⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-04 更新
High-Fidelity Speech Enhancement via Discrete Audio Tokens
Authors:Luca A. Lanzendörfer, Frédéric Berdoz, Antonis Asonitis, Roger Wattenhofer
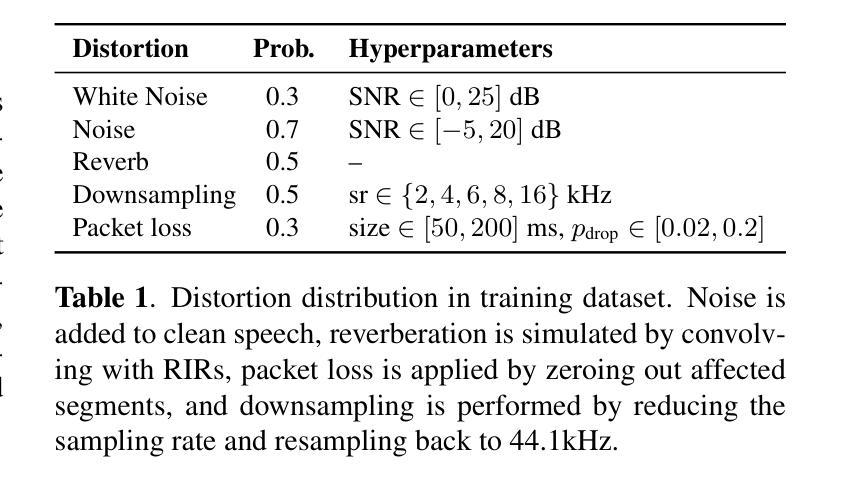
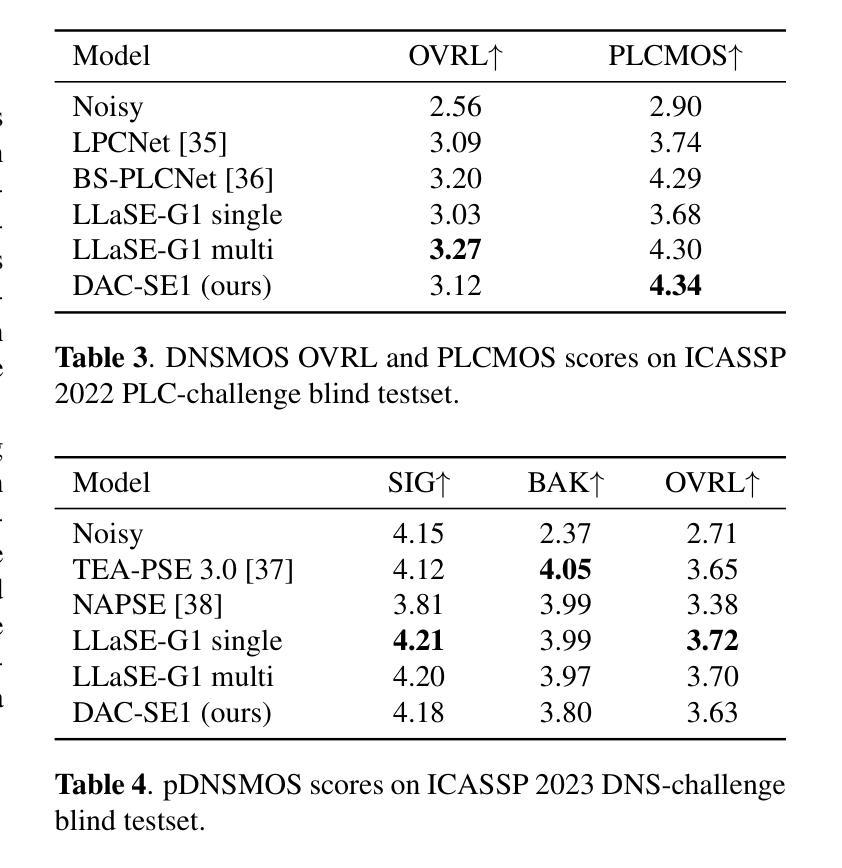
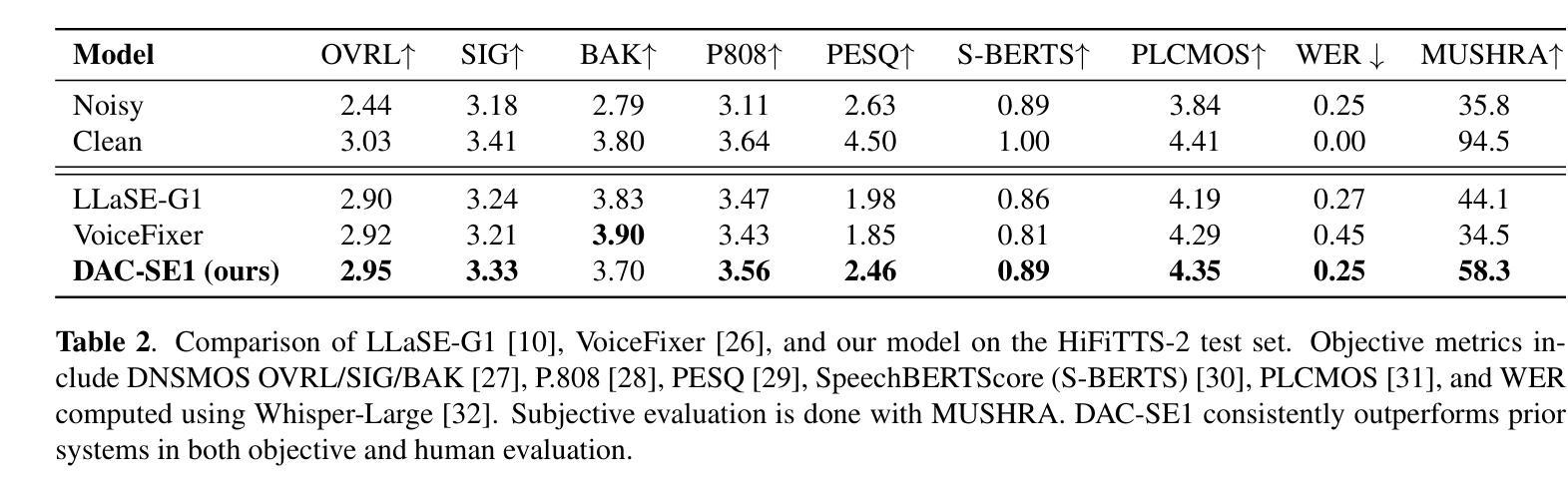
Recent autoregressive transformer-based speech enhancement (SE) methods have shown promising results by leveraging advanced semantic understanding and contextual modeling of speech. However, these approaches often rely on complex multi-stage pipelines and low sampling rate codecs, limiting them to narrow and task-specific speech enhancement. In this work, we introduce DAC-SE1, a simplified language model-based SE framework leveraging discrete high-resolution audio representations; DAC-SE1 preserves fine-grained acoustic details while maintaining semantic coherence. Our experiments show that DAC-SE1 surpasses state-of-the-art autoregressive SE methods on both objective perceptual metrics and in a MUSHRA human evaluation. We release our codebase and model checkpoints to support further research in scalable, unified, and high-quality speech enhancement.
最近基于自回归转换器的语音增强(SE)方法通过利用先进的语义理解和语音上下文建模,取得了令人鼓舞的结果。然而,这些方法通常依赖于复杂的多阶段管道和低采样率编解码器,将它们局限于狭窄且特定的语音增强任务。在这项工作中,我们介绍了DAC-SE1,这是一个基于简化语言模型的语音增强框架,利用离散的高分辨率音频表示;DAC-SE1在保持语义连贯性的同时,保留了精细的声学细节。我们的实验表明,DAC-SE1在客观感知指标和MUSHRA人类评估方面都超越了最新的自回归SE方法。我们公开了我们的代码库和模型检查点,以支持在可扩展、统一和高质量的语音增强方面的进一步研究。
论文及项目相关链接
Summary
基于最新的自回归Transformer语音增强方法通过先进的语义理解和语音上下文建模展现出良好的结果。然而,这些方法常常依赖于复杂的多阶段流程和低采样率编码,限制了其在特定任务中的语音增强应用。在这项研究中,我们推出DAC-SE1,一个基于简化语言模型的语音增强框架,利用离散的高分辨率音频表征;DAC-SE1在保持精细声学细节的同时维持语义连贯性。实验表明,DAC-SE1在客观感知指标和MUSHRA人类评估中都超越了最先进的自回归语音增强方法。我们发布我们的代码库和模型检查点以支持在可扩展、统一和高质量的语音增强方面的进一步研究。
Key Takeaways
- 自回归Transformer语音增强方法展现出良好结果,但仍存在复杂流程与采样率限制问题。
- DAC-SE1是一个基于简化语言模型的语音增强框架。
- DAC-SE1利用离散的高分辨率音频表征以保留精细声学细节。
- DAC-SE1能在保持语义连贯性的同时增强语音质量。
- 实验结果显示DAC-SE1在客观感知指标和人机评估上超越现有方法。
- 研究人员公开了代码库和模型检查点以支持后续研究。
点此查看论文截图
Exploring Resolution-Wise Shared Attention in Hybrid Mamba-U-Nets for Improved Cross-Corpus Speech Enhancement
Authors:Nikolai Lund Kühne, Jesper Jensen, Jan Østergaard, Zheng-Hua Tan
Recent advances in speech enhancement have shown that models combining Mamba and attention mechanisms yield superior cross-corpus generalization performance. At the same time, integrating Mamba in a U-Net structure has yielded state-of-the-art enhancement performance, while reducing both model size and computational complexity. Inspired by these insights, we propose RWSA-MambaUNet, a novel and efficient hybrid model combining Mamba and multi-head attention in a U-Net structure for improved cross-corpus performance. Resolution-wise shared attention (RWSA) refers to layerwise attention-sharing across corresponding time- and frequency resolutions. Our best-performing RWSA-MambaUNet model achieves state-of-the-art generalization performance on two out-of-domain test sets. Notably, our smallest model surpasses all baselines on the out-of-domain DNS 2020 test set in terms of PESQ, SSNR, and ESTOI, and on the out-of-domain EARS-WHAM_v2 test set in terms of SSNR, ESTOI, and SI-SDR, while using less than half the model parameters and a fraction of the FLOPs.
近期语音增强技术的进展表明,结合Mamba和注意力机制的模型表现出优异的跨语料库泛化性能。同时,将Mamba集成到U-Net结构中,达到了最先进的增强性能,同时减小了模型大小和计算复杂度。受到这些见解的启发,我们提出了RWSA-MambaUNet,这是一个结合Mamba和U-Net结构中的多头注意力机制的新型高效混合模型,旨在提高跨语料库性能。分辨率层面的共享注意力(RWSA)是指对应时间和频率分辨率之间的分层注意力共享。我们表现最佳的RWSA-MambaUNet模型在两个域外测试集上达到了最先进的泛化性能。值得注意的是,我们最小的模型在DNS 2020测试集(以PESQ、SSNR和ESTOI为标准)和EARS-WHAM_v2测试集(以SSNR、ESTOI和SI-SDR为标准)上的表现超过了所有基线模型,同时使用的模型参数不到一半,FLOPs也大大减少。
论文及项目相关链接
PDF Submitted to IEEE for possible publication
Summary
本文提出一种结合Mamba和多头注意力机制的U-Net结构模型RWSA-MambaUNet,旨在提高跨语料库性能。该模型采用分辨率共享注意力机制,并在两个跨域测试集上取得了最先进的泛化性能。其中,最小模型在DNS 2020测试集上的PESQ、SSNR和ESTOI指标上超越所有基线,同时在EARS-WHAM_v2测试集上的SSNR、ESTOI和SI-SDR指标上也有显著表现,同时模型参数和计算复杂度均大幅降低。
Key Takeaways
- 结合Mamba和多头注意力机制的模型RWSA-MambaUNet能够提高跨语料库性能。
- 模型结合了U-Net结构,达到当前最佳的增强性能。
- 通过在U-Net结构中集成Mamba,减少了模型大小和计算复杂性。
- RWSA-MambaUNet模型采用分辨率共享注意力机制(RWSA)。
- 该模型在两个跨域测试集上取得了最先进的泛化性能。
- 最小的RWSA-MambaUNet模型在DNS 2020和EARS-WHAM_v2测试集上的多项指标上超越基线。
点此查看论文截图

Emotional Text-To-Speech Based on Mutual-Information-Guided Emotion-Timbre Disentanglement
Authors:Jianing Yang, Sheng Li, Takahiro Shinozaki, Yuki Saito, Hiroshi Saruwatari
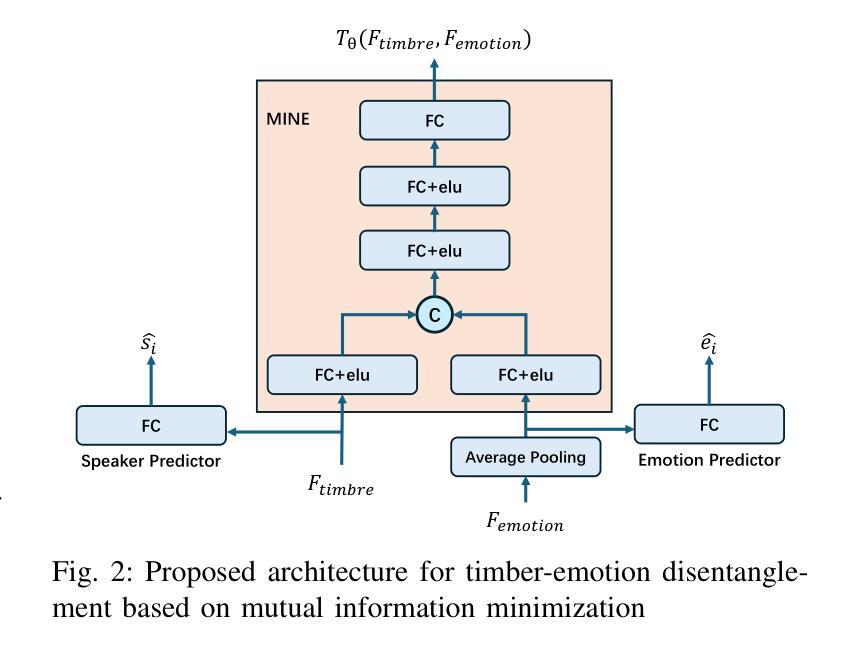
Current emotional Text-To-Speech (TTS) and style transfer methods rely on reference encoders to control global style or emotion vectors, but do not capture nuanced acoustic details of the reference speech. To this end, we propose a novel emotional TTS method that enables fine-grained phoneme-level emotion embedding prediction while disentangling intrinsic attributes of the reference speech. The proposed method employs a style disentanglement method to guide two feature extractors, reducing mutual information between timbre and emotion features, and effectively separating distinct style components from the reference speech. Experimental results demonstrate that our method outperforms baseline TTS systems in generating natural and emotionally rich speech. This work highlights the potential of disentangled and fine-grained representations in advancing the quality and flexibility of emotional TTS systems.
当前的情感文本转语音(TTS)和风格转换方法依赖于参考编码器来控制全局风格或情感向量,但它们没有捕捉到参考语音的微妙声学细节。为此,我们提出了一种新的情感TTS方法,它能够实现精细的音素级情感嵌入预测,同时解开参考语音的内在属性。所提出的方法采用风格分离方法来指导两个特征提取器,减少音质和情感特征之间的相互信息,有效分离参考语音中的不同风格成分。实验结果表明,我们的方法在生成自然且情感丰富的语音方面优于基线TTS系统。这项工作突出了解开和精细粒度表示在提升情感TTS系统的质量和灵活性方面的潜力。
论文及项目相关链接
PDF In Proceedings of the 17th Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC 2025)
总结
本文提出了一种新型的情感文本转语音(TTS)方法,能够在精细的语音级别上预测情感嵌入,同时解耦参考语音的内在属性。该方法采用风格解耦方法来指导两个特征提取器,减少音色和情感特征之间的互信息,有效地从参考语音中分离出不同的风格成分。实验结果证明,该方法在生成自然且情感丰富的语音方面优于基准TTS系统。本文强调了精细化和解耦表示在提升情感TTS系统质量和灵活性方面的潜力。
关键见解
- 当前情感文本转语音(TTS)和方法依赖于参考编码器来控制全局风格或情感向量,但无法捕捉参考语音的细微声学细节。
- 提出了一种新型的情感TTS方法,能够实现在精细的语音级别上的情感嵌入预测,同时解耦参考语音的内在属性。
- 采用风格解耦方法来指导两个特征提取器,减少音色和情感特征之间的互信息。
- 方法有效地从参考语音中分离出不同的风格成分,提升情感TTS系统的性能。
- 实验结果证明,该方法在生成自然且情感丰富的语音方面优于基准TTS系统。
- 所提方法对于提升情感TTS系统的质量和灵活性具有潜力。
点此查看论文截图
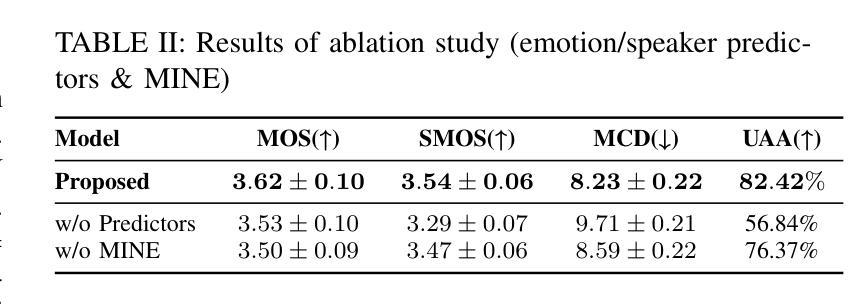
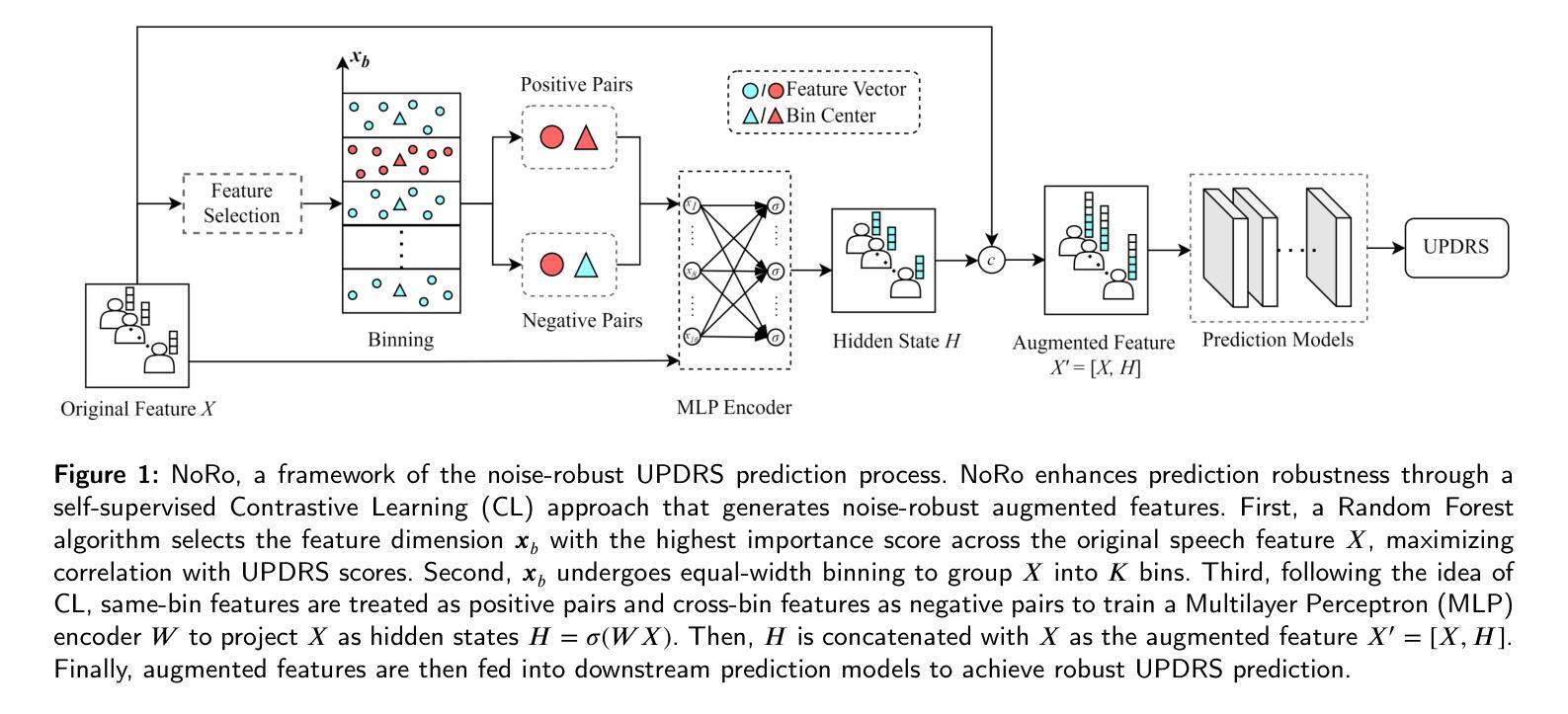
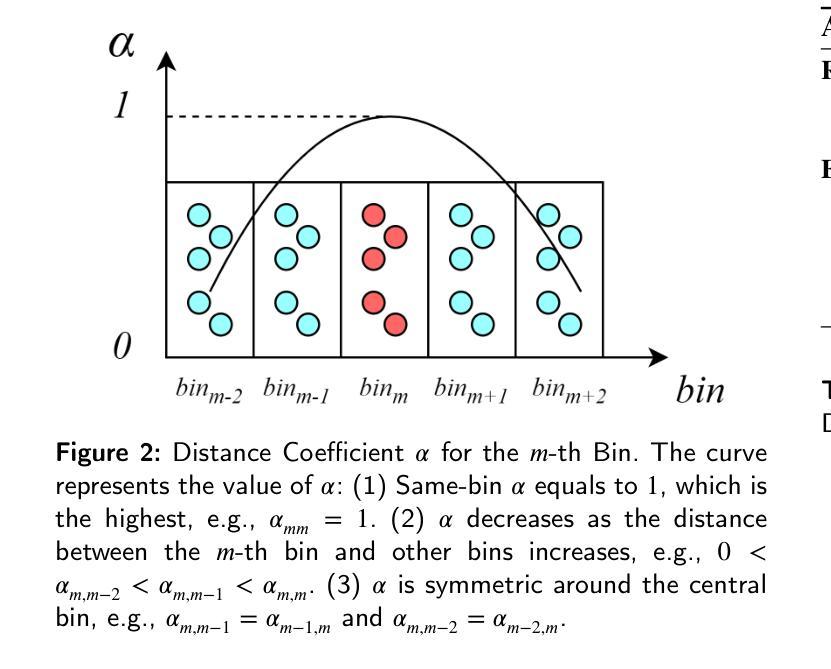
Enhancing Noise Robustness of Parkinson’s Disease Telemonitoring via Contrastive Feature Augmentation
Authors:Ziming Tang, Chengbin Hou, Tianyu Zhang, Bangxu Tian, Jinbao Wang, Hairong Lv
Parkinson’s disease (PD) is one of the most common neurodegenerative disorder. PD telemonitoring emerges as a novel assessment modality enabling self-administered at-home tests of Unified Parkinson’s Disease Rating Scale (UPDRS) scores, enhancing accessibility for PD patients. However, three types of noise would occur during measurements: (1) patient-induced measurement inaccuracies, (2) environmental noise, and (3) data packet loss during transmission, resulting in higher prediction errors. To address these challenges, NoRo, a noise-robust UPDRS prediction framework is proposed. First, the original speech features are grouped into ordered bins, based on the continuous values of a selected feature, to construct contrastive pairs. Second, the contrastive pairs are employed to train a multilayer perceptron encoder for generating noise-robust features. Finally, these features are concatenated with the original features as the augmented features, which are then fed into the UPDRS prediction models. Notably, we further introduces a novel evaluation approach with customizable noise injection module, and extensive experiments show that NoRo can successfully enhance the noise robustness of UPDRS prediction across various downstream prediction models under different noisy environments.
帕金森病(PD)是最常见的神经退行性疾病之一。PD遥测作为一种新的评估模式出现,使患者在家里能够自我进行统一帕金森病评分量表(UPDRS)的测试,提高了帕金森病患者的可访问性。然而,在测量过程中会产生三种噪声:(1)患者引起的测量误差、(2)环境噪声和(3)传输过程中的数据包丢失,导致预测误差增大。为了解决这些挑战,提出了一种噪声鲁棒的UPDRS预测框架NoRo。首先,根据选定特征的连续值,将原始语音特征分组为有序bin,以构建对比对。其次,利用对比对训练多层感知器编码器,以生成噪声鲁棒特征。最后,将这些特征与原始特征组合为增强特征,然后输入到UPDRS预测模型中。值得注意的是,我们进一步引入了一种具有可定制噪声注入模块的新型评估方法,大量实验表明,在各种噪声环境下,NoRo可以成功提高UPDRS预测在不同下游预测模型中的噪声鲁棒性。
论文及项目相关链接
Summary
帕金森病(PD)是一种常见的神经退行性疾病。远程监测(telemonitoring)作为一种新型的评估方式,让患者在家里进行帕金森病统一评分量表(UPDRS)的自我测试成为可能,从而提高了PD患者的评估便利性。然而,测量过程中可能会出现三种类型的噪声干扰评估准确性,包括患者操作误差、环境噪声以及数据传输过程中的数据包丢失。为解决这些问题,本文提出了一种噪声鲁棒的UPDRS预测框架(NoRo)。它通过特征分组和训练多层感知机编码器来生成鲁棒性特征,再通过新型评估方法在不同噪声环境下进行测试,证明其可以有效提高下游预测模型的预测精度。
Key Takeaways
- 帕金森病远程监测提高了患者自我评估的便利性。
- 存在三种主要的噪声干扰类型影响评估准确性:患者操作误差、环境噪声和数据传输问题。
- NoRo框架通过特征分组和训练多层感知机来提高预测特征的鲁棒性。
- NoRo引入了可定制噪声注入模块的新型评估方法。
- 实验证明,NoRo在不同噪声环境下和不同下游预测模型中都能提高预测精度。
点此查看论文截图
Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation
Authors:Chetwin Low, Weimin Wang, Calder Katyal
Audio-video generation has often relied on complex multi-stage architectures or sequential synthesis of sound and visuals. We introduce Ovi, a unified paradigm for audio-video generation that models the two modalities as a single generative process. By using blockwise cross-modal fusion of twin-DiT modules, Ovi achieves natural synchronization and removes the need for separate pipelines or post hoc alignment. To facilitate fine-grained multimodal fusion modeling, we initialize an audio tower with an architecture identical to that of a strong pretrained video model. Trained from scratch on hundreds of thousands of hours of raw audio, the audio tower learns to generate realistic sound effects, as well as speech that conveys rich speaker identity and emotion. Fusion is obtained by jointly training the identical video and audio towers via blockwise exchange of timing (via scaled-RoPE embeddings) and semantics (through bidirectional cross-attention) on a vast video corpus. Our model enables cinematic storytelling with natural speech and accurate, context-matched sound effects, producing movie-grade video clips. All the demos, code and model weights are published at https://aaxwaz.github.io/Ovi
音视频生成经常依赖于复杂的多阶段架构或声音和视觉的连续合成。我们引入了Ovi,这是一个音视频生成的统一范式,它将两种模式建模为一个单一的生成过程。通过使用双DiT模块的分块跨模态融合,Ovi实现了自然同步,并消除了对单独管道或事后对齐的需求。为了促进精细的跨模态融合建模,我们使用与强大的预训练视频模型相同的架构初始化音频塔。音频塔在数以万计的原始音频上从头开始训练,学习生成逼真的音效以及传达丰富的说话人身份和情感的语音。融合是通过联合训练相同的视频和音频塔获得的,通过定时(通过缩放RoPE嵌入)和语义(通过双向交叉注意力)进行块交换,在大量的视频语料库上进行训练。我们的模型以自然语音和准确、符合语境的音效进行电影叙事,生成电影级别的视频片段。所有演示、代码和模型权重都在https://aaxwaz.github.io/Ovi发布。
论文及项目相关链接
Summary
本文介绍了一种名为Ovi的音频视频生成统一框架,它将音频和视频作为单一生成过程进行建模。通过块级跨模态融合的双模态模块,Ovi实现了自然同步,无需单独管道或后期对齐。通过在大规模视频语料库上联合训练相同的视频和音频塔,进行时间和语义的块级交换,实现了精细的多模态融合建模。Ovi能生成富有表现力的语音和准确的上下文匹配音效,达到电影级别的视频剪辑效果。
Key Takeaways
- Ovi是一个音频视频生成的统一框架,将音频和视频视为单一生成过程。
- 通过块级跨模态融合实现自然同步。
- 无需单独的处理管道或后期对齐。
- 采用大规模视频语料库进行联合训练,实现时间和语义的块级交换。
- 精细的多模态融合建模,通过音频塔生成逼真的声音效果和富有表现力的语音。
- 模型能产生准确、上下文匹配的音效。
点此查看论文截图
An Analysis of the New EU AI Act and A Proposed Standardization Framework for Machine Learning Fairness
Authors:Mike Teodorescu, Yongxu Sun, Haren N. Bhatia, Christos Makridis
The European Union’s AI Act represents a crucial step towards regulating ethical and responsible AI systems. However, we find an absence of quantifiable fairness metrics and the ambiguity in terminology, particularly the interchangeable use of the keywords transparency, explainability, and interpretability in the new EU AI Act and no reference of transparency of ethical compliance. We argue that this ambiguity creates substantial liability risk that would deter investment. Fairness transparency is strategically important. We recommend a more tailored regulatory framework to enhance the new EU AI regulation. Further-more, we propose a public system framework to assess the fairness and transparency of AI systems. Drawing from past work, we advocate for the standardization of industry best practices as a necessary addition to broad regulations to achieve the level of details required in industry, while preventing stifling innovation and investment in the AI sector. The proposals are exemplified with the case of ASR and speech synthesizers.
欧盟的《人工智能法案》是朝着规范道德和负责任的人工智能系统迈出的重要一步。然而,我们发现存在缺乏可量化的公平指标和术语模糊的问题,特别是在新的欧盟《人工智能法案》中透明、可解释性和可解读性等关键词的互换使用,没有提及道德合规的透明度。我们认为这种模糊性会产生巨大的责任风险,从而阻碍投资。公平透明具有战略重要性。我们建议制定更具体的监管框架,以加强欧盟新的AI法规。此外,我们提出了一个公共系统框架来评估人工智能系统的公平性和透明度。借鉴过去的工作,我们主张标准化行业的最佳实践作为广泛法规的必要补充,以达到行业所需的细节水平,同时防止阻碍人工智能领域的创新和投资。以自动语音识别和语音合成器为例,对提案进行了说明。
论文及项目相关链接
PDF 6 pages; IEEE HPEC 2025 Poster Session 4-P1 (12:15-13:15): AI/ML/GenAI Poster Session Thursday September 18 2025
Summary
欧盟人工智能法案是朝着规范伦理和负责任的人工智能系统迈出的重要一步。然而,该法案缺乏可量化的公平性指标,术语使用模糊,尤其是对透明度、可解释性和可解读性等关键词的相互替换使用,且没有提及道德合规的透明度。我们认为这种模糊性造成了巨大的潜在责任风险,可能会阻碍投资。公平透明具有战略意义。我们建议使用更具体的监管框架来完善欧盟新的人工智能法规。此外,我们还提议建立一个公共系统框架来评估人工智能系统的公平性和透明度。结合过去的工作,我们主张标准化行业最佳实践作为对广泛法规的必要补充,以达到行业所需的细节水平,同时防止遏制人工智能领域的创新和投资。以自动语音识别和语音合成器为例说明了这些提议。
Key Takeaways
- 欧盟人工智能法案在规范人工智能系统方面迈出重要一步,但缺乏公平性指标和道德合规的透明度。
- 透明度、可解释性和可解读性等关键词在法案中的使用存在模糊和互换现象。
- 模糊性可能导致重大责任风险,可能阻碍投资。
- 公平透明具有战略意义。
- 建议使用更具体的监管框架来改善欧盟的人工智能法规。
- 提议建立公共系统框架来评估人工智能系统的公平性和透明度。
点此查看论文截图
NLDSI-BWE: Non Linear Dynamical Systems-Inspired Multi Resolution Discriminators for Speech Bandwidth Extension
Authors:Tarikul Islam Tamiti, Anomadarshi Barua
In this paper, we design two nonlinear dynamical systems-inspired discriminators – the Multi-Scale Recurrence Discriminator (MSRD) and the Multi-Resolution Lyapunov Discriminator (MRLD) – to \textit{explicitly} model the inherent deterministic chaos of speech. MSRD is designed based on Recurrence representations to capture self-similarity dynamics. MRLD is designed based on Lyapunov exponents to capture nonlinear fluctuations and sensitivity to initial conditions. Through extensive design optimization and the use of depthwise-separable convolutions in the discriminators, our framework surpasses prior AP-BWE model with a 44x reduction in the discriminator parameter count \textbf{($\sim$ 22M vs $\sim$ 0.48M)}. To the best of our knowledge, for the first time, this paper demonstrates how BWE can be supervised by the subtle non-linear chaotic physics of voiced sound production to achieve a significant reduction in the discriminator size.
在这篇论文中,我们设计了两个受非线性动力系统启发的判别器——多尺度复发判别器(MSRD)和多分辨率李雅普诺夫判别器(MRLD),以明确地模拟语音的固有确定性混沌。MSRD基于复发表示设计,用于捕捉自相似动态。MRLD则是基于李雅普诺夫指数设计,用于捕捉非线性波动和初始条件的敏感性。通过广泛的设计优化和判别器中深度可分离卷积的使用,我们的框架超越了先前的AP-BWE模型,判别器参数计数减少了44倍(约22M vs约0.48M)。据我们所知,本论文首次展示了如何通过有声音频产生的微妙非线性混沌物理来监督BWE,从而实现判别器大小的显著减少。
论文及项目相关链接
Summary
文本设计两种非线性动态系统启发鉴别器——多尺度递归鉴别器(MSRD)和多分辨率李雅普诺夫鉴别器(MRLD),以显式建模语音的固有确定性混沌。MSRD基于递归表示设计,用于捕捉自相似性动力学。MRLD基于李雅普诺夫指数设计,用于捕捉非线性波动和初始条件的敏感性。通过设计优化和鉴别器中深度可分离卷积的使用,我们的框架在参数计数方面超过了先前的AP-BWE模型,实现了44倍的参数减少(约22M vs约0.48M)。据我们所知,本文首次展示了如何通过利用有声声音产生的微妙非线性混沌物理来监督BWE,从而实现鉴别器大小的显著减少。
Key Takeaways
- 文本中提出了两种非线性动态系统启发鉴别器:多尺度递归鉴别器(MSRD)和多分辨率李雅普诺夫鉴别器(MRLD)。
- 它们被设计用于显式建模语音的固有确定性混沌。
- MSRD基于递归表示捕捉自相似性动力学。
- MRLD基于李雅普诺夫指数捕捉非线性波动和初始条件的敏感性。
- 通过设计优化和深度可分离卷积的使用,实现了鉴别器的参数显著减少。
- 与先前的AP-BWE模型相比,新的框架在参数计数上实现了显著改进。
点此查看论文截图
UniverSR: Unified and Versatile Audio Super-Resolution via Vocoder-Free Flow Matching
Authors:Woongjib Choi, Sangmin Lee, Hyungseob Lim, Hong-Goo Kang
In this paper, we present a vocoder-free framework for audio super-resolution that employs a flow matching generative model to capture the conditional distribution of complex-valued spectral coefficients. Unlike conventional two-stage diffusion-based approaches that predict a mel-spectrogram and then rely on a pre-trained neural vocoder to synthesize waveforms, our method directly reconstructs waveforms via the inverse Short-Time Fourier Transform (iSTFT), thereby eliminating the dependence on a separate vocoder. This design not only simplifies end-to-end optimization but also overcomes a critical bottleneck of two-stage pipelines, where the final audio quality is fundamentally constrained by vocoder performance. Experiments show that our model consistently produces high-fidelity 48 kHz audio across diverse upsampling factors, achieving state-of-the-art performance on both speech and general audio datasets.
在这篇论文中,我们提出了一种无需vocoder的音频超分辨率框架,它采用流匹配生成模型来捕捉复数谱系数的条件分布。不同于传统的两阶段扩散方法,它需要预测梅尔频谱图然后依赖于预训练的神经vocoder来合成波形,我们的方法直接通过逆短时傅里叶变换(iSTFT)重建波形,从而消除了对单独vocoder的依赖。这种设计不仅简化了端到端的优化,还克服了两阶段流程的关键瓶颈,其中最终音频质量从根本上受到vocoder性能的限制。实验表明,我们的模型在多种上采样因子下始终产生高保真度的48kHz音频,在语音和通用音频数据集上均达到了最新水平的表现。
论文及项目相关链接
PDF Submitted to ICASSP 2026
Summary
本文提出了一种无vocoder的音频超分辨率框架,采用流匹配生成模型捕捉复数谱系数的条件分布。不同于传统的两阶段扩散方法,该方法直接通过逆短时傅里叶变换(iSTFT)重建波形,从而消除了对单独vocoder的依赖。这种设计不仅简化了端到端的优化,还克服了两阶段管道的关键瓶颈,其中最终音频质量从根本上受到vocoder性能的限制。实验表明,该模型在语音和通用音频数据集上均实现了最先进的性能,并能一致地生成高保真48kHz音频,适用于多种上采样因子。
Key Takeaways
- 该框架是一个vocoder-free的音频超分辨率方法。
- 使用流匹配生成模型捕捉复数谱系数的条件分布。
- 直接通过iSTFT重建波形,消除了对单独vocoder的依赖。
- 简化了端到端的优化流程。
- 克服了两阶段管道中vocoder性能的瓶颈限制。
- 在语音和通用音频数据集上实现了最先进的性能。
点此查看论文截图
MambAttention: Mamba with Multi-Head Attention for Generalizable Single-Channel Speech Enhancement
Authors:Nikolai Lund Kühne, Jesper Jensen, Jan Østergaard, Zheng-Hua Tan
With the advent of new sequence models like Mamba and xLSTM, several studies have shown that these models match or outperform state-of-the-art models in single-channel speech enhancement, automatic speech recognition, and self-supervised audio representation learning. However, prior research has demonstrated that sequence models like LSTM and Mamba tend to overfit to the training set. To address this issue, previous works have shown that adding self-attention to LSTMs substantially improves generalization performance for single-channel speech enhancement. Nevertheless, neither the concept of hybrid Mamba and time-frequency attention models nor their generalization performance have been explored for speech enhancement. In this paper, we propose a novel hybrid architecture, MambAttention, which combines Mamba and shared time- and frequency-multi-head attention modules for generalizable single-channel speech enhancement. To train our model, we introduce VoiceBank+Demand Extended (VB-DemandEx), a dataset inspired by VoiceBank+Demand but with more challenging noise types and lower signal-to-noise ratios. Trained on VB-DemandEx, our proposed MambAttention model significantly outperforms existing state-of-the-art LSTM-, xLSTM-, Mamba-, and Conformer-based systems of similar complexity across all reported metrics on two out-of-domain datasets: DNS 2020 and EARS-WHAM_v2, while matching their performance on the in-domain dataset VB-DemandEx. Ablation studies highlight the role of weight sharing between the time- and frequency-multi-head attention modules for generalization performance. Finally, we explore integrating the shared time- and frequency-multi-head attention modules with LSTM and xLSTM, which yields a notable performance improvement on the out-of-domain datasets. However, our MambAttention model remains superior on both out-of-domain datasets across all reported evaluation metrics.
随着Mamba和xLSTM等新序列模型的兴起,多项研究表明,这些模型在单通道语音增强、自动语音识别和自我监督音频表示学习方面达到了或超越了现有模型的性能。然而,先前的研究表明,像LSTM和Mamba这样的序列模型容易对训练集过度拟合。为了解决这个问题,以前的研究表明,在LSTM中添加自注意力可以显著提高单通道语音增强的泛化性能。然而,关于混合Mamba和时间-频率注意力模型的概念及其泛化性能在语音增强方面的探索尚未出现。在本文中,我们提出了一种新型的混合架构MambAttention,它结合了Mamba和共享的时间与频率多头注意力模块,用于可泛化的单通道语音增强。为了训练我们的模型,我们引入了VoiceBank+Demand Extended(VB-DemandEx)数据集,该数据集以VoiceBank+Demand为灵感,但具有更具挑战性的噪声类型和更低的信噪比。在VB-DemandEx上训练的MambAttention模型在两个域外数据集DNS 2020和EARS-WHAM_v2上所有报告的指标中都显著超越了现有基于LSTM、xLSTM、Mamba和Conformer的类似复杂度的系统,同时在域内数据集VB-DemandEx上的性能与之相匹配。消融研究突出了时间和频率多头注意力模块权重共享在泛化性能中的作用。最后,我们探索了将共享的时间和频率多头注意力模块与LSTM和xLSTM相结合,这在域外数据集上取得了显著的性能提升。然而,我们的MambAttention模型在所有的评估指标上仍然在这两个域外数据集中表现最佳。
论文及项目相关链接
PDF Submitted to IEEE/ACM Transactions on Audio, Speech, and Language Processing for possible publication
Summary
本文提出了一个名为MambAttention的混合架构,结合了Mamba和共享时间-频率多头注意力模块,用于通用单通道语音增强。引入了一个新的数据集VB-DemandEx,训练出的MambAttention模型在DNS 2020和EARS-WHAM_v2两个跨域数据集上的性能显著优于现有先进的LSTM、xLSTM、Mamba和Conformer系统,同时在域内数据集VB-DemandEx上与之相匹配。
Key Takeaways
- 提出了结合Mamba和共享时间-频率多头注意力模块的混合架构MambAttention,旨在提高语音增强任务的泛化性能。
- 引入新的数据集VB-DemandEx,包含更具挑战性的噪声类型和较低信噪比,用于训练模型。
- MambAttention模型在跨域数据集DNS 2020和EARS-WHAM_v2上的性能显著优于其他先进系统。
- 消融研究强调了时间-频率多头注意力模块权重共享对泛化性能的作用。
- 将共享时间-频率多头注意力模块与LSTM和xLSTM结合,提高了跨域数据集的性能。
- MambAttention模型在所有报告的评价指标上均表现最佳。