⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-01 更新
MGM-Omni: Scaling Omni LLMs to Personalized Long-Horizon Speech
Authors:Chengyao Wang, Zhisheng Zhong, Bohao Peng, Senqiao Yang, Yuqi Liu, Haokun Gui, Bin Xia, Jingyao Li, Bei Yu, Jiaya Jia
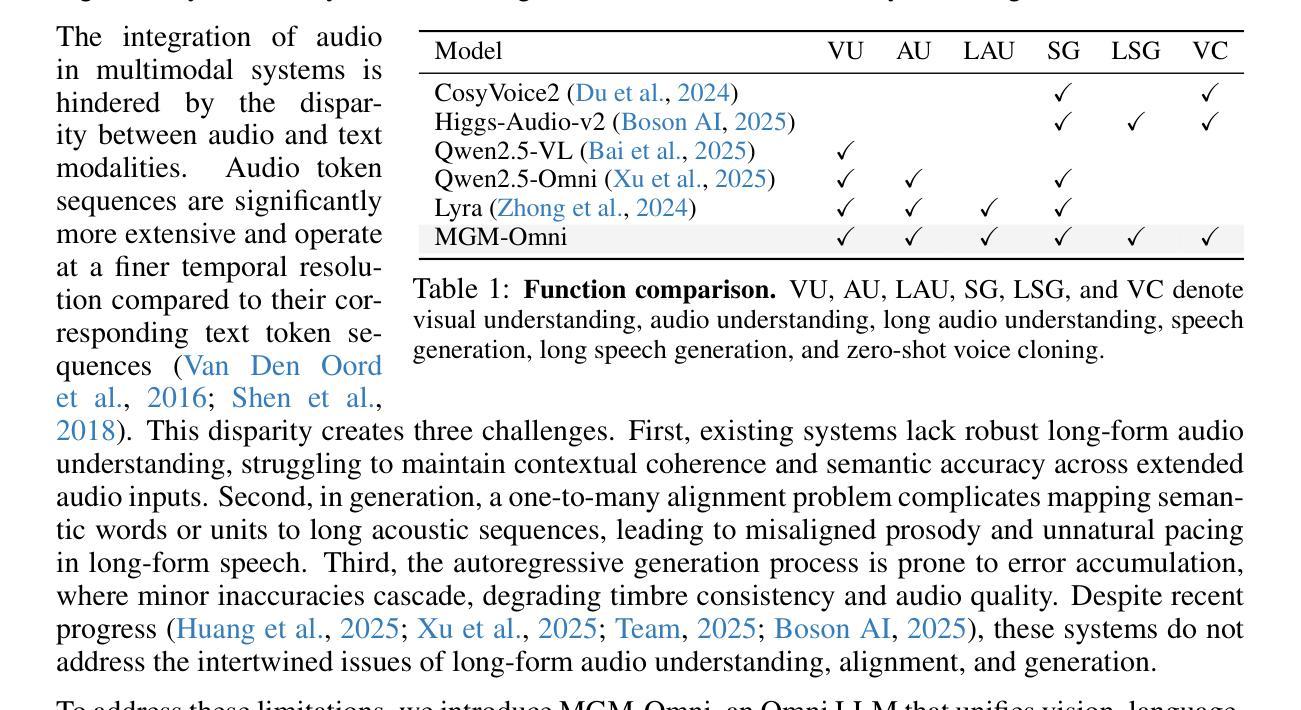
We present MGM-Omni, a unified Omni LLM for omni-modal understanding and expressive, long-horizon speech generation. Unlike cascaded pipelines that isolate speech synthesis, MGM-Omni adopts a “brain-mouth” design with a dual-track, token-based architecture that cleanly decouples multimodal reasoning from real-time speech generation. This design enables efficient cross-modal interaction and low-latency, streaming speech generation. For understanding, a unified training strategy coupled with a dual audio encoder design enables long-form audio perception across diverse acoustic conditions. For generation, a chunk-based parallel decoding scheme narrows the text speech token-rate gap, accelerating inference and supporting streaming zero-shot voice cloning with stable timbre over extended durations. Compared to concurrent work, MGM-Omni achieves these capabilities with markedly data-efficient training. Extensive experiments demonstrate that MGM-Omni outperforms existing open source models in preserving timbre identity across extended sequences, producing natural and context-aware speech, and achieving superior long-form audio and omnimodal understanding. MGM-Omni establishes an efficient, end-to-end paradigm for omnimodal understanding and controllable, personalised long-horizon speech generation.
我们提出了MGM-Omni,这是一个统一的Omni LLM,用于全模态理解和表达,以及长期视野的语音生成。不同于隔离语音合成的级联管道,MGM-Omni采用“脑-口”设计,具有双轨、基于令牌的结构,能够干净地将多模态推理与实时语音生成分离开来。这种设计实现了高效的跨模态交互和低延迟、流式语音生成。在理解方面,通过统一的训练策略和双音频编码器设计,能够实现对不同声学条件下长音频的感知。在生成方面,基于分块的并行解码方案缩小了文本语音令牌率差距,加速了推理,并支持扩展持续时间下的稳定音色零样本语音克隆的流式传输。与同期工作相比,MGM-Omni在数据高效训练方面实现了这些功能。大量实验表明,MGM-Omni在保留扩展序列中的音色身份、产生自然和上下文感知的语音、实现长音频和全能理解方面优于现有的开源模型。MGM-Omni为全模态理解和可控、个性化的长期视野语音生成建立了高效、端到端的范式。
论文及项目相关链接
PDF Code is available at https://github.com/dvlab-research/MGM-Omni
Summary
MGM-Omni是一个统一的全模态大型语言模型,用于全模态理解和表达、长期语音生成。它采用“脑-口”设计,具有双轨、基于令牌架构,干净地解耦了多模态推理和实时语音生成。这种设计实现了高效的跨模态交互和低延迟、流式语音生成。统一训练策略与双音频编码器设计相结合,实现了跨各种声学条件的长音频感知。基于分块的并行解码方案缩小了文本语音令牌率差距,加速了推理,并支持在扩展持续时间上进行稳定的音色零射击声克隆。与同期工作相比,MGM-Omni以显著的数据高效训练实现了这些功能。实验表明,MGM-Omni在扩展序列中保留音色身份、产生自然和上下文感知的语音、实现长期音频和全能理解方面优于现有开源模型。MGM-Omni为全能理解和可控、个性化的长期语音生成建立了高效、端到端的范式。
Key Takeaways
- MGM-Omni是一个全模态的大型语言模型,用于全模态理解和表达、长期语音生成。
- 采用“脑-口”设计和双轨、基于令牌的架构,实现多模态推理和实时语音生成的解耦。
- 双音频编码器设计和统一训练策略提升了长音频感知能力,适应各种声学条件。
- 基于分块的并行解码方案缩小了文本语音令牌率差距,加速了推理,支持流式零射击声克隆。
- MGM-Omni实现了高效、端到端的全能理解和可控、个性化的长期语音生成范式。
- 与其他模型相比,MGM-Omni在扩展序列中表现优越,能够保留音色身份、产生自然和上下文感知的语音。
- MGM-Omni的训练是数据高效的。
点此查看论文截图
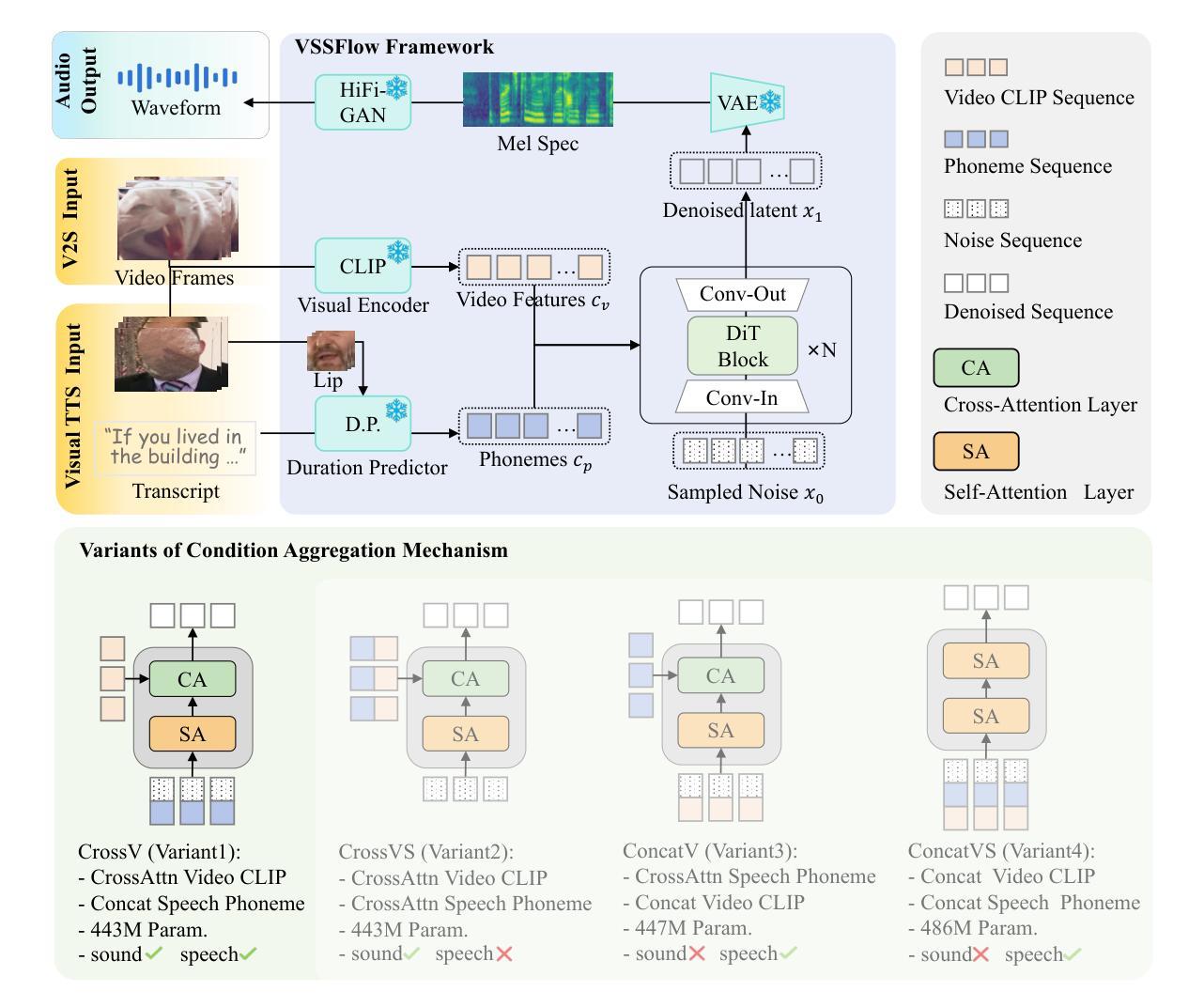
VSSFlow: Unifying Video-conditioned Sound and Speech Generation via Joint Learning
Authors:Xin Cheng, Yuyue Wang, Xihua Wang, Yihan Wu, Kaisi Guan, Yijing Chen, Peng Zhang, Xiaojiang Liu, Meng Cao, Ruihua Song
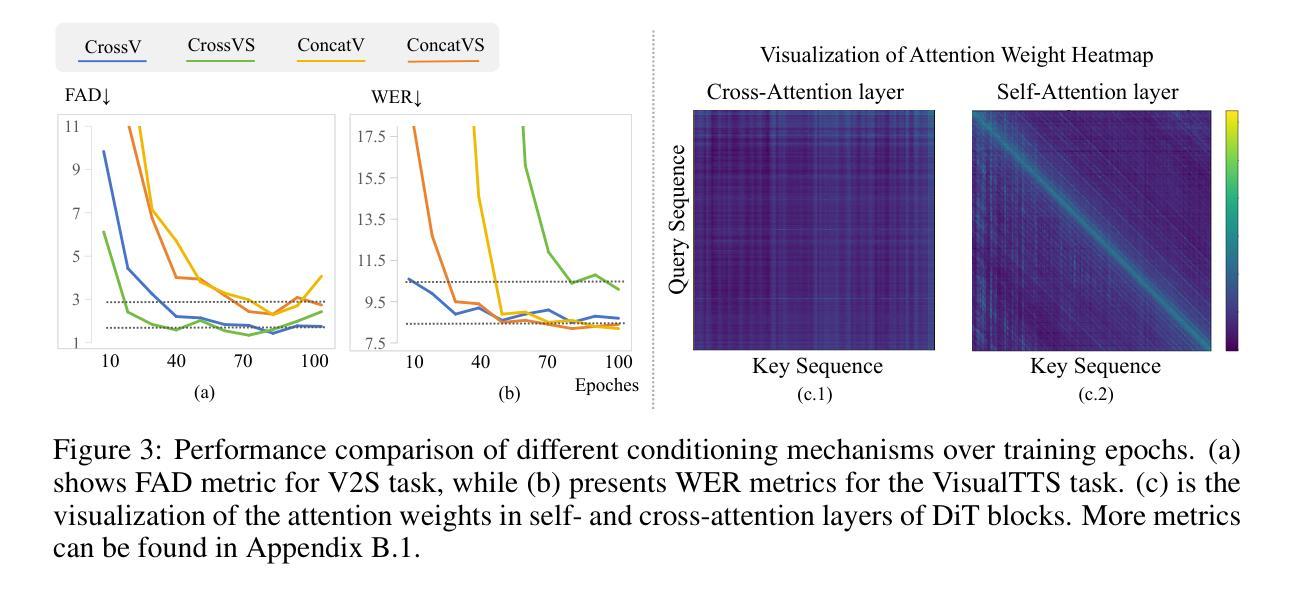
Video-conditioned sound and speech generation, encompassing video-to-sound (V2S) and visual text-to-speech (VisualTTS) tasks, are conventionally addressed as separate tasks, with limited exploration to unify them within a signle framework. Recent attempts to unify V2S and VisualTTS face challenges in handling distinct condition types (e.g., heterogeneous video and transcript conditions) and require complex training stages. Unifying these two tasks remains an open problem. To bridge this gap, we present VSSFlow, which seamlessly integrates both V2S and VisualTTS tasks into a unified flow-matching framework. VSSFlow uses a novel condition aggregation mechanism to handle distinct input signals. We find that cross-attention and self-attention layer exhibit different inductive biases in the process of introducing condition. Therefore, VSSFlow leverages these inductive biases to effectively handle different representations: cross-attention for ambiguous video conditions and self-attention for more deterministic speech transcripts. Furthermore, contrary to the prevailing belief that joint training on the two tasks requires complex training strategies and may degrade performance, we find that VSSFlow benefits from the end-to-end joint learning process for sound and speech generation without extra designs on training stages. Detailed analysis attributes it to the learned general audio prior shared between tasks, which accelerates convergence, enhances conditional generation, and stabilizes the classifier-free guidance process. Extensive experiments demonstrate that VSSFlow surpasses the state-of-the-art domain-specific baselines on both V2S and VisualTTS benchmarks, underscoring the critical potential of unified generative models.
视频条件声音和语音生成涵盖了视频到声音(V2S)和视觉文本到语音(VisualTTS)任务,通常被视为单独的任务来处理,对于在单一框架内统一它们的探索有限。最近尝试将V2S和VisualTTS统一起来,在处理不同条件类型(例如,不同的视频和文本条件)时面临挑战,并需要复杂的训练阶段。统一这两个任务仍然是一个开放的问题。为了弥补这一差距,我们提出了VSSFlow,它无缝地将V2S和VisualTTS任务集成到一个统一的流匹配框架中。VSSFlow使用了一种新型的条件聚合机制来处理不同的输入信号。我们发现,交叉注意力和自注意力层在引入条件的过程中表现出不同的归纳偏置。因此,VSSFlow利用这些归纳偏置来有效地处理不同的表示:交叉注意力用于模糊的视频条件,自注意力用于更确定的语音文本。此外,与普遍认为的联合训练这两个任务需要复杂的训练策略并可能降低性能相反,我们发现VSSFlow受益于声音和语音生成的端到端联合学习过程,而无需在训练阶段进行额外设计。详细分析将其归因于任务间学到的共享音频先验,这加速了收敛,增强了条件生成,并稳定了无分类器指导过程。大量实验表明,VSSFlow在V2S和VisualTTS基准测试中超越了最先进的领域特定基线,突显出统一生成模型的关键潜力。
论文及项目相关链接
PDF Paper Under Review
摘要
本文提出一种名为VSSFlow的统一框架,将视频到声音(V2S)和视觉文本到语音(VisualTTS)两个任务无缝集成。该框架使用新型条件聚合机制处理不同的输入信号。通过利用交叉注意力和自注意力层的不同诱导偏见,VSSFlow能有效处理不同的表征:交叉注意力用于处理模糊的视频条件,自注意力用于处理更确定的语音文本。研究发现,相较于复杂的训练策略可能会降低性能的观点相反,VSSFlow从端到端的联合学习过程受益,无需额外的训练阶段设计即可生成声音和语音。这归功于任务间共享的通用音频先验知识,其加速收敛、增强条件生成并稳定无分类器指导过程。实验表明,VSSFlow在V2S和VisualTTS基准测试中超越了最新的领域特定基线,突显了统一生成模型的关键潜力。
关键见解
- VSSFlow框架统一了视频到声音(V2S)和视觉文本到语音(VisualTTS)任务,填补了现有研究的空白。
- 提出了一种新的条件聚合机制来处理不同的输入信号。
- 利用交叉注意力和自注意力层的不同诱导偏见来处理不同的表征。
- 研究发现,联合学习两个任务的过程能从端到端的训练过程中受益,且无需复杂的训练策略或额外的训练阶段设计。
- 任务间共享的通用音频先验知识对加速收敛、增强条件生成和稳定指导过程起到关键作用。
- 实验证明VSSFlow在V2S和VisualTTS的基准测试中表现出超越现有方法的性能。
- 统一生成模型具有显著潜力。
点此查看论文截图

LatentEvolve: Self-Evolving Test-Time Scaling in Latent Space
Authors:Guibin Zhang, Fanci Meng, Guancheng Wan, Zherui Li, Kun Wang, Zhenfei Yin, Lei Bai, Shuicheng Yan
Test-time Scaling (TTS) has been demonstrated to significantly enhance the reasoning capabilities of Large Language Models (LLMs) during the inference phase without altering model parameters. However, existing TTS methods are largely independent, implying that LLMs have not yet evolved to progressively learn how to scale more effectively. With the objective of evolving LLMs to learn ``how to scale test-time computation,’’ we propose LatentEvolve, a self-evolving latent TTS framework inspired by the complementary learning system (CLS) theory. Analogous to the human brain’s dual system of a fast-recall hippocampus and a slow-consolidating neocortex, LatentEvolve comprises two evolutionary components: \textit{daytime scaling}, which rapidly retrieves historical latent representations to better guide current LLM reasoning; and \textit{nighttime scaling}, which integrates past latent optimizations in a manner akin to the human brain’s consolidation of experiences during sleep. The alternation of daytime and nighttime processes facilitates a fast and slow evolution of LLM TTS, mirroring human cognitive dynamics in a fully unsupervised manner. Extensive experiments across eight benchmarks and five model backbones demonstrate that our LatentEvolve surpasses state-of-the-art TTS methods such as LatentSeek and TTRL by up to $13.33%$ and exhibits exceptional cross-domain and cross-backbone generalization.
测试时缩放(TTS)已证明可以显著提高大型语言模型(LLM)在推理阶段的推理能力,而无需更改模型参数。然而,现有的TTS方法是相对独立的,这意味着LLM尚未进化到逐步学习如何更有效地缩放。为了进化LLM以学习“如何在测试时计算缩放”,我们提出了LatentEvolve,这是一种受辅助学习系统(CLS)理论启发的自我进化的潜在TTS框架。类似于人脑的快速回忆海马体和缓慢巩固的新皮层组成的双重系统,LatentEvolve包含两个进化组件:日间缩放,用于快速检索历史潜在表示,以更好地指导当前LLM推理;夜间缩放,以类似于人脑在睡眠中整合过去的潜在优化的方式整合过去的潜在优化。日间和夜间过程的交替促进了LLM TTS的快速和缓慢进化,以完全无监督的方式反映人类认知动态。在八个基准测试和五个模型主干上进行的大量实验表明,我们的LatentEvolve超越了最先进的TTS方法,如LatentSeek和TTRL,最高提升了13.33%,并表现出出色的跨域和跨主干泛化能力。
论文及项目相关链接
Summary
基于测试时间缩放(TTS)技术的潜在演化框架LatentEvolve,旨在提升大型语言模型(LLM)的推理能力。该框架包含日间和夜间两种缩放方式,分别快速检索历史潜在表征和引导当前LLM推理,以及整合过去潜在优化。通过八项基准测试和五种模型骨干的实验结果显示,LatentEvolve超越了现有TTS方法,具有出色的跨域和跨模型骨干的泛化性能。
Key Takeaways
- Test-time Scaling (TTS)技术可显著提升大型语言模型(LLM)的推理能力,且无需更改模型参数。
- 现有TTS方法大多是独立的,LLM尚未学会如何更有效地缩放。
- LatentEvolve框架受人类大脑的互补学习系统(CLS)理论启发,包含日间和夜间两种缩放方式。
- 日间缩放快速检索历史潜在表征以指导当前LLM推理。
- 夜间缩放整合过去的潜在优化,类似于人类大脑在睡眠中巩固经验。
- 日间和夜间过程的交替实现了LLM TTS的快速和慢速进化,完全模仿人类认知动态。
点此查看论文截图

VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning
Authors:Yixuan Zhou, Guoyang Zeng, Xin Liu, Xiang Li, Renjie Yu, Ziyang Wang, Runchuan Ye, Weiyue Sun, Jiancheng Gui, Kehan Li, Zhiyong Wu, Zhiyuan Liu
Generative models for speech synthesis face a fundamental trade-off: discrete tokens ensure stability but sacrifice expressivity, while continuous signals retain acoustic richness but suffer from error accumulation due to task entanglement. This challenge has driven the field towards multi-stage pipelines that rely on pre-trained speech tokenizers, but these create a semantic-acoustic divide, limiting holistic and expressive speech generation. We resolve these dilemma through hierarchical semantic-acoustic modeling with semi-discrete residual representations and present a novel tokenizer-free TTS model VoxCPM. Our framework introduces a differentiable quantization bottleneck that induces natural specialization: a Text-Semantic Language Model (TSLM) generates semantic-prosodic plans, while a Residual Acoustic Model (RALM) recovers fine-grained acoustic details. This hierarchical semantic-acoustic representation guides a local diffusion-based decoder to generate high-fidelity speech latents. Critically, the entire architecture is trained end-to-end under a simple diffusion objective, eliminating dependency on external speech tokenizers. Trained on a massive 1.8 million hours of bilingual corpus, our VoxCPM-0.5B model achieves state-of-the-art zero-shot TTS performance among open-source systems, demonstrating that our approach delivers expressive and stable synthesis. Besides, VoxCPM shows the capability to comprehend text to infer and generate appropriate prosody and style, delivering speech with context-aware expressiveness and natural flow. To facilitate community-driven research and development, VoxCPM is publicly accessible under Apache 2.0.
生成式语音合成模型面临一个基本权衡:离散符号保证了稳定性但牺牲了表达力,而连续信号保留了声音丰富性但受到任务纠缠导致的误差累积的影响。这一挑战促使领域朝着依赖预训练语音标记器的多阶段流程发展,但这些流程产生了语义声学鸿沟,限制了整体的表达性语音生成。我们通过具有半离散残差表示的分层次语义声学建模来解决这些难题,并推出了无需标记器的文本转语音合成(TTS)模型VoxCPM。我们的框架引入了一个可微分的量化瓶颈,以产生自然的专长:文本语义语言模型(TSLM)生成语义语调计划,而残差声学模型(RALM)恢复精细的声学细节。这种分层次的语义声学表示引导基于局部扩散的解码器生成高保真语音潜在表示。关键的是,整个架构在一个简单的扩散目标下进行端到端训练,消除了对外部语音标记器的依赖。在180万小时的双语语料库上进行训练后,我们的VoxCPM-0.5B模型在开源系统中实现了零射击文本转语音合成的最先进的性能,证明了我们的方法能够提供表达清晰、稳定的合成。此外,VoxCPM展现出理解文本并推断和生成适当语调和风格的能力,生成具有上下文感知的表达力和自然流利的语音。为了方便社区驱动的研究和开发,VoxCPM在Apache 2.0下公开访问。
论文及项目相关链接
PDF Technical Report
Summary
本文介绍了语音合成领域面临的挑战及解决方案。传统的生成模型在稳定性和表达性上存此消彼长的问题。作者提出一种基于层次语义声学建模的TTS模型VoxCPM,通过半离散残差表示解决这一问题。模型引入可微量化瓶颈,实现自然专项化,分为文本语义语言模型(TSLM)生成语义语调计划,残差声学模型(RALM)恢复精细声学细节。这种层次语义声学表示引导局部扩散式解码器生成高保真语音潜在表示。整个架构在简单的扩散目标下进行端到端训练,不依赖外部语音分词器。在18亿小时双语语料库上训练的VoxCPM-0.5B模型在零样本TTS性能方面达到开源系统最佳水平,展现理解文本、推断生成适当语调和风格的能力,生成具有语境感知表达力和自然流畅度的语音。
Key Takeaways
- 语音合成中的生成模型面临稳定性和表达性的权衡挑战。
- 传统方法依赖于预训练的语音分词器,但存在语义与声学分离的局限。
- 提出一种基于层次语义声学建模的TTS模型VoxCPM,结合半离散残差表示解决此挑战。
- 模型包含文本语义语言模型(TSLM)和残差声学模型(RALM),分别负责生成语义语调计划和恢复声学细节。
- 引入可微量化瓶颈实现自然专项化,并通过局部扩散式解码器生成高保真语音。
- 模型在大型双语语料库上训练,达到零样本TTS性能的最佳水平。
点此查看论文截图
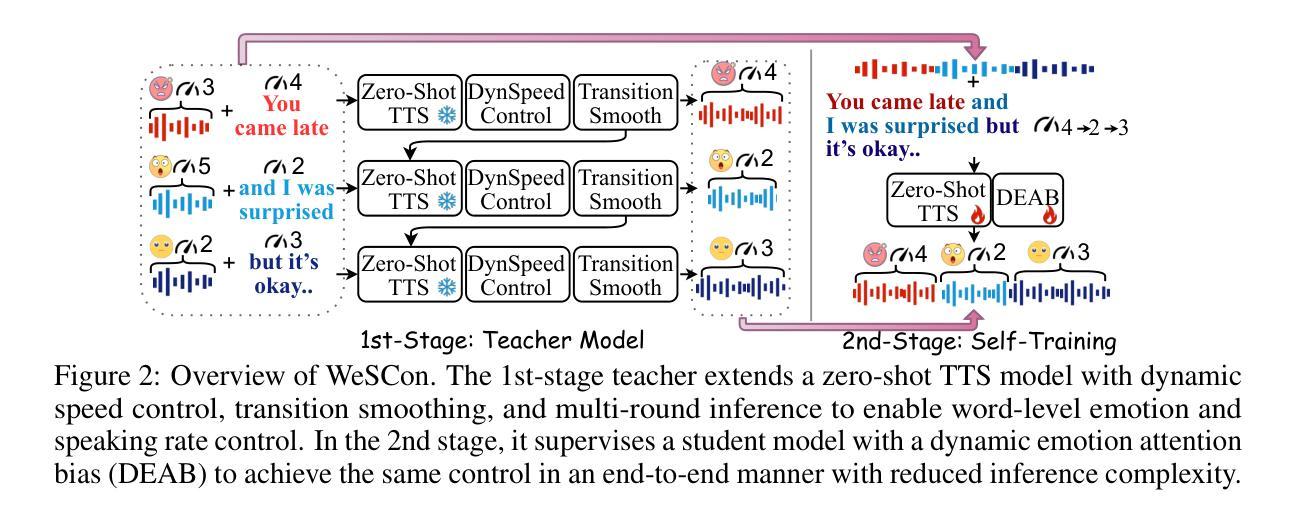
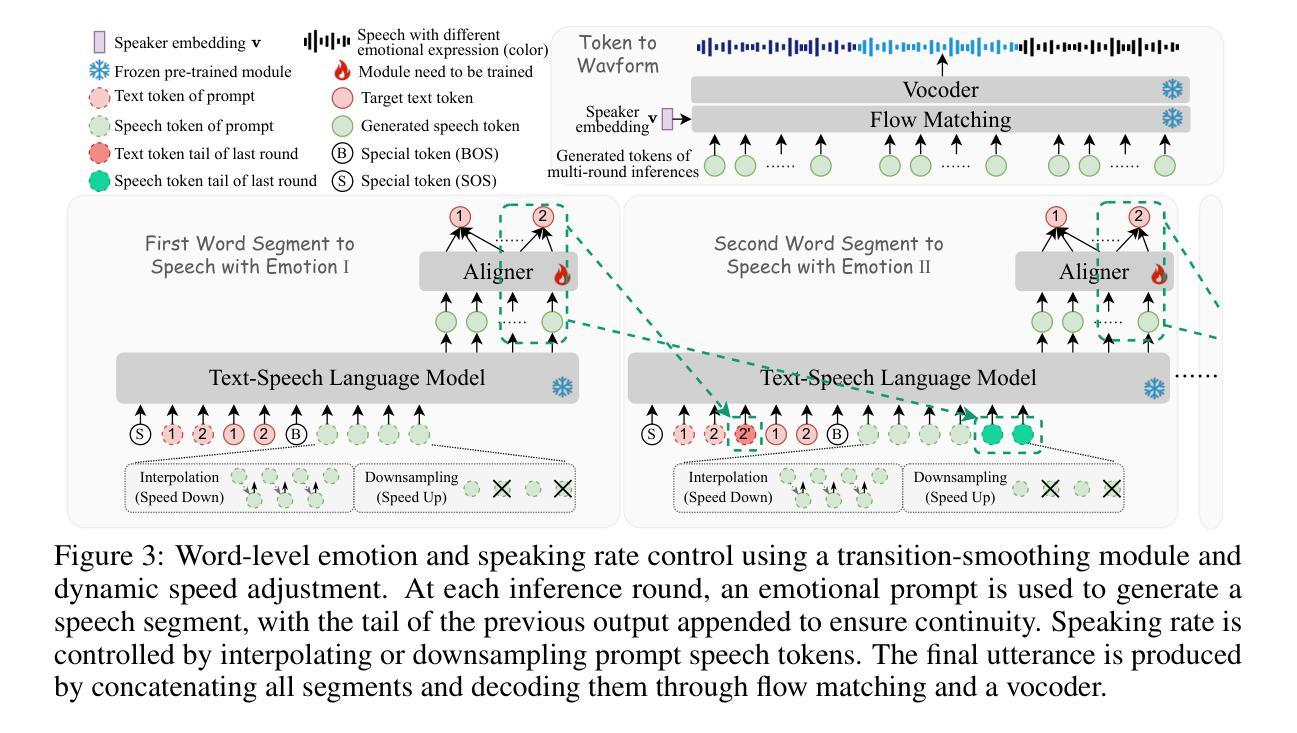
Word-Level Emotional Expression Control in Zero-Shot Text-to-Speech Synthesis
Authors:Tianrui Wang, Haoyu Wang, Meng Ge, Cheng Gong, Chunyu Qiang, Ziyang Ma, Zikang Huang, Guanrou Yang, Xiaobao Wang, Eng Siong Chng, Xie Chen, Longbiao Wang, Jianwu Dang
While emotional text-to-speech (TTS) has made significant progress, most existing research remains limited to utterance-level emotional expression and fails to support word-level control. Achieving word-level expressive control poses fundamental challenges, primarily due to the complexity of modeling multi-emotion transitions and the scarcity of annotated datasets that capture intra-sentence emotional and prosodic variation. In this paper, we propose WeSCon, the first self-training framework that enables word-level control of both emotion and speaking rate in a pretrained zero-shot TTS model, without relying on datasets containing intra-sentence emotion or speed transitions. Our method introduces a transition-smoothing strategy and a dynamic speed control mechanism to guide the pretrained TTS model in performing word-level expressive synthesis through a multi-round inference process. To further simplify the inference, we incorporate a dynamic emotional attention bias mechanism and fine-tune the model via self-training, thereby activating its ability for word-level expressive control in an end-to-end manner. Experimental results show that WeSCon effectively overcomes data scarcity, achieving state-of-the-art performance in word-level emotional expression control while preserving the strong zero-shot synthesis capabilities of the original TTS model.
虽然情感文本到语音(TTS)已经取得了重大进展,但现有的大多数研究仍然仅限于句子级别的情感表达,并不支持单词级别的控制。实现单词级别的情感表达控制提出了根本性的挑战,这主要是由于建模多情绪转换的复杂性和缺乏捕捉句子内情感和韵律变化的标注数据集。在本文中,我们提出了WeSCon,这是一个自我训练框架,它能够在预训练的零样本TTS模型中实现对单词级别的情感和语速的控制,无需依赖包含句子内情感或语速转换的数据集。我们的方法引入了一种过渡平滑策略和一个动态速度控制机制,以指导预训练的TTS模型通过多轮推理过程进行单词级别的表达合成。为了简化推理过程,我们引入了一种动态的情感注意力偏向机制,并通过自我训练对模型进行微调,从而以端到端的方式激活其单词级别的情感表达控制能力。实验结果表明,WeSCon有效地克服了数据稀缺问题,在单词级别的情感表达控制方面取得了最先进的性能,同时保留了原始TTS模型的零样本合成能力。
论文及项目相关链接
Summary
本文提出一种名为WeSCon的自训练框架,能够在预训练的零样本TTS模型中实现词级别的情感和语速控制。该框架通过引入过渡平滑策略、动态速度控制机制和多轮推理过程,实现词级别的表达合成。为解决数据稀缺问题,融入动态情感注意力偏差机制,通过自我训练微调模型,从而激活端到端的词级别表达控制能力。实验结果显示,WeSCon在词级别情感表达控制上取得了最佳性能,同时保留了原始TTS模型的零样本合成能力。
Key Takeaways
- 当前情感文本转语音(TTS)研究大多仅限于语句级别的情感表达,缺乏对词级别的控制。
- 实现词级别情感表达控制面临挑战,主要体现在建模多情感转换的复杂性和缺乏捕捉句内情感和语调变化的标注数据集。
- WeSCon框架通过引入过渡平滑策略和动态速度控制机制,能够在预训练的TTS模型中实现词级别的情感和语速控制。
- WeSCon框架采用多轮推理过程,简化推理过程。
- 动态情感注意力偏差机制的融入解决了数据稀缺问题。
- WeSCon框架在词级别情感表达控制上取得最佳性能,同时保留TTS模型的零样本合成能力。
点此查看论文截图
ISSE: An Instruction-Guided Speech Style Editing Dataset And Benchmark
Authors:Yun Chen, Qi Chen, Zheqi Dai, Arshdeep Singh, Philip J. B. Jackson, Mark D. Plumbley
Speech style editing refers to modifying the stylistic properties of speech while preserving its linguistic content and speaker identity. However, most existing approaches depend on explicit labels or reference audio, which limits both flexibility and scalability. More recent attempts to use natural language descriptions remain constrained by oversimplified instructions and coarse style control. To address these limitations, we introduce an Instruction-guided Speech Style Editing Dataset (ISSE). The dataset comprises nearly 400 hours of speech and over 100,000 source-target pairs, each aligned with diverse and detailed textual editing instructions. We also build a systematic instructed speech data generation pipeline leveraging large language model, expressive text-to-speech and voice conversion technologies to construct high-quality paired samples. Furthermore, we train an instruction-guided autoregressive speech model on ISSE and evaluate it in terms of instruction adherence, timbre preservation, and content consistency. Experimental results demonstrate that ISSE enables accurate, controllable, and generalizable speech style editing compared to other datasets. The project page of ISSE is available at https://ychenn1.github.io/ISSE/.
语音风格编辑是指修改语音的风格属性,同时保留其语言内容和说话者身份。然而,大多数现有方法依赖于明确的标签或参考音频,这限制了灵活性和可扩展性。近期尝试使用自然语言描述也受到过于简化的指令和粗糙的风格控制的限制。为了解决这些限制,我们推出了Instruction-guided Speech Style Editing Dataset(ISSE)数据集。该数据集包含近400小时的语音和超过10万组源目标配对,每组都与多样且详细的文本编辑指令对齐。我们还建立了一条系统的指令性语音数据生成管道,利用大型语言模型、表现力强的文本到语音和语音转换技术,构建高质量配对样本。此外,我们在ISSE上训练了一个指令引导的自回归语音模型,并根据指令遵循情况、音色保留和内容一致性对其进行评估。实验结果表明,与其他数据集相比,ISSE能够实现准确、可控且通用的语音风格编辑。ISSE的项目页面可通过以下链接访问:https://ychenn1.github.io/ISSE/。
论文及项目相关链接
Summary
本文介绍了针对语音风格编辑的新数据集ISSE。该数据集包含了近400小时的语音数据和超过百万个源目标配对,每个配对都与详细的文本编辑指令对齐。通过使用大型语言模型、文本转语音和语音转换技术,构建了高质量配对样本的系统化指令语音数据生成管道。此外,在ISSE上训练了一种指令引导的自动回归语音模型,并在指令遵循、音色保留和内容一致性方面进行了评估。实验结果表明,与其他数据集相比,ISSE能够实现准确、可控和通用的语音风格编辑。
Key Takeaways
- 语音风格编辑是修改语音的风格属性,同时保留其语言内容和说话者身份。
- 现有方法大多依赖于明确的标签或参考音频,限制了灵活性和可扩展性。
- ISSE数据集包含近400小时的语音数据和超过百万个源目标配对,与详细的文本编辑指令对齐。
- 通过大型语言模型、文本转语音和语音转换技术构建高质量配对样本的数据生成管道。
- 在ISSE上训练的指令引导自动回归语音模型在指令遵循、音色保留和内容一致性方面表现优秀。
- ISSE与其他数据集相比,能够实现更准确、可控和通用的语音风格编辑。
点此查看论文截图
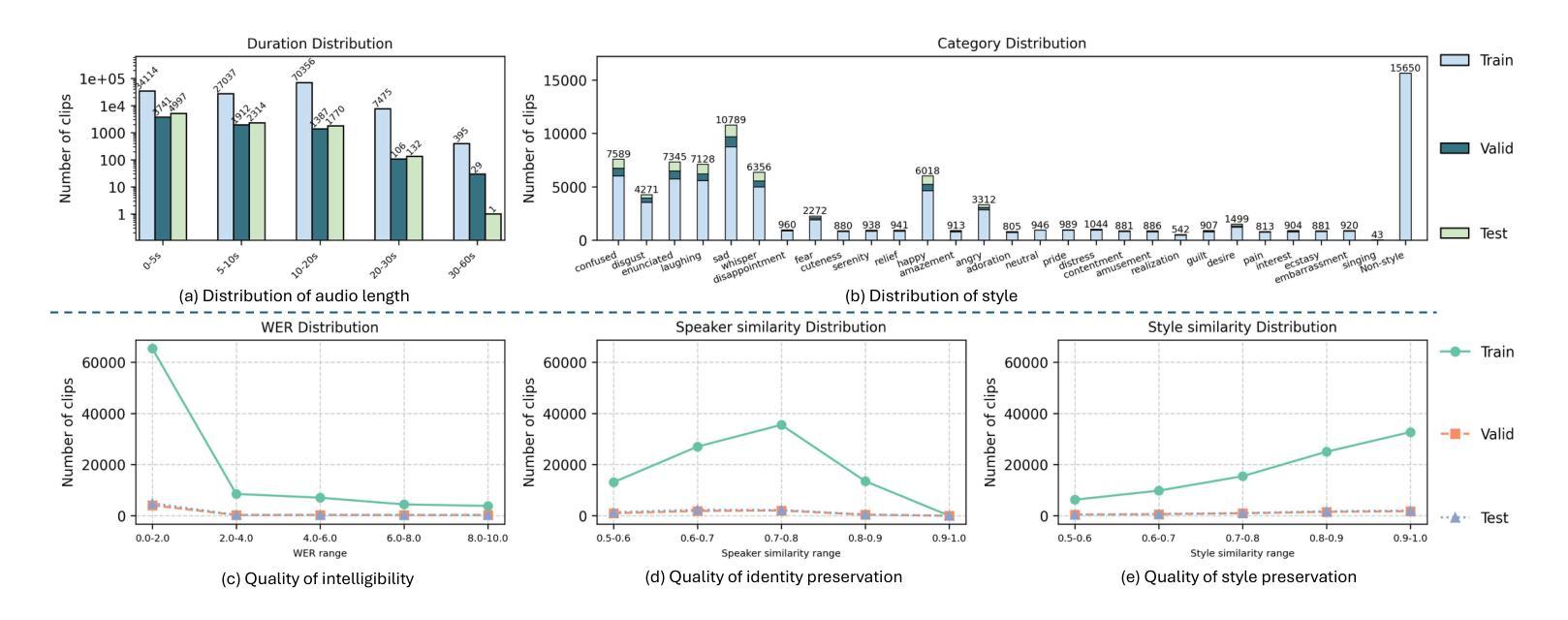
UniFlow-Audio: Unified Flow Matching for Audio Generation from Omni-Modalities
Authors:Xuenan Xu, Jiahao Mei, Zihao Zheng, Ye Tao, Zeyu Xie, Yaoyun Zhang, Haohe Liu, Yuning Wu, Ming Yan, Wen Wu, Chao Zhang, Mengyue Wu
Audio generation, including speech, music and sound effects, has advanced rapidly in recent years. These tasks can be divided into two categories: time-aligned (TA) tasks, where each input unit corresponds to a specific segment of the output audio (e.g., phonemes aligned with frames in speech synthesis); and non-time-aligned (NTA) tasks, where such alignment is not available. Since modeling paradigms for the two types are typically different, research on different audio generation tasks has traditionally followed separate trajectories. However, audio is not inherently divided into such categories, making a unified model a natural and necessary goal for general audio generation. Previous unified audio generation works have adopted autoregressive architectures, while unified non-autoregressive approaches remain largely unexplored. In this work, we propose UniFlow-Audio, a universal audio generation framework based on flow matching. We propose a dual-fusion mechanism that temporally aligns audio latents with TA features and integrates NTA features via cross-attention in each model block. Task-balanced data sampling is employed to maintain strong performance across both TA and NTA tasks. UniFlow-Audio supports omni-modalities, including text, audio, and video. By leveraging the advantage of multi-task learning and the generative modeling capabilities of flow matching, UniFlow-Audio achieves strong results across 7 tasks using fewer than 8K hours of public training data and under 1B trainable parameters. Even the small variant with only ~200M trainable parameters shows competitive performance, highlighting UniFlow-Audio as a potential non-auto-regressive foundation model for audio generation. Code and models will be available at https://wsntxxn.github.io/uniflow_audio.
音频生成包括语音、音乐和音效等,近年来发展迅速。这些任务可以分为两类:时间对齐(TA)任务,其中每个输入单元对应于输出音频的特定片段(例如,语音合成中的音素与帧对齐);以及非时间对齐(NTA)任务,其中这样的对齐是不可用的。由于两种类型的建模范式通常不同,因此针对不同音频生成任务的研究传统上遵循了不同的轨迹。然而,音频本身并不是固有地分为这些类别,因此构建统一的模型成为通用音频生成的自然且必要目标。先前统一的音频生成工作已经采用了自回归架构,而统一的非自回归方法仍然很大程度上未被探索。在这项工作中,我们提出了基于流匹配的通用音频生成框架UniFlow-Audio。我们提出了一种双融合机制,该机制在时间上将音频潜在变量与TA特征对齐,并通过每个模型块中的交叉注意力整合NTA特征。采用任务平衡数据采样以在TA和NTA任务上保持强劲性能。UniFlow-Audio支持文本、音频和视频等多种模式。通过利用多任务学习的优势和流匹配的生成建模能力,UniFlow-Audio在7个任务上取得了出色的结果,使用了少于8K小时的公开训练数据和不到1B的可训练参数。即使只有约2亿个可训练参数的小型变体也表现出竞争力,这突显了UniFlow-Audio作为音频生成潜在的非自回归基础模型的潜力。代码和模型将在https://wsntxxn.github.io/uniflow_audio上提供。
论文及项目相关链接
PDF Project page: https://wsntxxn.github.io/uniflow_audio
摘要
近年音频生成,包括语音、音乐和音效,发展迅速。可分为时间对齐和非时间对齐两类任务。过去的研究通常针对单一任务进行,但音频不是固有地分为这两类,因此统一模型成为音频生成的必要目标。本文提出了基于流匹配的通用音频生成框架UniFlow-Audio,采用双融合机制,临时对齐音频潜能与时间对齐特征,并通过交叉注意力集成非时间对齐特征。采用任务平衡数据采样以维持两种任务的性能。UniFlow-Audio支持文本、音频和视频等多种模式,利用多任务学习和流匹配的生成建模能力,在7个任务上取得了强大的结果,使用少于8K小时的公开训练数据和少于1B的可训练参数。即使只有约2亿可训练参数的小型变种也表现出竞争力,凸显了UniFlow-Audio作为音频生成的潜在非自回归基础模型的潜力。
关键见解
- 音频生成发展迅速,包括时间对齐和非时间对齐任务。
- 统一模型成为音频生成的必要目标,因为音频不是固有地分为这两类任务。
- UniFlow-Audio是一个基于流匹配的通用音频生成框架,支持多种模式(文本、音频、视频)。
- UniFlow-Audio采用双融合机制来集成时间对齐和非时间对齐特征。
- 通过任务平衡数据采样维持时间对齐和非时间对齐任务的性能。
- UniFlow-Audio在多个音频生成任务上取得了强大的结果,使用较少的公开训练数据和可训练参数。
- UniFlow-Audio具有成为非自回归音频生成基础模型的潜力。
点此查看论文截图
Code-switching Speech Recognition Under the Lens: Model- and Data-Centric Perspectives
Authors:Hexin Liu, Haoyang Zhang, Qiquan Zhang, Xiangyu Zhang, Dongyuan Shi, Eng Siong Chng, Haizhou Li
Code-switching automatic speech recognition (CS-ASR) presents unique challenges due to language confusion introduced by spontaneous intra-sentence switching and accent bias that blurs the phonetic boundaries. Although the constituent languages may be individually high-resource, the scarcity of annotated code-switching data further compounds these challenges. In this paper, we systematically analyze CS-ASR from both model-centric and data-centric perspectives. By comparing state-of-the-art algorithmic methods, including language-specific processing and auxiliary language-aware multi-task learning, we discuss their varying effectiveness across datasets with different linguistic characteristics. On the data side, we first investigate TTS as a data augmentation method. By varying the textual characteristics and speaker accents, we analyze the impact of language confusion and accent bias on CS-ASR. To further mitigate data scarcity and enhance textual diversity, we propose a prompting strategy by simplifying the equivalence constraint theory (SECT) to guide large language models (LLMs) in generating linguistically valid code-switching text. The proposed SECT outperforms existing methods in ASR performance and linguistic quality assessments, generating code-switching text that more closely resembles real-world code-switching text. When used to generate speech-text pairs via TTS, SECT proves effective in improving CS-ASR performance. Our analysis of both model- and data-centric methods underscores that effective CS-ASR requires strategies to be carefully aligned with the specific linguistic characteristics of the code-switching data.
代码切换自动语音识别(CS-ASR)由于句子内自发切换引发的语言混淆和口音偏差导致的独特挑战,口音偏差模糊了语音边界。尽管构成的语言可能个别为高资源语言,但标注的代码切换数据稀缺进一步加剧了这些挑战。在本文中,我们从模型中心和数据中心两个角度系统地分析CS-ASR。通过比较最新的算法方法,包括特定语言的处理和辅助语言感知多任务学习,我们讨论了它们在具有不同语言特征的数据集上的不同有效性。在数据方面,我们首先研究TTS作为一种数据增强方法。通过改变文本特征和说话人的口音,我们分析了语言混淆和口音偏差对CS-ASR的影响。为了进一步缓解数据稀缺并增强文本多样性,我们提出了一种基于简化等价约束理论(SECT)的提示策略,以指导大型语言模型(LLM)生成语言上有效的代码切换文本。所提出的SECT在语音识别性能和语言质量评估方面优于现有方法,生成更贴近现实世界的代码切换文本。当用于通过TTS生成语音文本对时,SECT在提高CS-ASR性能方面表现出色。我们对模型和数据中心方法的分析强调,有效的CS-ASR需要策略与代码切换数据的特定语言特征仔细对齐。
论文及项目相关链接
PDF 11 pages, 3 figures, 9 tables, submitted to IEEE TASLP
摘要
本文主要研究了代码切换自动语音识别(CS-ASR)面临的挑战,包括语言混淆和口音偏差问题。文章从模型和数据两个角度系统分析了CS-ASR,对比了当前先进的算法方法,包括语言特定处理和辅助语言感知多任务学习。同时,研究了TTS作为数据增强方法对CS-ASR的影响。为解决数据稀缺和文本多样性问题,本文提出了一种基于简化等价约束理论(SECT)的提示策略,用于指导大型语言模型(LLM)生成语言有效的代码切换文本。研究结果表明,所提出的SECT在语音识别性能和语言质量评估方面优于现有方法,生成的代码切换文本更接近真实世界的代码切换文本。通过TTS生成语音文本对时,SECT在提高CS-ASR性能方面证明有效。对模型和数据的分析强调,有效的CS-ASR需要策略与代码切换数据的特定语言特征仔细对齐。
关键见解
- 代码切换自动语音识别(CS-ASR)面临语言混淆和口音偏差的挑战。
- 文章从模型和数据两个角度系统分析了CS-ASR。
- 对比了语言特定处理和辅助语言感知多任务学习等先进算法方法。
- 研究了TTS作为数据增强方法对CS-ASR的影响。
- 提出了一种基于简化等价约束理论(SECT)的提示策略,用于指导大型语言模型生成语言有效的代码切换文本。
- SECT在语音识别性能和语言质量评估方面优于现有方法。
- 使用TTS生成的语音文本对时,SECT能有效提高CS-ASR性能。
点此查看论文截图

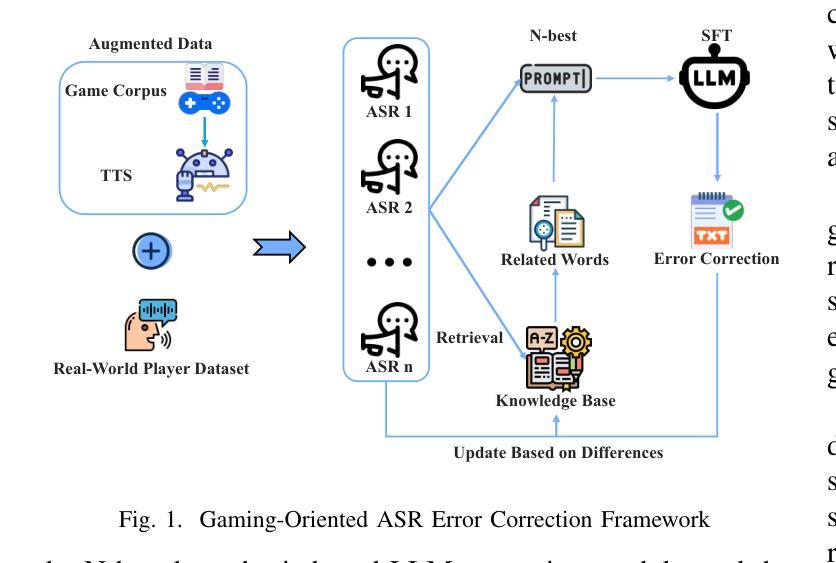
Game-Oriented ASR Error Correction via RAG-Enhanced LLM
Authors:Yan Jiang, Yongle Luo, Qixian Zhou, Elvis S. Liu
With the rise of multiplayer online games, real-time voice communication is essential for team coordination. However, general ASR systems struggle with gaming-specific challenges like short phrases, rapid speech, jargon, and noise, leading to frequent errors. To address this, we propose the GO-AEC framework, which integrates large language models, Retrieval-Augmented Generation (RAG), and a data augmentation strategy using LLMs and TTS. GO-AEC includes data augmentation, N-best hypothesis-based correction, and a dynamic game knowledge base. Experiments show GO-AEC reduces character error rate by 6.22% and sentence error rate by 29.71%, significantly improving ASR accuracy in gaming scenarios.
随着多人在线游戏的兴起,实时语音交流对于团队协作至关重要。然而,通用语音识别系统面临游戏特有的挑战,如短句、快速发言、行话和噪音等,导致经常出现错误。为了解决这一问题,我们提出了GO-AEC框架,它集成了大型语言模型、检索增强生成(RAG)和基于LLM和TTS的数据增强策略。GO-AEC包括数据增强、基于N-best假设的校正以及动态游戏知识库。实验表明,GO-AEC降低了6.22%的字符错误率和29.71%的句子错误率,显著提高了游戏场景中语音识别系统的准确性。
论文及项目相关链接
Summary
随着多人在线游戏的兴起,实时语音沟通对团队协作至关重要。然而,通用ASR系统在面对游戏特有的挑战时,如短语短促、语速快、专业术语和背景噪音等,易出现频繁错误。为解决这一问题,我们提出GO-AEC框架,它整合了大型语言模型、检索增强生成(RAG)以及使用TTS和LLM的数据增强策略。GO-AEC包括数据增强、基于N-best假设的校正以及动态游戏知识库。实验表明,GO-AEC降低了6.22%的字符错误率和29.71%的句子错误率,显著提高了游戏场景中的ASR准确性。
Key Takeaways
- 多人在线游戏中实时语音沟通的重要性。
- 通用ASR系统在处理游戏语音时面临的挑战,如短语句、快速语速、专业术语和噪音。
- GO-AEC框架的提出,集成了大型语言模型、检索增强生成(RAG)和基于TTS及LLM的数据增强策略。
- GO-AEC框架包括数据增强、基于N-best假设的校正以及动态游戏知识库等功能。
- 实验结果显示,GO-AEC能显著降低字符和句子错误率。
- GO-AEC框架显著提高了游戏场景中的ASR准确性。
- GO-AEC框架对于改善游戏团队协作中的实时语音通信具有潜在的应用价值。
点此查看论文截图
Generalizable Speech Deepfake Detection via Information Bottleneck Enhanced Adversarial Alignment
Authors:Pu Huang, Shouguang Wang, Siya Yao, Mengchu Zhou
Neural speech synthesis techniques have enabled highly realistic speech deepfakes, posing major security risks. Speech deepfake detection is challenging due to distribution shifts across spoofing methods and variability in speakers, channels, and recording conditions. We explore learning shared discriminative features as a path to robust detection and propose Information Bottleneck enhanced Confidence-Aware Adversarial Network (IB-CAAN). Confidence-guided adversarial alignment adaptively suppresses attack-specific artifacts without erasing discriminative cues, while the information bottleneck removes nuisance variability to preserve transferable features. Experiments on ASVspoof 2019/2021, ASVspoof 5, and In-the-Wild demonstrate that IB-CAAN consistently outperforms baseline and achieves state-of-the-art performance on many benchmarks.
神经网络语音合成技术已经能够实现高度逼真的语音深度伪造,这带来了重大的安全风险。语音深度伪造检测具有挑战性,因为欺骗方法中存在分布偏移以及说话人、通道和录制条件的差异性。我们探索学习共享判别特征作为稳健检测的途径,并提出基于信息瓶颈增强的置信度感知对抗网络(IB-CAAN)。置信度引导的对齐对抗性网络自适应地抑制攻击特定伪造的痕迹而不消除鉴别线索,而信息瓶颈消除了令人困扰的变异性来保留可迁移的特征。在ASVspoof 2019/2021、ASVspoof 5和野外实验上的结果表明,IB-CAAN始终优于基线并实现了许多基准测试的最先进性能。
论文及项目相关链接
总结
神经语音合成技术已经能够生成高度逼真的语音深度伪造内容,这带来了重大的安全风险。由于伪装方法的分布变化以及说话人、通道和录音条件的可变性,语音深度伪造检测面临挑战。本文探讨了学习共享判别特征作为稳健检测的途径,并提出了基于信息瓶颈增强的信心感知对抗网络(IB-CAAN)。信心引导的对齐对抗策略可以自适应地抑制攻击特定的伪像,而不会消除判别线索;而信息瓶颈则能够消除无用变量的干扰以保留可转移特征。在ASVspoof 2019/2021、ASVspoof 5和In-the-Wild上的实验表明,IB-CAAN性能稳定并超过了基线水平,且在多个基准测试中达到了业界前沿水平。
关键见解
- 神经语音合成技术已经能够生成高度逼真的语音深度伪造内容,带来重大安全风险。
- 语音深度伪造检测面临诸多挑战,包括伪装方法的分布变化和说话人、通道及录音条件的变化性。
- 学习共享判别特征是解决稳健检测的关键途径。
- 提出了信息瓶颈增强的信心感知对抗网络(IB-CAAN)。
- 信心引导的对齐对抗策略能够自适应地抑制攻击特定的伪像,同时保留判别线索。
- 信息瓶颈有助于消除无用变量的干扰,保留可转移特征。
点此查看论文截图
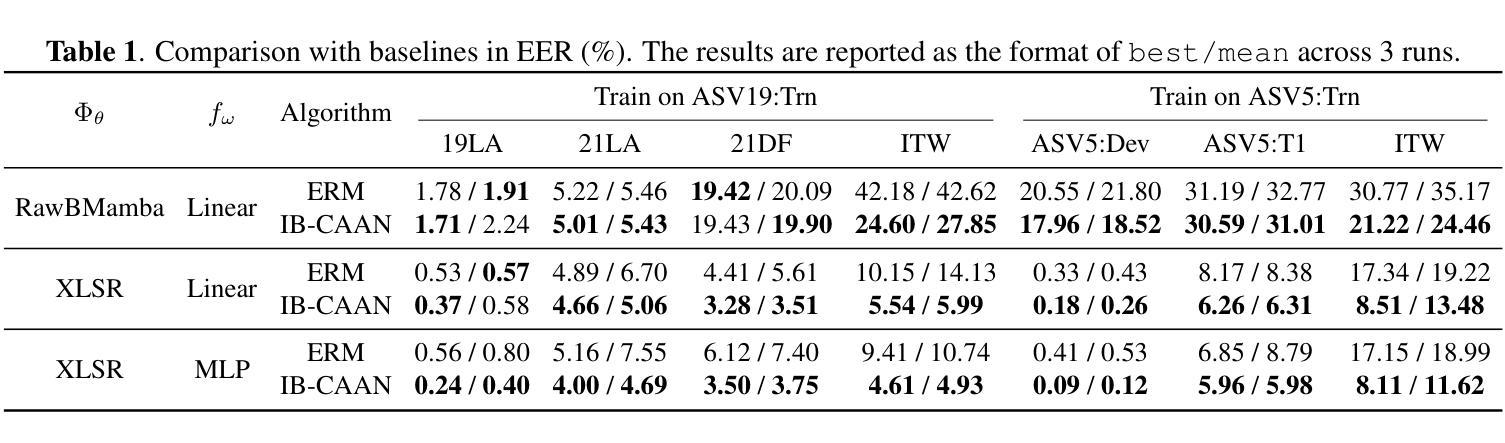
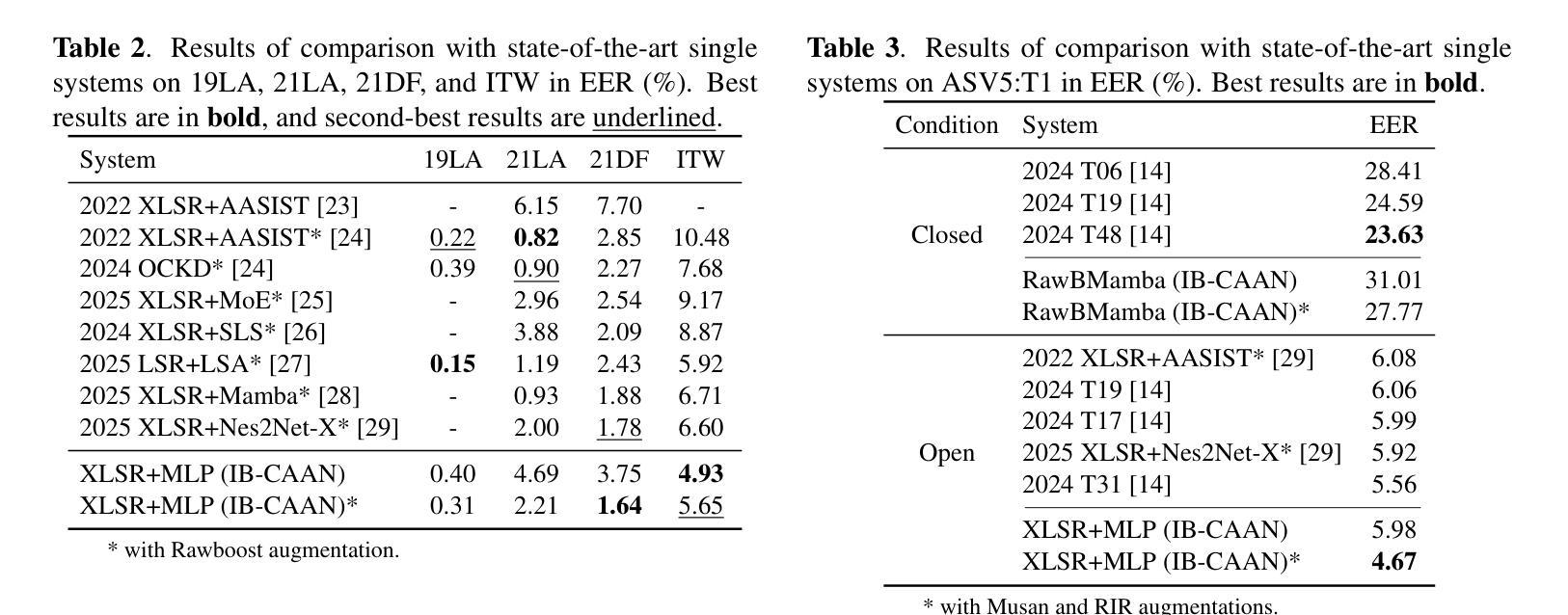
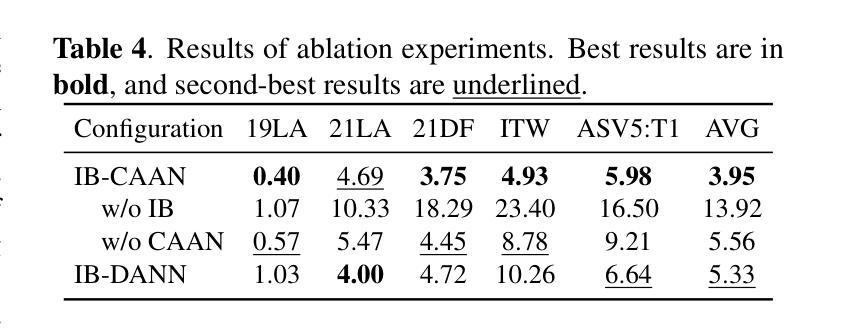
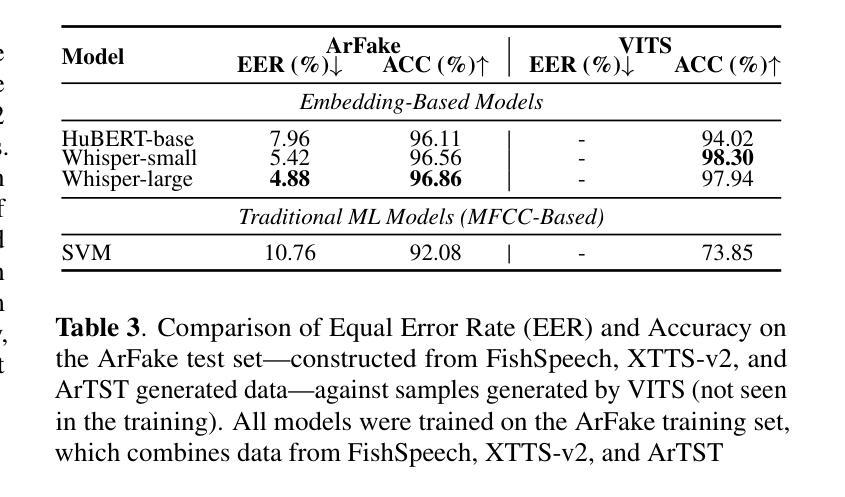
ArFake: A Multi-Dialect Benchmark and Baselines for Arabic Spoof-Speech Detection
Authors:Mohamed Maged, Alhassan Ehab, Ali Mekky, Besher Hassan, Shady Shehata
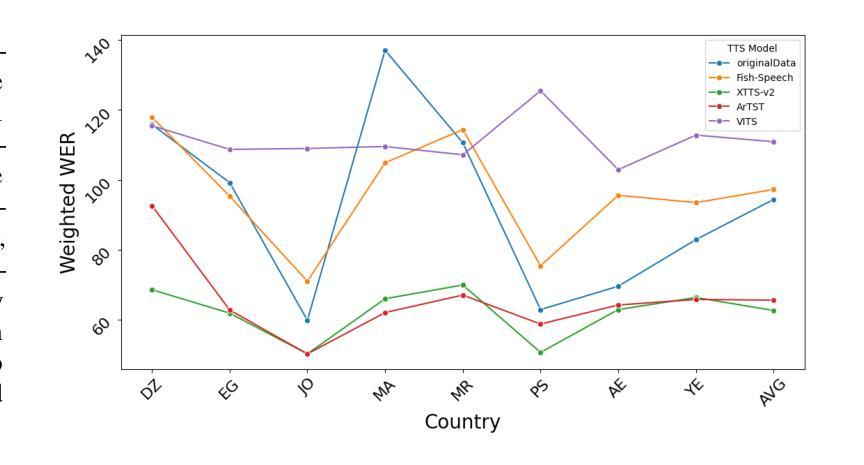
With the rise of generative text-to-speech models, distinguishing between real and synthetic speech has become challenging, especially for Arabic that have received limited research attention. Most spoof detection efforts have focused on English, leaving a significant gap for Arabic and its many dialects. In this work, we introduce the first multi-dialect Arabic spoofed speech dataset. To evaluate the difficulty of the synthesized audio from each model and determine which produces the most challenging samples, we aimed to guide the construction of our final dataset either by merging audios from multiple models or by selecting the best-performing model, we conducted an evaluation pipeline that included training classifiers using two approaches: modern embedding-based methods combined with classifier heads; classical machine learning algorithms applied to MFCC features; and the RawNet2 architecture. The pipeline further incorporated the calculation of Mean Opinion Score based on human ratings, as well as processing both original and synthesized datasets through an Automatic Speech Recognition model to measure the Word Error Rate. Our results demonstrate that FishSpeech outperforms other TTS models in Arabic voice cloning on the Casablanca corpus, producing more realistic and challenging synthetic speech samples. However, relying on a single TTS for dataset creation may limit generalizability.
随着生成式文本到语音模型的兴起,区分真实语音和合成语音变得具有挑战性,特别是对于阿拉伯语这种研究关注度相对较低的语言。大多数语音欺骗检测工作主要集中在英语上,为阿拉伯语及其多种方言留下了巨大的空白。在这项工作中,我们引入了首个多方言阿拉伯语虚假语音数据集。为了评估每个模型的合成音频的难度,并确定哪个模型产生了最具挑战性的样本,我们在构建最终数据集时,旨在通过合并多个模型的音频或选择表现最佳的模型来指导。我们建立了一个评估管道,包括使用两种方法来训练分类器:结合分类器头的现代基于嵌入的方法和应用于MFCC特征的经典机器学习算法;以及RawNet2架构。该管道还纳入了基于人类评分的计算平均意见得分,以及通过语音识别模型处理原始和合成数据集,以测量单词错误率。我们的结果表明,在阿拉伯语音克隆方面,FishSpeech在Casablanca语料库上的表现优于其他TTS模型,能产生更真实、更具挑战性的合成语音样本。然而,仅依赖单一的TTS进行数据集创建可能会限制其通用性。
论文及项目相关链接
Summary
本文介绍了随着生成文本-语音模型的发展,识别阿拉伯语音的真伪变得越来越困难。现有的欺骗检测研究主要集中在英语上,而针对阿拉伯语的欺骗语音数据集相对缺乏。本研究首次推出了多方言阿拉伯语欺骗语音数据集,并利用多种模型进行构建和评估,包括现代嵌入方法和分类器头结合的训练分类器、基于MFCC特征的经典机器学习算法以及RawNet2架构。通过计算基于人类评价的均值意见得分以及通过语音识别模型测量原始和合成数据集的词错误率来评估合成音频的难度。研究结果表明,FishSpeech在阿拉伯语音克隆上的表现优于其他TTS模型,但依赖单一TTS进行数据集创建可能会限制其泛化能力。
Key Takeaways
- 生成文本-语音模型的发展使得识别阿拉伯语音的真伪变得困难。
- 目前针对阿拉伯语的欺骗语音数据集研究相对较少。
- 本研究首次推出多方言阿拉伯语欺骗语音数据集。
- 通过多种模型构建和评估数据集,包括现代嵌入方法和分类器头结合的训练分类器、基于MFCC特征的经典机器学习算法以及RawNet2架构。
- 通过计算均值意见得分和词错误率来评估合成音频的难度。
- FishSpeech模型在阿拉伯语音克隆上表现优异。
点此查看论文截图
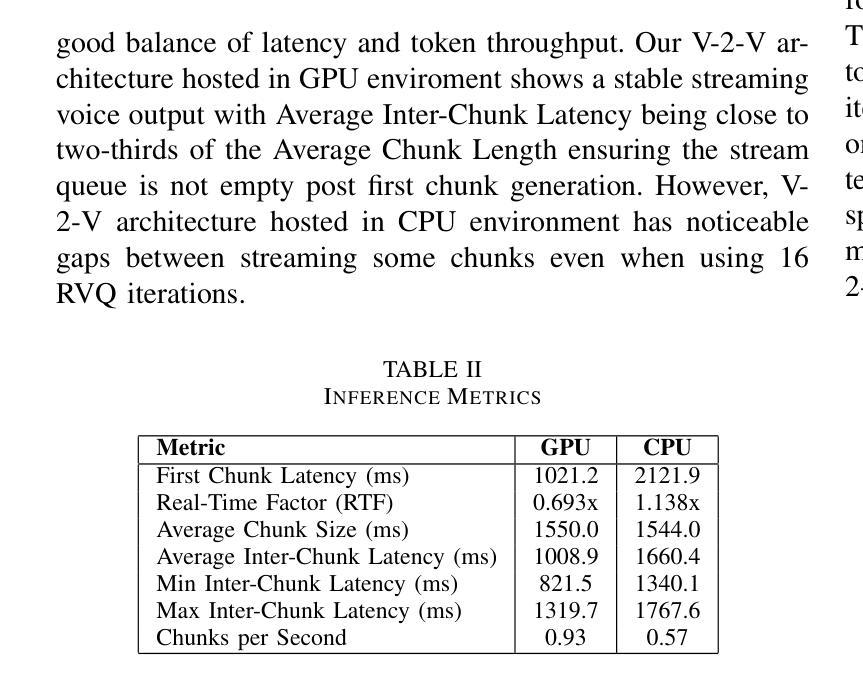
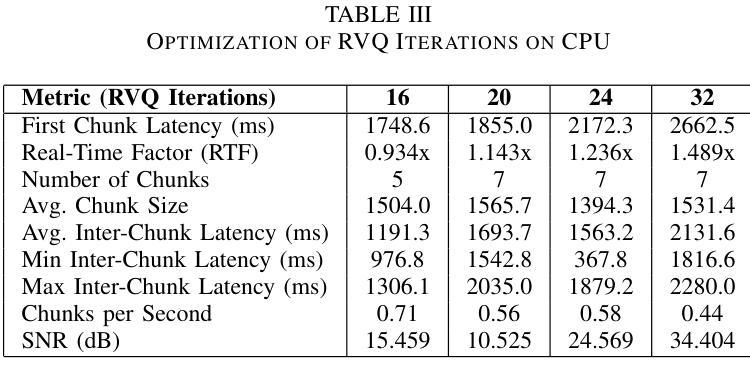
i-LAVA: Insights on Low Latency Voice-2-Voice Architecture for Agents
Authors:Anupam Purwar, Aditya Choudhary
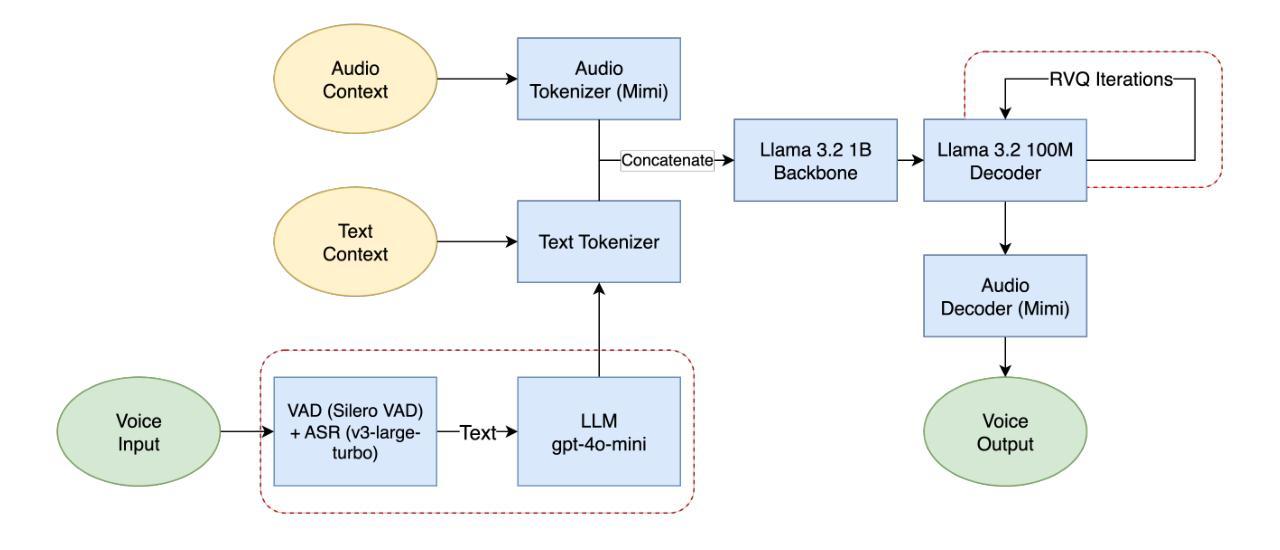
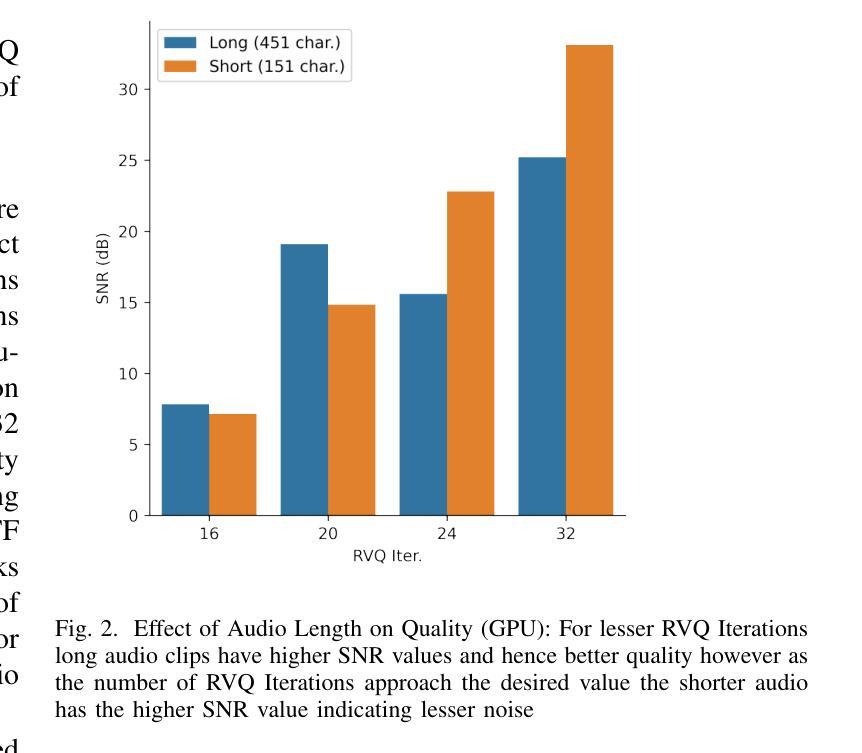
We experiment with a low-latency, end-to-end voice-to-voice communication model to optimize it for real-time conversational applications. By analyzing components essential to voice to voice (V-2-V) system viz. automatic speech recognition (ASR), text-to-speech (TTS), and dialog management, our work analyzes how to reduce processing time while maintaining high-quality interactions to identify the levers for optimizing V-2-V system. Our work identifies that TTS component which generates life-like voice, full of emotions including natural pauses and exclamations has highest impact on Real time factor (RTF). The experimented V-2-V architecture utilizes CSM1b has the capability to understand tone as well as context of conversation by ingesting both audio and text of prior exchanges to generate contextually accurate speech. We explored optimization of Residual Vector Quantization (RVQ) iterations by the TTS decoder which come at a cost of decrease in the quality of voice generated. Our experimental evaluations also demonstrate that for V-2-V implementations based on CSM most important optimizations can be brought by reducing the number of RVQ Iterations along with the codebooks used in Mimi.
我们实验了一种低延迟、端到端的语音到语音通信模型,以优化其适用于实时对话应用。通过分析语音到语音(V-2-V)系统的关键组件,包括自动语音识别(ASR)、文本到语音(TTS)和对话管理,我们的工作分析了如何在保持高质量交互的同时减少处理时间,以确定优化V-2-V系统的关键要素。我们的工作确定,TTS组件对实时因素(RTF)的影响最大,该组件可以生成逼真的声音,充满情感,包括自然停顿和感叹。所试验的V-2-V架构利用CSM1b,通过摄取先前的音频和文本交换,理解对话的语调以及语境,从而生成语境准确的语音。我们探索了通过TTS解码器优化剩余矢量量化(RVQ)迭代的方法,但这会降低生成的语音质量。我们的实验评估还表明,对于基于CSM的V-2-V实现,最重要的优化可以通过减少RVQ迭代次数以及Mimi中使用的代码本数量来实现。
论文及项目相关链接
PDF This paper analyzes a low-latency, end-to-end voice-to-voice (V-2-V) architecture, identifying that the Text-to-Speech (TTS) component has the highest impact on real-time performance. By reducing the number of Residual Vector Quantization (RVQ) iterations in the TTS model, latency can be effectively halved. Its accepted at AIML Systems 2025
Summary
文本内容关于如何通过分析语音转语音系统的重要组件(如自动语音识别、文本转语音和对话管理)来优化实时对话应用的低延迟端到端语音转语音通信模型。其中,文本转语音(TTS)组件对于保持实时因素(RTF)具有重大影响,因此本文特别关注优化该组件的方法。文中探讨了一种减少矢量量化迭代次数(RVQ)以降低生成的语音质量成本的方法。总体而言,该文本展示了如何通过减少RVQ迭代和使用的代码本数量来实现语音转语音系统的优化。
Key Takeaways
- 通过实验探讨了低延迟的端到端语音转语音(V-2-V)通信模型,旨在优化实时对话应用。
- 分析了语音转语音系统的关键组件,包括自动语音识别(ASR)、文本转语音(TTS)和对话管理。
- 指出TTS组件对于保持实时因素(RTF)具有重大影响,并探讨了优化该组件的方法。
- 通过减少矢量量化(RVQ)迭代次数来优化TTS解码器,但需注意这可能会降低生成的语音质量。
- 实验性评估表明,对于基于CSM的V-2-V实现,最重要的优化可以通过减少RVQ迭代次数和使用较少的代码本实现。
- 所采用的V-2-V架构利用CSM1b能够理解语调以及对话上下文的能力,通过同时处理先前的音频和文本交流来生成准确的语境化语音。
点此查看论文截图

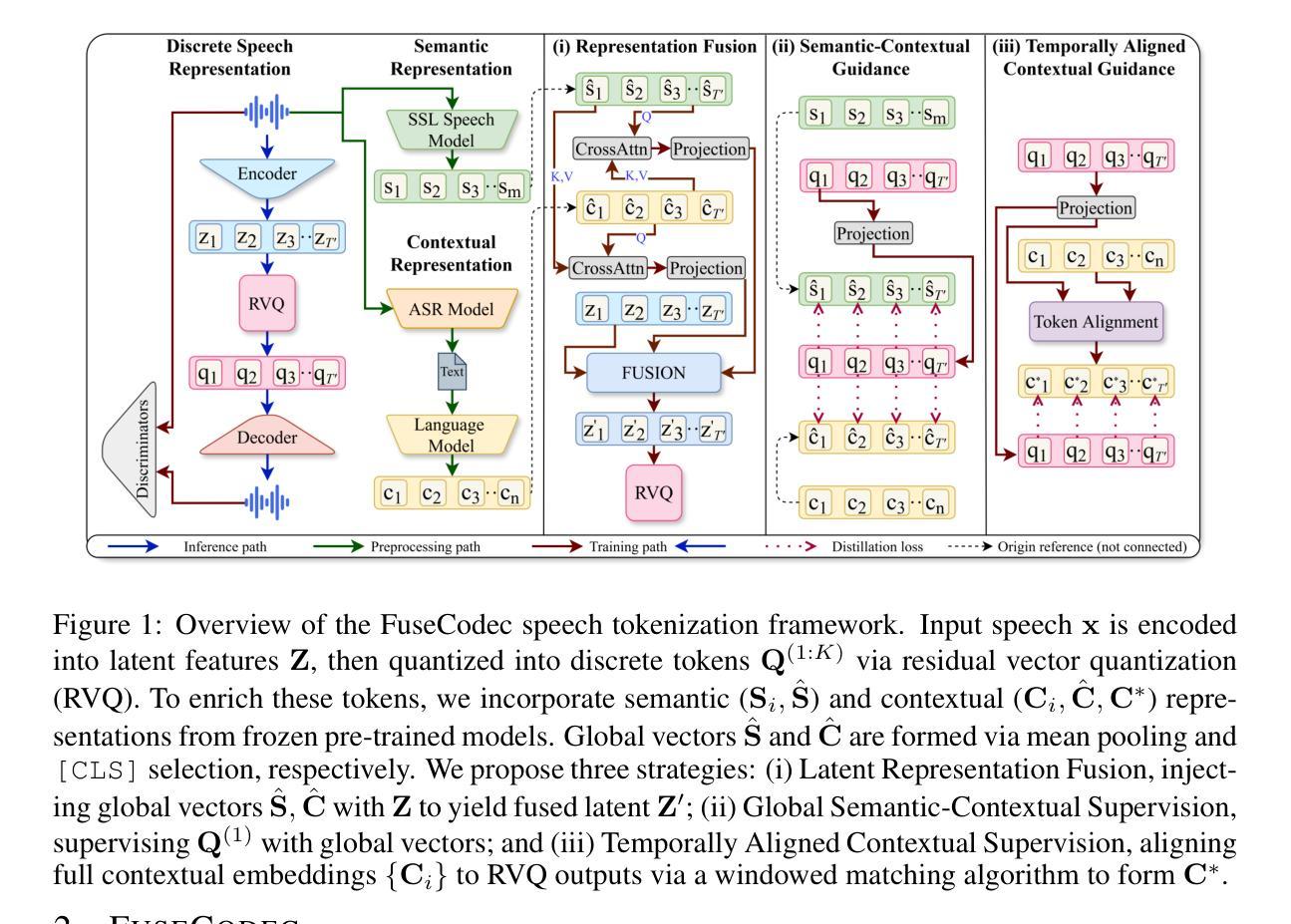
FuseCodec: Semantic-Contextual Fusion and Supervision for Neural Codecs
Authors:Md Mubtasim Ahasan, Rafat Hasan Khan, Tasnim Mohiuddin, Aman Chadha, Tariq Iqbal, M Ashraful Amin, Amin Ahsan Ali, Md Mofijul Islam, A K M Mahbubur Rahman
Speech tokenization enables discrete representation and facilitates speech language modeling. However, existing neural codecs capture low-level acoustic features, overlooking the semantic and contextual cues inherent to human speech. While recent efforts introduced semantic representations from self-supervised speech models or incorporated contextual representations from pre-trained language models, challenges remain in aligning and unifying the semantic and contextual representations. We introduce FuseCodec, which unifies acoustic, semantic, and contextual representations through strong cross-modal alignment and globally informed supervision. We propose three complementary techniques: (i) Latent Representation Fusion, integrating semantic and contextual features directly into the encoder latent space for robust and unified representation learning; (ii) Global Semantic-Contextual Supervision, supervising discrete tokens with globally pooled and broadcasted representations to enhance temporal consistency and cross-modal alignment; and (iii) Temporally Aligned Contextual Supervision, strengthening alignment by dynamically matching contextual and speech tokens within a local window for fine-grained token-level supervision. We further introduce FuseCodec-TTS, demonstrating our methodology’s applicability to zero-shot speech synthesis. Empirically, FuseCodec achieves state-of-the-art performance in LibriSpeech, surpassing EnCodec, SpeechTokenizer, and DAC in transcription accuracy, perceptual quality, intelligibility, and speaker similarity. Results highlight the effectiveness of contextually and semantically guided tokenization for speech tokenization and downstream tasks. Code and pretrained models are available at https://github.com/mubtasimahasan/FuseCodec.
语音标记化能够实现离散表示并促进语音语言建模。然而,现有的神经编解码器捕捉低级别的声学特征,忽略了人类语音所固有的语义和上下文线索。虽然最近的努力引入了来自自我监督语音模型的语义表示或结合了预训练语言模型的上下文表示,但在对齐和统一语义和上下文表示方面仍存在挑战。我们推出了FuseCodec,它通过强大的跨模态对齐和全局信息监督,统一了声学、语义和上下文表示。我们提出了三种互补的技术:(i)潜在表示融合,直接将语义和上下文特征集成到编码器潜在空间,以实现稳健和统一的表示学习;(ii)全局语义上下文监督,用全局池化和广播的表示来监督离散标记,以增强时间一致性和跨模态对齐;(iii)临时对齐上下文监督,通过在局部窗口内动态匹配上下文和语音标记来加强对齐,以实现精细的标记级监督。我们进一步推出了FuseCodec-TTS,展示了我们的方法在零样本语音合成中的适用性。经验表明,FuseCodec在LibriSpeech上达到了最先进的性能,在转录准确性、感知质量、清晰度和说话人相似性方面超越了EnCodec、SpeechTokenizer和DAC。结果突出了上下文和语义引导的标记化在语音标记化和下游任务中的有效性。代码和预先训练好的模型可在https://github.com/mubtasimahasan/FuseCodec 获得。
论文及项目相关链接
Summary
本文介绍了Speech tokenization的重要性以及现有神经编码器的挑战。为解决这些问题,文章提出了FuseCodec,它通过强大的跨模态对齐和全局监督,统一了声音、语义和上下文表示。文章还介绍了三种互补技术:潜在表示融合、全局语义上下文监督、时间对齐上下文监督。FuseCodec-TTS的引入证明了该方法在零样本语音合成中的适用性。实验结果表明,FuseCodec在LibriSpeech数据集上的表现优于其他方法,包括EnCodec、SpeechTokenizer和DAC,体现了上下文和语义引导tokenization在语音tokenization和下游任务中的有效性。
Key Takeaways
- Speech tokenization对于语音语言建模非常重要,它可以使语音表达离散化。
- 现有神经编码器主要捕捉低层次的声学特征,忽略了语音的语义和上下文线索。
- FuseCodec通过强大的跨模态对齐和全局监督来统一声学、语义和上下文表示。
- FuseCodec引入了三种互补技术:潜在表示融合、全局语义上下文监督和时间对齐上下文监督。
- FuseCodec-TTS的引入证明了该方法在零样本语音合成中的适用性。
- FuseCodec在LibriSpeech数据集上的表现优于其他方法,显示出其在转录准确性、感知质量、清晰度和说话人相似性方面的优越性。
点此查看论文截图


Streaming Sequence-to-Sequence Learning with Delayed Streams Modeling
Authors:Neil Zeghidour, Eugene Kharitonov, Manu Orsini, Václav Volhejn, Gabriel de Marmiesse, Edouard Grave, Patrick Pérez, Laurent Mazaré, Alexandre Défossez
We introduce Delayed Streams Modeling (DSM), a flexible formulation for streaming, multimodal sequence-to-sequence learning. Sequence-to-sequence generation is often cast in an offline manner, where the model consumes the complete input sequence before generating the first output timestep. Alternatively, streaming sequence-to-sequence rely on learning a policy for choosing when to advance on the input stream, or write to the output stream. DSM instead models already time-aligned streams with a decoder-only language model. By moving the alignment to a pre-processing step,and introducing appropriate delays between streams, DSM provides streaming inference of arbitrary output sequences, from any input combination, making it applicable to many sequence-to-sequence problems. In particular, given text and audio streams, automatic speech recognition (ASR) corresponds to the text stream being delayed, while the opposite gives a text-to-speech (TTS) model. We perform extensive experiments for these two major sequence-to-sequence tasks, showing that DSM provides state-of-the-art performance and latency while supporting arbitrary long sequences, being even competitive with offline baselines. Code, samples and demos are available at https://github.com/kyutai-labs/delayed-streams-modeling
我们引入了延迟流建模(DSM),这是一种用于流式、多模态序列到序列学习的灵活方法。序列到序列生成通常以一种离线的方式进行,即模型在生成第一个输出时间步之前消耗完整的输入序列。相比之下,流式序列到序列则依赖于学习策略,以确定何时推进输入流或写入输出流。然而,DSM使用仅解码的语言模型对已经时间对齐的流进行建模。通过将对齐移至预处理步骤,并在流之间引入适当的延迟,DSM提供了任意输出序列的流式推断,适用于许多序列到序列问题,适用于任意输入组合。特别是给定文本和音频流时,语音识别(ASR)对应于文本流延迟,而相反则给出文本到语音(TTS)模型。我们对这两个主要的序列到序列任务进行了大量实验,结果表明,DSM在提供最先进的性能和延迟的同时,还支持任意长序列,甚至与离线基准竞争。代码、样本和演示可在https://github.com/kyutai-labs/delayed-streams-modeling找到。
论文及项目相关链接
Summary
本文介绍了延迟流建模(DSM)这一灵活的多模态序列到序列学习框架。传统的序列到序列生成通常是离线进行的,而DSM则将输入流和输出流的对齐过程移至预处理阶段,通过引入适当的延迟,实现了任意输出序列的流式推断。这使得DSM适用于多种序列到序列问题,如语音识别和文本到语音转换。实验表明,DSM具有最先进的性能和低延迟,支持任意长序列,与离线基准测试相比具有竞争力。
Key Takeaways
- 延迟流建模(DSM)是一个灵活的多模态序列到序列学习框架,适用于流式处理。
- 传统序列到序列生成是离线的,而DSM实现流式推断,可在生成输出时逐步处理输入。
- DSM通过预处理的步骤进行输入和输出流的对齐。
- 通过引入适当的延迟,DSM可以应用于多种序列到序列问题,如语音识别和文本到语音转换(TTS)。
- 在主要任务上的实验表明,DSM具有先进的性能和低延迟。
- DSM支持任意长度的序列处理。
点此查看论文截图

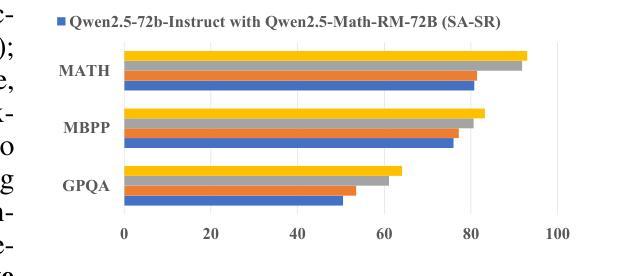
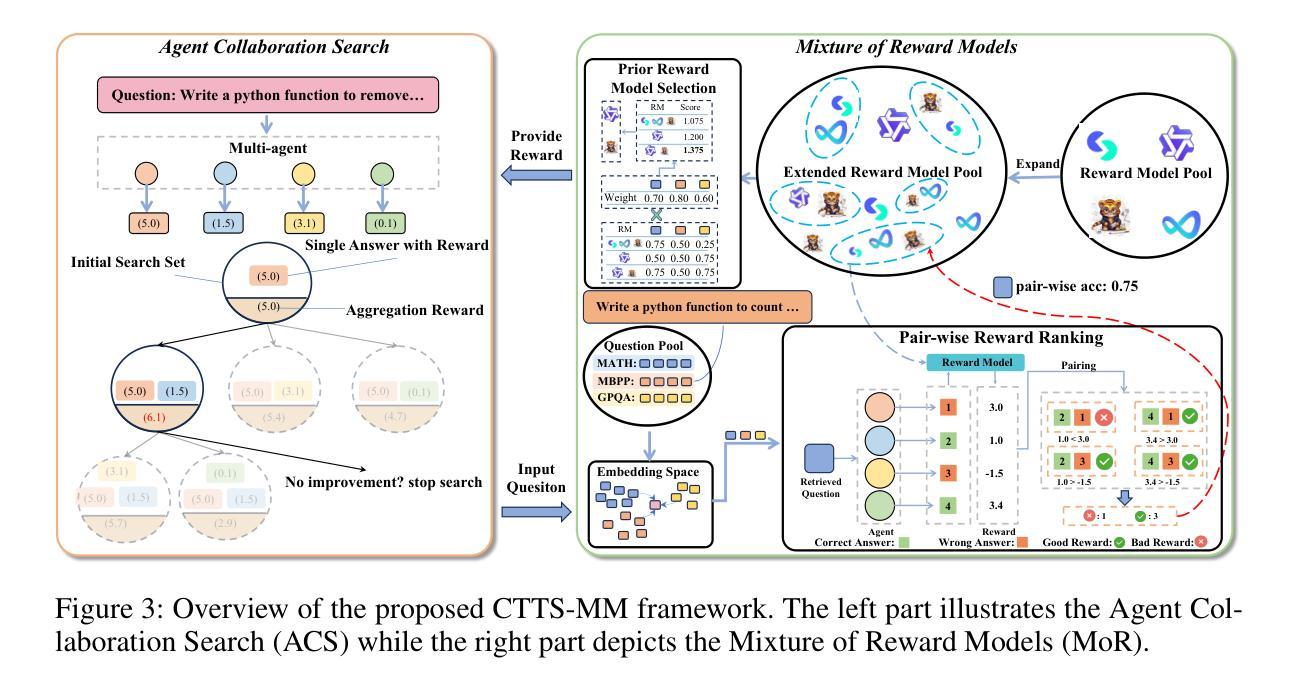
CTTS: Collective Test-Time Scaling
Authors:Zhende Song, Shengji Tang, Peng Ye, Jiayuan Fan, Lei Bai, Tao Chen, Wanli Ouyang
Test-time scaling (TTS) has emerged as a promising, training-free approach for enhancing large language model (LLM) performance. However, the efficacy of existing methods, such as Best-of-N and Self-Consistency, is fundamentally constrained by the dominant single test-time scaling (STTS) paradigm, which relies on a single LLM agent interacting with a single reward model (SA-SR). Inspired by recent work showing that collective methods can surpass the performance ceiling of individual models, we introduce Collective Test-Time Scaling (CTTS). First, we systematically investigate three primary interaction paradigms of existing multiple models: single-agent-multi-reward (SA-MR), multi-agent-single-reward (MA-SR), and multi-agent-multi-reward (MA-MR). Extensive experiments reveal that the MA-MR paradigm is consistently superior. Based on this finding, we further propose CTTS-MM, a novel framework that operationalizes multi-agent and multi-reward collaboration. CTTS-MM integrates two key technical contributions: (1) for agent collaboration, an Agent Collaboration Search (ACS) that identifies the most effective combination of LLMs from a candidate pool; and (2) for reward model collaboration, a Mixture of Reward Models (MoR) strategy that leverages a Prior Reward model Ensemble Selection (PRES) algorithm to select the optimal ensemble. Evaluations across seven mainstream benchmarks demonstrate that CTTS-MM significantly outperforms leading STTS methods (+4.82% over Best-of-N) and surpasses even flagship proprietary LLMs (+7.06% over GPT-4.1) and open-source LLMs. These results highlight the substantial potential of collective scaling to push the frontier of LLM inference. Code will be released at https://github.com/magent4aci/CTTS-MM.
测试时缩放(TTS)作为一种无需训练即可提高大语言模型(LLM)性能的方法,展现出巨大的潜力。然而,现有方法(如N选最佳和自一致性)的效力从根本上受到单一测试时缩放(STTS)范式的限制,该范式依赖于单个LLM代理与单个奖励模型(SA-SR)进行交互。最近的工作表明,集体方法能够超越个体模型的性能上限,因此我们引入了集体测试时缩放(CTTS)。首先,我们系统地研究了现有多个模型的主要交互范式:单代理多奖励(SA-MR)、多代理单奖励(MA-SR)和多代理多奖励(MA-MR)。大量实验表明,MA-MR范式始终具有优势。基于这一发现,我们进一步提出了CTTS-MM,一个操作化多代理和多奖励协作的新框架。CTTS-MM集成了两项关键技术贡献:(1) 对于代理协作,Agent Collaboration Search(ACS)能够从候选池中识别出最有效的LLM组合;(2) 对于奖励模型协作,采用Mixture of Reward Models(MoR)策略,利用Prior Reward model Ensemble Selection(PRES)算法选择最佳组合。在七个主流基准测试上的评估表明,CTTS-MM显著优于领先的STTS方法(+4.82%优于N选最佳),甚至超过旗舰专有LLM(+7.06%优于GPT-4.1)和开源LLM。这些结果凸显了集体缩放推动LLM推理前沿的巨大潜力。代码将在https://github.com/magent4aci/CTTS-MM发布。
论文及项目相关链接
Summary
本文介绍了测试时缩放(TTS)在提升大型语言模型(LLM)性能方面的潜力。然而,现有方法如Best-of-N和Self-Consistency受到单一测试时缩放(STTS)范式的限制。受多模型协同工作超越个体模型性能上限的启发,本文提出了集体测试时缩放(CTTS)。通过系统研究现有多个模型的三类交互范式,发现多代理多奖励(MA-MR)范式表现最佳。基于此,进一步提出了CTTS-MM框架,实现了多代理和多奖励的协同工作。该框架包括两个关键技术贡献:一是代理协作搜索(ACS),从候选池中识别最有效的LLM组合;二是奖励模型协作的混合奖励模型(MoR)策略,利用先验奖励模型集合选择(PRES)算法选择最佳集合。在七个主流基准测试上的评估表明,CTTS-MM显著优于领先的STTS方法(较Best-of-N提高4.82%),甚至超过了旗舰专有LLM(较GPT-4.1提高7.06%)。这突显了集体缩放推动LLM推理前沿的巨大潜力。
Key Takeaways
- 测试时缩放(TTS)是提升大型语言模型(LLM)性能的一种有前途的训练外方法。
- 现有方法受限于单一测试时缩放(STTS)范式,而多模型协同工作可突破性能上限。
- 引入集体测试时缩放(CTTS),通过系统研究三个主要交互范式,发现多代理多奖励(MA-MR)范式表现最佳。
- 提出CTTS-MM框架,实现多代理和多奖励的协同工作,包括代理协作搜索(ACS)和混合奖励模型(MoR)策略。
- CTTS-MM框架在七个主流基准测试上表现出显著优势,较领先的STTS方法和GPT-4.1有显著提升。
- 集体缩放具有巨大的潜力,可推动LLM推理前沿的进步。
点此查看论文截图