⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-09 更新
TokenChain: A Discrete Speech Chain via Semantic Token Modeling
Authors:Mingxuan Wang, Satoshi Nakamura
Machine Speech Chain, simulating the human perception-production loop, proves effective in jointly improving ASR and TTS. We propose TokenChain, a fully discrete speech chain coupling semantic-token ASR with a two-stage TTS: an autoregressive text-to-semantic model co-trained with ASR and a masked-generative semantic-to-acoustic model for synthesis only. End-to-end feedback across the text interface is enabled with straight-through argmax/Gumbel-Softmax and balanced with supervised ASR via dynamic weight averaging. Ablations examine optimal temperature schedules for in- and cross-domain transfer. Evaluation reveals TokenChain surpasses baseline accuracy 2-6 epochs earlier and yields 5-13% lower equal-epoch error with stable T2S on LibriSpeech, and reduces relative ASR WER by 56% and T2S WER by 31% on TED-LIUM with minimal forgetting, showing that chain learning remains effective with token interfaces and models.
模拟人类感知-生产循环的机器语音链,在联合改进语音识别(ASR)和文本转语音(TTS)方面表现出良好的效果。我们提出了TokenChain,这是一个完全离散的语音链,通过语义令牌将ASR与两阶段TTS耦合:一个与ASR联合训练的autoregressive文本到语义模型和一个仅用于合成的masked-generative语义到声学模型。通过直通argmax/Gumbel-Softmax在文本接口实现端到端反馈,并通过动态权重平均与监督ASR进行平衡。消融研究检查了跨域迁移的最佳温度计划。评估结果显示,TokenChain在LibriSpeech上的准确性超过了基线模型,并在2-6个周期内取得了优势,在相同周期内的误差降低了5-13%,并且语音转文本(T2S)表现稳定。在TED-LIUM上,TokenChain相对降低了语音识别(ASR)的WER(词错误率)56%,并降低了T2S的WER(词错误率)31%,且几乎不会遗忘,这表明链学习在令牌接口和模型中仍然有效。
论文及项目相关链接
PDF 5 pages, 3 figures. Submitted to IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2026
Summary
机器语音链模拟人类感知-生产循环,通过联合改进语音识别和文本转语音技术,证明其有效性。提出TokenChain,一个完全离散的语音链,将语义令牌语音识别与两阶段文本转语音相结合:与语音识别联合训练的autoregressive文本到语义模型和仅用于合成的masked-generative语义到音频模型。通过straight-through argmax/Gumbel-Softmax实现端到端文本界面反馈,并通过动态权重平均与监督语音识别进行平衡。消融实验研究了域内和跨域转移的最佳温度调度。评估显示,TokenChain在LibriSpeech上的准确度超过基线2-6个周期,具有稳定的T2S,相同周期的错误率降低5-13%,在TED-LIUM上的相对语音识别字词错误率降低56%,T2S字词错误率降低31%,且模型在令牌接口下仍能保持有效。
Key Takeaways
TokenChain 是一项创新的语音技术,它将语义令牌语音识别与两阶段文本转语音相结合。
TokenChain 引入了基于语义的端到端反馈机制以提高语音识别和文本转语音的性能。
通过联合训练文本到语义模型和语义到音频模型,TokenChain 实现了更高的准确性。
TokenChain 通过动态权重平均结合了监督语音识别技术以实现平衡。
研究发现,TokenChain 在不同的语音任务和数据集上都取得了显著的性能提升。
在LibriSpeech数据集上,TokenChain表现出较高的稳定性和较低的错误率。
点此查看论文截图
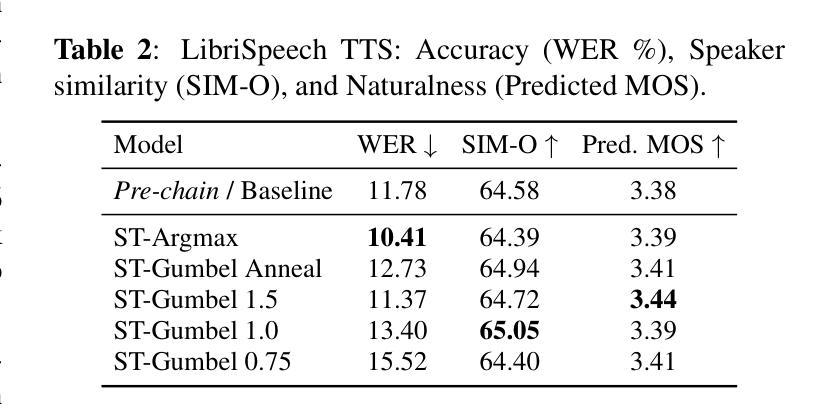
Pushing Test-Time Scaling Limits of Deep Search with Asymmetric Verification
Authors:Weihao Zeng, Keqing He, Chuqiao Kuang, Xiaoguang Li, Junxian He
Test-time compute can be scaled both sequentially and in parallel. Sequential scaling involves lengthening the generation process, while parallel scaling involves verifying and selecting among multiple candidate outputs. Combining these two strategies has led to the most powerful AI systems, such as Grok 4 Heavy and GPT-5 Pro. In certain contexts (e.g., solving Sudoku puzzles), verifying responses can be substantially easier than generating them. This property, referred to as \emph{asymmetric verification}, highlights the strong potential of test-time scaling (TTS). In this work, we study both sequential and parallel TTS of deep search agents, motivated by the intuition that verification in this setting is often much easier than generation. In experiments, we first show that sequential scaling methods, such as budget forcing, can be effective initially but soon degrade performance. Leveraging asymmetric verification, however, we are able to achieve substantial improvements by allocating only a modest amount of compute to the verifier. We conduct experiments with flagship open-source models and extend them to their ``Heavy’’ variants through TTS. These deep research agents achieve gains of up to 27 absolute points on benchmarks such as BrowseComp. Remarkably, as an open-source alternative, GLM-4.5 Heavy reaches accuracy of {\bf 54.0%} on BrowseComp and {\bf 66.0%} on GAIA, placing it comparable to the best proprietary choices such as OpenAI Deep Research. Tongyi-DeepResearch Heavy further achieves {\bf 69.0%} accuracy on BrowseComp, greatly surpassing the best proprietary results.
测试时的计算可以进行顺序和并行两种扩展。顺序扩展涉及延长生成过程,而并行扩展则涉及验证和选择多个候选输出。结合这两种策略,产生了最强大的AI系统,如Grok 4 Heavy和GPT-5 Pro。在某些情况下(例如解数独谜题),验证答案往往比生成答案更容易。这种特性被称为“不对称验证”,突出了测试时扩展(TTS)的强大潜力。在这项工作中,我们研究了深度搜索代理的顺序和并行TTS,我们的直觉是,在这种情况下验证通常比生成更容易。在实验中,我们首秀表明,顺序扩展方法(如预算强制)在初期可能有效,但很快就会降低性能。然而,利用不对称验证,我们只需为验证器分配适量的计算资源就能实现重大改进。我们使用旗舰开源模型进行实验,并通过TTS将其扩展到“重型”变体。这些深度研究代理在BrowseComp等基准测试上实现了高达27个绝对点的收益。值得注意的是,作为一个开源替代品,GLM-4.5 Heavy在BrowseComp上达到了54.0%的准确率,在GAIA上达到了66.0%的准确率,与最佳专有选择如OpenAI Deep Research相当。Tongyi-DeepResearch Heavy在BrowseComp上进一步达到了69.0%的准确率,大大超过了最佳专有结果。
论文及项目相关链接
Summary
测试时计算可通过序列和平行两种方式进行扩展。序列扩展通过延长生成过程,而平行扩展则通过验证和选择多个候选输出。结合这两种策略,诞生了最强大的AI系统,如Grok 4 Heavy和GPT-5 Pro。在某些情况下(例如解决数独谜题),验证答案可能比生成答案更容易,这种现象被称为不对称验证,突显了测试时扩展的强大潜力。本研究探讨了深度搜索代理的序列和并行测试时扩展,受到此设置中验证通常比生成更容易的直觉的启发。实验表明,序列扩展方法(如预算强制)虽然初期有效,但很快就会降低性能。利用不对称验证,我们只需为验证器分配很少的计算资源,就能实现显著改进。我们使用开源模型进行实验,并通过测试时扩展将其扩展到“重型”变体。这些深度研究代理在BrowseComp等基准测试上实现了高达27个绝对点的收益。值得注意的是,作为开源替代品,GLM-4.5 Heavy在BrowseComp上达到了54.0%的准确率,在GAIA上达到了66.0%,与最佳专有选择如OpenAI Deep Research相当。Tongyi-DeepResearch Heavy在BrowseComp上的准确率更是达到了惊人的69.0%,大大超过了最佳专有结果。
Key Takeaways
- 测试时计算可序列和平行扩展,影响AI系统的性能。
- 不对称验证是测试时扩展中的一个重要现象,验证通常比生成更容易。
- 序列扩展方法初期有效,但长期会降低AI系统性能。
- 利用不对称验证,可通过分配较少的计算资源实现显著改进。
- 深度研究代理通过测试时扩展在基准测试上取得显著成果。
- 开源模型如GLM-4.5 Heavy和Tongyi-DeepResearch Heavy的准确率与专有选择相当,甚至更佳。
点此查看论文截图
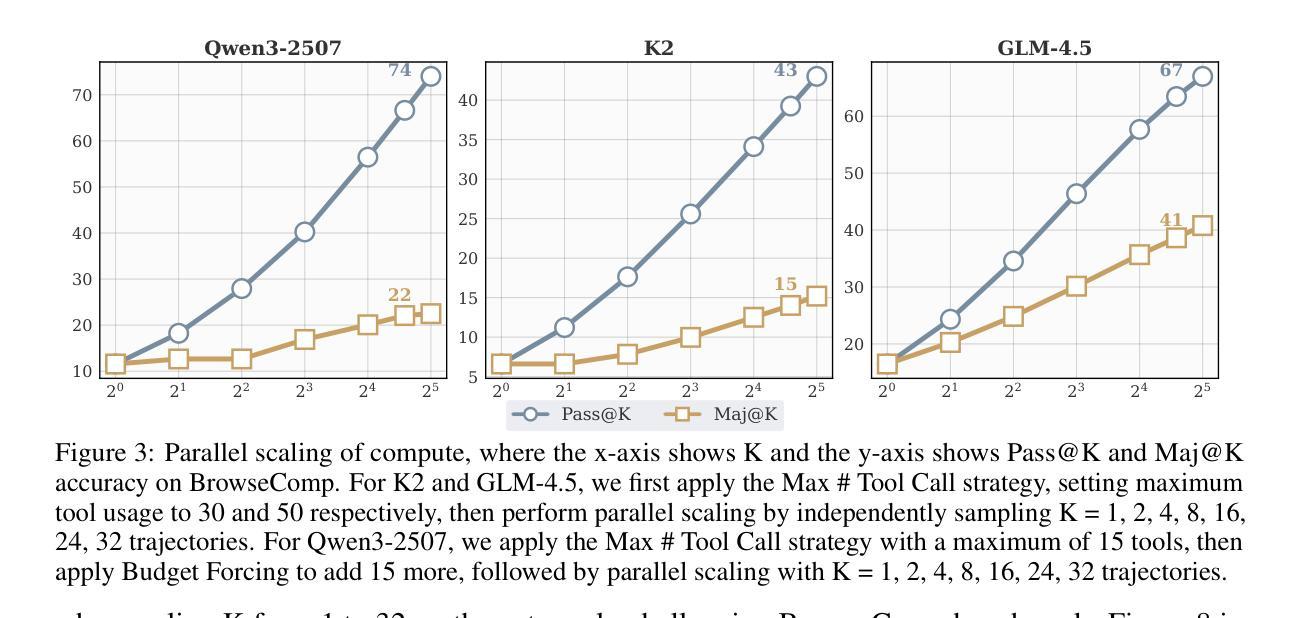

ECTSpeech: Enhancing Efficient Speech Synthesis via Easy Consistency Tuning
Authors:Tao Zhu, Yinfeng Yu, Liejun Wang, Fuchun Sun, Wendong Zheng
Diffusion models have demonstrated remarkable performance in speech synthesis, but typically require multi-step sampling, resulting in low inference efficiency. Recent studies address this issue by distilling diffusion models into consistency models, enabling efficient one-step generation. However, these approaches introduce additional training costs and rely heavily on the performance of pre-trained teacher models. In this paper, we propose ECTSpeech, a simple and effective one-step speech synthesis framework that, for the first time, incorporates the Easy Consistency Tuning (ECT) strategy into speech synthesis. By progressively tightening consistency constraints on a pre-trained diffusion model, ECTSpeech achieves high-quality one-step generation while significantly reducing training complexity. In addition, we design a multi-scale gate module (MSGate) to enhance the denoiser’s ability to fuse features at different scales. Experimental results on the LJSpeech dataset demonstrate that ECTSpeech achieves audio quality comparable to state-of-the-art methods under single-step sampling, while substantially reducing the model’s training cost and complexity.
扩散模型在语音合成中表现出了出色的性能,但通常需要多步采样,导致推理效率低下。最近的研究通过将扩散模型提炼成一致性模型来解决这个问题,实现了一次性高效生成。然而,这些方法引入了额外的训练成本,并严重依赖于预训练教师模型的性能。在本文中,我们提出了ECTSpeech,这是一个简单有效的一次性语音合成框架,首次将Easy Consistency Tuning(ECT)策略融入语音合成。通过对预训练的扩散模型上的一致性约束进行逐步加强,ECTSpeech实现了一次性高质量生成,同时显著降低了训练复杂度。此外,我们设计了一个多尺度门模块(MSGate),以提高去噪器在不同尺度上融合特征的能力。在LJSpeech数据集上的实验结果表明,ECTSpeech在一次性采样下生成的音频质量与最先进的方法相当,同时大大降低了模型的训练成本和复杂性。
论文及项目相关链接
PDF Accepted for publication by Proceedings of the 2025 ACM Multimedia Asia Conference(MMAsia ‘25)
Summary
本文提出了ECTSpeech框架,该框架采用Easy Consistency Tuning(ECT)策略,将扩散模型逐步调整为一致性模型,实现了一次性高质量语音合成,同时显著降低了训练复杂度。此外,还设计了一个多尺度门模块(MSGate)以增强去噪器在不同尺度上融合特征的能力。在LJSpeech数据集上的实验结果表明,ECTSpeech在单步采样下达到了与最先进方法相当的音频质量,同时显著降低了模型训练成本和复杂性。
Key Takeaways
- 扩散模型在语音合成中表现出卓越性能,但通常需要多步采样,导致推理效率低下。
- 研究者通过蒸馏扩散模型到一致性模型解决了这一问题,实现了一次性生成。
- 本文提出ECTSpeech框架,首次将Easy Consistency Tuning (ECT)策略应用于语音合成。
- ECTSpeech通过逐步加强预训练扩散模型的一致性约束,实现了一次性高质量生成并降低了训练复杂性。
- 设计了多尺度门模块(MSGate)以增强去噪器在不同尺度上融合特征的能力。
- 在LJSpeech数据集上的实验结果表明ECTSpeech在单步采样下达到音频质量与最先进方法相当。
点此查看论文截图

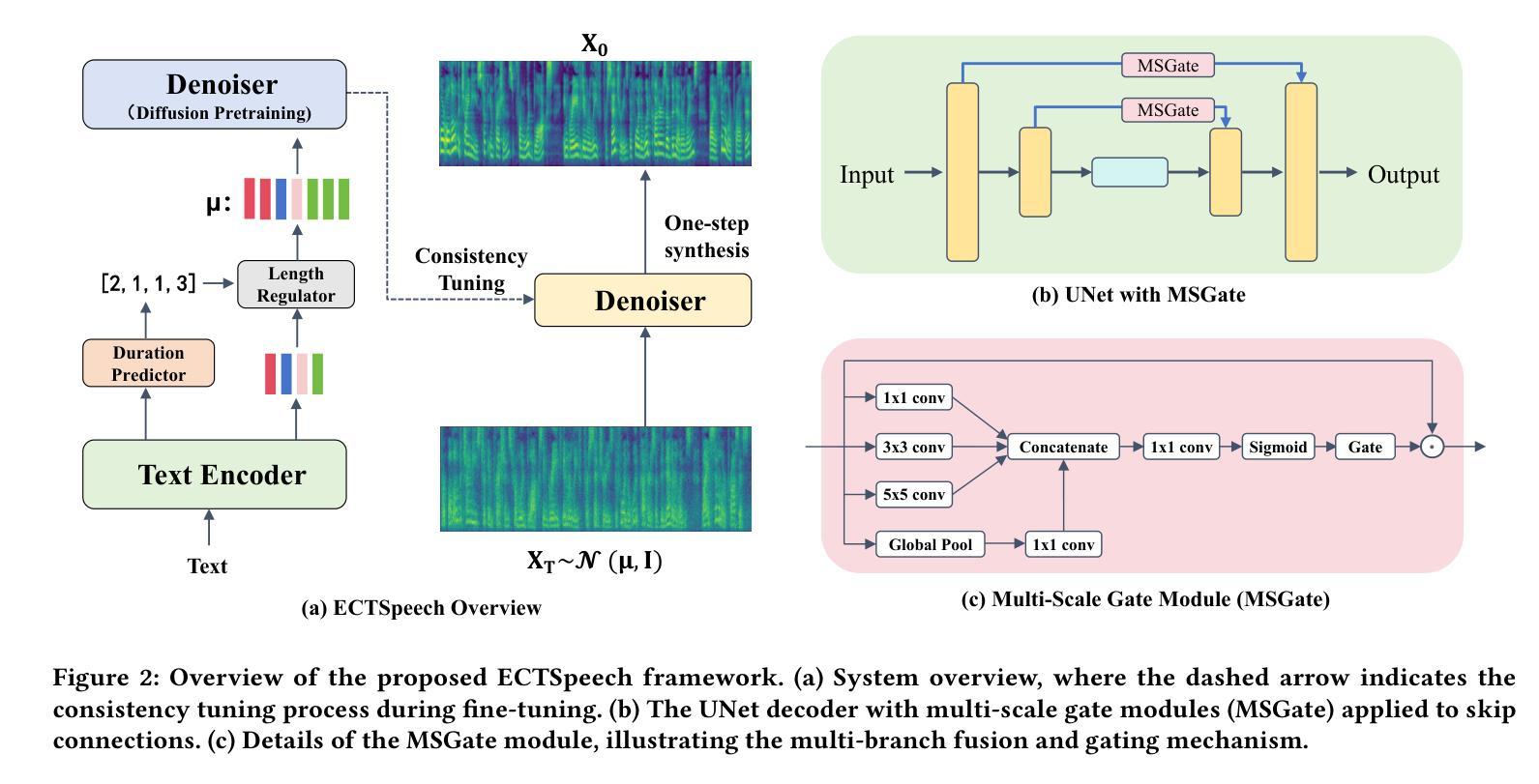
EMORL-TTS: Reinforcement Learning for Fine-Grained Emotion Control in LLM-based TTS
Authors:Haoxun Li, Yu Liu, Yuqing Sun, Hanlei Shi, Leyuan Qu, Taihao Li
Recent LLM-based TTS systems achieve strong quality and zero-shot ability, but lack fine-grained emotional control due to their reliance on discrete speech tokens. Existing approaches either limit emotions to categorical labels or cannot generalize to LLM-based architectures. We propose EMORL-TTS (Fine-grained Emotion-controllable TTS with Reinforcement Learning), a framework that unifies global intensity control in the VAD space with local emphasis regulation. Our method combines supervised fine-tuning with reinforcement learning guided by task-specific rewards for emotion category, intensity, and emphasis. Moreover, we further investigate how emphasis placement modulates fine-grained emotion intensity. Experiments show that EMORL-TTS improves emotion accuracy, intensity differentiation, and emphasis clarity, while preserving synthesis quality comparable to strong LLM-based baselines.
基于最新的大型语言模型(LLM)的文本转语音(TTS)系统已经实现了高质量和零射击能力,但由于它们依赖于离散的语音令牌,因此在精细情绪控制方面存在不足。现有方法要么将情绪限制为类别标签,要么无法推广到基于LLM的架构。我们提出了EMORL-TTS(基于强化学习的精细情绪控制TTS),一个统一了VAD空间的全局强度控制与局部重点调节的框架。我们的方法结合了监督微调,并使用任务特定奖励引导的强化学习来进行情绪类别、强度和重点的学习。此外,我们还进一步研究了重点放置如何调节精细的情绪强度。实验表明,EMORL-TTS提高了情绪准确性、强度区分度和重点清晰度,同时保持了与基于LLM的基线相当的合成质量。
论文及项目相关链接
PDF Under review for ICASSP 2026
Summary
近期LLM-based的TTS系统具有强大的性能和零发射能力,但在精细情绪控制方面存在不足,主要因为依赖于离散语音令牌。现有方法要么限制情绪为类别标签,要么无法推广到基于LLM的架构。本研究提出EMORL-TTS(结合强化学习的精细情绪控制TTS),将全局强度控制与VAD空间的局部强调调节相结合。本研究方法结合了监督微调与强化学习,由针对情绪类别、强度和重点的任务特定奖励引导。此外,本研究还深入探讨了重点放置如何调节精细的情绪强度。实验表明,EMORL-TTS提高了情绪准确性、强度差异和重点清晰度,同时保持了与强大的LLM基线相当的综合质量。
Key Takeaways
- LLM-based TTS系统虽具有高质量和零发射能力,但在精细情绪控制方面存在挑战。
- 现有方法往往将情绪限制为类别标签,无法适应LLM架构。
- EMORL-TTS结合了监督学习与强化学习,实现了全局强度控制与局部强调调节的统一。
- EMORL-TTS通过任务特定奖励引导强化学习,可针对情绪类别、强度和重点进行调整。
- 研究发现重点放置对精细情绪强度调节的重要性。
- EMORL-TTS提高了情绪准确性、强度差异和重点清晰度。
点此查看论文截图
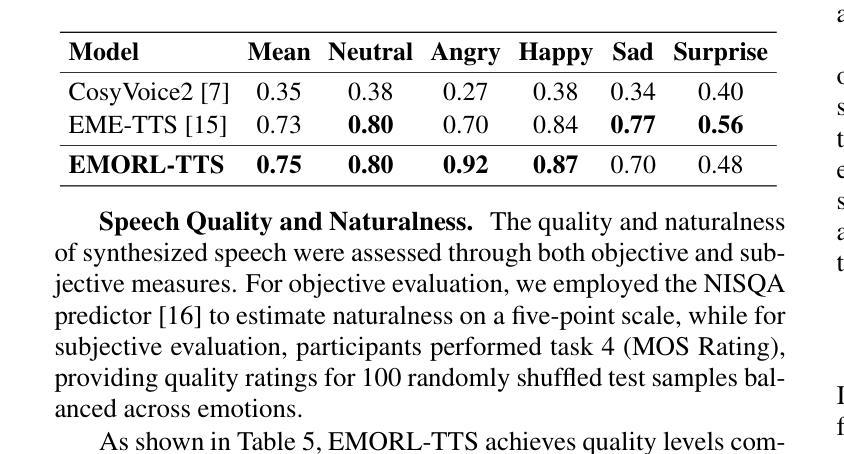
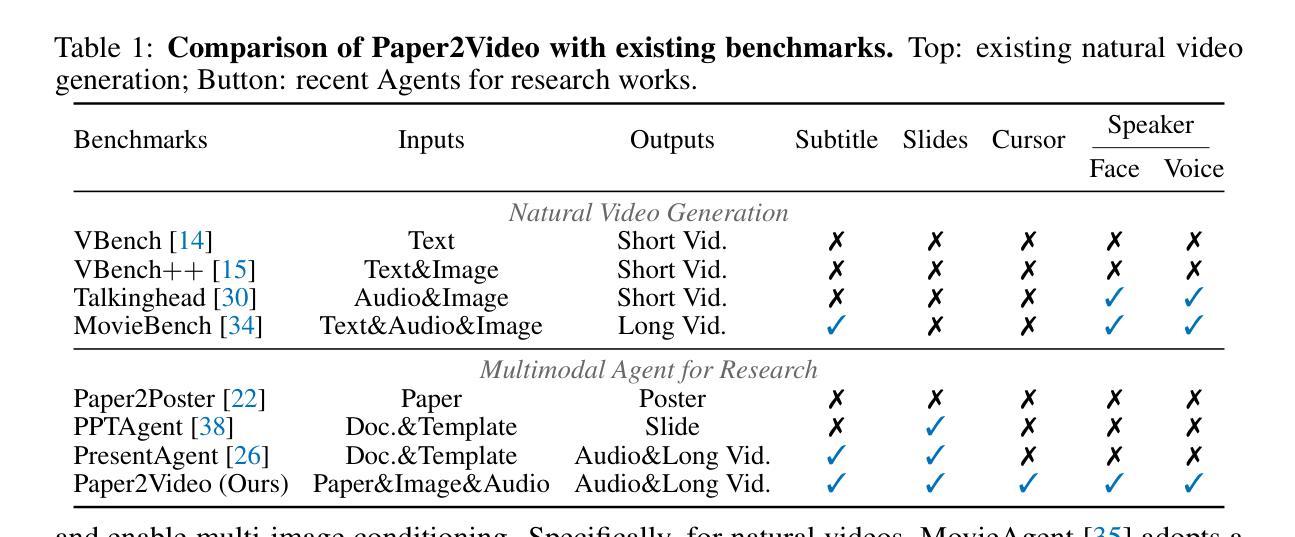
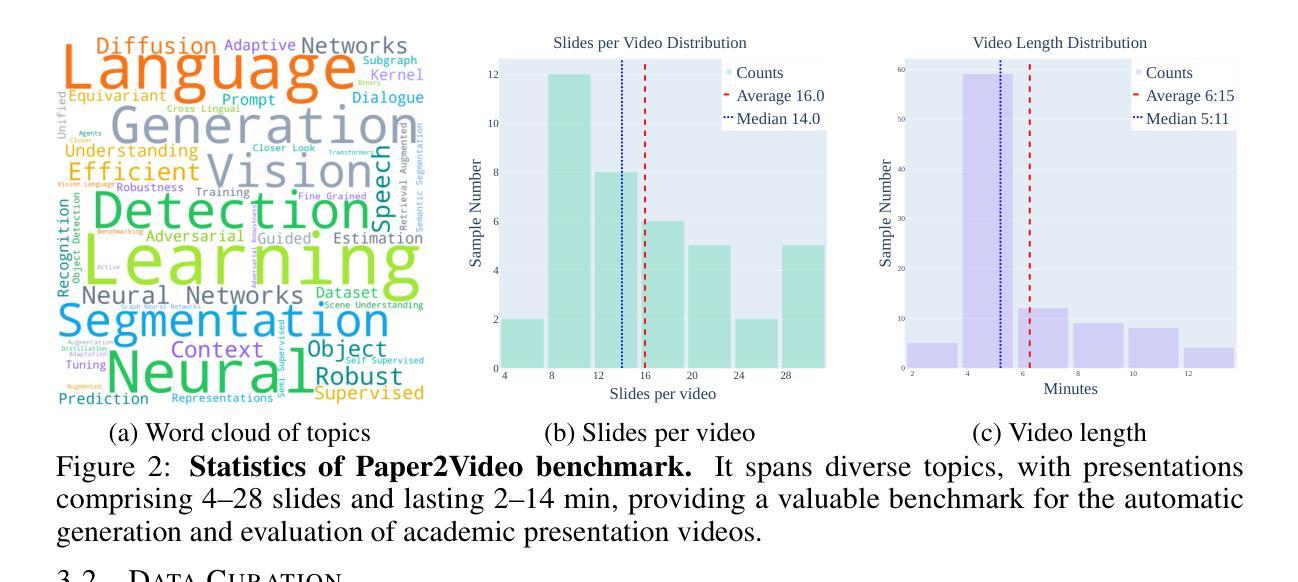
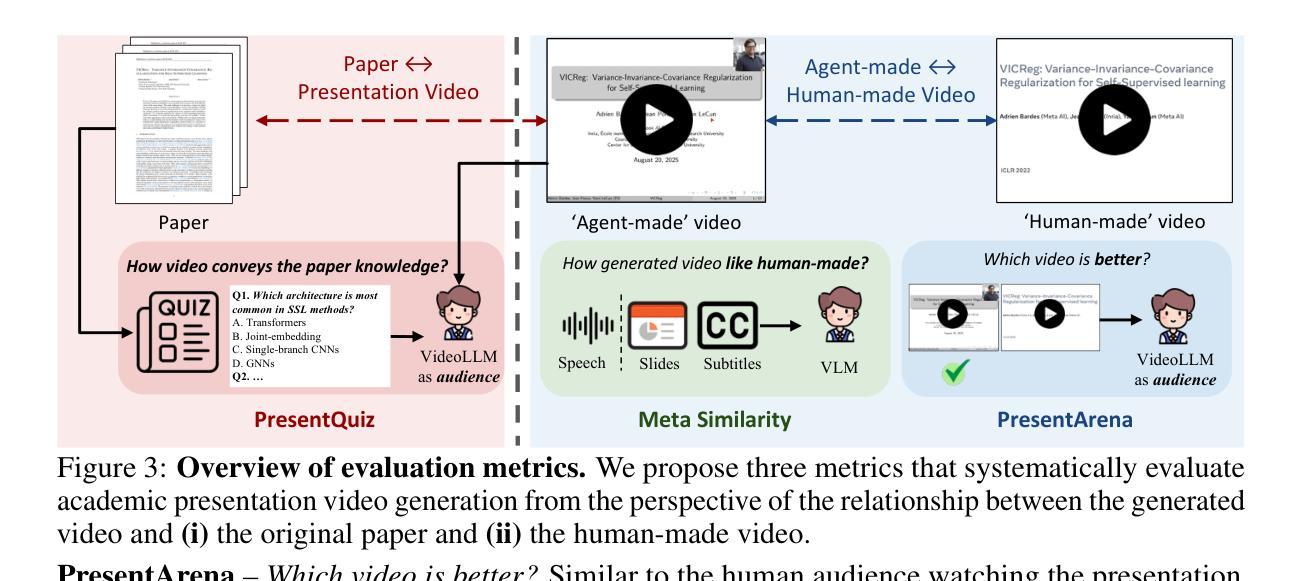
Paper2Video: Automatic Video Generation from Scientific Papers
Authors:Zeyu Zhu, Kevin Qinghong Lin, Mike Zheng Shou
Academic presentation videos have become an essential medium for research communication, yet producing them remains highly labor-intensive, often requiring hours of slide design, recording, and editing for a short 2 to 10 minutes video. Unlike natural video, presentation video generation involves distinctive challenges: inputs from research papers, dense multi-modal information (text, figures, tables), and the need to coordinate multiple aligned channels such as slides, subtitles, speech, and human talker. To address these challenges, we introduce PaperTalker, the first benchmark of 101 research papers paired with author-created presentation videos, slides, and speaker metadata. We further design four tailored evaluation metrics–Meta Similarity, PresentArena, PresentQuiz, and IP Memory–to measure how videos convey the paper’s information to the audience. Building on this foundation, we propose PaperTalker, the first multi-agent framework for academic presentation video generation. It integrates slide generation with effective layout refinement by a novel effective tree search visual choice, cursor grounding, subtitling, speech synthesis, and talking-head rendering, while parallelizing slide-wise generation for efficiency. Experiments on Paper2Video demonstrate that the presentation videos produced by our approach are more faithful and informative than existing baselines, establishing a practical step toward automated and ready-to-use academic video generation. Our dataset, agent, and code are available at https://github.com/showlab/Paper2Video.
学术报告视频已成为研究沟通的重要媒介,但其制作仍然是一项劳动密集型活动,通常需要花费数小时的时间来设计和编辑一个短暂的视频,一般在2到10分钟之间。与一般的视频不同,演示视频生成面临独特的挑战:包括来自研究论文的输入、密集的多模态信息(文本、图表、表格),以及需要协调多个对齐的通道,如幻灯片、字幕、语音和人类说话者。为了应对这些挑战,我们推出了PaperTalker,这是第一个包含作者创建的演示视频、幻灯片以及发言人元数据的论文基准测试平台,包含一百零一篇研究论文。我们进一步设计了四个定制的评价指标——Meta相似性、PresentArena、PresentQuiz和IP记忆——来衡量视频向观众传达论文信息的效果。在此基础上,我们提出了首个学术报告视频生成的多智能体框架PaperTalker。它将幻灯片生成与有效的布局优化相结合,通过新颖的有效树搜索视觉选择、光标定位、字幕添加、语音合成和头部渲染等技术,同时并行进行幻灯片级别的生成以提高效率。在Paper2Video上的实验表明,我们的方法生成的报告视频比现有基线更忠实且更具信息量,朝着自动化和即用的学术视频生成方向迈出了实际的一步。我们的数据集、智能体和代码可在https://github.com/showlab/Paper2Video找到。
论文及项目相关链接
PDF 20 pages, 8 figures
摘要:本研究针对学术交流中的视频生成挑战,提出了PaperTalker方法和框架。通过引入论文与视频配对的数据集,建立评价模型,并利用AI技术实现学术视频的自动生成。实验证明其有效性,为学术视频制作带来革新与进步,提高学术交流效率。相关信息和资源可通过公开平台获取。
关键要点:
点此查看论文截图


Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Authors:Yunlong Tang, Jing Bi, Pinxin Liu, Zhenyu Pan, Zhangyun Tan, Qianxiang Shen, Jiani Liu, Hang Hua, Junjia Guo, Yunzhong Xiao, Chao Huang, Zhiyuan Wang, Susan Liang, Xinyi Liu, Yizhi Song, Yuhe Nie, Jia-Xing Zhong, Bozheng Li, Daiqing Qi, Ziyun Zeng, Ali Vosoughi, Luchuan Song, Zeliang Zhang, Daiki Shimada, Han Liu, Jiebo Luo, Chenliang Xu
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
视频理解是计算机视觉领域最具挑战性的前沿课题,它要求模型能够推理复杂的时空关系、长期依赖关系和多种模态的证据。最近出现的视频大型多模态模型(Video-LMMs),集成了视觉编码器和基于强大解码器的语言模型,在视频理解任务中表现出了惊人的能力。然而,将这些模型从基本感知系统转变为先进推理引擎的后训练阶段,在文献中仍然零散。这篇综述提供了针对Video-LMM后训练方法的首次全面研究,包括三个基本支柱:通过思维链进行有监督微调(SFT)、基于可验证目标的强化学习(RL)以及通过增强推理计算进行的测试时间缩放(TTS)。我们提出了一种结构化的分类法,阐明了这些方法的作用、相互关联以及针对视频的特定适应,应对独特的挑战,如时间定位、时空定位、长视频效率和多模态证据集成。通过对代表性方法的系统分析,我们综合了关键的设计原则、见解和评估协议,同时确定了奖励设计、可扩展性和成本性能优化方面的关键开放挑战。我们还整理了重要的基准测试、数据集和指标,以促进对后训练效果的严格评估。本综述旨在为研究人员和从业者提供一个统一框架,以推进Video-LMM的能力。更多资源和更新请访问:https://github.com/yunlong10/Awesome-Video-LMM-Post-Training 。
论文及项目相关链接
PDF The 1st version
摘要
视频理解是计算机视觉领域最具挑战性的前沿课题,需要模型推理复杂的时空关系、长期依赖性和多模态证据。近期出现的视频大模态模型(Video-LMMs)通过集成视觉编码器和基于强大解码器的语言模型,在视频理解任务中展现出卓越的能力。然而,将这些模型从基本感知系统转变为先进的推理引擎的后训练阶段,在文献中仍显得零散。本文首次全面调查了Video-LMMs的后训练方法,包括三大基础支柱:以思维链进行的有监督微调(SFT)、以可验证目标进行强化学习(RL)以及通过增强推理计算进行的测试时缩放(TTS)。我们提出一个结构化分类法,阐明了这些方法在视频理解中的角色、相互关联和针对视频的特定适应,应对如时间定位、时空定位、长视频效率和多模态证据融合等独特挑战。通过对代表性方法的系统分析,我们总结了关键设计原则、见解和评估协议,同时确定了奖励设计、可扩展性和成本性能优化方面的关键开放挑战。此外,我们还整理了重要的基准测试、数据集和指标,以便对后训练的有效性进行严格评估。本文旨在为研究人员和从业者提供一个推进Video-LMM能力的统一框架。
关键见解
- 视频理解是当前计算机视觉领域最具挑战性的任务之一,需要模型处理复杂的时空关系、长期依赖和多模态证据。
- 视频大模态模型(Video-LMMs)已经显示出在视频理解任务中的出色性能,通过集成视觉编码器和语言模型。
- 后训练阶段对于将模型从基本感知系统转变为先进的推理引擎至关重要,但相关文献仍然零散。
- 本文首次全面调查了Video-LMMs的后训练方法,包括有监督微调(SFT)、强化学习(RL)和测试时缩放(TTS)三大基础支柱。
- 文中提出一个结构化分类法,以澄清这些方法在视频理解中的角色、相互关联和针对视频的特定适应。
- 通过系统分析,确定了奖励设计、可扩展性和成本性能优化等关键开放挑战。
点此查看论文截图
Speak, Edit, Repeat: High-Fidelity Voice Editing and Zero-Shot TTS with Cross-Attentive Mamba
Authors:Baher Mohammad, Magauiya Zhussip, Stamatios Lefkimmiatis
We introduce MAVE (Mamba with Cross-Attention for Voice Editing and Synthesis), a novel autoregressive architecture for text-conditioned voice editing and high-fidelity text-to-speech (TTS) synthesis, built on a cross-attentive Mamba backbone. MAVE achieves state-of-the-art performance in speech editing and very competitive results in zero-shot TTS, while not being explicitly trained on the latter task, outperforming leading autoregressive and diffusion models on diverse, real-world audio. By integrating Mamba for efficient audio sequence modeling with cross-attention for precise text-acoustic alignment, MAVE enables context-aware voice editing with exceptional naturalness and speaker consistency. In pairwise human evaluations on a random 40-sample subset of the RealEdit benchmark (400 judgments), 57.2% of listeners rated MAVE - edited speech as perceptually equal to the original, while 24.8% prefered the original and 18.0% MAVE - demonstrating that in the majority of cases edits are indistinguishable from the source. MAVE compares favorably with VoiceCraft and FluentSpeech both on pairwise comparisons and standalone mean opinion score (MOS) evaluations. For zero-shot TTS, MAVE exceeds VoiceCraft in both speaker similarity and naturalness, without requiring multiple inference runs or post-processing. Remarkably, these quality gains come with a significantly lower memory cost and approximately the same latency: MAVE requires ~6x less memory than VoiceCraft during inference on utterances from the RealEdit database (mean duration: 6.21s, A100, FP16, batch size 1). Our results demonstrate that MAVE establishes a new standard for flexible, high-fidelity voice editing and synthesis through the synergistic integration of structured state-space modeling and cross-modal attention.
我们介绍了MAVE(用于语音编辑和合成的跨注意力曼巴),这是一种新型的基于跨注意力曼巴的文本条件语音编辑和高保真文本到语音(TTS)合成的自回归架构。MAVE在语音编辑方面达到了最先进的性能,并在零样本TTS方面取得了具有竞争力的结果,同时,它并未专门针对后者进行训练。在多样化、现实世界的音频上,MAVE的表现超过了领先的自回归和扩散模型。通过整合曼巴的高效音频序列建模和跨注意力精确文本-声学对齐,MAVE能够实现具有出色自然度和说话者一致性的上下文感知语音编辑。在RealEdit基准测试集的随机40个样本子集(400次判断)的配对人工评估中,57.2%的听众认为MAVE编辑的语音在感知上等同于原始语音,而24.8%的听众更喜欢原始语音,18.0%则认为MAVE更好。这表明在大多数情况下,编辑的语音与原始语音无法区分。MAVE在配对比较和独立平均意见得分(MOS)评估中均优于VoiceCraft和FluentSpeech。对于零样本TTS,MAVE在说话人相似性和自然性方面都超过了VoiceCraft,而无需进行多次推理运行或后处理。值得注意的是,这些质量提升带来的内存成本显著降低,延迟时间大致相同:在RealEdit数据库(平均持续时间:6.21秒,A100,FP16,批处理大小为1)上进行推理时,MAVE所需的内存约为VoiceCraft的6倍。我们的结果表明,通过结构化状态空间建模和跨模态注意力的协同集成,MAVE为灵活、高保真度的语音编辑和合成设定了新的标准。
论文及项目相关链接
Summary
本文介绍了MAVE(基于跨注意力机制的曼巴语音编辑与合成模型)这一新型文本条件语音编辑和高保真文本到语音(TTS)合成自回归架构。MAVE在语音编辑方面达到了最新技术水平,并在零样本TTS方面取得了具有竞争力的结果。它结合了曼巴的高效音频序列建模能力和跨注意力机制,实现了精确的文本声学对齐,支持上下文感知的语音编辑,具有出色的自然度和说话人一致性。在RealEdit基准测试集的子集上进行的配对人类评估中,MAVE编辑的语音在多数情况下难以区分。此外,MAVE与VoiceCraft和FluentSpeech相比表现优越,并在零样本TTS任务中实现了更高的说话人相似性和自然度。最重要的是,这些质量提升伴随着显著减少的内存消耗和相近的延迟。
Key Takeaways
- MAVE是一个基于跨注意力机制的曼巴语音编辑与合成模型的新型自回归架构。
- MAVE在语音编辑方面达到了最新技术水平,支持上下文感知的语音编辑。
- MAVE在零样本TTS方面取得了具有竞争力的结果,且相较于其他模型如VoiceCraft,具有更高的说话人相似性和自然度。
- MAVE结合了曼巴的高效音频序列建模能力和跨注意力机制,实现精确的文本声学对齐。
- MAVE编辑的语音在多数情况下难以与原始语音区分。
- MAVE具有优越的性能表现,尤其是在与其他模型如VoiceCraft和FluentSpeech的对比中。
点此查看论文截图

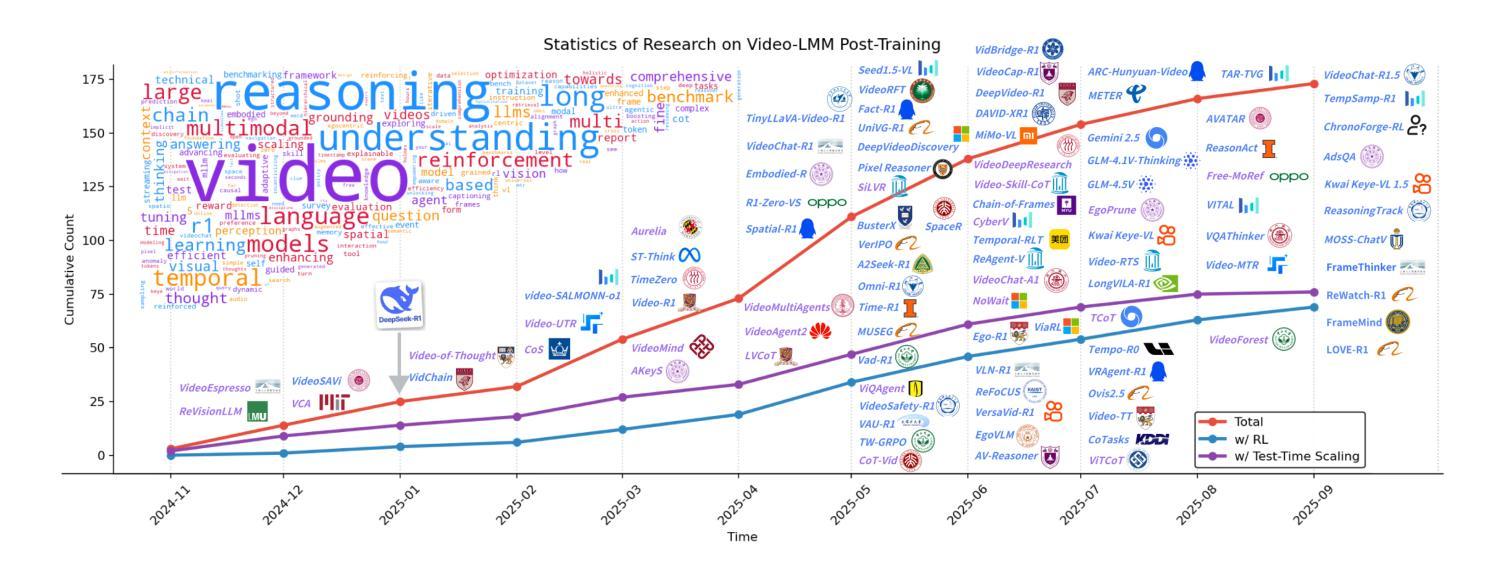
Synthetic Audio Forensics Evaluation (SAFE) Challenge
Authors:Kirill Trapeznikov, Paul Cummer, Pranay Pherwani, Jai Aslam, Michael S. Davinroy, Peter Bautista, Laura Cassani, Matthew Stamm, Jill Crisman
The increasing realism of synthetic speech generated by advanced text-to-speech (TTS) models, coupled with post-processing and laundering techniques, presents a significant challenge for audio forensic detection. In this paper, we introduce the SAFE (Synthetic Audio Forensics Evaluation) Challenge, a fully blind evaluation framework designed to benchmark detection models across progressively harder scenarios: raw synthetic speech, processed audio (e.g., compression, resampling), and laundered audio intended to evade forensic analysis. The SAFE challenge consisted of a total of 90 hours of audio and 21,000 audio samples split across 21 different real sources and 17 different TTS models and 3 tasks. We present the challenge, evaluation design and tasks, dataset details, and initial insights into the strengths and limitations of current approaches, offering a foundation for advancing synthetic audio detection research. More information is available at \href{https://stresearch.github.io/SAFE/}{https://stresearch.github.io/SAFE/}.
由先进文本到语音(TTS)模型生成合成语音的逼真度日益增加,再加上后处理和清洗技术,对音频取证检测提出了重大挑战。在本文中,我们介绍了SAFE(合成音频取证评估)挑战赛,这是一个完全盲评的框架,旨在针对越来越复杂的场景对检测模型进行基准测试:原始合成语音、处理过的音频(例如压缩、重新采样),以及旨在逃避取证分析的清洗音频。SAFE挑战赛共包含90小时的音频和21000个音频样本,分为21个不同的真实来源和17种不同的TTS模型,以及三项任务。我们介绍了挑战赛、评估设计任务、数据集细节以及对当前方法优势和局限性的初步见解,这为推进合成音频检测研究奠定了基础。更多信息请访问:[https://stresearch.github.io/SAFE/] 。
论文及项目相关链接
Summary
本文介绍了SAFE挑战,这是一个旨在评估检测模型在应对不同难度场景下的性能的全盲评估框架。框架包含90小时音频和21000个音频样本,涵盖真实源和语音合成技术的挑战任务。通过提出一系列测试设计和具体任务,本文旨在为推进合成语音检测研究奠定基础。更多信息可通过链接访问。
Key Takeaways
- SAFE挑战是一个全盲评估框架,旨在评估检测模型在应对不同难度场景下的性能。
- 该框架包含三种任务:原始合成语音、经过处理的音频(如压缩、重采样)以及旨在规避法医分析的伪装音频。
点此查看论文截图
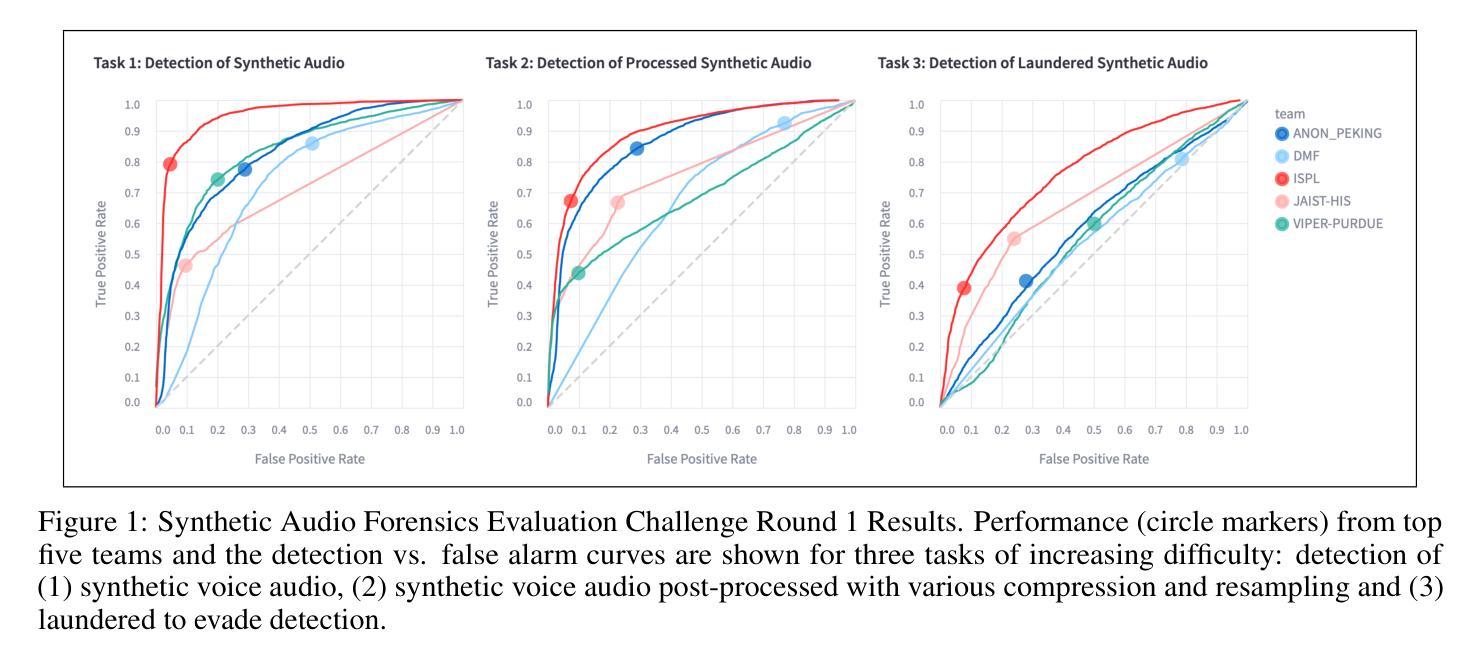


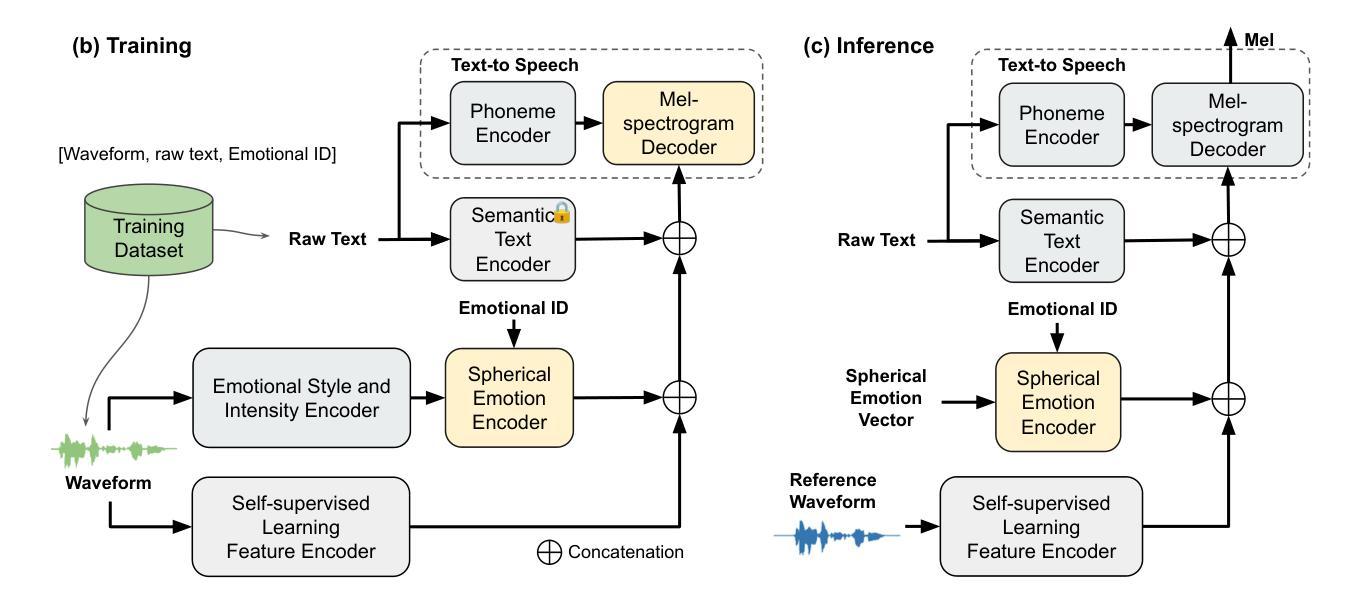
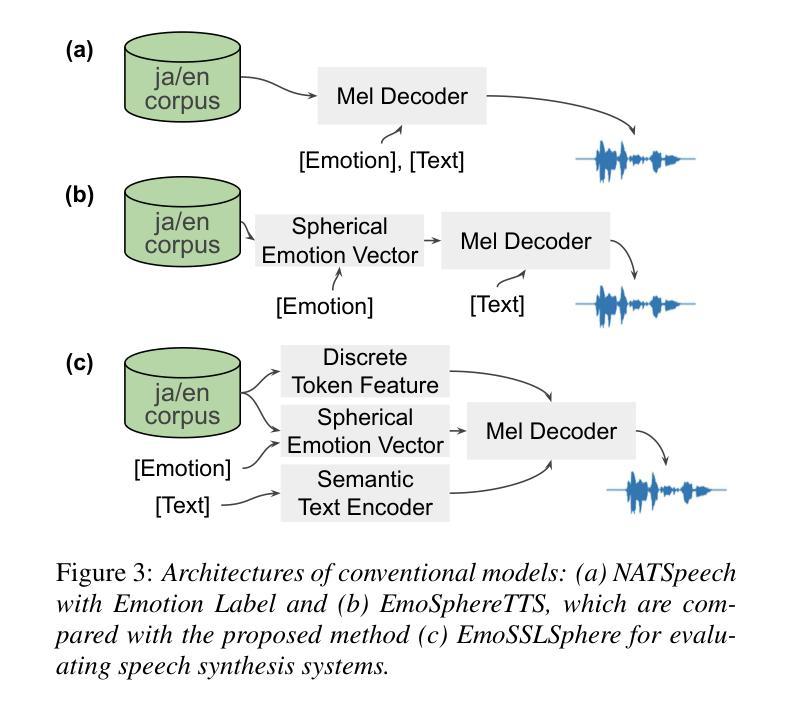
EmoSSLSphere: Multilingual Emotional Speech Synthesis with Spherical Vectors and Discrete Speech Tokens
Authors:Joonyong Park, Kenichi Nakamura
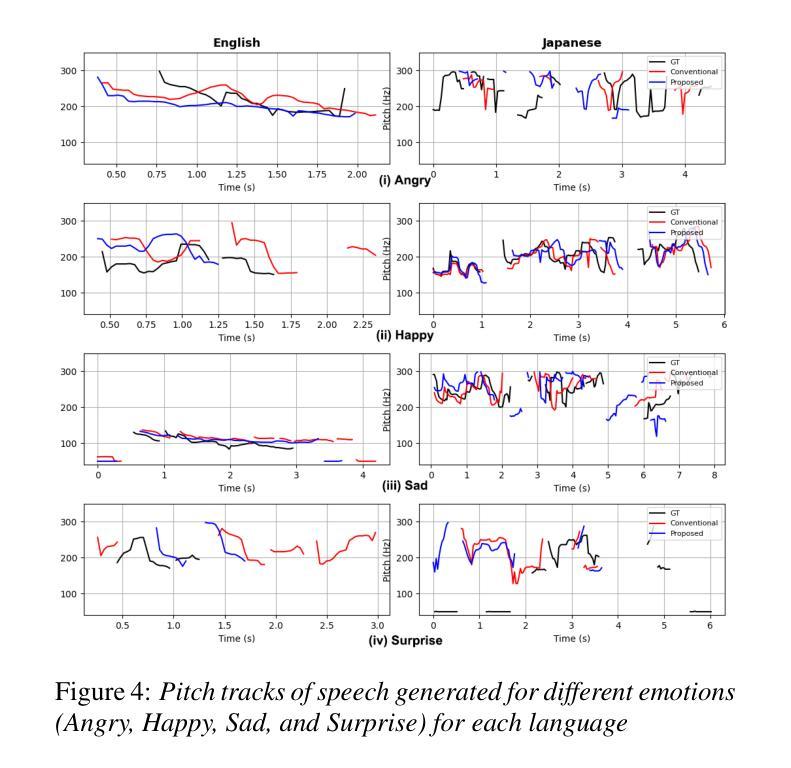
This paper introduces EmoSSLSphere, a novel framework for multilingual emotional text-to-speech (TTS) synthesis that combines spherical emotion vectors with discrete token features derived from self-supervised learning (SSL). By encoding emotions in a continuous spherical coordinate space and leveraging SSL-based representations for semantic and acoustic modeling, EmoSSLSphere enables fine-grained emotional control, effective cross-lingual emotion transfer, and robust preservation of speaker identity. We evaluate EmoSSLSphere on English and Japanese corpora, demonstrating significant improvements in speech intelligibility, spectral fidelity, prosodic consistency, and overall synthesis quality. Subjective evaluations further confirm that our method outperforms baseline models in terms of naturalness and emotional expressiveness, underscoring its potential as a scalable solution for multilingual emotional TTS.
本文介绍了EmoSSLSphere,这是一个用于多语种情感文本转语音(TTS)合成的新型框架,它将球形情感向量与自监督学习(SSL)得出的离散标记特征相结合。通过将情感编码在连续的球形坐标空间中,并利用基于SSL的语义和声音模型表示,EmoSSLSphere能够实现精细的情感控制、有效的跨语言情感转移和稳健的说话人身份保留。我们在英语和日语语料库上对EmoSSLSphere进行了评估,证明了其在语音清晰度、频谱保真度、语调一致性和整体合成质量方面的显著提高。主观评价进一步证实,我们的方法在自然度和情感表现力方面优于基准模型,凸显了其作为可扩展的多语言情感TTS解决方案的潜力。
论文及项目相关链接
PDF In Proceedings of the 13th ISCA Speech Synthesis Workshop
Summary
本文介绍了EmoSSLSphere,一个结合球面情感向量和自监督学习(SSL)的离散令牌特征的多语言情感文本到语音(TTS)合成的新框架。通过情感在连续球坐标空间中的编码以及基于SSL的语义和声学建模,EmoSSLSphere可实现精细的情感控制、有效的跨语言情感转移和稳健的说话人身份保留。我们在英语和日语语料库上评估了EmoSSLSphere,证明了其在语音清晰度、频谱保真度、语调一致性和整体合成质量方面的显著提高。主观评估进一步证明,我们的方法在自然度和情感表现力方面优于基准模型,突显了其在多语言情感TTS领域的可扩展解决方案潜力。
Key Takeaways
- EmoSSLSphere是一个多语言情感TTS合成的新框架,结合了球面情感向量和自监督学习。
- 框架通过情感在连续球坐标空间中的编码实现精细的情感控制。
- 利用SSL进行语义和声学建模,实现有效的跨语言情感转移和稳健的说话人身份保留。
- 在英语和日语语料库上的评估表明,EmoSSLSphere在语音清晰度、频谱保真度等方面有显著提高。
- 主观评估证实,EmoSSLSphere在自然度和情感表现力方面优于其他模型。
- EmoSSLSphere具有潜在的可扩展性,可应用于多语言情感TTS领域。
点此查看论文截图
Unlocking Multimodal Mathematical Reasoning via Process Reward Model
Authors:Ruilin Luo, Zhuofan Zheng, Yifan Wang, Xinzhe Ni, Zicheng Lin, Songtao Jiang, Yiyao Yu, Chufan Shi, Lei Wang, Ruihang Chu, Jin Zeng, Yujiu Yang
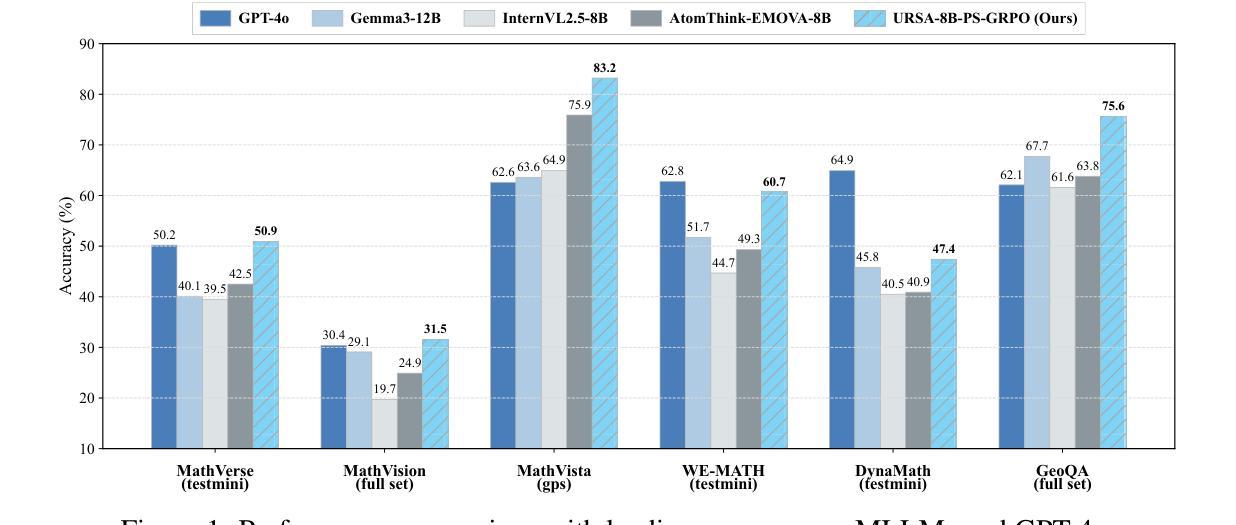
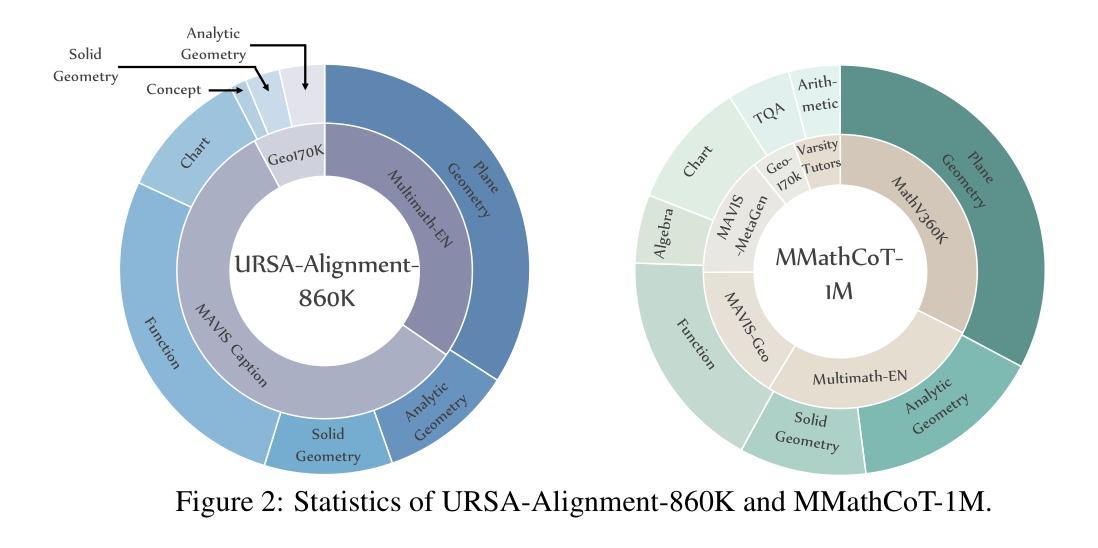
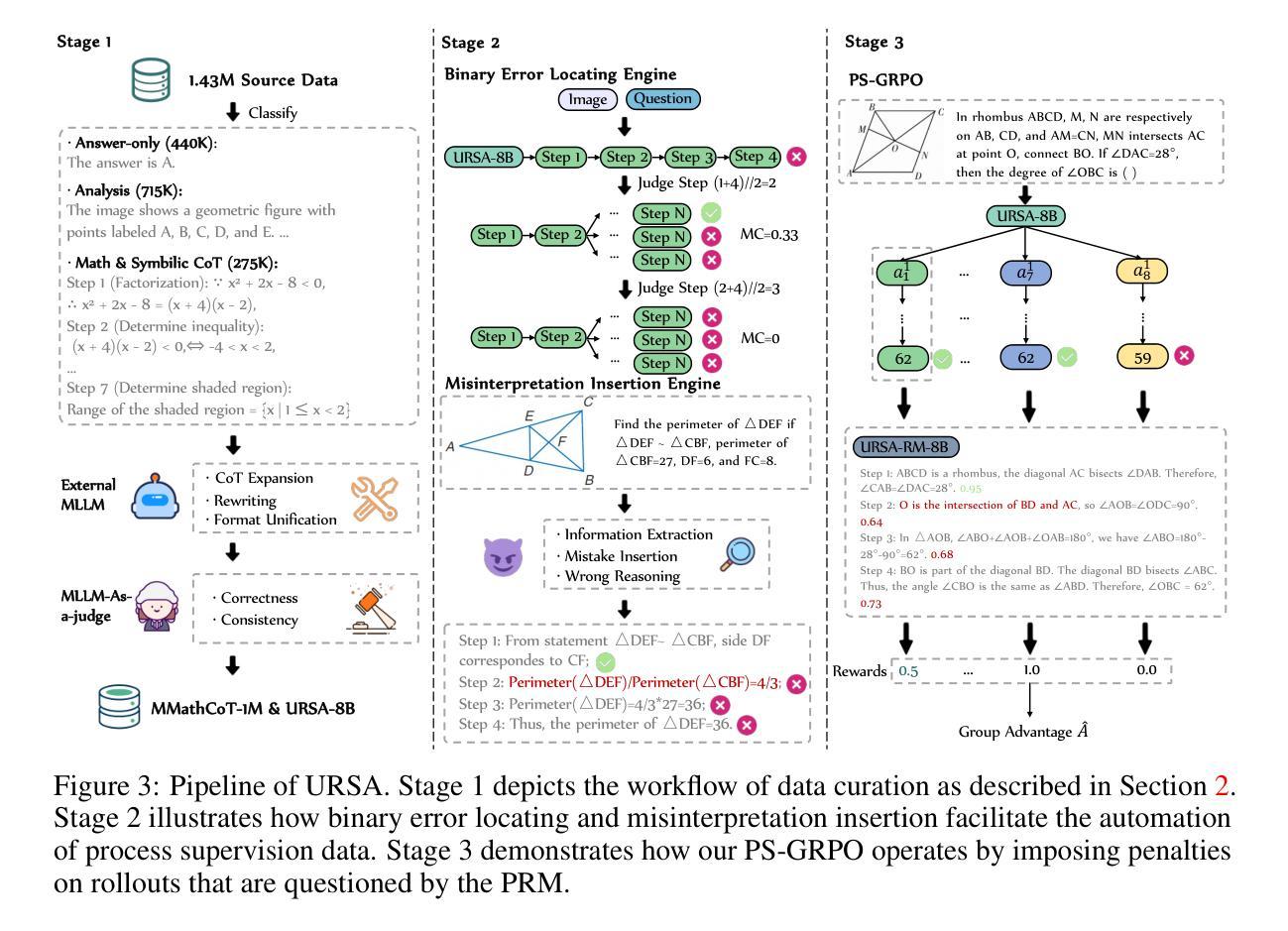
Process Reward Models (PRMs) have shown promise in enhancing the mathematical reasoning capabilities of Large Language Models (LLMs) through Test-Time Scaling (TTS). However, their integration into multimodal reasoning remains largely unexplored. In this work, we take the first step toward unlocking the potential of PRMs in multimodal mathematical reasoning. We identify three key challenges: (1) the scarcity of high-quality reasoning data constrains the capabilities of foundation Multimodal Large Language Models (MLLMs), which imposes further limitations on the upper bounds of TTS and reinforcement learning (RL); (2) a lack of automated methods for process labeling within multimodal contexts persists; (3) the employment of process rewards in unimodal RL faces issues like reward hacking, which may extend to multimodal scenarios. To address these issues, we introduce URSA, a three-stage Unfolding multimodal Process-Supervision Aided training framework. We first construct MMathCoT-1M, a high-quality large-scale multimodal Chain-of-Thought (CoT) reasoning dataset, to build a stronger math reasoning foundation MLLM, URSA-8B. Subsequently, we go through an automatic process to synthesize process supervision data, which emphasizes both logical correctness and perceptual consistency. We introduce DualMath-1.1M to facilitate the training of URSA-8B-RM. Finally, we propose Process-Supervised Group-Relative-Policy-Optimization (PS-GRPO), pioneering a multimodal PRM-aided online RL method that outperforms vanilla GRPO. With PS-GRPO application, URSA-8B-PS-GRPO outperforms Gemma3-12B and GPT-4o by 8.4% and 2.7% on average across 6 benchmarks. Code, data and checkpoint can be found at https://github.com/URSA-MATH.
过程奖励模型(PRM)通过测试时间缩放(TTS)增强大型语言模型(LLM)的数学推理能力显示出巨大潜力,但它们在多模态推理中的集成仍然鲜有研究。在这项工作中,我们朝着解锁PRM在多模态数学推理中的潜力迈出了第一步。我们确定了三个关键挑战:(1)高质量推理数据的稀缺性限制了基础多模态大型语言模型(MLLM)的能力,这给TTS和强化学习(RL)的上限带来了进一步的限制;(2)在多模态背景下,过程标签的自动化方法仍然缺乏;(3)在单模态RL中使用过程奖励面临着奖励操纵等问题,这些问题可能会扩展到多模态场景。为了解决这些问题,我们引入了URSA,这是一个三阶段展开的多模态过程监督辅助训练框架。首先,我们构建了MMathCoT-1M,这是一个高质量的大规模多模态思维链(CoT)推理数据集,以建立更强大的数学推理基础MLLM,URSA-8B。随后,我们通过一个自动过程来合成过程监督数据,这既强调逻辑的正确性又强调感知的一致性。我们引入了DualMath-1.1M来促进URSA-8B-RM的训练。最后,我们提出了过程监督组相对策略优化(PS-GRPO),开创了一种多模态PRM辅助的在线RL方法,该方法优于普通GRPO。通过应用PS-GRPO,URSA-8B-PS-GRPO在六个基准测试中平均超过了Gemma3-12B和GPT-4o,分别提高了8.4%和2.7%。相关代码、数据和检查点可在https://github.com/URSA-MATH找到。
论文及项目相关链接
PDF NeurIPS 2025 Main Track
Summary
基于Test-Time Scaling (TTS),过程奖励模型(PRM)在提升大型语言模型(LLM)的数学推理能力方面展现出潜力。本文首次探索了PRM在多模态数学推理中的应用,并提出了三个关键挑战。为解决这些挑战,本文引入了URSA训练框架,并构建了MMathCoT-1M大型多模态Chain-of-Thought(CoT)推理数据集。此外,还提出了PS-GRPO方法,优化了多模态PRM辅助的在线强化学习。该研究成果显著提升了数学推理能力,并在多个基准测试中表现优异。
Key Takeaways
- PRMs通过Test-Time Scaling增强了LLM的数学推理能力,但在多模态推理中的潜力尚未得到充分探索。
- 面临三个关键挑战:高质量推理数据的稀缺性、多模态语境中过程标签的自动化方法的缺乏、以及过程奖励在单模态强化学习中的奖励操纵问题。
- 引入URSA训练框架来解决这些挑战,并构建了MMathCoT-1M数据集以强化数学推理基础。
- 通过自动过程合成监督数据,强调逻辑正确性和感知一致性。
- 提出DualMath-1.1M来促进URSA-8B-RM的训练。
- 创新的PS-GRPO方法优化了多模态PRM辅助的在线强化学习,显著提升了性能。
点此查看论文截图