⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-07 更新
Product-Quantised Image Representation for High-Quality Image Synthesis
Authors:Denis Zavadski, Nikita Philip Tatsch, Carsten Rother
Product quantisation (PQ) is a classical method for scalable vector encoding, yet it has seen limited usage for latent representations in high-fidelity image generation. In this work, we introduce PQGAN, a quantised image autoencoder that integrates PQ into the well-known vector quantisation (VQ) framework of VQGAN. PQGAN achieves a noticeable improvement over state-of-the-art methods in terms of reconstruction performance, including both quantisation methods and their continuous counterparts. We achieve a PSNR score of 37dB, where prior work achieves 27dB, and are able to reduce the FID, LPIPS, and CMMD score by up to 96%. Our key to success is a thorough analysis of the interaction between codebook size, embedding dimensionality, and subspace factorisation, with vector and scalar quantisation as special cases. We obtain novel findings, such that the performance of VQ and PQ behaves in opposite ways when scaling the embedding dimension. Furthermore, our analysis shows performance trends for PQ that help guide optimal hyperparameter selection. Finally, we demonstrate that PQGAN can be seamlessly integrated into pre-trained diffusion models. This enables either a significantly faster and more compute-efficient generation, or a doubling of the output resolution at no additional cost, positioning PQ as a strong extension for discrete latent representation in image synthesis.
产品量化(PQ)是一种用于可扩展向量编码的经典方法,但在高保真图像生成中的潜在表示应用有限。在这项工作中,我们介绍了PQGAN,这是一个将PQ集成到众所周知的VQGAN的向量量化(VQ)框架中的量化图像自编码器。PQGAN在重建性能上实现了对最先进方法的显著改进,包括量化方法和它们的连续对应物。我们达到的PSNR分数为37dB,而先前的工作只达到27dB,并且能够将FID、LPIPS和CMMD分数降低高达96%。我们成功的关键是全面分析了码本大小、嵌入维度和子空间分解之间的相互作用,以向量和标量量化作为特殊情况。我们获得了新的发现,即在缩放嵌入维度时,VQ和PQ的性能表现相反。此外,我们的分析显示了PQ的性能趋势,有助于选择最佳超参数。最后,我们证明PQGAN可以无缝集成到预训练的扩散模型中。这使得要么生成过程更快、更节省计算资源,要么在不增加成本的情况下将输出分辨率翻倍,从而定位PQ作为图像合成中离散潜在表示的强大扩展。
论文及项目相关链接
Summary
本文介绍了PQGAN,一种将产品量化(PQ)融入VQGAN的向量量化框架的量化图像自编码器。PQGAN在重建性能上较现有方法有明显改进,实现了37dB的PSNR分数,并降低了FID、LPIPS和CMMD分数高达96%。其成功的关键在于对代码本大小、嵌入维度和子空间分解之间的相互作用进行了深入分析。此外,PQGAN可无缝集成到预训练的扩散模型中,可实现更快、更高效的生成或输出分辨率翻倍而无需额外成本。
Key Takeaways
- PQGAN结合了产品量化(PQ)和向量量化(VQ)框架,实现了高保真图像生成中的潜表示。
- PQGAN在重建性能上较现有方法有明显改进,PSNR分数达到37dB。
- PQGAN降低了FID、LPIPS和CMMD分数高达96%。
- 通过分析代码本大小、嵌入维度和子空间分解的相互作用,PQGAN取得了成功。
- VQ和PQ在扩大嵌入维度时表现相反,这是PQGAN的新发现。
- PQGAN的分析展示了PQ的性能趋势,有助于选择最佳超参数。
点此查看论文截图

HAVIR: HierArchical Vision to Image Reconstruction using CLIP-Guided Versatile Diffusion
Authors:Shiyi Zhang, Dong Liang, Hairong Zheng, Yihang Zhou
The reconstruction of visual information from brain activity fosters interdisciplinary integration between neuroscience and computer vision. However, existing methods still face challenges in accurately recovering highly complex visual stimuli. This difficulty stems from the characteristics of natural scenes: low-level features exhibit heterogeneity, while high-level features show semantic entanglement due to contextual overlaps. Inspired by the hierarchical representation theory of the visual cortex, we propose the HAVIR model, which separates the visual cortex into two hierarchical regions and extracts distinct features from each. Specifically, the Structural Generator extracts structural information from spatial processing voxels and converts it into latent diffusion priors, while the Semantic Extractor converts semantic processing voxels into CLIP embeddings. These components are integrated via the Versatile Diffusion model to synthesize the final image. Experimental results demonstrate that HAVIR enhances both the structural and semantic quality of reconstructions, even in complex scenes, and outperforms existing models.
从脑活动中重建视觉信息促进了神经科学和计算机视觉之间的跨学科融合。然而,现有方法仍然面临着在复杂视觉刺激中准确恢复方面的挑战。这一难题源于自然场景的特性:低级特征表现出异质性,而高级特征则因上下文重叠而显示出语义纠缠。受视觉皮层层次表示理论的启发,我们提出了HAVIR模型,该模型将视觉皮层分为两个层次区域,并从每个区域中提取不同的特征。具体来说,结构生成器从空间处理体素中提取结构信息并将其转换为潜在扩散先验信息,而语义提取器将语义处理体素转换为CLIP嵌入。这些组件通过通用扩散模型进行集成,以合成最终图像。实验结果表明,即使在复杂场景中,HAVIR也能提高重建的结构和语义质量,并且优于现有模型。
论文及项目相关链接
Summary
本文提出一种基于视觉皮层层次表示理论的HAVIR模型,该模型将视觉皮层分为两个层次区域,分别提取不同特征。通过结构生成器提取空间处理体素的结构信息并转换为潜在扩散先验,语义提取器则将语义处理体素转换为CLIP嵌入。通过通用扩散模型集成这些组件以合成最终图像。实验结果表明,HAVIR模型在复杂场景下能提升重建图像的结构和语义质量,并优于现有模型。
Key Takeaways
- 重建视觉信息面临挑战:现有方法难以准确恢复高度复杂的视觉刺激,源于自然场景的特性,即低级别特征的异质性和高级别特征的语义纠缠。
- HAVIR模型提出基于视觉皮层层次表示理论:该模型灵感来源于视觉皮层的层次表示理论,将视觉皮层分为两个层次区域进行特征提取。
- 结构生成器和语义提取器的功能:结构生成器从空间处理体素中提取结构信息并转换为潜在扩散先验,而语义提取器则将语义处理体素转换为CLIP嵌入。
- Versatile Diffusion模型的集成作用:通过通用扩散模型集成结构生成器和语义提取器的输出,以合成最终图像。
- HAVIR模型的优势:实验结果表明,HAVIR模型在复杂场景下能提升重建图像的结构和语义质量。
- HAVIR模型性能超越现有方法:相比其他模型,HAVIR表现出更好的性能。
点此查看论文截图

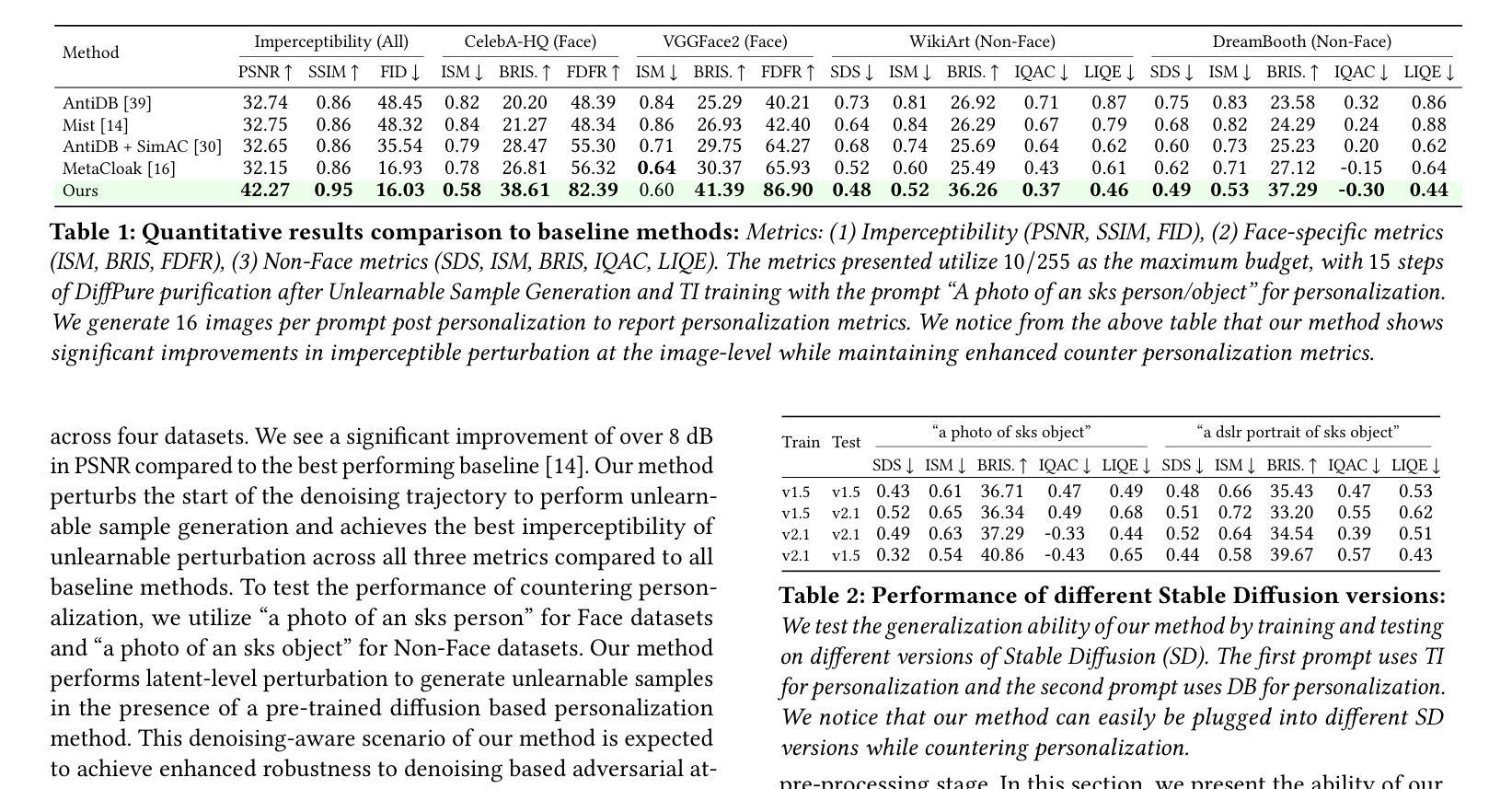
Latent Diffusion Unlearning: Protecting Against Unauthorized Personalization Through Trajectory Shifted Perturbations
Authors:Naresh Kumar Devulapally, Shruti Agarwal, Tejas Gokhale, Vishnu Suresh Lokhande
Text-to-image diffusion models have demonstrated remarkable effectiveness in rapid and high-fidelity personalization, even when provided with only a few user images. However, the effectiveness of personalization techniques has lead to concerns regarding data privacy, intellectual property protection, and unauthorized usage. To mitigate such unauthorized usage and model replication, the idea of generating ``unlearnable’’ training samples utilizing image poisoning techniques has emerged. Existing methods for this have limited imperceptibility as they operate in the pixel space which results in images with noise and artifacts. In this work, we propose a novel model-based perturbation strategy that operates within the latent space of diffusion models. Our method alternates between denoising and inversion while modifying the starting point of the denoising trajectory: of diffusion models. This trajectory-shifted sampling ensures that the perturbed images maintain high visual fidelity to the original inputs while being resistant to inversion and personalization by downstream generative models. This approach integrates unlearnability into the framework of Latent Diffusion Models (LDMs), enabling a practical and imperceptible defense against unauthorized model adaptation. We validate our approach on four benchmark datasets to demonstrate robustness against state-of-the-art inversion attacks. Results demonstrate that our method achieves significant improvements in imperceptibility ($\sim 8 % -10%$ on perceptual metrics including PSNR, SSIM, and FID) and robustness ( $\sim 10%$ on average across five adversarial settings), highlighting its effectiveness in safeguarding sensitive data.
文本到图像的扩散模型在快速高保真个性化方面表现出显著的有效性,即使只提供少量用户图像也是如此。然而,个性化技术的有效性引发了有关数据隐私、知识产权保护和未经授权使用等问题的担忧。为了缓解未经授权的使用和模型复制问题,利用图像中毒技术生成“不可学习”训练样本的想法应运而生。现有的方法有限的隐蔽性是因为它们在像素空间操作,导致图像出现噪声和伪影。在这项工作中,我们提出了一种基于模型的新型扰动策略,该策略在扩散模型的潜在空间内运行。我们的方法交替进行去噪和反演,同时改变去噪轨迹的起点:扩散模型。这种轨迹偏移采样确保扰动图像在保持对原始输入高视觉保真度的同时,抵抗下游生成模型的反演和个性化。这种方法将不可学习性集成到潜在扩散模型(LDM)的框架中,为对抗未经授权的模型适应提供了实用且隐蔽的防御手段。我们在四个基准数据集上验证了我们的方法,以展示其对抗最先进反演攻击的稳健性。结果表明,我们的方法在感知度量(包括PSNR、SSIM和FID)上实现了显著的可觉察性改进(约8%-10%),并在五种对抗设置上平均提高了约10%的稳健性,这突显了其在保护敏感数据方面的有效性。
论文及项目相关链接
Summary:本文提出一种基于模型扰动策略的防未授权使用策略,通过修改扩散模型的去噪轨迹起点来生成不可学习的训练样本,能够在保持图像高保真度的同时抵抗下游生成模型的逆向工程和个性化操作。该策略集成在潜在扩散模型(Latent Diffusion Models,简称LDM)框架中,通过验证显示,其在保护敏感数据方面具有良好的实用性和隐蔽性优势。此方法能显著提升防护隐蔽性感知度量标准(如PSNR、SSIM和FID等)约8%-10%,并在五种对抗环境中平均提高约10%的稳健性。
Key Takeaways:
- 文本到图像扩散模型的高效个性化能力引发关于数据隐私和知识产权的担忧。
- 为应对未经授权的使用和模型复制问题,提出利用图像中毒技术生成不可学习的训练样本。
- 现有方法因在像素空间操作而存在可见噪声和伪影的问题。
- 提出一种新型基于模型扰动的策略,在扩散模型的潜在空间内操作。
- 通过交替去噪和反转操作,修改去噪轨迹起点以生成具有高质量且对下游生成模型逆向工程和个性化抵抗的图像。
- 该策略集成在潜在扩散模型框架中,提升了防御策略在实际应用中的实用性和隐蔽性优势。
点此查看论文截图
PEO: Training-Free Aesthetic Quality Enhancement in Pre-Trained Text-to-Image Diffusion Models with Prompt Embedding Optimization
Authors:Hovhannes Margaryan, Bo Wan, Tinne Tuytelaars
This paper introduces a novel approach to aesthetic quality improvement in pre-trained text-to-image diffusion models when given a simple prompt. Our method, dubbed Prompt Embedding Optimization (PEO), leverages a pre-trained text-to-image diffusion model as a backbone and optimizes the text embedding of a given simple and uncurated prompt to enhance the visual quality of the generated image. We achieve this by a tripartite objective function that improves the aesthetic fidelity of the generated image, ensures adherence to the optimized text embedding, and minimal divergence from the initial prompt. The latter is accomplished through a prompt preservation term. Additionally, PEO is training-free and backbone-independent. Quantitative and qualitative evaluations confirm the effectiveness of the proposed method, exceeding or equating the performance of state-of-the-art text-to-image and prompt adaptation methods.
本文介绍了一种在给定简单提示时,提高预训练文本到图像扩散模型美学质量的新方法。我们的方法被称为提示嵌入优化(PEO),它利用预训练的文本到图像扩散模型作为骨干,并通过优化给定简单未整理的提示的文本嵌入来增强生成图像的可视质量。我们通过三方目标函数实现这一点,该函数提高了生成图像的美学保真度,确保遵循优化后的文本嵌入,并且与初始提示的偏差最小。后者是通过提示保留项来实现的。此外,PEO无需训练且独立于骨干网。定量和定性评估证实了所提出方法的有效性,其性能超过了或等同于最先进的文本到图像和提示适应方法。
论文及项目相关链接
Summary
本文提出了一种改进预训练文本到图像扩散模型美学质量的新方法,称为Prompt Embedding Optimization(PEO)。该方法利用预训练的文本到图像扩散模型作为骨干,优化给定简单未整理提示的文本嵌入,以提高生成图像的可视质量。通过三方目标函数实现,旨在提高生成图像的美学保真度,确保优化文本嵌入的遵循,并尽量减少与初始提示的偏差。此外,PEO具有无训练和独立于骨干的特点。定量和定性评估证明了该方法的有效性,超越了或等同于最先进文本到图像和提示适应方法的表现。
Key Takeaways
- 引入了一种名为Prompt Embedding Optimization (PEO)的新方法,用于改进预训练文本到图像扩散模型的美学质量。
- PEO利用预训练的文本到图像扩散模型作为骨干,优化给定提示的文本嵌入。
- 通过三方目标函数提高生成图像的美学质量,确保遵循优化后的文本嵌入,并尽量减少与初始提示的偏差。
- PEO具有无训练的特点,意味着它不需要额外的训练过程。
- PEO独立于骨干,意味着它可以应用于不同的预训练文本到图像扩散模型。
- 定量和定性评估表明PEO的有效性,在某些方面甚至超越了当前最先进的方法。
点此查看论文截图


Learning a distance measure from the information-estimation geometry of data
Authors:Guy Ohayon, Pierre-Etienne H. Fiquet, Florentin Guth, Jona Ballé, Eero P. Simoncelli
We introduce the Information-Estimation Metric (IEM), a novel form of distance function derived from an underlying continuous probability density over a domain of signals. The IEM is rooted in a fundamental relationship between information theory and estimation theory, which links the log-probability of a signal with the errors of an optimal denoiser, applied to noisy observations of the signal. In particular, the IEM between a pair of signals is obtained by comparing their denoising error vectors over a range of noise amplitudes. Geometrically, this amounts to comparing the score vector fields of the blurred density around the signals over a range of blur levels. We prove that the IEM is a valid global metric and derive a closed-form expression for its local second-order approximation, which yields a Riemannian metric. For Gaussian-distributed signals, the IEM coincides with the Mahalanobis distance. But for more complex distributions, it adapts, both locally and globally, to the geometry of the distribution. In practice, the IEM can be computed using a learned denoiser (analogous to generative diffusion models) and solving a one-dimensional integral. To demonstrate the value of our framework, we learn an IEM on the ImageNet database. Experiments show that this IEM is competitive with or outperforms state-of-the-art supervised image quality metrics in predicting human perceptual judgments.
我们介绍了信息估计度量(IEM),这是一种新的距离函数形式,它源于信号域上潜在连续概率密度的分布。IEM 源于信息论和估计论之间的基本关系,它联系了一个信号的对数概率与应用于该信号的带噪声观测的最佳去噪器的误差。特别地,一对信号之间的 IEM 是通过比较它们在一系列噪声幅度下的去噪误差向量而获得的。从几何角度上讲,这相当于在一系列模糊级别下比较围绕信号的模糊密度得分向量场。我们证明了 IEM 是一个有效的全局度量,并推导出了其局部二阶近似的闭式表达式,这产生了一个黎曼度量。对于高斯分布的信号,IEM 与马氏距离相符。但对于更复杂的分布,它会在局部和全局适应分布几何。在实践中,可以使用学习到的去噪器(类似于生成扩散模型)并求解一维积分来计算 IEM。为了证明我们框架的价值,我们在 ImageNet 数据库上学习了 IEM。实验表明,该 IEM 在预测人类感知判断方面与最先进的监督图像质量指标竞争或优于后者。
论文及项目相关链接
PDF Code available at https://github.com/ohayonguy/information-estimation-metric
Summary
信息估计度量(IEM)是一种新型的距离函数,它基于信号域上的连续概率密度分布。IEM 源于信息论与估计论之间的基本关系,它将信号的日志概率与应用于噪声观测信号的最佳去噪器的误差联系起来。通过对一系列噪声幅度下的去噪误差向量进行比较,获得两个信号之间的 IEM。从几何角度来看,相当于比较一系列模糊度下的围绕信号的模糊密度得分向量场。证明 IEM 是一种有效的全局度量,并推导出其局部二阶近似的封闭形式表达式,从而产生黎曼度量。对于高斯分布的信号,IEM 与马氏距离相符;而对于更复杂的分布,IEM 可适应分布的局部和全局几何特性。实践中,可使用学习到的去噪器(类似于生成扩散模型)并求解一维积分来计算 IEM。在 ImageNet 数据库上学习的 IEM 表明,它在预测人类感知判断方面表现出竞争力,甚至超过现有的最先进的监督图像质量度量。
Key Takeaways
- 信息估计度量(IEM)是一种新型距离函数,基于信号域上的连续概率密度分布。
- IEM 源于信息论与估计论的结合,关联信号的日志概率与去噪器误差。
- 通过比较不同噪声幅度下的去噪误差向量,计算两个信号之间的 IEM。
- IEM 在几何上表现为比较模糊密度得分向量场。
- IEM 被证明是一种有效的全局度量,并具备黎曼度量的局部二阶近似形式。
- 对于不同分布的信号,IEM 能自适应调整,尤其对于复杂分布。
点此查看论文截图

UniVerse: Unleashing the Scene Prior of Video Diffusion Models for Robust Radiance Field Reconstruction
Authors:Jin Cao, Hongrui Wu, Ziyong Feng, Hujun Bao, Xiaowei Zhou, Sida Peng
This paper tackles the challenge of robust reconstruction, i.e., the task of reconstructing a 3D scene from a set of inconsistent multi-view images. Some recent works have attempted to simultaneously remove image inconsistencies and perform reconstruction by integrating image degradation modeling into neural 3D scene representations. However, these methods rely heavily on dense observations for robustly optimizing model parameters. To address this issue, we propose to decouple robust reconstruction into two subtasks: restoration and reconstruction, which naturally simplifies the optimization process. To this end, we introduce UniVerse, a unified framework for robust reconstruction based on a video diffusion model. Specifically, UniVerse first converts inconsistent images into initial videos, then uses a specially designed video diffusion model to restore them into consistent images, and finally reconstructs the 3D scenes from these restored images. Compared with case-by-case per-view degradation modeling, the diffusion model learns a general scene prior from large-scale data, making it applicable to diverse image inconsistencies. Extensive experiments on both synthetic and real-world datasets demonstrate the strong generalization capability and superior performance of our method in robust reconstruction. Moreover, UniVerse can control the style of the reconstructed 3D scene. Project page: https://jin-cao-tma.github.io/UniVerse.github.io/
本文解决了稳健重建的挑战,即从一个不一致的多视角图像集中重建一个三维场景的任务。一些近期的工作尝试通过整合图像退化建模到神经三维场景表示中来同时移除图像的不一致性和进行重建。然而,这些方法严重依赖于密集的观测结果以稳健地优化模型参数。为了解决这一问题,我们提议将稳健重建分解成两个子任务:恢复和重建,这自然地简化了优化过程。为此,我们引入了UniVerse,这是一个基于视频扩散模型的稳健重建的统一框架。具体来说,UniVerse首先把不一致的图像转换成初始视频,然后使用专门设计的视频扩散模型将它们恢复成一致的图像,并最终从这些恢复的图像中重建三维场景。与针对每个视图的退化建模相比,扩散模型从大规模数据中学习一般的场景先验,使其适用于多种图像不一致性。在合成和真实世界数据集上的大量实验证明了我们的方法在稳健重建中的强大通用性和卓越性能。此外,UniVerse可以控制重建的三维场景的风格。项目页面:https://jin-cao-tma.github.io/UniVerse.github.io/
论文及项目相关链接
PDF page: https://jin-cao-tma.github.io/UniVerse.github.io/ code: https://github.com/zju3dv/UniVerse
Summary
本文提出一种基于视频扩散模型的稳健重建方法UniVerse,用于从一组不一致的多视角图像重建3D场景。该方法将重建过程分解为两个子任务:修复和重建,简化了优化过程。它通过视频扩散模型将不一致的图像转换为初始视频,再恢复成一致图像,并从这些恢复后的图像重建3D场景。此方法具有强大的泛化能力和卓越性能,并且可以控制重建3D场景的风格。
Key Takeaways
- 本文解决了从多个不一致的视角图像中重建3D场景的难题。
- 提出一种基于视频扩散模型的稳健重建方法——UniVerse。
- UniVerse将重建过程分解为修复和重建两个子任务,简化了优化流程。
- UniVerse使用视频扩散模型将不一致的图像转换为初始视频,然后恢复成一致图像。
- 该方法具有强大的泛化能力,可在合成和真实世界数据集上表现出卓越性能。
- UniVerse能处理多种图像不一致性,因为扩散模型从大规模数据中学习场景的一般先验。
点此查看论文截图

RichControl: Structure- and Appearance-Rich Training-Free Spatial Control for Text-to-Image Generation
Authors:Liheng Zhang, Lexi Pang, Hang Ye, Xiaoxuan Ma, Yizhou Wang
Text-to-image (T2I) diffusion models have shown remarkable success in generating high-quality images from text prompts. Recent efforts extend these models to incorporate conditional images (e.g., canny edge) for fine-grained spatial control. Among them, feature injection methods have emerged as a training-free alternative to traditional fine-tuning-based approaches. However, they often suffer from structural misalignment, condition leakage, and visual artifacts, especially when the condition image diverges significantly from natural RGB distributions. Through an empirical analysis of existing methods, we identify a key limitation: the sampling schedule of condition features, previously unexplored, fails to account for the evolving interplay between structure preservation and domain alignment throughout diffusion steps. Inspired by this observation, we propose a flexible training-free framework that decouples the sampling schedule of condition features from the denoising process, and systematically investigate the spectrum of feature injection schedules for a higher-quality structure guidance in the feature space. Specifically, we find that condition features sampled from a single timestep are sufficient, yielding a simple yet efficient schedule that balances structure alignment and appearance quality. We further enhance the sampling process by introducing a restart refinement schedule, and improve the visual quality with an appearance-rich prompting strategy. Together, these designs enable training-free generation that is both structure-rich and appearance-rich. Extensive experiments show that our approach achieves state-of-the-art results across diverse zero-shot conditioning scenarios.
文本到图像(T2I)扩散模型在根据文本提示生成高质量图像方面取得了显著的成功。最近的研究努力将这些模型扩展到结合条件图像(例如,Canny边缘)进行精细的空间控制。其中,特征注入方法作为一种无需训练的传统微调方法的替代方案而出现。然而,它们经常遭受结构错位、条件泄漏和视觉伪影的问题,尤其是当条件图像与自然的RGB分布相差很大时。通过对现有方法的实证分析,我们确定了一个关键限制:之前未被探索的条件特征的采样时间表未能考虑到结构保存在扩散步骤中的不断演变和领域对齐的交互作用。受此观察的启发,我们提出了一个灵活的无需训练框架,该框架将条件特征的采样时间表与去噪过程解耦,并系统地研究了特征注入时间表的频谱,以在特征空间中实现更高质量的结构引导。具体来说,我们发现从单一时间步长采样的条件特征就足够了,从而产生了一个简单而高效的时间表,平衡了结构对齐和外观质量。我们进一步通过引入重启细化时间表来增强采样过程,并使用丰富的外观提示策略提高了视觉质量。这些设计共同实现了无需训练的生成,既丰富结构又丰富外观。大量实验表明,我们的方法在多种零样本条件场景下面实现了最佳结果。
论文及项目相关链接
Summary
文本到图像(T2I)扩散模型已成功实现根据文本提示生成高质量图像。近期研究尝试将条件图像纳入其中以实现精细的空间控制。特征注入方法作为一种无训练的方法,被提出以解决传统微调方法所遇到的许多问题,例如结构不对齐、条件泄漏和视觉伪影等。本文分析了现有方法的采样时间表,发现其对扩散步骤中的结构保持和领域对齐的相互作用考虑不足。因此,本文提出了一个灵活的无训练框架,将条件特征的采样时间表与去噪过程分离,并系统地研究了特征注入的时间表,以在特征空间中实现更高质量的结构引导。实验表明,该方法在零样本条件场景下的结果达到领先水平。
Key Takeaways
- 文本到图像(T2I)扩散模型可根据文本提示生成高质量图像。
- 条件图像纳入模型可实现更精细的空间控制。
- 特征注入方法作为一种无训练方案解决了传统微调方法的问题,但仍面临结构不对齐等问题。
- 本文发现了现有方法采样时间表的不足,提出了灵活的框架进行系统性的研究。
- 单步采样条件特征策略找到了结构对齐和外观质量之间的平衡。
- 通过引入重启优化采样过程和外观丰富的提示策略,进一步提高了视觉质量和结构丰富性。
点此查看论文截图
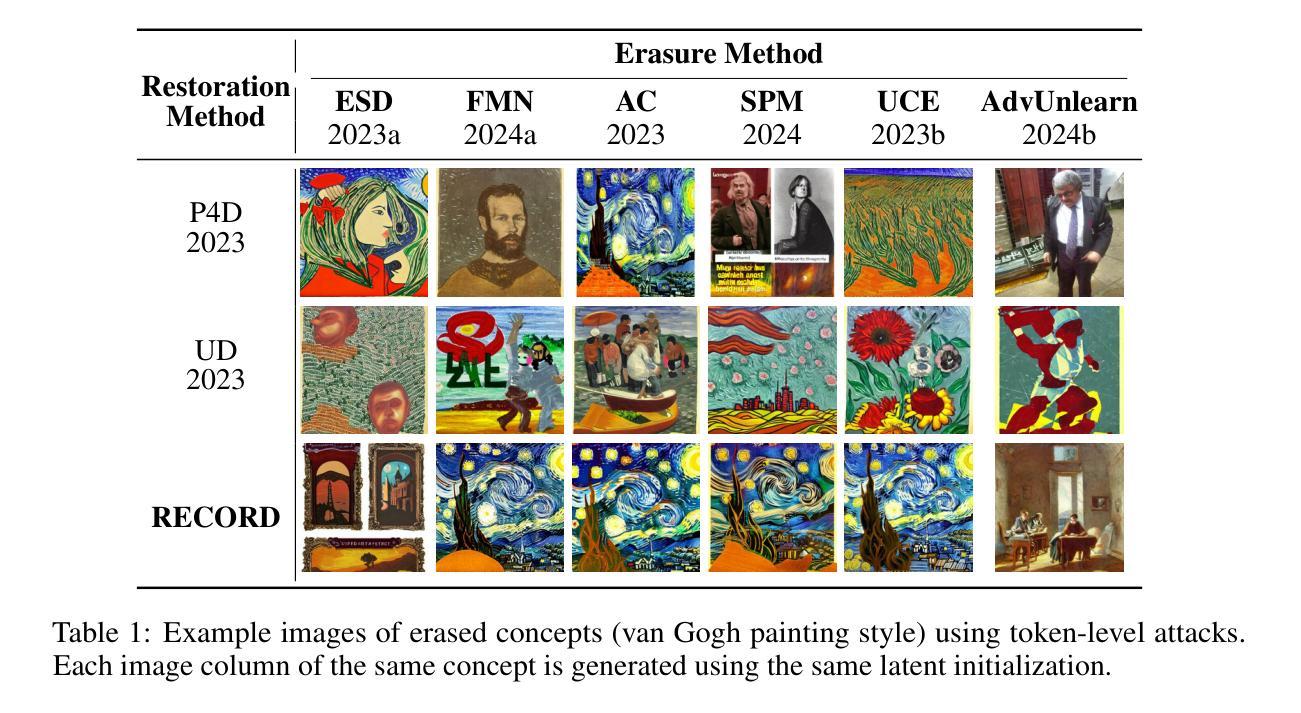
Rethinking the Vulnerability of Concept Erasure and a New Method
Authors:Alex D. Richardson, Kaicheng Zhang, Lucas Beerens, Dongdong Chen
The proliferation of text-to-image diffusion models has raised significant privacy and security concerns, particularly regarding the generation of copyrighted or harmful images. In response, concept erasure (defense) methods have been developed to “unlearn” specific concepts through post-hoc finetuning. However, recent concept restoration (attack) methods have demonstrated that these supposedly erased concepts can be recovered using adversarially crafted prompts, revealing a critical vulnerability in current defense mechanisms. In this work, we first investigate the fundamental sources of adversarial vulnerability and reveal that vulnerabilities are pervasive in the prompt embedding space of concept-erased models, a characteristic inherited from the original pre-unlearned model. Furthermore, we introduce RECORD, a novel coordinate-descent-based restoration algorithm that consistently outperforms existing restoration methods by up to 17.8 times. We conduct extensive experiments to assess its compute-performance tradeoff and propose acceleration strategies.
文本到图像扩散模型的普及引发了重大隐私和安全问题,尤其是关于生成版权或有害图像的问题。作为回应,已经开发了概念消除(防御)方法,通过事后微调来“遗忘”特定概念。然而,最新的概念恢复(攻击)方法已经证明,这些被认为已经被删除的概念可以使用对抗性构建的提示进行恢复,这揭示了当前防御机制中的关键漏洞。在这项工作中,我们首先研究对抗性漏洞的根本来源,并揭示概念消除模型的提示嵌入空间中普遍存在漏洞,这是从原始未学习模型继承的特征。此外,我们引入了基于坐标下降的新恢复算法RECORD,它始终优于现有恢复方法,最高可达1.7倍。我们进行了大量实验来评估其计算性能折衷,并提出了加速策略。
论文及项目相关链接
Summary
文本到图像扩散模型的普及引发了关于生成版权或有害图像的隐私和安全担忧。为此,开发了概念消除(防御)方法,通过微调后的模型进行特定的概念遗忘。然而,最新的概念恢复(攻击)方法证明,这些被消除的概念可以通过对抗性构造的提示进行恢复,揭示了当前防御机制的重大漏洞。本研究深入探讨了对抗性漏洞的根本来源,揭示了概念消除模型的提示嵌入空间中普遍存在漏洞,这一特性继承了未学习前的原始模型的特点。此外,我们引入了新型的基于坐标下降的恢复算法RECORD,该算法在性能上一直优于现有恢复方法,最高提升了达17.8倍。我们进行了大量实验来评估其计算性能权衡并提出了加速策略。
Key Takeaways
- 文本到图像扩散模型的普及引发了关于生成版权或有害图像的隐私和安全担忧。
- 概念消除(防御)方法旨在通过微调模型来遗忘特定概念。
- 现有的概念消除方法存在重大漏洞,可以被概念恢复(攻击)方法利用。
- 对抗性构造的提示可用于恢复被消除的概念。
- 概念消除模型的提示嵌入空间普遍存在漏洞,这一特性继承自原始模型。
- 引入了新型的基于坐标下降的恢复算法RECORD,其性能显著优于现有恢复方法。
点此查看论文截图