⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-10-09 更新
ReMoMask: Retrieval-Augmented Masked Motion Generation
Authors:Zhengdao Li, Siheng Wang, Zeyu Zhang, Hao Tang
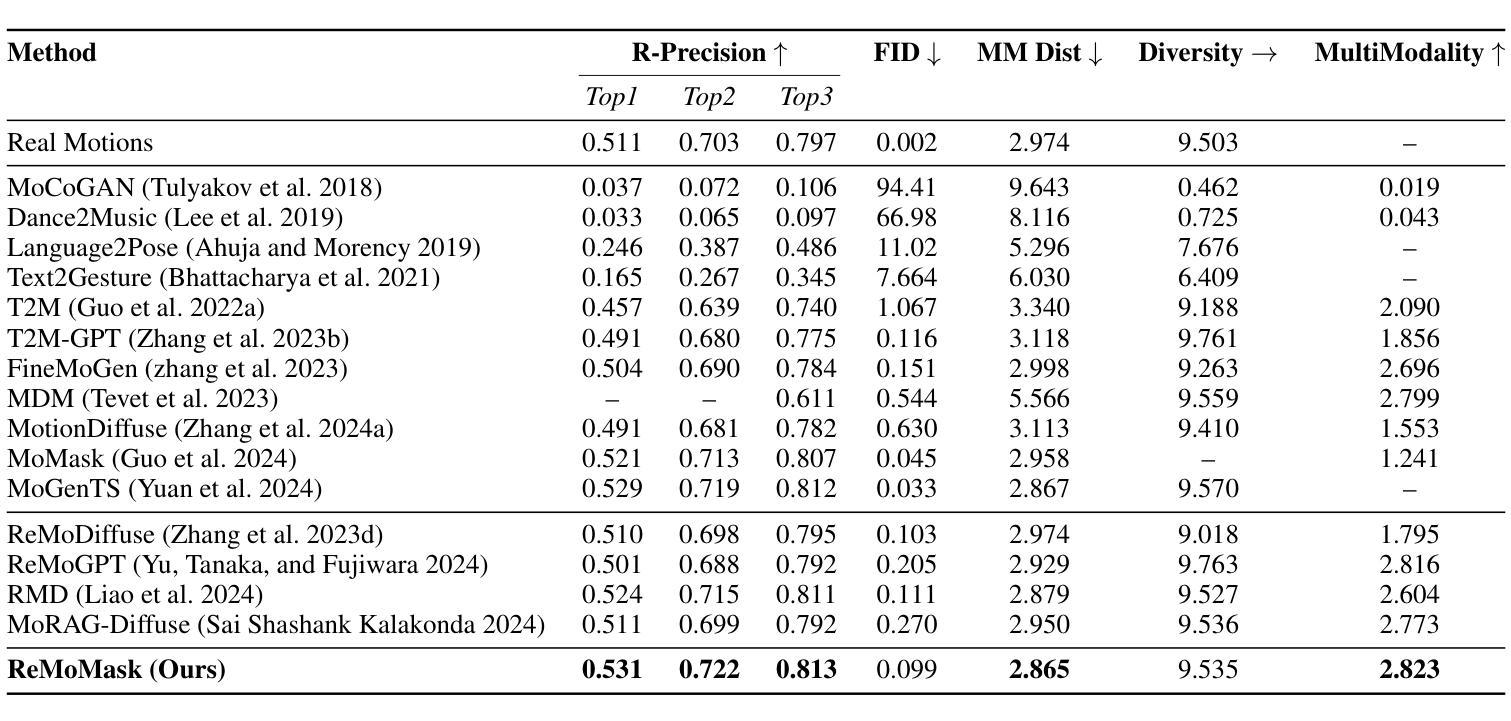
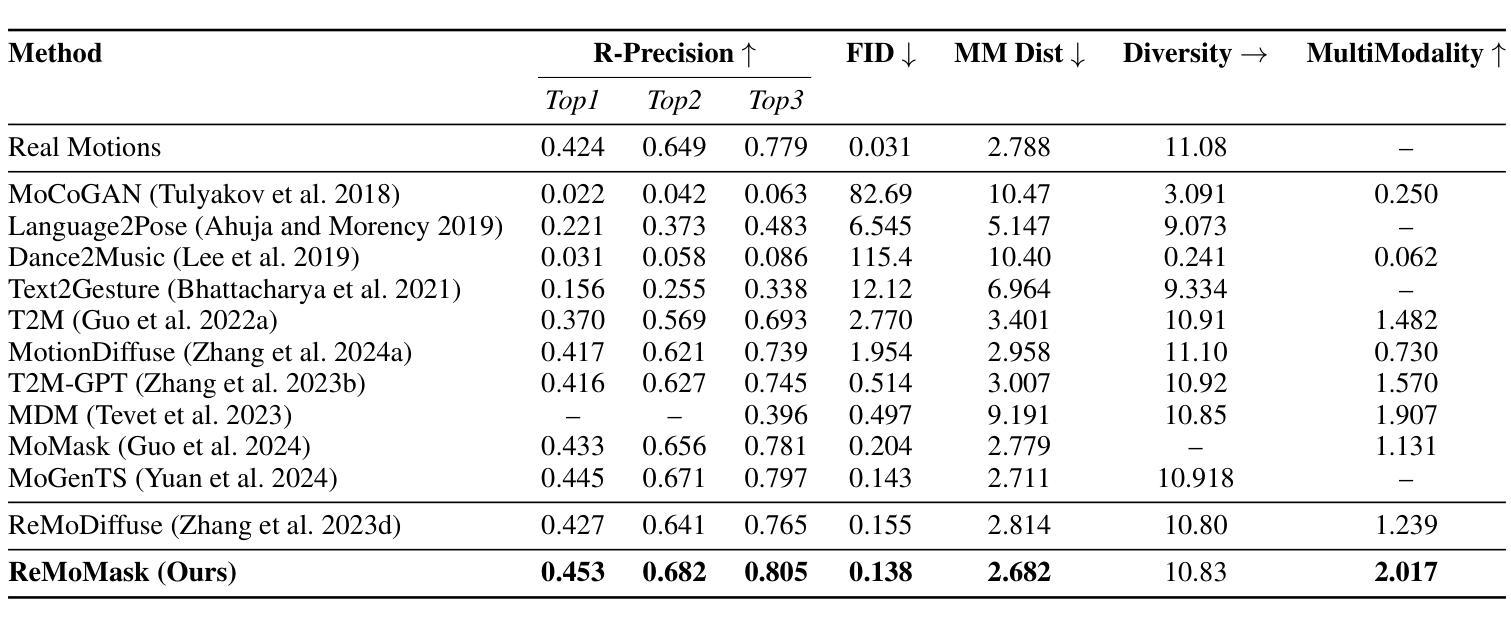
Text-to-Motion (T2M) generation aims to synthesize realistic and semantically aligned human motion sequences from natural language descriptions. However, current approaches face dual challenges: Generative models (e.g., diffusion models) suffer from limited diversity, error accumulation, and physical implausibility, while Retrieval-Augmented Generation (RAG) methods exhibit diffusion inertia, partial-mode collapse, and asynchronous artifacts. To address these limitations, we propose ReMoMask, a unified framework integrating three key innovations: 1) A Bidirectional Momentum Text-Motion Model decouples negative sample scale from batch size via momentum queues, substantially improving cross-modal retrieval precision; 2) A Semantic Spatio-temporal Attention mechanism enforces biomechanical constraints during part-level fusion to eliminate asynchronous artifacts; 3) RAG-Classier-Free Guidance incorporates minor unconditional generation to enhance generalization. Built upon MoMask’s RVQ-VAE, ReMoMask efficiently generates temporally coherent motions in minimal steps. Extensive experiments on standard benchmarks demonstrate the state-of-the-art performance of ReMoMask, achieving a 3.88% and 10.97% improvement in FID scores on HumanML3D and KIT-ML, respectively, compared to the previous SOTA method RAG-T2M. Code: https://github.com/AIGeeksGroup/ReMoMask. Website: https://aigeeksgroup.github.io/ReMoMask.
Text-to-Motion(T2M)生成旨在从自然语言描述中合成现实且语义对齐的人类运动序列。然而,当前的方法面临双重挑战:生成模型(例如,扩散模型)存在多样性有限、误差累积和物理不可行性的问题,而基于检索的增强生成(RAG)方法则表现出扩散惯性、部分模式崩溃和异步伪影。为了解决这些局限性,我们提出了ReMoMask,这是一个整合了三个关键创新点的统一框架:1)双向动量文本运动模型通过动量队列将负样本规模与批次大小解耦,从而大大提高了跨模态检索精度;2)语义时空注意力机制在部分级别融合过程中实施生物力学约束,以消除异步伪影;3)RAG-分类器自由引导结合了少量无条件生成,以提高泛化能力。基于MoMask的RVQ-VAE,ReMoMask能够高效地在少数步骤中生成时间连贯的运动。在标准基准测试上的广泛实验证明了ReMoMask的卓越性能,与之前的最佳方法RAG-T2M相比,HumanML3D和KIT-ML上的FID得分分别提高了3.88%和10.97%。代码:https://github.com/AIGeeksGroup/ReMoMask。网站:https://aigeeksgroup.github.io/ReMoMask。
论文及项目相关链接
Summary
文本描述了一种名为ReMoMask的统一框架,该框架旨在解决Text-to-Motion生成中的挑战。它结合了三项关键技术创新,解决了生成模型在多样性、误差累积和物理可信度方面存在的问题,同时也改善了检索增强生成方法中的惯性、部分模式崩溃和异步伪影问题。ReMoMask在标准基准测试上表现出卓越性能,与之前的最佳方法相比,在HumanML3D和KIT-ML上的FID得分分别提高了3.88%和10.97%。
Key Takeaways
- ReMoMask是一个统一框架,旨在解决Text-to-Motion生成中的挑战,包括生成模型的有限多样性、误差累积和物理不真实性。
- ReMoMask结合了三项关键技术创新:双向动量文本运动模型、语义时空注意机制和RAG-Classier-Free指导。
- 双向动量文本运动模型通过动量队列实现了负样本规模与批处理大小的解耦,提高了跨模态检索精度。
- 语义时空注意机制在部分级融合期间强制执行生物力学约束,消除了异步伪影。
- RAG-Classier-Free指导结合了无条件生成,增强了模型的泛化能力。
- ReMoMask建立在MoMask的RVQ-VAE之上,能够高效生成时间连贯的运动序列。
- 在标准基准测试上,ReMoMask表现出卓越性能,与之前的最佳方法相比,FID得分有显著提高。
点此查看论文截图