⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-07 更新
GS-Share: Enabling High-fidelity Map Sharing with Incremental Gaussian Splatting
Authors:Xinran Zhang, Hanqi Zhu, Yifan Duan, Yanyong Zhang
Constructing and sharing 3D maps is essential for many applications, including autonomous driving and augmented reality. Recently, 3D Gaussian splatting has emerged as a promising approach for accurate 3D reconstruction. However, a practical map-sharing system that features high-fidelity, continuous updates, and network efficiency remains elusive. To address these challenges, we introduce GS-Share, a photorealistic map-sharing system with a compact representation. The core of GS-Share includes anchor-based global map construction, virtual-image-based map enhancement, and incremental map update. We evaluate GS-Share against state-of-the-art methods, demonstrating that our system achieves higher fidelity, particularly for extrapolated views, with improvements of 11%, 22%, and 74% in PSNR, LPIPS, and Depth L1, respectively. Furthermore, GS-Share is significantly more compact, reducing map transmission overhead by 36%.
构建和共享三维地图对于许多应用至关重要,包括自动驾驶和增强现实。最近,三维高斯拼贴作为一种有前景的方法,在三维重建中展现出极高的准确性。然而,具有高清、持续更新和网络效率等特点的实际地图共享系统仍然难以捉摸。为了应对这些挑战,我们引入了GS-Share,这是一个具有紧凑表示的光照真实感地图共享系统。GS-Share的核心包括基于锚点的全球地图构建、基于虚拟图像的地图增强和增量地图更新。我们将GS-Share与最先进的方法进行了评估,结果表明我们的系统在保真度上实现了更高的性能,特别是对外推视图,在PSNR、LPIPS和Depth L1上分别提高了11%、22%和74%。此外,GS-Share更为紧凑,将地图传输开销减少了36%。
论文及项目相关链接
PDF 11 pages, 11 figures
Summary
基于三维高斯贴图技术,构建和共享三维地图对于自动驾驶和增强现实等应用至关重要。为解决现有系统的不足,我们提出了GS-Share系统,该系统具有基于锚点构建全局地图、基于虚拟图像增强地图以及增量更新地图的核心功能。评估结果表明,GS-Share在保真度、连续更新和网络效率方面表现优异,特别是在PSNR、LPIPS和Depth L1指标上分别提高了11%、22%和74%。同时,GS-Share系统更加紧凑,减少了地图传输开销达36%。
Key Takeaways
- 三维高斯贴图技术在构建和共享三维地图中的关键作用。
- GS-Share系统基于锚点构建全局地图,实现更高效的地图共享。
- GS-Share系统采用虚拟图像技术增强地图质量。
- GS-Share系统支持增量更新地图,满足连续更新的需求。
- GS-Share系统在保真度方面表现优异,特别是在PSNR、LPIPS和Depth L1等指标上的改进。
- GS-Share系统更加紧凑,降低了地图传输开销。
点此查看论文截图
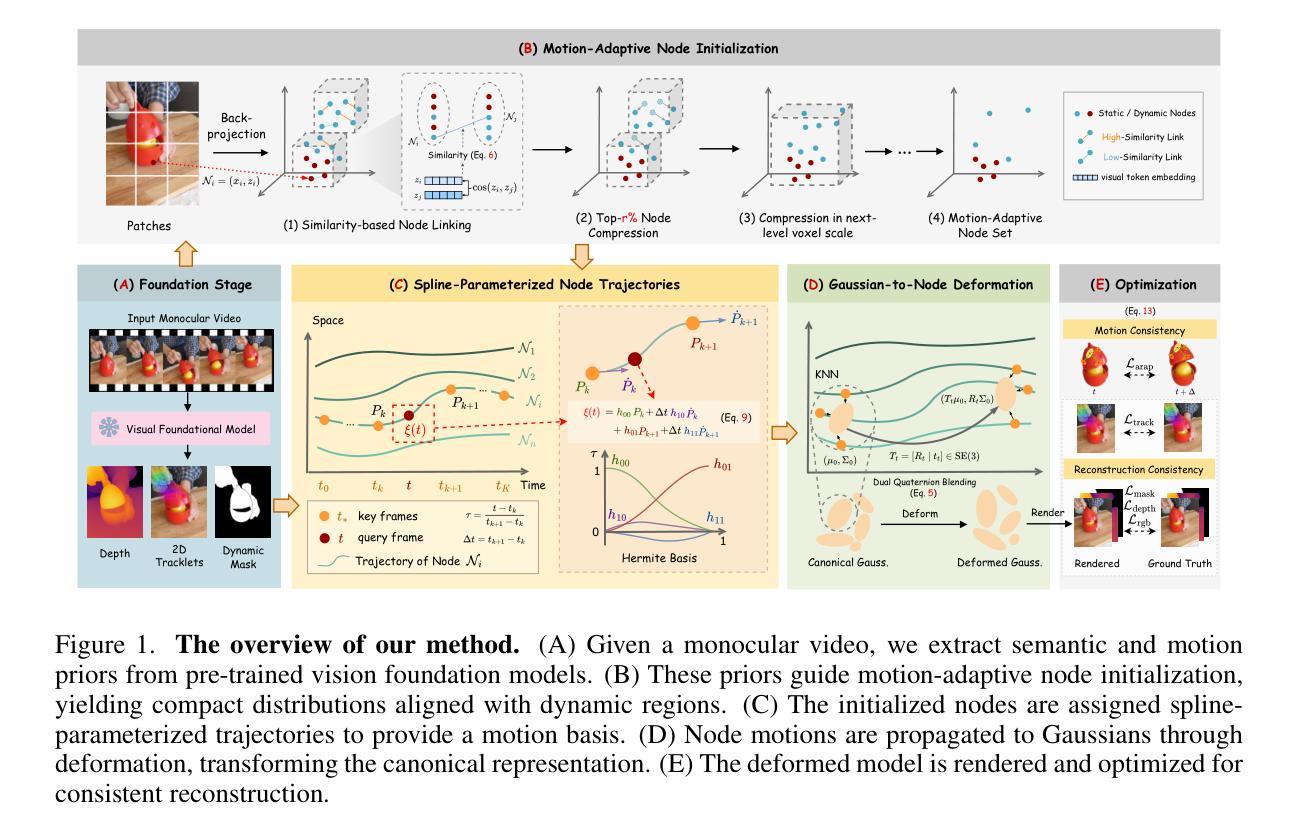
From Tokens to Nodes: Semantic-Guided Motion Control for Dynamic 3D Gaussian Splatting
Authors:Jianing Chen, Zehao Li, Yujun Cai, Hao Jiang, Shuqin Gao, Honglong Zhao, Tianlu Mao, Yucheng Zhang
Dynamic 3D reconstruction from monocular videos remains difficult due to the ambiguity inferring 3D motion from limited views and computational demands of modeling temporally varying scenes. While recent sparse control methods alleviate computation by reducing millions of Gaussians to thousands of control points, they suffer from a critical limitation: they allocate points purely by geometry, leading to static redundancy and dynamic insufficiency. We propose a motion-adaptive framework that aligns control density with motion complexity. Leveraging semantic and motion priors from vision foundation models, we establish patch-token-node correspondences and apply motion-adaptive compression to concentrate control points in dynamic regions while suppressing redundancy in static backgrounds. Our approach achieves flexible representational density adaptation through iterative voxelization and motion tendency scoring, directly addressing the fundamental mismatch between control point allocation and motion complexity. To capture temporal evolution, we introduce spline-based trajectory parameterization initialized by 2D tracklets, replacing MLP-based deformation fields to achieve smoother motion representation and more stable optimization. Extensive experiments demonstrate significant improvements in reconstruction quality and efficiency over existing state-of-the-art methods.
从单目视频进行动态3D重建仍然是一个挑战,这主要是因为从有限的视角推断3D运动存在歧义,以及建模时间上变化场景的计算需求。虽然最近的稀疏控制方法通过减少数百万个高斯点数千个控制点来缓解计算压力,但它们存在一个关键局限性:它们纯粹通过几何进行点分配,导致静态冗余和动态不足。我们提出了一种与运动复杂性相适应的控制密度框架。我们利用视觉基础模型的语义和运动先验,建立补丁令牌节点对应关系,并应用运动自适应压缩,在动态区域集中控制点,同时抑制静态背景的冗余。我们的方法通过迭代体素化和运动倾向评分实现了灵活的表现密度适应,直接解决了控制点分配与运动复杂性之间的基本不匹配问题。为了捕捉时间演化,我们引入了基于样条的轨迹参数化,由2D轨迹片段初始化,替代了基于MLP的变形场,以实现更平滑的运动表示和更稳定的优化。大量实验表明,与现有最先进的方法相比,重建质量和效率都有显著提高。
论文及项目相关链接
Summary
本文提出一种动态自适应的框架,用于根据运动复杂度调整控制点密度。该框架利用视觉基础模型的语义和运动先验信息,建立补丁令牌节点对应关系,通过运动自适应压缩技术,在动态区域集中控制点,同时抑制静态背景的冗余。该方法实现了灵活的表现密度自适应,通过迭代体素化和运动倾向评分,直接解决控制点分配与运动复杂度之间的根本性不匹配问题。引入基于样条的轨迹参数化,以二维轨迹初始化,实现更平滑的运动表示和更稳定的优化。实验表明,该方法在重建质量和效率上均显著优于现有先进技术。
Key Takeaways
- 动态3D重建从单目视频中仍然具有挑战性,因为从有限视角推断3D运动存在歧义,以及建模时间变化场景的计算需求较高。
- 最近的稀疏控制方法虽然通过减少数百万个高斯点到数千个控制点来减轻计算负担,但它们存在临界局限性:它们纯粹根据几何分配点,导致静态冗余和动态不足。
- 本文提出了一种运动自适应框架,该框架根据运动复杂度调整控制点密度,实现了灵活的表现密度自适应。
- 利用视觉基础模型的语义和运动先验信息,建立补丁令牌节点对应关系,实现精准的区域控制点分配。
- 通过运动自适应压缩技术,该方法在动态区域集中控制点,同时抑制静态背景的冗余。
- 引入基于样条的轨迹参数化,以二维轨迹初始化,实现更平滑的运动表示和更稳定的优化。
点此查看论文截图

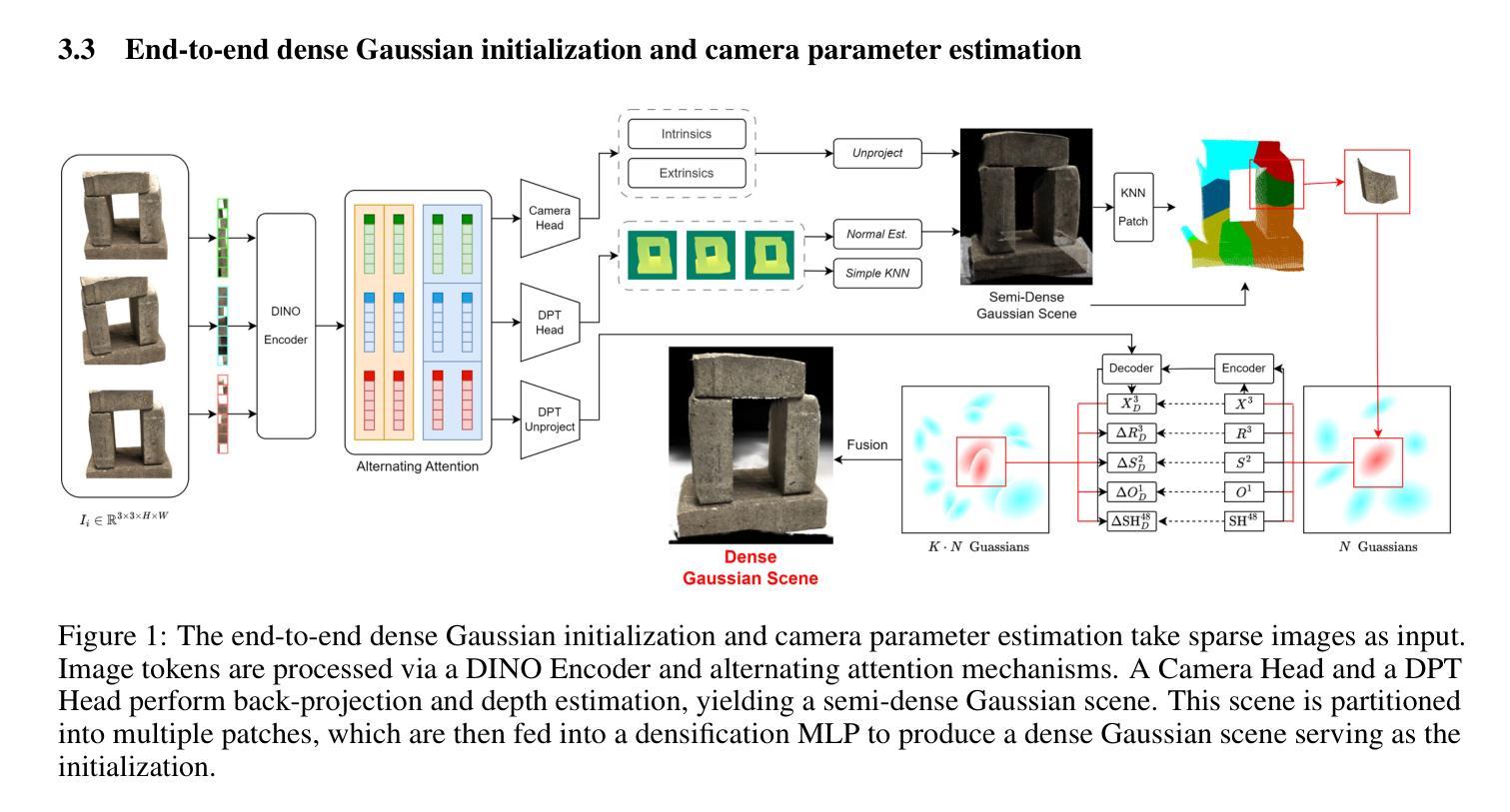
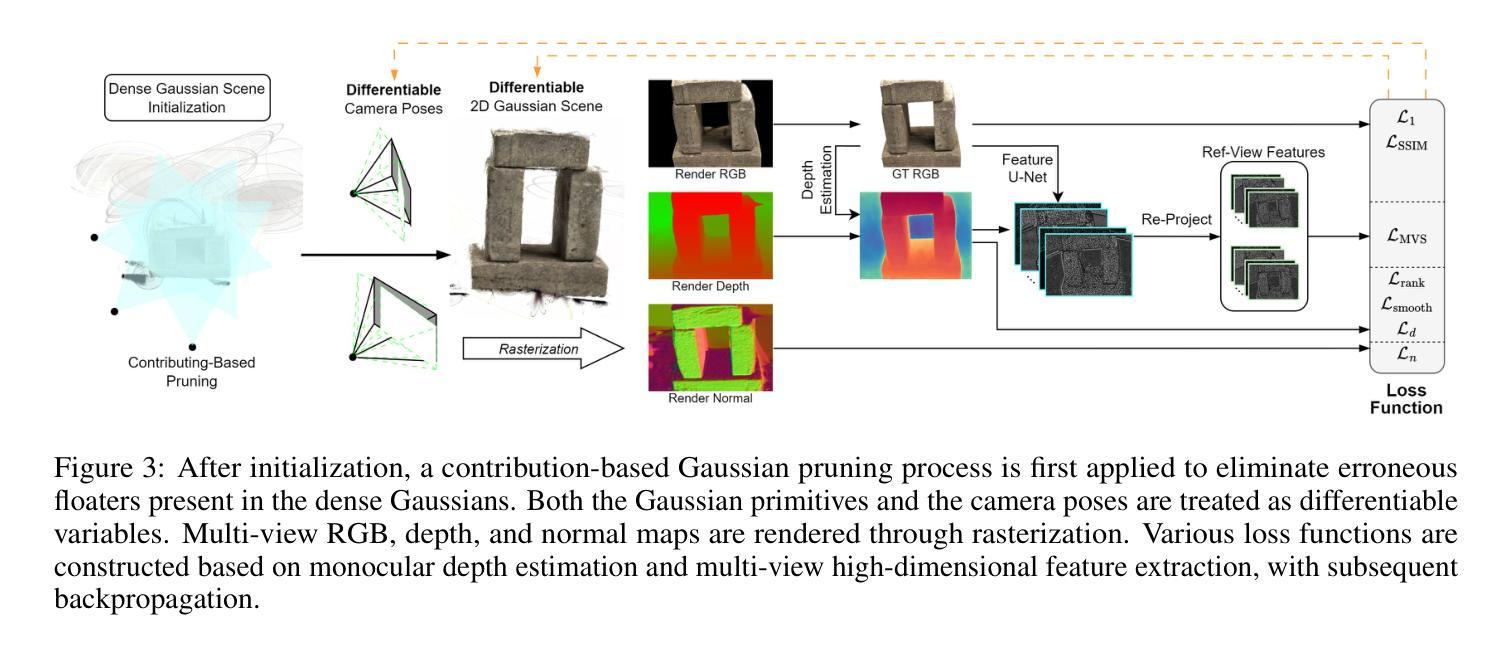
FSFSplatter: Build Surface and Novel Views with Sparse-Views within 3min
Authors:Yibin Zhao, Yihan Pan, Jun Nan, Jianjun Yi
Gaussian Splatting has become a leading reconstruction technique, known for its high-quality novel view synthesis and detailed reconstruction. However, most existing methods require dense, calibrated views. Reconstructing from free sparse images often leads to poor surface due to limited overlap and overfitting. We introduce FSFSplatter, a new approach for fast surface reconstruction from free sparse images. Our method integrates end-to-end dense Gaussian initialization, camera parameter estimation, and geometry-enhanced scene optimization. Specifically, FSFSplatter employs a large Transformer to encode multi-view images and generates a dense and geometrically consistent Gaussian scene initialization via a self-splitting Gaussian head. It eliminates local floaters through contribution-based pruning and mitigates overfitting to limited views by leveraging depth and multi-view feature supervision with differentiable camera parameters during rapid optimization. FSFSplatter outperforms current state-of-the-art methods on widely used DTU and Replica.
高斯平铺技术已成为一种领先的重构技术,以其高质量的新型视图合成和细致的重构而闻名。然而,大多数现有方法都需要密集且经过校准的视图。从自由稀疏图像进行重建往往由于重叠有限和过度拟合而导致表面质量不佳。我们介绍了FSFSplatter,一种从自由稀疏图像快速进行表面重建的新方法。我们的方法将端到端的密集高斯初始化、相机参数估计和几何增强的场景优化进行了整合。具体来说,FSFSplatter采用大型Transformer对多视图图像进行编码,并通过自分割高斯头生成密集且几何一致的高斯场景初始化。它通过基于贡献的修剪消除了局部浮标,并通过在快速优化过程中利用深度和多视图特征监督以及可微分相机参数,减轻了对有限视图的过度拟合。FSFSplatter在广泛使用的DTU和Replica数据集上的表现优于当前最先进的方法。
论文及项目相关链接
Summary
本文介绍了FSFSplatter方法,它是一种用于从自由稀疏图像进行快速表面重建的新技术。该方法集成了端到端的密集高斯初始化、相机参数估计和几何增强场景优化。通过采用大型Transformer编码多视角图像,生成密集且几何一致的高斯场景初始化,并通过贡献式修剪消除局部浮标,同时利用深度和多元视角特征监督以及可微分相机参数进行快速优化,缓解对有限视角的过拟合问题。
Key Takeaways
- FSFSplatter是一种新的从自由稀疏图像进行快速表面重建的方法。
- 该方法集成了密集高斯初始化、相机参数估计和几何增强场景优化。
- FSFSplatter采用大型Transformer编码多视角图像。
- 生成的高斯场景初始化是密集且几何一致的。
- 通过贡献式修剪消除局部浮标。
- 利用深度和多元视角特征监督以及可微分相机参数进行快速优化。
点此查看论文截图
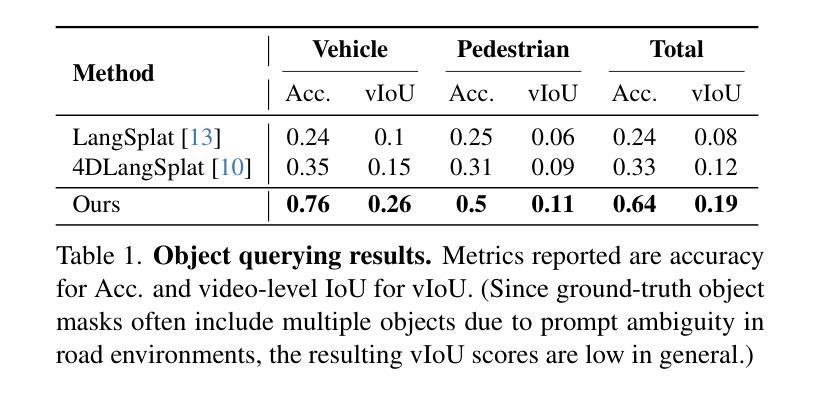
SIMSplat: Predictive Driving Scene Editing with Language-aligned 4D Gaussian Splatting
Authors:Sung-Yeon Park, Adam Lee, Juanwu Lu, Can Cui, Luyang Jiang, Rohit Gupta, Kyungtae Han, Ahmadreza Moradipari, Ziran Wang
Driving scene manipulation with sensor data is emerging as a promising alternative to traditional virtual driving simulators. However, existing frameworks struggle to generate realistic scenarios efficiently due to limited editing capabilities. To address these challenges, we present SIMSplat, a predictive driving scene editor with language-aligned Gaussian splatting. As a language-controlled editor, SIMSplat enables intuitive manipulation using natural language prompts. By aligning language with Gaussian-reconstructed scenes, it further supports direct querying of road objects, allowing precise and flexible editing. Our method provides detailed object-level editing, including adding new objects and modifying the trajectories of both vehicles and pedestrians, while also incorporating predictive path refinement through multi-agent motion prediction to generate realistic interactions among all agents in the scene. Experiments on the Waymo dataset demonstrate SIMSplat’s extensive editing capabilities and adaptability across a wide range of scenarios. Project page: https://sungyeonparkk.github.io/simsplat/
利用传感器数据进行驾驶场景操纵正成为传统虚拟驾驶模拟器的一种有前途的替代方案。然而,由于有限的编辑能力,现有框架难以高效生成逼真的场景。为了解决这些挑战,我们推出了SIMSplat,这是一款具有语言对齐高斯涂斑技术的预测性驾驶场景编辑器。作为一款语言控制的编辑器,SIMSplat能够通过自然语言提示实现直观的操作。通过将语言与高斯重建的场景进行对齐,它还支持对道路对象的直接查询,从而实现精确灵活的编辑。我们的方法提供了详细的对象级编辑,包括添加新对象并修改车辆和行人的轨迹,同时还通过多智能体运动预测融入预测路径优化,以生成场景中所有智能体之间的逼真交互。在Waymo数据集上的实验证明了SIMSplat广泛的编辑能力和在各种场景下的适应性。项目页面:https://sungyeonparkk.github.io/simsplat/
论文及项目相关链接
Summary
本文介绍了一种基于语言控制的驾驶场景编辑器SIMSplat,它使用语言对齐的高斯溅射技术,能够直观地进行场景操作。该技术能够详细地进行物体级别的编辑,添加新物体并修改车辆和行人的轨迹,同时通过多智能体运动预测进行路径修正,生成真实场景中的智能体互动。
Key Takeaways
- SIMSplat是一种预测驾驶场景编辑器,采用语言对齐的高斯溅射技术。
- 通过自然语言提示实现直观的场景操作。
- 提供物体级别的详细编辑,包括添加新物体和修改车辆、行人轨迹。
- 集成多智能体运动预测,生成真实场景中各智能体间的互动。
- 使用Waymo数据集进行的实验证明了SIMSplat广泛的编辑能力和广泛的场景适应性。
- SIMSplat能够支持直接查询道路物体,实现精确和灵活的编辑。
点此查看论文截图
ExGS: Extreme 3D Gaussian Compression with Diffusion Priors
Authors:Jiaqi Chen, Xinhao Ji, Yuanyuan Gao, Hao Li, Yuning Gong, Yifei Liu, Dan Xu, Zhihang Zhong, Dingwen Zhang, Xiao Sun
Neural scene representations, such as 3D Gaussian Splatting (3DGS), have enabled high-quality neural rendering; however, their large storage and transmission costs hinder deployment in resource-constrained environments. Existing compression methods either rely on costly optimization, which is slow and scene-specific, or adopt training-free pruning and quantization, which degrade rendering quality under high compression ratios. In contrast, recent data-driven approaches provide a promising direction to overcome this trade-off, enabling efficient compression while preserving high rendering quality.We introduce ExGS, a novel feed-forward framework that unifies Universal Gaussian Compression (UGC) with GaussPainter for Extreme 3DGS compression. UGC performs re-optimization-free pruning to aggressively reduce Gaussian primitives while retaining only essential information, whereas GaussPainter leverages powerful diffusion priors with mask-guided refinement to restore high-quality renderings from heavily pruned Gaussian scenes. Unlike conventional inpainting, GaussPainter not only fills in missing regions but also enhances visible pixels, yielding substantial improvements in degraded renderings.To ensure practicality, it adopts a lightweight VAE and a one-step diffusion design, enabling real-time restoration. Our framework can even achieve over 100X compression (reducing a typical 354.77 MB model to about 3.31 MB) while preserving fidelity and significantly improving image quality under challenging conditions. These results highlight the central role of diffusion priors in bridging the gap between extreme compression and high-quality neural rendering.Our code repository will be released at: https://github.com/chenttt2001/ExGS
神经场景表示,如3D高斯切片(3DGS),已经实现了高质量的神经营渲染;然而,它们的高存储和传输成本阻碍了其在资源受限环境中的部署。现有的压缩方法要么依赖于昂贵且缓慢的场景特定优化,要么采用无训练裁剪和量化,这在高压缩比下会降低渲染质量。相比之下,最近的数据驱动方法为解决这一权衡提供了有前景的方向,能够在保持高质量渲染的同时实现高效压缩。我们介绍了ExGS,这是一种新型的前馈框架,它将通用高斯压缩(UGC)与GaussPainter相结合,用于实现极端的3DGS压缩。UGC通过无优化重配置的裁剪方法大幅度减少高斯原始数据,同时保留必要信息;而GaussPainter则利用强大的扩散先验和掩膜引导细化技术,从大量裁剪的高斯场景中恢复高质量渲染。不同于传统的图像补全技术,GaussPainter不仅能填充缺失区域,还能增强可见像素,显著改善了退化的渲染效果。为了确保实用性,它采用了轻量级的VAE和一步扩散设计,实现了实时恢复。我们的框架甚至可以实现超过100倍的压缩(将一个典型的354.77 MB模型压缩到约3.31 MB),同时保持保真度并在具有挑战性的条件下显著改善图像质量。这些结果凸显了扩散先验在极端压缩与高质量神经渲染之间的桥梁作用。我们的代码仓库将在https://github.com/chenttt2001/ExGS发布。
论文及项目相关链接
Summary
该摘要指出,神经场景表示技术如三维高斯样条法(3DGS)可以实现高质量神经渲染,但其存储和传输成本较高,不适合资源受限的环境。现有压缩方法存在优化成本高、速度慢且场景特定的问题,或者采用无训练优化的修剪和量化,但在高压缩比下会降低渲染质量。最近的数据驱动方法为克服这一权衡提供了有前景的方向,能够在保持高质量渲染的同时实现高效压缩。本研究引入了ExGS,这是一个结合了通用高斯压缩(UGC)和GaussPainter的新前馈框架,用于实现极端的3DGS压缩。其中,UGC实现了无优化修剪,有效减少了高斯原始数据同时保留关键信息;GaussPainter则利用扩散先验和掩膜导向细化,从高度修剪的高斯场景中恢复高质量渲染。其采用轻量级VAE和一步扩散设计,保证了实用性,并能实现实时恢复。该框架能在保持保真度的同时实现超过100倍的压缩(将典型的354.77MB模型压缩至约3.31MB),并在具有挑战性的条件下显著提高图像质量。这表明扩散先验在弥合极端压缩与高质量神经渲染之间差距中扮演着核心角色。
Key Takeaways
- 神经场景表示技术如3DGS可实现高质量神经渲染,但存储和传输成本较高。
- 现有压缩方法存在优化成本高、速度慢或降低渲染质量的问题。
- 数据驱动方法为平衡压缩与高质量渲染提供了新方向。
- ExGS框架结合了通用高斯压缩(UGC)和GaussPainter技术,实现了高效且高质量的3DGS压缩。
- UGC能够实现无优化修剪,有效减少高斯原始数据同时保留关键信息。
- GaussPainter利用扩散先验和掩膜导向细化,可从高度修剪的场景中恢复高质量渲染。
点此查看论文截图

