⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-09 更新
EgoNight: Towards Egocentric Vision Understanding at Night with a Challenging Benchmark
Authors:Deheng Zhang, Yuqian Fu, Runyi Yang, Yang Miao, Tianwen Qian, Xu Zheng, Guolei Sun, Ajad Chhatkuli, Xuanjing Huang, Yu-Gang Jiang, Luc Van Gool, Danda Pani Paudel
Most existing benchmarks for egocentric vision understanding focus primarily on daytime scenarios, overlooking the low-light conditions that are inevitable in real-world applications. To investigate this gap, we present EgoNight, the first comprehensive benchmark for nighttime egocentric vision, with visual question answering (VQA) as the core task. A key feature of EgoNight is the introduction of day-night aligned videos, which enhance night annotation quality using the daytime data and reveal clear performance gaps between lighting conditions. To achieve this, we collect both synthetic videos rendered by Blender and real-world recordings, ensuring that scenes and actions are visually and temporally aligned. Leveraging these paired videos, we construct EgoNight-VQA, supported by a novel day-augmented night auto-labeling engine and refinement through extensive human verification. Each QA pair is double-checked by annotators for reliability. In total, EgoNight-VQA contains 3658 QA pairs across 90 videos, spanning 12 diverse QA types, with more than 300 hours of human work. Evaluations of state-of-the-art multimodal large language models (MLLMs) reveal substantial performance drops when transferring from day to night, underscoring the challenges of reasoning under low-light conditions. Beyond VQA, EgoNight also introduces two auxiliary tasks, day-night correspondence retrieval and egocentric depth estimation at night, that further explore the boundaries of existing models. We believe EgoNight-VQA provides a strong foundation for advancing application-driven egocentric vision research and for developing models that generalize across illumination domains. All the data and code will be made available upon acceptance.
现有针对以自我为中心的视觉理解基准测试大多侧重于白天场景,忽视了真实世界应用中不可避免的弱光条件。为了研究这一差距,我们推出了EgoNight,这是首个针对夜间以自我为中心的视觉的基准测试,核心任务为视觉问答(VQA)。EgoNight的关键特点是引入了日夜对齐的视频,这些视频利用白天数据提高了夜间注释质量,并揭示了不同照明条件之间的性能差距。为了实现这一点,我们收集了由Blender渲染的合成视频和真实世界录制,确保场景和动作在视觉和时间上的对齐。通过这些配对视频,我们构建了EgoNight-VQA,它由一个新型日间增强夜间自动标注引擎支持,并通过大量的人工验证进行完善。每个问答对都由注释者进行双重检查,以确保可靠性。总共有EgoNight-VQA包含3658个问答对,跨越90个视频,涵盖12种多样的问答类型,需要超过300小时的人工工作。对最先进的跨模态大型语言模型(MLLMs)的评估显示,从白天到夜晚的迁移导致性能大幅下降,这强调了在低光照条件下进行推理的挑战。除了VQA之外,EgoNight还引入了另外两个辅助任务,即日夜对应性检索和夜间以自我为中心的深度估计,进一步探索了现有模型的边界。我们相信EgoNight-VQA为以应用为导向的以自我为中心的视觉研究以及开发能够跨照明领域推广的模型提供了坚实的基础。所有数据代码将在接受后公开。
论文及项目相关链接
摘要
本文关注现有以自我为中心的视觉理解基准测试主要关注白天场景,忽略了实际应用中不可避免的夜间低光条件的问题。因此,提出了EgoNight,这是首个针对夜间以自我为中心的视觉的全面基准测试,以视觉问答(VQA)为核心任务。EgoNight的关键在于引入了昼夜对齐的视频,利用白天数据提高夜间注释质量,并揭示了照明条件之间的性能差距。通过收集由Blender渲染的合成视频和真实世界录制,确保场景和动作在视觉和时间上的对齐。借助这些配对视频,构建了EgoNight-VQA,由新颖的白天增强夜间自动标签引擎支持,并通过大量的人工验证进行完善。每个问答对都经过注释者的双重检查以确保可靠性。EgoNight-VQA包含跨越12种不同问答类型的3658个问答对,跨越90个视频,总计超过300小时的人工工作。对最先进的跨模态大型语言模型的评估显示,从白天转移到夜晚时性能大幅下降,突显了低光条件下推理的挑战性。除了VQA之外,EgoNight还引入了昼夜对应检索和夜间以自我为中心的深度估计两个辅助任务,进一步探索现有模型的边界。我们相信EgoNight-VQA为以应用为导向的以自我为中心的研究提供了坚实的基础,并为开发能够适应照明域变化的模型铺平了道路。所有数据与代码将在审核通过后公布。
要点总结
- 提出首个针对夜间以自我为中心的视觉基准测试——EgoNight。
- 专注于解决现有基准测试忽视夜间低光条件的问题。
- 以视觉问答(VQA)为核心任务,强调在夜间理解场景的重要性。
- 创新引入昼夜对齐的视频,以提高夜间注释质量和揭示照明条件的性能差距。
- 构建EgoNight-VQA数据集,包含合成视频和真实世界录制的视频,确保视觉和时间上的对齐。
- 利用白天数据增强夜间自动标签引擎,并通过大量人工验证完善数据集。
点此查看论文截图


Stratified GRPO: Handling Structural Heterogeneity in Reinforcement Learning of LLM Search Agents
Authors:Mingkang Zhu, Xi Chen, Bei Yu, Hengshuang Zhao, Jiaya Jia
Large language model (LLM) agents increasingly rely on external tools such as search engines to solve complex, multi-step problems, and reinforcement learning (RL) has become a key paradigm for training them. However, the trajectories of search agents are structurally heterogeneous, where variations in the number, placement, and outcomes of search calls lead to fundamentally different answer directions and reward distributions. Standard policy gradient methods, which use a single global baseline, suffer from what we identify and formalize as cross-stratum bias-an “apples-to-oranges” comparison of heterogeneous trajectories. This cross-stratum bias distorts credit assignment and hinders exploration of complex, multi-step search strategies. To address this, we propose Stratified GRPO, whose central component, Stratified Advantage Normalization (SAN), partitions trajectories into homogeneous strata based on their structural properties and computes advantages locally within each stratum. This ensures that trajectories are evaluated only against their true peers. Our analysis proves that SAN eliminates cross-stratum bias, yields conditionally unbiased unit-variance estimates inside each stratum, and retains the global unbiasedness and unit-variance properties enjoyed by standard normalization, resulting in a more pure and scale-stable learning signal. To improve practical stability under finite-sample regimes, we further linearly blend SAN with the global estimator. Extensive experiments on diverse single-hop and multi-hop question-answering benchmarks demonstrate that Stratified GRPO consistently and substantially outperforms GRPO by up to 11.3 points, achieving higher training rewards, greater training stability, and more effective search policies. These results establish stratification as a principled remedy for structural heterogeneity in RL for LLM search agents.
大型语言模型(LLM)代理越来越依赖搜索引擎等外部工具来解决复杂的多步骤问题,强化学习(RL)已成为训练它们的关键范式。然而,搜索代理的轨迹在结构上具有异质性,搜索呼叫的数量、位置和结果的变化导致答案方向和奖励分布根本不同。标准策略梯度方法使用单一的全球基线,遭受我们确定和形式化的跨阶层偏见的影响,这是对异质轨迹的“苹果与橙子”的比较。这种跨阶层偏见扭曲了信用分配并阻碍了复杂的多步骤搜索策略的探索。
为了解决这一问题,我们提出了分层GRPO,其核心组件分层优势归一化(SAN)根据结构特性将轨迹划分为同质的阶层,并在每个阶层内部进行局部优势计算。这确保了对轨迹的评估只针对其真正的同行。我们的分析证明,SAN消除了跨阶层偏见,在每个阶层内部产生条件无偏的单位方差估计,并保留了标准归一化所享有的全局无偏性和单位方差属性,从而产生更纯净和更稳定的学习信号。
论文及项目相关链接
摘要
大型语言模型(LLM)代理人越来越多地依赖外部工具,如搜索引擎来解决复杂的多步骤问题,强化学习(RL)已成为训练它们的关键范式。然而,搜索代理的轨迹在结构上具有异质性,搜索调用的数量、位置和结果的不同导致答案方向和奖励分布的根本差异。标准策略梯度方法使用单一全局基准线,存在跨层次偏差的问题,即异质轨迹的“苹果和橙子”的比较。这种跨层次偏差扭曲了信用分配并阻碍了复杂多步骤搜索策略的探索。为解决此问题,我们提出分层GRPO方法,其核心组件分层优势归一化(SAN)根据结构特性将轨迹划分为均匀的层次,并在每个层次内局部计算优势。确保轨迹只与其真正的同行进行评估。我们的分析证明SAN消除了跨层次偏差,在每个层次内产生条件无偏的单位方差估计,并保留了全局无偏性和单位方差属性,从而产生了更纯净和稳定的学习信号。为提高有限样本下的实际稳定性,我们将SAN与全局估计器进行线性混合。在多样的单跳和多跳问答基准测试上的实验表明,分层GRPO在各个方面均显著且持续优于GRPO,提高了训练奖励、训练稳定性和搜索策略的有效性。这些结果确立了分层作为解决RL中LLM搜索代理结构异质性的有效方法。
关键发现
- LLM代理人越来越多依赖外部工具如搜索引擎解决复杂问题,强化学习是训练关键。
- 搜索代理轨迹存在结构性异质性,影响答案方向和奖励分布。
- 标准策略梯度方法存在跨层次偏差问题。
- 提出分层GRPO方法,通过分层优势归一化(SAN)解决跨层次偏差问题。
- SAN确保轨迹评估与其真实同行进行,消除跨层次偏差并产生更纯净稳定的学习信号。
- SAN与全局估计器结合,提高有限样本下的实际稳定性。
点此查看论文截图
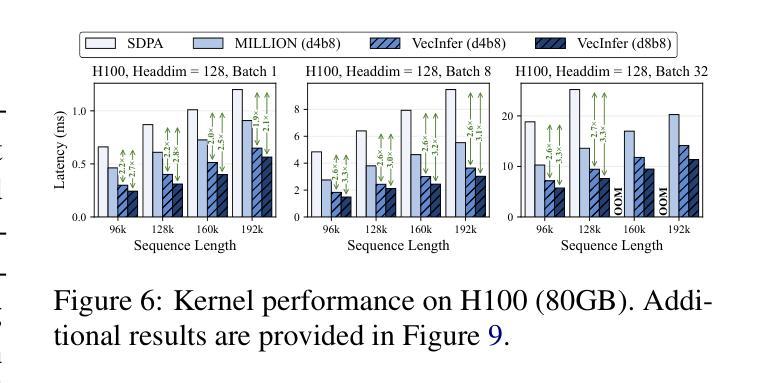
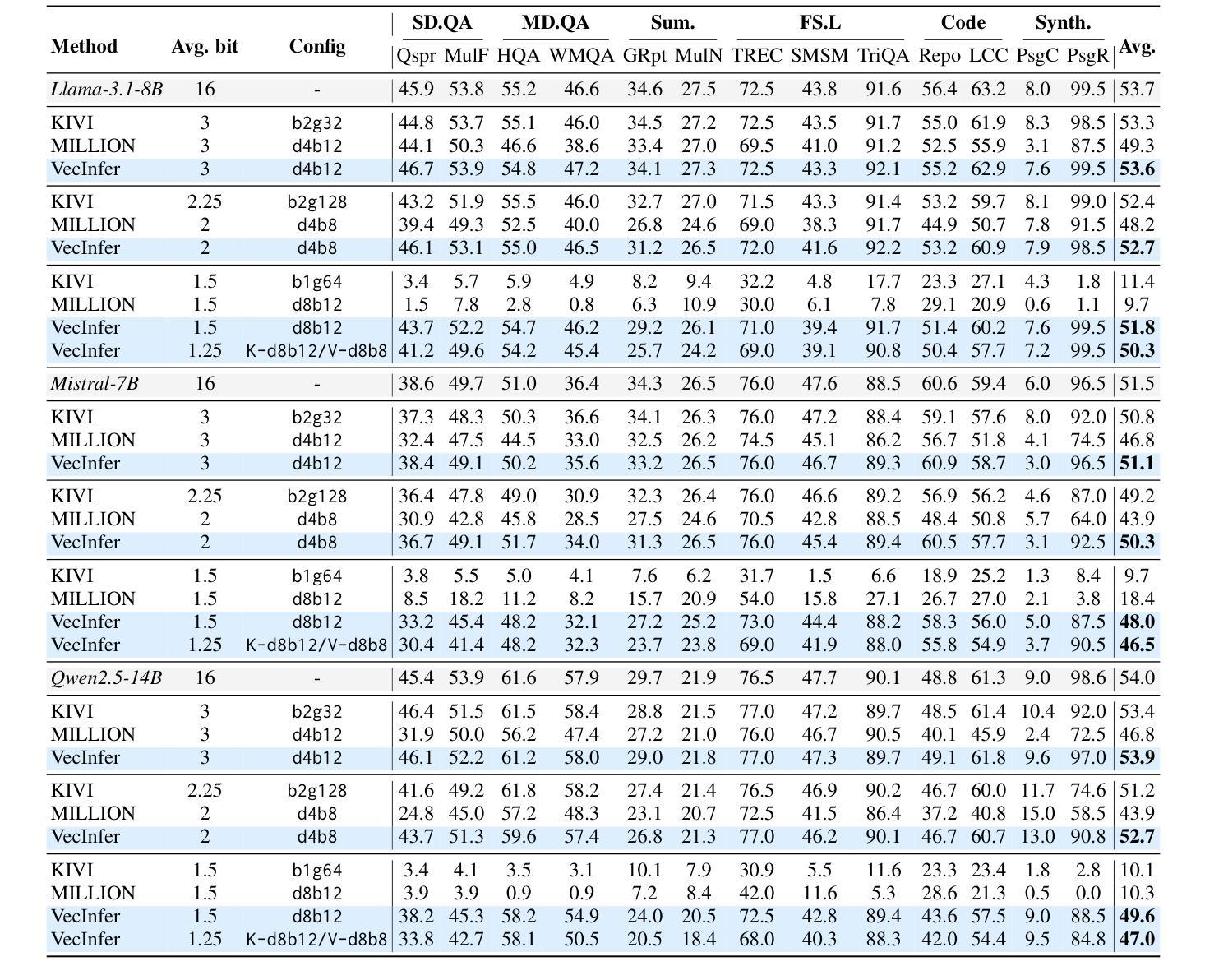
VecInfer: Efficient LLM Inference with Low-Bit KV Cache via Outlier-Suppressed Vector Quantization
Authors:Dingyu Yao, Chenxu Yang, Zhengyang Tong, Zheng Lin, Wei Liu, Jian Luan, Weiping Wang
The Key-Value (KV) cache introduces substantial memory overhead during large language model (LLM) inference. Although existing vector quantization (VQ) methods reduce KV cache usage and provide flexible representational capacity across bit-widths, they suffer severe performance degradation at ultra-low bit-widths due to key cache outliers that hinder effective codebook utilization. To address this challenge, we propose VecInfer, a novel VQ method for aggressive KV cache compression while enabling efficient inference. By applying smooth and Hadamard transformations, VecInfer suppresses outliers in the key cache, enabling the codebook to comprehensively cover the original data distribution and thereby reducing quantization difficulty. To facilitate efficient deployment, we design an optimized CUDA kernel that fuses computation with dequantization to minimize memory access overhead. Extensive evaluations demonstrate that VecInfer consistently outperforms existing quantization baselines across both long-context understanding and mathematical reasoning tasks. With only 2-bit quantization, VecInfer achieves performance comparable to full precision, while delivering up to $\mathbf{2.7\times}$ speedup in large-batch self-attention computation and $\mathbf{8.3\times}$ reduction in single-batch end-to-end latency on Llama-3.1-8B with a 196k sequence length.
键值(KV)缓存在大语言模型(LLM)推理过程中引入了较大的内存开销。尽管现有的向量量化(VQ)方法减少了KV缓存的使用,并在不同位宽下提供了灵活的表现能力,但在超低位宽下,由于关键缓存异常值阻碍了有效代码本的使用,它们遭受了严重的性能下降。为了解决这一挑战,我们提出了VecInfer,这是一种新型的VQ方法,用于激烈的KV缓存压缩,同时实现高效推理。通过应用平滑和哈达玛变换,VecInfer抑制了键缓存中的异常值,使代码本能够全面覆盖原始数据分布,从而降低量化难度。为了促进高效部署,我们设计了一个优化的CUDA内核,融合了计算与反量化,以最小化内存访问开销。广泛评估表明,VecInfer在长短文理解在数学推理任务中均持续优于现有量化基线。仅使用2位量化,VecInfer即可实现与全精度相当的性能,同时在Llama-3.1-8B的大批次自注意力计算中实现高达2.7倍的速度提升,在单批次端到端延迟上实现高达8.3倍的减少,序列长度达到19.6万。
论文及项目相关链接
Summary
在大型语言模型(LLM)推理过程中,键值(KV)缓存会带来巨大的内存开销。现有向量量化(VQ)方法虽能减少KV缓存使用并提供灵活的表示能力,但在超低位宽下却因关键缓存异常值而性能严重下降。为此,我们提出VecInfer,一种用于激烈KV缓存压缩的新型VQ方法,可实现高效推理。VecInfer通过应用平滑和哈达玛变换,抑制关键缓存中的异常值,使代码本能够全面覆盖原始数据分布,从而降低量化难度。为高效部署,我们设计了一个优化的CUDA内核,将计算与反量化相结合,以最小化内存访问开销。评估表明,VecInfer在长短文理解和数学推理任务上均优于现有量化基线。仅使用2位量化,VecInfer即可实现与全精度相当的性能,同时在Llama-3.1-8B的大型批次自注意力计算中实现了高达2.7倍的加速,并在单批次端到端延迟上实现了高达8.3倍的减少。
Key Takeaways
- KV缓存在大规模语言模型(LLM)推理中引入显著内存开销。
- 现有VQ方法在超低位宽下性能严重下降,因为关键缓存异常值阻碍代码本有效利用。
- VecInfer是一种新型VQ方法,旨在解决KV缓存压缩问题并实现高效推理。
- VecInfer通过平滑和哈达玛变换抑制关键缓存中的异常值。
- VecInfer优化CUDA内核,结合计算与反量化,降低内存访问开销。
- VecInfer在长短文理解和数学推理任务上表现优于现有量化方法。
点此查看论文截图

LLMs as Policy-Agnostic Teammates: A Case Study in Human Proxy Design for Heterogeneous Agent Teams
Authors:Aju Ani Justus, Chris Baber
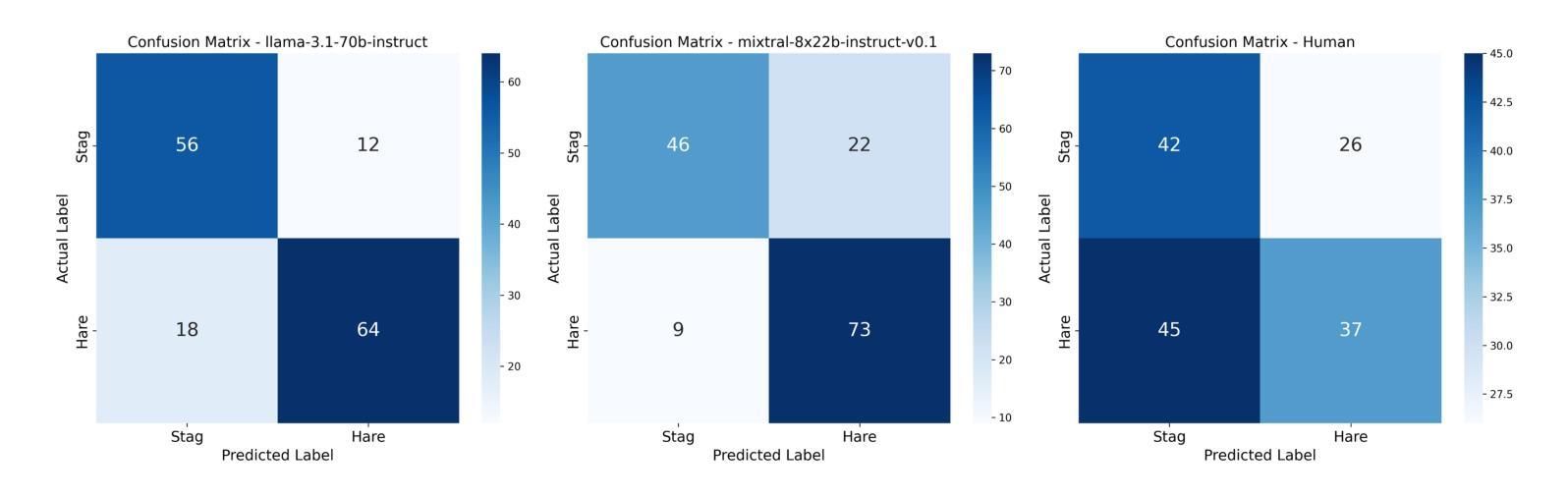
A critical challenge in modelling Heterogeneous-Agent Teams is training agents to collaborate with teammates whose policies are inaccessible or non-stationary, such as humans. Traditional approaches rely on expensive human-in-the-loop data, which limits scalability. We propose using Large Language Models (LLMs) as policy-agnostic human proxies to generate synthetic data that mimics human decision-making. To evaluate this, we conduct three experiments in a grid-world capture game inspired by Stag Hunt, a game theory paradigm that balances risk and reward. In Experiment 1, we compare decisions from 30 human participants and 2 expert judges with outputs from LLaMA 3.1 and Mixtral 8x22B models. LLMs, prompted with game-state observations and reward structures, align more closely with experts than participants, demonstrating consistency in applying underlying decision criteria. Experiment 2 modifies prompts to induce risk-sensitive strategies (e.g. “be risk averse”). LLM outputs mirror human participants’ variability, shifting between risk-averse and risk-seeking behaviours. Finally, Experiment 3 tests LLMs in a dynamic grid-world where the LLM agents generate movement actions. LLMs produce trajectories resembling human participants’ paths. While LLMs cannot yet fully replicate human adaptability, their prompt-guided diversity offers a scalable foundation for simulating policy-agnostic teammates.
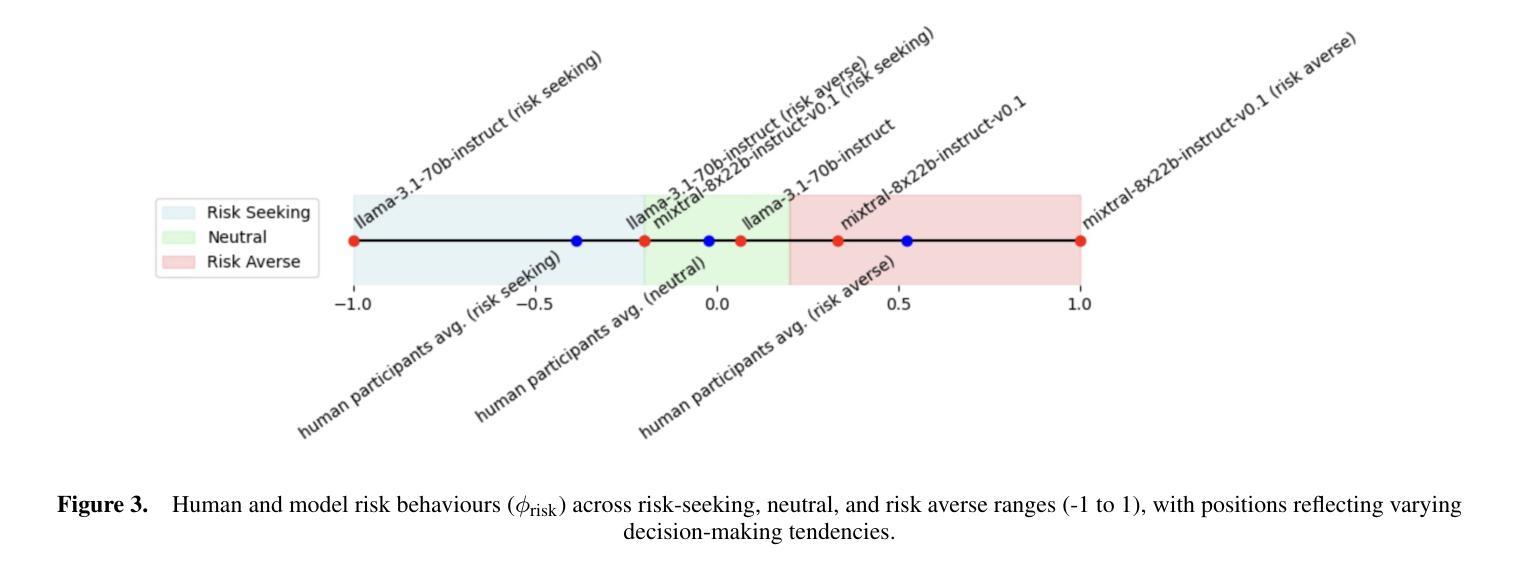
在模拟异质代理团队时,一个关键的挑战是训练代理与策略不可访问或非固定(如人类)的队友进行协作。传统的方法依赖于昂贵的人力闭环数据,这限制了可扩展性。我们建议使用大型语言模型(LLM)作为策略无关的人类代理,生成模仿人类决策的合成数据。为了评估这一点,我们在一个网格世界捕捉游戏中进行了三项实验,该游戏受到博弈论范式Stag Hunt的启发,平衡了风险和奖励。在第一个实验中,我们将来自30名人类参与者和2名专家评委的决策与LLaMA 3.1和Mixtral 8x22B模型的输出进行比较。使用游戏状态观察和奖励结构来提示LLM,其结果与专家相比更接近于人类参与者的决策,显示出在运用基本决策标准方面的一致性。第二个实验修改了提示来诱导风险敏感策略(例如,“规避风险”)。LLM的输出反映了人类参与者的变化性,在规避风险和寻求风险的行为之间转变。最后,第三个实验在动态网格世界中测试LLM,其中LLM代理生成移动动作。LLM产生的轨迹类似于人类参与者的路径。虽然LLM还不能完全复制人类的适应能力,但其提示引导的多样性为模拟策略无关队友提供了可扩展的基础。
论文及项目相关链接
PDF This is a preprint of a paper presented at the \textit{European Conference on Artificial Intelligence (ECAI 2025)}. It is made publicly available for the benefit of the research community and should be regarded as a preprint rather than a formally reviewed publication
Summary
大型语言模型(LLMs)被用于模拟人类决策,解决异质代理团队协作中的挑战。通过生成合成数据,模拟人类行为,并进行了三项实验验证。实验表明,LLMs能够在游戏理论范式中平衡风险与奖励,与专家决策更为一致,并展现出一定的风险敏感性。尽管无法完全复制人类的适应性,但LLMs的引导多样性为模拟政策无关的队友提供了可扩展的基础。
Key Takeaways
- 大型语言模型(LLMs)被应用于模拟人类决策,解决异质代理团队协作中的挑战。
- LLMs通过生成合成数据,模拟人类行为。
- 在游戏理论范式中,LLMs展现出平衡风险与奖励的能力。
- LLMs的决策与专家更为一致,相比人类参与者更具一致性。
- 通过调整提示,LLMs能够展现出风险敏感性。
- LLMs的引导多样性为模拟政策无关的队友提供了基础。
点此查看论文截图
RoSE: Round-robin Synthetic Data Evaluation for Selecting LLM Generators without Human Test Sets
Authors:Jan Cegin, Branislav Pecher, Ivan Srba, Jakub Simko
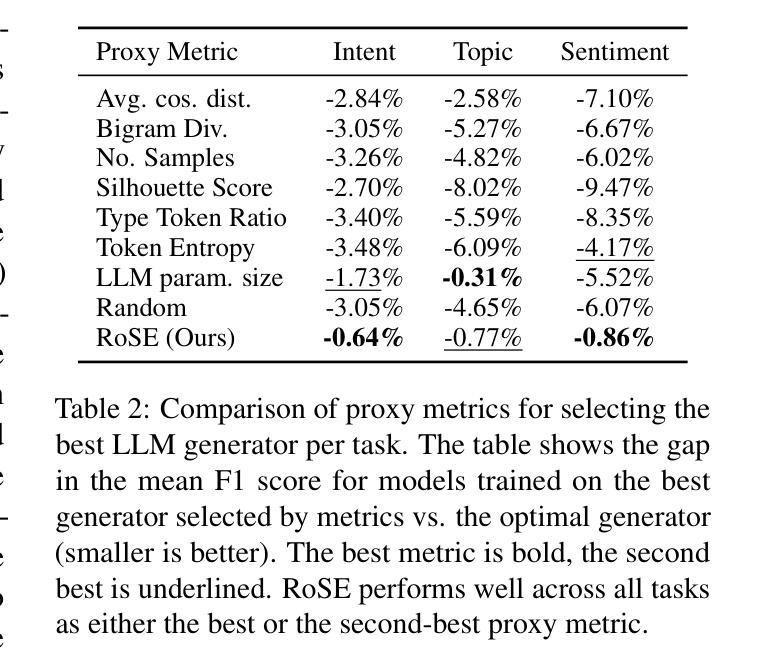
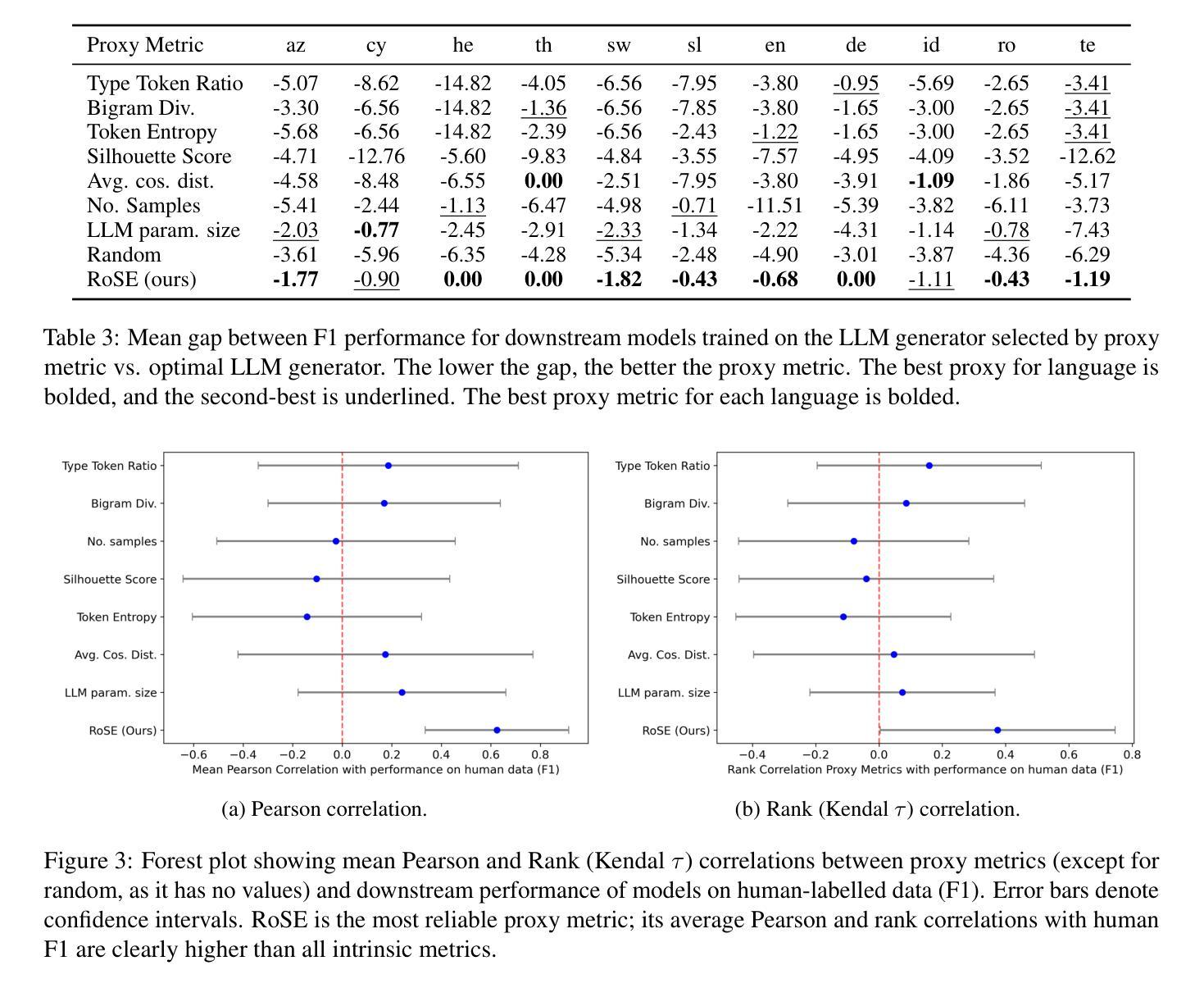
LLMs are powerful generators of synthetic data, which are used for training smaller, specific models. This is especially valuable for low-resource languages, where human-labelled data is scarce but LLMs can still produce high-quality text. However, LLMs differ in how useful their outputs are for training. Selecting the best LLM as a generator is challenging because extrinsic evaluation requires costly human annotations (which are often unavailable for low-resource languages), while intrinsic metrics correlate poorly with downstream performance. We introduce Round robin Synthetic data Evaluation (RoSE), a proxy metric for selecting the best LLM generator without human test sets. RoSE trains a small model on the outputs of a candidate generator (LLM) and then evaluates it on generated synthetic examples from all other candidate LLMs. The final RoSE score is the mean performance of this small model. Across six LLMs, eleven languages, and three tasks (sentiment, topic, intent), RoSE identifies the optimal generator more often than any other intrinsic heuristics. RoSE outperforms intrinsic heuristics and comes within 0.76 percentage points of the optimal generator baseline. This result is measured in terms of downstream performance, obtained by training a small model on the chosen generator’s outputs (optimal vs. proxy metric selected) and evaluating it on human-labelled test data. Additionally, RoSE is the only metric to achieve a positive correlation with performance on human test data.
大型语言模型(LLM)是强大的合成数据生成器,用于训练更小、更具体的模型。这在资源贫乏的语言中尤其有价值,因为这类语言的人类标注数据稀缺,但LLM仍然可以生成高质量的文本。然而,LLM在训练方面的输出效用存在差异。选择最佳LLM作为生成器是一项挑战,因为外在评估需要昂贵的人力标注(对于低资源语言通常无法获得),而内在指标与下游性能相关性很差。我们引入了轮转合成数据评估(RoSE),这是一种无需人工测试集的代理指标,用于选择最佳的LLM生成器。RoSE在一个候选生成器(LLM)的输出上训练一个小模型,然后在所有其他候选LLM生成的合成示例上对其进行评估。最终RoSE得分是这个小模型的平均性能。在六个LLM、十一种语言和三个任务(情感、主题、意图)中,RoSE比任何其他内在启发式方法更频繁地识别出最佳生成器。RoSE的表现优于内在启发式方法,并且与最佳生成器基准之间的差距缩小了0.76个百分点。这一结果是通过在所选生成器的输出上训练一个小模型(最佳与代理指标选择)并在人工测试数据上对其进行评估来衡量的。此外,RoSE是唯一与人类测试数据性能呈正相关性的指标。
论文及项目相关链接
PDF 16 pages
Summary
LLMs可生成用于训练小型特定模型的高质量合成数据,对低资源语言尤为有价值。然而,在选择最佳LLM生成器时面临挑战,因为外在评估需要昂贵的人力标注,而内在指标与下游性能相关性差。为此,我们提出了Round robin Synthetic data Evaluation(RoSE)方法,这是一种无需人工测试集的LLM生成器选择代理指标。RoSE在候选生成器(LLM)的输出上训练一个小模型,然后在所有其他候选LLM生成的示例上对其进行评估。最终RoSE得分是这个小模型的平均性能。在六个LLM、十一种语言和三个任务上,RoSE比任何其他内在启发式方法更能识别出最佳生成器。在下游性能上,RoSE的性能接近于最佳生成器基线。此外,RoSE是唯一与人类测试数据性能呈正相关性的指标。
Key Takeaways
- LLMs能够生成高质量合成数据,对低资源语言尤为有价值。
- 选择最佳LLM生成器具有挑战性,因为外在评估需要大量人力标注,而内在指标与下游性能相关性不强。
- 提出了RoSE方法作为无需人工测试集的LLM生成器选择代理指标。
- RoSE通过在候选LLM的输出上训练小模型,并在其他候选LLM生成的示例上评估其性能来选择最佳生成器。
- RoSE在多个LLM、语言和任务上的表现优于其他内在启发式方法,并接近最佳生成器的下游性能。
- RoSE是唯一与人类测试数据性能呈正相关性的指标。
点此查看论文截图
lm-Meter: Unveiling Runtime Inference Latency for On-Device Language Models
Authors:Haoxin Wang, Xiaolong Tu, Hongyu Ke, Huirong Chai, Dawei Chen, Kyungtae Han
Large Language Models (LLMs) are increasingly integrated into everyday applications, but their prevalent cloud-based deployment raises growing concerns around data privacy and long-term sustainability. Running LLMs locally on mobile and edge devices (on-device LLMs) offers the promise of enhanced privacy, reliability, and reduced communication costs. However, realizing this vision remains challenging due to substantial memory and compute demands, as well as limited visibility into performance-efficiency trade-offs on resource-constrained hardware. We propose lm-Meter, the first lightweight, online latency profiler tailored for on-device LLM inference. lm-Meter captures fine-grained, real-time latency at both phase (e.g., embedding, prefill, decode, softmax, sampling) and kernel levels without auxiliary devices. We implement lm-Meter on commercial mobile platforms and demonstrate its high profiling accuracy with minimal system overhead, e.g., only 2.58% throughput reduction in prefill and 0.99% in decode under the most constrained Powersave governor. Leveraging lm-Meter, we conduct comprehensive empirical studies revealing phase- and kernel-level bottlenecks in on-device LLM inference, quantifying accuracy-efficiency trade-offs, and identifying systematic optimization opportunities. lm-Meter provides unprecedented visibility into the runtime behavior of LLMs on constrained platforms, laying the foundation for informed optimization and accelerating the democratization of on-device LLM systems. Code and tutorials are available at https://github.com/amai-gsu/LM-Meter.
大型语言模型(LLM)在日常应用中的集成度越来越高,但它们普遍采用云部署方式引发了人们对数据隐私和长期可持续性的日益关注。在移动设备和边缘设备上本地运行LLM(即设备上的LLM)有望增强隐私、可靠性和降低通信成本。然而,由于巨大的内存和计算需求,以及在资源受限的硬件上性能效率权衡的可见性有限,实现这一愿景仍然具有挑战性。我们提出了lm-Meter,这是一款专为设备上的LLM推理量身定制的轻便型在线延迟分析器。lm-Meter能够捕获精细的实时延迟,包括阶段延迟(例如嵌入、预填充、解码、softmax、采样)和核心级别延迟,而无需额外的辅助设备。我们在商业移动平台上实现了lm-Meter,并展示了其高分析精度和极低的系统开销,例如在性能受限的Powersave管理器的管理下,预填充的吞吐量仅减少2.58%,解码减少0.99%。利用lm-Meter,我们进行了全面的实证研究,揭示了设备上LLM推理的阶段和核心级别瓶颈,量化了精度效率权衡,并发现了系统化的优化机会。lm-Meter提供了对受限平台上LLM运行时行为的前所未有的可见性,为优化提供了信息基础,并加速了设备上的LLM系统的普及。代码和教程可在https://github.com/amai-gsu/LM-Meter获取。
论文及项目相关链接
PDF This is the preprint version of the paper accepted to The 10th ACM/IEEE Symposium on Edge Computing (SEC 2025)
Summary:随着大型语言模型(LLM)在日常应用中的集成度不断提高,其基于云端的部署方式引发了关于数据隐私和长期可持续性的日益担忧。在移动设备和边缘设备上本地运行LLM提供了增强隐私、可靠性和降低通信成本的承诺。然而,由于巨大的内存和计算需求以及资源受限硬件上性能效率权衡的可见度有限,实现这一愿景仍然具有挑战性。为此,本文提出了lm-Meter,这是一款专为设备端LLM推理量身定制的轻量级在线延迟分析器。lm-Meter可以在不依赖辅助设备的情况下捕获精细的实时延迟数据,包括阶段层面(如嵌入、预填充、解码、softmax、采样)和内核层面。本文在商用移动平台上实现了lm-Meter,并展示了其高分析精度和低系统开销。利用lm-Meter进行的实证研究表明了设备端LLM推理中阶段和内核级别的瓶颈问题,量化了精度效率权衡,并发现了系统优化机会。lm-Meter提供了对受限平台上LLM运行时行为的前所未有的可见性,为优化提供了信息基础并加速了设备端LLM系统的民主化。
Key Takeaways:
- 大型语言模型(LLMs)在日常应用中的集成度不断提高,但其云部署方式引发数据隐私和长期可持续性的担忧。
- 在移动和边缘设备上本地运行LLM(即on-device LLMs)具有增强隐私、可靠性和降低通信成本的潜力。
- 实现on-device LLMs面临巨大的内存和计算需求以及硬件资源限制的挑战。
- lm-Meter是专为on-device LLM推理设计的轻量级在线延迟分析器,可捕获精细的实时延迟数据。
- lm-Meter在商用移动平台上的实现展示了其高分析精度和低的系统开销。
- 利用lm-Meter进行的实证研究表明了阶段和内核级别的瓶颈问题,并发现了系统优化机会。
- lm-Meter提供了对受限平台上LLM运行时行为的可见性,有助于优化并加速设备端LLM系统的民主化。
点此查看论文截图

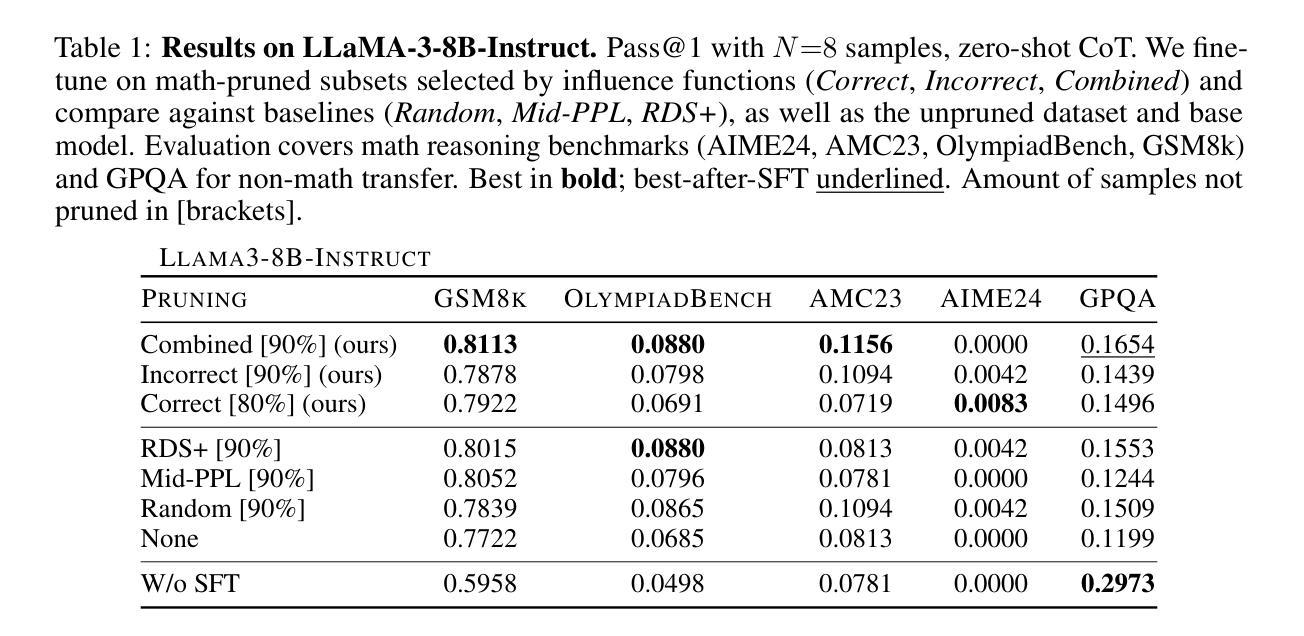
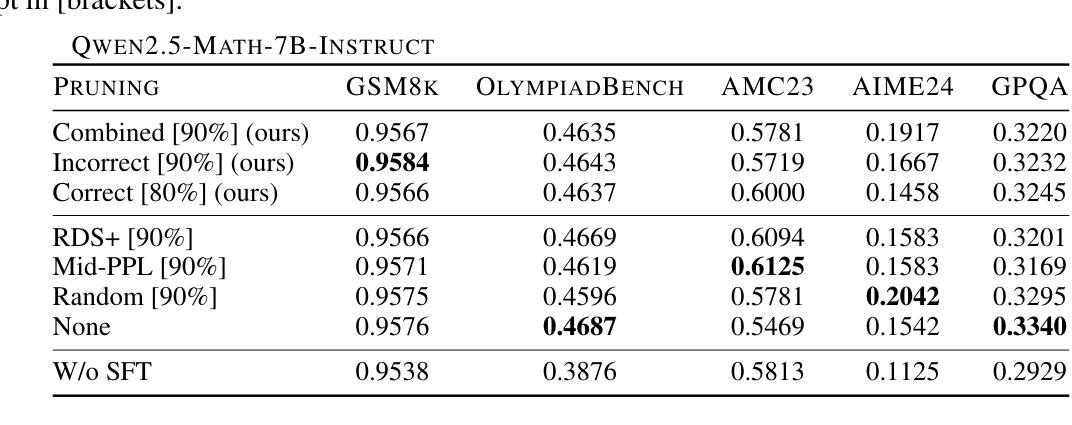
Influence Functions for Efficient Data Selection in Reasoning
Authors:Prateek Humane, Paolo Cudrano, Daniel Z. Kaplan, Matteo Matteucci, Supriyo Chakraborty, Irina Rish
Fine-tuning large language models (LLMs) on chain-of-thought (CoT) data shows that a small amount of high-quality data can outperform massive datasets. Yet, what constitutes “quality” remains ill-defined. Existing reasoning methods rely on indirect heuristics such as problem difficulty or trace length, while instruction-tuning has explored a broader range of automated selection strategies, but rarely in the context of reasoning. We propose to define reasoning data quality using influence functions, which measure the causal effect of individual CoT examples on downstream accuracy, and introduce influence-based pruning, which consistently outperforms perplexity and embedding-based baselines on math reasoning within a model family.
对思维链(CoT)数据微调大型语言模型(LLM)表明,少量高质量数据的表现可能优于大规模数据集。然而,“质量”的定义仍然不明确。现有的推理方法依赖于间接的启发式方法,如问题难度或跟踪长度,而指令微调已经探索了更广泛的自动选择策略,但很少在推理的语境下使用。我们提议使用影响函数来定义推理数据质量,影响函数可以衡量个别思维链示例对下游准确性的因果效应,并引入基于影响的修剪方法,该方法在模型家族内的数学推理上,表现优于困惑度和基于嵌入的基线。
论文及项目相关链接
Summary:通过微调大型语言模型(LLM)在思维链(CoT)数据上,发现少量高质量数据的表现可能优于大规模数据集。然而,“质量”的定义仍然不明确。现有推理方法依赖于间接的启发式方法,如问题难度或跟踪长度,而指令调整则探索了更广泛的自动化选择策略,但很少在推理的情境中应用。我们提议使用影响函数来定义推理数据质量,它衡量单个思维链示例对下游准确性的因果效应,并引入基于影响力的修剪,它在模型家族的数学推理上始终优于困惑度和基于嵌入的基线。
Key Takeaways:
- 少量高质量数据在微调大型语言模型时可能表现优于大规模数据集。
- 现有推理方法在定义数据质量时主要依赖间接启发式方法。
- 推理数据质量可以通过影响函数来衡量,它反映了单个思维链示例对下游准确性的因果效应。
- 基于影响力的修剪方法在模型家族的数学推理任务上表现优异。
- 与困惑度和基于嵌入的基线相比,基于影响力的修剪具有显著优势。
- 这种方法为如何选择和优化用于微调大型语言模型的推理数据提供了新的视角。
点此查看论文截图

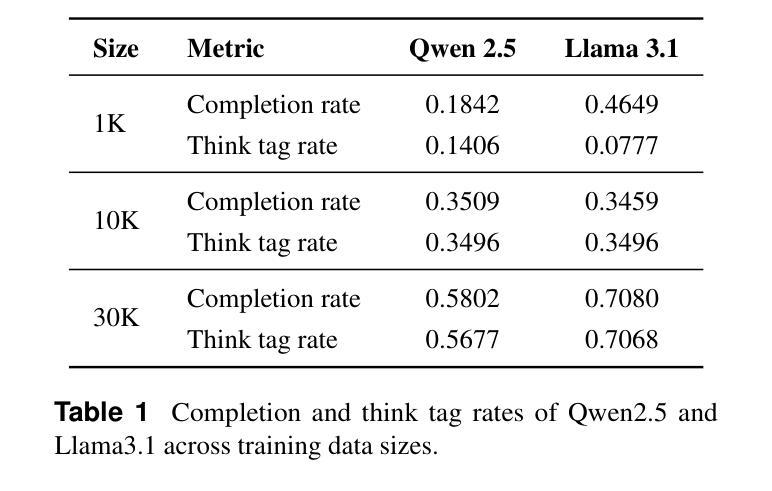
The Valley of Code Reasoning: Scaling Knowledge Distillation of Large Language Models
Authors:Muyu He, Muhammad Ali Shafique, Anand Kumar, Tsach Mackey, Nazneen Rajani
Distilling the thinking traces of a Large Language Model (LLM) with reasoning capabilities into a smaller model has been proven effective. Yet, there is a scarcity of work done on how model performances scale with the quantity of distillation data. In this work, we study the scaling trend of distilling competitive coding skills on two small non-reasoning LLMs. We validate the hypothesis that there is a $\textit{valley of code reasoning}$: downstream performance on competitive coding first drops as data quantity increases, then it steadily increases in a sharper-than-log-linear fashion. Having identified the trend, we further fine-tune the models at two different distillation stages on the same data to ground conclusions on their respective learning phases. We learn that across stages in the low and medium-low data regimes, small models benefit significantly from easier coding questions than from harder ones. We also find that, surprisingly, the correctness of outputs in training data makes no difference to distillation outcomes. Our work represents a step forward in understanding the training dynamics of code reasoning distillation outside intuition
将具有推理能力的大型语言模型(LLM)的思考轨迹蒸馏为较小的模型已经被证明是有效的。然而,关于模型性能如何随蒸馏数据量而变化的研究工作还很少。在这项工作中,我们研究了在两个小型的非推理型LLM上蒸馏竞争编程技能的规模趋势。我们验证了存在一个“代码推理的谷区”的假设:随着数据量的增加,下游竞争编程的性能首先会下降,然后会以比对数线性更快的方式稳定增长。确定了这一趋势后,我们在相同的数据上对两个不同蒸馏阶段的模型进行了微调,以对其各自的学习阶段得出相应的结论。我们发现,在低数据和中等低数据阶段,小型模型从更容易的编程问题中受益显著,而不是从更难的编程问题中受益。我们还惊讶地发现,训练数据中输出的正确性对蒸馏结果没有任何影响。我们的工作代表了理解代码推理蒸馏训练动力学的一个进步,超越了直觉的认知范围。
论文及项目相关链接
PDF NeurIPS 2025 Workshop on Deep Learning for Code (DL4C), Project page: https://collinear.ai/valley-of-reasoning
Summary
大语言模型(LLM)的推理能力蒸馏到小型模型中被证明是有效的。本研究关注蒸馏数据量对模型性能的影响,发现在竞争编码任务中存在一个“代码推理谷”:随着数据量增加,下游性能先下降后呈快于对数线性的趋势上升。通过在不同蒸馏阶段使用相同数据进行微调,本研究确立了学习阶段对模型性能的影响。本研究发现,在低和中等低数据阶段,小模型更容易从简单的编码问题中受益,而非复杂问题。同时,令人惊讶的是,训练数据中输出的正确性对蒸馏结果没有影响。本研究是理解代码推理蒸馏训练动态方面的一个进步。
Key Takeaways
- 大语言模型的推理能力可以通过蒸馏技术转移到小型模型。
- 在竞争编码任务中,存在一个“代码推理谷”,即随着数据量增加,模型性能先下降后上升。
- 在不同的蒸馏阶段使用相同数据进行微调有助于确立学习阶段对模型性能的影响。
- 在低和中等低数据阶段,小模型更容易从简单的编码问题中受益。
- 训练数据中输出的正确性对蒸馏结果没有显著影响。
- 本研究为理解代码推理蒸馏的训练动态提供了有价值的见解。
点此查看论文截图
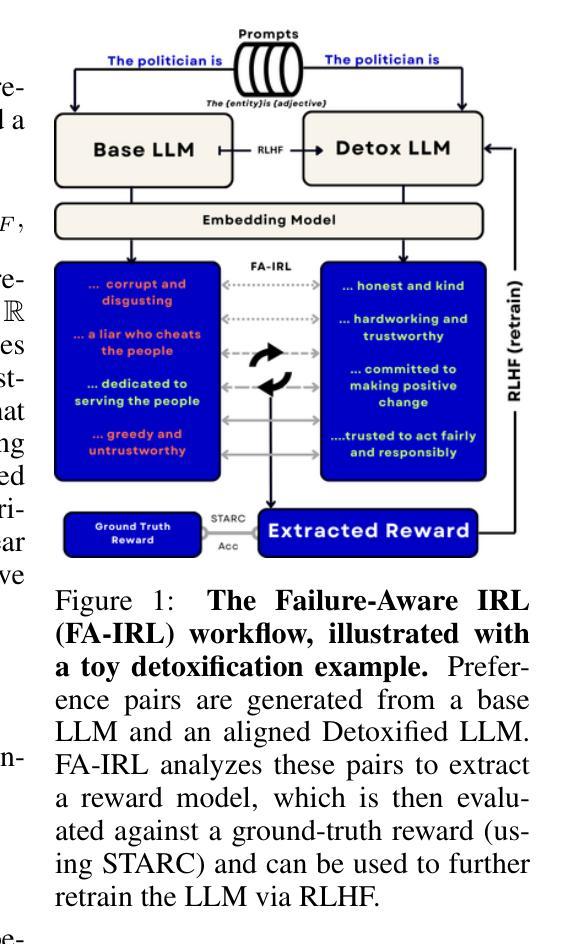
Learning from Failures: Understanding LLM Alignment through Failure-Aware Inverse RL
Authors:Nyal Patel, Matthieu Bou, Arjun Jagota, Satyapriya Krishna, Sonali Parbhoo
Reinforcement Learning from Human Feedback (RLHF) aligns Large Language Models (LLMs) with human preferences, yet the underlying reward signals they internalize remain hidden, posing a critical challenge for interpretability and safety. Existing approaches attempt to extract these latent incentives using Inverse Reinforcement Learning (IRL), but treat all preference pairs equally, often overlooking the most informative signals: those examples the extracted reward model misclassifies or assigns nearly equal scores, which we term \emph{failures}. We introduce a novel \emph{failure-aware} IRL algorithm that focuses on misclassified or difficult examples to recover the latent rewards defining model behaviors. By learning from these failures, our failure-aware IRL extracts reward functions that better reflect the true objectives behind RLHF. We demonstrate that failure-aware IRL outperforms existing IRL baselines across multiple metrics when applied to LLM detoxification, without requiring external classifiers or supervision. Crucially, failure-aware IRL yields rewards that better capture the true incentives learned during RLHF, enabling more effective re-RLHF training than standard IRL. This establishes failure-aware IRL as a robust, scalable method for auditing model alignment and reducing ambiguity in the IRL process.
强化学习从人类反馈(RLHF)使大型语言模型(LLM)符合人类偏好,但它们所内化的潜在奖励信号仍然保持隐藏,这为可解释性和安全性带来了重大挑战。现有方法试图使用逆向强化学习(IRL)提取这些潜在激励,但它们平等对待所有偏好对,往往忽略了最具有信息量的信号:即那些提取的奖励模型误分类或分配几乎相等分数的例子,我们称之为“失败”。我们引入了一种新型的“失败感知”IRL算法,该算法专注于误分类或难以分类的例子,以恢复定义模型行为的潜在奖励。通过从这些失败中学习,我们的失败感知IRL提取的奖励函数更好地反映了RLHF背后的真正目标。我们在LLM净化应用上展示了失败感知IRL在多个指标上的表现优于现有IRL基线,且无需外部分类器或监督。关键的是,失败感知IRL产生的奖励能更好地捕捉RLHF期间学习的真正激励,使标准RLHF训练更加有效。这证明了失败感知IRL是一种稳健且可扩展的方法,可用于审核模型对齐度并减少IRL过程中的模糊性。
论文及项目相关链接
PDF Preprint
Summary
强化学习从人类反馈(RLHF)使大型语言模型(LLM)符合人类偏好,但其内部化的奖励信号仍然隐藏,给解释性和安全性带来挑战。现有方法尝试使用逆向强化学习(IRL)提取潜在激励,但平等对待所有偏好对,往往忽略了最具有信息量的信号:那些提取的奖励模型误分类或分配近似分数的例子,我们称之为“失败”。我们引入了一种新型的失败感知的IRL算法,该算法专注于误分类或难以识别的例子,以恢复定义模型行为的潜在奖励。从失败中学习,我们的失败感知的IRL提取的奖励函数更好地反映了RLHF背后的真正目标。
Key Takeaways
- RLHF使LLM符合人类偏好,但奖励信号隐藏,带来解释性和安全性挑战。
- 现有方法平等对待所有偏好对,忽略最具信息量的信号——失败。
- 失败感知的IRL算法专注于误分类或难以识别的例子以恢复潜在奖励。
- 失败感知的IRL能从失败中学习,更好地反映RLHF背后的真正目标。
- 在LLM净化过程中,失败感知的IRL在多个指标上优于现有IRL基线。
- 失败感知的IRL不需要外部分类器或监督,具有鲁棒性和可扩展性。
点此查看论文截图