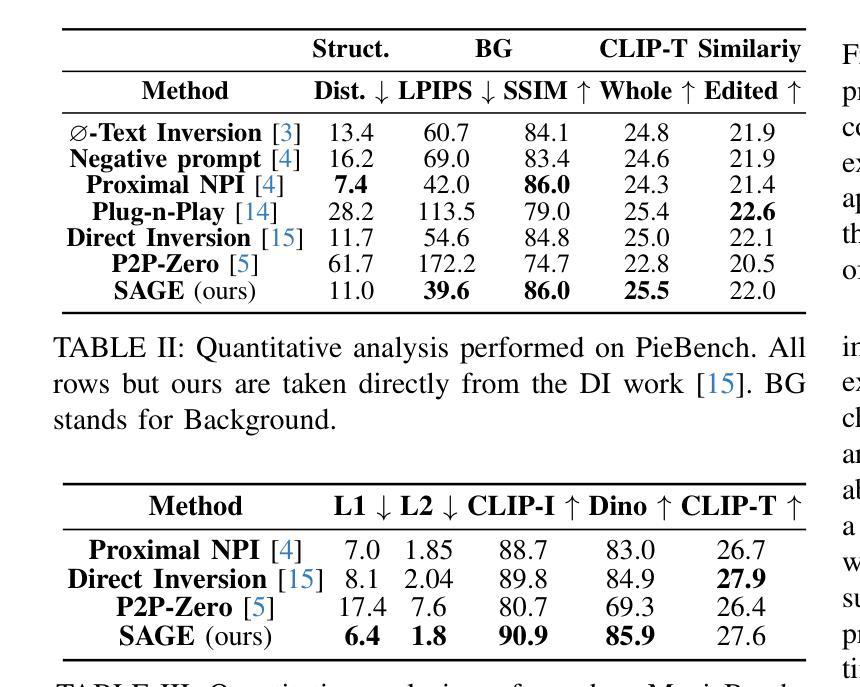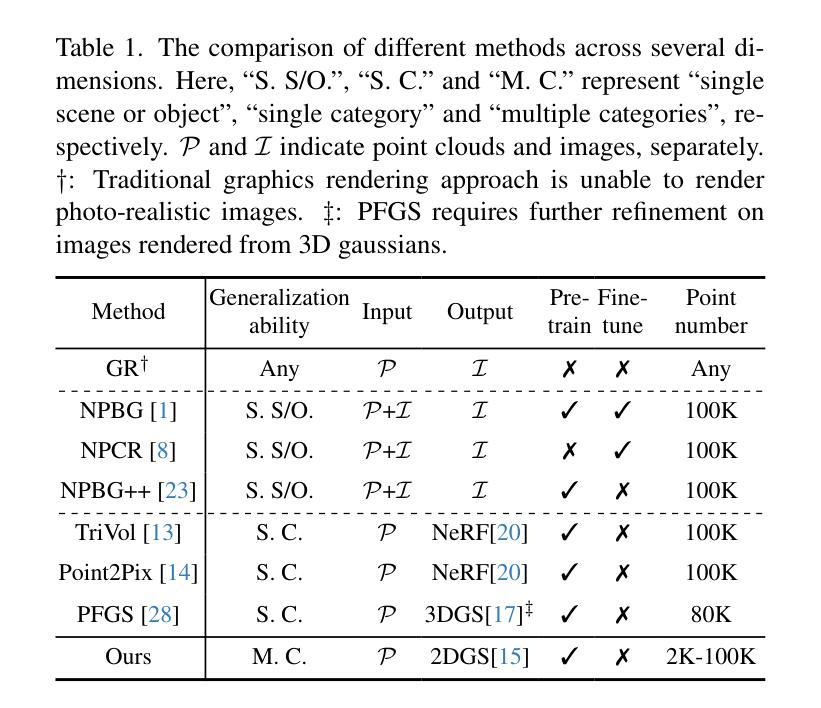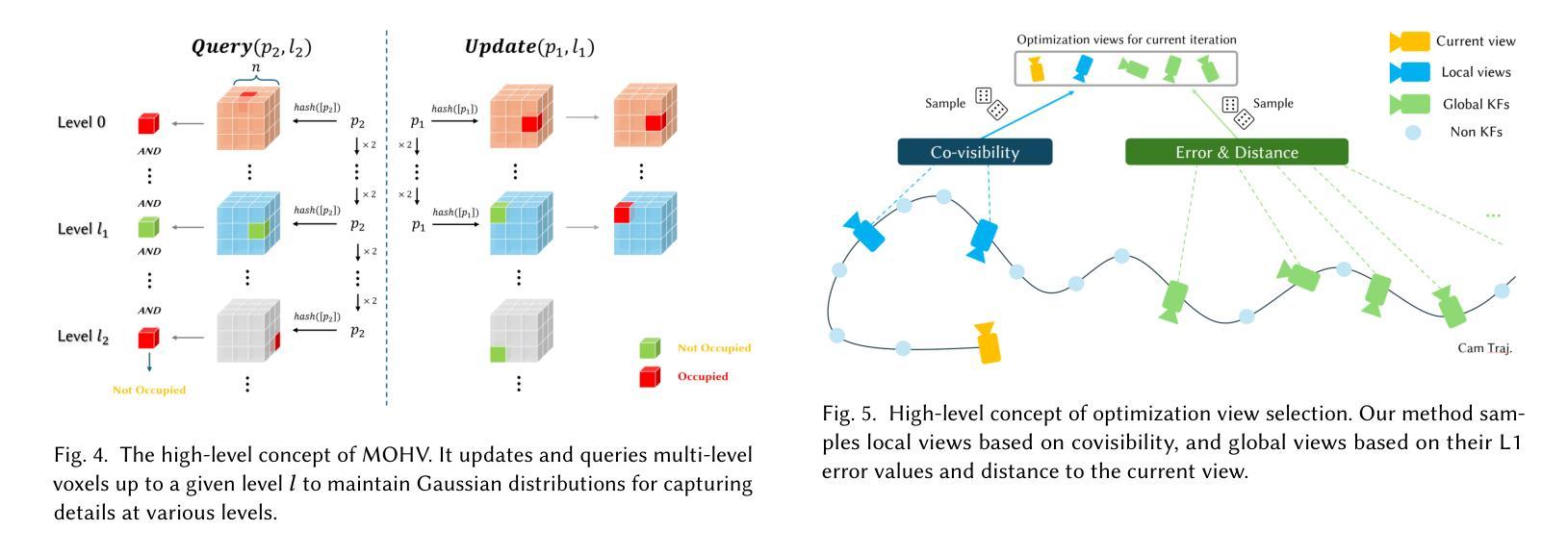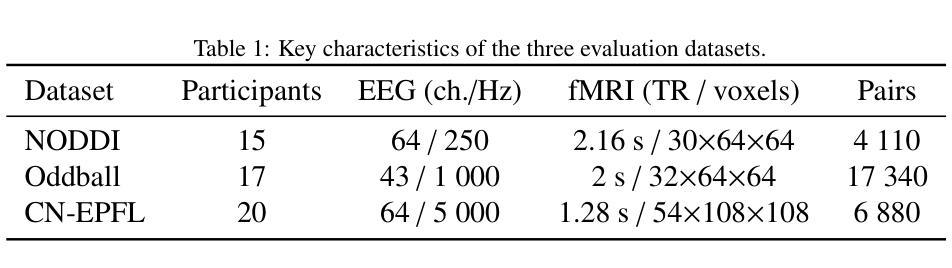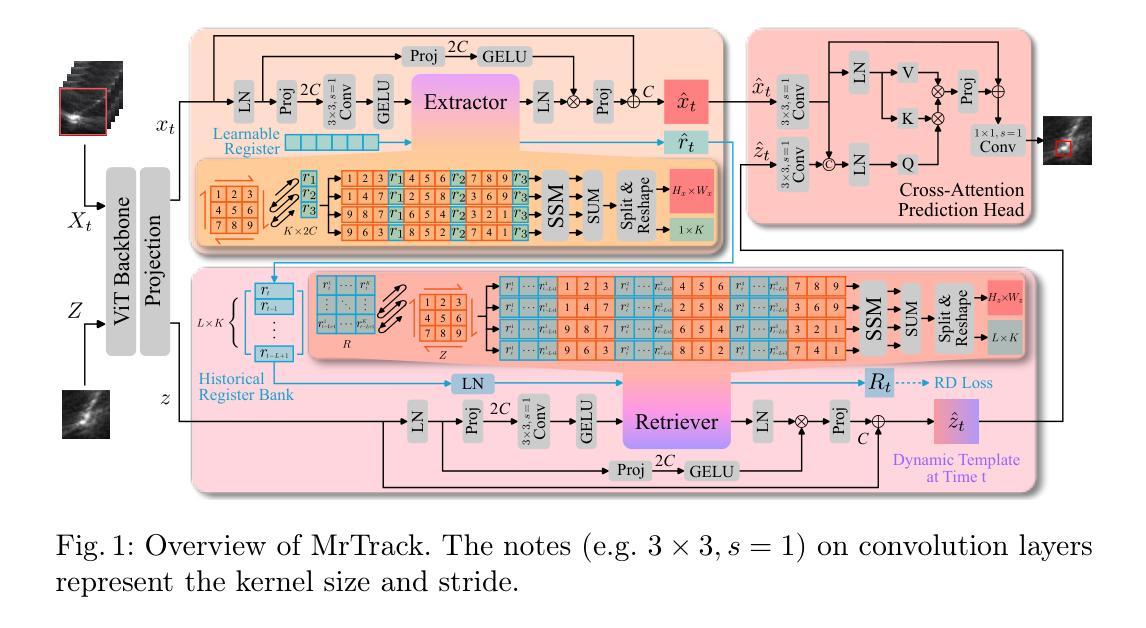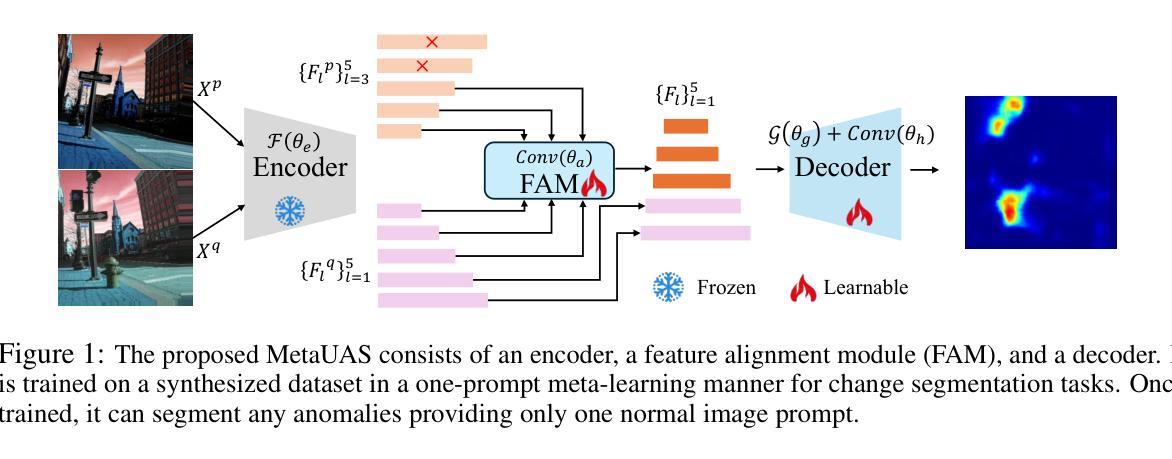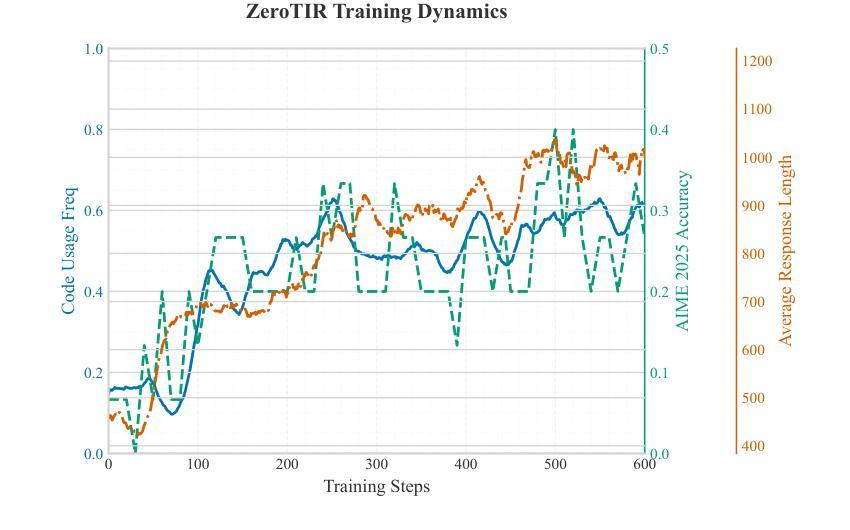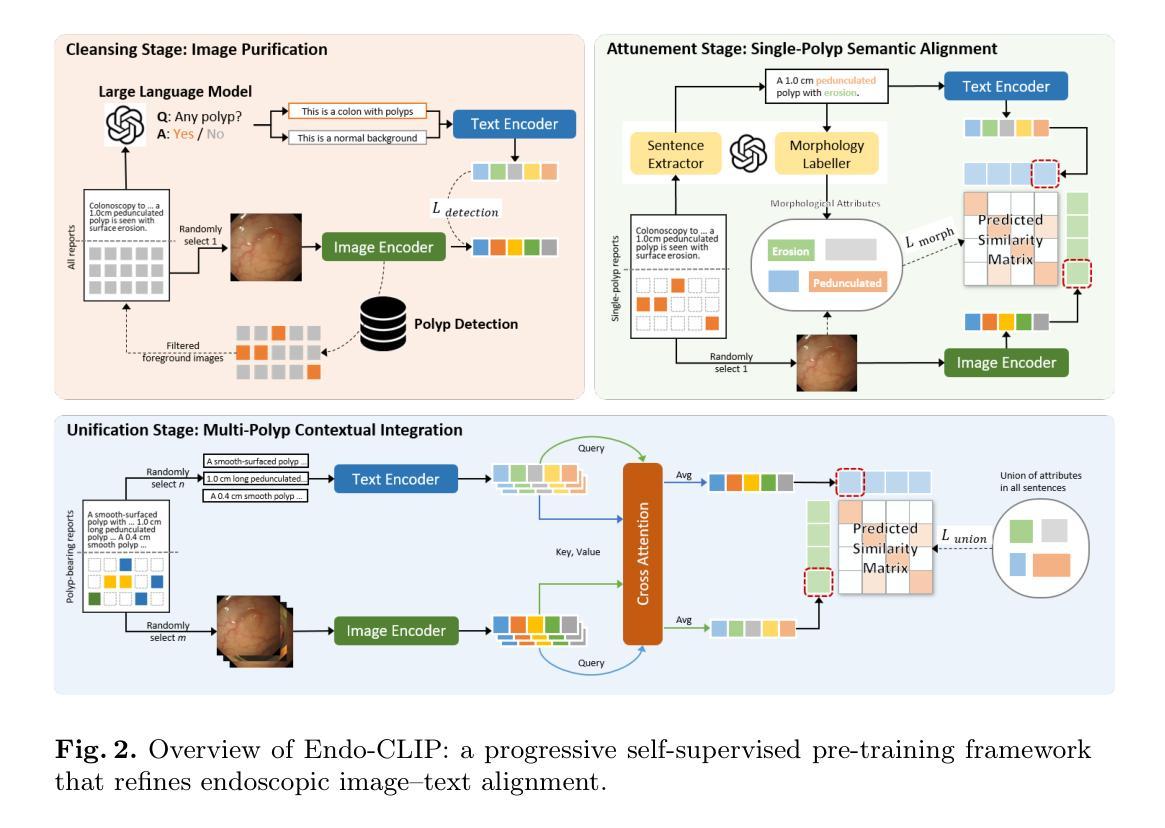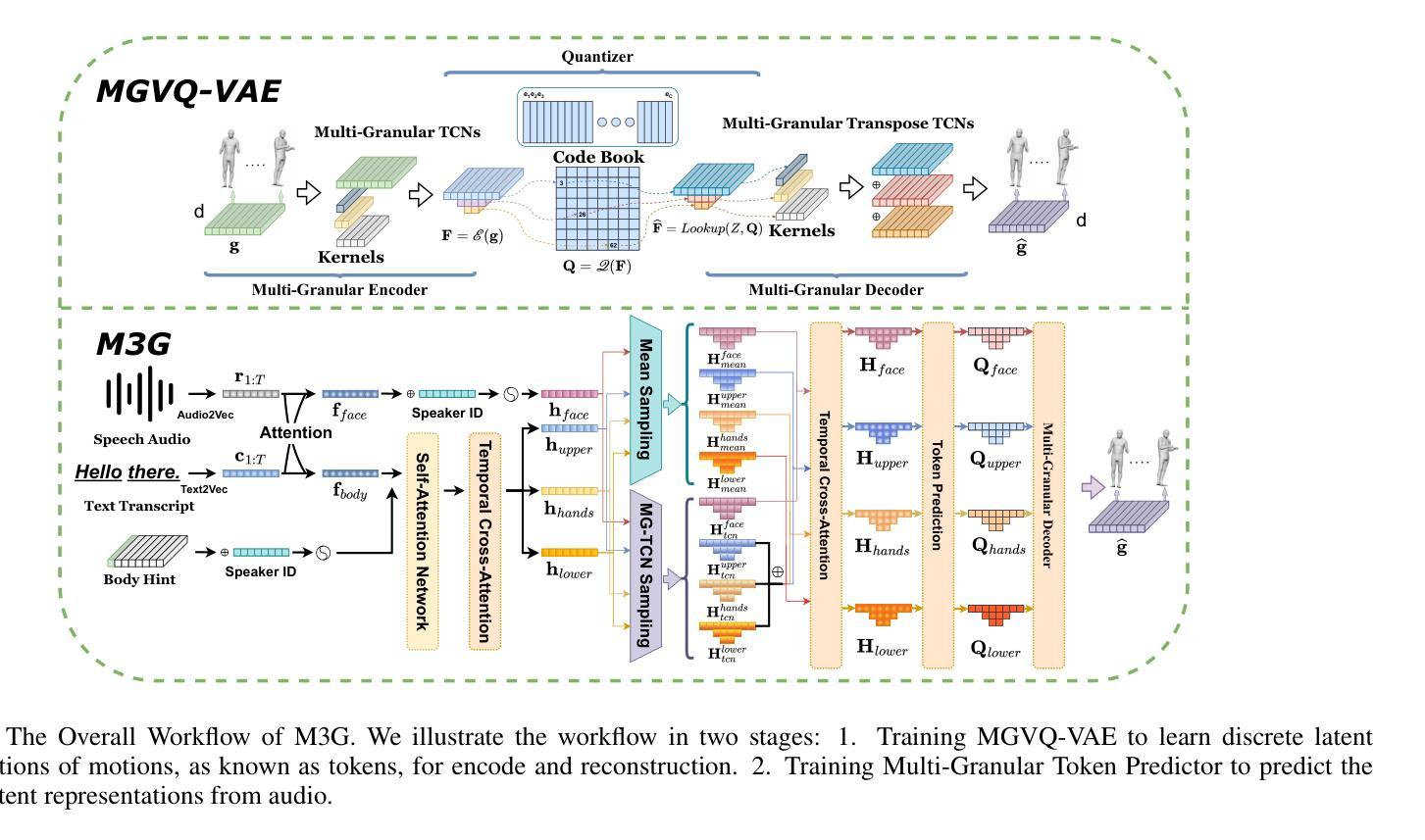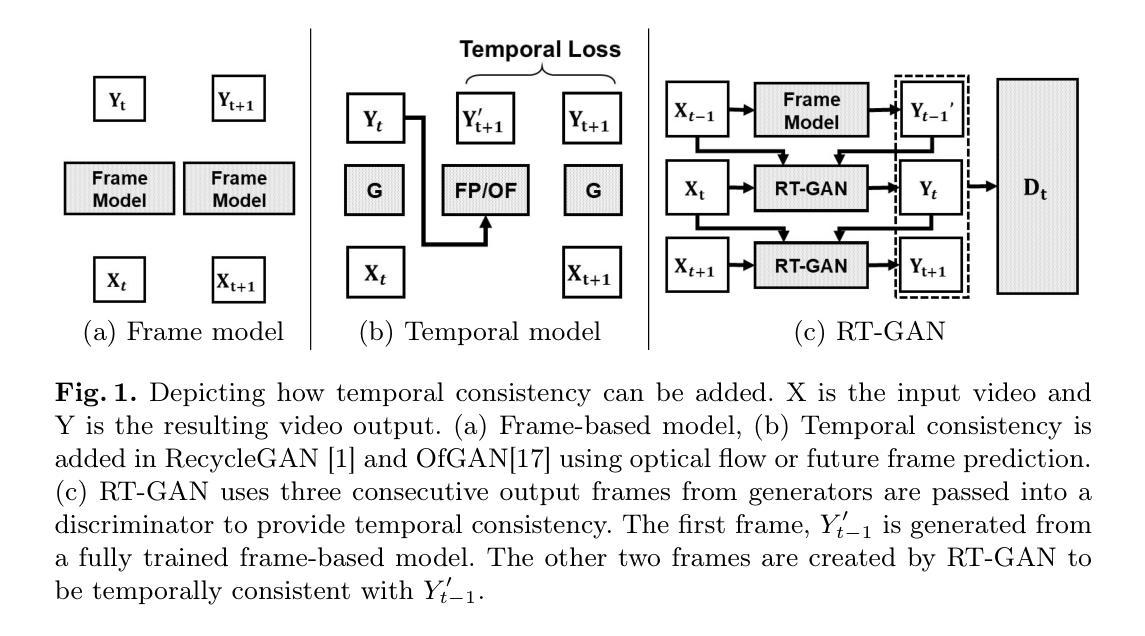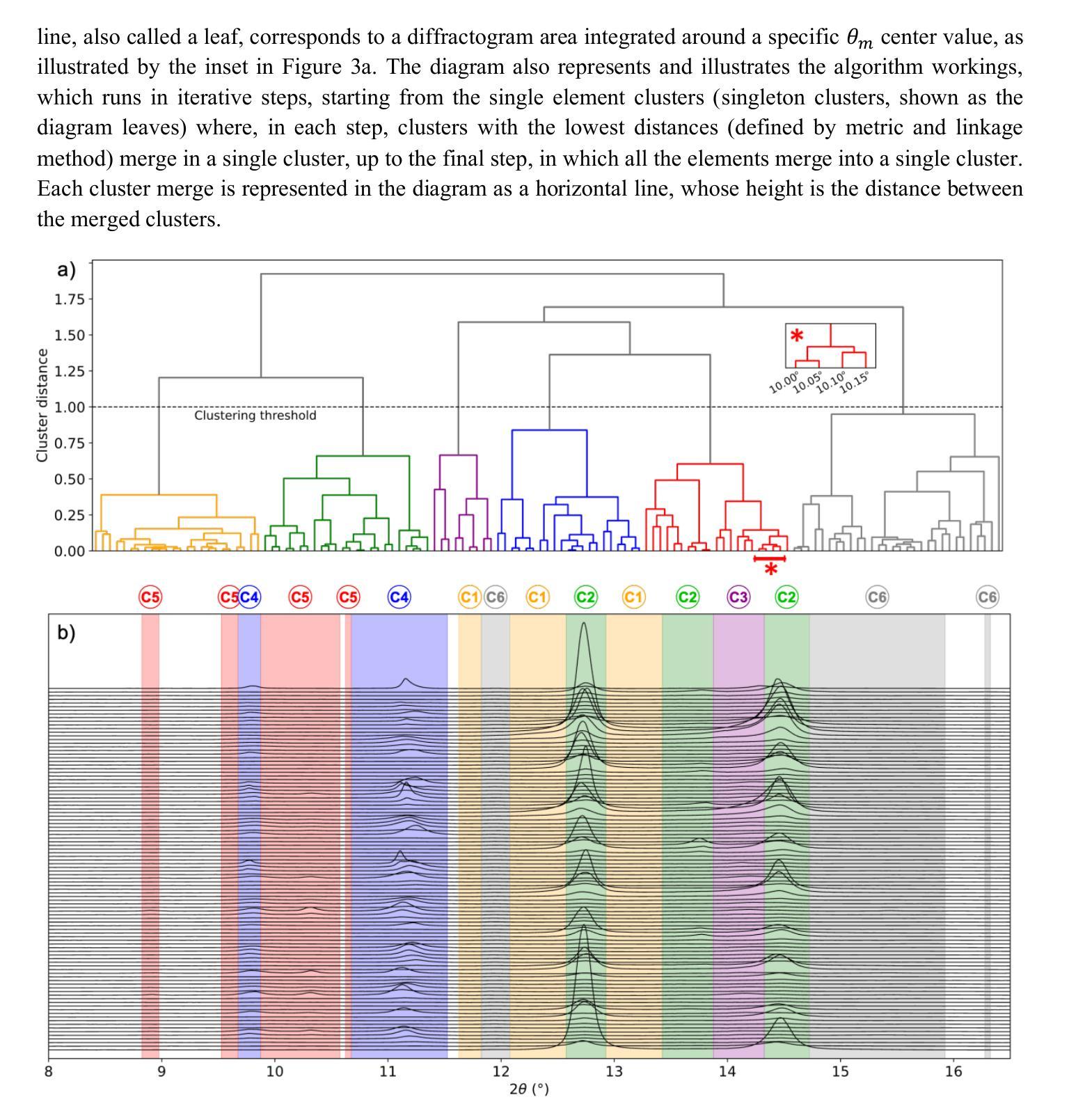
医学图像 方向最新论文已更新,请持续关注 Update in 2025-05-16 Meta-learning Slice-to-Volume Reconstruction in Fetal Brain MRI using Implicit Neural Representations
2025-05-16