⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-07 更新
CBVLM: Training-free Explainable Concept-based Large Vision Language Models for Medical Image Classification
Authors:Cristiano Patrício, Isabel Rio-Torto, Jaime S. Cardoso, Luís F. Teixeira, João C. Neves
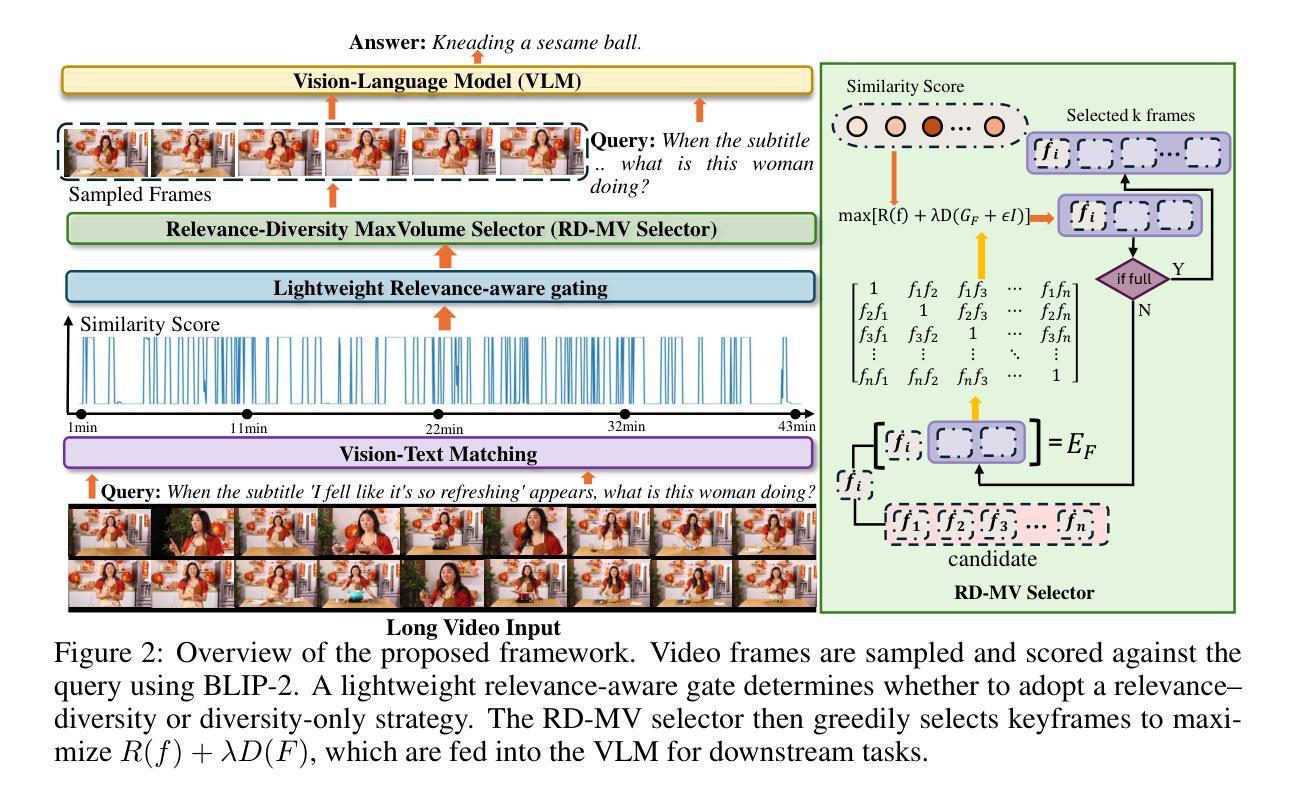
The main challenges limiting the adoption of deep learning-based solutions in medical workflows are the availability of annotated data and the lack of interpretability of such systems. Concept Bottleneck Models (CBMs) tackle the latter by constraining the model output on a set of predefined and human-interpretable concepts. However, the increased interpretability achieved through these concept-based explanations implies a higher annotation burden. Moreover, if a new concept needs to be added, the whole system needs to be retrained. Inspired by the remarkable performance shown by Large Vision-Language Models (LVLMs) in few-shot settings, we propose a simple, yet effective, methodology, CBVLM, which tackles both of the aforementioned challenges. First, for each concept, we prompt the LVLM to answer if the concept is present in the input image. Then, we ask the LVLM to classify the image based on the previous concept predictions. Moreover, in both stages, we incorporate a retrieval module responsible for selecting the best examples for in-context learning. By grounding the final diagnosis on the predicted concepts, we ensure explainability, and by leveraging the few-shot capabilities of LVLMs, we drastically lower the annotation cost. We validate our approach with extensive experiments across four medical datasets and twelve LVLMs (both generic and medical) and show that CBVLM consistently outperforms CBMs and task-specific supervised methods without requiring any training and using just a few annotated examples. More information on our project page: https://cristianopatricio.github.io/CBVLM/.
在医疗工作流中采用基于深度学习的解决方案的主要挑战在于标注数据的可用性和这些系统缺乏可解释性。概念瓶颈模型(CBM)通过限制模型输出在一组预先定义和可解释的概念上解决后者的问题。然而,通过基于概念的解释来提高可解释性意味着更高的标注负担。而且,如果要添加新概念,整个系统都需要重新训练。受大型视觉语言模型(LVLM)在少量样本环境中的出色性能启发,我们提出了一种简单而有效的方法,即CBVLM,它解决了上述两个挑战。首先,对于每个概念,我们提示LVLM回答概念是否存在于输入图像中。然后,我们让LVLM基于先前的概念预测对图像进行分类。而且,在这两个阶段中,我们融入了一个检索模块,负责选择最佳样本进行上下文学习。通过将最终诊断建立在预测的概念上,我们确保了可解释性,并通过利用LVLM的少量样本能力,我们大大降低了标注成本。我们通过四个医疗数据集和十二个(通用和医疗)LVLM的广泛实验验证了我们的方法,并表明CBVLM始终优于CBM和特定任务的有监督方法,而且无需任何训练,只需使用少量标注样本即可。更多关于我们项目页面的信息:https://cristianopatricio.github.io/CBVLM/。
论文及项目相关链接
PDF Accepted for publication in Computers in Biology and Medicine
Summary
本文提出了CBVLM方法,旨在解决深度学习在医疗工作流程中面临的两个主要挑战:标注数据的可用性和系统解释性的缺乏。通过利用大型视觉语言模型(LVLMs)的少量样本学习能力,CBVLM方法能够在提高系统解释性的同时降低标注成本。该方法通过预测概念并基于这些概念进行图像分类,同时融入检索模块以选择最佳上下文学习样本。实验验证显示,CBVLM在四个医疗数据集上均表现优异,一致优于概念瓶颈模型(CBMs)和任务特定监督方法,且无需任何训练,仅使用少量标注样本即可。
Key Takeaways
- CBVLM方法旨在解决深度学习在医疗领域的两个主要挑战:标注数据可用性和系统解释性。
- 通过利用大型视觉语言模型(LVLMs)的少量样本学习能力,CBVLM能够提高系统解释性并降低标注成本。
- CBVLM通过预测概念并基于这些概念进行图像分类,实现医疗图像的分析和诊断。
- CBVLM融入检索模块,选择最佳上下文学习样本,进一步提高模型的性能。
- 实验验证显示CBVLM在多个医疗数据集上表现优异,优于概念瓶颈模型(CBMs)和任务特定监督方法。
- CBVLM方法无需任何训练,仅使用少量标注样本即可实现高性能。
点此查看论文截图

Fine-grained Abnormality Prompt Learning for Zero-shot Anomaly Detection
Authors:Jiawen Zhu, Yew-Soon Ong, Chunhua Shen, Guansong Pang
Current zero-shot anomaly detection (ZSAD) methods show remarkable success in prompting large pre-trained vision-language models to detect anomalies in a target dataset without using any dataset-specific training or demonstration. However, these methods often focus on crafting/learning prompts that capture only coarse-grained semantics of abnormality, e.g., high-level semantics like “damaged”, “imperfect”, or “defective” objects. They therefore have limited capability in recognizing diverse abnormality details that deviate from these general abnormal patterns in various ways. To address this limitation, we propose FAPrompt, a novel framework designed to learn Fine-grained Abnormality Prompts for accurate ZSAD. To this end, a novel Compound Abnormality Prompt learning (CAP) module is introduced in FAPrompt to learn a set of complementary, decomposed abnormality prompts, where abnormality prompts are enforced to model diverse abnormal patterns derived from the same normality semantic. On the other hand, the fine-grained abnormality patterns can be different from one dataset to another. To enhance the cross-dataset generalization, another novel module, namely Data-dependent Abnormality Prior learning (DAP), is introduced in FAPrompt to learn a sample-wise abnormality prior from abnormal features of each test image to dynamically adapt the abnormality prompts to individual test images. Comprehensive experiments on 19 real-world datasets, covering both industrial defects and medical anomalies, demonstrate that FAPrompt substantially outperforms state-of-the-art methods in both image- and pixel-level ZSAD tasks. Code is available at https://github.com/mala-lab/FAPrompt.
当前的无训练异常检测(Zero-Shot Anomaly Detection,ZSAD)方法在无需使用任何特定数据集的训练或演示的情况下,成功引导大型预训练视觉语言模型在目标数据集中检测异常。然而,这些方法通常侧重于设计/学习提示,这些提示只能捕捉到异常的粗粒度语义,例如“损坏”、“不完美”或“有缺陷”的对象的高级语义。因此,它们在识别以各种方式偏离这些一般异常模式的各种异常细节方面能力有限。为了解决这个问题,我们提出了FAPrompt,这是一个旨在学习精细异常提示的新型框架,以实现准确的ZSAD。为此,在FAPrompt中引入了一种新型复合异常提示学习(CAP)模块,用于学习一组互补的分解异常提示,其中异常提示被强制建模从相同正常语义派生的各种异常模式。另一方面,精细的异常模式可能因数据集而异。为了提高跨数据集的泛化能力,我们在FAPrompt中引入了另一种名为数据依赖异常先验学习(DAP)的新模块,该模块从每个测试图像中的异常特征中学习样本级的异常先验,以动态适应个别测试图像的异常提示。在涵盖工业缺陷和医学异常的19个真实数据集上的综合实验表明,FAPrompt在图像和像素级的ZSAD任务中均显著优于现有方法。代码可在https://github.com/mala-lab/FAPrompt找到。
论文及项目相关链接
PDF Accepted to ICCV 2025; 11 pages, 3 figures
Summary
FAPrompt框架通过引入精细异常提示(Fine-grained Abnormality Prompts)解决零样本异常检测(ZSAD)中的局限性,能更准确地识别各种异常。通过Compound Abnormality Prompt学习(CAP)模块,FAPrompt学会一系列互补的异常提示,这些提示从相同的正常语义中派生出多种异常模式。同时,借助Data-dependent Abnormality Prior学习(DAP)模块,根据每个测试图像的异常特征学习样本级异常先验,使异常提示能动态适应个别测试图像。在多个真实世界数据集上的实验表明,FAPrompt在图像和像素级的ZSAD任务中均显著优于现有方法。
Key Takeaways
- FAPrompt解决了现有零样本异常检测方法(ZSAD)在识别多样化异常细节方面的局限性。
- 通过引入精细异常提示(Fine-grained Abnormality Prompts),FAPrompt能更准确地检测各种异常。
- Compound Abnormality Prompt(CAP)模块使FAPrompt能够学习一系列互补的异常提示,从正常语义中派生出多种异常模式。
- Data-dependent Abnormality Prior(DAP)模块允许FAPrompt根据每个测试图像的异常特征学习样本级异常先验。
- FAPrompt通过动态适应个别测试图像,提高了异常检测的准确性。
- 在多个真实世界数据集上的实验证明,FAPrompt在图像和像素级的ZSAD任务中表现优于其他方法。
点此查看论文截图