⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-07 更新
Neural Posterior Estimation with Autoregressive Tiling for Detecting Objects in Astronomical Images
Authors:Jeffrey Regier
Upcoming astronomical surveys will produce petabytes of high-resolution images of the night sky, providing information about billions of stars and galaxies. Detecting and characterizing the astronomical objects in these images is a fundamental task in astronomy – and a challenging one, as most of these objects are faint and many visually overlap with other objects. We propose an amortized variational inference procedure to solve this instance of small-object detection. Our key innovation is a family of spatially autoregressive variational distributions that partition and order the latent space according to a $K$-color checkerboard pattern. By construction, the conditional independencies of this variational family mirror those of the posterior distribution. We fit the variational distribution, which is parameterized by a convolutional neural network, using neural posterior estimation (NPE) to minimize an expectation of the forward KL divergence. Using images from the Sloan Digital Sky Survey, our method achieves state-of-the-art performance. We further demonstrate that the proposed autoregressive structure greatly improves posterior calibration.
未来的天文调查将产生数以千计的关于夜空的高分辨率图像,这些图像包含了关于数十亿恒星和星系的信息。在这些图像中检测和识别出天文物体是天文学中的一项基本任务,而且由于大部分天文物体较为微弱且许多物体在视觉上与其他物体重叠,这使得任务变得具有挑战性。我们提出了一种摊销变分推断程序来解决此次的小目标检测问题。我们的关键创新在于一组空间自回归变分分布,它根据k色棋盘模式划分和排列潜在空间。通过构建,该变分分布的条件独立性反映了后验分布的条件独立性。我们使用神经后验估计(NPE)拟合由卷积神经网络参数化的变分分布,以最小化正向KL散度的期望值。使用斯隆数字巡天图像,我们的方法达到了最先进的性能。我们进一步证明,所提出的自回归结构大大提高了后验校准。
论文及项目相关链接
Summary
该文介绍了即将进行的天文学调查将产生大量高清晰度夜空图像,如何检测并描述这些图像中的天文物体是一项基本且具挑战性的任务。文章提出了一种基于摊销变分推断的程序来解决小型物体检测问题。主要创新点在于设计了一种空间自回归变分分布家族,该家族根据K色棋盘模式对潜在空间进行划分和排序。通过构建,该变分分布的条件独立性反映了后验分布的条件独立性。利用卷积神经网络参数化变分分布,通过神经后验估计最小化正向KL散度的期望值。使用斯隆数字巡天图像,该方法取得了最先进的性能,并证明了自回归结构极大提高了后验校准。
Key Takeaways
- 天文学调查将产生大量高清晰度夜空图像,物体检测是基本且具挑战性的任务。
- 文章提出了一种基于摊销变分推断的程序来解决小型物体检测问题。
- 创新点在于设计了一种空间自回归变分分布家族,该家族根据K色棋盘模式划分和排序潜在空间。
- 变分分布的条件独立性反映后验分布的条件独立性。
- 使用卷积神经网络参数化变分分布,通过神经后验估计最小化正向KL散度的期望值。
- 该方法在斯隆数字巡天图像上取得了最先进的性能。
点此查看论文截图
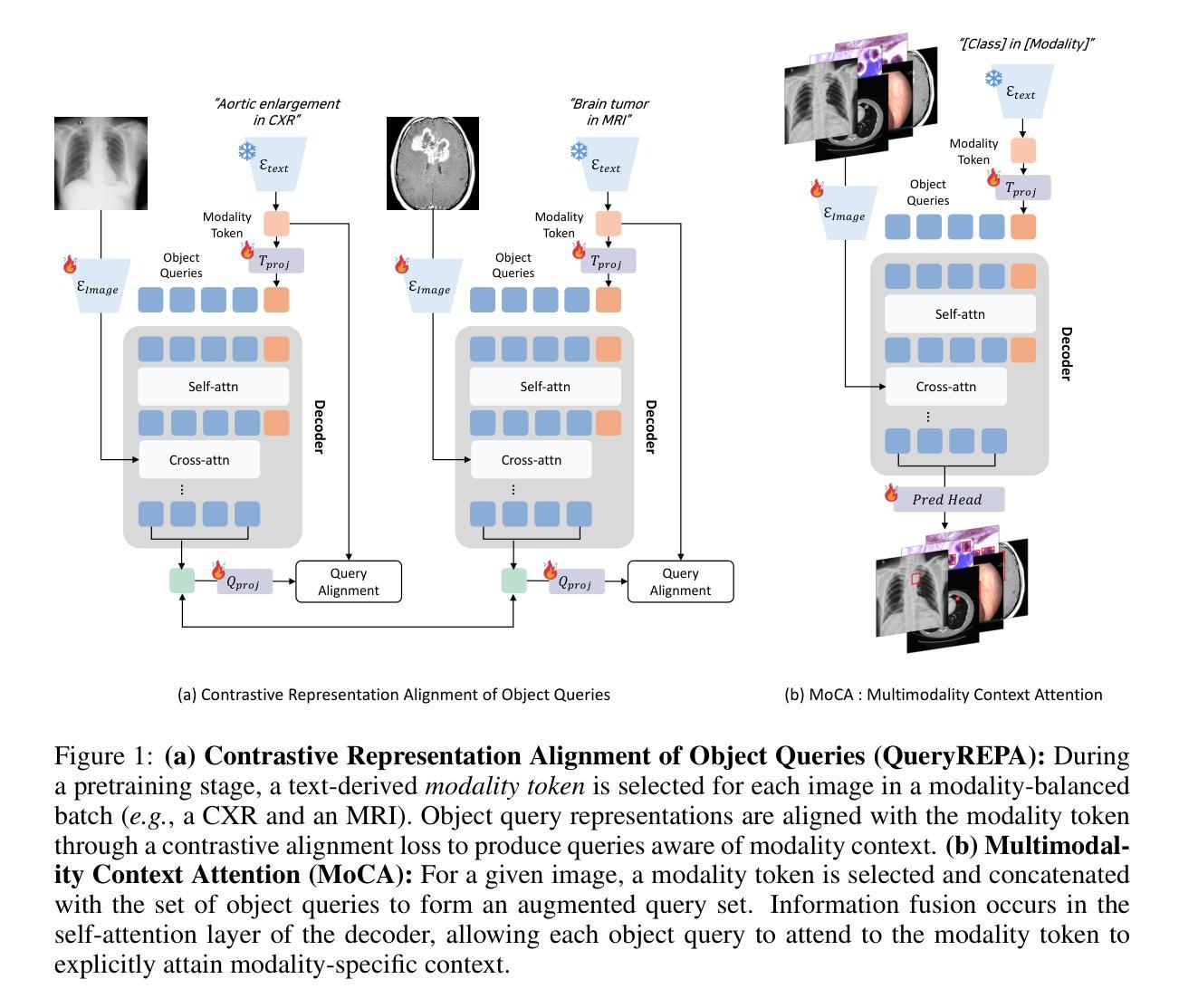
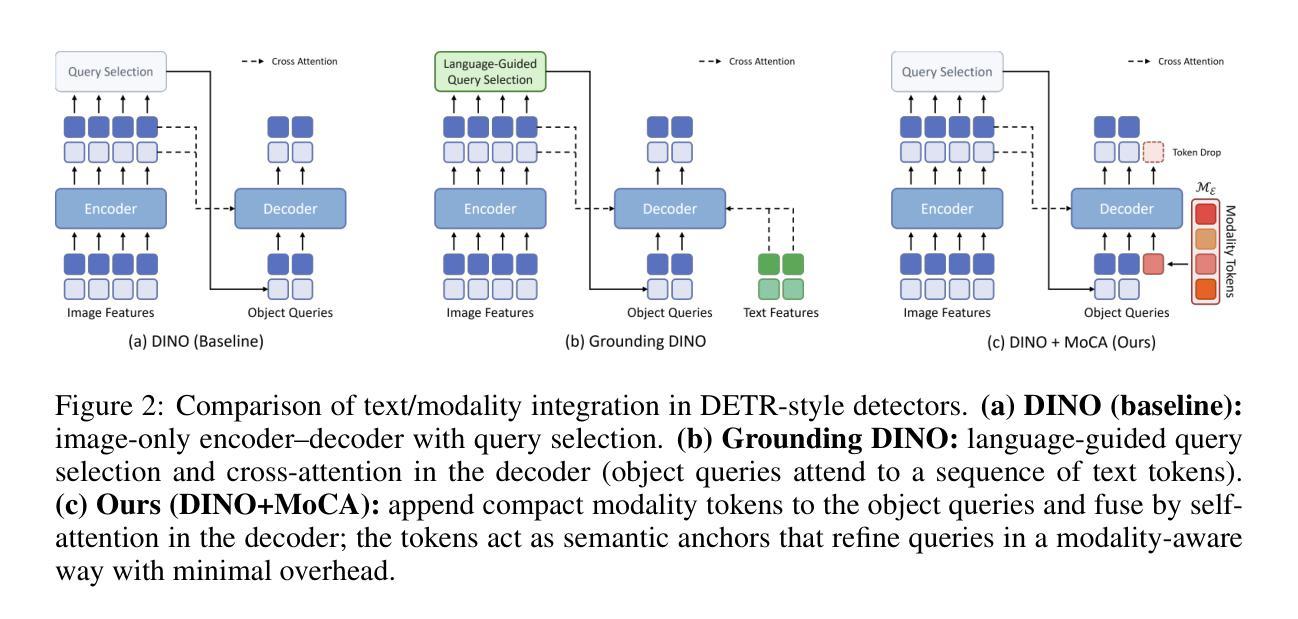
Align Your Query: Representation Alignment for Multimodality Medical Object Detection
Authors:Ara Seo, Bryan Sangwoo Kim, Hyungjin Chung, Jong Chul Ye
Medical object detection suffers when a single detector is trained on mixed medical modalities (e.g., CXR, CT, MRI) due to heterogeneous statistics and disjoint representation spaces. To address this challenge, we turn to representation alignment, an approach that has proven effective for bringing features from different sources into a shared space. Specifically, we target the representations of DETR-style object queries and propose a simple, detector-agnostic framework to align them with modality context. First, we define modality tokens: compact, text-derived embeddings encoding imaging modality that are lightweight and require no extra annotations. We integrate the modality tokens into the detection process via Multimodality Context Attention (MoCA), mixing object-query representations via self-attention to propagate modality context within the query set. This preserves DETR-style architectures and adds negligible latency while injecting modality cues into object queries. We further introduce QueryREPA, a short pretraining stage that aligns query representations to their modality tokens using a task-specific contrastive objective with modality-balanced batches. Together, MoCA and QueryREPA produce modality-aware, class-faithful queries that transfer effectively to downstream training. Across diverse modalities trained altogether, the proposed approach consistently improves AP with minimal overhead and no architectural modifications, offering a practical path toward robust multimodality medical object detection. Project page: https://araseo.github.io/alignyourquery/.
在混合医疗模态(如CXR、CT、MRI)上训练单个医疗物体检测器时,由于统计数据的异质性和表示空间的离散性,检测性能会受到影响。为了应对这一挑战,我们转向表示对齐的方法,这种方法在将不同来源的特征引入到共享空间中已被证明是有效的。具体来说,我们针对DETR风格的目标查询表示,提出了一个简单、检测器无关的对齐框架,与模态上下文进行对齐。首先,我们定义了模态令牌:紧凑的文本衍生嵌入,编码成像模态,轻便且无需额外注释。我们通过多模态上下文注意力(MoCA)将模态令牌集成到检测过程中,通过自注意力混合目标查询表示,在查询集中传播模态上下文。这保留了DETR风格架构,增加了微不足道的延迟,同时将模态线索注入目标查询中。我们还引入了QueryREPA,这是一个简短的预训练阶段,通过将查询表示与模态令牌对齐,使用任务特定的对比目标和模态平衡批次来实现。MoCA和QueryREPA一起产生对模态有感知的忠实类查询,有效地转移到下游训练中。在多种模态共同训练的情况下,所提出的方法在不影响额外开销和无需修改架构的情况下,始终提高了平均精度(AP),为迈向稳健的多模态医疗物体检测提供了实用途径。项目页面:https://araseo.github.io/alignyourquery/。
论文及项目相关链接
PDF Project page: https://araseo.github.io/alignyourquery/
Summary
针对医学多模态检测面临的挑战,本文提出了一种简单且检测器无关的框架,用于对齐不同模态下的对象查询表示。通过引入模态令牌和多模态上下文注意力机制,该框架能够在保持DETR风格架构的同时,将模态上下文注入对象查询中。此外,还引入了查询表示对齐预训练阶段,以实现对查询表示和模态令牌的对齐。该框架可有效地提高多模态医学对象检测的稳健性,具有实际应用价值。
Key Takeaways
- 医学多模态检测面临挑战,因为不同模态的数据具有异质统计和离散表示空间。
- 引入模态令牌来编码成像模态信息,该信息轻量级且无需额外注释。
- 提出多模态上下文注意力机制(MoCA),通过自我注意力将对象查询表示混合,在查询集中传播模态上下文。
- 引入查询表示对齐预训练阶段(QueryREPA),使用任务特定的对比目标和模态平衡批次来对齐查询表示和模态令牌。
- 该方法提高了跨不同模态训练的医学对象检测的准确率,具有一致性、轻微的计算开销和不改变架构的优点。
点此查看论文截图
Towards Size-invariant Salient Object Detection: A Generic Evaluation and Optimization Approach
Authors:Shilong Bao, Qianqian Xu, Feiran Li, Boyu Han, Zhiyong Yang, Xiaochun Cao, Qingming Huang
This paper investigates a fundamental yet underexplored issue in Salient Object Detection (SOD): the size-invariant property for evaluation protocols, particularly in scenarios when multiple salient objects of significantly different sizes appear within a single image. We first present a novel perspective to expose the inherent size sensitivity of existing widely used SOD metrics. Through careful theoretical derivations, we show that the evaluation outcome of an image under current SOD metrics can be essentially decomposed into a sum of several separable terms, with the contribution of each term being directly proportional to its corresponding region size. Consequently, the prediction errors would be dominated by the larger regions, while smaller yet potentially more semantically important objects are often overlooked, leading to biased performance assessments and practical degradation. To address this challenge, a generic Size-Invariant Evaluation (SIEva) framework is proposed. The core idea is to evaluate each separable component individually and then aggregate the results, thereby effectively mitigating the impact of size imbalance across objects. Building upon this, we further develop a dedicated optimization framework (SIOpt), which adheres to the size-invariant principle and significantly enhances the detection of salient objects across a broad range of sizes. Notably, SIOpt is model-agnostic and can be seamlessly integrated with a wide range of SOD backbones. Theoretically, we also present generalization analysis of SOD methods and provide evidence supporting the validity of our new evaluation protocols. Finally, comprehensive experiments speak to the efficacy of our proposed approach. The code is available at https://github.com/Ferry-Li/SI-SOD.
本文探讨了一个显著性对象检测(SOD)中基础但尚未被充分研究的问题:评估协议中的大小不变特性,特别是在单个图像中出现多个大小显著不同的对象时的场景。我们首先提出了一种新颖的观点,揭示了现有广泛使用的SOD指标所固有的大小敏感性。通过仔细的理论推导,我们表明,在当前SOD指标下对图像的评估结果可以基本分解为几个可分量的和,每个分量的贡献与其对应的区域大小直接成比例。因此,预测误差主要由较大的区域主导,而较小但可能更具语义重要性的对象常常被忽视,从而导致性能评估偏差和实际性能下降。为了解决这一挑战,我们提出了通用的大小不变评估(SIEva)框架。其核心思想是对每个可分离组件进行单独评估,然后汇总结果,从而有效地减轻对象之间大小不平衡的影响。在此基础上,我们进一步开发了一个专用的优化框架(SIOpt),它遵循大小不变原则,并显著提高了各种大小显著对象的检测效果。值得注意的是,SIOpt与模型无关,可以无缝地与各种SOD主干网络集成。在理论上,我们还对SOD方法进行了泛化分析,并提供证据支持我们新的评估协议的有效性。最后,综合实验证明了我们提出的方法的有效性。代码可在https://github.com/Ferry-Li/SI-SOD上找到。
论文及项目相关链接
Summary
本文探讨显著目标检测(SOD)中的一个基础但尚未充分研究的问题:评估协议中的尺寸不变特性。特别是在单个图像中出现多个大小显著不同的目标时,现有的广泛使用的SOD指标存在固有的尺寸敏感性。本文通过细致的理论推导展示了当前SOD指标的评估结果可以分解为多个可分量的和,每个分量的贡献与其对应的区域大小直接成比例。因此,预测误差主要由较大的区域主导,而较小但语义上更重要的对象常被忽视,导致性能评估偏差和实际性能下降。为解决此挑战,提出了通用的尺寸不变评估(SIEva)框架,核心思想是对每个可分离成分进行单独评估,然后汇总结果,从而有效减轻对象间尺寸不平衡的影响。在此基础上,进一步开发了一个专用的优化框架(SIOpt),遵循尺寸不变原则,并显著提高各种尺寸显著目标的检测效果。特别是,SIOpt与模型无关,可以无缝集成到各种SOD主干网络中。本文还进行了SOD方法的一般性分析,为我们的新评估协议提供证据支持。最后,全面的实验证明了所提方法的有效性。
Key Takeaways
- 当前SOD指标存在尺寸敏感性,导致评估结果偏差。
- 评估结果可分解为多个与区域大小成比例的分量。
- 预测误差主要由较大区域主导,较小对象常被忽视。
- 提出通用的尺寸不变评估(SIEva)框架,以减轻尺寸不平衡的影响。
- 开发专用优化框架(SIOpt),提高各种尺寸显著目标的检测效果。
- SIOpt与模型无关,可无缝集成到各种SOD网络中。
- 全面的实验证明了所提方法的有效性。
点此查看论文截图


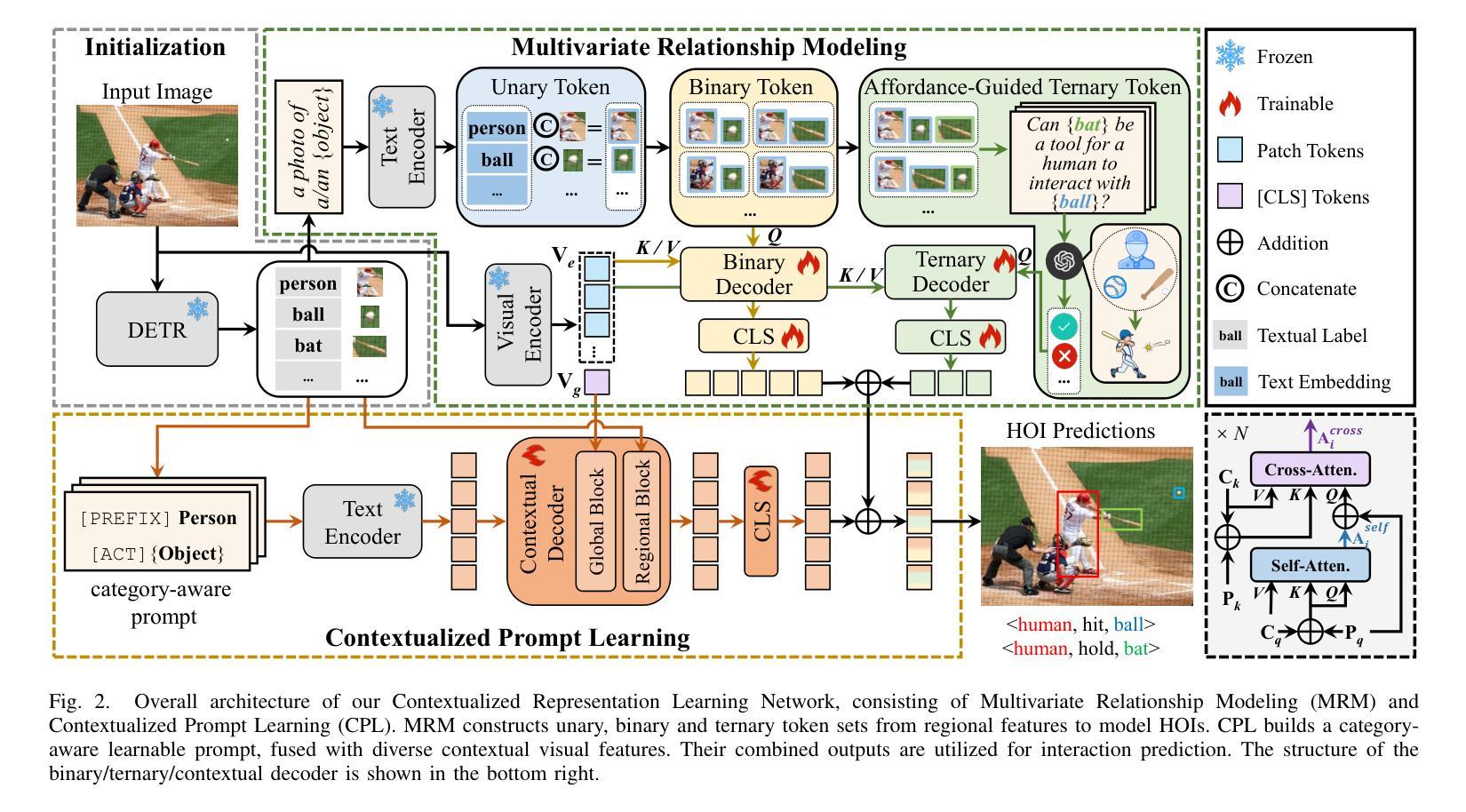
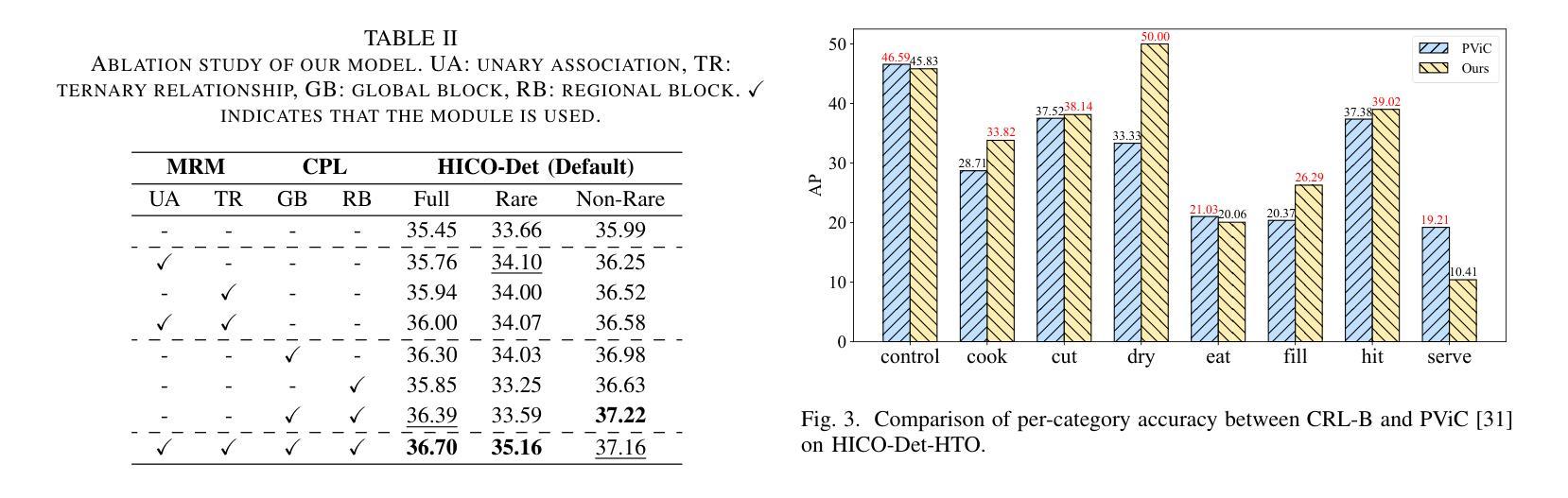
Contextualized Representation Learning for Effective Human-Object Interaction Detection
Authors:Zhehao Li, Yucheng Qian, Chong Wang, Yinghao Lu, Zhihao Yang, Jiafei Wu
Human-Object Interaction (HOI) detection aims to simultaneously localize human-object pairs and recognize their interactions. While recent two-stage approaches have made significant progress, they still face challenges due to incomplete context modeling. In this work, we introduce a Contextualized Representation Learning that integrates both affordance-guided reasoning and contextual prompts with visual cues to better capture complex interactions. We enhance the conventional HOI detection framework by expanding it beyond simple human-object pairs to include multivariate relationships involving auxiliary entities like tools. Specifically, we explicitly model the functional role (affordance) of these auxiliary objects through triplet structures <human, tool, object>. This enables our model to identify tool-dependent interactions such as ‘filling’. Furthermore, the learnable prompt is enriched with instance categories and subsequently integrated with contextual visual features using an attention mechanism. This process aligns language with image content at both global and regional levels. These contextualized representations equip the model with enriched relational cues for more reliable reasoning over complex, context-dependent interactions. Our proposed method demonstrates superior performance on both the HICO-Det and V-COCO datasets in most scenarios. The source code is available at https://github.com/lzzhhh1019/CRL.
人机交互(HOI)检测旨在同时定位人机交互对并识别其交互。虽然最近的两个阶段的方法已经取得了显著的进步,但由于上下文建模不完整,它们仍然面临挑战。在这项工作中,我们引入了一种上下文表示学习,它将效用引导推理和上下文提示与视觉线索相结合,以更好地捕捉复杂的交互。我们通过对传统的人机交互检测框架进行扩展,将其从简单的人机交互对扩展到包括涉及工具等辅助实体的多元关系。具体来说,我们通过三元结构<人、工具、对象>明确地模拟这些辅助对象的功能角色(效用)。这使我们的模型能够识别工具依赖的交互,如“填充”。此外,可学习的提示通过实例类别进行丰富,然后通过注意力机制与上下文视觉特征相结合。这个过程使语言与图像内容在全球和区域层面保持一致。这些上下文表示使模型具备丰富的关系线索,以便对复杂、依赖于上下文的交互进行更可靠地推理。在大多数场景下,我们提出的方法在HICO-Det和V-COCO数据集上的表现均优于其他方法。源代码可在https://github.com/lzzhhh1019/CRL获取。
论文及项目相关链接
Summary
本文介绍了人类物体交互(HOI)检测中的上下文表示学习方法。该方法结合了工具导向推理和上下文提示,以更好地捕捉复杂交互。通过扩展传统HOI检测框架,不仅识别简单的人-物体对,还包含涉及辅助实体的多元关系。通过三元结构<人,工具,物体>显式建模辅助对象的功能角色(可负担性),并丰富可学习的提示与实例类别,然后通过注意力机制与上下文视觉特征集成。这将对语言与图像内容在全局和区域层面进行对齐。这些上下文表示赋予了模型丰富的关系线索,以进行更可靠的复杂、上下文相关的交互推理。
Key Takeaways
- 人类物体交互(HOI)检测旨在同时定位人-物体对并识别其交互。
- 近期两阶段方法虽有所进展,但仍面临因上下文建模不完全而带来的挑战。
- 引入的上下文表示学习方法结合了工具导向推理和上下文提示,以更好地捕捉复杂交互。
- 方法扩展了传统HOI检测框架,以识别涉及辅助实体的多元关系。
- 通过三元结构<人,工具,物体>显式建模辅助对象的功能角色。
- 丰富的可学习提示与实例类别,通过注意力机制与上下文视觉特征集成。
点此查看论文截图

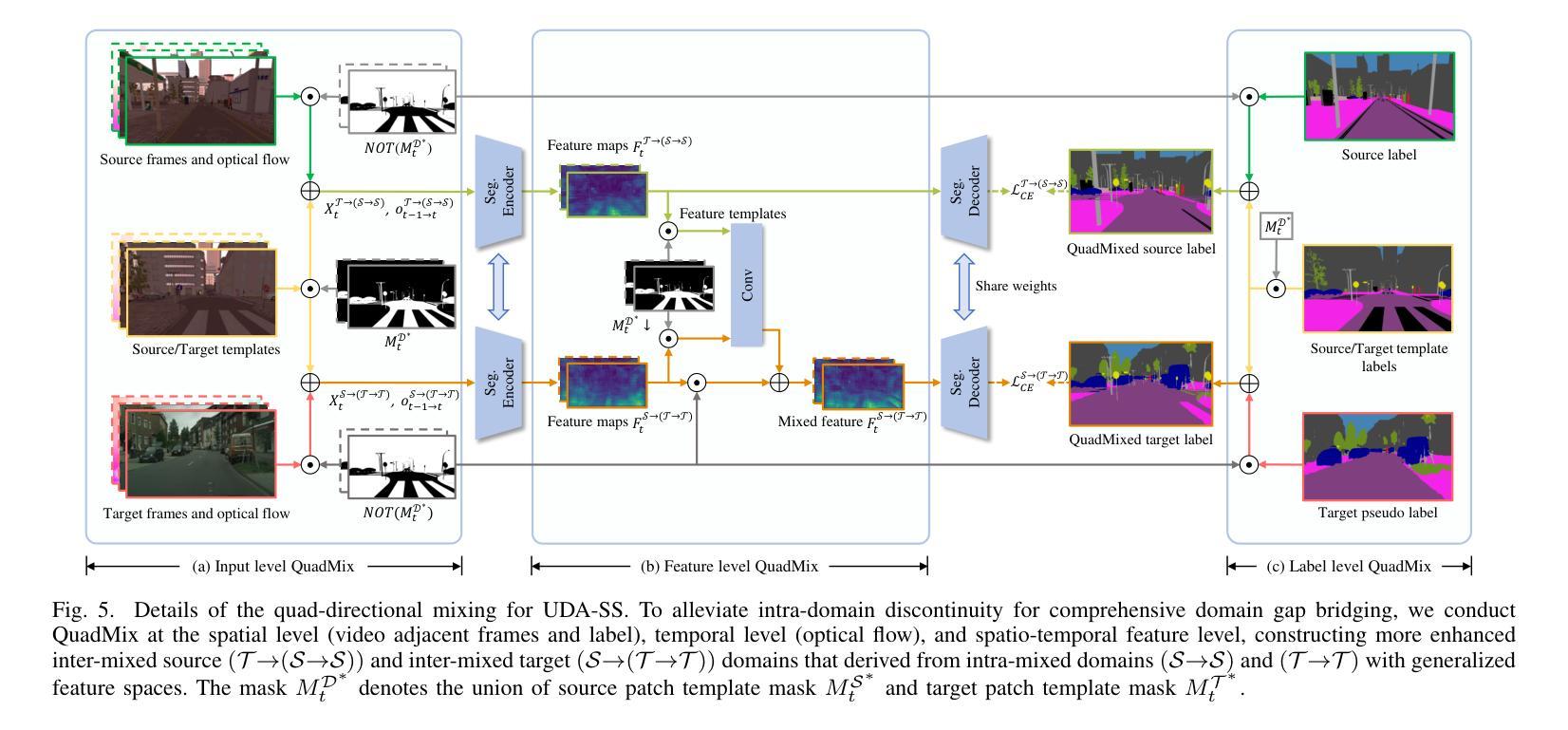
Unified Domain Adaptive Semantic Segmentation
Authors:Zhe Zhang, Gaochang Wu, Jing Zhang, Xiatian Zhu, Dacheng Tao, Tianyou Chai
Unsupervised Domain Adaptive Semantic Segmentation (UDA-SS) aims to transfer the supervision from a labeled source domain to an unlabeled target domain. The majority of existing UDA-SS works typically consider images whilst recent attempts have extended further to tackle videos by modeling the temporal dimension. Although the two lines of research share the major challenges – overcoming the underlying domain distribution shift, their studies are largely independent, resulting in fragmented insights, a lack of holistic understanding, and missed opportunities for cross-pollination of ideas. This fragmentation prevents the unification of methods, leading to redundant efforts and suboptimal knowledge transfer across image and video domains. Under this observation, we advocate unifying the study of UDA-SS across video and image scenarios, enabling a more comprehensive understanding, synergistic advancements, and efficient knowledge sharing. To that end, we explore the unified UDA-SS from a general data augmentation perspective, serving as a unifying conceptual framework, enabling improved generalization, and potential for cross-pollination of ideas, ultimately contributing to the overall progress and practical impact of this field of research. Specifically, we propose a Quad-directional Mixup (QuadMix) method, characterized by tackling distinct point attributes and feature inconsistencies through four-directional paths for intra- and inter-domain mixing in a feature space. To deal with temporal shifts with videos, we incorporate optical flow-guided feature aggregation across spatial and temporal dimensions for fine-grained domain alignment. Extensive experiments show that our method outperforms the state-of-the-art works by large margins on four challenging UDA-SS benchmarks. Our source code and models will be released at https://github.com/ZHE-SAPI/UDASS.
无监督领域自适应语义分割(UDA-SS)的目标是将监督信息从有标签的源域转移到无标签的目标域。现有的大多数UDA-SS工作主要关注图像,而最近的尝试通过建模时间维度进一步处理视频。尽管这两类研究面临着主要的挑战——克服潜在领域分布转移,但它们的研究在很大程度上是独立的,导致碎片化见解、缺乏整体理解和错失思想交流的机会。这种碎片化阻碍了方法的统一,导致了冗余的努力和跨图像和视频领域的知识转移次优。基于这一观察,我们主张统一UDA-SS在视频和图像场景的研究,以实现更全面的理解、协同发展和有效的知识共享。为此,我们从一般的数据增强角度探索了统一的UDA-SS,作为统一的概念框架,提高了泛化能力,并有可能促进思想交流,最终推动该领域研究的整体进步和实际应用影响。具体来说,我们提出了一种Quad-directional Mixup(QuadMix)方法,其特点是通过四个方向的路径在特征空间内进行和跨领域混合来解决不同的点属性和特征不一致问题。为了处理视频的临时变化,我们结合了光学流引导的特征聚合,在空间和时间维度上进行精细领域对齐。大量实验表明,我们的方法在四个具有挑战性的UDA-SS基准测试上大幅超越了最先进的工作。我们的源代码和模型将在https://github.com/ZHE-SAPI/UDASS上发布。
论文及项目相关链接
PDF 34 pages (main paper and supplementary material), 25 figures, 19 tables. Accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
Summary
本文介绍了无监督域自适应语义分割(UDA-SS)的目标,即将从标记源域的监督信息转移到未标记的目标域。虽然现有的UDA-SS研究主要集中在图像上,但最近的尝试已经开始扩展到视频,通过建模时间维度来处理视频。然而,图像和视频域的UDA-SS研究存在碎片化问题,缺乏整体理解,错过了交叉授粉的机会。因此,作者主张统一视频和图像场景下的UDA-SS研究,以提供更全面的理解、协同进步和有效的知识共享。作者从一般的数据增强角度探索了统一的UDA-SS,提出了QuadMix方法,通过四个方向的路径解决点属性和特征不一致的问题,进行跨域混合。为了处理视频的临时变化,作者结合了基于光流的特征聚合方法,实现精细的域对齐。实验表明,该方法在四个具有挑战性的UDA-SS基准测试中优于现有技术。
Key Takeaways
- UDA-SS旨在将从标记源域的监督信息转移到未标记的目标域。
- 尽管存在针对图像和视频域的UDA-SS研究,但两者之间存在碎片化问题,缺乏整体理解和交叉融合的机会。
- 作者主张统一视频和图像场景下的UDA-SS研究,以提供更全面的理解、协同进步和有效的知识共享。
- 作者从数据增强角度探索了统一的UDA-SS,并提出了QuadMix方法,解决了点属性和特征不一致的问题。
- QuadMix方法通过四个方向的路径进行跨域混合。
- 为了处理视频的临时变化,结合了基于光流的特征聚合方法。
点此查看论文截图