⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-04 更新
Multi-Domain Brain Vessel Segmentation Through Feature Disentanglement
Authors:Francesco Galati, Daniele Falcetta, Rosa Cortese, Ferran Prados, Ninon Burgos, Maria A. Zuluaga
The intricate morphology of brain vessels poses significant challenges for automatic segmentation models, which usually focus on a single imaging modality. However, accurately treating brain-related conditions requires a comprehensive understanding of the cerebrovascular tree, regardless of the specific acquisition procedure. Our framework effectively segments brain arteries and veins in various datasets through image-to-image translation while avoiding domain-specific model design and data harmonization between the source and the target domain. This is accomplished by employing disentanglement techniques to independently manipulate different image properties, allowing them to move from one domain to another in a label-preserving manner. Specifically, we focus on manipulating vessel appearances during adaptation while preserving spatial information, such as shapes and locations, which are crucial for correct segmentation. Our evaluation effectively bridges large and varied domain gaps across medical centers, image modalities, and vessel types. Additionally, we conduct ablation studies on the optimal number of required annotations and other architectural choices. The results highlight our framework’s robustness and versatility, demonstrating the potential of domain adaptation methodologies to perform cerebrovascular image segmentation in multiple scenarios accurately. Our code is available at https://github.com/i-vesseg/MultiVesSeg.
大脑血管的复杂形态给自动分割模型带来了重大挑战,这些模型通常专注于单一的成像模式。然而,准确地治疗与大脑相关的疾病需要对脑血管树有全面的了解,无论采用何种特定的采集程序。我们的框架通过图像到图像的翻译有效地分割了各个数据集的大脑动脉和静脉,同时避免了针对特定领域的模型设计和源域与目标域之间的数据调和。这是通过采用分离技术独立操作不同的图像属性来实现的,使它们能够以保留标签的方式从一个域转移到另一个域。具体来说,我们在适应过程中专注于操作血管的外观,同时保留空间信息,如形状和位置,这对于正确的分割至关重要。我们的评估有效地弥合了不同医学中心、图像模式和血管类型之间的大型和多变领域差距。此外,我们对所需注释的最佳数量和其他架构选择进行了消融研究。结果突出了我们框架的稳健性和通用性,证明了域适应方法在多种场景下准确进行脑血管图像分割的潜力。我们的代码可在https://github.com/i-vesseg/MultiVesSeg找到。
论文及项目相关链接
PDF 19 pages, 7 figures, 3 tables. Joint first authors: Francesco Galati and Daniele Falcetta. Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2025:021. Code available at https://github.com/i-vesseg/MultiVesSeg
Summary
本文提出一种框架,能有效在不同数据集上实现脑血管的自动分割,通过图像到图像的翻译技术避免了特定领域的模型设计和源域与目标域之间的数据调和问题。采用分离技术独立操作不同图像属性,实现在不同领域间标签保留的迁移。评估结果有效跨越了医学中心、图像模态和血管类型之间的巨大差异。
Key Takeaways
- 脑血管的复杂形态为自动分割模型带来挑战,需综合考虑多种成像模式。
- 提出的框架通过图像到图像的翻译技术实现脑血管的自动分割。
- 框架避免了特定领域的模型设计和源域与目标域之间的数据调和问题。
- 采用分离技术独立操作图像属性,实现标签保留的迁移。
- 评估结果有效跨越了医学中心、图像模态和血管类型之间的领域差异。
- 框架具有鲁棒性和通用性,展示了在不同场景下进行脑血管图像分割的潜力。
点此查看论文截图

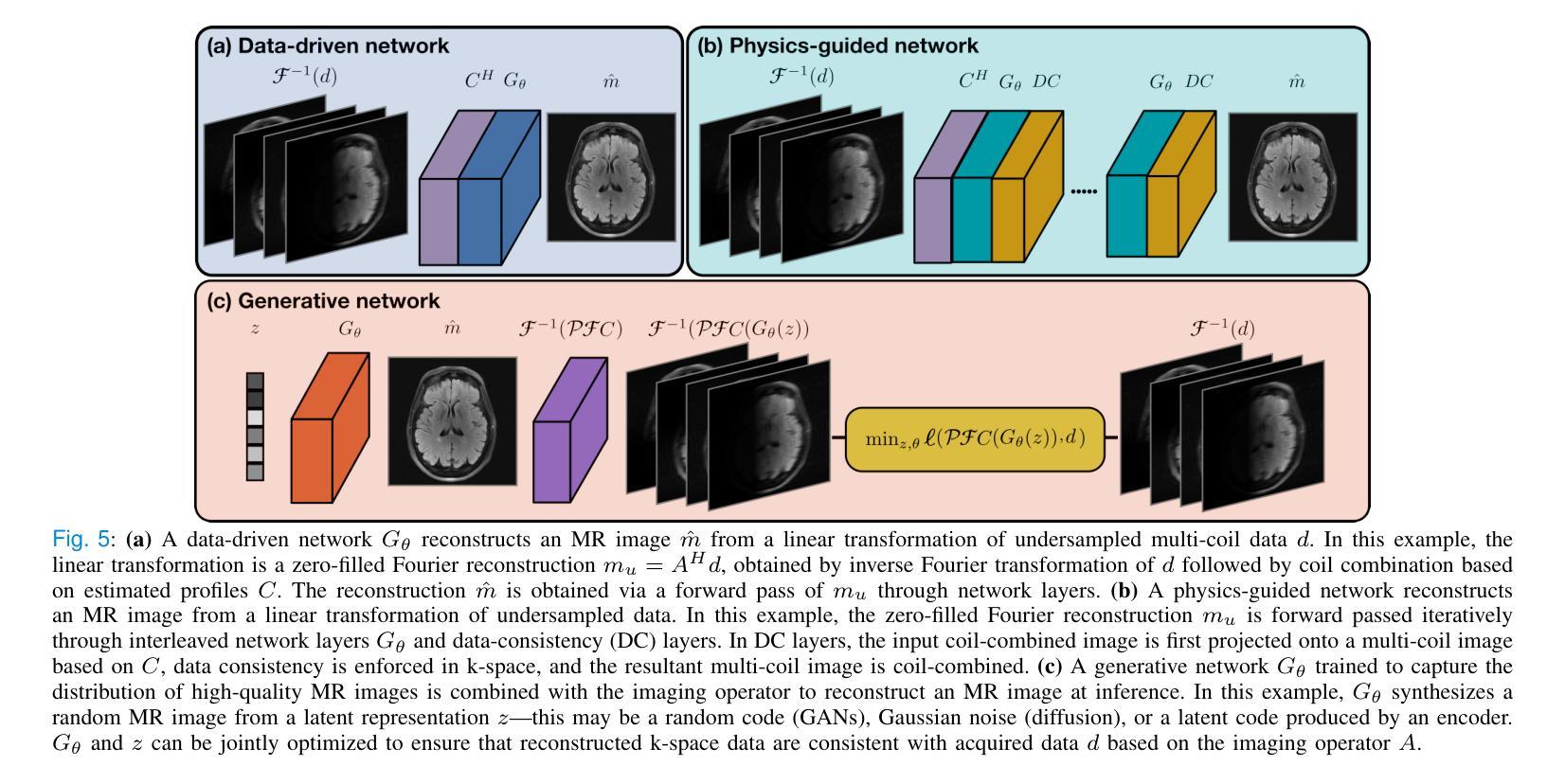
A Tutorial on MRI Reconstruction: From Modern Methods to Clinical Implications
Authors:Tolga Çukur, Salman U. H. Dar, Valiyeh Ansarian Nezhad, Yohan Jun, Tae Hyung Kim, Shohei Fujita, Berkin Bilgic
MRI is an indispensable clinical tool, offering a rich variety of tissue contrasts to support broad diagnostic and research applications. Clinical exams routinely acquire multiple structural sequences that provide complementary information for differential diagnosis, while research protocols often incorporate advanced functional, diffusion, spectroscopic, and relaxometry sequences to capture multidimensional insights into tissue structure and composition. However, these capabilities come at the cost of prolonged scan times, which reduce patient throughput, increase susceptibility to motion artifacts, and may require trade-offs in image quality or diagnostic scope. Over the last two decades, advances in image reconstruction algorithms–alongside improvements in hardware and pulse sequence design–have made it possible to accelerate acquisitions while preserving diagnostic quality. Central to this progress is the ability to incorporate prior information to regularize the solutions to the reconstruction problem. In this tutorial, we overview the basics of MRI reconstruction and highlight state-of-the-art approaches, beginning with classical methods that rely on explicit hand-crafted priors, and then turning to deep learning methods that leverage a combination of learned and crafted priors to further push the performance envelope. We also explore the translational aspects and eventual clinical implications of these methods. We conclude by discussing future directions to address remaining challenges in MRI reconstruction. The tutorial is accompanied by a Python toolbox (https://github.com/tutorial-MRI-recon/tutorial) to demonstrate select methods discussed in the article.
磁共振成像(MRI)是一种不可或缺的临床工具,它提供了丰富的组织对比度,支持广泛的诊断和科学研究应用。在临床检查中,通常获取多个结构序列,为鉴别诊断提供补充信息;而研究协议通常包含高级的功能、扩散、光谱和松弛序列,以获取对组织结构和组成的多维见解。然而,这些功能带来了扫描时间延长的成本,降低了患者通过率,增加了运动伪影的易感性,并可能需要在图像质量或诊断范围上进行权衡。在过去的二十年中,图像重建算法的进步,以及硬件和脉冲序列设计的改进,使得在保留诊断质量的同时加速采集成为可能。这一进展的核心是融入先验信息以规范重建问题的解决方案。在本教程中,我们概述了磁共振成像重建的基础知识,并重点介绍了最新方法。首先从依赖明确的手工先验条件的经典方法开始,然后转向利用学习和手工先验条件的结合来进一步突破性能界限的深度学习方法。我们还探讨了这些方法的转化方面以及最终的临床影响。最后,我们讨论了解决磁共振成像重建中剩余挑战的未来发展方向。本教程还附带了一个Python工具箱(https://github.com/tutorial-MRI-recon/tutorial),以演示文章中讨论的选择性方法。
论文及项目相关链接
PDF Accepted for publication in IEEE Transactions on Biomedical Engineering. The final published version is available at https://doi.org/10.1109/TBME.2025.3617575
Summary:
MRI是一种不可或缺的临床工具,其提供了丰富的组织对比信息以支持广泛的诊断和研发应用。本教程介绍了MRI重建的基本原理和最新进展,包括从经典的手动设计先验知识方法到结合深度学习和先验知识的先进方法,旨在加速成像并保留诊断质量。同时探讨了这些方法的临床转化和潜在影响。未来研究方向包括解决MRI重建中仍存在的一些挑战。本教程附带一个Python工具箱用于演示其中讨论的一些方法。
Key Takeaways:
- MRI为诊断和研究提供了多种序列选项,并支持广泛的临床和研究应用。它已成为不可或缺的临床工具。但长时间扫描带来的挑战也限制了其实际应用效果。
点此查看论文截图