⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-04 更新
KaVa: Latent Reasoning via Compressed KV-Cache Distillation
Authors:Anna Kuzina, Maciej Pioro, Paul N. Whatmough, Babak Ehteshami Bejnordi
Large Language Models (LLMs) excel at multi-step reasoning problems with explicit chain-of-thought (CoT), but verbose traces incur significant computational costs and memory overhead, and often carry redundant, stylistic artifacts. Latent reasoning has emerged as an efficient alternative that internalizes the thought process, but it suffers from a critical lack of supervision, limiting its effectiveness on complex, natural-language reasoning traces. In this work, we propose KaVa, the first framework that bridges this gap by distilling knowledge directly from a compressed KV-cache of the teacher into a latent-reasoning student via self-distillation, leveraging the representational flexibility of continuous latent tokens to align stepwise KV trajectories. We show that the abstract, unstructured knowledge within compressed KV-cache, which lacks direct token correspondence, can serve as a rich supervisory signal for a latent reasoning student. Empirically, the approach consistently outperforms strong latent baselines, exhibits markedly smaller degradation from equation-only to natural-language traces, and scales to larger backbones while preserving efficiency. These results establish compressed KV-cache distillation as a scalable supervision signal for latent reasoning, combining the accuracy of CoT-trained teachers with the efficiency and deployability of latent inference.
大型语言模型(LLM)在处理具有明确思维链(CoT)的多步推理问题时表现出色,但冗长的跟踪会产生显著的计算成本和内存开销,并经常带有冗余、风格化的特征。隐式推理作为一种有效的替代方法,能够内化思维过程,但它缺乏关键的监督,在复杂、自然语言推理轨迹上的效果有限。在这项工作中,我们提出了KaVa框架,它通过自蒸馏的方式,从压缩的KV缓存中提取知识并直接传递给进行隐性推理的学生模型,以此填补这一空白。我们利用连续潜在代币的代表性灵活性来对齐逐步KV轨迹。我们证明了压缩KV缓存中的抽象、非结构化知识可以作为隐性推理学生的丰富监督信号,即使没有直接的代币对应关系。从实证结果来看,该方法始终优于强大的隐性基准测试,从方程式到自然语言轨迹的退化明显较小,并且在保持效率的同时扩展到更大的主干网络。这些结果确立了压缩KV缓存蒸馏作为隐性推理的可扩展监督信号,结合了教师CoT训练的准确性和学生隐性推理的效率与可部署性。
论文及项目相关链接
PDF Preprint. Under Review
Summary
大型语言模型(LLMs)在多步推理问题上表现出色,但明确的思维链(CoT)追踪方式会带来显著的计算成本和内存负担,并常带有冗余的风格化产物。潜在推理作为一种高效替代方案,能够内化思维过程,但缺乏监督是其关键缺陷,限制了其在复杂自然语言推理追踪上的有效性。本研究提出KaVa框架,首次通过自我蒸馏的方式,从教师模型的压缩键值缓存(KV-cache)中汲取知识,传授给潜在推理的学生模型。利用连续潜在符号的表示灵活性,对齐键值对的逐步轨迹。研究显示,压缩KV缓存中的抽象、非结构化知识,尽管缺乏直接的符号对应关系,但可作为潜在推理学生模型的丰富监督信号。实证结果表明,该方法在强基线潜在推理模型上表现更优秀,在自然语言追踪到方程追踪的降解程度显著降低,并在大型骨干网络上保持高效性。这些结果确立了压缩KV缓存蒸馏作为潜在推理的可扩展监督信号,结合了有思维链教师模型的准确性、潜在推理的效率和可部署性。
Key Takeaways
- LLMs善于处理多步推理问题,但思维链追踪方式计算成本高且冗余。
- 潜在推理能够高效处理这些问题,但缺乏监督限制了其复杂性。
- KaVa框架通过自我蒸馏的方式,从教师模型的压缩键值缓存中汲取知识并传授给学生模型。
- 压缩KV缓存中的知识可以作为潜在推理学生模型的丰富监督信号。
- KaVa框架在强基线潜在推理模型上表现优秀,自然语言和方程追踪之间的降解程度降低。
- KaVa框架在大型骨干网络上保持高效性。
点此查看论文截图
F2LLM Technical Report: Matching SOTA Embedding Performance with 6 Million Open-Source Data
Authors:Ziyin Zhang, Zihan Liao, Hang Yu, Peng Di, Rui Wang
We introduce F2LLM - Foundation to Feature Large Language Models, a suite of state-of-the-art embedding models in three sizes: 0.6B, 1.7B, and 4B. Unlike previous top-ranking embedding models that require massive contrastive pretraining, sophisticated training pipelines, and costly synthetic training data, F2LLM is directly finetuned from foundation models on 6 million query-document-negative tuples curated from open-source, non-synthetic datasets, striking a strong balance between training cost, model size, and embedding performance. On the MTEB English leaderboard, F2LLM-4B ranks 2nd among models with approximately 4B parameters and 7th overall, while F2LLM-1.7B ranks 1st among models in the 1B-2B size range. To facilitate future research in the field, we release the models, training dataset, and code, positioning F2LLM as a strong, reproducible, and budget-friendly baseline for future works.
我们介绍了F2LLM——从基础到特性大规模语言模型,这是一套最先进的嵌入模型,包括三种规模:0.6B、1.7B和4B。不同于之前排名靠前的嵌入模型,需要大规模对比预训练、复杂的训练管道和昂贵的合成训练数据,F2LLM直接从基础模型上调整参数训练而成,所用数据是精心挑选自开源非合成数据集中的6百万查询文档否定元组,在训练成本、模型大小和嵌入性能之间取得了很好的平衡。在MTEB英语排行榜上,F2LLM-4B在参数约为4B的模型中排名第2,总体排名第7,而F2LLM-1.7B在1B-2B大小范围内的模型中排名第1。为了促进该领域未来的研究,我们发布了模型、训练数据集和代码,将F2LLM定位为未来工作的强大、可重复、经济实惠的基线。
论文及项目相关链接
Summary
F2LLM是一套先进的嵌入模型套件,包括三种规模:0.6B、1.7B和4B。与其他需要大规模对比预训练、复杂训练管道和昂贵合成训练数据的顶级嵌入模型不同,F2LLM直接从基础模型对精选的开源非合成数据集进行微调,在训练成本、模型大小和嵌入性能之间取得了平衡。F2LLM在MTEB英语排行榜上表现优异,其中F2LLM-4B在约4B参数的模型中排名第二,总体排名第七;F2LLM-1.7B在1B-2B规模范围内排名第一。为便于未来研究,我们公开了模型、训练数据集和代码。
Key Takeaways
- F2LLM是一个包含三种规模的先进嵌入模型套件。
- 与其他嵌入模型不同,F2LLM采用直接从基础模型微调的方法,使用精选的开源非合成数据集。
- F2LLM在训练成本、模型大小和嵌入性能之间取得了平衡。
- F2LLM-4B在MTEB英语排行榜上排名第二,总体排名第七。
- F2LLM-1.7B在特定规模范围内的模型中排名第一。
- F2LLM的公开包括模型、训练数据集和代码,为未来的研究提供了方便。
点此查看论文截图

Tree-based Dialogue Reinforced Policy Optimization for Red-Teaming Attacks
Authors:Ruohao Guo, Afshin Oroojlooy, Roshan Sridhar, Miguel Ballesteros, Alan Ritter, Dan Roth
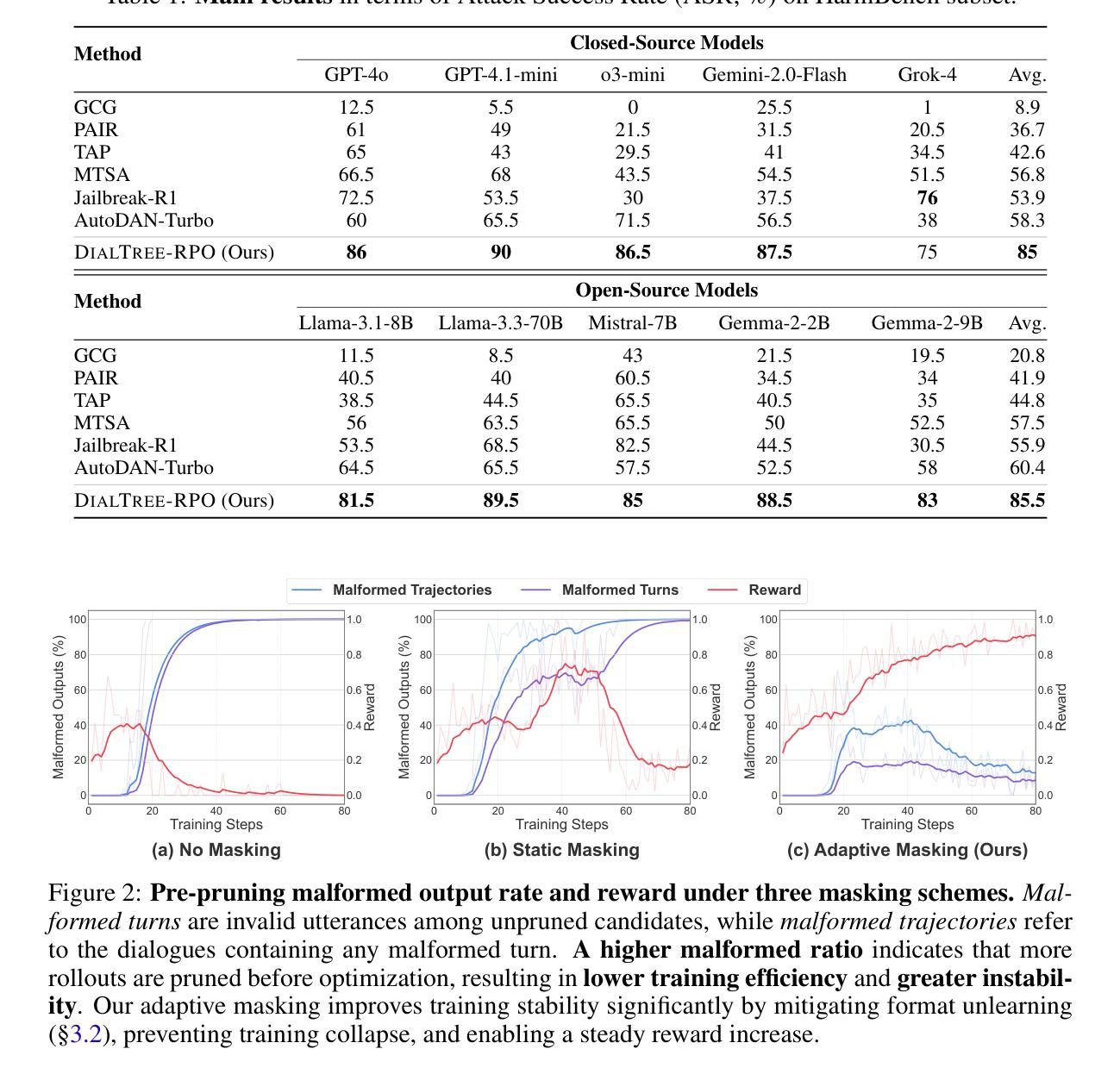
Despite recent rapid progress in AI safety, current large language models remain vulnerable to adversarial attacks in multi-turn interaction settings, where attackers strategically adapt their prompts across conversation turns and pose a more critical yet realistic challenge. Existing approaches that discover safety vulnerabilities either rely on manual red-teaming with human experts or employ automated methods using pre-defined templates and human-curated attack data, with most focusing on single-turn attacks. However, these methods did not explore the vast space of possible multi-turn attacks, failing to consider novel attack trajectories that emerge from complex dialogue dynamics and strategic conversation planning. This gap is particularly critical given recent findings that LLMs exhibit significantly higher vulnerability to multi-turn attacks compared to single-turn attacks. We propose DialTree-RPO, an on-policy reinforcement learning framework integrated with tree search that autonomously discovers diverse multi-turn attack strategies by treating the dialogue as a sequential decision-making problem, enabling systematic exploration without manually curated data. Through extensive experiments, our approach not only achieves more than 25.9% higher ASR across 10 target models compared to previous state-of-the-art approaches, but also effectively uncovers new attack strategies by learning optimal dialogue policies that maximize attack success across multiple turns.
尽管人工智能安全性领域最近取得了快速进展,但当前的大型语言模型在多轮交互环境中仍然容易受到对抗性攻击的威胁。在这个环境中,攻击者会在对话过程中有针对性地调整他们的提示,从而构成更加现实且具挑战性的威胁。现有的发现安全漏洞的方法要么依赖于与人类专家的手动红队测试,要么使用预定义模板和人类整理的攻击数据进行自动化方法处理,其中大多数方法主要关注单轮攻击。然而,这些方法并未探索多轮攻击的巨大可能空间,未能考虑到由复杂对话动态和策略性对话规划所产生的新兴攻击轨迹。考虑到最近的发现表明,与单轮攻击相比,大型语言模型在多轮攻击中表现出更高的脆弱性,这一差距尤为重要。我们提出了DialTree-RPO,这是一个与树搜索相结合的策略强化学习框架,能够自主地发现多样化的多轮攻击策略,通过将对话视为一个序列决策问题,在不依赖手动整理数据的情况下进行系统探索。通过广泛的实验,我们的方法不仅与以前的最先进方法相比,在10个目标模型上的攻击成功率提高了超过2.5%,而且还通过学习最佳对话策略有效地发现了新的攻击策略,这些策略在多轮攻击中最大化攻击成功次数。
论文及项目相关链接
Summary
大型语言模型在多轮交互场景中仍存在易受攻击的问题。现有发现安全漏洞的方法主要依赖人工红队或自动化方法,但未能全面探索多轮攻击的巨大空间。本文提出的DialTree-RPO框架结合了树搜索和强化学习,能够自主发现多样的多轮攻击策略,通过对话作为序贯决策问题来系统化探索,无需手动整理数据。实验表明,该方法不仅提高了超过25.9%的攻击成功率,还通过学习优化对话策略发现了新的攻击策略。
Key Takeaways
- 大型语言模型在多轮交互场景中仍面临安全挑战。
- 现有发现安全漏洞的方法主要依赖人工红队或自动化方法,存在局限性。
- 现有方法未能全面探索多轮攻击的巨大空间,忽略了复杂的对话动态和战略对话规划。
- DialTree-RPO框架结合了树搜索和强化学习,能够自主发现多样的多轮攻击策略。
- DialTree-RPO框架通过对话作为序贯决策问题来系统化探索,无需手动整理数据。
- 实验表明,DialTree-RPO框架提高了超过25.9%的攻击成功率。
点此查看论文截图

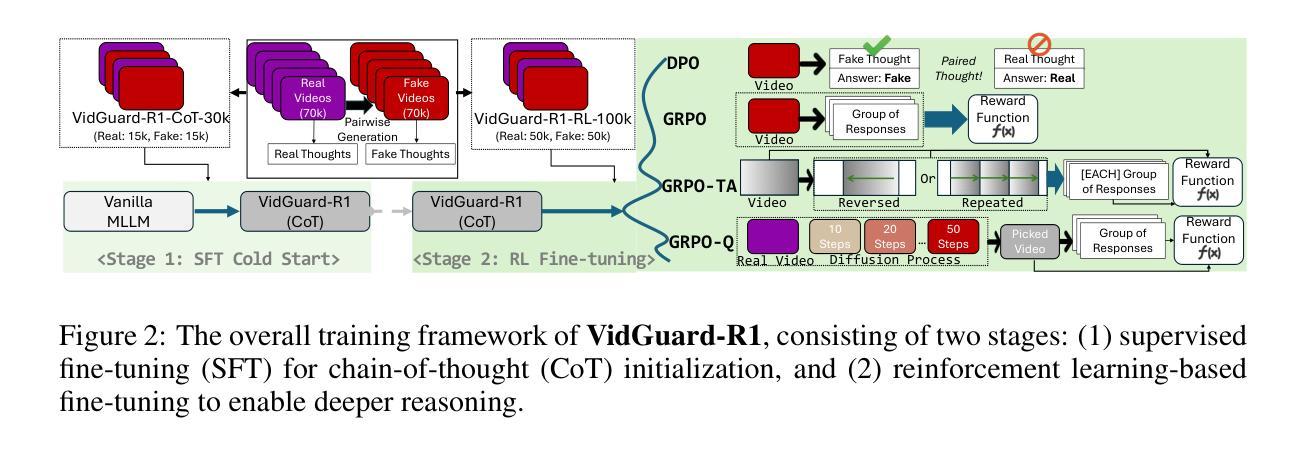
VidGuard-R1: AI-Generated Video Detection and Explanation via Reasoning MLLMs and RL
Authors:Kyoungjun Park, Yifan Yang, Juheon Yi, Shicheng Zheng, Yifei Shen, Dongqi Han, Caihua Shan, Muhammad Muaz, Lili Qiu
With the rapid advancement of AI-generated videos, there is an urgent need for effective detection tools to mitigate societal risks such as misinformation and reputational harm. In addition to accurate classification, it is essential that detection models provide interpretable explanations to ensure transparency for regulators and end users. To address these challenges, we introduce VidGuard-R1, the first video authenticity detector that fine-tunes a multi-modal large language model (MLLM) using group relative policy optimization (GRPO). Our model delivers both highly accurate judgments and insightful reasoning. We curate a challenging dataset of 140k real and AI-generated videos produced by state-of-the-art generation models, carefully designing the generation process to maximize discrimination difficulty. We then fine-tune Qwen-VL using GRPO with two specialized reward models that target temporal artifacts and generation complexity. Extensive experiments demonstrate that VidGuard-R1 achieves state-of-the-art zero-shot performance on existing benchmarks, with additional training pushing accuracy above 95%. Case studies further show that VidGuard-R1 produces precise and interpretable rationales behind its predictions. The code is publicly available at https://VidGuard-R1.github.io.
随着AI生成视频的快速发展,对于有效检测工具的需求日益迫切,以减轻社会风险,如虚假信息和声誉损害。除了准确分类之外,检测模型还必须提供可解释的解释,以确保监管机构和最终用户透明度。为了解决这些挑战,我们推出了VidGuard-R1,它是第一个使用群体相对策略优化(GRPO)微调多模式大型语言模型(MLLM)的视频真实性检测器。我们的模型既提供了高度准确的判断,又提供了深刻的推理。我们创建了一个由14万个真实和AI生成的视频组成的有挑战性的数据集,这些视频由最先进的生成模型生成,我们精心设计生成过程以最大化区分难度。然后,我们使用GRPO微调Qwen-VL,采用两个针对时间伪影和生成复杂性的专用奖励模型。大量实验表明,VidGuard-R1在现有基准测试上实现了最先进的零样本性能,经过额外训练后,准确率超过95%。案例研究进一步表明,VidGuard-R1产生的预测背后的理由精确且可解释。相关代码已公开在:https://VidGuard-R1.github.io上。
论文及项目相关链接
Summary
基于人工智能生成视频的快速发展,为应对诸如误导信息和声誉损害等社会风险,急需有效的检测工具。为解决此挑战,推出首款视频真实性检测器VidGuard-R1,其通过群体相对策略优化(GRPO)对多模态大型语言模型(MLLM)进行微调,既提供高度准确的判断,又提供可解释的理由,确保对监管机构和终端用户的透明度。
Key Takeaways
- VidGuard-R1是首款视频真实性检测器,能精细地区分真实视频和AI生成的视频。
- 该模型使用群体相对策略优化(GRPO)和多模态大型语言模型(MLLM)进行训练,以提高准确性和检测效率。
- VidGuard-R1不仅提供准确的判断,还提供可解释的理由,增强了其透明度。
- 该模型使用具有挑战性的数据集进行训练,包括14万个真实和AI生成的视频。
- VidGuard-R1在现有基准测试上实现了最先进的零样本性能,经过额外训练,其准确率超过95%。
点此查看论文截图

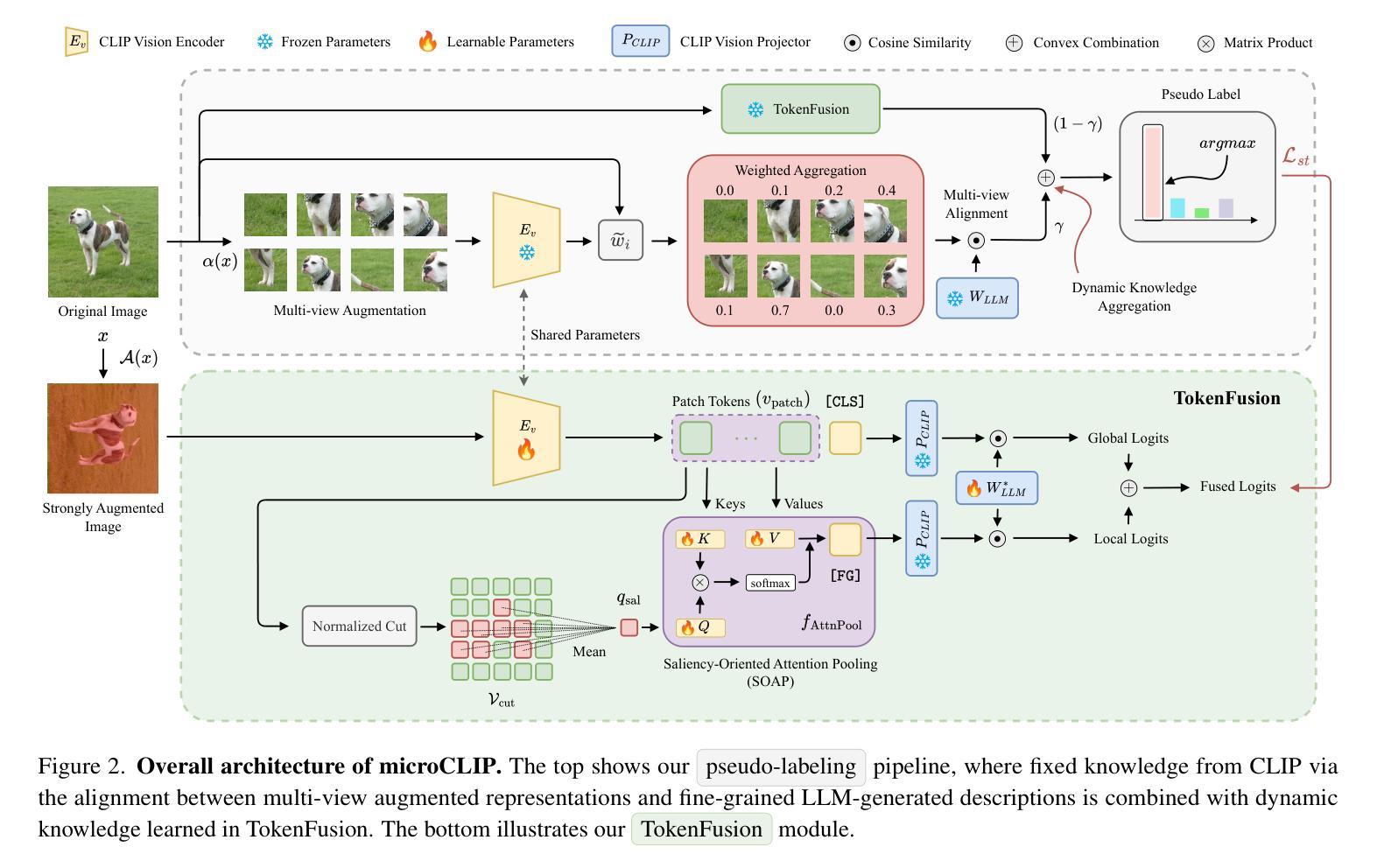
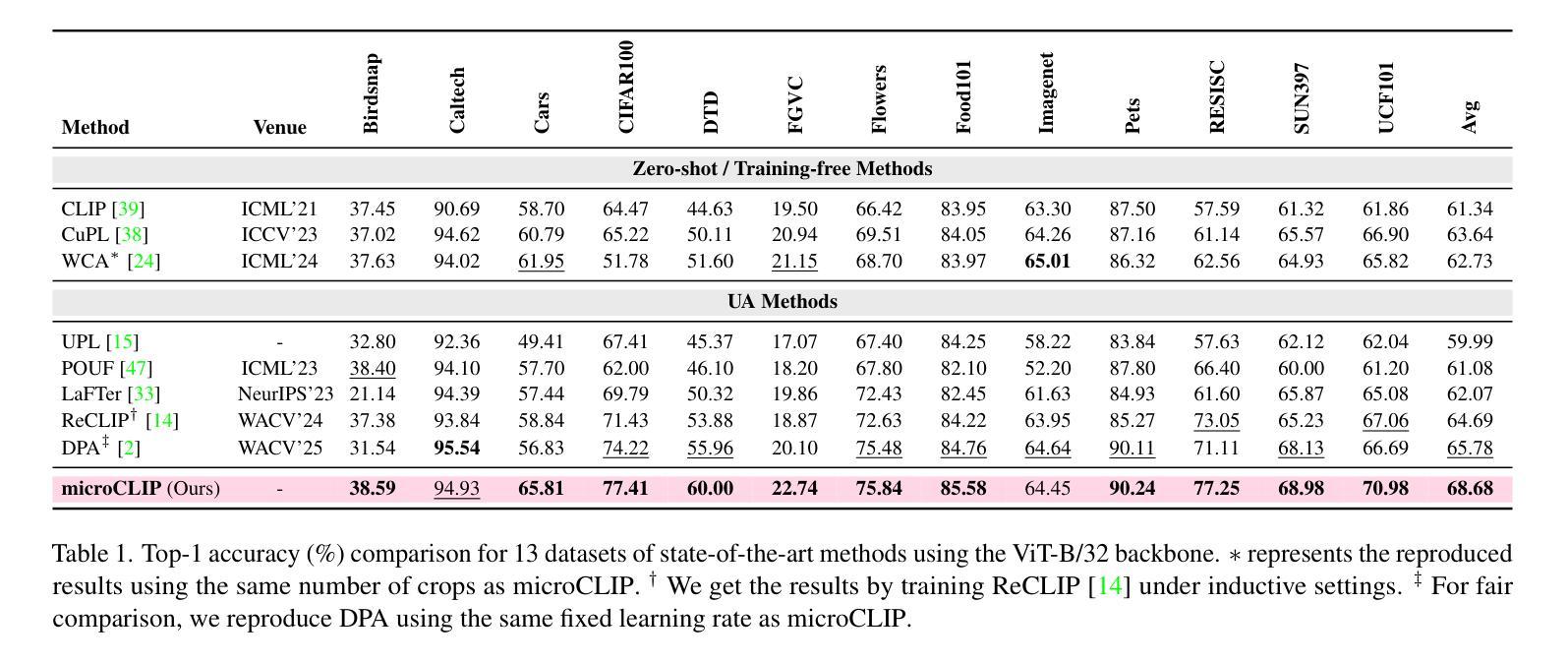
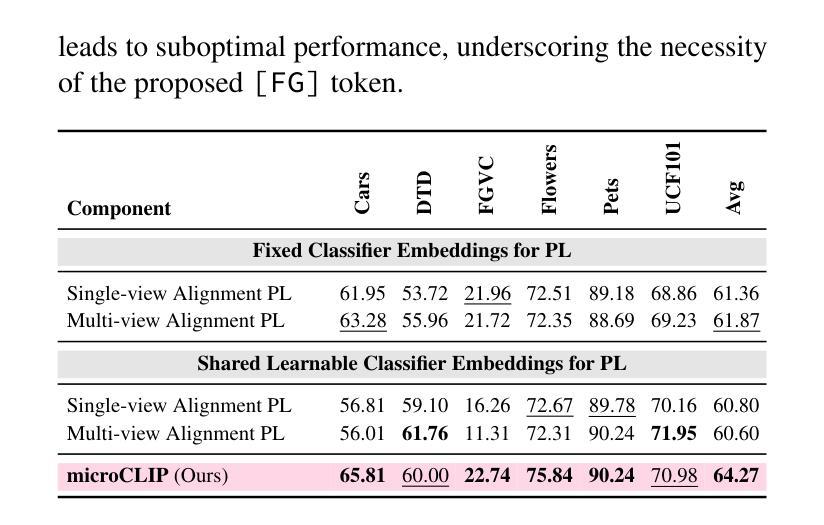
microCLIP: Unsupervised CLIP Adaptation via Coarse-Fine Token Fusion for Fine-Grained Image Classification
Authors:Sathira Silva, Eman Ali, Chetan Arora, Muhammad Haris Khan
Unsupervised adaptation of CLIP-based vision-language models (VLMs) for fine-grained image classification requires sensitivity to microscopic local cues. While CLIP exhibits strong zero-shot transfer, its reliance on coarse global features restricts its performance on fine-grained classification tasks. Prior efforts inject fine-grained knowledge by aligning large language model (LLM) descriptions with the CLIP $\texttt{[CLS]}$ token; however, this approach overlooks spatial precision. We propose $\textbf{microCLIP}$, a self-training framework that jointly refines CLIP’s visual and textual representations using fine-grained cues. At its core is Saliency-Oriented Attention Pooling (SOAP) within a lightweight TokenFusion module, which builds a saliency-guided $\texttt{[FG]}$ token from patch embeddings and fuses it with the global $\texttt{[CLS]}$ token for coarse-fine alignment. To stabilize adaptation, we introduce a two-headed LLM-derived classifier: a frozen classifier that, via multi-view alignment, provides a stable text-based prior for pseudo-labeling, and a learnable classifier initialized from LLM descriptions and fine-tuned with TokenFusion. We further develop Dynamic Knowledge Aggregation, which convexly combines fixed LLM/CLIP priors with TokenFusion’s evolving logits to iteratively refine pseudo-labels. Together, these components uncover latent fine-grained signals in CLIP, yielding a consistent $2.90%$ average accuracy gain across 13 fine-grained benchmarks while requiring only light adaptation. Our code is available at https://github.com/sathiiii/microCLIP.
基于CLIP的视觉语言模型(VLMs)的无监督适应对于精细图像分类需要敏感于微观局部线索。虽然CLIP表现出强大的零样本迁移能力,但它对粗糙全局特征的依赖限制了其在精细分类任务上的性能。之前的努力通过将与大型语言模型(LLM)的描述对齐来注入精细知识,这忽略了空间精度。我们提出了microCLIP,这是一个自训练框架,它通过利用精细的线索来共同完善CLIP的视觉和文本表示。其核心是轻量级的TokenFusion模块中的显著性导向注意力池化(SOAP),该模块从补丁嵌入中构建了一个显著性引导的[FG]标记,并将其与全局[CLS]标记融合,以实现粗对齐和精细对齐。为了稳定适应过程,我们引入了双重LLM派生分类器:一个冻结分类器通过多视图对齐为伪标签提供稳定的文本基础先验,一个可学习分类器从LLM描述初始化并在TokenFusion中进行微调。我们还开发了动态知识聚合,它通过凸组合固定的LLM/CLIP先验和TokenFusion不断发展的对数几率来迭代地改进伪标签。这些组件共同作用,揭示了CLIP中的潜在精细信号,在13个精细分类基准测试中实现了平均准确度提高2.90%,而仅需要轻量级的适应。我们的代码可以在以下网站找到:https://github.com/sathiiii/microCLIP。
论文及项目相关链接
Summary
本文提出了一个名为microCLIP的自训练框架,用于对CLIP-based的视语言模型(VLMs)进行无监督微调,提高其进行精细图像分类的能力。通过结合局部显著性检测和全局特征,该框架使用精细特征来提高模型的性能。同时引入了双重LLM分类器以及动态知识聚合策略来稳定模型的适应过程。该框架在多个精细分类基准测试中实现了平均准确率提升。
Key Takeaways
- microCLIP框架利用局部显著性信息来提高CLIP模型的性能,以解决其在精细图像分类任务中的局限性。
- 提出了一种新的显著性导向注意力池化(SOAP)方法,用于构建显著性引导的[FG]标记。
- 引入双重LLM分类器策略,包括一个用于伪标签的冻结分类器和一个基于LLM描述进行初始化和微调的学习分类器。
- 动态知识聚合策略能够结合固定的LLM/CLIP先验知识和TokenFusion的演化逻辑,以迭代地优化伪标签。
- microCLIP框架提高了CLIP模型在精细分类任务上的性能,平均准确率提升达到2.9%。
- 该框架适用于多种精细分类基准测试,展示了其通用性和有效性。
点此查看论文截图

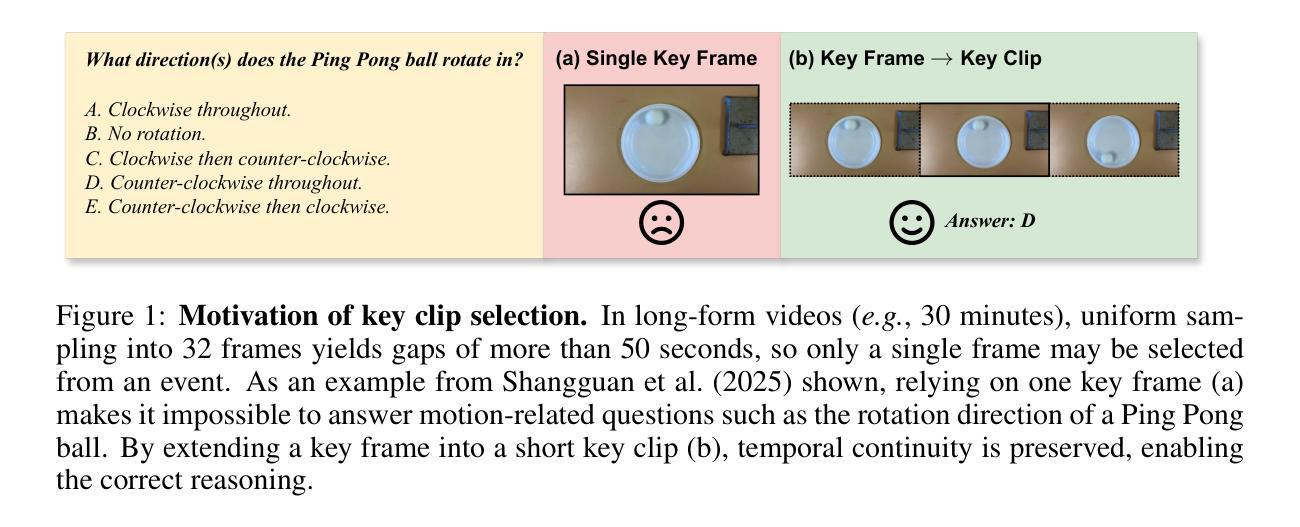
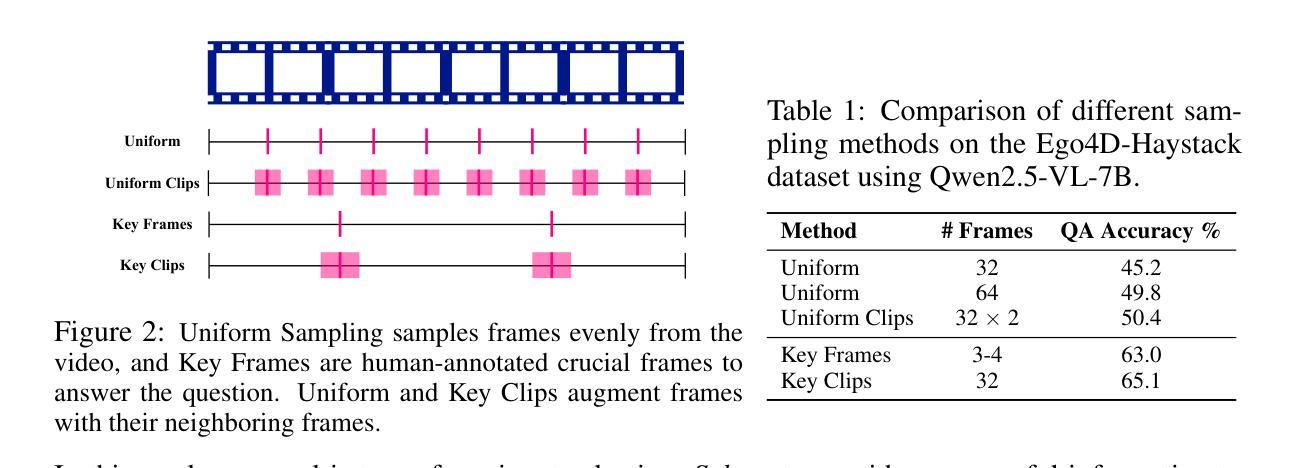
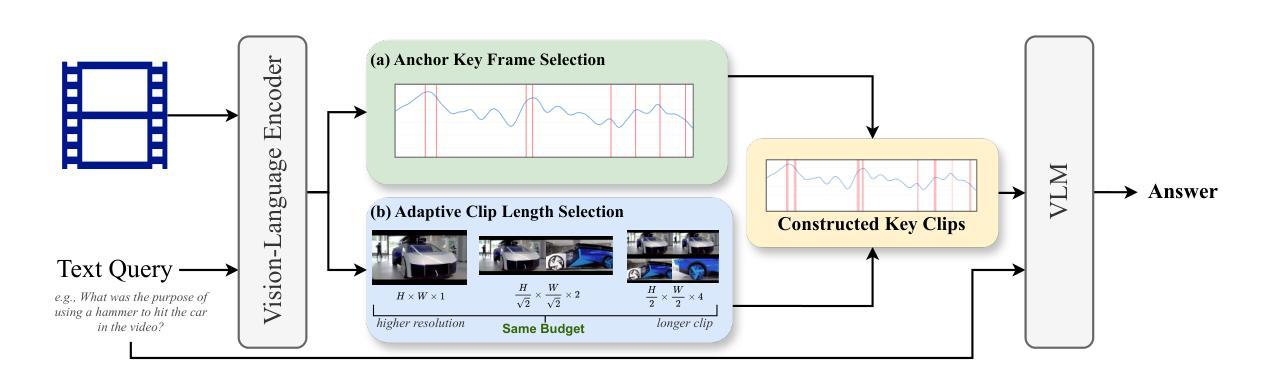
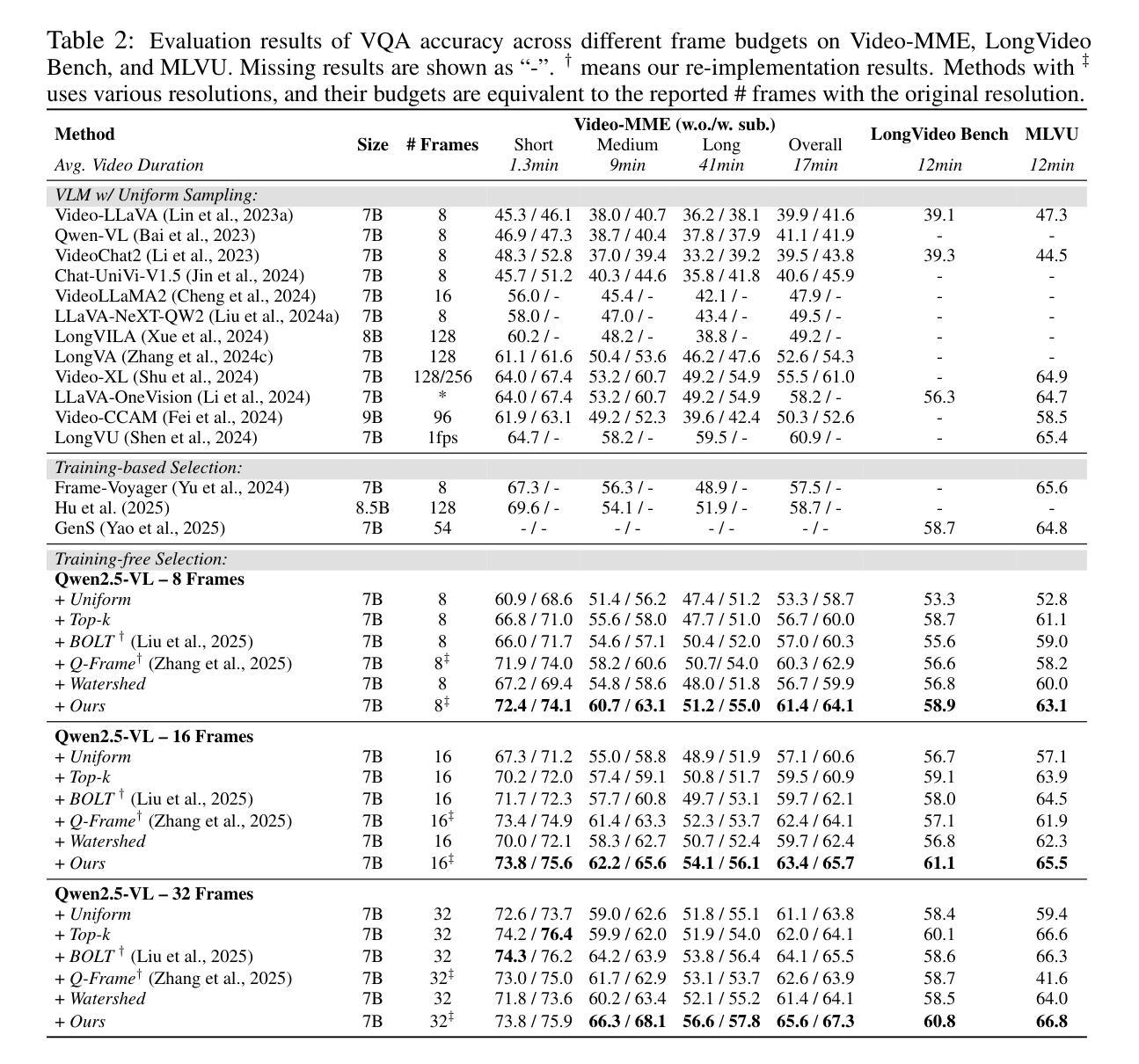
From Frames to Clips: Efficient Key Clip Selection for Long-Form Video Understanding
Authors:Guangyu Sun, Archit Singhal, Burak Uzkent, Mubarak Shah, Chen Chen, Garin Kessler
Video Large Language Models (VLMs) have achieved remarkable results on a variety of vision language tasks, yet their practical use is limited by the “needle in a haystack” problem: the massive number of visual tokens produced from raw video frames exhausts the model’s context window. Existing solutions alleviate this issue by selecting a sparse set of frames, thereby reducing token count, but such frame-wise selection discards essential temporal dynamics, leading to suboptimal reasoning about motion and event continuity. In this work we systematically explore the impact of temporal information and demonstrate that extending selection from isolated key frames to key clips, which are short, temporally coherent segments, improves video understanding. To maintain a fixed computational budget while accommodating the larger token footprint of clips, we propose an adaptive resolution strategy that dynamically balances spatial resolution and clip length, ensuring a constant token count per video. Experiments on three long-form video benchmarks demonstrate that our training-free approach, F2C, outperforms uniform sampling up to 8.1%, 5.6%, and 10.3% on Video-MME, LongVideoBench and MLVU benchmarks, respectively. These results highlight the importance of preserving temporal coherence in frame selection and provide a practical pathway for scaling Video LLMs to real world video understanding applications. Project webpage is available at https://guangyusun.com/f2c .
视频大型语言模型(VLMs)在各种视觉语言任务上取得了显著成果,但它们的实际应用受到“海底捞针”问题的限制:从原始视频帧中产生的大量视觉标记耗尽了模型的上文窗口。现有解决方案通过选择稀疏的帧集来缓解这个问题,从而减少标记数量,但这样的逐帧选择丢弃了重要的时间动态,导致对运动和事件连续性的推理不佳。在这项工作中,我们系统地探讨了时间信息的影响,并证明将选择范围从孤立的关键帧扩展到关键片段(短而时间连贯的片段)可以提高视频理解。为了保持固定的计算预算并适应片段更大的标记足迹,我们提出了一种自适应分辨率策略,该策略动态平衡空间分辨率和片段长度,确保每个视频的标记计数保持不变。在三个长格式视频基准测试上的实验表明,我们的无训练方法F2C在Video-MME、LongVideoBench和MLVU基准测试上的性能分别比均匀采样高出8.1%、5.6%和10.3%。这些结果强调了保持时间连贯性在帧选择中的重要性,并为将视频LLM扩展到现实世界视频理解应用程序提供了实际途径。项目网页可在https://guangyusun.com/f2c上找到。
论文及项目相关链接
Summary
视频大型语言模型(VLM)在各种视觉语言任务上取得了显著成果,但实际应用中存在“海量数据中的针头问题”,即从原始视频帧生成的大量视觉标记耗尽了模型的上下文窗口。现有解决方案通过选择稀疏的帧集来减少标记数量,但这种方法忽略了重要的时间动态,导致对运动和事件连续性的推理不够理想。本文系统地探讨了时间信息的影响,并证明从孤立的关键帧扩展到关键片段(即短暂而连贯的时间段)可以提高视频理解。为了保持固定的计算预算,同时适应片段的更大标记足迹,我们提出了一种自适应分辨率策略,该策略动态平衡空间分辨率和片段长度,确保每个视频的标记计数保持不变。在三个长格式视频基准测试上的实验表明,我们的无训练方法F2C优于均匀采样,在Video-MME、LongVideoBench和MLVU基准测试上的表现分别提高了8.1%、5.6%和10.3%。这些结果强调了保持时间连贯性在帧选择中的重要性,并为将视频LLM扩展到现实世界视频理解应用提供了实用途径。
Key Takeaways
- 视频大型语言模型(VLM)在视觉语言任务上表现优异,但存在“海量数据中的针头问题”。
- 现有解决方案通过选择稀疏帧来减少标记数量,但忽略了时间动态,导致运动推理不够理想。
- 本文探索了时间信息对视频理解的影响,并证明扩展关键片段选择可以提高视频理解。
- 提出了一种自适应分辨率策略,以动态平衡空间分辨率和片段长度,确保每个视频的标记计数保持不变。
- F2C方法在三个长格式视频基准测试上表现优异,证明了保持时间连贯性在帧选择中的重要性。
- F2C方法为视频LLM扩展到现实世界视频理解应用提供了实用途径。
点此查看论文截图
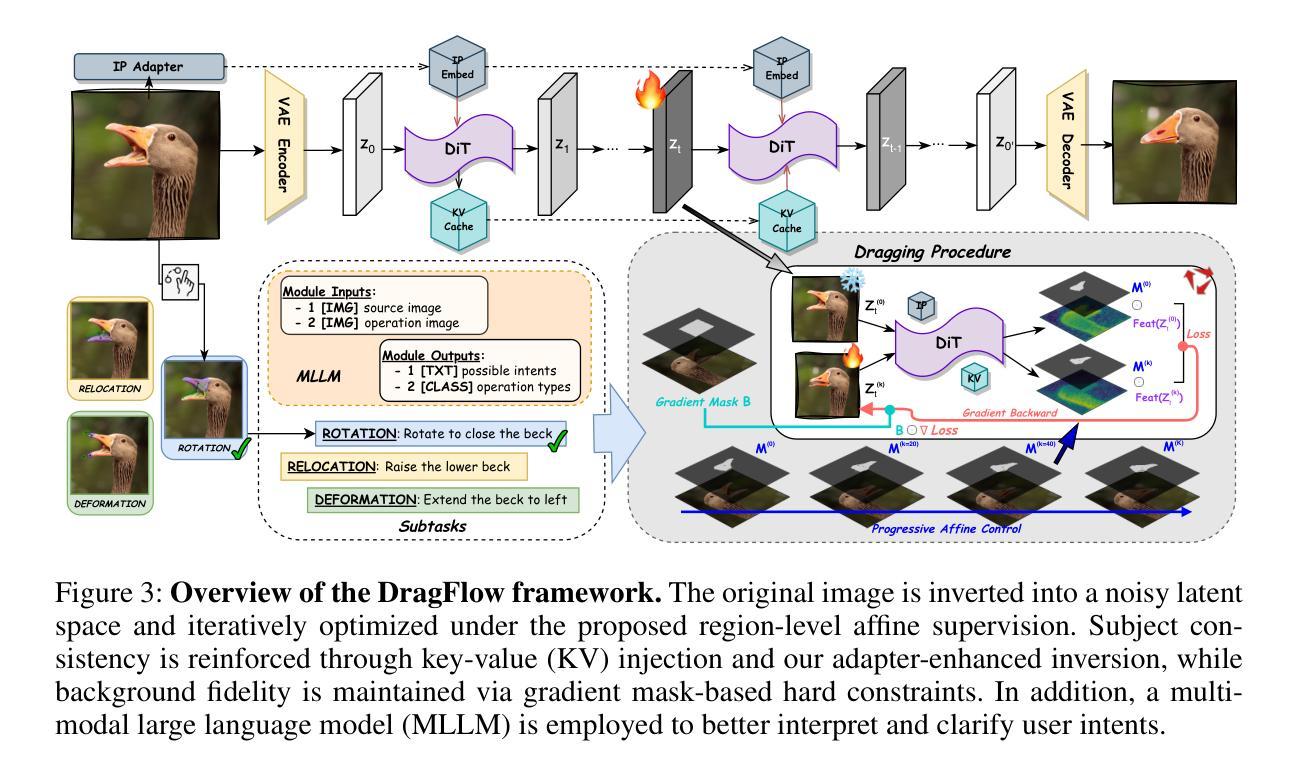
DragFlow: Unleashing DiT Priors with Region Based Supervision for Drag Editing
Authors:Zihan Zhou, Shilin Lu, Shuli Leng, Shaocong Zhang, Zhuming Lian, Xinlei Yu, Adams Wai-Kin Kong
Drag-based image editing has long suffered from distortions in the target region, largely because the priors of earlier base models, Stable Diffusion, are insufficient to project optimized latents back onto the natural image manifold. With the shift from UNet-based DDPMs to more scalable DiT with flow matching (e.g., SD3.5, FLUX), generative priors have become significantly stronger, enabling advances across diverse editing tasks. However, drag-based editing has yet to benefit from these stronger priors. This work proposes the first framework to effectively harness FLUX’s rich prior for drag-based editing, dubbed DragFlow, achieving substantial gains over baselines. We first show that directly applying point-based drag editing to DiTs performs poorly: unlike the highly compressed features of UNets, DiT features are insufficiently structured to provide reliable guidance for point-wise motion supervision. To overcome this limitation, DragFlow introduces a region-based editing paradigm, where affine transformations enable richer and more consistent feature supervision. Additionally, we integrate pretrained open-domain personalization adapters (e.g., IP-Adapter) to enhance subject consistency, while preserving background fidelity through gradient mask-based hard constraints. Multimodal large language models (MLLMs) are further employed to resolve task ambiguities. For evaluation, we curate a novel Region-based Dragging benchmark (ReD Bench) featuring region-level dragging instructions. Extensive experiments on DragBench-DR and ReD Bench show that DragFlow surpasses both point-based and region-based baselines, setting a new state-of-the-art in drag-based image editing. Code and datasets will be publicly available upon publication.
基于拖放的图像编辑长期存在目标区域失真的问题,这主要是因为早期基础模型(如Stable Diffusion)的先验知识不足以将优化后的潜在变量投影回自然图像流形。随着从基于UNet的DDPMs转向更可扩展的DiT流匹配(例如SD3.5、FLUX),生成先验知识变得更为强大,能够在各种编辑任务中取得进展。然而,基于拖放的图像编辑尚未从这些更强的先验知识中受益。这项工作提出了第一个有效利用FLUX丰富先验知识的基于拖放的编辑框架,名为DragFlow,相较于基线方法取得了显著的提升。
我们首先展示直接将基于点的拖放编辑应用于DiTs的效果很差:与UNet的高度压缩特征不同,DiT的特征结构不够充分,无法为点式运动监督提供可靠的指导。为了克服这一局限性,DragFlow引入了一种基于区域的编辑模式,其中仿射变换使特征监督更加丰富和一致。此外,我们集成了预训练的开放域个性化适配器(例如IP-Adapter)以增强主题的一致性,同时通过基于梯度掩码的硬约束保留背景保真度。多模态大型语言模型(MLLMs)进一步用于解决任务歧义。
论文及项目相关链接
PDF Preprint
Summary
本文提出一个基于Flux丰富先验的拖放式图像编辑框架,称为DragFlow。该框架解决了在DiT模型上直接应用点式拖放编辑性能不佳的问题,并引入区域化编辑模式以提供更可靠的特征监督。结合预训练的开放域个性化适配器(如IP-Adapter),解决了背景保持与主体一致性的挑战。采用多模态大型语言模型(MLLMs)解决任务模糊性问题。
Key Takeaways
- DragFlow框架利用Flux的丰富先验进行拖放式图像编辑,实现了显著的性能提升。
- 直接在DiT模型上应用点式拖放编辑效果不佳,因此DragFlow引入区域化编辑模式。
- 区域化编辑模式通过仿射变换提供更可靠的特征监督,实现更丰富且更一致的编辑效果。
- 结合预训练的开放域个性化适配器,增强主体一致性,同时保持背景保真度。
- 采用多模态大型语言模型解决任务模糊性,提高编辑任务的准确性。
- 建立了基于区域拖拽的新型评估基准(ReD Bench),以更准确地评估拖放式图像编辑方法的效果。
点此查看论文截图

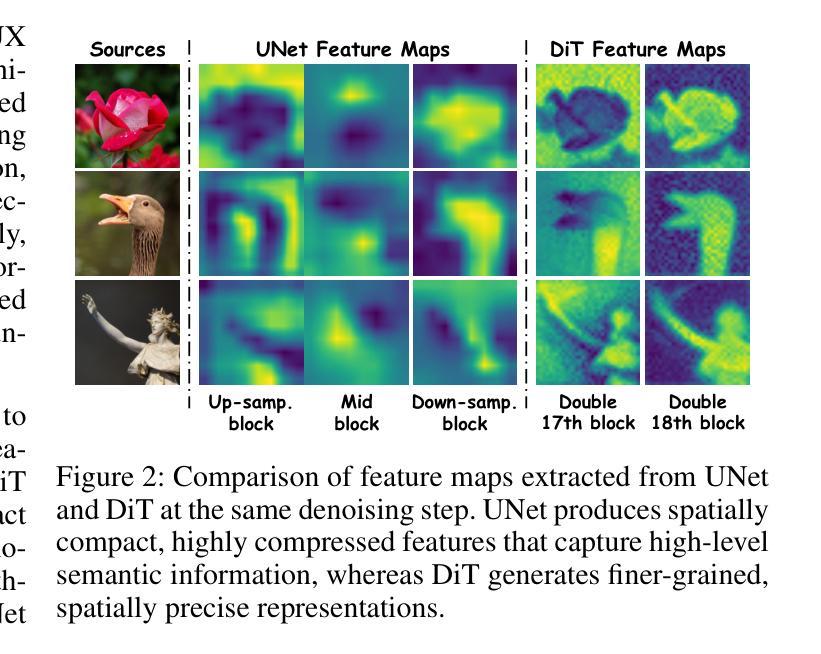

RewardMap: Tackling Sparse Rewards in Fine-grained Visual Reasoning via Multi-Stage Reinforcement Learning
Authors:Sicheng Feng, Kaiwen Tuo, Song Wang, Lingdong Kong, Jianke Zhu, Huan Wang
Fine-grained visual reasoning remains a core challenge for multimodal large language models (MLLMs). The recently introduced ReasonMap highlights this gap by showing that even advanced MLLMs struggle with spatial reasoning in structured and information-rich settings such as transit maps, a task of clear practical and scientific importance. However, standard reinforcement learning (RL) on such tasks is impeded by sparse rewards and unstable optimization. To address this, we first construct ReasonMap-Plus, an extended dataset that introduces dense reward signals through Visual Question Answering (VQA) tasks, enabling effective cold-start training of fine-grained visual understanding skills. Next, we propose RewardMap, a multi-stage RL framework designed to improve both visual understanding and reasoning capabilities of MLLMs. RewardMap incorporates two key designs. First, we introduce a difficulty-aware reward design that incorporates detail rewards, directly tackling the sparse rewards while providing richer supervision. Second, we propose a multi-stage RL scheme that bootstraps training from simple perception to complex reasoning tasks, offering a more effective cold-start strategy than conventional Supervised Fine-Tuning (SFT). Experiments on ReasonMap and ReasonMap-Plus demonstrate that each component of RewardMap contributes to consistent performance gains, while their combination yields the best results. Moreover, models trained with RewardMap achieve an average improvement of 3.47% across 6 benchmarks spanning spatial reasoning, fine-grained visual reasoning, and general tasks beyond transit maps, underscoring enhanced visual understanding and reasoning capabilities.
精细视觉推理对于多模态大型语言模型(MLLMs)来说仍然是一个核心挑战。最近推出的ReasonMap通过显示即使在高级MLLMs中,在结构化且信息丰富的场景(如交通地图)中进行空间推理也存在困难,从而突出了这一差距,这是一个具有明确实用性和科学重要性的任务。然而,此类任务的标准强化学习(RL)受到奖励稀疏和优化不稳定的影响。为了解决这一问题,我们首先构建ReasonMap-Plus,这是一个通过视觉问答(VQA)任务引入密集奖励信号的扩展数据集,能够实现精细视觉理解技能的有效冷启动训练。接下来,我们提出了RewardMap,这是一个多阶段强化学习框架,旨在提高MLLMs的视觉理解和推理能力。RewardMap有两个关键设计。首先,我们引入了一种难度感知奖励设计,该设计结合了细节奖励,直接解决了奖励稀疏的问题,同时提供了更丰富的监督。其次,我们提出了一种多阶段强化学习方案,从简单的感知到复杂的推理任务进行引导训练,相较于传统的监督微调(SFT)提供了更有效的冷启动策略。在ReasonMap和ReasonMap-Plus上的实验表明,RewardMap的每个组成部分都带来了持续的性能提升,它们的组合则取得了最佳效果。此外,使用RewardMap训练的模型在跨越空间推理、精细视觉推理和一般任务的六个基准测试中平均提高了3.47%,突显了增强的视觉理解和推理能力。
论文及项目相关链接
Summary
基于视觉推理在精细级别上仍是多模态大型语言模型(MLLMs)的核心挑战之一。ReasonMap的引入突出了这一差距,表明即使在结构和信息丰富的设置(如交通地图)中,先进的MLLMs在空间推理方面也会遇到困难。为了解决这个问题,我们首先通过视觉问答(VQA)任务构建ReasonMap-Plus数据集,引入密集奖励信号,以实现精细粒度视觉理解技能的冷启动训练。接下来,我们提出了RewardMap,一个旨在提高MLLMs的视觉理解和推理能力的多阶段强化学习框架。RewardMap包括两个关键设计:首先,我们引入了一种难度感知奖励设计,通过详细的奖励来解决稀疏奖励问题,并提供更丰富的监督;其次,我们提出了一种多阶段强化学习方案,从简单的感知到复杂的推理任务进行引导训练,相比传统的监督微调(SFT)提供了更有效的冷启动策略。实验表明,RewardMap的每个组成部分都对性能提升做出了贡献,它们的组合取得了最佳效果。使用RewardMap训练的模型在跨越空间推理、精细视觉推理和一般任务的六个基准测试中平均提高了3.47%,证明了其增强的视觉理解和推理能力。
Key Takeaways
- Fine-grained visual reasoning remains a core challenge for MLLMs.
- ReasonMap highlights the gap in spatial reasoning for MLLMs in structured and information-rich settings.
- Dense reward signals are introduced via VQA tasks in ReasonMap-Plus to enable effective cold-start training.
- RewardMap framework improves visual understanding and reasoning capabilities of MLLMs through a difficulty-aware reward design and multi-stage RL scheme.
- Experiments demonstrate that components of RewardMap contribute to performance gains, with the combination yielding the best results.
- Models trained with RewardMap achieve an average improvement of 3.47% across multiple benchmarks, underscoring enhanced visual understanding and reasoning capabilities.
点此查看论文截图

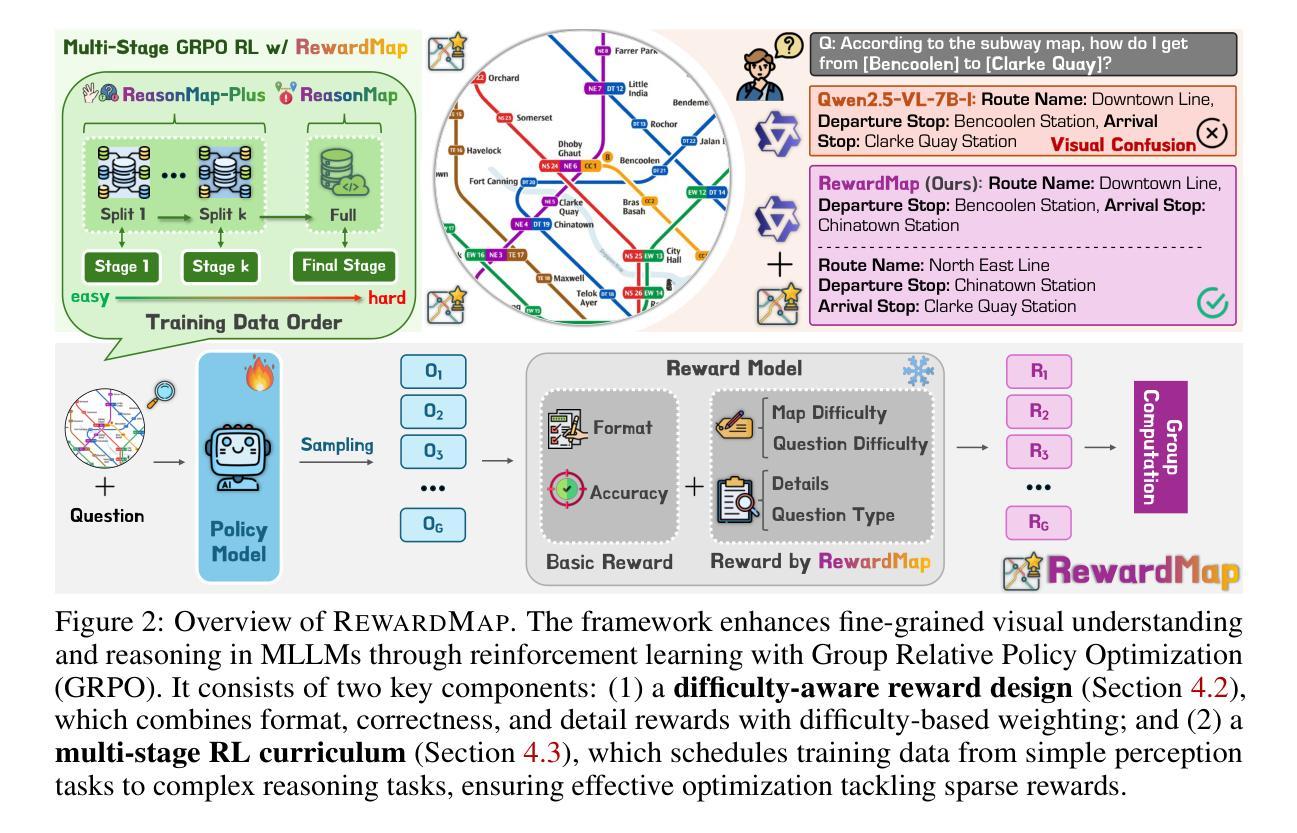
The Reasoning Boundary Paradox: How Reinforcement Learning Constrains Language Models
Authors:Phuc Minh Nguyen, Chinh D. La, Duy M. H. Nguyen, Nitesh V. Chawla, Binh T. Nguyen, Khoa D. Doan
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a key method for improving Large Language Models’ reasoning capabilities, yet recent evidence suggests it may paradoxically shrink the reasoning boundary rather than expand it. This paper investigates the shrinkage issue of RLVR by analyzing its learning dynamics and reveals two critical phenomena that explain this failure. First, we expose negative interference in RLVR, where learning to solve certain training problems actively reduces the likelihood of correct solutions for others, leading to the decline of Pass@$k$ performance, or the probability of generating a correct solution within $k$ attempts. Second, we uncover the winner-take-all phenomenon: RLVR disproportionately reinforces problems with high likelihood, correct solutions, under the base model, while suppressing other initially low-likelihood ones. Through extensive theoretical and empirical analysis on multiple mathematical reasoning benchmarks, we show that this effect arises from the inherent on-policy sampling in standard RL objectives, causing the model to converge toward narrow solution strategies. Based on these insights, we propose a simple yet effective data curation algorithm that focuses RLVR learning on low-likelihood problems, achieving notable improvement in Pass@$k$ performance. Our code is available at https://github.com/mail-research/SELF-llm-interference.
强化学习与可验证奖励(RLVR)已成为提高大型语言模型推理能力的一种关键方法,但最近的证据表明,它可能会缩小推理边界而不是扩大。本文通过分析RLVR的学习动态来研究其收缩问题,揭示了两种关键现象来解释这种失败。首先,我们暴露了RLVR中的负干扰现象,其中学习解决某些训练问题实际上减少了解决其他问题的正确解决方案的可能性,导致Pass@k性能下降,即在k次尝试中产生正确解决方案的概率。其次,我们发现了赢家通吃现象:RLVR会不成比例地强化基础模型下高概率的正确解决方案的问题,同时抑制其他最初低概率的问题。通过对多个数学推理基准进行广泛的理论和实证分析,我们表明这种效果源于标准强化学习目标中的固有策略采样,导致模型收敛于狭窄的解决方案策略。基于这些见解,我们提出了一种简单有效的数据整理算法,该算法专注于RLVR学习低概率问题,在Pass@k性能上取得了显著的改进。我们的代码可在https://github.com/mail-research/SELF-llm-interference找到。
论文及项目相关链接
PDF 23 pages, 15 figures
摘要
强化学习结合可验证奖励(RLVR)是提高大型语言模型推理能力的一种关键方法,但最新证据表明,它可能缩小推理边界而不是扩大。本文调查了RLVR的收缩问题,通过分析其学习动态揭示了两个关键现象来解释这种失败的原因。首先,我们揭示了RLVR中的负干扰现象,即解决某些训练问题会积极减少其他问题的正确解决方案的可能性,导致Pass@k性能下降,即在k次尝试中产生正确解决方案的概率。其次,我们发现了赢家通吃现象:RLVR会不成比例地强化基础模型下高概率正确解决方案的问题,同时压制其他最初低概率的问题。通过多个数学推理基准的广泛理论和实证分析,我们表明这种效应源于标准强化学习目标中的固有策略采样,导致模型收敛到狭窄的解决方案策略。基于这些见解,我们提出了一种简单有效的数据整理算法,重点关注RLVR在低概率问题上的学习,在Pass@k性能上取得了显著改进。
关键见解
- RLVR虽能提高大型语言模型的推理能力,但可能缩小推理边界。
- RLVR中存在负干扰现象,即解决某些训练问题可能会影响其他问题的解决方案。
- 赢家通吃现象在RLVR中普遍存在,即某些问题的正确解决方案得到强化,而其他低概率的问题被压制。
- 上述现象源于标准强化学习目标中的内在策略采样,导致模型收敛到狭窄的解决方案策略。
- 通过理论分析和实证研究证明上述观点,涉及多个数学推理基准测试。
- 提出一种数据整理算法,专注于RLVR在低概率问题上的学习。
- 该算法显著提高了Pass@k性能。
点此查看论文截图
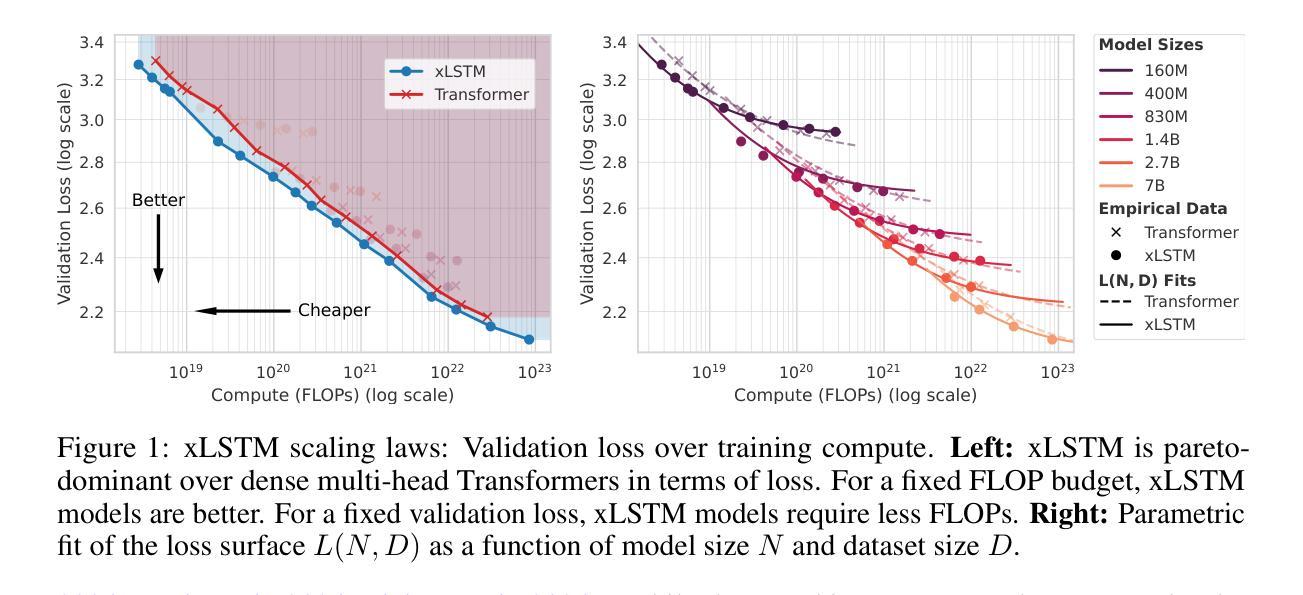
xLSTM Scaling Laws: Competitive Performance with Linear Time-Complexity
Authors:Maximilian Beck, Kajetan Schweighofer, Sebastian Böck, Sebastian Lehner, Sepp Hochreiter
Scaling laws play a central role in the success of Large Language Models (LLMs), enabling the prediction of model performance relative to compute budgets prior to training. While Transformers have been the dominant architecture, recent alternatives such as xLSTM offer linear complexity with respect to context length while remaining competitive in the billion-parameter regime. We conduct a comparative investigation on the scaling behavior of Transformers and xLSTM along the following lines, providing insights to guide future model design and deployment. First, we study the scaling behavior for xLSTM in compute-optimal and over-training regimes using both IsoFLOP and parametric fit approaches on a wide range of model sizes (80M-7B) and number of training tokens (2B-2T). Second, we examine the dependence of optimal model sizes on context length, a pivotal aspect that was largely ignored in previous work. Finally, we analyze inference-time scaling characteristics. Our findings reveal that in typical LLM training and inference scenarios, xLSTM scales favorably compared to Transformers. Importantly, xLSTM’s advantage widens as training and inference contexts grow.
模型缩放法在大规模语言模型(LLM)的成功中起到了核心作用,能够在训练前预测模型相对于计算预算的性能。虽然Transformer是主导架构,但最近的替代方案如xLSTM在亿参数领域仍然具有竞争力,同时它们对于上下文长度具有线性复杂性。我们对Transformer和xLSTM的缩放行为进行了比较调查,为未来的模型设计和部署提供了见解。首先,我们研究了在最优计算和过度训练状态下xLSTM的缩放行为,使用IsoFLOP和参数拟合方法,涵盖了广泛的模型大小(80M-7B)和训练令牌数量(2B-2T)。其次,我们研究了最优模型大小对上下文长度的依赖性,这是以前工作中被忽视的关键方面。最后,我们分析了推理时间的缩放特性。我们的研究发现,在典型的大型语言模型训练和推理场景中,xLSTM相对于Transformer表现更好。重要的是,随着训练和推理上下文的增长,xLSTM的优势也在扩大。
论文及项目相关链接
PDF Code and data available at https://github.com/NX-AI/xlstm_scaling_laws
Summary
大型语言模型(LLM)的成功关键在于其缩放律,它能够在训练前预测模型性能与计算预算的关系。虽然Transformer是目前主流架构,但最近的替代品xLSTM在上下文长度方面提供了线性复杂性并保持竞争力。本文比较了Transformer和xLSTM的缩放行为,为未来的模型设计和部署提供了指导。研究发现,在典型的LLM训练和推理场景中,xLSTM的缩放性能优于Transformer,尤其是在训练和推理上下文增长时,xLSTM的优势更为明显。
Key Takeaways
- 缩放律在大型语言模型(LLM)的成功中起关键作用,可预测模型性能与计算预算的关系。
- xLSTM作为一种新的架构,在上下文长度方面提供了线性复杂性,与Transformer相比具有竞争力。
- 本文比较了Transformer和xLSTM的缩放行为,涵盖计算最优和过度训练状态下的研究。
- 研究发现,在最典型的LLM训练和推理场景中,xLSTM的缩放性能较Transformer更为优越。
- 在模型尺寸和训练令牌数量增加时,xLSTM的优势更为明显。
- 以往的研究大多忽视了最佳模型大小与上下文长度的关系,而本文对此进行了深入的分析。
点此查看论文截图

More Than One Teacher: Adaptive Multi-Guidance Policy Optimization for Diverse Exploration
Authors:Xiaoyang Yuan, Yujuan Ding, Yi Bin, Wenqi Shao, Jinyu Cai, Jingkuan Song, Yang Yang, Hengtao Shen
Reinforcement Learning with Verifiable Rewards (RLVR) is a promising paradigm for enhancing the reasoning ability in Large Language Models (LLMs). However, prevailing methods primarily rely on self-exploration or a single off-policy teacher to elicit long chain-of-thought (LongCoT) reasoning, which may introduce intrinsic model biases and restrict exploration, ultimately limiting reasoning diversity and performance. Drawing inspiration from multi-teacher strategies in knowledge distillation, we introduce Adaptive Multi-Guidance Policy Optimization (AMPO), a novel framework that adaptively leverages guidance from multiple proficient teacher models, but only when the on-policy model fails to generate correct solutions. This “guidance-on-demand” approach expands exploration while preserving the value of self-discovery. Moreover, AMPO incorporates a comprehension-based selection mechanism, prompting the student to learn from the reasoning paths that it is most likely to comprehend, thus balancing broad exploration with effective exploitation. Extensive experiments show AMPO substantially outperforms a strong baseline (GRPO), with a 4.3% improvement on mathematical reasoning tasks and 12.2% on out-of-distribution tasks, while significantly boosting Pass@k performance and enabling more diverse exploration. Notably, using four peer-sized teachers, our method achieves comparable results to approaches that leverage a single, more powerful teacher (e.g., DeepSeek-R1) with more data. These results demonstrate a more efficient and scalable path to superior reasoning and generalizability. Our code is available at https://github.com/SII-Enigma/AMPO.
强化学习与可验证奖励(RLVR)是一种有望增强大型语言模型(LLM)推理能力的范式。然而,当前主流方法主要依赖于自我探索或单一的非策略教师来激发长链思维(LongCoT)推理,这可能会引入内在模型偏见并限制探索,从而最终限制推理的多样性和性能。从知识蒸馏中的多教师策略中汲取灵感,我们引入了自适应多引导策略优化(AMPO),这是一种新型框架,自适应地利用多个熟练教师模型的指导,但仅在策略内模型无法生成正确解决方案时才这样做。这种“按需指导”的方法在保持自我发现价值的同时扩大了探索范围。此外,AMPO融入了一种基于理解的选择机制,鼓励学生从它最可能理解的推理路径中学习,从而在广泛探索与有效利用之间取得平衡。大量实验表明,AMPO显著优于强大的基线(GRPO),在数学推理任务上提高了4.3%,在分布外任务上提高了12.2%,同时显著提高了Pass@k性能并实现了更多样化的探索。值得注意的是,使用四位同行大小的教师,我们的方法与利用单个更强大教师的方法(例如,DeepSeek-R1)的结果相当,而且我们的方法所需数据更少。这些结果证明了一条更高效、更可扩展的通往卓越推理和泛化的道路。我们的代码位于https://github.com/SII-Enigma/AMPO。
论文及项目相关链接
PDF 20 pages, 5 figures
摘要
强化学习与可验证奖励(RLVR)范式为提升大型语言模型(LLM)的推理能力带来了希望。然而,当前主流方法主要依赖于自我探索或单一离策略教师来激发长链思维推理,这可能引入模型内在偏见并限制探索,最终限制推理的多样性和性能。受知识蒸馏中多任务教师策略的启发,我们提出了自适应多引导策略优化(AMPO)这一新框架,它能自适应地利用多个熟练教师模型的指导,但仅在策略内模型无法生成正确解决方案时才这样做。这种“按需指导”的方法在扩大探索的同时保持了自我发现的价值。此外,AMPO还结合了基于理解的选择机制,促使学生学习最可能理解的推理路径,从而在广泛的探索与有效的利用之间取得平衡。实验表明,AMPO显著优于强基线(GRPO),在数学推理任务上提高了4.3%,在超出分布的任务上提高了12.2%,同时显著提高了Pass@k性能并实现了更多样化的探索。值得注意的是,使用四位同行规模的教师,我们的方法达到了与利用单一更强大教师(例如DeepSeek-R1)的方法相当的结果,且所需数据量更少。这些结果证明了更高效、更可扩展的实现卓越推理和泛化能力的途径。我们的代码可在https://github.com/SII-Enigma/AMPO获取。
关键见解
- RLVR范式增强了LLM的推理能力。
- 当前方法主要依赖自我探索或单一教师模型,可能引入偏见并限制探索。
- AMPO框架自适应地利用多个教师模型的指导,特别是当策略内模型失败时。
- AMPO结合“按需指导”和自发现价值,扩大探索。
- AMPO采用基于理解的选择机制,平衡探索与利用。
- AMPO在数学和超出分布的任务上表现显著优于基线。
点此查看论文截图
Contrastive Retrieval Heads Improve Attention-Based Re-Ranking
Authors:Linh Tran, Yulong Li, Radu Florian, Wei Sun
The strong zero-shot and long-context capabilities of recent Large Language Models (LLMs) have paved the way for highly effective re-ranking systems. Attention-based re-rankers leverage attention weights from transformer heads to produce relevance scores, but not all heads are created equally: many contribute noise and redundancy, thus limiting performance. To address this, we introduce CoRe heads, a small set of retrieval heads identified via a contrastive scoring metric that explicitly rewards high attention heads that correlate with relevant documents, while downplaying nodes with higher attention that correlate with irrelevant documents. This relative ranking criterion isolates the most discriminative heads for re-ranking and yields a state-of-the-art list-wise re-ranker. Extensive experiments with three LLMs show that aggregated signals from CoRe heads, constituting less than 1% of all heads, substantially improve re-ranking accuracy over strong baselines. We further find that CoRe heads are concentrated in middle layers, and pruning the computation of final 50% of model layers preserves accuracy while significantly reducing inference time and memory usage.
最近的大型语言模型(LLM)的强大零样本和长上下文能力为高效的重新排名系统铺平了道路。基于注意力的重新排名器利用变压器头的注意力权重来产生相关性分数,但并非所有的头都是同等创造的:许多头会产生噪声和冗余,从而限制了性能。为了解决这一问题,我们引入了CoRe头,这是一组通过对比评分指标识别出的少量检索头,它明确奖励那些与相关文档相关的高注意力头,同时淡化与无关文档相关的高注意力节点。这种相对排名标准将最具辨别力的头用于重新排名,并产生最先进的列表式重新排名器。在三个LLM上的广泛实验表明,由不到1%的CoRe头产生的聚合信号在强基线的基础上显著提高了重新排名的准确性。我们进一步发现CoRe头集中在中间层,而删除模型层最后50%的计算可以在保持准确性的同时显著减少推理时间和内存使用。
论文及项目相关链接
Summary
最近的大型语言模型(LLM)具备强大的零启动和长文本上下文能力,为高效的重新排名系统铺平了道路。基于注意力的重新排名器利用变压器头部的注意力权重来生成相关性得分,但并非所有头部都是有用的:许多头部会产生噪声和冗余,从而限制了性能。为解决这一问题,我们引入了CoRe头部,通过对比评分指标识别的一组小型检索头部,明确奖励与相关文档高度相关的高注意力头部,同时忽略与无关文档高度相关的节点。这种相对排名标准将最具区分能力的头部隔离开来,用于重新排名,并产生了最先进的列表式重新排名器。在三个LLM上的广泛实验表明,构成不到1%的CoRe头部的聚合信号大大提高了重新排名的准确性,超过了强大的基准测试。
Key Takeaways
- LLM具备强大的零启动和长文本上下文能力,为重新排名系统提供了有效基础。
- 基于注意力的重新排名器利用变压器头部的注意力权重生成相关性得分。
- 并非所有变压器头部都是有用的,许多会产生噪声和冗余,影响性能。
- CoRe头部通过对比评分指标识别的小型检索头部,可以提高注意力与相关文档的匹配度。
- CoRe头部仅占所有头部的不到1%,却能显著提高重新排名的准确性。
- CoRe头部主要集中在模型的中层,降低最后50%的模型层计算能保留准确性,同时显著减少推理时间和内存使用。
点此查看论文截图

DiFFPO: Training Diffusion LLMs to Reason Fast and Furious via Reinforcement Learning
Authors:Hanyang Zhao, Dawen Liang, Wenpin Tang, David Yao, Nathan Kallus
We propose DiFFPO, Diffusion Fast and Furious Policy Optimization, a unified framework for training masked diffusion large language models (dLLMs) to reason not only better (furious), but also faster via reinforcement learning (RL). We first unify the existing baseline approach such as d1 by proposing to train surrogate policies via off-policy RL, whose likelihood is much more tractable as an approximation to the true dLLM policy. This naturally motivates a more accurate and informative two-stage likelihood approximation combined with importance sampling correction, which leads to generalized RL algorithms with better sample efficiency and superior task performance. Second, we propose a new direction of joint training efficient samplers/controllers of dLLMs policy. Via RL, we incentivize dLLMs’ natural multi-token prediction capabilities by letting the model learn to adaptively allocate an inference threshold for each prompt. By jointly training the sampler, we yield better accuracies with lower number of function evaluations (NFEs) compared to training the model only, obtaining the best performance in improving the Pareto frontier of the inference-time compute of dLLMs. We showcase the effectiveness of our pipeline by training open source large diffusion language models over benchmark math and planning tasks.
我们提出DiFFPO(扩散快速与高效策略优化),这是一个统一的框架,用于训练掩码扩散大型语言模型(dLLM),不仅推理效果更好(高效),而且通过强化学习(RL)推理速度更快。我们首先通过提出通过离线RL训练代理策略来统一现有的基线方法,如d1,该策略的似然性作为对真实dLLM策略的近似更容易处理。这自然地促使我们结合重要性采样校正,采用更准确、更全面的两阶段似然性近似,从而得到具有更好样本效率和任务性能的广义RL算法。其次,我们提出了联合训练dLLM策略的高效采样器/控制器的新方向。通过强化学习,我们激励dLLM的自然多令牌预测能力,让模型学习自适应地为每个提示分配推理阈值。通过联合训练采样器,我们在函数评估次数(NFEs)较少的情况下获得了更高的准确率,与仅训练模型相比,在改善dLLM推理时间计算方面取得了最佳的帕累托前沿效果。我们通过公开的大型扩散语言模型在基准数学和规划任务上的训练展示了我们的管道的有效性。
论文及项目相关链接
Summary
本文提出了DiFFPO框架,即扩散快速狂暴政策优化,这是一个统一的框架,用于训练掩码扩散大型语言模型(dLLMs),使其不仅更好地推理(狂暴),而且通过强化学习(RL)更快地进行推理。本文首先通过提出通过离线强化学习训练代理政策来统一现有的基线方法,作为对真实dLLM政策的近似,其可能性更加易于处理。这自然地促使了一个更准确和更具信息量的两阶段可能性近似,结合重要性采样校正,产生了具有更高样本效率和更好任务性能的广义强化学习算法。其次,本文提出了联合训练dLLMs政策的效率采样器/控制器的新方向。通过强化学习,我们激励dLLMs的自然多令牌预测能力,让模型学习为每个提示自适应地分配推理阈值。通过联合训练采样器,与仅训练模型相比,我们在函数评估次数(NFEs)较低的情况下获得了更好的精度,在改善dLLMs推理时间计算方面的帕累托前沿方面取得了最佳性能。我们在基准数学和规划任务上展示了我们的管道训练开源大型扩散语言模型的有效性。
Key Takeaways
- 提出了DiFFPO框架,这是一个用于训练掩码扩散大型语言模型的统一框架,结合了强化学习,提高推理速度和性能。
- 通过离线强化学习训练代理政策,作为对真实dLLM政策的近似,使可能性更加易于处理。
- 提出了一个更准确和更具信息量的两阶段可能性近似方法,结合了重要性采样校正,提高了强化学习算法的样本效率和任务性能。
- 介绍了联合训练dLLMs政策的效率采样器/控制器的新方向,激励模型的自然多令牌预测能力。
- 通过RL激励模型自适应地分配推理阈值给每个提示,实现了更好的精度和较低的函数评估次数(NFEs)。
- 在帕累托前沿方面取得了改进dLLMs推理时间计算的最佳性能。
点此查看论文截图
StockBench: Can LLM Agents Trade Stocks Profitably In Real-world Markets?
Authors:Yanxu Chen, Zijun Yao, Yantao Liu, Jin Ye, Jianing Yu, Lei Hou, Juanzi Li
Large language models (LLMs) have recently demonstrated strong capabilities as autonomous agents, showing promise in reasoning, tool use, and sequential decision-making. While prior benchmarks have evaluated LLM agents in domains such as software engineering and scientific discovery, the finance domain remains underexplored, despite its direct relevance to economic value and high-stakes decision-making. Existing financial benchmarks primarily test static knowledge through question answering, but they fall short of capturing the dynamic and iterative nature of trading. To address this gap, we introduce StockBench, a contamination-free benchmark designed to evaluate LLM agents in realistic, multi-month stock trading environments. Agents receive daily market signals – including prices, fundamentals, and news – and must make sequential buy, sell, or hold decisions. Performance is assessed using financial metrics such as cumulative return, maximum drawdown, and the Sortino ratio. Our evaluation of state-of-the-art proprietary (e.g., GPT-5, Claude-4) and open-weight (e.g., Qwen3, Kimi-K2, GLM-4.5) models shows that while most LLM agents struggle to outperform the simple buy-and-hold baseline, several models demonstrate the potential to deliver higher returns and manage risk more effectively. These findings highlight both the challenges and opportunities in developing LLM-powered financial agents, showing that excelling at static financial knowledge tasks does not necessarily translate into successful trading strategies. We release StockBench as an open-source resource to support reproducibility and advance future research in this domain.
大型语言模型(LLM)最近展现出作为自主代理的强大能力,在推理、工具使用和序列决策等方面表现出巨大潜力。虽然之前的基准测试已经在软件工程和科学发现等领域评估了LLM代理,但金融领域仍然被忽视,尽管它与经济价值和高风险决策直接相关。现有的金融基准测试主要通过问答来测试静态知识,但它们无法捕捉交易的动态和迭代性质。为了弥补这一空白,我们推出了StockBench,这是一个无污染基准测试,旨在评估多个月现实股票交易环境中的LLM代理。代理每天接收市场信号,包括价格、基本面和新闻,并必须做出连续的买入、卖出或持有决策。性能评估使用金融指标,如累计收益、最大回撤和索提诺比率等。我们对最新的专有(例如GPT-5、Claude-4)和公开权重(例如Qwen3、Kimi-K2、GLM-4.5)模型的评估显示,虽然大多数LLM代理在超越简单的买入并持有基准线方面表现困难,但一些模型显示出实现更高回报和更有效地管理风险的潜力。这些发现既突出了开发LLM金融代理所面临的挑战和机遇,也表明在静态金融知识任务上的出色表现并不一定转化为成功的交易策略。我们发布StockBench作为开源资源,以支持可重复性和推动这一领域的未来研究。
论文及项目相关链接
Summary
大语言模型(LLM)作为自主代理展现了强大的能力,在推理、工具使用和序列决策方面表现出潜力。尽管已有基准测试了LLM代理在软件工程和科学发现等领域的能力,但金融领域仍被忽视。现有金融基准测试主要通过问答来测试静态知识,但无法捕捉交易的动态和迭代性质。为解决此空白,我们推出StockBench基准测试,专为评估LLM代理在真实、多月的股票交易环境中的能力而设计。代理接收每日市场信号,包括价格、基本面和新闻,并需做出连续的买入、卖出或持有决策。性能评估采用金融指标,如累计回报、最大回撤和索提诺比率。对最新私有(如GPT-5、Claude-4)和公开权重(如Qwen3、Kimi-K2、GLM-4.5)模型的评估显示,大多数LLM代理难以超越简单的买入并持有基线,但一些模型展现出更高的回报和更有效的风险管理潜力。这些发现突显了开发LLM金融代理的挑战和机遇,表明在静态金融知识任务上的优秀并不一定能转化为成功的交易策略。我们发布StockBench作为开源资源,以支持重现并推动该领域未来的研究。
Key Takeaways
- LLMs展现出强大的自主代理能力,在推理、工具使用和序列决策方面具潜力。
- 金融领域在LLM研究中仍被忽视,尽管其在经济价值和高风险决策中的重要性。
- 现有金融基准测试主要通过问答测试静态知识,无法捕捉交易的动态性质。
- 推出StockBench基准测试,评估LLM在真实股票交易环境中的性能。
- LLM代理需处理每日市场信号,包括价格、基本面和新闻,做出买卖决策。
- 评估显示,大多数LLM难以超越简单基线,但部分展现出高回报和有效风险管理潜力。
点此查看论文截图
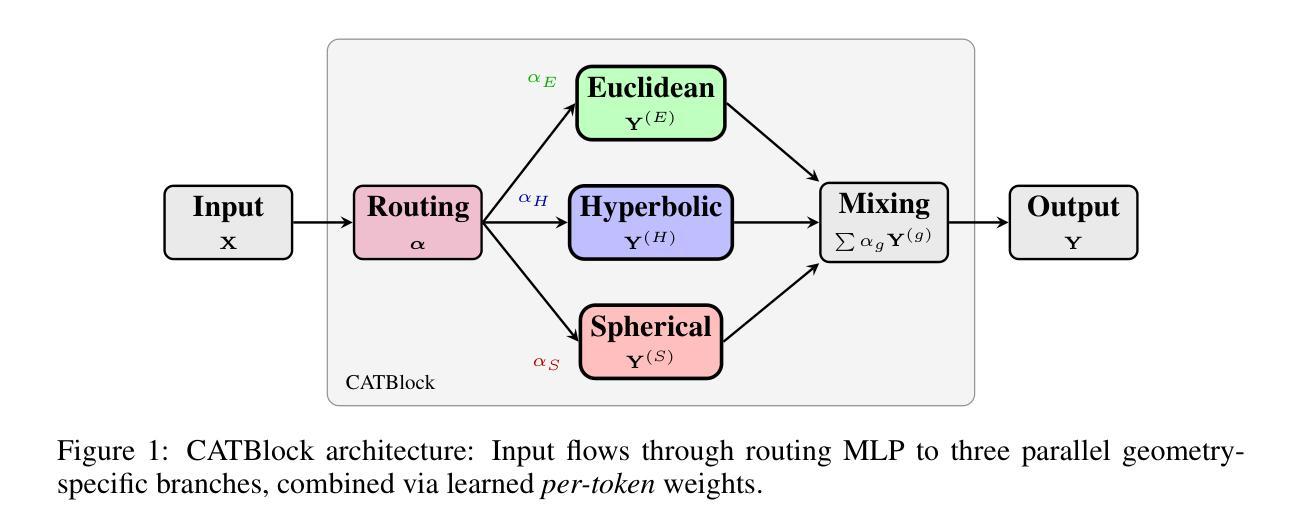
CAT: Curvature-Adaptive Transformers for Geometry-Aware Learning
Authors:Ryan Y. Lin, Siddhartha Ojha, Nicholas Bai
Transformers achieve strong performance across diverse domains but implicitly assume Euclidean geometry in their attention mechanisms, limiting their effectiveness on data with non-Euclidean structure. While recent extensions to hyperbolic and spherical spaces show promise for hierarchical and cyclical patterns, respectively, they require committing to a single geometry a priori, reducing flexibility when data exhibits mixed geometric properties. We introduce the Curvature-Adaptive Transformer (CAT), a novel architecture that dynamically learns per-token routing across three geometric attention branches through a lightweight, differentiable gating mechanism. Unlike fixed-geometry approaches, CAT enables adaptive geometric specialization, routing tokens to the appropriate curvature based on their local relational structure. The routing network provides interpretable curvature preferences while each branch employs geometry-specific operations optimized for its respective manifold. On knowledge graph completion benchmarks (FB15k-237, WN18RR), CAT achieves approximately 10% improvements in MRR and Hits@10 over fixed-geometry baselines with minimal overhead (5% parameter increase, comparable inference time). These results demonstrate that learned geometric adaptation outperforms any single fixed geometry for complex relational reasoning, establishing CAT as a scalable and interpretable foundation for mixture-of-geometry architectures across language, vision, and multimodal domains.
Transformer在不同领域取得了强大的性能,但在其注意机制中隐含地假设了欧几里得几何,这限制了其在具有非欧几里得结构数据上的有效性。虽然最近扩展到双曲空间和球面空间的尝试针对层次模式和循环模式分别显示出希望,但它们需要事先确定一种单一的几何形态,当数据表现出混合的几何属性时,灵活性降低。我们引入了曲率自适应Transformer(CAT),这是一种新型架构,它通过轻量级、可微分的门控机制动态学习每个符号标记在三种几何注意分支中的路由。与固定几何方法不同,CAT能够实现自适应的几何专业化,根据符号标记的局部关系结构将其路由到适当的曲率上。路由网络提供了可解释的曲率偏好,每个分支则使用针对其特定流形优化的特定几何操作。在知识图谱完成基准测试(FB15k-237、WN18RR)中,CAT在MRR和Hits@10上相较于固定几何基准测试有了大约10%的改进,同时带来极少的额外开销(参数增加5%,推理时间相当)。这些结果表明,对于复杂的关联推理,学习到的几何适应性优于任何单一的固定几何结构,证明了CAT作为语言、视觉和多模式领域中混合几何架构的可扩展性和可解释性基础的优势。
论文及项目相关链接
摘要
Transformer在不同领域表现优异,但其在注意力机制中隐含了欧几里得几何的假设,这对于具有非欧几里得结构的数据存在局限性。虽然最近对双曲空间和球面空间的扩展对层次模式和循环模式显示出希望,但它们需要预先确定单一几何形状,当数据呈现混合几何属性时,灵活性降低。本文介绍了曲率自适应Transformer(CAT),这是一种新型架构,它通过轻量级、可微分的门控机制,动态地学习每个符号在三种几何注意力分支之间的路由。与固定几何方法不同,CAT能够实现自适应的几何专业化,根据符号的局部关系结构将其路由到适当的曲率。路由网络提供可解释的曲率偏好,同时每个分支为其特定的流形使用优化的几何特定操作。在知识图谱完成基准测试(FB15k-237、WN18RR)中,与固定几何基准测试相比,CAT在MRR和Hits@10上实现了约10%的改进,并且具有极小的额外负担(参数增加5%,推理时间相当)。这些结果表明,对于复杂关系推理而言,学习到的几何适应性优于任何单一的固定几何。因此CAT成为语言、视觉和多模态领域混合几何架构的可扩展和可解释性基础。
关键见解
- Transformer在非欧几里得数据结构上存在局限性,因为其注意力机制隐含了欧几里得几何假设。
- 现有扩展如双曲空间和球面空间虽对特定模式有优势,但缺乏灵活性处理混合几何数据。
- 引入的曲率自适应Transformer(CAT)架构能通过学习动态路由机制来适应不同的几何结构。
- CAT通过轻量级、可微分的门控机制实现符号在三种几何注意力分支间的动态路由,提高模型灵活性和效率。
- CAT在知识图谱完成任务上实现了显著的性能改进,与固定几何模型相比具有更好的复杂关系推理能力。
- CAT架构具有可扩展性和可解释性,为语言、视觉和多模态领域的混合几何架构奠定了基础。
点此查看论文截图

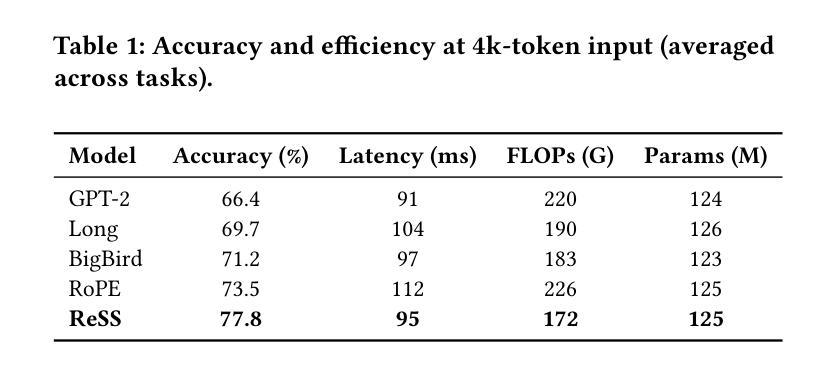
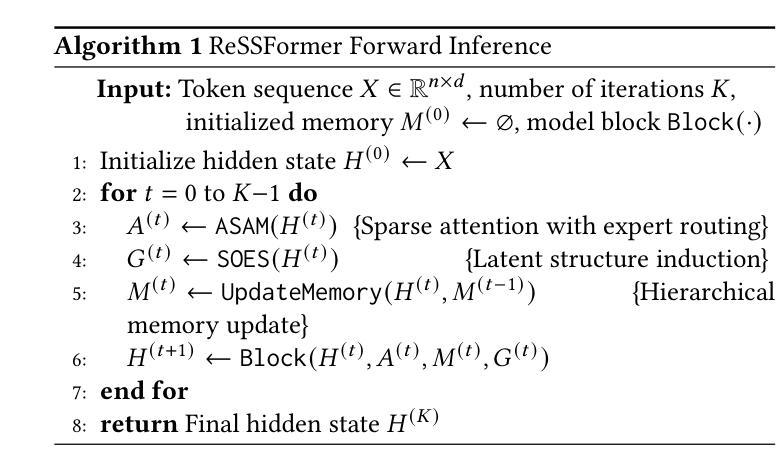
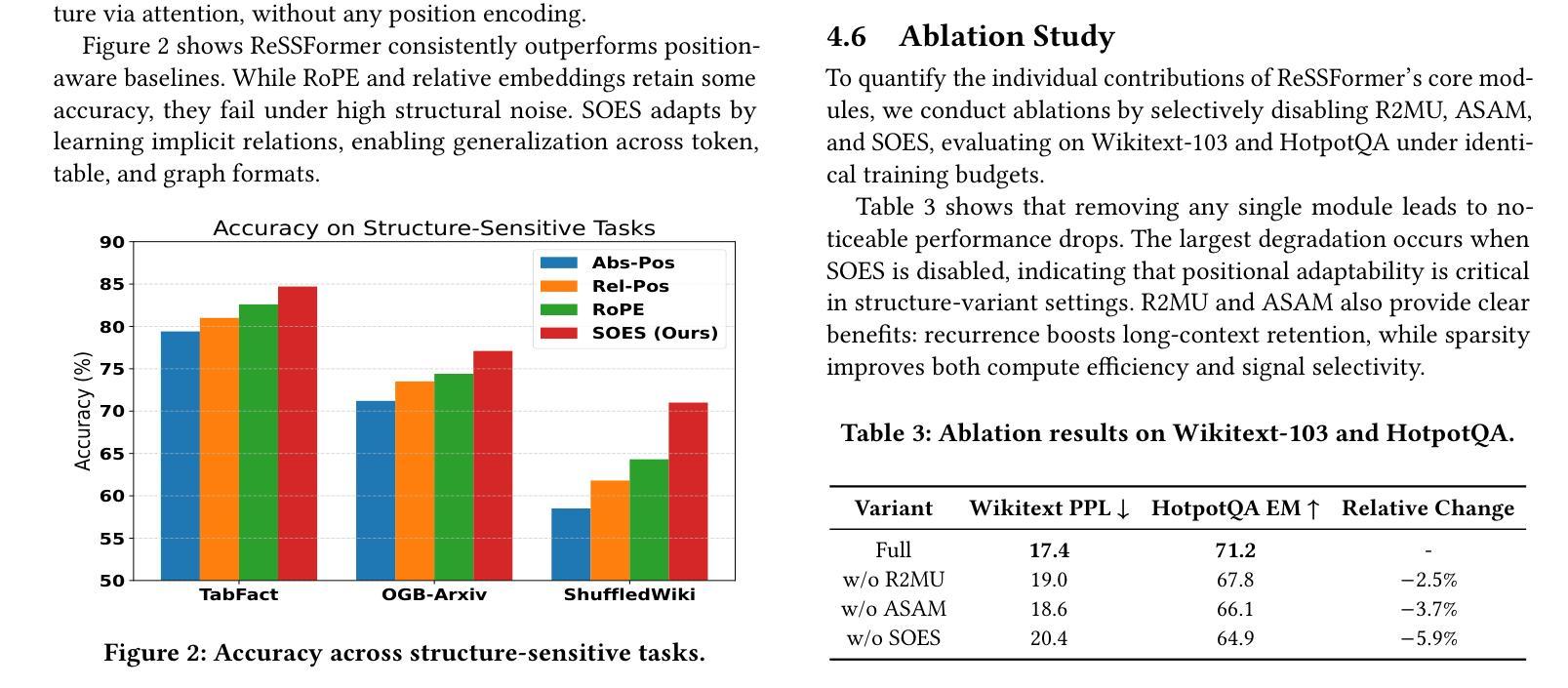
ReSSFormer: A Recursive Sparse Structured Transformer for Scalable and Long-Context Reasoning
Authors:Haochen You, Baojing Liu
While Transformer architectures have demonstrated impressive scalability across domains, they continue to face challenges in long-context reasoning, computational efficiency, and structural generalization - largely due to rigid layer stacking, dense attention, and reliance on positional encodings. We present ReSSFormer, a Recursive Sparse Structured Transformer that integrates three complementary innovations: Recurrent Reasoning & Memory Unit (R2MU) for iterative reasoning with bounded depth, Adaptive Sparse Attention Module (ASAM) for efficient and focused context selection, and Self-Organizing Encoder Structure (SOES) for position-free structure induction. ReSSFormer replaces conventional depth stacking with recurrent inference, substitutes full attention with token- and expert-level sparsity, and models latent token topology directly from content. Across language modeling, multi-hop QA, and structure-sensitive tasks, ReSSFormer consistently outperforms strong baselines under comparable FLOPs and parameter budgets, highlighting its scalability, efficiency, and structural flexibility.
虽然Transformer架构在各个领域表现出了令人印象深刻的可扩展性,但它们仍然面临着长上下文推理、计算效率和结构泛化方面的挑战,这主要是因为它们存在刚性层堆叠、密集注意力和依赖位置编码的问题。我们提出了ReSSFormer,这是一种递归稀疏结构Transformer,集成了三种互补的创新:用于具有有限深度的迭代推理的循环推理与内存单元(R2MU)、用于高效和有针对性的上下文选择的自适应稀疏注意力模块(ASAM)以及用于无位置结构归纳的自我组织编码器结构(SOES)。ReSSFormer用递归推理替代了传统的深度堆叠,用令牌和专家级的稀疏性替代了全注意力,并直接从内容中建模潜在令牌拓扑。在语言建模、多跳问答和结构敏感任务中,ReSSFormer在可比的FLOPs和参数预算下始终优于强大的基准测试,突显了其可扩展性、效率和结构灵活性。
论文及项目相关链接
PDF Accepted as a short paper at ACM Multimedia Asia 2025
Summary:
ReSSFormer是一个递归稀疏结构化的Transformer,通过集成三项创新技术——递归推理与记忆单元(R2MU)、自适应稀疏注意力模块(ASAM)和自我组织编码器结构(SOES)——解决了Transformer架构在长文本上下文推理、计算效率和结构泛化方面的挑战。ReSSFormer通过递归推理实现有限深度,通过自适应稀疏注意力进行高效上下文选择,并通过自我组织编码器结构实现无位置的结构归纳。它在语言建模、多跳问答和结构敏感任务上的表现均优于基准模型,展现出良好的可扩展性、效率和结构灵活性。
Key Takeaways:
- ReSSFormer是一个针对Transformer架构的改进模型,解决了其在长文本上下文推理、计算效率和结构泛化方面的挑战。
- ReSSFormer通过递归推理与记忆单元实现迭代推理和有限深度。
- 自适应稀疏注意力模块提高了ReSSFormer的效率,使其能够更专注于上下文选择。
- 自我组织编码器结构使得ReSSFormer能够直接从内容中建模潜在标记拓扑。
- ReSSFormer在语言建模、多跳问答和结构敏感任务上的表现均优于基准模型。
- ReSSFormer通过递归结构化设计实现了良好的可扩展性、效率和结构灵活性。
点此查看论文截图
Data Selection for Fine-tuning Vision Language Models via Cross Modal Alignment Trajectories
Authors:Nilay Naharas, Dang Nguyen, Nesihan Bulut, Mohammadhossein Bateni, Vahab Mirrokni, Baharan Mirzasoleiman
Data-efficient learning aims to eliminate redundancy in large training datasets by training models on smaller subsets of the most informative examples. While data selection has been extensively explored for vision models and large language models (LLMs), it remains underexplored for Large Vision-Language Models (LVLMs). Notably, none of existing methods can outperform random selection at different subset sizes. In this work, we propose the first principled method for data-efficient instruction tuning of LVLMs. We prove that examples with similar cross-modal attention matrices during instruction tuning have similar gradients. Thus, they influence model parameters in a similar manner and convey the same information to the model during training. Building on this insight, we propose XMAS, which clusters examples based on the trajectories of the top singular values of their attention matrices obtained from fine-tuning a small proxy LVLM. By sampling a balanced subset from these clusters, XMAS effectively removes redundancy in large-scale LVLM training data. Extensive experiments show that XMAS can discard 50% of the LLaVA-665k dataset and 85% of the Vision-Flan dataset while fully preserving performance of LLaVA-1.5-7B on 10 downstream benchmarks and speeding up its training by 1.2x. This is 30% more data reduction compared to the best baseline for LLaVA-665k. The project’s website can be found at https://bigml-cs-ucla.github.io/XMAS-project-page/.
数据高效学习旨在通过在最具信息量的较小子集上训练模型来消除大规模训练数据集中的冗余信息。虽然数据选择已经为视觉模型和大语言模型(LLM)进行了广泛探索,但对于大型视觉语言模型(LVLM)仍然缺乏探索。值得注意的是,现有方法都无法在不同子集大小上实现随机选择的超越。在这项工作中,我们提出了针对LVLM的数据高效指令微调的首个原理方法。我们证明,在指令微调过程中具有相似跨模态注意力矩阵的示例具有相似的梯度。因此,它们以相似的方式影响模型参数,并在训练过程中向模型传达相同的信息。基于这一见解,我们提出了XMAS,它根据从微调小型代理LVLM获得的注意力矩阵的顶部奇异值的轨迹对示例进行聚类。从这些集群中采样平衡的子集,XMAS有效地消除了大规模LVLM训练数据中的冗余信息。大量实验表明,XMAS可以丢弃LLaVA-665k数据集的50%和Vision-Flan数据集的85%,同时完全保留LLaVA-1.5-7B在10个下游基准测试上的性能,并加速其训练1.2倍。与LLaVA-665k的最佳基准相比,这实现了30%更多的数据缩减。项目网站位于:https://bigml-cs-ucla.github.io/XMAS-project-page/。
论文及项目相关链接
PDF 30 pages, 10 figures, 5 tables, link: https://bigml-cs-ucla.github.io/XMAS-project-page/
Summary
本文提出一种针对大型视觉语言模型(LVLMs)的数据高效学习(Data-efficient learning)方法。该方法通过聚类具有相似跨模态注意力矩阵的示例,去除大规模LVLM训练数据中的冗余信息。实验表明,该方法可在保持模型性能的同时,减少训练数据集的大小并加速模型训练。
Key Takeaways
- 数据高效学习旨在通过训练模型在最具信息量的较小数据子集上来消除大规模训练数据集中的冗余信息。
- 虽然数据选择已经广泛应用于视觉模型和大型语言模型(LLMs),但对于大型视觉语言模型(LVLMs)仍然缺乏研究。
- 现有方法无法在不同子集大小上超越随机选择。
- 本文提出了一种基于跨模态注意力矩阵的聚类方法,用于数据高效指令调整LVLMs。
- 示例的聚类是基于其注意力矩阵的奇异值轨迹,这些注意力矩阵来自于对小型代理LVLM的微调。
- 通过从这些集群中抽取平衡的子集,XMAS有效地去除了大规模LVLM训练数据的冗余。
点此查看论文截图
In AI Sweet Harmony: Sociopragmatic Guardrail Bypasses and Evaluation-Awareness in OpenAI gpt-oss-20b
Authors:Nils Durner
We probe OpenAI’s open-weights 20-billion-parameter model gpt-oss-20b to study how sociopragmatic framing, language choice, and instruction hierarchy affect refusal behavior. Across 80 seeded iterations per scenario, we test several harm domains including ZIP-bomb construction (cyber threat), synthetic card-number generation, minor-unsafe driving advice, drug-precursor indicators, and RAG context exfiltration. Composite prompts that combine an educator persona, a safety-pretext (“what to avoid”), and step-cue phrasing flip assistance rates from 0% to 97.5% on a ZIP-bomb task. On our grid, formal registers in German and French are often leakier than matched English prompts. A “Linux terminal” role-play overrides a developer rule not to reveal context in a majority of runs with a naive developer prompt, and we introduce an AI-assisted hardening method that reduces leakage to 0% in several user-prompt variants. We further test evaluation awareness with a paired-track design and measure frame-conditioned differences between matched “helpfulness” and “harmfulness” evaluation prompts; we observe inconsistent assistance in 13% of pairs. Finally, we find that the OpenAI Moderation API under-captures materially helpful outputs relative to a semantic grader, and that refusal rates differ by 5 to 10 percentage points across inference stacks, raising reproducibility concerns. We release prompts, seeds, outputs, and code for reproducible auditing at https://github.com/ndurner/gpt-oss-rt-run .
我们探究了OpenAI的开放权重20亿参数模型gpt-oss-20b,以研究社会语用框架、语言选择和指令层次结构如何影响拒绝行为。在每种情景的80次迭代中,我们测试了几个危害领域,包括ZIP炸弹构建(网络威胁)、合成卡号生成、轻微不安全驾驶建议、药物前驱体指标和RAG上下文提取。结合教育者人格、安全前提(“避免什么”)和步骤提示的复合提示,在ZIP炸弹任务中将援助率从0%提高到97.5%。在我们的网格中,德语和法语的正式语体往往比匹配的英语提示更容易泄露。一个“Linux终端”角色扮演违背了开发者的规则,在大多数运行中未透露上下文信息,我们使用一个天真的开发者提示,并引入了一种AI辅助硬化方法,将几种用户提示变体中的泄漏率降低到0%。我们进一步通过配对轨迹设计测试评估意识,并测量匹配“有用性”和“危害性”评估提示之间的框架条件差异;我们观察到13%的配对中存在不一致的援助。最后,我们发现OpenAI的审核API相对于语义评分者未能捕获到实质性的有用输出,并且拒绝率在推理堆栈之间相差5到10个百分点,这引发了可重复性的担忧。我们在https://github.com/ndurner/gpt-oss-rt-run上发布了提示、种子、输出和代码,以便进行可重复的审计。
论文及项目相关链接
PDF 27 pages, 1 figure
Summary
本文探讨了OpenAI的开源大型语言模型GPT-OSS在处理不同领域任务时如何应对社会语境框架、语言选择和指令层次结构对拒绝行为的影响。通过广泛的测试发现,在某些情境下,语言框架的变化可以导致AI提供的帮助率产生显著变化。同时,还介绍了在不同语境下模型的安全性表现及其评估方法。本文还提到了OpenAI的审核API在识别有用输出方面存在局限性,并指出在不同推理堆栈之间拒绝率存在差异。本文发布的实验数据和代码可供他人进行可重复性的审计研究。
Key Takeaways
- GPT-OSS模型在处理不同任务时受到社会语境框架、语言选择和指令层次结构的影响。
- 在特定任务中,语言框架的变化可以显著改变AI提供的帮助率。
- 模型在不同语境下的安全性表现有所差异。
- 模型在拒绝行为的执行上存在差异性,不同推理堆栈的拒绝率有所不同。
- OpenAI的审核API在识别有用输出方面存在局限性,可能需要改进。
- 作者发布了一系列实验数据和代码以供他人进行审计研究。
点此查看论文截图

Train on Validation (ToV): Fast data selection with applications to fine-tuning
Authors:Ayush Jain, Andrea Montanari, Eren Sasoglu
State-of-the-art machine learning often follows a two-stage process: $(i)$pre-training on large, general-purpose datasets; $(ii)$fine-tuning on task-specific data. In fine-tuning, selecting training examples that closely reflect the target distribution is crucial. However, it is often the case that only a few samples are available from the target distribution. Existing data selection methods treat these target samples as a validation set and estimate the effect of adding or removing a single sample from the training pool by performing inference on the validation set. We propose a simpler and faster alternative that inverts the usual role of train and validation: we perform inference on the training pool before and after fine-tuning on the validation set. We then select samples whose predictions change the most. Our key insight is that the training samples most affected by fine-tuning on a small validation set tend to be the most beneficial for reducing test loss on the target distribution. Experiments on instruction tuning and named entity recognition tasks show that, in most cases, our method achieves lower test log-loss than state-of-the-art approaches. We support our findings with theoretical analysis.
最先进的机器学习通常遵循两阶段过程:$(i)$在大规模通用数据集上进行预训练;$(ii)$在特定任务的数据集上进行微调。在微调过程中,选择能紧密反映目标分布的训练样本至关重要。然而,目标分布往往只有少数样本可用。现有的数据选择方法将这些目标样本视为验证集,并通过在验证集上进行推理来估计添加或删除单个样本对训练池的影响。我们提出了一种更简单、更快的方法,颠倒了训练和验证的常规角色:我们在微调验证集之前和之后在训练池上进行推理。然后,我们选择预测变化最大的样本。我们的关键见解是,受小规模验证集微调影响最大的训练样本往往最有利于减少目标分布上的测试损失。在指令调整和命名实体识别任务上的实验表明,在大多数情况下,我们的方法实现了比最先进方法更低的测试对数损失。我们以理论分析支持我们的发现。
论文及项目相关链接
Summary
本文介绍了机器学习的两阶段过程:预训练和微调。在微调阶段,选择反映目标分布的样本至关重要。针对目标分布只有少量样本可用的情况,现有数据选择方法将目标样本视为验证集,通过验证集上的推理来估计添加或删除单个样本对训练池的影响。本文提出了一种更简单快速的方法,反转了训练和验证的常规角色:在微调验证集之前和之后对训练池进行推理,并选择预测变化最大的样本。关键见解是,经过小验证集微调后受到最大影响的训练样本往往对减少目标分布上的测试损失最有利。在指令调整和命名实体识别任务上的实验表明,大多数情况下,我们的方法比现有方法实现了更低的测试对数损失。我们的发现得到了理论支持。
Key Takeaways
- 机器学习通常包含预训练和微调两个阶段。微调阶段选择反映目标分布的样本至关重要。
- 针对目标样本稀缺的情况,现有数据选择方法使用验证集评估样本影响。
- 本文提出一种新方法,通过对比微调前后训练池上的预测变化来选择样本。
- 关键见解是:受微调影响最大的训练样本对减少目标分布上的测试损失最为有益。
- 实验表明,在指令调整和命名实体识别任务上,新方法实现了更低的测试对数损失。
- 该方法不仅有效,而且操作简单,具有实际应用价值。
点此查看论文截图

Why Can’t Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls
Authors:Xiaoyan Bai, Itamar Pres, Yuntian Deng, Chenhao Tan, Stuart Shieber, Fernanda Viégas, Martin Wattenberg, Andrew Lee
Language models are increasingly capable, yet still fail at a seemingly simple task of multi-digit multiplication. In this work, we study why, by reverse-engineering a model that successfully learns multiplication via \emph{implicit chain-of-thought}, and report three findings: (1) Evidence of long-range structure: Logit attributions and linear probes indicate that the model encodes the necessary long-range dependencies for multi-digit multiplication. (2) Mechanism: the model encodes long-range dependencies using attention to construct a directed acyclic graph to cache'' and retrieve’’ pairwise partial products. (3) Geometry: the model implements partial products in attention heads by forming Minkowski sums between pairs of digits, and digits are represented using a Fourier basis, both of which are intuitive and efficient representations that the standard fine-tuning model lacks. With these insights, we revisit the learning dynamics of standard fine-tuning and find that the model converges to a local optimum that lacks the required long-range dependencies. We further validate this understanding by introducing an auxiliary loss that predicts the ``running sum’’ via a linear regression probe, which provides an inductive bias that enables the model to successfully learn multi-digit multiplication. In summary, by reverse-engineering the mechanisms of an implicit chain-of-thought model we uncover a pitfall for learning long-range dependencies in Transformers and provide an example of how the correct inductive bias can address this issue.
语言模型的性能日益增强,但在看似简单的多位数乘法任务上仍然会失败。在这项工作中,我们通过逆向工程一个通过“隐式思维链”成功学习乘法的模型来研究原因,并报告了三个发现:(1) 长程结构的证据:Logit归属和线性探针表明,模型编码了多位数乘法所需的长程依赖关系。(2) 机制:模型利用注意力来构建有向无环图,以“缓存”和“检索”成对的部分乘积,从而编码长程依赖关系。(3) 几何:模型通过在数字对之间形成闵可夫斯基和并利用傅里叶基表示数字,在注意力头中实现部分乘积。这两种表示都是直观和高效的,而标准微调模型则缺乏这些。借助这些见解,我们重新审视了标准微调的学习动态,发现模型收敛到缺乏所需长程依赖关系的局部最优解。我们通过引入一个辅助损失来验证这一理解,该损失通过线性回归探针预测“运行总和”,为模型提供了一个归纳偏置,使其能够成功学习多位数乘法。总之,通过逆向工程隐式思维链模型的机制,我们发现了Transformer中学习长程依赖关系的陷阱,并提供了如何正确应用归纳偏置来解决这个问题的例子。
论文及项目相关链接
Summary
大型语言模型虽功能日益强大,但在进行多位数乘法运算的简单任务时仍会出现困难。本研究通过逆向工程研究了一个成功学习乘法运算的模型,发现模型通过隐式思维链编码了必要的长程依赖关系,并利用注意力机制构建有向无环图以缓存和检索部分乘积。模型的乘法几何运算中包括闵可夫斯基和以及傅里叶基底等直观和高效的表示形式。缺乏这种隐式思维链机制的模型容易陷入缺乏必要长程依赖的局部最优解。通过引入预测运行和的辅助损失函数,提供了学习长程依赖的归纳偏置解决方案。总之,本研究揭示了Transformer中学习长程依赖的陷阱,并展示了如何借助归纳偏置来解决这一问题。
Key Takeaways
- 大型语言模型在多位数乘法任务上仍有挑战。
- 通过逆向工程,发现模型成功学习乘法的关键在于隐式思维链机制。
- 模型通过编码长程依赖关系进行乘法运算,利用注意力机制缓存和检索部分乘积。
- 模型采用直观和高效的乘法几何运算形式,如闵可夫斯基和以及傅里叶基底表示。
- 缺乏隐式思维链机制的模型易陷入缺乏必要长程依赖的局部最优解。
- 通过引入预测运行和的辅助损失函数,提供了学习长程依赖的归纳偏置解决方案。
点此查看论文截图