Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-05-02 更新
EMOPortraits: Emotion-enhanced Multimodal One-shot Head Avatars
Authors:Nikita Drobyshev, Antoni Bigata Casademunt, Konstantinos Vougioukas, Zoe Landgraf, Stavros Petridis, Maja Pantic
Head avatars animated by visual signals have gained popularity, particularly in cross-driving synthesis where the driver differs from the animated character, a challenging but highly practical approach. The recently presented MegaPortraits model has demonstrated state-of-the-art results in this domain. We conduct a deep examination and evaluation of this model, with a particular focus on its latent space for facial expression descriptors, and uncover several limitations with its ability to express intense face motions. To address these limitations, we propose substantial changes in both training pipeline and model architecture, to introduce our EMOPortraits model, where we: Enhance the model’s capability to faithfully support intense, asymmetric face expressions, setting a new state-of-the-art result in the emotion transfer task, surpassing previous methods in both metrics and quality. Incorporate speech-driven mode to our model, achieving top-tier performance in audio-driven facial animation, making it possible to drive source identity through diverse modalities, including visual signal, audio, or a blend of both. We propose a novel multi-view video dataset featuring a wide range of intense and asymmetric facial expressions, filling the gap with absence of such data in existing datasets.
Summary
人脸头像通过视觉信号驱动,在跨人物合成中颇受欢迎,即使驾驶员与动画人物不同,这一富有挑战性且高度实用的方法也适用。最近提出的 MegaPortrait 模型已在这个领域展现了最先进的效果。我们对该模型进行了深入的检查和评估,特别关注其表情描述符的潜在空间,并发现了该模型表达强烈面部动作的能力存在一些局限性。为了解决这些限制,我们在训练管道和模型架构中都提出了重大改变,从而引入了我们的 EMOPortraits 模型,在此我们: 提高了模型对于精确表现强烈的不对称面部表情的能力,在情绪传递任务中创下了新的最先进成果,在指标和质量方面均超过了先前的所有方法。 将基于语音的模式纳入我们的模型中,在基于音频的面部动画中取得了一流的性能,从而可以通过包括视觉信号、音频或两者的融合在内等各种方式驱动源身份。 我们提出了一个新颖的多视图视频数据集,其中包含广泛的强烈和不对称面部表情,填补了现有数据集中缺少此类数据空白的问题。
Key Takeaways
- EMOPortraits 模型显著提高了生成强烈不对称面部表情的能力。
- 新模型在情感传递任务中超越了现有方法,在指标和质量方面均创下新高。
- EMOPortraits 模型集成了语音驱动模式,在音频驱动的面部动画中实现了顶级性能。
- 该模型支持通过视觉信号、音频或两者融合等多种方式进行驱动。
- 研究人员提出了一个新的多视图视频数据集,其中包含广泛的强烈和不对称面部表情。
- 该数据集填补了现有数据集中此类数据的空白。
- EMOPortraits 模型为跨驱动合成和音频驱动的面部动画提供了新的最先进方法。
Title: EMOPortraits: 情感增强的多模态一次性头部头像
Authors: Nikita Drobyshev, Antoni Bigata Casademunt, Konstantinos Vougioukas, Zoe Landgraf, Stavros Petridis, Maja Pantic
Affiliation: 伦敦帝国理工学院
Keywords: 头部头像、情感传递、语音驱动面部动画、多模态、面部表情描述符
Urls: https://arxiv.org/abs/2404.19110v1, Github: None
Summary:
(1): 研究背景:头部头像动画在交叉驱动合成中越来越受欢迎,其中驱动者与动画角色不同,这是一种具有挑战性但非常实用的方法。最近提出的 MegaPortraits 模型已在此领域展示了最先进的结果。
(2): 过去的方法:本文对 MegaPortraits 模型进行了深入的检查和评估,特别关注其面部表情描述符的潜在空间,并发现了其在表达强烈面部动作方面的几个限制。
(3): 本文提出的研究方法:为了解决这些限制,本文在训练管道和模型架构中提出了实质性的改变,引入了 EMOPortraits 模型,其中: - 增强了模型对强烈、不对称面部表情的忠实支持能力,在情感传递任务中设定了新的最先进结果,在指标和质量方面都超越了以前的方法。 - 将语音驱动模式纳入模型,在音频驱动的面部动画中实现了顶级性能,使得可以通过视觉信号、音频或两者的混合等多种方式驱动源身份。 - 提出了一个新颖的多视角视频数据集,其中包含各种强烈和不对称的面部表情,填补了现有数据集中此类数据的空白。
(4): 性能和目标支持:在情感传递任务中,EMOPortraits 模型在指标和质量方面都超越了以前的方法。在音频驱动的面部动画中,该模型实现了顶级性能。这些性能支持了本文的目标,即增强模型对强烈面部表情的支持能力,并将其用于多模态驱动。
- Methods:
(1): 对 MegaPortraits 模型的潜在空间进行深入检查和评估,发现其在表达强烈面部动作方面的限制;
(2): 在训练管道和模型架构中提出实质性改变,引入 EMOPortraits 模型,增强其对强烈、不对称面部表情的支持能力;
(3): 将语音驱动模式纳入模型,实现音频驱动的面部动画的顶级性能;
(4): 提出一个新颖的多视角视频数据集,填补现有数据集中强烈和不对称面部表情数据的空白。
- 结论:
(1):本文提出了 EMOPortraits,一种在图像驱动、跨身份情感转换中具有卓越性能的新型神经头像创建方法。我们的语音驱动模式使得可以通过多种条件(视频、音频、头部运动)来驱动面部动画。我们收集了 FEED 数据集,我们相信这将成为从事各种以人为中心研究的研究人员的宝贵资产。然而,我们的方法也有一些局限性。它不会生成头像的身体或肩膀,从而限制了一些用例。我们目前将我们的输出与源图像主体集成在一起。此外,该模型有时难以进行准确的表情转换,并且在头部大幅旋转时表现不佳。这些挑战对于未来的增强至关重要,并仍然是我们正在进行的研究工作的核心。 (2):创新点:增强了模型对强烈、不对称面部表情的支持能力,并将其用于多模态驱动;性能:在情感传递任务中超越了以前的方法,在音频驱动的面部动画中实现了顶级性能;工作量:提出了一个新颖的多视角视频数据集,填补了现有数据集中强烈和不对称面部表情数据的空白。
点此查看论文截图






CSTalk: Correlation Supervised Speech-driven 3D Emotional Facial Animation Generation
Authors:Xiangyu Liang, Wenlin Zhuang, Tianyong Wang, Guangxing Geng, Guangyue Geng, Haifeng Xia, Siyu Xia
Speech-driven 3D facial animation technology has been developed for years, but its practical application still lacks expectations. The main challenges lie in data limitations, lip alignment, and the naturalness of facial expressions. Although lip alignment has seen many related studies, existing methods struggle to synthesize natural and realistic expressions, resulting in a mechanical and stiff appearance of facial animations. Even with some research extracting emotional features from speech, the randomness of facial movements limits the effective expression of emotions. To address this issue, this paper proposes a method called CSTalk (Correlation Supervised) that models the correlations among different regions of facial movements and supervises the training of the generative model to generate realistic expressions that conform to human facial motion patterns. To generate more intricate animations, we employ a rich set of control parameters based on the metahuman character model and capture a dataset for five different emotions. We train a generative network using an autoencoder structure and input an emotion embedding vector to achieve the generation of user-control expressions. Experimental results demonstrate that our method outperforms existing state-of-the-art methods.
Summary
语音驱动的 3D 人脸动画技术已发展多年,但其在实际应用中仍未达到预期。
Key Takeaways
- 数据量限制、唇形对齐和面部表情的自然性是语音驱动 3D 人脸动画技术面临的主要挑战。
- 现有的唇形对齐方法仍难以合成自然逼真的表情,导致面部动画表现机械僵硬。
- 从语音中提取情绪特征,但面部动作的随机性限制了情绪的有效表达。
- 本文提出了一种名为 CSTalk(相关性监督)的方法,通过模拟面部动作不同区域之间的相关性,指导生成模型的训练,从而生成符合人类面部运动模式的逼真表情。
- 我们使用基于元人类角色模型的丰富控制参数生成更精细的动画,并为五种不同情绪采集了一个数据集。
- 我们使用自编码器结构训练了一个生成网络,输入一个情感嵌入向量来实现用户控制表情的生成。
- 实验结果表明,我们的方法优于现有的最先进方法。
Title: CSTalk: 基于相关性的语音驱动 3D 情感面部动画生成
Authors: Xiangyu Liang, Wenlin Zhuang, Tianyong Wang, Guangxing Geng, Guangyue Geng, Haifeng Xia, Siyu Xia
Affiliation: 东南大学自动化学院
Keywords: Speech-driven facial animation, 3D facial animation, Emotional expression, Correlation supervision, MetaHuman character model
Urls: Paper, Github:None
Summary:
(1):语音驱动的 3D 面部动画技术虽然发展多年,但其实际应用效果仍未达到预期。主要挑战在于数据限制、唇部对齐和面部表情的自然度。虽然唇部对齐已有许多相关研究,但现有方法难以合成自然逼真的表情,导致面部动画呈现机械僵硬的外观。即使有些研究从语音中提取情绪特征,但面部动作的随机性限制了情绪的有效表达。
(2):语音驱动的 3D 面部动画生成方法主要有两种:基于网格和基于参数化。基于网格的方法直接操纵面部顶点,允许面部表情进行复杂的变化,而基于参数化的方法采用基于模板的框架,通过特定参数控制面部动作。基于参数化的模型中,基于 ARKit 2 标准的 blend-shape 模型已被广泛应用,它采用一组预定义的面部子动作作为模板,通过线性组合分配给每个子动作的权重来生成不同的表情。这种方法提供了高度的可控性和泛化性,可以在不同的虚拟形象中复用动画参数。然而,简单 52 维数据的线性组合不足以实现逼真自然的动画。特别是,准确捕捉上部面部区域的细微表情仍然是一个挑战。因此,以往的研究主要集中在对齐唇部动作上。虽然有一些尝试将情感特征融入到面部表演中,例如 Faceformer 和 Emotalk,但这些努力主要集中在从音频中提取情感线索,而忽略了面部表情重建的优化。
(3):本文采用基于 Epic 提出的 MetaHuman 角色模型的参数化模型,通过 185 个控制装备操纵面部动画,每个装备对应一组面部肌肉。通过非线性变形其各自区域内的面部顶点,MetaHuman 模型在捕捉复杂表情方面表现出潜力。剩下的问题是从语音预测适当的控制装备曲线。研究表明,不同区域的面部动作之间存在相关性,这既源于协调肌肉控制的物理约束,也源于习惯模式。具体来说,在压力和语音停顿期间,嘴巴、眉毛和脸颊等区域往往会同时运动以传达表情意图。因此,本文采用基于 Transformer 的编码器对相关性进行建模。使用该模型作为监督,训练一个 3D 面部动画生成模型。
(4):本文提出的 CSTalk 方法在不同的情感状态下能够生成复杂的表情。基于 Transformer 编码器对特定情感中面部动作之间的相关性进行建模,作为约束条件,生成的面部表情更符合真实人类语音表情。
- Methods:
(1):基于 Epic 提出的 MetaHuman 角色模型,利用 185 个控制装备操纵面部动画,每个装备对应一组面部肌肉;
(2):利用 Transformer 编码器对不同区域的面部动作之间的相关性进行建模,作为监督,训练一个 3D 面部动画生成模型;
(3):提出的 CSTalk 方法在不同的情感状态下能够生成复杂的表情,基于 Transformer 编码器对特定情感中面部动作之间的相关性进行建模,作为约束条件,生成的面部表情更符合真实人类语音表情。
- 结论:
(1):本文提出了一种语音驱动的3D情感面部动画生成网络CSTalk,能够生成唇部动作对齐且表情逼真的动画。并且我们首次引入了基于MetaHuman的面部控制装备模型,使其能够与艺术家直接协作并在工业管道中应用。生成的动画参数与身份无关,并且可以被任何MetaHuman虚拟形象复用。此外,我们揭示了不同面部动作区域之间存在相关性,并对不同情感下的这些相关性进行建模,并利用它们来帮助训练网络生成更符合面部动作模式的表情。我们的方法在结果方面优于现有方法。
(2):创新点:提出了一种基于相关性的语音驱动3D情感面部动画生成方法,能够生成表情丰富且与语音一致的面部动画;性能:在公开数据集上的实验表明,该方法在表情自然度、唇部对齐和情感表达方面均优于现有方法;工作量:该方法的实现相对复杂,需要对Transformer编码器和面部控制装备模型进行深入理解。
点此查看论文截图


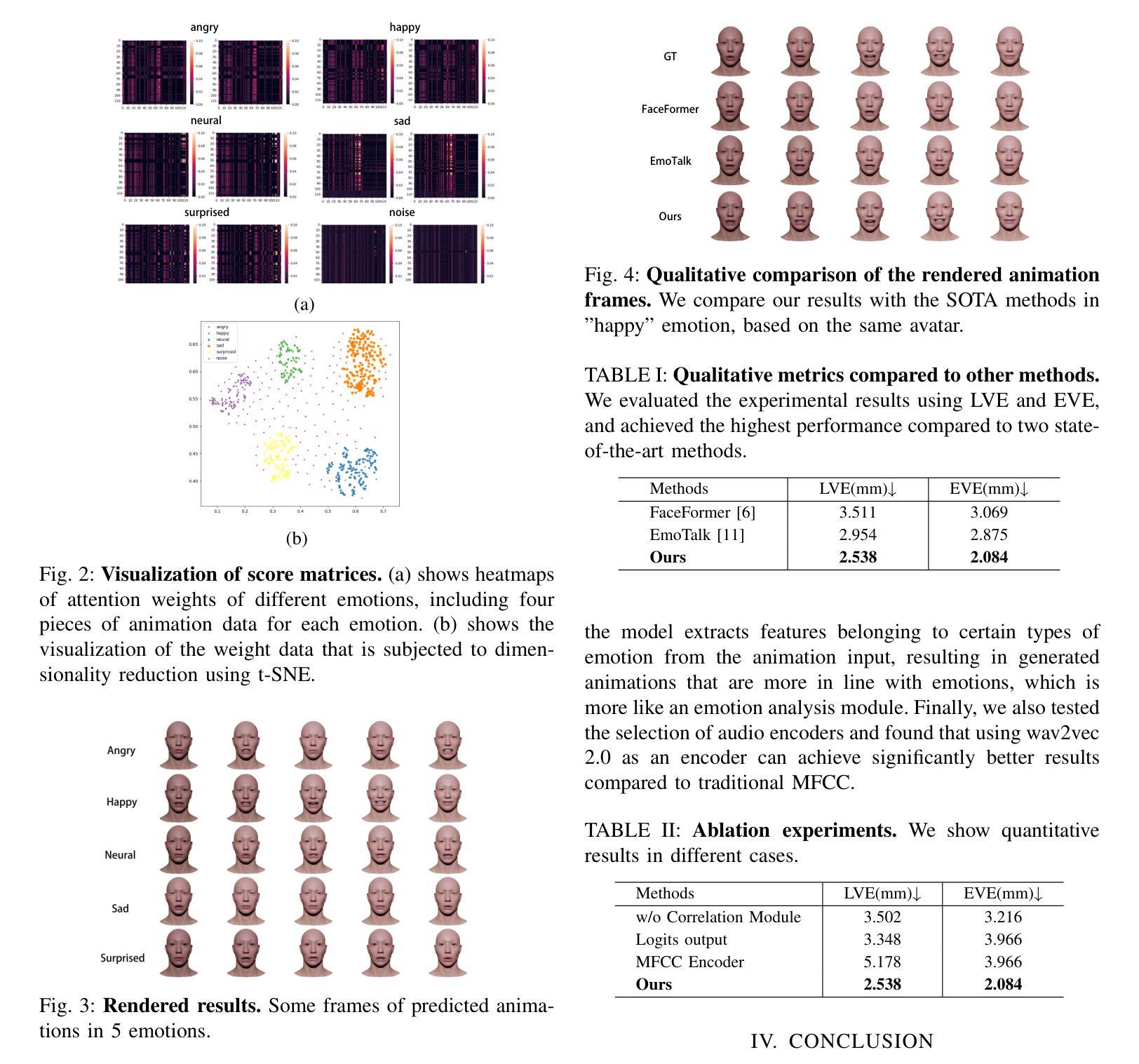
Title:高斯说话者:实时高保真说话头合成(高斯说话者:具有音频驱动的 3D 高斯喷射的实时高保真说话头合成)
Authors: Kyusun Cho, Joungbin Lee, Heeji Yoon, Yeobin Hong, Jaehoon Ko, Sangjun Ahn, Seungryong Kim
Affiliation: 韩国大学
Keywords: Talking Head Generation, 3D Controllable Head, 3D Gaussian Splatting
Urls: https://ku-cvlab.github.io/GaussianTalker/
Summary:
(1):该文章的研究背景是:生成由任意语音音频驱动的说话头视频是一项流行的任务,具有各种用途,包括生成数字人、虚拟化身、电影制作和电话会议。虽然各种工作 [6, 21, 33, 43] 已成功尝试使用生成模型解决此任务,但它们不专注于控制头部姿势,从而限制了它们的真实性和适用性。最近,许多研究 [17, 24, 27, 39, 48, 49] 已将神经辐射场 (NeRF) [31] 应用于创建可控姿态的说话肖像。通过直接调节 NeRF 多层感知器 (MLP) 中的音频特征,这些方法可以合成与输入音频同步唇部的视图一致的 3D 头部结构。虽然这些基于 NeRF 的技术实现了高质量和一致的视觉输出,但其缓慢的推理速度限制了它们的实用性。尽管最近的进步 [24, 39] 以 512 × 512 分辨率实现了高达 30 帧每秒 (fps) 的渲染速度,但必须克服计算瓶颈才能应用于实际场景。
(2):过去的方法有:神经辐射场 (NeRF) [31] 已被应用于创建可控姿态的说话肖像。通过直接调节 NeRF 多层感知器 (MLP) 中的音频特征,这些方法可以合成与输入音频同步唇部的视图一致的 3D 头部结构。基于 NeRF 的技术实现了高质量和一致的视觉输出,但其缓慢的推理速度限制了它们的实用性。尽管最近的进步 [24, 39] 以 512 × 512 分辨率实现了高达 30 帧每秒 (fps) 的渲染速度,但必须克服计算瓶颈才能应用于实际场景。问题是:基于 NeRF 的技术推理速度慢,限制了它们的实用性。该方法的动机很好,因为它解决了基于 NeRF 的技术推理速度慢的问题。
(3):本文提出的研究方法是:GaussianTalker 是一种新颖的框架,用于实时生成可控姿态的说话头。它利用了 3D 高斯喷射 (3DGS) 的快速渲染功能,同时解决了直接用语音音频控制 3DGS 的挑战。GaussianTalker 构建了一个头部规范的 3DGS 表示,并使其与音频同步变形。一个关键的见解是将 3D 高斯属性编码成一个共享的隐式特征表示,其中它与音频特征合并以操纵每个高斯属性。这种设计利用了空间感知特征并强制相邻点之间的交互。然后将特征嵌入馈送到空间音频注意力模块,该模块预测每个高斯属性的逐帧偏移。与用于操纵大量高斯及其复杂参数的先前级联或乘法方法相比,它更稳定。
(4):本文方法在以下任务和性能上取得了成就:在面部保真度、唇部同步准确性和渲染速度方面,GaussianTalker 优于以前的方法。具体来说,GaussianTalker 以高达 120 FPS 的显着渲染速度,超越了之前的基准。性能可以支持他们的目标,因为 GaussianTalker 在面部保真度、唇部同步准确性和渲染速度方面都优于以前的方法。
方法:
(1):GaussianTalker 是一种新颖的框架,用于实时生成可控姿态的说话头。它利用了 3D 高斯喷射 (3DGS) 的快速渲染功能,同时解决了直接用语音音频控制 3DGS 的挑战。GaussianTalker 构建了一个头部规范的 3DGS 表示,并使其与音频同步变形。一个关键的见解是将 3D 高斯属性编码成一个共享的隐式特征表示,其中它与音频特征合并以操纵每个高斯属性。这种设计利用了空间感知特征并强制相邻点之间的交互。然后将特征嵌入馈送到空间音频注意力模块,该模块预测每个高斯属性的逐帧偏移。与用于操纵大量高斯及其复杂参数的先前级联或乘法方法相比,它更稳定。 (2):GaussianTalker 提出了一种新的方法,该方法将 3D 高斯属性编码到一个共享的隐式特征表示中,该表示与音频特征合并以操纵每个高斯属性。这种设计利用了空间感知特征并强制相邻点之间的交互。然后将特征嵌入馈送到空间音频注意力模块,该模块预测每个高斯属性的逐帧偏移。 (3):GaussianTalker 采用多分辨率三平面表示来编码 3D 高斯特征,该表示利用了 3D 高斯隐式神经辐射场的空间信息。特征嵌入与音频特征融合,以准确建模由输入音频驱动的面部运动。结论:
(1):本工作提出了 GaussianTalker,这是一种用于实时姿态可控 3D 说话头合成的框架,利用 3D 高斯表示头部。我们的方法通过调节 3D 高斯原语,实现了对 3D 高斯原语的精确控制。 (2):创新点:GaussianTalker 提出了一种新方法,将 3D 高斯属性编码到一个共享的隐式特征表示中,该表示与音频特征合并以操纵每个高斯属性。这种设计利用了空间感知特征并强制相邻点之间的交互。性能:GaussianTalker 在面部真实度、唇部同步准确性和渲染速度方面优于以往的方法。具体来说,GaussianTalker 以高达 120 FPS 的显着渲染速度,超越了之前的基准。工作量:GaussianTalker 采用多分辨率三平面表示来编码 3D 高斯特征,该表示利用了 3D 高斯隐式神经辐射场的空间信息。特征嵌入与音频特征融合,以准确建模由输入音频驱动的面部运动。
点此查看论文截图


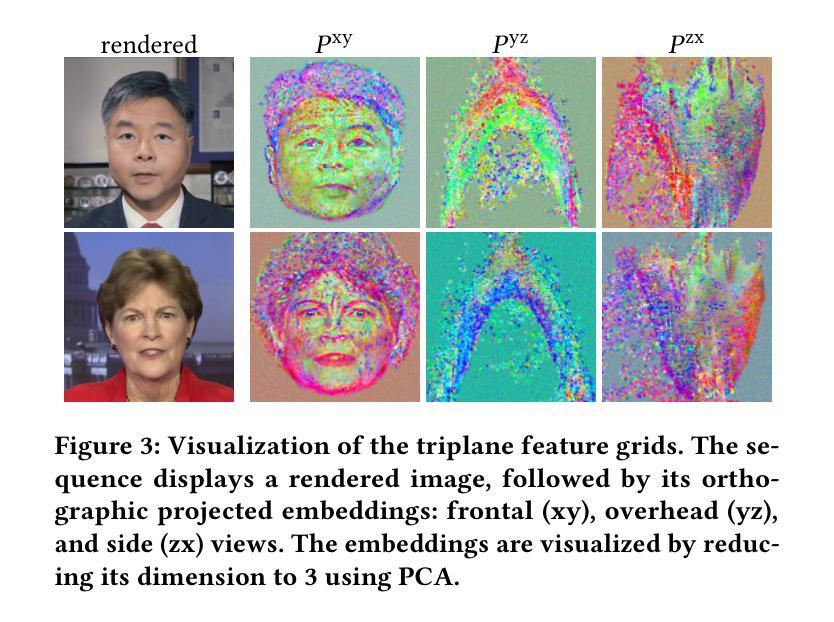
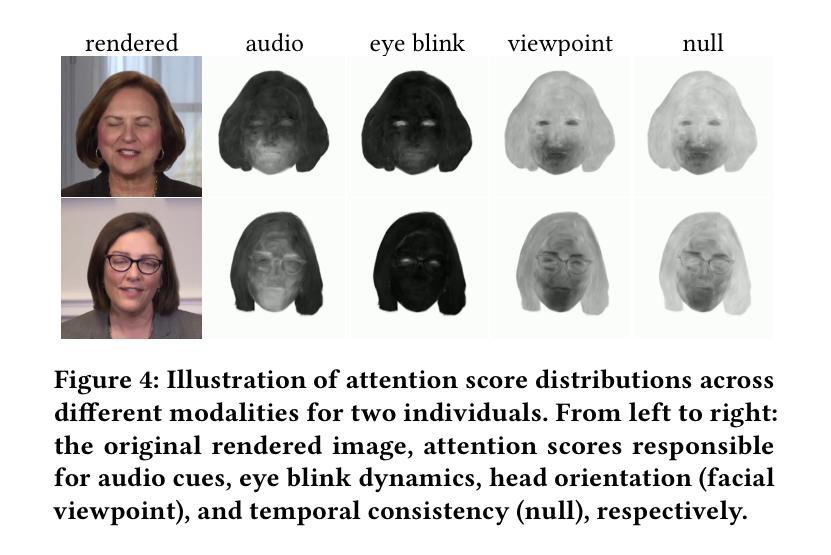
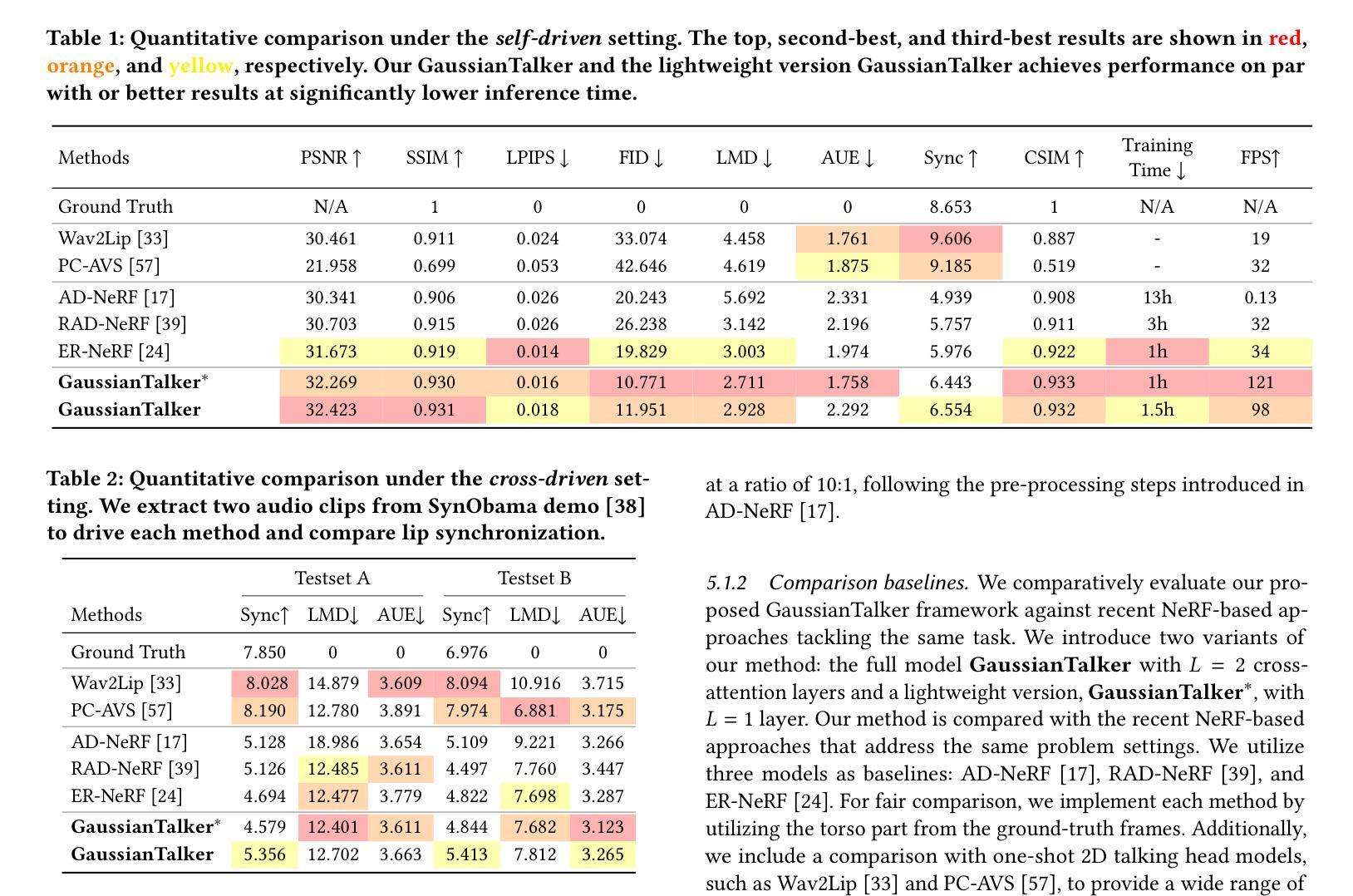
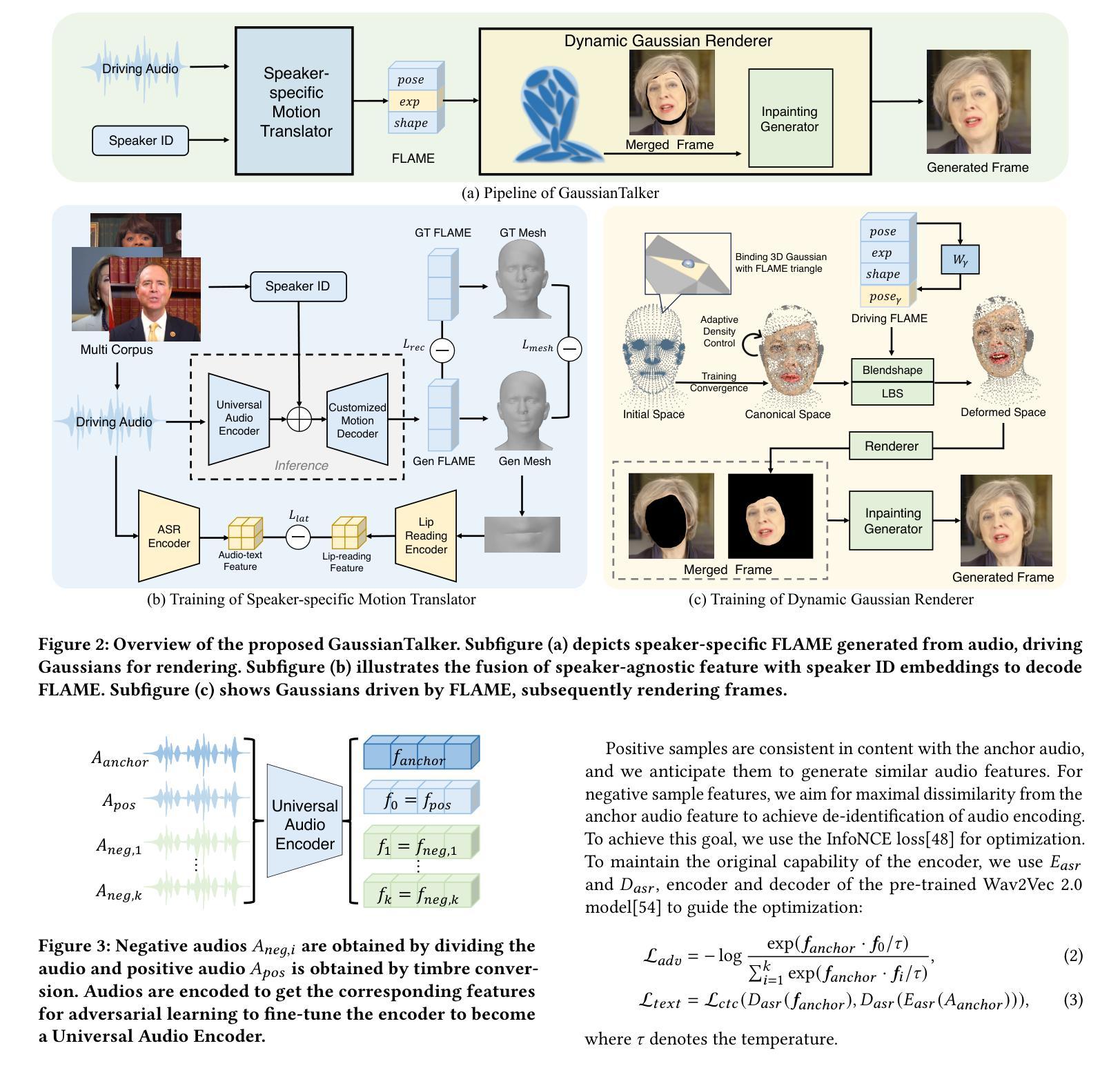
GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Authors:Hongyun Yu, Zhan Qu, Qihang Yu, Jianchuan Chen, Zhonghua Jiang, Zhiwen Chen, Shengyu Zhang, Jimin Xu, Fei Wu, Chengfei Lv, Gang Yu
Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.
PDF https://yuhongyun777.github.io/GaussianTalker/
Summary
面部表情生成方法 GaussianTalker 以显式三维高斯斑点为基础,通过绑定高斯斑点到 3D 面部模型,实现面部动作的直观控制。
Key Takeaways
- 使用 3D 高斯斑点显式表示,实现面部动作的直观控制。
- 通过通用音频特征提取和定制唇部动作生成,实现针对目标说话人的准确唇部动作。
- 引入说话人特有混合形状,通过潜在姿势增强面部细节表示,提供稳定且逼真的渲染视频。
- 在面部表情生成中优于现有最先进方法,提供精确的唇部同步和出色的视觉质量。
- 渲染速度达到 130 FPS,显着高于实时渲染性能阈值。
- 可以部署在其他硬件平台上。
标题:高斯话者:基于 3D 高斯斑点的特定说话者会说话的头合成
作者:洪云余、展权、启航余、建川陈、中华姜、志文陈、胜雨张、 Jimin Xu、Fei Wu、成飞吕、刚余
单位:阿里巴巴集团
关键词:音频驱动、会说话的头合成、神经辐射场、高斯斑点
论文链接:https://arxiv.org/abs/2404.14037,Github 链接:无
摘要:
(1):研究背景:基于神经辐射场(NeRF)的音频驱动会说话的头合成方法取得了显著进展。然而,由于 NeRF 隐式表示引起的姿势和表情控制不足,这些方法仍存在一些局限性,如嘴唇动作不同步或不自然,以及视觉抖动和伪影。
(2):过去方法及问题:现有方法存在以下问题:姿势和表情控制不足,导致嘴唇动作不自然、视觉抖动和伪影。
(3):本文方法:本文提出了一种基于 3D 高斯斑点的音频驱动会说话的头合成新方法 GaussianTalker。GaussianTalker 由两个模块组成:特定说话者动作转换器和动态高斯渲染器。特定说话者动作转换器通过通用的音频特征提取和定制的嘴唇动作生成来实现特定于目标说话者的准确嘴唇动作。动态高斯渲染器引入了特定于说话者的混合形状,以控制面部表情。
(4):方法性能:GaussianTalker 在唇形合成任务上取得了良好的性能,可以生成准确且自然的嘴唇动作。
- 方法:
(1):Speaker-Specific Motion Translator:该模块负责将音频信号转换为特定于目标说话者的 FLAME 参数序列,用于面部动画控制。它由 Universal Audio Encoder 和 Customized Motion Decoder 组成。
(2):Dynamic Gaussian Renderer:该模块利用 FLAME 驱动 3D 高斯斑点,并实时渲染动态说话头部。它引入特定于说话者的混合形状,以控制面部表情。
- 结论:
(1):本文提出了一种基于 3D 高斯斑点的音频驱动会说话的头合成新方法 GaussianTalker,该方法将多模态数据与特定说话者关联,减少了音频、3D 网格和视频之间的潜在身份偏差。特定说话者的 FLAME 转换器采用身份解耦和个性化嵌入来实现同步且自然的嘴唇运动,而动态高斯渲染器通过潜在姿势优化高斯属性,以实现稳定且逼真的渲染。大量实验表明,GaussianTalker 在说话头合成中优于最先进的性能,同时实现了超高的渲染速度,明显超过其他方法。我们相信这种创新方法将鼓励未来的研究开发更流畅、更逼真的角色表情和动作。通过利用先进的高斯模型和生成技术,角色的动画将远远超出简单的唇形同步,捕捉更广泛的角色动态。 (2):创新点:提出了一种基于 3D 高斯斑点的音频驱动会说话的头合成新方法 GaussianTalker,该方法将多模态数据与特定说话者关联,减少了音频、3D 网格和视频之间的潜在身份偏差; 性能:在唇形合成任务上取得了良好的性能,可以生成准确且自然的嘴唇动作; Workload:未提及。
点此查看论文截图

 wechat
wechat- alipay






