⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-04 更新
Taking a SEAT: Predicting Value Interpretations from Sentiment, Emotion, Argument, and Topic Annotations
Authors:Adina Nicola Dobrinoiu, Ana Cristiana Marcu, Amir Homayounirad, Luciano Cavalcante Siebert, Enrico Liscio
Our interpretation of value concepts is shaped by our sociocultural background and lived experiences, and is thus subjective. Recognizing individual value interpretations is important for developing AI systems that can align with diverse human perspectives and avoid bias toward majority viewpoints. To this end, we investigate whether a language model can predict individual value interpretations by leveraging multi-dimensional subjective annotations as a proxy for their interpretive lens. That is, we evaluate whether providing examples of how an individual annotates Sentiment, Emotion, Argument, and Topics (SEAT dimensions) helps a language model in predicting their value interpretations. Our experiment across different zero- and few-shot settings demonstrates that providing all SEAT dimensions simultaneously yields superior performance compared to individual dimensions and a baseline where no information about the individual is provided. Furthermore, individual variations across annotators highlight the importance of accounting for the incorporation of individual subjective annotators. To the best of our knowledge, this controlled setting, although small in size, is the first attempt to go beyond demographics and investigate the impact of annotation behavior on value prediction, providing a solid foundation for future large-scale validation.
我们对价值概念的理解受到我们的社会文化背景和生活经历的影响,因此是主观的。识别个体的价值解读对于开发能够与多样化的人类视角相吻合并避免偏向多数观点的AI系统很重要。为此,我们调查语言模型是否可以利用多维主观注释作为解读透镜的代理来预测个体价值解读。也就是说,我们评估提供个人如何注释情感、情绪、观点和话题(SEAT维度)的例子是否有助于语言模型预测他们的价值解读。我们在不同的零样本和少样本设置下的实验表明,同时提供所有SEAT维度相比单独维度和一个不提供个体信息的基准线能带来更好的性能。此外,标注者之间的个体差异突显了需要考虑融入个体主观标注者的重要性。据我们所知,这个受控设置虽然规模较小,但是首次尝试超越人口统计学,研究标注行为对价值预测的影响,为未来的大规模验证提供了坚实的基础。
论文及项目相关链接
PDF Accepted at VALE workshop (ECAI 2025)
Summary
本文探讨了个人价值观念的解读受到社会文化背景和生活经历的影响,具有主观性。为了发展能够符合多元人类视角并避免偏向主流观点的AI系统,研究是否可以通过利用多维主观注释作为个体解读的透镜来预测个体价值解读。实验表明,在不同零样本和少样本设置下,同时提供情感、情绪、论证和主题(SEAT维度)的注释信息能提高预测性能,且比仅提供个别维度或没有提供个体信息的基础模型表现更佳。研究还发现,不同注释者之间的个体差异凸显出考虑个体主观注释的重要性。该实验虽规模较小,但却是首次尝试超越人口统计学去探究注释行为对价值预测的影响,为未来大规模验证提供了坚实的基础。
Key Takeaways
- 个人价值观念的解读具有主观性,受到社会文化背景和生活经历的影响。
- 通过利用多维主观注释作为个体解读价值的透镜,可以预测个体价值解读。
- 实验表明,同时提供情感、情绪、论证和主题的注释信息能提高预测性能。
- 个体差异在价值预测中很重要,需要考虑到不同注释者之间的差异性。
- 此研究是首次尝试超越人口统计学探究注释行为对价值预测的影响。
- 提供了一种基于少量数据验证的有效方法,为未来的大规模验证提供了基础。
点此查看论文截图
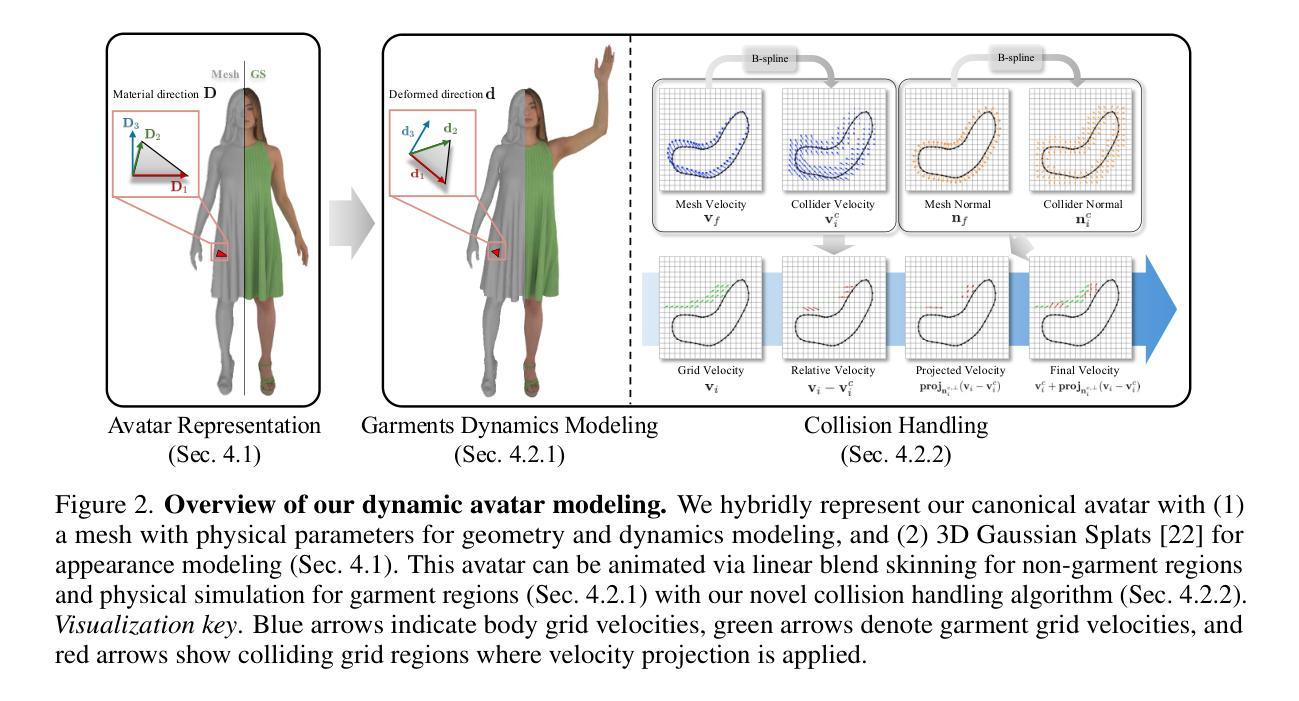
MPMAvatar: Learning 3D Gaussian Avatars with Accurate and Robust Physics-Based Dynamics
Authors:Changmin Lee, Jihyun Lee, Tae-Kyun Kim
While there has been significant progress in the field of 3D avatar creation from visual observations, modeling physically plausible dynamics of humans with loose garments remains a challenging problem. Although a few existing works address this problem by leveraging physical simulation, they suffer from limited accuracy or robustness to novel animation inputs. In this work, we present MPMAvatar, a framework for creating 3D human avatars from multi-view videos that supports highly realistic, robust animation, as well as photorealistic rendering from free viewpoints. For accurate and robust dynamics modeling, our key idea is to use a Material Point Method-based simulator, which we carefully tailor to model garments with complex deformations and contact with the underlying body by incorporating an anisotropic constitutive model and a novel collision handling algorithm. We combine this dynamics modeling scheme with our canonical avatar that can be rendered using 3D Gaussian Splatting with quasi-shadowing, enabling high-fidelity rendering for physically realistic animations. In our experiments, we demonstrate that MPMAvatar significantly outperforms the existing state-of-the-art physics-based avatar in terms of (1) dynamics modeling accuracy, (2) rendering accuracy, and (3) robustness and efficiency. Additionally, we present a novel application in which our avatar generalizes to unseen interactions in a zero-shot manner-which was not achievable with previous learning-based methods due to their limited simulation generalizability. Our project page is at: https://KAISTChangmin.github.io/MPMAvatar/
在3D阿凡达(avatar)从视觉观察进行创作的领域取得了显著进展的同时,用宽松衣物模拟人类物理上可行的动态仍然是一个具有挑战性的问题。虽然有一些现有工作通过利用物理模拟来解决这个问题,但它们在准确性和对新型动画输入的稳健性方面存在局限。在这项工作中,我们提出了MPMAvatar框架,它可以从多视角视频创建3D人类阿凡达,支持高度逼真、稳健的动画,以及从自由视角进行真实感渲染。为了进行精确而稳健的动态建模,我们的核心思想是使用基于物质点方法的模拟器,我们精心定制它来模拟衣物的复杂变形以及与底层身体的接触,通过引入一个各向异性本构模型和一种新型碰撞处理算法。我们将这种动态建模方案与我们的规范阿凡达相结合,该阿凡达可以使用带有准阴影的3D高斯贴图进行渲染,为物理真实的动画提供高保真渲染。在我们的实验中,我们证明了MPMAvatar在(1)动态建模准确性、(2)渲染准确性和(3)稳健性和效率方面显著优于现有的基于物理的阿凡达技术。此外,我们还展示了一项新颖的应用,即我们的阿凡达能够以零镜头的方式泛化到未见过的交互-这是以前基于学习的方法由于有限的模拟泛化能力而无法实现的。我们的项目页面是:https://KAISTChangmin.github.io/MPMAvatar/ 。
论文及项目相关链接
PDF Accepted to NeurIPS 2025
Summary
本文介绍了MPMAvatar框架,该框架支持从多视角视频创建3D人类角色动画,具有逼真、稳健的特点,并能从自由视角进行照片级渲染。关键思想是采用基于物质点方法的模拟器来精确模拟衣物的复杂变形以及与底层身体的接触碰撞。通过实验证明,MPMAvatar在动力学建模、渲染准确性以及稳健性和效率方面均优于现有技术。此外,还展示了其在新互动场景下的零样本泛化能力。
Key Takeaways
- MPMAvatar框架支持从多视角视频创建高度逼真的3D人类角色动画。
- 采用物质点方法模拟器,能精确模拟衣物的复杂变形和与身体的接触碰撞。
- MPMAvatar在动力学建模、渲染准确性以及稳健性和效率方面超越了现有技术。
- 展示了对未见互动的零样本泛化能力。
- 该框架能够处理复杂场景下的物理仿真,提高了动画的真实感和观看体验。
- MPMAvatar通过结合物质点方法和典型角色模型,实现了物理现实主义的动画渲染。
点此查看论文截图

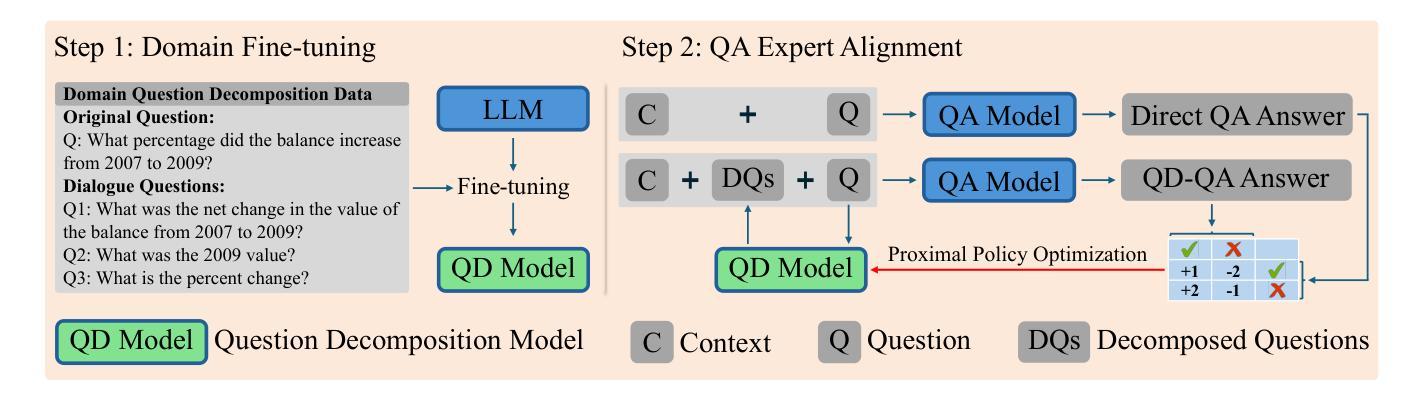
One More Question is Enough, Expert Question Decomposition (EQD) Model for Domain Quantitative Reasoning
Authors:Mengyu Wang, Sotirios Sabanis, Miguel de Carvalho, Shay B. Cohen, Tiejun Ma
Domain-specific quantitative reasoning remains a major challenge for large language models (LLMs), especially in fields requiring expert knowledge and complex question answering (QA). In this work, we propose Expert Question Decomposition (EQD), an approach designed to balance the use of domain knowledge with computational efficiency. EQD is built on a two-step fine-tuning framework and guided by a reward function that measures the effectiveness of generated sub-questions in improving QA outcomes. It requires only a few thousand training examples and a single A100 GPU for fine-tuning, with inference time comparable to zero-shot prompting. Beyond its efficiency, EQD outperforms state-of-the-art domain-tuned models and advanced prompting strategies. We evaluate EQD in the financial domain, characterized by specialized knowledge and complex quantitative reasoning, across four benchmark datasets. Our method consistently improves QA performance by 0.6% to 10.5% across different LLMs. Our analysis reveals an important insight: in domain-specific QA, a single supporting question often provides greater benefit than detailed guidance steps.
领域特定的量化推理对于大型语言模型(LLM)来说仍然是一个主要挑战,特别是在需要专业知识和复杂问答(QA)的领域。在这项工作中,我们提出了专家问题分解(EQD)方法,旨在平衡领域知识的使用与计算效率。EQD建立在两步微调框架上,并受奖励函数的指导,该奖励函数衡量生成的子问题在提高问答结果方面的有效性。它只需要几千个训练样本和一个A100 GPU进行微调,推理时间与零样本提示相当。除了高效性外,EQD还优于最先进的领域调整模型和高级提示策略。我们在金融领域评估了EQD,该领域具有专业知识和复杂的量化推理,跨越四个基准数据集。我们的方法在不同的大型语言模型上始终提高了问答性能,幅度从0.6%到10.5%。我们的分析揭示了一个重要见解:在特定领域的问答中,一个支持问题往往比详细的指导步骤更能带来益处。
论文及项目相关链接
PDF Accepted by EMNLP 2025
Summary
领域特定的量化推理对于大型语言模型(LLM)仍然是一个挑战,特别是在需要专业知识和复杂问答(QA)的领域。本研究提出了专家问题分解(EQD)方法,旨在平衡领域知识的使用与计算效率。EQD建立在两步微调框架上,由奖励函数引导,该奖励函数衡量生成的子问题在提高问答结果方面的有效性。它仅需要几千个训练样本和一个A100 GPU进行微调,推理时间与零样本提示相当。在财务领域,EQD的表现优于最先进的领域调整模型和高级提示策略。在四个基准数据集上的评估显示,我们的方法在跨不同LLM的QA性能方面提高了0.6%至10.5%。分析表明,在特定领域的问答中,一个支持问题往往比详细的指导步骤更能带来益处。
Key Takeaways
- 大型语言模型(LLM)在领域特定的量化推理方面存在挑战,尤其是在需要专业知识和复杂问答的领域。
- 专家问题分解(EQD)方法旨在平衡领域知识的使用与计算效率。
- EQD通过两步微调框架和奖励函数引导,奖励函数衡量生成的子问题在提高问答结果方面的有效性。
- EQD仅需要有限的训练样本和计算资源进行微调,并且推理时间与零样本提示相当。
- 在财务领域的评估中,EQD表现优于其他先进方法,提高了问答性能的0.6%至10.5%。
- 分析显示,在特定领域的问答中,一个关键的支持问题比详细的指导步骤更有益。
- EQD方法为领域特定的量化推理提供了一个有效的解决方案,具有广泛的应用前景。
点此查看论文截图
LVTINO: LAtent Video consisTency INverse sOlver for High Definition Video Restoration
Authors:Alessio Spagnoletti, Andrés Almansa, Marcelo Pereyra
Computational imaging methods increasingly rely on powerful generative diffusion models to tackle challenging image restoration tasks. In particular, state-of-the-art zero-shot image inverse solvers leverage distilled text-to-image latent diffusion models (LDMs) to achieve unprecedented accuracy and perceptual quality with high computational efficiency. However, extending these advances to high-definition video restoration remains a significant challenge, due to the need to recover fine spatial detail while capturing subtle temporal dependencies. Consequently, methods that naively apply image-based LDM priors on a frame-by-frame basis often result in temporally inconsistent reconstructions. We address this challenge by leveraging recent advances in Video Consistency Models (VCMs), which distill video latent diffusion models into fast generators that explicitly capture temporal causality. Building on this foundation, we propose LVTINO, the first zero-shot or plug-and-play inverse solver for high definition video restoration with priors encoded by VCMs. Our conditioning mechanism bypasses the need for automatic differentiation and achieves state-of-the-art video reconstruction quality with only a few neural function evaluations, while ensuring strong measurement consistency and smooth temporal transitions across frames. Extensive experiments on a diverse set of video inverse problems show significant perceptual improvements over current state-of-the-art methods that apply image LDMs frame by frame, establishing a new benchmark in both reconstruction fidelity and computational efficiency.
计算成像方法越来越依赖于强大的生成扩散模型,以应对具有挑战性的图像恢复任务。特别是,最先进的零样本图像逆求解器利用提炼的文本到图像的潜在扩散模型(LDM)以极高的计算效率实现了前所未有的精度和感知质量。然而,将这些进展扩展到高清视频恢复仍然是一项重大挑战,因为需要在恢复精细空间细节的同时捕捉微妙的时间依赖性。因此,基于图像的方法(例如在逐帧基础上应用LDM先验的方法)常常会导致时间不一致的重构。我们通过利用视频一致性模型(VCM)的最新进展来解决这一挑战,该模型将视频潜在扩散模型提炼为快速生成器,能够显式捕获时间因果关系。在此基础上,我们提出了LVTINO,它是第一个用于高清视频恢复的零样本或即插即用逆求解器,通过VCM编码先验知识。我们的条件机制绕过自动微分,通过几次神经功能评估即可实现业界领先的视频重建质量,同时确保强大的测量一致性和跨帧的平滑时间过渡。在多种视频反问题的广泛实验表明,与当前最先进的方法相比(即在逐帧应用图像LDM的方法),感知性能得到了显著改善,在重建保真度和计算效率方面都树立了新的基准。
论文及项目相关链接
PDF 23 pages, 12 figures
Summary
本文提出利用视频一致性模型(VCMs)蒸馏视频潜在扩散模型的方法来解决高清视频恢复问题。通过构建LVTINO模型,该模型利用VCMs编码先验知识,作为零样本或即插即用逆求解器,首次实现了高清晰度视频恢复。该方法避免了自动微分的需求,以较少的神经网络评估次数实现了领先的视频重建质量,确保了强大的测量一致性和平滑的帧间过渡。实验表明,与逐帧应用图像LDM的当前最先进方法相比,该方法在重建保真度和计算效率方面都取得了显著的感知改进。
Key Takeaways
- 扩散模型在处理图像恢复任务时表现出强大的生成能力。
- 高清视频恢复面临恢复精细空间细节和捕捉微妙时间依赖性的挑战。
- 单纯应用基于图像的LDM先验的帧-帧方法会导致时间上的不一致重建。
- 利用视频一致性模型(VCMs)来解决这一问题,显式捕捉时间因果关系。
- LVTINO模型是首个利用VCMs先验知识的零样本或即插即用逆求解器,用于高清视频恢复。
- LVTINO模型实现了领先的视频重建质量,并具有强大的测量一致性和平滑的帧间过渡。
点此查看论文截图

GRAD: Generative Retrieval-Aligned Demonstration Sampler for Efficient Few-Shot Reasoning
Authors:Oussama Gabouj, Kamel Charaf, Ivan Zakazov, Nicolas Baldwin, Robert West
Large Language Models (LLMs) achieve strong performance across diverse tasks, but their effectiveness often depends on the quality of the provided context. Retrieval-Augmented Generation (RAG) enriches prompts with external information, but its reliance on static databases constrains adaptability and can result in irrelevant demonstrations. In this work, we propose a Generative Retrieval-Aligned Demonstrator (GRAD), a dynamic demonstration-based approach where an LLM model is trained to generate input-specific concise demonstrations. By tailoring demonstrations to each input, our method offers better contextual support than traditional RAG approaches. We demonstrate the superiority of GRAD under budget constraints, where we limit both the number of tokens used per demonstration and the number of tokens used for the final output. Trained solely on a math dataset, GRAD consistently outperforms strong baselines on Qwen2.5-14B across mathematical reasoning and advanced STEM questions, highlighting GRAD’s robust generalization to out-of-distribution (OOD) domains such as physics, chemistry, and computer science. Furthermore, we show that demonstrations generated by trained smaller models can effectively guide larger target models, reducing training costs while maintaining competitive accuracy. Overall, this work introduces a scalable demonstration generator model presenting the first step toward a dynamic few-shot learning paradigm in resource-constrained settings. We release the code used for the project.
大型语言模型(LLM)在多种任务中表现出强大的性能,但其有效性往往取决于提供的上下文的质量。检索增强生成(RAG)通过外部信息丰富提示,但其对静态数据库的依赖限制了适应性,并可能导致出现不相关的演示。在这项工作中,我们提出了一种基于生成的检索对齐演示器(GRAD),这是一种动态演示方法,其中LLM模型经过训练以生成针对输入的简洁演示。通过为每个输入定制演示,我们的方法在提供上下文支持方面优于传统RAG方法。我们在预算约束下证明了GRAD的优越性,我们限制了每个演示和最终输出所使用的令牌数量。仅在数学数据集上进行训练,GRAD在Qwen2.5-14B上始终优于强大的基线,在数学推理和高级STEM问题方面表现突出,突显了GRAD对分布外(OOD)领域的稳健概括能力,如物理、化学和计算机科学。此外,我们还表明,由训练有素的小型模型生成的演示可以有效地指导大型目标模型,在保持竞争准确性的同时降低训练成本。总的来说,这项工作介绍了一种可扩展的演示生成器模型,朝着资源受限环境中的动态少样本学习模式迈出了第一步。我们发布了用于该项目的代码。
论文及项目相关链接
PDF EMNLP 2025 (findings)
Summary
大型语言模型(LLMs)在多种任务中表现出强大的性能,但其有效性往往取决于提供的上下文质量。检索增强生成(RAG)通过外部信息丰富提示,但其对静态数据库的依赖限制了适应性,并可能导致不相关的演示。在本文中,我们提出了一种基于生成的检索对齐演示者(GRAD)方法,这是一种动态演示方法,其中LLM模型经过训练以针对每个输入生成简洁的演示。通过为每个输入定制演示,我们的方法在上下文支持方面优于传统RAG方法。在预算有限的情况下,我们证明了GRAD的优越性,在演示和最终输出的令牌数量受到限制的情况下,仅凭数学数据集训练的GRAD在Qwen2.5-14B上始终优于强大的基线,在数学推理和高级STEM问题上表现出色。此外,我们还表明,由训练过的较小模型生成的演示可以有效地指导更大的目标模型,在保持竞争性的准确性的同时降低训练成本。总的来说,这项工作介绍了一种可扩展的演示生成器模型,朝着资源受限环境中的动态少样本学习范式迈出了第一步。
Key Takeaways
- LLMs的效力依赖于提供的上下文质量。
- 检索增强生成(RAG)方法存在静态数据库依赖的问题。
- GRAD是一种动态演示方法,针对每个输入生成特定的演示,提供更佳的上下文支持。
- 在预算有限和令牌数量受限的情况下,GRAD在数学数据集上的表现优于基线。
- GRAD在跨数学推理和高级STEM问题上表现优越,尤其在物理、化学和计算机科学等OOD领域。
- 由较小模型生成的演示可以有效地指导较大的目标模型,降低训练成本。
点此查看论文截图

FusionAdapter for Few-Shot Relation Learning in Multimodal Knowledge Graphs
Authors:Ran Liu, Yuan Fang, Xiaoli Li
Multimodal Knowledge Graphs (MMKGs) incorporate various modalities, including text and images, to enhance entity and relation representations. Notably, different modalities for the same entity often present complementary and diverse information. However, existing MMKG methods primarily align modalities into a shared space, which tends to overlook the distinct contributions of specific modalities, limiting their performance particularly in low-resource settings. To address this challenge, we propose FusionAdapter for the learning of few-shot relationships (FSRL) in MMKG. FusionAdapter introduces (1) an adapter module that enables efficient adaptation of each modality to unseen relations and (2) a fusion strategy that integrates multimodal entity representations while preserving diverse modality-specific characteristics. By effectively adapting and fusing information from diverse modalities, FusionAdapter improves generalization to novel relations with minimal supervision. Extensive experiments on two benchmark MMKG datasets demonstrate that FusionAdapter achieves superior performance over state-of-the-art methods.
多模态知识图谱(MMKGs)结合了多种模式,包括文本和图像,以增强实体和关系表示。值得注意的是,同一实体的不同模式通常呈现互补和多样化的信息。然而,现有的MMKG方法主要将模式对齐到共享空间,这往往忽视了特定模式的独特贡献,特别是在低资源环境中限制了其性能。为了应对这一挑战,我们为MMKG中的学习少样本关系(FSRL)提出了FusionAdapter。FusionAdapter引入了(1)一个适配器模块,使每个模式都能有效地适应未见过的关系;(2)一种融合策略,在保留多样化模式特定特性的同时,融合了多模式实体表示。通过有效地适应和融合来自多种模式的信息,FusionAdapter在少量监督下提高了对新型关系的泛化能力。在两个基准MMKG数据集上的广泛实验表明,FusionAdapter在最新技术方面实现了卓越的性能。
论文及项目相关链接
PDF Archived paper
Summary
多模态知识图谱(MMKG)融合多种模态,如文本和图像,以增强实体和关系表示。现有方法主要将不同模态对齐到共享空间,这忽略了特定模态的独特贡献,特别是在资源有限的情况下限制了性能。为解决此挑战,我们提出用于多模态知识图谱中少样本关系学习的FusionAdapter方法。该方法引入适配器模块,使每个模态都能有效适应未见过的关系,并提出融合策略,整合多模态实体表示的同时保留不同模态的特定特征。通过适应和融合来自不同模态的信息,FusionAdapter在少量监督下提高了对新型关系的泛化能力。实验表明,FusionAdapter在基准MMKG数据集上的性能优于现有方法。
Key Takeaways
- 多模态知识图谱(MMKG)结合多种模态以增强实体和关系表示。
- 现有MMKG方法主要将不同模态对齐到共享空间,忽略了特定模态的独特贡献。
- FusionAdapter通过引入适配器模块,使每个模态都能有效适应未见过的关系。
- FusionAdapter提出融合策略,整合多模态实体表示的同时保留不同模态的特定特征。
- FusionAdapter提高了对新型关系的泛化能力,特别是在资源有限的情况下。
- 实验证明,FusionAdapter在基准MMKG数据集上的性能优于现有方法。
点此查看论文截图
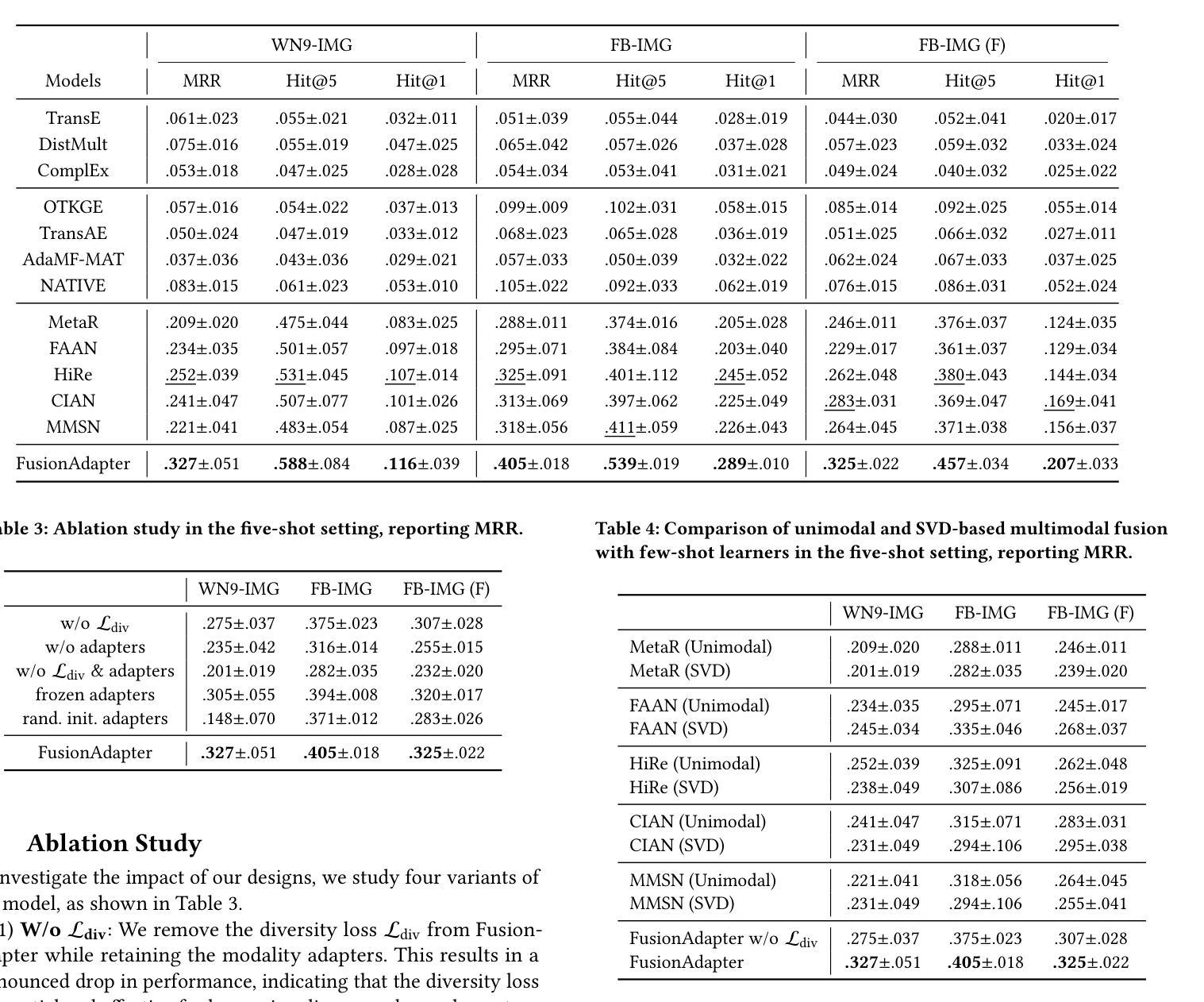
Agent Fine-tuning through Distillation for Domain-specific LLMs in Microdomains
Authors:Yawen Xue, Masaya Tsunokake, Yuta Koreeda, Ekant Muljibhai Amin, Takashi Sumiyoshi, Yasuhiro Sogawa
Agentic large language models (LLMs) have become prominent for autonomously interacting with external environments and performing multi-step reasoning tasks. Most approaches leverage these capabilities via in-context learning with few-shot prompts, but this often results in lengthy inputs and higher computational costs. Agent fine-tuning offers an alternative by enabling LLMs to internalize procedural reasoning and domain-specific knowledge through training on relevant data and demonstration trajectories. While prior studies have focused on general domains, their effectiveness in specialized technical microdomains remains unclear. This paper explores agent fine-tuning for domain adaptation within Hitachi’s JP1 middleware, a microdomain for specialized IT operations. We fine-tuned LLMs using JP1-specific datasets derived from domain manuals and distilled reasoning trajectories generated by LLMs themselves, enhancing decision making accuracy and search efficiency. During inference, we used an agentic prompt with retrieval-augmented generation and introduced a context-answer extractor to improve information relevance. On JP1 certification exam questions, our method achieved a 14% performance improvement over the base model, demonstrating the potential of agent fine-tuning for domain-specific reasoning in complex microdomains.
大型语言模型(LLM)在自主与外部环境中交互并执行多步骤推理任务方面表现出显著优势。大多数方法通过利用上下文学习(context learning)和少量的提示(few-shot prompts)来发挥这些能力,但这通常会导致输入冗长并增加计算成本。通过针对相关数据和应用轨迹进行训练,Agent fine-tuning(模型微调)为LLM提供了一种替代方案,使其能够内化程序推理和特定领域的专业知识。虽然先前的研究主要集中在通用领域,但它们对特定技术微域的效用尚不清楚。本文探讨了针对日立JP1中间件的域适应的Agent fine-tuning方法,这是一个用于专业IT操作的微域。我们使用从域手册派生的JP1特定数据集对LLM进行微调,并使用LLM本身生成的推理轨迹进行训练,以提高决策准确性和搜索效率。在推理过程中,我们使用了带检索增强的生成式的代理提示,并引入了一个上下文答案提取器以提高信息的相关性。在JP1认证考试问题上,我们的方法相较于基础模型实现了14%的性能提升,证明了针对特定领域的复杂微域中的推理的Agent fine-tuning方法的潜力。
论文及项目相关链接
PDF Accepted by AIxB 2025
Summary
大型语言模型(LLM)在自主与外部交互和多步推理任务中表现突出。大多数方法通过少数示例提示进行上下文学习来利用这些能力,但这常常导致冗长的输入和更高的计算成本。Agent fine-tuning通过训练LLM在相关数据和演示轨迹上内化程序推理和领域特定知识,提供了一种替代方案。尽管先前的研究集中在一般领域,但在专业技术微领域内的有效性仍不明确。本研究探讨了针对日立公司JP1中间件的领域自适应的agent fine-tuning,这是一个用于专业IT操作的微领域。通过使用JP1特定数据集和由LLM本身生成的精炼推理轨迹对LLM进行微调,提高了决策准确性和搜索效率。在推理过程中,使用了带检索增强生成功能的agentic提示,并引入了上下文答案提取器以提高信息相关性。在JP1认证考试问题上,我们的方法相较于基础模型实现了14%的性能提升,证明了agent fine-tuning在复杂微领域中的领域特定推理潜力。
Key Takeaways
- 大型语言模型(LLM)具备自主与外部交互及多步推理任务的能力。
- 通过少数示例提示进行上下文学习虽能利用这些能力,但会导致冗长输入和计算成本增加。
- Agent fine-tuning使LLM能够在相关数据和演示轨迹上内化程序推理和领域知识。
- 在专业技术微领域的有效性尚未明确,本研究探索了针对JP1中间件的agent fine-tuning应用。
- 使用JP1特定数据集和LLM生成的推理轨迹微调模型,提高了决策准确性和搜索效率。
- 在推理过程中使用带检索增强生成功能的agentic提示和上下文答案提取器,增强了信息相关性。
点此查看论文截图
RS-OOD: A Vision-Language Augmented Framework for Out-of-Distribution Detection in Remote Sensing
Authors:Chenhao Wang, Yingrui Ji, Yu Meng, Yunjian Zhang, Yao Zhu
Out-of-distribution (OOD) detection represents a critical challenge in remote sensing applications, where reliable identification of novel or anomalous patterns is essential for autonomous monitoring, disaster response, and environmental assessment. Despite remarkable progress in OOD detection for natural images, existing methods and benchmarks remain poorly suited to remote sensing imagery due to data scarcity, complex multi-scale scene structures, and pronounced distribution shifts. To this end, we propose RS-OOD, a novel framework that leverages remote sensing-specific vision-language modeling to enable robust few-shot OOD detection. Our approach introduces three key innovations: spatial feature enhancement that improved scene discrimination, a dual-prompt alignment mechanism that cross-verifies scene context against fine-grained semantics for spatial-semantic consistency, and a confidence-guided self-training loop that dynamically mines pseudo-labels to expand training data without manual annotation. RS-OOD consistently outperforms existing methods across multiple remote sensing benchmarks and enables efficient adaptation with minimal labeled data, demonstrating the critical value of spatial-semantic integration.
在遥感应用中,异常分布(Out-of-Distribution,简称OOD)检测是一个关键挑战。在新的或异常模式的有效识别中,这对自主监控、灾害响应和环境评估至关重要。尽管在自然图像的OOD检测方面取得了显著进展,但由于数据稀缺、复杂的场景结构以及明显的分布转移等问题,现有的方法和基准测试并不适合遥感图像。为此,我们提出了RS-OOD,这是一个新的框架,它利用遥感特定的视觉语言建模来实现稳健的少量异常分布检测。我们的方法引入了三个关键的创新点:空间特征增强提高了场景鉴别能力;双提示对齐机制通过场景上下文与精细语义的交叉验证实现空间语义一致性;以及基于置信度的自训练循环可以动态挖掘伪标签以扩充训练数据,无需人工标注。在多个遥感基准测试中,RS-OOD始终优于现有方法,并且能够在最少的标记数据下实现高效适应,证明了空间语义集成的关键价值。
论文及项目相关链接
总结
在遥感应用中,对新型或异常模式的可靠识别对于自主监控、灾害响应和环境评估至关重要,因此,新型分布外(OOD)检测是一项关键挑战。尽管在自然图像中的OOD检测取得了显著进展,但由于数据稀缺、复杂的多尺度场景结构和明显的分布偏移等问题,现有方法和基准测试对遥感图像并不适用。为此,我们提出了RS-OOD框架,利用遥感专用视觉语言建模,实现稳健的少数镜头OOD检测。我们的方法引入了三个关键创新点:空间特征增强提高了场景鉴别能力;双提示对齐机制通过场景上下文与精细语义对比验证空间语义一致性;信心引导的自我训练循环动态挖掘伪标签来扩展训练数据而无需手动注释。RS-OOD在多个遥感基准测试中均优于现有方法,并在少量标注数据的情况下实现了有效的适应,证明了空间语义整合的关键价值。
关键见解
- OOD检测在遥感应用中至关重要,用于识别新型或异常模式,有助于自主监控、灾害响应和环境评估。
- 现有OOD检测方法和基准测试因数据稀缺、复杂场景结构和分布偏移等问题,在遥感图像上表现不佳。
- RS-OOD框架利用遥感专用视觉语言建模实现稳健的少数镜头OOD检测。
- RS-OOD引入空间特征增强,提高场景鉴别能力。
- 双提示对齐机制通过场景上下文与精细语义对比,验证空间语义一致性。
- 信心引导的自我训练循环能动态挖掘伪标签,扩展训练数据,减少对手动注释的依赖。
点此查看论文截图

One Policy to Run Them All: an End-to-end Learning Approach to Multi-Embodiment Locomotion
Authors:Nico Bohlinger, Grzegorz Czechmanowski, Maciej Krupka, Piotr Kicki, Krzysztof Walas, Jan Peters, Davide Tateo
Deep Reinforcement Learning techniques are achieving state-of-the-art results in robust legged locomotion. While there exists a wide variety of legged platforms such as quadruped, humanoids, and hexapods, the field is still missing a single learning framework that can control all these different embodiments easily and effectively and possibly transfer, zero or few-shot, to unseen robot embodiments. We introduce URMA, the Unified Robot Morphology Architecture, to close this gap. Our framework brings the end-to-end Multi-Task Reinforcement Learning approach to the realm of legged robots, enabling the learned policy to control any type of robot morphology. The key idea of our method is to allow the network to learn an abstract locomotion controller that can be seamlessly shared between embodiments thanks to our morphology-agnostic encoders and decoders. This flexible architecture can be seen as a potential first step in building a foundation model for legged robot locomotion. Our experiments show that URMA can learn a locomotion policy on multiple embodiments that can be easily transferred to unseen robot platforms in simulation and the real world.
深度强化学习技术正在实现最先进的稳健的腿足运动结果。尽管存在多种腿足平台,如四足、人形和六足等,但该领域仍然缺少一个单一的学习框架,能够轻松有效地控制所有这些不同的体现形式,并可能以零或少量样本的方式转移到未见过的机器人体现形式。我们引入URMA,即统一机器人形态架构,以弥补这一空白。我们的框架将端到端多任务强化学习方法引入到腿足机器人的领域,使学习到的策略能够控制任何类型的机器人形态。我们的方法的关键思想是让网络学习一个抽象的运动控制器,由于我们的形态无关编码器和解码器,该控制器可以在各种形态之间无缝共享。这种灵活架构可以被视为构建腿足机器人运动基础模型的一个潜在的第一步。我们的实验表明,URMA可以在多种形态上学习运动策略,并可以轻松将其转移到模拟和真实世界中的未知机器人平台。
论文及项目相关链接
Summary
统一机器人形态架构(URMA)的出现填补了不同形态腿式机器人学习控制的空白。URMA采用端到端多任务强化学习,使得学习到的策略可以控制任何类型的机器人形态。其关键思想在于允许网络学习一个抽象的步态控制器,借助形态无关的编码器和解码器在不同的形态之间无缝共享。该灵活的架构可被视为构建腿式机器人运动基础模型的第一步。实验表明,URMA可以在多种形态上学习步态策略,并轻松应用于仿真和现实世界中未见过的新平台。
Key Takeaways
- URMA为不同形态的腿式机器人提供了统一的学习框架。
- 该框架采用端到端的Multi-Task强化学习方法。
- URMA允许网络学习抽象的步态控制器,适应多种机器人形态。
- 借助形态无关的编码器和解码器,URMA实现了在不同形态间的无缝共享控制策略。
- URMA的灵活架构被视为构建腿式机器人运动基础模型的重要一步。
- 实验显示URMA在仿真和现实中均能有效应用于新平台。
点此查看论文截图

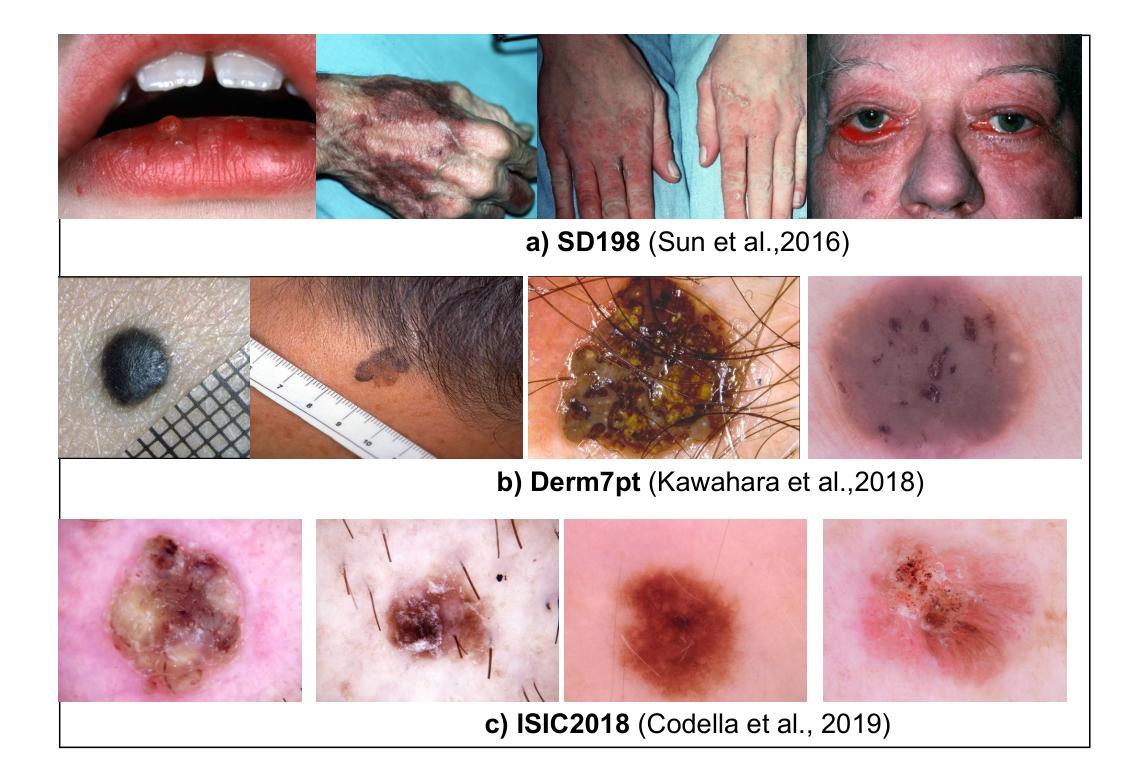
Meta-Transfer Derm-Diagnosis: Exploring Few-Shot Learning and Transfer Learning for Skin Disease Classification in Long-Tail Distribution
Authors:Zeynep Özdemir, Hacer Yalim Keles, Ömer Özgür Tanrıöver
Building accurate models for rare skin diseases remains challenging due to the lack of sufficient labeled data and the inherently long-tailed distribution of available samples. These issues are further complicated by inconsistencies in how datasets are collected and their varying objectives. To address these challenges, we compare three learning strategies: episodic learning, supervised transfer learning, and contrastive self-supervised pretraining, within a few-shot learning framework. We evaluate five training setups on three benchmark datasets: ISIC2018, Derm7pt, and SD-198. Our findings show that traditional transfer learning approaches, particularly those based on MobileNetV2 and Vision Transformer (ViT) architectures, consistently outperform episodic and self-supervised methods as the number of training examples increases. When combined with batch-level data augmentation techniques such as MixUp, CutMix, and ResizeMix, these models achieve state-of-the-art performance on the SD-198 and Derm7pt datasets, and deliver highly competitive results on ISIC2018. All the source codes related to this work will be made publicly available soon at the provided URL.
针对罕见皮肤疾病建立精确模型仍然是一个挑战,因为缺乏足够的标记数据以及可用样本的固有长尾分布。这些问题还因数据集收集方式的不一致和其不同目标而进一步复杂化。为了应对这些挑战,我们在小样本学习框架内比较了三种学习策略:情景学习、监督迁移学习和对比自监督预训练。我们在三个基准数据集(ISIC2018、Derm7pt和SD-198)上评估了五种训练设置。我们的研究结果表明,随着训练样本数量的增加,基于MobileNetV2和Vision Transformer(ViT)架构的传统迁移学习方法始终表现出色,超越了情景学习和自监督方法。结合批量级别的数据增强技术(如MixUp、CutMix和ResizeMix),这些模型在SD-198和Derm7pt数据集上达到了最先进的性能,并在ISIC2018上取得了具有竞争力的结果。与此工作相关的所有源代码很快将在提供的URL上公开发布。
论文及项目相关链接
PDF This is the accepted version of the article to appear in IEEE Journal of Biomedical and Health Informatics. DOI: 10.1109/JBHI.2025.3615479
Summary
本文探讨了罕见皮肤疾病建模的挑战,包括缺乏足够的标记数据和样本分布长尾化的问题。为解决这些问题,作者在少样本学习框架下比较了三种学习策略:情景学习、监督迁移学习和对比自监督预训练。在三个基准数据集ISIC2018、Derm7pt和SD-198上进行实验,发现传统迁移学习方法,特别是基于MobileNetV2和Vision Transformer(ViT)架构的方法,在训练样本数量增加时表现最佳。结合批量级数据增强技术如MixUp、CutMix和ResizeMix,这些模型在SD-198和Derm7pt数据集上达到最新性能,并在ISIC2018上取得有竞争力的结果。
Key Takeaways
- 罕见皮肤疾病建模面临数据不足和样本分布长尾化挑战。
- 情景学习、监督迁移学习和对比自监督预训练是应对这些挑战的策略。
- 在基准数据集上的实验表明传统迁移学习方法表现最佳。
- 基于MobileNetV2和Vision Transformer(ViT)架构的方法表现尤其出色。
- 结合批量级数据增强技术可进一步提高模型性能。
- 模型在SD-198和Derm7pt数据集上达到最新性能,并在ISIC2018上表现有竞争力。
点此查看论文截图