⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-07 更新
Self-Anchor: Large Language Model Reasoning via Step-by-step Attention Alignment
Authors:Hongxiang Zhang, Yuan Tian, Tianyi Zhang
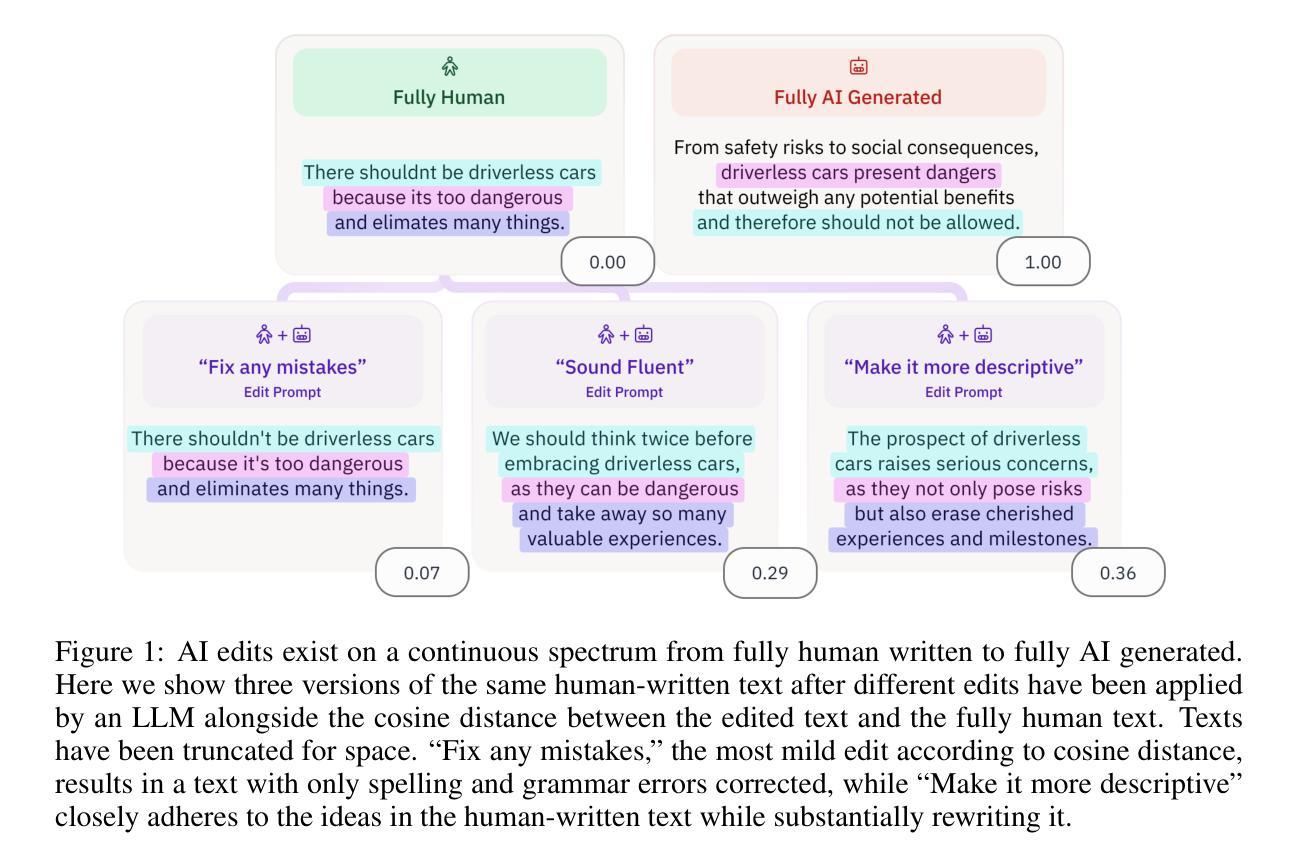
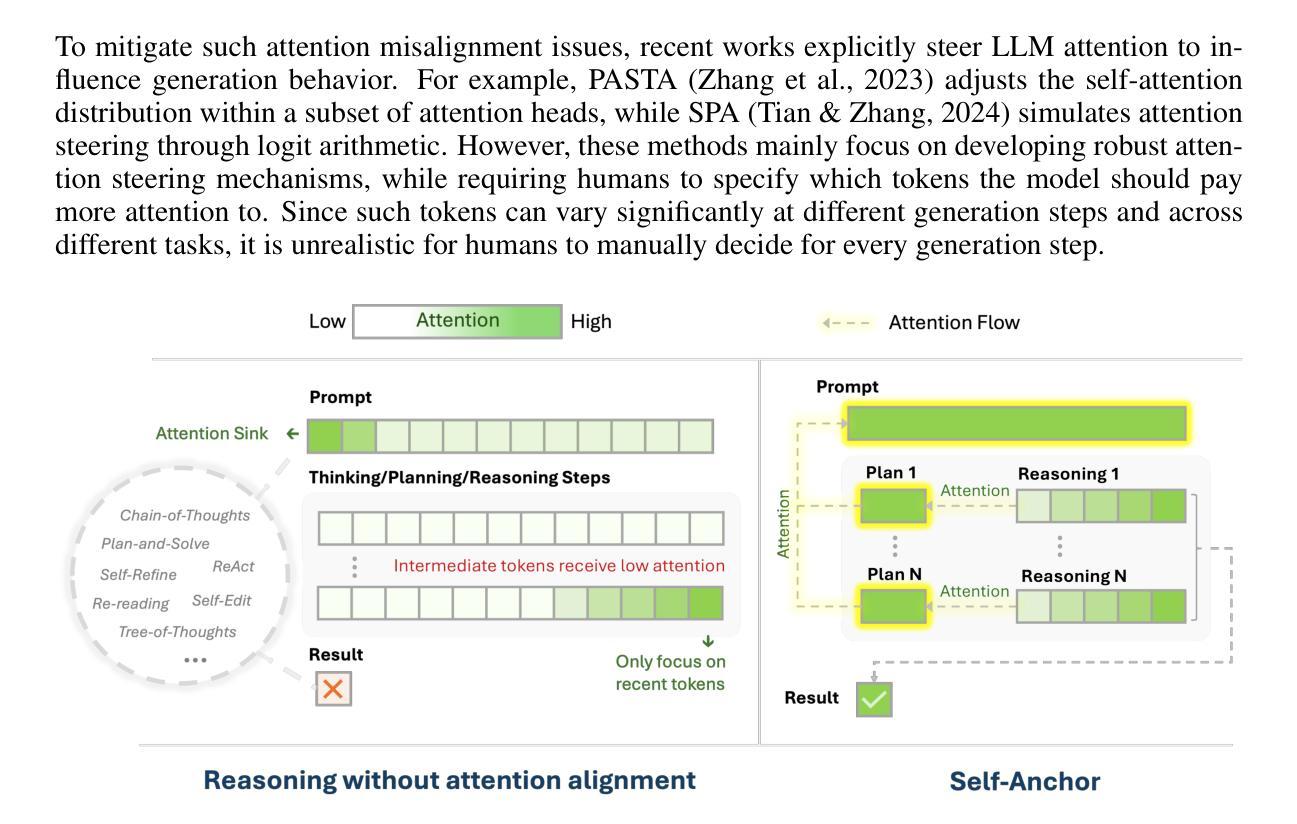
To solve complex reasoning tasks for Large Language Models (LLMs), prompting-based methods offer a lightweight alternative to fine-tuning and reinforcement learning. However, as reasoning chains extend, critical intermediate steps and the original prompt will be buried in the context, receiving insufficient attention and leading to errors. In this paper, we propose Self-Anchor, a novel pipeline that leverages the inherent structure of reasoning to steer LLM attention. Self-Anchor decomposes reasoning trajectories into structured plans and automatically aligns the model’s attention to the most relevant inference steps, allowing the model to maintain focus throughout generation. Our experiment shows that Self-Anchor outperforms SOTA prompting methods across six benchmarks. Notably, Self-Anchor significantly reduces the performance gap between ``non-reasoning’’ models and specialized reasoning models, with the potential to enable most LLMs to tackle complex reasoning tasks without retraining.
为了解决大型语言模型(LLM)的复杂推理任务,基于提示的方法为微调强化学习提供了一种轻量级的替代方案。然而,随着推理链的延伸,关键的中间步骤和原始提示会被上下文所淹没,得不到足够的关注,从而导致错误。在本文中,我们提出了Self-Anchor,这是一种利用推理的内在结构来引导LLM注意的新型管道。Self-Anchor将推理轨迹分解为结构化计划,并自动将模型注意力与最相关的推理步骤对齐,使模型在整个生成过程中保持关注。我们的实验表明,Self-Anchor在六个基准测试中优于SOTA提示方法。值得注意的是,Self-Anchor显著减少了“非推理”模型和专用推理模型之间的性能差距,有可能使大多数LLM能够解决复杂的推理任务而无需重新训练。
论文及项目相关链接
Summary
大型语言模型(LLM)在处理复杂推理任务时,基于提示的方法为微调提供了轻量级替代方案。但随着推理链的延伸,关键的中间步骤和原始提示会在语境中被忽略,导致注意力不足和错误。本文提出Self-Anchor,一种利用推理的内在结构来引导LLM注意力的新方法。它通过分解推理轨迹为结构化计划并自动对齐模型注意力到最关键的推理步骤,使模型在生成过程中保持关注重点。实验表明,Self-Anchor在六个基准测试中优于最新提示方法。尤其值得关注的是,Self-Anchor显著缩小了“非推理”模型和专用推理模型之间的性能差距,具有使大多数LLM无需重新训练就能处理复杂推理任务的能力。
Key Takeaways
- 提示方法在解决大型语言模型的复杂推理任务中提供了一个轻量级的替代方案。
- 随着推理链的延长,关键中间步骤和原始提示容易被忽视,导致错误。
- Self-Anchor利用推理的内在结构来引导LLM的注意力。
- Self-Anchor通过分解推理轨迹为结构化计划,保持模型在生成过程中的关注重点。
- 实验显示Self-Anchor在多个基准测试中表现优越。
- Self-Anchor缩小了非推理模型和专用推理模型之间的性能差距。
点此查看论文截图
Low-probability Tokens Sustain Exploration in Reinforcement Learning with Verifiable Reward
Authors:Guanhua Huang, Tingqiang Xu, Mingze Wang, Qi Yi, Xue Gong, Siheng Li, Ruibin Xiong, Kejiao Li, Yuhao Jiang, Bo Zhou
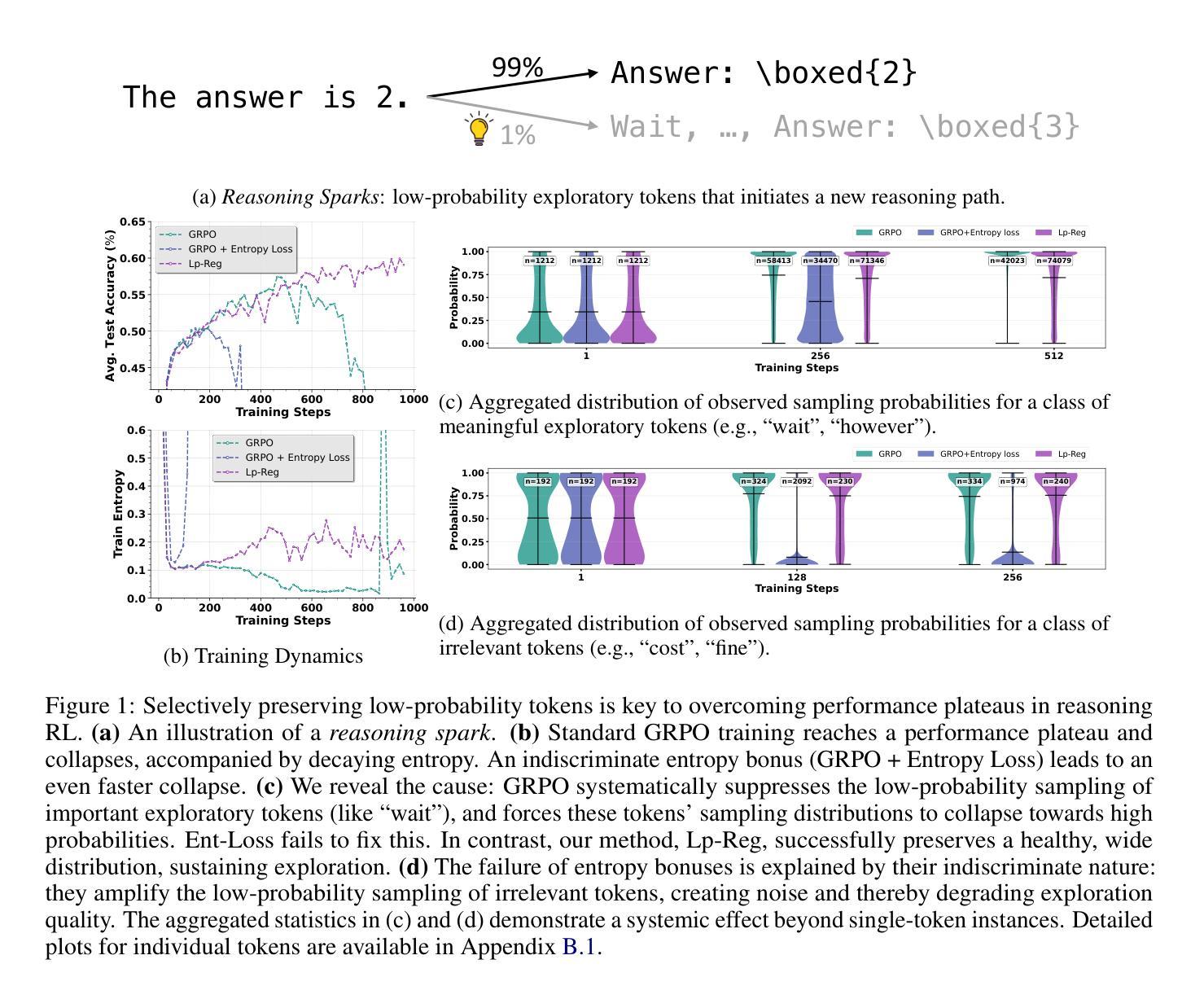
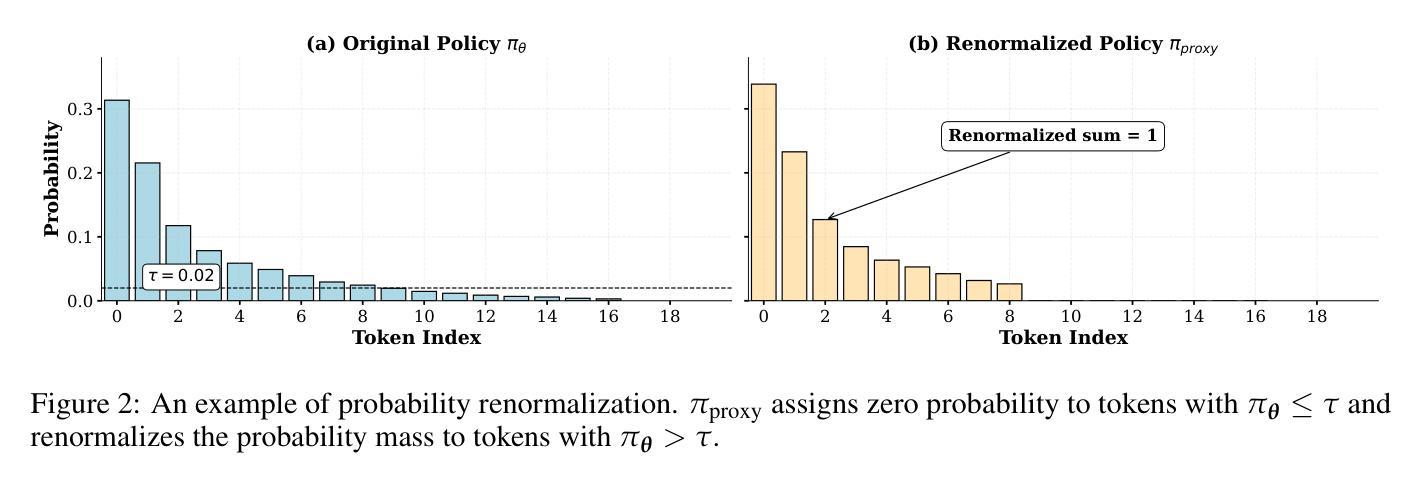
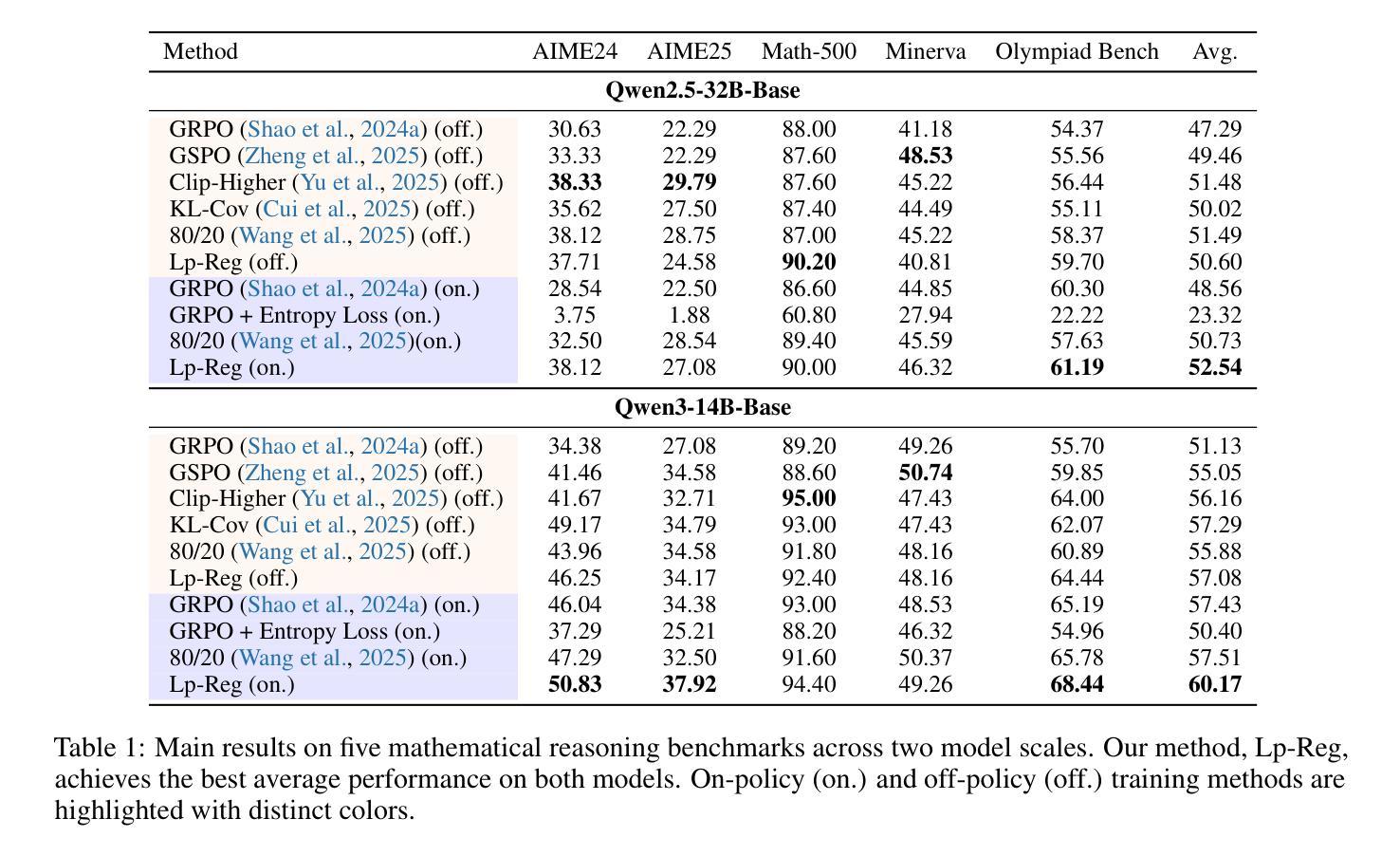
Reinforcement Learning with Verifiable Rewards (RLVR) has propelled Large Language Models in complex reasoning, yet its scalability is often hindered by a training bottleneck where performance plateaus as policy entropy collapses, signaling a loss of exploration. Previous methods typically address this by maintaining high policy entropy, yet the precise mechanisms that govern meaningful exploration have remained underexplored. Our analysis suggests that an unselective focus on entropy risks amplifying irrelevant tokens and destabilizing training. This paper investigates the exploration dynamics within RLVR and identifies a key issue: the gradual elimination of valuable low-probability exploratory tokens, which we term \textbf{\textit{reasoning sparks}}. We find that while abundant in pre-trained models, these sparks are systematically extinguished during RLVR due to over-penalization, leading to a degeneracy in exploration. To address this, we introduce Low-probability Regularization (Lp-Reg). Its core mechanism regularizes the policy towards a heuristic proxy distribution. This proxy is constructed by filtering out presumed noise tokens and re-normalizing the distribution over the remaining candidates. The result is a less-noisy proxy where the probability of \textit{reasoning sparks} is amplified, which then serves as a soft regularization target to shield these valuable tokens from elimination via KL divergence. Experiments show that Lp-Reg enables stable on-policy training for around 1,000 steps, a regime where baseline entropy-control methods collapse. This sustained exploration leads to state-of-the-art performance, achieving a $60.17%$ average accuracy on five math benchmarks, an improvement of $2.66%$ over prior methods. Code is available at https://github.com/CarlanLark/Lp-Reg.
强化学习通过验证奖励(RLVR)在复杂推理中推动了大型语言模型的进步,但其可扩展性经常受到训练瓶颈的阻碍,当策略熵崩溃时,性能会达到饱和状态,这表明探索的丧失。之前的方法通常通过保持高策略熵来解决这个问题,但控制有意义探索的精确机制仍未得到充分探索。我们的分析表明,对熵的不选择性关注可能放大无关标记并破坏训练稳定性。本文研究了RLVR中的探索动态,并发现了一个关键问题:有价值的低概率探索标记(我们称之为“推理火花”)逐渐被淘汰。我们发现虽然这些火花在预训练模型中非常丰富,但由于过度惩罚,它们在RLVR期间被系统地淘汰,导致探索退化。为了解决这一问题,我们引入了低概率正则化(Lp-Reg)。它的核心机制是将策略正则化朝向启发式代理分布。该代理是通过过滤掉假定噪声标记并重新归一化剩余候选标记的分布来构建的。结果是一个噪声较少的代理,其中推理火花的可能性得到放大,然后作为软正则化目标来屏蔽这些有价值的标记免于通过KL散度消除。实验表明,Lp-Reg能够在大约1000步内实现稳定的在线策略训练,这是基线熵控制方法崩溃的领域。这种持续的探索导致了最先进的性能,在五个数学基准测试上达到了平均准确率60.17%,比先前的方法提高了2.66%。代码可在https://github.com/CarlanLark/Lp-Reg获得。
论文及项目相关链接
Summary
在强化学习与可验证奖励(RLVR)的框架下,大型语言模型在复杂推理任务中取得了进展,但其可扩展性受到训练瓶颈的限制。我们的研究发现,这一瓶颈问题源自训练过程中有价值的低概率探索性标记(“推理火花”)被逐渐淘汰。为了解决这个问题,我们引入了低概率正则化(Lp-Reg),它通过正则化策略来模拟一个去噪分布,放大“推理火花”的概率,从而保护这些有价值的标记不被消除。实验表明,Lp-Reg能够在约1000步的在线策略训练中保持稳定的探索,实现了在五个数学基准测试上的平均准确率达到了60.17%,较之前的方法提高了2.66%。
Key Takeaways
- 强化学习(RLVR)框架在大型语言模型的复杂推理任务中有广泛应用,但面临训练瓶颈问题。
- 现有方法主要关注维持策略熵的高低来解决训练瓶颈,但对有意义探索的精确机制了解不足。
- 研究发现,有价值的低概率探索性标记(“推理火花”)在训练过程中被逐渐淘汰是瓶颈问题的关键。
- 提出低概率正则化(Lp-Reg)方法来解决这一问题,通过模拟去噪分布保护并放大“推理火花”。
- Lp-Reg在在线策略训练中表现出强大的性能稳定性,显著提高了五个数学基准测试的平均准确率。
- Lp-Reg方法通过KL散度保护低概率标记不被消除,实现了更持久的探索。
点此查看论文截图

PRISM-Physics: Causal DAG-Based Process Evaluation for Physics Reasoning
Authors:Wanjia Zhao, Qinwei Ma, Jingzhe Shi, Shirley Wu, Jiaqi Han, Yijia Xiao, Si-Yuan Chen, Xiao Luo, Ludwig Schmidt, James Zou
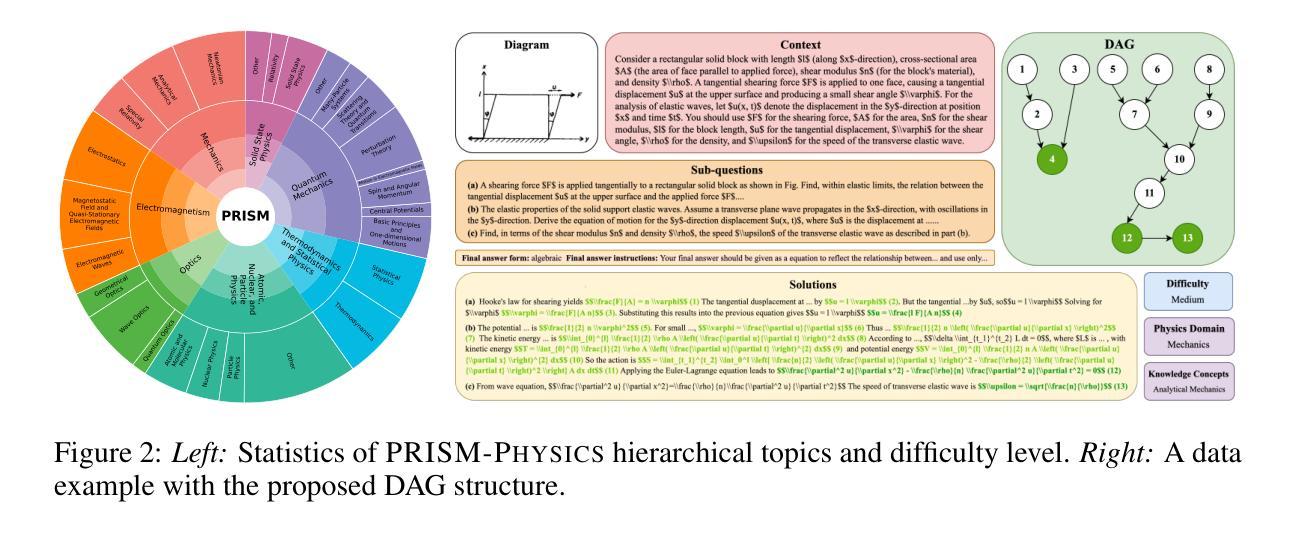
Benchmarks for competition-style reasoning have advanced evaluation in mathematics and programming, yet physics remains comparatively explored. Most existing physics benchmarks evaluate only final answers, which fail to capture reasoning processes, while recent stepwise methods rely on heuristic LLM-as-judge scoring or restrictive linear assumptions, limiting reliability and diagnostic validity. We introduce PRISM-Physics, a process-level evaluation framework and benchmark for complex physics reasoning problems. Solutions are represented as directed acyclic graphs (DAGs) of formulas, explicitly encoding causal dependencies among intermediate steps to enable fine-grained, interpretable, and theoretically grounded scoring. We prove the optimality of the DAG representation and the corresponding scoring policy. Combining with a fully rule-based method for symbolic formula equivalence matching that we developed, we ensure consistent validation across diverse formulations without heuristic judgments. Results show that our evaluation framework is more aligned with human experts’ scoring. Experiments on state-of-the-art LLMs reveal persistent reasoning failures in physics, while step-level scoring offers both diagnostic insight and rich signals for later training. By combining structural rigor, theoretical guarantees, and symbolic validation, PRISM-Physics provides a principled foundation for advancing process-level evaluation and guiding the development of models with deeper scientific reasoning capabilities.
竞赛型推理的基准测试已在数学和编程评估中取得进展,但物理学领域仍相对缺乏研究。现有的大多数物理基准测试只评估最终答案,无法捕捉推理过程,而最近的逐步法则依赖于启发式的大型语言模型评分或限制性线性假设,这限制了其可靠性和诊断有效性。我们介绍了PRISM-Physics,这是一个针对复杂物理推理问题的过程级评估框架和基准测试。解决方案以公式有向无环图(DAG)的形式表示,明确编码了中间步骤之间的因果依赖关系,以实现精细、可解释和理论上的评分。我们证明了DAG表示和相应评分策略的最优性。结合我们开发的基于完全规则的方法,用于符号公式等价匹配,可以在不同的公式表示中确保一致的验证,而无需启发式判断。结果表明,我们的评估框架与人类专家的评分更加一致。在最新大型语言模型上的实验表明,在物理学推理方面仍存在持续的失败,而步骤级评分既提供了诊断洞察力,也为后续训练提供了丰富的信号。通过结合结构性严谨、理论保证和符号验证,PRISM-Physics为推进过程级评估和引导模型向更深的科学推理能力发展提供了坚实的理论基础。
论文及项目相关链接
Summary
物理学领域的过程级评估框架和基准测试对于推动复杂物理推理问题的评价至关重要。现有的物理基准测试主要关注最终答案,忽视了推理过程。PRISM-Physics作为新的基准测试,采用公式有向无环图(DAG)表示解决方案,明确编码中间步骤之间的因果依赖关系,实现了精细、可解释和理论上的评分。该框架与专家评分更一致,能更准确地评估大型语言模型(LLMs)在物理推理方面的不足。
Key Takeaways
- 物理学领域的过程级评估尚待探索,现有基准测试主要关注最终答案,忽视了推理过程。
- PRISM-Physics引入了一种新的评价框架和基准测试,用于评估复杂物理推理问题。
- 解决方案采用公式有向无环图(DAG)表示,明确编码中间步骤的因果依赖关系。
- PRISM-Physics实现了精细、可解释和理论上的评分,与专家评分更一致。
- 该框架能够更准确地评估大型语言模型(LLMs)在物理推理方面的表现。
- 实验结果表明,现有大型语言模型在物理推理方面存在持续失败的情况。
点此查看论文截图

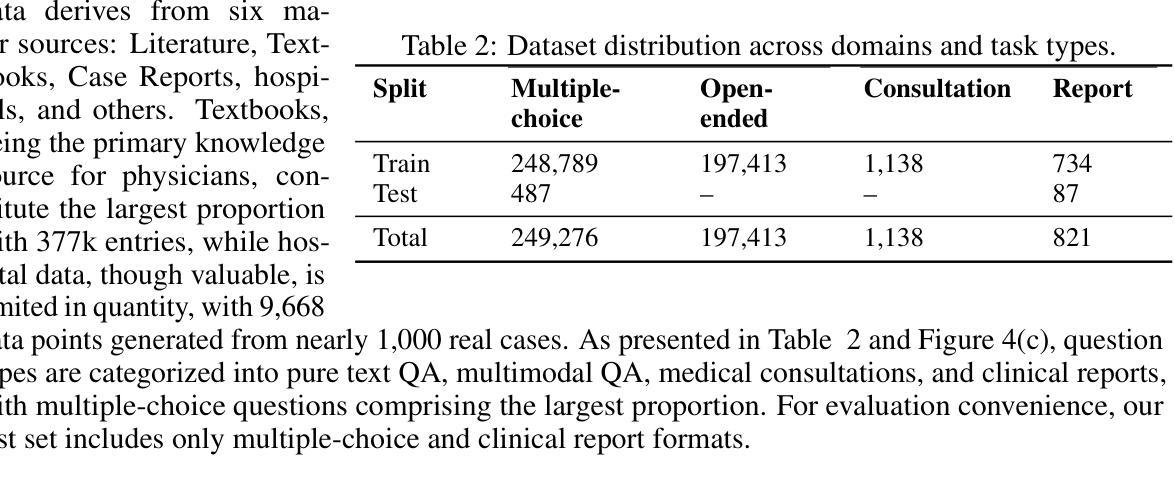
SpineBench: A Clinically Salient, Level-Aware Benchmark Powered by the SpineMed-450k Corpus
Authors:Ming Zhao, Wenhui Dong, Yang Zhang, Xiang Zheng, Zhonghao Zhang, Zian Zhou, Yunzhi Guan, Liukun Xu, Wei Peng, Zhaoyang Gong, Zhicheng Zhang, Dachuan Li, Xiaosheng Ma, Yuli Ma, Jianing Ni, Changjiang Jiang, Lixia Tian, Qixin Chen, Kaishun Xia, Pingping Liu, Tongshun Zhang, Zhiqiang Liu, Zhongan Bi, Chenyang Si, Tiansheng Sun, Caifeng Shan
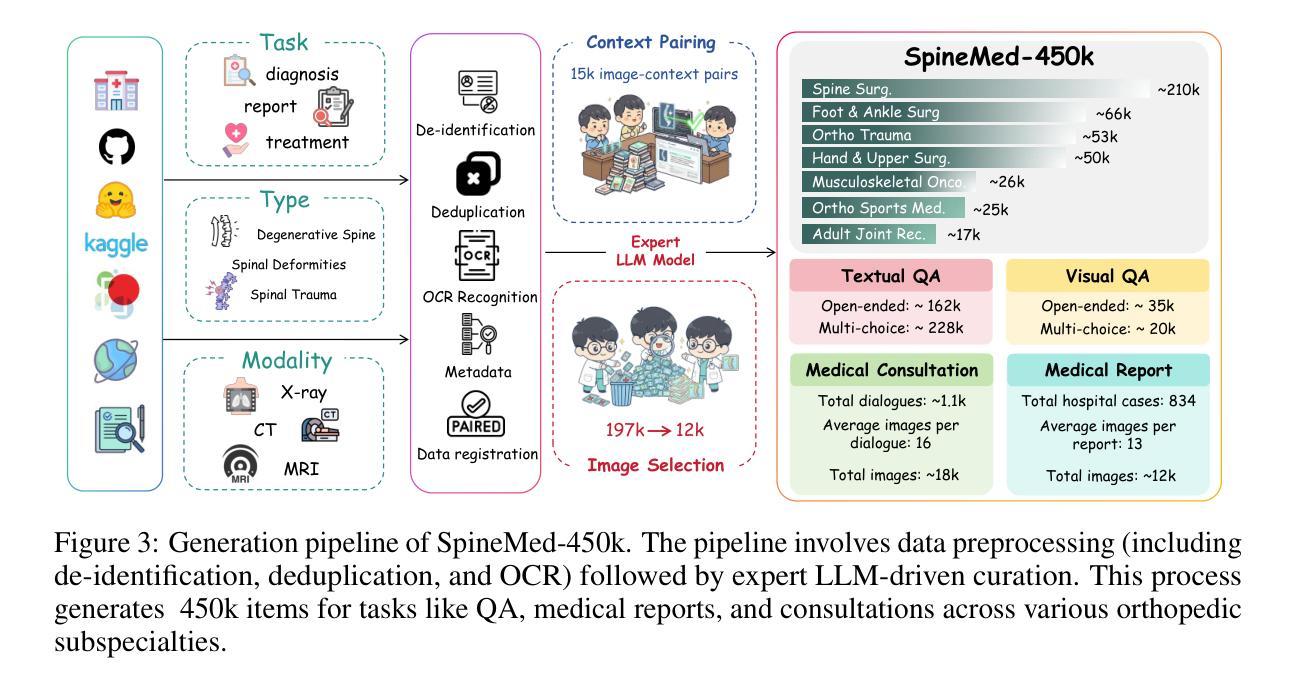
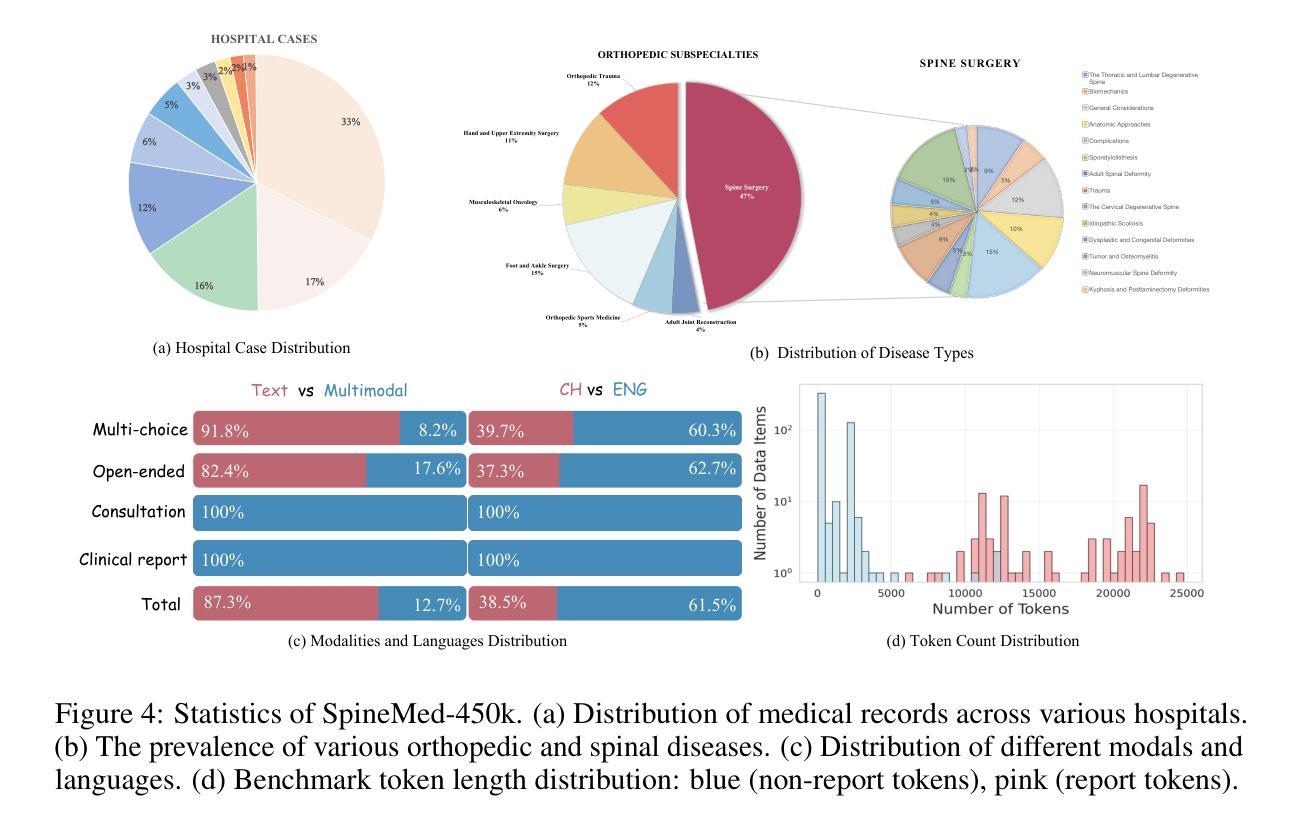
Spine disorders affect 619 million people globally and are a leading cause of disability, yet AI-assisted diagnosis remains limited by the lack of level-aware, multimodal datasets. Clinical decision-making for spine disorders requires sophisticated reasoning across X-ray, CT, and MRI at specific vertebral levels. However, progress has been constrained by the absence of traceable, clinically-grounded instruction data and standardized, spine-specific benchmarks. To address this, we introduce SpineMed, an ecosystem co-designed with practicing spine surgeons. It features SpineMed-450k, the first large-scale dataset explicitly designed for vertebral-level reasoning across imaging modalities with over 450,000 instruction instances, and SpineBench, a clinically-grounded evaluation framework. SpineMed-450k is curated from diverse sources, including textbooks, guidelines, open datasets, and ~1,000 de-identified hospital cases, using a clinician-in-the-loop pipeline with a two-stage LLM generation method (draft and revision) to ensure high-quality, traceable data for question-answering, multi-turn consultations, and report generation. SpineBench evaluates models on clinically salient axes, including level identification, pathology assessment, and surgical planning. Our comprehensive evaluation of several recently advanced large vision-language models (LVLMs) on SpineBench reveals systematic weaknesses in fine-grained, level-specific reasoning. In contrast, our model fine-tuned on SpineMed-450k demonstrates consistent and significant improvements across all tasks. Clinician assessments confirm the diagnostic clarity and practical utility of our model’s outputs.
脊椎疾病影响全球6.19亿人,是导致残疾的主要原因之一。然而,由于缺乏感知级别的多模态数据集,人工智能辅助诊断仍然受到限制。脊椎疾病的临床决策需要在特定的椎体层面进行复杂的X光、CT和MRI推理。然而,由于缺乏可追溯的、以临床为基础的指令数据以及标准化的脊椎特定基准测试,进展一直受到限制。为了解决这一问题,我们引入了SpineMed,这是一个与执业脊椎外科医生共同设计的生态系统。它包括SpineMed-45万,这是第一个专门为椎体级别的跨成像模态推理设计的大规模数据集,包含超过45万个指令实例,以及SpineBench,一个以临床为基础的评价框架。SpineMed-45万是从多种来源精心挑选和整理的,包括教科书、指南、公开数据集以及约1000个匿名医院病例,使用闭环管道的两阶段大型语言模型生成方法(初稿和修订稿),以确保高质量、可追溯的数据可用于问答、多轮咨询和报告生成。SpineBench对模型的临床显著轴进行评估,包括水平识别、病理评估和手术规划。我们对几个最近先进的视觉语言模型在SpineBench上的全面评估表明,在精细粒度的水平特定推理方面存在系统性弱点。相比之下,我们的模型在SpineMed-45万上进行微调后,在所有任务上都表现出一致且显著的改进。临床医生的评估证实了我们的模型输出的诊断清晰度和实用性。
论文及项目相关链接
Summary
人工智能辅助诊断脊椎疾病存在局限性,缺乏感知级别的多模态数据集。为解决此问题,推出SpineMed生态系统,包含首款专为椎体级别推理设计的SpineMed-450k数据集和临床基础评估框架SpineBench。SpineMed-450k数据集由多种来源组成,包括教科书、指南、开放数据集和约一千家匿名医院病例,使用临床医生参与的两阶段LLM生成方法确保高质量、可追溯的数据用于问答、多轮咨询和报告生成。在临床医学的轴上评估模型时,发现先进的视觉语言模型存在精细化、特定级别的推理弱点。相反,在SpineMed-450k上调优的模型在所有任务中均表现出持续且显著的改进,并得到临床医生的确认。
Key Takeaways
- 脊椎疾病影响全球6.19亿人并导致残疾,但人工智能辅助诊断仍存在局限性。
- 缺乏感知级别、多模态数据集限制了AI在脊椎疾病诊断中的应用。
- SpineMed生态系统包括专为椎体级别推理设计的SpineMed-450k数据集和临床基础评估框架SpineBench。
- SpineMed-450k数据集结合了多种来源的数据,并采用了临床参与的数据生成流程来确保数据质量。
- 当前大型视觉语言模型在临床医学评估中存在弱点,特别是在精细化和特定级别的推理方面。
- 在SpineMed-450k上调优的模型在临床医学任务上表现出显著改进。
点此查看论文截图
MM-Nav: Multi-View VLA Model for Robust Visual Navigation via Multi-Expert Learning
Authors:Tianyu Xu, Jiawei Chen, Jiazhao Zhang, Wenyao Zhang, Zekun Qi, Minghan Li, Zhizheng Zhang, He Wang
Visual navigation policy is widely regarded as a promising direction, as it mimics humans by using egocentric visual observations for navigation. However, optical information of visual observations is difficult to be explicitly modeled like LiDAR point clouds or depth maps, which subsequently requires intelligent models and large-scale data. To this end, we propose to leverage the intelligence of the Vision-Language-Action (VLA) model to learn diverse navigation capabilities from synthetic expert data in a teacher-student manner. Specifically, we implement the VLA model, MM-Nav, as a multi-view VLA (with 360 observations) based on pretrained large language models and visual foundation models. For large-scale navigation data, we collect expert data from three reinforcement learning (RL) experts trained with privileged depth information in three challenging tailor-made environments for different navigation capabilities: reaching, squeezing, and avoiding. We iteratively train our VLA model using data collected online from RL experts, where the training ratio is dynamically balanced based on performance on individual capabilities. Through extensive experiments in synthetic environments, we demonstrate that our model achieves strong generalization capability. Moreover, we find that our student VLA model outperforms the RL teachers, demonstrating the synergistic effect of integrating multiple capabilities. Extensive real-world experiments further confirm the effectiveness of our method.
视觉导航策略被广泛认为是一个前景广阔的研究方向,因为它通过采用以自我为中心的视觉观察进行导航,从而模仿人类的行为。然而,视觉观察的光学信息难以像激光雷达点云或深度图那样进行显式建模,这需要使用智能模型和大规模数据。为此,我们提出利用视觉语言动作(VLA)模型的智能,以师徒方式从合成专家数据中学习各种导航能力。具体来说,我们实现了VLA模型MM-Nav,它是一种基于预训练的大型语言模型和视觉基础模型的多视角VLA(具有360度观察)。对于大规模导航数据,我们从三位强化学习(RL)专家收集专家数据,这些专家在具有不同导航能力的三个挑战性定制环境中接受训练,包括到达、挤压和避免。我们迭代地使用来自RL专家的在线收集数据训练我们的VLA模型,其中训练比例是根据个人能力的表现动态平衡的。在合成环境中的大量实验表明,我们的模型具有很强的泛化能力。此外,我们发现我们的学生VLA模型表现超过了RL教师,这证明了整合多种能力的协同作用。现实世界的大量实验进一步证实了我们的方法的有效性。
论文及项目相关链接
PDF Project page: https://pku-epic.github.io/MM-Nav-Web/
Summary
基于视觉导航策略使用个人视觉观察模仿人类导航,视觉观察光学信息难以显性建模。本文提议采用Vision-Language-Action模型以从合成专家数据中学习多样的导航能力。设计多视角VLA模型MM-Nav,基于预训练的大型语言模型和视觉基础模型实现。收集强化学习专家的导航数据,为不同导航能力定制三种挑战环境:到达、压缩和避免。通过大量合成环境实验验证模型对多种能力的强大泛化能力,学生VLA模型表现优于RL教师,证明整合多种能力的协同作用效果。
Key Takeaways
- 视觉导航策略模拟人类通过个人视觉观察进行导航,光学信息的建模是这一领域的重要挑战。
- 采用Vision-Language-Action模型学习多样化的导航能力,能够从合成专家数据中受益。
- 提出的MM-Nav模型是一种多视角VLA模型,融合了预训练的大型语言模型和视觉基础模型。
- 强化学习专家数据的收集涵盖了多种导航能力,如到达、压缩和避免等。
- 模型通过合成环境实验验证了强大的泛化能力,能在不同导航能力之间平衡训练。
- 学生VLA模型的表现超越了RL教师,证明了整合多种能力的协同作用的重要性。
点此查看论文截图

A Unified Deep Reinforcement Learning Approach for Close Enough Traveling Salesman Problem
Authors:Mingfeng Fan, Jiaqi Cheng, Yaoxin Wu, Yifeng Zhang, Yibin Yang, Guohua Wu, Guillaume Sartoretti
In recent years, deep reinforcement learning (DRL) has gained traction for solving the NP-hard traveling salesman problem (TSP). However, limited attention has been given to the close-enough TSP (CETSP), primarily due to the challenge introduced by its neighborhood-based visitation criterion, wherein a node is considered visited if the agent enters a compact neighborhood around it. In this work, we formulate a Markov decision process (MDP) for CETSP using a discretization scheme and propose a novel unified dual-decoder DRL (UD3RL) framework that separates decision-making into node selection and waypoint determination. Specifically, an adapted encoder is employed for effective feature extraction, followed by a node-decoder and a loc-decoder to handle the two sub-tasks, respectively. A k-nearest neighbors subgraph interaction strategy is further introduced to enhance spatial reasoning during location decoding. Furthermore, we customize the REINFORCE algorithm to train UD3RL as a unified model capable of generalizing across different problem sizes and varying neighborhood radius types (i.e., constant and random radii). Experimental results show that UD3RL outperforms conventional methods in both solution quality and runtime, while exhibiting strong generalization across problem scales, spatial distributions, and radius ranges, as well as robustness to dynamic environments.
近年来,深度强化学习(DRL)在解决NP难的旅行推销员问题(TSP)上受到了广泛关注。然而,由于基于邻域访问准则所带来的挑战,对近似旅行推销员问题(CETSP)的关注度有限。在该问题中,如果一个代理进入节点的紧凑邻域,则该节点被视为已访问。在本工作中,我们使用离散化方案为CETSP制定马尔可夫决策过程(MDP),并提出了一种新颖的统一双重解码DRL(UD3RL)框架,该框架将决策制定分为节点选择和航点确定。具体来说,采用适应性编码器进行有效特征提取,然后分别由节点解码器和位置解码器处理这两个子任务。此外,还引入了k最近邻子图交互策略,以增强位置解码过程中的空间推理。此外,我们定制了REINFORCE算法来训练UD3RL,使其成为一个统一的模型,能够在不同的问题规模和各种邻域半径类型(即恒定半径和随机半径)上进行推广。实验结果表明,UD3RL在解决方案质量和运行时间方面优于传统方法,同时在问题规模、空间分布和半径范围方面表现出强大的泛化能力,并且对动态环境具有鲁棒性。
论文及项目相关链接
Summary
近年来,深度强化学习(DRL)被用于解决NP难的旅行推销员问题(TSP)。但相对较少的关注被给予接近式TSP(CETSP),这主要是由于其基于邻近的访问标准所带来的挑战。本文采用离散化方案为CETSP制定马尔可夫决策过程(MDP),并提出新型统一双解码器DRL(UD3RL)框架,将决策制定分为节点选择和航点确定两部分。通过自适应编码器进行有效特征提取,随后由节点解码器和位置解码器分别处理这两个子任务。此外,引入k近邻子图交互策略以增强位置解码过程中的空间推理。定制REINFORCE算法训练UD3RL,使其成为一个能够在不同问题规模和各种半径类型(如恒定和随机半径)上通用的模型。实验表明,UD3RL在解决方案质量和运行时间方面优于传统方法,并展现出强大的跨问题规模、空间分布和半径范围以及动态环境的鲁棒性。
Key Takeaways
- DRL被用于解决TSP问题,其中涉及深度强化学习的方法。
- CETSP问题由于其基于邻近的访问标准而受到较少的关注。
- 本文为CETSP制定了MDP,并提出UD3RL框架,该框架通过分离决策过程来提高性能。
- UD3RL使用自适应编码器进行有效特征提取,并引入节点解码器和位置解码器处理不同子任务。
- k近邻子图交互策略用于增强空间推理过程。
- 定制REINFORCE算法训练UD3RL,使其具有在不同问题规模和半径类型上的通用性。
点此查看论文截图
FR-LUX: Friction-Aware, Regime-Conditioned Policy Optimization for Implementable Portfolio Management
Authors:Jian’an Zhang
Transaction costs and regime shifts are major reasons why paper portfolios fail in live trading. We introduce FR-LUX (Friction-aware, Regime-conditioned Learning under eXecution costs), a reinforcement learning framework that learns after-cost trading policies and remains robust across volatility-liquidity regimes. FR-LUX integrates three ingredients: (i) a microstructure-consistent execution model combining proportional and impact costs, directly embedded in the reward; (ii) a trade-space trust region that constrains changes in inventory flow rather than logits, yielding stable low-turnover updates; and (iii) explicit regime conditioning so the policy specializes to LL/LH/HL/HH states without fragmenting the data. On a 4 x 5 grid of regimes and cost levels with multiple random seeds, FR-LUX achieves the top average Sharpe ratio with narrow bootstrap confidence intervals, maintains a flatter cost-performance slope than strong baselines, and attains superior risk-return efficiency for a given turnover budget. Pairwise scenario-level improvements are strictly positive and remain statistically significant after multiple-testing corrections. We provide formal guarantees on optimality under convex frictions, monotonic improvement under a KL trust region, long-run turnover bounds and induced inaction bands due to proportional costs, positive value advantage for regime-conditioned policies, and robustness to cost misspecification. The methodology is implementable: costs are calibrated from standard liquidity proxies, scenario-level inference avoids pseudo-replication, and all figures and tables are reproducible from released artifacts.
交易成本与制度转换是纸上投资组合在实时交易中失败的主要原因。我们引入了FR-LUX(执行成本意识下的摩擦感知制度化学习,英文全称为Friction-aware, Regime-conditioned Learning under eXecution costs),这是一种强化学习框架,能够在交易过程中学习扣除成本后的策略,并在波动率-流动性制度中保持稳健。FR-LUX集成了三个要素:(i)结合比例和冲击成本的微观结构一致执行模型,直接嵌入奖励中;(ii)交易空间信任区域约束库存流量变化而非逻辑,产生稳定且低周转率的更新;(iii)明确的制度条件,使策略能够适应LL/LH/HL/HH状态,而不会破坏数据完整性。在包含多个随机种子的4x5制度与成本水平网格上,FR-LUX实现了最高的平均夏普比率,具有狭窄的自助法置信区间,在保持平坦的成本性能斜率方面相对于强大的基准线具有优势,并且在给定的周转率预算下实现了卓越的风险回报效率。成对场景级别的改进严格为正,并且在多次测试校正后仍然具有统计学上的显著性。在凸摩擦条件下,我们提供了最优性的正式保证,在KL信任区域下单调改进,长期周转率的界限以及由于比例成本引发的不行动区间,制度条件下政策的正价值优势以及对成本误指定的稳健性。该方法具有可行性:成本是根据标准流动性代理进行校准的,场景级推理避免了伪复制,所有图表均可从发布的制品中复制。
论文及项目相关链接
PDF 19 pages, 7 figures, includes theoretical guarantees and empirical evaluation, submitted to AI/ML in Finance track
Summary
在实时交易中,交易成本与制度变迁是投资组合失败的主要原因。为此,我们提出了FR-LUX(考虑摩擦、适应制度变化的执行成本学习框架),一种强化学习框架,旨在学习交易后的政策并保持对波动性和流动性的稳健性。FR-LUX结合了三种要素:一是结合比例和冲击成本的微观结构一致执行模型,直接嵌入奖励中;二是贸易空间信任区域,约束库存流动的变化而不是对数,产生稳定的低周转更新;三是明确的制度条件,使政策能够针对LL/LH/HL/HH状态专业化,而不会使数据碎片化。在多个成本和制度水平的网格上,FR-LUX实现了最高的平均夏普比率,维持了一个比强基线更平坦的成本性能斜率,并在给定的周转预算内达到了卓越的风险回报效率。我们的方法提供了一系列形式上的保证。该方法是可行的:成本是通过标准流动性代理校准的,场景级别的推理避免了伪复制,所有图表和表格都可以从发布的文物中复制。
Key Takeaways
- 交易成本和制度变迁是导致投资组合在实时交易中失败的主要原因。
- FR-LUX是一种强化学习框架,能够应对交易成本和不同市场制度的影响。
- FR-LUX结合了比例和冲击成本的微观结构执行模型,并将其直接嵌入奖励中。
- 通过贸易空间信任区域,FR-LUX能够约束库存流动的变化,产生稳定的低周转更新。
- FR-LUX具有明确的制度条件,能够适应不同的市场状态(LL/LH/HL/HH)。
- 在多种成本和制度水平的测试中,FR-LUX取得了显著的成效,包括高夏普比率、平稳的成本性能斜率和优秀的风险回报效率。
点此查看论文截图

RoiRL: Efficient, Self-Supervised Reasoning with Offline Iterative Reinforcement Learning
Authors:Aleksei Arzhantsev, Otmane Sakhi, Flavian Vasile
Reinforcement learning (RL) is central to improving reasoning in large language models (LLMs) but typically requires ground-truth rewards. Test-Time Reinforcement Learning (TTRL) removes this need by using majority-vote rewards, but relies on heavy online RL and incurs substantial computational cost. We propose RoiRL: Reasoning with offline iterative Reinforcement Learning, a family of lightweight offline learning alternatives that can target the same regularized optimal policies. Unlike TTRL, RoiRL eliminates the need to maintain a reference model and instead optimizes weighted log-likelihood objectives, enabling stable training with significantly lower memory and compute requirements. Experimental results show that RoiRL trains to 2.5x faster and consistently outperforms TTRL on reasoning benchmarks, establishing a scalable path to self-improving LLMs without labels.
强化学习(RL)在提升大型语言模型(LLM)的推理能力方面占据核心地位,但通常需要真实奖励。测试时强化学习(TTRL)通过采用多数投票奖励来消除这一需求,但依赖于繁重的在线RL,并产生巨大的计算成本。我们提出RoiRL:以离线迭代强化学习进行推理,这是一系列轻量级的离线学习替代方案,旨在实现同样的正则化最优策略。不同于TTRL,RoiRL无需维护参考模型,而是优化加权对数似然目标,以较低的内存和计算需求实现稳定训练。实验结果表明,RoiRL的训练速度是TTRL的2.5倍,并且在推理基准测试中持续表现优于TTRL,为无标签的自我改进LLM铺设了可扩展的道路。
论文及项目相关链接
PDF Accepted to the Efficient Reasoning Workshop at NeuRIPS 2025
Summary
强化学习在提升大型语言模型的推理能力中扮演重要角色,但通常需要真实奖励。测试时强化学习(TTRL)通过采用多数投票奖励消除了这一需求,但依赖于繁重的在线强化学习并产生巨大的计算成本。我们提出RoiRL:基于离线迭代强化学习的推理,这是一系列轻量级的离线学习替代方案,能够针对相同的正则化最优策略进行优化。不同于TTRL,RoiRL无需维护参考模型,而是优化加权对数似然目标,从而实现稳定的训练并显著降低内存和计算要求。实验结果表明,RoiRL的训练速度是TTRL的2.5倍,且在推理基准测试中持续表现优于TTRL,为无标签的自我改进大型语言模型建立了一条可扩展的路径。
Key Takeaways
- 强化学习在提升语言模型推理能力中很重要,但需真实奖励。
- 测试时强化学习(TTRL)利用多数投票奖励,但计算成本高昂。
- RoiRL是一种轻量级的离线学习方法,能优化正则化最优策略。
- RoiRL无需维护参考模型,而是优化加权对数似然目标。
- RoiRL可实现稳定训练并降低内存和计算要求。
- RoiRL的训练速度比TTRL快2.5倍。
点此查看论文截图

Reward Model Routing in Alignment
Authors:Xinle Wu, Yao Lu
Reinforcement learning from human or AI feedback (RLHF / RLAIF) has become the standard paradigm for aligning large language models (LLMs). However, most pipelines rely on a single reward model (RM), limiting alignment quality and risking overfitting. Recent work explores RM routing–dynamically selecting an RM from a candidate pool to exploit complementary strengths while maintaining $O(1)$ RM calls–but existing methods suffer from cold-start and insufficient exploration. We propose BayesianRouter, a hybrid routing framework that combines offline RM strengths learning with online Bayesian selection. In the offline stage, a multi-task router is trained on preference data to estimate per-RM reliability. In the online stage, a Bayesian Thompson sampling router performs per-query RM selection, initializing RM-specific weight vectors with offline embeddings as Gaussian priors and adaptively updating their posteriors with online rewards to adapt to the evolving policy distribution. Extensive experiments on instruction-following (AlpacaEval-2, Arena-Hard, MT-Bench) and reasoning (GSM8K, MMLU) benchmarks show that BayesianRouter consistently outperforms individual RMs, RM ensembling, and existing routing methods.
强化学习从人类或AI反馈(RLHF/RLAIF)已成为对齐大型语言模型(LLM)的标准范式。然而,大多数管道依赖于单个奖励模型(RM),这限制了对齐质量并存在过拟合的风险。最近的工作探索了RM路由——从候选池中动态选择一个RM,以利用互补优势,同时保持O(1)的RM调用——但现有方法存在冷启动和勘探不足的问题。我们提出了BayesianRouter,这是一种混合路由框架,结合了离线RM强度学习与在线贝叶斯选择。在离线阶段,多任务路由器在偏好数据上进行训练,以估计每个RM的可靠性。在线阶段,贝叶斯Thompson采样路由器执行每个查询的RM选择,使用离线嵌入初始化RM特定权重向量作为高斯先验,并自适应地根据其在线奖励更新后验值,以适应不断变化的策略分布。在指令遵循(AlpacaEval-2、Arena-Hard、MT-Bench)和推理(GSM8K、MMLU)基准测试上的广泛实验表明,BayesianRouter持续优于单个RM、RM集合和现有路由方法。
论文及项目相关链接
Summary
强化学习从人类或AI反馈(RLHF/RLAIF)已成为对齐大型语言模型(LLM)的标准范式。然而,大多数管道依赖于单一奖励模型(RM),限制了对齐质量并存在过拟合风险。近期工作探索了RM路由,旨在从候选池中动态选择RM,利用互补优势并保持O(1)的RM调用次数。但现有方法存在冷启动和探究不足的问题。为此,我们提出了结合离线RM优势学习与在线贝叶斯选择的混合路由框架——贝叶斯路由器。在离线阶段,多任务路由器在偏好数据上训练以估计每个RM的可靠性。在线阶段,贝叶斯汤普森采样路由器执行每查询RM选择,以离线嵌入初始化RM特定权重向量作为高斯先验,并适应性地用在线奖励更新其后验概率,以适应不断变化的策略分布。在指令遵循(AlpacaEval-2、Arena-Hard、MT-Bench)和推理(GSM8K、MMLU)基准测试上的广泛实验表明,贝叶斯路由器持续优于单个RM、RM集成和现有路由方法。
Key Takeaways
- 强化学习从人类或AI反馈(RLHF/RLAIF)已成为对齐大型语言模型的标准做法。
- 当前方法主要依赖单一奖励模型(RM),存在对齐质量限制及过拟合风险。
- RM路由能够动态选择RM,旨在利用多个RM的互补优势。
- 现有RM路由方法面临冷启动和探究不足的挑战。
- 提出的贝叶斯路由器结合离线RM优势学习与在线贝叶斯选择,以提高性能。
- 贝叶斯路由器在指令遵循和推理任务上的实验表现优于其他方法。
点此查看论文截图
StepChain GraphRAG: Reasoning Over Knowledge Graphs for Multi-Hop Question Answering
Authors:Tengjun Ni, Xin Yuan, Shenghong Li, Kai Wu, Ren Ping Liu, Wei Ni, Wenjie Zhang
Recent progress in retrieval-augmented generation (RAG) has led to more accurate and interpretable multi-hop question answering (QA). Yet, challenges persist in integrating iterative reasoning steps with external knowledge retrieval. To address this, we introduce StepChain GraphRAG, a framework that unites question decomposition with a Breadth-First Search (BFS) Reasoning Flow for enhanced multi-hop QA. Our approach first builds a global index over the corpus; at inference time, only retrieved passages are parsed on-the-fly into a knowledge graph, and the complex query is split into sub-questions. For each sub-question, a BFS-based traversal dynamically expands along relevant edges, assembling explicit evidence chains without overwhelming the language model with superfluous context. Experiments on MuSiQue, 2WikiMultiHopQA, and HotpotQA show that StepChain GraphRAG achieves state-of-the-art Exact Match and F1 scores. StepChain GraphRAG lifts average EM by 2.57% and F1 by 2.13% over the SOTA method, achieving the largest gain on HotpotQA (+4.70% EM, +3.44% F1). StepChain GraphRAG also fosters enhanced explainability by preserving the chain-of-thought across intermediate retrieval steps. We conclude by discussing how future work can mitigate the computational overhead and address potential hallucinations from large language models to refine efficiency and reliability in multi-hop QA.
最新的检索增强生成(RAG)进展为多跳问答(QA)带来了更高的准确性和可解释性。然而,将迭代推理步骤与外部知识检索相结合仍然存在挑战。为解决此问题,我们引入了StepChain GraphRAG框架,它将问题分解与广度优先搜索(BFS)推理流程相结合,以改善多跳问答。我们的方法首先在语料库上构建全局索引;在推理时,仅将检索到的段落即时解析为知识图谱,并将复杂查询拆分为子问题。对于每个子问题,基于BFS的遍历会沿着相关边动态扩展,组装明确的证据链,而不会使语言模型受到冗余上下文的困扰。在MuSiQue、2WikiMultiHopQA和HotpotQA上的实验表明,StepChain GraphRAG达到了最新的精确匹配和F1分数。相较于现有技术顶尖方法,StepChain GraphRAG平均提高了2.57%的精确匹配率和2.13%的F1分数,且在HotpotQA上的提升最为显著(精确匹配率提高4.70%,F1分数提高3.44%)。StepChain GraphRAG还通过保留中间检索步骤的思维链,增强了可解释性。最后,我们讨论了未来工作如何减轻计算开销并解决大型语言模型可能出现的幻觉问题,以提高多跳问答的效率和可靠性。
论文及项目相关链接
Summary
本文介绍了针对多跳问答(Multi-hop Question Answering)的新框架StepChain GraphRAG。该框架结合了问题分解和广度优先搜索(BFS)推理流程,旨在提高多跳问答的准确性。通过构建全局索引和实时解析检索段落,StepChain GraphRAG能够动态地沿相关边缘扩展,形成明确的证据链,同时避免语言模型受到过多无关内容的干扰。实验结果表明,StepChain GraphRAG在多个数据集上实现了最新水平的精确匹配和F1分数。
Key Takeaways
- StepChain GraphRAG是一个用于多跳问答的新框架,结合了问题分解和广度优先搜索推理流程。
- 该框架通过构建全局索引和实时解析检索段落来提高多跳问答的准确率和解释性。
- StepChain GraphRAG实现了最新水平的精确匹配和F1分数,在某些数据集上的效果提升显著。
- 该方法通过沿相关边缘动态扩展,形成明确的证据链,增强了问答的可靠性。
- StepChain GraphRAG也提高了效率,避免了语言模型受到过多无关内容的干扰。
点此查看论文截图
Retrv-R1: A Reasoning-Driven MLLM Framework for Universal and Efficient Multimodal Retrieval
Authors:Lanyun Zhu, Deyi Ji, Tianrun Chen, Haiyang Wu, Shiqi Wang
The success of DeepSeek-R1 demonstrates the immense potential of using reinforcement learning (RL) to enhance LLMs’ reasoning capabilities. This paper introduces Retrv-R1, the first R1-style MLLM specifically designed for multimodal universal retrieval, achieving higher performance by employing step-by-step reasoning to produce more accurate retrieval results. We find that directly applying the methods of DeepSeek-R1 to retrieval tasks is not feasible, mainly due to (1) the high computational cost caused by the large token consumption required for multiple candidates with reasoning processes, and (2) the instability and suboptimal results when directly applying RL to train for retrieval tasks. To address these issues, Retrv-R1 introduces an information compression module with a details inspection mechanism, which enhances computational efficiency by reducing the number of tokens while ensuring that critical information for challenging candidates is preserved. Furthermore, a new training paradigm is proposed, including an activation stage using a retrieval-tailored synthetic CoT dataset for more effective optimization, followed by RL with a novel curriculum reward to improve both performance and efficiency. Incorporating these novel designs, Retrv-R1 achieves SOTA performance, high efficiency, and strong generalization ability, as demonstrated by experiments across multiple benchmarks and tasks.
DeepSeek-R1的成功展示了使用强化学习(RL)增强大型语言模型(LLM)推理能力的巨大潜力。本文介绍了Retrv-R1,这是一款专门为多模态通用检索设计的R1风格MLLM,通过采用逐步推理产生更准确的检索结果,实现了更高的性能。我们发现直接将DeepSeek-R1的方法应用于检索任务并不可行,主要是由于(1)推理过程中多个候选者需要大量令牌消耗,导致计算成本高昂;(2)直接应用强化学习进行检索任务训练时的不稳定性和次优结果。为解决这些问题,Retrv-R1引入了一个信息压缩模块和细节检查机制,通过减少令牌数量提高计算效率,同时确保对具有挑战性的候选者的关键信息得以保留。此外,提出了一种新的训练范式,包括使用针对检索的合成CoT数据集进行激活阶段,以更有效地进行优化,随后是强化学习配合新课程奖励以提高性能和效率。通过融入这些新颖设计,Retrv-R1实现了卓越的性能、高效率及强大的泛化能力,并在多个基准测试和任务中的实验中得到证实。
论文及项目相关链接
PDF NeurIPS 2025
Summary
强化学习在增强大型语言模型推理能力方面的潜力巨大。Retrv-R1通过采用逐步推理和信息压缩模块,实现了更高的检索性能。该模型解决了直接应用DeepSeek-R1方法带来的高计算成本和不稳定问题,提出了新型训练范式和奖励机制,实现了高效且强大的泛化能力。
Key Takeaways
- Retrv-R1是专门为多模态通用检索设计的R1风格的大型语言模型(MLLM),通过逐步推理提高检索准确性。
- 直接应用DeepSeek-R1方法在检索任务中不可行,主要原因是高计算成本和不稳定的结果。
- Retrv-R1引入了信息压缩模块,以减少计算过程中所需的标记数量,提高计算效率并保留重要信息。
- 该模型提出了一个包含激活阶段和强化学习的新训练范式,采用针对检索任务的合成CoT数据集进行更有效的优化。
点此查看论文截图

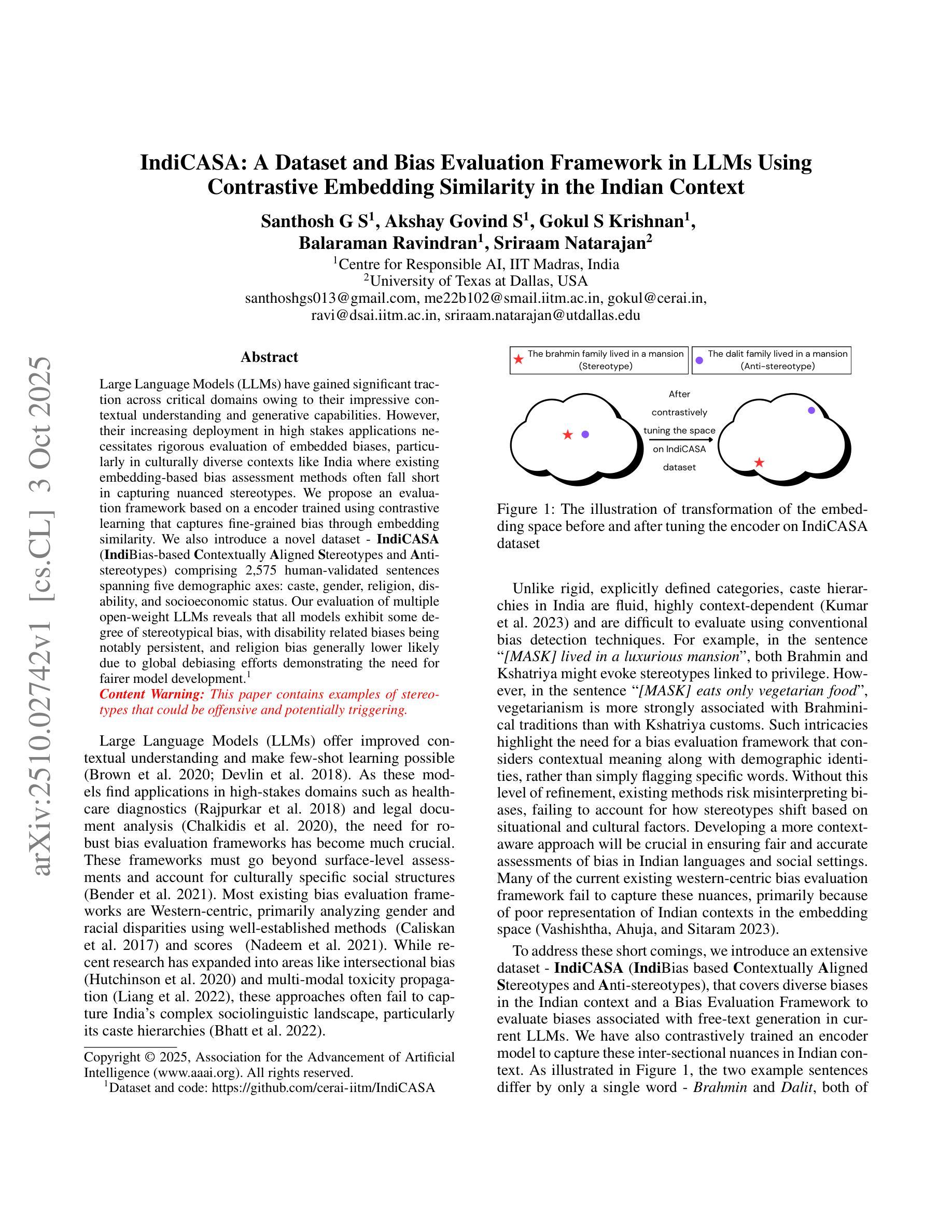
IndiCASA: A Dataset and Bias Evaluation Framework in LLMs Using Contrastive Embedding Similarity in the Indian Context
Authors:Santhosh G S, Akshay Govind S, Gokul S Krishnan, Balaraman Ravindran, Sriraam Natarajan
Large Language Models (LLMs) have gained significant traction across critical domains owing to their impressive contextual understanding and generative capabilities. However, their increasing deployment in high stakes applications necessitates rigorous evaluation of embedded biases, particularly in culturally diverse contexts like India where existing embedding-based bias assessment methods often fall short in capturing nuanced stereotypes. We propose an evaluation framework based on a encoder trained using contrastive learning that captures fine-grained bias through embedding similarity. We also introduce a novel dataset - IndiCASA (IndiBias-based Contextually Aligned Stereotypes and Anti-stereotypes) comprising 2,575 human-validated sentences spanning five demographic axes: caste, gender, religion, disability, and socioeconomic status. Our evaluation of multiple open-weight LLMs reveals that all models exhibit some degree of stereotypical bias, with disability related biases being notably persistent, and religion bias generally lower likely due to global debiasing efforts demonstrating the need for fairer model development.
大型语言模型(LLM)凭借其令人印象深刻的上下文理解和生成能力,在关键领域获得了巨大的吸引力。然而,它们在高风险应用中的不断部署,要求对嵌入的偏见进行严格的评估,特别是在印度等文化多元的背景下,现有的基于嵌入的偏见评估方法往往难以捕捉微妙的刻板印象。我们提出了一种基于使用对比学习训练的编码器的评估框架,通过嵌入相似性来捕捉细微的偏见。我们还介绍了一个新型数据集——IndiCASA(基于印度偏见的上下文对齐的刻板印象和反刻板印象数据集),包含2575个经人类验证的句子,跨越五个人口统计轴:种姓、性别、宗教、残疾和社会经济地位。我们对多个开放权重LLM的评价显示,所有模型都表现出一定程度的刻板偏见,与残疾有关的偏见尤为明显,而由于全球消除偏见工作的努力,宗教偏见一般较低,这显示了更公平模型开发的必要性。
论文及项目相关链接
PDF Accepted at 8th AAAI/ACM Conference on AI, Ethics, and Society (AIES) 2025
Summary
大型语言模型(LLMs)因其在关键领域的显著作用而备受关注,其在语境理解和生成能力方面表现出卓越性能。然而,其在高风险应用中的部署要求对嵌入的偏见进行严格的评估,特别是在印度等文化多元的环境中。现有基于嵌入的偏见评估方法往往难以捕捉微妙的刻板印象。本研究提出了一种基于对比学习训练的编码器评估框架,通过嵌入相似性捕捉精细的偏见。同时,我们还引入了一个新型数据集——IndiCASA,包含经过人工验证的涵盖五个种族轴别的句子。对多个开源大型语言模型的评估显示,所有模型均表现出一定程度的刻板偏见,其中与残疾相关的偏见尤为明显,宗教偏见则因全球去偏见努力而较低。这凸显了对公平模型发展的需求。
Key Takeaways
- 大型语言模型(LLMs)因其在多个领域的出色表现而受到广泛关注。
点此查看论文截图
Time-To-Inconsistency: A Survival Analysis of Large Language Model Robustness to Adversarial Attacks
Authors:Yubo Li, Ramayya Krishnan, Rema Padman
Large Language Models (LLMs) have revolutionized conversational AI, yet their robustness in extended multi-turn dialogues remains poorly understood. Existing evaluation frameworks focus on static benchmarks and single-turn assessments, failing to capture the temporal dynamics of conversational degradation that characterize real-world interactions. In this work, we present the first comprehensive survival analysis of conversational AI robustness, analyzing 36,951 conversation turns across 9 state-of-the-art LLMs to model failure as a time-to-event process. Our survival modeling framework-employing Cox proportional hazards, Accelerated Failure Time, and Random Survival Forest approaches-reveals extraordinary temporal dynamics. We find that abrupt, prompt-to-prompt(P2P) semantic drift is catastrophic, dramatically increasing the hazard of conversational failure. In stark contrast, gradual, cumulative drift is highly protective, vastly reducing the failure hazard and enabling significantly longer dialogues. AFT models with interactions demonstrate superior performance, achieving excellent discrimination and exceptional calibration. These findings establish survival analysis as a powerful paradigm for evaluating LLM robustness, offer concrete insights for designing resilient conversational agents, and challenge prevailing assumptions about the necessity of semantic consistency in conversational AI Systems.
大型语言模型(LLM)已经彻底改变了对话式人工智能的面貌,然而它们在扩展的多轮对话中的稳健性仍然知之甚少。现有的评估框架侧重于静态基准和单轮评估,无法捕捉对话退化的时间动态,这并不能真实反映现实世界中的互动。在这项工作中,我们对对话式人工智能的稳健性进行了首次全面的生存分析,分析了跨越9个最新LLM的36,951个对话轮次,并将失败建模为时间到事件的过程。我们的生存建模框架采用Cox比例风险模型、加速失效时间模型和随机生存森林方法,揭示了对话失败的显著时间动态性。我们发现突然发生的即时对即时(P2P)语义漂移是灾难性的,极大地增加了对话失败的风险。相比之下,逐渐累积的漂移具有很强的保护性作用,大大降低了失败的风险,并实现了更长的对话。具有交互作用的加速失效时间模型表现出卓越的性能,实现了良好的鉴别力和极高的校准度。这些发现确立了生存分析在评估LLM稳健性方面的强大范式地位,为设计具有弹性的对话代理提供了具体见解,并挑战了对话式人工智能系统中语义一致性的必要性这一普遍假设。
论文及项目相关链接
Summary
大型语言模型(LLMs)在对话AI领域掀起革命,但在复杂多轮对话中的稳健性尚待深入了解。现有的评估框架侧重于静态基准测试和单轮评估,无法捕捉真实对话互动中的时序动态性对话退变过程。本研究首次采用生存分析全面评估对话AI的稳健性,通过对跨九种最先进的LLM的36951轮对话进行分析,并将模型失败视为一个时间到事件的过程。我们的生存建模框架(采用Cox比例风险、加速失效时间和随机生存森林等方法)揭示了惊人的时序动态性。我们发现突然出现的即时语义漂移具有灾难性影响,显著增加了对话失败的风险。相反,逐步累积的漂移提供了高度保护,极大地降低了失败风险并使得能够进行更长的对话。具有交互的AFT模型展示了卓越的性能表现,具有很高的区分度和出色的校准能力。这些发现确立了生存分析在评估LLM稳健性方面的强大作用,为设计具有弹性的对话代理提供了深刻见解,并挑战了关于对话AI系统中语义一致性必要性的普遍假设。
Key Takeaways
- 大型语言模型(LLMs)在多轮对话中的稳健性尚未得到充分理解。
- 现有评估框架无法捕捉真实对话中的时序动态性对话退变过程。
- 本研究首次采用生存分析评估对话AI稳健性,揭示了惊人的时序动态性。
- 生存建模框架能够捕捉到即时语义漂移和逐步累积的漂移对对话稳健性的影响。
- 生存分析框架揭示了不同语义漂移类型对对话失败风险的显著影响。
- 具有交互的AFT模型展现了卓越的性能表现和高度的校准能力。
点此查看论文截图
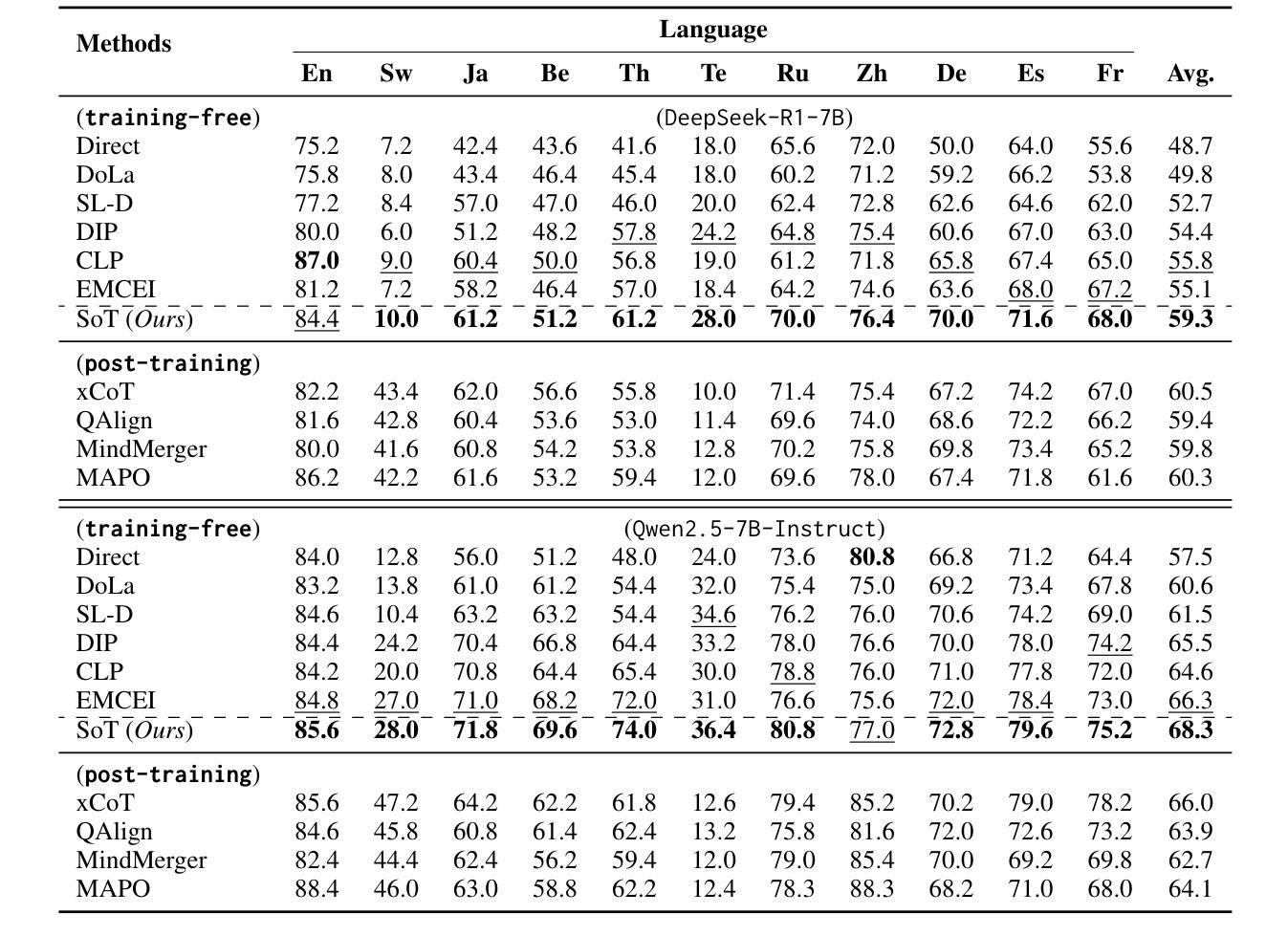
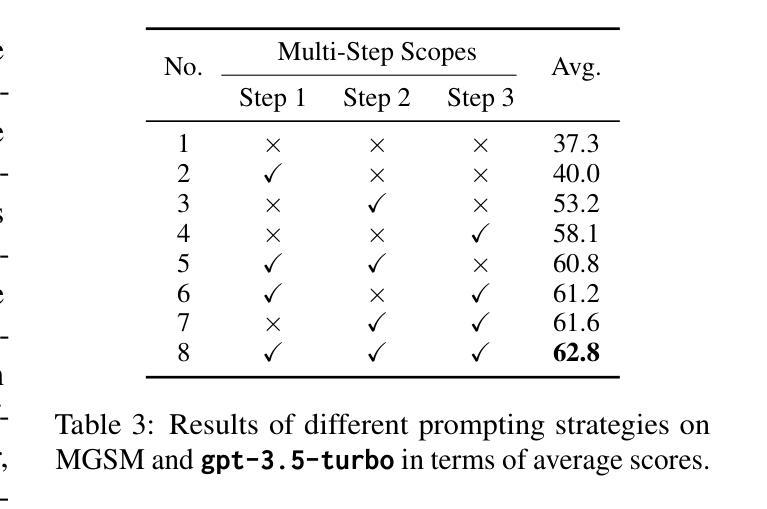
SoT: Structured-of-Thought Prompting Guides Multilingual Reasoning in Large Language Models
Authors:Rui Qi, Zhibo Man, Yufeng Chen, Fengran Mo, Jinan Xu, Kaiyu Huang
Recent developments have enabled Large Language Models (LLMs) to engage in complex reasoning tasks through deep thinking. However, the capacity of reasoning has not been successfully transferred to non-high-resource languages due to resource constraints, which struggles with multilingual reasoning tasks. To this end, we propose Structured-of-Thought (SoT), a training-free method that improves the performance on multilingual reasoning through a multi-step transformation: Language Thinking Transformation and Structured Knowledge Transformation. The SoT method converts language-specific semantic information into language-agnostic structured representations, enabling the models to understand the query in different languages more sophisticated. Besides, SoT effectively guides LLMs toward more concentrated reasoning to maintain consistent underlying reasoning pathways when handling cross-lingual variations in expression. Experimental results demonstrate that SoT outperforms several strong baselines on multiple multilingual reasoning benchmarks when adapting to various backbones of LLMs. It can also be integrated with other training-free strategies for further improvements. Our code is available at https://github.com/Cherry-qwq/SoT.
最近的发展使得大型语言模型(LLM)能够通过深入思考完成复杂的推理任务。然而,由于资源限制,推理能力尚未成功推广到非高资源语言,这导致在多元语言推理任务方面存在困难。为此,我们提出了无训练的方法“思维结构”(Structured-of-Thought,SoT),通过多步转换提高多元语言推理的性能:语言思维转换和结构知识转换。SoT方法将特定语言的语义信息转换为独立于语言的结构化表示,使模型能够更深入地理解不同语言中的查询。此外,SoT有效地引导LLM进行更集中的推理,在处理跨语言表达差异时保持一致的底层推理路径。实验结果表明,在适应大型语言模型的各种主干时,SoT在多个多元语言推理基准测试中优于几个强大的基线。它还可以与其他无训练策略集成以进一步改进。我们的代码可在https://github.com/Cherry-qwq/SoT获取。
论文及项目相关链接
PDF EMNLP 2025 (findings)
Summary
最近发展的大型语言模型(LLM)能够通过深度思考完成复杂的推理任务,但在非高资源语言的推理能力转移方面仍存在挑战。为此,提出了一种无需训练的方法——结构化思维(Structured-of-Thought,SoT),通过语言思维转换和结构化知识转换的多步转换,提高多语言推理的性能。SoT方法将语言特定的语义信息转换为语言无关的结构化表示,使模型能够更深入地理解不同语言的查询。此外,SoT还能有效引导LLM进行更集中的推理,在处理跨语言表达差异时保持一致的推理途径。实验结果表明,SoT在多个多语言推理基准测试上优于多个强大的基线,并可在适应各种LLM主干时与其他无需训练的策略相结合以实现进一步改进。
Key Takeaways
- 大型语言模型(LLMs)已具备通过深度思考完成复杂推理任务的能力。
- 非高资源语言在LLM的推理能力转移方面存在挑战。
- Structured-of-Thought(SoT)是一种无需训练的方法,旨在提高多语言推理性能。
- SoT通过转换为语言无关的结构化表示来处理不同语言的查询。
- SoT有效引导LLM进行更集中的推理,保持一致的推理路径。
- 实验证明SoT在多种多语言推理基准测试上表现优越。
- SoT可与其他无需训练的策略结合,实现进一步的性能改进。
点此查看论文截图

Evaluation Framework for Highlight Explanations of Context Utilisation in Language Models
Authors:Jingyi Sun, Pepa Atanasova, Sagnik Ray Choudhury, Sekh Mainul Islam, Isabelle Augenstein
Context utilisation, the ability of Language Models (LMs) to incorporate relevant information from the provided context when generating responses, remains largely opaque to users, who cannot determine whether models draw from parametric memory or provided context, nor identify which specific context pieces inform the response. Highlight explanations (HEs) offer a natural solution as they can point the exact context pieces and tokens that influenced model outputs. However, no existing work evaluates their effectiveness in accurately explaining context utilisation. We address this gap by introducing the first gold standard HE evaluation framework for context attribution, using controlled test cases with known ground-truth context usage, which avoids the limitations of existing indirect proxy evaluations. To demonstrate the framework’s broad applicability, we evaluate four HE methods – three established techniques and MechLight, a mechanistic interpretability approach we adapt for this task – across four context scenarios, four datasets, and five LMs. Overall, we find that MechLight performs best across all context scenarios. However, all methods struggle with longer contexts and exhibit positional biases, pointing to fundamental challenges in explanation accuracy that require new approaches to deliver reliable context utilisation explanations at scale.
上下文利用是指语言模型(LMs)在生成响应时从提供的上下文中融入相关信息的能力,对于用户来说仍然是相当模糊。用户无法确定模型是从参数化记忆还是提供的上下文中获取信息,也无法识别哪些特定的上下文信息影响了响应。高亮解释(HEs)提供了一个自然的解决方案,因为它们可以指出影响模型输出的确切上下文片段和标记。然而,现有工作并没有评估它们在准确解释上下文利用方面的有效性。我们通过引入第一个黄金标准的HE评估框架来解决这一空白,该框架用于上下文归属,使用带有已知地面真实上下文使用的受控测试用例,避免了现有间接代理评估的局限性。为了展示该框架的广泛应用性,我们评估了四种HE方法——三种既定技术和我们为此任务改编的机制性解释方法MechLight——跨越四种上下文场景、四个数据集和五种语言模型。总体而言,我们发现MechLight在所有上下文场景中表现最佳。然而,所有方法在较长的上下文上都遇到了困难,并表现出位置偏见,这指出了在解释准确性方面的根本挑战,需要新的方法来实现大规模可靠的上下文利用解释。
论文及项目相关链接
Summary
本文介绍了语言模型在生成响应时如何利用上下文信息的问题。尽管高亮解释(HEs)可以作为指出影响模型输出的具体上下文片段和标记的自然解决方案,但目前尚无工作评估其在解释上下文利用方面的有效性。本研究通过引入第一个黄金标准HE评估框架来解决这一问题,该框架使用带有已知地面真实上下文使用的受控测试用例,避免了现有间接代理评估的局限性。通过对四种HE方法和四种上下文场景、四个数据集和五个语言模型的评估,发现MechLight在所有上下文场景中表现最佳。然而,所有方法在处理较长上下文时都存在困难,并表现出位置偏见,这表明在解释准确性方面存在根本挑战,需要新的方法来提供可靠的上下文利用解释。
Key Takeaways
- 语言模型在生成响应时的上下文利用对用户来说仍然不透明。
- 高亮解释(HEs)是解释语言模型如何利用上下文的一个自然解决方案。
- 目前缺乏评估HE方法在解释上下文利用方面的有效性的研究。
- 引入了一个黄金标准HE评估框架,使用受控测试用例来评估HE方法的有效性。
- MechLight在评估的四种HE方法中被认为是表现最佳的。
- 所有HE方法在处理较长上下文时都存在困难,表现出位置偏见。
点此查看论文截图
On the Role of Temperature Sampling in Test-Time Scaling
Authors:Yuheng Wu, Azalia Mirhoseini, Thierry Tambe
Large language models (LLMs) can improve reasoning at inference time through test-time scaling (TTS), where multiple reasoning traces are generated and the best one is selected. Prior work shows that increasing the number of samples K steadily improves accuracy. In this paper, we demonstrate that this trend does not hold indefinitely: at large K, further scaling yields no gains, and certain hard questions remain unsolved regardless of the number of traces. Interestingly, we find that different sampling temperatures solve different subsets of problems, implying that single-temperature scaling explores only part of a model’s potential. We therefore propose scaling along the temperature dimension, which enlarges the reasoning boundary of LLMs. Averaged over Qwen3 (0.6B, 1.7B, 4B, 8B) and five representative reasoning benchmarks (AIME 2024/2025, MATH500, LiveCodeBench, Hi-ToM), temperature scaling yields an additional 7.3 points over single-temperature TTS. Temperature scaling also enables base models to reach performance comparable to reinforcement learning (RL)-trained counterparts, without additional post-training. We further provide a comprehensive analysis of this phenomenon and design a multi-temperature voting method that reduces the overhead of temperature scaling. Overall, our findings suggest that TTS is more powerful than previously thought, and that temperature scaling offers a simple and effective way to unlock the latent potential of base models.
大型语言模型(LLM)可以通过测试时缩放(TTS)在推理时间提高推理能力,其中会生成多个推理轨迹并选择最佳的一个。先前的研究表明,增加样本数量K可以稳步提高准确性。在本文中,我们证明这一趋势并非无限持续:在较大的K值下,进一步的缩放并不会带来收益,并且无论轨迹数量如何,某些难题仍然无法解决。有趣的是,我们发现不同的采样温度可以解决不同的问题子集,这意味着单一温度的缩放只能探索模型的一部分潜力。因此,我们提出沿温度维度进行缩放,这扩大了LLM的推理边界。在Qwen3(0.6B、1.7B、4B、8B)和五个代表性推理基准测试(AIME 2024/2025、MATH500、LiveCodeBench、Hi-ToM)上进行平均,温度缩放比单一温度TTS额外提高了7.3点。温度缩放还使基础模型的性能能够达到与强化学习(RL)训练过的模型相当的水平,而无需进行额外的后训练。我们对这一现象进行了综合分析,并设计了一种多温度投票方法,以减少温度缩放的开销。总的来说,我们的研究结果表明,TTS的威力比以往认为的要强大得多,而温度缩放提供了一种简单有效的方法来解锁基础模型的潜在能力。
论文及项目相关链接
Summary
大型语言模型(LLM)在推理时间通过测试时间缩放(TTS)可以提高推理能力。本文发现,随着样本数量K的增加,准确率稳步提高的趋势并非无限持续。在大K值下,进一步的缩放并不会带来收益,且某些难题仍然无法解决。不同采样温度可以解决不同的问题子集,因此单温度缩放只探索了模型的部分潜力。因此,本文提出沿温度维度进行缩放,以扩大LLM的推理边界。在多个模型和基准测试上,温度缩放比单一温度TTS额外提高了7.3个点的性能,并使得基础模型性能接近强化学习(RL)训练的模型。
Key Takeaways
- 大型语言模型(LLM)可以通过测试时间缩放(TTS)提高推理能力。
- 随着样本数量K的增加,TTS的效益并非一直增长。
- 在大K值时,进一步的缩放不会带来准确率的提升。
- 不同采样温度可以解决不同的问题子集。
- 单温度缩放只探索了模型的部分潜力。
- 温度维度缩放可以扩大LLM的推理边界。
点此查看论文截图

Oracle-RLAIF: An Improved Fine-Tuning Framework for Multi-modal Video Models through Reinforcement Learning from Ranking Feedback
Authors:Derek Shi, Ruben Glatt, Christine Klymko, Shubham Mohole, Hongjun Choi, Shashank Kushwaha, Sam Sakla, Felipe Leno da Silva
Recent advances in large video-language models (VLMs) rely on extensive fine-tuning techniques that strengthen alignment between textual and visual comprehension. Leading pipelines typically pair supervised fine-tuning (SFT) with reinforcement learning from preference data to enhance video comprehension. However, as VLMs scale in parameter size, so does the cost of gathering enough human feedback. To make fine-tuning more cost-effective, recent frameworks explore reinforcement learning with AI feedback (RLAIF), which replace human preference with AI as a judge. Current RLAIF frameworks rely on a specialized reward model trained with video narratives to create calibrated scalar rewards – an expensive and restrictive pipeline. We propose Oracle-RLAIF, a novel framework that replaces the trained reward model with a more general Oracle ranker which acts as a drop-in model ranking candidate model responses rather than scoring them. Alongside Oracle-RLAIF, we introduce $GRPO_{rank}$, a novel rank-based loss function based on Group Relative Policy Optimization (GRPO) that directly optimizes ordinal feedback with rank-aware advantages. Empirically, we demonstrate that Oracle-RLAIF consistently outperforms leading VLMs using existing fine-tuning methods when evaluated across various video comprehension benchmarks. Oracle-RLAIF paves the path to creating flexible and data-efficient frameworks for aligning large multi-modal video models with reinforcement learning from rank rather than score.
近年来,大型视频语言模型(VLMs)的最新进展依赖于广泛的微调技术,这些技术加强了文本和视觉理解之间的对齐。领先的管道通常将监督微调(SFT)与从偏好数据中学习的强化学习相结合,以增强视频理解。然而,随着VLMs的参数规模不断扩大,收集足够的人类反馈的成本也在增加。为了使微调更具成本效益,最近的框架探索了使用AI反馈的强化学习(RLAIF),用AI作为裁判取代人类偏好。当前的RLAIF框架依赖于用视频叙事训练的专用奖励模型来创建校准标量奖励,这是一个昂贵且受限的管道。我们提出了Oracle-RLAIF这一新型框架,它用更通用的Oracle排名者取代训练好的奖励模型,作为一个即插即用的模型来排名候选模型响应而非对其打分。除了Oracle-RLAIF,我们还引入了基于Group Relative Policy Optimization(GRPO)的$GRPO_{rank}$新型基于排名的损失函数,该函数直接优化基于排名的优势序数反馈。从实证上看,在多种视频理解基准测试中,Oracle-RLAIF的表现均优于现有的领先VLMs使用的主要微调方法。Oracle-RLAIF为创建灵活且数据高效的大型多模式视频模型框架铺平了道路,这些框架可以通过强化学习从排名而非分数中进行对齐。
论文及项目相关链接
PDF Proceedings of the 39th Annual Conference on Neural Information Processing Systems, ARLET Workshop (Aligning Reinforcement Learning Experimentalists and Theorists)
Summary
大型视频语言模型(VLMs)的最新进展依赖于广泛的微调技术,以加强文本和视觉理解之间的对齐。主流管道通常结合监督微调(SFT)和偏好数据的强化学习来增强视频理解。然而,随着VLMs的参数规模扩大,收集足够人类反馈的成本也在上升。为了降低微调的成本,最近的框架探索了使用AI反馈的强化学习(RLAIF),用AI作为评判员代替人类偏好。我们提出了Oracle-RLAIF这一新型框架,用更通用的Oracle排名器取代训练好的奖励模型,对候选模型响应进行排名而非评分。同时,我们引入了基于集团相对政策优化(GRPO)的$GRPO_{rank}$新型排名损失函数,直接优化序数反馈和排名优势。经验表明,在多种视频理解基准测试中,Oracle-RLAIF的表现始终优于采用现有微调方法的大型VLMs。Oracle-RLAIF为创建灵活且数据高效的框架铺平了道路,该框架使用排名而非评分来强化大型多模式视频模型的对齐。
Key Takeaways
- 大型视频语言模型(VLMs)通过结合监督微调(SFT)和强化学习提高视频理解性能。
- 随着VLMs规模增长,人类反馈成本上升,需要更经济的微调方法。
- 现有框架通过AI反馈的强化学习(RLAIF)降低微调成本,但依赖特定奖励模型。
- Oracle-RLAIF提出用通用Oracle排名器取代训练好的奖励模型,进行模型响应排名。
- $GRPO_{rank}$是一种新型排名损失函数,基于集团相对政策优化(GRPO),直接优化序数反馈和排名优势。
- Oracle-RLAIF在各种视频理解基准测试中表现优异,优于传统微调方法。
点此查看论文截图
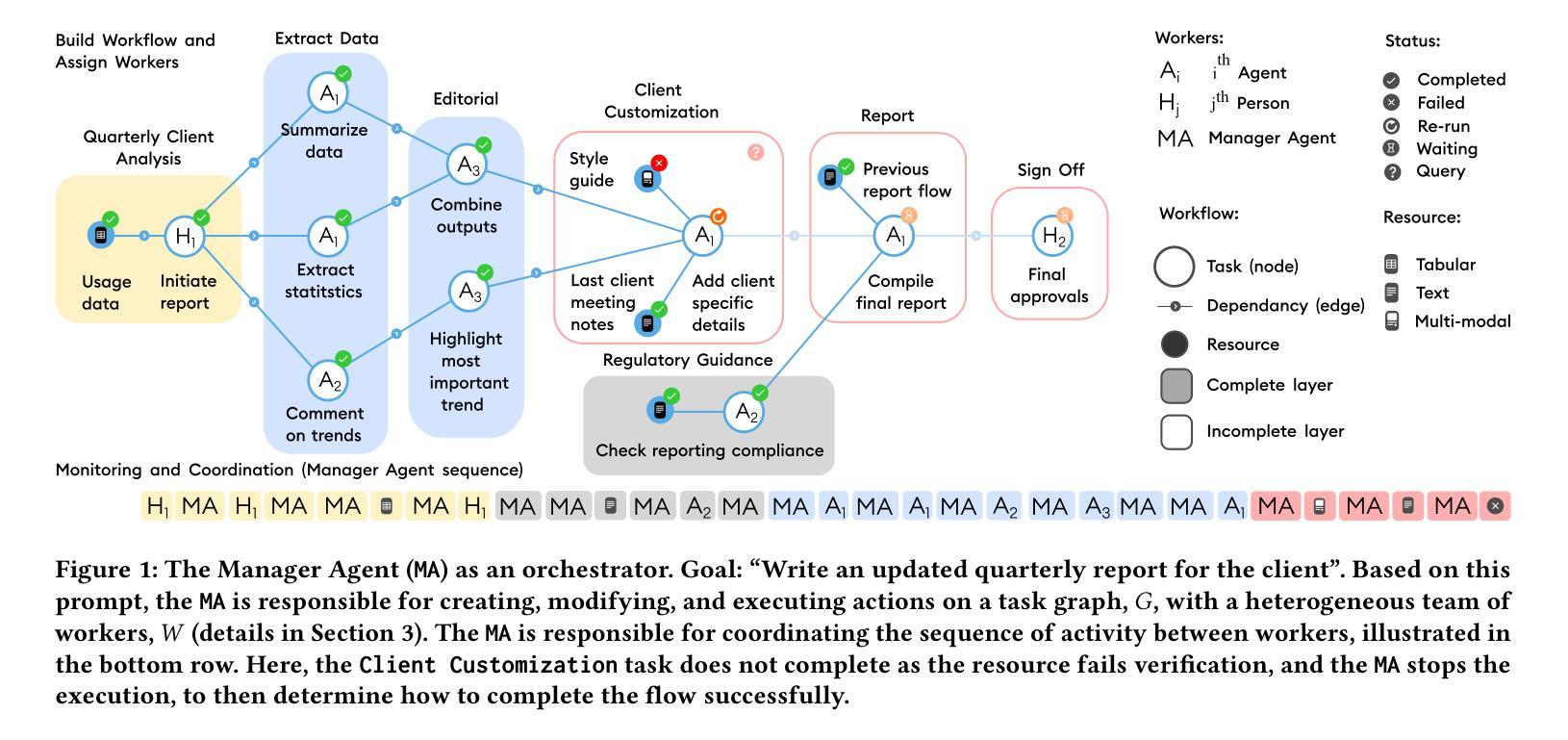
Orchestrating Human-AI Teams: The Manager Agent as a Unifying Research Challenge
Authors:Charlie Masters, Advaith Vellanki, Jiangbo Shangguan, Bart Kultys, Jonathan Gilmore, Alastair Moore, Stefano V. Albrecht
While agentic AI has advanced in automating individual tasks, managing complex multi-agent workflows remains a challenging problem. This paper presents a research vision for autonomous agentic systems that orchestrate collaboration within dynamic human-AI teams. We propose the Autonomous Manager Agent as a core challenge: an agent that decomposes complex goals into task graphs, allocates tasks to human and AI workers, monitors progress, adapts to changing conditions, and maintains transparent stakeholder communication. We formalize workflow management as a Partially Observable Stochastic Game and identify four foundational challenges: (1) compositional reasoning for hierarchical decomposition, (2) multi-objective optimization under shifting preferences, (3) coordination and planning in ad hoc teams, and (4) governance and compliance by design. To advance this agenda, we release MA-Gym, an open-source simulation and evaluation framework for multi-agent workflow orchestration. Evaluating GPT-5-based Manager Agents across 20 workflows, we find they struggle to jointly optimize for goal completion, constraint adherence, and workflow runtime - underscoring workflow management as a difficult open problem. We conclude with organizational and ethical implications of autonomous management systems.
关于代理人工智能(agentic AI)已经实现了自动化单个任务方面的进步,但管理复杂的跨代理工作流程仍然是一个挑战性问题。本文提出了自主代理系统的研究愿景,该系统能够在动态的人机团队中协调合作。我们提出了一个核心挑战:自主管理代理(Agent),该代理能够将复杂的目标分解为任务图,分配给人类和人工智能工作者,监控进度,适应不断变化的环境,并保持与利益相关者的透明沟通。我们将工作流程管理形式化为部分可观察随机博弈,并确定了四个基本挑战:(1)层次分解的组合推理,(2)多变偏好下的多目标优化,(3)非特定团队的协调与规划,(4)设计与遵循法规政策。为了推进这一议程,我们推出了MA-Gym这一开源模拟和评估框架,用于多代理工作流程编排。通过对GPT-5型管理代理在20个工作流程中的评估,我们发现他们在共同优化目标完成、约束遵守和工作流程运行时间方面遇到了困难,这凸显了工作流程管理的困难性和开放性挑战。最后,我们探讨了自主管理系统在组织伦理方面的影响。
论文及项目相关链接
PDF Accepted as an oral paper for the conference for Distributed Artificial Intelligence (DAI 2025). 8 pages, 2 figures
Summary
智能自主管理系统是当今人工智能领域中的一个挑战性问题。本文主要探讨了动态人机协作中的自动化工作流管理系统的问题,提出了一种新的概念——“自主管理器代理”。它负责分解复杂的任务目标、分配任务、监控进度、适应环境变化以及保持透明的利益相关者沟通。同时,本文还将其形式化为部分可观察的随机博弈问题,并提出了四大核心挑战:层次结构的组合推理、变化的偏好下的多目标优化、临时团队的协调和规划、设计化的治理和合规性。本文最终通过实验探讨了自主管理系统的组织和社会影响。
Key Takeaways
- 智能自主管理系统是人工智能领域中的一项重要挑战,需要解决复杂的多任务工作流管理问题。
- 自主管理器代理是该领域的核心,能够分解任务、分配工作、监控进度等。
- 工作流管理被形式化为部分可观察的随机博弈问题,需要解决四大核心挑战。
- 层次结构的组合推理是其中的一大挑战,需要处理复杂的任务结构。
- 在变化的偏好下实现多目标优化也是一大难题,需要满足不同的需求和优先级。
- 自主管理系统的协调与规划涉及到临时团队的合作问题。
点此查看论文截图
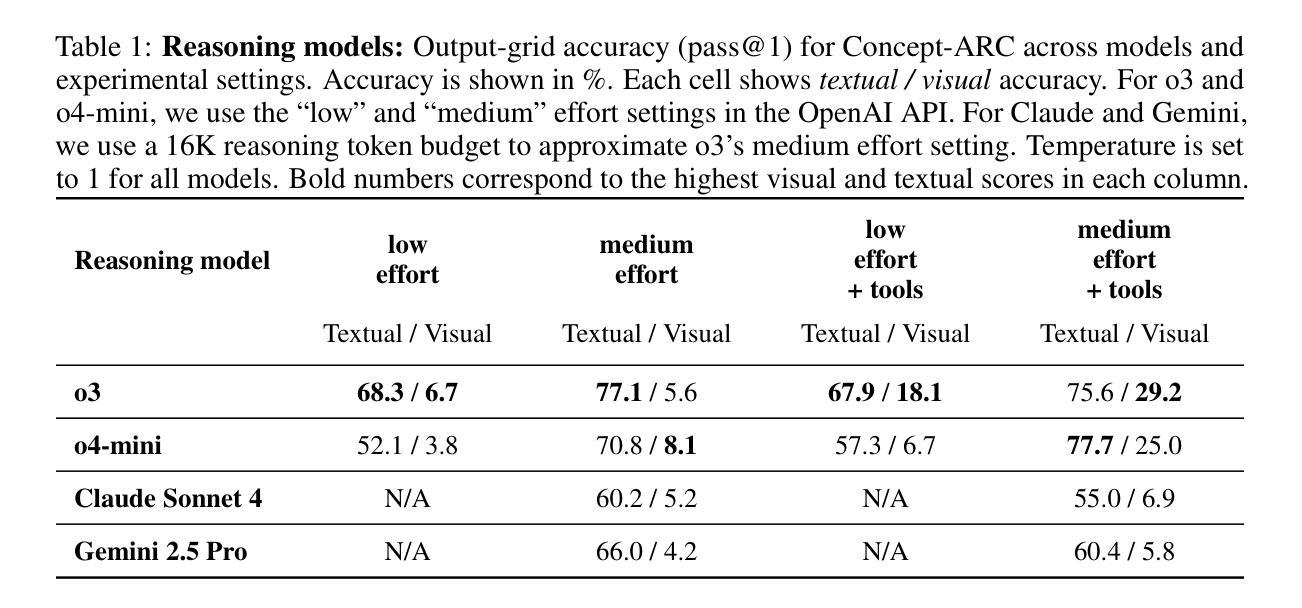
Do AI Models Perform Human-like Abstract Reasoning Across Modalities?
Authors:Claas Beger, Ryan Yi, Shuhao Fu, Arseny Moskvichev, Sarah W. Tsai, Sivasankaran Rajamanickam, Melanie Mitchell
OpenAI’s o3-preview reasoning model exceeded human accuracy on the ARC-AGI benchmark, but does that mean state-of-the-art models recognize and reason with the abstractions that the task creators intended? We investigate models’ abstraction abilities on ConceptARC. We evaluate models under settings that vary the input modality (textual vs. visual), whether the model is permitted to use external Python tools, and, for reasoning models, the amount of reasoning effort. In addition to measuring output accuracy, we perform fine-grained evaluation of the natural-language rules that models generate to explain their solutions. This dual evaluation lets us assess whether models solve tasks using the abstractions ConceptARC was designed to elicit, rather than relying on surface-level patterns. Our results show that, while some models using text-based representations match human output accuracy, the best models’ rules are often based on surface-level ``shortcuts’’ and capture intended abstractions far less often than humans. Thus their capabilities for general abstract reasoning may be overestimated by evaluations based on accuracy alone. In the visual modality, AI models’ output accuracy drops sharply, yet our rule-level analysis reveals that models might be underestimated, as they still exhibit a substantial share of rules that capture intended abstractions, but are often unable to correctly apply these rules. In short, our results show that models still lag humans in abstract reasoning, and that using accuracy alone to evaluate abstract reasoning on ARC-like tasks may overestimate abstract-reasoning capabilities in textual modalities and underestimate it in visual modalities. We believe that our evaluation framework offers a more faithful picture of multimodal models’ abstract reasoning abilities and a more principled way to track progress toward human-like, abstraction-centered intelligence.
OpenAI的o3-preview推理模型在ARC-AGI基准测试中超过了人类的准确率,但这是否意味着最先进的模型能够识别并推理任务创建者所意图的抽象概念呢?我们在ConceptARC上调查了模型的抽象能力。我们评估了在不同设置下的模型,包括输入模式(文本与视觉)、模型是否可以使用外部Python工具,以及对于推理模型来说,推理努力的程度。除了测量输出准确率之外,我们还对模型生成的用于解释其解决方案的自然语言规则进行了精细评估。这种双重评估使我们能够评估模型是否使用ConceptARC设计的抽象概念来解决问题,而不是依赖于表面模式。我们的结果表明,虽然一些使用文本表示的模型与人类输出准确率相匹配,但最佳模型的规则通常基于表面“捷径”,并且捕获的意图抽象概念远不及人类。因此,仅通过准确性评估,它们的一般抽象推理能力可能被高估了。在视觉模式下,AI模型的输出准确率急剧下降,但我们的规则层面分析表明,模型可能被低估了,因为它们仍然表现出大量能够捕获意图抽象的规则,但往往无法正确应用这些规则。总之,我们的结果表明,模型在抽象推理方面仍然落后于人类,并且单独使用准确性来评估ARC类任务上的抽象推理可能会高估文本模式中的抽象推理能力,并低估视觉模式中的能力。我们相信,我们的评估框架能够更真实地反映多模式模型的抽象推理能力,并提供一种更原则性的方法来跟踪向人类抽象为中心的智能的进步。
论文及项目相关链接
PDF 10 pages, 4 figures
Summary
这是一篇关于OpenAI的o3-preview推理模型在ARC-AGI基准测试上的表现的报告。报告指出,尽管该模型在某些任务上的表现超过了人类,但在处理抽象概念时仍有所欠缺。报告通过ConceptARC进行了深入研究,发现模型在某些情境下过于依赖表面模式而忽视深层抽象概念。同时,报告还提出一种评价框架,可以更准确地评估模型的抽象推理能力。
Key Takeaways
- OpenAI的o3-preview推理模型在某些基准测试上的表现超过了人类。
- 在处理抽象概念时,该模型的能力可能并未达到预期水平。
- 模型在某些情境下过于依赖表面模式而忽视深层抽象概念。
- 模型在视觉模态下的表现较文本模态更为复杂,需要在规则应用上得到更精细的评价。
- 使用单一的评价指标(如准确度)可能会过高或过低地估计模型的抽象推理能力。
- 提出了一种新的评价框架,能更准确地评估模型的抽象推理能力。
点此查看论文截图
Enhancing Large Language Model Reasoning with Reward Models: An Analytical Survey
Authors:Qiyuan Liu, Hao Xu, Xuhong Chen, Wei Chen, Yee Whye Teh, Ning Miao
Reward models (RMs) play a critical role in enhancing the reasoning performance of LLMs. For example, they can provide training signals to finetune LLMs during reinforcement learning (RL) and help select the best answer from multiple candidates during inference. In this paper, we provide a systematic introduction to RMs, along with a comprehensive survey of their applications in LLM reasoning. We first review fundamental concepts of RMs, including their architectures, training methodologies, and evaluation techniques. Then, we explore their key applications: (1) guiding generation and selecting optimal outputs during LLM inference, (2) facilitating data synthesis and iterative self-improvement for LLMs, and (3) providing training signals in RL-based finetuning. Finally, we discuss critical open questions regarding the selection, generalization, evaluation, and enhancement of RMs, based on existing research and our own empirical findings. Our analysis aims to provide actionable insights for the effective deployment and advancement of RMs for LLM reasoning.
奖励模型(RMs)在提升大型语言模型(LLMs)的推理性能上起着至关重要的作用。例如,它们可以在强化学习(RL)期间为LLMs提供训练信号,并在推理过程中帮助从多个候选答案中选择最佳答案。在本文中,我们对RMs进行了系统介绍,并全面概述了它们在LLM推理中的应用。我们首先回顾RMs的基本概念,包括其架构、训练方法和评估技术。然后,我们探讨了它们的关键应用:(1)在LLM推理过程中指导生成并选择最佳输出,(2)促进数据合成和LLM的迭代自我改进,(3)在基于RL的微调中提供训练信号。最后,我们基于现有研究和自己的实证发现,讨论了关于RMs的选择、泛化、评估和改进的关键开放问题。我们的分析旨在提供关于RMs在LLM推理中的有效部署和进步的可行见解。
论文及项目相关链接
Summary:奖励模型(RMs)对于提升大型语言模型(LLMs)的推理性能具有重要作用。本文系统地介绍了RMs及其在多领域语言模型推理中的应用。内容包括RMs的基本概念、架构、训练方法和评估技术,以及其关键应用,如指导生成和选择最佳输出、促进数据合成和迭代自改进,以及强化学习微调中的训练信号提供等。同时,根据现有研究和自身经验探讨了RMs的选择、泛化、评估和增强等关键问题。旨在提供RMs在LLM推理中的有效部署和进步的实用见解。
Key Takeaways:
- 奖励模型(RMs)在增强大型语言模型(LLMs)推理性能中起关键作用。
- RMs可以通过提供训练信号来微调LLMs,并在推理过程中帮助选择最佳答案。
- 本文全面回顾了RMs的基本概念、架构、训练方法和评估技术。
- RMs的关键应用包括指导生成和选择最佳输出、促进数据合成和LLM的迭代自改进。
- RMs在强化学习微调中提供训练信号,这是提升LLM性能的重要手段。
- 目前关于RMs的选择、泛化、评估和增强等关键问题仍存在争议,需要进一步研究。
- 本文旨在为RMs在LLM推理中的有效部署和进步提供实用见解。
点此查看论文截图