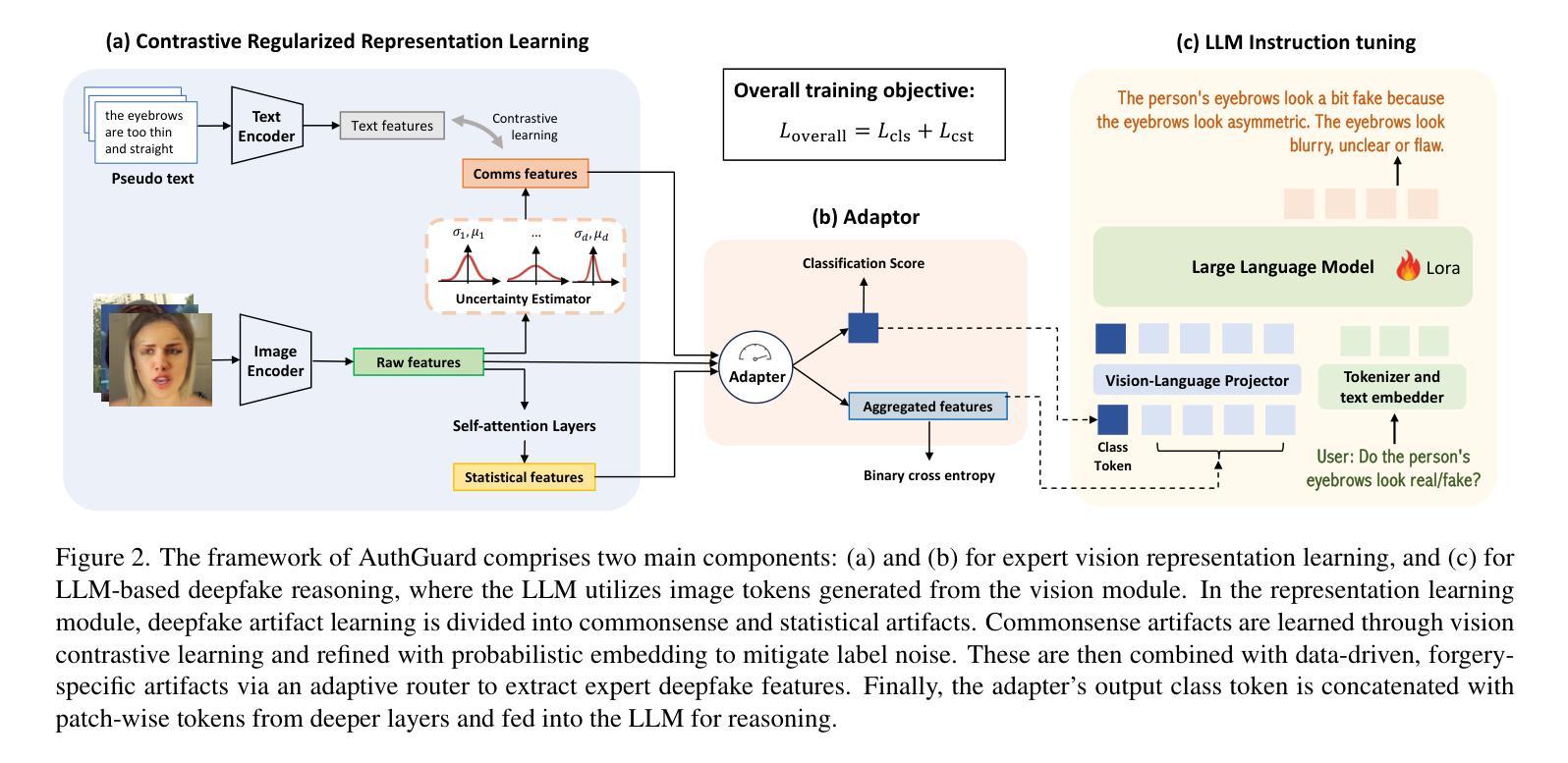
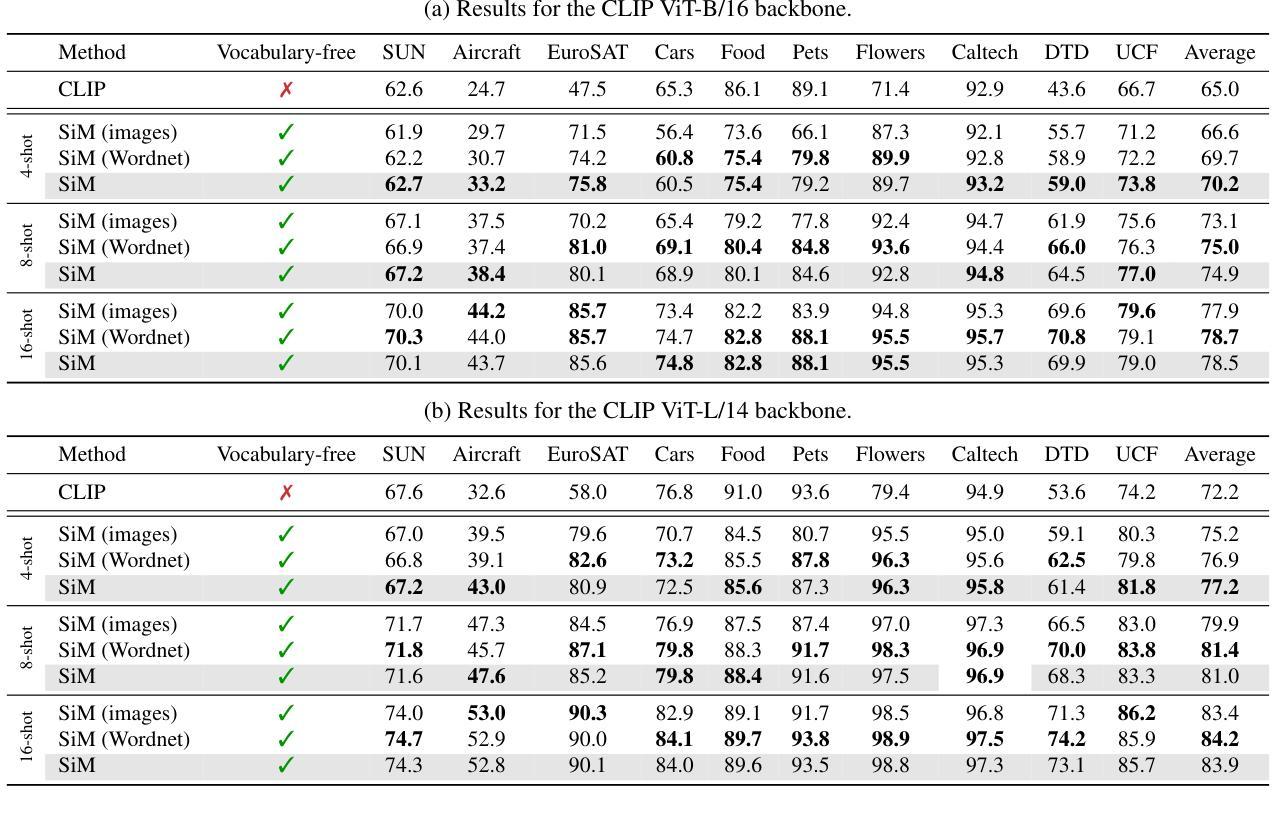
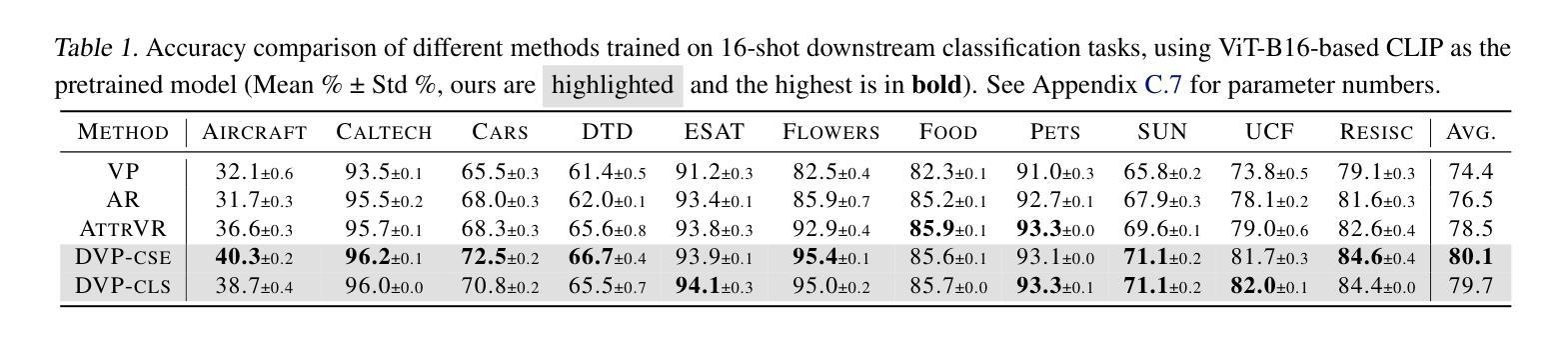
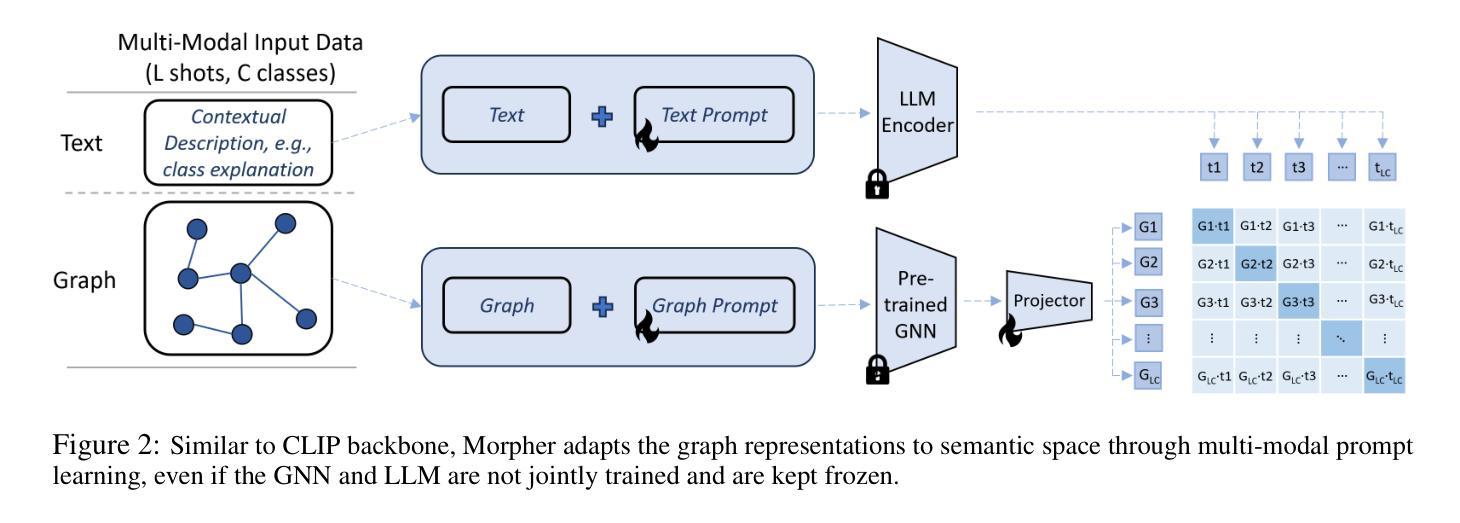
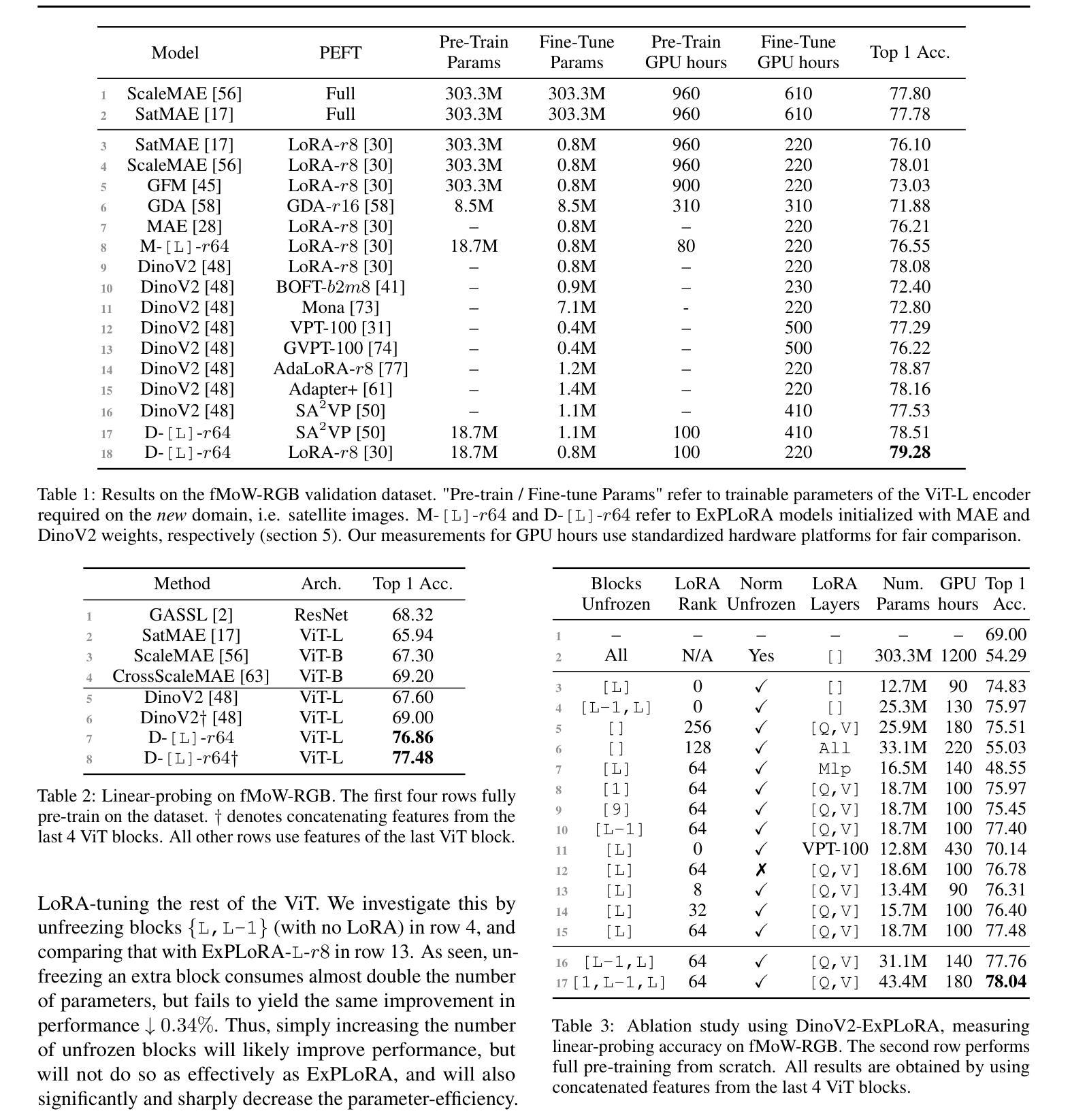
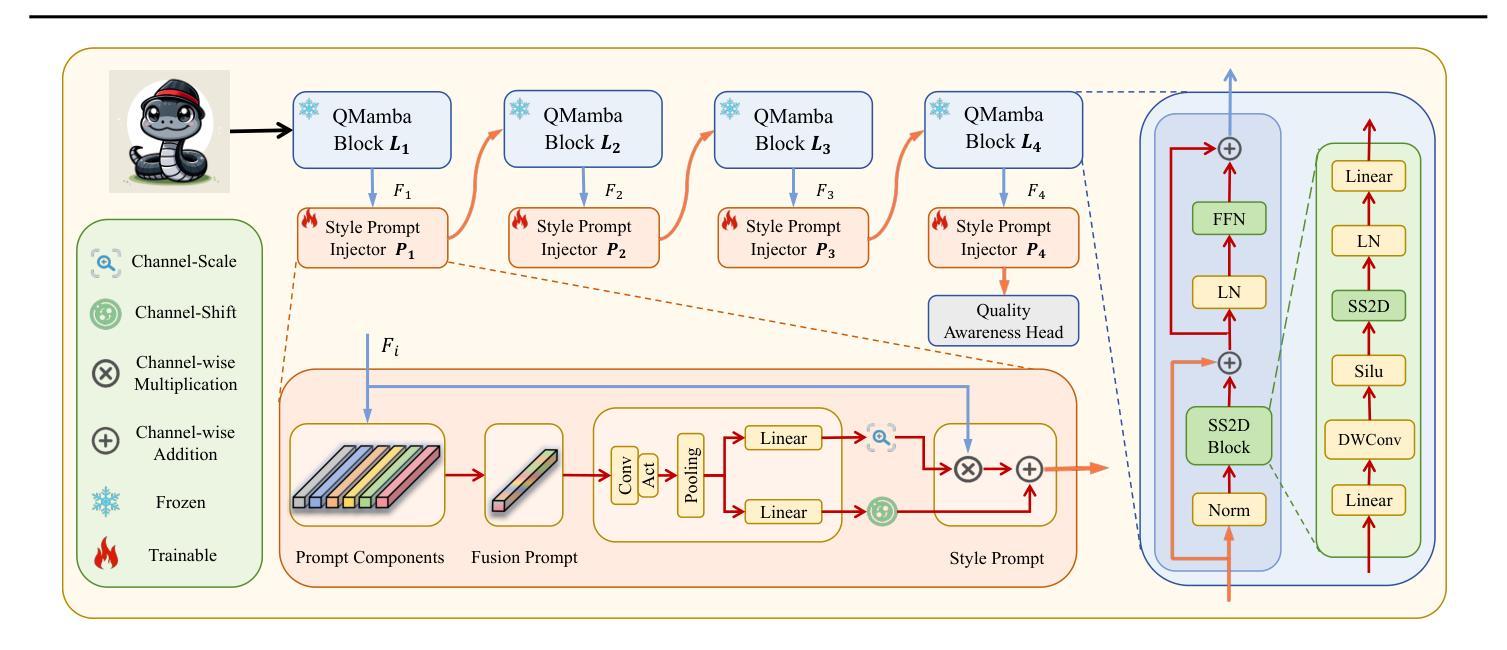
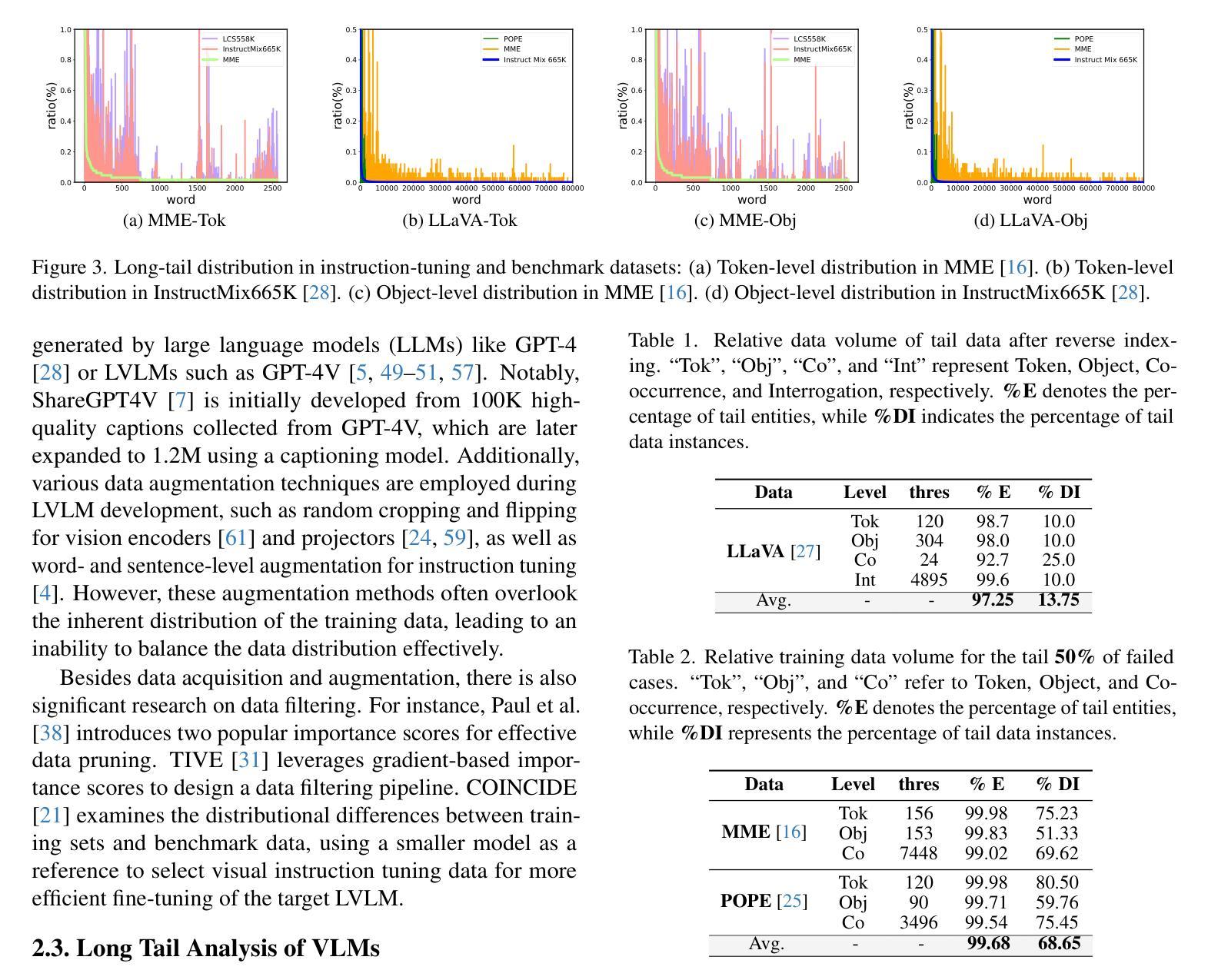
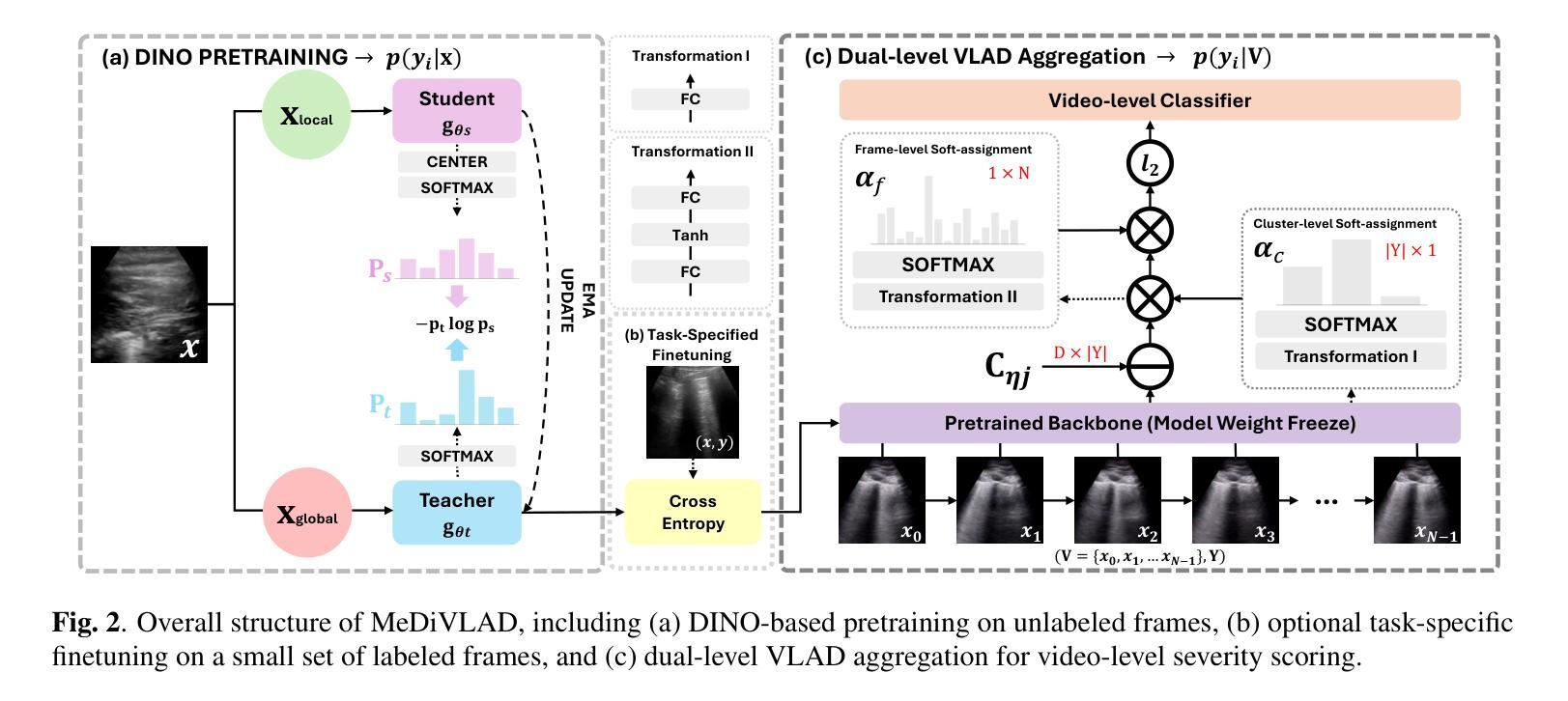
Vision Transformer 方向最新论文已更新,请持续关注 Update in 2025-07-03 A Closer Look at Conditional Prompt Tuning for Vision-Language Models
2025-07-03