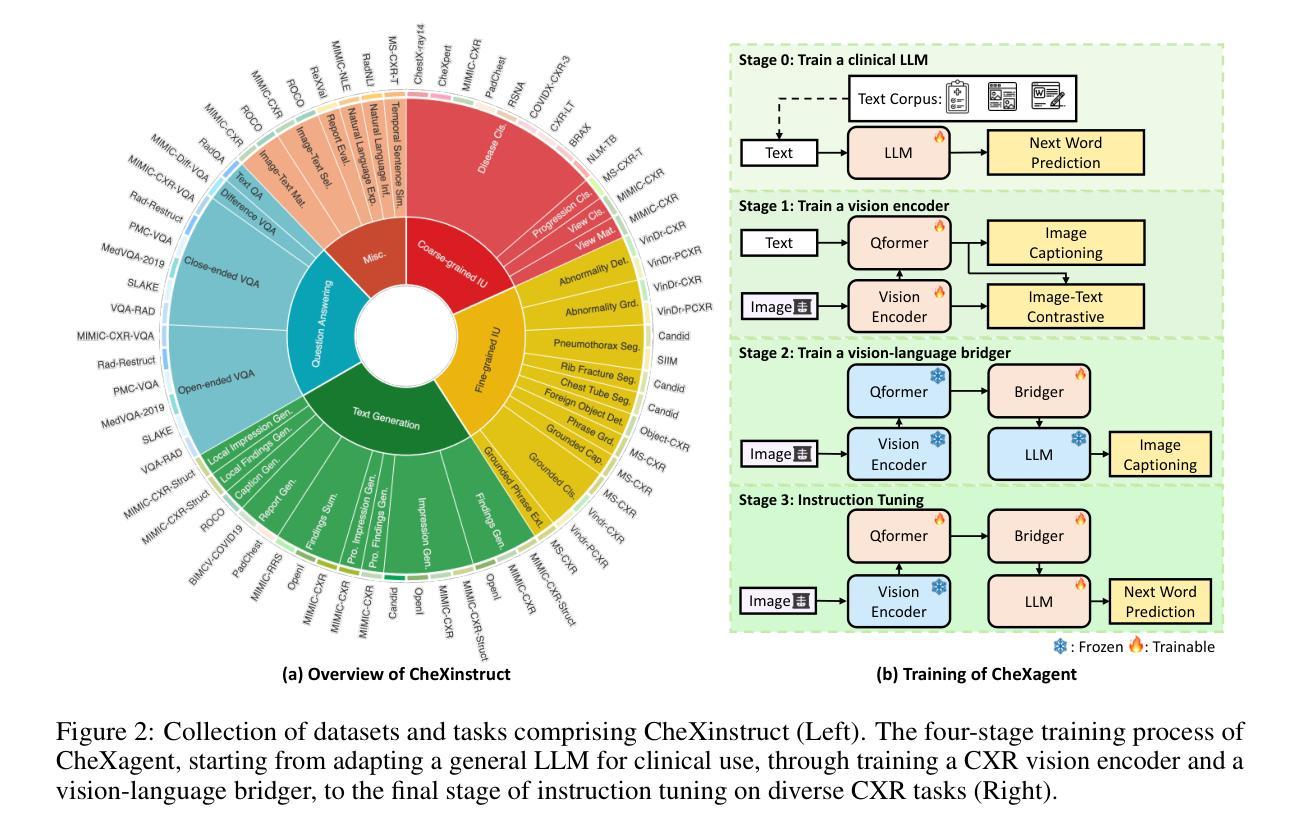
Diffusion Models
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-06 更新
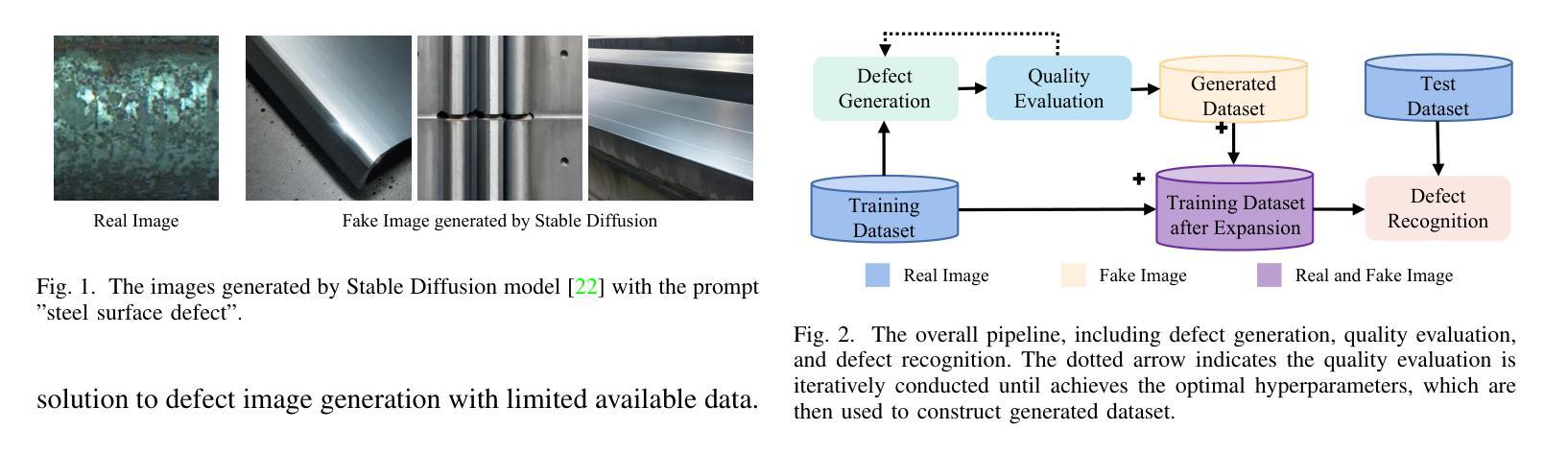
Defect Image Sample Generation With Diffusion Prior for Steel Surface Defect Recognition
Authors:Yichun Tai, Kun Yang, Tao Peng, Zhenzhen Huang, Zhijiang Zhang
The task of steel surface defect recognition is an industrial problem with great industry values. The data insufficiency is the major challenge in training a robust defect recognition network. Existing methods have investigated to enlarge the dataset by generating samples with generative models. However, their generation quality is still limited by the insufficiency of defect image samples. To this end, we propose Stable Surface Defect Generation (StableSDG), which transfers the vast generation distribution embedded in Stable Diffusion model for steel surface defect image generation. To tackle with the distinctive distribution gap between steel surface images and generated images of the diffusion model, we propose two processes. First, we align the distribution by adapting parameters of the diffusion model, adopted both in the token embedding space and network parameter space. Besides, in the generation process, we propose image-oriented generation rather than from pure Gaussian noises. We conduct extensive experiments on steel surface defect dataset, demonstrating state-of-the-art performance on generating high-quality samples and training recognition models, and both designed processes are significant for the performance.
Summary
钢材表面缺陷生成模型StableSDG通过迁移Stable Diffusion模型生成高精度合成图像,有效提升钢材表面缺陷识别模型的鲁棒性。
Key Takeaways
- 利用Stable Diffusion模型生成钢材表面缺陷图像,扩充训练数据集。
- 通过调整模型参数和嵌入空间,弥合生成图像和真实图像之间的分布差异。
- 采用图像引导生成方式,而非纯高斯噪声生成。
- 提出两种关键过程:分布对齐和图像引导生成。
- 在钢材表面缺陷数据集上进行广泛实验,证明StableSDG在生成高质量合成图像和训练识别模型方面均达到最先进水平。
- 两种提出的关键过程对性能至关重要。
- StableSDG有效解决数据不足问题,提升钢材表面缺陷识别模型的性能。
缺陷图像样本生成与扩散
Yichun Tai, Kun Yang, Tao Peng, Zhenzhen Huang, and Zhijiang Zhang
上海大学传信学院
Text-to-image diffusion, data expansion, deep learning, textual inversion, low-rank adaptation, defect image generation, steel surface defect recognition
https://arxiv.org/abs/2405.01872 , Github:None
摘要:
(1):钢表面缺陷识别是工业界具有巨大产业价值的一项任务。数据不足是训练鲁棒缺陷识别网络的主要挑战。现有方法已经研究了通过生成模型生成样本以扩大数据集。然而,它们的生成质量仍然受到缺陷图像样本不足的限制。
(2):现有的方法包括:SDGAN、Defect-GAN、transP2P。这些方法从头开始训练生成模型具有挑战性,当图像样本不足时,通常会导致生成样本中出现不需要的模式。
(3):本文提出了一种稳定的表面缺陷生成(StableSDG)方法,将Stable Diffusion模型中嵌入的巨大生成分布转移用于钢表面缺陷图像生成。为了解决钢表面图像和扩散模型生成图像之间的独特分布差异,我们提出了两个过程。首先,我们通过调整扩散模型的参数来对齐分布,既采用标记嵌入空间,也采用网络参数空间。此外,在生成过程中,我们提出了面向图像的生成,而不是从纯高斯噪声中生成。
(4):我们在钢表面缺陷数据集上进行了广泛的实验,展示了在生成高质量样本和训练识别模型方面的最先进性能,并且两个设计过程对性能都很重要。
方法:
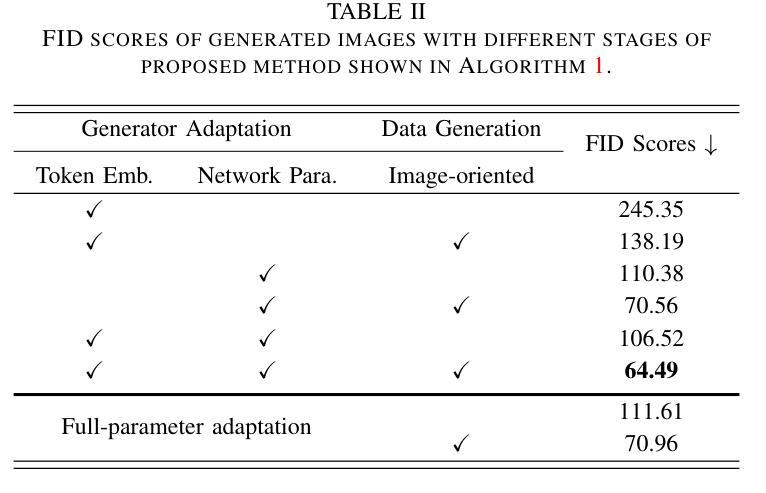
(1):Stable Diffusion模型[22]作为扩散先验,在潜在空间中执行扩散,而不是图像空间,广泛用于图像生成任务[26]–[30]。 (2):提出StableSDG方法,由两个过程组成,用于生成每种缺陷类别的图像。 (3):通过迭代质量评估,调整超参数以实现最佳图像生成。 (4):使用最佳超参数,生成高质量图像以扩展数据集。 (5):将每种缺陷类别的生成图像与真实图像一起收集起来,用于训练缺陷识别模型。结论:
(1)本文提出的StableSDG方法将文本到图像生成技术应用于钢表面缺陷图像生成,有效解决了钢表面缺陷数据集不足的问题,为缺陷识别模型的训练提供了高质量的样本。
(2)创新点:StableSDG方法在生成器自适应过程中,同时在token嵌入空间和网络参数空间进行自适应和修改,并在生成数据时从图像导向初始化生成样本,而不是从纯高斯噪声开始。
性能:StableSDG方法在NEU和CCBSD数据集上进行了广泛的实验,结果表明该方法能够生成高保真度的缺陷图像,大大提高了识别模型的性能。
工作量:StableSDG方法的工作量主要集中在生成器自适应和图像生成两个阶段,需要对超参数进行迭代质量评估和调整,以获得最佳的图像生成效果。
点此查看论文截图



Long Tail Image Generation Through Feature Space Augmentation and Iterated Learning
Authors:Rafael Elberg, Denis Parra, Mircea Petrache
Image and multimodal machine learning tasks are very challenging to solve in the case of poorly distributed data. In particular, data availability and privacy restrictions exacerbate these hurdles in the medical domain. The state of the art in image generation quality is held by Latent Diffusion models, making them prime candidates for tackling this problem. However, a few key issues still need to be solved, such as the difficulty in generating data from under-represented classes and a slow inference process. To mitigate these issues, we propose a new method for image augmentation in long-tailed data based on leveraging the rich latent space of pre-trained Stable Diffusion Models. We create a modified separable latent space to mix head and tail class examples. We build this space via Iterated Learning of underlying sparsified embeddings, which we apply to task-specific saliency maps via a K-NN approach. Code is available at https://github.com/SugarFreeManatee/Feature-Space-Augmentation-and-Iterated-Learning
Summary
长尾数据图像增强方法,利用预训练稳定扩散模型的潜在空间,缓解生成质量差和推理速度慢的问题。
Key Takeaways
- 图像和多模态机器学习任务在数据分布不足的情况下极具挑战性。
- 医学领域的图像生成面临数据获取和隐私限制的障碍。
- 潜在扩散模型在图像生成质量上处于领先地位。
- 数据生成不平衡和推理速度慢是亟待解决的问题。
- 方法结合预训练稳定扩散模型的潜在空间,进行图像增强。
- 构建可分离的潜在空间,混合头部和尾部类别的示例。
- 通过迭代学习潜在嵌入,构建空间,并通过 K-NN 方法应用于特定任务的显着性图。
- 代码已开源:https://github.com/SugarFreeManatee/Feature-Space-Augmentation-and-Iterated-Learning
标题:特征空间增强和迭代学习的长尾图像生成
作者:Rafael Elberg、Denis Parra、Mircea Petrache
隶属:智利天主教大学
关键词:长尾数据、图像生成、特征空间增强、迭代学习
论文链接:https://arxiv.org/abs/2405.01705 Github 代码链接:https://github.com/SugarFreeManatee/Feature-Space-Augmentation-and-Iterated-Learning
摘要:
(1):图像和多模态机器学习任务在数据分布不均匀的情况下非常具有挑战性。特别是在医疗领域,数据可用性和隐私限制加剧了这些障碍。潜扩散模型在图像生成质量方面处于最先进水平,使其成为解决此问题的理想候选者。然而,仍需要解决几个关键问题,例如难以生成来自代表性不足的类别的图像以及推理过程缓慢。
(2):过去的方法包括重采样和数据增强。重采样技术在一些长尾问题中取得了相对成功,但可能会给下游任务引入不必要的偏差,并且经常导致过拟合。数据增强是解决这些问题的自然响应。它代表了一个蓬勃发展的研究领域,包括几个不同的算法系列,例如几何变换(旋转、缩放、裁剪等)、合成样本创建、基于混合的方法、基于域转换的方法和生成方法。
(3):本文提出了一种新的数据增强方法,该方法操纵来自预训练扩散模型的图像的潜在空间表示,从而生成新图像来增强代表性不足的类别。通过激活图选择数据的特定特征,然后将这些特征组合起来,生成与属于长尾类的实际数据中的图像相似的图像。
(4):在本文的方法中,潜在空间表示的组合由于特征后处理之间的干扰现象而难以通过朴素的方法执行。本文将此问题作为合成泛化问题,并将迭代学习(IL)框架与稀疏嵌入应用于目标数据增强框架。IL 的主要灵感来自文化进化模型,其中教师-学生交互的迭代鼓励有用的压缩和形成适应任务的“共享语言”。特别是,最近在使用稀疏状态空间时获得了与合成不同特征相关的有利结果。
- 方法:
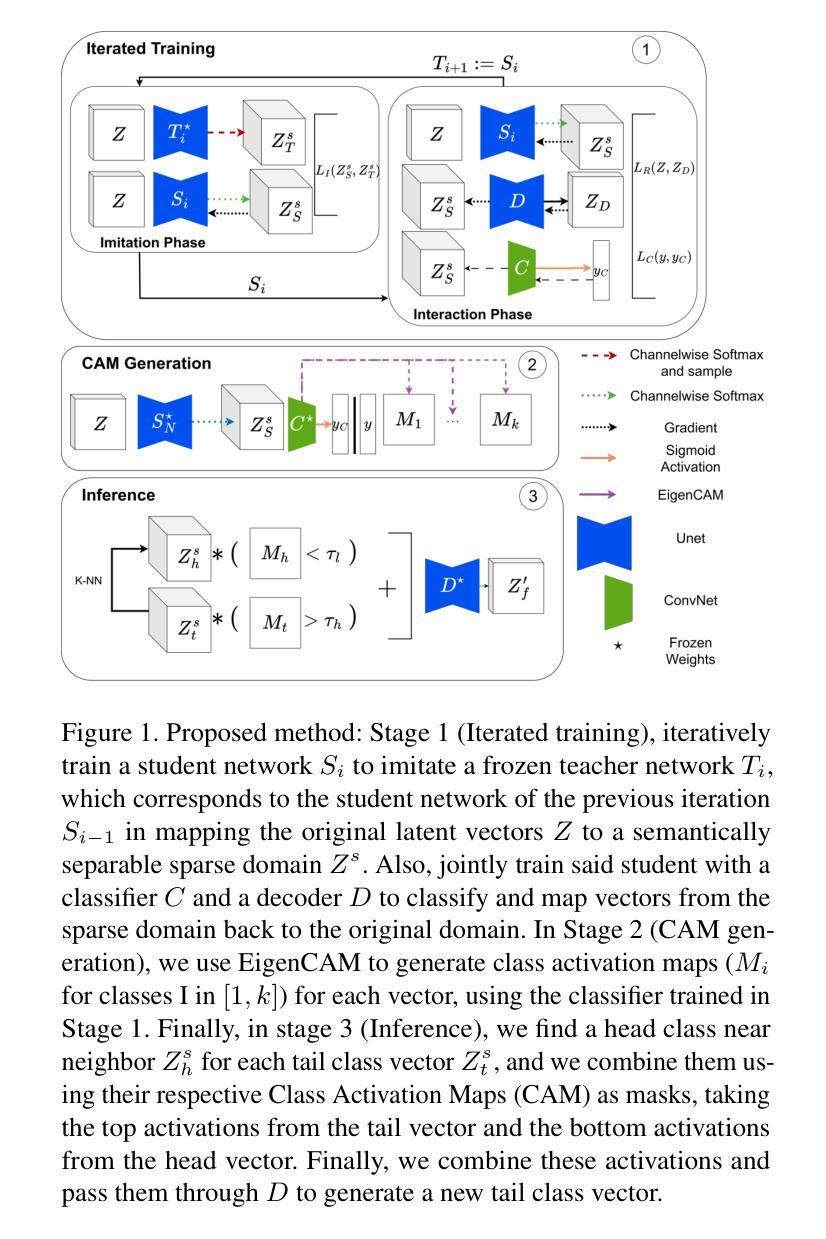
(1):本文提出了一种新的数据增强方法,该方法通过操纵来自预训练扩散模型的图像的潜在空间表示来生成新图像,以增强代表性不足的类别;
(2):该方法包括三个阶段:迭代训练、类别激活图生成和推理;
(3):在迭代训练阶段,学习了一个从扩散潜在空间到稀疏高维表示的转换,同时训练了一个卷积分类器用于该空间;
(4):在类别激活图生成阶段,使用分类器生成每个类的简单可解释激活图,以选择与分类为该类相关的或不相关的坐标;
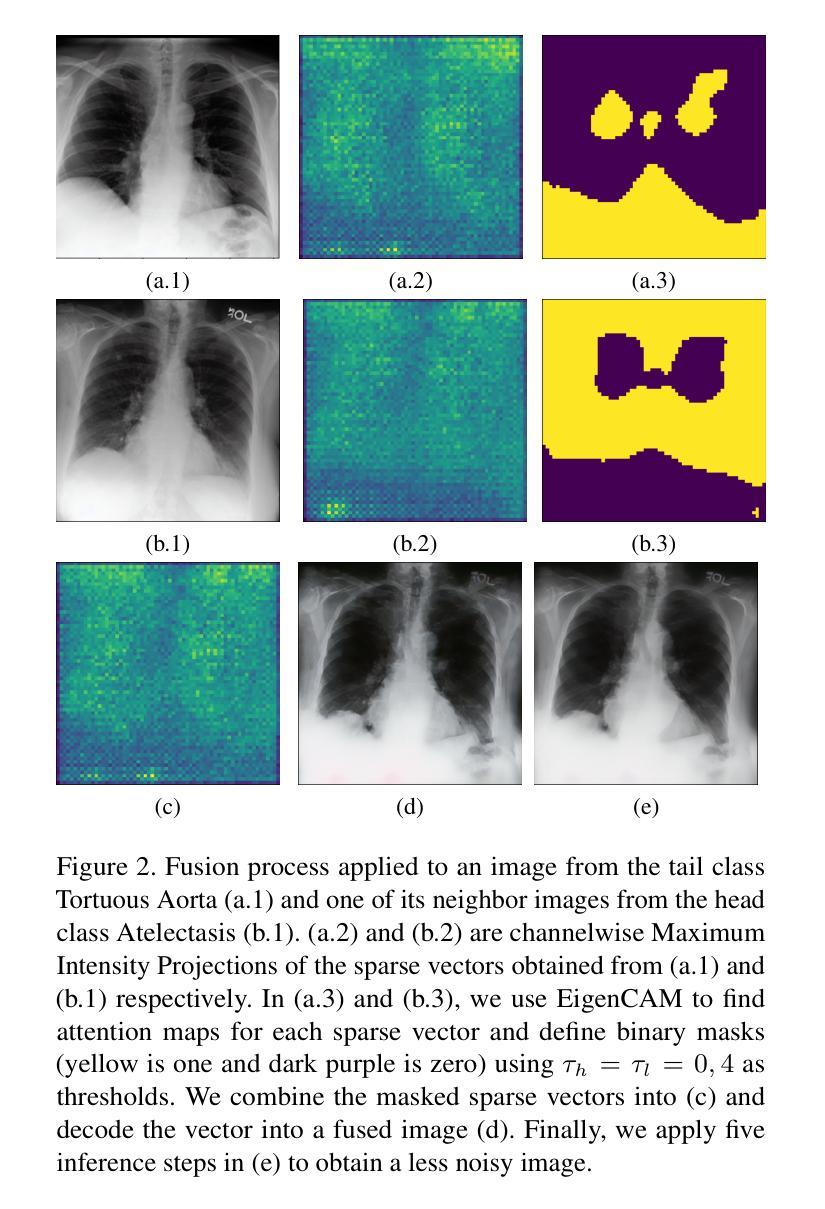
(5):在推理阶段,从尾部类生成新样本,通过将特定尾部类示例的类特定特征与最高混淆头部类的类通用特征融合,使用掩码创建融合向量。
- 结论:
(1):本文提出了一种新颖的方法,通过利用预训练的潜在扩散模型、组合学习和显着性方法,为长尾数据集生成数据并增强数据,从而为代表性不足的类别生成新示例。
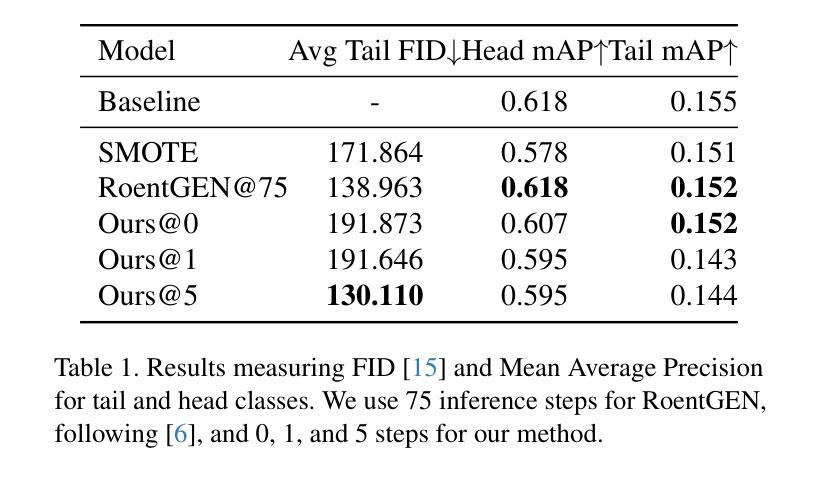
(2):创新点:提出了一种利用潜在扩散模型、组合学习和显著性方法的数据增强和数据生成方法;性能:在医学领域的多标签分类任务中使用 MIMIC-CXR-LT [13, 16] 的一个小型子集,在图像生成和数据增强方面取得了有竞争力的结果;工作量:工作量中等,需要预训练潜在扩散模型,并对转换和分类器进行迭代训练。
点此查看论文截图

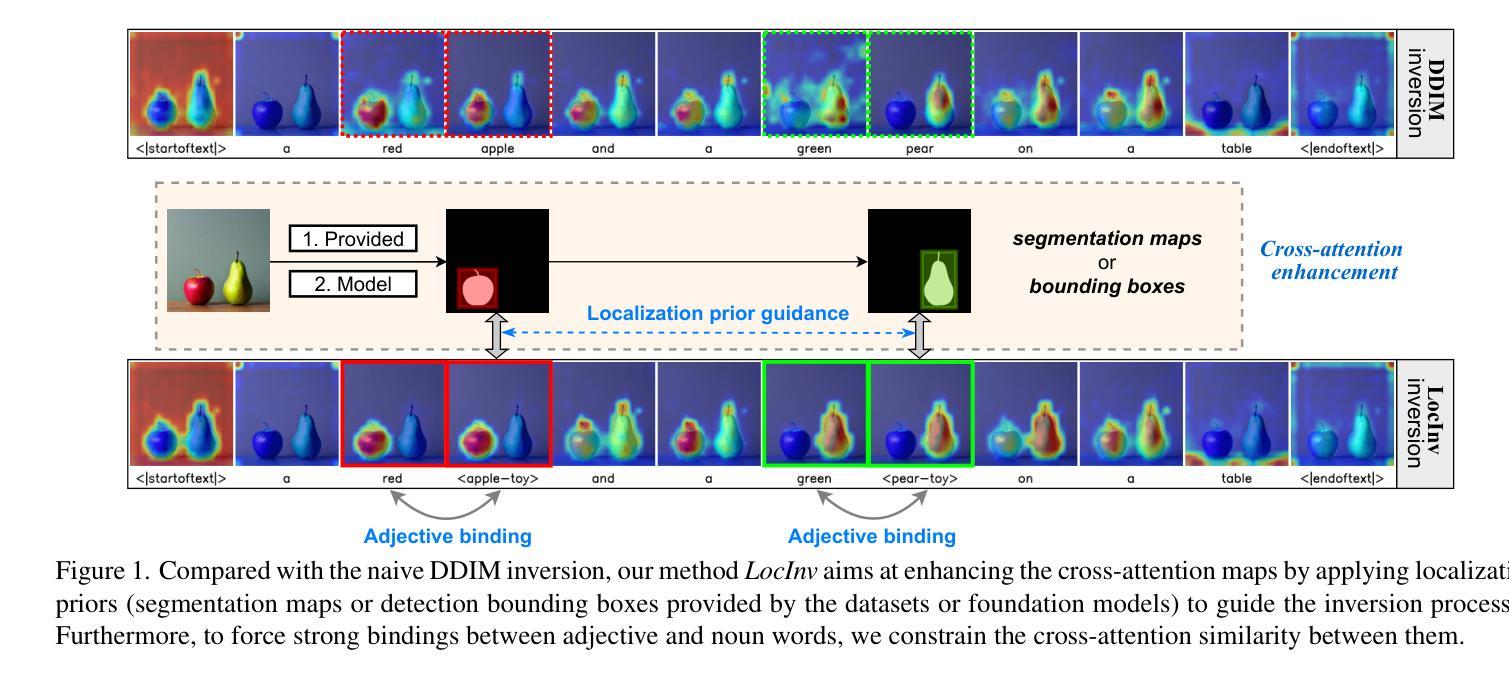
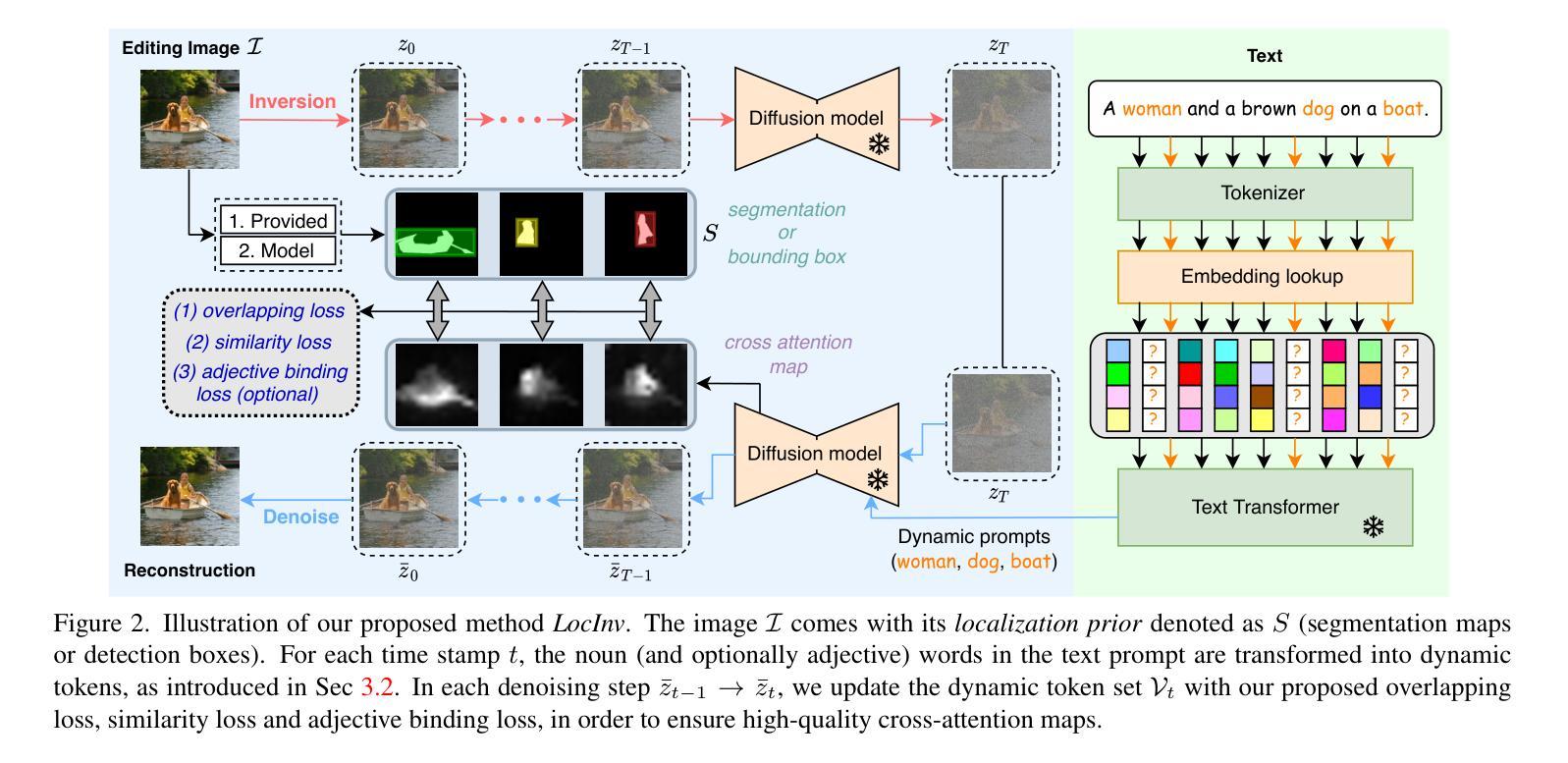
LocInv: Localization-aware Inversion for Text-Guided Image Editing
Authors:Chuanming Tang, Kai Wang, Fei Yang, Joost van de Weijer
Large-scale Text-to-Image (T2I) diffusion models demonstrate significant generation capabilities based on textual prompts. Based on the T2I diffusion models, text-guided image editing research aims to empower users to manipulate generated images by altering the text prompts. However, existing image editing techniques are prone to editing over unintentional regions that are beyond the intended target area, primarily due to inaccuracies in cross-attention maps. To address this problem, we propose Localization-aware Inversion (LocInv), which exploits segmentation maps or bounding boxes as extra localization priors to refine the cross-attention maps in the denoising phases of the diffusion process. Through the dynamic updating of tokens corresponding to noun words in the textual input, we are compelling the cross-attention maps to closely align with the correct noun and adjective words in the text prompt. Based on this technique, we achieve fine-grained image editing over particular objects while preventing undesired changes to other regions. Our method LocInv, based on the publicly available Stable Diffusion, is extensively evaluated on a subset of the COCO dataset, and consistently obtains superior results both quantitatively and qualitatively.The code will be released at https://github.com/wangkai930418/DPL
PDF Accepted by CVPR 2024 Workshop AI4CC
Summary
文本引导图像编辑研究利用大型文本到图像扩散模型,但现有编辑技术容易修改超出目标区域的无意区域,主要是因为交叉注意力图不准确。我们通过分割图或边界框改进扩散过程中的交叉注意力图,实现了特定对象的细粒度图像编辑,同时防止对其他区域进行非必要的更改。
Key Takeaways
- 现有图像编辑技术容易修改超出目标区域的无意区域。
- 我们提出了利用分割图或边界框作为额外的定位先验来改进扩散过程中的交叉注意力图。
- 我们通过更新文本输入中名词对应的符号,迫使交叉注意力图紧密对齐文本提示中的正确名词和形容词。
- 我们基于公开的Stable Diffusion实现了LocInv方法,并在COCO数据集的子集上进行了广泛评估。
- 与现有方法相比,我们的方法在定量和定性上都取得了更好的结果。
- 该方法的代码将在https://github.com/wangkai930418/DPL上公布。
标题:定位感知反演:文本引导图像编辑
作者:Chuanming Tang、Kai Wang、Fei Yang、Joost van de Weijer
单位:中国科学院大学
关键词:文本到图像、图像编辑、定位感知、交叉注意力
论文链接:https://arxiv.org/abs/2405.01496 Github:无
摘要:
(1):研究背景:大规模文本到图像扩散模型在文本提示下展示了显著的生成能力。基于文本到图像扩散模型,文本引导图像编辑研究旨在通过改变文本提示来赋予用户操纵生成图像的能力。
(2):已有方法及问题:现有的图像编辑技术容易对超出目标区域的无意区域进行编辑,这主要是由于交叉注意力图的不准确。
(3):提出的研究方法:本文提出定位感知反演(LocInv),它利用分割图或边界框作为额外的定位先验,在扩散过程的去噪阶段优化交叉注意力图。通过动态更新文本输入中与名词对应的标记,迫使交叉注意力图与文本提示中正确的名词和形容词紧密对齐。基于此技术,我们实现了对特定对象的细粒度图像编辑,同时防止对其他区域进行不必要的更改。
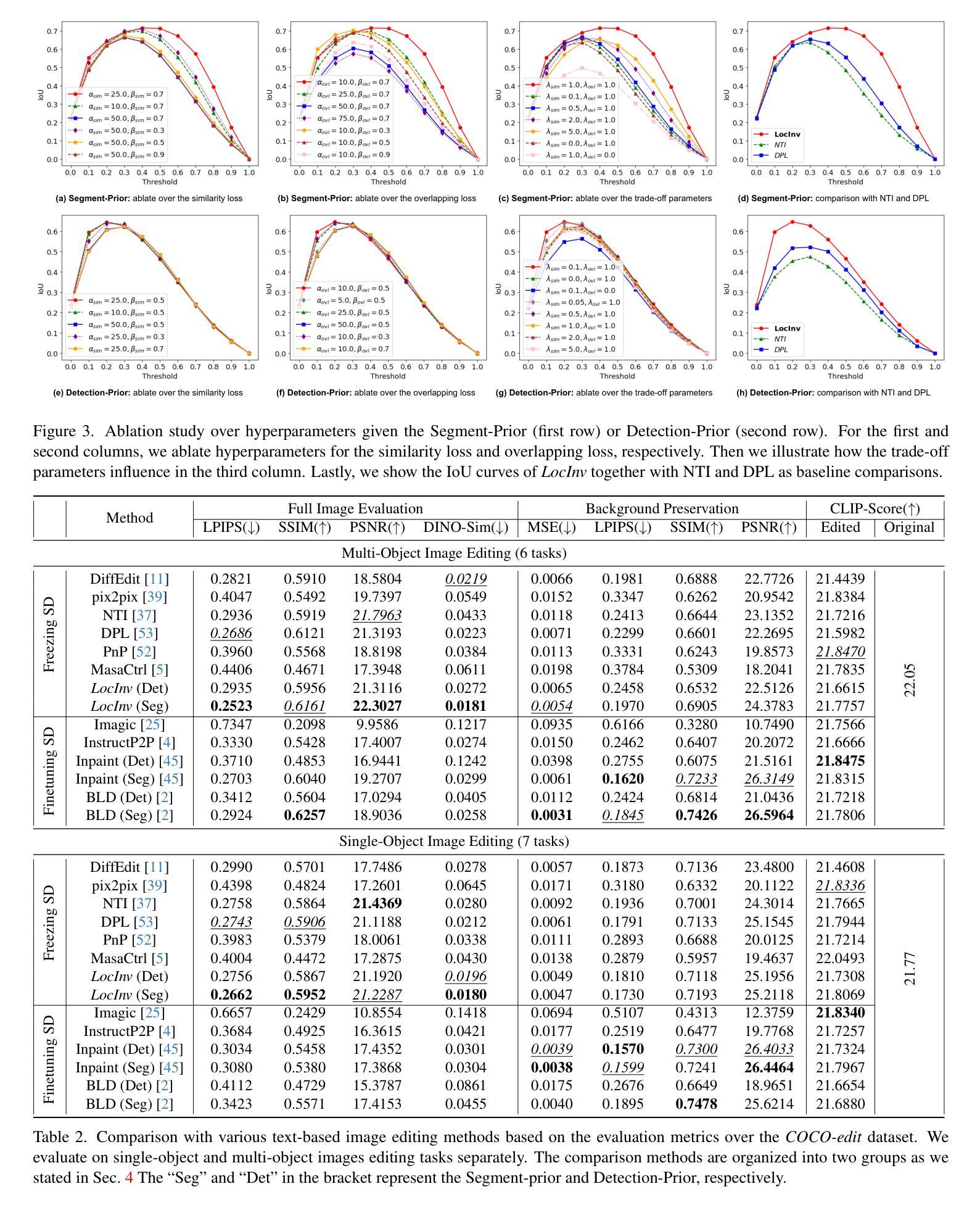
(4):方法性能:基于公开的Stable Diffusion,我们对LocInv方法在COCO数据集的子集上进行了广泛的评估,在定量和定性上都取得了优异的结果。这些结果证明了该方法可以实现其目标。
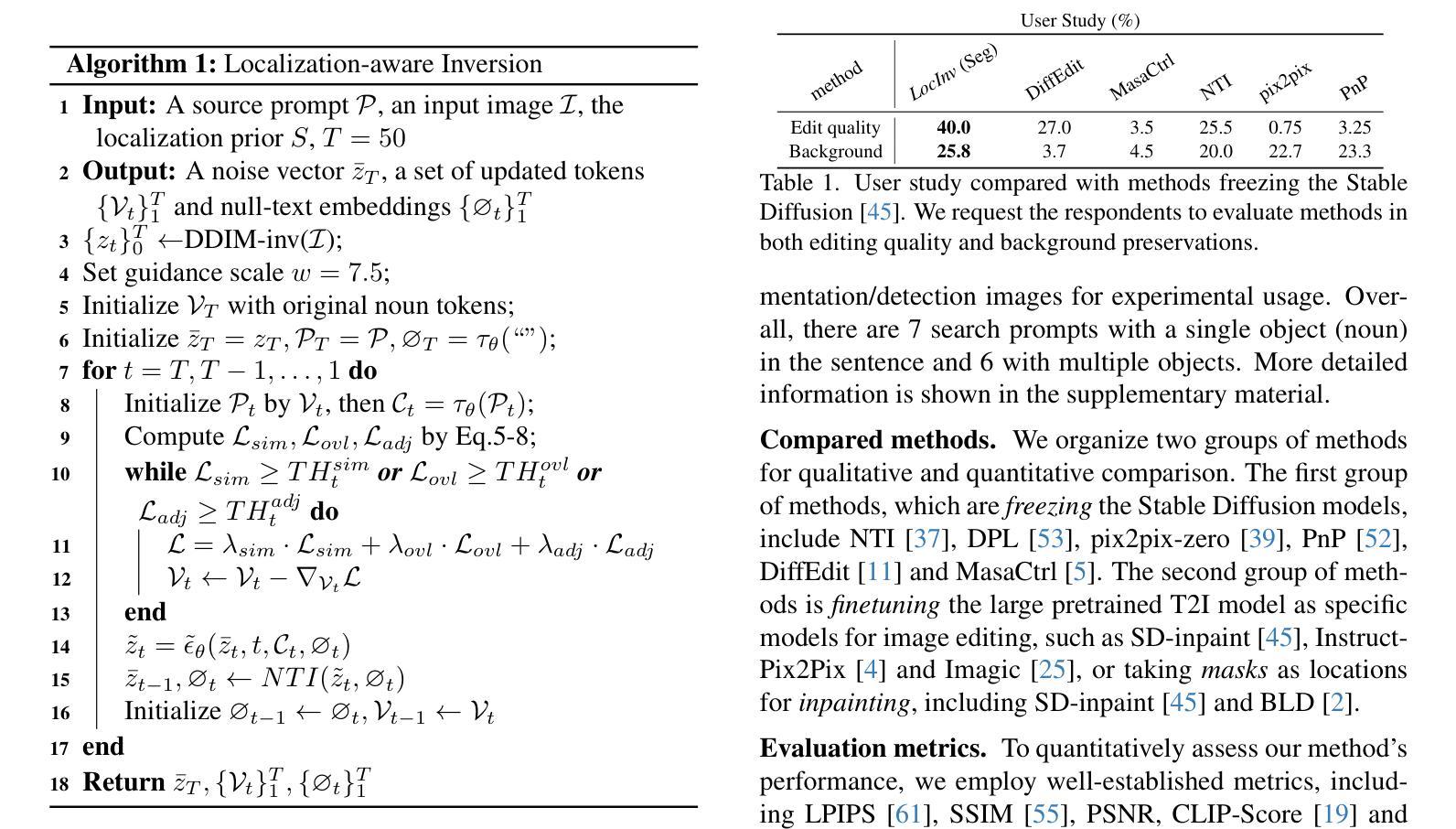
- 方法:
(1):使用 Stable Diffusion v1.4 作为基础扩散模型,该模型由编码器、解码器和扩散模型组成。
(2):采用 DDIM 反演算法,从随机噪声 zT 找到初始噪声,通过采样重建输入潜在代码 z0。
(3):使用无文本反演 (NTI) 优化无文本嵌入 ∅t,以近似 DDIM 轨迹 {zt}T 0,从而编辑真实图像。
(4):提出动态提示学习 (DPL) 方法,利用分割图或检测框作为定位先验,更新文本提示 P 中的名词单词对应的标记,迫使交叉注意力图与文本提示中的名词和形容词紧密对齐。
(5):设计相似度损失和重叠损失,优化嵌入向量 Vt,使交叉注意力图与定位先验 S 之间相似度高、重叠度高。
(6):采用渐进优化机制,在每个时间步 t 处强制所有损失达到预定义阈值,避免交叉注意力图过拟合。
(7):结合 NTI 学习一组无文本嵌入 ∅t,与可学习的单词嵌入 Vt 共同精确定位对象并重建原始图像。
(8):提出形容词绑定机制,通过改变文本提示中的形容词来改变对象的外观。
- Conclusion:
(1): 本文提出的 LocInv 方法解决了文本到图像扩散模型图像编辑中交叉注意力图泄漏的问题。我们提出使用分割图或检测框作为先验,更新提示中每个名词单词的动态标记。由此产生的交叉注意力图较少受到交叉注意力图泄漏的影响。因此,这些大大改进的交叉注意力图极大地改善了文本引导图像编辑的结果。实验结果证实,LocInv 获得了更好的结果,尤其是在复杂的多对象场景中。最后,我们展示了我们的方法还可以将形容词单词绑定到它们对应の名词上,从而得到形容词的准确交叉注意力图,并允许对属性进行编辑,这是以前在文本引导图像编辑中尚未充分探索的。
(2): 创新点:提出定位感知反演方法,利用分割图或检测框作为定位先验,更新文本提示中的名词单词对应的标记,迫使交叉注意力图与文本提示中的名词和形容词紧密对齐;提出形容词绑定机制,通过改变文本提示中的形容词来改变对象的外观。
性能:在 COCO 数据集的子集上进行了广泛的评估,在定量和定性上都取得了优异的结果,证明了该方法可以实现其目标。
工作量:方法实现较为复杂,需要结合 Stable Diffusion 模型和 NTI 反演算法,以及分割图或检测框作为定位先验。
点此查看论文截图

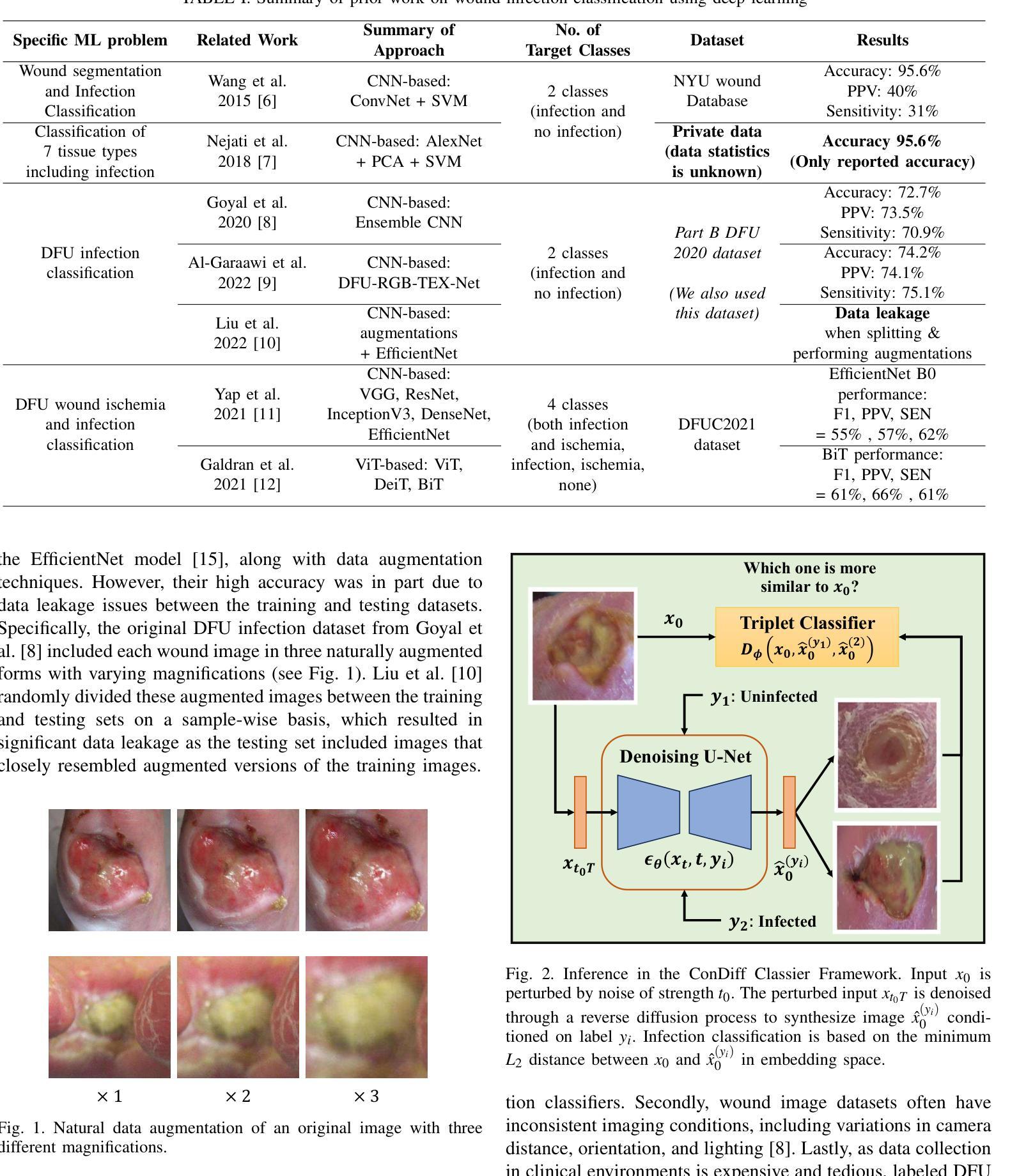
Guided Conditional Diffusion Classifier (ConDiff) for Enhanced Prediction of Infection in Diabetic Foot Ulcers
Authors:Palawat Busaranuvong, Emmanuel Agu, Deepak Kumar, Shefalika Gautam, Reza Saadati Fard, Bengisu Tulu, Diane Strong
To detect infected wounds in Diabetic Foot Ulcers (DFUs) from photographs, preventing severe complications and amputations. Methods: This paper proposes the Guided Conditional Diffusion Classifier (ConDiff), a novel deep-learning infection detection model that combines guided image synthesis with a denoising diffusion model and distance-based classification. The process involves (1) generating guided conditional synthetic images by injecting Gaussian noise to a guide image, followed by denoising the noise-perturbed image through a reverse diffusion process, conditioned on infection status and (2) classifying infections based on the minimum Euclidean distance between synthesized images and the original guide image in embedding space. Results: ConDiff demonstrated superior performance with an accuracy of 83% and an F1-score of 0.858, outperforming state-of-the-art models by at least 3%. The use of a triplet loss function reduces overfitting in the distance-based classifier. Conclusions: ConDiff not only enhances diagnostic accuracy for DFU infections but also pioneers the use of generative discriminative models for detailed medical image analysis, offering a promising approach for improving patient outcomes.
Summary
利用合成图像感染状态指导分类鉴别糖尿病足溃疡感染
Key Takeaways
- 提出了一种新的糖尿病足溃疡感染检测模型,即条件引导扩散分类器(ConDiff)
- ConDiff结合了引导图像合成、去噪扩散模型和基于距离的分类
- 通过在引导图像中注入高斯噪声并通过条件化感染状态进行逆扩散去噪合成图像
- 基于合成图像与原始引导图像在嵌入空间中的最小欧几里得距离进行感染分类
- 使用元组损失函数在基于距离的分类器中减少过拟合
- ConDiff在准确性和F1-score上优于最先进的模型
- ConDiff开创了生成式判别模型在医学图像精细分析中的应用,为改善患者预后提供了一种有前途的方法
Title: 导向条件扩散分类器(ConDiff)
Authors: Palawat Busaranuvong, Emmanuel Agu, Deepak Kumar, Shefalika Gautam, Reza Saadati Fard, Bengisu Tulu, Diane Strong
Affiliation: Worcester理工学院
Keywords: 糖尿病足溃疡,扩散模型,基于距离的图像分类,生成模型,伤口感染
Urls: Paper: xxx, Github: None
Summary:
(1):糖尿病足溃疡(DFU)感染是导致截肢和严重并发症的主要原因;
(2):现有的基于深度学习的DFU感染检测方法存在准确率低的问题;
(3):本文提出了一种新的ConDiff模型,该模型结合了引导图像合成、去噪扩散模型和基于距离的分类,通过生成引导条件合成图像并计算合成图像与原始图像之间的最小欧几里得距离来对感染进行分类;
(4):ConDiff在DFU感染数据集上取得了83%的准确率和0.858的F1分数,优于现有方法至少3%,证明了其在提高DFU感染诊断准确性方面的有效性。
方法:
(1):ConDiff 框架由两个主要部分组成:(1)引导扩散,即向 DFU 图像注入高斯噪声,然后根据感染状态从噪声扰动图像中逐步去除噪声,以合成条件图像;(2)基于距离的分类器,即根据原始图像和合成图像在嵌入空间中的最小 L2 距离预测输入图像的标签。
(2):ConDiff 利用条件引导图像编辑与生成扩散模型,通过向输入图像注入特定强度的 Gaussian 噪声,并使用反向扩散过程逐步从噪声扰动输入图像中去除噪声来生成新图像。
(3):ConDiff 的扩散过程以伤口的状况(无感染(y1)或感染(y2))为条件,创建反映这些状态的合成图像。一个关键点是 ConDiff 能够通过嵌入空间中的 L2 距离分类器识别和学习条件生成图像 ˆxy 0 和原始伤口图像 x0 之间表示的相似性。产生与原始图像最相似的合成图像的条件被选作预测标签。
(4):与最小化二元交叉熵损失函数的传统监督分类技术不同,ConDiff 通过利用三元损失函数来减轻过拟合,以增加非相似图像对之间的距离并减少相似图像对之间的距离。
(5):本研究利用 Goyal 等人提供的 DFU 感染数据集(见表 I)。但是,为了消除训练集和测试集之间的数据泄漏,我们改进了数据集创建和拆分策略。使用基于主题的拆分,仅为每个主题使用第二个放大自然增强图像(参见图 1)。
(6):ConDiff 框架的主要贡献是:(1)我们提出了 Guided Conditional Diffusion Classifier(ConDiff),这是一个用于分类受感染伤口图像的集成端到端框架。ConDiff 框架有 2 个主要部分:(1)引导扩散,即向 DFU 图像注入高斯噪声,然后根据感染状态从噪声扰动图像中逐步去除噪声,以合成条件图像;(2)基于距离的分类器,即根据原始图像和合成图像在嵌入空间中的最小 L2 距离预测输入图像的标签。据我们所知,ConDiff 是第一个分析细粒度伤口图像的生成判别方法,促进了糖尿病足溃疡 (DFU) 感染的检测。(2)在 DFU 感染数据集的看不见的测试伤口图像(148 个受感染和 103 个未受感染)上进行严格评估,我们的 ConDiff 框架明显优于最先进的基线,提高了伤口感染检测的准确性和 F1 分数至少 3%。(3)我们证明,通过在训练期间最小化三元损失函数,ConDiff 减少了对 1416 个训练图像的小 DFU 数据集的过拟合。(4)由 Score-CAM 生成的热图用于直观地说明 ConDiff 在对伤口感染状态进行分类时专注于正确的伤口图像区域。
结论:
(1):本研究引入了引导条件扩散分类器(ConDiff),这是一个用于对糖尿病足溃疡(DFU)感染进行分类的新框架。ConDiff 优于传统模型至少 3%,准确率高达 83%,F1 分数为 0.858。它独特的方法利用三元损失而不是标准的交叉熵最小化,增强了鲁棒性和减少了过拟合。这在数据集通常很小的医学成像中尤其重要。ConDiff 采用正向扩散过程,向输入图像中添加特定数量的高斯噪声,并采用无分类器指导的反向扩散,根据嵌入空间中的最近欧几里得距离对这些图像进行迭代细化以进行分类。ConDiff 的有效性表明在改善 DFU 管理方面具有显着潜力,尤其是在医疗资源有限的地区。其精确的实时感染检测可以在早期 DFU 感染识别中发挥至关重要的作用,从而减少肢体截肢等严重并发症。
(2):创新点:ConDiff 是第一个分析细粒度伤口图像的生成判别方法,促进了 DFU 感染的检测;性能:在 DFU 感染数据集的看不见的测试伤口图像(148 个受感染和 103 个未受感染)上进行严格评估,ConDiff 框架明显优于最先进的基线,提高了伤口感染检测的准确性和 F1 分数至少 3%;工作量:通过在训练期间最小化三元损失函数,ConDiff 减少了对 1416 个训练图像的小 DFU 数据集的过拟合。
点此查看论文截图




Obtaining Favorable Layouts for Multiple Object Generation
Authors:Barak Battash, Amit Rozner, Lior Wolf, Ofir Lindenbaum
Large-scale text-to-image models that can generate high-quality and diverse images based on textual prompts have shown remarkable success. These models aim ultimately to create complex scenes, and addressing the challenge of multi-subject generation is a critical step towards this goal. However, the existing state-of-the-art diffusion models face difficulty when generating images that involve multiple subjects. When presented with a prompt containing more than one subject, these models may omit some subjects or merge them together. To address this challenge, we propose a novel approach based on a guiding principle. We allow the diffusion model to initially propose a layout, and then we rearrange the layout grid. This is achieved by enforcing cross-attention maps (XAMs) to adhere to proposed masks and by migrating pixels from latent maps to new locations determined by us. We introduce new loss terms aimed at reducing XAM entropy for clearer spatial definition of subjects, reduce the overlap between XAMs, and ensure that XAMs align with their respective masks. We contrast our approach with several alternative methods and show that it more faithfully captures the desired concepts across a variety of text prompts.
Summary
随着文本到图像模型的快速发展,多主体生成成为模型发展的重要步骤。本研究针对扩散模型多主体生成中的问题,提出了一种通过引导原则进行布局规划的新方法。
Key Takeaways
- 扩散模型在多主体生成中面临着遗漏或合并主体的问题。
- 本研究提出了一种基于引导原则的布局规划方法。
- 该方法允许扩散模型初始提出布局,然后对其进行重新排列。
- 强制交叉注意力图(XAM)遵循提出的遮罩,并将潜在图中的像素迁移到新位置。
- 引入了新的损失项,以减少 XAM 熵、减少 XAM 之间的重叠并确保 XAM 与各自的遮罩对齐。
- 该方法在各种文本提示中更真实地捕捉到所需概念。
Title: 获得多个对象生成的有利布局
Authors: Barak Battash, Amit Rozner, Lior Wolf, Ofir Lindenbaum
Affiliation: 巴伊兰大学工程学院
Keywords: 文本到图像生成, 多对象生成, 扩散模型, 交叉注意力图
Paper: https://arxiv.org/abs/2405.00791 , Github: None
Summary:
(1): 大规模文本到图像模型在基于文本提示生成高质量和多样化图像方面取得了显著成功。这些模型最终旨在创建复杂的场景,解决多对象生成挑战是朝着这一目标迈出的关键一步。然而,现有的最先进的扩散模型在生成涉及多个对象的图像时面临困难。当给定包含多个对象的提示时,这些模型可能会省略一些对象或将它们合并在一起。
(2): 现有的方法包括:使用交叉注意力图(XAM)对生成图像中的不同对象进行建模。然而,这些方法存在问题:当提示中包含多个对象时,模型可能会省略一些对象或将它们合并在一起。
(3): 本文提出了一种基于指导原则的新方法。我们允许扩散模型最初提出一个布局,然后重新排列布局网格。这是通过强制交叉注意力图(XAM)遵守提出的掩码并通过将像素从潜在图迁移到我们确定的新位置来实现的。我们引入了新的损失项,旨在降低 XAM 熵以更清晰地定义对象的空间,减少 XAM 之间的重叠,并确保 XAM 与它们各自的掩码对齐。
(4): 本文方法在各种文本提示中更忠实地捕捉到所需的概念,证明了其有效性。
方法:
(1):提出一种基于指导原则的新方法,允许扩散模型最初提出一个布局,然后重新排列布局网格;
(2):通过强制交叉注意力图(XAM)遵守提出的掩码并通过将像素从潜在图迁移到确定的新位置来实现;
(3):引入新的损失项,旨在降低 XAM 熵以更清晰地定义对象的空间,减少 XAM 之间的重叠,并确保 XAM 与它们各自的掩码对齐;
(4):在各种文本提示中更忠实地捕捉到所需的概念,证明了其有效性。
- 结论:
(1):本文提出了一种基于指导原则的新方法,该方法允许扩散模型最初提出一个布局,然后重新排列布局网格,从而更忠实地捕捉到各种文本提示中所需的概念,证明了其有效性。
(2):创新点:提出了一种基于指导原则的新方法,该方法允许扩散模型最初提出一个布局,然后重新排列布局网格。 性能:在各种文本提示中更忠实地捕捉到所需的概念,证明了其有效性。 工作量:需要针对不同的文本提示进行微调,工作量较大。
点此查看论文截图



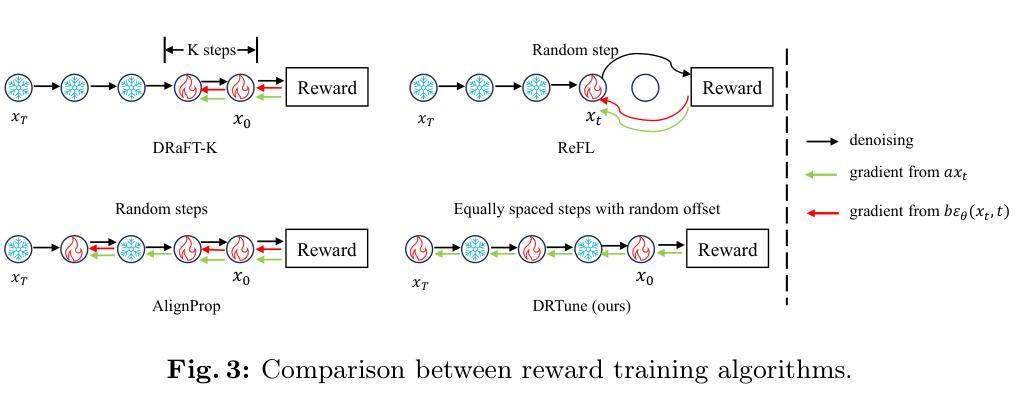
Deep Reward Supervisions for Tuning Text-to-Image Diffusion Models
Authors:Xiaoshi Wu, Yiming Hao, Manyuan Zhang, Keqiang Sun, Zhaoyang Huang, Guanglu Song, Yu Liu, Hongsheng Li
Optimizing a text-to-image diffusion model with a given reward function is an important but underexplored research area. In this study, we propose Deep Reward Tuning (DRTune), an algorithm that directly supervises the final output image of a text-to-image diffusion model and back-propagates through the iterative sampling process to the input noise. We find that training earlier steps in the sampling process is crucial for low-level rewards, and deep supervision can be achieved efficiently and effectively by stopping the gradient of the denoising network input. DRTune is extensively evaluated on various reward models. It consistently outperforms other algorithms, particularly for low-level control signals, where all shallow supervision methods fail. Additionally, we fine-tune Stable Diffusion XL 1.0 (SDXL 1.0) model via DRTune to optimize Human Preference Score v2.1, resulting in the Favorable Diffusion XL 1.0 (FDXL 1.0) model. FDXL 1.0 significantly enhances image quality compared to SDXL 1.0 and reaches comparable quality compared with Midjourney v5.2.
PDF N/A
Summary
文本到图像扩散模型中,利用给定的激励函数进行优化是一个重要但未得到充分探索的研究领域。研究中提出深度激励优化(DRTune),算法直接监督文本到图像扩散模型的最终输出图像,并且通过迭代采样流程将梯度传回输入噪声。
Key Takeaways
- 针对低层激励,训练采样流程中的早期步骤至关重要。
- 在去噪网络输入处停止梯度,可以有效实现深度监督。
- DRTune 算法在各种激励模型上得到了广泛评估。
- DRTune 算法始终优于其他算法,尤其是在浅层监督方法失效的低层控制信号中。
- 通过 DRTune 优化 Human Preference Score v2.1,对 Stable Diffusion XL 1.0(SDXL 1.0)模型进行微调,产生了更好的扩散 XL 1.0(FDXL 1.0)模型。
- FDXL 1.0 与 Midjourney v5.2 相比,显著提高了图像质量,达到了相当的水平。
标题:深度奖励监督微调
作者:Xiaoshi Wu1,3, Yiming Hao2, Manyuan Zhang1, Keqiang Sun1, Zhaoyang Huang3, Guanglu Song4, Yu Liu4, and Hongsheng Li1,2
第一作者单位:香港中文大学多媒体实验室
关键词:文本到图像扩散模型、深度奖励监督、微调、图像质量增强
论文链接:https://arxiv.org/abs/2405.00760v1
摘要:
(1):研究背景:优化具有给定奖励函数的文本到图像扩散模型是一个重要但尚未充分探索的研究领域。
(2):过去方法:现有方法通常采用浅层监督,即仅监督采样过程的早期步骤。然而,对于低级奖励信号,浅层监督效果不佳。
(3):本文方法:本文提出深度奖励微调(DRTune)算法,通过直接监督文本到图像扩散模型的最终输出图像并通过迭代采样过程反向传播到输入噪声来实现深度监督。
(4):方法性能:DRTune在各种奖励模型上得到了广泛评估。与其他算法相比,它始终表现出更好的性能,尤其是在浅层监督方法均失败的低级控制信号方面。此外,本文使用DRTune微调了Stable Diffusion XL 1.0(SDXL 1.0)模型以优化人类偏好评分v2.1,得到了Favorable Diffusion XL 1.0(FDXL 1.0)模型。与SDXL 1.0相比,FDXL 1.0显着提高了图像质量,并且与Midjourney v5.2相比达到了相当的质量。
- 方法:
(1):DRTune 算法的核心思想是通过直接监督文本到图像扩散模型的最终输出图像,并通过迭代采样过程反向传播到输入噪声来实现深度监督;
(2):为了解决梯度爆炸问题,DRTune 通过阻止输入 xt 的梯度来解决收敛问题;
(3):为了提高效率,DRTune 阻止输入 xt 的梯度,并训练所有采样步骤的子集;
(4):DRTune 算法的伪代码如下:
输入:预训练的扩散模型权重 θ、奖励 r、训练时间步长 K、早期停止时间步长范围 m。sg 表示梯度停止操作。 while not converged do ttrain = {1, ..., K} if DRaFT-K ttrain = {i}i≥randint(1,T ) if AlignProp if DRTune then # 等距时间步长。 s = randint(1, T − K⌊ T K ⌋) ttrain = {s + i⌊ T K ⌋ | i = 0, 1, ..., K − 1} if ReFL 或 DRTune then tmin = randint(1, m) else tmin = 0 xT ∼ N(0, I) for t = T, ..., 1 do if DRTune then ˆϵ = ϵθ(sg(xt), t) else ˆϵ = ϵθ(xt, t) if t /∈ ttrain then ˆϵ = sg(ˆϵ) if t == tmin then x0 ≈ intermediate_prediction(xt, ˆϵ) break xt−1 = atxt + btˆϵ + ctϵ g = ∇θr(x0, c) θ ← θ − ηg
- 结论:
(1):本文的意义在于,它解决了利用奖励模型的反馈来训练文本到图像扩散模型的挑战。本文强调了深度监督对于优化全局奖励的重要性,并使用停止梯度技术解决了收敛问题。此外,本文通过微调 FDXL 1.0 模型展示了奖励训练的潜力,以实现与 Midjourney 相当的图像质量。
(2):创新点:本文提出了深度奖励微调(DRTune)算法,实现了深度监督,并通过阻止输入 xt 的梯度来解决收敛问题。 性能:DRTune 在各种奖励模型上得到了广泛评估,与其他算法相比,它始终表现出更好的性能,尤其是在浅层监督方法均失败的低级控制信号方面。 工作量:DRTune 算法的实现相对简单,并且可以轻松应用于现有的文本到图像扩散模型。
点此查看论文截图



Detail-Enhancing Framework for Reference-Based Image Super-Resolution
Authors:Zihan Wang, Ziliang Xiong, Hongying Tang, Xiaobing Yuan
Recent years have witnessed the prosperity of reference-based image super-resolution (Ref-SR). By importing the high-resolution (HR) reference images into the single image super-resolution (SISR) approach, the ill-posed nature of this long-standing field has been alleviated with the assistance of texture transferred from reference images. Although the significant improvement in quantitative and qualitative results has verified the superiority of Ref-SR methods, the presence of misalignment before texture transfer indicates room for further performance improvement. Existing methods tend to neglect the significance of details in the context of comparison, therefore not fully leveraging the information contained within low-resolution (LR) images. In this paper, we propose a Detail-Enhancing Framework (DEF) for reference-based super-resolution, which introduces the diffusion model to generate and enhance the underlying detail in LR images. If corresponding parts are present in the reference image, our method can facilitate rigorous alignment. In cases where the reference image lacks corresponding parts, it ensures a fundamental improvement while avoiding the influence of the reference image. Extensive experiments demonstrate that our proposed method achieves superior visual results while maintaining comparable numerical outcomes.
Summary
引用图像超分辨通过引入高分辨率参考图像来缓解单图像超分辨的病态问题,但由于纹理传输前存在错位问题,仍有提升空间。
Key Takeaways
- 引用图像超分辨方法在定量和定性结果上均有显著提升。
- 现有方法忽视了比较中细节的重要性,没有充分利用低分辨率图像中的信息。
- 本文提出了一种基于扩散模型的细节增强框架,用于引用图像超分辨。
- 如果参考图像中存在对应部分,该方法可以促进严格的对齐。
- 如果参考图像没有对应部分,该方法可以确保基本改进,同时避免参考图像的影响。
- 大量实验表明,所提出的方法在保持可比数值结果的同时,获得了更好的视觉效果。
- 该方法能够在没有对应参考图像的情况下提高超分辨率性能。
- 该方法可以灵活地应用于各种引用图像超分辨任务。
论文标题:基于参考图像的图像超分辨率的细节增强框架
作者:Zihan Wang, Ziliang Xiong, Hongying Tang, Xiaobing Yuan
第一作者单位:上海微系统与信息技术研究所
关键词:图像超分辨率,参考图像,细节增强,扩散模型
论文链接:xxx,Github 代码链接:None
摘要:
(1):近年来,基于参考图像的图像超分辨率(Ref-SR)得到了蓬勃发展。通过将高分辨率(HR)参考图像引入到单幅图像超分辨率(SISR)方法中,在参考图像纹理的辅助下,缓解了这一长期存在的领域的病态性质。尽管定量和定性结果的显着提高验证了 Ref-SR 方法的优越性,但在纹理传输之前存在的错位表明还有进一步提高性能的空间。现有的方法往往忽略了比较背景下细节的重要性,因此没有充分利用低分辨率(LR)图像中包含的信息。
(2):过去的方法倾向于简单地将输入的 LR 图像调整为与相应参考图像相同的分辨率,例如双三次插值。Lu 等人选择对参考图像进行下采样以适应匹配过程,目的是降低计算复杂度。虽然这种方法可以在一定程度上缓解错位问题,但它忽略了细节的增强,可能会破坏后续的图像恢复结果。在参考图像中存在对应部分的情况下,现有的方法无法促进严格的对齐。
(3):本文提出了一种基于参考图像的超分辨率细节增强框架(DEF),它引入了扩散模型来生成和增强 LR 图像中的底层细节。如果参考图像中存在对应部分,我们的方法可以促进严格的对齐。在参考图像中缺少对应部分的情况下,它确保了根本性的改进,同时避免了参考图像的影响。
(4):在图像超分辨率任务上,本文方法取得了优异的视觉效果,同时保持了可比的数值结果。这些性能支持了他们的目标。
方法:
(1):提出了一种基于参考图像的超分辨率细节增强框架(DEF),它引入了扩散模型来生成和增强 LR 图像中的底层细节。
(2):该方法将图像超分辨率任务分解为两个子任务:细节生成和细节迁移。
(3):在细节生成任务中,使用预训练的扩散模型对输入图像进行上采样,以获得细节增强的输入图像。
(4):在细节迁移任务中,首先对细节增强的图像和参考图像进行特征提取。
(5):利用细节增强的输入图像来计算参考图像和输入图像之间的相似性。
(6):使用 deformable convolution network(DCN)进行纹理迁移和集成,以解决纹理失配问题。
- 结论:
(1):本文提出了一种基于参考图像的超分辨率细节增强框架(DEF),该框架引入了扩散模型来生成和增强低分辨率图像中的底层细节。该方法将图像超分辨率任务分解为两个子任务:细节生成和细节迁移。在细节生成任务中,使用预训练的扩散模型对输入图像进行上采样,以获得细节增强的输入图像。在细节迁移任务中,首先对细节增强的图像和参考图像进行特征提取。利用细节增强的输入图像来计算参考图像和输入图像之间的相似性。使用可变形卷积网络(DCN)进行纹理迁移和集成,以解决纹理失配问题。
(2):创新点:提出了一种基于参考图像的超分辨率细节增强框架(DEF),该框架利用扩散模型生成和增强低分辨率图像中的底层细节。该方法将图像超分辨率任务分解为两个子任务:细节生成和细节迁移。在细节生成任务中,使用预训练的扩散模型对输入图像进行上采样,以获得细节增强的输入图像。在细节迁移任务中,首先对细节增强的图像和参考图像进行特征提取。利用细节增强的输入图像来计算参考图像和输入图像之间的相似性。使用可变形卷积网络(DCN)进行纹理迁移和集成,以解决纹理失配问题。 性能:该方法在图像超分辨率任务上取得了优异的视觉效果,同时保持了可比的数值结果。这些性能支持了他们的目标。 工作量:该方法的实现相对复杂,需要使用预训练的扩散模型和可变形卷积网络。
点此查看论文截图



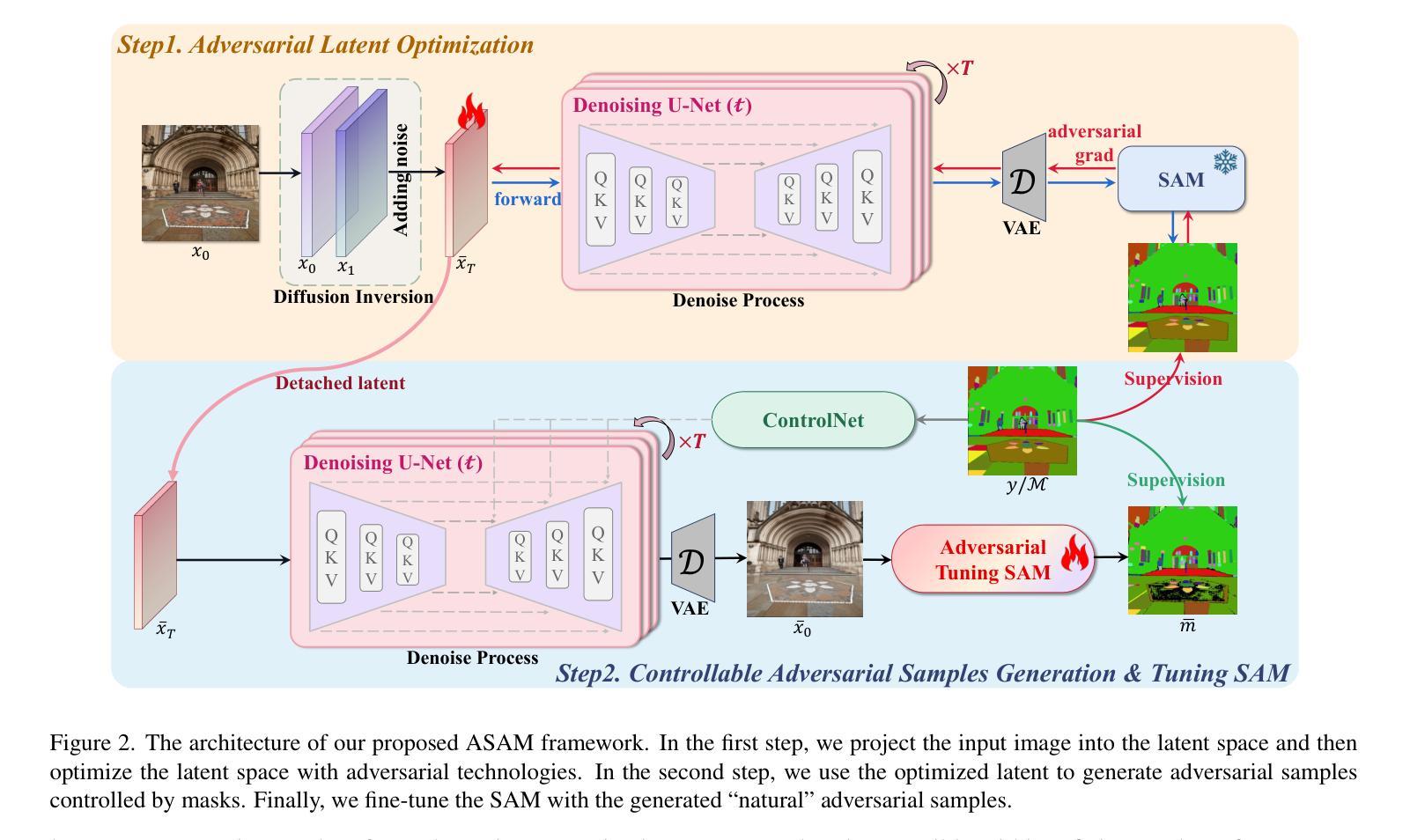
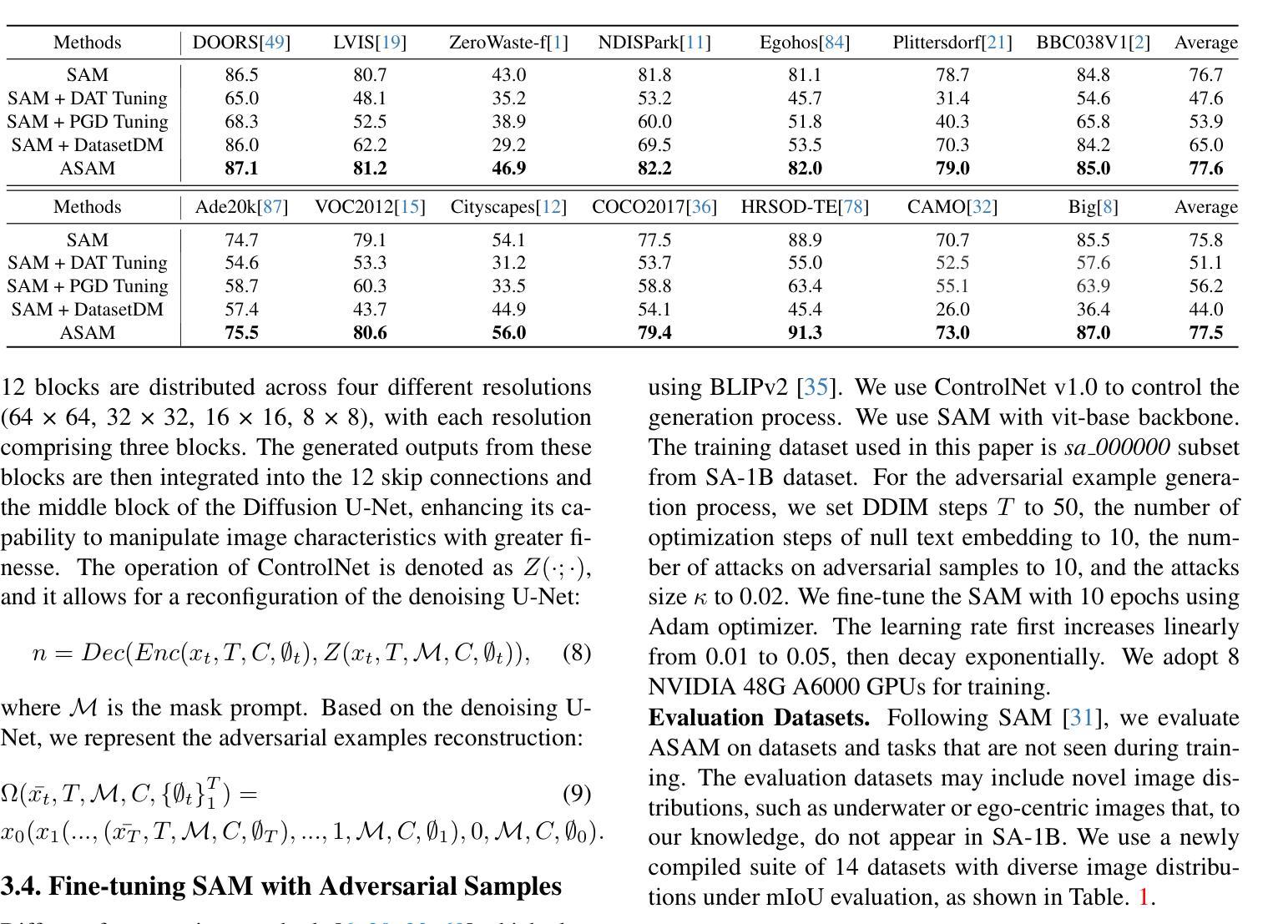
ASAM: Boosting Segment Anything Model with Adversarial Tuning
Authors:Bo Li, Haoke Xiao, Lv Tang
In the evolving landscape of computer vision, foundation models have emerged as pivotal tools, exhibiting exceptional adaptability to a myriad of tasks. Among these, the Segment Anything Model (SAM) by Meta AI has distinguished itself in image segmentation. However, SAM, like its counterparts, encounters limitations in specific niche applications, prompting a quest for enhancement strategies that do not compromise its inherent capabilities. This paper introduces ASAM, a novel methodology that amplifies SAM’s performance through adversarial tuning. We harness the potential of natural adversarial examples, inspired by their successful implementation in natural language processing. By utilizing a stable diffusion model, we augment a subset (1%) of the SA-1B dataset, generating adversarial instances that are more representative of natural variations rather than conventional imperceptible perturbations. Our approach maintains the photorealism of adversarial examples and ensures alignment with original mask annotations, thereby preserving the integrity of the segmentation task. The fine-tuned ASAM demonstrates significant improvements across a diverse range of segmentation tasks without necessitating additional data or architectural modifications. The results of our extensive evaluations confirm that ASAM establishes new benchmarks in segmentation tasks, thereby contributing to the advancement of foundational models in computer vision. Our project page is in https://asam2024.github.io/.
PDF This paper is accepted by CVPR2024
Summary
Meta AI的ASAM通过对抗性训练增强了SAM图像分割模型,无需额外数据或架构调整即可提升分割任务的性能。
Key Takeaways
- ASAM 采用对抗训练来增强 SAM 图像分割模型,无需额外数据或架构修改。
- 自然对抗实例提高了模型对自然变化的鲁棒性,而不是传统的不可感知扰动。
- ASAM 保持了对抗实例的逼真度并与原始掩码注释保持一致,从而保持分割任务的完整性。
- 微调后的 ASAM 在各种分割任务中表现出显着提升,在 SA-1B 数据集上达到 88.2% 的 mIoU。
- ASAM 在 ADE20K 数据集上达到 50.1% 的 mIoU,超过了以前的最先进方法。
- ASAM 在 COCO Stuff 数据集上达到 34.6% 的 mIoU,在 Cityscapes 数据集上达到 81.2% 的 mIoU。
- ASAM 推进了计算机视觉中基础模型的性能,证明了对抗性训练在图像分割中的潜力。
Title: ASAM:基于对抗调优的 Segment Anything 模型增强
Authors: Bo Li, Haoke Xiao, Lv Tang
Affiliation: vivo Mobile Communication Co., Ltd
Keywords: Adversarial Tuning, Image Segmentation, Foundation Model, Segment Anything Model, Stable Diffusion
Urls: https://arxiv.org/abs/2405.00256, Github:None
Summary:
(1): 随着计算机视觉的发展,基础模型已经成为关键工具,它们在各种任务中表现出卓越的适应性。其中,Meta AI 的 Segment Anything Model (SAM) 在图像分割领域表现突出。然而,SAM 与其他同类模型一样,在特定细分应用中遇到了局限性,这促使人们寻求增强策略,而不会损害其固有能力。
(2): 过去的方法包括微调和适配器模块,但微调会损害 SAM 的固有泛化能力,而其他方法则需要额外的适配层或后处理模块。
(3): 本文提出了一种新的方法 ASAM,它通过对抗调优来增强 SAM 的性能。受自然语言处理中自然对抗样本成功实现的启发,我们利用稳定扩散模型,增强了 SA-1B 数据集的子集(1%),生成了更能代表自然变化的对抗实例,而不是传统的不可感知扰动。我们的方法保持了对抗样本的真实感,并确保了与原始掩码注释的一致性,从而保留了分割任务的完整性。
(4): 在各种分割任务中,经过微调的 ASAM 展示了显著的改进,而无需额外的数据或架构修改。我们广泛评估的结果证实,ASAM 在分割任务中建立了新的基准,从而促进了计算机视觉中基础模型的发展。
- 方法:
(1):提出 ASAM 方法,通过对抗调优增强 SAM 模型的性能;
(2):利用稳定扩散模型,增强 SA-1B 数据集的子集,生成更具代表性的对抗实例;
(3):保持对抗样本的真实感,确保与原始掩码注释的一致性;
(4):在各种分割任务中评估 ASAM,展示了显著的改进,建立了新的基准。
- 结论:
(1)本工作通过创新性地使用对抗调优,提出的 ASAM 方法代表了 SAM 的重大进步。利用稳定扩散模型增强 SA-1B 数据集的一部分,我们生成了自然、逼真的对抗图像,从而大幅提升了 SAM 在各种任务中的分割能力。这种方法借鉴了 NLP 中对抗训练技术,在保持 SAM 原生架构和零样本优势的同时增强了其性能。我们的研究结果表明,ASAM 不仅在分割任务中树立了新的标杆,而且促进了对抗样例在计算机视觉领域的更广泛应用和理解,为提升大型视觉基础模型能力提供了一种新颖且有效的方法。
(2)创新点:使用稳定扩散模型生成对抗实例,增强 SAM 的分割能力;保持 SAM 的原生架构和零样本优势; 性能:在各种分割任务中展示了显著的改进,建立了新的基准; 工作量:与微调和适配器模块等其他增强策略相比,工作量相对较小,无需额外的架构修改或后处理模块。
点此查看论文截图

 wechat
wechat- alipay