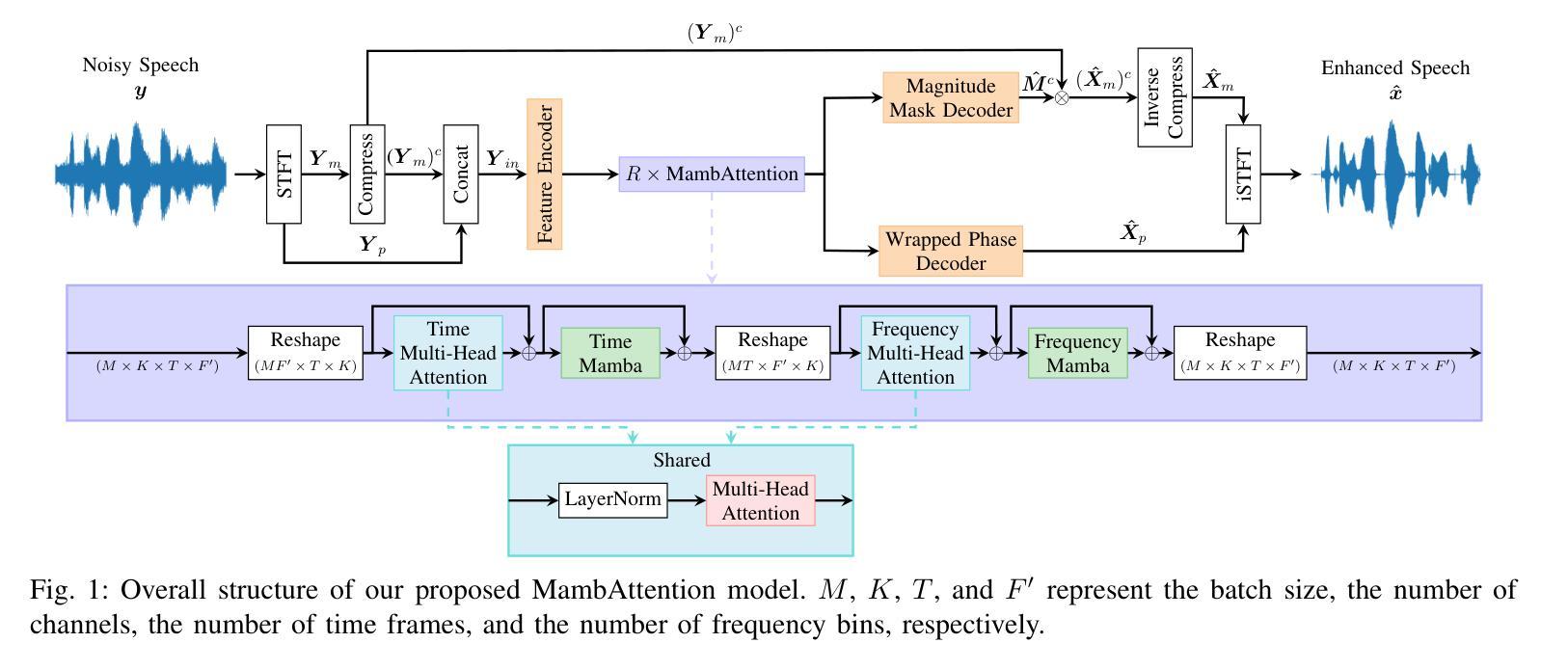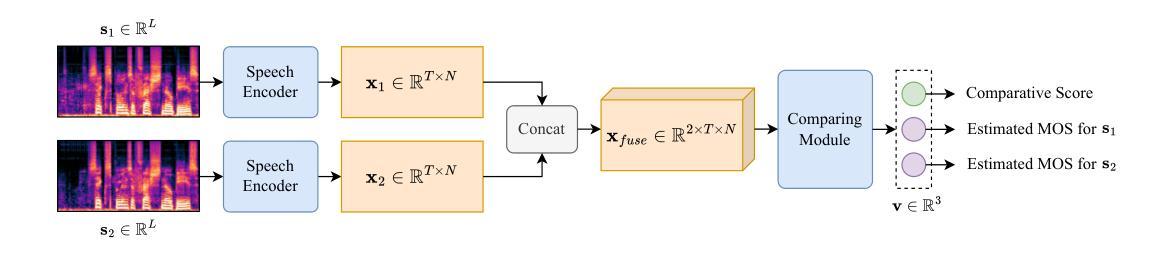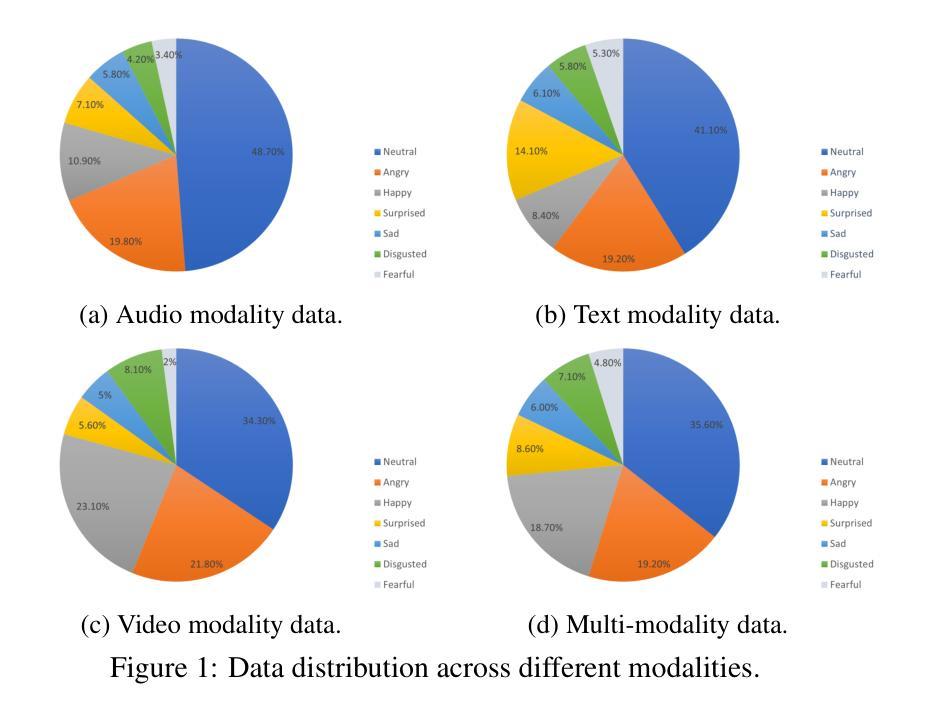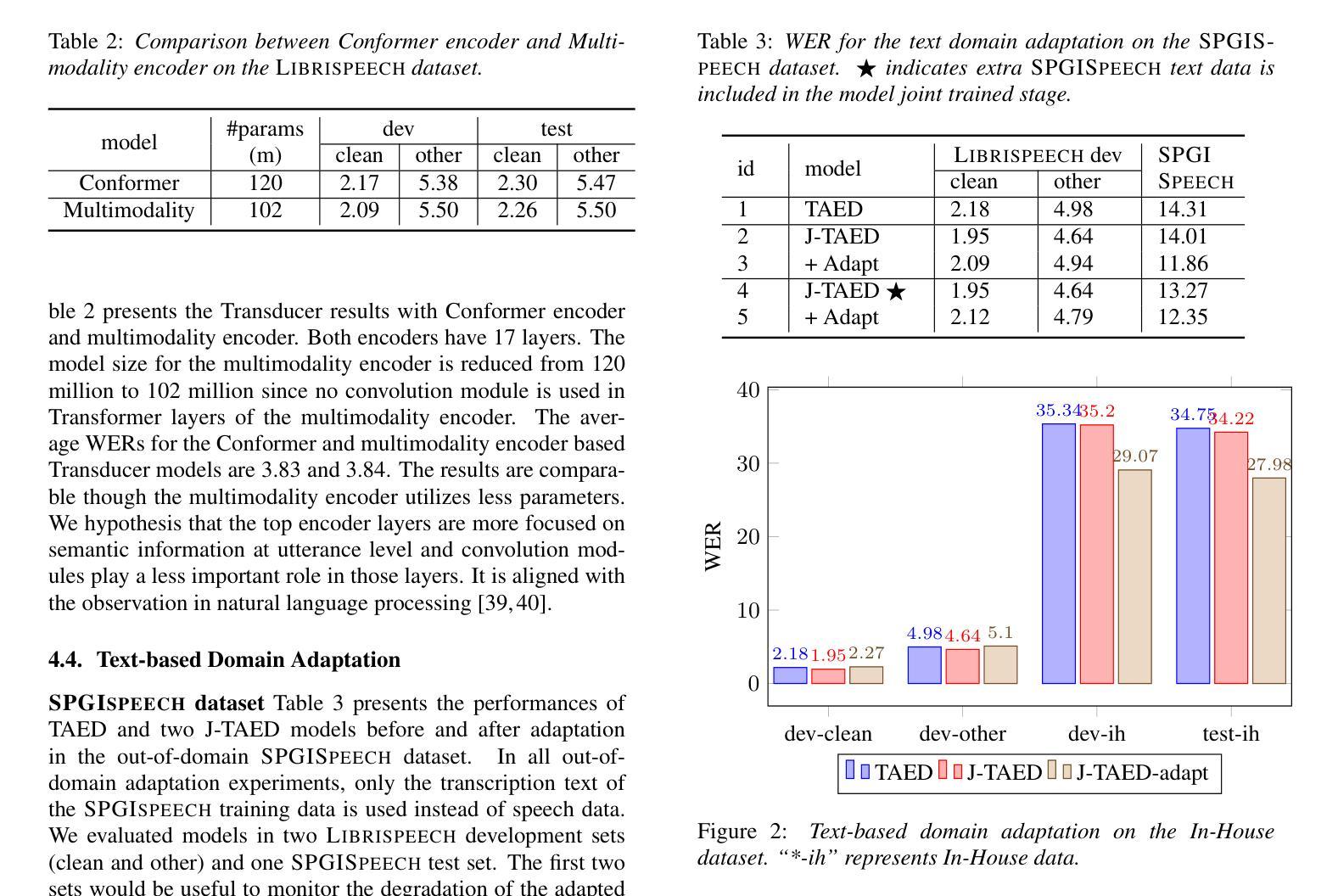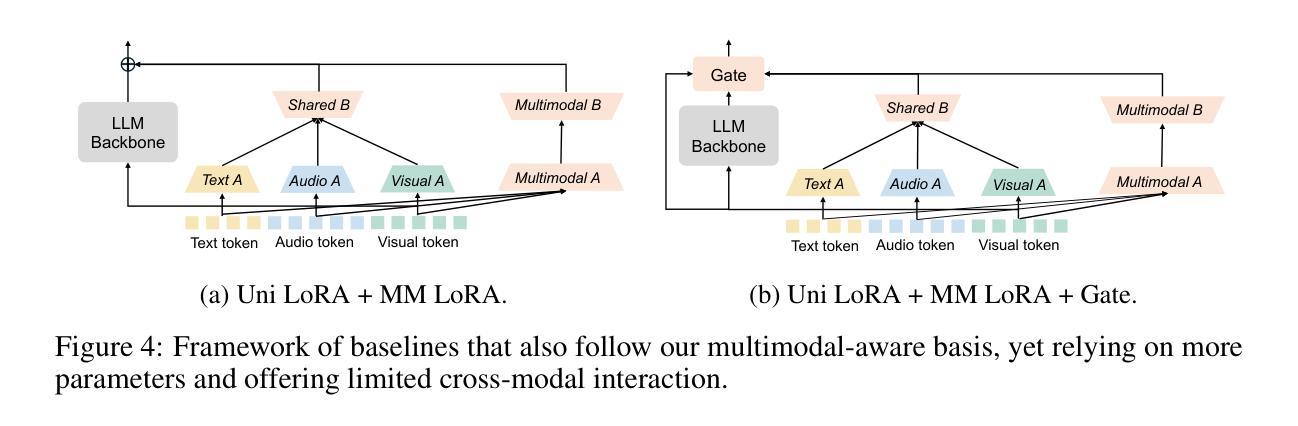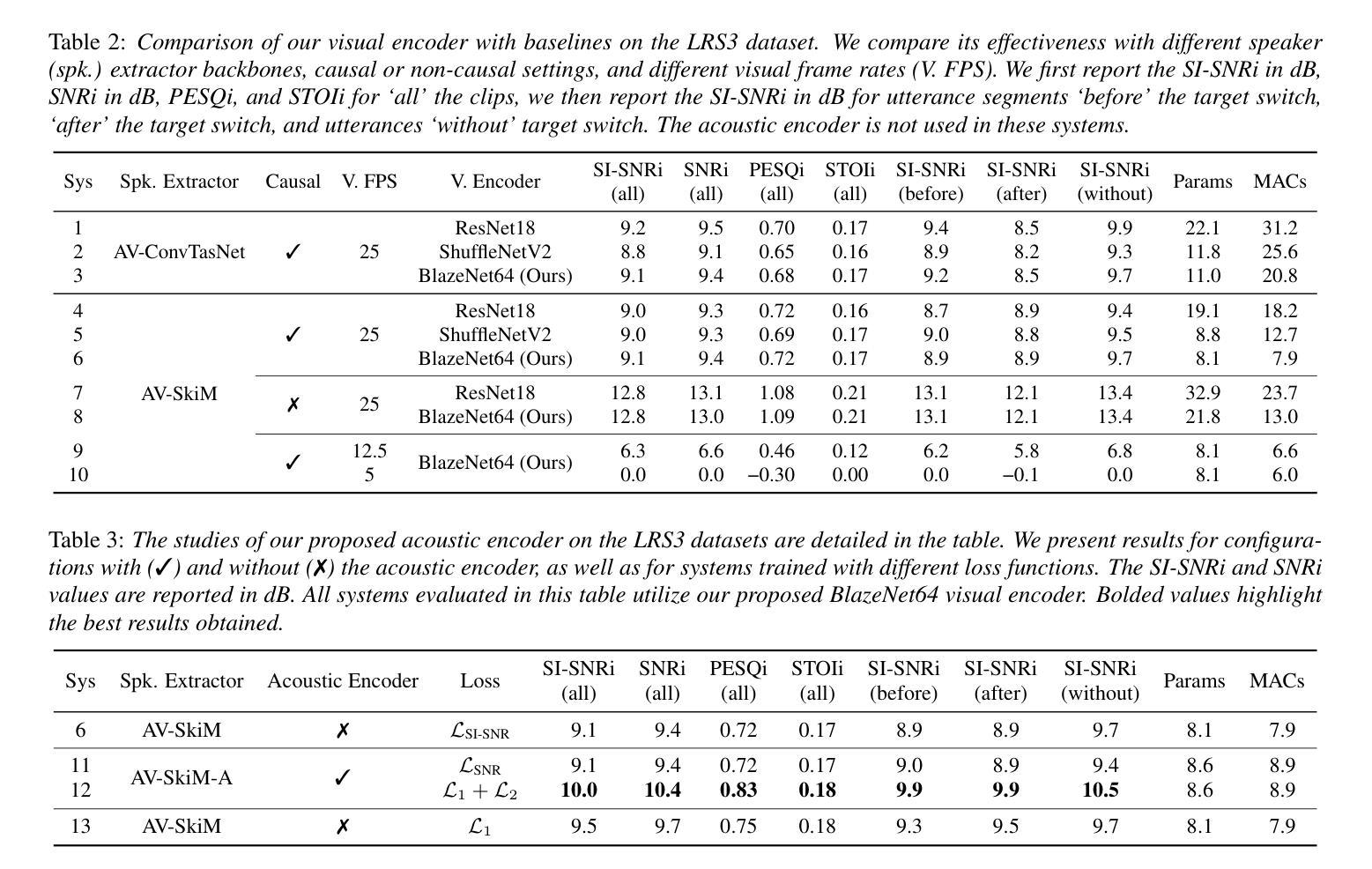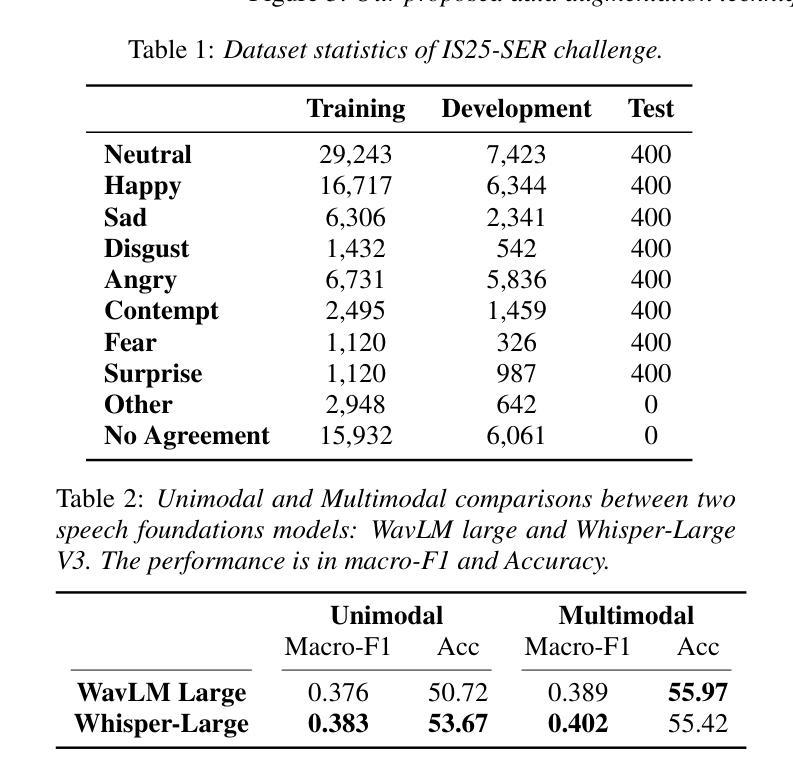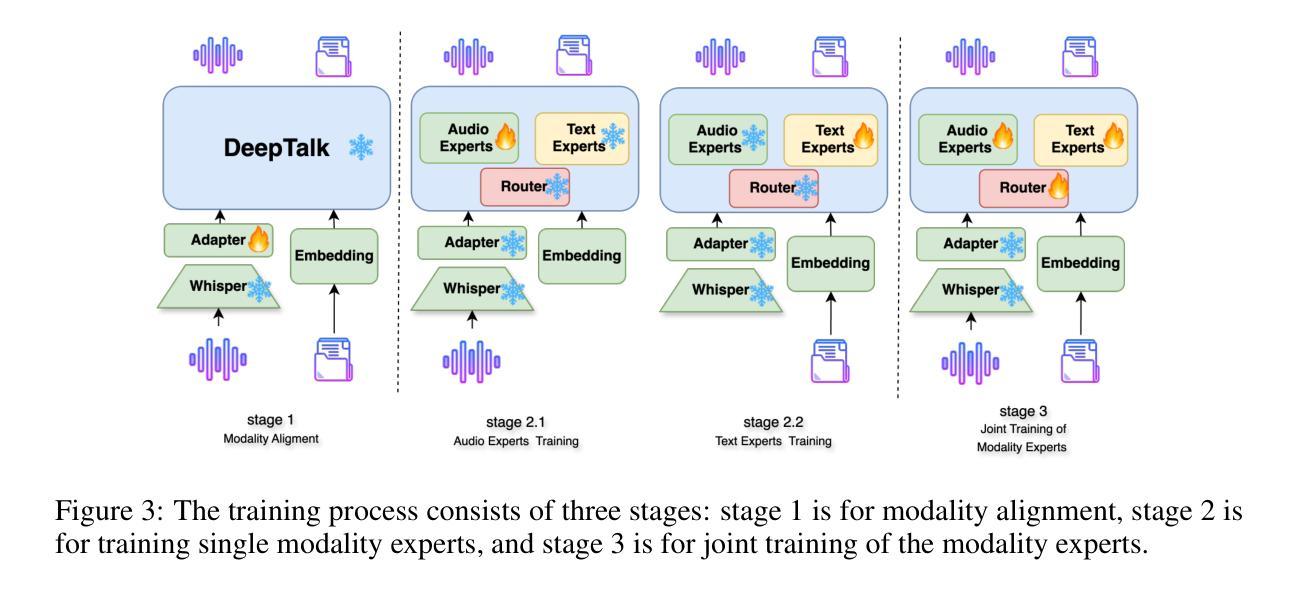
Speech 方向最新论文已更新,请持续关注 Update in 2025-07-11 KAConvText Novel Approach to Burmese Sentence Classification using Kolmogorov-Arnold Convolution
2025-07-11