⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-01 更新
Confidence-Guided Error Correction for Disordered Speech Recognition
Authors:Abner Hernandez, Tomás Arias Vergara, Andreas Maier, Paula Andrea Pérez-Toro
We investigate the use of large language models (LLMs) as post-processing modules for automatic speech recognition (ASR), focusing on their ability to perform error correction for disordered speech. In particular, we propose confidence-informed prompting, where word-level uncertainty estimates are embedded directly into LLM training to improve robustness and generalization across speakers and datasets. This approach directs the model to uncertain ASR regions and reduces overcorrection. We fine-tune a LLaMA 3.1 model and compare our approach to both transcript-only fine-tuning and post hoc confidence-based filtering. Evaluations show that our method achieves a 10% relative WER reduction compared to naive LLM correction on the Speech Accessibility Project spontaneous speech and a 47% reduction on TORGO, demonstrating the effectiveness of confidence-aware fine-tuning for impaired speech.
我们研究了大型语言模型(LLM)在自动语音识别(ASR)后处理模块中的应用,重点关注它们对混乱语音的错误纠正能力。特别是,我们提出了基于置信度的提示方法,将词级不确定性估计直接嵌入到LLM训练中,以提高跨说话者和数据集的鲁棒性和泛化能力。这种方法引导模型进入不确定的ASR区域,并减少过度纠正。我们对LLaMA 3.1模型进行了微调,并将我们的方法与仅基于转录的微调以及基于事后置信度的过滤方法进行了比较。评估表明,我们的方法在语音访问项目(Speech Accessibility Project)的自发言语上实现了相对于单纯LLM校正的10%相对字词错误率(WER)降低,在TORGO上降低了47%,证明了置信度感知微调对于受损语音的有效性。
论文及项目相关链接
PDF Preprint submitted to ICASSP
总结
本文主要探讨了大型语言模型(LLMs)在自动语音识别(ASR)后处理模块中的应用,特别是在对口语障碍者的语音识别错误纠正方面的能力。研究提出了一种基于置信度信息的提示方法,将词级不确定性估计直接嵌入到LLM训练中,以提高跨说话者和数据集的鲁棒性和泛化能力。通过微调LLaMA 3.1模型并与其他方法进行比较,实验结果表明,该方法在语音访问项目口语和TORGO数据集上的词错误率分别降低了10%和47%,证明了置信度感知微调在受损语音中的有效性。
关键见解
- 大型语言模型被用作自动语音识别(ASR)的后处理模块,专注于口语障碍者的语音识别错误纠正。
- 提出了基于置信度信息的提示方法,将不确定性估计嵌入LLM训练,提高模型的鲁棒性和泛化能力。
- 方法指导模型定位到ASR的不确定性区域,减少过度纠正的情况。
- 通过微调LLaMA 3.1模型进行实验验证,证明该方法的有效性。
- 与仅基于转录的微调方法和基于置信度的过滤方法相比,该方法在词错误率上取得了显著减少。
- 在语音访问项目口语和TORGO数据集上的实验结果表明,该方法具有广泛的应用潜力。
点此查看论文截图
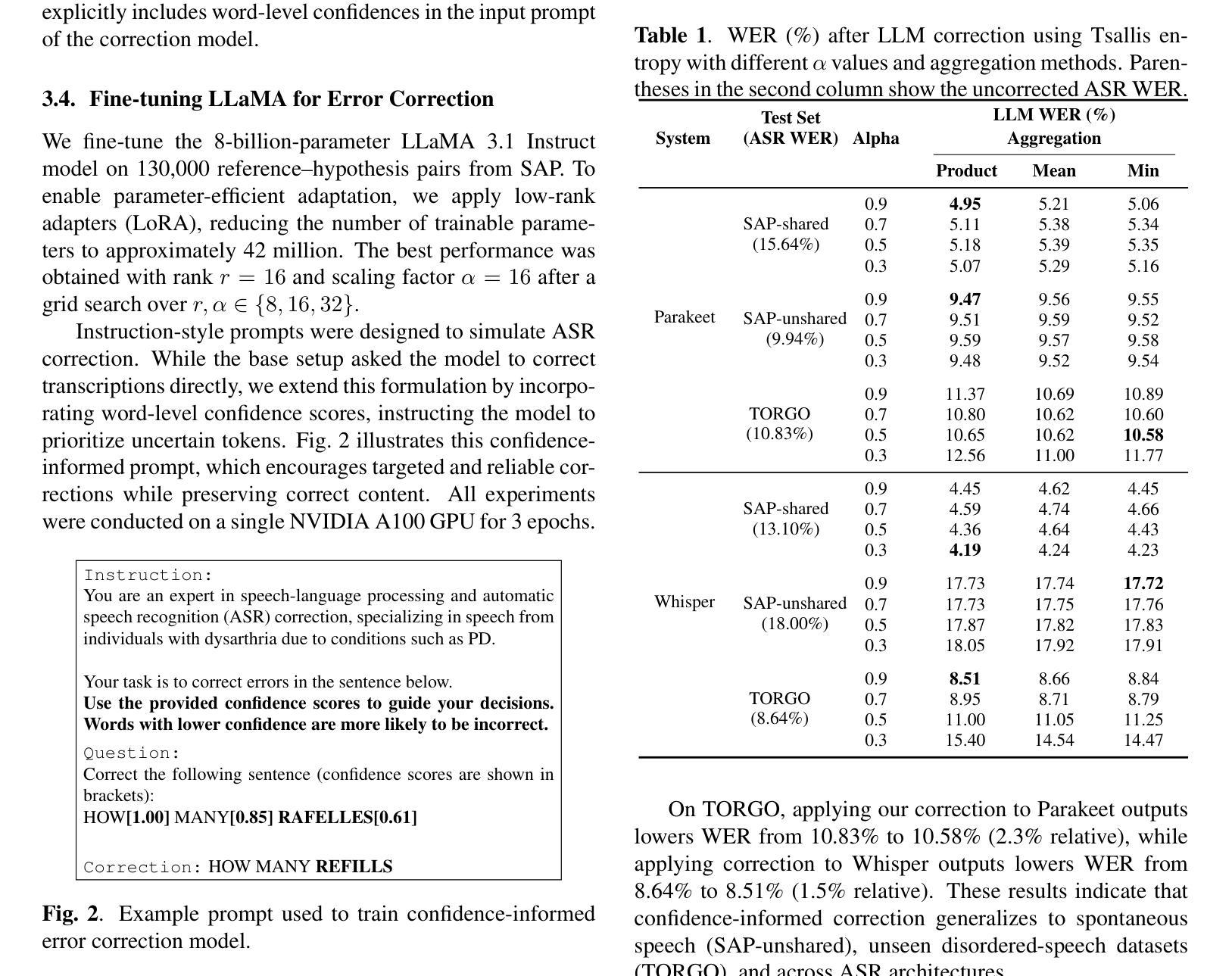
DelRec: learning delays in recurrent spiking neural networks
Authors:Alexandre Queant, Ulysse Rançon, Benoit R Cottereau, Timothée Masquelier
Spiking neural networks (SNNs) are a bio-inspired alternative to conventional real-valued deep learning models, with the potential for substantially higher energy efficiency. Interest in SNNs has recently exploded due to a major breakthrough: surrogate gradient learning (SGL), which allows training SNNs with backpropagation, strongly outperforming other approaches. In SNNs, each synapse is characterized not only by a weight but also by a transmission delay. While theoretical works have long suggested that trainable delays significantly enhance expressivity, practical methods for learning them have only recently emerged. Here, we introduce ‘’DelRec’’, the first SGL-based method to train axonal or synaptic delays in recurrent spiking layers, compatible with any spiking neuron model. DelRec leverages a differentiable interpolation technique to handle non-integer delays with well-defined gradients at training time. We show that trainable recurrent delays outperform feedforward ones, leading to new state-of-the-art (SOTA) on two challenging temporal datasets (Spiking Speech Command, an audio dataset, and Permuted Sequential MNIST, a vision one), and match the SOTA on the now saturated Spiking Heidelberg Digit dataset using only vanilla Leaky-Integrate-and-Fire neurons with stateless (instantaneous) synapses. Our results demonstrate that recurrent delays are critical for temporal processing in SNNs and can be effectively optimized with DelRec, paving the way for efficient deployment on neuromorphic hardware with programmable delays. Our code is available at : https://github.com/alexmaxad/DelRec.
脉冲神经网络(SNNs)是受到生物启发的传统实值深度学习模型的替代方案,具有更高的能源效率潜力。由于对替代梯度学习(SGL)的重大突破,SNNs的兴趣近期爆炸式增长,SGL使得SNNs可以使用反向传播进行训练,并显著优于其他方法。在SNNs中,每个突触不仅由权重特征化,而且还由传输延迟特征化。虽然理论工作长期表明可训练的延迟会显著增强表现力,但实践中的学习方法最近才出现。在这里,我们介绍了“DelRec”,这是基于SGL的方法,可在递归脉冲层中训练轴突或突触延迟,与任何脉冲神经元模型兼容。DelRec利用可微分的插值技术来处理非整数延迟,在训练时有定义明确的梯度。我们显示可训练的递归延迟优于前馈延迟,从而在两个具有挑战性的时间数据集(脉冲语音命令(音频数据集)和置换序列MNIST(视觉数据集))上达到了最新状态,并在现在已饱和的Spiking Heidelberg Digit数据集上使用仅使用普通的泄漏积分和点火神经元以及无状态(瞬时)突触达到了最新状态。我们的结果表明,递归延迟对于SNNs中的时间处理至关重要,并且可以使用DelRec进行有效优化,为在具有可编程延迟的神经形态硬件上有效部署铺平了道路。我们的代码可在:https://github.com/alexmaxad/DelRec找到。
论文及项目相关链接
Summary
近期,脉冲神经网络(SNNs)领域取得重大突破,即出现了一种名为代理梯度学习(SGL)的技术,使得SNNs可以通过反向传播进行训练,并且性能超越了其他方法。现在有一种名为DelRec的新方法,能够在递归脉冲层中进行轴突或突触延迟的训练,并且适用于任何脉冲神经元模型。研究表明,可训练的递归延迟性能优于前馈延迟,并在两个具有挑战性的时序数据集上达到了最新水平。这表明递归延迟对于脉冲神经网络中的时序处理至关重要,并且可以通过DelRec进行有效优化。
Key Takeaways
- 脉冲神经网络(SNNs)是一种生物启发的深度学习模型,具有更高的能源效率潜力。
- 代理梯度学习(SGL)允许使用反向传播训练SNNs,且性能优于其他方法。
- DelRec是第一种能够在递归脉冲层中训练轴突或突触延迟的SGL方法。
- DelRec通过使用可微分的插值技术来处理非整数延迟,在训练时具有明确定义的梯度。
- 可训练的递归延迟性能优于前馈延迟,在两个具有挑战性的时序数据集上达到最新水平。
- 递归延迟对于脉冲神经网络中的时序处理至关重要。
点此查看论文截图
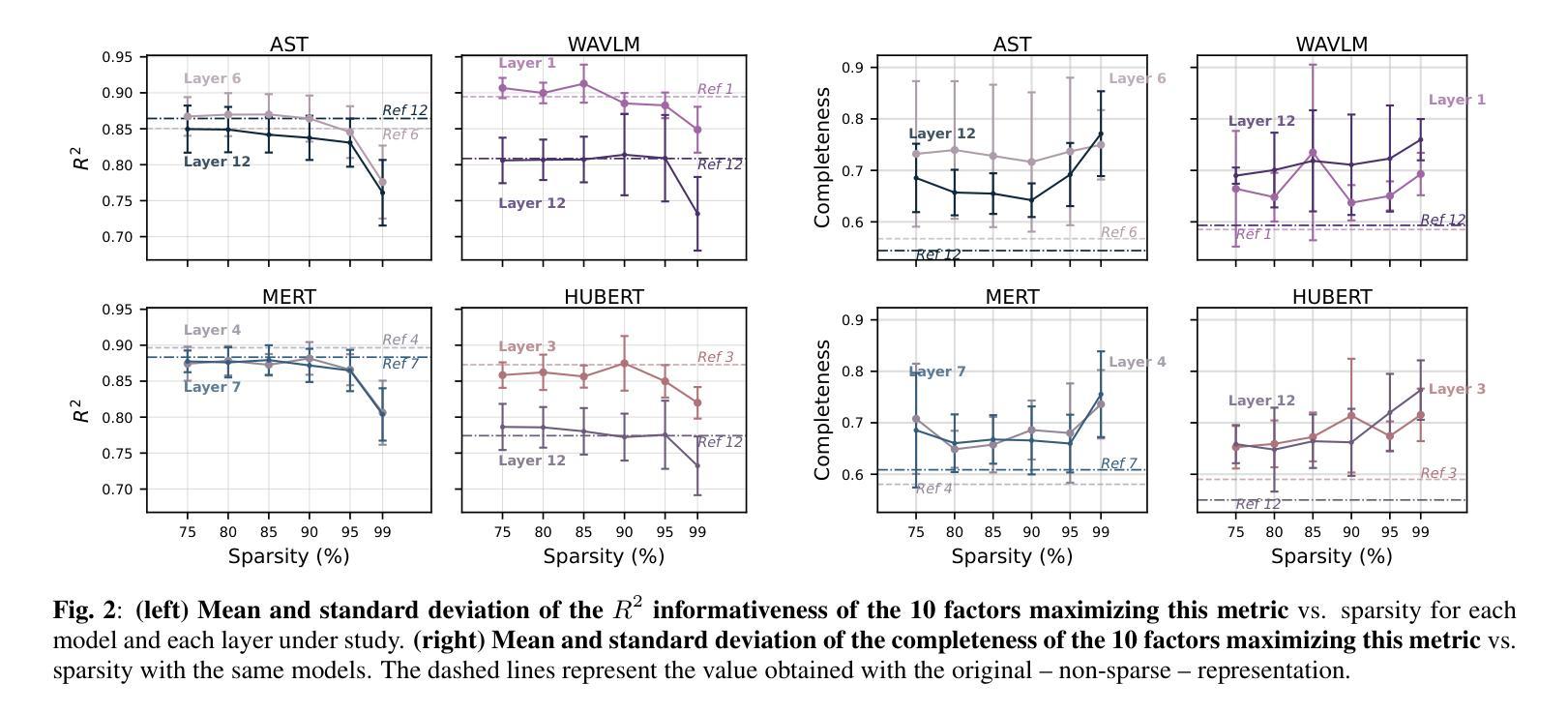
Sparse Autoencoders Make Audio Foundation Models more Explainable
Authors:Théo Mariotte, Martin Lebourdais, Antonio Almudévar, Marie Tahon, Alfonso Ortega, Nicolas Dugué
Audio pretrained models are widely employed to solve various tasks in speech processing, sound event detection, or music information retrieval. However, the representations learned by these models are unclear, and their analysis mainly restricts to linear probing of the hidden representations. In this work, we explore the use of Sparse Autoencoders (SAEs) to analyze the hidden representations of pretrained models, focusing on a case study in singing technique classification. We first demonstrate that SAEs retain both information about the original representations and class labels, enabling their internal structure to provide insights into self-supervised learning systems. Furthermore, we show that SAEs enhance the disentanglement of vocal attributes, establishing them as an effective tool for identifying the underlying factors encoded in the representations.
音频预训练模型被广泛应用于语音处理、声音事件检测或音乐信息检索中的各种任务。然而,这些模型所学的表示形式尚不清楚,其分析主要局限于对隐藏表示的线性探测。在这项工作中,我们探讨了稀疏自动编码器(SAE)在预训练模型的隐藏表示分析中的应用,以歌唱技巧分类为例进行研究。我们首先证明SAE既保留了原始表示的原始信息又保留了类别标签,使得其内部结构能够为我们深入了解自监督学习系统提供见解。此外,我们还表明SAE增强了语音属性的解耦,使其成为识别表示中编码的潜在因素的有效工具。
论文及项目相关链接
PDF 5 pages, 5 figures, 1 table, submitted to ICASSP 2026
Summary
本文探讨了使用Sparse Autoencoders(SAE)分析预训练模型隐藏表征的方法,并以歌唱技巧分类为例进行了深入研究。研究发现SAE能够保留原始表征和类别标签的信息,其内部结构有助于了解自监督学习系统的原理。此外,SAE还能增强对嗓音属性的解构,成为识别隐藏表征中编码因素的有效工具。
Key Takeaways
- 预训练模型广泛应用于语音处理、声音事件检测或音乐信息检索等任务。
- 预训练模型的隐藏表征分析主要局限于线性探测。
- SAE能够保留原始表征和类别标签的信息。
- SAE的内部结构有助于了解自监督学习系统的原理。
- SAE在歌唱技巧分类的案例中表现出增强解构嗓音属性的能力。
- SAE成为识别预训练模型隐藏表征中编码因素的有效工具。
点此查看论文截图

VSSFlow: Unifying Video-conditioned Sound and Speech Generation via Joint Learning
Authors:Xin Cheng, Yuyue Wang, Xihua Wang, Yihan Wu, Kaisi Guan, Yijing Chen, Peng Zhang, Xiaojiang Liu, Meng Cao, Ruihua Song
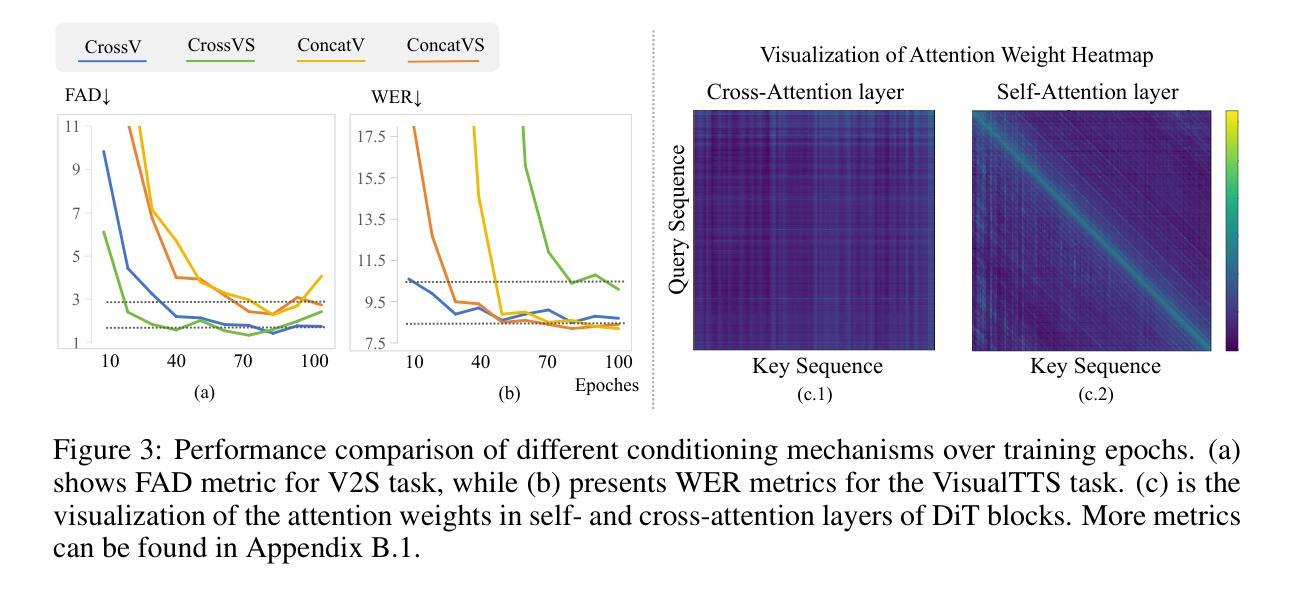
Video-conditioned sound and speech generation, encompassing video-to-sound (V2S) and visual text-to-speech (VisualTTS) tasks, are conventionally addressed as separate tasks, with limited exploration to unify them within a signle framework. Recent attempts to unify V2S and VisualTTS face challenges in handling distinct condition types (e.g., heterogeneous video and transcript conditions) and require complex training stages. Unifying these two tasks remains an open problem. To bridge this gap, we present VSSFlow, which seamlessly integrates both V2S and VisualTTS tasks into a unified flow-matching framework. VSSFlow uses a novel condition aggregation mechanism to handle distinct input signals. We find that cross-attention and self-attention layer exhibit different inductive biases in the process of introducing condition. Therefore, VSSFlow leverages these inductive biases to effectively handle different representations: cross-attention for ambiguous video conditions and self-attention for more deterministic speech transcripts. Furthermore, contrary to the prevailing belief that joint training on the two tasks requires complex training strategies and may degrade performance, we find that VSSFlow benefits from the end-to-end joint learning process for sound and speech generation without extra designs on training stages. Detailed analysis attributes it to the learned general audio prior shared between tasks, which accelerates convergence, enhances conditional generation, and stabilizes the classifier-free guidance process. Extensive experiments demonstrate that VSSFlow surpasses the state-of-the-art domain-specific baselines on both V2S and VisualTTS benchmarks, underscoring the critical potential of unified generative models.
视频条件的声音和语音生成,包括视频到声音(V2S)和视觉文本到语音(VisualTTS)任务,传统上被视为单独的任务,并且在统一框架内对其进行探索的尝试有限。最近尝试将V2S和VisualTTS统一起来在处理不同条件类型(例如,不同的视频和文本条件)方面面临挑战,并且需要复杂的训练阶段。统一这两个任务仍然是一个开放的问题。为了弥合这一差距,我们推出了VSSFlow,它无缝地将V2S和VisualTTS任务集成到一个统一的流匹配框架中。VSSFlow使用一种新型的条件聚合机制来处理不同的输入信号。我们发现,在引入条件的过程中,跨注意力和自注意力层表现出不同的归纳偏见。因此,VSSFlow利用这些归纳偏见来有效地处理不同的表示形式:跨注意力用于模糊的视频条件,自注意力用于更确定的语音文本。此外,与普遍的观点相反,即两个任务的联合训练需要复杂的训练策略并可能降低性能,我们发现VSSFlow受益于声音和语音生成的端到端联合学习过程,而无需在训练阶段进行额外设计。详细分析将其归功于任务之间学到的通用音频先验的共享,这加速了收敛,增强了条件生成,并稳定了无分类器指导过程。大量实验表明,VSSFlow在V2S和VisualTTS基准测试中超越了最先进的领域特定基准测试,突显了统一生成模型的巨大潜力。
论文及项目相关链接
PDF Paper Under Review
摘要
视频条件音频与语音生成涵盖视频转声音(V2S)与视觉文本转语音(VisualTTS)任务,传统上被视为独立处理。近期尝试统一V2S和VisualTTS在处理不同条件类型(如异质视频和文字脚本)时面临挑战,并需要复杂的训练阶段。为填补这一空白,我们提出VSSFlow,它将V2S和VisualTTS任务无缝集成到一个统一的流匹配框架中。VSSFlow采用新型条件聚合机制来处理不同的输入信号。我们发现交叉注意力和自注意力层在处理条件引入过程中展现出不同的归纳偏置。因此,VSSFlow利用这些归纳偏置来有效处理不同的表示形式:交叉注意力用于模糊的视频条件,自注意力用于更确定的语音脚本。此外,尽管普遍观点认为对两个任务进行联合训练需要复杂的训练策略并可能影响性能,但我们发现VSSFlow受益于声音和语音生成的端到端联合学习过程,无需额外的训练阶段设计。这得益于任务间学习的通用音频先验,它加速收敛,增强条件生成,并稳定无分类指导过程。大量实验表明,VSSFlow在V2S和VisualTTS基准测试中超越了最新领域的专项方法,突显出统一生成模型的关键潜力。
关键见解
- VSSFlow提出一个统一的流匹配框架,整合视频转声音(V2S)和视觉文本转语音(VisualTTS)任务。
- 采用新型条件聚合机制处理不同的输入信号。
- 交叉注意力和自注意力层在处理不同条件类型时展现出不同归纳偏置,VSSFlow利用这一特性优化处理。
- VSSFlow受益于端到端的联合学习过程,无需复杂训练策略或额外训练阶段。
- 通用音频先验在联合学习任务中起到关键作用,加速收敛并增强性能。
- VSSFlow在V2S和VisualTTS基准测试中表现超越现有方法。
点此查看论文截图
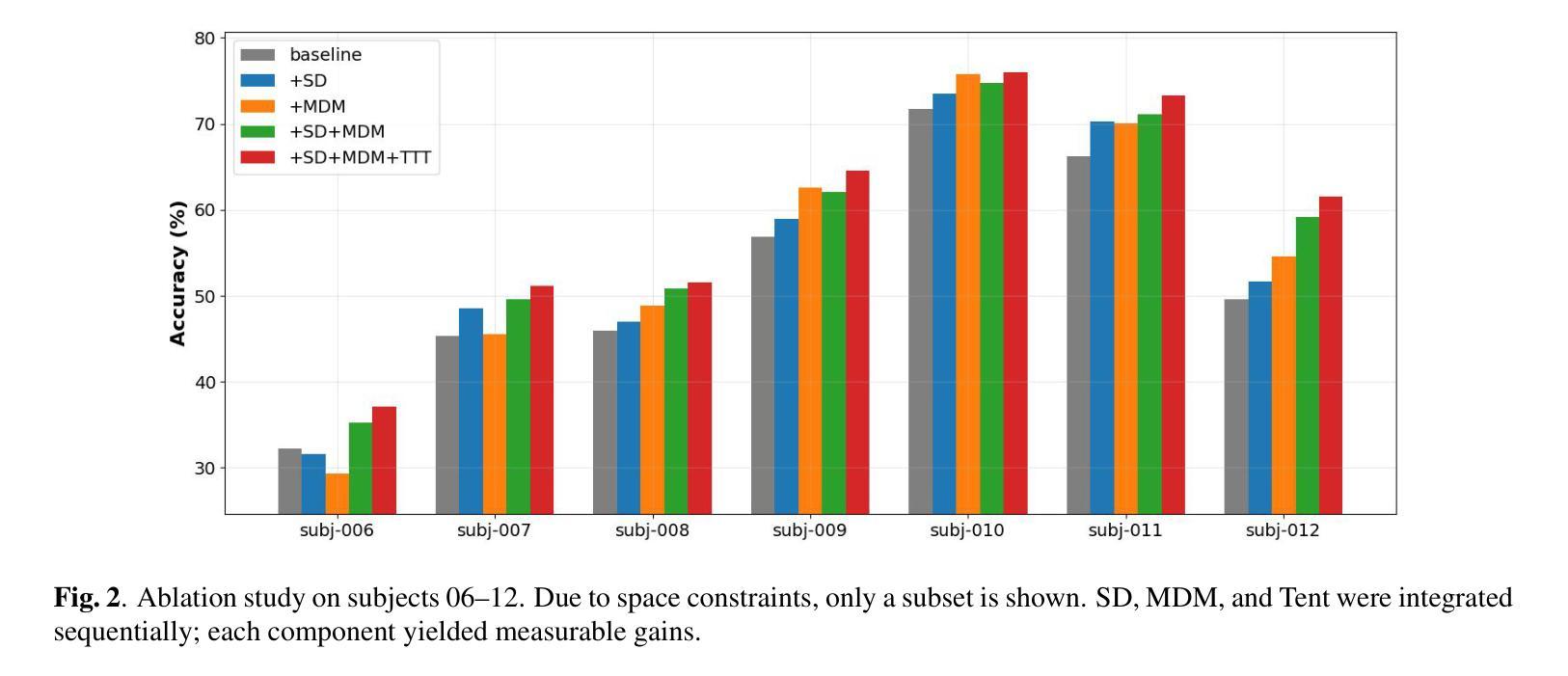
A Robust Multi-Scale Framework with Test-Time Adaptation for sEEG-Based Speech Decoding
Authors:Suli Wang, Yang-yang Li, Siqi Cai, Haizhou Li
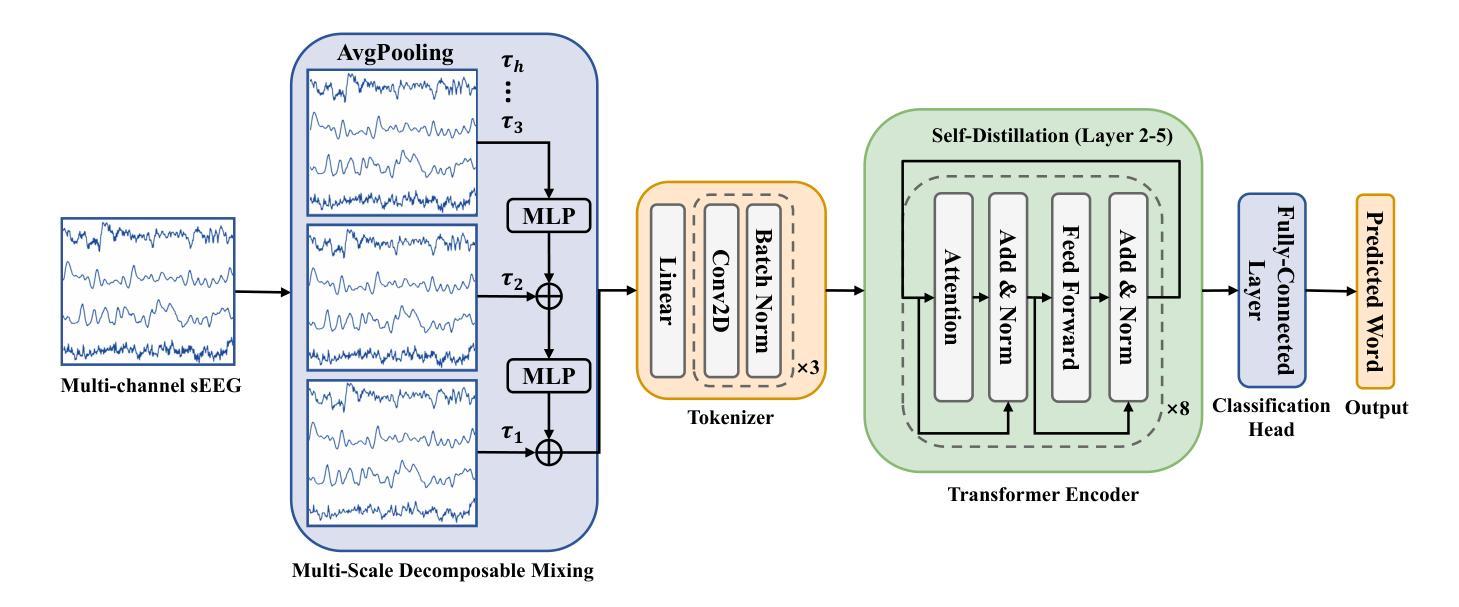
Decoding speech from stereo-electroencephalography (sEEG) signals has emerged as a promising direction for brain-computer interfaces (BCIs). Its clinical applicability, however, is limited by the inherent non-stationarity of neural signals, which causes domain shifts between training and testing, undermining decoding reliability. To address this challenge, a two-stage framework is proposed for enhanced robustness. First, a multi-scale decomposable mixing (MDM) module is introduced to model the hierarchical temporal dynamics of speech production, learning stable multi-timescale representations from sEEG signals. Second, a source-free online test-time adaptation (TTA) method performs entropy minimization to adapt the model to distribution shifts during inference. Evaluations on the public DU-IN spoken word decoding benchmark show that the approach outperforms state-of-the-art models, particularly in challenging cases. This study demonstrates that combining invariant feature learning with online adaptation is a principled strategy for developing reliable BCI systems. Our code is available at https://github.com/lyyi599/MDM-TENT.
从立体脑电图(sEEG)信号中解码语音已成为脑机接口(BCI)的一个有前途的研究方向。然而,其临床应用的可行性受限于神经信号固有的非平稳性,导致训练和测试之间的领域偏移,从而降低了解码的可靠性。为了解决这一挑战,提出了一个两阶段的框架以增强稳健性。首先,引入了一种多尺度可分解混合(MDM)模块,以模拟语音产生的分层时间动态,从sEEG信号中学习稳定的多尺度表示。其次,无源在线测试时间适应(TTA)方法执行熵最小化,以在推理过程中使模型适应分布变化。在公共DU-IN口语单词解码基准测试上的评估表明,该方法优于最新模型,特别是在具有挑战的情况下。这项研究表明,将不变特征学习与在线适应相结合是开发可靠BCI系统的一种有原则的策略。我们的代码可在https://github.com/lyyi599/MDM-TENT找到。
论文及项目相关链接
Summary
基于立体脑电图(sEEG)信号的语音解码在脑机接口(BCI)领域展现出巨大潜力。然而,由于神经信号的固有非平稳性,其临床应用受到限制。为此,本文提出一个两阶段框架以提高模型稳健性:第一阶段通过引入多尺度可分解混合(MDM)模块建模语音产生的层次时间动态,从sEEG信号中学习稳定的多尺度表示;第二阶段采用无源在线测试时自适应(TTA)方法进行熵最小化,使模型在推理时适应分布变化。在公开DU-IN口语词解码基准测试上的评估表明,该方法优于最新模型,尤其在挑战性场景下表现更优异。本研究证明了结合不变特征学习与在线自适应是开发可靠BCI系统的有效策略。
Key Takeaways
- 立体脑电图(sEEG)信号在脑机接口(BCI)中的语音解码表现出潜力。
- 神经信号的固有非平稳性限制了sEEG在临床应用中的可靠性。
- 提出一个两阶段框架以提高模型稳健性,包括多尺度可分解混合(MDM)模块和无源在线测试时自适应(TTA)方法。
- MDM模块学习稳定的多尺度表示,以建模语音产生的层次时间动态。
- TTA方法通过熵最小化在推理时适应分布变化。
- 在DU-IN口语词解码基准测试上,该方法优于其他最新模型。
- 结合不变特征学习与在线自适应是开发可靠BCI系统的有效策略。
点此查看论文截图
HiKE: Hierarchical Evaluation Framework for Korean-English Code-Switching Speech Recognition
Authors:Gio Paik, Yongbeom Kim, Soungmin Lee, Sangmin Ahn, Chanwoo Kim
Despite advances in multilingual automatic speech recognition (ASR), code-switching (CS), the mixing of languages within an utterance common in daily speech, remains a severely underexplored challenge. In this paper, we introduce HiKE: the Hierarchical Korean-English code-switching benchmark, the first globally accessible evaluation framework for Korean-English CS, aiming to provide a means for the precise evaluation of multilingual ASR models and to foster research in the field. The proposed framework not only consists of high-quality, natural CS data across various topics, but also provides meticulous loanword labels and a hierarchical CS-level labeling scheme (word, phrase, and sentence) that together enable a systematic evaluation of a model’s ability to handle each distinct level of code-switching. Through evaluations of diverse multilingual ASR models and fine-tuning experiments, this paper demonstrates that while most multilingual ASR models initially struggle with CS-ASR, this capability can be enabled through fine-tuning with CS data. HiKE will be available at https://github.com/ThetaOne-AI/HiKE.
尽管多语种自动语音识别(ASR)技术有所进步,但语言切换(CS)在日常对话中常见的混合语言现象仍然是一个被严重忽视的挑战。在本文中,我们介绍了HiKE:分层韩英语言切换基准测试,这是首个面向韩英语言切换的全球可访问评估框架,旨在提供精确评估多语种ASR模型的手段,并推动该领域的研究。所提出的框架不仅包括高质量、跨各种主题的天然语言切换数据,还提供细致的借词标签和分层语言切换级别标签方案(单词、短语和句子),它们共同使得系统评价模型处理各种独特级别的语言切换能力成为可能。通过对各种多语种ASR模型的评估和微调实验,本文表明,虽然大多数多语种ASR模型最初在语言切换方面遇到困难,但通过用语言切换数据进行微调,这种能力是可以实现的。HiKE将在https://github.com/ThetaOne-AI/HiKE上提供。
论文及项目相关链接
PDF 5 pages, 2 figures, Submitted to ICASSP2026
Summary
本文介绍了HiKE:一个面向韩语-英语代码切换的层次化基准测试平台。该平台旨在提供精确评估多语言自动语音识别模型的能力,推动相关领域研究。HiKE不仅包含高质量的自然代码切换数据,还提供详细的借词标签和层次化的代码切换级别标签方案(单词、短语和句子),通过评估和微调实验表明,大多数多语言自动语音识别模型在代码切换自动语音识别上具有一定潜力。
Key Takeaways
- 代码切换(CS)在日常语言中普遍存在,但在多语言自动语音识别(ASR)中仍是一个未被充分研究的挑战。
- HiKE是首个面向韩语-英语代码切换的全球性评估框架,旨在精确评估多语言ASR模型。
- HiKE提供了高质量的自然代码切换数据,涵盖各种主题。
- HiKE具有详细的借词标签和层次化的代码切换级别标签方案,包括单词、短语和句子。
- 多数多语言ASR模型在初始阶段对代码切换的识别存在困难。
- 通过使用HiKE平台上的数据进行微调,可以提高模型对代码切换的识别能力。
点此查看论文截图

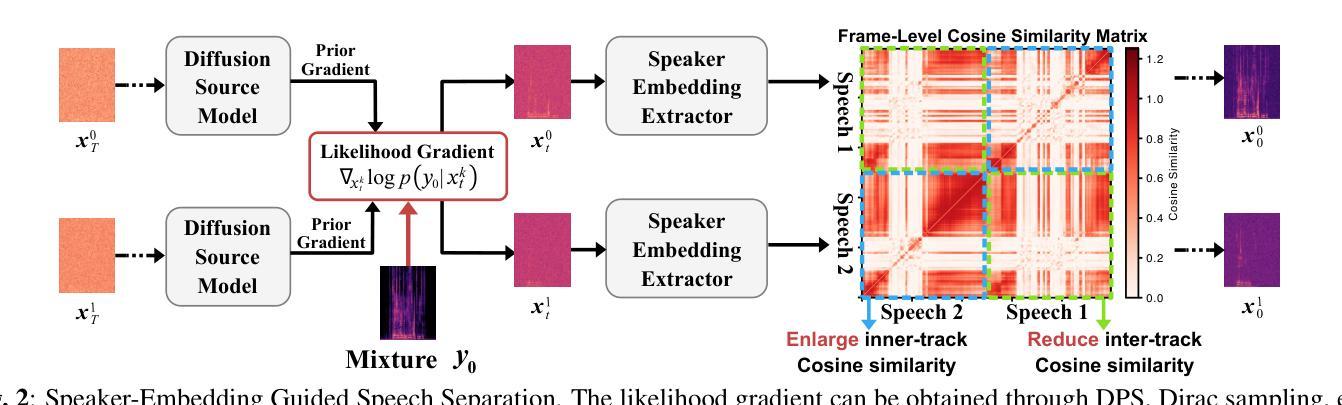
Unsupervised Single-Channel Speech Separation with a Diffusion Prior under Speaker-Embedding Guidance
Authors:Runwu Shi, Kai Li, Chang Li, Jiang Wang, Sihan Tan, Kazuhiro Nakadai
Speech separation is a fundamental task in audio processing, typically addressed with fully supervised systems trained on paired mixtures. While effective, such systems typically rely on synthetic data pipelines, which may not reflect real-world conditions. Instead, we revisit the source-model paradigm, training a diffusion generative model solely on anechoic speech and formulating separation as a diffusion inverse problem. However, unconditional diffusion models lack speaker-level conditioning, they can capture local acoustic structure but produce temporally inconsistent speaker identities in separated sources. To address this limitation, we propose Speaker-Embedding guidance that, during the reverse diffusion process, maintains speaker coherence within each separated track while driving embeddings of different speakers further apart. In addition, we propose a new separation-oriented solver tailored for speech separation, and both strategies effectively enhance performance on the challenging task of unsupervised source-model-based speech separation, as confirmed by extensive experimental results. Audio samples and code are available at https://runwushi.github.io/UnSepDiff_demo.
语音分离是音频处理中的一项基本任务,通常通过使用在配对混合物上训练的完全监督系统来解决。虽然这些方法很有效,但它们通常依赖于合成数据管道,可能无法反映真实世界的条件。相反,我们重新访问源模型范式,仅使用无回声语音训练扩散生成模型,并将分离问题表述为扩散反问题。然而,无条件扩散模型缺乏说话人级别的条件约束,它们可以捕捉局部声学结构,但在分离的源中产生时间上不一致的说话人身份。为了解决这一局限性,我们提出了说话人嵌入引导(Speaker-Embedding guidance),在反向扩散过程中保持每个分离轨迹内的说话人一致性,同时使不同说话人的嵌入彼此远离。此外,我们针对语音分离提出了一种新的面向分离的求解器(separation-oriented solver),这两种策略均有效地提高了基于源模型的监督语音分离的复杂任务性能,广泛的实验结果证实了这一点。音频样本和代码可在https://runwushi.github.io/UnSepDiff_demo获取。
论文及项目相关链接
PDF 5 pages, 2 figures, submitted to ICASSP 2026
Summary
本文介绍了语音分离作为音频处理中的一项基础任务,传统方法依赖于合成数据管道的全监督系统进行训练,这可能无法反映真实世界的情况。为此,文章重新探讨了源模型范式,通过训练仅适用于无回声语音的扩散生成模型,并将分离问题表述为扩散逆问题。为解决无条件扩散模型缺乏说话人级别的条件限制问题,文章提出了说话人嵌入引导机制,在反向扩散过程中保持每个分离轨迹的说话人一致性,同时使不同说话人的嵌入进一步分离。此外,文章还提出了一种针对语音分离的新分离导向求解器,这两种策略均能有效提升基于源模型的非监督语音分离的性能,通过广泛的实验结果得到了验证。
Key Takeaways
- 语音分离是音频处理中的基础任务,传统方法依赖于合成数据管道的全监督系统,存在无法反映真实世界情况的局限性。
- 文章重新探讨了源模型范式,通过训练仅适用于无回声语音的扩散生成模型来解决语音分离问题。
- 无条件扩散模型缺乏说话人级别的条件限制,会导致分离出的语音源在时间上出现不一致的说话人身份。
- 提出了说话人嵌入引导机制,以保持每个分离轨迹的说话人一致性,并使得不同说话人的嵌入进一步分离。
- 文章还提出了一种针对语音分离的新分离导向求解器,以进一步提升性能。
- 提出的策略在挑战性的基于源模型的非监督语音分离任务中表现有效。
点此查看论文截图

UniFlow-Audio: Unified Flow Matching for Audio Generation from Omni-Modalities
Authors:Xuenan Xu, Jiahao Mei, Zihao Zheng, Ye Tao, Zeyu Xie, Yaoyun Zhang, Haohe Liu, Yuning Wu, Ming Yan, Wen Wu, Chao Zhang, Mengyue Wu
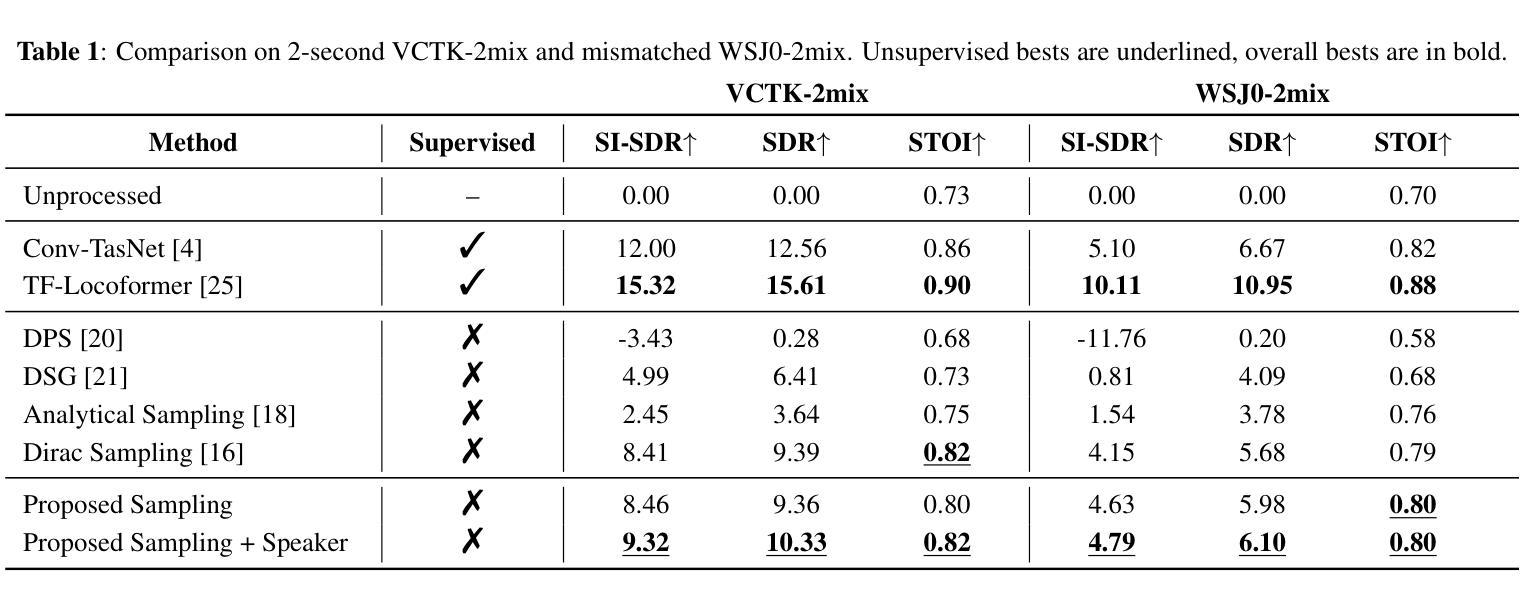
Audio generation, including speech, music and sound effects, has advanced rapidly in recent years. These tasks can be divided into two categories: time-aligned (TA) tasks, where each input unit corresponds to a specific segment of the output audio (e.g., phonemes aligned with frames in speech synthesis); and non-time-aligned (NTA) tasks, where such alignment is not available. Since modeling paradigms for the two types are typically different, research on different audio generation tasks has traditionally followed separate trajectories. However, audio is not inherently divided into such categories, making a unified model a natural and necessary goal for general audio generation. Previous unified audio generation works have adopted autoregressive architectures, while unified non-autoregressive approaches remain largely unexplored. In this work, we propose UniFlow-Audio, a universal audio generation framework based on flow matching. We propose a dual-fusion mechanism that temporally aligns audio latents with TA features and integrates NTA features via cross-attention in each model block. Task-balanced data sampling is employed to maintain strong performance across both TA and NTA tasks. UniFlow-Audio supports omni-modalities, including text, audio, and video. By leveraging the advantage of multi-task learning and the generative modeling capabilities of flow matching, UniFlow-Audio achieves strong results across 7 tasks using fewer than 8K hours of public training data and under 1B trainable parameters. Even the small variant with only ~200M trainable parameters shows competitive performance, highlighting UniFlow-Audio as a potential non-auto-regressive foundation model for audio generation. Code and models will be available at https://wsntxxn.github.io/uniflow_audio.
近年来,音频生成(包括语音、音乐和音效)取得了迅速的发展。这些任务可以分为两类:时间对齐(TA)任务,每个输入单元对应于输出音频的特定片段(例如语音合成中的音素与帧对齐);以及非时间对齐(NTA)任务,其中无法获得这样的对齐信息。由于两种类型的建模范式通常不同,因此针对不同音频生成任务的研究一直遵循不同的轨迹。然而,音频本身并不固有地分为这些类别,因此构建统一的音频生成模型成为了一个自然且必要的目标。之前统一的音频生成工作已经采用了自回归架构,而统一的非自回归方法仍然在很大程度上未被探索。在这项工作中,我们提出了基于流匹配的通用音频生成框架UniFlow-Audio。我们提出了一种双融合机制,该机制可以在时间上对齐音频潜在空间与TA特征,并通过每个模型块中的交叉注意力集成NTA特征。采用任务平衡数据采样以在TA和NTA任务上保持强劲性能。UniFlow-Audio支持多种模式,包括文本、音频和视频。通过利用多任务学习的优势和流匹配的生成建模能力,UniFlow-Audio在7项任务上取得了强大的结果,使用少于8K小时的公开训练数据和不到1B的可训练参数。即使是只有约2亿个可训练参数的小型变体也表现出有竞争力的性能,这突显了UniFlow-Audio作为音频生成潜在的非自回归基础模型的潜力。代码和模型将在https://wsntxxn.github.io/uniflow_audio上提供。
论文及项目相关链接
PDF Project page: https://wsntxxn.github.io/uniflow_audio
摘要
近期音频生成技术,包括语音、音乐和音效,发展迅速。音频生成任务可分为时间对齐(TA)和非时间对齐(NTA)两大类。以往针对不同类型的音频生成任务的研究通常采用单独的模型,但缺乏统一的框架。本文提出了基于流匹配的通用音频生成框架UniFlow-Audio,采用双融合机制实现TA和NTA特征的整合。该框架支持多种模态,包括文本、音频和视频。借助多任务学习的优势和流匹配的生成建模能力,UniFlow-Audio在7个任务上取得了显著成果,使用少于8K小时的公开训练数据和不到1B的可训练参数。代码和模型将公开在链接。
关键见解
- 音频生成技术快速发展,涵盖语音、音乐和音效等领域。
- 音频生成任务分为时间对齐(TA)和非时间对齐(NTA)两大类别,需要不同的建模方法。
- 现有的音频生成研究通常采用单独的模型,缺乏统一框架。
- UniFlow-Audio是一个基于流匹配的通用音频生成框架,采用双融合机制整合TA和NTA特征。
- UniFlow-Audio支持多种模态,包括文本、音频和视频。
- 该框架在多任务学习和流匹配的生成建模能力上表现出优势,在7个任务上取得显著成果。
点此查看论文截图
Code-switching Speech Recognition Under the Lens: Model- and Data-Centric Perspectives
Authors:Hexin Liu, Haoyang Zhang, Qiquan Zhang, Xiangyu Zhang, Dongyuan Shi, Eng Siong Chng, Haizhou Li
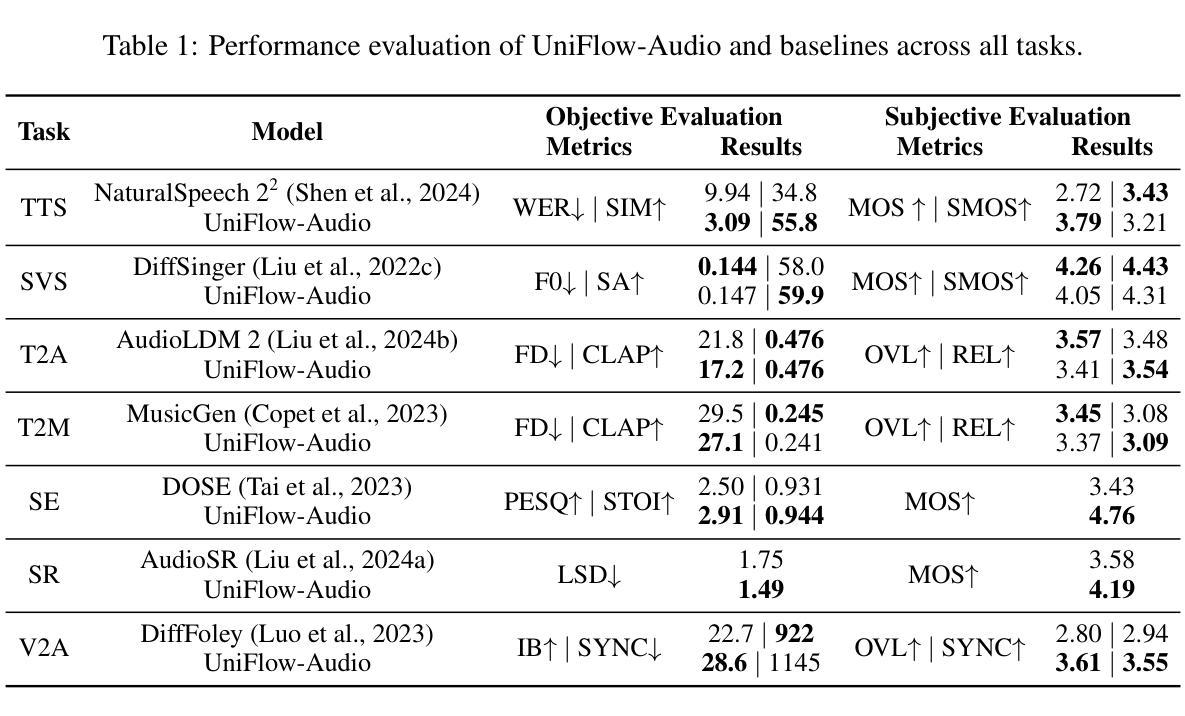
Code-switching automatic speech recognition (CS-ASR) presents unique challenges due to language confusion introduced by spontaneous intra-sentence switching and accent bias that blurs the phonetic boundaries. Although the constituent languages may be individually high-resource, the scarcity of annotated code-switching data further compounds these challenges. In this paper, we systematically analyze CS-ASR from both model-centric and data-centric perspectives. By comparing state-of-the-art algorithmic methods, including language-specific processing and auxiliary language-aware multi-task learning, we discuss their varying effectiveness across datasets with different linguistic characteristics. On the data side, we first investigate TTS as a data augmentation method. By varying the textual characteristics and speaker accents, we analyze the impact of language confusion and accent bias on CS-ASR. To further mitigate data scarcity and enhance textual diversity, we propose a prompting strategy by simplifying the equivalence constraint theory (SECT) to guide large language models (LLMs) in generating linguistically valid code-switching text. The proposed SECT outperforms existing methods in ASR performance and linguistic quality assessments, generating code-switching text that more closely resembles real-world code-switching text. When used to generate speech-text pairs via TTS, SECT proves effective in improving CS-ASR performance. Our analysis of both model- and data-centric methods underscores that effective CS-ASR requires strategies to be carefully aligned with the specific linguistic characteristics of the code-switching data.
代码切换自动语音识别(CS-ASR)由于句子内自发切换引发的语言混淆和口音偏差导致的语音边界模糊而面临独特挑战。尽管构成的语言可能单独是高资源的,但代码切换数据的稀缺性进一步加剧了这些挑战。在本文中,我们从模型中心和数据中心两个角度系统地分析了CS-ASR。通过比较最先进的算法方法,包括语言特定处理和辅助语言感知多任务学习,我们讨论了它们在具有不同语言特征的数据集上的不同效果。在数据方面,我们首先研究TTS作为数据增强方法。通过改变文本特征和说话者口音,我们分析了语言混淆和口音偏差对CS-ASR的影响。为了进一步缓解数据稀缺性并增强文本多样性,我们提出了一种基于简化等价约束理论(SECT)的提示策略,以指导大型语言模型(LLM)生成语言上有效的代码切换文本。所提出的SECT在语音识别性能和语言质量评估方面优于现有方法,生成更贴近现实世界的代码切换文本。当用于通过TTS生成语音文本对时,SECT在提高CS-ASR性能方面证明是有效的。我们对模型和数据中心方法的分析强调,有效的CS-ASR需要策略与代码切换数据的特定语言特征仔细对齐。
论文及项目相关链接
PDF 11 pages, 3 figures, 9 tables, submitted to IEEE TASLP
Summary
本文系统分析了代码切换自动语音识别(CS-ASR)面临的挑战,包括语言混淆和口音偏差问题。通过对比先进的算法方法,如特定语言处理和辅助多语言多任务学习,探讨了它们在具有不同语言特征的数据集上的有效性。同时,本文研究了文本转语音(TTS)作为数据增强方法的影响,并提出了基于简化等价约束理论(SECT)的提示策略来缓解数据稀缺问题并增强文本多样性。实验表明,所提出的SECT在语音识别性能与语言质量评估方面优于现有方法,生成的代码切换文本更接近真实场景。将SECT用于生成语音文本对时,通过TTS可有效提高CS-ASR性能。总体而言,有效的CS-ASR需要策略与代码切换数据的特定语言特征紧密配合。
Key Takeaways
- CS-ASR面临语言混淆和口音偏差的挑战。
- 先进的算法方法在CS-ASR中的有效性因数据集的语言特性而异。
- TTS作为数据增强方法被研究,以分析语言混淆和口音偏差对CS-ASR的影响。
- 提出了基于简化等价约束理论(SECT)的提示策略来缓解数据稀缺问题并增强文本多样性。
- SECT在语音识别性能与语言质量评估方面表现出优势。
- 结合TTS,SECT在生成语音文本对时能提高CS-ASR性能。
点此查看论文截图

ELASTIQ: EEG-Language Alignment with Semantic Task Instruction and Querying
Authors:Muyun Jiang, Shuailei Zhang, Zhenjie Yang, Mengjun Wu, Weibang Jiang, Zhiwei Guo, Wei Zhang, Rui Liu, Shangen Zhang, Yong Li, Yi Ding, Cuntai Guan
Recent advances in electroencephalography (EEG) foundation models, which capture transferable EEG representations, have greatly accelerated the development of brain-computer interfaces (BCI). However, existing approaches still struggle to incorporate language instructions as prior constraints for EEG representation learning, limiting their ability to leverage the semantic knowledge inherent in language to unify different labels and tasks. To address this challenge, we present ELASTIQ, a foundation model for EEG-Language Alignment with Semantic Task Instruction and Querying. ELASTIQ integrates task-aware semantic guidance to produce structured and linguistically aligned EEG embeddings, thereby enhancing decoding robustness and transferability. In the pretraining stage, we introduce a joint Spectral-Temporal Reconstruction (STR) module, which combines frequency masking as a global spectral perturbation with two complementary temporal objectives: random masking to capture contextual dependencies and causal masking to model sequential dynamics. In the instruction tuning stage, we propose the Instruction-conditioned Q-Former (IQF), a query-based cross-attention transformer that injects instruction embeddings into EEG tokens and aligns them with textual label embeddings through learnable queries. We evaluate ELASTIQ on 20 datasets spanning motor imagery, emotion recognition, steady-state visual evoked potentials, covert speech, and healthcare tasks. ELASTIQ achieves state-of-the-art performance on 14 of the 20 datasets and obtains the best average results across all five task categories. Importantly, our analyses reveal for the first time that explicit task instructions serve as semantic priors guiding EEG embeddings into coherent and linguistically grounded spaces. The code and pre-trained weights will be released.
近期脑电图(EEG)基础模型的进步,这些模型能够捕捉可迁移的EEG表示,极大地加速了脑机接口(BCI)的发展。然而,现有方法仍然难以将语言指令作为先验约束融入EEG表示学习中,限制了其利用语言中所固有的语义知识来统一不同标签和任务的能力。为了应对这一挑战,我们提出了EEG-语言对齐基础模型ELASTIQ(结合了语义任务指令和查询)。ELASTIQ集成了任务感知语义指导,以产生结构化和语言对齐的EEG嵌入,从而提高了解码的稳健性和可迁移性。在预训练阶段,我们引入了联合谱时间重建(STR)模块,该模块将频率掩码作为全局谱扰动与两种互补的时间目标相结合:随机掩码以捕捉上下文依赖性,因果掩码以模拟序列动态。在指令微调阶段,我们提出了指令条件Q-Formers(IQF),这是一种基于查询的跨注意力变压器,它将指令嵌入注入EEG令牌中,并通过可学习的查询将它们与文本标签嵌入对齐。我们在跨越运动想象、情感识别、稳态视觉诱发电位、隐性语言和医疗任务的20个数据集上评估了ELASTIQ。ELASTIQ在其中的14个数据集上取得了最佳性能,并在所有五个任务类别中获得了最佳平均结果。重要的是,我们的分析首次表明,明确的任务指令作为语义先验指导EEG嵌入到连贯且语言基础的空间中。代码和预训练权重将被发布。
论文及项目相关链接
Summary
该文本介绍了一种名为ELASTIQ的脑电图(EEG)-语言对齐基础模型。该模型结合了任务感知语义指导,产生结构化且语言对齐的脑电图嵌入,提高解码的稳健性和可转移性。模型在预训练阶段采用联合谱时重建(STR)模块,在指令微调阶段提出指令条件Q-Formers(IQF)。模型在多个数据集上取得最佳性能,并首次揭示明确的任务指令作为语义先验,引导脑电图嵌入到连贯且语言基础的空间中。
Key Takeaways
- ELASTIQ是一个用于脑电图(EEG)-语言对齐的基础模型,旨在解决现有方法无法将语言指令作为先验约束来整合EEG表示学习的问题。
- ELASTIQ通过任务感知语义指导产生结构化且语言对齐的EEG嵌入,增强解码的稳健性和可转移性。
- 模型的预训练阶段采用联合谱时重建(STR)模块,结合全局谱扰动和两种互补的时间目标来实现。
- 在指令微调阶段,提出指令条件的Q-Formers(IQF),通过查询将指令嵌入注入EEG令牌并与文本标签嵌入对齐。
- ELASTIQ在多个数据集上的性能达到最佳,尤其是在电机图像、情绪识别、稳态视觉诱发电位、隐蔽性语言和医疗任务等领域。
- ELASTIQ的发布将为公开源码和预训练权重提供便利。
点此查看论文截图

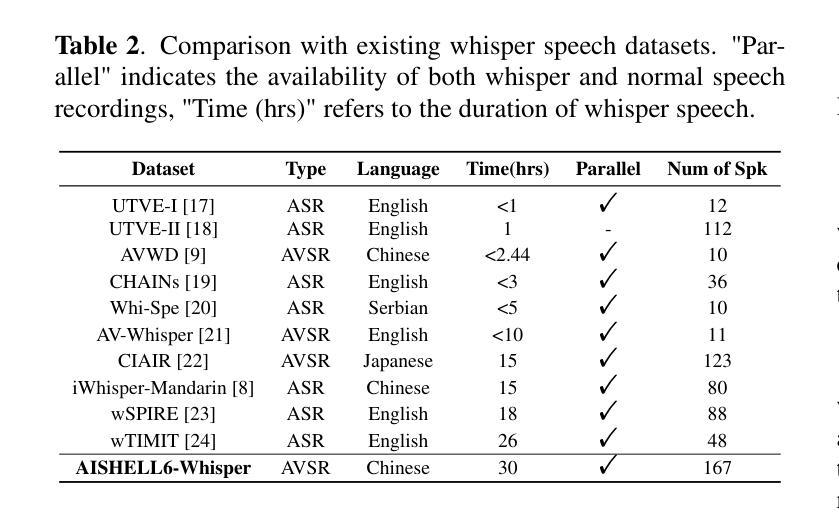
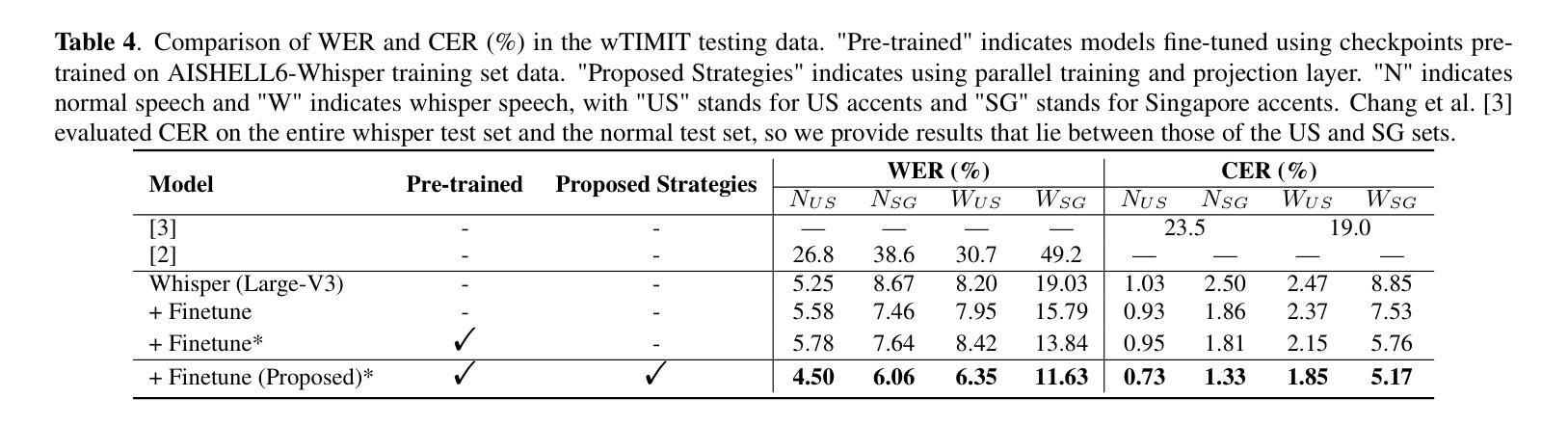
AISHELL6-whisper: A Chinese Mandarin Audio-visual Whisper Speech Dataset with Speech Recognition Baselines
Authors:Cancan Li, Fei Su, Juan Liu, Hui Bu, Yulong Wan, Hongbin Suo, Ming Li
Whisper speech recognition is crucial not only for ensuring privacy in sensitive communications but also for providing a critical communication bridge for patients under vocal restraint and enabling discrete interaction in noise-sensitive environments. The development of Chinese mandarin audio-visual whisper speech recognition is hindered by the lack of large-scale datasets. We present AISHELL6-Whisper, a large-scale open-source audio-visual whisper speech dataset, featuring 30 hours each of whisper speech and parallel normal speech, with synchronized frontal facial videos. Moreover, we propose an audio-visual speech recognition (AVSR) baseline based on the Whisper-Flamingo framework, which integrates a parallel training strategy to align embeddings across speech types, and employs a projection layer to adapt to whisper speech’s spectral properties. The model achieves a Character Error Rate (CER) of 4.13% for whisper speech and 1.11% for normal speech in the test set of our dataset, and establishes new state-of-the-art results on the wTIMIT benchmark. The dataset and the AVSR baseline codes are open-sourced at https://zutm.github.io/AISHELL6-Whisper.
轻声语音识别的应用不仅对确保敏感通信的隐私至关重要,还为声音受限的患者提供了关键的沟通桥梁,并能在噪声敏感环境中实现离散交互。汉语普通话视听轻声语音识别的开发受到了大规模数据集缺乏的阻碍。我们推出了AISHELL6-Whisper数据集,这是一个大规模的开源视听轻声语音数据集,其中包含30小时的轻声语音和同步正常语音,并配有正面面部视频。此外,我们基于Whisper-Flamingo框架提出了视听语音识别(AVSR)基线模型,该模型采用并行训练策略来对齐不同语音类型的嵌入向量,并借助投影层以适应轻声语音的频谱特性。在我们的数据集测试集中,该模型取得了4.13%的轻声语音字符错误率和正常语音的1.11%字符错误率,并在wTIMIT基准测试中取得了最新成果。数据集和AVSR基线代码已公开在https://zutm.github.io/AISHELL6-Whisper。
论文及项目相关链接
Summary
文本介绍了无声口语识别技术在敏感通讯保障、患者沟通桥梁及噪音环境下离散交互等领域的重要性。为解决中文普通话无声口语识别发展受限于大规模数据集的问题,推出AISHELL6-Whisper大型开放音频无声口语数据集,包括每小时有同步面部视频的30小时无声口语和并行正常口语数据。基于Whisper-Flamingo框架提出视听语音识别(AVSR)基线系统,通过并行训练策略对齐不同语音类型的嵌入,并采用投影层适应无声口语的频谱特性。模型在测试集上实现了字符错误率(CER)为无声口语4.13%,正常口语1.11%,并在wTIMIT基准测试上取得最新成果。数据集和AVSR基线代码已公开于:https://zutm.github.io/AISHELL6-Whisper。
Key Takeaways
- 无声口语识别技术对于敏感通讯、患者沟通和噪音环境下的交互至关重要。
- 缺乏大规模数据集是中文普通话无声口语识别发展的主要障碍。
- 推出AISHELL6-Whisper数据集,包含无声口语和并行正常口语的同步数据。
- 基于Whisper-Flamingo框架提出AVSR基线系统,采用并行训练策略和对齐嵌入技术。
- AVSR模型在测试集上表现优异,实现了低字符错误率。
- 模型在wTIMIT基准测试上取得最新成果。
点此查看论文截图
LORT: Locally Refined Convolution and Taylor Transformer for Monaural Speech Enhancement
Authors:Junyu Wang, Zizhen Lin, Tianrui Wang, Meng Ge, Longbiao Wang, Jianwu Dang
Achieving superior enhancement performance while maintaining a low parameter count and computational complexity remains a challenge in the field of speech enhancement. In this paper, we introduce LORT, a novel architecture that integrates spatial-channel enhanced Taylor Transformer and locally refined convolution for efficient and robust speech enhancement. We propose a Taylor multi-head self-attention (T-MSA) module enhanced with spatial-channel enhancement attention (SCEA), designed to facilitate inter-channel information exchange and alleviate the spatial attention limitations inherent in Taylor-based Transformers. To complement global modeling, we further present a locally refined convolution (LRC) block that integrates convolutional feed-forward layers, time-frequency dense local convolutions, and gated units to capture fine-grained local details. Built upon a U-Net-like encoder-decoder structure with only 16 output channels in the encoder, LORT processes noisy inputs through multi-resolution T-MSA modules using alternating downsampling and upsampling operations. The enhanced magnitude and phase spectra are decoded independently and optimized through a composite loss function that jointly considers magnitude, complex, phase, discriminator, and consistency objectives. Experimental results on the VCTK+DEMAND and DNS Challenge datasets demonstrate that LORT achieves competitive or superior performance to state-of-the-art (SOTA) models with only 0.96M parameters, highlighting its effectiveness for real-world speech enhancement applications with limited computational resources.
在语音增强领域,实现在保持低参数计数和计算复杂度的同时达到优越的增强性能仍然是一个挑战。本文介绍了一种新型架构LORT,它集成了空间通道增强泰勒变换器和局部精细卷积,用于高效稳健的语音增强。我们提出了一种增强型的泰勒多头自注意力(T-MSA)模块,该模块配备了空间通道增强注意力(SCEA),旨在促进通道间的信息交换,并缓解基于泰勒的变压器固有的空间注意力限制。为了补充全局建模,我们进一步提出了一种局部精细卷积(LRC)块,它集成了卷积前馈层、时频密集局部卷积和门控单元,以捕获精细的局部细节。LORT建立在类似U-Net的编码器-解码器结构上,编码器只有1e6个输出通道。它通过交替的下采样和上采样操作,使用多分辨率T-MSA模块处理噪声输入。增强的幅度和相位谱独立解码,并通过联合考虑幅度、复数、相位、鉴别器和一致性目标的复合损失函数进行优化。在VCTK+DEMAND和DNS挑战数据集上的实验结果表明,LORT仅以0.96M的参数取得了与最新技术相竞争或更优越的性能,这突显了其在计算资源有限的实际语音增强应用中的有效性。
论文及项目相关链接
PDF Speech Communication
Summary
本论文针对语音增强领域中的挑战,提出了一种新的架构LORT,该架构结合了空间通道增强Taylor Transformer和局部精细卷积,以实现高效且稳健的语音增强。通过引入Taylor多头自注意力模块并结合空间通道增强注意力,促进了通道间的信息交换,并缓解了基于Taylor的Transformer固有的空间注意力限制。为补充全局建模,还提出了局部精细卷积块,以捕获精细的局部细节。LORT基于U-Net类似的编码解码器结构,通过多分辨率的T-MSA模块处理带噪输入,并采用复合损失函数进行优化。在VCTK+DEMAND和DNS Challenge数据集上的实验结果表明,LORT的参数仅为0.96M,但性能具有竞争力,突出其在有限计算资源下实现真实语音增强的有效性。
Key Takeaways
- LORT是一种新的语音增强架构,结合了空间通道增强Taylor Transformer和局部精细卷积。
- 提出了Taylor多头自注意力模块(T-MSA),并结合空间通道增强注意力(SCEA),促进通道间的信息交换。
- 为补充全局建模,引入了局部精细卷积(LRC)块,以捕获精细的局部细节。
- LORT基于U-Net编码解码器结构,采用多分辨率的T-MSA模块处理带噪输入。
- 通过复合损失函数优化增强幅度和相位谱的独立解码。
- 在VCTK+DEMAND和DNS Challenge数据集上的实验结果表明LORT性能优越,参数效率较高。
点此查看论文截图

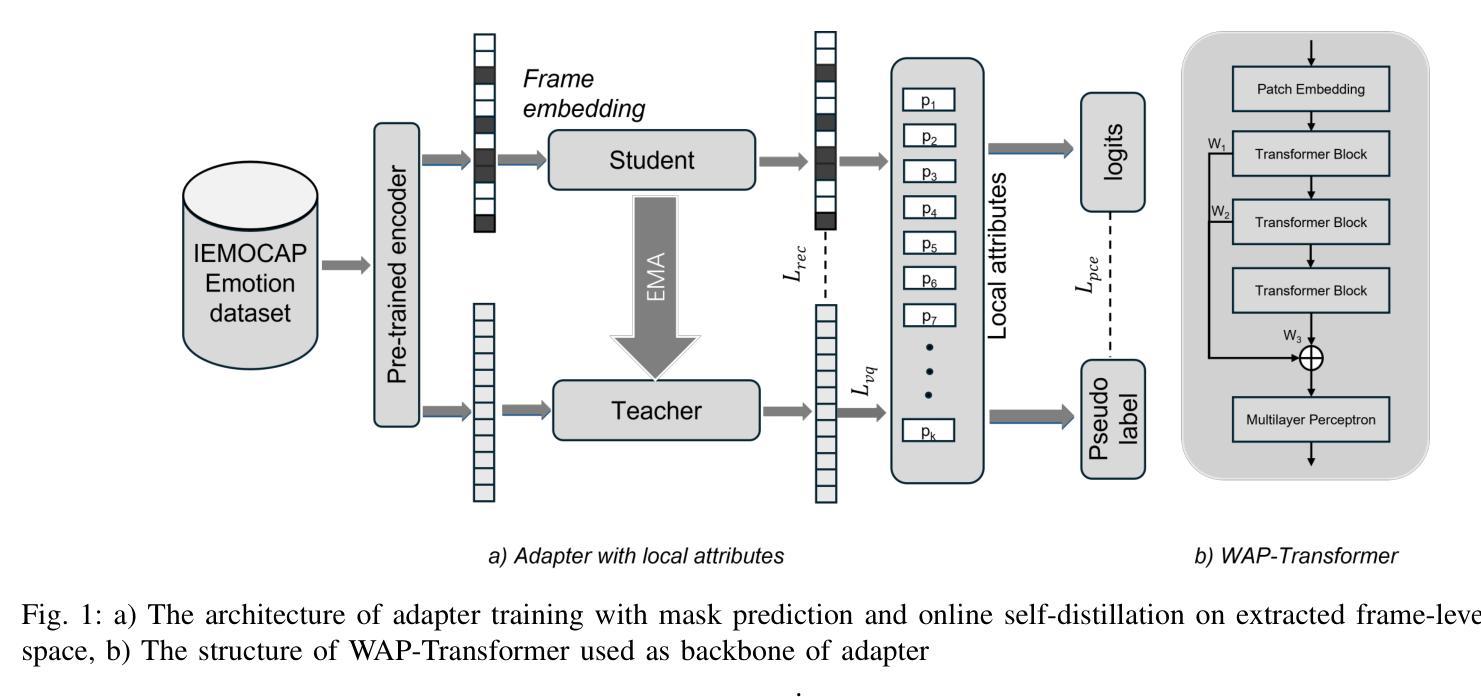
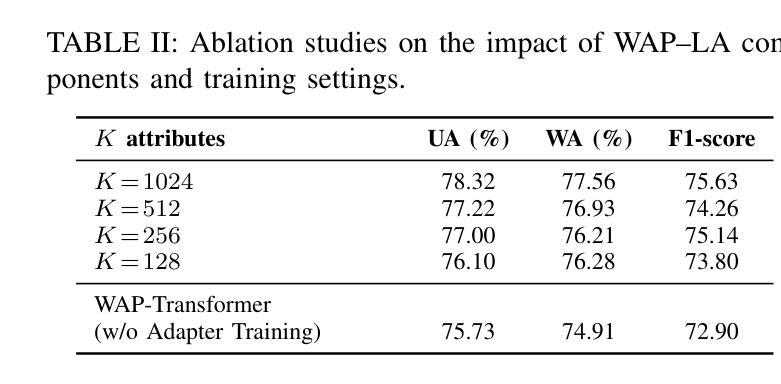
An Efficient Transfer Learning Method Based on Adapter with Local Attributes for Speech Emotion Recognition
Authors:Haoyu Song, Ian McLoughlin, Qing Gu, Nan Jiang, Yan Song
Existing speech emotion recognition (SER) methods commonly suffer from the lack of high-quality large-scale corpus, partly due to the complex, psychological nature of emotion which makes accurate labeling difficult and time consuming. Recently, transfer learning based methods that exploit the encoders pretrained on large-scale speech corpus (e.g., Wav2Vec2.0 and HuBERT) have shown strong potential for downstream SER tasks. However, task-specific fine-tuning remains necessary for various conversational scenarios of different topics, speakers and languages to achieve satisfactory performance. It generally requires costly encoder retraining for individual SER tasks. To address this issue, we propose to train an adapter with local attributes for efficient transfer learning. Specifically, a weighted average pooling-Transformer (WAP-Transformer) is proposed as a lightweight backbone to enrich the frame-level representation. An adapter with teacher-student branches is exploited for task-agnostic transfer learning, where the student branch is jointly optimized via mask prediction and self-distillation objectives, and the teacher branch is obtained online from the student via exponential moving average (EMA). Meanwhile, local attributes are learned from the teacher branch via unsupervised clustering, which aims to act as a universal model that provides additional semantic-rich supervisions. A statistical attentive pooling (SAP) module is proposed to obtain utterance representation for fine-tuning. To evaluate the effectiveness of the proposed adapter with local attributes, extensive experiments have been conducted on IEMOCAP. Superior performance has been reported, compared to the previous state-of-the-art methods in similar settings.
现有语音情感识别(SER)方法通常面临缺乏高质量大规模语料库的挑战,这在一定程度上是由于情感的复杂心理特性使得准确标注困难和耗时。最近,基于迁移学习的利用在大规模语音语料库上预训练的编码器(如Wav2Vec 2.0和HuBERT)的方法在下游SER任务中显示出强大的潜力。然而,针对各种话题、发言者和语言的对话场景,仍需要进行特定的任务微调以达到令人满意的表现,通常需要针对个别SER任务进行昂贵的编码器重新训练。为了解决这一问题,我们提出训练带有局部属性的适配器以实现有效的迁移学习。具体来说,提出了一种加权平均池化-Transformer(WAP-Transformer)作为轻量级主干,以丰富帧级表示。利用带有教师学生分支的适配器进行任务无关的迁移学习,其中学生分支通过掩模预测和自我蒸馏目标进行优化,教师分支则通过学生分支的指数移动平均(EMA)在线获得。同时,从教师分支中学习局部属性,通过无监督聚类,旨在充当通用模型,提供额外的语义丰富的监督。还提出了一种统计注意力池化(SAP)模块,用于获得用于精细调整的语句表示。为了评估带有局部属性的提议适配器的有效性,已经在IEMOCAP上进行了大量实验。与类似设置中的先前最先进的相比,报告了卓越的性能。
论文及项目相关链接
Summary
本文探讨了语音情感识别(SER)领域中的问题,包括缺乏高质量的大规模语料库和针对不同任务、说话者、语言的个性化微调挑战。文章提出了使用带有本地属性的适配器进行高效迁移学习的方法,通过WAP-Transformer作为轻量级主干来丰富帧级表示,并引入教师-学生分支的适配器进行任务无关的迁移学习。同时,通过无监督聚类从教师分支中学习本地属性,旨在作为通用模型提供丰富的语义监督。此外,还引入了SAP模块以获得用于精细调整的语句表示。在IEMOCAP上的实验表明,与类似设置中的先前最先进方法相比,该适配器具有优越的性能。
Key Takeaways
- 语音情感识别(SER)面临缺乏高质量大规模语料库和复杂情绪标签的挑战。
- 迁移学习方法,特别是利用大规模语音语料库的预训练编码器(如Wav2Vec2.0和HuBERT),在SER任务中具有潜力。
- 任务特定的微调对于应对不同话题、说话者和语言的对话场景是必要的。
- 引入带有本地属性的适配器来解决迁移学习中的挑战,包括WAP-Transformer作为轻量级主干和引入教师-学生分支。
- 教师分支通过无监督聚类学习本地属性,旨在作为通用模型提供丰富的语义监督。
- 引入SAP模块以获取用于精细调整的语句表示。
- 在IEMOCAP上的实验表明,该方法在类似设置中具有优越性能。
点此查看论文截图

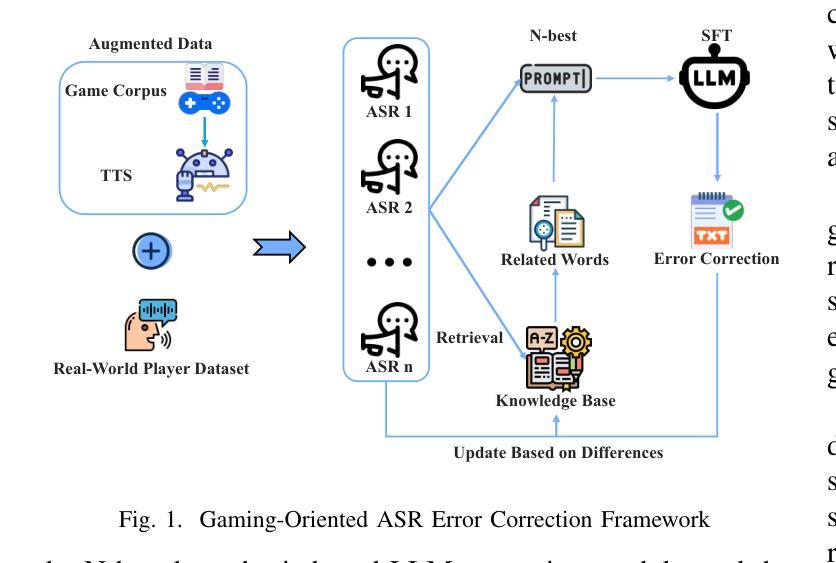
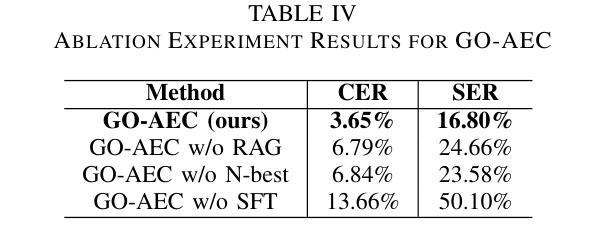
Game-Oriented ASR Error Correction via RAG-Enhanced LLM
Authors:Yan Jiang, Yongle Luo, Qixian Zhou, Elvis S. Liu
With the rise of multiplayer online games, real-time voice communication is essential for team coordination. However, general ASR systems struggle with gaming-specific challenges like short phrases, rapid speech, jargon, and noise, leading to frequent errors. To address this, we propose the GO-AEC framework, which integrates large language models, Retrieval-Augmented Generation (RAG), and a data augmentation strategy using LLMs and TTS. GO-AEC includes data augmentation, N-best hypothesis-based correction, and a dynamic game knowledge base. Experiments show GO-AEC reduces character error rate by 6.22% and sentence error rate by 29.71%, significantly improving ASR accuracy in gaming scenarios.
随着多人在线游戏的兴起,实时语音交流对于团队协作至关重要。然而,通用的语音识别系统面临着游戏特有的挑战,如短句、语速快、专业术语和噪音,导致频繁出错。为了解决这个问题,我们提出了GO-AEC框架,它融合了大型语言模型、检索增强生成(RAG)和基于LLM和TTS的数据增强策略。GO-AEC包括数据增强、基于N-best假设的校正以及动态游戏知识库。实验表明,GO-AEC降低了6.22%的字符错误率和29.71%的句子错误率,显著提高了游戏场景中语音识别系统的准确性。
论文及项目相关链接
Summary:
随着多人在线游戏的兴起,实时语音通信对团队协作至关重要。然而,通用ASR系统在面对游戏特定挑战时,如短句、快速语音、行话和噪音等,容易出现频繁错误。为解决这一问题,我们提出了GO-AEC框架,它集成了大型语言模型、检索增强生成(RAG)和基于LLM和TTS的数据增强策略。GO-AEC包括数据增强、基于N-best假设的校正和一个动态游戏知识库。实验表明,GO-AEC降低了字符错误率6.22%,句子错误率降低了29.71%,显著提高了游戏场景中ASR的准确性。
Key Takeaways:
- 实时语音通信在多玩家在线游戏中对团队协作至关重要。
- 通用ASR系统在处理游戏特定挑战(如短句、快速语音、行话和噪音)时存在频繁错误。
- GO-AEC框架集成了大型语言模型、检索增强生成(RAG)和基于LLM及TTS的数据增强策略。
- GO-AEC通过数据增强、基于N-best假设的校正以及动态游戏知识库来提高ASR性能。
- 实验显示,GO-AEC降低了字符错误率和句子错误率,分别达到了6.22%和29.71%的改善。
- GO-AEC框架显著提高在游戏场景中ASR的准确性。
点此查看论文截图
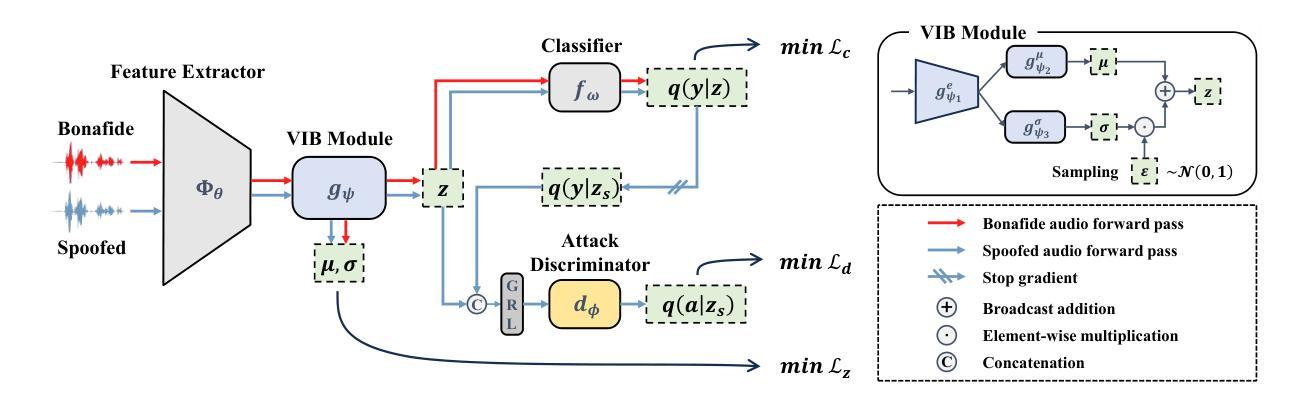
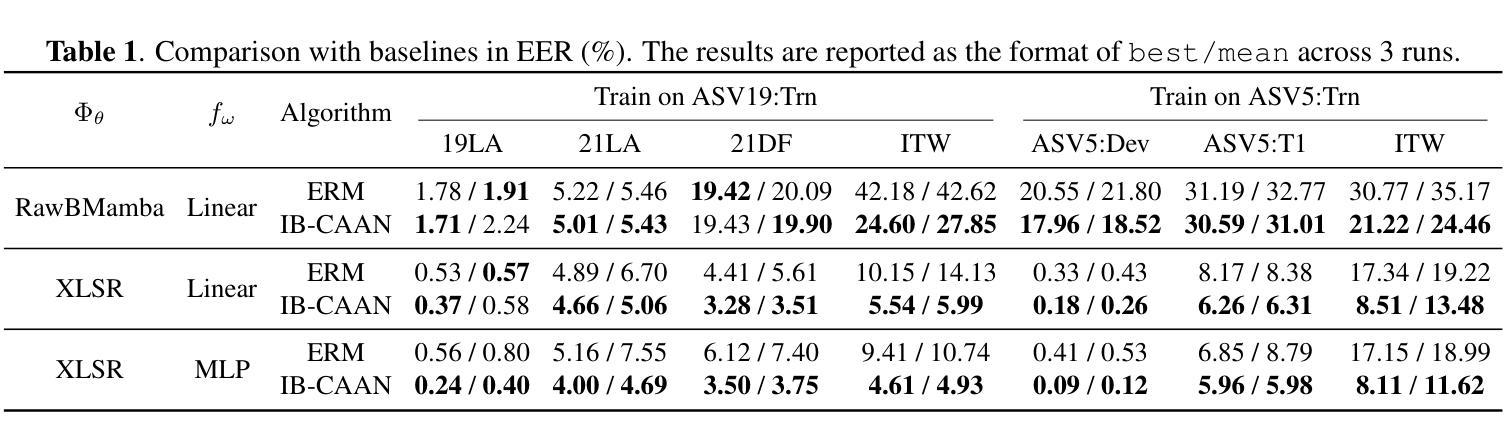
Generalizable Speech Deepfake Detection via Information Bottleneck Enhanced Adversarial Alignment
Authors:Pu Huang, Shouguang Wang, Siya Yao, Mengchu Zhou
Neural speech synthesis techniques have enabled highly realistic speech deepfakes, posing major security risks. Speech deepfake detection is challenging due to distribution shifts across spoofing methods and variability in speakers, channels, and recording conditions. We explore learning shared discriminative features as a path to robust detection and propose Information Bottleneck enhanced Confidence-Aware Adversarial Network (IB-CAAN). Confidence-guided adversarial alignment adaptively suppresses attack-specific artifacts without erasing discriminative cues, while the information bottleneck removes nuisance variability to preserve transferable features. Experiments on ASVspoof 2019/2021, ASVspoof 5, and In-the-Wild demonstrate that IB-CAAN consistently outperforms baseline and achieves state-of-the-art performance on many benchmarks.
神经语音合成技术已经能够实现高度逼真的语音深度伪造,这带来了重大的安全风险。语音深度伪造检测颇具挑战性,因为假冒方法之间存在分布转移,且说话人、通道和录音条件具有多变性和差异性。我们探索学习共享判别特征作为实现稳健检测的途径,并提出基于信息瓶颈增强的信心感知对抗网络(IB-CAAN)。信心引导对抗对齐能够自适应地抑制特定攻击的伪迹,而不会消除判别线索,而信息瓶颈则能够消除干扰变量以保留可迁移特征。在ASVspoof 2019/2021、ASVspoof 5和野外实验上的实验表明,IB-CAAN始终优于基线并实现了许多基准测试的最新性能。
论文及项目相关链接
Summary
神经网络语音合成技术已能生成高度逼真的语音深度伪造内容,给安全带来重大风险。由于伪装方法的分布变化以及说话人、信道和录音条件的可变性,语音深度伪造检测的难点在于实现稳健的检测。本研究探索了学习共享判别特征作为稳健检测的途径,并提出了基于信息瓶颈增强型信心感知对抗网络(IB-CAAN)。信心引导的对抗对齐可以自适应地抑制攻击特定的伪像,而不会消除判别线索;信息瓶颈则能够消除干扰变化以保留可转移的特征。在ASVspoof 2019/2021、ASVspoof 5以及真实环境下的实验表明,IB-CAAN持续优于基线方法并在多个基准测试中达到业界最佳水平。
Key Takeaways
- 神经网络语音合成技术可以生成高度逼真的语音深度伪造内容,存在重大安全风险。
- 语音深度伪造检测面临多种挑战,包括分布变化、说话人、信道和录音条件的可变性。
- 学习共享判别特征是实现稳健语音深度伪造检测的重要途径。
- 提出的IB-CAAN方法结合了信息瓶颈和信心感知对抗网络。
- 信心引导的对抗对齐能够自适应地抑制攻击特定的伪像,同时保留判别线索。
- 信息瓶颈有助于消除干扰变化,保留可转移的特征。
点此查看论文截图

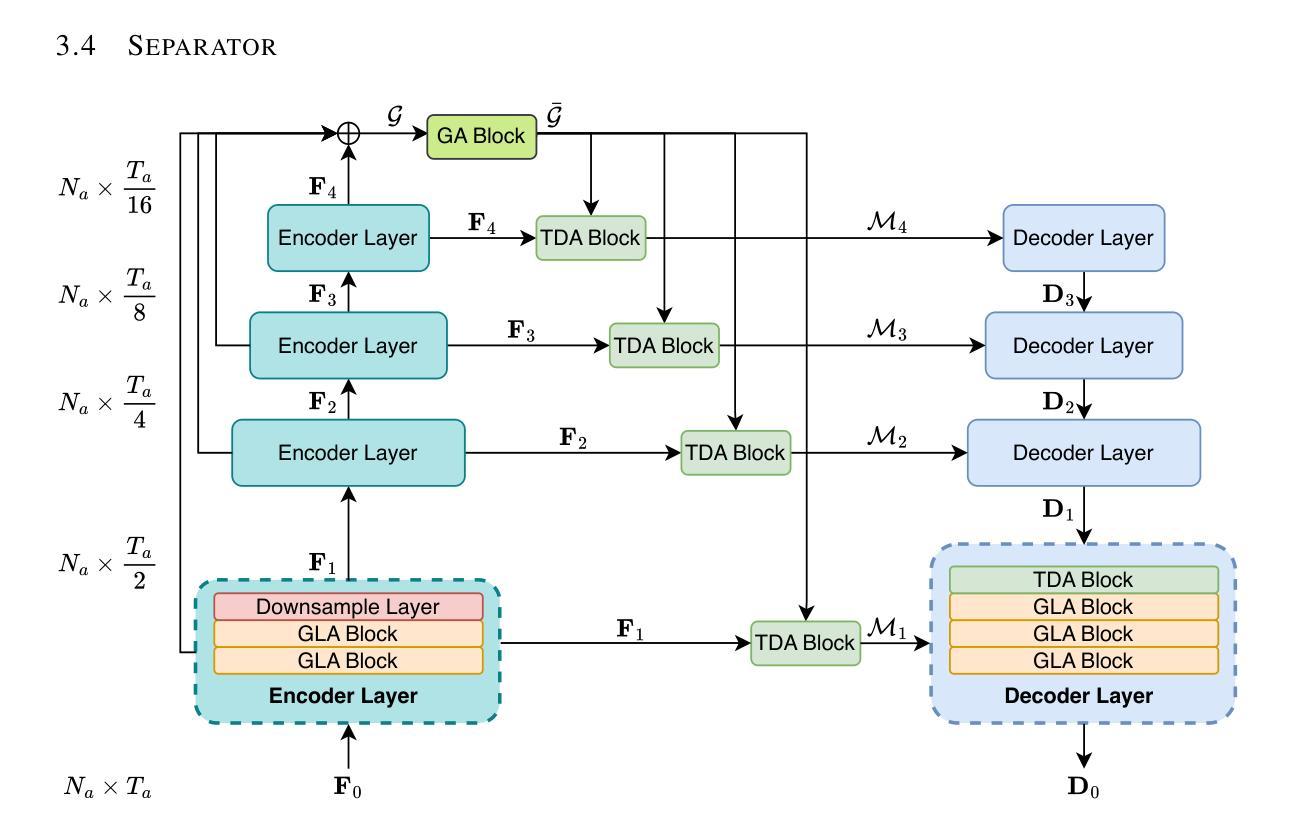
Efficient Audio-Visual Speech Separation with Discrete Lip Semantics and Multi-Scale Global-Local Attention
Authors:Kai Li, Kejun Gao, Xiaolin Hu
Audio-visual speech separation (AVSS) methods leverage visual cues to extract target speech and have demonstrated strong separation quality in noisy acoustic environments. However, these methods usually involve a large number of parameters and require high computational cost, which is unacceptable in many applications where speech separation serves as only a preprocessing step for further speech processing. To address this issue, we propose an efficient AVSS method, named Dolphin. For visual feature extraction, we develop DP-LipCoder, a dual-path lightweight video encoder that transforms lip-motion into discrete audio-aligned semantic tokens. For audio separation, we construct a lightweight encoder-decoder separator, in which each layer incorporates a global-local attention (GLA) block to efficiently capture multi-scale dependencies. Experiments on three benchmark datasets showed that Dolphin not only surpassed the current state-of-the-art (SOTA) model in separation quality but also achieved remarkable improvements in efficiency: over 50% fewer parameters, more than 2.4x reduction in MACs, and over 6x faster GPU inference speed. These results indicate that Dolphin offers a practical and deployable solution for high-performance AVSS in real-world scenarios. Our code and demo page are publicly available at http://cslikai.cn/Dolphin/.
视听语音分离(AVSS)方法利用视觉线索提取目标语音,在嘈杂的声学环境中表现出了强大的分离质量。然而,这些方法通常涉及大量参数,计算成本高,这在许多仅将语音分离作为进一步语音处理的预处理步骤的应用中是不可接受的。为了解决这一问题,我们提出了一种高效的AVSS方法,命名为Dolphin。对于视觉特征提取,我们开发了DP-LipCoder,这是一种双路径轻量化视频编码器,可将唇部运动转换为离散的音频对齐语义标记。对于音频分离,我们构建了一个轻量级的编码器-解码器分离器,其中每一层都嵌入了一个全局-局部注意力(GLA)块,以有效地捕获多尺度依赖性。在三个基准数据集上的实验表明,Dolphin不仅在分离质量上超越了当前最先进的模型,而且在效率上也取得了显著的改进:参数减少了50%以上,MACs减少了2.4倍以上,GPU推理速度提高了6倍以上。这些结果表明,Dolphin为现实场景中的高性能AVSS提供了实用且可部署的解决方案。我们的代码和演示页面可在http://cslikai.cn/Dolphin/公开访问。
论文及项目相关链接
PDF Technical Report
Summary
本文介绍了一种高效的视听语音分离方法——海豚(Dolphin)。该方法采用双路径轻量级视频编码器DP-LipCoder提取视觉特征,通过全球局部注意力(GLA)块构建轻量级编码器-解码器分离器,实现多尺度依赖性的高效捕获。实验结果表明,Dolphin不仅在分离质量上超越了当前最佳模型,而且在效率上也有显著提高:参数减少50%以上,MACs减少2.4倍以上,GPU推理速度提高6倍以上。
Key Takeaways
- Dolphin是一种高效的视听语音分离方法,可应用于噪声环境下的语音分离。
- DP-LipCoder是双路径轻量级视频编码器,可将唇部动作转化为离散音频对齐语义令牌,用于视觉特征提取。
- 全球局部注意力(GLA)块被用于构建轻量级编码器-解码器分离器,以捕获多尺度依赖性。
- Dolphin在三个基准数据集上的实验结果表明其分离质量超越当前最佳模型。
- Dolphin在效率上有显著改善,包括参数减少、MACs减少和GPU推理速度提高。
- 海豚方法提供实用且可部署的视听语音分离解决方案,适用于真实世界场景。
点此查看论文截图

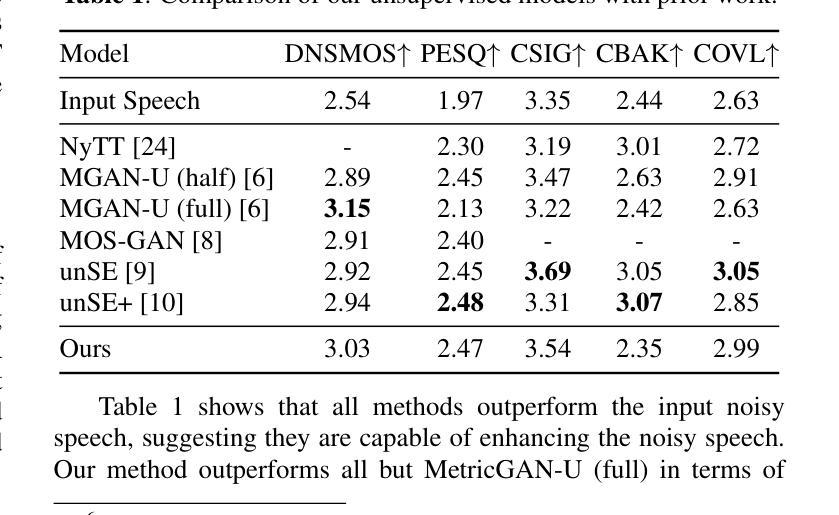
MeanFlowSE: One-Step Generative Speech Enhancement via MeanFlow
Authors:Yike Zhu, Boyi Kang, Ziqian Wang, Xingchen Li, Zihan Zhang, Wenjie Li, Longshuai Xiao, Wei Xue, Lei Xie
Speech enhancement (SE) recovers clean speech from noisy signals and is vital for applications such as telecommunications and automatic speech recognition (ASR). While generative approaches achieve strong perceptual quality, they often rely on multi-step sampling (diffusion/flow-matching) or large language models, limiting real-time deployment. To mitigate these constraints, we present MeanFlowSE, a one-step generative SE framework. It adopts MeanFlow to predict an average-velocity field for one-step latent refinement and conditions the model on self-supervised learning (SSL) representations rather than VAE latents. This design accelerates inference and provides robust acoustic-semantic guidance during training. In the Interspeech 2020 DNS Challenge blind test set and simulated test set, MeanFlowSE attains state-of-the-art (SOTA) level perceptual quality and competitive intelligibility while significantly lowering both real-time factor (RTF) and model size compared with recent generative competitors, making it suitable for practical use. The code will be released upon publication at https://github.com/Hello3orld/MeanFlowSE.
语音增强(SE)从噪声信号中恢复清洁语音,对于电信和自动语音识别(ASR)等应用至关重要。虽然生成方法达到了很强的感知质量,但它们通常依赖于多步采样(扩散/流匹配)或大型语言模型,限制了实时部署。为了缓解这些约束,我们提出了MeanFlowSE,这是一个一步生成SE框架。它采用MeanFlow来预测一步潜在精化的平均速度场,并以自监督学习(SSL)表示而不是VAE潜藏量对模型进行条件处理。这种设计加速了推理,并在训练过程中提供了稳健的声学语义指导。在Interspeech 2020 DNS Challenge的盲测试集和模拟测试集中,MeanFlowSE达到了最先进的感知质量和有竞争力的清晰度,同时大大降低了实时因子(RTF)和模型大小,与最近的生成竞争对手相比,适合实际应用。代码将在https://github.com/Hello3orld/MeanFlowSE上发布。
论文及项目相关链接
PDF Submitted to ICASSP 2026
Summary
文章介绍了MeanFlowSE,这是一种一步生成式语音增强框架。它采用MeanFlow预测平均速度场进行一步潜在优化,并在自监督学习表示条件下进行训练。该框架在语音增强领域实现了业界领先的感知质量和可识别性,同时降低了实时因子和模型大小,适合实际应用。
Key Takeaways
- MeanFlowSE是一种一步生成式语音增强框架,旨在解决传统生成式方法面临的约束问题。
- 它采用MeanFlow预测平均速度场,用于一步潜在优化,提高了语音质量。
- 该框架结合了自监督学习表示条件训练模型,增强了模型的泛化能力。
- 在Interspeech 2020 DNS Challenge的盲测集和模拟测试集中,MeanFlowSE达到了业界领先的感知质量和可识别性。
- 与其他生成式方法相比,MeanFlowSE显著降低了实时因子和模型大小,更适合实际应用。
- MeanFlowSE的代码将在发布时公开在GitHub上。
点此查看论文截图
Unsupervised Speech Enhancement using Data-defined Priors
Authors:Dominik Klement, Matthew Maciejewski, Sanjeev Khudanpur, Jan Černocký, Lukáš Burget
The majority of deep learning-based speech enhancement methods require paired clean-noisy speech data. Collecting such data at scale in real-world conditions is infeasible, which has led the community to rely on synthetically generated noisy speech. However, this introduces a gap between the training and testing phases. In this work, we propose a novel dual-branch encoder-decoder architecture for unsupervised speech enhancement that separates the input into clean speech and residual noise. Adversarial training is employed to impose priors on each branch, defined by unpaired datasets of clean speech and, optionally, noise. Experimental results show that our method achieves performance comparable to leading unsupervised speech enhancement approaches. Furthermore, we demonstrate the critical impact of clean speech data selection on enhancement performance. In particular, our findings reveal that performance may appear overly optimistic when in-domain clean speech data are used for prior definition – a practice adopted in previous unsupervised speech enhancement studies.
大多数基于深度学习的语音增强方法都需要成对的干净和带噪声的语音数据。在现实世界的条件下大规模收集此类数据是不可行的,这导致社区依赖于合成生成的带噪声语音。然而,这会在训练和测试阶段之间产生差距。在这项工作中,我们提出了一种用于无监督语音增强的新型双分支编码器-解码器架构,该架构将输入分离为干净语音和剩余噪声。采用对抗训练对每分支施加先验,先验由干净语音的未配对数据集定义,以及可选的噪声。实验结果表明,我们的方法与领先的无监督语音增强方法相比取得了相当的性能。此外,我们证明了干净语音数据选择对增强性能的关键影响。特别是,我们的研究结果表明,当使用领域内的干净语音数据进行先验定义时,性能可能过于乐观——这是之前在无监督语音增强研究中采用的做法。
论文及项目相关链接
PDF Submitted to ICASSP 2026
摘要
深度学习为基础的语音增强方法多数需要配对清洁噪声语音数据。在现实世界的条件下大规模收集此类数据是不可行的,这促使人们依赖合成生成的噪声语音。然而,这会在训练和测试阶段之间产生差距。在此研究中,我们提出了一种新型的双分支编码器-解码器架构,用于无监督语音增强,将输入分为清洁语音和剩余噪声。利用对抗训练对每个分支施加先验知识,这些先验知识由清洁语音和(可选的)噪声的非配对数据集定义。实验结果表明,我们的方法可以达到领先的非监督语音增强方法的可比性能。此外,我们展示了清洁语音数据选择对增强性能的关键影响。特别是我们的研究发现,当使用领域内的清洁语音数据进行先验定义时,性能可能过于乐观——这是之前非监督语音增强研究中采用的做法。
关键见解
- 深度学习语音增强方法通常需要配对清洁-噪声语音数据,但现实条件下收集大规模数据不可行。
- 合成噪声语音导致训练和测试阶段的差距。
- 提出一种新型双分支编码器-解码器架构用于无监督语音增强。
- 对抗训练用于对每个分支施加先验知识,这些先验知识由非配对数据集定义。
- 实验结果显示该方法性能与领先的非监督语音增强方法相当。
- 清洁语音数据选择对增强性能有关键影响。
- 使用领域内的清洁语音数据进行先验定义可能导致性能评估过于乐观。
点此查看论文截图

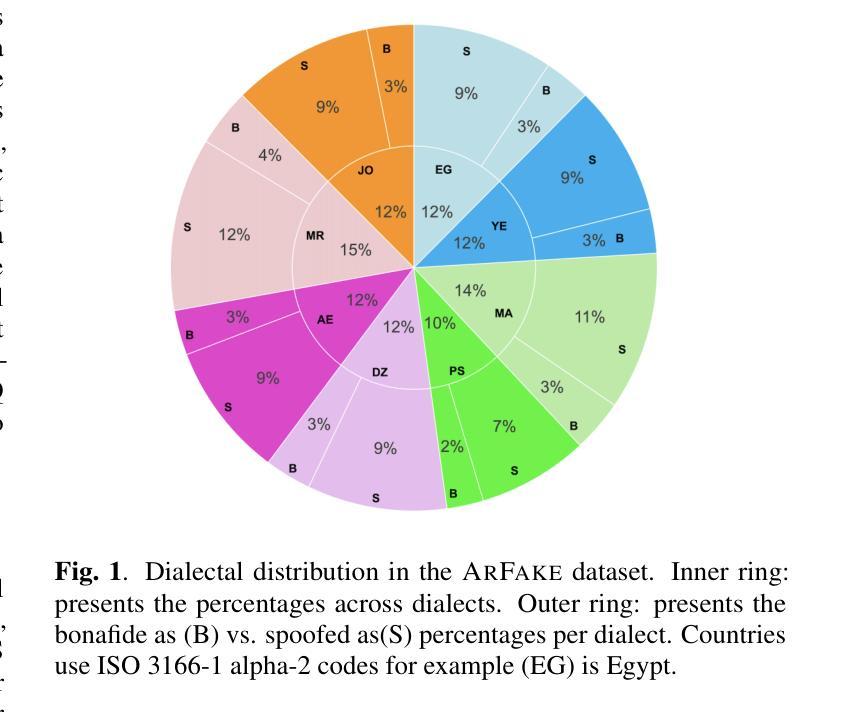
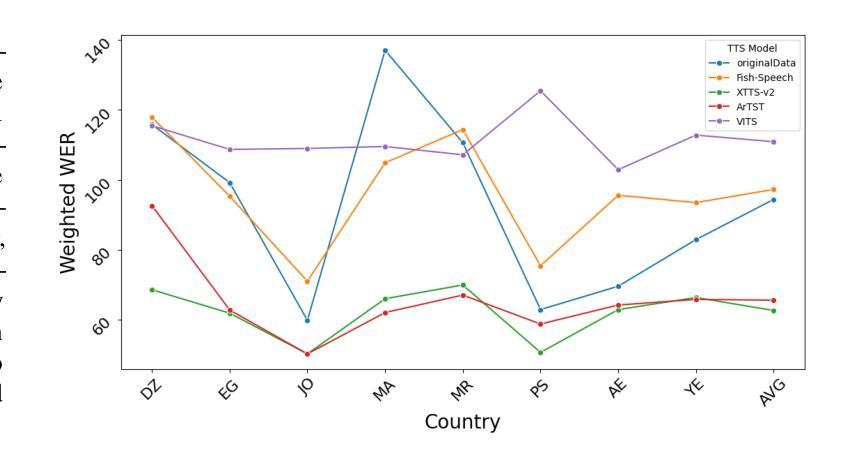
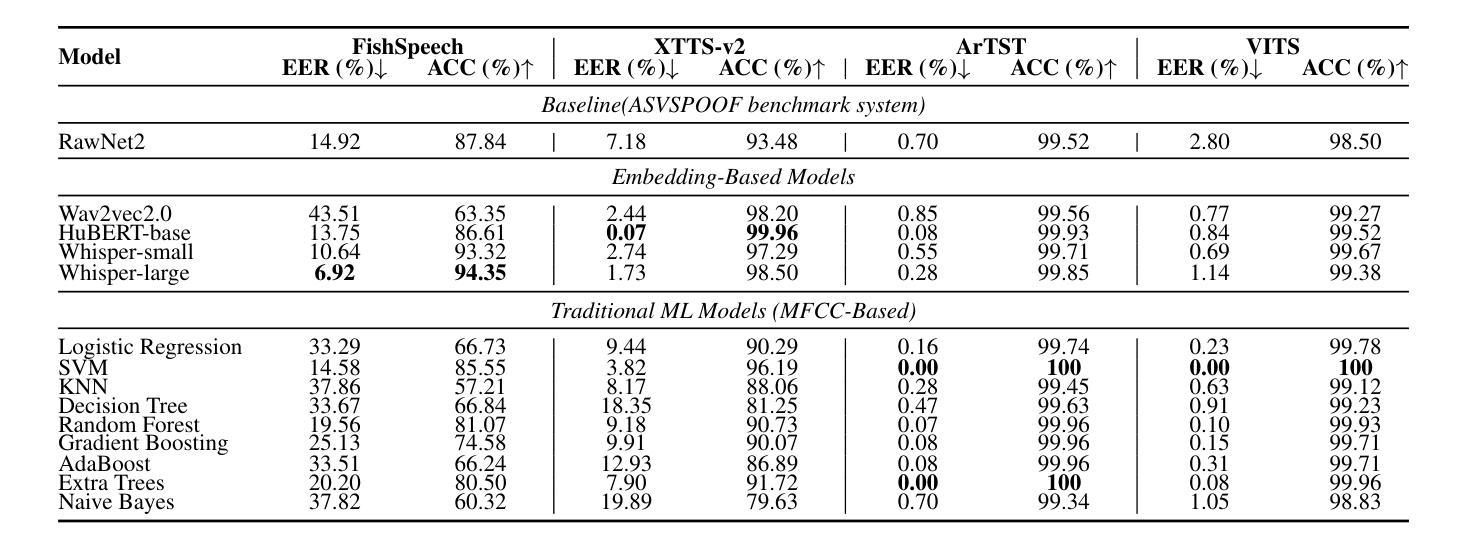
ArFake: A Multi-Dialect Benchmark and Baselines for Arabic Spoof-Speech Detection
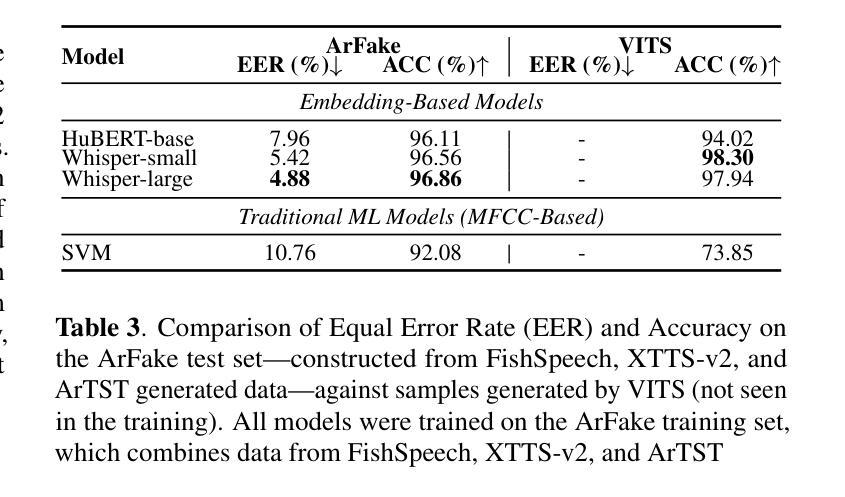
Authors:Mohamed Maged, Alhassan Ehab, Ali Mekky, Besher Hassan, Shady Shehata
With the rise of generative text-to-speech models, distinguishing between real and synthetic speech has become challenging, especially for Arabic that have received limited research attention. Most spoof detection efforts have focused on English, leaving a significant gap for Arabic and its many dialects. In this work, we introduce the first multi-dialect Arabic spoofed speech dataset. To evaluate the difficulty of the synthesized audio from each model and determine which produces the most challenging samples, we aimed to guide the construction of our final dataset either by merging audios from multiple models or by selecting the best-performing model, we conducted an evaluation pipeline that included training classifiers using two approaches: modern embedding-based methods combined with classifier heads; classical machine learning algorithms applied to MFCC features; and the RawNet2 architecture. The pipeline further incorporated the calculation of Mean Opinion Score based on human ratings, as well as processing both original and synthesized datasets through an Automatic Speech Recognition model to measure the Word Error Rate. Our results demonstrate that FishSpeech outperforms other TTS models in Arabic voice cloning on the Casablanca corpus, producing more realistic and challenging synthetic speech samples. However, relying on a single TTS for dataset creation may limit generalizability.
随着生成式文本到语音模型的兴起,区分真实语音和合成语音已经变得具有挑战性,尤其是对于研究关注度较低的阿拉伯语来说更是如此。大多数的伪装检测工作主要集中在英语上,这为阿拉伯语及其众多方言留下了巨大的空白。在这项研究中,我们介绍了第一个多方言阿拉伯语伪装语音数据集。为了评估每个模型的合成音频的困难程度,并确定哪个模型产生了最具挑战性的样本,我们的目标是通过合并多个模型的音频或选择表现最佳的模型来指导我们最终数据集的建设。我们建立了一个评估流程,包括使用两种方法进行分类器训练:现代基于嵌入的方法与分类器头相结合;应用于MFCC特征的经典机器学习算法;以及RawNet2架构。该流程还纳入了基于人类评分的计算平均意见得分,以及通过语音识别模型处理原始和合成数据集,以测量单词错误率。我们的结果表明,在Casablanca语料库上,FishSpeech在阿拉伯语语音克隆方面优于其他TTS模型,能够产生更真实、更具挑战性的合成语音样本。然而,仅依赖单一的TTS进行数据集创建可能会限制其通用性。
论文及项目相关链接
Summary
随着生成式文本到语音模型的兴起,区分真实和合成语音变得具有挑战性,尤其是阿拉伯语的研究相对较少。大多数语音欺骗检测工作都集中在英语上,为阿拉伯语及其多种方言留下了显著差距。在此工作中,我们介绍了首个多方言阿拉伯语欺骗语音数据集。为了评估各合成音频模型的难度并确定哪些模型产生最具挑战性的样本,我们通过合并多个模型的音频或选择表现最佳的模型来指导最终数据集的建设。我们采用了包括使用现代嵌入方法和分类器头训练分类器、应用MFCC特征的经典机器学习算法和RawNet2架构的评价流程。流程还纳入了基于人类评分的平均意见得分计算,以及通过语音识别模型处理原始和合成数据集以测量词错误率。我们的结果表明,FishSpeech在阿拉伯语音克隆的Casablanca语料库上优于其他TTS模型,能产生更真实和更具挑战性的合成语音样本。但仅依赖单一TTS进行数据集创建可能会限制其通用性。
Key Takeaways
- 生成式文本到语音模型的兴起使得区分真实和合成语音具有挑战性,尤其是在阿拉伯语中。
- 现有的语音欺骗检测工作主要集中在英语,忽视了阿拉伯语及其多方言的需求。
- 介绍了首个多方言阿拉伯语欺骗语音数据集。
- 通过合并多个模型的音频或选择表现最佳的模型来构建数据集。
- 采用了多种评估方法,包括分类器训练、平均意见得分计算和词错误率测量。
- FishSpeech模型在阿拉伯语音克隆任务上表现最佳。
点此查看论文截图

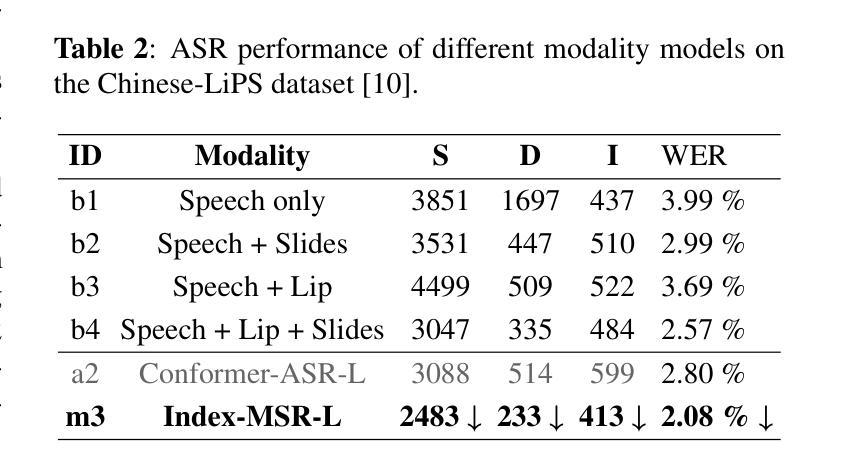
Index-MSR: A high-efficiency multimodal fusion framework for speech recognition
Authors:Jinming Chen, Lu Wang, Zheshu Song, Wei Deng
Driven by large scale datasets and LLM based architectures, automatic speech recognition (ASR) systems have achieved remarkable improvements in accuracy. However, challenges persist for domain-specific terminology, and short utterances lacking semantic coherence, where recognition performance often degrades significantly. In this work, we present Index-MSR, an efficient multimodal speech recognition framework. At its core is a novel Multimodal Fusion Decoder (MFD), which effectively incorporates text-related information from videos (e.g., subtitles and presentation slides) into the speech recognition. This cross-modal integration not only enhances overall ASR accuracy but also yields substantial reductions in substitution errors. Extensive evaluations on both an in-house subtitle dataset and a public AVSR dataset demonstrate that Index-MSR achieves sota accuracy, with substitution errors reduced by 20,50%. These results demonstrate that our approach efficiently exploits text-related cues from video to improve speech recognition accuracy, showing strong potential in applications requiring strict audio text synchronization, such as audio translation.
驱动的大规模数据集和基于大型语言模型(LLM)的架构使得自动语音识别(ASR)系统在精度上取得了显著的改进。然而,对于特定领域的术语以及缺乏语义连贯性的简短话语,挑战仍然存在,识别性能往往会显著下降。在这项工作中,我们提出了Index-MSR,这是一个高效的跨模态语音识别框架。其核心是一种新型的多模态融合解码器(MFD),它有效地将视频中的文本相关信息(例如字幕和演示幻灯片)融入语音识别。这种跨模态融合不仅提高了整体的ASR精度,还大大减少了替换错误。对内部字幕数据集和公共AVSR数据集的广泛评估表明,Index-MSR达到了最先进的准确性,替换错误减少了20.5%。这些结果表明,我们的方法能够有效地利用视频中的文本相关线索来提高语音识别的准确性,在需要严格音视频同步的应用中显示出强大的潜力,如音频翻译。
论文及项目相关链接
PDF Submit to icassp 2026
Summary
自动语音识别(ASR)系统受益于大规模数据集和基于大型语言模型(LLM)的架构,在准确性方面取得了显著的提升。然而,对于特定领域的术语和缺乏语义连贯性的简短话语,仍存在挑战,识别性能往往会显著下降。本研究提出了Index-MSR,一个高效的多模态语音识别框架。其核心是一个新颖的多模态融合解码器(MFD),它有效地将视频中的文本相关信息(如字幕和演示幻灯片)融入语音识别。这种跨模态融合不仅提高了ASR的整体准确性,还大大降低了替换错误。在内部字幕数据集和公共AVSR数据集上的广泛评估表明,Index-MSR达到了最先进水平的准确性,替换错误降低了20.5%。这些结果证明了我们的方法能够有效地利用视频中的文本线索来提高语音识别准确性,在需要严格音视频同步的应用中显示出强大的潜力,如音频翻译。
Key Takeaways
- 大规模数据集和基于大型语言模型的架构提升了自动语音识别(ASR)系统的准确性。
- 对于特定领域的术语和缺乏语义连贯性的简短话语,ASR系统仍面临挑战。
- Index-MSR是一个多模态语音识别框架,通过融合视频中的文本信息来提高ASR的准确性。
- 多模态融合解码器(MFD)是Index-MSR的核心,它有效地结合文本和语音信息。
- 跨模态融合降低了替换错误,提高了ASR的整体性能。
- 在内部和公共数据集上的评估表明,Index-MSR达到了先进的准确性水平。
点此查看论文截图