SyncTalk The Devil is in the Synchronization for Talking Head Synthesis
SyncTalk: The Devil is in the Synchronization for Talking Head SynthesisPaper : https://arxiv.org/abs/2311.17590
Project : https://ziqiaopeng.github.io/synctalk/
Video : https://ziqiaopeng.github.io/synctalk/#teaser
Code : https://github.com/ziqiaopeng/SyncTalk
摘要
神经辐射场 - 生成对抗网络框架用于实现说话人头部视频的同步合成。
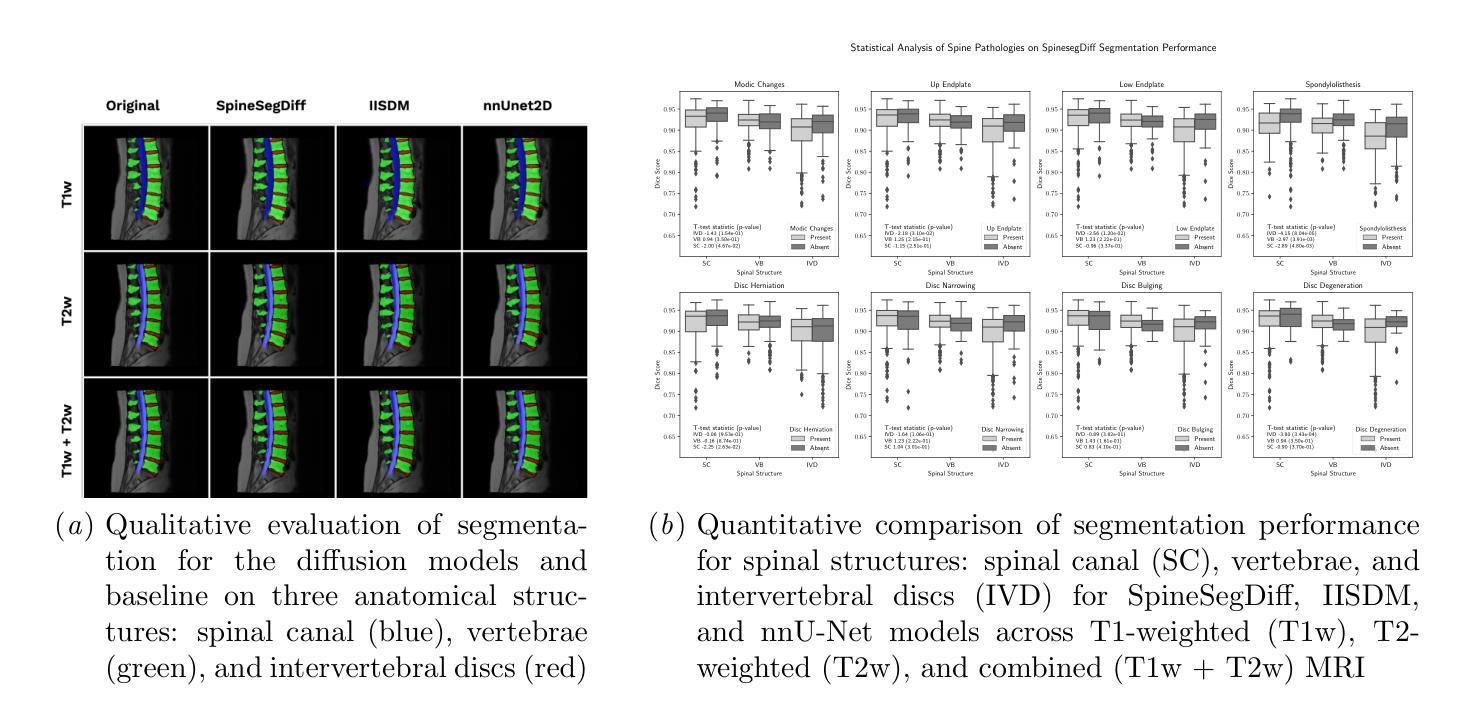
(1)研究背景: 生成逼真的、由语音驱动的谈话头部视频是一项具有挑战性的任务。传统生成对抗网络(GAN)难以保持一致的面部身份,而神经辐射场(NeRF)方法虽然可以解决这个问题,但通常会产生不匹配的唇部动作、不充分的面部表情和不稳定的头部姿势。一个逼真的谈话头部需要同步协调主体身份、唇部动作、面部表情和头部姿势。缺乏这些同步是导致不真实和人工结果的根本缺陷。
(2)过去的方法及其问 ...

VividTalk One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid PriorPaper : https://arxiv.org/pdf/2312.01841.pdf
Project : https://humanaigc.github.io/vivid-talk/
Video : https://www.youtube.com/watch?v=lJVzt7JCe_4
Code : https://github.com/HumanAIGC/VividTalk (Maybe Comming Soon)
摘要
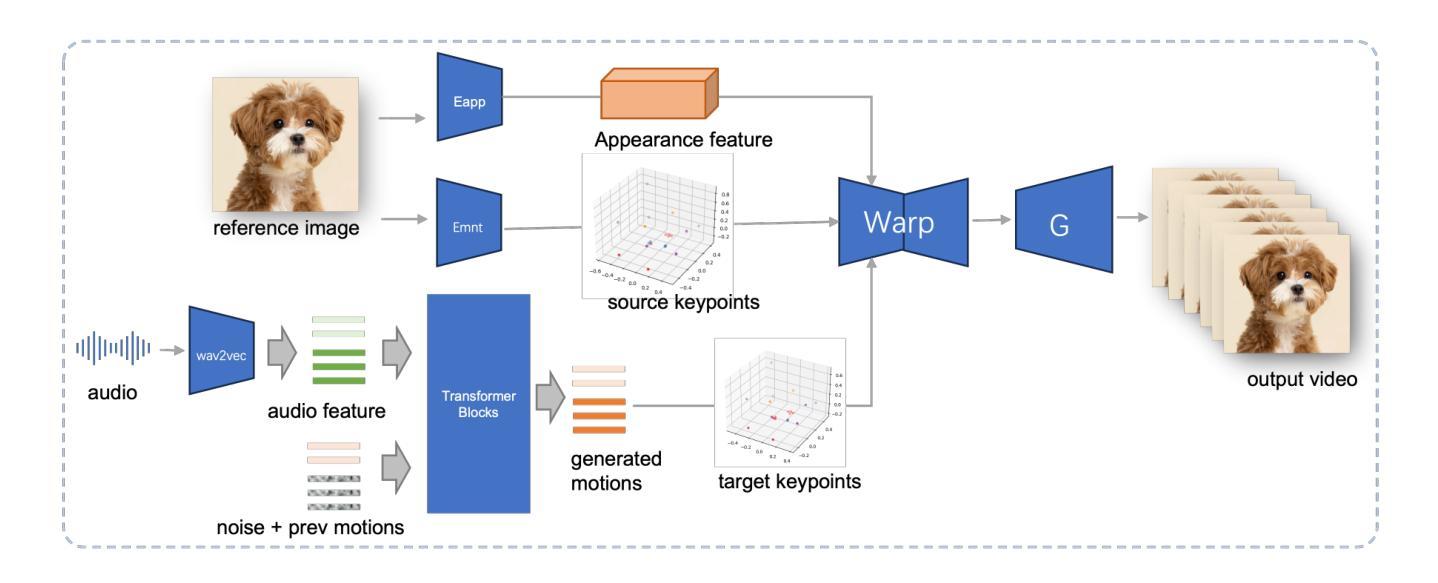
创新的两阶段框架 VividTalk 可生成高质量视觉效果的说话人头部视频,包括唇形同步、丰富的面部表情、自然的头部姿势等。
(1)音频驱动的说话头生成已经引起广泛关注,在唇形同步、面部表情、头部姿势生成和视频质量方面取得了进展。然而,由于音频和动作之间的一对多映射,还没有模型能够在所有这些指标上达到最优SOTA。(2)以往的方法通常使用混合形状Blendshape或顶点偏移verte ...

Diffusion Models
Diffusion Models 方向最新论文已更新,请持续关注 Update in 2024-03-04 DistriFusion Distributed Parallel Inference for High-Resolution Diffusion Models

EMO Emote Portrait Alive - 阿里HumanAIGC
EMO: Emote Portrait Alive - 阿里HumanAIGC最近这一个星期,也就是2月28日的时候,阿里巴巴的HumanAIGC团队发布了一款全新的生成式AI模型EMO(Emote Portrait Alive)。EMO仅需一张人物肖像照片和音频,就可以让照片中的人物按照音频内容“张嘴”唱歌、说话,且口型基本一致,面部表情和头部姿态非常自然,发布的视频效果非常好,好的几乎难以置信,特别是蔡徐坤唱rap的第一段,效果非常好。
EMO不仅能够生成唱歌和说话的视频,还能在保持角色身份稳定性的同时,根据输入音频的长度生成不同时长的视频。
所以我就想借此机会,学习一下EMO的大概框架,剖析一下里面的一些技术要点,首先给出论文的链接和代码链接,不过HumanAIGC已经很久没有开源代码了,不过技术方向还是值得一看的。
论文:EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
项目:https: ...

NeRF
NeRF 方向最新论文已更新,请持续关注 Update in 2024-02-29 Learning Dynamic Tetrahedra for High-Quality Talking Head Synthesis

3DGS
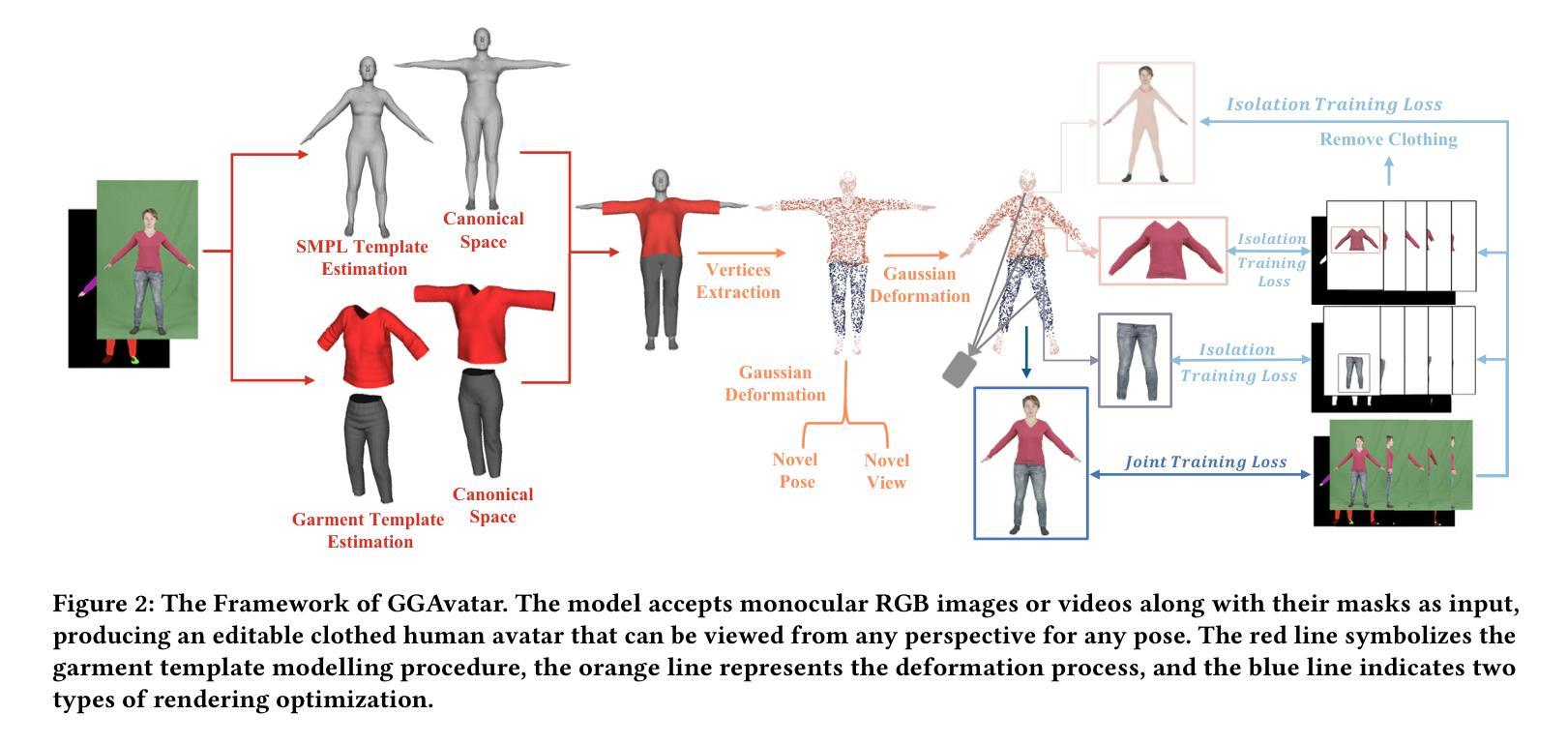
3DGS 方向最新论文已更新,请持续关注 Update in 2024-02-29 VastGaussian Vast 3D Gaussians for Large Scene Reconstruction
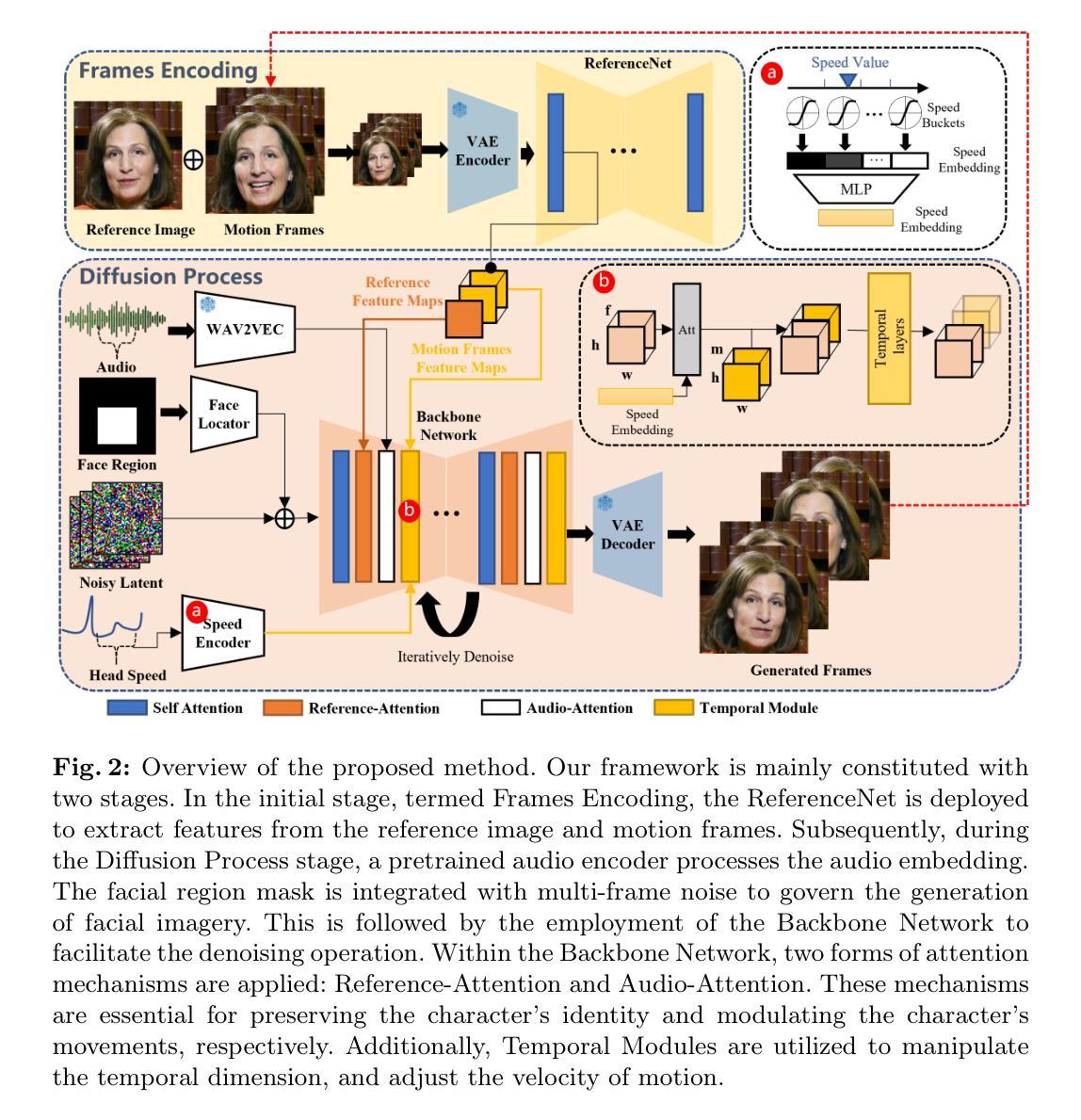
Talking Head Generation
Talking Head Generation 方向最新论文已更新,请持续关注 Update in 2024-02-29 G4GA Generic Framework for High Fidelity Talking Face Generation with Fine-grained Intra-modal Alignment
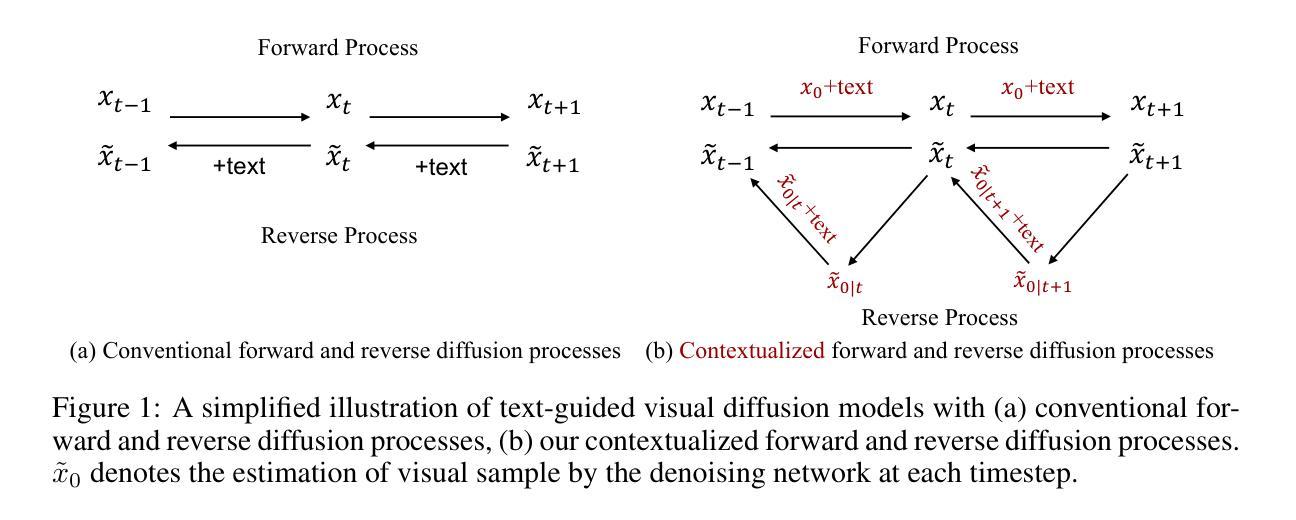
Diffusion Models
Diffusion Models 方向最新论文已更新,请持续关注 Update in 2024-02-29 Objective and Interpretable Breast Cosmesis Evaluation with Attention Guided Denoising Diffusion Anomaly Detection Model

NeRF
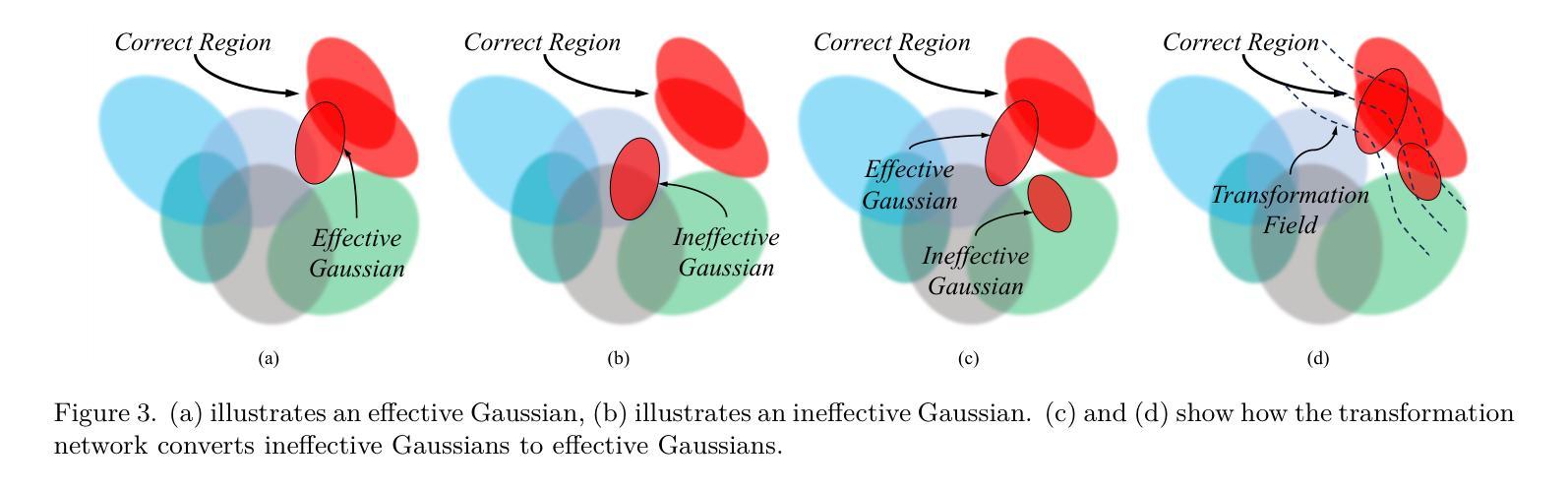
NeRF 方向最新论文已更新,请持续关注 Update in 2024-02-23 Identifying Unnecessary 3D Gaussians using Clustering for Fast Rendering of 3D Gaussian Splatting
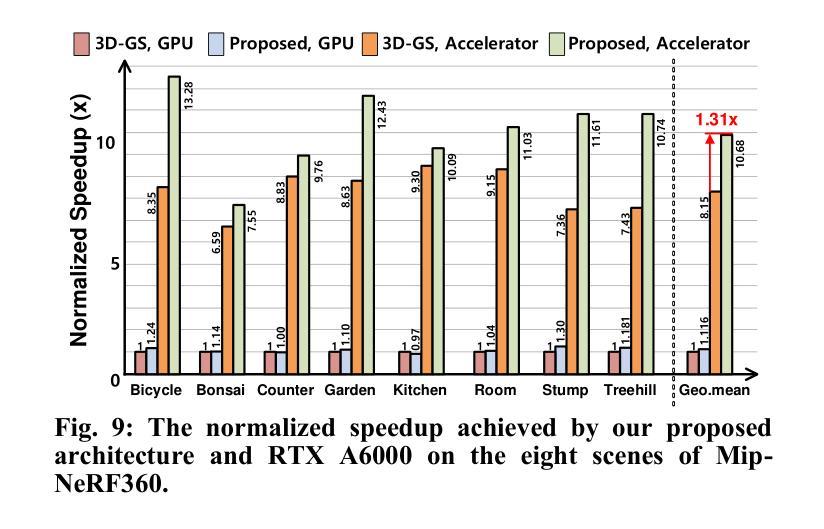
3DGS
3DGS 方向最新论文已更新,请持续关注 Update in 2024-02-23 Identifying Unnecessary 3D Gaussians using Clustering for Fast Rendering of 3D Gaussian Splatting