⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-09 更新
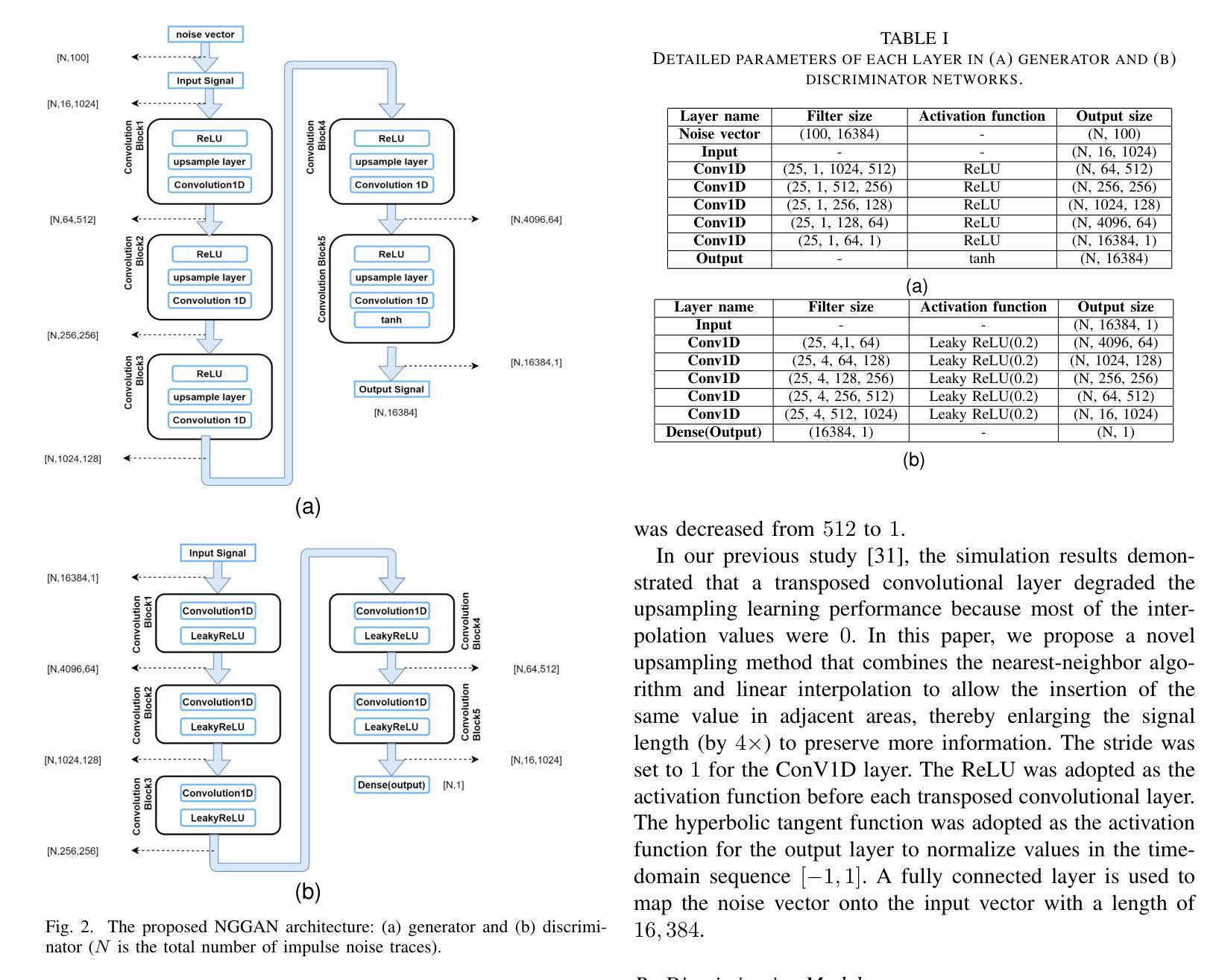
NGGAN: Noise Generation GAN Based on the Practical Measurement Dataset for Narrowband Powerline Communications
Authors:Ying-Ren Chien, Po-Heng Chou, You-Jie Peng, Chun-Yuan Huang, Hen-Wai Tsao, Yu Tsao
To effectively process impulse noise for narrowband powerline communications (NB-PLCs) transceivers, capturing comprehensive statistics of nonperiodic asynchronous impulsive noise (APIN) is a critical task. However, existing mathematical noise generative models only capture part of the characteristics of noise. In this study, we propose a novel generative adversarial network (GAN) called noise generation GAN (NGGAN) that learns the complicated characteristics of practically measured noise samples for data synthesis. To closely match the statistics of complicated noise over the NB-PLC systems, we measured the NB-PLC noise via the analog coupling and bandpass filtering circuits of a commercial NB-PLC modem to build a realistic dataset. To train NGGAN, we adhere to the following principles: 1) we design the length of input signals that the NGGAN model can fit to facilitate cyclostationary noise generation; 2) the Wasserstein distance is used as a loss function to enhance the similarity between the generated noise and training data; and 3) to measure the similarity performances of GAN-based models based on the mathematical and practically measured datasets, we conduct both quantitative and qualitative analyses. The training datasets include: 1) a piecewise spectral cyclostationary Gaussian model (PSCGM); 2) a frequency-shift (FRESH) filter; and 3) practical measurements from NB-PLC systems. Simulation results demonstrate that the generated noise samples from the proposed NGGAN are highly close to the real noise samples. The principal component analysis (PCA) scatter plots and Fr'echet inception distance (FID) analysis have shown that NGGAN outperforms other GAN-based models by generating noise samples with superior fidelity and higher diversity.
针对窄带电力线通信(NB-PLC)收发器中的脉冲噪声处理,捕获非周期性异步脉冲噪声(APIN)的全面统计数据是一项关键任务。然而,现有的数学噪声生成模型只能捕捉噪声部分特征。本研究提出了一种名为噪声生成对抗网络(NGGAN)的新型生成对抗网络,用于合成数据,学习实际测量噪声样本的复杂特征。为了紧密匹配NB-PLC系统上复杂噪声的统计信息,我们通过商业NB-PLC调制解调器的模拟耦合和带通滤波电路来测量NB-PLC噪声,以构建现实数据集。为了训练NGGAN,我们遵循以下原则:1)设计NGGAN模型能够适应的输入信号长度,以促进循环平稳噪声生成;2)使用Wasserstein距离作为损失函数,提高生成噪声与训练数据之间的相似性;3)为了测量基于数学和实际测量数据集的GAN模型的相似性性能,我们进行了定量和定性分析。训练数据集包括:1)分段谱循环平稳高斯模型(PSCGM);2)频率偏移(FRESH)滤波器;3)来自NB-PLC系统的实际测量数据。仿真结果表明,所提出的NGGAN生成的噪声样本非常接近真实噪声样本。主成分分析(PCA)散点图和Fréchet inception距离(FID)分析表明,NGGAN相比其他基于GAN的模型生成了具有更高保真度和多样性的噪声样本,表现出更好的性能。
论文及项目相关链接
PDF 16 pages, 15 figures, 11 tables, and published in IEEE Transactions on Instrumentation and Measurement, Vol. 74, 2025
Summary
本文提出一种针对窄带电力线通信(NB-PLC)的噪声生成对抗网络(NGGAN),用于捕捉非周期性异步脉冲噪声(APIN)的综合统计特征,进行数据合成。该研究通过测量实际噪声样本构建数据集,设计符合NB-PLC系统特点的NGGAN模型,使用Wasserstein距离作为损失函数提高生成噪声与训练数据的相似性。仿真结果表明,NGGAN生成的噪声样本与真实噪声样本高度接近,且在主成分分析(PCA)散点图和Fréchet inception距离(FID)分析中表现出卓越的性能。
Key Takeaways
- 研究提出NGGAN模型,针对NB-PLC系统的APIN噪声进行综合统计特征的捕捉。
- 通过测量实际噪声样本构建数据集,模拟复杂噪声的统计特性。
- 设计符合NB-PLC系统特点的NGGAN模型,包括输入信号长度设计、使用Wasserstein距离作为损失函数等。
- NGGAN能生成与真实噪声样本高度接近的噪声样本。
- PCA散点图和FID分析显示NGGAN在生成噪声样本的保真度和多样性上表现优越。
- NGGAN相较于其他GAN-based模型有更好的性能。
点此查看论文截图

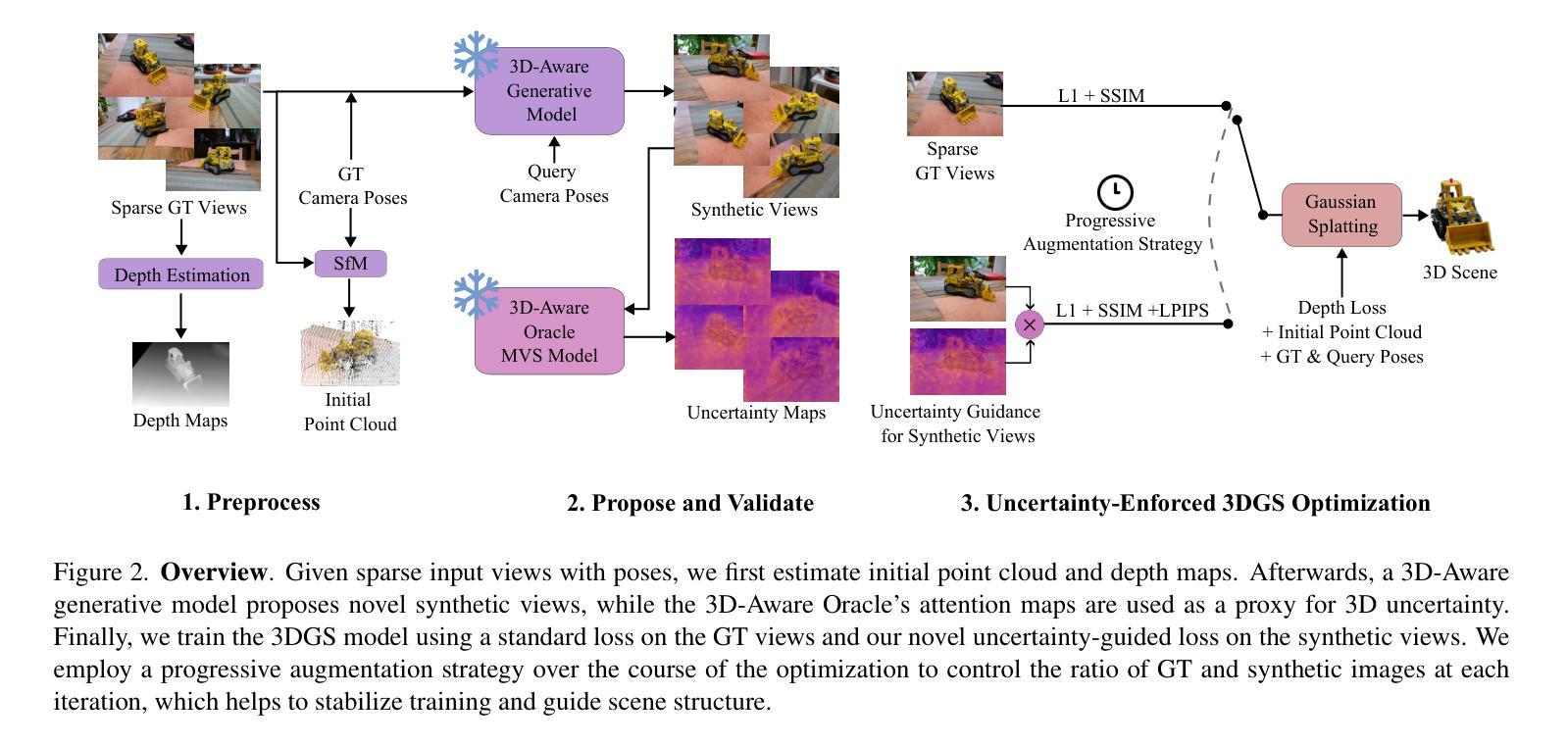
OracleGS: Grounding Generative Priors for Sparse-View Gaussian Splatting
Authors:Atakan Topaloglu, Kunyi Li, Michael Niemeyer, Nassir Navab, A. Murat Tekalp, Federico Tombari
Sparse-view novel view synthesis is fundamentally ill-posed due to severe geometric ambiguity. Current methods are caught in a trade-off: regressive models are geometrically faithful but incomplete, whereas generative models can complete scenes but often introduce structural inconsistencies. We propose OracleGS, a novel framework that reconciles generative completeness with regressive fidelity for sparse view Gaussian Splatting. Instead of using generative models to patch incomplete reconstructions, our “propose-and-validate” framework first leverages a pre-trained 3D-aware diffusion model to synthesize novel views to propose a complete scene. We then repurpose a multi-view stereo (MVS) model as a 3D-aware oracle to validate the 3D uncertainties of generated views, using its attention maps to reveal regions where the generated views are well-supported by multi-view evidence versus where they fall into regions of high uncertainty due to occlusion, lack of texture, or direct inconsistency. This uncertainty signal directly guides the optimization of a 3D Gaussian Splatting model via an uncertainty-weighted loss. Our approach conditions the powerful generative prior on multi-view geometric evidence, filtering hallucinatory artifacts while preserving plausible completions in under-constrained regions, outperforming state-of-the-art methods on datasets including Mip-NeRF 360 and NeRF Synthetic.
稀疏视角的新视角合成从根本上是不适定的,因为存在严重的几何模糊性。当前的方法陷入了权衡之中:回归模型在几何上忠实但不完整,而生成模型可以完成场景但经常引入结构不一致性。我们提出了OracleGS这一新型框架,它能在稀疏视角的高斯拼贴中协调生成完整性与回归忠实性。与其他方法不同,我们并不使用生成模型来修补不完全的重建,而是采用了一种“提出并验证”的框架。首先,我们利用一个预训练的3D感知扩散模型来合成新视角以提出一个完整的场景。然后,我们将多视图立体(MVS)模型重新用作一个3D感知的“专家”,以验证生成视角的3D不确定性,并使用其注意力图来揭示哪些区域受到多视角证据的有力支持,以及哪些区域由于遮挡、缺乏纹理或直接不一致而陷入高度不确定性的区域。这种不确定性信号直接指导了通过不确定性加权损失优化一个3D高斯拼贴模型。我们的方法在多视角几何证据上设置了强大的生成先验条件,过滤了幻觉伪影,同时在缺乏约束的区域保留了合理的完成效果,在包括Mip-NeRF 360和NeRF合成数据集上的表现均优于最先进的方法。
论文及项目相关链接
PDF Project page available at: https://atakan-topaloglu.github.io/oraclegs/
Summary
本文提出了一种名为OracleGS的新框架,旨在解决稀疏视图高斯展布中的生成与回归之间的权衡问题。该框架采用“提出并验证”的方法,先利用预训练的3D感知扩散模型合成新视图以提出完整场景,再使用多视图立体(MVS)模型作为3D感知的评估者,验证生成视图的3D不确定性。这种不确定性信号直接指导了优化3D高斯展布模型的过程。该框架利用多视图几何证据来约束强大的生成先验,过滤虚幻的伪影,同时保留在欠约束区域的合理完成,表现优于包括Mip-NeRF 360和NeRF合成在内的数据集上的其他最新方法。
Key Takeaways
- 稀疏视图下的新颖视角合成存在根本上的不明确性,因为存在严重的几何模糊性。
- 当前方法面临回归模型和生成模型之间的权衡:回归模型在几何上忠实但可能不完整,而生成模型可以完成场景但可能引入结构不一致性。
- OracleGS框架通过结合预训练的3D感知扩散模型和MVS模型来解决这一权衡问题。
- 扩散模型用于合成新视图以提出完整场景,而MVS模型则作为验证几何不确定性的工具。
- 利用不确定性信号来指导优化3D高斯展布模型,并通过不确定性加权损失实现优化。
- 该框架将强大的生成先验与多视图几何证据相结合,能在保持场景合理性的同时过滤掉虚幻的伪影。
点此查看论文截图

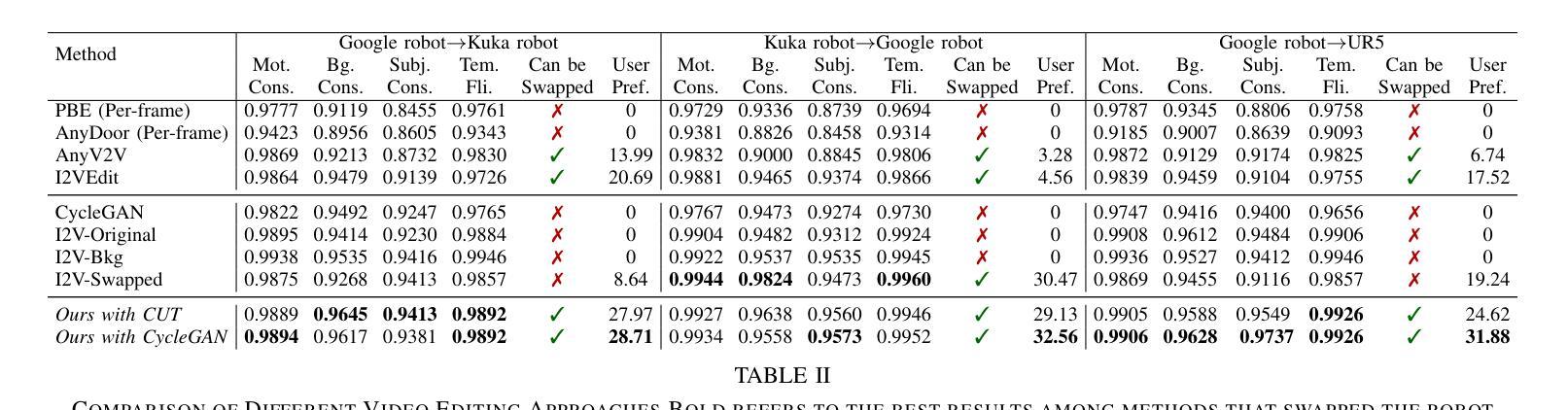
RoboSwap: A GAN-driven Video Diffusion Framework For Unsupervised Robot Arm Swapping
Authors:Yang Bai, Liudi Yang, George Eskandar, Fengyi Shen, Dong Chen, Mohammad Altillawi, Ziyuan Liu, Gitta Kutyniok
Recent advancements in generative models have revolutionized video synthesis and editing. However, the scarcity of diverse, high-quality datasets continues to hinder video-conditioned robotic learning, limiting cross-platform generalization. In this work, we address the challenge of swapping a robotic arm in one video with another: a key step for crossembodiment learning. Unlike previous methods that depend on paired video demonstrations in the same environmental settings, our proposed framework, RoboSwap, operates on unpaired data from diverse environments, alleviating the data collection needs. RoboSwap introduces a novel video editing pipeline integrating both GANs and diffusion models, combining their isolated advantages. Specifically, we segment robotic arms from their backgrounds and train an unpaired GAN model to translate one robotic arm to another. The translated arm is blended with the original video background and refined with a diffusion model to enhance coherence, motion realism and object interaction. The GAN and diffusion stages are trained independently. Our experiments demonstrate that RoboSwap outperforms state-of-the-art video and image editing models on three benchmarks in terms of both structural coherence and motion consistency, thereby offering a robust solution for generating reliable, cross-embodiment data in robotic learning.
最近生成模型的进展已经彻底改变了视频合成和编辑。然而,多样且高质量数据集的稀缺继续阻碍着受视频控制的机器人学习,并限制了跨平台的泛化。在这项工作中,我们解决了将一个视频中的机械臂替换为另一个机械臂的挑战,这是跨体态学习的关键步骤。与之前依赖于相同环境设置中的配对视频演示的方法不同,我们提出的RoboSwap框架操作来自不同环境的非配对数据,减轻了数据收集的需求。RoboSwap引入了一种新的视频编辑管道,集成了GANs和扩散模型,结合了它们的独立优势。具体来说,我们从背景中分割出机械臂,并训练一个非配对GAN模型来将一个机械臂转换为另一个机械臂。翻译的机械臂与原始视频背景混合,并使用扩散模型进行精炼,以提高连贯性、运动现实感和物体交互。GAN和扩散阶段是独立训练的。我们的实验表明,RoboSwap在结构连贯性和运动一致性方面优于最先进视频和图像编辑模型,从而在机器人学习中为生成可靠、跨体态数据提供了稳健的解决方案。
论文及项目相关链接
摘要
新一代生成模型革命性地改变了视频合成与编辑。但缺乏多样且高质量的数据集仍是制约视频条件下的机器人学习的瓶颈,限制了跨平台泛化能力。本研究解决将一个视频中机器人手臂换为另一个的技术难题,这是跨形体学习的重要步骤。不同于依赖相同环境设置下的配对视频演示的先前方法,我们提出的RoboSwap框架利用来自不同环境的非配对数据,减轻了数据采集需求。RoboSwap引入新型视频编辑管道,整合生成对抗网络(GANs)和扩散模型,结合各自优势。具体来说,我们从背景中分割出机器人手臂,训练一个非配对GAN模型将一机器人手臂转换为另一个。翻译后的手臂与原始视频背景混合,并使用扩散模型进行精炼,增强连贯性、运动真实性和物体交互性。GAN和扩散阶段独立训练。实验证明RoboSwap在结构连贯性和运动一致性方面优于当前最先进的视频和图像编辑模型,在三项基准测试中表现良好,为机器人学习中可靠跨形体数据的生成提供了稳健解决方案。
要点解析
- 文中提到了新型生成模型的发展给视频合成与编辑带来的革新性变化。
- 当前数据多样性缺乏的问题限制了视频条件下的机器人学习以及跨平台泛化能力。
- 研究重点解决机器人手臂在视频中的替换问题,这是跨形体学习的重要步骤。
- 提出名为RoboSwap的新框架,能够处理非配对数据,涵盖不同环境的数据采集需求减轻的问题。
点此查看论文截图


GSRF: Complex-Valued 3D Gaussian Splatting for Efficient Radio-Frequency Data Synthesis
Authors:Kang Yang, Gaofeng Dong, Sijie Ji, Wan Du, Mani Srivastava
Synthesizing radio-frequency (RF) data given the transmitter and receiver positions, e.g., received signal strength indicator (RSSI), is critical for wireless networking and sensing applications, such as indoor localization. However, it remains challenging due to complex propagation interactions, including reflection, diffraction, and scattering. State-of-the-art neural radiance field (NeRF)-based methods achieve high-fidelity RF data synthesis but are limited by long training times and high inference latency. We introduce GSRF, a framework that extends 3D Gaussian Splatting (3DGS) from the optical domain to the RF domain, enabling efficient RF data synthesis. GSRF realizes this adaptation through three key innovations: First, it introduces complex-valued 3D Gaussians with a hybrid Fourier-Legendre basis to model directional and phase-dependent radiance. Second, it employs orthographic splatting for efficient ray-Gaussian intersection identification. Third, it incorporates a complex-valued ray tracing algorithm, executed on RF-customized CUDA kernels and grounded in wavefront propagation principles, to synthesize RF data in real time. Evaluated across various RF technologies, GSRF preserves high-fidelity RF data synthesis while achieving significant improvements in training efficiency, shorter training time, and reduced inference latency.
给定发射器和接收器位置(例如接收信号强度指示器RSSI),合成无线电射频(RF)数据对于无线通信和网络应用(如室内定位)至关重要。然而,由于包括反射、衍射和散射在内的复杂传播交互,这仍然是一个挑战。当前最先进的基于神经辐射场(NeRF)的方法能够实现高保真RF数据合成,但由于训练时间长和推理延迟高而受到限制。我们引入了GSRF框架,它将三维高斯喷绘(3DGS)从光学领域扩展到射频领域,实现了高效的射频数据合成。GSRF通过三个关键创新实现了这一适应:首先,它引入了带有混合傅里叶-勒让德基础的复数值三维高斯,以模拟方向和相位依赖的辐射亮度。其次,它采用正交喷绘技术,以高效识别射线与高斯之间的交点。第三,它结合了基于射频定制CUDA内核的复杂值光线追踪算法,并基于波前传播原理,以实时合成射频数据。经过对各种射频技术的评估,GSRF保留了高保真射频数据合成的同时,实现了训练效率的提高、缩短了训练时间并降低了推理延迟。
论文及项目相关链接
Summary
本文介绍了GSRF框架,它将三维高斯展平技术从光学领域扩展到射频领域,实现了高效的射频数据合成。该框架通过引入复数三维高斯数、采用正交展平和复杂的射线追踪算法等技术,实现了高保真度的射频数据合成,并提高了训练效率和缩短了推理时间。
Key Takeaways
- GSRF框架首次将三维高斯展平技术引入到射频领域,实现了高效的射频数据合成。
- 通过引入复数三维高斯数和混合傅里叶-勒让德基,GSRF框架能够建模方向和相位依赖的辐射亮度。
- GSRF采用正交展平技术,能够高效地识别射线与高斯之间的交点。
- 复杂的射线追踪算法是GSRF框架的核心,该算法基于波前传播原理,能够在射频自定义CUDA内核上执行,实现实时射频数据合成。
- GSRF框架在多种射频技术上的表现都保持了高保真度的射频数据合成。
- 相较于现有方法,GSRF框架在训练效率和推理时间上都有显著的提升。
