⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-09 更新
Stratified GRPO: Handling Structural Heterogeneity in Reinforcement Learning of LLM Search Agents
Authors:Mingkang Zhu, Xi Chen, Bei Yu, Hengshuang Zhao, Jiaya Jia
Large language model (LLM) agents increasingly rely on external tools such as search engines to solve complex, multi-step problems, and reinforcement learning (RL) has become a key paradigm for training them. However, the trajectories of search agents are structurally heterogeneous, where variations in the number, placement, and outcomes of search calls lead to fundamentally different answer directions and reward distributions. Standard policy gradient methods, which use a single global baseline, suffer from what we identify and formalize as cross-stratum bias-an “apples-to-oranges” comparison of heterogeneous trajectories. This cross-stratum bias distorts credit assignment and hinders exploration of complex, multi-step search strategies. To address this, we propose Stratified GRPO, whose central component, Stratified Advantage Normalization (SAN), partitions trajectories into homogeneous strata based on their structural properties and computes advantages locally within each stratum. This ensures that trajectories are evaluated only against their true peers. Our analysis proves that SAN eliminates cross-stratum bias, yields conditionally unbiased unit-variance estimates inside each stratum, and retains the global unbiasedness and unit-variance properties enjoyed by standard normalization, resulting in a more pure and scale-stable learning signal. To improve practical stability under finite-sample regimes, we further linearly blend SAN with the global estimator. Extensive experiments on diverse single-hop and multi-hop question-answering benchmarks demonstrate that Stratified GRPO consistently and substantially outperforms GRPO by up to 11.3 points, achieving higher training rewards, greater training stability, and more effective search policies. These results establish stratification as a principled remedy for structural heterogeneity in RL for LLM search agents.
大型语言模型(LLM)代理越来越依赖搜索引擎等外部工具来解决复杂的多步骤问题,强化学习(RL)已成为训练它们的关键范式。然而,搜索代理的轨迹在结构上具有异质性,搜索呼叫的数量、位置和结果的变化导致答案方向和奖励分布的根本不同。标准策略梯度方法使用单一的全球基线,这会导致我们确定和形式化的跨阶层偏见——对异质轨迹进行“苹果和桔子”的比较。这种跨阶层偏见会扭曲信用分配并阻碍复杂的多步骤搜索策略的探索。为了解决这一问题,我们提出了分层GRPO,其核心组件分层优势归一化(SAN)根据结构特性将轨迹划分为均匀的阶层,并在每个阶层内部局部计算优势。这确保了轨迹只与其真正的同行进行评估。我们的分析证明,SAN消除了跨阶层偏见,在每个阶层内部产生有条件的无偏单位方差估计,并保留了标准归一化所享有的全局无偏性和单位方差属性,从而产生更纯净和更稳定的学习信号。为了在实际有限样本条件下提高稳定性,我们进一步将SAN与全局估计器线性混合。在多种单跳和多跳问答基准测试上的广泛实验表明,分层GRPO在各个方面始终且大幅度地优于GRPO,最高可达11.3分,实现更高的训练奖励、更大的训练稳定性和更有效的搜索策略。这些结果证明了分层是解决大型语言模型搜索代理强化学习中结构性异质问题的有效方法。
论文及项目相关链接
摘要
大型语言模型(LLM)代理越来越多地依赖搜索引擎等外部工具来解决复杂的多步骤问题,强化学习(RL)已成为训练它们的关键范式。然而,搜索代理的轨迹在结构上存在异质性,搜索调用的数量、位置和结果的不同会导致答案方向和奖励分布的根本性差异。标准策略梯度方法使用单一全局基准线,会遭受我们确定为跨阶层偏差的影响,这是对结构异质性轨迹的“苹果与橙子”的比较。这种跨阶层偏差会扭曲信用分配并阻碍复杂多步骤搜索策略的探索。为解决此问题,我们提出分层GRPO,其核心组件分层优势归一化(SAN)根据结构特性将轨迹划分为同质阶层,并在每个阶层内部进行局部优势计算。这确保了对等轨迹之间的评估。我们的分析证明SAN消除了跨阶层偏差,在每个阶层内部产生条件无偏的单位方差估计,并保留了标准归一化所享有的全局无偏性和单位方差属性,从而产生更纯净、更稳定的学习信号。为了提高有限样本下的实际稳定性,我们将SAN与全局估计器进行线性混合。在多样的单跳和多跳问答基准测试上的实验表明,分层GRPO在训练奖励、训练稳定性和搜索策略方面始终且大幅度地优于GRPO,达到高达11.3点。这些结果确立了分层作为解决LLM搜索代理中结构异质性的有效方法。
要点提炼
- 大型语言模型(LLM)代理越来越多依赖外部工具如搜索引擎解决复杂多步骤问题,强化学习(RL)成为关键训练范式。
- 搜索代理轨迹存在结构性异质性,导致答案方向和奖励分布差异。
- 标准策略梯度方法遭受跨阶层偏差影响,无法准确评估异质轨迹。
- 提出分层GRPO方法,核心为分层优势归一化(SAN),将轨迹按结构特性分层,并在各层内评估优势。
- SAN消除跨阶层偏差,提供更准确的信用分配,并促进复杂多步骤搜索策略的探索。
- SAN与全局估计器结合,提高有限样本下的稳定性。
点此查看论文截图
Peeking inside the Black-Box: Reinforcement Learning for Explainable and Accurate Relation Extraction
Authors:Xinyu Guo, Zhengliang Shi, Minglai Yang, Mahdi Rahimi, Mihai Surdeanu
This paper introduces a framework for relation extraction (RE) that enhances both accuracy and explainability. The framework has two key components: (i) a reasoning mechanism that formulates relation extraction as a series of text-processing steps inspired by cognitive science, and (ii) an optimization process driven by reinforcement learning (RL) with a novel reward function designed to improve both task accuracy and explanation quality. We call our approach CogRE. Our framework addresses the lack of supervision for language-based explanations in traditional RE by promoting outputs that include important relation keywords. These keywords are drawn from a high-quality dictionary that is automatically constructed using an LLM. We evaluate our approach for the task of one-shot RE using two LLMs and two RE datasets. Our experiments show that CogRE improves explanation quality by addressing two common failure patterns in one-shot RE: poor attention focus and limited one-shot learning capability. For example, our cognitive-structured reasoning with Qwen2.5-15B-Instruct on One-shot NYT29 achieves 24.65% F1, surpassing prior reasoning-based designs. Optimizing this approach with RL using our reward further improves performance by +23.46% (absolute). Finally, human evaluation shows that our best model generates relational keywords closely aligned with gold labels, increasing human explanation quality ratings by 54% (relative).
本文介绍了一个关系抽取(RE)的框架,该框架提高了准确性和可解释性。该框架有两个关键组成部分:(i)一个将关系抽取制定为一系列受认知科学启发的文本处理步骤的推理机制;(ii)一个由强化学习(RL)驱动的优化过程,以及一个新型奖励函数,旨在提高任务准确性和解释质量。我们将我们的方法称为CogRE。我们的框架通过鼓励输出包含重要关系关键词来解决传统RE中基于语言的解释缺乏监督的问题。这些关键词来自使用大型语言模型(LLM)自动构建的高质量词典。我们使用两个LLM和两个RE数据集,针对一次性RE任务来评估我们的方法。我们的实验表明,CogRE通过解决一次性RE中的两个常见失败模式——注意力集中不足和一次性学习能力有限——来提高解释质量。例如,使用One-shot NYT29上的Qwen2.5-15B-Instruct进行认知结构化推理,实现24.65%的F1分数,超越了先前的基于推理的设计。使用我们的奖励函数通过强化学习进一步优化此方法,性能提高了+23.46%(绝对值)。最后,人类评估表明,我们最好的模型生成的关键词与黄金标准紧密对齐,人类解释质量评分提高了54%(相对)。
论文及项目相关链接
PDF Working in process
Summary
关系抽取框架增强准确性与解释性介绍。该框架包括两个关键部分:(一)将关系抽取公式化为一系列受认知科学启发的文本处理步骤的推理机制;(二)通过强化学习驱动的优化过程,设计新型奖励函数以提高任务准确性和解释质量。我们称这种方法为CogRE。它通过促进包含重要关系关键词的输出,解决了传统关系抽取中缺乏语言解释的监督问题。这些关键词来自使用大型语言模型自动构建的高质量词典。实验表明,CogRE通过解决一次性关系抽取中的两个常见失败模式——注意力不足和有限的一次性学习能力,提高了解释质量。使用大型语言模型和关系抽取数据集进行的评估显示,我们的方法取得了显著的性能提升。
Key Takeaways
- 论文提出了一种新的关系抽取框架CogRE,旨在提高准确性和解释性。
- 框架包含两个关键部分:受认知科学启发的推理机制以及强化学习驱动的优化过程。
- CogRE解决了传统关系抽取中缺乏语言解释监督的问题,通过促进包含重要关系关键词的输出。
- 实验表明,CogRE能改善一次性关系抽取中的两个常见问题:注意力不足和有限的一次性学习能力。
- 使用大型语言模型和关系抽取数据集进行的评估显示,CogRE显著提高了性能。
- 人类评估显示,最佳模型生成的关键词与金标准标签高度一致,人类解释质量评分提高相对54%。
- CogRE框架在关系抽取任务中具有广泛的应用前景,特别是在需要高准确性和解释性的场景中。
点此查看论文截图
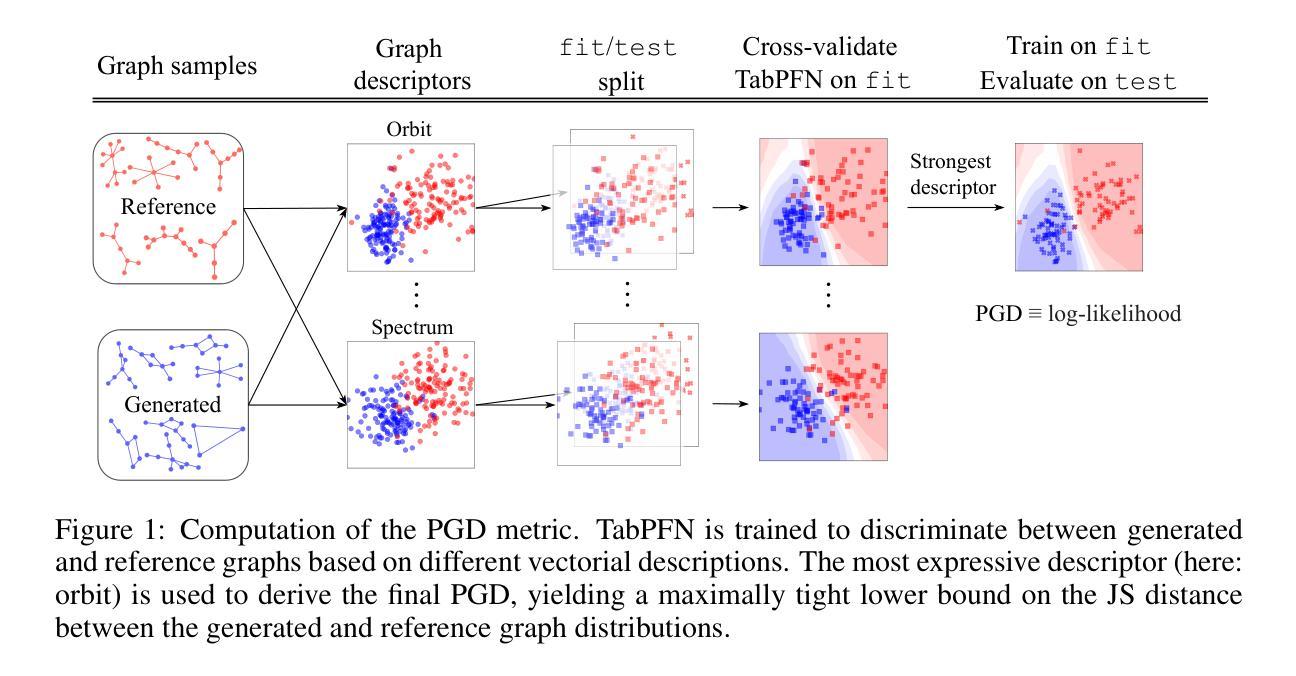
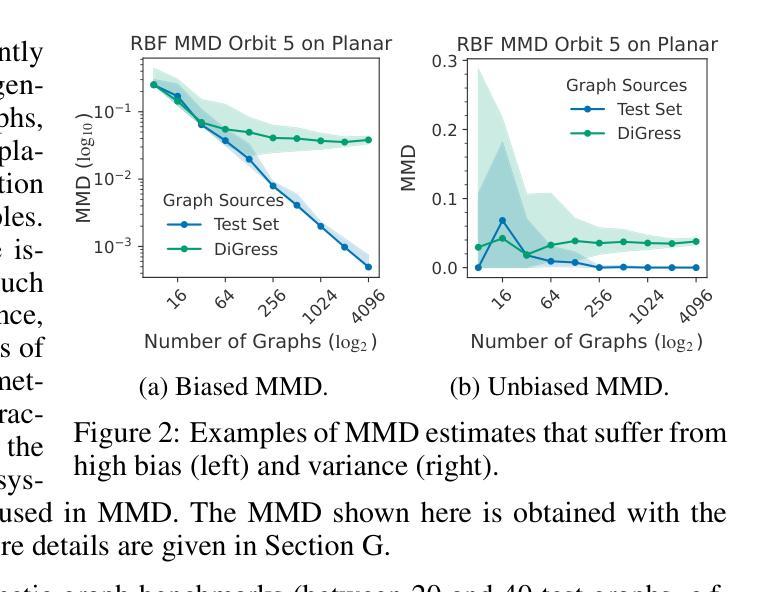
PolyGraph Discrepancy: a classifier-based metric for graph generation
Authors:Markus Krimmel, Philip Hartout, Karsten Borgwardt, Dexiong Chen
Existing methods for evaluating graph generative models primarily rely on Maximum Mean Discrepancy (MMD) metrics based on graph descriptors. While these metrics can rank generative models, they do not provide an absolute measure of performance. Their values are also highly sensitive to extrinsic parameters, namely kernel and descriptor parametrization, making them incomparable across different graph descriptors. We introduce PolyGraph Discrepancy (PGD), a new evaluation framework that addresses these limitations. It approximates the Jensen-Shannon distance of graph distributions by fitting binary classifiers to distinguish between real and generated graphs, featurized by these descriptors. The data log-likelihood of these classifiers approximates a variational lower bound on the JS distance between the two distributions. Resulting metrics are constrained to the unit interval [0,1] and are comparable across different graph descriptors. We further derive a theoretically grounded summary metric that combines these individual metrics to provide a maximally tight lower bound on the distance for the given descriptors. Thorough experiments demonstrate that PGD provides a more robust and insightful evaluation compared to MMD metrics. The PolyGraph framework for benchmarking graph generative models is made publicly available at https://github.com/BorgwardtLab/polygraph-benchmark.
现有评估图生成模型的方法主要依赖于基于图描述符的最大均值差异(MMD)指标。虽然这些指标可以对生成模型进行排名,但它们并不能提供绝对的性能度量。它们的值对外部参数(即内核和描述符参数化)高度敏感,导致在不同的图描述符之间无法进行比较。我们引入了PolyGraph差异(PGD),这是一种新的评估框架,解决了这些限制。它通过拟合二进制分类器来区分真实和生成的图,特征由这些描述符构成,从而近似图分布的Jensen-Shannon距离。这些分类器的数据对数似然近似两个分布之间的JS距离的可变下界。所得指标限制在单位区间[0,1]内,可在不同的图形描述符中进行比较。我们进一步推导出了一个有理论基础的汇总指标,该指标结合了这些单个指标,为给定描述符的距离提供了最紧密的下界。通过彻底实验证明,与MMD指标相比,PGD提供了更稳健和深入的评估。PolyGraph图生成模型基准测试框架已在https://github.com/BorgwardtLab/polygraph-benchmark上公开可用。
论文及项目相关链接
Summary
Graph生成模型评估框架PolyGraph Discrepancy(PGD)介绍。PGD通过拟合二元分类器来区分真实和生成的图,以近似计算图分布的Jensen-Shannon距离。新框架解决了现有基于MMD度量方法的局限性,如参数敏感性和跨不同图描述符的不可比性。PGD提供单位间隔内的度量值,并通过实验证明其较MMD度量更为稳健和深刻。PolyGraph框架公开可用。
Key Takeaways
- PolyGraph Discrepancy (PGD)是一个新的评估框架,用于解决现有图形生成模型评估中的限制问题。
- PGD通过拟合二元分类器来区分真实和生成的图形,从而近似计算图分布的Jensen-Shannon距离。
- 与基于MMD的度量相比,PGD度量值被约束在单位间隔内,并且可以在不同的图形描述符之间进行比较。
- PGD提供了一个理论上的基础摘要度量,结合了各个指标,为给定描述符提供了最紧密的下界距离估计。
- 实验证明,与MMD度量相比,PGD提供了更为稳健和深刻的评估结果。
- PolyGraph框架可用于基准测试图形生成模型,并已经公开发布在https://github.com/BorgwardtLab/polygraph-benchmark。
点此查看论文截图
Influence Functions for Efficient Data Selection in Reasoning
Authors:Prateek Humane, Paolo Cudrano, Daniel Z. Kaplan, Matteo Matteucci, Supriyo Chakraborty, Irina Rish
Fine-tuning large language models (LLMs) on chain-of-thought (CoT) data shows that a small amount of high-quality data can outperform massive datasets. Yet, what constitutes “quality” remains ill-defined. Existing reasoning methods rely on indirect heuristics such as problem difficulty or trace length, while instruction-tuning has explored a broader range of automated selection strategies, but rarely in the context of reasoning. We propose to define reasoning data quality using influence functions, which measure the causal effect of individual CoT examples on downstream accuracy, and introduce influence-based pruning, which consistently outperforms perplexity and embedding-based baselines on math reasoning within a model family.
对大型语言模型(LLM)进行链式思维(CoT)数据的微调表明,少量高质量数据可以超越大规模数据集。然而,“质量”的定义仍然不明确。现有的推理方法依赖于间接的启发式方法,如问题难度或跟踪长度,而指令调整则探索了更广泛的自动化选择策略,但很少在推理的情境中探索。我们建议使用影响函数来定义推理数据质量,这些函数衡量个别CoT示例对下游准确性的因果效应,并引入基于影响的修剪,它在模型家族的数学推理上始终优于困惑度和基于嵌入的基线。
论文及项目相关链接
Summary
在大型语言模型(LLM)上通过链式思维(CoT)数据进行微调显示,少量高质量数据可以超越大规模数据集的表现。然而,“质量”的定义仍然不明确。现有推理方法依赖于如问题难度或轨迹长度的间接启发式信息,而指令微调已经探索了更广泛的自动选择策略,但很少用于推理背景。本文建议使用影响函数来定义推理数据质量,它衡量个别CoT示例对下游准确度的因果效应,并引入基于影响力的修剪,它在模型家族的数学推理上持续优于困惑度和基于嵌入的基线。
Key Takeaways
- 少量高质量数据在链式思维微调中可超越大规模数据集表现。
- 目前对“高质量”数据的定义尚不清楚。
- 现有推理方法主要依赖间接启发式信息,如问题难度和轨迹长度。
- 指令微调在更广泛的自动选择策略方面有探索,但很少应用于推理场景。
- 引入影响函数来定义推理数据质量,衡量单个CoT示例对下游准确度的直接影响。
点此查看论文截图

The Valley of Code Reasoning: Scaling Knowledge Distillation of Large Language Models
Authors:Muyu He, Muhammad Ali Shafique, Anand Kumar, Tsach Mackey, Nazneen Rajani
Distilling the thinking traces of a Large Language Model (LLM) with reasoning capabilities into a smaller model has been proven effective. Yet, there is a scarcity of work done on how model performances scale with the quantity of distillation data. In this work, we study the scaling trend of distilling competitive coding skills on two small non-reasoning LLMs. We validate the hypothesis that there is a $\textit{valley of code reasoning}$: downstream performance on competitive coding first drops as data quantity increases, then it steadily increases in a sharper-than-log-linear fashion. Having identified the trend, we further fine-tune the models at two different distillation stages on the same data to ground conclusions on their respective learning phases. We learn that across stages in the low and medium-low data regimes, small models benefit significantly from easier coding questions than from harder ones. We also find that, surprisingly, the correctness of outputs in training data makes no difference to distillation outcomes. Our work represents a step forward in understanding the training dynamics of code reasoning distillation outside intuition
将具有推理能力的大型语言模型(LLM)的思考轨迹蒸馏为较小的模型已经被证明是有效的。然而,关于蒸馏数据量与模型性能如何扩展的研究工作很少。在这项工作中,我们研究了在两个小型的非推理LLM上蒸馏竞争编程技能的扩展趋势。我们验证了存在一个“代码推理的谷区”的假设:随着数据量的增加,竞争编程的下游性能首先下降,然后以对数线性更陡峭的方式稳定增长。在确定了这一趋势后,我们在相同的蒸馏数据上对两个不同蒸馏阶段的模型进行了微调,以根据各自的学习阶段得出结论。我们发现,在低数据和中等低数据阶段,小模型从简单的编程问题中获得的收益远大于从复杂问题中获得的收益。我们还惊讶地发现,训练数据中输出的正确性对蒸馏结果没有影响。我们的工作代表了理解代码推理蒸馏训练动态方面的一大进步,超越了直觉认知。
论文及项目相关链接
PDF NeurIPS 2025 Workshop on Deep Learning for Code (DL4C), Project page: https://collinear.ai/valley-of-reasoning
Summary
大型语言模型(LLM)的推理能力通过蒸馏技术转化为小型模型已被证实有效。然而,关于蒸馏数据量对模型性能的影响的研究仍显不足。本研究针对竞争编码技能的蒸馏,发现存在“编码推理谷值”:随着数据量的增加,下游竞争编码性能先下降后急剧上升,且上升速度超过对数线性。通过对模型的验证和调优,我们发现早期蒸馏阶段的小模型更容易从简单的编码问题中受益而非复杂问题。此外,令人惊讶的是,训练数据的正确性对蒸馏结果并无影响。本研究为理解代码推理蒸馏的训练动态提供了新视角。
Key Takeaways
- 大型语言模型的推理能力可以通过蒸馏技术转化为小型模型的有效性能。
- 存在一个被称为“编码推理谷值”的现象,即在特定数据量范围内模型性能先下降后上升。
- 在低数据和中等低数据阶段,小型模型从简单的编码问题中受益更大。
- 训练数据的正确性对蒸馏结果没有显著影响。
- 蒸馏技术在竞争编码技能上的应用是当前研究的重点。
- 通过研究模型的蒸馏阶段和不同的学习阶段,可以更好地理解模型性能的变化。
点此查看论文截图
Learning from Failures: Understanding LLM Alignment through Failure-Aware Inverse RL
Authors:Nyal Patel, Matthieu Bou, Arjun Jagota, Satyapriya Krishna, Sonali Parbhoo
Reinforcement Learning from Human Feedback (RLHF) aligns Large Language Models (LLMs) with human preferences, yet the underlying reward signals they internalize remain hidden, posing a critical challenge for interpretability and safety. Existing approaches attempt to extract these latent incentives using Inverse Reinforcement Learning (IRL), but treat all preference pairs equally, often overlooking the most informative signals: those examples the extracted reward model misclassifies or assigns nearly equal scores, which we term \emph{failures}. We introduce a novel \emph{failure-aware} IRL algorithm that focuses on misclassified or difficult examples to recover the latent rewards defining model behaviors. By learning from these failures, our failure-aware IRL extracts reward functions that better reflect the true objectives behind RLHF. We demonstrate that failure-aware IRL outperforms existing IRL baselines across multiple metrics when applied to LLM detoxification, without requiring external classifiers or supervision. Crucially, failure-aware IRL yields rewards that better capture the true incentives learned during RLHF, enabling more effective re-RLHF training than standard IRL. This establishes failure-aware IRL as a robust, scalable method for auditing model alignment and reducing ambiguity in the IRL process.
强化学习从人类反馈(RLHF)使大型语言模型(LLM)与人类偏好保持一致,但它们内部化的潜在奖励信号仍然隐蔽,为可解释性和安全性带来了关键挑战。现有方法试图使用逆向强化学习(IRL)来提取这些潜在激励因素,但平等对待所有偏好对,往往忽略了最有信息量的信号:那些提取的奖励模型错误分类或分配几乎相等分数的例子,我们称之为“失败”。我们引入了一种新型的“失败感知”IRL算法,该算法专注于错误分类或难以分类的例子,以恢复定义模型行为的潜在奖励。通过从这些失败中学习,我们的失败感知IRL能够从RLHF中提取更好的反映真实目标的奖励函数。我们在LLM净化任务上应用失败感知IRL,并在多个指标上超过了现有IRL基线,无需外部分类器或监督。关键的是,失败感知IRL产生的奖励能更好地捕捉RLHF期间学习的真实激励,使重新进行RLHF训练比标准IRL更有效。这证明了失败感知IRL是一种稳健、可扩展的方法,可用于审计模型对齐度并减少IRL过程中的模糊性。
论文及项目相关链接
PDF Preprint
Summary
强化学习从人类反馈(RLHF)使大型语言模型(LLM)与人类偏好对齐,但内部奖励信号保持隐藏,给解释性和安全性带来挑战。现有方法尝试使用逆向强化学习(IRL)提取潜在激励,但平等对待所有偏好对,往往忽视最有信息的信号——那些提取的奖励模型误分类或分配近似分数的例子(我们称之为“失败”)。我们引入了一种新型的失败感知IRL算法,它专注于误分类或困难的例子来恢复定义模型行为的潜在奖励。通过从失败中学习,我们的失败感知IRL更好地反映了RLHF背后的真正目标。在LLM净化方面的应用显示,它在多个指标上优于现有的IRL基线,且无需外部分类器或监督。最重要的是,失败感知IRL产生的奖励能更好地捕捉RLHF期间学习的真正激励,使再训练RLHF比标准IRL更有效。这确立了失败感知IRL作为审核模型对齐和减少IRL过程中歧义的一种稳健、可扩展的方法。
Key Takeaways
- 强化学习从人类反馈(RLHF)使大型语言模型(LLM)与人类偏好对齐,但存在解释性和安全性的挑战。
- 现有方法平等对待所有偏好对,忽视最有信息的信号——模型误分类或近似分数的例子(失败)。
- 失败感知IRL算法专注于误分类或困难的例子来恢复潜在奖励。
- 失败感知IRL能从失败中学习,更好地反映RLHF背后的真正目标。
- 在LLM净化方面的应用显示,失败感知IRL在多个指标上优于现有方法,且无需外部监督。
- 失败感知IRL产生的奖励能更好地捕捉RLHF期间的真正激励,使再训练更有效。
点此查看论文截图
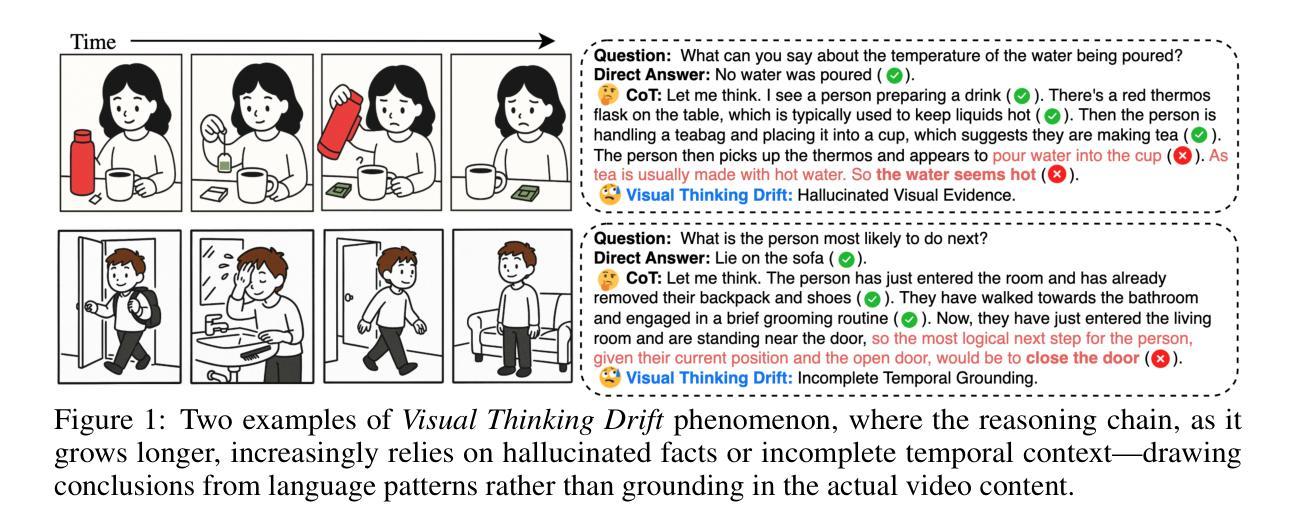
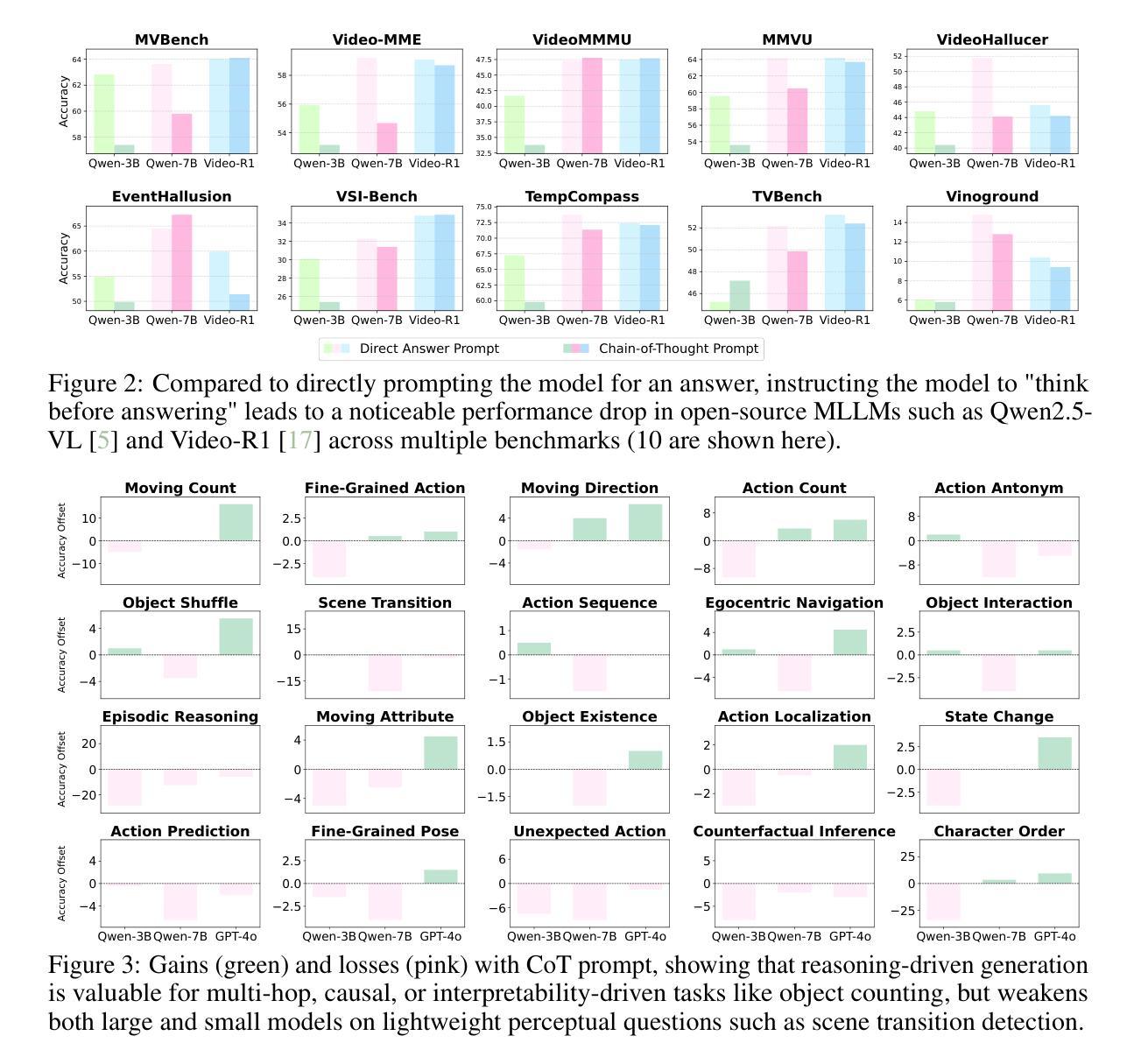
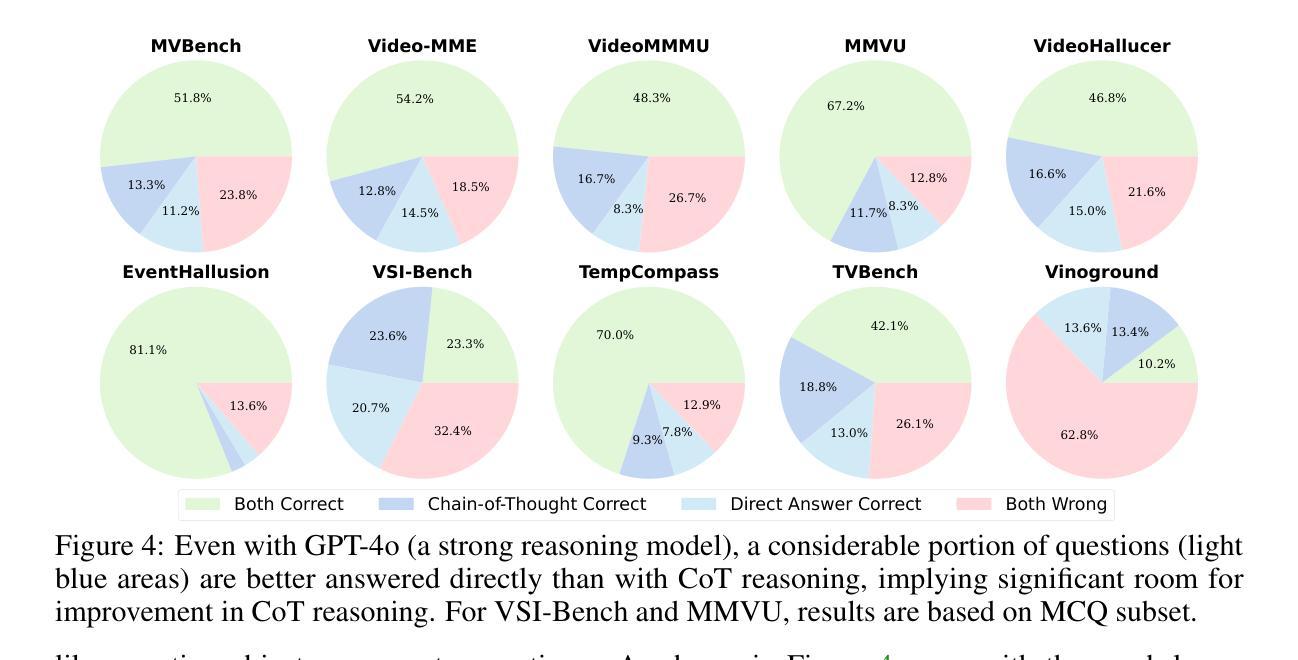
When Thinking Drifts: Evidential Grounding for Robust Video Reasoning
Authors:Mi Luo, Zihui Xue, Alex Dimakis, Kristen Grauman
Video reasoning, the task of enabling machines to infer from dynamic visual content through multi-step logic, is crucial for advanced AI. While the Chain-of-Thought (CoT) mechanism has enhanced reasoning in text-based tasks, its application to video understanding remains underexplored. This paper presents a systematic analysis revealing that CoT often degrades performance in video reasoning, generating verbose but misleading internal monologues, and leading to hallucinated visual details and overridden correct intuitions - a phenomenon we term “visual thinking drift”. We explain this drift through a Bayesian lens, positing that CoT traces often diverge from actual visual evidence, instead amplifying internal biases or language priors, causing models to storytell rather than engage in grounded reasoning. To counteract this, we introduce Visual Evidence Reward (VER), a novel reinforcement learning framework that explicitly rewards the generation of reasoning traces that are verifiably grounded in visual evidence. Comprehensive evaluation across 10 diverse video understanding benchmarks demonstrates that our Video-VER consistently achieves top performance. Our work sheds light on the distinct challenges of video-centric reasoning and encourages the development of AI that robustly grounds its inferences in visual evidence - for large multimodal models that not only “think before answering”, but also “see while thinking”.
视频推理任务是通过多步骤逻辑从动态视觉内容中进行推断,对于高级人工智能来说至关重要。虽然链式思维(CoT)机制在基于文本的任务中增强了推理能力,但其在视频理解中的应用仍然被探索得不够深入。本文对CoT在视频推理中的表现进行了系统分析,发现它经常导致性能下降,产生冗长且具误导性的内部独白,并导致虚构的视觉细节和覆盖正确的直觉——我们将这种现象称为“视觉思维漂移”。我们通过贝叶斯视角解释了这种漂移,认为CoT轨迹往往与实际的视觉证据相悖,而是放大了内部偏见或语言先验知识,导致模型更倾向于讲故事,而不是进行基于事实的推理。为了应对这一问题,我们引入了视觉证据奖励(VER),这是一种新型强化学习框架,旨在明确奖励那些有确凿视觉证据支持的推理轨迹的生成。在10个多样化的视频理解基准测试上的综合评估表明,我们的视频-VER持续实现最佳性能。我们的工作揭示了以视频为中心的推理的独特挑战,并鼓励开发一种人工智能,其推理能稳健地基于视觉证据——对于不仅“在回答之前思考”,而且“在思考时观察”的大型多模式模型。
论文及项目相关链接
PDF Accepted by NeurIPS 2025, Project page: https://vision.cs.utexas.edu/projects/video-ver/
Summary
在高级人工智能中,视频推理任务至关重要,它能够让机器通过多步骤逻辑从动态视觉内容中进行推断。尽管链式思维(CoT)机制在文本任务中增强了推理能力,但其在视频理解中的应用仍然被忽视。这篇论文揭示了CoT在视频推理中性能下降的表象并阐述了这种现象的原因——“视觉思考漂移”。为此论文从贝叶斯视角进行分析解释并提出视觉证据奖励(VER)框架以克服这一问题。该框架通过奖励与视觉证据相符的推理轨迹来对抗视觉思考漂移。全面评估十大视频理解基准测试表明,Video-VER始终取得顶尖表现。这项工作揭示了视频中心推理的独特挑战并鼓励开发一种既要在回答前思考,又要在思考时观察的人工智能模型。简而言之,本论文聚焦于提升机器的视频理解能力。
Key Takeaways
- 视频推理是高级人工智能的重要任务,涉及机器从动态视觉内容中进行推断的能力。
- 链式思维(CoT)机制在文本任务中增强了推理能力,但在视频理解中的应用仍然有限。
- CoT在视频推理中可能导致性能下降,出现“视觉思考漂移”现象。这种现象表现为模型生成冗长且误导的内部独白,导致虚构的视觉细节和覆盖正确的直觉。
- 本论文从贝叶斯视角解释了视觉思考漂移现象,并提出视觉证据奖励(VER)框架以克服这一问题。
点此查看论文截图
Reasoning under Vision: Understanding Visual-Spatial Cognition in Vision-Language Models for CAPTCHA
Authors:Python Song, Luke Tenyi Chang, Yun-Yun Tsai, Penghui Li, Junfeng Yang
CAPTCHA, originally designed to distinguish humans from robots, has evolved into a real-world benchmark for assessing the spatial reasoning capabilities of vision-language models. In this work, we first show that step-by-step reasoning is crucial for vision-language models (VLMs) to solve CAPTCHAs, which represent high-difficulty spatial reasoning tasks, and that current commercial vision-language models still struggle with such reasoning. In particular, we observe that most commercial VLMs (e.g., Gemini, Claude, GPT, etc.) fail to effectively solve CAPTCHAs and thus achieve low accuracy (around 21.9 percent). However, our findings indicate that requiring the model to perform step-by-step reasoning before generating the final coordinates can significantly enhance its solving accuracy, underscoring the severity of the gap. To systematically study this issue, we introduce CAPTCHA-X, the first real-world CAPTCHA benchmark with reasoning, covering seven categories of CAPTCHAs (such as Gobang, hCaptcha, etc.) with step-by-step action solutions and grounding annotations. We further define five reasoning-oriented metrics that enable a comprehensive evaluation of models reasoning capabilities. To validate the effectiveness of reasoning, we also propose a general agentic VLM-based framework that incorporates the models inherent reasoning abilities. Our method achieves state-of-the-art performance across five high-difficulty CAPTCHA types, with an average solving accuracy of 83.9 percent, substantially surpassing existing baselines. These results reveal the limitations of current models and highlight the importance of reasoning in advancing visual-spatial challenges in the future.
验证码(CAPTCHA)最初是为了区分人类和机器人而设计的,现已演变为评估视觉语言模型空间推理能力的现实世界基准测试。在这项工作中,我们首先展示了逐步推理对于视觉语言模型(VLM)解决验证码(代表高难度空间推理任务)至关重要,并且当前的商业视觉语言模型仍然难以应对此类推理。特别地,我们观察到大多数商业VLM(例如双子座、克劳德、GPT等)无法解决验证码问题,因此准确率很低(约为21.9%)。然而,我们的研究结果表明,要求模型在生成最终坐标之前进行逐步推理可以显著提高解决验证码的准确性,这凸显了差距的严重性。为了系统地研究这个问题,我们引入了CAPTCHA-X,这是第一个具有推理功能的现实世界的CAPTCHA基准测试,涵盖了七种验证码类别(如Gobang、hCaptcha等),具有逐步行动解决方案和接地注释。我们进一步定义了五个面向推理的指标,能够对模型的推理能力进行全面评估。为了验证推理的有效性,我们还提出了一个基于通用代理的VLM框架,该框架结合了模型固有的推理能力。我们的方法在五种高难度CAPTCHA类型上实现了最先进的性能,平均解决准确率为83.9%,大大超过了现有基线。这些结果揭示了当前模型的局限性,并强调了未来在视觉空间挑战中推理的重要性。
论文及项目相关链接
PDF 14pages, 11figures
摘要
CAPTCHA最初是为区分人类和机器人而设计的,现已成为评估视觉语言模型空间推理能力的现实世界基准测试。本研究首先表明,逐步推理对于视觉语言模型(VLM)解决高难度空间推理任务至关重要,而当前商业视觉语言模型在处理此类推理任务时仍面临困难。特别是大多数商业VLM(如Gemini、Claude、GPT等)在解决CAPTCHA时无法实现有效推理,准确率仅为约21.9%。然而,我们的研究发现,要求模型在生成最终坐标之前进行逐步推理可以显著提高解决准确性,这突显了当前差距的严重性。为了系统地研究这个问题,我们引入了第一个带有推理功能的现实世界CAPTCHA基准测试——CAPTCHA-X,涵盖七种类型的CAPTCHA(如Gobang、hCaptcha等),并提供逐步行动解决方案和注释。我们还定义了五个面向推理的指标,能够对模型的推理能力进行全面评估。为了验证推理的有效性,我们还提出了一个基于VLM的通用框架,该框架结合了模型的内在推理能力。我们的方法在五种高难度CAPTCHA类型上实现了最先进的性能,平均解决准确率为83.9%,显著超越了现有基线。这些结果揭示了当前模型的局限性,并强调了推理在未来应对视觉空间挑战中的重要性。
关键见解
- CAPTCHA已演变为评估视觉语言模型空间推理能力的现实世界基准测试。
- 逐步推理对视觉语言模型解决高难度空间推理任务至关重要。
- 当前商业视觉语言模型在解决CAPTCHA时的准确率较低(约21.9%)。
- 要求模型进行逐步推理可以显著提高解决CAPTCHA的准确性。
- 引入了一个新的现实世界的CAPTCHA基准测试——CAPTCHA-X,包含多种类型的CAPTCHA并提供逐步行动解决方案和注释。
- 定义了五个面向推理的指标,用于全面评估模型的推理能力。
- 提出了一种基于VLM的通用框架,通过结合模型的内在推理能力,实现了在五种高难度CAPTCHA类型上的先进性能。
点此查看论文截图


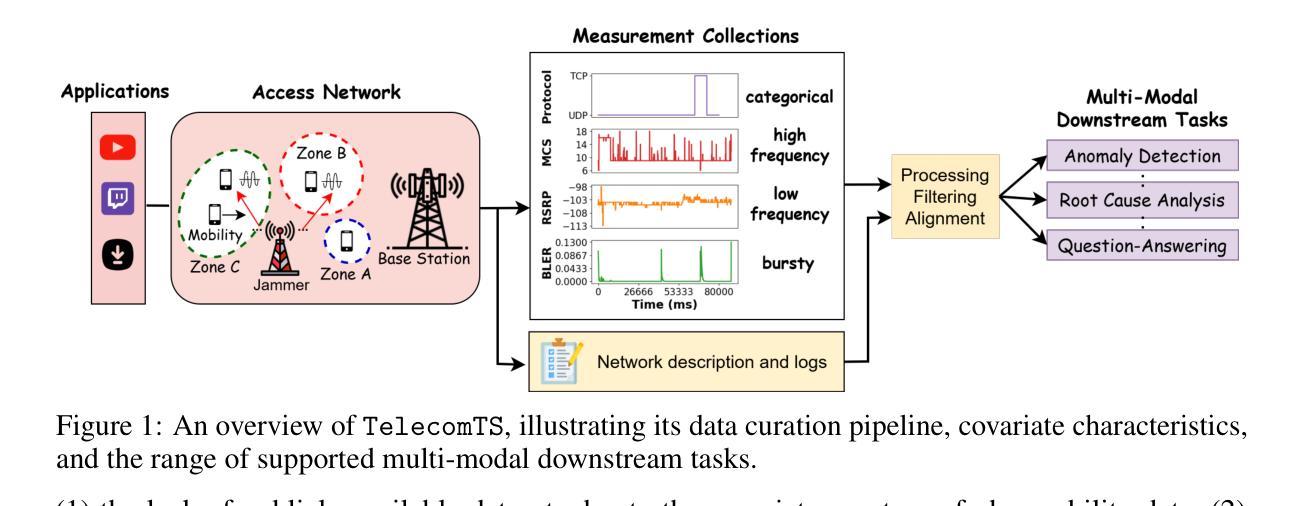
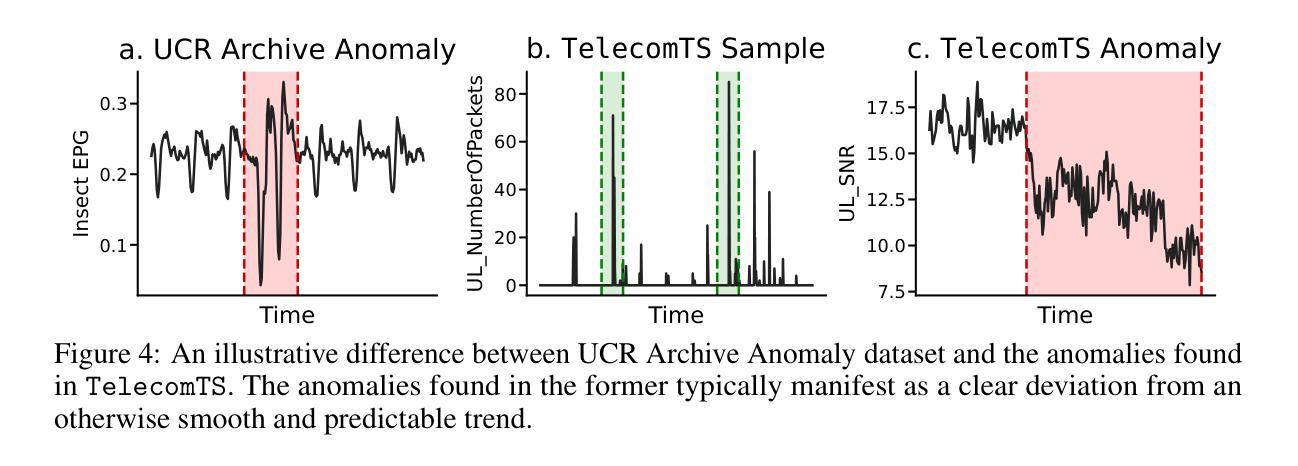
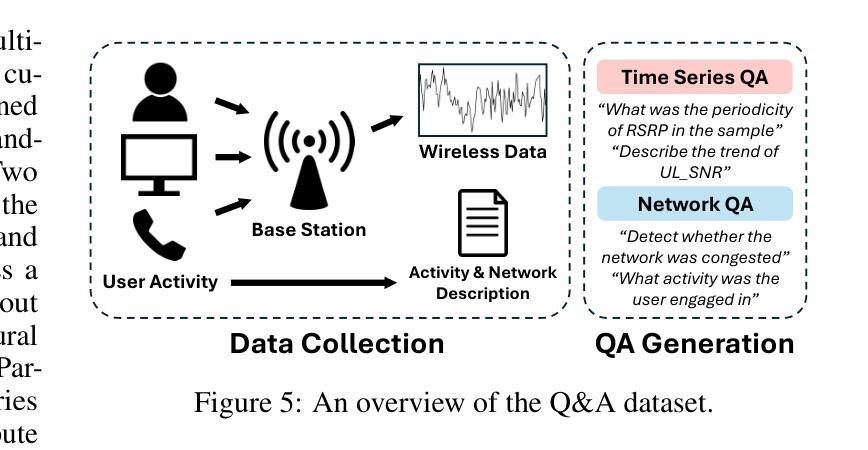
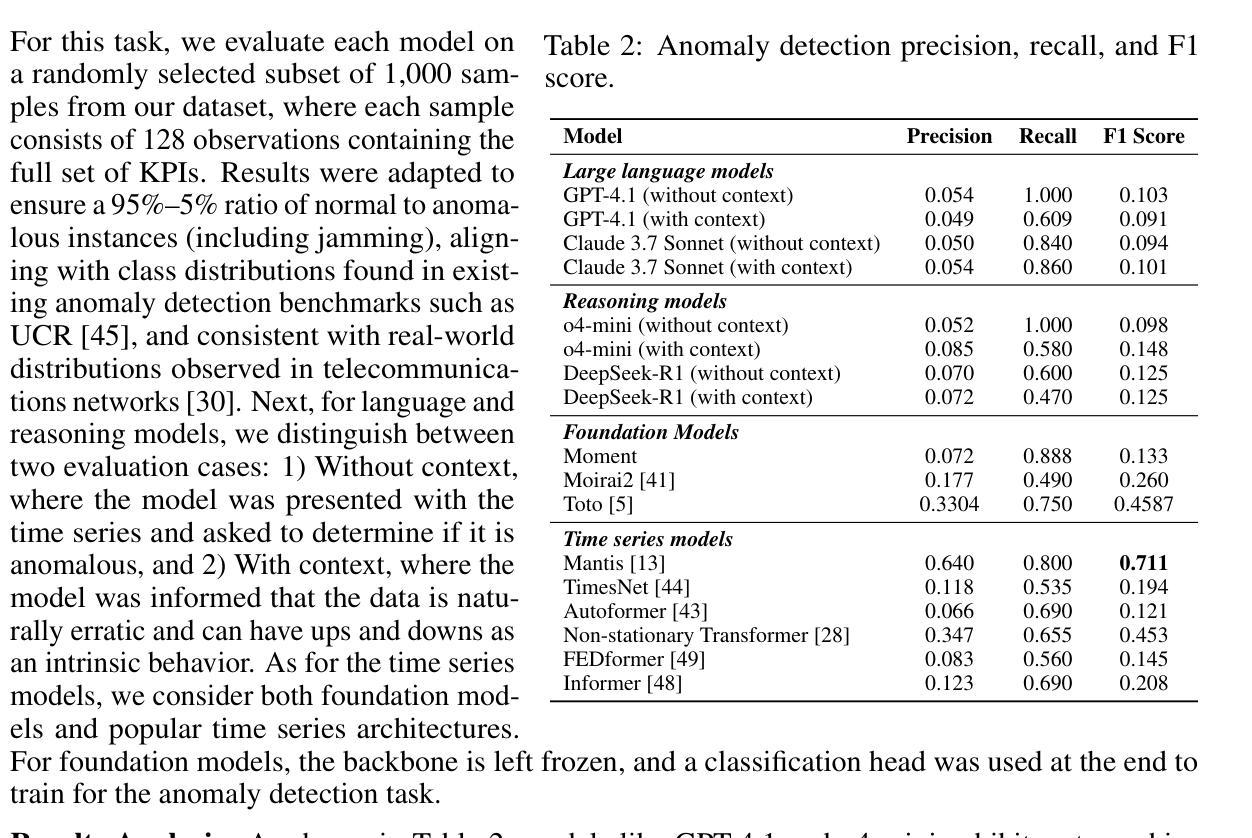
TelecomTS: A Multi-Modal Observability Dataset for Time Series and Language Analysis
Authors:Austin Feng, Andreas Varvarigos, Ioannis Panitsas, Daniela Fernandez, Jinbiao Wei, Yuwei Guo, Jialin Chen, Ali Maatouk, Leandros Tassiulas, Rex Ying
Modern enterprises generate vast streams of time series metrics when monitoring complex systems, known as observability data. Unlike conventional time series from domains such as weather, observability data are zero-inflated, highly stochastic, and exhibit minimal temporal structure. Despite their importance, observability datasets are underrepresented in public benchmarks due to proprietary restrictions. Existing datasets are often anonymized and normalized, removing scale information and limiting their use for tasks beyond forecasting, such as anomaly detection, root-cause analysis, and multi-modal reasoning. To address this gap, we introduce TelecomTS, a large-scale observability dataset derived from a 5G telecommunications network. TelecomTS features heterogeneous, de-anonymized covariates with explicit scale information and supports a suite of downstream tasks, including anomaly detection, root-cause analysis, and a question-answering benchmark requiring multi-modal reasoning. Benchmarking state-of-the-art time series, language, and reasoning models reveals that existing approaches struggle with the abrupt, noisy, and high-variance dynamics of observability data. Our experiments also underscore the importance of preserving covariates’ absolute scale, emphasizing the need for foundation time series models that natively leverage scale information for practical observability applications.
现代企业在监控复杂系统时,会产生大量的时间序列指标,这被称为可观察性数据。与天气等领域中的传统时间序列不同,可观察性数据具有零膨胀、高度随机性和最小的时序结构。尽管它们很重要,但由于专有权限的限制,可观察性数据集在公共基准测试中的代表性不足。现有的数据集通常被匿名化和标准化,从而消除了规模信息,并限制了它们在预测之外的任务(如异常检测、根本原因分析和多模式推理)的使用。为了弥补这一空白,我们引入了TelecomTS,这是一个来自5G电信网络的大型可观察性数据集。TelecomTS具有异质的、非匿名的协变量和明确的规模信息,并支持一系列下游任务,包括异常检测、根本原因分析和一个需要多模式推理的问答基准测试。对最先进的时序、语言和推理模型进行基准测试表明,现有方法难以应对可观察性数据的突发、噪声大和高方差动态变化。我们的实验还强调了保留协变量绝对规模的重要性,强调了需要基础时序模型来利用规模信息进行实际的观察应用。
论文及项目相关链接
Summary
现代企业监测复杂系统时产生大量时间序列指标,形成可观性数据。此类数据具有零膨胀、高度随机性,且几乎不含时间结构信息。尽管它们非常重要,但由于产权限制,可观性数据集在公共基准测试中代表性不足。现有数据集经常被匿名化处理且规范化,丧失了规模信息,使其不能用于除预测以外的任务,如异常检测、根本原因分析及多模态推理等。为填补这一空白,我们推出了TelecomTS——源自5G电信网络的大规模可观性数据集。TelecomTS具备异质、非匿名化的协变量和明确的规模信息,并支持一系列下游任务,包括异常检测、根本原因分析及需要多模态推理的问答基准测试等。对先进的时间序列、语言和推理模型的基准测试表明,现有方法难以应对可观性数据的突发、噪声大和高方差特性。我们的实验也强调了保留协变量绝对规模的重要性,强调了需要开发原生利用规模信息的时序模型以应用于实际的可观性应用。
Key Takeaways
- 现代企业生成大量基于复杂系统监测的时间序列指标,称为可观性数据。
- 可观性数据具有零膨胀、高度随机性和缺乏时间结构的特点。
- 由于产权限制,可观性数据集在公共基准测试中的代表性不足。
- 现有数据集经常经过匿名化和归一化处理,限制了它们在除预测以外的任务(如异常检测、根本原因分析和多模态推理)中的应用。
- 引入了一个新的数据集TelecomTS,它是从5G电信网络中衍生出来的,具有异质的、非匿名化的协变量和明确的规模信息。
- TelecomTS支持多种下游任务,包括异常检测、根本原因分析和需要多模态推理的问答基准测试。
点此查看论文截图
ASPO: Asymmetric Importance Sampling Policy Optimization
Authors:Jiakang Wang, Runze Liu, Lei Lin, Wenping Hu, Xiu Li, Fuzheng Zhang, Guorui Zhou, Kun Gai
Recent Large Language Model (LLM) post-training methods rely on token-level clipping mechanisms during Reinforcement Learning (RL). However, we identify a fundamental flaw in this Outcome-Supervised RL (OSRL) paradigm: the Importance Sampling (IS) ratios of positive-advantage tokens are mismatched, leading to unbalanced token weighting for positive and negative tokens. This mismatch suppresses the update of low-probability tokens while over-amplifying already high-probability ones. To address this, we propose Asymmetric Importance Sampling Policy Optimization (ASPO), which uses a simple yet effective strategy that flips the IS ratios of positive-advantage tokens, aligning their update direction with the learning dynamics of negative ones. AIS further incorporates a soft dual-clipping mechanism to stabilize extreme updates while maintaining gradient flow. Comprehensive experiments on coding and mathematical reasoning benchmarks demonstrate that ASPO significantly mitigates premature convergence, improves training stability, and enhances final performance over strong GRPO-based baselines. Our analysis provides new insights into the role of token-level weighting in OSRL and highlights the critical importance of correcting IS in LLM RL. The code and models of ASPO are available at https://github.com/wizard-III/Archer2.0.
最近的大型语言模型(LLM)后训练方法依赖于强化学习(RL)中的token级别裁剪机制。然而,我们发现了结果监督强化学习(OSRL)范式中的一个基本缺陷:正优势token的重要性采样(IS)比率不匹配,导致正负面token的token权重不平衡。这种不匹配会抑制低概率token的更新,同时过度放大已经高概率的token。为了解决这一问题,我们提出了不对称重要性采样策略优化(ASPO),它采用了一种简单有效的策略,即翻转正优势token的IS比率,使其更新方向与负面token的学习动态相一致。ASPO还进一步融入了一种柔和的双重裁剪机制,以稳定极端更新并保持梯度流。在编码和数学推理基准测试上的全面实验表明,ASPO显著减轻了过早收敛问题,提高了训练稳定性,并在基于GRPO的强基线之上增强了最终性能。我们的分析为OSRL中token级别权重的作用提供了新的见解,并强调了纠正LLM RL中IS的关键重要性。ASPO的代码和模型可在https://github.com/wizard-III/Archer2.0获得。
论文及项目相关链接
Summary:
近期的大型语言模型(LLM)后训练方法依赖于强化学习(RL)中的token级别剪辑机制。然而,我们发现了一种成果监督强化学习(OSRL)范式中的基本缺陷:正向优势token的重要性采样(IS)比率不匹配,导致正负token的权重不平衡。这种不匹配会抑制低概率token的更新,同时过度放大已经高概率的token。为解决这一问题,我们提出了不对称重要性采样策略优化(ASPO),采用简单有效的策略翻转正向优势token的IS比率,使其更新方向与负向token的学习动态一致。ASPO还结合了软双剪辑机制,以稳定极端更新并保持梯度流。在编码和数学推理基准测试上的综合实验表明,ASPO显著缓解了过早收敛问题,提高了训练稳定性,并在基于GRPO的强基线之上增强了最终性能。我们的分析提供了关于OSRL中token级别权重的新见解,并强调了纠正IS在LLM RL中的关键作用。
Key Takeaways:
- 近期的大型语言模型后训练方法依赖强化学习中的token级别剪辑机制。
- 成果监督强化学习范式中存在基本缺陷:正向优势token的重要性采样比率不匹配,导致权重不平衡。
- 这种不匹配会抑制低概率token的更新,过度放大已高概率的token。
- 提出了一种新的解决方法:不对称重要性采样策略优化(ASPO)。
- ASPO通过翻转正向优势token的IS比率,使更新方向与负向token的学习动态一致。
- ASPO结合了软双剪辑机制,以稳定训练过程。
点此查看论文截图
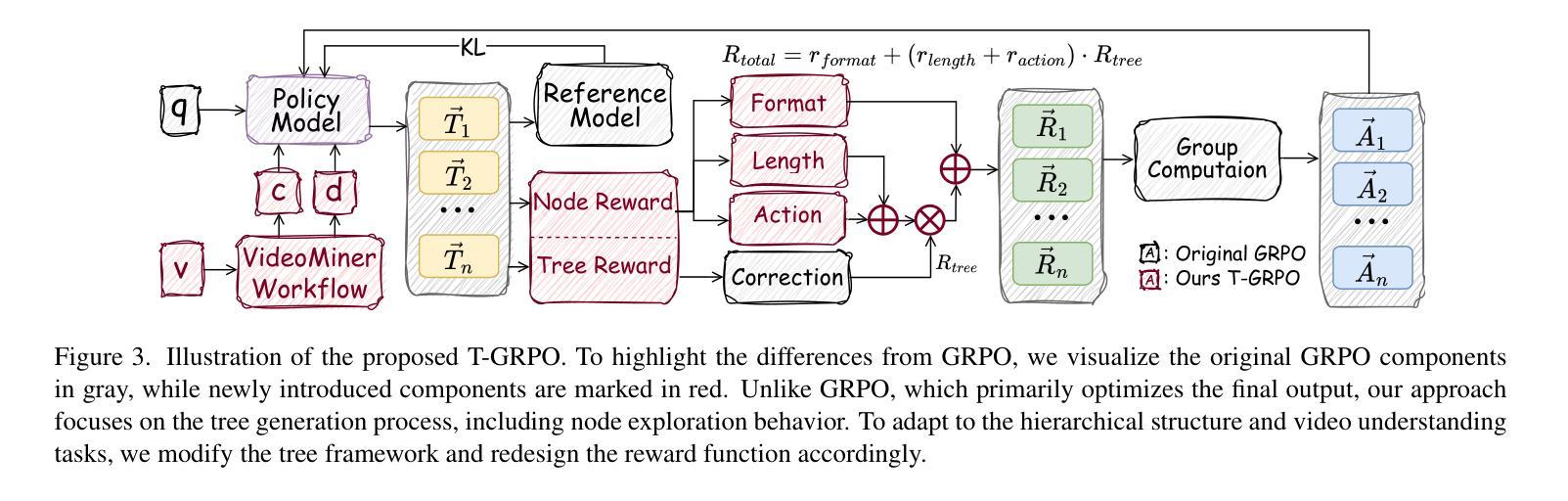
VideoMiner: Iteratively Grounding Key Frames of Hour-Long Videos via Tree-based Group Relative Policy Optimization
Authors:Xinye Cao, Hongcan Guo, Jiawen Qian, Guoshun Nan, Chao Wang, Yuqi Pan, Tianhao Hou, Xiaojuan Wang, Yutong Gao
Understanding hour-long videos with multi-modal large language models (MM-LLMs) enriches the landscape of human-centered AI applications. However, for end-to-end video understanding with LLMs, uniformly sampling video frames results in LLMs being overwhelmed by a vast amount of irrelevant information as video length increases. Existing hierarchical key frame extraction methods improve the accuracy of video understanding but still face two critical challenges. 1) How can the interference of extensive redundant information in long videos be mitigated? 2) How can a model dynamically adapt to complex hierarchical structures while accurately identifying key frames? To address these issues, we propose VideoMiner, which iteratively segments, captions, and clusters long videos, forming a hierarchical tree structure. The proposed VideoMiner progresses from long videos to events to frames while preserving temporal coherence, effectively addressing the first challenge. To precisely locate key frames, we introduce T-GRPO, a tree-based group relative policy optimization in reinforcement learning method that guides the exploration of the VideoMiner. The proposed T-GRPO is specifically designed for tree structures, integrating spatiotemporal information at the event level while being guided by the question, thus solving the second challenge. We achieve superior performance in all long-video understanding tasks and uncover several interesting insights. Our proposed T-GRPO surprisingly incentivizes the model to spontaneously generate a reasoning chain. Additionally, the designed tree growth auxin dynamically adjusts the expansion depth, obtaining accuracy and efficiency gains. The code is publicly available at https://github.com/caoxinye/VideoMiner.
利用多模态大型语言模型(MM-LLMs)理解长达一小时的视频,丰富了以人类为中心的AI应用领域。然而,在利用LLMs进行端到端视频理解时,对视频帧进行统一采样会导致LLMs面临大量不相关信息的干扰,随着视频长度的增加,这种干扰会愈发严重。现有的层次化关键帧提取方法提高了视频理解的准确性,但仍面临两个关键挑战。1)如何减轻长视频中大量冗余信息的干扰?2)如何在准确识别关键帧的同时,使模型能够动态适应复杂的层次结构?为了解决这些问题,我们提出了VideoMiner,它迭代地对长视频进行分段、标注和聚类,形成层次树结构。VideoMiner从长视频逐步过渡到事件再到帧,同时保持时间连贯性,有效地解决了第一个挑战。为了精确地定位关键帧,我们引入了基于树的群体相对策略优化方法T-GRPO,这是一种强化学习方法,用于指导VideoMiner的探索。我们专门设计的T-GRPO方法特别适用于树状结构,在事件层面整合时空信息,同时受问题的引导,从而解决了第二个挑战。我们在所有长视频理解任务中都取得了卓越的性能,并发现了几个有趣的见解。令人惊讶的是,我们提出的T-GRPO激励模型自发地生成推理链。此外,设计的树生长辅助素能动态调整扩展深度,从而提高准确性和效率。代码已公开在https://github.com/caoxinye/VideoMiner。
论文及项目相关链接
PDF Accepted by ICCV 2025
Summary
视频理解是人工智能领域的重要应用之一。在处理长视频时,传统的采样方法会导致模型受到大量冗余信息的干扰。针对这一问题,本文提出了VideoMiner模型,通过迭代分割、标注和聚类长视频,形成层次树结构,有效地从长视频中提取关键信息。为精确定位关键帧,引入基于树的群体相对策略优化方法T-GRPO,解决了在复杂层次结构中准确识别关键帧的问题。VideoMiner模型在长视频理解任务中表现优异,并能自发产生推理链,具有动态调整扩展深度的能力,实现了准确性和效率的提升。
Key Takeaways
- 处理长视频时,传统的均匀采样视频帧会导致大型语言模型受到大量冗余信息的干扰。
- VideoMiner模型通过迭代分割、标注和聚类长视频,形成层次树结构,提高视频理解的准确性。
- T-GRPO方法用于精确定位关键帧,解决了在复杂层次结构中准确识别关键帧的挑战。
- VideoMiner模型在长视频理解任务中表现优异,实现准确性和效率的提升。
- VideoMiner模型能自发产生推理链,这有助于进一步理解视频内容的内在逻辑。
- VideoMiner通过设计的树增长辅助因子动态调整扩展深度,以适应不同的视频内容和任务需求。
点此查看论文截图
ARISE: An Adaptive Resolution-Aware Metric for Test-Time Scaling Evaluation in Large Reasoning Models
Authors:Zhangyue Yin, Qiushi Sun, Zhiyuan Zeng, Zhiyuan Yu, Qipeng Guo, Xuanjing Huang, Xipeng Qiu
Test-time scaling has emerged as a transformative paradigm for enhancing the performance of large reasoning models, enabling dynamic allocation of computational resources during inference. However, as the landscape of reasoning models rapidly expands, a critical question remains: how can we systematically compare and evaluate the test-time scaling capabilities across different models? In this paper, we introduce ARISE (Adaptive Resolution-aware Scaling Evaluation), a novel metric specifically designed to assess the test-time scaling effectiveness of large reasoning models. Unlike existing evaluation approaches, ARISE incorporates two key innovations: (1) sample-level awareness that effectively penalizes negative scaling behaviors where increased computation leads to performance degradation, and (2) a dynamic sampling mechanism that mitigates the impact of accuracy fluctuations and token count instability on the final assessment. We conduct comprehensive experiments evaluating state-of-the-art reasoning models across diverse domains including mathematical reasoning, code generation, and agentic tasks. Our results demonstrate that ARISE provides a reliable and fine-grained measurement of test-time scaling capabilities, revealing significant variations in scaling efficiency across models. Notably, our evaluation identifies Claude Opus as exhibiting superior scaling characteristics compared to other contemporary reasoning models.
测试时缩放已成为提高大型推理模型性能的一种变革性范式,能够在推理过程中实现计算资源的动态分配。然而,随着推理模型景观的快速发展,一个关键问题仍然存在:我们如何系统地比较和评估不同模型的测试时缩放能力?在本文中,我们介绍了ARISE(自适应分辨率感知缩放评估),这是一种专门设计用于评估大型推理模型的测试时缩放效果的新指标。不同于现有的评估方法,ARISE结合了两种关键创新:1)样本级感知,有效地惩罚负面缩放行为,即增加计算导致性能下降;2)动态采样机制,减轻准确性波动和令牌计数不稳定对最终评估的影响。我们在多个领域进行了全面的实验,评估了最先进的推理模型,包括数学推理、代码生成和代理任务。我们的结果表明,ARISE提供了可靠的测试时缩放能力精细测量,揭示了模型之间在缩放效率方面的显著差异。值得注意的是,我们的评估认为Claude Opus在缩放特性方面表现出优于其他当代推理模型的优势。
论文及项目相关链接
PDF 19 pages, 7 figures
Summary
大模型推理任务的测试时缩放评估对于提高模型性能并动态分配计算资源至关重要。本文提出了一种新型的评估指标ARISE(自适应分辨率感知缩放评估),用以评估大模型的测试时缩放能力。相较于现有的评价方式,ARISE引入了两个创新点:一是对样本级别的计算效益感知惩罚机制,能有效规避负向计算导致性能降低的情况;二是采用动态采样机制减少准确性波动和标记符计数不稳定对评估的影响。实验证明,ARISE能够可靠且精细地衡量测试时缩放能力,揭示不同模型在效率上的显著差异,并且指出Claude Opus在特定场景中具有优异的缩放特性。
Key Takeaways
- 测试时缩放已成为增强大型推理模型性能的关键范式,允许在推理过程中动态分配计算资源。
- ARISE是一种新型的评估指标,专门用于评估大型推理模型的测试时缩放效果。
- ARISE引入样本级别感知机制,有效惩罚负向计算导致的性能下降。
- ARISE采用动态采样机制来减少准确性波动和标记符计数不稳定对评估结果的潜在影响。
- 实验结果显示ARISE能可靠、精细地衡量模型的测试时缩放能力。
- 在各种领域中,如数学推理、代码生成和智能任务等,测试时缩放能力在不同模型之间存在显著差异。
点此查看论文截图
Training-Free Time Series Classification via In-Context Reasoning with LLM Agents
Authors:Songyuan Sui, Zihang Xu, Yu-Neng Chuang, Kwei-Herng Lai, Xia Hu
Time series classification (TSC) spans diverse application scenarios, yet labeled data are often scarce, making task-specific training costly and inflexible. Recent reasoning-oriented large language models (LLMs) show promise in understanding temporal patterns, but purely zero-shot usage remains suboptimal. We propose FETA, a multi-agent framework for training-free TSC via exemplar-based in-context reasoning. FETA decomposes a multivariate series into channel-wise subproblems, retrieves a few structurally similar labeled examples for each channel, and leverages a reasoning LLM to compare the query against these exemplars, producing channel-level labels with self-assessed confidences; a confidence-weighted aggregator then fuses all channel decisions. This design eliminates the need for pretraining or fine-tuning, improves efficiency by pruning irrelevant channels and controlling input length, and enhances interpretability through exemplar grounding and confidence estimation. On nine challenging UEA datasets, FETA achieves strong accuracy under a fully training-free setting, surpassing multiple trained baselines. These results demonstrate that a multi-agent in-context reasoning framework can transform LLMs into competitive, plug-and-play TSC solvers without any parameter training. The code is available at https://github.com/SongyuanSui/FETATSC.
时间序列分类(TSC)涵盖了多种应用场景,但标注数据通常稀缺,使得针对特定任务的训练成本高昂且不够灵活。最近以推理为导向的大型语言模型(LLM)在理解时间模式方面显示出潜力,但纯零样本使用仍然不够理想。我们提出了基于范例的上下文推理无训练TSC多智能体框架FETA。FETA将多元时间序列分解为通道级的子问题,为每个通道检索几个结构相似的标注示例,并利用推理LLM将查询与这些范例进行比较,生成具有自我评估置信度的通道级标签;然后,置信度加权聚合器融合所有通道决策。这种设计无需进行预训练或微调,通过删除无关通道和控制输入长度提高了效率,并通过范例定位和置信度估计提高了可解释性。在九个具有挑战性的UEA数据集上,FETA在无训练设置中实现了较高的准确性,超越了多个训练基线。这些结果表明,多智能体上下文推理框架可以将LLM转化为无需任何参数训练的竞争性、即插即用TSC求解器。代码可在https://github.com/SongyuanSui/FETATSC找到。
论文及项目相关链接
PDF 8 pages main content, 12 pages total including appendix, 1 figure
Summary
时间序列分类(TSC)应用场景广泛,但缺乏标注数据导致任务特定训练成本高昂且不灵活。提出一种基于范例的零训练TSC多智能体框架FETA,通过范例上下文推理实现无需训练。FETA将多元序列分解为通道级子问题,检索每个通道的结构相似标注范例,利用推理大型语言模型(LLM)比较查询与范例,生成具有自我评估置信度的通道级标签;置信度加权聚合器融合所有通道决策。该设计无需预训练或微调,提高了效率,增强了可解释性。在UEA数据集上,FETA在零训练设置下实现高准确率,超越多个训练基线。
Key Takeaways
- 时间序列分类(TSC)面临标注数据稀缺问题,导致训练成本高且缺乏灵活性。
- 提出一种名为FETA的多智能体框架,用于基于范例的零训练TSC。
- FETA将多元序列分解为通道级子问题,检索结构相似的标注范例。
- 利用推理大型语言模型(LLM)比较查询与范例,生成通道级标签,具有自我评估置信度。
- 置信度加权聚合器融合所有通道决策,无需预训练或微调。
- FETA提高了效率,通过剔除无关通道和控制输入长度来实现。
点此查看论文截图

Towards Label-Free Biological Reasoning Synthetic Dataset Creation via Uncertainty Filtering
Authors:Josefa Lia Stoisser, Lawrence Phillips, Aditya Misra, Tom A. Lamb, Philip Torr, Marc Boubnovski Martell, Julien Fauqueur, Kaspar Märtens
Synthetic chain-of-thought (CoT) traces are widely used to train large reasoning models (LRMs), improving generalization by providing step-level supervision. Yet most approaches require ground-truth labels to seed or filter these traces - an expensive bottleneck in domains like biology where wet-lab data are scarce. We propose a label-free alternative: uncertainty-based filtering, which uses a model’s own confidence - quantified through established uncertainty metrics like self-consistency and predictive perplexity - as a substitute for external labels. We sample multiple reasoning traces and retain only low-uncertainty subsets. Applied to biological perturbation prediction, a domain where wet-lab labels are especially costly, we show that the filtered subset has higher accuracy, and that supervised fine-tuning (SFT) on uncertainty-filtered data outperforms unfiltered synthetic data, narrows the gap to ground-truth training, and surpasses strong LRM baselines. Ablations show that per-class filtering corrects for class-specific uncertainty scales and that hybrid uncertainty metrics yield higher-quality datasets. Our results suggest that model-internal confidence is a powerful signal for efficient reasoning dataset creation, enabling LRMs in domains where supervision is expensive.
合成思维链(CoT)轨迹广泛应用于训练大型推理模型(LRM),通过提供步骤级监督来提高泛化能力。然而,大多数方法都需要真实标签来播种或过滤这些轨迹,这在生物学等领域是一个昂贵的瓶颈,因为湿实验室数据非常稀缺。我们提出了一种无标签的替代方案:基于不确定性的过滤,它使用模型本身的信心——通过已建立的不确定性度量指标(如自我一致性和预测困惑度)进行量化,作为外部标签的替代品。我们对多个推理轨迹进行采样,仅保留低不确定性的子集。在生物扰动预测领域应用,这是一个湿实验室标签特别昂贵的应用领域,我们证明了过滤后的子集具有更高的准确性,并且在不确定性过滤数据上进行监督微调(SFT)优于未过滤的合成数据,缩小了与真实训练数据的差距,并超越了强大的LRM基线。消融实验表明,按类别过滤可以纠正特定类别的不确定性规模,混合不确定性度量指标可以生成更高质量的数据集。我们的结果表明,模型内部信心是一个强大的信号,可用于有效地创建推理数据集,使监督成本高昂的领域也能使用大型推理模型。
论文及项目相关链接
Summary
本文介绍了合成思维链(CoT)痕迹训练大型推理模型(LRMs)的方法。尽管大多数方法需要真实标签来筛选或生成这些痕迹,但在生物领域等缺乏实验数据的情况下,这种做法成本高昂。本文提出了一种无标签替代方法——基于不确定性的筛选,该方法使用模型自身的置信度作为外部标签的替代品。模型通过自我一致性等不确定性指标进行量化评估,并通过筛选低不确定性的推理痕迹来提高准确性。在生物扰动预测领域的应用表明,使用不确定性筛选的数据进行微调优于未筛选的合成数据,缩小了与真实训练数据的差距,并超过了强大的LRM基线。结果表明,模型内部信心是创建高效推理数据集的有力信号,尤其适用于监督成本高昂的领域。
Key Takeaways
- 合成思维链(CoT)痕迹用于训练大型推理模型(LRMs),提高模型的泛化能力。
- 现有方法依赖真实标签来生成或筛选CoT痕迹,这在某些领域如生物学中成本高昂。
- 提出了一种无标签方法——基于不确定性的筛选,使用模型自身的置信度替代外部标签。
- 通过自我一致性等不确定性指标量化评估模型。
- 在生物扰动预测领域应用此方法,发现筛选后的数据子集准确性更高。
- 使用不确定性筛选的数据进行微调优于未筛选的合成数据,并接近真实训练数据的效果。
点此查看论文截图
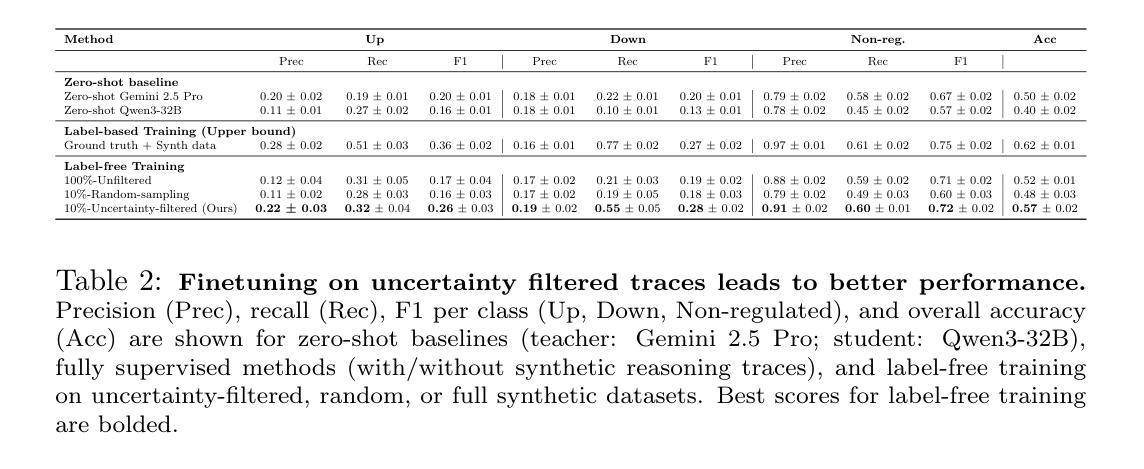
EEPO: Exploration-Enhanced Policy Optimization via Sample-Then-Forget
Authors:Liang Chen, Xueting Han, Qizhou Wang, Bo Han, Jing Bai, Hinrich Schutze, Kam-Fai Wong
Balancing exploration and exploitation remains a central challenge in reinforcement learning with verifiable rewards (RLVR) for large language models (LLMs). Current RLVR methods often overemphasize exploitation, leading to entropy collapse, diminished exploratory capacity, and ultimately limited performance gains. Although techniques that increase policy stochasticity can promote exploration, they frequently fail to escape dominant behavioral modes. This creates a self-reinforcing loop-repeatedly sampling and rewarding dominant modes-that further erodes exploration. We introduce Exploration-Enhanced Policy Optimization (EEPO), a framework that promotes exploration via two-stage rollouts with adaptive unlearning. In the first stage, the model generates half of the trajectories; it then undergoes a lightweight unlearning step to temporarily suppress these sampled responses, forcing the second stage to explore different regions of the output space. This sample-then-forget mechanism disrupts the self-reinforcing loop and promotes wider exploration during rollouts. Across five reasoning benchmarks, EEPO outperforms GRPO, achieving average relative gains of 24.3% on Qwen2.5-3B, 33.0% on Llama3.2-3B-Instruct, and 10.4% on Qwen3-8B-Base.
在具有可验证奖励的强化学习(RLVR)中,对于大型语言模型(LLM),平衡探索与利用仍然是一个核心挑战。当前的RLVR方法通常过于强调利用,导致熵崩溃、探索能力减弱,最终性能提升有限。虽然增加策略随机性的技术可以促进探索,但它们经常无法摆脱主导的行为模式。这创建了一个自我强化的循环——反复采样和奖励主导模式——进一步侵蚀了探索。我们引入了探索增强策略优化(EEPO),这是一个通过两阶段推出和自适应遗忘来促进探索的框架。在第一阶段,模型生成一半的轨迹;然后它经历一个轻量级的遗忘步骤,暂时抑制这些采样到的响应,迫使第二阶段探索输出空间的不同区域。这种采样然后遗忘的机制破坏了自我强化的循环,并在推出过程中促进了更广泛的探索。在五个推理基准测试中,EEPO的表现优于GRPO,在Qwen2.5-3B上平均相对增益为24.3%,在Llama3.2-3B-Instruct上为33.0%,在Qwen3-8B-Base上为10.4%。
论文及项目相关链接
Summary
在强化学习可验证奖励(RLVR)为大语言模型(LLM)带来挑战时,平衡探索与利用成为核心问题。当前RLVR方法常常过度重视利用,导致熵崩溃、探索能力减弱和性能提升受限。尽管增加策略随机性的技术可以促进探索,但它们常无法摆脱主导的行为模式。为此,我们引入探索增强策略优化(EEPO)框架,通过两阶段滚动和自适应遗忘来促进探索。第一阶段,模型生成一半轨迹;然后经历轻量级遗忘步骤,暂时抑制这些采样响应,迫使第二阶段探索输出空间的不同区域。这种采样后遗忘机制打破了自我强化循环,促进了滚动过程中的更广泛探索。
Key Takeaways
- 在强化学习可验证奖励(RLVR)中,平衡探索与利用是关键挑战。
- 当前方法常过度重视利用,导致探索能力减弱和性能受限。
- 增加策略随机性的技术虽能促进探索,但仍受主导行为模式的限制。
- EEPO框架通过两阶段滚动和自适应遗忘促进探索。
- 第一阶段生成轨迹,第二阶段强制探索不同区域,打破自我强化循环。
- EEPO在五个推理基准测试中表现出优于GRPO的性能,取得了显著的平均相对增益。
点此查看论文截图
VCoT-Grasp: Grasp Foundation Models with Visual Chain-of-Thought Reasoning for Language-driven Grasp Generation
Authors:Haoran Zhang, Shuanghao Bai, Wanqi Zhou, Yuedi Zhang, Qi Zhang, Pengxiang Ding, Cheng Chi, Donglin Wang, Badong Chen
Robotic grasping is one of the most fundamental tasks in robotic manipulation, and grasp detection/generation has long been the subject of extensive research. Recently, language-driven grasp generation has emerged as a promising direction due to its practical interaction capabilities. However, most existing approaches either lack sufficient reasoning and generalization capabilities or depend on complex modular pipelines. Moreover, current grasp foundation models tend to overemphasize dialog and object semantics, resulting in inferior performance and restriction to single-object grasping. To maintain strong reasoning ability and generalization in cluttered environments, we propose VCoT-Grasp, an end-to-end grasp foundation model that incorporates visual chain-of-thought reasoning to enhance visual understanding for grasp generation. VCoT-Grasp adopts a multi-turn processing paradigm that dynamically focuses on visual inputs while providing interpretable reasoning traces. For training, we refine and introduce a large-scale dataset, VCoT-GraspSet, comprising 167K synthetic images with over 1.36M grasps, as well as 400+ real-world images with more than 1.2K grasps, annotated with intermediate bounding boxes. Extensive experiments on both VCoT-GraspSet and real robot demonstrate that our method significantly improves grasp success rates and generalizes effectively to unseen objects, backgrounds, and distractors. More details can be found at https://zhanghr2001.github.io/VCoT-Grasp.github.io.
机器人抓取是机器人操作中最基本的任务之一,而抓取检测/生成一直是广泛研究的主题。最近,语言驱动抓取生成因其实际交互能力而成为一个有前景的研究方向。然而,大多数现有方法要么缺乏推理和泛化能力,要么依赖于复杂的模块化流程。此外,当前的抓取基础模型往往过于强调对话和对象语义,导致性能较差且仅限于单个对象的抓取。为了在处理杂乱的环境中保持强大的推理能力和泛化能力,我们提出了VCoT-Grasp,这是一种端到端的抓取基础模型,它结合了视觉思维链推理,以增强对抓取生成的视觉理解。VCoT-Grasp采用多轮处理范式,动态关注视觉输入,同时提供可解释的推理轨迹。在训练方面,我们完善并介绍了一个大型数据集VCoT-GraspSet,其中包含16.7万张合成图像和超过136万次的抓取动作,以及400多张真实世界图像和超过1200次的抓取动作,这些都通过中间边界框进行了注释。在VCoT-GraspSet和真实机器人上的大量实验表明,我们的方法显著提高了抓取的成功率,并能够有效地泛化到未见过的对象、背景和干扰物。更多详细信息可在https://zhanghr2001.github.io/VCoT-Grasp.github.io找到。
论文及项目相关链接
Summary
文本主要介绍了机器人抓取操作中的视觉链式思维推理增强型抓取生成模型VCoT-Grasp。该模型结合了视觉链式思维推理技术,以提高抓取生成时的视觉理解能力。它采用多轮处理模式,能动态聚焦于视觉输入并提供可解释的推理轨迹。同时,文章还介绍了用于训练VCoT-Grasp的大型数据集VCoT-GraspSet。该模型在虚拟和真实机器人实验中都表现出更高的抓取成功率和对未见物体、背景和干扰项的泛化能力。更多详细信息可通过链接查看。
Key Takeaways
- VCoT-Grasp是一种基于视觉链式思维推理技术的抓取生成模型,旨在提高机器人抓取操作的视觉理解能力。
- 该模型采用多轮处理模式,能够动态聚焦于视觉输入,同时提供可解释的推理轨迹。
- VCoT-Grasp通过结合视觉链式思维推理技术,强化了模型的推理能力和泛化能力,使其能够在复杂的混乱环境中进行强力的抓取操作。
- VCoT-Grasp的训练数据集VCoT-GraspSet包含大量合成图像和真实图像数据,并标注了中间边界框,用于模型训练。
- 实验结果表明,VCoT-Grasp在虚拟和真实机器人实验中的抓取成功率显著提高,且对未见物体、背景和干扰项具有良好的泛化能力。
- 与现有方法相比,VCoT-Grasp既具有强大的推理能力,又具备较好的泛化能力,且在对话和对象语义方面取得了平衡。
点此查看论文截图
EMORL-TTS: Reinforcement Learning for Fine-Grained Emotion Control in LLM-based TTS
Authors:Haoxun Li, Yu Liu, Yuqing Sun, Hanlei Shi, Leyuan Qu, Taihao Li
Recent LLM-based TTS systems achieve strong quality and zero-shot ability, but lack fine-grained emotional control due to their reliance on discrete speech tokens. Existing approaches either limit emotions to categorical labels or cannot generalize to LLM-based architectures. We propose EMORL-TTS (Fine-grained Emotion-controllable TTS with Reinforcement Learning), a framework that unifies global intensity control in the VAD space with local emphasis regulation. Our method combines supervised fine-tuning with reinforcement learning guided by task-specific rewards for emotion category, intensity, and emphasis. Moreover, we further investigate how emphasis placement modulates fine-grained emotion intensity. Experiments show that EMORL-TTS improves emotion accuracy, intensity differentiation, and emphasis clarity, while preserving synthesis quality comparable to strong LLM-based baselines.
最近的基于大型语言模型(LLM)的文本转语音(TTS)系统具有强大的质量和零样本能力,但由于它们依赖于离散的语音标记,缺乏精细的情绪控制。现有方法要么将情绪限制为类别标签,要么无法适应基于LLM的架构。我们提出了EMORL-TTS(基于强化学习的精细情绪控制TTS),一个统一了VAD空间中的全局强度控制与局部重点调节的框架。我们的方法结合了监督微调与强化学习,通过特定任务的奖励来进行情绪类别、强度和重点的学习。此外,我们还进一步研究了重点放置如何调节精细的情绪强度。实验表明,EMORL-TTS提高了情绪准确性、强度区分度和重点清晰度,同时保持了与强大的基于LLM的基线相当的综合质量。
论文及项目相关链接
PDF Under review for ICASSP 2026
Summary
基于最新的大型语言模型(LLM)的文本转语音(TTS)系统虽然具有良好的质量和零样本学习能力,但由于依赖于离散语音标记,它们在精细情感控制方面存在不足。现有方法要么限制情感为分类标签,要么无法推广到基于LLM的架构。为此,我们提出了EMORL-TTS(一种结合强化学习的精细情感控制TTS),它统一了VAD空间中的全局强度控制与局部重点调节。我们的方法结合了监督微调,并使用针对情感类别、强度和重点的任务特定奖励来引导强化学习。此外,我们还深入研究了重点放置如何调节精细情感强度。实验表明,EMORL-TTS提高了情感准确性、强度区分度和重点清晰度,同时保持了与强大的基于LLM的基线相当的合成质量。
Key Takeaways
- LLM-based TTS系统虽具有高质量和零样本学习能力,但在精细情感控制方面存在局限。
- 现有TTS方法在情感控制方面要么局限于分类标签,要么无法适应LLM架构。
- EMORL-TTS结合强化学习,实现了全局强度控制与局部重点调节的统一。
- EMORL-TTS通过监督微调和强化学习,针对情感类别、强度和重点进行优化。
- 重点放置对精细情感强度具有调节作用。
- EMORL-TTS提高了情感准确性、强度区分度和重点清晰度。
点此查看论文截图
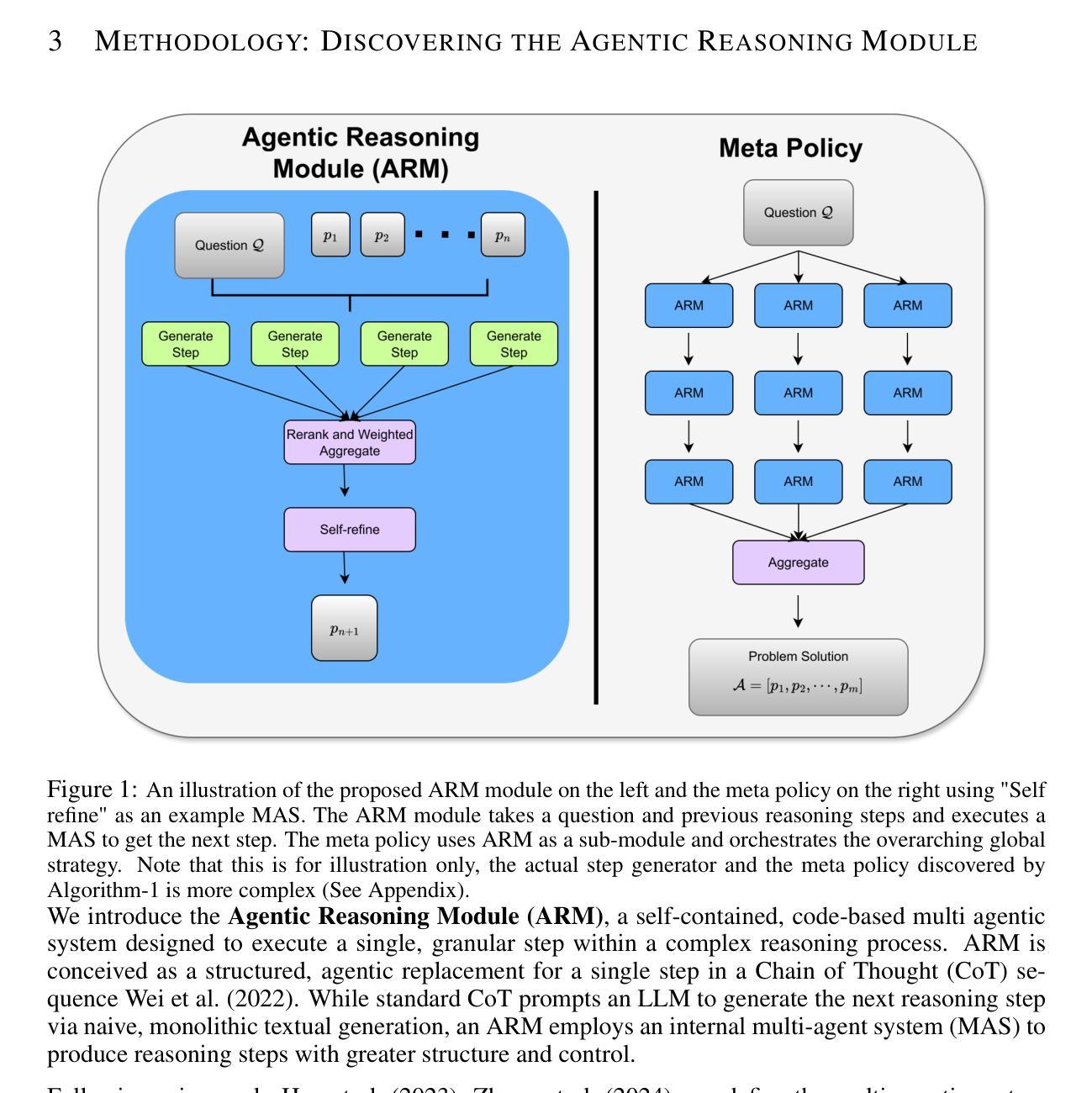
ARM: Discovering Agentic Reasoning Modules for Generalizable Multi-Agent Systems
Authors:Bohan Yao, Shiva Krishna Reddy Malay, Vikas Yadav
Large Language Model (LLM)-powered Multi-agent systems (MAS) have achieved state-of-the-art results on various complex reasoning tasks. Recent works have proposed techniques to automate the design of MASes, eliminating the need for manual engineering. However, these techniques perform poorly, often achieving similar or inferior performance to simple baselines. Furthermore, they require computationally expensive re-discovery of architectures for each new task domain and expensive data annotation on domains without existing labeled validation sets. A critical insight is that simple Chain of Thought (CoT) reasoning often performs competitively with these complex systems, suggesting that the fundamental reasoning unit of MASes, CoT, warrants further investigation. To this end, we present a new paradigm for automatic MAS design that pivots the focus to optimizing CoT reasoning. We introduce the Agentic Reasoning Module (ARM), an agentic generalization of CoT where each granular reasoning step is executed by a specialized reasoning module. This module is discovered through a tree search over the code space, starting from a simple CoT module and evolved using mutations informed by reflection on execution traces. The resulting ARM acts as a versatile reasoning building block which can be utilized as a direct recursive loop or as a subroutine in a learned meta-orchestrator. Our approach significantly outperforms both manually designed MASes and state-of-the-art automatic MAS design methods. Crucially, MASes built with ARM exhibit superb generalization, maintaining high performance across different foundation models and task domains without further optimization.
基于大型语言模型(LLM)的多智能体系统(MAS)在各种复杂的推理任务上取得了最先进的成果。近期的研究提出了自动化设计MAS的技术,从而消除了对人工工程的需求。然而,这些技术的表现并不理想,往往达到与简单基准线相似或更低的表现。此外,它们还需要为每个新的任务领域重新发现架构,并在没有现有标记验证集的领域进行昂贵的数据注释。一个重要的见解是,简单的思维链(CoT)推理通常与这些复杂系统的表现相竞争,这表明MAS的基本推理单元——思维链需要进一步调查。为此,我们提出了一种新的自动MAS设计范式,将重点转向优化思维链推理。我们引入了Agentic推理模块(ARM),这是思维链的agentic概括,其中每个粒度的推理步骤都由专门的推理模块执行。该模块是通过代码空间中的树搜索发现的,从简单的思维链模块开始,并通过根据执行轨迹的反思来进行变异进化。所得的ARM充当通用的推理构建块,可以作为直接的递归循环使用,也可以作为学习元编排器中的子程序使用。我们的方法显著优于手动设计的MAS和最新的自动MAS设计方法。关键的是,使用ARM构建的多智能体系统表现出卓越泛化能力,在不同的基础模型和任务领域上都能保持高性能,无需进一步优化。
论文及项目相关链接
PDF 29 pages, 2 figures
Summary
大语言模型驱动的多智能体系统已在各种复杂的推理任务上取得最新成果。新的技术可以自动设计智能体系统,减少了对人工工程的依赖。然而,这些技术在性能上表现不佳,经常与简单基线相似或较差。它们还需要为每个新任务域重新发现架构,并在没有现有标记验证集的域上进行昂贵的数据注释。关键的见解是,简单的链式思维推理往往能与这些复杂系统竞争,这表明智能体系统的基本推理单元——链式思维值得进一步研究。为此,我们提出了一种新的自动智能体设计范式,以优化链式思维推理。我们引入了Agentic推理模块(ARM),这是链式思维的一种智能体概括,每个颗粒状推理步骤都由一个专门的推理模块执行。该模块通过代码空间中的树搜索发现,从简单的链式思维模块开始,并通过根据执行轨迹的反思进行变异而进化。产生的ARM充当一个通用的推理构建块,可以作为直接的递归循环使用,也可以作为学习元编排器中的子程序使用。我们的方法显著优于手动设计智能体系统和最新的自动智能体设计方法。最重要的是,使用ARM构建的智能体表现出卓越泛化能力,在不同基础模型和任务域上无需进一步优化即可维持高性能。
Key Takeaways
- LLM驱动的多智能体系统在复杂推理任务上表现优异。
- 自动设计智能体系统的技术虽然减少了对人工工程的依赖,但性能有待提高。
- 简单的链式思维推理与复杂系统竞争力相当,引发对智能体系统基本推理单元的研究。
- 提出一种新的自动智能体设计范式,以优化链式思维推理,引入Agentic推理模块(ARM)。
- ARM通过树搜索发现,从简单的链式思维模块进化而来,具有强大的泛化能力。
- ARM可以作为递归循环或子程序在智能体系统中使用。
点此查看论文截图

FinReflectKG - EvalBench: Benchmarking Financial KG with Multi-Dimensional Evaluation
Authors:Fabrizio Dimino, Abhinav Arun, Bhaskarjit Sarmah, Stefano Pasquali
Large language models (LLMs) are increasingly being used to extract structured knowledge from unstructured financial text. Although prior studies have explored various extraction methods, there is no universal benchmark or unified evaluation framework for the construction of financial knowledge graphs (KG). We introduce FinReflectKG - EvalBench, a benchmark and evaluation framework for KG extraction from SEC 10-K filings. Building on the agentic and holistic evaluation principles of FinReflectKG - a financial KG linking audited triples to source chunks from S&P 100 filings and supporting single-pass, multi-pass, and reflection-agent-based extraction modes - EvalBench implements a deterministic commit-then-justify judging protocol with explicit bias controls, mitigating position effects, leniency, verbosity and world-knowledge reliance. Each candidate triple is evaluated with binary judgments of faithfulness, precision, and relevance, while comprehensiveness is assessed on a three-level ordinal scale (good, partial, bad) at the chunk level. Our findings suggest that, when equipped with explicit bias controls, LLM-as-Judge protocols provide a reliable and cost-efficient alternative to human annotation, while also enabling structured error analysis. Reflection-based extraction emerges as the superior approach, achieving best performance in comprehensiveness, precision, and relevance, while single-pass extraction maintains the highest faithfulness. By aggregating these complementary dimensions, FinReflectKG - EvalBench enables fine-grained benchmarking and bias-aware evaluation, advancing transparency and governance in financial AI applications.
大型语言模型(LLM)正越来越多地被用于从非结构化金融文本中提取结构化知识。尽管先前的研究已经探索了各种提取方法,但在构建金融知识图谱(KG)方面,尚无通用的基准测试或统一的评估框架。我们介绍了FinReflectKG-EvalBench,这是一个用于从SEC 10-K文件中提取KG的基准测试和评估框架。FinReflectKG基于代理和整体评估原则,将经过审核的三重链接到标准普尔100文件的源块,并支持单通道、多通道和基于反射代理的提取模式。EvalBench实现了具有明确偏见控制的确定性先提交后验证判断协议,减轻了位置效应、宽容度、冗长和依赖世界知识的问题。每个候选三重性都是通过忠实度、精确度和相关性的二元判断来评估的,而综合评估则是在块级别上进行三级序数量表评估(良好、部分、不良)。我们的研究结果表明,配备明确偏见控制时,LLM作为法官的协议提供了一种可靠且成本效益高的替代人工注释的方法,同时能够进行结构化误差分析。基于反射的提取方法显示出其优越性,在综合性、精确度和相关性方面表现最佳,而单通道提取保持了最高的忠实度。通过聚合这些互补维度,FinReflectKG-EvalBench能够实现精细的基准测试和偏见感知评估,提高金融人工智能应用中的透明度和治理水平。
论文及项目相关链接
Summary
本文介绍了金融领域知识图谱构建的新基准评价体系——FinReflectKG-EvalBench。该框架从SEC 10-K文件中提取结构化知识,并采用确定性评判协议,对候选三元组进行忠实度、精确度和相关性的二元判断,同时对片段级别的完整性进行三级评估。研究表明,在明确的偏见控制下,LLM-as-Judge协议为可靠且经济的替代人工标注方法,并可进行结构化错误分析。其中,反射型提取方式展现出最佳的完整性、精确度和相关性,而单遍提取保持最高忠实度。通过聚合这些互补维度,FinReflectKG-EvalBench推动了金融AI应用的透明性和治理进步。
Key Takeaways
- FinReflectKG-EvalBench是一个针对金融知识图谱构建的基准评价体系,用于从SEC 10-K文件中提取结构化知识。
- 该框架采用确定性评判协议,对候选三元组进行忠实度、精确度和相关性的评估。
- LLM-as-Judge协议在明确的偏见控制下,作为可靠且经济的替代人工标注方法,并可进行结构化错误分析。
- 反射型提取方式在完整性、精确度和相关性方面表现最佳,而单遍提取保持最高忠实度。
- FinReflectKG-EvalBench通过聚合多种评估维度,推动了金融AI应用的透明性和治理进步。
- 该框架支持多种提取模式,包括单遍提取、多遍提取和反射代理基提取。
点此查看论文截图



Joint Communication Scheduling and Velocity Control for Multi-UAV-Assisted Post-Disaster Monitoring: An Attention-Based In-Context Learning Approach
Authors:Yousef Emami, Seyedsina Nabavirazavi, Jingjing Zheng, Hao Zhou, Miguel Gutierrez Gaitan, Kai Li, Luis Almeida
Recently, Unmanned Aerial Vehicles (UAVs) are increasingly being investigated to collect sensory data in post-disaster monitoring scenarios, such as tsunamis, where early actions are critical to limit coastal damage. A major challenge is to design the data collection schedules and flight velocities, as unfavorable schedules and velocities can lead to transmission errors and buffer overflows of the ground sensors, ultimately resulting in significant packet loss. Meanwhile, online Deep Reinforcement Learning (DRL) solutions have a complex training process and a mismatch between simulation and reality that does not meet the urgent requirements of tsunami monitoring. Recent advances in Large Language Models (LLMs) offer a compelling alternative. With their strong reasoning and generalization capabilities, LLMs can adapt to new tasks through In-Context Learning (ICL), which enables task adaptation through natural language prompts and example-based guidance without retraining. However, LLM models have input data limitations and thus require customized approaches. In this paper, a joint optimization of data collection schedules and velocities control for multiple UAVs is proposed to minimize data loss. The battery level of the ground sensors, the length of the queues, and the channel conditions, as well as the trajectories of the UAVs, are taken into account. Attention-Based In-Context Learning for Velocity Control and Data Collection Schedule (AIC-VDS) is proposed as an alternative to DRL in emergencies. The simulation results show that the proposed AIC-VDS outperforms both the Deep-Q-Network (DQN) and maximum channel gain baselines.
近期,无人飞行器(UAVs)在灾后监测场景中的感官数据收集越来越受到关注,例如在海啸等灾难中,早期行动对于限制沿海破坏至关重要。一个主要挑战是设计数据收集计划和飞行速度,因为不利的时间和速度设置会导致地面传感器的传输错误和缓冲区溢出,最终造成重大数据包丢失。同时,在线深度强化学习(DRL)解决方案存在训练过程复杂以及在仿真与现实之间存在不匹配的问题,无法满足海啸监测的紧迫需求。最近的大型语言模型(LLM)的进步提供了一个吸引人的替代方案。凭借强大的推理和泛化能力,LLM可以通过上下文学习(ICL)适应新任务,通过自然语言提示和基于示例的指导来适应任务,无需重新训练。然而,LLM模型存在输入数据限制,因此需要定制的方法。在本文中,提出了一种对多个无人飞行器的数据收集计划和速度控制的联合优化方案,以最小化数据丢失。考虑到地面传感器的电池水平、队列长度、信道条件以及无人飞行器的轨迹。提出基于注意力的上下文学习用于速度控制和数据收集计划(AIC-VDS)作为紧急情况中DRL的替代方案。仿真结果表明,所提出的AIC-VDS在性能上优于深度Q网络(DQN)和最大信道增益基线。
论文及项目相关链接
Summary
无人机在灾后监测场景中收集感官数据越来越受到关注,如海啸等灾害。数据收集日程和飞行速度的设计是一大挑战,不合理的设置会导致传输错误和地面传感器缓冲区溢出,造成数据包丢失。深度强化学习解决方案虽可用于此场景,但其复杂的训练过程和模拟与现实的差异无法满足海啸监测的紧急需求。大型语言模型具有强大的推理和泛化能力,可以通过上下文学习适应新任务。本文提出了一种联合优化无人机数据收集日程和速度控制的方法,以最小化数据损失,考虑地面传感器电池水平、队列长度、通道条件以及无人机轨迹等因素。模拟结果表明,提出的基于注意力的上下文学习在速度控制和数据收集日程上的表现优于深度Q网络(DQN)和最大通道增益基线方法。
Key Takeaways
- UAVs在灾后监测中扮演重要角色,特别是在海啸等灾害的早期行动中。
- 数据收集日程和飞行速度设计是确保数据准确性的关键,以避免传输错误和数据包丢失。
- DRL解决此问题面临训练复杂性和模拟与现实的差异挑战。
- 大型语言模型具有强大的推理和泛化能力,能够通过上下文学习适应新任务。
- 提出的联合优化方法考虑了多种因素,如地面传感器电池水平、队列长度和通道条件等。
- 基于注意力的上下文学习方法在速度控制和数据收集日程上的表现优于DQN和最大通道增益基线方法。
点此查看论文截图

