⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-07 更新
Model-Based Ranking of Source Languages for Zero-Shot Cross-Lingual Transfer
Authors:Abteen Ebrahimi, Adam Wiemerslage, Katharina von der Wense
We present NN-Rank, an algorithm for ranking source languages for cross-lingual transfer, which leverages hidden representations from multilingual models and unlabeled target-language data. We experiment with two pretrained multilingual models and two tasks: part-of-speech tagging (POS) and named entity recognition (NER). We consider 51 source languages and evaluate on 56 and 72 target languages for POS and NER, respectively. When using in-domain data, NN-Rank beats state-of-the-art baselines that leverage lexical and linguistic features, with average improvements of up to 35.56 NDCG for POS and 18.14 NDCG for NER. As prior approaches can fall back to language-level features if target language data is not available, we show that NN-Rank remains competitive using only the Bible, an out-of-domain corpus available for a large number of languages. Ablations on the amount of unlabeled target data show that, for subsets consisting of as few as 25 examples, NN-Rank produces high-quality rankings which achieve 92.8% of the NDCG achieved using all available target data for ranking.
我们提出了NN-Rank算法,这是一种用于跨语言转移的源语言排名算法,它利用多语言模型的隐藏表示和未标记的目标语言数据。我们在两个预训练的多语言模型和两个任务上进行实验:词性标注(POS)和命名实体识别(NER)。我们考虑了51种源语言,并在POS和NER上分别对56种和72种目标语言进行评估。在使用领域数据时,NN-Rank击败了利用词汇和语言学特征的最新基线,平均改进了高达35.56的NDCG(对于POS)和18.14的NDCG(对于NER)。由于先前的方法在目标语言数据不可用时会回落到语言级特征,我们表明,仅使用《圣经》(一个可用于多种语言的领域外语料库)时,NN-Rank仍具有竞争力。关于未标记目标数据量的消融实验表明,对于仅包含25个例子的子集,NN-Rank能够产生高质量的排名,实现使用所有可用目标数据进行排名时的92.8%的NDCG。
论文及项目相关链接
PDF Accepted to EMNLP 2025 (Main)
Summary
本文介绍了NN-Rank算法,该算法用于跨语言转移学习中源语言的排名。它利用多语言模型的隐藏表示和未标记的目标语言数据进行排名。实验涉及两种预训练的多语言模型和两种任务:词性标注(POS)和命名实体识别(NER)。考虑51种源语言,并在POS和NER上分别对56种和72种目标语言进行评估。使用领域数据,NN-Rank优于利用词汇和语言特征的最新基线,POS和NER的平均改进分别高达35.56 NDCG和18.14 NDCG。在目标语言数据不可用的情况下,NN-Rank仍然具有竞争力,仅使用大型语言共有的《圣经》语料库。针对目标数据不同数量的消融实验表明,即使只有25个例子,NN-Rank也能产生高质量排名,其NDCG得分达到使用所有可用目标数据排名的92.8%。
Key Takeaways
- NN-Rank是一种用于跨语言转移学习的源语言排名算法。
- 该算法利用多语言模型的隐藏表示和未标记的目标语言数据。
- 实验涉及词性标注(POS)和命名实体识别(NER)两种任务。
- NN-Rank在多种源语言与大量目标语言的POS和NER任务上表现优异。
- 与依赖词汇和语言特征的基线方法相比,NN-Rank有显著的平均改进。
- NN-Rank在目标语言数据有限的情况下仍具有竞争力,甚至可以使用《圣经》这一多语言共有的语料库。
点此查看论文截图
Improving Cooperation in Collaborative Embodied AI
Authors:Hima Jacob Leven Suprabha, Laxmi Nag Laxminarayan Nagesh, Ajith Nair, Alvin Reuben Amal Selvaster, Ayan Khan, Raghuram Damarla, Sanju Hannah Samuel, Sreenithi Saravana Perumal, Titouan Puech, Venkataramireddy Marella, Vishal Sonar, Alessandro Suglia, Oliver Lemon
The integration of Large Language Models (LLMs) into multiagent systems has opened new possibilities for collaborative reasoning and cooperation with AI agents. This paper explores different prompting methods and evaluates their effectiveness in enhancing agent collaborative behaviour and decision-making. We enhance CoELA, a framework designed for building Collaborative Embodied Agents that leverage LLMs for multi-agent communication, reasoning, and task coordination in shared virtual spaces. Through systematic experimentation, we examine different LLMs and prompt engineering strategies to identify optimised combinations that maximise collaboration performance. Furthermore, we extend our research by integrating speech capabilities, enabling seamless collaborative voice-based interactions. Our findings highlight the effectiveness of prompt optimisation in enhancing collaborative agent performance; for example, our best combination improved the efficiency of the system running with Gemma3 by 22% compared to the original CoELA system. In addition, the speech integration provides a more engaging user interface for iterative system development and demonstrations.
将大型语言模型(LLMs)集成到多智能体系统中,为与人工智能代理人的协作推理和合作提供了新的可能性。本文探讨了不同的提示方法,并评估了它们在提高代理协作行为和决策制定方面的有效性。我们增强了CoELA(一种为利用LLMs进行多智能体通信、推理和任务协调而设计的协作实体代理框架),该框架适用于共享虚拟空间。通过系统实验,我们研究了不同的LLMs和提示工程策略,以找出优化的组合,以最大限度地提高协作性能。此外,我们通过集成语音功能,实现了无缝的基于语音的协作交互。我们的研究结果突出了提示优化在提高协作代理性能方面的有效性;例如,我们的最佳组合与原始CoELA系统相比,使Gemma3系统的运行效率提高了22%。此外,语音集成还为迭代系统开发和演示提供了更具吸引力的用户界面。
论文及项目相关链接
PDF In proceedings of UKCI 2025
Summary
大型语言模型(LLMs)多智能体系统的集成开启了与人工智能智能体进行协作推理和协作的新可能性。本文通过探究不同的提示方法,评估其在提高智能体协作行为和决策制定方面的有效性。我们对CoELA框架进行了增强,该框架用于构建利用LLMs进行多智能体通信、推理和任务协调的协作式实体智能体。通过系统实验,我们探索了不同的LLMs和提示工程策略,以找出优化组合,最大化协作性能。此外,通过集成语音功能,我们实现了无缝的基于语音的协作交互。研究发现提示优化在提高协作智能体性能方面的有效性;例如,我们最佳组合方案的效率比原始CoELA系统提高了22%。此外,语音集成为用户提供了一个更交互式的界面,用于迭代系统开发和演示。
Key Takeaways
- 大型语言模型(LLMs)与多智能体系统的集成促进了协作推理和AI智能体之间的合作。
- 通过探究不同的提示方法,评估其在提升智能体协作和决策制定方面的效果。
- 增强了CoELA框架,用于构建利用LLMs的协作式实体智能体,支持多智能体通信、推理和任务协调。
- 系统实验显示,某些LLMs和提示工程策略的组合能最大化协作性能。
- 语音功能的集成实现了无缝的基于语音的协作交互,增强了用户体验。
- 提示优化在提高协作智能体性能方面效果显著。
点此查看论文截图
Revisiting Direct Speech-to-Text Translation with Speech LLMs: Better Scaling than CoT Prompting?
Authors:Oriol Pareras, Gerard I. Gállego, Federico Costa, Cristina España-Bonet, Javier Hernando
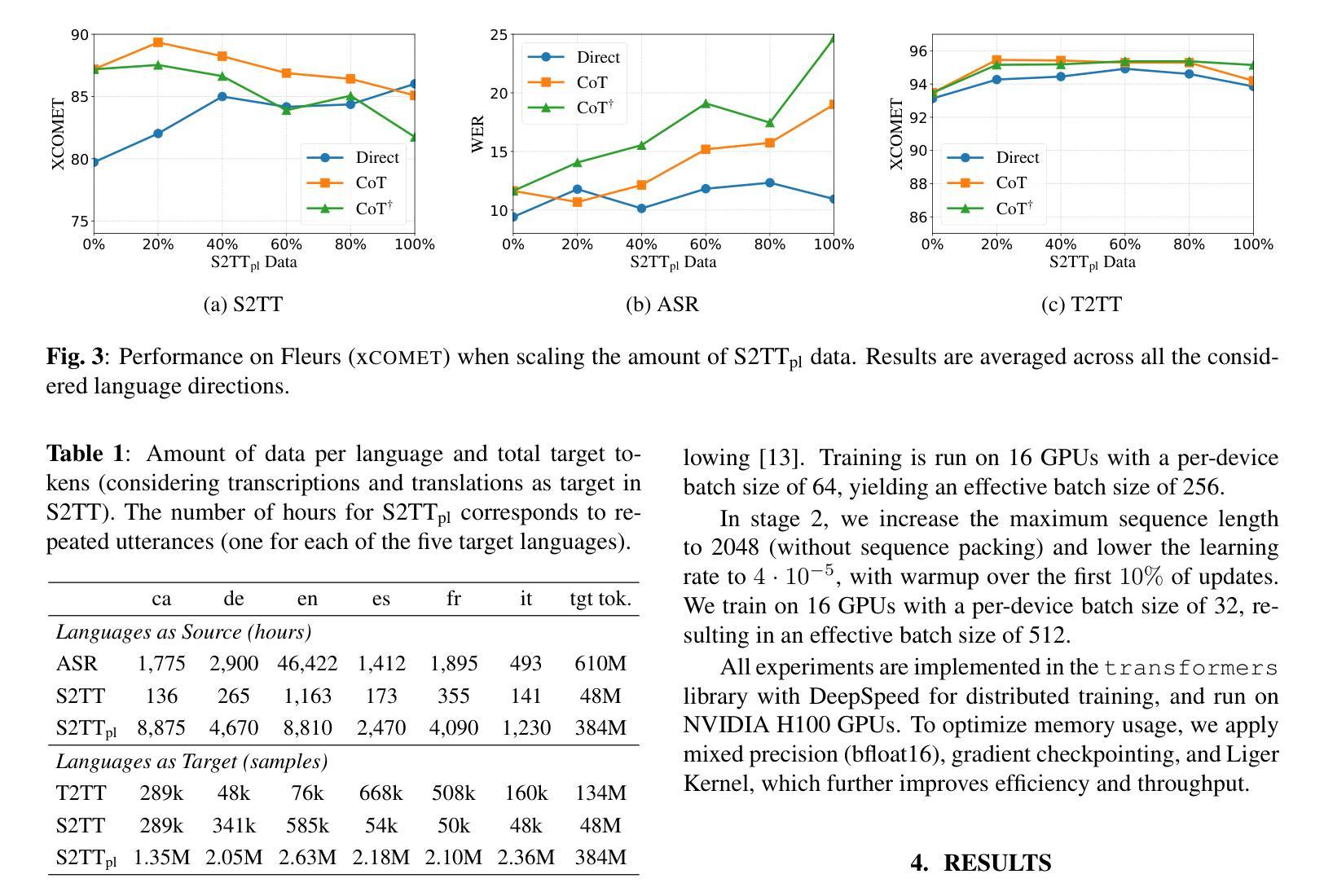
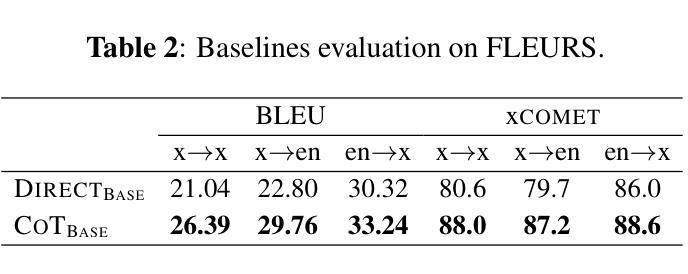
Recent work on Speech-to-Text Translation (S2TT) has focused on LLM-based models, introducing the increasingly adopted Chain-of-Thought (CoT) prompting, where the model is guided to first transcribe the speech and then translate it. CoT typically outperforms direct prompting primarily because it can exploit abundant Automatic Speech Recognition (ASR) and Text-to-Text Translation (T2TT) datasets to explicitly model its steps. In this paper, we systematically compare CoT and Direct prompting under increasing amounts of S2TT data. To this end, we pseudo-label an ASR corpus by translating its transcriptions into six European languages, and train LLM-based S2TT systems with both prompting strategies at different data scales. Our results show that Direct improves more consistently as the amount of data increases, suggesting that it may become a more effective approach as larger S2TT resources are created.
近期关于语音到文本翻译(S2TT)的研究主要集中在基于大语言模型(LLM)的模型上,并引入了日益被采用的思维链(CoT)提示方法,该方法引导模型首先转录语音,然后将其翻译成文本。思维链通常在直接提示法之前表现出较好的性能,主要是因为它能够利用丰富的自动语音识别(ASR)和文本到文本翻译(T2TT)数据集来明确建模其步骤。在本文中,我们在不断增加的S2TT数据量下系统地比较了思维链和直接提示法。为此,我们通过将转录翻译成六种欧洲语言来对ASR语料库进行伪标签标注,并在不同的数据量下使用这两种提示策略训练基于LLM的S2TT系统。我们的结果表明,随着数据量的增加,直接提示法的改进更为稳定,这表明随着S2TT资源的不断增多,它可能会成为一种更有效的方法。
论文及项目相关链接
Summary
本文主要探讨了基于大型语言模型(LLM)的语音到文本翻译(S2TT)技术中的两种主要策略:链式思维(CoT)和直接提示法。文章通过对比这两种策略在不同规模的S2TT数据下的表现,发现随着数据量的增加,直接提示法的表现更为稳定。因此,随着更多S2TT资源的创建,直接提示法可能成为更有效的策略。
Key Takeaways
- 语音到文本翻译(S2TT)领域的研究已经聚焦于基于大型语言模型(LLM)的方法。
- 链式思维(CoT)策略首先转录语音然后进行翻译。这种策略通常会使用丰富的自动语音识别(ASR)和文本到文本翻译(T2TT)数据集来建模其步骤。
- 直接提示法是一种在语音到文本翻译中的策略,与链式思维策略不同。
- 在本文中,作者通过伪标签方式将自动语音识别语料库翻译成六种欧洲语言,并在此数据集上训练了基于LLM的S2TT系统。
- 随着数据量的增加,直接提示法的表现更为稳定。这表明随着更多S2TT资源的出现,直接提示法可能变得更为有效。
- 直接提示法比链式思维法在更多的数据中表现得更好,这意味着其在更大的数据集上可能具有更大的潜力。
点此查看论文截图
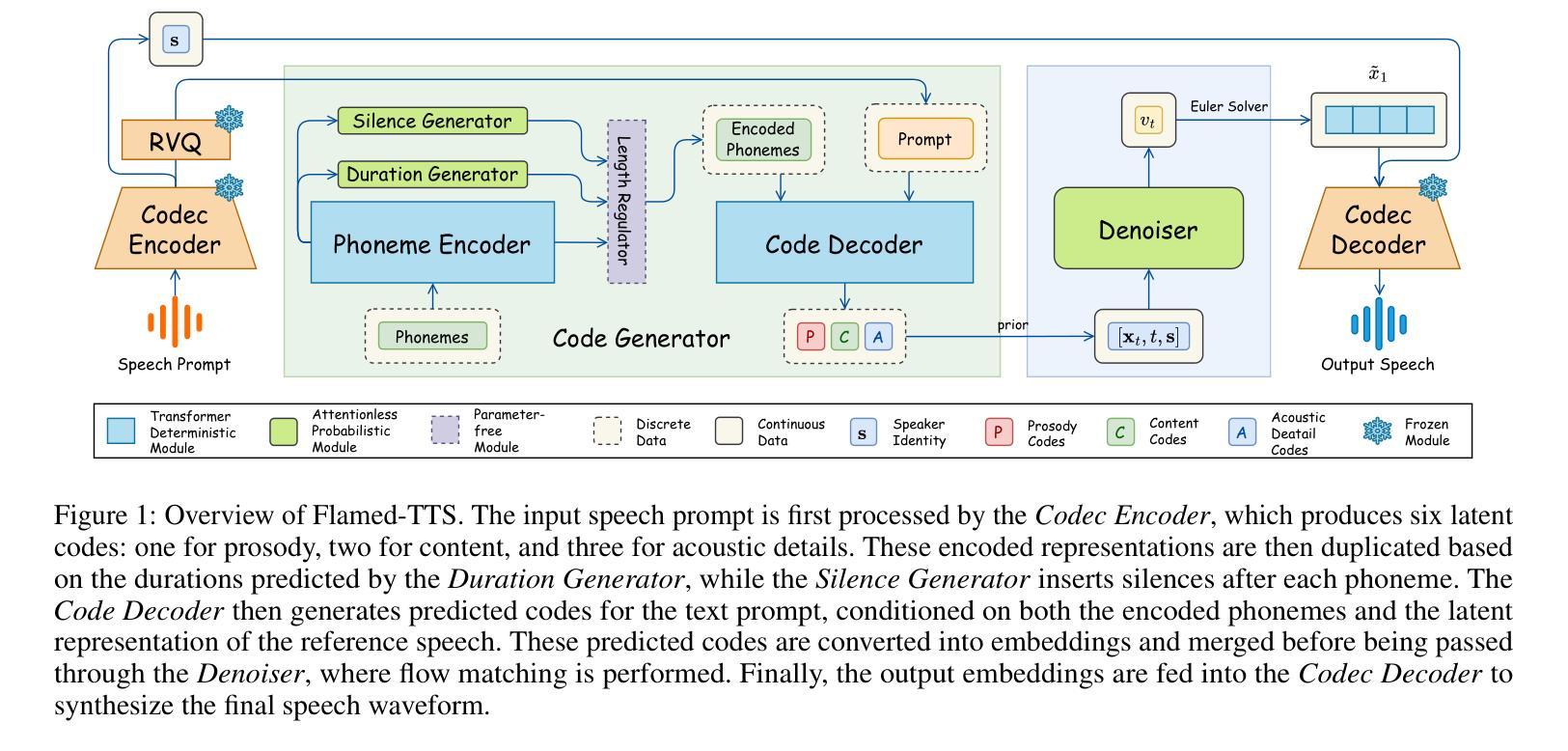
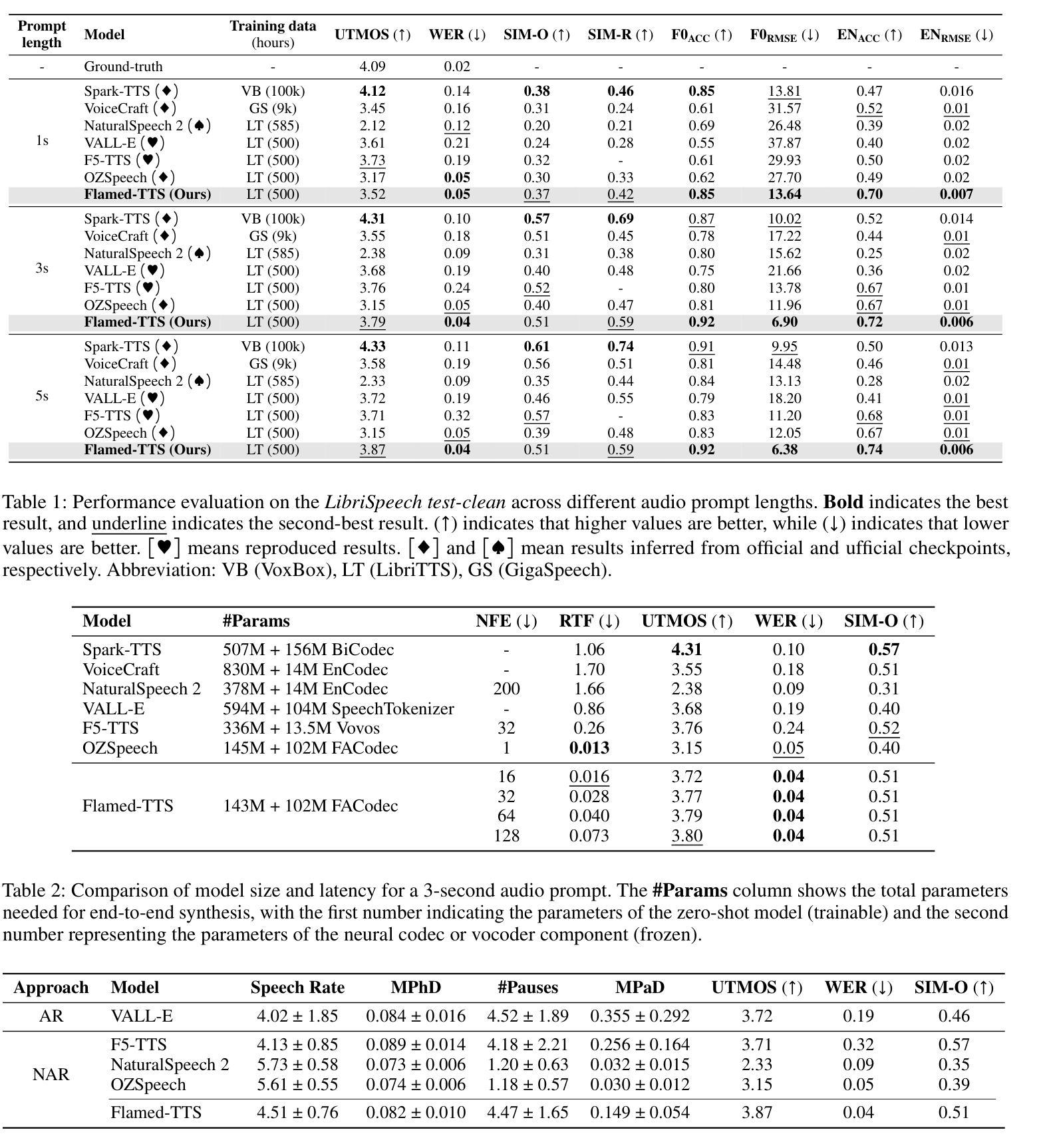
Flamed-TTS: Flow Matching Attention-Free Models for Efficient Generating and Dynamic Pacing Zero-shot Text-to-Speech
Authors:Hieu-Nghia Huynh-Nguyen, Huynh Nguyen Dang, Ngoc-Son Nguyen, Van Nguyen
Zero-shot Text-to-Speech (TTS) has recently advanced significantly, enabling models to synthesize speech from text using short, limited-context prompts. These prompts serve as voice exemplars, allowing the model to mimic speaker identity, prosody, and other traits without extensive speaker-specific data. Although recent approaches incorporating language models, diffusion, and flow matching have proven their effectiveness in zero-shot TTS, they still encounter challenges such as unreliable synthesis caused by token repetition or unexpected content transfer, along with slow inference and substantial computational overhead. Moreover, temporal diversity-crucial for enhancing the naturalness of synthesized speech-remains largely underexplored. To address these challenges, we propose Flamed-TTS, a novel zero-shot TTS framework that emphasizes low computational cost, low latency, and high speech fidelity alongside rich temporal diversity. To achieve this, we reformulate the flow matching training paradigm and incorporate both discrete and continuous representations corresponding to different attributes of speech. Experimental results demonstrate that Flamed-TTS surpasses state-of-the-art models in terms of intelligibility, naturalness, speaker similarity, acoustic characteristics preservation, and dynamic pace. Notably, Flamed-TTS achieves the best WER of 4% compared to the leading zero-shot TTS baselines, while maintaining low latency in inference and high fidelity in generated speech. Code and audio samples are available at our demo page https://flamed-tts.github.io.
零样本文本转语音(TTS)最近取得了显著进展,使得模型能够使用简短、有限上下文提示来从文本合成语音。这些提示充当语音范例,使模型能够在没有大量特定说话人数据的情况下模仿说话人的身份、语调和其他特征。虽然最近采用语言模型、扩散和流量匹配的方法已经证明它们在零样本TTS中的有效性,但它们仍然面临挑战,如由令牌重复或意外内容转移引起的不可靠合成,以及推理速度慢和计算开销大。此外,对于增强合成语音的自然度至关重要的时间多样性仍很大程度上被忽视。为了解决这些挑战,我们提出了Flamed-TTS,这是一种新型零样本TTS框架,侧重于低计算成本、低延迟和高语音保真度,以及丰富的时间多样性。为实现这一点,我们重新制定了流量匹配训练范式,并融入了与语音不同属性相对应的离散和连续表示。实验结果表明,Flamed-TTS在清晰度、自然度、说话人相似性、声学特征保留和动态语速等方面超越了最新模型。值得注意的是,Flamed-TTS的词错误率(WER)达到了领先的零样本TTS基准测试的4%,同时在推理过程中保持了低延迟和生成的语音高保真度。代码和音频样本可在我们的演示页面https://flamed-tts.github.io查看。
论文及项目相关链接
摘要
本文介绍了零样本文本转语音(TTS)技术的最新进展。通过短而有限的上下文提示,模型能够模仿说话人的身份、语调和其他特征,实现语音合成。虽然现有方法采用语言模型、扩散和流程匹配等技术取得了显著成效,但仍面临如合成不可靠、内容转移不精确、推理速度慢和计算量大等挑战。针对这些问题,提出了名为Flamed-TTS的新框架,具有低计算成本、低延迟和高语音保真度等特点,同时丰富了时序多样性。实验结果表明,Flamed-TTS在可理解性、自然性、说话人相似性、声学特性保持和动态速度等方面均优于现有技术。特别是,Flamed-TTS的单词错误率达到了领先的零样本TTS基准测试的4%,同时在推理过程中保持了低延迟和高质量的语音生成。相关代码和音频样本可在我们的演示页面查看。
关键见解
- 零样本文本转语音(TTS)技术通过模仿说话人的身份、语调等特征,实现了基于简短提示的语音合成。
- 尽管现有方法取得了显著成效,但仍面临合成不可靠、推理速度慢和计算量大等挑战。
- Flamed-TTS框架旨在解决这些挑战,强调低计算成本、低延迟和高语音保真度,同时实现丰富的时序多样性。
- Flamed-TTS通过改革流程匹配训练范式并融合离散和连续表示,对应于语音的不同属性来达到这一目标。
- 实验结果显示,Flamed-TTS在多个方面超越了现有技术,包括可理解性、自然性、说话人相似性等方面。
- Flamed-TTS的单词错误率达到了领先的零样本TTS基准测试的4%,表明其卓越性能。
点此查看论文截图
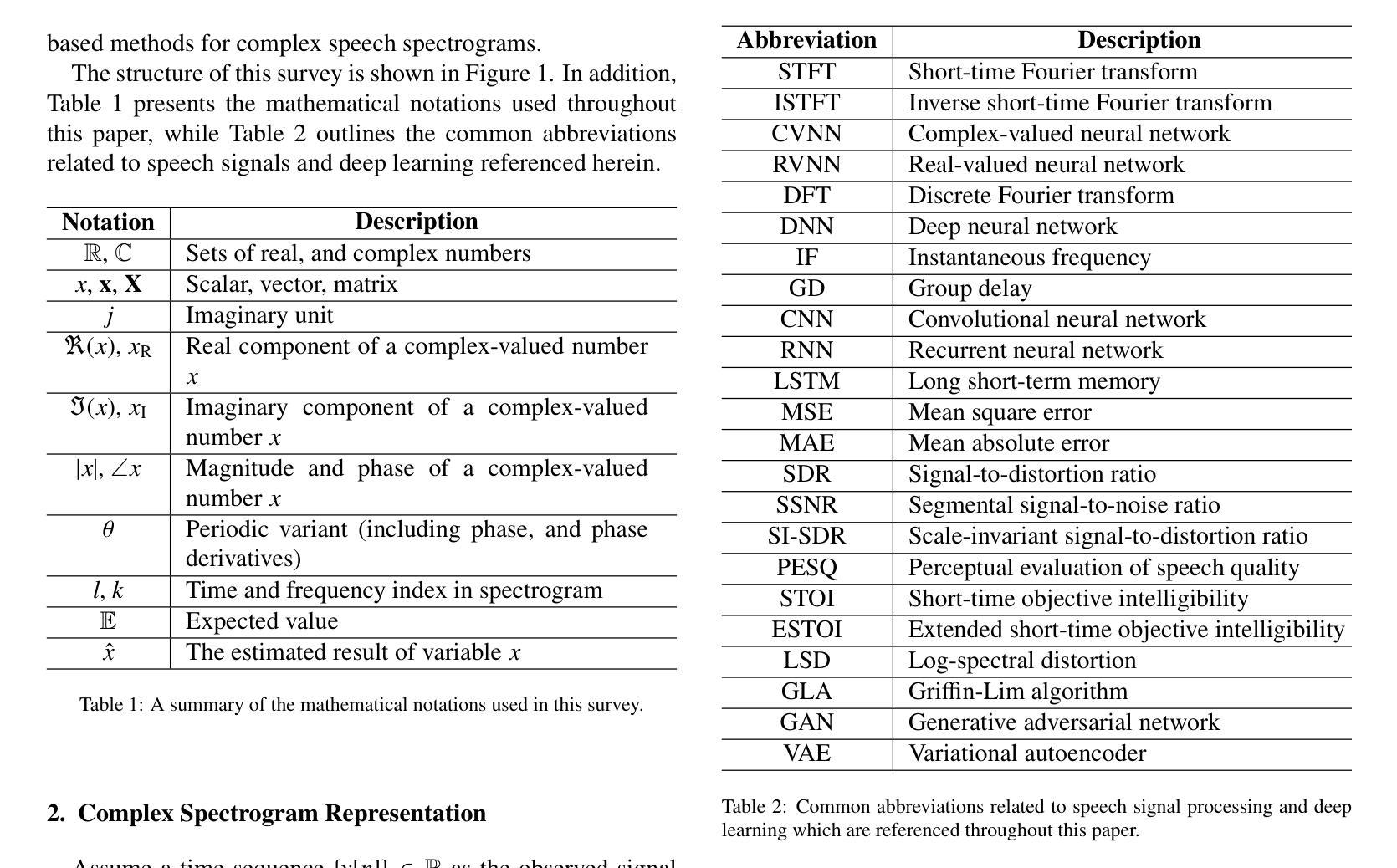
A Survey of Deep Learning for Complex Speech Spectrograms
Authors:Yuying Xie, Zheng-Hua Tan
Recent advancements in deep learning have significantly impacted the field of speech signal processing, particularly in the analysis and manipulation of complex spectrograms. This survey provides a comprehensive overview of the state-of-the-art techniques leveraging deep neural networks for processing complex spectrograms, which encapsulate both magnitude and phase information. We begin by introducing complex spectrograms and their associated features for various speech processing tasks. Next, we examine the key components and architectures of complex-valued neural networks, which are specifically designed to handle complex-valued data and have been applied to complex spectrogram processing. As recent studies have primarily focused on applying real-valued neural networks to complex spectrograms, we revisit these approaches and their architectural designs. We then discuss various training strategies and loss functions tailored for training neural networks to process and model complex spectrograms. The survey further examines key applications, including phase retrieval, speech enhancement, and speaker separation, where deep learning has achieved significant progress by leveraging complex spectrograms or their derived feature representations. Additionally, we examine the intersection of complex spectrograms with generative models. This survey aims to serve as a valuable resource for researchers and practitioners in the field of speech signal processing, deep learning and related fields.
近期深度学习领域的进展对语音信号处理领域产生了重大影响,特别是在分析和处理复杂谱图方面。这篇综述全面概述了利用深度神经网络处理复杂谱图的最新技术。复杂谱图包含了幅度和相位信息。我们首先介绍复杂谱图及其用于各种语音处理任务的相关特征。接下来,我们研究复杂值神经网络的关键组件和架构,这些网络专门设计用于处理复数数据,并已应用于复杂谱图处理。由于近期研究主要集中在将实值神经网络应用于复杂谱图上,因此我们重新审视了这些方法及其架构设计。然后,我们讨论了针对训练神经网络处理复杂谱图的定制的各种训练策略和损失函数。这篇综述还深入探讨了关键应用,包括相位恢复、语音增强和说话人分离,其中深度学习通过利用复杂谱图或其衍生的特征表示取得了显著进展。此外,我们还研究了复杂谱图与生成模型的交集。这篇综述旨在成为语音信号处理、深度学习和相关领域的研究者和实践者的宝贵资源。
论文及项目相关链接
Summary
深度学习的最新进展对语音信号处理领域产生了重大影响,特别是在分析和处理复杂谱图方面。本综述提供了运用深度神经网络处理复杂谱图的最新技术概览,这些技术能够同时处理幅度和相位信息。本文介绍了复杂谱图及其在各种语音处理任务中的相关特征,探讨了专门处理复数数据的关键组件和复数神经网络架构,并重新审视了应用于复杂谱图的实值神经网络及其架构设计。此外,本文还讨论了为训练处理复杂谱图的神经网络而定制的各种训练策略和损失函数。本文还探讨了复杂谱图在相位恢复、语音增强和说话人分离等关键应用中的进展,以及与生成模型的交叉点。本综述旨在为语音信号处理、深度学习及相关领域的研究人员和实践者提供有价值的资源。
Key Takeaways
- 深度学习在语音信号处理中的应用已经显著影响复杂谱图的分析和处理。
- 复杂谱图能够同时包含幅度和相位信息,对于语音处理任务至关重要。
- 复数神经网络架构专门设计来处理复数数据,已应用于复杂谱图处理。
- 实值神经网络在复杂谱图处理中的应用及其架构设计受到重新审视。
- 定制的训练策略和损失函数对于训练处理复杂谱图的神经网络至关重要。
- 复杂谱图在相位恢复、语音增强和说话人分离等应用中取得显著进展。
点此查看论文截图