⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-04 更新
From Frames to Clips: Efficient Key Clip Selection for Long-Form Video Understanding
Authors:Guangyu Sun, Archit Singhal, Burak Uzkent, Mubarak Shah, Chen Chen, Garin Kessler
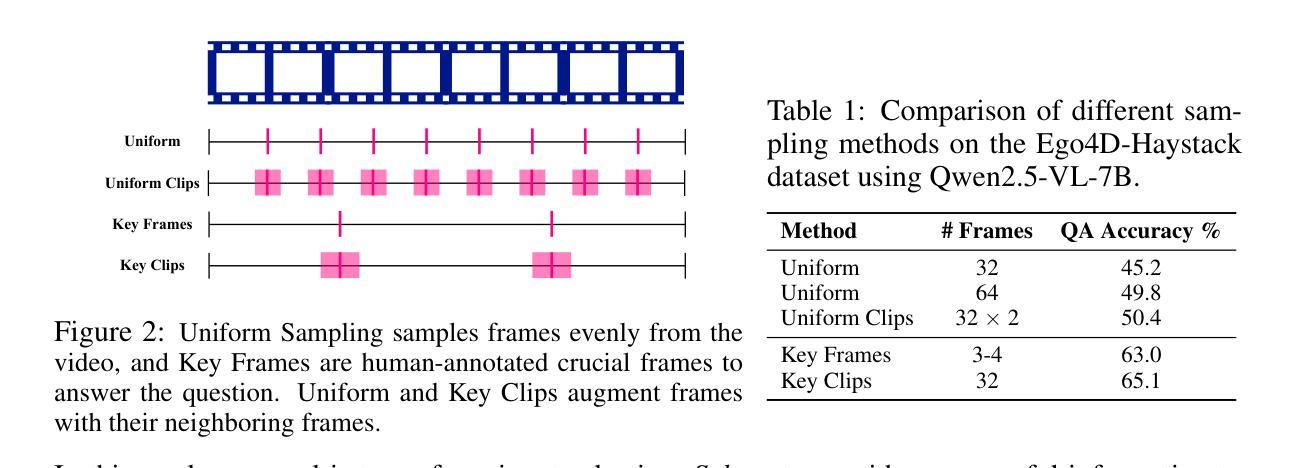
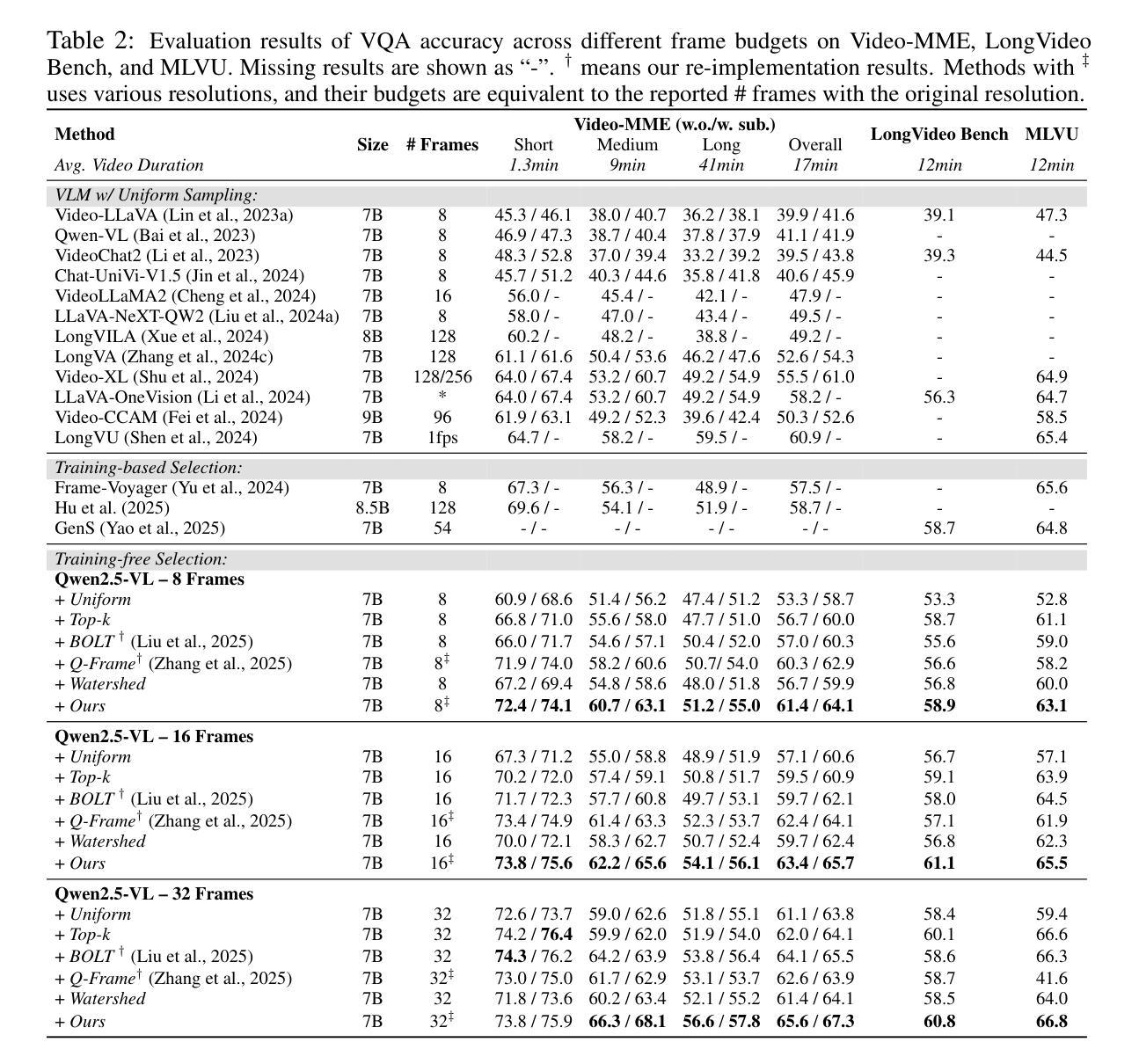
Video Large Language Models (VLMs) have achieved remarkable results on a variety of vision language tasks, yet their practical use is limited by the “needle in a haystack” problem: the massive number of visual tokens produced from raw video frames exhausts the model’s context window. Existing solutions alleviate this issue by selecting a sparse set of frames, thereby reducing token count, but such frame-wise selection discards essential temporal dynamics, leading to suboptimal reasoning about motion and event continuity. In this work we systematically explore the impact of temporal information and demonstrate that extending selection from isolated key frames to key clips, which are short, temporally coherent segments, improves video understanding. To maintain a fixed computational budget while accommodating the larger token footprint of clips, we propose an adaptive resolution strategy that dynamically balances spatial resolution and clip length, ensuring a constant token count per video. Experiments on three long-form video benchmarks demonstrate that our training-free approach, F2C, outperforms uniform sampling up to 8.1%, 5.6%, and 10.3% on Video-MME, LongVideoBench and MLVU benchmarks, respectively. These results highlight the importance of preserving temporal coherence in frame selection and provide a practical pathway for scaling Video LLMs to real world video understanding applications. Project webpage is available at https://guangyusun.com/f2c .
视频大型语言模型(VLMs)在各种视觉语言任务上取得了显著成果,但它们在实践中的使用受到了“海底捞针”问题的限制:来自原始视频帧的众多视觉标记符号消耗了大量的模型上下文窗口。现有解决方案通过选择稀疏的帧集来缓解这个问题,从而减少标记符号的数量,但这种基于帧的选择丢弃了重要的时间动态信息,导致对运动和事件连续性的推理不够理想。在这项工作中,我们系统地探讨了时间信息的影响,并证明将选择范围从孤立的关键帧扩展到关键片段(短而时间连贯的片段)可以提高视频理解能力。为了维持固定的计算预算,同时适应片段更大的标记符号足迹,我们提出了一种自适应分辨率策略,该策略动态平衡空间分辨率和片段长度,确保每个视频的标记符号计数保持恒定。在三个长格式视频基准测试上的实验表明,我们的无需训练的方法F2C在Video-MME、LongVideoBench和MLVU基准测试上的表现分别优于均匀采样高达8.1%、5.6%和10.3%。这些结果强调了保持时间连贯性在帧选择中的重要性,并为视频大型语言模型在现实世界的视频理解应用中扩展提供了实用途径。项目网页可在https://guangyusun.com/f2c上找到。
论文及项目相关链接
摘要
视频大语言模型(VLMs)在多种视觉语言任务上取得了显著成果,但其实际应用中面临“沙里淘金”的问题:从原始视频帧产生的海量视觉令牌耗尽了模型的上下文窗口。现有解决方案通过选择少量的帧来减少令牌数量,但这种基于帧的选择方式忽略了重要的时间动态信息,导致对动作和事件连续性的推理不佳。本研究系统性地探讨了时间信息的影响,并证明将选择从孤立的关键帧扩展到关键片段(即短而时间连贯的片段)可以提高视频理解。为了维持固定的计算预算,同时适应片段较大的令牌足迹,我们提出了一种自适应分辨率策略,动态平衡空间分辨率和片段长度,确保每个视频的令牌计数保持不变。在三个长格式视频基准测试上的实验表明,我们的无训练方法F2C在Video-MME、LongVideoBench和MLVU基准测试上的表现分别优于均匀采样高达8.1%、5.6%和10.3%。这些结果强调了保持时间连贯性在帧选择中的重要性,并为视频大语言模型在现实视频理解应用中的扩展提供了实用途径。
关键见解
- VLMs在多种视觉语言任务上表现出色,但面临“沙里淘金”问题:海量视频令牌导致模型上下文窗口受限。
- 现有解决方案通过选择少量帧减少令牌数量,但这种方法忽略了重要的时间动态信息。
- 提出了一种新的方法F2C,通过选择关键片段而不是孤立的帧来提高视频理解。
- F2C采用自适应分辨率策略,在维持固定计算预算的同时,适应片段的较大令牌足迹。
- F2C在三个长视频基准测试上的表现优于均匀采样,证明了保持时间连贯性在帧选择中的重要性。
- F2C为视频大语言模型在现实视频理解应用中的扩展提供了实用途径。
- 项目网页地址:https://guangyusun.com/f2c。
点此查看论文截图

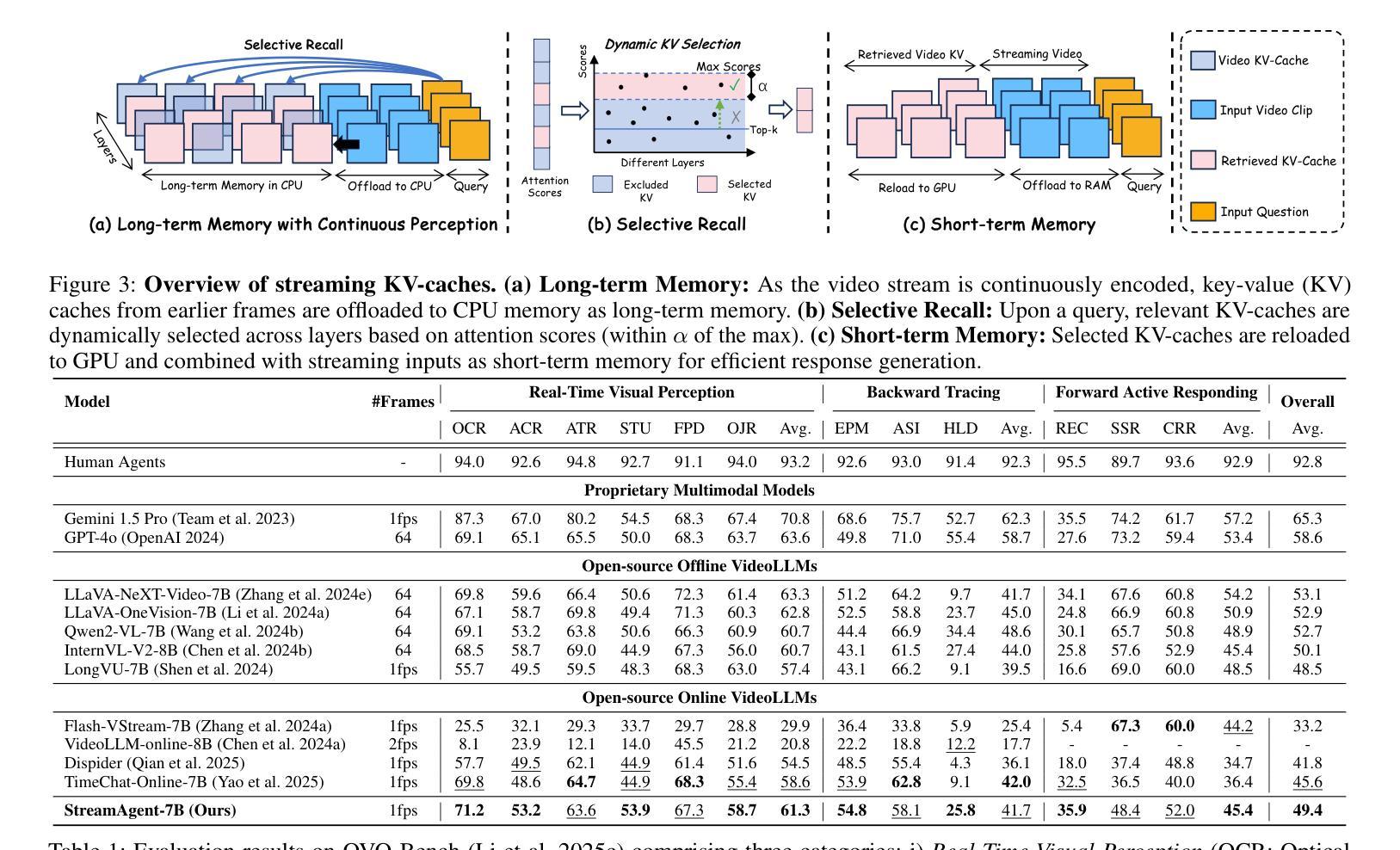
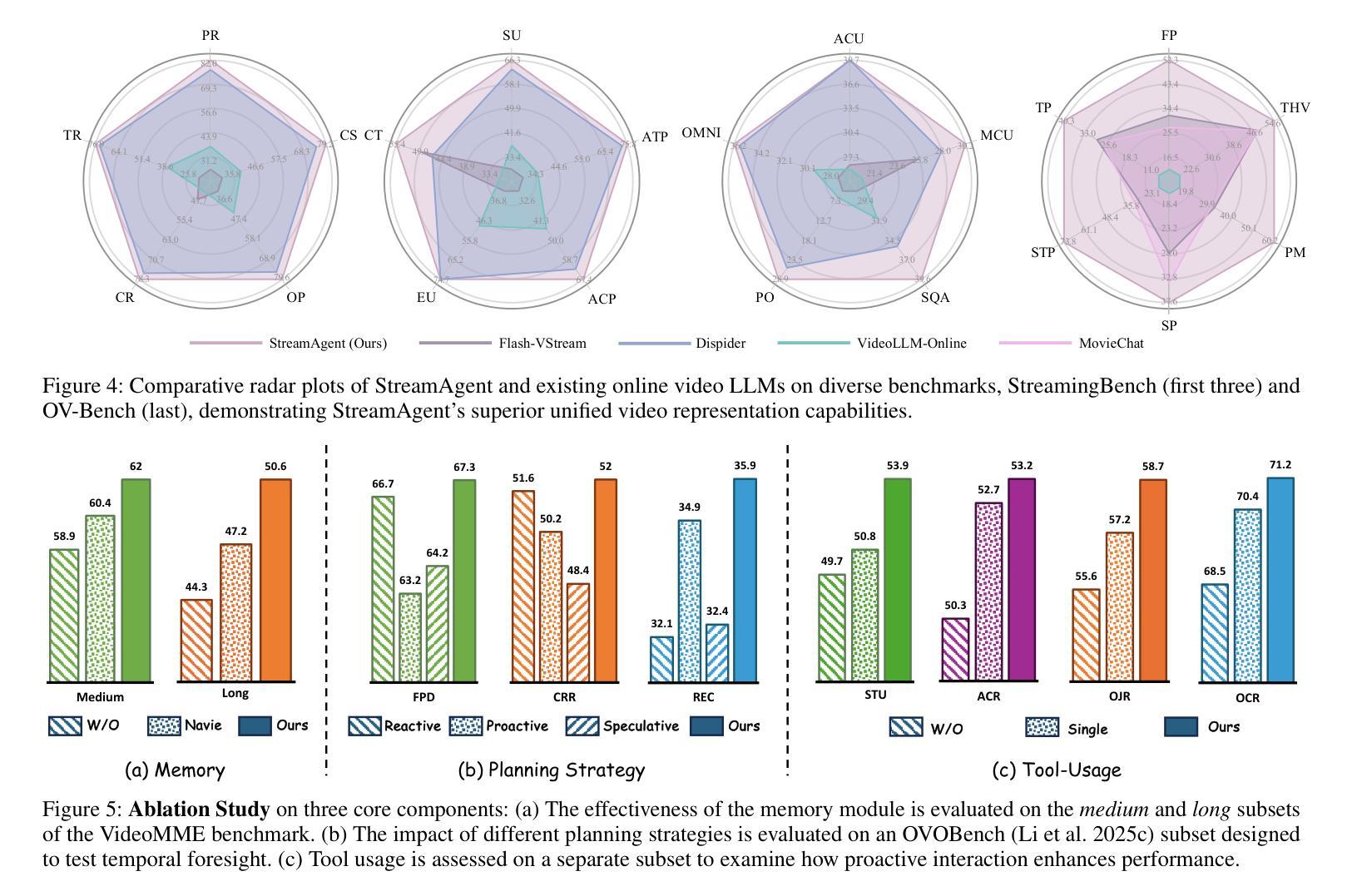
StreamAgent: Towards Anticipatory Agents for Streaming Video Understanding
Authors:Haolin Yang, Feilong Tang, Linxiao Zhao, Xiang An, Ming Hu, Huifa Li, Xinlin Zhuang, Boqian Wang, Yifan Lu, Xiaofeng Zhang, Abdalla Swikir, Junjun He, Zongyuan Ge, Imran Razzak
Real-time streaming video understanding in domains such as autonomous driving and intelligent surveillance poses challenges beyond conventional offline video processing, requiring continuous perception, proactive decision making, and responsive interaction based on dynamically evolving visual content. However, existing methods rely on alternating perception-reaction or asynchronous triggers, lacking task-driven planning and future anticipation, which limits their real-time responsiveness and proactive decision making in evolving video streams. To this end, we propose a StreamAgent that anticipates the temporal intervals and spatial regions expected to contain future task-relevant information to enable proactive and goal-driven responses. Specifically, we integrate question semantics and historical observations through prompting the anticipatory agent to anticipate the temporal progression of key events, align current observations with the expected future evidence, and subsequently adjust the perception action (e.g., attending to task-relevant regions or continuously tracking in subsequent frames). To enable efficient inference, we design a streaming KV-cache memory mechanism that constructs a hierarchical memory structure for selective recall of relevant tokens, enabling efficient semantic retrieval while reducing the overhead of storing all tokens in the traditional KV-cache. Extensive experiments on streaming and long video understanding tasks demonstrate that our method outperforms existing methods in response accuracy and real-time efficiency, highlighting its practical value for real-world streaming scenarios.
在自动驾驶和智能监控等领域,实时流媒体视频理解面临的挑战超出了传统的离线视频处理范围。它要求基于动态演变的视觉内容,进行连续感知、主动决策和响应交互。然而,现有方法依赖于交替感知反应或异步触发,缺乏任务驱动的规划和未来预测,这限制了它们在实时流媒体中的反应速度和主动决策能力。为此,我们提出了一个StreamAgent,能够预测未来任务相关信息的预期时间间隔和空间区域,以实现目标驱动的主动响应。具体来说,我们通过提示预测代理来整合问题语义和历史观察,预测关键事件的时间进展,将当前观察与预期的未来证据对齐,并随后调整感知行为(例如,关注任务相关区域或在后续帧中进行持续跟踪)。为了实现高效推理,我们设计了一种流KV缓存机制,构建了一种分层内存结构,用于有选择地回忆起相关令牌,从而在减少存储所有令牌的传统KV缓存开销的同时,实现高效语义检索。在流媒体和长视频理解任务上的大量实验表明,我们的方法在响应准确性和实时效率方面优于现有方法,突显了其在真实世界流媒体场景中的实用价值。
论文及项目相关链接
Summary
本文探讨了实时流媒体视频理解在自动驾驶和智能监控等领域面临的挑战。现有方法缺乏任务驱动的规划和未来预测,限制了其在实时流媒体视频中的响应能力和主动决策能力。为此,本文提出了一种StreamAgent,能够预测未来任务相关信息的时空区间,实现目标驱动的响应。通过整合问题语义和历史观察,促使预测代理预测关键事件的时间进展,将当前观察与预期的未来证据对齐,并调整感知动作。同时,设计了一种流式KV缓存机制,构建了分层内存结构,实现了相关标记的选择性召回,提高了语义检索效率,降低了传统KV缓存存储所有标记的开销。实验表明,该方法在响应准确性和实时效率方面优于现有方法,具有实际应用价值。
Key Takeaways
- 实时流媒体视频理解在自动驾驶和智能监控等领域面临挑战,需要连续感知、主动决策和基于动态视觉内容的响应交互。
- 现有方法主要依赖交替感知反应或异步触发,缺乏任务驱动的规划和未来预测。
- StreamAgent通过预测未来任务相关信息的时空区间,实现目标驱动的响应,解决现有方法的局限性。
- 整合问题语义和历史观察,促使预测代理预测关键事件的时间进展。
- 当前观察与预期的未来证据对齐,并调整感知动作以应对动态变化的视频流。
- 设计的流式KV缓存机制构建分层内存结构,实现相关标记的选择性召回,提高语义检索效率。
点此查看论文截图