⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-09 更新
ArchitectHead: Continuous Level of Detail Control for 3D Gaussian Head Avatars
Authors:Peizhi Yan, Rabab Ward, Qiang Tang, Shan Du
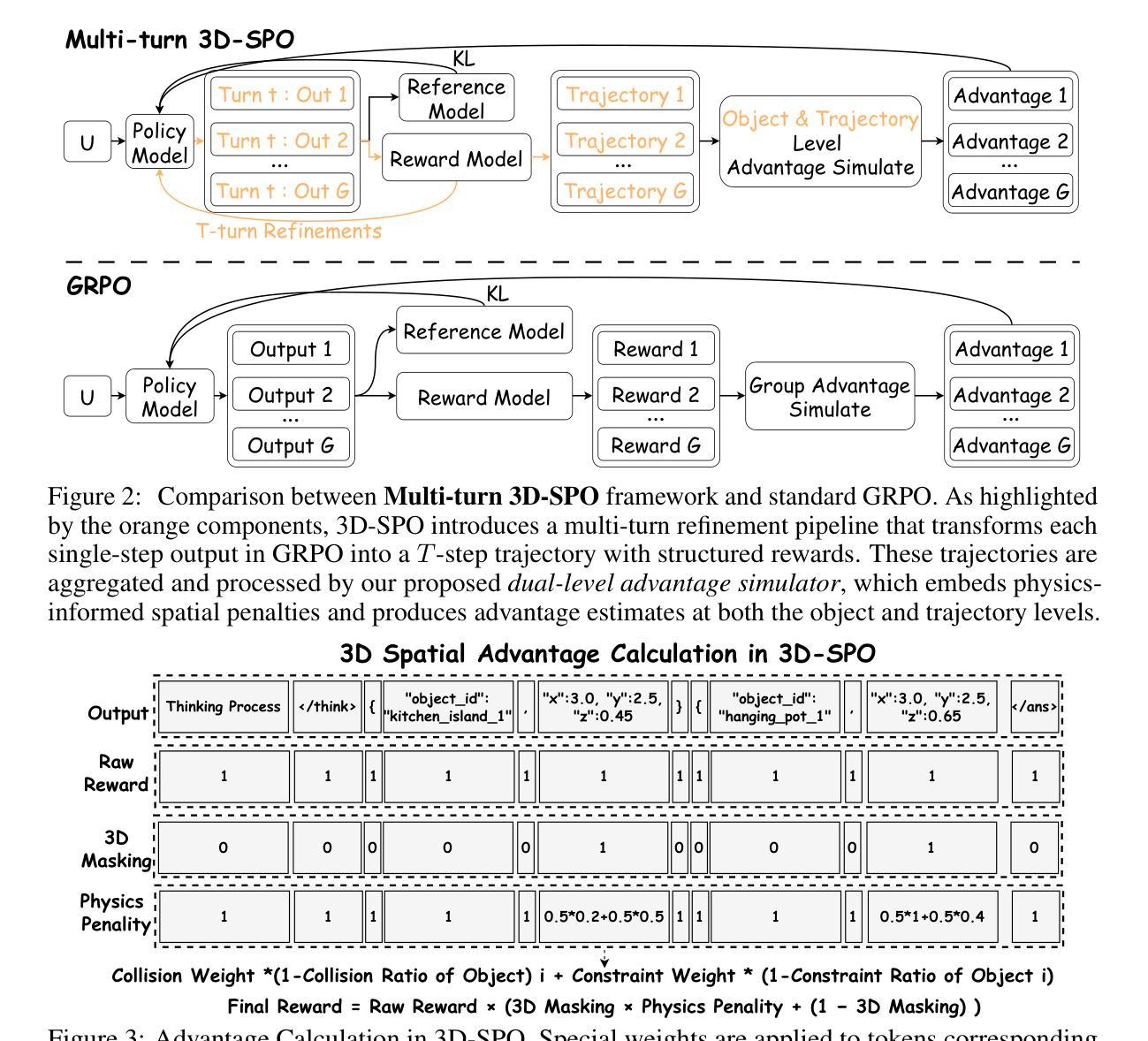
3D Gaussian Splatting (3DGS) has enabled photorealistic and real-time rendering of 3D head avatars. Existing 3DGS-based avatars typically rely on tens of thousands of 3D Gaussian points (Gaussians), with the number of Gaussians fixed after training. However, many practical applications require adjustable levels of detail (LOD) to balance rendering efficiency and visual quality. In this work, we propose “ArchitectHead”, the first framework for creating 3D Gaussian head avatars that support continuous control over LOD. Our key idea is to parameterize the Gaussians in a 2D UV feature space and propose a UV feature field composed of multi-level learnable feature maps to encode their latent features. A lightweight neural network-based decoder then transforms these latent features into 3D Gaussian attributes for rendering. ArchitectHead controls the number of Gaussians by dynamically resampling feature maps from the UV feature field at the desired resolutions. This method enables efficient and continuous control of LOD without retraining. Experimental results show that ArchitectHead achieves state-of-the-art (SOTA) quality in self and cross-identity reenactment tasks at the highest LOD, while maintaining near SOTA performance at lower LODs. At the lowest LOD, our method uses only 6.2% of the Gaussians while the quality degrades moderately (L1 Loss +7.9%, PSNR –0.97%, SSIM –0.6%, LPIPS Loss +24.1%), and the rendering speed nearly doubles.
3D高斯拼贴技术(3DGS)已经实现了对3D头部化身的光照现实实时渲染。现有的基于3DGS的化身通常需要数以万计的三维高斯点(Gaussians),并且高斯点的数量在训练后固定。然而,许多实际应用需要可调整的细节层次(LOD)来平衡渲染效率和视觉质量。在这项工作中,我们提出了“ArchitectHead”框架,它是第一个支持连续控制LOD的创建三维高斯头部化身的框架。我们的核心思想是在二维UV特征空间中对高斯进行参数化,并提出由多层可学习特征图组成的UV特征场来编码其潜在特征。然后,一个轻量级的神经网络解码器将这些潜在特征转换为用于渲染的三维高斯属性。ArchitectHead通过动态地从UV特征场中重新采样特征图,以所需分辨率控制高斯点的数量。这种方法无需重新训练即可实现高效的连续LOD控制。实验结果表明,在最高LOD下,ArchitectHead在自我和跨身份重建任务上达到了最新技术水平,同时在较低LOD下保持了接近最新技术水平的性能。在最低LOD下,我们的方法仅使用6.2%的高斯点,同时质量略有下降(L1损失增加7.9%,PSNR下降0.97%,SSIM下降0.6%,LPIPS损失增加24.1%),渲染速度几乎翻倍。
论文及项目相关链接
Summary
基于3D高斯喷绘技术(3DGS)创建三维头像化身,支持细节层次(LOD)的连续控制。通过参数化二维UV特征空间的高斯,提出UV特征场和多层可学习特征图编码潜在特征。使用轻量级神经网络解码器将这些潜在特征转换为3D高斯属性进行渲染。该方法可在不重新训练的情况下,通过动态重采样UV特征场的特征图来实现Gaussians数量的控制,从而实现对LOD的有效和连续控制。实验结果表明,ArchitectHead在最高LOD的自身和跨身份重播任务中达到最新技术水平,同时在较低LOD上保持接近最新性能。在最低LOD时,我们的方法仅使用6.2%的高斯质量略有下降(L1损失+7.9%,PSNR -0.97%,SSIM -0.6%,LPIPS损失+24.1%),渲染速度几乎翻倍。
Key Takeaways
- 3DGS技术已用于创建三维头像化身,实现真实感和实时渲染。
- 现有基于3DGS的化身通常依赖于大量固定数量的三维高斯点(Gaussians)。
- 实践应用中需要可调细节层次(LOD)以平衡渲染效率和视觉质量。
- 提出“ArchitectHead”框架,首次创建支持LOD连续控制的三维高斯头像。
- 通过参数化二维UV特征空间的高斯,使用UV特征场和多层可学习特征图进行编码。
- 使用轻量级神经网络解码器将潜在特征转换为3D高斯属性进行渲染。
点此查看论文截图
MetaFind: Scene-Aware 3D Asset Retrieval for Coherent Metaverse Scene Generation
Authors:Zhenyu Pan, Yucheng Lu, Han Liu
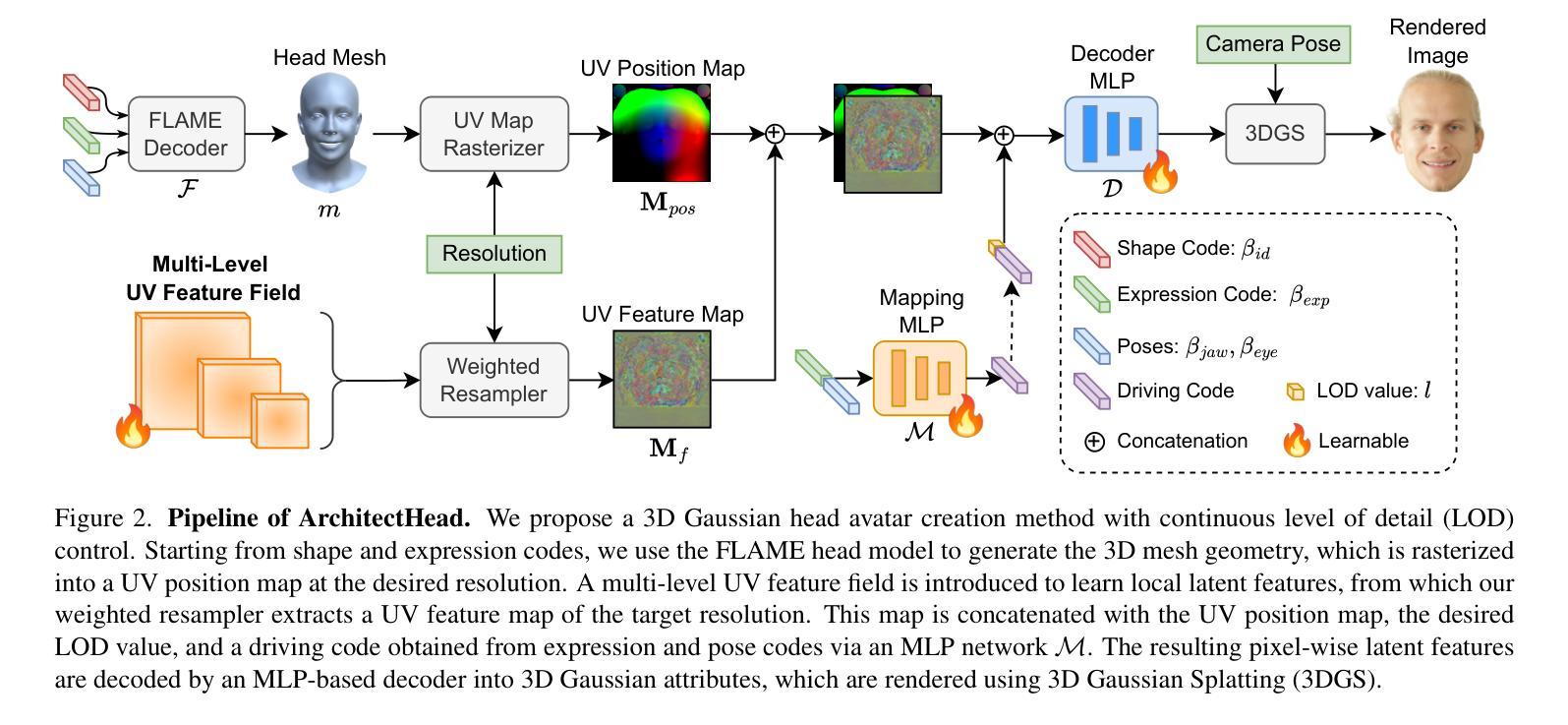
We present MetaFind, a scene-aware tri-modal compositional retrieval framework designed to enhance scene generation in the metaverse by retrieving 3D assets from large-scale repositories. MetaFind addresses two core challenges: (i) inconsistent asset retrieval that overlooks spatial, semantic, and stylistic constraints, and (ii) the absence of a standardized retrieval paradigm specifically tailored for 3D asset retrieval, as existing approaches mainly rely on general-purpose 3D shape representation models. Our key innovation is a flexible retrieval mechanism that supports arbitrary combinations of text, image, and 3D modalities as queries, enhancing spatial reasoning and style consistency by jointly modeling object-level features (including appearance) and scene-level layout structures. Methodologically, MetaFind introduces a plug-and-play equivariant layout encoder ESSGNN that captures spatial relationships and object appearance features, ensuring retrieved 3D assets are contextually and stylistically coherent with the existing scene, regardless of coordinate frame transformations. The framework supports iterative scene construction by continuously adapting retrieval results to current scene updates. Empirical evaluations demonstrate the improved spatial and stylistic consistency of MetaFind in various retrieval tasks compared to baseline methods.
我们介绍了MetaFind,这是一个场景感知的三模态组合检索框架,旨在通过从大规模存储库中检索3D资产来增强元宇宙的场景生成。MetaFind解决了两个核心挑战:(i)资产检索的不一致性,忽视了空间、语义和风格约束;(ii)缺乏专门针对3D资产检索的标准检索范式,因为现有方法主要依赖于通用3D形状表示模型。我们的关键创新之处在于灵活的检索机制,它支持文本、图像和3D模式的任意组合作为查询,通过联合建模对象级特征(包括外观)和场景级布局结构,增强空间推理和风格一致性。方法上,MetaFind引入了一个即插即用的等变布局编码器ESSGNN,捕捉空间关系和对象外观特征,确保检索到的3D资产在上下文和风格上与现有场景一致,而无论坐标框架如何变换。该框架支持通过不断适应当前场景更新来进行迭代场景构建。经验评估表明,与基准方法相比,MetaFind在各种检索任务中提高了空间和风格的一致性。
论文及项目相关链接
PDF The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS 2025)
Summary
MetaFind框架旨在通过从大规模仓库中检索3D资产,增强元宇宙的场景生成。它解决了资产检索的不一致性和缺乏针对3D资产检索的标准化检索模式这两个核心挑战。MetaFind支持文本、图像和3D模态的任意组合查询,通过联合建模对象级特征(包括外观)和场景级布局结构,增强了空间推理和风格一致性。它引入了一个灵活的场景生成框架来迭代建设场景并连续适应当前的场景更新。相比于基础方法,实证评估证明MetaFind在各种检索任务中提高了空间布局和风格的一致性。
Key Takeaways
- MetaFind是一个场景感知的三模态组合检索框架,旨在增强元宇宙的场景生成。
- 它解决了资产检索的不一致性和缺乏标准化检索模式的问题。
- 支持任意组合的文本、图像和3D查询模式。
- 通过联合建模对象级特征和场景级布局结构,增强了空间推理和风格一致性。
- 引入了一个灵活的场景生成框架来迭代建设场景并支持连续的场景更新适应。
点此查看论文截图
MetaSpatial: Reinforcing 3D Spatial Reasoning in VLMs for the Metaverse
Authors:Zhenyu Pan, Han Liu
We present MetaSpatial, the first reinforcement learning (RL)-based framework designed to enhance 3D spatial reasoning in vision-language models (VLMs), enabling real-time 3D scene generation without the need for hard-coded optimizations. MetaSpatial addresses two core challenges: (i) the lack of internalized 3D spatial reasoning in VLMs, which limits their ability to generate realistic layouts, and (ii) the inefficiency of traditional supervised fine-tuning (SFT) for layout generation tasks, as perfect ground truth annotations are unavailable. Our key innovation is a multi-turn RL-based optimization mechanism that integrates physics-aware constraints and rendered image evaluations, ensuring generated 3D layouts are coherent, physically plausible, and aesthetically consistent. Methodologically, MetaSpatial introduces an adaptive, iterative reasoning process, where the VLM refines spatial arrangements over multiple turns by analyzing rendered outputs, improving scene coherence progressively. Empirical evaluations demonstrate that MetaSpatial significantly enhances the spatial consistency and formatting stability of various scale models. Post-training, object placements are more realistic, aligned, and functionally coherent, validating the effectiveness of RL for 3D spatial reasoning in metaverse, AR/VR, digital twins, and game development applications. Our code, data, and training pipeline are publicly available at https://github.com/PzySeere/MetaSpatial.
我们推出MetaSpatial,这是首个基于强化学习(RL)的框架,旨在提升视觉语言模型(VLM)的3D空间推理能力,实现无需硬编码优化的实时3D场景生成。MetaSpatial解决了两个核心挑战:(i)VLM内部缺乏3D空间推理能力,限制了其生成真实布局的能力;(ii)对于布局生成任务,传统的监督微调(SFT)效率低下,因为无法获得完美的真实标注。我们的关键创新在于采用基于多回合的RL优化机制,结合了物理感知约束和渲染图像评估,确保生成的3D布局连贯、物理上可行且美学上一致。方法论上,MetaSpatial引入了一种自适应的迭代推理过程,VLM通过分析渲染输出,在多回合中不断完善空间布局,逐步改进场景的一致性。经验评估表明,MetaSpatial显著提高了各种规模模型的空间一致性和格式稳定性。训练后,对象放置更加真实、对齐且功能连贯,验证了强化学习在元宇宙、AR/VR、数字孪生和游戏开发应用中的3D空间推理有效性。我们的代码、数据和训练管道可在https://github.com/PzySeere/MetaSpatial公开访问。
论文及项目相关链接
PDF Working Paper
摘要
MetaSpatial是一个基于强化学习(RL)的框架,旨在增强视觉语言模型(VLMs)的3D空间推理能力,实现实时3D场景生成而无需硬编码优化。该框架解决了两个核心挑战:一是VLMs缺乏内在化的3D空间推理能力,限制了其生成真实布局的能力;二是传统监督微调(SFT)在布局生成任务中的效率不高,因为完美的真实标注不可用。MetaSpatial的关键创新在于采用了一种多轮RL优化机制,该机制集成了物理感知约束和渲染图像评估,确保生成的3D布局具有连贯性、物理可行性和审美一致性。经验评估表明,MetaSpatial显著提高了各种规模模型的空间一致性和格式稳定性。训练后,对象放置更加真实、对齐和功能连贯,验证了强化学习在元宇宙、AR/VR、数字孪生和游戏开发应用中的3D空间推理的有效性。
关键见解
- MetaSpatial是首个基于强化学习(RL)的框架,用于增强视觉语言模型的3D空间推理能力。
- 该框架解决了VLMs缺乏内在化的3D空间推理能力的问题,使得它们能够生成更真实的布局。
- MetaSpatial采用多轮RL优化机制,集成物理感知约束和渲染图像评估,确保生成的3D布局的连贯性、物理可行性和审美一致性。
- MetaSpatial通过自适应迭代推理过程,使VLM能够逐步改进场景的一致性。
- 经验评估表明,MetaSpatial提高了模型的空间一致性和格式稳定性。
- 训练后,对象放置更加真实、对齐和功能连贯,验证了强化学习在3D空间推理中的有效性。
- MetaSpatial在元宇宙、AR/VR、数字孪生和游戏开发等领域具有广泛的应用前景。
点此查看论文截图