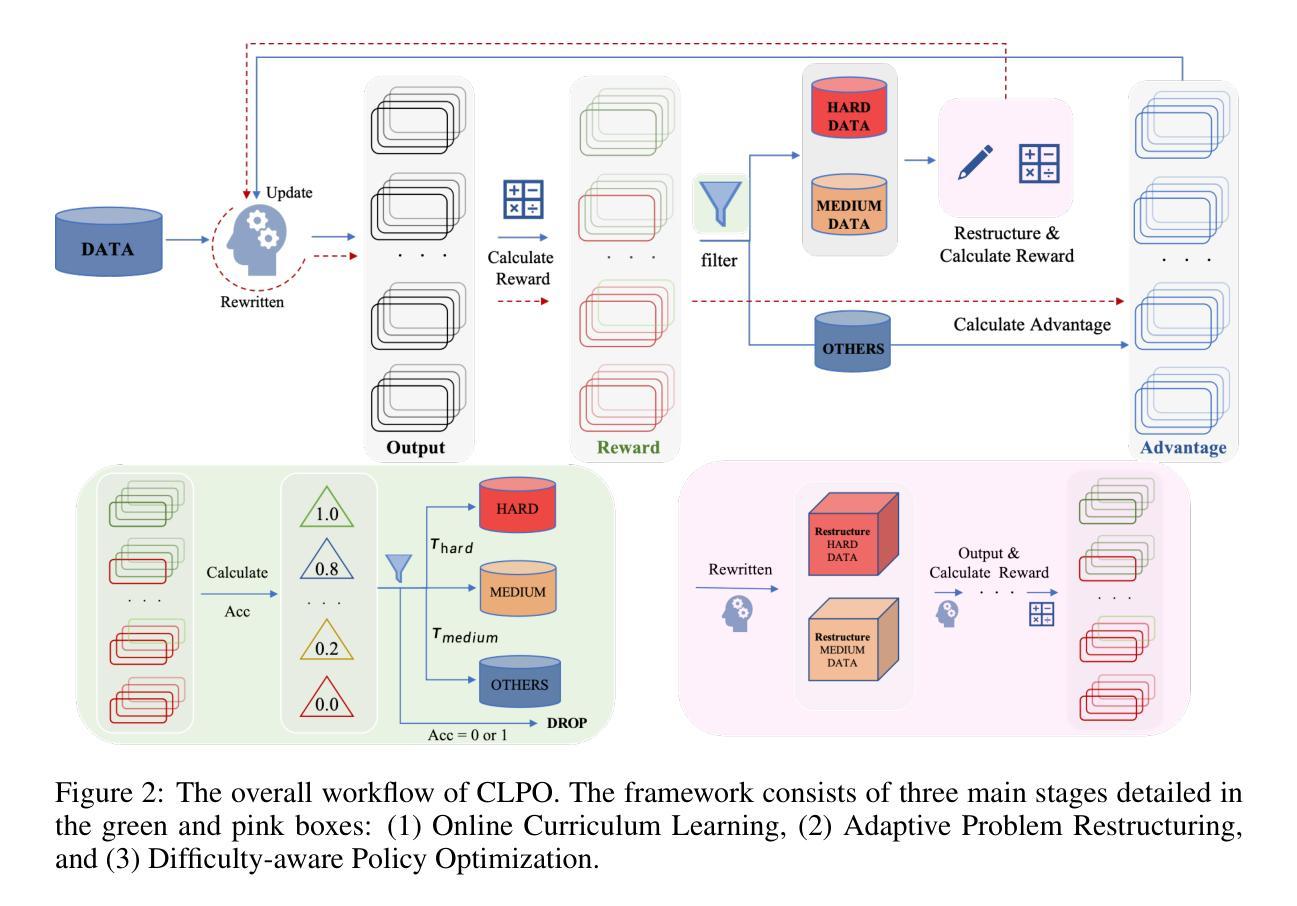
CLPO: Curriculum Learning meets Policy Optimization for LLM Reasoning
Authors:Shijie Zhang, Guohao Sun, Kevin Zhang, Xiang Guo, Rujun Guo
Recently, online Reinforcement Learning with Verifiable Rewards (RLVR) has become a key paradigm for enhancing the reasoning capabilities of Large Language Models (LLMs). However, existing methods typically treat all training samples uniformly, overlooking the vast differences in problem difficulty relative to the model’s current capabilities. This uniform training strategy leads to inefficient exploration of problems the model has already mastered, while concurrently lacking effective guidance on problems that are challenging its abilities the most, limiting both learning efficiency and upper-bound performance. To address this, we propose CLPO (Curriculum-guided Learning for Policy Optimization), a novel algorithm that creates a dynamic pedagogical feedback loop within the policy optimization process. The core of CLPO leverages the model’s own rollout performance to conduct real-time difficulty assessment, thereby constructing an Online Curriculum. This curriculum then guides an Adaptive Problem Restructuring mechanism, where the model acts as its own teacher: it diversifies medium-difficulty problems to promote generalization and simplifies challenging problems to make them more attainable. Our approach transforms the static training procedure into a dynamic process that co-evolves with the model’s capabilities. Experiments show that CLPO achieves state-of-the-art performance across eight challenging mathematical and general reasoning benchmarks, with an average pass@1 improvement of 6.96% over other methods, demonstrating its potential for more efficiently training more capable reasoning models.
最近,在线强化学习与可验证奖励(RLVR)已成为增强大型语言模型(LLM)推理能力的主要范式。然而,现有方法通常对所有训练样本进行统一处理,忽略了问题难度与模型当前能力之间的巨大差异。这种统一训练策略导致模型对已掌握的问题进行低效探索,同时缺乏针对最具挑战性问题的有效指导,从而限制了学习效率和最高性能。为解决这一问题,我们提出了CLPO(用于策略优化的课程指导学习),这是一种新型算法,可在策略优化过程中创建动态的教学反馈循环。CLPO的核心是利用模型自身的滚动性能进行实时难度评估,从而构建在线课程。然后,此课程引导自适应问题重建机制,模型在其中扮演自己的老师:它通过多样化中等难度问题来促进推广,并简化有挑战性的问题使它们更容易解决。我们的方法将静态训练程序转变为一个与模型能力共同发展的动态过程。实验表明,CLPO在八个具有挑战性的数学和通用推理基准测试中实现了最先进的性能,与其他方法相比,平均通过率提高了6.96%,证明了其在更高效训练更强大的推理模型方面的潜力。
论文及项目相关链接
Summary
强化学习可验证奖励(RLVR)是增强大型语言模型(LLM)推理能力的关键范式。然而,现有方法往往对所有训练样本一视同仁,忽略了问题难度与模型当前能力之间的巨大差异。针对这一问题,我们提出了CLPO(用于策略优化的课程引导学习)算法,该算法在策略优化过程中创建了一个动态的反馈循环。CLPO的核心是利用模型自身的滚动性能进行实时难度评估,从而构建在线课程。这门课程然后引导自适应问题重构机制,模型充当自己的老师:它使中等难度的问题多样化以促进推广,并简化具有挑战性的问题使其更容易获得。我们的方法将静态训练过程转变为与模型能力共同演化的动态过程。实验表明,CLPO在八个具有挑战性的数学和一般推理基准测试中取得了最新性能,在其他方法的基础上平均提高了6.96%的通过率,显示出其在训练更具能力的推理模型方面的潜力。
Key Takeaways
- 强化学习可验证奖励(RLVR)对于增强大型语言模型(LLM)的推理能力是关键范式。
- 现有方法忽略问题难度与模型当前能力的差异,导致训练效率低下。
- CLPO算法利用模型自身的滚动性能进行实时难度评估,构建在线课程。
- CLPO引导自适应问题重构机制,模型充当自己的老师,促进问题的多样化并简化挑战性任务。
- CLPO将静态训练过程转变为动态过程,与模型能力共同演化。
- 实验显示CLPO在多个基准测试中取得最新性能,平均通过率有所提高。
点此查看论文截图
Attention Surgery: An Efficient Recipe to Linearize Your Video Diffusion Transformer
Authors:Mohsen Ghafoorian, Denis Korzhenkov, Amirhossein Habibian
Transformer-based video diffusion models (VDMs) deliver state-of-the-art video generation quality but are constrained by the quadratic cost of self-attention, making long sequences and high resolutions computationally expensive. While linear attention offers sub-quadratic complexity, prior attempts fail to match the expressiveness of softmax attention without costly retraining. We introduce \textit{Attention Surgery}, an efficient framework for \textit{linearizing} or \textit{hybridizing} attention in pretrained VDMs without training from scratch. Inspired by recent advances in language models, our method combines a novel hybrid attention mechanism-mixing softmax and linear tokens-with a lightweight distillation and fine-tuning pipeline requiring only a few GPU-days. Additionally, we incorporate a cost-aware block-rate strategy to balance expressiveness and efficiency across layers. Applied to Wan2.1 1.3B, a state-of-the-art DiT-based VDM, Attention Surgery achieves the first competitive sub-quadratic attention video diffusion models, reducing attention cost by up to 40% in terms of FLOPs, while maintaining generation quality as measured on the standard VBench and VBench-2.0 benchmarks.
基于Transformer的视频扩散模型(VDM)提供了最先进的视频生成质量,但由于自注意力的二次成本而受到限制,使得长序列和高分辨率的计算成本很高。虽然线性注意力提供了次二次复杂性,但之前的尝试在没有昂贵重新训练的情况下,无法匹配softmax注意力的表现力。我们引入了”注意力手术”,这是一个有效的框架,可以在预训练的VDM中对注意力进行”线性化”或”混合化”,而无需从头开始训练。我们的方法结合了最近语言模型的最新进展,提出了一种新型混合注意力机制——混合softmax和线性令牌,以及一个轻量级的蒸馏和微调管道,只需几天的GPU时间。此外,我们还采用了一种成本感知的块率策略,以在层之间平衡表现力和效率。将该方法应用于Wan2.1 .DiT视频扩散模型的前瞻技术后显示,“注意力手术”在保持了类似于VBench和VBench-2.0标准的基准生成质量的情况下成功推出第一批具有竞争力的次二次注意力视频扩散模型,从浮点运算量来看,注意力成本降低了高达百分之四十。
论文及项目相关链接
Summary
本文主要介绍了针对基于Transformer的视频扩散模型(VDMs)的高效注意力机制改进方案。由于现有VDMs面临自注意力机制的二次成本问题,导致长序列和高分辨率的计算成本高昂。本文提出了“注意力手术”框架,旨在在不重新训练的情况下对预训练VDM中的注意力进行线性化或混合化改进。该方法结合了新型的混合注意力机制和轻量级蒸馏与微调管道,仅需几天的GPU时间。此外,通过引入成本感知的块率策略,平衡了各层的表达性和效率。应用于Wan2.1 1.3B这一最先进的基于DiT的视频扩散模型,注意力手术实现了首个具有竞争力的次二次注意力视频扩散模型,在FLOPs方面减少了高达40%的注意力成本,同时在VBench和VBench-2.0标准基准测试中维持了生成质量。
Key Takeaways
- Transformer-based视频扩散模型(VDMs)由于自注意力机制的二次成本面临计算效率问题。
- 提出了一种新的“注意力手术”框架,旨在改善预训练VDM中的注意力机制,实现线性化或混合化。
- 结合了新型的混合注意力机制和轻量级蒸馏与微调管道,减少了计算成本。
- 通过引入成本感知的块率策略,优化了表达性和效率之间的平衡。
- 成功应用于Wan2.1 1.3B模型,实现了首个具有竞争力的次二次注意力视频扩散模型。
- 在FLOPs方面减少了高达40%的注意力成本。
点此查看论文截图

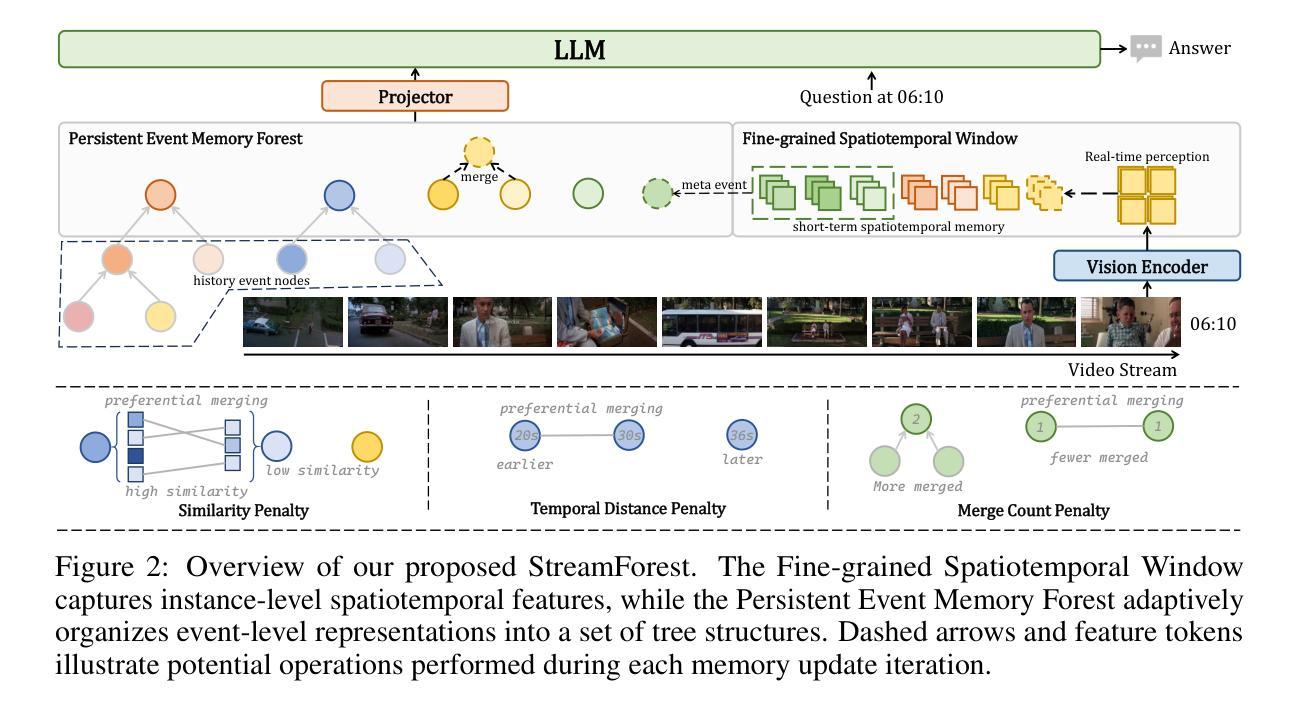
StreamForest: Efficient Online Video Understanding with Persistent Event Memory
Authors:Xiangyu Zeng, Kefan Qiu, Qingyu Zhang, Xinhao Li, Jing Wang, Jiaxin Li, Ziang Yan, Kun Tian, Meng Tian, Xinhai Zhao, Yi Wang, Limin Wang
Multimodal Large Language Models (MLLMs) have recently achieved remarkable progress in video understanding. However, their effectiveness in real-time streaming scenarios remains limited due to storage constraints of historical visual features and insufficient real-time spatiotemporal reasoning. To address these challenges, we propose StreamForest, a novel architecture specifically designed for streaming video understanding. Central to StreamForest is the Persistent Event Memory Forest, a memory mechanism that adaptively organizes video frames into multiple event-level tree structures. This process is guided by penalty functions based on temporal distance, content similarity, and merge frequency, enabling efficient long-term memory retention under limited computational resources. To enhance real-time perception, we introduce a Fine-grained Spatiotemporal Window, which captures detailed short-term visual cues to improve current scene perception. Additionally, we present OnlineIT, an instruction-tuning dataset tailored for streaming video tasks. OnlineIT significantly boosts MLLM performance in both real-time perception and future prediction. To evaluate generalization in practical applications, we introduce ODV-Bench, a new benchmark focused on real-time streaming video understanding in autonomous driving scenarios. Experimental results demonstrate that StreamForest achieves the state-of-the-art performance, with accuracies of 77.3% on StreamingBench, 60.5% on OVBench, and 55.6% on OVO-Bench. In particular, even under extreme visual token compression (limited to 1024 tokens), the model retains 96.8% of its average accuracy in eight benchmarks relative to the default setting. These results underscore the robustness, efficiency, and generalizability of StreamForest for streaming video understanding.
多模态大型语言模型(MLLMs)在视频理解方面取得了显著的进步。然而,由于其历史视觉特征的存储限制和实时时空推理的不足,它们在实时流媒体场景中的有效性仍然有限。为了解决这些挑战,我们提出了专门用于流媒体视频理解的全新架构StreamForest。StreamForest的核心是持久事件记忆森林(Persistent Event Memory Forest),这是一种记忆机制,能够自适应地将视频帧组织成多个事件级的树结构。这一过程由基于时间距离、内容相似性和合并频率的惩罚函数引导,能够在有限的计算资源下实现高效的长期记忆保留。为了提高实时感知能力,我们引入了细粒度时空窗口(Fine-grained Spatiotemporal Window),可以捕捉短期的详细视觉线索,以提高对当前场景的认知。此外,我们还推出了适用于流媒体视频任务的指令调整数据集OnlineIT。OnlineIT显著提升了MLLM在实时感知和未来预测方面的性能。为了评估在实际应用中的泛化能力,我们引入了ODV-Bench,这是一个专注于自动驾驶场景中实时流媒体视频理解的新基准测试。实验结果表明,StreamForest达到了最先进的性能,在StreamingBench上达到了77.3%的准确率,在OVBench上达到了60.5%的准确率,在OVO-Bench上达到了55.6%的准确率。尤其值得一提的是,即使在极端视觉令牌压缩(限制为1024个令牌)的情况下,该模型在八个基准测试中的平均准确率仍能保持96.8%,相对于默认设置。这些结果证明了StreamForest在流媒体视频理解方面的稳健性、效率和泛化能力。
论文及项目相关链接
PDF Accepted as a Spotlight at NeurIPS 2025
摘要
多模态大型语言模型(MLLMs)在视频理解方面取得了显著进展,但在实时流媒体场景中的有效性仍然有限,主要是由于历史视觉特征的存储约束和实时时空推理不足。为解决这些挑战,提出了StreamForest,一种专为流媒体视频理解设计的新型架构。其核心是持久事件记忆森林,一种记忆机制,可自适应地将视频帧组织成多个事件级树结构。这一过程受到基于时间距离、内容相似性和合并频率的惩罚函数的指导,可在有限的计算资源下实现高效的长程记忆保留。为提高实时感知能力,引入了细粒度时空窗口,可捕捉短期视觉线索,提高当前场景感知。此外,还推出了OnlineIT,一个针对流媒体视频任务量身定制的指令调整数据集。OnlineIT显著提高了MLLM在实时感知和未来预测方面的性能。为评估在实际应用中的泛化能力,引入了ODV-Bench,一个新的基准测试,专注于自动驾驶场景中的实时流媒体视频理解。实验结果表明,StreamForest达到了最新技术水平,StreamingBench上的准确率为77.3%,OVBench上为60.5%,OVO-Bench上为55.6%。即使在极端视觉令牌压缩(限制为1024个令牌)下,模型在八个基准测试中的平均准确率仍保持在默认设置的96.8%。这些结果突显了StreamForest在流媒体视频理解方面的稳健性、效率和泛化能力。
关键见解
- 多模态大型语言模型(MLLMs)在视频理解方面已取得显著进展,但在实时流媒体场景中面临存储和推理挑战。
- StreamForest架构通过持久事件记忆森林和细粒度时空窗口解决了这些挑战。
- 持久事件记忆森林通过自适应组织视频帧成事件级树结构,实现了高效的长程记忆保留。
- OnlineIT数据集的引入显著提升了MLLM在实时感知和未来预测方面的性能。
- ODV-Bench基准测试的引入,为评估实时流媒体视频理解的泛化能力提供了新标准。
- StreamForest在多个基准测试中达到了最新技术水平,包括StreamingBench、OVBench和OVO-Bench。
点此查看论文截图
Diamonds in the rough: Transforming SPARCs of imagination into a game concept by leveraging medium sized LLMs
Authors:Julian Geheeb, Farhan Abid Ivan, Daniel Dyrda, Miriam Anschütz, Georg Groh
Recent research has demonstrated that large language models (LLMs) can support experts across various domains, including game design. In this study, we examine the utility of medium-sized LLMs, models that operate on consumer-grade hardware typically available in small studios or home environments. We began by identifying ten key aspects that contribute to a strong game concept and used ChatGPT to generate thirty sample game ideas. Three medium-sized LLMs, LLaMA 3.1, Qwen 2.5, and DeepSeek-R1, were then prompted to evaluate these ideas according to the previously identified aspects. A qualitative assessment by two researchers compared the models’ outputs, revealing that DeepSeek-R1 produced the most consistently useful feedback, despite some variability in quality. To explore real-world applicability, we ran a pilot study with ten students enrolled in a storytelling course for game development. At the early stages of their own projects, students used our prompt and DeepSeek-R1 to refine their game concepts. The results indicate a positive reception: most participants rated the output as high quality and expressed interest in using such tools in their workflows. These findings suggest that current medium-sized LLMs can provide valuable feedback in early game design, though further refinement of prompting methods could improve consistency and overall effectiveness.
最近的研究表明,大型语言模型(LLM)可以支持包括游戏设计在内的各个领域的专家。在这项研究中,我们评估了中型LLM的实用性,这些模型通常在小型工作室或家庭环境中可用的消费者级硬件上运行。我们首先确定了构成强大游戏概念的十个关键方面,并使用ChatGPT生成了三十个游戏想法样本。然后,我们提示了三个中型LLM,即LLaMA 3.1、Qwen 2.5和DeepSeek-R1,根据先前确定的关键方面对这些想法进行评估。两位研究人员进行的定性评估比较了这些模型的输出,结果表明,尽管质量上存在一些差异,但DeepSeek-R1提供的反馈始终是最有用的。为了探索现实世界的适用性,我们对十名参加游戏开发叙事课程的学生进行了试点研究。在各自项目的早期阶段,学生们使用我们的提示和DeepSeek-R1来完善他们的游戏概念。结果表明反馈积极:大多数参与者认为输出质量很高,并表示有兴趣将这种工具纳入他们的工作流程中。这些发现表明,当前的中型LLM可以在早期游戏设计中提供有价值的反馈,不过对提示方法的进一步改进可以提高一致性和总体效果。
论文及项目相关链接
PDF Appears in Proceedings of AI4HGI ‘25, the First Workshop on Artificial Intelligence for Human-Game Interaction at the 28th European Conference on Artificial Intelligence (ECAI ‘25), Bologna, October 25-30, 2025
Summary
大型语言模型(LLM)可支持游戏设计等领域的专家工作。本研究探讨了中等规模LLM(可在小型工作室或家庭环境中运行的常规硬件上运行的模型)的实用性。通过识别影响游戏概念的关键要素并利用ChatGPT生成游戏想法样本,研究发现DeepSeek-R1模型在评估游戏想法时表现出最一致的反馈效果。通过试点研究评估这些模型在现实世界中的适用性,结果表明大多数参与者对模型输出持积极态度,并有兴趣将其纳入工作流程中。总体而言,当前中等规模的LLM在早期游戏设计中可提供有价值的反馈,提示方法的改进可进一步提高一致性和总体效果。
Key Takeaways
- 大型语言模型(LLM)可以支持包括游戏设计在内的各种领域的专家工作。
- 中等规模的LLM具有实用价值,能在常规硬件上运行,适用于小型工作室或家庭环境。
- 通过识别关键要素并利用ChatGPT生成游戏想法样本,研究发现DeepSeek-R1模型在评估游戏概念时表现出最佳效果。
- LLM能够生成有价值的反馈来支持早期游戏设计。
- 试点研究结果表明,大多数参与者对LLM的输出持积极态度,并愿意将其纳入工作流程中。
- 当前中等规模的LLM在某些情况下可能存在质量波动,需要进一步改进提示方法来提高一致性和总体效果。
点此查看论文截图

LLaDA-MoE: A Sparse MoE Diffusion Language Model
Authors:Fengqi Zhu, Zebin You, Yipeng Xing, Zenan Huang, Lin Liu, Yihong Zhuang, Guoshan Lu, Kangyu Wang, Xudong Wang, Lanning Wei, Hongrui Guo, Jiaqi Hu, Wentao Ye, Tieyuan Chen, Chenchen Li, Chengfu Tang, Haibo Feng, Jun Hu, Jun Zhou, Xiaolu Zhang, Zhenzhong Lan, Junbo Zhao, Da Zheng, Chongxuan Li, Jianguo Li, Ji-Rong Wen
We introduce LLaDA-MoE, a large language diffusion model with the Mixture-of-Experts (MoE) architecture, trained from scratch on approximately 20T tokens. LLaDA-MoE achieves competitive performance with significantly reduced computational overhead by maintaining a 7B-parameter capacity while activating only 1.4B parameters during inference. Our empirical evaluation reveals that LLaDA-MoE achieves state-of-the-art performance among diffusion language models with larger parameters, surpassing previous diffusion language models LLaDA, LLaDA 1.5, and Dream across multiple benchmarks. The instruct-tuned model LLaDA-MoE-7B-A1B-Instruct demonstrates capabilities comparable to Qwen2.5-3B-Instruct in knowledge understanding, code generation, mathematical reasoning, agent and alignment tasks, despite using fewer active parameters. Our results show that integrating a sparse MoE architecture into the training objective of masked diffusion language models still brings out MoE’s strengths under efficient inference with few active parameters, and opens ample room for further exploration of diffusion language models. LLaDA-MoE models are available at Huggingface.
我们介绍了LLaDA-MoE,这是一个采用专家混合(MoE)架构的大型语言扩散模型,使用约20万亿个令牌从头开始训练。LLaDA-MoE以7B参数的容量实现了具有竞争力的性能,同时在推理时仅激活1.4B参数,显著减少了计算开销。我们的经验评估表明,LLaDA-MoE在具有更大参数的扩散语言模型中实现了最先进的性能,超越了之前的扩散语言模型LLaDA、LLaDA 1.5和Dream等多个基准测试。指令调整模型LLaDA-MoE-7B-A1B-Instruct在知识理解、代码生成、数学推理、代理和对齐任务中,表现出与Qwen2.5-3B-Instruct相当的能力,尽管使用的激活参数较少。我们的结果表明,将稀疏的MoE架构整合到掩蔽扩散语言模型的训练目标中,仍然可以在高效的推理和少量激活参数下发挥出MoE的优势,并为进一步探索扩散语言模型提供了广阔的空间。LLaDA-MoE模型已在Huggingface上提供。
论文及项目相关链接
Summary
LLaDA-MoE是一个基于大型语言扩散模型与专家混合(MoE)架构的模型,使用约20T的令牌从头开始训练。LLaDA-MoE在维持7B参数容量的同时,推理时仅激活1.4B参数,实现了显著的计算效率。实证评估显示,LLaDA-MoE在多个基准测试中达到了扩散语言模型的最先进水平,超过了之前的LLaDA、LLaDA 1.5和Dream等模型。此外,LLaDA-MoE-7B-A1B-Instruct模型在知识理解、代码生成、数学推理、代理和对齐任务上的能力与Qwen2.5-3B-Instruct相当。整合稀疏MoE架构到掩码扩散语言模型的训练目标中,仍能在高效的推理和少量活跃参数下发挥MoE的优势,为扩散语言模型的进一步探索提供了广阔的空间。
Key Takeaways
- LLaDA-MoE是一个结合大型语言扩散模型和专家混合(MoE)架构的模型。
- LLaDA-MoE通过维护7B参数的容量,在推理时仅激活1.4B参数,实现了计算效率的显著提高。
- 实证评估显示LLaDA-MoE在多个基准测试中超过了其他扩散语言模型。
- LLaDA-MoE-7B-A1B-Instruct模型在知识理解、代码生成等方面表现出色。
- MoE架构整合到掩码扩散语言模型的训练目标中,实现了高效推理和优异性能。
- LLaDA-MoE模型在扩散语言模型的进一步探索中具有广阔的空间。
点此查看论文截图
Speculative Verification: Exploiting Information Gain to Refine Speculative Decoding
Authors:Sungkyun Kim, Jaemin Kim, Dogyung Yoon, Jiho Shin, Junyeol Lee, Jiwon Seo
LLMs have low GPU efficiency and high latency due to autoregressive decoding. Speculative decoding (SD) mitigates this using a small draft model to speculatively generate multiple tokens, which are then verified in parallel by a target model. However, when speculation accuracy is low, the overhead from rejected tokens can offset the benefits, limiting SD’s effectiveness, especially at large batch sizes. To address this, we propose Speculative Verification (SV), an efficient augmentation to SD that dynamically predicts speculation accuracy and adapts the verification length to maximize throughput. SV introduces a companion model - a small auxiliary model similar in size to the draft model - to estimate the alignment between draft and target model distributions. By maximizing the information gain from quantifying this alignment, SV refines verification decisions, reducing wasted computation on rejected tokens and improving decoding efficiency. Moreover, SV requires no modifications to the draft or target models and is compatible with existing SD variants. We extensively evaluated SV on publicly available LLMs across three NLP tasks using nine combinations of draft, companion, and target models, including 13B-72B target models and three types of variations: base (no finetuning), instruction-tuned, and task fine-tuned. Across all experiments and batch sizes (4-80), SV consistently outperforms both SD and standard decoding with the target model. It improves SD performance by up to 2$\times$, with an average speedup of 1.4 $\times$ in large-batch settings (batch sizes 32-80). These results demonstrate SV’s robustness, scalability, and practical utility for efficient LLM inference.
LLM由于自回归解码而具有较低的GPU效率和较高的延迟。投机解码(SD)通过使用小型草稿模型来投机生成多个令牌,然后将其并行验证目标模型来缓解这一问题。然而,当投机准确性较低时,拒绝令牌的开销可能会抵消好处,限制SD的有效性,特别是在大批量情况下。为了解决这一问题,我们提出了“投机验证”(SV),这是SD的一种有效增强功能,能够动态预测投机准确性并适应验证长度以最大化吞吐量。SV引入了一个配套模型——一个与草稿模型大小相似的辅助小模型,以估计草稿和目标模型分布之间的对齐程度。通过最大化这种对齐的量化信息收益,SV优化了验证决策,减少了拒绝令牌上的浪费计算,提高了解码效率。此外,SV不需要对草稿或目标模型进行任何修改,并且可以与现有的SD变体兼容。我们在三个NLP任务上全面评估了SV,使用九个组合的草稿、配套和目标模型,包括目标模型的基准(无微调)、指令微调以及任务微调。在所有实验和批量大小(4-80)中,SV始终优于SD和目标模型的常规解码。它提高了SD的性能高达两倍,在大批量设置(批量大小32-80)中平均加速1.4倍。这些结果证明了SV在高效LLM推理中的稳健性、可扩展性和实用性。
论文及项目相关链接
PDF 14 pages, 6 figures
Summary
LLMs存在GPU效率低和延迟高的问题,原因是自动回归解码。为解决这一问题,研究者提出了基于推测解码(Speculative Decoding)的改进方案——Speculative Verification(SV)。SV通过动态预测推测精度,并根据目标模型的分布情况进行适应性地验证长度,以实现更高效的推断处理。相比于已有的SD技术,SV在不同的大规模模型和NLP任务测试中,都有着更佳的表现。特别是在大批次场景中,SV不仅具有优异的加速效果,还能够实现约平均一倍的提升效果。这不仅显示出其理论研究的实用性价值,同时还在技术中体现出高度优化的高效推理效率与规模化拓展性优势。同时也不需要修改草图和目标模型。相较于常规解码技术,SV表现出了明显的优势。总之,SV的提出有望显著提高LLM的性能效率并减少计算资源消耗。为此项研究提供了新的思路和视角。提高了工作效率。具有潜在的实际应用价值前景广阔。提高了推理性能与扩展性优势。研究内容丰富、技术新颖,具有一定的实用价值和应用前景。体现了创新性技术实力与应用价值高度统一的优势特征,体现了高度的前瞻性趋势特点。。针对当前研究问题提出了一种具有实际可行性的高效解决策略。。为此领域提供了切实可行的技术方案具有重要的学术价值和实际应用价值。。研究结果表明其实际应用前景广阔并展现出显著的技术优势特征。在实际应用中展现出较高的性能和稳定性表现突出。将具有广阔的应用前景和行业影响空间广以及对推进整个领域的跨越发展也具有不可小觑的重要作用与价值潜能持续对行业技术的创新和改革升级作出重要的推动作用具有实用价值体现同时并展望未来保持前沿的研究探索。。这将是一项创新突破并对未来的AI应用提供强大助力为加速大型语言模型性能的提高开拓了更广阔的思路与方法领域带来新的应用突破和变革。为行业带来革命性的进步和变革趋势。
Key Takeaways
- LLM存在GPU效率低和延迟高的问题,影响了实际应用中的性能表现。
- Speculative Verification(SV)作为一种新的解码技术被提出以解决上述问题,它通过动态预测推测精度并优化验证过程来提高效率。
- SV相较于已有的推测解码技术有更好的表现,特别是在大规模批次处理场景下。它在提高性能的同时,还具有良好的可扩展性和实用性。
点此查看论文截图
ELASTIQ: EEG-Language Alignment with Semantic Task Instruction and Querying
Authors:Muyun Jiang, Shuailei Zhang, Zhenjie Yang, Mengjun Wu, Weibang Jiang, Zhiwei Guo, Wei Zhang, Rui Liu, Shangen Zhang, Yong Li, Yi Ding, Cuntai Guan
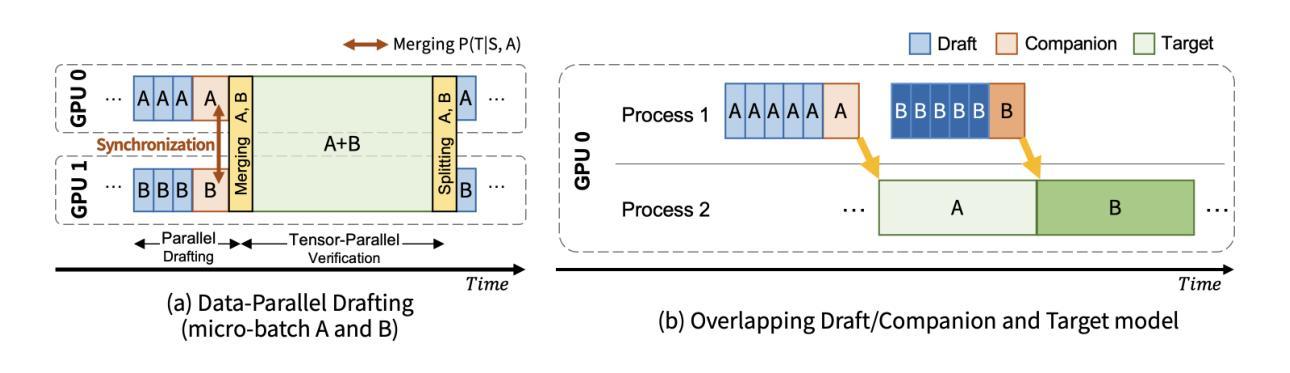
Recent advances in electroencephalography (EEG) foundation models, which capture transferable EEG representations, have greatly accelerated the development of brain-computer interfaces (BCI). However, existing approaches still struggle to incorporate language instructions as prior constraints for EEG representation learning, limiting their ability to leverage the semantic knowledge inherent in language to unify different labels and tasks. To address this challenge, we present ELASTIQ, a foundation model for EEG-Language Alignment with Semantic Task Instruction and Querying. ELASTIQ integrates task-aware semantic guidance to produce structured and linguistically aligned EEG embeddings, thereby enhancing decoding robustness and transferability. In the pretraining stage, we introduce a joint Spectral-Temporal Reconstruction (STR) module, which combines frequency masking as a global spectral perturbation with two complementary temporal objectives: random masking to capture contextual dependencies and causal masking to model sequential dynamics. In the instruction tuning stage, we propose the Instruction-conditioned Q-Former (IQF), a query-based cross-attention transformer that injects instruction embeddings into EEG tokens and aligns them with textual label embeddings through learnable queries. We evaluate ELASTIQ on 20 datasets spanning motor imagery, emotion recognition, steady-state visual evoked potentials, covert speech, and healthcare tasks. ELASTIQ achieves state-of-the-art performance on 14 of the 20 datasets and obtains the best average results across all five task categories. Importantly, our analyses reveal for the first time that explicit task instructions serve as semantic priors guiding EEG embeddings into coherent and linguistically grounded spaces. The code and pre-trained weights will be released.
最近脑电图(EEG)基础模型的进步,这些模型能够捕捉可迁移的EEG表示,极大地加速了脑机接口(BCI)的发展。然而,现有方法仍然难以将语言指令作为先验约束融入EEG表示学习中,限制了其利用语言中固有的语义知识来统一不同标签和任务的能力。为了解决这一挑战,我们提出了ELA STIQ,一个结合语义任务指令和查询的EEG-语言对齐基础模型。ELA STIQ整合任务感知语义指导,以产生结构化且语言对齐的EEG嵌入,从而提高解码的稳健性和可迁移性。在预训练阶段,我们引入了一个联合的时频重建(STR)模块,该模块将频率掩码作为全局频谱扰动与两个互补的时间目标相结合:随机掩码以捕捉上下文依赖关系和有向掩码以模拟序列动态。在指令微调阶段,我们提出了指令条件Q-Formers(IQF),一种基于查询的跨注意力转换器,它将指令嵌入注入EEG令牌中,并通过可学习的查询将它们与文本标签嵌入对齐。我们在跨越运动想象、情绪识别、稳态视觉诱发电位、隐蔽性语言和医疗任务的20个数据集上评估了ELA STIQ。ELA STIQ在其中的14个数据集上取得了最先进的性能表现,并在所有五个任务类别中获得了最佳平均结果。重要的是,我们的分析首次表明,明确的任务指令作为语义先验指导EEG嵌入到连贯且语言基础的空间中。代码和预训练权重将被发布。
论文及项目相关链接
Summary
本文介绍了EEG语言对齐模型ELASTIQ,该模型结合了任务感知语义指导,生成结构化且语言对齐的EEG嵌入,提高了解码稳健性和迁移性。通过引入联合谱时序重建(STR)模块以及指令调节Q-Formers(IQF),使EEG令牌与文本标签嵌入对齐。在多个数据集上的评估显示,ELASTIQ在多个任务上取得最佳性能,并首次揭示明确的任务指令作为语义先验,引导EEG嵌入进入连贯且语言基础的空间。
Key Takeaways
- ELASTIQ是一个结合任务感知语义指导的EEG语言对齐模型,能够生成结构化且语言对齐的EEG嵌入。
- ELASTIQ通过引入联合谱时序重建(STR)模块,结合频率掩码和两种时间目标(随机掩码和因果掩码),提高EEG数据的解码稳健性和迁移性。
- ELASTIQ采用指令调节Q-Formers(IQF),一个基于查询的交叉注意变压器,将指令嵌入到EEG令牌中,并与文本标签嵌入对齐。
- ELASTIQ在多个数据集上的评估结果显示,它在多个任务上取得最佳性能。
- 该研究首次揭示明确的任务指令作为语义先验,对引导EEG嵌入进入连贯且语言基础的空间具有重要作用。
- ELASTIQ的代码和预训练权重将公开发布。
点此查看论文截图

Transformer Tafsir at QIAS 2025 Shared Task: Hybrid Retrieval-Augmented Generation for Islamic Knowledge Question Answering
Authors:Muhammad Abu Ahmad, Mohamad Ballout, Raia Abu Ahmad, Elia Bruni
This paper presents our submission to the QIAS 2025 shared task on Islamic knowledge understanding and reasoning. We developed a hybrid retrieval-augmented generation (RAG) system that combines sparse and dense retrieval methods with cross-encoder reranking to improve large language model (LLM) performance. Our three-stage pipeline incorporates BM25 for initial retrieval, a dense embedding retrieval model for semantic matching, and cross-encoder reranking for precise content retrieval. We evaluate our approach on both subtasks using two LLMs, Fanar and Mistral, demonstrating that the proposed RAG pipeline enhances performance across both, with accuracy improvements up to 25%, depending on the task and model configuration. Our best configuration is achieved with Fanar, yielding accuracy scores of 45% in Subtask 1 and 80% in Subtask 2.
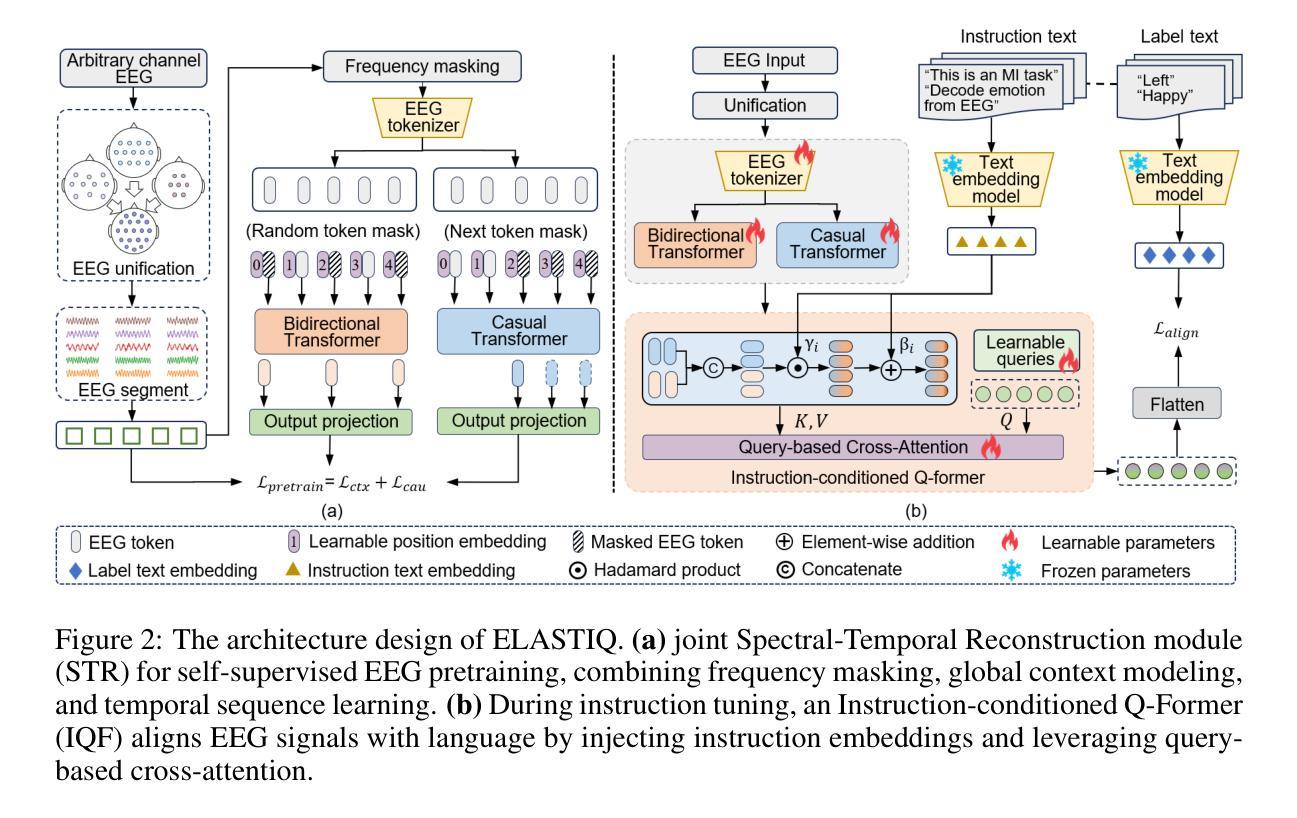
本文是为QIAS 2025关于伊斯兰知识理解与推理的共享任务提交的作品。我们开发了一种混合检索增强生成(RAG)系统,该系统结合了稀疏和密集检索方法,并使用跨编码器重新排序,以提高大语言模型(LLM)的性能。我们的三阶段管道结合了BM25进行初步检索、密集嵌入检索模型进行语义匹配和跨编码器重新排序以进行精确内容检索。我们在两个子任务上对我们的方法进行了评估,使用了Fanar和Mistral两个LLM,结果表明,所提出的RAG管道在这两个方面都提高了性能,准确度的提高幅度高达25%,这取决于任务和模型配置。使用Fanar的最佳配置在Subtask 1中达到45%的准确率,在Subtask 2中达到80%的准确率。
论文及项目相关链接
PDF Accepted at ArabicNLP 2025, co-located with EMNLP 2025
总结
本文介绍了对QIAS 2025共享任务的伊斯兰知识理解与推理的提交内容。开发了一种混合检索增强生成(RAG)系统,该系统结合了稀疏和密集检索方法以及跨编码器重排,以提高大型语言模型(LLM)的性能。该系统的三阶段管道结合了BM25初始检索、密集嵌入检索模型进行语义匹配和跨编码器重排进行精确内容检索。通过两个LLM(Fanar和Mistral)对两个子任务进行评估,证明了所提出的RAG管道在两者中都提高了性能,准确率提高了高达25%,具体取决于任务和模型配置。使用Fanar的最佳配置在Subtask 1中达到45%的准确率,在Subtask 2中达到80%的准确率。
关键见解
- 论文提交于QIAS 2025共享任务,专注于伊斯兰知识理解与推理。
- 提出了一种混合检索增强生成(RAG)系统,旨在提高大型语言模型(LLM)的性能。
- RAG系统采用三阶段管道:BM25初始检索、密集嵌入检索模型进行语义匹配和跨编码器重排进行精确内容检索。
- 在两个子任务上评估了两种LLM(Fanar和Mistral),证明RAG系统能够提高性能。
- RAG系统的准确率提高幅度最高可达25%,具体取决于任务和模型配置。
- 使用Fanar的最佳配置在Subtask 1的准确率为45%,在Subtask 2的准确率为80%。
- 该研究展示了跨编码器重排技术在提高LLM性能方面的潜力。
点此查看论文截图
FraudTransformer: Time-Aware GPT for Transaction Fraud Detection
Authors:Gholamali Aminian, Andrew Elliott, Tiger Li, Timothy Cheuk Hin Wong, Victor Claude Dehon, Lukasz Szpruch, Carsten Maple, Christopher Read, Martin Brown, Gesine Reinert, Mo Mamouei
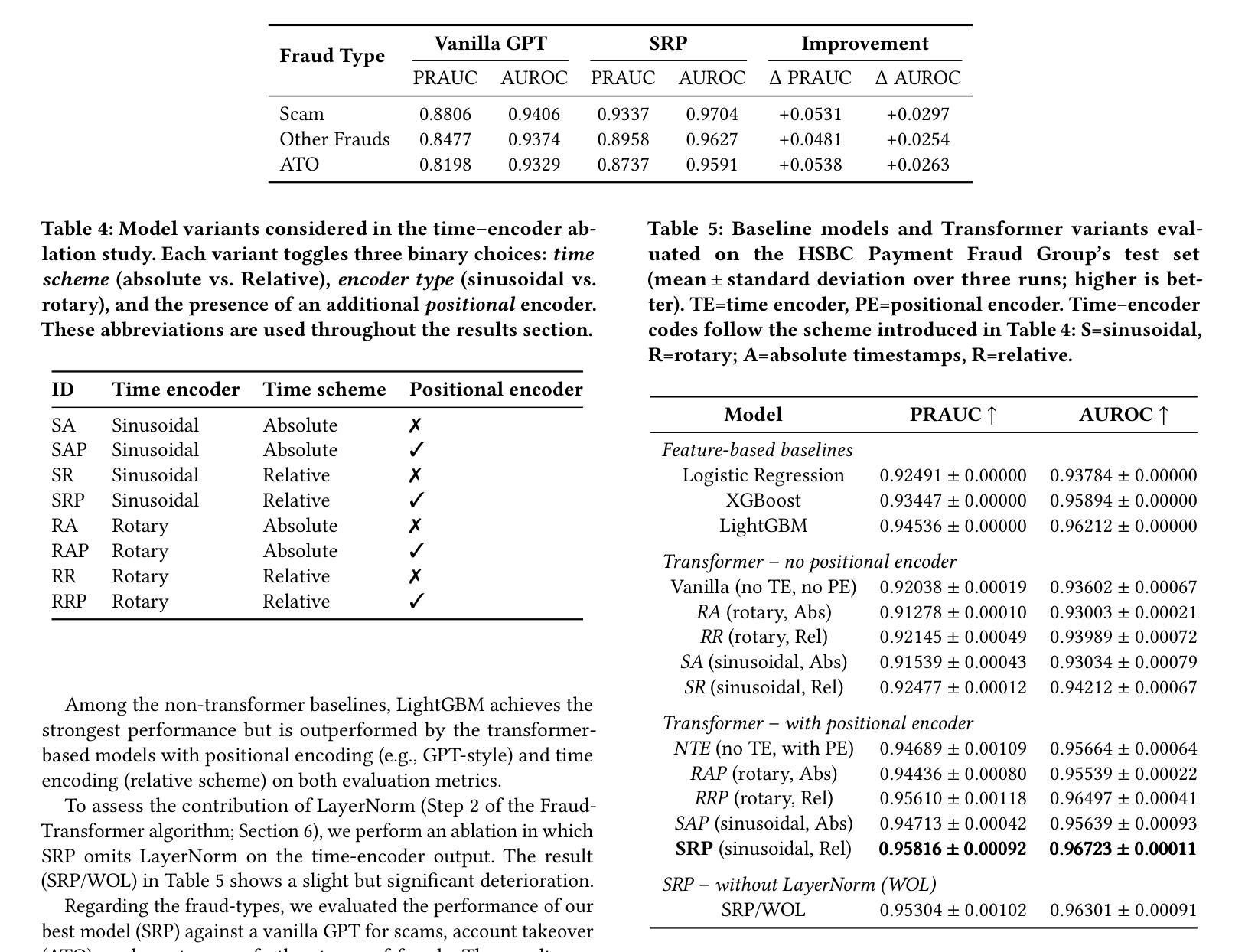
Detecting payment fraud in real-world banking streams requires models that can exploit both the order of events and the irregular time gaps between them. We introduce FraudTransformer, a sequence model that augments a vanilla GPT-style architecture with (i) a dedicated time encoder that embeds either absolute timestamps or inter-event values, and (ii) a learned positional encoder that preserves relative order. Experiments on a large industrial dataset – tens of millions of transactions and auxiliary events – show that FraudTransformer surpasses four strong classical baselines (Logistic Regression, XGBoost and LightGBM) as well as transformer ablations that omit either the time or positional component. On the held-out test set it delivers the highest AUROC and PRAUC.
在真实世界的银行流水交易中检测支付欺诈,需要能够利用事件顺序和事件之间不规则时间间隔的模型。我们引入了FraudTransformer,这是一个序列模型,它增强了一般GPT风格的架构,包括(i)专用时间编码器,可以嵌入绝对时间戳或事件间值,(ii)学习位置编码器,可以保留相对顺序。在大型工业数据集(数千万笔交易和辅助事件)上的实验表明,FraudTransformer超越了四个强大的经典基线(逻辑回归、XGBoost和LightGBM),以及省略了时间或位置组件的转换器消融模型。在保留的测试集上,它达到了最高的AUROC和PRAUC。
论文及项目相关链接
PDF Pre-print
Summary
本文介绍了FraudTransformer模型,该模型结合了事件顺序和事件间的不规则时间间隔,用于检测真实银行流中的欺诈行为。模型采用GPT风格的架构,并配备了专门的时间编码器和学习的位置编码器。实验证明,FraudTransformer在大型工业数据集上的表现超过了四个强大的经典基线以及省略了时间或位置组件的转换器。它在测试集上取得了最高的AUROC和PRAUC。
Key Takeaways
- FraudTransformer模型用于检测真实银行流中的支付欺诈。
- 模型结合了事件顺序和事件间时间间隔的信息。
- 模型采用GPT风格架构,并配备了时间编码器和位置编码器。
- 时间编码器能够嵌入绝对时间戳或事件间隔值。
- 位置编码器能够保持相对顺序。
- 在大型工业数据集上,FraudTransformer表现超过四个强大的经典机器学习模型和省略了某些组件的转换器。
点此查看论文截图