⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-01 更新
Walk the Talk: Is Your Log-based Software Reliability Maintenance System Really Reliable?
Authors:Minghua He, Tong Jia, Chiming Duan, Pei Xiao, Lingzhe Zhang, Kangjin Wang, Yifan Wu, Ying Li, Gang Huang
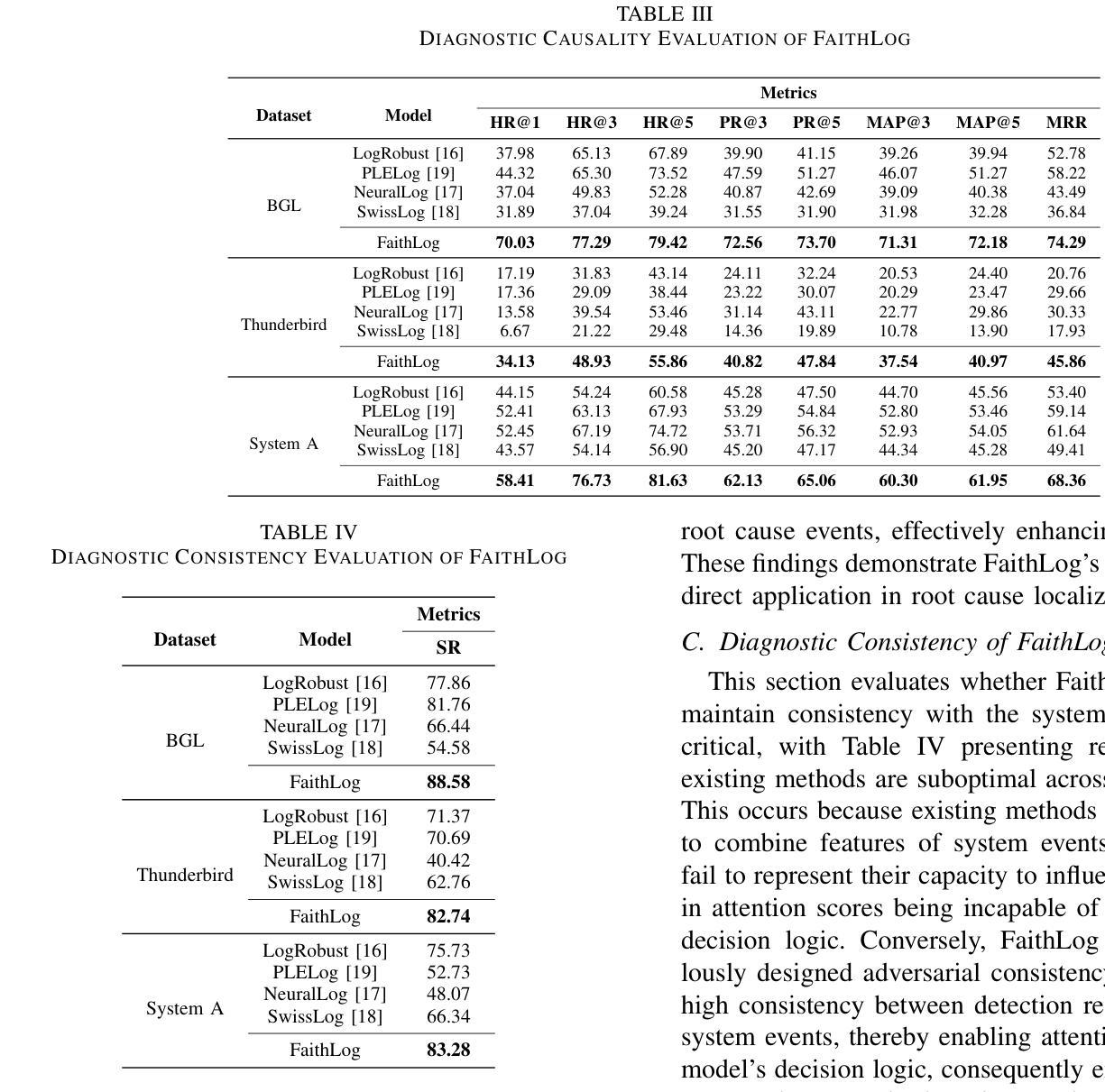
Log-based software reliability maintenance systems are crucial for sustaining stable customer experience. However, existing deep learning-based methods represent a black box for service providers, making it impossible for providers to understand how these methods detect anomalies, thereby hindering trust and deployment in real production environments. To address this issue, this paper defines a trustworthiness metric, diagnostic faithfulness, for models to gain service providers’ trust, based on surveys of SREs at a major cloud provider. We design two evaluation tasks: attention-based root cause localization and event perturbation. Empirical studies demonstrate that existing methods perform poorly in diagnostic faithfulness. Consequently, we propose FaithLog, a faithful log-based anomaly detection system, which achieves faithfulness through a carefully designed causality-guided attention mechanism and adversarial consistency learning. Evaluation results on two public datasets and one industrial dataset demonstrate that the proposed method achieves state-of-the-art performance in diagnostic faithfulness.
基于日志的软件可靠性维护系统对于维持稳定的客户体验至关重要。然而,现有的深度学习方法对于服务提供者来说是一个黑盒子,使得提供者无法了解这些方法是如何检测异常的,从而阻碍了其在真实生产环境中的信任度和部署。针对这一问题,本文基于大型云服务商的SRE调查,定义了一个用于模型获取服务提供者信任的可信度量指标——诊断保真度。我们设计了两个评估任务:基于注意力的根本原因定位和事件扰动。实证研究证明,现有方法在诊断保真度方面的表现较差。因此,我们提出了FaithLog,一个忠诚的基于日志的异常检测系统,通过精心设计的因果引导注意机制和对抗一致性学习来实现保真度。在两个公开数据集和一个工业数据集上的评估结果表明,该方法在诊断保真度上达到了最先进的性能。
论文及项目相关链接
PDF Accepted by ASE 2025 (NIER Track)
摘要
基于日志的软件可靠性维护系统对于维持稳定的客户体验至关重要。然而,现有的深度学习方法对于服务提供商来说是一个黑盒子,无法了解它们是如何检测异常的,这影响了服务提供商的信任以及在真实生产环境中的部署。为解决这一问题,本文基于一家主要云服务商的SRE调查,定义了一个用于模型的可信度量标准——诊断忠实度。我们设计了两个评估任务:基于注意力的根本原因定位和事件扰动。实证研究证明现有方法在诊断忠实度方面的表现较差。因此,我们提出了FaithLog,一个忠诚的日志异常检测系统,通过精心设计的因果引导注意机制和对抗一致性学习来实现忠实度。在两个公开数据集和一个工业数据集上的评估结果表明,该方法在诊断忠实度方面达到了最新水平。
关键见解
- 基于日志的软件可靠性维护系统对维持稳定的客户体验至关重要。
- 现有的深度学习方法对于服务提供商来说是一个黑盒子,难以了解其异常检测机制。
- 定义了一个新的模型可信度量标准——诊断忠实度,以提高服务提供商对模型的信任。
- 设计了基于注意力和事件扰动的两个评估任务来评估模型的诊断忠实度。
- 实证研究指出,现有方法在诊断忠实度方面表现不足。
- 提出FaithLog系统,通过因果引导注意机制和对抗一致性学习实现高诊断忠实度。
点此查看论文截图
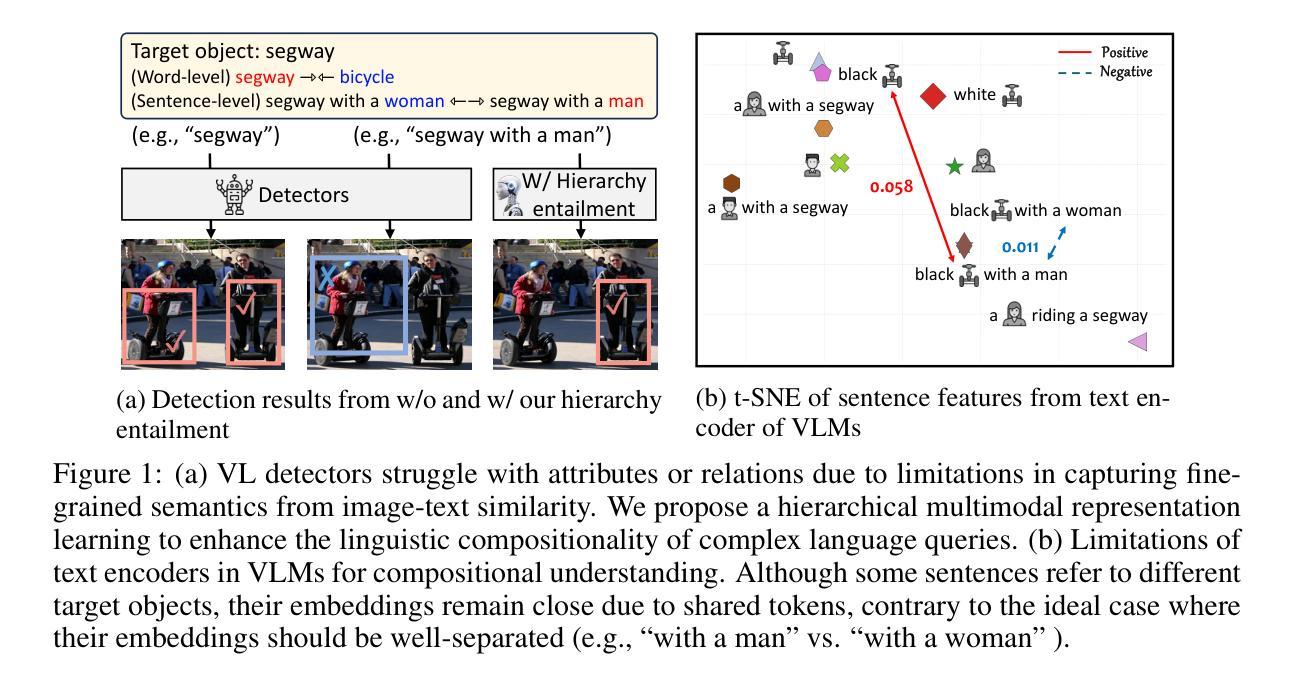
Talk in Pieces, See in Whole: Disentangling and Hierarchical Aggregating Representations for Language-based Object Detection
Authors:Sojung An, Kwanyong Park, Yong Jae Lee, Donghyun Kim
While vision-language models (VLMs) have made significant progress in multimodal perception (e.g., open-vocabulary object detection) with simple language queries, state-of-the-art VLMs still show limited ability to perceive complex queries involving descriptive attributes and relational clauses. Our in-depth analysis shows that these limitations mainly stem from text encoders in VLMs. Such text encoders behave like bags-of-words and fail to separate target objects from their descriptive attributes and relations in complex queries, resulting in frequent false positives. To address this, we propose restructuring linguistic representations according to the hierarchical relations within sentences for language-based object detection. A key insight is the necessity of disentangling textual tokens into core components-objects, attributes, and relations (“talk in pieces”)-and subsequently aggregating them into hierarchically structured sentence-level representations (“see in whole”). Building on this principle, we introduce the TaSe framework with three main contributions: (1) a hierarchical synthetic captioning dataset spanning three tiers from category names to descriptive sentences; (2) Talk in Pieces, the three-component disentanglement module guided by a novel disentanglement loss function, transforms text embeddings into subspace compositions; and (3) See in Whole, which learns to aggregate disentangled components into hierarchically structured embeddings with the guide of proposed hierarchical objectives. The proposed TaSe framework strengthens the inductive bias of hierarchical linguistic structures, resulting in fine-grained multimodal representations for language-based object detection. Experimental results under the OmniLabel benchmark show a 24% performance improvement, demonstrating the importance of linguistic compositionality.
虽然视觉语言模型(VLMs)在多模态感知(例如开放词汇对象检测)方面已经取得了显著进展,并且能够通过简单的语言查询实现这一点,但最先进的VLMs在处理涉及描述性属性和关系从句的复杂查询时,感知能力仍然有限。我们的深入分析表明,这些限制主要源于VLMs中的文本编码器。这种文本编码器表现得像词袋,并且无法从复杂查询中的目标对象、描述性属性和关系中分离目标对象,从而导致频繁的误报。针对这一问题,我们提出根据句子内的层次关系重构语言表示,以实现基于语言的对象检测。一个重要的见解是将文本标记分解为核心组件——对象、属性和关系(“分段对话”),然后将其聚合成具有层次结构的句子级表示(“整体观察”)。基于这一原理,我们引入了TaSe框架,其主要贡献有三点:1)一个层次合成描述数据集,涵盖从类别名称到描述句子的三个层次;2)以新型解纠缠损失函数为指导的“分段对话”三组件解纠缠模块,将文本嵌入转换为子空间组合;3)“整体观察”,学习将解纠缠的组件聚合成具有层次结构的嵌入,借助所提出的层次目标进行引导。所提出的TaSe框架加强了层次语言结构的归纳偏见,为基于语言的对象检测生成精细的多模态表示。在OmniLabel基准测试下的实验结果显示性能提高了24%,这证明了语言组合性的重要性。
论文及项目相关链接
PDF 23 pages, 17 figures
Summary
本文指出当前视觉语言模型在处理复杂查询时存在局限性,主要体现在对目标对象、描述性属性和关系的处理上。为解决这一问题,提出了TaSe框架,包括分层合成数据集的构建、Talk in Pieces模块实现文本嵌入的解耦转换以及See in Whole模块学习聚合解耦成分。该框架强化了层次化语言结构的归纳偏见,提高了基于语言的目标检测的细粒度多模态表示性能。
Key Takeaways
- 当前视觉语言模型在处理涉及描述性属性和关系条款的复杂查询时存在局限性。
- 局限性主要源于文本编码器无法区分目标对象、描述性属性和关系。
- TaSe框架被提出以解决这一问题,包括分层合成数据集、Talk in Pieces模块和See in Whole模块。
- Talk in Pieces模块通过解耦文本标记,将文本嵌入转化为子空间组合。
- See in Whole模块学习将解耦的组件聚合为分层结构化的嵌入。
- TaSe框架强化了层次化语言结构的归纳偏见,提高了语言基础目标检测的细粒度多模态表示性能。
点此查看论文截图